
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
A recommender system (RS) provides assistance for users to filter out items of their interest in the presence of millions of available items. The reason is to find out the likewise user with the assumption that if users have shared similar interest in the past then they may share the same in future. Collaborative filtering (CF) is the widely used recommendation algorithm due to its ease of use but suffers with the problems of sparsity and cold start problem. In this paper, we propose a trust and distrust-based cross domain context aware recommender system in the multi-agent environment which tries to reduce the problem of data sparsity in collaborative-filtering recommender system and improves coverage. Cross Domain Recommender System (CDRS) utilizes data from multiple domains to reduce the problem of sparsity. Moreover, the combination of trust and distrust in recommendation help to improve trustworthiness of generated recommendation. Distrust provides higher accuracy in recommendation by incorporating knowledge about the malicious users. Prototype of the system is developed using JADE and Java technology for the tourism domain consisting of restaurant, hotel, travel places and shopping places as sub-domains. The performance of the proposed trust and distrust-based cross domain recommender system is compared with the traditional approach of recommendation along with the cross domain approach and trust-based cross-domain approach in terms of accuracy and coverage. The results show that the proposed system outperforms in terms of both accuracy and coverage.
Introduction
Popularity of recommender systems is increasing amongst the users to find the information of their interest on the web. This information is transforming a wide variety of services, whether it is movies, e-commerce, tourism, news, or online music choices (Das Citation2007), (Bedi, Agarwal, Jindal and Richa Citation2014), (Yeung and Yang Citation2010). The diversity in services of recommendation also has the diversity in users and their rapidly changing interest in the related area. The major source of information is user supplied reviews either in the form of rating or in the form of text reviews. There are also other sources to capture the implicit user interest. In the present scenario web is flooded with the information, so to assist them recommender system comes into existence (Resnick and Hal Citation1997). Recommender system is broadly divided into four types: collaborative filtering, content-based, , and hybrid approach. Collaborative filtering is the most widely adopted approach among various e-commerce sites because of its ease of use.
Collaborative filtering (CF) is based on the assumption that if user has shared the similar interest in past then they may share the same in future (Schafer et al. Citation2007). CF has further divided into two – user-based collaborative filtering and item-based collaborative filtering. User-based approach analyzes users behavior to find out similar users on the basis of past ratings whereas item-based CF considers similar items rather than similar users (Badrul et al. Citation2001). Pearson Correlation Coefficient (PCC) and cosine similarity are two widely used similarity measures in CF recommender systems (Benesty, Huan, and Chen Citation2009). Constrained Pearson Correlation Coefficient (CPCC) takes the positive and negative ratings into account from the absolute rating scale used in recommendation (Shardanand and Maes Citation1995). So the system can consider the absolute rating difference on the basis of the scale of ratings. Although CF is widely used but it suffers with the problem of sparsity and cold start problem. Sparsity problem is introduced because of the presence of millions of items as well as users in the real world scenario. Even if the user rates a few items, this will be a very small amount which results into sparse data. The cold start problem occurs due to the introduction of new users as well as new items in the system. The reason behind is, initially the system has not data rated by the new user or for the newly introduced items.
The problem of sparsity has been widely discussed among the researchers and many solutions have been suggested in the literature. Cross domain recommender system (CDRS) is one such solution suggested in literature for the problem of sparsity (Cremonesi, Tripodi, and Turrin Citation2011), (Cantador et al. Citation2015). In CDRS, multiple source domains are used to find out the similar users to the target user. The objective of this approach is to handle the problem of sparse data (Berkovsky, Kuflik, and Ricci, Citation2007a). It imports and aggregates the data from source domains to enrich the data in the target domain (Berkovsky, Kuflik, and Ricci, Citation2007b). For example, users rating from book recommender can be used in the movie recommender by providing recommendation of movie using the genre of the book. Integration of all the available ratings from various domains and items will be beneficial for the sparse user data. So the tedious task of handling data from various domains can be wisely incorporated in cross domain recommendation.
To provide effective recommendation in the age of explosive growth of the voluminous data on the internet several researchers suggested the incorporation of trust in recommendation process. Various researchers defined trust by giving priority to different perspective. (Jøsang, Ismail, and Boyd Citation2007) defined trust by highlighting the situation of a user as “the extent to which one party is willing to depend on something or somebody in a given situation, even though negative consequences are possible”. (O’Donovan and Smyth Citation2005) gave preference to accuracy in recommendation and reliability of a user involved with the trust factor. In recommendation, trust is the user’s ability to provide an accurate recommendation. Trust has the potential to address many problems involved with recommendation such as accuracy, cold start problem. Apart from accuracy, trust also helps to improve the prediction coverage. The trust computation involves user’s implicit and explicit participation.
Collaborative filtering (CF) is a method whose basis is “word-of-mouth” where people recommend various items to others. The basis of CF is previous ratings which can be collected in explicit and/or implicit way. The explicit way of computation uses feedback provided by users, e.g., ratings, and the implicit way involves the analysis of user’s behavior while using the internet. Trust can be incorporated either by user’s explicit involvement, i.e., by specifying their personalized web-of-trust or to build some trust model by involving users direct or indirect feedback. Involving user’s feedback directly into the trust computation has a drawback of additional effort by user which results into cold start problem. So the effective way of trust computation is on the basis of items and user profile. The propagation of trust is the combination of direct and indirect trust (Guha et al. Citation2004). A direct trust is the factor for which a user has expressed or the computation provides trust value for other users. Indirect trust involves with the propagation of trust where direct trusted neighbors propagate their trust score to other users in the process. Also, a user can't remain trustworthy as time passes i.e. after some time trust formation process should be repeated. Trust propagation can be understood as: suppose a user ‘i’ trust user ‘j’ and user ‘j’ trust user ‘k’. So by applying transitive operation on the trust propagation strategy this can be concluded that user ‘i’ might trust user ‘k’. The same trust propagation can be applied to other case in the related area by using some other operation. Incorporation of trust in the recommendation process solves several issues of recommendation. But now the question arises that whether all users are trustworthy and all of them are allowed to get involved in the propagation network. The problem has been discussed by several researchers which results into another important factor of recommendation “distrust”.
The formation of distrust is different from trust, i.e., it is a distinct entity from trust. Trust score zero for any user in the neighborhood cannot be considered as distrust and it cannot be considered as negative trust score as well. Different researchers have conceptualized distrust according to the experience with the real world. Addressing distrust at the time of incorporating trust in recommendation plays an important role while collecting user reliable information (Victor et al. Citation2009a). Distrust propagation cannot be same as trust propagation. This can be explained by this informal saying “enemy of enemy can be friends,” e.g. suppose user ‘i’ distrust ‘j’ and user ‘j’ distrust ‘k’. But this cannot be concluded as ‘i’ distrust ‘k’. In this paper distrust is included with the cross domain recommendation by computing intra-domain trust computation followed by intra-domain trust propagation and inter-domain trust computation.
The traditional recommender system usually works in two dimensions, one is user and another is items. But due to the information overload problem, there is a need to add a third dimension in the recommendation computation. Context is found as the third dimension of recommendation which helps to tackle the overload problem. The context in recommendation has become an important factor which improves user satisfaction (Dey Citation2001). It can be defined as “any information that can be used to characterize the situation of an entity”. To provide context in terms of recommendation according to (Abowd et al. Citation1997) “a system is context aware if it uses context to provide relevant information and/or services to the user, where relevancy depends on the user’s task”. The vast growth of e-commerce and personalization recognizes context as an important factor. Tourism domain is one of the popular domains used by researchers working in the area of recommender systems. The tourism domain is the combination of several independent domains. The combination of multiple domains in tourism using the context aware recommendation provides a better approach for personalized system and can also be used to handle the problem of sparse data and cold start problem.
In this paper, we present a combination of trust and distrust-based cross domain context aware recommender system (TDCDCARS) which is not done previously according to our survey. The presented system is a multi-agent based framework which helps to achieve the task either individually or collectively. The ratings of user and their contextual information are used to compute the cross domain neighborhood. In each domain trust score is computed and is propagated within the domain which in our case is termed as intra-domain trust computation and propagation. The intra domain trust score is computed using the user ratings within the domain. Using the trust score, an inter-domain trust is computed which shows the overall trust value of the user. Inter-domain trust computation provides the overall trust score of a user between the domains and is computed by averaging the intra-domain trust score of users. The inter-domain trust score is basically the understanding of trustworthiness of the user with other users. We have proposed a new way to find distrust between users using CPCC which is used to initiate the distrust factor. CPCC is used to compute the similarity score of user which is the basis of the computation of distrusted user. The final neighborhood is computed using the combined list of trust, cross domain and distrust. The framework helps to increase the trustworthiness of user and with the improved accuracy of recommendation.
Rest of the paper is organized as follows: Next section provides literature survey followed by proposed work in section-3 which includes the architecture and working of the system. Recommendation algorithm is detailed in section-4 and experimental analysis is presented in section-5. Finally, section-6 concludes the paper.
Related Work
Recommender system is an information filtering approach which assists the user in their decision-making process (Ricci et al. Citation2011). Collaborative filtering is one the most widely used approach of recommendation among e-commerce sites (Schafer et al. Citation2007). It is further divided into two, user based collaborative filtering and item-based collaborative filtering. User-user collaborative-filtering computes the similarity on the basis of user whose rating behavior for the items matches whereas item-item collaborative filtering does the filtering on the basis of items rated together. This approach is very renowned among the researchers as a lot of work has already been done in this area. (Chen Citation2005) has presented collaborative filtering along with the context aware system. Today’s Web is growing in an exponential rate and by including additional factor in recommendation helps to increase the recommendation quality, e.g., including contextual factors of user helps to increase the quality of recommendation and user acceptance in the system (Adomavicius and Tuzhilin Citation2011). It provides recommendation to the user by considering different contextual information in recommendation on the basis of their past experiences. A situation aware proactive approach is presented by (Bedi and Agarwal Citation2012) which pushes recommendation on the basis of the user’s context according to the user’s location and when the situation seems appropriate. Another approach of recommendation is content-based recommendation which is a model-based approach. A model-based proactive approach in recommendation is presented in (Bedi, Richa, Agarwal, and Bhasin Citation2016). (Melville, Mooney, and Nagarajan Citation2002) has combined both of the approaches to provide personalized recommendation for the users. (Li, Lu, and Xuefeng Citation2005) presents a hybrid collaborative approach by combining both user-based and item-based collaborative filtering. They have presented user-based and item-based collaborative filtering for multiple content recommendations to improve the quality. Collaborative filtering has also been applied in multiple domains (Zhang, Bin, and Yeung Citation2010). The reason for combining multiple domains is to find out a solution of the data sparsity problem in recommendation. It uses the relationship among different domains by having a probabilistic framework which uses matrix factorization technique. Another hybrid approach is proposed by (Burke Citation1999) which combines the knowledge-based approach with collaborative filtering. They considered the collaborative filtering to use as post-filter in the knowledge-based recommendation. Another approach of context aware is presented in (Richa & Bedi Citation2016) which provides a GPU-based context aware approach to accelerate the recommendation process.
A number of algorithms have been used for the similarity computation for recommendation generation, e.g., Pearson’s correlation coefficient, cosine similarity, Jacard coefficient. Constrained Pearson correlation coefficient is an attempt to overcome and reduce the drawback of cosine similarity and Pearson’s correlation coefficient (Shardanand and Maes Citation1995) as CPCC can distinguish the positive or negative rating among absolute rating scale. (Liu et al. Citation2014) presents a new similarity measure to improve the recommendation performance. This measure considers not only the local contextual preferences of the user but it also considers the global behavior of users. We have used the Constrained Pearson Correlation Coefficient (CPCC) proposed by (Shardanand and Maes Citation1995) as the similarity computation in trust and distrust computation phase.
Trust in recommendation found its place among researchers as an important additional factor to provide personalized recommendation. (O’Donovan and Smyth Citation2005) provide the computational models of trust and also showed that incorporating trust into standard approach improves prediction accuracy. The trust modeling, propagation and aggregation has been discussed by (Victor, Cock, and Cornelis Citation2011) as trust enhancement in recommendation approach. Further, they discussed about the importance of trust enhancement focusing on the trust metric and the operators used in trust-based recommendation. A trust-based collaborative filtering for the recommendation purpose is proposed by (Massa and Avesani Citation2004). A trust-based approach in CF is introduced by (Papagelis, Plexousakis, and Kutsuras Citation2005) which uses trust inferences as transitive association between users in social network using context. They have proposed a trust computational model that applies confidence and uncertainty properties in the subjective notion of trust that helps to deal with sparsity and cold-start problems. CF is a widely used algorithm in recommendation which is further enhanced by introducing trust factor in collaborative approach by (Lathia, Hailes, and Capra Citation2008). (Hwang and Chen Citation2007) has made another attempt to introduce trust in CF by directly including trust factor in CF recommendation process. They compute the trust score directly from the user rating data and included trust propagation from the web-of-trust. A CF approach using clustering of trust and distrust is proposed by (Ma et al. Citation2017). They have used SVD sign based clustering algorithm to process trust and distrust-based matrix to discover the community of trusted user. A classification scheme for trust metric is proposed by (Ziegler and Lausen Citation2004) for semantic web scenarios for the computation of local group trust computation.(Abdul-Rahman and Hailes Citation2000) has proposed a community-based trust model in the real world social trust characteristics using reputation mechanism. An effort has been made by (Golbeck, Parsia, and Hendler Citation2003) which exploits trust metrics in social networks. They discussed the semantic web in the multi-dimensional networks which evolves from ontological trust specification. (Jamali and Ester Citation2009) combines the trust and collaborative filtering approach to measure the confidence of the recommendation approach.
Trust is a gradual phenomenon so the absence of distrust cannot differentiate between the malicious users from unknown users (Victor et al. Citation2009). Distrust is an important aspect of recommendation which cannot be ignored while considering trust. Combination of trust and distrust has the potential of providing more personalized recommendation in trust networks as compared to traditional approach of recommendation (Victor et al. Citation2009a). A classification-based recommendation approach is proposed by (Ma, Lu, and Gan Citation2015) to address the trust and distrust prediction problem. They managed a set of relevant features of personal, interpersonal, and impersonal aspects and developed a logical regression model to predict the continuous trust and distrust values of users. A fuzzy trust propagation scheme is given by (Kant and Bharadwaj Citation2011) to alleviate the sparsity problem. They incorporate trust in linguistic terms rather than numerical values and discussed the related operators as trust propagation, modeling and aggregation in fuzzy terms. A weighting strategy (Rafailidis and Crestani Citation2017) is provided to capture the correlation of users' preferences by exploiting users' trust and distrust relationship. A framework of trust propagation scheme is proposed by (Guha et al. Citation2004) for the large trust network it shows that the small number of expressed trust/distrust can predict the trust score with higher accuracy. A CF-based framework is proposed in (Anand and Bharadwaj Citation2013) which computes user trust by utilizing functional and referral trust and distrust information. A theoretical conceptual model is proposed by (Xiao and Benbasat Citation2003) to analyze the process of trust and distrust formation. We have used trust score into intra domain trust propagation and inter-domain trust computation, whereas distrust computation is performed by the similarity measure CPCC. Later, we have combined the trust and distrust along with cross-domain recommendation. We are combining trust and distrust in cross-domain recommendation to provide trustworthy recommendation by forming a trusted neighborhood for the target user. Cross domain helps to improve the sparse data problem by importing and aggregating data from other domains whereas distrust helps to provide accuracy in trust formation between users. In this paper, we have defined a new approach to find the distrust among users which is further used for the prediction generation for the target along with the trustworthy users. CPCC is used to find out the distrust score among the users.
Recommendation has two major problems one is sparsity and another is cold start problem. CDRS is found as a solution of sparse data problem by many researchers which use data from multiple domains to solve this problem (Berkovsky, Kuflik, and Ricci Citation2007a), (Cantador et al. Citation2015). This approach provides recommendation in the target domain by utilizing the knowledge of source domain (Berkovsky, Kuflik, and Ricci Citation2007a). A literature survey of cross domain recommendation is presented by (Khan and Ibrahim Citation2017) to identify the common features, basic definition and the current research in the area. CDRS is also utilized in semantic network by (Fernández-Tobías et al. Citation2011) to integrate and exploit the knowledge on several domains. This links the concepts in two different domain and applied the spreading activation technique to identify the target items. (Berkovsky, Eytani, and Kuflik Citation2007) presented a combination of decentralized distributed storage of user profile with data modification technique. A distributed and heterogeneous recommendation approach is proposed by (Rosa, González, and López Citation2005) with the integration of multiple agent-based service. A study is presented in (Fernández-Tobías and Cantador Citation2015) which compares collaborative-filtering methods with user personality traits and cross domain technique. Additional ratings of source domain, to enrich user model, improves the accuracy of recommendation in the target domain. (Berkovsky, Kuflik, and Ricci Citation2008) discusses four generic user modeling mediation: cross-user, cross-item, cross-context and cross-representation. These mediation techniques provide the potential of user modeling to improve the quality of recommendation. The presented paper combines the cross domain approach with trust and distrust factor. This combination provides the accuracy in presented recommendation because cross domain helps to reduce the sparse data problem whereas trust and distrust help to include the opinion of trustworthy users as well as good coverage in recommendation computation.
Tourism has gained popularity because of the exponentially increase in the data available on the web and the growing use of handheld devices, e.g., smart phones. A survey (Borras, Antonio, and Aida Citation2014) is presented the applications in tourism domain and provides an up-to-date survey which includes different kinds of interfaces and diversity of recommendation algorithm. A mobile-based tourism recommender system (Wan-Shiou and Hwang Citation2013) is developed to provide with on-tour attraction recommendation. On the basis of point of interest (POI) profiles and users, a set of models and algorithm is proposed by (Santos, Almeida, and Martins Citation2017) for the tourism recommender system. The work aimed to find a recommendation approach which finds user’s functionality level regarding physical or psychological limitation. To get an insight of behavior of tourist user geo-referenced images are exploited by (Gallo et al. Citation2017). To achieve this task the metadata of the images are used for the identification of trends, patterns, and relationship. The agent can perform the task either autonomously or with the cooperation with the other agents (Morais, Eugénio, and Alípio Citation2012). The agents can use their intelligence to accomplish the goal and to react when the environment changes (Fabiana et al. Citation2010).
We have not come across any work in literature that combines the trust and distrust in cross domain context aware recommendation approach. This paper also provides the inter domain trust score and intra domain trust propagation. The prediction computation of items is the combined effort of cross domain context aware recommendation with trust and distrust.
Proposed Trust and Distrust-Based Cross Domain Context Aware Recommender System (TDCDCARS)
Proposed system is a trust and distrust-based cross domain context aware recommender system (TDCDCARS) that works in a multi-agent environment. A multi-agent architecture combines multiple agents to complete the assigned task either individually or with the help of other agents.
Architecture of Proposed System
The architecture of the proposed system is presented in . Rating of the users is stored in the local repository where user-item rating matrix is used for the computation purpose.
Figure 1. Trust and distrust-based cross domain recommender system (TDCDCARS)
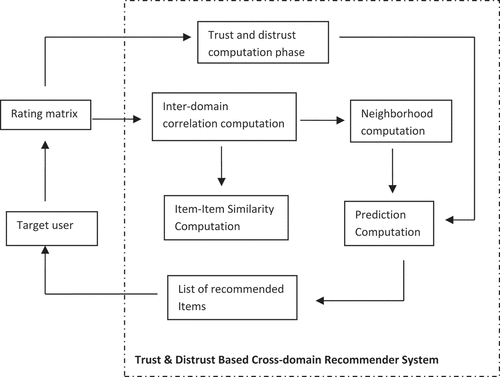
The cross domain recommendation computation uses the data from various source domains to enrich the data in the target domain. Similarity score for the target domain are computed using the user item data in the source/remote domain which provides a similarity score along with the list of neighborhood. As the agents of target domain receive the list of neighborhood from the source domain, it computes the overall similarity computation using the local similarity score, the list of neighborhood received from source domain and inter-domain correlation. The inter-domain correlation is used to find out the similarity between the two domains. To find out the inter-domain correlation computation the item-item similarity is used. The overall similarity computation between the target user and other users in the domain is done by averaging the similarity score of remote domain’s neighborhood along with the local similarity score and inter-domain correlation computation. The overall computation provides the list of neighborhood for the target user in the domain.
The next phase is trust and distrust computation phase. This phase provides the trustful and distrustful users whose opinions are used for the recommendation computation for the target user. The propagation phase of trust and distrust helps to combine those users which are not directly connected to the target user but may affect the recommendation when suggestions from them will be incorporated. Also, it may be possible that the users choice is not very effective at present but after some time it may begin with the trustworthy recommendation for the target user. The propagation steps consider this situation. The list of neighborhood from the cross domain approach is again filtered according to the presented list of trusted and distrusted user. After the filtering, prediction computation for the target user is generated in the target domain. Finally, the top-n list of recommendation is selected for the user.
Figure 2. Trust and distrust computation phase
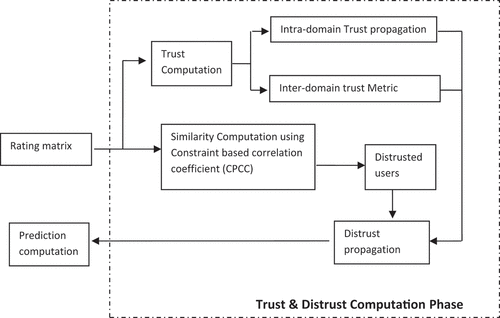
The trust and distrust computation phase of recommendation is shown in which uses rating list provided by the users for computation. The distrust computation phase is processed using the CPCC. The CPCC is a similarity computation method and it can find a difference between the positive and negative ratings provided by the user. A user, which shows the negative behavior as compared with the ratings of the target user, is considered as distrusted user. Trust score is computed using the prediction generated by comparing the ratings between the two users. The trust computation is divided into intra-domain trust computation followed by the intra-domain trust propagation and inter-domain trust computation.
The intra-domain trust is computed using the rating of users. The basic idea behind inter-domain trust is to find out the opinion of entire community about a particular user. So average of intra-domain trust value provides inter-domain trust score. The propagation step provides a chance to the other users in the domain whose choices may affect the target user’s interest but they are not directly connected by the target user. The same behavior is maintained for the distrust propagation also. Users which are considered as distrusted user, because of the negative similarity on the basis of their ratings provided, are filtered from the list of neighborhood. Distrust is propagated for the remaining users which can be reached through propagation but for which no distrust propagation path can be found. So the final prediction is computed by considering the trustful and distrustful users. The list of top-n items is passed as recommendation to the target user.
Working of Proposed System
Working of the proposed system is shown in .
Figure 3. Working of proposed TDCDCARS
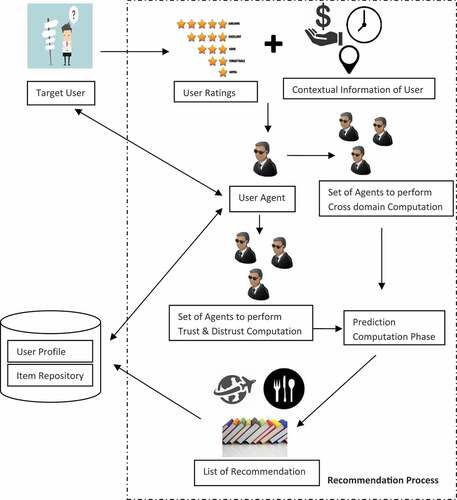
The system starts when the user enters into the system. It collects the ratings and the contextual information of the user and stores them into local repository. Corresponding to each user a user agent (UA) is created which is responsible for the communication between user and the system. User agent passes the query of user to the related agent and responds back with the recommendation once it is available after computation. Cross domain computation starts when the agents of the target domain requests to the agents of source domain to provide data for the target user. For the cross domain computation, the agents are created for various tasks, e.g., for the task of inter-domain correlation computation Inter-domain Correlation Agent (ICA) is formed. The similarity computation task is divided into two set of agents, first is to compute similarity score locally by Local Similarity Agent (LSA) and another is for the computation of similarity in remote domains by Remote Similarity Agent (RSA). The agents to compute overall similarity are Overall Similarity Agent (OSA) between the target user and other users in the domain.
The list of similar user as per the target user along with their similarity score is responded back to the target domain. After having the results from each corresponding agents OSA averages the result from the remote agents, i.e., RSA along with the inter-domain correlation agents, i.e., ICA and local similarity computation agent, i.e., LSA. This concludes the neighborhood computation from the cross domain recommendation process. Similarly for the trust and distrust computation corresponding agents trust agent (TA) and distrust agent (DA) perform computation for the users. For the trust and distrust propagation phase agents works periodically on their updates. The changes made by users in their rating patterns are included in the computation immediately by the agents.
Algorithm
The proposed TDCDCARS is divided into four phases: pre-processing phase, cross domain similarity computation phase, trust and distrust computation phase, and the recommendation phase.
Pre-processing Phase
The pre-processing step of computation involves the processing and managing the ratings of user into the local repository. The steps for the processing are
Step-1 Collection of ratings from the users
This step is used to collect ratings from the users for various domains involved in the computation. The rating for the items is collected in the scale of 1–5 where each has their own meaning. Rating −1 stands for awful, rating-2 means forgettable, rating-3 means good, rating-4 stands for excellent and rating-5 is for awesome. Corresponding to each user an agent UA is created by the system which processes the ratings of the user to the repository and keeps update about the same.
Step-2 Formation of input data
This step is responsible for managing the user data in the local repository. The data is collected for multiple domains and each domain consists of two-dimensional rating matrix which shares the same structure.
Cross Domain Similarity Computation Phase
This phase of computation involves multiple domains where the domains are divided into source domain and target domain. Domain for which the computation is performed is target domain and the rest of the domain who responds to the request is the source domain. Target user enters into the system and queries for the recommendation. This query is processed by UA to the set of agents for the cross domain computation. Following steps are used for the computation:
Step-1 Similarity computation between users
For similarity computation between two users in source domain Pearson’s correlation coefficient is used. Pearson’s correlation coefficient is formulated as:
Where,
and
denote the ratings of users x and y for ith item, respectively.
and
denote the average ratings of user x and y respectively.
Step-2 Inter-domain correlation computation
This step is used in the overall similarity computation as weight factor. The reason for computation of the inter-domain correlation is to find out the closeness between the two domains, i.e., remote domain and target domain. It is computed as follows:
Where,
is the similarity between two items.
is the set of items in the domain t.
There are two types of correlation technique that are used in the cross domain recommendation. One is content based correlation and another is rating based correlation. Here we are considering the second approach of correlation computation. The assumption behind the rating based correlation is that the two domains share non empty set of common users.
Step-3 Item-item similarity for inter-domain correlation
The inter-domain correlation computation uses item-item similarity computation. The correlation between two items belongs to two different domains. This computation is processed using pearson’s correlation coefficient. An item-item matrix is generated by iterating all the items and computing the similarity score for each pair of them in the corresponding domain.
Where,
is the average of the ith item ratings.
is the rating for an item i by user u.
Step-4 Overall Similarity computation
The cross domain recommendation is used to find out the neighborhood for the target user. After receiving the request of user from the agents of the target domain agents of remote domain starts computation for the similarity computation between the target user and other users locally. The computation provides neighborhood along with the similarity score of neighborhood. Combining the similarity score from the source domain and the inter-domain correlation are used to compute the overall similarity computation for the target user. Formula for the overall similarity computation is as follows:
Where,
denote the local similarity value between user a and b in tth domain.
denote the correlation between the target domain t and remote domain s.
Trust Computation and Propagation Phase
This phase is related to the computation of trust along with the propagation of trust.
Step-1 Intra-domain Trust Computation
For the intra-domain trust computation ratings provided by user in a domain is considered. When a target user ‘a’ provides rating for an item ‘i’ then corresponding to that item all the ratings is examined to find out the trustworthy users who have rated same as the target user. That means for the user item rating matrix it will iterate over the entire matrix for each row and for column of item ‘i’ to compare other users opinion:
Where,
denote the prediction for the rating generated from user b for target user a on item i.
rmax is the maximum rating scale.
is the rating for an item i by user a.
This Equationequation 5(5)
(5) provides a trust score of zero if the user has not rated the item. But if user has rated the item then a positive trust score will be returned. Again for user who have rated exactly same as target user a trust score 1 will be considered. The trust score varies linearly if the user will rate according to the scale of rating. The comparison of two ratings will provide the trust score between other users and the target user. So the trust score for user will be updated by averaging the value of all the ratings that the user has contributed.
Where,
represent the trust score of user a to user b
is all the ratings contributed by the user.
Step-2 Inter-domain Trust Metric
The inter-domain trust computation is user’s overall trust from all the domains present in the system. This computation for a user is basically the combination of local trust received from other users. Averaging the local trust score given by users for a user ua for the direct connection of the trust web.
Where,
is the overall trust score of the user t.
is the local trust score of the user t and
is the neighborhood of the
.
Step-3 Intra-domain Trust Propagation
Trust propagation is used to expand the list of trusted user in the user-item rating matrix by including users who have rated the target items but they are not directly connected to the target user. That means target user has no previous experience with the other user, i.e., there is no commonly rated item between them. The following formula is used for the trust propagation (Victor et al. Citation2009a):
Where,
is the mean value of user a.
is the trust value between user a and user u.
is the set of user which has a positive correlation with the user.
is the set of user whose positive correlation is found above the threshold for the target user.
The reason behind taking this strategy is to include all the possible way to obtain a positive weight for the user who has rated the particular item. The second term of the equation emphasize on the indirect relation to include a user’s weight.
Distrust Computation Phase
Step-1 Preprocessing phase
For the preprocessing of the distrust computation rating provided by the user is considered. This rating is in the scale of 1–5. Each rating has its meaning, i.e., 1-awful, 2-forgettable, 3-good, 4-excellent, 5-awesome. Since the rating scale is absolute this means that ratings below 3 is negative and above 3 is positive.
Step-2 Applying Constrained Pearson Correlation Coefficient
To consider the impact of positive and negative ratings we have used Constrained Pearson Correlation Coefficient (CPCC). The formula of CPCC is as follows:
Where,
is the average of the ith item ratings.
is the rating for an item i by user u.
is the median value in the rating scale.
The median value for this scale of 1-5 is 3. This will provide the similarity score between users in terms of both positive as well as negative. Since distrust is about how dissimilar two users are. So we can consider the users having negative similarity score as distrustful user for the target user. The distrusted users are filter out from the list and prepare for the distrust propagation phase.
Step-3 Distrust Propagation
Distrust propagation is basically used in the same manner as in Equationequation (7)(7)
(7) for the remaining those users which can be reached through propagation but for which no distrust propagation path can be found, and Constrained Pearson Correlation Coefficient scores for those in
with
, i.e., the remaining ones which have a positive correlation with a but do not belong to
nor
, i.e., neither trust nor distrust information is available about them (Victor et al. Citation2009a).
Where,
is the mean value of user a and
is the trust value between user a and user u.
is the set of user which has positive correlation with the user.
is the set of distrusted user having negative similarity compared with the target user.
is the set of user whose positive correlation is found above the threshold for the target user.
set of trust and distrust users.
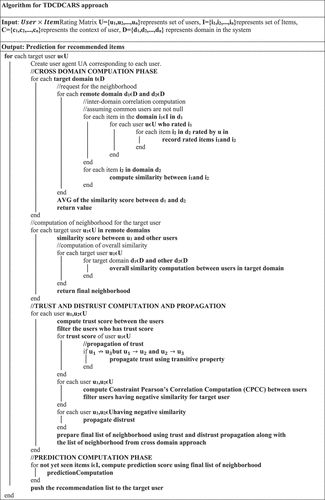
Prediction Computation and Recommendation Phase
Final list of neighborhood is the combination of both trust, distrust, and cross domain list. Further the propagation of trust and distrust provides a chance to include the experience of indirectly connected users. This list of users (directly connected or propagated) periodically updated by agents as it keeps an eye on the users rating pattern. The prediction computation is done on the basis of final list of neighborhood. The top-n item is selected according to decreasing order of prediction score and the list is sent to UA responding to the users query. This list of recommendations is further saved for future recommendation.
Experimental Analysis
A prototype of the TDCDCARS is designed and developed in the tourism domain using Java and JADE (Java Agent Development Environment) for constructing multi-agent environment. In the implemented system, the combination of food, lodging, shops, and places to travel is taken into consideration. NetBeans IDE 8.1 is used to develop the java programs. JADE is used to develop the Multi-Agent system and MySql 5.0.21 provides the data repository.
Dataset
We have used the tourism dataset which includes four domain of available restaurants, tourist places, shopping places, and places to stay of Delhi (India) is collected. The information about restaurants includes restaurants name, address, their opening and closing time, average cost per person etc. For hotels, this information includes hotel name, their location, charges etc. For shopping places and travel places, it includes their name, location, opening and closing time etc. The detail of restaurants, hotels, places, travel places, and shopping location is collected using the website http://www.zomato.com/ncr/restaurants, http://www.delhitourism.gov.in/delhitourism/tourist_place/index.jsp, http://www.zakoopi.com,http://www.shopkhoj.com, www.makemytrip.com,www.tripadvisor.in. This information is stored in the database and further processed to get longitudes and latitudes of each entry of the above mentioned. http://www.distancesfrom.com/latitude-longitude.aspxis used to collect the longitude and latitude by using available reverse geo-coding tools. The dataset contains 3857 restaurants, 1023 hotels, 139 places to shop, and 115 places to visit for entertainment or tourist spot.
Evaluation Measures
The performance of the system is evaluated in terms of accuracy and coverage. For the accuracy measure mean average error (MAE) is computed and shown in . The formula for MAE used is given below:
Table 1. MAE comparison for various domains
Where,
is the predicted rating for item i and
is the actual rating for item I and N is the total number of items in the list.
The same table is shown graphically in . The comparison of MAE is shown between the traditional recommendation approach (CF), Cross domain context aware recommender system (CDCARS), trust based cross domain recommender system (TCDCARS) and trust distrust-based cross domain context aware recommender system (TDCDCARS). The comparison of MAE shows that the proposed system TDCDCARS performs better.
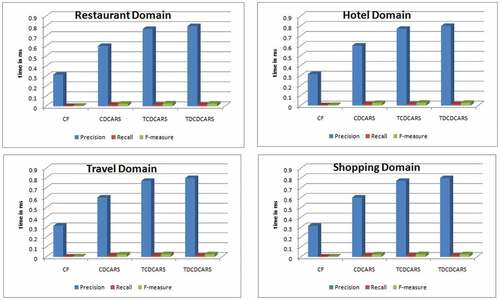
The coverage of the proposed approach is measured in terms of precision, recall, and f-measure. Precision is the ratio of relevant and retrieved from the number of items retrieved by the system. Recall is the ratio of relevant and retrieved from the items actually relevant. Formula for precision and recall is given as:
Precision and recall are conflicting in nature. Both precision and recall are the important factors that evaluate the system performance to generate the Top-n recommendations. So both precision and recall are combined to get the metric F-measure. The formula of F-measure is:
The precision, recall, and f-measure are shown in and the same is presented graphically ().
Table 2. Precision, recall, and F-measure comparison between various domains
Again the performance of the proposed system is compared with CF, CDCARS, TCDCARS, and TDCCARS. The tables show that the proposed system is more efficient than other approach.
The precision, recall, and F-measure values, shown in , suggest that the proposed system TDCDCARS is more efficient than other compared approaches.
Figure 4. MAE comparison for various domains
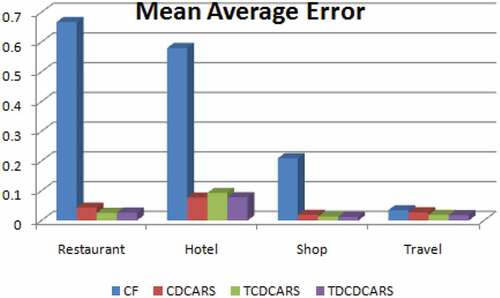
Figure 5. Precision, recall, and F-measure comparison between various domains
Conclusion
In this paper, we presented a trust and distrust-based cross domain context aware recommender system. The proposed system is a multi-agent-based system where multiple agents work simultaneously for the computation and other related tasks. An effort has been made in this paper to improve the accuracy and coverage of the list of recommendations. The rating data has been used in both trust and distrust computation as well as in cross domain computation. Cross domain computation exploits data from multiple domains to solve the sparse data problem. Once the agents of remote domain obtain request for the neighborhood computation from the agents of target domain, the computation process starts and the related agents of domain respond back with the list of neighborhood along with their similarity score. The trust computation is performed using the rating matrix of the user data. The inter-domain trust computation provides the trust factor of users across the domains. Distrust over trust has also significant effect on the recommendation. It helps to enhance the trust awareness between users and improve recommendation. Trust and distrust propagation provides the opportunity to include the experience of those users which are not directly connected with the target user but they can be reached by the directly connected users. Final neighborhood list is the combined effort by trust and distrust along with the contribution of cross domain computation. The prototype of the system is developed using jade and java technologies. Tourism domain consisting of four sub-domains restaurant, hotel, travel places, and shopping places is used for experimental study. Accuracy of the system is evaluated using MAE and for the coverage, we have used precision, recall, and f-measure. The proposed system TDCDCARS outperformed as compared to the traditional CF approach as well as CDCARS and TCDCARS in terms of precision, recall, f-measure, and accuracy.
Acknowledgments
The Author duly acknowledges University Grant Commission (UGC) of India for supporting this research work via UGC MRP Grant No. [42-139/2013 (SR)] to Dr. Punam Bedi.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
References
- Abdul-Rahman, A., and S. Hailes, 2000. Supporting trust in virtual communities. In System Sciences 33rd Annual Hawaii International Conference. Maui, HI, USA, USA. IEEE.
- Abowd, G. D., Christopher G. Atkeson, Jason Hong, Sue Long, Rob Kooper, and Mike Pinkerton 1997. Cyberguide: A mobile context-aware tour guide. Wireless Networks. 3(5):pp.421–33. doi:10.1023/A:1019194325861.
- Adomavicius, G., and A. Tuzhilin. 2011. Context-aware recommender systems. In Recommender systems handbook, 217–53. Boston, MA: Springer.
- Anand, D., and K. K. Bharadwaj. 2013. Pruning trust–distrust network via reliability and risk estimates for quality recommendations. Social Network Analysis and Mining 3 (1):65–84. doi:10.1007/s13278-012-0049-9.
- Badrul, S., G. Karypis, J. Konstan, and J. Riedl, 2001. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web. Hong Kong: ACM.
- Bedi, P., and S. K. Agarwal, 2012. Situation aware proactive recommender system. In 12th International Conference on Hybrid Intelligent Systems. Pune, India, IEEE Xplore.
- Bedi, P., S. K. Agarwal, V. Jindal, and Richa. 2014. MARST: Multi-Agent Recommender System for e-Tourism Using Reputation Based Collaborative Filtering. In Springer, ed. International Workshop on Databases in Networked Information Systems, 189–201. Aizu-Wakamatsu City, Japan: Springer International publishing.
- Bedi, P., Richa, S. K. Agarwal, and V. Bhasin, 2016. ELM based imputation-boosted proactive recommender systems. In Advances in Computing, Communications and Informatics (ICACCI). Jaipur India, IEEE.
- Benesty, J., Y. Huan, and J. Chen, 2009. Pearson correlation Coefficient. In Springer Berlin Heidelberg: Springer Topics in Signal Processing. Tianjin, China: Springer, Berlin, Heidelberg.
- Berkovsky, S., T. Kuflik, and F. Ricci, 2007a. Cross-domain mediation in collaborative filtering. In International Conference on User Modeling, Corfu, Greece : Springer Berlin Heidelberg.
- Berkovsky, S., T. Kuflik, and F. Ricci, 2007b. Distributed collaborative filtering with domain specialization. In ACM conference on Recommender systems. Minneapolis, MN, USA, ACM.
- Berkovsky, S., T. Kuflik, and F. Ricci. 2008. Mediation of user models for enhanced personalization in recommender systems. User Modeling and User-adapted Interaction 18 (3):245–86. doi:10.1007/s11257-007-9042-9.
- Berkovsky, S., Y. Eytani, and T. Kuflik, 2007. Enhancing privacy and preserving accuracy of a distributed collaborative filtering. In ACM conference on Recommender systems. Minneapolis, Minnesota, USA, ACM.
- Borras, J., M. Antonio, and V. Aida. 2014. Intelligent tourism recommender systems: A survey. Expert Systems with Applications 41 (16):pp.7370–89. doi:10.1016/j.eswa.2014.06.007.
- Burke, R., 1999. Integrating knowledge-based and collaborative-filtering recommender systems. In Workshop on AI and Electronic Commerce, Orlando, Florida. AAAI.
- Cantador, I., I. Fernández-Tobías, S. Berkovsky, and P. Cremonesi. 2015. Cross-domain recommender systems. In Recommender Systems Handbook, 919–59. US: Springer, Boston, MA.
- Chen, A. 2005. Context-aware collaborative filtering system: predicting the user’s preference in the ubiquitous computing environment. LoCA 3479:244–53.
- Cremonesi, P., A. Tripodi, and R. Turrin, 2011. Cross-domain recommender systems. In Data Mining Workshops (ICDMW). Vancouver, Canada: IEEE.
- Das, A. S., 2007. Google news personalization: Scalable online collaborative filtering. In Proceedings of the 16th international conference on World Wide Web. New York; NY; United States, ACM.
- Dey, A. K. 2001. Understanding and using context. Personal and Ubiquitous Computing 5 (1):pp.4–7. doi:10.1007/s007790170019.
- Fabiana, L., Fabio Arreguy Camargo Correa, Ana LC Bazzan, Mara Abel, and Francesco Ricci 2010. A multiagent recommender system with task-based agent specialization. In Agent-Mediated Electronic Commerce and Trading Agent Design and Analysis. New York, USA: Springer Berlin Heidelberg.
- Fernández-Tobías, I., and I. Cantador, 2015. On the use of cross-domain user preferences and personality traits in collaborative filtering. In International Conference on User Modeling, Adaptation, and Personalization. Cham, Springer.
- Fernández-Tobías, I., I. Cantador, M. Kaminskas, and F. Ricci, 2011. A generic semantic-based framework for cross-domain recommendation. In 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems. Chicago, Illinois, USA, ACM.
- Gallo, G., G. Signorello, G. M. Farinella, and A. Torrisi, 2017. Exploiting Social Images to Understand Tourist Behaviour. In International Conference on Image Analysis and Processing. Catania, Italy, Springer, Cham.
- Golbeck, J., B. Parsia, and J. Hendler. 2003. Trust networks on the semantic web. In Cooperative information agents, 238–249. Helsinki, Finland: Springer.
- Guha, R., R. Kumar, P. Raghavan, and A. Tomkins, 2004. Propagation of trust and distrust. In 13th international conference on World Wide Web. New York, USA: ACM.
- Hwang, C.-S., and Y.-P. Chen, 2007. Using trust in collaborative filtering recommendation. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. Wrocław, Poland, Springer, Berlin, Heidelberg.
- Jamali, M., and M. Ester, 2009. Trustwalker: A random walk model for combining trust-based and item-based recommendation. In 15th ACM SIGKDD international conference on Knowledge discovery and data mining. Paris, France, ACM.
- Jøsang, A., R. Ismail, and C. Boyd. 2007. A survey of trust and reputation systems for online service provision. Decision Support Systems 43 (2):pp.618–44. doi:10.1016/j.dss.2005.05.019.
- Kant, V., and K. K. Bharadwaj, 2011. Incorporating fuzzy trust in collaborative filtering based recommender systems. In International Conference on Swarm, Evolutionary, and Memetic Computing. Visakhapatnam, India, Springer, Berlin, Heidelberg.
- Khan, M. M., and R. Ibrahim. 2017. Cross Domain Recommender Systems: A Systematic Literature Review. ACM Computing Surveys (CSUR) 50 (3):pp.1–34. doi:10.1145/3073565.
- Lathia, N., S. Hailes, and L. Capra, 2008. Trust-based collaborative filtering. In IFIP International Conference on Trust Management. Boston, MA, Springer.
- Li, Y., L. Lu, and L. Xuefeng. 2005. A hybrid collaborative filtering method for multiple-interests and multiple-content recommendation in E-Commerce. Expert Systems with Applications 28 (1):pp.67–77. doi:10.1016/j.eswa.2004.08.013.
- Liu, H., Zheng Hu, Ahmad Mian, Hui Tian, and Xuzhen Zhu. 2014. A new user similarity model to improve the accuracy of collaborative filtering. Knowledge-Based Systems 56:pp.156–66. doi:10.1016/j.knosys.2013.11.006.
- Ma, X., H. Lu, and Z. Gan, 2015. Implicit trust and distrust prediction for recommender systems. In International Conference on Web Information Systems Engineering. Shanghai, China: Springer International Publishing.
- Ma, X., H. Lu, Z. Gan, and J. Zeng. 2017. An explicit trust and distrust clustering based collaborative filtering recommendation approach. Electronic Commerce Research and Applications 25:pp.29–39. doi:10.1016/j.elerap.2017.06.005.
- Massa, P., and P. Avesani. 2004. Trust-aware collaborative filtering for recommender systems. CoopIS/DOA/ODBASE 3290 (1):pp.492–508.
- Melville, P., R. J. Mooney, and R. Nagarajan, 2002. Content-boosted collaborative filtering for improved recommendations. In Aaai/ iaai. Edmonton, Alberta, Canada, AAAI.
- Morais, A. J., E. Oliveira, and A. M. Jorge, 2012. A Multi-Agent Recommender System. In: Omatu, S., J. De Paz Santana, S. González, J. Molina, A. Bernardos, J. Rodríguez (eds) Distributed Computing and Artificial Intelligence. Advances in Intelligent and Soft Computing, vol 151. Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-642-28765-7_33
- O’Donovan, J., and B. Smyth, 2005. Trust in recommender systems. In 10th international conference on Intelligent user interfaces. San Diego, California, USA: ACM.
- Papagelis, M., D. Plexousakis, and T. Kutsuras, 2005. Alleviating the sparsity problem of collaborative filtering using trust inferences. In Trust management. Paris, France, Springer-Verlag Berlin Heidelberg.
- Rafailidis, D., and F. Crestani, 2017. Learning to Rank with Trust and Distrust in Recommender Systems. In Eleventh ACM Conference on Recommender Systems. Como, Italy, ACM.
- Resnick, P., and V. R. Hal. 1997. Recommender systems. Communications of the ACM 40 (3):56–58. doi:10.1145/245108.245121.
- Ricci, F., L. Rokach, B. Shapira, and P. B. Kantor. 2011. Recommender Systems Handbook. New York, USA: Springer.
- Richa and Punam Bedi, P., 2016. Parallel context aware recommender system using GPU and JCuda. In IEEE, ed. In Advances in Computing, Communications and Informatics (ICACCI). Jaipur, IEEE.
- Rosa, A. J. L. D. L., G. González, and B. López, 2005. A multi-agent smart user model for cross-domain recommender systems. In Proceedings of Beyond Personalization IUI’05. San Diego, California, USA, AAAI.
- Santos, F., A. Almeida, and C. Martins. 2017. Using POI functionality and accessibility levels for delivering personalized tourism recommendations. Computers, Environment and Urban Systems, 77 (1).
- Schafer, J. B., D. Frankowski, J. Herlocker, and S. Sen. 2007. Collaborative filtering recommender systems, In The adaptive web 4321. Berlin, Heidelberg: Springer.
- Shardanand, U., and P. Maes, 1995. Social information filtering: Algorithms for automating “word of mouth”. In SIGCHI conference on Human factors in computing systems. Denver, Colorado, USA: ACM Press/Addison-Wesley Publishing Co.
- Victor, P., C. Cornelis, M. D. Cock, and A. Teredesai, 2009a. A comparative analysis of trust-enhanced recommenders for controversial Items. In ICWSM. San Jose, California: AAAI.
- Victor, P., C. Cornelis, M. D. Cock, and A. Teredesai. 2009b. Trust-and distrust-based recommendations for controversial reviews. IEEE Intelligent Systems 26 (1):pp.48–55. doi:10.1109/MIS.2011.22.
- Victor, P., C. Cornelis, M. D. Cock, and P. P. D. Silva. 2009. Gradual trust and distrust in recommender systems. Fuzzy Sets and Systems 160 (10):pp.1367–82. doi:10.1016/j.fss.2008.11.014.
- Victor, P., M. Cock, and C. Cornelis. 2011. Trust and recommendations. In Recommender Systems Handbook edited by Ricci F., Rokach L., Shapira B., Kantor P, 645–75. Boston, MA: Springer.
- Wan-Shiou, Y., and S.-Y. Hwang. 2013. iTravel: A recommender system in mobile peer-to-peer environment. Journal of Systems and Software 86 (1):pp.12–20. doi:10.1016/j.jss.2012.06.041.
- Xiao, S., and I. Benbasat, 2003. The formation of trust and distrust in recommendation agents in repeated interactions: A process-tracing analysis. In 5th international conference on Electronic commerce. Pittsburgh, Pennsylvania, USA, ACM.
- Yeung, K. F., and Y. Yang, 2010. A proactive personalized mobile news recommendation system. In Developments in E-systems Engineering (DESE). London, UK: IEEE.
- Zhang, Y., C. Bin, and D.-Y. Yeung, 2010. Multi-domain collaborative filtering. In 26th conference on Uncertainty in Artificial Intelligence. Catalina Island, CA, USA. arXiv.
- Ziegler, C.-N., and G. Lausen, 2004. Spreading activation models for trust propagation. In e-Technology, e-Commerce and e-Service, EEE’04. Taipei, Taiwan, IEEE.