
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
AI technology has developed so fast, and it has been applied to the commercial area. In order to predict the customer preference and adjust the placement of product or advertisement, etc., the intelligent surveillance video analysis technique has been proposed to gather the sufficient customer information and realize crowd counting and density map drawing. In this paper, a series of deep learning techniques are adopted to realize surveillance video analysis. This work covers different subproblems such as object detection, tracking and human identification. A skeleton recognition algorithm is adopted instead of object detection algorithm to overcome the severe occlusion problem. A multiple human tracking algorithm combing the human re-identification technology is adopted to realize the human tracking and counting. Finally, the density map and statistics information are obtained which can be used to evaluate and adjust the current business plan. A real store surveillance video is analyzed by the algorithm, and the results show the advantage of the algorithm.
Introduction
As the rapid development of high technology, AI has applied to kinds of area, including the commercial area. How can we make accurate and reliable predictions about actions or behaviors of consumer? The merchants deploy knowledge management and business intelligence systems to help them organize data, and gain insights from the data in order to make predictions about sales, operating costs, customer preferences, etc. (Nagar and Malone Citation2011). Historically, before the computer age, such forecasts were done by human experts (working individually or in teams). With application of computer technology, the merchants have made use of predictive algorithms to detect and predict customer preferences based on relevant data collected by employees. However, the data, such as customer preferences in fashion-driven businesses, are often unstructured which is problematic to obtain and realize in computer (Negash and Gray Citation2013).
In the past decade, automated scene analysis has already attracted much research attention in the computer vision community. The intelligent surveillance in replace of the traditional passive video surveillance is an important application (Ratre and Pankajakshan Citation2018). In the intelligent surveillance analysis system, it has accurate data processing and efficient information fusion with fewer human operators (Guo et al. Citation2016). In reality, it has a great advantage compared to the traditional manually observation which require a high human resource cost to constantly monitor surveillance cameras (Saleh et al. Citation2015). It has been used for automatic detecting and counting people, and also detecting of anomalies crowd automatically.
Nowadays, video surveillance system is an essential part of the store. Surveillance video contains abundant information, such as customer preferences, etc. The intelligent surveillance video analysis technique can be used for crowd estimation and gathering intelligence for further analysis and inference such as gauge people’s interest in a product of a store and this information can be used for appropriate product placement, etc. Therefore, the commercial prediction problem can be realized based on the analysis of earlier surveillance video of the store. Estimating the customer preference and drawing density maps by the surveillance video are a crowd counting and density estimation problem. Crowd counting aims to count the number of people in a crowd image and the density estimation aims to map the corresponding density map of crowd image which indicates the density of people at certain position (Sindagi and Patel Citation2018).
Crowd estimating, tracking and density maps drawing from crowd images have a wide range of applications such as video surveillance, traffic monitoring, public safety, disaster management, intelligence gathering and analysis, forensic search and urban planning. The complexity of the problem together with the wide range of applications has led to an increased focus of the researchers in the recent years. This challenge work covers different subproblems such as object detection, localization and tracking, etc. This task is also riddled with many challenges such as occlusions, nonuniform distribution of people and illumination, intrascene and interscene variations in appearance, scale and perspective, etc. (Sindagi and Patel Citation2017).
At the earlier stage, researchers have attempted to use a variety of approaches to address the issue of crowd estimation and density drawing, such as detection-based, clustering-based and regression-based methods. Generally, the problem of human counting and density estimation of crowd can be handled by two types of approaches: direct and indirect approaches (Saleh, Suandi, and Ibrahim Citation2015). The indirect approach is called feature-based method, human counting is achieved by the learning algorithms using some features of the crowd (Zhang and Li Citation2012). The feature-based methods usually extract several local and global features of the groups of people in foreground image. For this reason, many feature extraction methods for the foreground have been proposed such as foreground area, texture features, edge features to realize crowd counting and estimating by a regression function, like Gaussian probability, neural network, etc. However, it is often limited to the presence of the occlusions and perspective problem. The direct approach is also called object detection-based method which tries to segment and detect each human in the crowd and then count them. In this method, counting people is relied on the correct segment of human which is more complex when a severe crowd or occlusions occurred (Hou and Pang Citation2011). In early time, the indirect methods are more efficient because feature extraction is easier than detecting persons due to the slow developing object detection algorithm.
The detection-based approaches attempt to determine the number of people by identifying single persons and their locations simultaneously. Human detection is a more complex task in the presence of crowded and occlusion conditions. A sliding window is adopted as detector to count the number of people in the image. The detection is usually realized either in the monolithic or parts-based style. Monolithic detection approaches (Enzweiler and Gavrila Citation2009; Li et al. Citation2008) usually extracted features of the whole body for training classifier by Haar wavelets (Viola and Jones Citation2004), edgelet (Wu and Nevatia Citation2007) and shapelet (Sabzmeydani and Mori Citation2007) information. Various classifiers have been adopted with varying degree of success such as support vector machines, boosting (Jones and Viola Citation2007), random forest (Gall et al. Citation2011), etc. However, these methods are adversely affected by the presence of high-density crowds. The part-based detection methods (Felzenszwalb et al. Citation2010; Lin et al. Citation2001; Wu and Nevatia Citation2007) construct the classifiers based on the specific parts of human such as the head, hand and shoulder to estimate the people counts (Zhang, Li, and Nevatia Citation2008). The parts-based methods were also not successful at the situation of extremely dense crowds and high background clutter. In order to overcome these issues, the regression methods learn to map the features extracted from local image patches to their counts (Chen et al. Citation2012). These methods are independent of detectors which is easy to capture the global feature of the image. Some other local feature extraction method is combined, such as foreground features, edge features, texture and gradient features, to further improve the performance of regression models. Once these global and local features are extracted, different regression techniques, such as linear regression, piecewise linear regression, ridge regression, Gaussian process regression and neural network, are used to map low-level feature to realize crowd count. While the regression methods ignored the important spatial information as they were based on the global features. Some researches (Lempitsky and Zisserman Citation2010) combined the local patch features with corresponding object spatial information in the learning process to improve the detection performance. Zhan et al. (Citation2008) point out that conventional computer vision processing technology may be ineffective when dealing with the analysis of crowded video sequences. Indeed, in a high-density situation the presence of severe occlusions consistently limits the performance of traditional methods for object detection and visual tracking (Jacques Junior et al. Citation2010). Although, it is often limited to small variations in crowd density and scales, the human information can be obtained by the direct way.
Over the last few years, the object detection-based crowd estimation has developed the ability to perform on a wide range of scenarios successfully. The success of crowd estimation methods can be largely attributed to the development of deep learning (Babaee et al. Citation2017; Brahimi et al. Citation2017) and publications of challenging datasets, especially the convolutional neural network (CNN). Some famous object detection algorithms are proposed, such as Faster RCNN, SSD, YOLO, etc. (Liu et al. Citation2018). The CNN has been applied to numerous computer vision tasks successfully (Dolata et al. Citation2018; Ferreira et al. Citation2017; Li et al. Citation2018), and it inspired researchers to exploit their nonlinear learning abilities for estimating the corresponding density maps or counting from the crowd image. The CNN-based approaches have demonstrated significant advantages over previous conventional object detection methods. Therefore, more researchers are drawn into exploring CNN-based approaches further for crowd analysis-related problems. Some CNN-based advanced methods (Boominathan et al. Citation2016; Hu et al. Citation2016; Jing et al. Citation2017; Oñoro-Rubio and López-Sastre Citation2016; Shao et al. Citation2015; Walach Citation2016; Zhang et al. Citation2016) and some new challenging crowd datasets are proposed (Zhang et al. Citation2016; Zhang et al. Citation2015). CNN-based approaches have achieved drastically lower error rates, and the creation of new datasets has made the models more generalized. Although, the deep learning technology has accelerated the development of the object detection algorithm, as mentioned previously, conventional pipeline of human detection and the subsequent tracking of those detections can hardly perform accurate human detection and tracking due to the increasing density of the crowd, the severe scene clutter and severe occlusions (Zhou et al. Citation2011).
Therefore, a special scheme is adopted for human detection in this paper. A skeleton detection algorithm is used to recognize the human skeleton which has a better performance in human detection than the object detection algorithm. The outline of human can be determined according to the skeleton data. And then, this paper makes use of some compound deep learning technique to realize crowd counting and density maps drawing based on the surveillance video of the store. After that, the merchants can predict the customer preference and adjust the goods arrangement according to the customer information.
Method
The object detection-based crowd counting and density map drawing for the surveillance video usually can be categorized into three main steps: (1) detection, (2) tracking and (3) analysis. The problem of human detection aims to localize all humans in the given image or video sequence. The human tracking aims to following the human motion trail to predict the motion or for drawing density map. There are different researches for different tasks at the analysis steps, such as customer preference prediction for this paper or density map analysis according to the previous steps. In this paper, the flowchart of the application is shown in .
Figure 1. The flowchart of the system
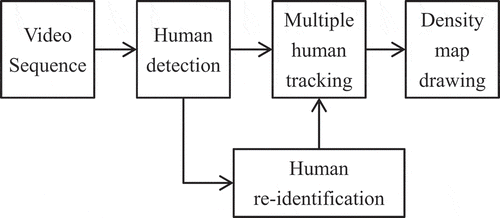
Figure 2. The diagram of openpose
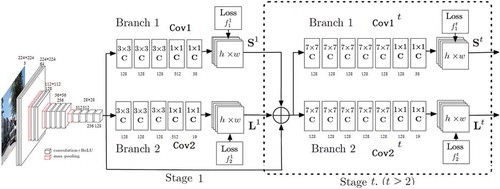
Figure 3. The flowchart of human tracking
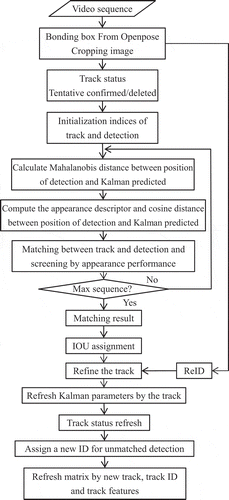
Figure 4. The diagram of ReID
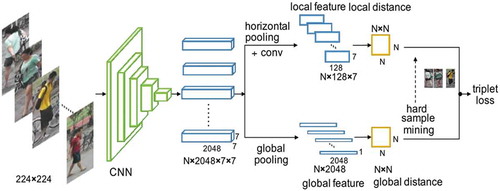
Figure 5. The principle of ReID
Human detection
Object detection is a basic and important problem in the computer vision, including the human detection. In crowd counting of surveillance video, one of the key tasks is to detect and identify humans in crowd. With the development of deep learning technology, CNN-based object detection methods have achieved great success. There are two categorized CNN-based object detection methods. Region-based methods make use of the candidate regions to potentially cover object, such as RCNN (Girshick et al. Citation2014), SPPNet (Zhang et al. Citation2015), Fast RCNN (Girshick Citation2015) and Faster RCNN (Ren et al. Citation2017). Regression-based methods have better real-time characteristic, such as YOLO (Redmon et al. Citation2016; Redmon and Farhadi Citation2017, Citation2018) and SSD (Liu et al. Citation2016). These methods have got good results than the conventional object detection methods. Although these algorithms have been developed to detect, track and understand the behaviors of various objects in video, they were mainly designed for common scenes with a low density of population (Morris and Trivedi Citation2008). The performance of these methods is modest at the situation of heavy occlusion.
In fact, the density of people substantially affects their appearance in video sequences. Especially in dense crowds, people occlude each other and only some parts of each individual are visible (Fradi and Dugelay Citation2015). Therefore, it is a big challenge for the CNN-based object detection algorithm. However, in this paper, the people must be detected accurately for counting and density map drawing. Human skeleton recognition is a special application which is designed for human (Hbali et al. Citation2018; Manzi et al. Citation2018). It has a robust recognition ability for human. Therefore, a human 2D pose estimation algorithm (openpose) (Cao et al. Citation2017; Wei et al. Citation2016) is adopted to detect human instead of object detection algorithm. The skeleton recognizing algorithms can recognize the human skeleton despite of occlusion occurring. Therefore, the skeleton recognition algorithm is adopted to detect human which has better performance than conventional object detection algorithm. The bounding box will be obtained when the skeleton data are gathered. The openpose algorithm adopts part of VGG19 as the backbone in . The image coming from the surveillance video inputs the ten layers of the CNN of VGG19 and additional two convolutional layers, and then generates the featuremaps for two handling branches of the first stage. The confidence maps and part affinity fields
are generated by the CNNs
and
.
At stage t, the original featuremaps (F) of VGG19, and
are the input of the branches. Then, the confidence map and part affinity vector are generated by EquationEquations (1)
(1)
(1) and (Equation2
(2)
(2) ).
And then, a loss value f is calculated according to and
to train the network.
where is the groundtruth part of confidence map,
is the groundtruth part of affinity vector field. W is a binary mask with W(p) = 0 when annotation is missing at an image location p. f is the overall objective.
The openpose outputs a vector with 19 key points (1: nose, 2: neck, 3: right shoulder, 4: right elbow, 5: right wrist, 6: left shoulder, 7: left elbow, 8: left wrist, 9: right hip, 10: right knee, 11: right ankle, 12: left hip, 13: left knee, 14: left, 15: left eye, 16: right eye, 17: left ear, 18: right ear, 19: background).
According to these parameters, the bounding box can be generated by EquationEquation (6)(6)
(6) .
where are the central coordinates and size information of bounding box.
Making use of the skeleton data, a bounding box parameter (x,y,h,w) of the human can be obtained. The human object can be detected by this way even though there is a problem of occlusion. This parameter will be used as the input of the multiple human tracking algorithm to select the corresponding human for counting and tracking.
Multiple human tracking
Automatic tracking of people in video sequence is one of the most fundamental and challenging tasks in the research of video analysis and its results lay the foundations of a wide range of applications such as video surveillance, behavior analysis, security applications and traffic control. The task of multiple human tracking aims to locate multiple human, maintain their identities and individual trajectories according to the given video sequence. Visual tracking has achieved a great progress in recent years (Beyan and Temizel Citation2012; Tesfaye et al. Citation2016; Xie et al. Citation2013). Many tracking algorithms use the tracking-by-detection method which estimates the tracks of multiple objects based on previous object detections. The detection-based tracking algorithm has become the leading paradigm in multiple object tracking (Wojke et al. Citation2017). Generally speaking, it is largely attributed to the development of object detection methods which is based on deep learning technique. They have also significantly advanced the state-of-the-art of object tracking.
Traditional multiple human tracking methods (Fortmann et al. Citation2003; Reid Citation1979) perform a frame-by-frame data association on which have been improved by a tracking-by-detection way (Kim et al. Citation2015; Rezatofighi et al. Citation2015) and shown promising results. However, the computation and implement is complex. The flow network (Berclaz et al. Citation2011; Pirsiavash et al. Citation2011; Zhang et al. Citation2008) and probabilistic graphical models (Milan et al. Citation2013; Nevatia Citation2012; Roth Citation2012; Yang and Nevatia Citation2012) are popular frameworks based on the tracking-by-detection method. However, these methods are not applicable in online system due to the batch processing.
Simple online and real-time tracking (SORT) (Bewley et al. Citation2016) is a much simpler framework which has the advantage of high frame rates. However, SORT returns a relatively huge number of identity switches while achieving good precision and accuracy performance in tracking. Therefore, SORT has a deficiency in tracking at the situation of occlusions as they typically appear in frontal-view camera scenes. The deepSORT (Wojke, Bewley, and Paulus Citation2017) integrates the motion and appearance information to improve the performance of SORT. It is also easy to implement and apply to online system efficiently. Therefore, the deepSORT method is adopted to realize multiple human tracking in this paper, and some improvements are carried out in order to improve the performance of deepSORT. The object detection section of deepSORT is replaced by the openpose (above mentioned) in order to overcome the occlusion problem. After obtaining the bounding box data by openpose, the motion matching according to the Kalman filter and appearance matching are combined to build the association problem. The parameters of tracker are defined by a vector []. [
] is the bounding box center,
is the aspect ratio,
is the height size and [
] is the velocity of these parameters. The standard Kalman filter with constant velocity motion and linear observation model is adopted to observe the state of [
]. In the association of predicted Kalman states and newly detected status, the motion and appearance information are integrated as a comprehensive metrics. The Mahalanobis distance is adopted in the motion metrics between predicted Kalman states and newly detected human by following equation.
where is the matching degree of motion information between jth detection and ith tracker.
is the covariance matrix of ith tracker in the current observation space by Kalman filter.
and
are the tracker status [
] by detection and prediction.
While the Mahalanobis distance is suitable for lower motion uncertainty, unaccounted camera motion, the Kalman filtering provides only a rough estimate of the object location. Therefore, the second metric appearance descriptor for each bounding box is calculated. The smallest cosine distance between the ith tracker and jth detection in the appearance space is the second metric,
is the appearance descriptor with
, and a buffer of the last
appearance descriptors
for each constructed tracker k. And then, the two metrics are combined by a weighted sum.
A max sequent frame number N is set to determine the object is out of the vision or should be tracked continually. If the object cannot be found in the following N frames, it can be deleted from the tracker.
In the human tracking process, the human re-identification is an important part (Chen et al. Citation2016). In order to further improve the tracking performance of the deepSORT, a person re-identification (ReID) algorithm AlignedReID (Zhang et al. Citation2017) is integrated after the “IOU assignment” step in this paper. The whole process of the deepSORT algorithm is shown as .
AlignedReID adopts ImageNet pretrained Resnet50 and Resnet50-Xception (Resnet-X) as the backbone as . The Resnet output the feature maps of the selected human with size of 2048*7*7. Then, these features are handled through two branches, a local feature processing channel and a global processing channel. The local and global branches together discriminate two images in the learning stage. The global feature is extracted by a global pooling operation. A horizontal pooling is adopted in local feature process, and then the feature map with size of 2048*7*1 is obtained. A 1*1 convolution is followed to reduce the channel number to 128*7.
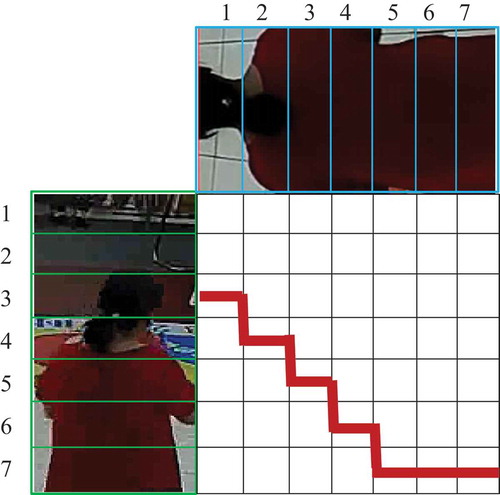
In order to deal with the alignment problem for two people with different size, the algorithm adopts a special matching method as .
Analysis of customer information
In order to attract, retain and satisfy customers and maintain its competitiveness and business growth, the merchant must determinate and establish the customer’s preferences and expectations in today’s markets. The surveillance video contains sufficient information about the customer.
After successfully tracking the customer of the surveillance video, the information about the customer in the store can be recorded, such as gender and age estimation, track route, stopping time at certain position, etc. Therefore, we can analyze the whole trajectory of customers according to the tracking route, and then adjust the placement of the product and advertising, and also the density map can be drawn. Based on the accumulation of gender and age information, the age distribution of customers and preferences for different products at different ages can be estimated.
Experiments
The proposed approach is applied to a real application for analyzing the customer preferences of certain store in China. In the system, some improvements are adopted to improve the performance of the algorithm, including the human detection and tracking techniques.
Human detection
Human detection is the base of this project. Therefore, in order to demonstrate the effectiveness of the proposed human detection method, we compare our results to the conventional objection algorithm (SSD and Faster RCNN). In particular, the occlusion problem is tested for these algorithms. One frame of the surveillance video is shown in . The marked area has a severe occlusion problem which can testify the performance the algorithms.
Figure 6. One image of the surveillance video

As shown in and , the human detection results are worse using conventional object detection algorithm. Although, the Faster RCNN adopts different threshold values to detect human and a smaller threshold value may detect more person, only six persons are detected with small threshold from the nine persons and a large proportion of occlusion is tactless as shown in . Although, the SSD algorithm performs better than Faster RCNN especially for the occlusion region, some persons are also undetected or some persons are marked twice when different threshold values are adopted. That is why, we consider adopting skeleton recognition method to detect human.
Figure 7. The detection results of Faster RCNN under different threshold: (a) threshold = 0.8 and (b) threshold = 0.5

Figure 8. The detection results of SSD under different threshold: (a) threshold = 0.17 and (b) threshold = 0.1

The skeleton recognition algorithm can detect the skeleton of human even at the situation of severe occlusion as shown in ), and then the person can be marked according to the skeleton data as shown in ). Accurate human detection is the base of the system. The detected human can be clipped and used for human ReID, tracking or counting, etc.
Figure 9. Human detection based on skeleton recognition: (a) skeleton recognition result and (b) human detection result based on skeleton

Human tracking
After the detection of human, lots of works can be achieved, such as human counting, tracking and heat map drawing, etc. shows the human tracking results. ) shows the initial stage of human tracking. We can see that the human are detected and marked by detection algorithm, and then the tracking algorithm will track the corresponding person and combine the ReID algorithm. ) and (b) are the middle frames which we can see that the persons are tracked and the trajectories are marked by different color lines. ) shows a comprehensive human tracking result. According to , we can see the human can be tracked well by the algorithm.
Figure 10. Human tracking results: (a) the initial frame, (b) the middle frame, (c) the latter frame and (d) the last frame

Others
After the detection of human, the human countering can be achieved and the heat map also can be draw. shows the heat map diagram. ) shows the heat map of certain scene as given in and . ) shows the heat map corresponding to the scene. The upper area of the figure is a passageway, therefore the human number is larger than other area and it is a hot area. According to the heat map diagram, the area where customers often walk can be obtain which can be used for adjusting advertisement placement.
Figure 11. The heat map diagram

According to the statistical result, the customer constitution is shown as .
Table 1. The customer constitution
Conclusions
Intelligent surveillance video analysis has applied kinds of area, such as traffic, security, commerce, etc. The key point of video analysis is the object detection, especially the human detection. Some famous object detection algorithms have been proposed, such as Faster RCNN, SSD, etc. However, they cannot handle the severe occlusion problem. Therefore, a skeleton recognition algorithm is adopted to detect the human according to skeleton data which has better performance than conventional algorithm. After the detection of human, human counting and tracking can be achieved. A multiple human tracking algorithm combing the ReID is adopted to realize human tracking. According to the statistical data, the heat map can be drawn. According to the statistical results, the customer constitution and preference can be achieved which can be used for product placement adjustment.
Acknowledgments
This work was supported by the National Nature Science Foundation of China under Grant (61973184, 61803227, 61603214 and 61573213); Shandong Provincial Key Research and Development Plan under Grant (2018GGX101039).
Additional information
Funding
References
- Babaee, E., N. B. Anuar, A. W. A. Wahab, S. Shamshirband and A. T. Chronopoulos. An overview of audio event detection methods from feature extraction to classification. Applied Artificial Intelligence 31(9-10): 661-714.
- Berclaz, J., F. Fleuret, E. Türetken. and P. Fua. 2011. Multiple object tracking using k-shortest paths optimization. IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (9):1806–19.
- Bewley, A., Z.Ge, L. Ott, F. Ramos, B. Upcroft. 2016. Simple online and realtime tracking. In:IEEE International Conference on Image Processing(pp. 3464–68) Phoenix, AZ, USA.
- Beyan, C., and A. Temizel. 2012. Adaptive mean-shift for automated multi object tracking. Iet Computer Vision 6 (11):1–12. doi:10.1049/iet-cvi.2011.0054.
- Boominathan, L., S. S. S. Kruthiventi, and R. V. Babu 2016. Crowdnet: A deep convolutional network for dense crowd counting. In:Proceedings of the 2016 ACM on Multimedia Conference(pp. 640–44) Amsterdam, Netherlands.
- Brahimi, M., K. Boukhalfa, and A. Moussaoui. 2017. Deep learning for tomato diseases: Classification and symptoms visualization. Applied Artificial Intelligence 31(4): 299-315.
- Cao, Z., T. Simon, S.E. Wei and Y. Sheikh. 2017. Realtime multi-person 2d pose estimation using part affinity fields. In:2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2017)(pp. 1302-10)Honolulu, Hawaii.
- Chen, K., C. L. Chen, S. Gong and T. Xiang. 2012. Feature mining for localised crowd counting. In: Proceedings of British Machine Vision Conference (pp. 21.1-11), Surrey, UK.
- Chen, Y., Z. Huo, and C. Hua. 2016. Multi-directional saliency metric learning for person re-identification. Iet Computer Vision 10 (10):623–33. doi:10.1049/iet-cvi.2015.0343.
- Dolata, P., M. Mrzygłód, and J. Reiner. 2018. Double-stream convolutional neural networks for machine vision inspection of natural products. Applied Artificial Intelligence (3):1–17.
- Enzweiler, M., and D. M. Gavrila. 2009. Monocular pedestrian detection: Survey and experiments. IEEE Transactions on Pattern Analysis and Machine Intelligence 31 (12):2179–95. doi:10.1109/TPAMI.2008.260.
- Felzenszwalb, P. F., R. B. Girshick, D. Mcalleste and D. Ramanan. 2010. Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence 32 (9):1627–45. doi:10.1109/TPAMI.2009.167.
- Ferreira, B. V., E. Carvalho, M. R. Ferreira, P. A. Vargas, J. Ueyama and G. Pessin. 2017. Exploiting the use of convolutional neural networks for localization in indoor environments. Applied Artificial Intelligence 31 (2010):1–9.
- Fortmann, T. E., Y. Barshalom, and M. Scheffe. 2003. Sonar tracking of multiple targets using joint probabilistic data association. Ieee Journal of Oceanic Engineering 8 (3):173–84. doi:10.1109/JOE.1983.1145560.
- Fradi, H., and J. L. Dugelay. 2015. Towards crowd density-aware video surveillance applications. Information Fusion 24:3–15. doi:10.1016/j.inffus.2014.09.005.
- Gall, J., A. Yao, N. Razavi, L. Van Gool and V. Lempitsky. 2011. Hough forests for object detection, tracking, and action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (11):2188–202. doi:10.1109/TPAMI.2011.70.
- Girshick, R. 2015. Fast r-cnn. In:2015 IEEE International Conference on Computer Vision (ICCV)(pp. 1440–1448) Santiago, Chile.
- Girshick, R., J. Donahue, T. Darrell and J. Malik. 2014. Rich feature hierarchies for accurate object detection and semantic segmentation. In:2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2014)(pp. 580–87) Columbus, OH, USA.
- Guo, H., J. Wang, and H. Lu. 2016. Multiple deep features learning for object retrieval in surveillance videos. Iet Computer Vision 10 (4):268–72. doi:10.1049/iet-cvi.2015.0291.
- Hbali, Y., S. Hbali, L. Ballihi and M. Sadgal. 2018. Skeleton-based human activity recognition for elderly monitoring systems. Iet Computer Vision 12 (10):16–26. doi:10.1049/iet-cvi.2017.0062.
- He, K., X. Zhang, S. Ren and J. Sun. 2015. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 37 (9):1904–16. doi:10.1109/TPAMI.2015.2389824.
- Hou, Y. L., and G. K. H. Pang. 2011. People counting and human detection in a challenging situation. IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans 41 (1):24–33. doi:10.1109/TSMCA.2010.2064299.
- Hu, Y., T. Li, Y.C. Hu, F.D. Nian, Y. Wang. 2016. Dense crowd counting from still images with convolutional neural networks. Journal of Visual Communication and Image Representation 38 (C):530–39. doi:10.1016/j.jvcir.2016.03.021.
- Jacques Junior, J. C. S., S. Raupp Musse, and C. R. Jung. 2010. Crowd analysis using computer vision techniques. Signal Processing Magazine IEEE 27 (5):66–77.
- Jing, S., C. L. Chen, K. Kai and X. Wang. 2017. Crowded scene understanding by deeply learned volumetric slices. IEEE Transactions on Circuits & Systems for Video Technology 27 (3):613–23. doi:10.1109/TCSVT.2016.2593647.
- Jones, M., and P. Viola. 2007. Detecting pedestrians using patterns of motion and apprearance in videos. International Journal of Computer Vision 63 (2):153–61.
- Kim, C., F. Li, A. Ciptadi and J. M. Rehg. 2015. Multiple hypothesis tracking revisited. In:IEEE International Conference on Computer Vision(pp. 4696–704) Santiago, Chile.
- Lempitsky, V. S., and A. Zisserman. 2010. Learning to count objects in images.In: Proceedings of the 23rd International Conference on Neural Information Processing Systems(pp. 1324–32), Whistler, Canada.
- Li, B., K. C. P. Wang, A. Zhang E. Yang and G. Wang. 2018. Automatic classification of pavement crack using deep convolutional neural network. International Journal of Pavement Engineering 21(4):457-463.
- Li, M., Z. Zhang, K. Huang, T. Tan. 2008. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In:2008 19th International Conference on Pattern Recognition(pp. 1–4) Tampa, FL, USA.
- Lin, S. F., J. Y. Chen, and H. X. Chao. 2001. Estimation of number of people in crowded scenes using perspective transformation. Systems Man & Cybernetics Part A Systems & Humans IEEE Transactions On 31 (6):645–54. doi:10.1109/3468.983420.
- Liu, L., W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu and M. Pietikäinen. 2020. Deep Learning for Generic Object Detection: A Survey. International Journal of Computer Vision volume 128: 261–318.
- Liu, W., D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu and A.C. Berg. 2016. Ssd: Single shot multibox detector. In:2016 European Conference on Computer Vision(pp. 21–37) Amsterdam, Netherlands.
- Manzi, A., L. Fiorini, R. Limosani, R. Limosani, P. Dario and F. Cavallo. 2018. Two-person activity recognition using skeleton data. Iet Computer Vision 12 (8):27–35. doi:10.1049/iet-cvi.2017.0118.
- Milan, A., K. Schindler, and S. Roth 2013. Detection- and trajectory-level exclusion in multiple object tracking. In:2013 IEEE Conference on Computer Vision and Pattern Recognition(pp. 3682–89) Portland, OR, USA.
- Morris, B. T., and M. M. Trivedi. 2008. A survey of vision-based trajectory learning and analysis for surveillance. IEEE Transactions on Circuits & Systems for Video Technology 18 (8):1114–27. doi:10.1109/TCSVT.2008.927109.
- Nagar, Y., and T. Malone 2011. Making business predictions by combining human and machine intelligence in prediction markets. In:Thirty Second International Conference on Information Systems (pp. 1–16) Shanghai, China.
- Negash, S., and P. Gray. 2013. Business intelligence. Communications of the Association for Information Systems 13 (13):177–95.
- Nevatia, R. 2012. An online learned crf model for multi-target tracking. In:2012 IEEE Conference on Computer Vision and Pattern Recognition(pp. 2034–41) Providence, RI, USA.
- Oñoro-Rubio, D., and R. J. López-Sastre 2016. Towards perspective-free object counting with deep learning. In:European Conference on Computer Vision(pp. 615–29), Amsterdam, Netherlands.
- Pirsiavash, H., D. Ramanan, and C. C. Fowlkes 2011) Globally-optimal greedy algorithms for tracking a variable number of objects. In:IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011. (pp. 1201–08) Colorado Springs, CO, USA.
- Ratre, A., and V. Pankajakshan. 2018. Tucker tensor decomposition-based tracking and gaussian mixture model for anomaly localisation and detection in surveillance videos. Iet Computer Vision 12 (7):933–40. doi:10.1049/iet-cvi.2017.0469.
- Redmon, J., S. Divvala, R. Girshick and A. Farhadi. 2016. You only look once: Unified, real-time object detection. In:2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. 779–88) Las Vegas, NV, USA.
- Redmon, J., and A. Farhadi 2017. Yolo9000: Better, faster, stronger. In:2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. 6517–25) Honolulu, HI, USA.
- Redmon, J., and A. Farhadi. 2018. Yolov3: An incremental improvement. arXiv abs/1804.02767.
- Reid, D. B. 1979. An algorithm for tracking multiple targets. IEEE Transaction on Automatics Control 24 (6):1202–11.
- Ren, S., K. He, R. Girshick, and J. Sun. 2017. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (6):1137–49. doi:10.1109/TPAMI.2016.2577031.
- Rezatofighi, S. H., A. Milan, Z. Zhang, Q. Shi, A. Dick and I. Reid. 2015. Joint probabilistic data association revisited. In:IEEE International Conference on Computer Vision(pp. 3047–55) Santiago, Chile.
- Roth, S. 2012. Discrete-continuous optimization for multi-target tracking. In:2012 IEEE Conference on Computer Vision and Pattern Recognition(pp. 1926–33) Providence, RI, USA.
- Sabzmeydani, P., and G. Mori 2007. Detecting pedestrians by learning shapelet features. In:IEEE Conference on Computer Vision and Pattern Recognition, CVPR2007(pp. 1–8) Minneapolis, MN, USA.
- Saleh, S. A. M., S. A. Suandi, and H. Ibrahim. 2015. Recent survey on crowd density estimation and counting for visual surveillance. Engineering Applications of Artificial Intelligence 41:103–14. doi:10.1016/j.engappai.2015.01.007.
- Shao, J., K. Kang, C. L. Chen and X. Wang. 2015. Deeply learned attributes for crowded scene understanding. In:2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. 4657–66) Boston, MA, USA.
- Sindagi, V. A., and V. M. Patel. 2017. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognition Letters 107:3–16. doi:10.1116/j.patrec.2017.07.007.
- Sindagi, V. A., and V. M. Patel. 2018. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognition Letters 107:3–16. doi:10.1016/j.patrec.2017.07.007.
- Tesfaye, Y. T., E. Zemene, M. Pelillo and A. Prati. 2016. Multi-object tracking using dominant sets. Iet Computer Vision 10 (9):289–98. doi:10.1049/iet-cvi.2015.0297.
- Tuzel, O., F. Porikli, and P. Meer. 2008. Pedestrian detection via classification on riemannian manifolds. IEEE Transactions on Pattern Analysis and Machine Intelligence 30 (10):1713–27. doi:10.1109/TPAMI.2008.75.
- Viola, P., and M. J. Jones. 2004. Robust real-time face detection. International Journal of Computer Vision 57 (2):137–54. doi:10.1023/B:VISI.0000013087.49260.fb.
- Walach, E., L. Wolf. 2016. Learning to count with cnn boosting. In: The 14th European Conference on Computer Vision (pp. 660–76), Amsterdam, The Netherlands.
- Wei, S. E., V. Ramakrishna, T. Kanade and Y. Sheikh. 2016. Convolutional pose machines. In:2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016)(pp. 4724–32) Las Vegas, NV, United States.
- Wojke, N., A. Bewley, and D. Paulus. 2017. Simple online and realtime tracking with a deep association metric. CoRR abs/1703.07402.
- Wu, B., and R. Nevatia. 2007. Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors. International Journal of Computer Vision 75 (2):247–66. doi:10.1007/s11263-006-0027-7.
- Xie, C., J. Tan, P. Chen, J. Zhang and L. He. 2013. Multiple instance learning tracking method with local sparse representation. Iet Computer Vision 7 (14):320–34. doi:10.1049/iet-cvi.2012.0228.
- Yang, B., and R. Nevatia 2012. Multi-target tracking by online learning of non-linear motion patterns and robust appearance models. In:2012 IEEE Conference on Computer Vision and Pattern Recognition(pp. 1918–25) Providence, RI, USA.
- Zhan, B., D. N. Monekosso, P. Remagnino, S. A.Velastin and L. Q. Xu.. 2008. Crowd analysis: A survey. Machine Vision and Applications 19 (5–6):345–57. doi:10.1007/s00138-008-0132-4.
- Zhang, A. Z., and M. Li. 2012. Crowd density estimation based on statistical analysis of local intra-crowd motions for public area surveillance. Optical Engineering 51 (4):7204.
- Zhang, C., K. Kang, H. Li, X. Wang, R. Xie and X. Yang. 2016. Data-driven crowd understanding: A baseline for a large-scale crowd dataset. Ieee Transactions On Multimedia 18 (6):1048–61. doi:10.1109/TMM.2016.2542585.
- Zhang, C., H. Li, X. Wang and X. Yang.. 2015. Cross-scene crowd counting via deep convolutional neural networks. In:IEEE Conference on Computer Vision and Pattern Recognition(pp. 833–41) Boston, MA, USA.
- Zhang, L., Y. Li, and R. Nevatia 2008. Global data association for multi-object tracking using network flows. In:IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2008. (pp. 1–8) Anchorage, AK, USA.
- Zhang, X., H. Luo, X. Fan, W. Xiang, Y. Sun, Q. Xiao, W. Jiang, C. Zhang and J. Sun. 2017. Alignedreid: Surpassing human-level performance in person re-identification. arXiv prePrint 1711.08184.
- Zhang, Y., D. Zhou, S. Chen, S. Gao and Y. Ma. 2016. Single-image crowd counting via multi-column convolutional neural network. In:2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(pp. 589–97) Las Vegas, NV, USA.
- Zhou, B., X. Wang, and X. Tang 2011. Random field topic model for semantic region analysis in crowded scenes from tracklets. In:IEEE Conference on Computer Vision and Pattern Recognition(pp. 3441–48) Colorado Springs, CO, USA.