
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Facial age estimation has grasped the attention of numerous researchers in recent times. It is a challenging task as a consequence of illumination, pose variations, occlusion, complex background, facial expression, and facial makeup. Estimating the age of an individual with an arbitrary pose is quite a challenging job because most of the age estimation system focuses on the frontal view. In this paper, a novel framework for multi-view age estimation by amalgamating the local and global features is proposed. A novel texture feature, Median Gradient Ternary Pattern is proposed in this paper. The Pseudo Zernike Moment extracts the shape features and the View-based Active Appearance Model constructs an appearance model from the facial images. Further, all three features are combined into a feature vector by executing feature-level fusion. The dimension of the combined feature is reduced using Principal Component Analysis. Multi-class Support Vector Machine is utilized to divide the images into four poses. For each pose, a Support Vector Regression with RBF kernel is applied to train a model for estimating the actual age of an individual. The proposed methodology is performed on two databases, namely, FG-NET and CACD which showcase eminent performance.
Introduction
The face of a human embraces lots of data identified with individual qualities, for instance, age, identification, race, emotion, and sex. As of now, age can assume an imperative part in several applications, for instance, age-based access control, age prediction systems to find out the lost kids, internet access control, crime investigation, age-based retrieval of face images from the search engine, and vending machine. For example, it can keep away minors from getting liquor or cigarettes from vending machines, or it can convey digital content depending on age to adapt messages accordingly. Facial aging is a confounded procedure and it is irreversible and slow. The face growth and aging forms in human beings’ lifetime constitute two phases namely newborn to adulthood and from adulthood to old age. In the initial phase, craniofacial change is tremendous and the least change in skin texture. The later stage exhibits a rapid change in skin texture. Intrinsic (i.e., ethnicity, heredity, sexual orientation) and external factors (i.e., environment, lifestyle) can impact aging. All these components cause difficulty to accurately estimate a person’s age, even by people. Additionally, different perturbations on facial pictures, for example, lighting, facial expression, posture, occlusion, blur, facial cosmetics, plastic surgery, make the age estimation even more difficult. Among these factors, estimating the age of a person with an arbitrary pose is the most troublesome issue. In this paper, a novel framework for multi-view age estimation by utilizing hybrid features is proposed. The hybrid features, which is a mixture of local and global features, have gotten adequate consideration since the flaws found in individual global and local feature can be made up using this strategy. The human pose is partitioned into three rotations: [−20°, +20°] pitch, roll (360°) and yaw [−90°, +90°]. To simplify the multi-pose issue and without loss of generality, only yaw rotation is taken into account. Yaw rotation represents the face turned to the left and the right side. VAAM is a global feature and they offer greater amounts of information concerning the texture and shape of a face. VAAM (Cootes, Walker, and Taylor Citation2000) is utilized to construct an appearance model which embodies both the shape and texture variability in the images. Four different models are trained on labeled images for four different poses. Every single example pose can then be approximated using the suitable appearance model with a vector of parameters, c. As there is a change in orientation, the parameters approximately trace out an elliptical path. PZM (Pang, Teoh, and Ngo Citation2015) relies on the global information of the image and it is used as a shape feature descriptor in numerous pattern recognition applications. PZM is robust to image quantization error and provides better feature representation capability. The proposed Median Gradient Ternary Pattern (MGTP) is a local feature that amalgamates the advantage of Local Gradient Pattern (LGP) (Jun and Kim Citation2012) and Median Ternary Pattern (MTP) (Khan et al. Citation2013) in the same compact encoding scheme. In MGTP, the pixel values in the neighborhoods of the specified central pixel are replaced with the gradient values and the center pixel value is substituted by the median of the gradient values, which give rise to a better representation of the large-scale structure and more robust to random noises. Based on the local median and a threshold value defined by the user, a three-value (1, 0,-1) ternary code is obtained for every single pixel. This three-level coding pattern produces consistent texture patterns with the local image property and a certain degree of magnitude difference information is incorporated in the feature representation which makes it more robust in the presence of non-monotonic illumination variation. All the three features are fused using a feature level fusion and given as an input to PCA for dimensionality reduction. Estimating the age from a multi-view facial image is more complex and designing a feature invariant to orientation is very difficult. For that reason, the input image is partition into four poses according to face orientations. Therefore, the multi-view problem is disintegrated into easier classification tasks. Multi-class SVM is used to classify the reduced feature into four poses according to its orientation. Images in the range [0°~+45°] are grouped as right-half profile (PO1), images in the range [+45°~+90°] are grouped as right profile (PO2), images in the range [0~-45°] are grouped as left-half profile (PO3), and images in the range [−45°~-90°] are grouped as left profile (PO4). For each pose, SVR with RBF kernel is used to determine the age of an individual.
Our research is novel in the accompanying three courses, contrasted with the past works. Firstly, a new framework is proposed for multi-view age estimation. Secondly, the age estimation accuracy is incredibly enhanced by merging local and global features. Thirdly, a novel texture feature descriptor is proposed to boost the performance of the hybrid feature.
The rest of this paper is structured in this fashion: Section 2 elaborates the related work on age estimation. The proposed framework is explained in Section 3. Section 4 gives details about the experimental results of the proposed approach and Section 5 summarizes our work with future directions.
Related Works
There has been an enormous number of researches for facial age estimation. Kwon and Lobo (Citation1999) calculated geometric distance amongst various facial features. The age was grouped into 3 categories, namely, babies, adults, and seniors depending on the size of the chosen facial characteristics and the number of facial wrinkles. However, various facial orientation, accurate estimation of top of the skull and robustness to facial hair was not explored. Thukral et al. (Thukral, Mitra, and Chellappa Citation2012) used five classifiers such as μ-SVC, Fisher Linear Discriminant, Partial Least Squares (PLS), Naive Bayes, and Nearest Neighbor to classify the age. The age of an individual was estimated by the Relevance Vector Machine. The framework lacks the incorporation of texture features. In the Aging Pattern Subspace (Geng, Zhou, and Smith-Miles Citation2007), the aging pattern is described as a grouping of face pictures from a similar individual which is arranged in a time-based order. FG-NET database was used to analyze the performance of the approach and accomplished a Mean Absolute Error (MAE) of 6.77 years. The preprocessing involved in the methodology relies on landmark points. The face size varies across ages, the methodology lacks face size information during preprocessing. However, it is difficult to collect numerous face pictures of a similar person at different ages. Li et al. (Li et al. Citation2012) predicted the age of an individual by concentrating on ordinal discriminative feature learning. Various feature selection methods, such as Laplacian Score, Rank Boost, Least Angle Regression (LAR), Piecewise Linear Orthonormal (PLO), and Fisher Score were utilized to reduce the dimension of the information from both the ordinal information and locality information by decreasing the rank correlation and non-linear correlation. Amongst all the feature selection techniques, the PLO was considered the best as it achieved an accuracy of 88.0%. Guo and Mu (Citation2011) utilized the Kernel Partial Least Squares regression (KPLS) to estimate the age of a person. The dimension of the feature was reduced by KPLS and the aging function was also learned. The dimensionality of the original space was reduced by KPLS by finding a petite number of latent variables which can increase the performance of the method. A craniofacial growth model was built by Ramanathan and Chellappa (Citation2006). This model was used to characterize the facial shape growth variations by facial landmarks. Their framework only classified a facial image into 4 categories, namely, babies, young adults, and seniors, but the exact age of a person was not estimated. The framework does not take into account texture model, facial hair, and change in baby fat. Chang et al. (Chang, Chen, and Hung Citation2011) separated the age estimation issue as a series of sub-problems of binary classifications by using ordinal hyperplane ranking (OH Ranker). Gao and Ai (Citation2009) utilized the Gabor feature and fuzzy Linear Discriminant Analysis (LDA) and categorized the age into four groups like baby, child, adult, and old. 5408 pictures were used for training and 91% accuracy was achieved. Age estimation was viewed as a regression problem by Yan et al. (Yan et al. Citation2007) with non-negative label intervals and the issue was handled using definite programming. They solved this regression problem by introducing an EM algorithm and the optimization process was speeded up. Rather than learning a specific aging pattern for every person, a typical aging trend or pattern can be gained from numerous people of various ages. Yan et al. (Yan et al. Citation2008) introduced a patch-based regression method and the regression error was reduced. Each image was programmed as a group of order less coordinate patches of GMM (Gaussian Mixture Model) distribution. Then, a patch-kernel was designed which illustrate the Kullback-Leibler divergence among the derived models. To improve its discriminating power, inter-modality similarity synchronization was utilized. Kernel regression was utilized to estimate the age of an individual. The coordinate patch models geometric regions indicate head pose moments and is robust to image occlusion thereby contributing better performance. Khanmohammadi et al. (Khanmohammadi, Ghaemi, and Samadi Citation2013) extracted the texture and wrinkle features utilizing the Local Binary Pattern (LBP) and Histograms of Oriented Gradients (HOG). The age was categorized into 4 Groups: Underage (0–18), Young-age (19–35), Middle-age (36–59), and Old-age (60–94). This algorithm provides better accuracy with the restriction of a wide-ranging age group. Yasumoto et al. (Yasumoto, Niwa, and Koshimizu Citation2002), the age prediction was done by extracting the wrinkles from the face. 300 images captured under controlled conditions ranging from 14–65 years were used for training. To enrich the wrinkles features, histogram equalization was done on the facial skin region. DTHT (Digital Template Hough Transform) was utilized to extract the wrinkles which are longer and shorter. The age was estimated by utilizing a look-up table. 72% of accuracy was achieved for age estimation. It was difficult to extract the wrinkles on females because of the presence of facial make-up. Zhang and Yeung (Citation2010) formulated the inference of each person’s age as a Warped Gaussian Process (WGP) estimation problem and developed a multi-task extension of WGP to tackle the issue. Since different individuals have different aging processes, personalization is valuable for age estimation. The major advantage of the framework is, the model parameters θ and σ are learned automatically without using model selection. Malek et al. (Malek, Azimifar, and Boostani Citation2017) estimated the age of a person using Zernike Moment (Mahesh, Noel, and Raj Citation2018). Both local and global characteristics of a face are captured by the Zernike Moment and work well even in the presence of makeup and accessories. The features extracted using Zernike Moment are fed to three classifiers, namely, K-Nearest Neighbor (KNN), Support Vector Regression (SVR), and Multi-Layer Perceptron (MLP) neural network. The system was evaluated on the FG-NET dataset and obtained a MAE of 4.21, 6.21, and 9.35 for MLP, SVR, and KNN classifiers, respectively. The main advantage of Zernike Moment is scale, shift and rotation -invariant of orthogonal moments. Sahoo and Banka (Citation2018) developed an age estimation system that preserved personalized aging traits and was robust to change in appearance, texture, pose, shape, expression, wrinkle, and illumination. Shape, wrinkle, and texture features are extracted using Active Shape Model (ASM), Gabor filter, and Multi-block Local Binary Pattern (MBLBP) respectively. Canonical Correlation Analysis (CCA) was used to combine two or more independent features. The age of a person was estimated by a three-level SVM and SVR-based hierarchical classifier by choosing a suitable combination of hybrid features at different levels. The experimental results show that a MAE of 4.05 years and 3.26 years were obtained for FG-NET-AD and MORPH Album-2 database. The lack of labeled facial images for age estimation was addressed by Dong et al. (Dong, Lang, and Feng Citation2019). The ordinal relationships among various age labels are learned with limited training samples. A structured sparse multiclass classification model was employed. The structured sparse regularization encodes the ordinal relationships among various age labels. The samples with similar age labels are close to each other in the feature space. The methodology was evaluated using two datasets namely, FG-NET and MORPH II datasets, and achieved a MAE of 4.25. Local Direction and Moment Pattern (LDMP) was proposed to utilize the textural and directional variation due to aging (Sawant, Addepalli, and Bhurchandi Citation2019). The orientation is encoded in eight directions. The magnitudes of higher order moments are encoded into texture information. The orientation and texture are amalgamated into a feature descriptor. A warped Gaussian process regression is applied to estimate the age. LDMP preserves the wrinkles and shapes with the directional filters. The experiment was performed with FG-NET and MORPH II databases achieving a MAE of 4.6. Guehairia et al. (Guehairia et al. Citation2020) used Deep Random Forest (DRF) to address the problem of image-based age estimation. DRF is an ensemble of decision trees ensembles tied in a cascade form. FG-NET, PAL, and MORPH II databases were used to assess the performance of the system and obtained a MAE of 3.82.
The Proposed Framework
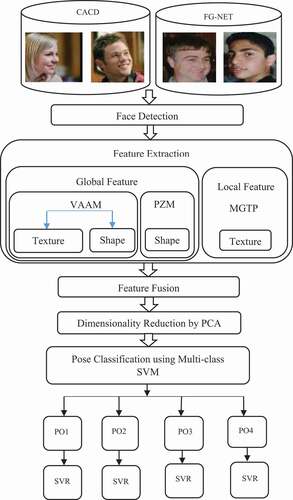
The architecture of the proposed multi-view age estimation framework is shown in .
Figure 1. Architecture for the proposed multi-view age estimation.
Face Detection
Face detection is the initial process of age estimation (V. Kumar, Namboodiri, and Jawahar Citation2015). Dense-SIFT is extracted from the images and a k-means based vocabulary is generated followed by feature quantization. Term frequencies (TF) and inverse document frequencies (IDF) are obtained and inverted files are constructed alike Bag-of-words (BOW) retrieval scheme. During testing, all the exemplars jointly take part in the Hough-based voting process that utilizes the spatial locations of features to locate the faces in a given image (Gall et al. Citation2011). The input image and face detection output are shown in . The detected face is given as an input to the feature extraction process.
Figure 2. (a) Input image (b) Detected face.

Feature Extraction
View-based Active Appearance Model
The combination of shape and texture variation are encoded in an appearance model. Based on the PCA, the shape and the texture model are learned independently from the training images. PCA on texture and shape data yield a parametric face model that portrays new faces along with learned faces. 68 landmark points are generated on the eyes, chin, mouth, and nose. The facial images with 68 landmark points are shown in .
Figure 3. Facial images with 68 landmark points.

A model which depicts the shape variation is build using PCA on the whole set of landmark points. A shape is portrayed as a vector of coordinates from the landmark points. The facial shape is represented as s and texture is represented as t. The shape and the texture are controlled by the appearance model parameters, c, according to
where indicates the mean shape,
indicates the mean texture and
and
matrices portraying the types of variation from the training set.
and
are formed from the Eigenvectors of the covariance matrices of the data. A sample image can be synthesized for a given c by developing a texture image from the vector t and warping it by utilizing the control points portrayed by s.
Pseudo Zernike Moment
PZM is a statistical-based feature extraction technique, which relies on the global information of the image to extract the feature vector elements. The pseudo-Zernike basis is a set of an orthogonal polynomial, which is depicted as follows
where the polynomials are well-defined over the polar coordinates inside a unit circle is the angle between this vector and x-axis,
is the order of PZM and b is the repetition of PZM
is called radial polynomial and it is defined as
The PZM for an image f(x,y) is calculated as
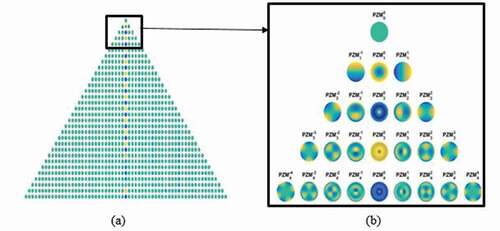
where and PZM is calculated for the positive value of b. PZM is robust to slight changes in shape and noise. ) shows the pseudo-Zernike polynomials with orders a = 0 to 30. For a more clear understanding, ) shows the first 4 pseudo-Zernike polynomials.
Figure 4. (a). Pseudo-Zernike polynomial for order 0 to 30 (b). Pseudo-Zernike polynomial for orders 0 to 4.
Median Gradient Ternary Pattern
A novel texture descriptor called Median Gradient Ternary Pattern is proposed in this paper. The MGTP operator makes utilization of the neighborhood gradient values of the specified central pixel. The neighborhood pixel values of the given central pixel are replaced with the gradient values and the center pixel value is substituted by the median of the gradient values. With a specified pixel as the center, a circle with radius R is considered with N sampling points on the circle. The gradient value between the center pixel and its neighboring pixel
is characterized as
and the median of N gradient values is calculated
. The MGTP at a location (x,y) can be defined as
where g is the gradient gray level, t is a threshold defined by the user and n runs over the 8 neighbors of the center pixel so that the length of the resulting histogram (including the bin-0 location) is 38. Hence, 38 = 6561 bins are required to represent the values in a histogram. This increases the computational complexity, so to reduce the computational complexity, each MGTP code is divided into its corresponding positive (PMGTP) and negative binary codes (NMGTP). Thereby, the bin number is reduced from 38 to 2 × 28 = 512. The “positive” code, is calculated as:
The “negative” code, is calculated as:
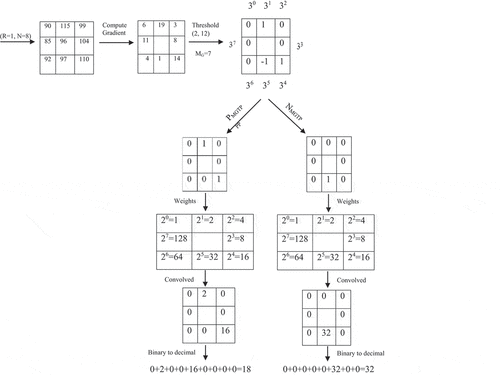
The histograms generated from PMGTP and NMGTP are then concatenated to create the final MGTP histogram. This combined histogram is then used as a final feature vector. shows the procedure for calculating the MGTP.
Figure 5. Illustration of MGTP for a 3 × 3 neighborhood.
Feature Fusion
Feature level fusion, decision level fusion, and score level fusion are used to amalgamate multiple features in biometrics (Ross and Jain Citation2003). Combining features using feature-level fusion comprises richer information about the raw data (Ross and Govindarajan Citation2004). Hence, feature-level fusion is used to amalgamate the local and global features. After extracting the three features, namely, VAAM PZM
, and MGTP
, feature normalization is carried out using z-score normalization as,
where indicates the
feature vector,
indicates the mean and
indicates the standard deviation of the
feature vector and
indicates the normalized feature vector. The normalized features are concatenated to create the fused feature as
The feature dimension increases due to concatenation, therefore PCA is used to reduce the feature dimension.
Principle Component Analysis
The PCA finds a lower-dimensional subspace that gives promising details of age estimation. The PCA method find out the embedding that maximizes the projected variance given underneath
where is the scatter matrix,
is the mean vector of training data and
is the
feature vector with D dimension. A set of d D eigenvectors (Z) related to the d largest eigenvalues of S is attained. The dimensionality reduction is performed by calculating
where
is the projected new feature with dimension d.
Multi-class SVM
Support Vector Machine (SVM) (Cortes and Vapnik Citation1995) was initially designed to perform binary classification. Later, the classification was expanded to multi-class classification by using methods such as one-against-all, one-against-one, etc (Hsu and Lin Citation2002). Multi-class SVM is designed as a pose classifier based on the “one-against-all” technique to classify the images into four poses. Four binary SVM classifiers are formed with a non-linear radial basis kernel, where each classifier distinguishes one pose class from the remaining three pose classes. The m training points of the form where
represents the feature vector of the
sample, and
represents the class label of
, the
SVM solves the following problem:
s.t ,
where if
and
otherwise. The decision function is given by
. A new sample u will be classified in the class which attains the highest value of
i.e. u is in
th class when
. If more than one class attains this maximum, then the new sample u will be classified in the class related to the lowest index
by convention.
Support Vector Regression (SVR) With RBF Kernel
Given the m training points ,
,
, i = 1, …, m where
denotes sample i with label
. The SVR predicts a function v = f(u), which is defined as:
where ) is the feature vector of an input image, which is mapped from space u to a higher-dimensional space, b is the bias and w is the vector for the regression coefficient. SVR concurrently tries to maximize the margin width and minimize the regression error. The optimal regression function is termed as
where C > 0 finds out the trade-off between the flatness of f and data deviations, and are slack variables. A radial basis function is defined in EquationEquation. (16
(16)
(16) )
where is a constant to adjust the width of the Gaussian function. Given the kernel mapping, the solution of the non-linear SVR is attained as
and
where are the Lagrange multipliers.
Algorithm 1 explains the steps involved in the proposed multi-view age estimation framework.
Algorithm 1: Multi-view age estimation algorithm
Input: Face image from the dataset
Output: Estimated age of the input image
1: for i = 1 → n do ►n is the total number of images in the dataset
2: The face region is detected using an exemplar-based method
3: Crop the face and convert it into a grayscale image
4: Compute the VAAM feature
5: Landmark points are marked on each face
6: The training images are divided into four pose sets.
7: For each pose
8: Align landmark points with Procrustes Analysis
9: Apply PCA to the aligned landmark points and obtain the mean shape and shape model
10: Wrap each training image landmarks to the learned mean shape, acquiring a “shape-free patch.”
11: Apply PCA to the warped images and obtain the mean texture and texture model.
12: Apply PCA to the concatenated shape and texture parameters to acquire a combined appearance model.
13: end for
14: The PZM of order a and repetition b for an image f(x,y) is formulated as
15: Extract the MGTP feature
16: Compute the gradient value between the center pixel and its neighboring pixel
as
17: The MGTP descriptor is computed as
18: The MGTP code is divided into “positive (” and “negative (
” binary codes.
19: Concatenate and
to form a feature vector
20: Combine,
and
by feature level fusion
21: Reduce feature dimension using Principle Component Analysis.
22: Multi-class SVM classifies the reduced feature into four poses (PO1 ([0°~+45°]), PO2 ([+45°~+90°], PO3 ([0 ~ −45°]),), PO4 ([−45°~ −90°]),).
23: for each pose, PO = 1 → 4
24: Estimate the age using SVR Based RBF kernel
25: end for
26: end procedure
Experimental Details and Result Analysis
FG-NET (Lanitis and Tsapatsoulis Citation2015) and Cross-Age Celebrity Dataset (CACD) (Chen, Chen, and Hsu Citation2015) are the benchmark databases for age estimation and it comprises pictures caught in the wild condition. FG-NET database comprising of 1,002 face pictures belonging to 82 subjects with an age range of 0–69 years. All the images are annotated with pose information, landmark points, and age information and are subjective to pose variation, illumination, and facial expression. Cross-Age Celebrity Dataset (CACD) is the largest public cross-age database of 2000 celebrities were collected from the internet. This database contains 163,446 pictures with an age range of 16–62 years. The images are subjected to pose variation, facial makeup, and illumination variation. The celebrities’ age can be ascertained by subtracting the birth year from the time at which the picture was taken. The summary of the database used in our experiment is shown in . Sample facial images from FG-NET, CACD with their age for yaw rotation are shown in . MATLAB is used for implementing the proposed methodology. . The database used in our experiment
Table 1. The database used in our experiment
Figure 6. Images with Yaw rotation (a) FG-NET (b) CACD.

The face detection process is done using an exemplar-based method, which utilizes an accumulation of discriminatively trained exemplars for detection. Every single exemplar casts a vote utilizing retrieval framework and generalized Hough voting, to discover the faces in the test picture. The detected face is cropped and changed into a grayscale image. The feature extraction strategy takes this grayscale picture as an input. For VAAM feature representation, the face landmark points have to be given in advance. FG-NET database has been provided with the 68 landmark points for each face image but for the CACD database, the 68 landmark points were annotated manually. These 68 landmark feature points were utilized for VAAM training. Four distinct models were trained for four different poses. The Procrustes analysis is performed to align the landmark sets and to construct a shape model. To acquire a shape-free patch, each training sample landmarks are warped to the learned mean shape. The shape-free patch’s texture intensities are normalized using a linear transformation. Now, PCA is utilized to construct a texture model. Finally, a correlation between the shape and the texture models are learned to build a combined model. Next, the pseudo-Zernike moment for the different order of moment (a) is calculated. In MGTP, the face images were divided into 3 × 3, 5 × 5, 7 × 7 sub-region, and the Mean Absolute Error (MAE) was computed for all the sub-region. The threshold value t was set to 5 and the sub-region is chosen as 7 × 7 as it gives less MAE. All three features are fused and fed into PCA for reducing the dimension of the feature. The parameters C = 36 and γ = 12 are considered a good choice for SVR. Mean Absolute error (MAE) is used as the criteria for evaluating the performance of the proposed approach. MAE is defined in EquationEquation. (19(19)
(19) )
where and xi are the estimated age and the true age of the
image and N is the total number of the test images. The distribution of training and test data chosen from the FG- NET and CACD database for various pose categories is shown in .
Table 2. Explanation of training and test data from the FG-NET and CACD database
. Explanation of training and test data from the FG-NET and CACD database.
A total of 7681 images are chosen randomly from the CACD face database. shows the performance of the LGP, MTP, and MGTP for the sub-region (3 × 3, 5 × 5, 7 × 7) with threshold value t = 5 on FG-NET and CACD databases for various pose category and putting all poses in one model (AP). The bold value in the table shows the less MAE in each dataset.
Table 3. MAE (in years) for LGP using SVR
Table 4. MAE for MTP using SVR
Table 5. MAE for MGTP using SVR
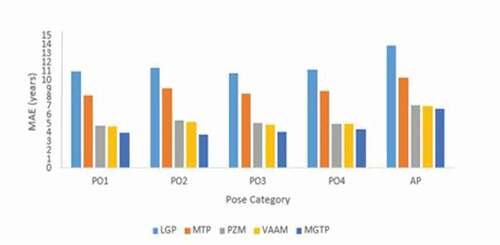
The sub-region 7 × 7 gives better results for age estimation. The performance of VAAM on FG-NET and CACD database for various pose categories and all poses in one model is shown in . shows the performance of PZM on the FG-NET and CACD database for various pose categories and all poses in one model. The outcomes indicate that the PZM descriptor with an order of moment (a = 30) provides better results. The comparison of MAE for LGP, MTP, VAAM, PZM, and MGTP on FG-NET and CACD databases are shown in .
Table 6. MAE for VAAM using SVR
Table 7. MAE for PZM using SVR
Figure 7. The comparison of MAE for LGP, MTP, VAAM, PZM, and MGTP on the FG-NET database.
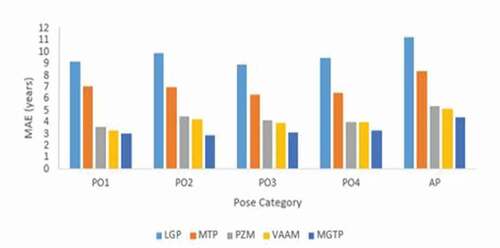
Figure 8. The comparison of MAE for LGP, MTP, VAAM, PZM, and MGTP on the CACD database.
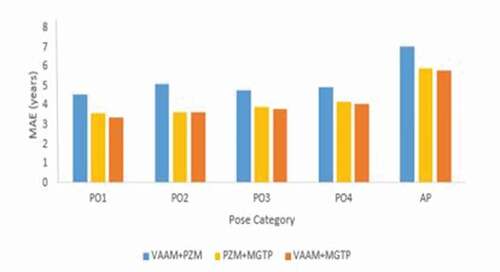
shows the two feature analysis using SVR with a = 30 for PZM and sub-region (7 × 7) for MGTP. We observe that the MAE for the combination of VAAM and MGTP is less when compared to the other combination of features. The comparison of MAE for two features combination on FG-NET and CACD are shown in .
Table 8. MAE for two feature analysis using SVR
Figure 9. The comparison of MAE for two feature combinations on the FG-NET database.
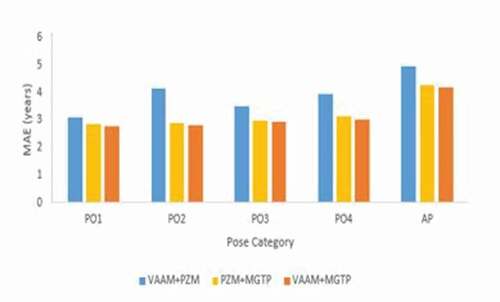
Figure 10. The comparison of MAE for two feature combinations on the CACD database.
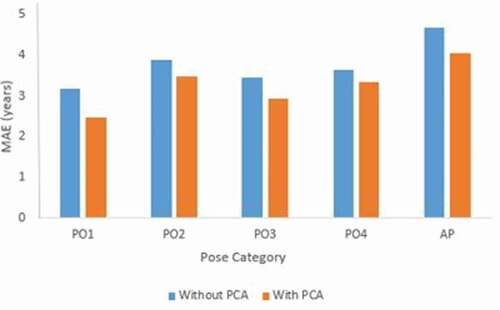
Three features are combined and the performance of the proposed framework is analyzed with PCA and without PCA and the analysis is shown in . The experimental result demonstrates that the system performs better with PCA for FG-NET and CACD databases. The MAE is compared for the combination of three features with and without PCA on CACD and FG-NET database are shown in .
Table 9. MAE for three feature analysis with and without PCA
Figure 11. Comparison of MAE for the combination of three features with and without PCA on the FG-NET database.

Figure 12. Comparison of MAE for the combination of three features with and without PCA on the CACD database.
The training and testing time comparison for FG-NET and CACD databases is shown in . and shows the performance of our methodology compared with the state-of-the-art age estimation algorithms on FG-NET and CACD databases respectively. Our approach outperforms the state-of-the-art methods on both FG-NET and CACD databases. shows the age estimation results for the CACD and FG-NET databases.
Table 10. The processing time comparison for training and testing
Table 11. Comparison of MAE of the state-of-the-art methods and the proposed method on the FG-NET database
Table 12. Comparison of MAE of the state-of-the-art methods and the proposed method on the CACD database
Figure 13. Age estimation output (a) CACD (b) FG-NET.
Conclusion
In this paper, a novel framework for multi-view age estimation by combining the local and global features is proposed. Also, a novel descriptor termed MGTP is proposed to extract the texture features which give rise to a better representation of the large-scale structure and more robust to random noises and non-monotonic illumination variation. The shape feature of a facial image is extracted using PZM. An appearance model which embodied both shape and texture variation is constructed using VAAM. Multi-class SVM is used to partition the images into four poses and for each pose, SVR is used to find the exact age of an individual. The performance of the proposed framework is analyzed for various pose categories by trying different parameters for MGTP and PZM. The experimental outcomes indicate that partitioning the images into different poses effectively estimates the ages for the facial images from the FG-NET and CACD database using a combination of local and global features than putting all the poses in one model. In future work, real-time database will be used and the effect of age will be studied on gender recognition and age can be estimated for different factors like race, facial expression, etc.
References
- Akbari, A., M. Awais, Z.-H. Feng, A. Farooq, and J. Kittler. 2020. A flatter loss for bias mitigation in cross-dataset facial age estimation. http://arxiv.org/abs/2010.10368.
- Chang, K. Y., C. S. Chen, and Y. P. Hung. 2011. Ordinal hyperplanes ranker with cost sensitivities for age estimation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 585–92, Colorado Springs, USA.
- Chen, B. C., C. S. Chen, and W. H. Hsu. 2015. Face recognition and retrieval using cross-age reference coding with cross-age celebrity dataset. IEEE Transactions on Multimedia 17 (6):804–15. doi:https://doi.org/10.1109/TMM.2015.2420374.
- Cootes, T. F., K. Walker, and C. J. Taylor. 2000. View-based active appearance models. Proceedings - 4th IEEE International Conference on Automatic Face and Gesture Recognition, 227–32, Grenoble, France.
- Cortes, C., and V. Vapnik. 1995. SUPPORT-VECTOR NETWORKS. Machine Learning 20 (3):273–97. doi:https://doi.org/10.1007/BF00994018.
- Dong, Y., C. Lang, and S. Feng. 2019. General structured sparse learning for human facial age estimation. Multimedia Systems 25 (1):49–57. doi:https://doi.org/10.1007/s00530-017-0534-0.
- Gall, J., A. Yao, N. Razavi, L. Van Gool, and V. Lempitsky. 2011. Hough forests for object detection, tracking, and action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (11):2188–202. doi:https://doi.org/10.1109/TPAMI.2011.70.
- Gao, F., and H. Ai. Face Age Classification on Consumer Images with Gabor Feature and Fuzzy LDA Method. International Conference on Biometrics, ICB 2009. Lecture Notes in Computer Science, Springer, 5558, 132–41, Berlin, Heidelberg
- Geng, X., Z.-H. Zhou, and K. Smith-Miles. 2007. Automatic age estimation based on facial aging patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 29 (12):2234–40. doi:https://doi.org/10.1109/TPAMI.2007.70733.
- Guehairia, O., A. Ouamane, F. Dornaika, and A. Taleb-Ahmed. 2020. Deep random forest for facial age estimation based on face images. 1st International Conference on Communications, Control Systems and Signal Processing (CCSSP), 305–09, El Oued, Algeria.
- Guo, G., and G. Mu. 2011. Simultaneous dimensionality reduction and human age estimation via kernel partial least squares regression. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 657–64, Colorado Springs, USA.
- Han, H., and A. K. Jain. 2014. Age, Gender and Race Estimation from Unconstrained Face Images. MSU Technical Report (MSU-CSE-14-5):1–9.
- Han, J., W. Wang, S. Karaoglu, W. Zeng, and T. Gevers. 2021. Pose invariant age estimation of face images in the wild. Computer Vision and Image Understanding 202:103123. doi:https://doi.org/10.1016/j.cviu.2020.103123.
- Hsu, C., and C. Lin. 2002. A comparison of methods for multiclass support vector machines. IEEE Transactions on Neural Networks 13 (2):415–25. doi:https://doi.org/10.1109/72.991427.
- Jun, B., and D. Kim. 2012. Robust face detection using local gradient patterns and evidence accumulation. Pattern Recognition 45 (9):3304–16. doi:https://doi.org/10.1016/j.patcog.2012.02.031.
- Khan, A., F. Bashar, F. Ahmed, and H. Kabir. 2013. Median ternary pattern (MTP) for face recognition. International Conference on Informatics, Electronics and Vision (ICIEV), 6–10, Dhaka, Bangladesh.
- Khanmohammadi, S., S. Ghaemi, and F. Samadi. 2013. Human age group estimation based on ANFIS using the HOG and LBP features. Electrical and Electronics Engineering: An International Journal (ELEIJ) 2 (1):21–29.
- Kumar, T., and S. Haider. 2018. Multi-feature-based facial age estimation using an incomplete facial aging database. Arabian Journal for Science and Engineering 43 (12):8057–78. doi:https://doi.org/10.1007/s13369-018-3293-0.
- Kumar, V., A. Namboodiri, and C. V. Jawahar. 2015. Visual phrases for exemplar face detection. Proceedings of the IEEE International Conference on Computer Vision, 1994–2002, Santiago, Chile.
- Kwon, Y. H., and V. Lobo. 1999. Age classification from facial images. Computer Vision and Image Understanding 74 (1):1–21. doi:https://doi.org/10.1006/cviu.1997.0549.
- Lanitis, A., and N. Tsapatsoulis. 2015. An overview of research on facial aging using the FG-NET aging database. Iet Biometrics 5 (2):37–46.
- Li, C., Q. Liu, J. Liu, and H. Lu. 2012. Learning ordinal discriminative features for age estimation. IEEE Conference on Computer Vision and Pattern Recognition, 2570–77, RI, USA.
- Liu, T., Z. Lei, J. Wan, and S. Z. Li. 2015. DFDnet: Discriminant face descriptor network for facial age estimation. chinese conference on biometric recognition. Lecture Notes in Computer Science, Springer 9428:649–58.
- Mahesh, V. G. V., A. Noel, and J. Raj. 2018. Zernike moments and machine learning based gender classification using facial images. International Conference on Soft Computing and Pattern Recognition, 398-408. Cham: Springer.
- Malek, M. E., Z. Azimifar, and R. Boostani. 2017. Facial age estimation using zernike moments and multi-layer perceptron. International Conference on Digital Signal Processing (DSP), 1–5, London.
- Pang, Y., A. B. J. Teoh, and D. C. L. Ngo. 2015. A discriminant pseudo zernike moments in face recognition. Journal of Research and Practice in Information Technology 38 (2):197–211.
- Ramanathan, N., and R. Chellappa. 2006. Modeling age progression in young faces. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 387–394. New York, USA.
- Ross, A., and A. Jain. 2003. Information fusion in biometrics. Pattern Recognition Letters 24 (13):2115–25. doi:https://doi.org/10.1016/S0167-8655(03)00079-5.
- Ross, A., and R. Govindarajan. 2004. Feature level fusion in biometric systems. Proceedings of Biometric Consortium Conference (BCC),1–2. http://www.nws-sa.com/biometrics/ear/featureFusion.pdf.
- Rothe, R., R. Timofte, and L. Van Gool. 2018. Deep expectation of real and apparent age from a single image without facial landmarks. International Journal of Computer Vision 126 (2–4):144–57. doi:https://doi.org/10.1007/s11263-016-0940-3.
- Sahoo, T. K., and H. Banka. 2018. Multi-feature-based facial age estimation using an incomplete facial aging database. Arabian Journal for Science & Engineering (Springer Science & Business Media BV) 43 (12):8057–8078
- Sawant, M., S. Addepalli, and K. Bhurchandi. 2019. Age estimation using local direction and moment pattern (LDMP) features. Multimedia Tools and Applications 78 (21):30419–41. doi:https://doi.org/10.1007/s11042-019-7589-1.
- Sawant, M. M., and K. Bhurchandi. 2019. Hierarchical facial age estimation using gaussian process regression. IEEE Access 7:9142–52. doi:https://doi.org/10.1109/ACCESS.2018.2889873.
- Shen, W., Y. Guo, Y. Wang, K. Zhao, B. Wang, and A. lle. 2021. Deep differentiable random forests for age estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (2):404–19. doi:https://doi.org/10.1109/TPAMI.2019.2937294.
- Tan, Z., S. Zhou, J. Wan, Z. Lei, and S. Z. Li. 2017. Age estimation based on a single network with soft softmax of aging modeling. Asian Conference on Computer Vision, ACCV. Lecture Notes in Computer Science, Springer, 10113, 203–16.
- Tan, Z., Y. Yang, J. Wan, G. Guo, and S. Z. Li. 2019. Deeply-learned hybrid representations for facial age estimation. International Joint Conference on Artificial Intelligence (IJCAI), 3548–54.
- Thukral, P., K. Mitra, and R. Chellappa. 2012. A hierarchical approachffor human age estimation, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1529–32, Kyoto, Japan.
- Tokola, R., D. Bolme, D. Barstow, and K. Ricanek. 2014. Discriminating projections for estimating face age in wild images. IEEE International Joint Conference on Biometrics, 1–8, Clearwater, FL, USA.
- Yan, S., H. Wang, T. S. Huang, Q. Yang, and X. Tang. 2007. Ranking with uncertain labels, IEEE International Conference on media and Expo, 96–99, Beijing, China.
- Yan, S., X. Zhou, M. Hasegawa-johnson, and T. S. Huang. 2008. Regression from Patch-Kernel. IEEE Conference on Computer Vision and Pattern Recognition, 1–8, AK, USA.
- Yasumoto, J. H. M., H. Y. Niwa, and H. Koshimizu. 2002. Age and gender estimation from facial image processing. Proceedings of the 41st SICE Annual Conference,5, Osaka, Japan.
- Zhang, Y., and D. Yeung. 2010. Multi-task warped Gaussian process for personalized age estimation. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2622–29, San Francisco, CA, USA.
- Zou, M., J. Niu, J. Chen, Y. Liu, and X. Zhao. 2016. Facial ages Estimation with images in the wild, in multimedia modeling, MMM 2016. Lecture Notes in Computer Science, Springer 9516:454–65.