
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
GDP is a measure of the size of the economy and how an economy is performing. The mining industry has become a focal point in the total economic picture of many countries; however, the factors affecting the contribution of the mining sector to the growth of GDP (GDPMS) have not been investigated in depth yet. In this paper, heuristic approaches were adopted to predict the GDPMS. Therefore, the effect of three parameters, namely, value added of GDP, the value of industrial output per capita and per capita value added on GDP MS, has been investigated. For this purpose, the data of countries that are actively participating in the mining industry was applied to a hybrid intelligent technique and an effective model was proposed. The results showed that a combination of a neuro-fuzzy inference system and a genetic algorithm has relatively the best performance to predict GDPMS. Furthermore, multiple parametric sensitivity analysis was conducted on the output of the model, and the outcomes showed that GDPMS is highly sensitive to all three input parameters; also, per capita value added and value added of GDP have the highest and the least effect on GDPMS, respectively.
Introduction
Macroeconomics is a branch of economics that is linked to macroeconomic efficiency, structure, behavior, and economic decision-making. The macroeconomic field includes a national, regional, and global economy (Clements et al. Citation2017). Macroeconomics studies the aggregate indices such as GDP, unemployment, national income, price index, and interrelationships between different sectors of the economy in order to better understand how the economy works (Song and Xue Citation2017). Among the macroeconomic indicators, GDP is the most important index to evaluate economic performance in the field of product analysis (Karaca, Bayrak, and Yetkin Citation2017). The gross domestic product comprises the total value of final goods and services that are produced in a country over a specific annual or seasonal period (Leigh and Du Citation2015). Considering the increasing importance of mines and minerals in the economy of developed and developing countries, it is necessary to understand the contribution of the mining sector to GDP (Zhao and Niu Citation2017). Some parameters such as purchasing power parity, per capita human development, financial independence and active participation of women in the community have been used as the criteria to compare the economic state of different countries. Nowadays, many researchers have tried to predict GDP using many effective parameters (Christofides et al. Citation2015). A variety of approaches have been adopted by many researchers to predict GDP using different parameters ().
Table 1. Contribution of the mining sector of different countries to their GDP index and effective parameters
Nowadays intelligent approaches have been used to predict GDP. They have two important advantage over econometric approaches (Junoh Citation2004). First, any assumption about underlying population distribution is not necessary; second, inputs are highly corelated or are missing, or the system is nonlinear (Junoh Citation2004). In another research, economic forecasting was conducted using artificial intelligence approaches, and the result showed that the intelligent approach performance is as good as the conventional statistical model (Kurihara and Fukushima Citation2019). Many artificial intelligence approaches, such as artificial neural networks (ANN), Adaptive Neuro-Fuzzy Inference System (ANFIS), genetic programming (GP), support vector regression (SVR), machines extreme learning and other machine learning (ML) techniques, have been adopted to predict the most important economic indexes, like gross domesticproduct (GDP), unemployment rate, consumer price indices (CPI), interest rate, exports, and consumption of energy (Ramírez, Hormaza, and Soto Citation2020). Moreover, machine Learning (ML) techniques have been employed to predict economic recession using GDP, and the results showed that the ML approach was able to predict economic downturns (Cicceri, Inserra, and Limosani Citation2020). The machine learning method, specifically, a gradient boosting model and a random forest model, was used to forecast real GDP growth of Japan between 2001 to 2018. The results showed that the gradient boosting model and random forest model are more accurate than the benchmark forecasts (Yoon Citation2021). However, there is no comprehensive research on the parameters, which may affect the contribution of mining sector to the growth of GDP (GDPMS) using artificial intelligent approaches.
In this paper, heuristic approaches have been adopted to predict the contribution of mining sector to the growth of Gross Domestic Product index (GDPMS). For this purpose, the information of 87 countries, which practice mining activities, was gathered from database, and the effect of three parameters, namely, value added of GDP (GDPVA), the value of industrial output per capita (IOVpc) and per capita value added (VAPC) on GDPMS, has been investigated using heuristic methods. The best models were proposed, and multiple parametric sensitivity analysis (MPSA) was applied to the best model outputs to discover the input variables that have the highest influence on the average output variable.
Data Gathering
In order to investigate the effect of important parameters on GDPMS, the value of GDPMS in many countries that have made contribution to the mining sector have been employed to investigate the influence of the mining industry on their GDP (Leader Citation2017; Mataloni Citation2017; OECD Citation2017; Situation Citation2017). The data used in this study are related to 2017 and presented in .
Table 2. Contribution of the mining sector of different countries to their GDP index and effective parameters (Leader Citation2017; Mataloni Citation2017; OECD Citation2017; The Economic; Situation Citation2017)
Applied Techniques
In this paper, contribution of the mining sector to the gross domestic product index (GDPMS) has been investigated using an MLP-ANN, ANFIS, ANFIS-GA, ANFIS-PSO, ANFIS-DE and ANFIS-ACOR. In the following sections, each method is briefly introduced.
Artificial Neural Network (ANN)
ANNs are known as one of the best and common applied methods for prediction. Many studies have been conducted using ANNs to explore rock engineering problems (Lu et al. Citation2020; Nikafshan Rad et al. Citation2020). The ANN model includes three layers, mainly input, hidden, and output (Zhou et al. Citation2020). Multi-layer perceptron (MLP) is one of the most common types of ANN, and there is a sequence of layers that are connected to each other by neurons. Performing nontrivial calculations, learning from input data, and generalization in the training step are the most vital elements of layered networks. The complexity of the problem and the nature of data determine the number of neurons. The middle layers, which are known as hidden layers, do not have connection to the outside world (Shojaeian and Asadizadeh Citation2020). Xn inputs are transformed to outputs by MLP through non-linear or linear functions (Rezaei and Asadizadeh Citation2020; Shojaeian and Asadizadeh Citation2020). The comprehensive details of MLP can be found in the literature (Díaz-Rodríguez et al. Citation2015). A view of the MLP ANN is shown in .
Figure 1. Schematic view of MLP ANN with two hidden layers.
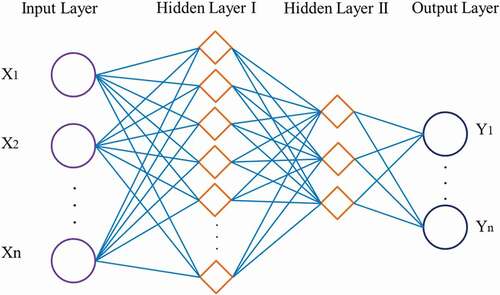
Figure 2. (a) Schematic structure of the TSK fuzzy model. (b) ANFIS model structure (Jang Citation1993).
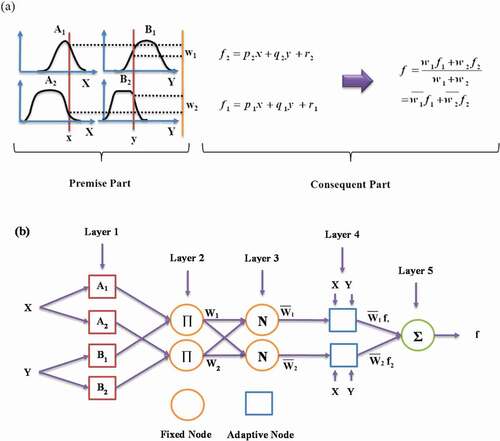
Figure 3. A simple flow sheet of GA (Islam et al. Citation2016). Simple flow sheet of GA (Martin et al. Citation2011).
Adaptive Neuro-fuzzy Inference System (ANFIS)
ANFIS is a feed-forward network consists of neural network learning algorithms and fuzzy reasoning to link inputs into outputs, and it was first introduced by Jang (Citation1993). ANFIS is usually used for training purposes to tune the Sugeno Fuzzy Inference System (FIS) to link the inputs and outputs with minimum error. ANFIS uses the least squares estimate (LSE) and gradient descent method as the learning algorithm. It can be employed to construct a set of fuzzy “If–Then” rules with suitable membership functions to create the preliminary input–output pairs. The network consists of nodes with specific functions, or duties, collected in layers with specific functions (Moghaddamnia et al. Citation2009). A learning phase can be divided into two steps: the first stage involves the propagation of input patterns and applying the iterative least mean square process to assess the optimal resulted parameters, the next stage is to repeat patterns, and then, the back propagation algorithm is employed to adjust the ancestor variables (Shojaeian and Asadizadeh Citation2020). The structure of the ANFIS system is shown in . As shown in this figure, the ANFIS is composed of a network with a five-layer neural structure: the first layer consisting of input nodes, the second layer containing nodes of membership rules or functions, and the third layer representing nodes of the first part of fuzzy rules to calculate the ratio of normalized rules. The fourth layer contains the resulting nodes of the fuzzy rules, and the fifth layer represents the phase of fuzzy decoupling, or output node, which calculates the final output as the sum of all the input signals (Jang Citation1993).
Genetic Algorithm (GA)
The GA is a stochastic optimization technique and search algorithm developed by Holland (Citation1992). This method is inspired by the evolution of biological species and the mechanism of natural selection, and it is commonly used to provide best solution for search and optimization problems. The GA, which is a member of a wide class of evolutionary algorithms (EA), can provide solutions for optimization issues using techniques inspired by natural evolution concepts, such as inheritance, mutation, selection, and crossover (Martin et al. Citation2011). As shown in , the algorithm starts with the initial population, and its optimal size is dependent on the complexity of the problem (Höglund Citation2017). As the first-generation size (initial population) is determined, the chromosomes are produced by chance. The selection of the main chromosomes for the production process is done using a roulette wheel.
A cross mechanism combines two selected chromosomes to form two new chromosomes. It is then selected and repeated until a new offspring is generated. The next step is called crossover, and the main step is that the genetic algorithm combines genetic data from two parents to produce new offspring in the production process (Shojaeian and Asadizadeh Citation2020). Another key parameter of the genetic algorithm is the mutation rate, which is used to maintain the genetic truth from one generation of chromosomes to the next. One or more gene values in a chromosome can change using the mutation process. As the new population has been created, the fitness function for the chromosomes is checked and the selection process will start. The evolutionary process then goes on until the best solution to the problem is obtained (Momeni et al. Citation2014).
Particle Swarm Optimization (PSO)
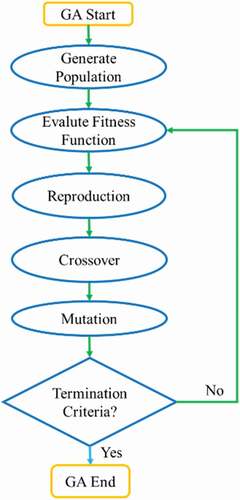
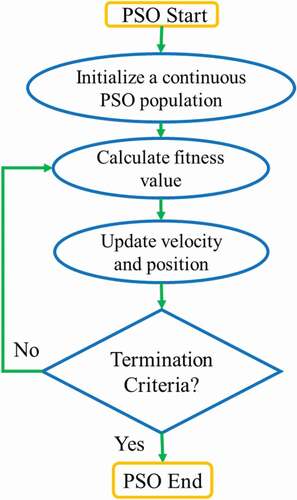
PSO is a metaheuristic and population-based approach that iteratively searches to find a better possible solution by an optimization process (Huang et al. Citation2020). In this approach, particles move in a multidimensional search space to find the best solution. Therefore, in any optimization issue, many particles should be generated and distributed in the search space (Hajihassani et al. Citation2015). The main drawback of PSO is its slow converging, but it is very appropriate for searching local extremums (Victoire and Jeyakumar Citation2004). The position of the particles in the search space changes based on their history and their adjacent particles.
A population, which is literary known as a swarm, would be created by the particles. The simple flow of the PSO algorithm is shown in .
Figure 4. Flow diagram of the particle swarm (Ayd et al. Citation2013).
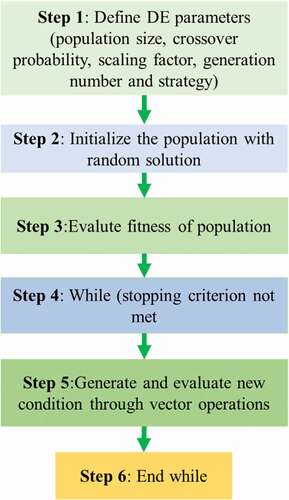
Differential Evolution (DE)
The DE algorithm was introduced by Price and Storn (Citation1997) on the bases of vector operations to produce possible solution to resolve optimization issues. User friendly, simple structure, robustness, escaping from local optimal and speed are the main benefits of this method. The critical action behind this algorithm is a plan for producing trial variable vectors. The main controlling parameters in DE are the number of population (N), probability of crossover (CR) and scaling factor (F). The main stages of the DE algorithm are illustrated in .
Figure 5. Differential evolution algorithm (Selvadurai and Głowacki Citation2008).
Ant Colony optimization (ACO)
The ant colony optimization that was introduced by Sanchez-Ruiz, Gonzalez-Calero, and Diaz-Agudo (Citation2007) is based on the food searching habit of ant colonies. One of the most important features of this algorithm is adopting indirect communication experiences of ants using pheromone paths to search for optimal trials in a problem. The pheromone paths are numerical data converted by ants; these data mirror the experiences of ants while resolving a special issue. This state-of-the-art algorithm has been adopted to solve various problems, particularly problems that require the shortest path to be identified (Zhang et al. Citation2013).
GDPMS Modeling
In this paper, ANN, ANFIS-PSO, ANFIS-GA, ANFIS-E and ANFIS-ACO models are employed and proposed to estimate GDPMS of different countries, which the mining sector contributes to their GDP. An appropriate selection of input data for training and testing of the models is crucial. In this study, 87 data arrays were selected for models, virtually 71% of which for training and the other for testing the models. In this research, testing and training data sets were chosen randomly. In order to have an effective training phase in soft computing methods, normalization of data sets was carried out to the domain of [0,1] by EquationEquation (1)(1)
(1) (Jahed Armaghani et al. Citation2016).
in which x is an input variable and and
are minimum and maximum amounts of each variable, respectively. Development of these suggested models is outlined in the following sub-sections.
ANN Modeling
In this research, a multi-layer perceptron ANN, which is known as MLP ANN, was employed to predict GDPMS. The number of hidden neurons was calculated by trial and error. The proposed network has three inputs in first layer, six neurons in hidden layer and 1 neuron in output layer. The characteristics of the trained network are presented in .
Table 3. Information of optimum network architecture
ANFIS-GA/PSO/DE/ACOR Modeling
In these approaches, GDPMS is predicted by the ANFIS, and in order to train the ANFIS model, PSO, GA, DE and ACO learning algorithms are adopted separately to achieve a good performance as well as high accuracy. The data array presented in is employed to train the ANFIS model utilizing PSO, GA, DE and ACO algorithms. The suggested ANFIS structure has three inputs and one output. The PSO/GA/DE/ACO-based ANFIS approaches are implemented using a program. The program model GDPMS based input variable geometries. In these approaches, the purpose of PSO/GA/DE/ACO defined in prior section is performed to obtain the optimum parameters of the ANFIS model. Finally, when the learning phase was completed, the optimum amounts of PSO/GA/DE/ACO-based ANFIS model parameters to forecast GDPMS are given in .
Table 4. The optimum values of ANFIS-PSO/GA/DE/ACO
Verification of the Proposed Models
In order to verify the proposed ANN, ANFIS-PSO, ANFIS-GA, ANFIS-E and ANFIS-ACO models, their outputs have been investigated in comparison with real data. The evaluation data (24 data series), which was not used in the models’ construction, was employed for this verification. The prediction performance and ability of the suggested models are controlled based on the evaluation data. For this aim, four statistical indices (SIs) comprising correlation coefficient (R), mean absolute error (MAE), mean square error (MSE) and variance account for VAF were employed and computed for each model. The R index indicates the correlation between the models’ outputs and experimental datasets. On the other hand, the MSE and MAE indices the models’ error compared to the real measured values. Finally, the difference amount between the variances of the experimental datasets and the model outputs are calculated by the VAF index. In general, the higher values of R and VAF (nearer to 100%) and lower amount of the MSE and MAE (near to zero) revealed better performance and capability of the model. These equations are utilized to calculate the above-mentioned indices:
where n is the dataset number, is the average of the measured datasets,
is the average of the predicted datasets and
and
are the ith measured in laboratory and predicted by models’ components, respectively.
Based on the 24 evaluation data series, the prior mentioned statistical indices were calculated for all of the suggested models and presented in . As shown in , the performance of the proposed intelligent models in terms of R, MSE, MAE and VAF is much more than the statistical model. However, the accuracy of the hybrid models (ANFIS-GA/PASO/DE) is somewhat better than that of the other models. In addition, the performance ANFIS-GA is better than the other one. For more evaluation, correlation between the measured data and estimated ones from the ANFIS-GA, ANFIS-PSO, ANFIS-DE, ANFIS, ANN and ANFIS-ACOR models is demonstrated in , respectively. This comparison also proved that the results of the suggested hybrid intelligent models except ANFIS-ACOR are more associated with the measured data compared to the other models and their results are virtually close to each other. Finally, comparison of the suggested models results with the measured evaluation datasets is depicted in , which verified the prediction capabilities of the proposed hybrid intelligent models.
Table 5. Comparing the proposed models performances using the computed statistical indices
Figure 6. Correlation between the ANFIS-GA model outputs and experimental data.
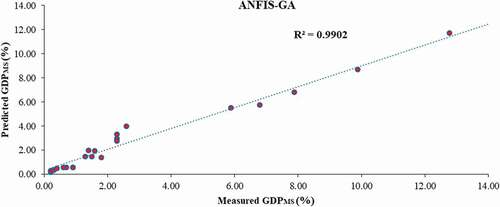
Figure 7. Correlation between the ANFIS-PSO model outputs and experimental data.
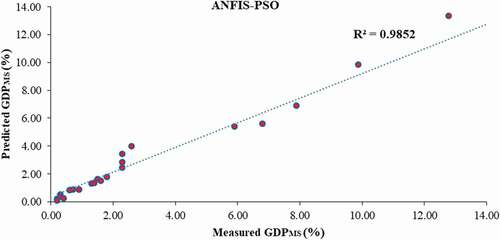
Figure 8. Correlation between the ANFIS-DE model output and experimental data.
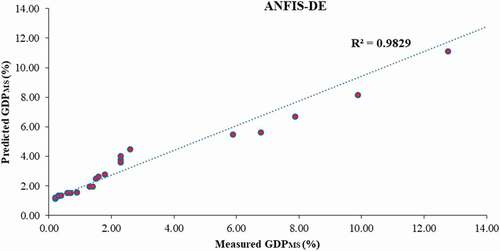
Figure 9. Correlation between the ANFIS model output and experimental data.
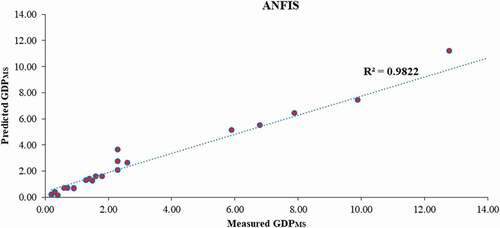
Figure 10. Correlation between the ANN model outputs and experimental data.
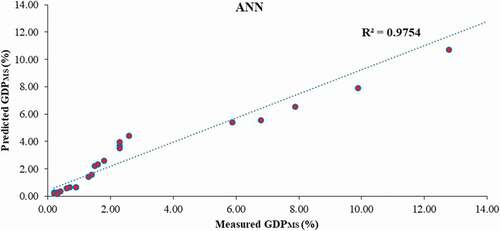
Figure 11. Correlation between the ANFIS-ACOR model output and experimental data.
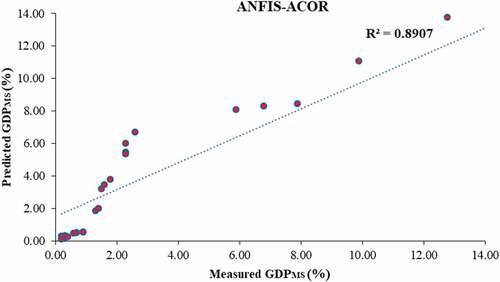
Figure 12. Comparing the suggested models results with the measured evaluation datasets.

Multiple Parametric Sensitivity Analysis (MPSA)
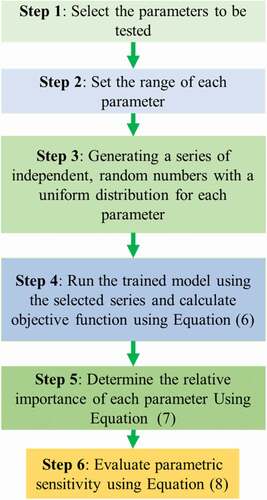
A parametric study was conducted on the models’ outputs to discover the input variables that have the highest influence on the average output variables. The following steps presented in may be followed for a certain set of parameters to apply MPSA to a model output.
Figure 13. Multiple Parametric Sensitivity Analysis algorithm (Correa et al. Citation2005).
The sum of square errors between the observed and modeled values has been used to evaluate the objective function..
where is the objective function value for a specific GDPMS variable h,
is the observed value at this variable,
is the computed value
for variable h for each input series, and k isthe number of variables contained in the random series. The range used for each parameter to be evaluated is presented in . Monte Carlo simulation was applied to generate 24 random numbers for each parameter. In each run of the model, the generated numbers for one variable were applied to the trained models. The relative importance of each parameter independently was evaluated using the following equation:
Table 6. γ index for model parameter sensitivity (Correa et al. Citation2005)
in which h introduces each pair input. By applying the described procedure to the GDPMS model, the results were obtained for each evaluated parameter. These results were obtained using (7). The relative importance of each parameter is calculated using following equation:
where the GDPMS is evaluated from h = 1 (the first series of data) to the maximum value (), which is equal to 24 for this model.
For each parameter, the higher the value of the γ index, the more sensitive the GDPMS model is to this parameter. According to the γ index, the following calcification for model parameter sensitivity has been presented:
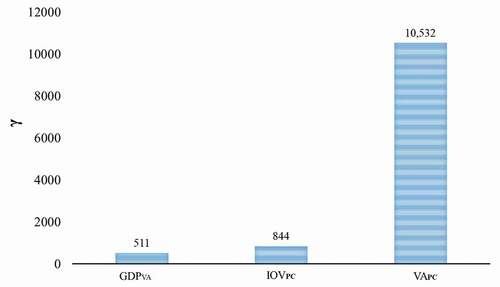
The calculated γ index for GDPMS model is presented in . According to this sensitivity analysis, the GDPMS model is highly sensitive to all three input parameters and VAPC and GDPVA have the highest and the least effect on the GDPMS model, respectively.
Figure 14. The effect of each input parameter on GDPMS according to γ index.
Conclusion
In this research, heuristic approaches were applied to predict the contribution of the mining sector to the gross domestic product index (GDPMS). The influence of three parameters, namely, value added of GDP (GDPVA), the value of industrial output per capita (IOVPC) and added value per capita (AVPC) on GDPMS, was investigated using heuristic methods such as ANN and ANFIS models as well as for newly hybrid intelligent models (ANFIS-PSO, ANFIS-GA, ANFIS-DE and ANFIS-ACOR). The models’ construction and evaluation were made on the basis 87 pair data gathered form all electronic resources. To verify the new hybrid intelligent models, their achieved results were compared with measured evaluation data using the R, MSE, MAE and VAF indices. This comparison proved that the ANFIS-GA model performance is virtually higher than those of the other models. The hybrid models of PSO and DE are in next order. Moreover, the simulation results of the new hybrid intelligent models are in extremely close accordance with real gathered data. As the last step of the modeling, sensitivity analysis was carried out using the best model and discovered that GDPMS is highly sensitive to all parameters [i.e., value added of mining resources (GDPVA), the value of industrial output per capita (IOVpc), per capita value added (VAPC)]; also, it was concluded that GDPMS is more sensitive to VAPC and less sensitive to GDPVA among input variables.
Disclosure statement
No potential conflict of interest was reported by the authors.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
References
- Anghelache C., Manole A., Anghel M. G., Anghel G. 2015. Analysis of final consumption and gross investment influence on GDP – multiple linear regression model. Theor Appl Econ 22:137–42.
- Armeanu D, Andrei J V, Lache L, Panait M. 2017. A multifactor approach to forecasting Romanian gross domestic product (GDP) in the short run. PLoS One 12:1–23. https://doi.org/https://doi.org/10.1371/journal.pone.0181379
- Astakhova N, Demidova L, Nikulchev E, Pluzhnik E. 2015. Forecasting of Time Series ’ Groups with Application of Fuzzy c-Mean Algorithm and Forecasting Models on the Base of Strictly Binary Trees and Modified Clonal 2015:861–73
- Ayd, M., C. Karakuzu, and M. Uçar. 2013. Prediction of surface roughness and cutting zone temperature in dry turning processes of AISI304 stainless steel using ANFIS with PSO learning. Int J Adv Manuf Technol 67, 957–967 (2013). https://doi.org/https://doi.org/10.1007/s00170-012-4540-2
- Camacho M, Dal Bianco M, Martinez-Martin J. 2015. Short-run forecasting of Argentinian gross domestic product growth. Emerg Mark Financ Trade 51:473–85. https://doi.org/https://doi.org/10.1080/1540496X.2015.1025668
- Chai S. H., Lim J. S. 2016. Forecasting business cycle with chaotic time series based on a neural network with weighted fuzzy membership functions. Chaos, Solitons and Fractals :1–9. https://doi.org/https://doi.org/10.1016/j.chaos.2016.03.037
- Chen S., Huang J. .2018. Forecasting China’s primary energy demand based on an improved AI model. Chinese J Popul Resour Environ 16:36–48. https://doi.org/https://doi.org/10.1080/10042857.2018
- Christofides, C., T. S. Eicher, C. Papa-, C. Christofides, and T. S. Eicher. 2015. Author ’ s accepted manuscript did established early warning signals predict the 2008 crises ?*. European Economic Review. doi:https://doi.org/10.1016/j.euroecorev.2015.04.004.
- Cicceri, G., G. Inserra, and M. Limosani. 2020. A machine learning approach to forecast economic recessions-an Italian case study. Mathematics 8:1–20. doi:https://doi.org/10.3390/math8020241.
- Clements, M. P., A. B. Galvão. 2017. Predicting early data revisions to U.S. GDP and the effects of releases on equity markets. Journal of Business & Economic Statistics 35(3):389-406. doi: https://doi.org/10.1080/07350015.2015.1076726
- Correa, J. M., F. A. Farret, V. A. Popov, M. G. Simoes, J. M. Corrêa, S. S. Member. 2005. Sensitivity analysis of the modeling parameters used in simulation of proton exchange membrane fuel cells. IEEE Transactions on Energy Conversion 20:211–18. doi:https://doi.org/10.1109/TEC.2004.842382.
- Díaz-Rodríguez, P., J. C. Cancilla, G. Matute, and J. S. Torrecilla. 2015. Viscosity estimation of binary mixtures of ionic liquids through a multi-layer perceptron model. Journal of Industrial and Engineering Chemistry 21:1350–53. doi:https://doi.org/10.1016/j.jiec.2014.06.005.
- Hajihassani, M., D. Jahed Armaghani, M. Monjezi, E. T. Mohamad, and A. Marto. 2015. Blast-induced air and ground vibration prediction: A particle swarm optimization-based artificial neural network approach. Environmental Earth Sciences 74 (4):2799–817. doi:https://doi.org/10.1007/s12665-015-4274-1.
- Höglund, H. 2017. Tax payment default prediction using genetic algorithm-based variable selection. Expert Systems with Applications 88:368–75. doi:https://doi.org/10.1016/j.eswa.2017.07.027.
- Holland, J. H. 1992. Adaptation in natural and artificial systems, vol. 1. The MIT Press. https://direct.mit.edu/books/book/2574/Adaptation-in-Natural-and-Artificial-SystemsAn
- Huang, J., P. G. Asteris, S. Manafi Khajeh Pasha, A. S. Mohammed, and M. Hasanipanah. 2020. A new auto-tuning model for predicting the rock fragmentation: A cat swarm optimization algorithm. Engineering with Computers 1–12. doi:https://doi.org/10.1007/s00366-020-01207-4.
- Islam, S. M. Mohandes, S. Rehman, 2016. Vertical extrapolation of wind speed using artificial neural network hybrid system. Neural Computing and Applications 28:2351–2361. https://doi.org/10.1007/s00521-016-2373-x
- Jahed Armaghani, D., E. Tonnizam Mohamad, M. Hajihassani, S. V. Alavi Nezhad Khalil Abad, A. Marto, and M. R. Moghaddam. 2016. Evaluation and prediction of flyrock resulting from blasting operations using empirical and computational methods. Engineering with Computers 32 (1):109–21. https://doi.org/https://doi.org/10.1007/s00366-015-0402-5.
- Jang, J.-S. 1993. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics 23 (3):665–85. doi:https://doi.org/10.1109/21.256541.
- Junoh, M. 2004. Predicting GDP growth in malaysia using knowledge-based economy indicator: A comparison between neural network and econometric approach. Sunw Coll J 1:39–50.
- Karaca, Y., Ş. Bayrak, and E. F. Yetkin. 2017. The Classification of Turkish Economic Growth by Artificial Neural Network Algorithms. In: Gervasi O. et al. (eds) Computational Science and Its Applications – ICCSA 2017. ICCSA 2017. Lecture Notes in Computer Science, vol 10405. Springer, Cham. https://doi.org/https://doi.org/10.1007/978-3-319-62395-5_9
- Kreinovich V, Sriboonchitta S, Chakpitak N. 2017. Predictive Econometrics and Big Data :19. https://doi.org/https://doi.org/10.1007/978–3–319–70942–0
- Kuosmanen, P., Vataja J. .2018. Time-varying predictive content of financial variables in forecasting. Q Rev Econ Financ. https://doi.org/https://doi.org/10.1016/j.qref.2018.08.002
- Kurihara, Y., and A. Fukushima. 2019. AR model or machine learning for forecasting GDP and consumer price for G7 countries. Applied Economics and Finance 6 (3):1. doi:https://doi.org/10.11114/aef.v6i3.4126.
- Kyo K, Noda H. 2018. A Bayesian Approach for Analyzing the Dynamic Dependence of GDP on the Unemployment Rate in Japan. International Journal of Modeling and Optimization 8:55–61. https://doi.org/https://doi.org/10.7763/ijmo.2018.v8.624
- Leader, T. 2017. Annual economic report (2016). Tajikistan. vol. 1.
- Leigh, J. P., and J. Du. 2015. Brief report: Forecasting the economic burden of autism in 2015 and 2025 in the United States. Journal of Autism and Developmental Disorders 45 (12):4135–39. doi:https://doi.org/10.1007/s10803-015-2521-7.
- Lu, X., M. Hasanipanah, K. Brindhadevi, H. Bakhshandeh Amnieh, and S. Khalafi. 2020. ORELM: A novel machine learning approach for prediction of flyrock in mine blasting. Natural Resources Research 29 (2):641–54. doi:https://doi.org/10.1007/s11053-019-09532-2.
- Martin, A., V. Gayathri, G. Saranya, P. Gayathri, and P. Venkatesan. 2011. A hybrid model for bankruptcy prediction using genetic algorithm,Fuzzy C-Means and Mars. International Journal on Soft Computing 2 (1):12–24. doi:https://doi.org/10.5121/ijsc.2011.2102.
- Mataloni, L. 2017. OECD. OECD Economic Survey. http://www.oecd.org.
- Moghaddamnia, A., M. Ghafari Gousheh, J. Piri, S. Amin, and D. Han. 2009. Evaporation estimation using artificial neural networks and adaptive neuro-fuzzy inference system techniques. Advances in Water Resources 32 (1):88–97. doi:https://doi.org/10.1016/j.advwatres.2008.10.005.
- Momeni, E., R. Nazir, D. Jahed Armaghani, and H. Maizir. 2014. Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–31. doi:https://doi.org/10.1016/j.measurement.2014.08.007.
- Nikafshan Rad, H., I. Bakhshayeshi, W. A. Wan Jusoh, M. M. Tahir, and L. K. Foong. 2020. Prediction of flyrock in mine blasting: A new computational intelligence approach. Natural Resources Research 29 (2):609–23. doi:https://doi.org/10.1007/s11053-019-09464-x.
- OECD. 2017. México. OECD Economic Surveys 46. https://doi.org/https://doi.org/10.1787/eco_surveys-mex-2017-en
- Price, K., and R. Storn. 1997. Differential evolution – a simple and efficient heuristic for global optimization over continuous spaces. Journal of Global Optimization 341–59. doi:https://doi.org/10.1023/A:1008202821328.
- Proietti T., Marczak M., Mazzi G. 2017. Euro mind- D: A Density Estimate of Monthly Gross Domestic Product for the Euro Area. Journal of Applied Econometrics 32:683–703. https://doi.org/https://doi.org/10.1002/jae.2556
- Rakic G., Markovic S., Jovic S., et al .2018. Analysing of exchange rate and gross domestic product (GDP) by adaptive neuro-fuzzy inference system (ANFIS). Physica A: Statistical Mechanics and its Applications 513:333–338. https://doi.org/https://doi.org/10.1016/j.physa.2018.09.009
- Ramírez, K. M., J. M. Hormaza, and S. V. Soto. 2020. Artificial intelligence and its impact on the prediction of economic indicators. ACM International Conference Proceedings Series. doi:https://doi.org/10.1145/3410352.3410827.
- Rezaei, M., and M. Asadizadeh. 2020. Journal of Mining and Environment (JME) predicting unconfined compressive strength of intact rock using new hybrid intelligent models. Journal of Mining Environment 11:231–46. doi:https://doi.org/10.22044/jme.2019.8839.1774.
- Sanchez-Ruiz, A. A., P. A. Gonzalez-Calero, and B. Diaz-Agudo. 2007. Combining HTN-DL planning and CBR to compound semantic web services. CEUR Workshop Proceedings 275:104–05. doi:https://doi.org/10.1109/MCI.2006.329691.
- Selvadurai, A. P. S., and A. Głowacki. 2008. Permeability hysterisis of limestone during isotropic compression. Groundwater 46 (1):113–19. doi:https://doi.org/10.1111/j.1745-6584.2007.00390.x.
- Semuel H., Nurina S., Semuel Nurina H. S. 2015. Analysis of the Effect of Inflation, Interest Rates, and Exchange Rates on Gross Domestic Product (GDP) in Indonesia. Proc Int Conf Glob Business, Econ Financ Soc Sci, GB15_Thai Conf :20–2.
- Shojaeian, A., and M. Asadizadeh. 2020. Prediction of surface tension of the binary mixtures containing ionic liquid using heuristic approaches; an input parameters investigation. Journal of Molecular Liquids 298:111976. doi:https://doi.org/10.1016/j.molliq.2019.111976.
- Situation, T. E. 2017. Economics E-Journal. http://www.economics-ejournal.org.
- Song, R., and X. Xue. 2017. Freight volume forecast based on improved radial basis function neural network. Bol Tec Bull 55:419–23.
- Stevanović M, Vujičić S, Gajić A. M. 2018. Gross domestic product estimation based on electricity utilization by the artificial neural network. Physica A: Statistical Mechanics and its Applications 489:28–31. https://doi.org/https://doi.org/10.1016/j.physa.2017.07.023
- Victoire, T. A. A., and A. E. Jeyakumar. 2004. Hybrid PSO–SQP for economic dispatch with valve-point effect. Electric Power Systems Research 71:51–59. doi:https://doi.org/10.1016/j.epsr.2003.12.017.
- Yoon, J. 2021. Forecasting of real GDP growth using machine learning models: gradient boosting and random forest approach. Computational Economics 57:247–65. doi:https://doi.org/10.1007/s10614-020-10054-w.
- Zhang, X., Q. Wang, F. T. S. Chan, S. Mahadevan, and Y. Deng. 2013. A physarum polycephalum optimization algorithm for the bi-objective shortest path problem. International Journal of Unconventional Computing 10:143–62.
- Zhao, W., and D. Niu. 2017. Prediction of CO2emission in China’s power generation industry with Gauss optimized Cuckoo search algorithm and wavelet neural network based on STIRPAT model with ridge regression. Sustain 9. doi:https://doi.org/10.3390/su9122377.
- Zhou, J., N. Aghili, E. N. Ghaleini, D. T. Bui, M. M. Tahir, M. Koopialipoor, and A. Monte. 2020. Carlo simulation approach for effective assessment of flyrock based on intelligent system of neural network. Engineering with Computers 36:713–23. doi:https://doi.org/10.1007/s00366-019-00726-z.