
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper presents the task of normalizing Vietnamese transcribed texts in Speech-to-Text (STT) systems. The main purpose is to develop a text normalizer that automatically converts proper nouns and other context-specific formatting of the transcription such as dates, time, and numbers into their appropriate expressions. To this end, we propose a solution that exploits deep neural networks with rich features followed by manually designed rules to recognize and then convert these text sequences. We also introduce a new corpus of 13 K spoken sentences to facilitate the process of the text normalization. The experimental results on this corpus are quite promising. The proposed method yields 90.67% in the F1 score in recognizing sequences of texts that need converting. We hope that this initial work will inspire other follow-up research on this important but unexplored problem.
Introduction
As the name would indicate, Speech-to-Text is a system that gets speech input and instantly generates texts as it is recognized from streaming audio or as the user is speaking. This type of automatic speech recognition systems generally produces un-normalized text (as indicated in ) which is difficult to read for humans and degrades the performance of many downstream machine processing tasks. Restoring the norm-texts greatly improves the readability of transcripts and increases the effectiveness of subsequent processing, like machine translation, summarization, question answering, sentiment analysis, syntactic parsing, and information extraction, etc. Normalizing transcribed texts, therefore, plays an important role in STT systems. It usually consists of two main tasks:
Punctuator detection which mainly focuses on periods (sentence boundaries).
Automatically recognize and convert the spoken form of texts into their written expressions adhering to a single canonical rule.
Figure 1. An example of normalizing texts: one year (2018), one person name (Ms. Sáu), and a number (12) are recognized and converted into their written formats
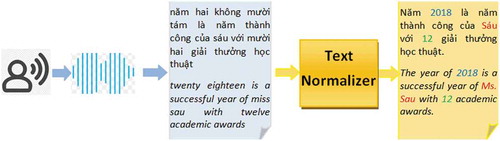
In this study, we assume that the former task is solved by using a simple technique based on the information of long silence between speeches, to identify sentence boundary. We, hence, concentrate on the latter task which aims to automatically transcribe proper nouns and typical context-specific formatting. Three main types of proper nouns which are person names, organization names, and location names; and three typical context-specific formattings such as dates, time, and numbers are considered in this research. Such proper nouns and formatting are called entities in this paper.
General speaking, detecting such entities requires quite a bit of linguistic sophistication and native speaker intuition (Schutze (Citation1997)). In the running example of , the first occurrence of ‘year’ is ambiguous with the digit ‘five,’ or the person name ‘Sáu’ is ambiguous with the number ‘six’ if their surrounding contexts are not fully considered. Hence, automatically disambiguating these cases is a challenging task because of different ambiguity issues existing in both un-normal texts and other forms of texts.
To our knowledge, it seems that there has no related public research on text normalization in spoken forms of texts so far. Hence, this paper is the first work that formulates the task and provides a preliminary solution to solve it. To this end, the proposed solution is a hybrid architecture that exploits deep neural networks with rich features followed by rule-based processing. Specifically, LSTM (Hochreiter and Schmidhuber (Citation1997); Lample et al. (Citation2016)) and CNN (LeCun et al. (Citation1989)) models integrated with rich manually built features are used to automatically detect these entities. Then, some necessary rules are built to convert these detected entities into their appropriate written expressions. A new corpus consisting of 13 K spoken sentences is also annotated to allow deep learning solutions to be deployed. In conclusion, this paper makes the following contributions:
Presents the new task of normalizing texts in Vietnamese STT systems.
Provides a preliminary solution based on neural networks with rich features followed by rules.
Introduce a new corpus to conduct experiments and facilitate the process of normalizing texts in STT systems.
The rest of this paper is organized as follows. The next section discusses related work. Then, we formally define the problem, and propose a solution to solve it. After that, we introduce our new manually built corpus in a general domain and shows some statistics. Experimental setups, experimental results, and some discussions are also reported. Finally, we conclude the paper and point out some future lines of work.
Related Work
Text normalization is an important stage in processing non-canonical language from natural sources such as social texts, speech, short messages, etc. This is a new research field and most of its papers published are done for popular languages such as English, Japanese, Chinese, etc. All of these text normalization systems usually focus on social texts (Eryigit and Torunoglu-selamet (Citation2017); Ikeda, Shindo, and Matsumoto (Citation2016); Hassan and Menezes (Citation2013)), short messages (Aw et al. (Citation2006)), text-to-speech systems (Yolchuyeva, Gyires-Toth, and Nemeth (Citation2018)), etc. For example, Eryigit and Torunoglu-selamet (Citation2017) present the first work on the social media text normalization of an MRL and introduces the first text normalization system for Turkish. Ikeda, Shindo, and Matsumoto (Citation2016) present a Japanese text normalization using Encoder-Decoder model. Aw et al. (Citation2006) propose a phrase-based statistical model for normalizing SMS texts. For text normalization systems involving speech and language technologies, there have been several works to convert texts from written expressions into their appropriate ‘spoken’ forms. For example, Yolchuyeva, Gyires-Toth, and Nemeth (Citation2018) introduce a novel CNNs based text normalizer and verify its effectiveness on the dataset of a text normalization challenge on Kaggle.Footnote1
To our knowledge, there is no public research focusing on the spoken forms of texts in STT systems, especially in Vietnamese. Spoken forms of texts behave quite differently from normal written texts and have some very special phenomena. They are much longer and highly ambiguous (as can be seen in the above examples). To normalize the spoken texts, a straightforward approach is to use predefined rules because they seem to follow some underlying syntactical patterns. These rules can be designed by observing the output of STT systems. However, the approach still poses some disadvantages such as difficult to construct highly accurate rules, time-consuming, need domain-expert skills, difficult to maintain and extend rules, and not really effective. This is due to the fact that the rule-based approach usually could not deal well with ambiguity problems. To a large extent, it is necessary to consider semantic information of texts and their surrounding contexts.
Rather than using rules, this paper proposes a machine learning-based architecture to solve the task. This approach exploits deep neural networks with rich features followed by some language-specific heuristic rules to recognize and convert text sequences need normalizing into their right formats.
A Solution to Normalize Texts in STT Systems
In this section, we first formally state the problem and then propose a solution to address it.
Problem Statement
The problem can be stated as follows: Given a sequence of syllables which are outputs of an STT system S = {s1, s2, …, sn}, si is the ith syllable (assuming that the output was sentence-segmented), it is required to transcribe S into clean verbatim text formats as follows:
Capitalize the first letter of the first syllable s1 in S.
Capitalize the first letter of each syllable sk in any proper noun. For our analysis, we consider three common types of proper nouns which are person names, organization names, and location names.
Capitalize all letters in a syllable sk if sk is a course identifier (e.g. VN247) or an abbreviation of organization names (e.g. WHO, FPT, VNPT, etc.).
Write out numbers zero through ten unless they are part of some cases such as sports records (2–0), time, binary, date, etc. Numbers above 10 represent numerical digits. For numbers above 999.999, substitute million, billion, etc., for the zeros. For dates/time, we use the Vietnamese formats of dd/MM/yyyy and hh:mm:ss.
Replace uoms (unit-of-measurements) with their symbols such as Hz, %, USD, etc.
A Proposed Solution to Normalize Texts
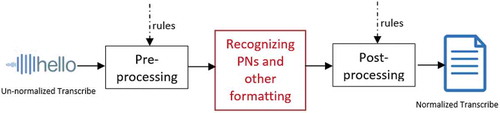
The overall architecture is presented in with three main steps as follows:
Pre-processing: The texts are pre-processed to capture phone numbers, URLs, e-mail address, … if they follow their formal syntactical patterns.
Recognizing Proper Nouns and other text formatting: This is the most critical and difficult step. To automatically recognize if segments of texts are currently considered as valid entities, it is necessary to know its surrounding contexts. In this work, instead of using heuristic rules, we exploit machine learning techniques by modeling the task as a sequence labeling problem. A fast and effective strategy to label each word is to use its own features to predict labels independently. The best solution is to make the optimal label for a given element dependent on the choices of nearby elements. To this end, we use CRFs (Lafferty, McCallum, and Perera (Citation2001)) which are widely applied, and yield state-of-the-art results in many NLP problems (Bach, Linh, and Phuong (Citation2018); Tran and Luong (Citation2018)).
Figure 2. An overall architecture of the text normalization in STT system
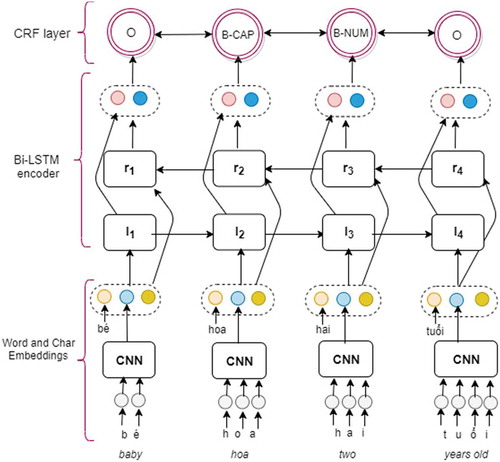
To build a strong model, CRFs need a good feature set. These features will be automatically learned via neural models and then enriched with manual-built features m. shows the architecture of applying neural architectures to automatically extract useful features for the model. We first use convolutional neural networks by LeCun et al. (Citation1989); Zhu et al. (Citation2017) to encode character-level information of a tth word into its character-level representation lt. lt was initialized randomly and trained with the whole network of CNNs. We then combine lt with word-level representations wt and manually built features mt feed xt = concat (lt, wt, mt) into bi-LSTM networks (Lample et al. (Citation2016); Mikolov et al. (Citation2011)) to model context information of each word. Formally, the formulas to update an LSTM unit at time t are:
Figure 3. An architecture to detect entities in STT output using biLSTMs
where is the element-wise sigmoid function and
is the element-wise product. xt is the input vector (concatenation of character, word, and manual rich features embeddings) at time t. ht is the hidden state vector which stores all the useful information up to time t. Ui, Uf, Uc, and Uo denote the weight matrices of different gates for input xt, and Wi, Wf, Wc, and Wo are the weight matrices for hidden state ht. bi, bf, bc, and bo denote the bias vectors.
The idea of using bi-LSTMs is to present each sequence forwards and backward to capture past and future information, respectively. These two hidden states lt and rt are then concatenated to form the final output. Finally, a CRF is used to take into account neighboring tags, yielding the final context predictions for every word of the input texts.
(3) Post-processing: After detected, this step applies some rules to convert these entities into their written expressions as follows:
If a syllable belongs to any recognized proper nouns, just capitalize its first letter. We do a further step to check if this syllable appears in a pre-defined list of course identifiers; we just capitalize every single character of it.
If a sequence of syllables is determined as a date, time, or a number, we built corresponding rules to convert it into its written form. To design these rules, we ask the help of two linguistic experts to write down all possible reading methods/styles in different regions of Vietnam. Then, rules are gradually composed to catch up almost these possible methods.
For uom, a list is manually built to help converting them into their correct symbols.
Experiments
Corpus Building
This section introduces the steps we took to annotate the corpus. We first describe the annotation process, and then show some statistical figures on this corpus. The annotation process is illustrated in . It includes the following four main steps:
Collecting raw data: Texts from different sources, mainly from online newspapers, were collected.
Pre-processing: Like other standard practices, the texts were split into sentences and the main punctuation was removed. During normalization, all words were converted to lowercases, and words with a dash or a colon were separated, keeping the dash and colon as words. Numbers/dates/time/phone numbers/abbreviations/course numbers, etc., were transformed to their full, spoken forms. Then, we randomly selected 13 K sentences and asked two annotators to manually label them with the required information.
Label designing: We designed a corresponding set of labels that facilitates the goal of normalizing the output of STT systems. We developed guidelines containing these labels. The guidelines provided detailed examples of the annotations, as well as specific information for each label that helped the annotators easier to annotate and solve conflicts in ambiguous cases. Three labels were chosen are Proper_Noun, Dates/Time, and Numbers.
Data tagging: To speed up the labeling step, a tool is built to automatically transform written texts into spoken forms of texts by using some rules such as:
Phone-similar digit strings are transformed into spoken forms of each discrete digit.
Some abbreviations are converted into their full forms by using a predefined list of Vietnamese abbreviations. This list is composed of scanning the newspapers to find out abbreviated words (they usually are not valid Vietnamese words). Then, a person is required to manually check and finalize the list.
Long and short dates/time: We varied different reading methods of these dates/time. Popular reading methods are randomly chosen with higher probabilities.
Numbers: similar to dates/time, we also diversify different reading methods for each number.
Then, we hire two annotators to manually check and correct wrong labels and unnatural reading of a given text using the predefined set of labels designed in the previous step. To measure the inter-annotator agreement, we used Cohen’s kappa coefficient (Cohen (Citation1960)). Some statistics about the corpus are given in . Cohen’s kappa coefficient of our corpus was 0.91, which usually is interpreted as almost perfect agreement.
Table 1. Some statistics about the corpus
Experimental Setups
To create word embeddings, we collected the raw data from Vietnamese newspapers (~9GB texts) to train the word vector model using GloveFootnote2 (Pennington, Socher, and Manning (Citation2014)). We fixed the number of word embedding dimensions at 50, the number of character embedding dimensions at 25. We also defined our own features and then mapped them into a vector of 10 dimensions.
For each experiment type, we conducted fivefold cross-validation tests. The hyper-parameters were chosen via a search on the development set. We randomly select 10% of the training data as the development set. The system performance is evaluated using precision, recall, and the F1 score as in many sequence labeling problems (Yadav and Bethard (Citation2018)) as follows:
where TP (True Positive) is the number of entities that are correctly identified. FP (False Positive) is the number of text sequences that are mistakenly identified as valid entities. FN (False Negative) is the number of entities that are not identified.
Experimental Results
In this section, we presented two types of experiments. The first one is to evaluate the effectiveness of the proposed method in detecting entities that need converting. This type includes three experiments to evaluate the baseline, the proposed method with/without using rich features. The second type is to integrate this text normalizer into a real STT system to measure its final performance on real output texts.
Experimental Results of the Baseline Using Rules to Detect Entities
Based on some dictionaries about Vietnamese person names, location names, organization names, we designed some rules to captures these proper nouns automatically. For dates/time and numbers, we try to capture some popular reading ways of human beings among different regions of Vietnam. These rules are implemented by using the module re of Python language. shows its experimental results.
Table 2. Experiment results using the rule-based baseline to detect entities
The baseline had a higher precision than recall in general due to the fact that if a match is found it is probably correct. It got a precision of 82.64%, a recall of 84.07% and an F1 score of 83.36% averaged on five folds.
Experimental Results of the Proposed Model without Using Rich Features
illustrates the experimental results of the proposed model. As can be seen that the proposed method got much higher results. The recall, precision, and F1 scores are significantly increased on all five folds. Overall, it can greatly improve the efficiency of recognizing these entities. Specifically, compared to the baseline, this method remarkably boosted the F1 metric by 4.11%, precision by 6.9%, and recall by 1.43%.
Table 3. Experiment results using the neural architectures without rich features
Experimental Results of the Proposed Model Integrated with Rich Features
shows the experimental results using rich features. The results suggested that integrating rich features into neural models boosts the performance of the final system in detecting entities. In comparison to not using rich features, it increased the precision by 4.07%, the recall by 2.42%, and the F1 score by 3.2%, respectively.
Table 4. Experiment results using the neural network with rich features
shows experimental results of the F1 scores on each label. As can be seen that numbers are easiest to detect, followed by dates/time. Proper nouns are the most difficult to recognize because they are highly ambiguous.
Figure 4. The annotation process in building the new corpus

Experimental Results of the Final System on the Output of a Real STT System
We integrated the best entity recognition model using biLSTM with rich features into our STT system to test its performance. The evaluation of the model was performed on 1000 real-world examples. Testers were required to read these randomly selected sentences as inputs and collect the outputs. Then, we also measured precision, recall, and F1 scores based on the numbers of the entities such as proper nouns, dates/time, and numbers. The experimental results show that the text normalizer yields 75.78% in precision, 82.2% in recall, and 78.86% in the F1 score.
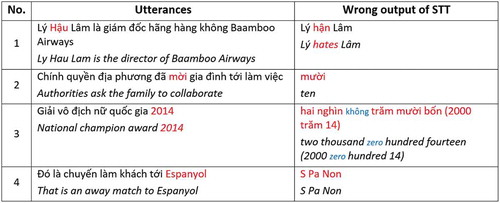
These results are lower than previous experiments on ideal spoken forms of texts. The main reason is that the real output of the STT produces some wrong words which make our text normalizer could not detect the sequence of texts that need converting. Some examples are shown in . The first case shows the wrong output of the middle name of a person. In the second case, the verb ‘ask’ was wrongly recognized as a number ‘ten.’ The third case shows an example of elision where a syllable ‘zero’ is dropped in the STT system. Observing the data, we saw several English words not correctly produced by STT system. This problem also causes a decrease in our text normalizer‘s performance as shown in the fourth case. There are also other types of errors which the entity recognizer could not detect out the right proper nouns, dates, and time.
Figure 5. Performance on each label in the F1 scores (in %)
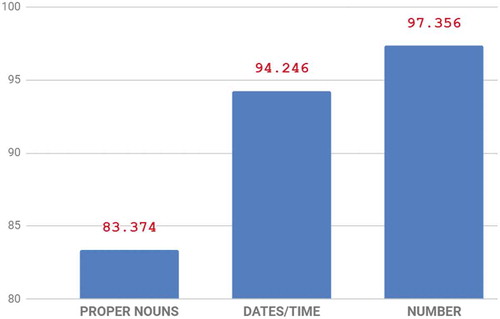
Figure 6. Some examples of wrong outputs of STT integrated with the text normalizer. (It highlights wrong expressions in red)
Conclusion
We presented the first text normalization system for Vietnamese STT using deep neural architectures with rich features followed by manually designed rules. The neural architecture uses CNNs to encode character contexts of a word. Then, we concatenate them with pre-trained word embeddings and rich features to feed into a bi-LSTM encoder. A CRF is then applied on the top to predict label for each word. To conduct experiments, a newly built corpus is also presented for Vietnamese to facilitate the process of normalizing the output of STTs. This new dataset can serve as a benchmark for this task in Vietnamese. Experimental results on this corpus were promising. We achieved 90.67% in the F1 score in recognizing segments of texts that need normalizing, and 78.86% in the F1 score when tested on the real output of an STT system.
Through extensive experiments on this dataset, we acknowledge several insights such as using machine learning techniques is more robust and effective than rules in detecting entities in STT output texts, and some types of entities (e.g. numbers) are easier to detect than others (e.g. proper nouns). We hope that this initial study will inspire other follow-up research on this important but unexplored problem.
Acknowledgement
This research is funded by International School, Vietnam National University, Hanoi (VNU-IS) under project number CS.NNC/2020-05.
Notes
References
- Aw, A., M. Zhang, J. Xiao, and J. Su. 2006. A phrase-based statistical model for SMS text normalization. In The COLING/ACL on Main conference poster sessions. Association for Computational Linguistics, Sydney, Australia, 33–40.
- Bach, N. X., N. D. Linh, and T. M. Phuong. 2018. An empirical study on POS tagging for vietnamese social media text. Computer Speech & Language 50:1–15. doi:10.1016/j.csl.2017.12.004.
- Cohen, J. 1960. A coefficient of agreement for nominal scales. Journal Educational and Psychological Measurement 20 (1):37–46. doi:10.1177/001316446002000104.
- Eryigit, G., and D. Torunoglu-selamet. 2017. Social media text normalization for Turkish. Journal of Natural Language Engineering 23 (6):835–75. doi:10.1017/S1351324917000134.
- Hassan, H., and A. Menezes. 2013. Social text normalization using contextual graph random walks. In 51st Annual Meeting of the Association for Computational Linguistics, Bulgaria, vol. 1, 1577–86.
- Hochreiter, S., and J. Schmidhuber. 1997. Long short-term memory. Journal Neural Computation 9 (8):1735–80. doi:10.1162/neco.1997.9.8.1735.
- Ikeda, T., H. Shindo, and Y. Matsumoto. 2016. Japanese text normalization with encoder-decoder model. In The COLING 2016 Organizing Committee, Proceedings of the 2nd Workshop on Noisy Usergenerated Text (WNUT), Osaka, Japan, 129–37.
- Lafferty, J. D., A. McCallum, and F. C. N. Perera. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In 18th International Conference on Machine Learning, 282–89. San Francisco: Morgan Kaufmann Publishers Inc.
- Lample, G., M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer. 2016. Neural architectures for named entity recognition. In 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 260–70. San Diego: Association for Computational Linguistics.
- LeCun, Y., B. E. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. E. Hubbard, and L. D. Jackel. 1989. Handwritten digit recognition with a back-propagation network. In Advances in Neural Information Processing Systems 2, 396–404. CA, United States: Morgan-Kaufmann Publisher.
- Mikolov, T., S. Kombrink, L. Burget, J. Ernock, and S. Khudanpur. 2011. Extensions of recurrent neural network language model. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5528–31. Prague, Czech Republic.
- Pennington, J., R. Socher, and C. D. Manning. 2014. Glove: Global vectors for word representation. In The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), vol 14, 1532–43. Doha, Qatar: Association for Computational Linguistics publisher.
- Schutze, H. 1997. Ambiguity Resolution in Language Learning: Computational and Cognitive Models, 176. Stanford, CA : CSLI Publications.
- Tran, T. O., and C. T. Luong. 2018. Towards understanding user requests in AI bots. In 15th Pacific Rim International Conference on Artificial Intelligence (PRICAI), 864–77, Nanjing, China.
- Yadav, V., and S. Bethard. 2018. A survey on recent advances in named entity recognition from deep learning models. In The 27th International Conference on Computational Linguistics, Santa Fe, New Mexico, USA, 2145–58.
- Yolchuyeva, S., B. Gyires-Toth, and G. Nemeth. 2018. Text normalization with convolutional neural networks. International Journal of Speech Technology 21 (4):589–600. doi:10.1007/s10772-018-9521-x.
- Zhu, Q., X. Li, A. Conesa, and C. Pereira. 2017. GRAM-CNN: A deep learning approach with local context for named entity recognition in biomedical text. Journal Bioinformatics 34 (9):1547–54. doi:10.1093/bioinformatics/btx815.