
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In image classification and retrieval applications, images are represented by a set of features. These features are extracted from both spatial and wavelet transformed input images. The wavelet transform decomposes images into multiple resolutions by separating smooth and sharp information in individual channels to give more details about the image. Each level of smooth and sharp decomposed channels is individually involved in texture feature extraction. It is difficult to achieve better results in image classification and retrieval applications with fewer discriminant details of the image. Even though each level of the smooth channel correlates with its successive decomposition levels, these feature extraction methods do not consider the relationship between the multiple levels of decomposed images. This motivates the proposed work to extract the correlation between the different levels of wavelet decomposed images. The proposed work (i) encodes the local difference obtained from multiple radii across the different levels of wavelet decomposed channels, (ii) assesses the proposed texture feature extraction method using classification and retrieval experiments with five different wavelet filters over twelve image databases and (iii) analyses the importance of similarity measures involved in the proposed feature-based image retrieval experiments.
Introduction
Recent advancements in visual data capturing sensors provide digital images in different qualities, resolution, and costs. This encourages the growth of digital image accumulation over the fields of medicine (Ji, Engel, and Craine Citation2000), satellite (Anys and He Citation1995), defense (Tuceryan and Jain Citation1993), surveillance (Kellokumpu, Zhao, and Pietikäinen Citation2008), industry (Tajeripour, Kabir, and Sheikhi Citation2007), web application (Liua et al. Citation2007), etc. These recent advancements in technologies also provide cost-effective storage for huge digital image collections. However, managing these huge digital image collections is not feasible when the image relies only on human text annotation. This kind of annotation is time-consuming and purely depends on human perception (i.e., using human resources to create annotations for images). This increases the necessity of a non-human annotation system to manage the rapidly growing image collection. Thus, it and attracts the research communities toward the automatic image searching and retrieving field (Hassaballah and Hosny Citation2019). Researchers have developed content-based image retrieval (CBIR) system to perform automatic visual annotation, image search, and retrieval over massive image datasets. The CBIR system generates visual annotation using the key elements/features (i.e., color, texture, shape, spatial layout, and interest points) available in both query and huge digital image collections. It performs an automatic search over the image collections for retrieving relevant images. The combination of more than one key feature gives a clear description of the image than a single key feature. Meanwhile, multiple key feature integrated CBIR systems have problems in assigning an optimal weight to the set of features involved in the integration process (Pavithra and SreeSharmila Citation2018; Bhunia et al. Citation2020; Vimina and Divya Citation2020). Li, Yang, and Ma (Citation2020) have extracted the image feature with the help of a convolutional neural network (CNN) classification model. Then, they used SURF to match similar images with the help of CNN features. SURF fails to match the same class of images, which are taken from different locations. Whereas Singh and Batra (Citation2020) has extracted color moments (i.e, color feature), wavelet-based texture features from the image, then they have used the support vector machine (SVM) for the classification. The classification result is directly related to the retrieval results. If classification fails to give the correct category of an image, then it will greatly affect the retrieval performance. Similarly, the cascaded CBIR system faces difficulty in optimal feature selection at the first stage of the retrieval process (Bella and Vasuki Citation2019; Walia, Vesal, and Pal Citation2014). Ali Khan, Javed, and Ashraf (Citation2021)has extracted the color, texture and shape features from the given image at the first level. The combination of the shape and texture features filtered some similar images for the second level of the process. In the second level, the shape and color feature combination along with the similarity measure will give more number of similar images as a result. If the first level fails to filter more similar images for the next (Second) level retrieval process, it will affect the final performance.
Thus, classification and retrieval systems rely on a feature that helps to extract the discriminant property of the image in low complexity that gives relevant results. Among the color, texture, shape, and spatial layout key descriptors, the texture is widely used in pattern recognition, image retrieval, and classification. Texture analysis is applicable for images represented in any color models (i.e., HSV, YCbCr, and Lab). In an image, texture information is analyzed by taking the structural and statistical (Liu et al. Citation2011) details from the image. These techniques effectively extract information about the different types of patterns available in the image in two ways, they are local and global. The Local Binary Patterns (LBPs) (Ojala, Pietikainen, and Maenpaa Citation2002; Pietikainen et al. Citation2011) are called local texture descriptors. This descriptor locally estimates the patterns available around each pixel. On the other hand, the global texture features (i.e., Gray Level Co-occurrence Matrix (GLCM) (Haralick, Shanmugam, and Dinstein Citation1973) are obtained by measuring the statistical details directly from the original and transformed images. In general, texture details extraction techniques run over the single resolution intensity channel of the image. Even though the single resolution intensity channel is effectively used in global and local texture feature extraction, it fails to reveal complex details clearly (Bai et al. Citation2012). This makes the multi-resolution analysis as an important texture feature representation technique (since it gives complex details of the images in different resolution and separates low and high-level components effectively; Cong Bai et al. (Citation2012)). The intensity palette (i.e., ‘Y’) of the YCbCr color space is decomposed into two levels and the histogram over the detailed coefficients of decomposed images acts as the texture feature (Cong Bai et al. Citation2012). The global texture features of Gabor transform of an image with different scale and orientation are acquired using mean and standard deviation (Manjunath and Ma Citation1996). The statistical measures such as histogram (Singha et al. Citation2012) contrast, correlation, angular moments, and diagonal distribution are estimated globally from discrete wavelet transform (Ouma, Tetuko, and Tateishi Citation2008). These features are greatly affected by illumination, rotation, and scale changes present in the image. This creates the necessity of invariant robust texture feature generation, which remains stable for the changes available in the image (Awad and Hassaballah Citation2016). The global texture feature extraction method (Pun and Lee Citation2003) presented the rotation and scale-invariant texture feature representation from energy signatures of the log-polar wavelet packet decomposition result.
The local texture extraction over the discrete wavelet transform is attained by Completed-LBP (CLBP) (Taha H. Rassem, Alsewari, and Makbol Citation2017). This technique has good classification accuracy when the level of decomposition is three. This increases the feature vector length and the time complexity in feature extraction. This local feature extraction technique has limited performance in classification and retrieval. There are a number of LBPs (i.e., CLBP (Rassem, Alsewari, and Makbol Citation2017), Directional Local Ternary Co-occurrences Pattern (Amit Singhal, Agarwal, and Pachori Citation2020), Frequency decoded local descriptor (Dubey Citation2019), Local Derivative Pattern (LDP) (Zhang et al. Citation2010), Local Ternary Pattern (LTP) (Srivastava, Binh, and Khare Citation2014; Tan and Triggs Citation2010), Local Tetra Pattern (LTrP) (Murala, Maheshwari, and Balasubramanian Citation2012) and Dominant Local Binary Patterns (DLBP) (S. Liao, Law, and Chung Citation2009)) introduced in the field of local texture feature extraction. The conventional LBP relies on the raw intensity values present in the center pixel and its neighborhood, and the patterns are extracted from small subspaces like 3 3 (Bai et al. Citation2012). Instead of taking the pattern around the single raw pixel, pattern available in the radial direction was preferred for noise invariant texture feature extraction (Liu et al. Citation2012). Subsequently, the scale, rotation and noise invariant texture features are suggested by the Median Robust extended LBP (MRLBP). This technique took binary pattern by subtracting the neighboring pixel details from the median value of different sized subspace around the center pixel, and thus, it improves the accuracy of texture classification (Liu et al. Citation2016). Similarly, each sampling point is calculated from the mean value of the neighborhood values within the radius one (Liu et al. Citation2014). The number of sampling points depends on the size of subspace that is taken for local feature extraction. This feature gives rotation-and-noise-invariant discriminant binary patterns from the pyramidal transformed images (Qian et al. Citation2011). The multi-scale local binary pattern has suggested a different combination of eight sampling points feature extraction that gives the number of images for GLCM feature extraction (Srivastava and Khare Citation2018). Additionally, radial-mean-value-based-neighborhood sampling points are introduced to classify the noisy texture efficiently (Shakoor and Boostani Citation2018). Recently, the weighted integration of local and global texture feature extraction on the approximation coefficients of Dual-Tree Complex Wavelet Transform (DTCWT) and DTCWT detail coefficients of the log-polar transform image provides the illumination, scale and rotation invariant texture features (Yang, Zhang, and Yang Citation2018). Even though this approach improves the classification accuracy, the level of decomposition (i.e., five levels) and approximated weight selection in feature integration increases the complexity of the technique. On the other hand, Discrete Wavelet Transform (DWT) based decomposition is applied over the gray scale images up to seven levels. Then, the texture features such as LBP, the mean, standard deviation, Kurtosis and skewness are extracted from the low- and high-frequency channel coefficients present in each level of the decomposed image (Yadav et al. Citation2015). The two-bin normalized histogram of the approximation and horizontal and vertical components of three-level wavelet decomposed RGB color space images are taken as texture features (Khokher and Talwar Citation2017). The conventional local feature representation technique extracted the texture patterns from a single image by changing the sub-image resolution and the number of neighborhood points considered in each resolution (i.e., sub-image resolution). Even in multi-resolution analysis techniques such as wavelet and pyramid transform (Dash and Jena Citation2017), texture features are gained from each level of the decomposed image separately. Then, they are concatenated for local feature representation. However, it does not communicate the relationship between the images in different decomposition levels. Even though this relationship records the discriminant details of the local patterns in different decomposition levels, the conventional feature extraction methods failed to record it (i.e., each level of decomposition reveals the complex details present in a single raw image). This motivates the proposed work to extract the correlation between the images represented in different decomposition levels. Furthermore, the proposed feature extraction technique does not let the relationship between the center pixel and its neighborhoods on the different radii and decomposition levels. It performs this as the initial process to get local patterns in each level, and the relationships between these decomposition levels are captured. Furthermore, the feature vector length of the proposed work is compact compared to the other methods used in the literature.
In the image retrieval system, apart from the image feature representation, similarity measure plays an important role since this system searches similar images based on the shortest distance information. This increases the retrieval time of the CBIR system corresponding to the image dataset size. Because of this, it performs a linear search and fails to match with the high-level human understandings (Seetharaman and Kamarasan Citation2014). To settle down the drawbacks available in distance measures based CBIR using the low-level feature, supervised machine learning, and deep learning techniques are introduced in the field of image retrieval (Krizhevsky et al. Citation2012). These techniques split the datasets into two groups named training and testing sets and train the system to match with the high-level human views. The outcome of these models has minimized the search space and the retrieval time associated with the CBIR system. Due to the huge amount of complexity associated with the deep learning training model (Singh and Srivastava Citation2017), this work takes the machine learning techniques to simplify the retrieval task.
This work generates a content-based image retrieval system based on (i) different similarity measures (i.e., Approach 1) and (ii) supervised classification model (i.e., Approach 2) for the proposed texture feature. The proposed significant texture detail of an image is statistically assessed from the radial difference between the local patterns available in multi-resolution and different scales. In the proposed work, un-decimated wavelet transform is preferred for representing texture details in different resolutions. Then, the local texture structural patterns are determined from the circular neighborhood information available in different radii. Here, the radial difference between the multi-scale and multi-resolution image is encoded as a novel robust texture that is invariant to illumination, noise, and scale distortions, which are present in the image. Moreover, this work analyses the performance of the above mentioned two CBIR systems (i.e., Approach 1 – retrieval based on different similarity measures and Approach 2 – retrieval based on classification model) in terms of their retrieval accuracy, searching time, and search space using the proposed texture feature. This work takes five different kinds of similarity measures to analyze the CBIR systems as mentioned above. In image classification, instead of using the single classification model, this work preferred the majority voting technique to select the relevant class images. The paper is organized as follows: the structure of the proposed multi-resolution radial-gradient binary pattern is discussed in section 2. Section 3 consists of experiments of various datasets and their results. Finally, the conclusion of this work is given in Section 4.
The Proposed Framework
The main contribution of this work lies in the part of texture extraction. The process involved in the proposed work are as follows.
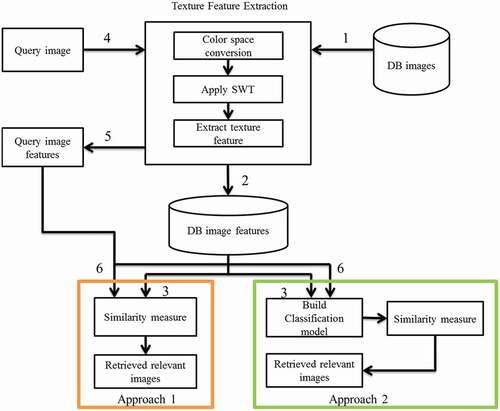
Step 1 In the texture extraction technique, color space of the original image is converted into HSV, and SWT is applied over these converted images. Then, the resultant images are used to take the radial difference local patterns across different decomposition levels and scales.
Step 2 The extracted textures are stored in feature database.
Step 3 Using the extracted texture, a set of five similarity measures are calculated in Approach 1. The similarity measures are as follows: (i) Euclidean, (ii) Bray Curtis, (iii) Square Chord, (iv) D1 and (v) Chess board. In Approach 2, the features from the database images are used for building the classification model using the supervised classification techniques.
Step 4 The proposed texture extraction technique accepts the query image and performs feature extraction over that image.
Step 5 The feature vector of the query image is collected from the proposed extraction technique.
Step 6 The feature vector of the query image is given as the input for Approaches 1 and 2. Approach 1 performs image retrieval using distance measures between the features of the query and database images. Approach 2 uses the query image feature to test the classficication model build over the features of the database images.
The stepwise processes involved in the proposed work are indicated in numbers, which iare clearly depicted in . Though the RGB (R-Red, G-Green, and B-Blue) color channel does not isolate the intensity details, the texture features are available on the intensity channel of the image. Hence, most of the texture extraction techniques suggested the HSV (H-Hue, S-Saturation, and V–Value) color channel for extracting the texture. This color channel separately holds the color values in H and S channels and intensity value in V-channel. The complex structure of the intensity channel is analyzed by the techniques that are used in the multiresolution analysis. In the multiresolution analysis, wavelets and pyramids are used to simplify the complex image representation (i.e., image consists of multiple objects in different sizes and brightness). The compressed and denoised version of the original image is illustrated in wavelet transform. Moreover, the wavelet is highly advantageous in separating high and low-level components effectively, compared to pyramid transform. This work preferred wavelet transform to characterize the texture details of the image. Among different kinds of wavelet transforms, the SWT or undecimated decomposed image is shift-invariant. Shift-invariance is an important parameter for pattern matching, whereas DWT cutdowns (i.e., downsample by factor 2) the resolution by half in each level and produced shift variant results (Khare et al. Citation2018). Though the decimation is not performed and the filter coefficients are diluted by introducing zeros between the original coefficents, the SWT maintains the original image resolution at each level (Priyadharsini, Sharmila, and Rajendran Citation2018). The single-level SWT decomposition is achieved by applying the low and high-level filters over the image in row and column, respectively. Unlike DWT, SWT ensures that the approximation channel (LL channel), detail channels (horizontal (HL channel), vertical (LH channel) and diagonal (HH channel) resolutions are the same as the original image. Here, the approximation channel is further considered for the next level SWT decomposition.
Figure 1. The schematic diagram of the proposed texture based image classification and retrieval model.
Multi-Level Gradient Radial Difference Binary Pattern
The proposed multi-level gradient radial difference binary pattern measures the local pattern available in different scales around each pixel of the decomposed image. Then, the relationship between the local texture patterns presents in the low and the high levels of the decomposed image corresponding to each pixel location is obtained by taking the binary value from the radial difference information. This proposed technique encodes the local patterns around the pixel available across the different level decomposed image, which gives the discriminant texture. The equations involved in (proposed) multi-level gradient radial difference binary pattern are given below.
where, and
;
;
holds the information about the level of decomposition (h,h1).
denotes the histogram representation of the multi-resolution radial difference image1 and image2.
represents the center pixel of the m radius circle at l1 level decomposition. m,n indicates the radius of the circular neighborhoods where
. p denotes the total number of equally spaced pixel values on the circular neighborhood. k takes the values from 0 to p-1. i,j denote the rows and columns of the image and they vary from 1 to the total number of rows and columns present in the image, respectively.
Then, the statistical information of the proposed MRRD binary pattern image is calculated by deriving a histogram over the texture pattern of the image. The histogram gives a feature vector with length of 256 for every single image. Here, texture details are available in two different images (i.e., MRRD1 and MRRD2). Thus, histograms of these two images (2 × 256 = 512) are concatenated and form feature vector with the a length of 512. The uniform local binary pattern is elicited to minimize the length of the feature vector. It takes the binary pattern representation for each pixel in the proposed texture image. It considers the binary pattern in a circular manner and allows two successive transitions (0 to 1 or 1 to 0) within the pattern. The 8-bit binary pattern such as 00100000 and 00000011 is called a uniform binary pattern, whereas 01101011 and 01011001 do not have a uniform binary pattern. The number of equally spaced points on the circular neighborhood decides the length of the uniform feature vector using . Therefore, 8 points on the circular neighborhood give uniform binary pattern feature vector length as 59 (i.e., 8(8–1)+3 = 59). illustrates the process of creating a proposed texture feature in a step by step manner.
Figure 2. Multi-level gradient radial difference binary pattern.
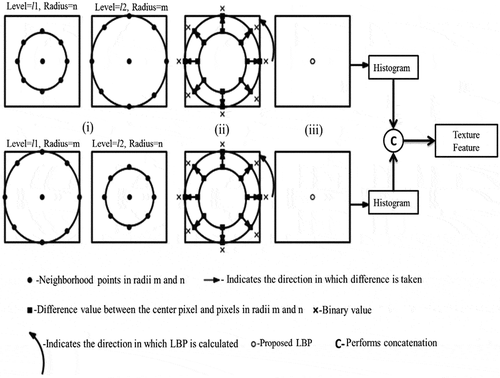
The multilevel gradient radial difference binary pattern is obtained by performing the following steps:
Take the difference between center point and equally spaced circular neighborhood pixels
The SWT coefficients of the image in each level are different. The level of decomposition and the coefficients values of the image in each level are proportional to each other. The coefficients of the image in Nth level have less value than the coefficients in the (N + 1)th level of the decomposed image. This work calculates the difference between the center point and the surrounding pixels at different radii to preserve the local details around each pixel of the image in different decomposition levels. This is shown in (i). Here, l1 and l2 are the decomposition levels and m and n denote the radius of the circular neighborhood from the center pixel. EquationEquations (1(1)
(1) –Equation5
(5)
(5) ) are used to calculate texture pattern information.
Estimate the radial difference value of the circular neighborhoods at different radii across the decomposition levels
The difference value of the circular neighborhood collected from step 1 involved in radial difference calculation. The radial difference is measured by subtracting the outer radial difference from the inner radial difference. The positive and negative values of the subtraction results are coded as 1 and 0, respectively. For example, two-level decomposed images with two different radii (i.e., 1 and 2) circular neighborhood information are taken for texture extraction. This technique considers radii 1 and 2 in two different images without compensating any detail present in these radii. This information encodes the relationship between the images represented in different decomposition levels since each level of the decomposed image discloses the undetected detail of that image. In this proposed work, the number of radii (r) considered for this texture feature extraction decides the total number (r×(r-1)) of texture images. The texture extraction from the three different radii information of the two different levels of decomposed images is recorded in six texture feature images.
Update the local pattern information
The output image resolution is the same as the original image that is involved in texture extraction. The binary value obtained from step 2 is taken from the anticlockwise direction to get the decimal value of the local pattern. (iii) depicts the updated local pattern decimal value in the place of the center pixel. This is shown in ). After updating all the pixel positions of the output images, the histograms of the images are concatenated to give the texture information.
Similarity Measure-Based Image Retrieval
The performance of the image retrieval system relies on feature and similarity measures used in the retrieval process. The texture feature obtained from section 2.2 acts as an input for the similarity measures used in the retrieval task. The similarity measure is taken between the proposed texture feature of the query and database images. The similarity measure result estimates the closeness details of the database images. Depending on the closeness value, the database images are sorted and displayed at the top of the retrieval results. This work takes five different similarity measures to estimate the relevant images from the closeness details.
Euclidean measure
Bray Curtis measure
Square Chord measure
D1 measure
Chessboard measure
where TF denotes the total number of features extracted in the texture extraction process and indicates the query and database images of fth the feature, respectively. The image retrieval system based on distance measure performs a consecutive linear search on the database images texture feature. This kind of retrieval system does not perform training on the database images.
Classification Model in Image Retrieval
The classification models are promoted in an image retrieval system to cut down non-relevant images from a similar image searching process. The classification model is placed above the similarity measure used in the retrieval task to achieve this benefit. This increases the image retrieval system’s overall performance by reducing the search space where the similarity measures do the linear search within the single class images. The classification model based on supervised learning tries to map the user requirement approximately with the database images. The classification model trains the database image features approximately according to human perception. Hence, the well-trained classification model automatically accepts the query image feature, classifies the feature to the appropriate class, and reduces the CBIR system’s retrieval time. This work uses the ensemble classifier such as random forest classification algorithm, which is based multiple parallel weak decision trees. The results of multiple decision trees are combined in the form of majority voting or averaging to make a firm decision over the given input. The random forest algorithm’s training phase randomly divides the feature set of the database images into several small subsets. These subsets are individually used to train the number of decision trees, and the decision trees select the optimal feature from each subset on the top tree to split them well. Once the query feature enters this ensemble classification, it meets all the decision trees. The output of all these trees is considered to make a final prediction in that texture image classification.
The similarity measures are expressed in EquationEquations (6)(6)
(6) –(Equation10
(10)
(10) ) used to estimate the closeness between the database images and query image. The estimated low value indicates that the image is more relevant to the query image.
Experimental Results and Discussion
The proposed texture descriptor is tested over twelve different databases. The database details are given in . These twelve databases are grouped into five different categories, namely, natural images databases (i.e., Wang’s (Jia and Wang, Citation2003), Corel-10k (Tao et al., Citation2007), OT-Scene (Oliva and Torralba, Citation2001), Free photo (Anderson Rocha et al., Citation2010), and GHIM (Liu, Citation2015)), texture images databases (i.e., (Brodatz, Citation1966), Color Brodatz (Safia and He, Citation2013), and KTH-TIPS2b (Mallikarjuna et al., Citation2006)), land-use image databases (i.e., UC dataset (Yang and Newsam, Citation2010) and RS dataset (Laban et al., Citation2017)), a single object with different rotation (i.e., Coil-100 (Nene et al., Citation1996)), and objects under different illumination conditions (i.e., FTVL (Rocha et al., Citation2004)). Five various studies are carried out in the proposed texture extraction method using the twelve datasets. The studies are (i) effect of texture extraction method using the different families of wavelet filters, (ii) impact of different levels of decomposition involved in texture extraction, (iii) impact of radius values involved in proposed texture extraction, (iv) impact of varying sampling points involved in texture extraction, and (v) impact of proposed texture extraction across varying levels of decomposition and different radii. Finally, the performance of the proposed descriptor is tested against the feature extraction method available in the texture representation.
Table 1. Database details
Impact of Different Families of Wavelet Filters in the Proposed Texture Feature
Here, the proposed descriptor takes the approximation coefficients of SWT based on different wavelet filters, namely, Haar (dbN, N = 1), Daubechies (dbN, N = 2,3,4,5,6), Coiflet (CoifN,N = 1,2,3,4,5), Symlet (symN, N = 1,2,3,4,5), and Biorthogonal (biorN, N = 1.1,1.3,1.5,2.2,2.4) with different filter lengths (i.e., N). Among the number of length details available in each family of filters, the wavelet filter with the best performing length is selected for the experimental analysis. Thus, Haar with length 1, Daubechies with length 6, Coiflet and Symlet with length 4, and Biorthogonal with length 2.4 are selected for further analysis.
Image Retrieval
In image retrieval applications, the impact of texture extraction based on different families of wavelet filters is tested with five different kinds of distance measures (as given in EquationEquations (9)(9)
(9) –(13)) since distance measure plays a significant role in image retrieval. presents the recall value associated with five different distance measures applied over the proposed texture feature extracted from the five different wavelet filters. The experimental results illustrated in show that the image retrieval system based on D1_distance measure gives a more number of similar images on top of the retrieval results compared to other distance measures involved in the retrieval process. Next to D1_distance measure, the Bray Curtis distance measure-based image retrieval system has high precision in retrieval results. Meanwhile, the chessboard distance-based retrieval system fails to give more number of similar images in the top results. Thus, the D1_distance measure is preferred in further experiments of this work.
Table 2. Performance analysis of the proposed method based on five different wavelet families and distance measures over 12 different image databases
Image Classification
The random forest image classification method takes the proposed descriptor extracted from the different families of wavelet filters images. This experiment takes 100 different decision trees to build a random forest classification model. In addition to that, 80% of the feature dataset corresponding to each image dataset is involved in training the model. The remaining 20% of the feature dataset from each dataset is taken for testing the model. This classification model is tested ten different times, and the mean and standard deviation of the classification accuracy are taken for performance assessment, which is shown in . The accuracy of the classification model is estimated using EquationEquation (11)(11)
(11) .
Figure 3. Proposed feature descriptors’ average classification accuracy and standard deviation using a random forest classifier [Haar (H), Daubechies (D), Coiflet (C), Symlet (S), Biorthogonal (B)].
![Figure 3. Proposed feature descriptors’ average classification accuracy and standard deviation using a random forest classifier [Haar (H), Daubechies (D), Coiflet (C), Symlet (S), Biorthogonal (B)].](/cms/asset/efd8ef97-cc96-48f0-ac34-c19461316b2c/uaai_a_2001176_f0003_b.gif)
where TCP is the number of correctly classified test samples and TS is the number of samples involved in testing the classification model.
The standard deviation gives lower and higher boundaries values of the classification accuracy. The classification model, which has high accuracy and small standard deviation, is considered the best model. According to image retrieval and classification experiments, the proposed texture feature extraction based on Symlet families of the filter is more suitable than the other families of filters involved in texture feature extraction. The Symlet wavelet has a linear phase, and the levels of artifacts available in boundaries of the decomposed images are less. Thus, the Symlet family wavelet filter based proposed descriptor is considered in further image retrieval and classification experiments of this work.
Impact of Different Levels of Decomposition in the Proposed Texture Feature
The effect of different levels of wavelet decomposed images in the proposed texture feature extraction is studied by conducting image retrieval and classification experiments over them. Here, images decompose up to four levels. The proposed feature extraction algorithm is applied over four different levels in five different combinations (levels 1 and 2, levels 2 and 3, levels 3 and 4, levels 1and 3, and levels 1 and 4). Among the four different decomposed image combinations involved in proposed feature extraction, levels 1 and 2 give the most prominent image retrieval and classification experiments shown in and , respectively. Each level of wavelet decomposition depends on the previous level approximation channel information, which is not applicable for the first level of decomposition. The first level of wavelet decomposition directly depends on the original image. The further levels of decomposed images take the smoother version of the image obtained from the approximation channels. Moreover, levels of decomposition and system complexity are proportional to each other; each level of stationary wavelet decomposition increases the redundancy and requires more memory space for processing. Thus, this work considers the decomposed images from levels 1 and 2 of the stationary wavelet in the following experiments.
Table 3. Performance analysis of the proposed method based on different levels of wavelet decomposition
Figure 4. Classification accuracy of proposed descriptor obtained from different levels of decomposed images.
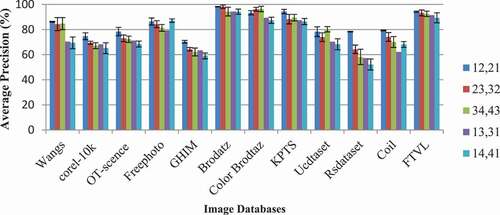
Impact of Different Radius in the Proposed Texture Feature
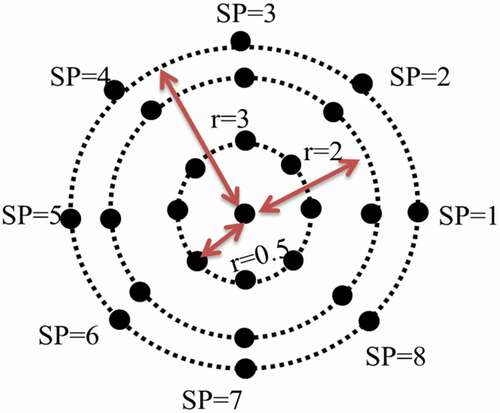
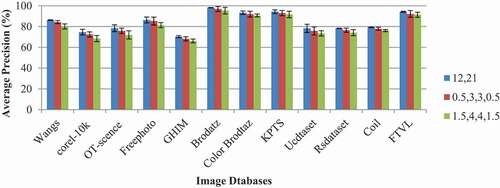
The importance of radius used in the proposed work is studied by varying the radius values from 0.5 to 4 in each subspace. A different number of equally spaced neighboring pixel information is taken from each radius. For example, shows the equally spaced eight sampling points over radii 0.5, 2, and 3. In this experiment, features are extracted from the following:
Radii 1 and 2 from levels 2 and 1 and radii 2 and 1 from levels 1 and 2.
Radii 0.5 and 3 from levels 1 and 2 and radii 3 and 0.5 from levels 1 and 2.
Radii 1.5 and 4 from levels 2 and 1 and radii 4 and 1.5 from levels 1 and 2.
Figure 5. Equally spaced eight sampling points at different radii.
Here, padding of zero values in between the filter coefficients of each level gives redundant information. Thus, sampling points available in the small circle of the radius has a high correlation with the image point present in the center of the circle than the sampling points present in a higher radius. and show that the sampling points available in radius 12 have more information than the sampling points available in radii 0.5 and 3 and 1.5 and 3 at decomposition levels 1 and 2. The result of this experiment suggests that the sampling point available in a radius less than 2 has more correlation with the center point than the sampling points on radii 3 and 4. Thus, the radii 1 and 2 and 2 and 1 on levels 1 and 2 are considered in the proposed texture feature extraction in further experiments.
Table 4. Performance analysis of the proposed method based on different radii
Figure 6. Classification accuracy of the proposed descriptor obtained from different radii and levels of decomposed images.
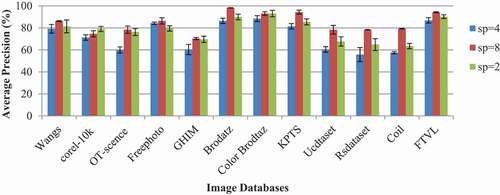
Impact of Different Sampling Points in the Proposed Texture Feature
Like radius, the number of equally spaced neighboring pixel points taken from the radius is also important in the proposed texture feature extraction. The sampling points on the preferred radius give specific details about the local region taken for the feature extraction process. Thus, the proposed texture feature extraction algorithm considers four, eight, and twelve equally spaced neighboring pixels in each decomposition level to represent the image. Then, the performances of the extracted features are tested in image retrieval and classification experiments. shows that the image retrieval system based on the number of sampling points equal to 4 has a low precision rate than the proposed descriptor extracted from the sampling points 8 and 12. This indicates that the proposed descriptor, based on the sampling point 4, is not enough to hold more details about the image. The proposed descriptor, based on the sampling points 8 and 12, gives a performance that is closer to each other. The proposed descriptor based on the twelve equally spaced sampling points gives a slightly better performance in Color Brodatz (0.51% better) database than the performance based on the eight equally spaced sampling points on this database. The proposed descriptor based on the equally spaced sampling points 8 has slightly better performance in the remaining databases. The original precision rate and its betterment percentage against the twelve equally spaced sampling point based proposed descriptor is given as follows: Wang’s- (86.36%) (0.04% better), Corel 10k-(57.92%) (1.58% better), OT-Scene-(72.45%) (0.71% better), free photo-(81.24%) (0.2% better), Brodatz (97.81%) (0.25% better), Colored Brodatz (88.54%) (0.54% better), UC-dataset-(79.74%) (3.5% better), RS-dataset-(63.47%) (3.04% better), Coil-(78.72%) (4.48% better), and FTVL-(90.88%) (4.71% better) databases, whereas in classification (refer ), the proposed descriptor based on eight equally spaced sampling points has higher accuracy than the other two sampling points considered in the proposed texture feature extraction. In image classification, a Color Brodatz class proposed descriptor based on 8 and 12 equally spaced sampling points has an accuracy of 93.054% and 93.054%, and its corresponding standard deviations are 1.653% and 2.91%. The 12 and 8 sampling points based method has equal accuracy in the Color Brodatz database; its standard deviation measure reveals that the accuracy will span between 90.14% and 95.96%, whereas eight equally spaced sampling point based retrieval accuracy lies between 91.40% and 94.7%. A deviation on classification accuracy is obtained in the proposed descriptor based on eight sampling points, which gives better performance than the 12 sampling points based on proposed texture feature extraction.
Table 5. Performance analysis of the proposed method based on different sampling points
Figure 7. Classification accuracy of the proposed descriptor obtained from different sampling points of decomposed images.
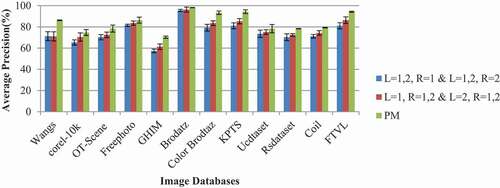
Impact of the Proposed Texture Feature Extraction across Different Levels of Decomposition and Different Radii
The impact of the proposed texture feature extraction method across the varying decomposition levels and different radii is examined against two kinds of features. They are (i) feature vectors extracted from the same level with different radii and (ii) different levels with the same radius. These two methods perform encoding using the procedure followed in the proposed descriptor. The first kind of the feature extraction method encodes the discriminant information available in the level 1 decomposed image from radii 1 and 2. Subsequently, it encodes the details available in the level-2 decomposed image from radii 1 and 2 and concatenates them to form a feature vector. The second method encodes the details of decomposed images in levels 1 and 2 with radius 1. Then, it encodes the details present in radius 2 from levels 1 and 2 of the decomposed images. Finally, this information is concatenated to form the feature descriptor. This experiment highlights the importance of feature extraction across different levels of decomposition and radii. The image retrieval precision-recall rate and classification accuracy of the proposed descriptor is high compared to the performance of the other two feature extraction methods described above, which is clearly shown in and . Encoding local difference information available at the same radius present in levels 1 and 2 gives low performance since the level of decomposition increases the redundancy. Hence, encoding the particular radius neighboring point’s local difference around each point of the decomposed images available across the different levels extracts only the redundant noisy details. On the other hand, encoding the different radius neighboring points’ local difference around each point of the particular level decomposed image fails to extract the correlation between the decomposed images on successive levels. Thus, it has high retrieval precision and classification accuracy compared to the first kind of feature extraction method and low performance compared to the proposed texture feature extraction methods.
Table 6. Performance analysis of the proposed method based on different levels of decomposition and different radii
Figure 8. Classification accuracy of texture features obtained at different levels of decomposition and different radii.
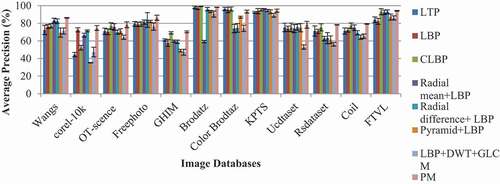
Performance Analysis of the Proposed Feature Descriptor against the State-of-the-Art Texture Feature Extraction Methods
The proposed feature descriptor performance in image retrieval and classification experiments is compared against the popular texture feature extraction methods such as LBP (Ojala, Pietikainen, and Maenpaa Citation2002), CLBP (Rassem, Alsewari, and Makbol Citation2017), LTP (Srivastava, Binh, and Khare Citation2014), radial difference LBP (Liu et al. Citation2012), pyramid+LBP (Qian et al. Citation2011), radial mean LBP (Shakoor and Boostani Citation2018), and LBP+DWT+GLCM (Khare et al. Citation2018). highlights the proposed work performance against other popular techniques involved in texture feature extraction. The image retrieval experiment on natural image databases reveals that the proposed feature extraction technique gives a more suitable image representation than the other feature extraction techniques. Wang’s and GHIM database images are averagely 86.36% and 68.25% correctly retrieved using the proposed descriptor. Subsequently, the LBP feature descriptor has high retrieval rates of 82.6% and 60.3% over Wang’s and GHIM databases. In Corel −10k database, the proposed texture feature extraction method achieves an average retrieval rate of 57.92%, which is 0.75% higher than the highest performing existing radial difference LBP (Liu et al. Citation2012) texture feature on this database. The OT-Scene database images are approximately 74.45% correctly retrieved by the proposed descriptor, whereas LBP (Ojala, Pietikainen, and Maenpaa Citation2002) and pyramid + LBP (Qian et al. Citation2011) texture features give approximately 70.1% and 70.01% matched images at the top of the retrieval results. On average, 81.24% of free photo database images are correctly matched with the given query image, averagely 6.53% less than the radial difference LBP (Liu et al. Citation2012) texture features. The Brodatz texture database images are approximately 97.81% correctly retrieved by the image retrieval experiment based on the proposed feature extraction technique.
Table 7. Performance analysis of the proposed method and existing texture extraction methods
In comparison, the LTP (Srivastava, Binh, and Khare Citation2014) and CLBP (Rassem, Alsewari, and Makbol Citation2017) outperform the proposed descriptor performance in the Color Brodatz database by 6.68% and 1.48%, respectively. Moreover, radial mean LBP (Shakoor and Boostani Citation2018) represents the KTH-TIPS2b images very well; this improves the retrieval precision by 7.49% compared to the proposed method. The image retrieval experiments over the UC and RS databases give high precision rates of 79.74% and 63.47%, which are 12.7% and 4.37% higher than the second best-performing feature descriptor CLBP (Rassem, Alsewari, and Makbol Citation2017). Coil-100 and FTVL database images’ average retrieval precision values are high as 78.92% and 90.88% when the experiments use the proposed texture feature vectors as input to the image retrieval system. Like in image retrieval experiments, in image classification as well (ref. ), using the proposed descriptor gives higher image accuracy in natural image database (Wang’s-(86.23% 0.321%), Corel-10k- (74.653%
2.753), OT-Scene-(78.387%
3.321%), Free photo-(86.37%
2.84%), and GHIM-(70.3%
1.04%)), land-use image databases (i.e., UC-(78.32%
3.92) and RS (78.325
0.214%)), single object with different rotation (i.e., Coil-100-(79.321%
0.32%)), and objects under different illumination conditions (i.e., FTVL-(94.234%
0.452%)). The random forest classification algorithm based on CLBP (Rassem, Alsewari, and Makbol Citation2017) features more precisely classifies the Brodatz texture database than the proposed method. Moreover, LTP (Srivastava, Binh, and Khare Citation2014) features are more suitable for representing the Color-Brodatz database images; thus, it gives an average accuracy of 96.45% with a standard deviation of 1.86%. The radial mean LBP (Shakoor and Boostani Citation2018) representation is well suitable to give high classification accuracy as 93.14% over the KTH-TIPS2b database images with a standard deviation of 2.14%. The SVM based classification method, which uses the color and wavelet texture feature (Singh and Batra (Citation2020)) has given a small number of relevant images at the final result. In addition to the texture feature, it considers the color details from the image. The combination of color moments and wavelet texture feature fails to give more relevant images in the retrieval result. The hybrid system introduced by Ali Khan, Javed, and Ashraf (Citation2021) has given less number of similar images at the search result. Moreover, extracting shape, color and texture features from Brodatz, and KTH-TIPS2b (texture image database) database has given very low retrieval results. The image retrieval experiments based on distance measure increase the image retrieval system’s time complexity since each query of the retrieval system will search the whole database to give the relevant images at the top of the retrieval results. The image retrieval system’s retrieval time is proportional to the number of images available in the image database. On the other hand, the image classification model decreases the distance-based retrieval method’s complexity by placing the classification model in between the feature extraction and the similarity measure process block of the image retrieval system. This reduces the time taken to find a prominent match among the different categories of images. Once the classification model is fixed above the similarity measure block, the classification model is trained by each image’s proposed feature vector and its corresponding class labels. The testing is done using the query image after completing the training process. Once features are extracted from the query image, the extracted features are given as input to the classification model. The classification model predicts the query image based on its class. Then, the similarity measure is calculated between the query and the predicted class images. This reduces the time complexity associated with the distance-based retrieval system. The prediction rate of the classification model based image retrieval system depends on the classification accuracy of the classifier (i.e., prediction rate and classification accuracy are identical).
Figure 9. Classification accuracy of the proposed and other texture feature descriptors.
Conclusion
The proposed texture descriptor encoded the correlation between the multi radii local pixel differences around every point available in the two different levels of the stationary wavelet decomposed images. The image retrieval and classification experiments on different kinds of wavelet filters involved in proposed feature extraction reveal that the Symlet wavelet filter based stationary wavelet transform gives a high retrieval rate and classification accuracy. The study on the parameters involved in the proposed feature extraction method revealed that the eight equally spaced sampling points available in a radius less than two of the decomposed images in levels 1 and 2 hold the discriminant details about the image. Moreover, the proposed work was evaluated over twelve databases such as Wang’s, Corel-10k OT-Scene, Free photo, GHIM, Brodatz, Color Brodatz, KTH-TIPS2b, UC, RS, Coil-100 and FTVL-databases and they give 86.36%, 72.45%, 57.92%, 81.24%, 68.25%, 97.81%, 88.54%, 87.17%, 79.74%, 63.47%, 78.72%, and 90.88% retrieval results, respectively. The proposed texture feature-based image retrieval system has approximately 7.49% (KTH-TIPS2b) and 6.53% (free photo) reduced performance compared to the retrieval system based on radial difference and radial mean texture feature. The future scope of this work can be efficiently encoding the correlation of the three different levels of decomposed images by taking the different number of sampling points over the multi-scale local regions for a large dataset.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
References
- Ali Khan, U., A. Javed, and R. Ashraf. 2021. An effective hybrid framework for content based image retrieval (CBIR). Multimedia Tools and Applications 80: 26911–26937. doi:https://doi.org/https://doi.org/10.1007/s11042-021-10530-x
- Anderson Rocha, D. C., J. W. Hauagge, S. Goldenstein, and S. Goldenstein. 2010. Automatic fruit and vegetable classification from images. Computers and Electronics in Agriculture 70 (1):96–104 Free photo Accessed December 24, 2020 http://www.ic.unicamp.br/~rocha/pub/downloads/free-foto-nature.tar.gz
- Anys, H., and D. C. He. 1995. Evaluation of textural and multi polarization radar features for crop classification. IEEE Transactions on Geoscience and Remote Sensing 33 (5):1170–81. doi:https://doi.org/10.1109/36.469481.
- Awad, A. I., and M. Hassaballah. 2016. Image feature detectors and descriptors: Foundations and applications, 630. Switzerland: Springer.
- Bai, C., W. Zou, K. Kpalma, and J. Ronsin. 2012. Efficient color texture image retrieval by combination of color and texture features in wavelet domain. Electronics Letters 48 (23):23. doi:https://doi.org/10.1049/el.2012.2656.
- Bella, M. I. T., and A. Vasuki. 2019. An efficient image retrieval framework using fused information feature. Computers & Electrical Engineering 75:46–60. doi:https://doi.org/10.1016/j.compeleceng.2019.01.022.
- Bhunia, A. K., A. Bhattacharyya, P. Banerjee, P. P. Roy, and S. Murala; Murala. 2020. A novel feature descriptor for image retrieval by combining modified color histogram and diagonally symmetric co-occurrence texture pattern. Pattern Analysis and Applications 23 (2):703–23. doi:https://doi.org/10.1007/s10044-019-00827-x.
- Brodatz, P. 1966. Textures: A photographic album for artists and designers. New York: Dover Publications. Brodatz database: Accessed December 23, 2020. http://sipi.usc.edu/database/database.php?volume=rotate
- Dash, S., and U. R. Jena. 2017. Texture classification using steerable pyramid based laws masks. Journal of Electrical Systems and Information Technology 4 (1):185–97. doi:https://doi.org/10.1016/j.jesit.2016.10.001.
- Dubey, S. R. 2019. Face retrieval using frequency decoded local descriptor. Multimedia Tools and Applications 78 (12):16411–31. doi:https://doi.org/10.1007/s11042-018-7028-8.
- Haralick, R. M., K. Shanmugam, and I. Dinstein. 1973. Textural Features for Image Classification. IEEE Transactions on Systems, Man, and Cybernetics SCM-3. SMC-3 (6):610–21. doi:https://doi.org/10.1109/TSMC.1973.4309314.
- Hassaballah, M., and K. M. Hosny. 2019. Recent advances in computer vision: Theories and applications, vol. 804. Switzerland: Springer.
- Ji, Q., J. Engel, and E. Craine. 2000. Texture analysis for classification of cervix lesions. IEEE Transactions on Medical Imaging 19 (11):1144–49. doi:https://doi.org/10.1109/42.896790.
- Jia, L., and J. Z. Wang. 2003. Automatic linguistic indexing of pictures by a statistical modeling approach. IEEE Transactions on Pattern Analysis and Machine Intelligence 25 (9):1075–88 Wang’s Database: Accessed December 18, 2020. http://wang.ist.psu.edu/docs/related/
- Kellokumpu, V., G. Zhao, and M. Pietikäinen 2008. Human activity recognition using a dynamic texture based method. British Machine Vision Conference, University of Leeds, West Yorkshire, England, 88.1–88.10.
- Khare, M., P. Srivastava, and J. Gwak . 2018. A multiresolution approach for content-based image retrieval using wavelet transform of local binary pattern. In Intelligent information and database systems, ed. N. Nguyen, D. Hoang, T. P. Hong, H. Pham, and B. Trawiński, ACIIDS 2018. Lecture Notes in Computer Science vol. 10752. Cham: Springer, 529–538 .
- Khokher, A., and R. Talwar. 2017. A fast and effective image retrieval scheme using color-, texture-, and shape-based histograms. Multimedia Tools and Applications 76 (20):21787–809. doi:https://doi.org/10.1007/s11042-016-4096-5.
- Krizhevsky, A, I Sutskever, and Hinton, G. E. 2012. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems. 60: 1097–105.
- Laban, N., B. Abdellatif, H. M. Ebied, H. A. Shedeed, and M. F. Tolba. 2017. Performance enhancement of satellite image classification using a convolutional neural network, Conference: International Conference on Advanced Intelligent Systems and Informatics Cairo, Egypt Accessed December 12, 2020. http://dsp.whu.edu.cn/cn/staff/yw/HRSscene.html
- Li, X., J. Yang, and J. Ma. 2020. Large scale category-structured image retrieval for object identification through supervised learning of CNN and SURF-Based matching[J]. IEEE Access 8:57796–809. doi:https://doi.org/10.1109/ACCESS.2020.2982560.
- Liao, S., M. W. K. Law, and A. C. S. Chung. 2009. Dominant local binary patterns for texture classification. IEEE Transactions on Image Processing 18 (5):1107–18. doi:https://doi.org/10.1109/TIP.2009.2015682.
- Liu, G. H., Z. Y. Li, L. Zhang, and Y. Xu. 2011. Image retrieval based on micro-structure descriptor. Pattern Recognition 44 (9):2123–33. doi:https://doi.org/10.1016/j.patcog.2011.02.003.
- Liu, G.-H. 2015. Content-Based image retrieval based on visual attention and the conditional probability, International Conference on Chemical, Material and Food Engineering, Kunming, Yunnan, China. GHIM Database: Accessed December 24, 2020. http://www.ci.gxnu.edu.cn/cbir/Dataset.aspx
- Liu, L., L. Zhao, Y. Long, G. Kuang, and P. Fieguth. 2012. Extended local binary patterns for texture classification. Image and Vision Computing 30 (2):86–99. doi:https://doi.org/10.1016/j.imavis.2012.01.001.
- Liu, L., P. W. Yunli Long, S. L. Fieguth, and G. Zhao. 2014. BRINT: Binary rotation invariant and noise tolerant texture classification. IEEE Transactions On Image Processing 23 (7):3071–84. doi:https://doi.org/10.1109/TIP.2014.2325777.
- Liu, L., S. Lao, P. W. Fieguth, Y. Guo, X. Wang, and M. Pietikäinen. 2016. Median robust extended local binary pattern for texture classification. IEEE Transactions on Image Processing 25 (3):1368–81. doi:https://doi.org/10.1109/TIP.2016.2522378.
- Liua, Y., D. Zhang, L. Guojun, and M. Wei-Ying. 2007. A survey of content-based image retrieval with high-level semantics. Pattern Recognition 40 (1):262–82. doi:https://doi.org/10.1016/j.patcog.2006.04.045.
- Mallikarjuna, P., A. T. Targhi, M. Fritz, E. Hayman, B. Caputo, and J.-O. Eklundh THE KTH-TIPS2 database. Computational Vision and Active Perception Laboratory (CVAP): KTH-TIPS-2B database, 2006 Accessed December 2020 12, 2020. http://www.nada.kth.se/cvap/databases/kth-tips/
- Manjunath, B. S., and W. Y. Ma. 1996. Texture features for browsing and retrieval of image data. IEEE Transactions on Pattern Analysis and Machine Intelligence 18 (8):837–42. doi:https://doi.org/10.1109/34.531803.
- Murala, S., R. P. Maheshwari, and R. Balasubramanian. 2012. Local tetra patterns: A new feature descriptor for Content-based image retrieval. IEEE Transactions on Image Processing 21 (5):2874–86. doi:https://doi.org/10.1109/TIP.2012.2188809.
- Nene, S. A., S. K. Nayar, and H. Murase. 1996. Columbia Object Image Library (COIL-100), Technical Report CUCS-006-96. Coil −100 Database: Accessed December 12, 2020. http://www1.cs.columbia.edu/CAVE/software/softlib/coil-100.php
- Ojala, T., M. Pietikainen, and T. Maenpaa. 2002. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence 24 (7):971–87. doi:https://doi.org/10.1109/TPAMI.2002.1017623.
- Oliva, A., and A. Torralba. 2001 Modeling the shape of the scene: A holistic representation of the spatial envelope . International Journal of Computer Vision. 42 (3):145–75. OTScene Database Accessed December 18, 2020 http://cvcl.mit.edu/database.htm
- Ouma, Y. O., J. Tetuko, and R. Tateishi. 2008. Analysis of co‐occurrence and discrete wavelet transform textures for differentiation of forest and non‐forest vegetation in very‐high‐resolution optical‐sensor imagery. International Journal of Remote Sensing 29 (12):3417–56. doi:https://doi.org/10.1080/01431160701601782.
- Pavithra, L. K., and T. SreeSharmila. 2018. A n efficient framework for image retrieval using color, texture and edge features. Computers & Electrical Engineering 70:580–93. doi:https://doi.org/10.1016/j.compeleceng.2017.08.030.
- Pietikainen, M., Hadid, A, Zhao, G, and Ahonen, T, 2011. Local Binary Patterns for Still Images . . Computer Vision Using Local Binary Patterns 40 Computational Imaging and Vision, London: Springer 13–47 .
- Priyadharsini, R., T. S. Sharmila, and V. Rajendran. 2018. A wavelet transform based contrast enhancement method for underwater acoustic images. Multidimensional Systems and Signal Processing 29 (4):1845–59. doi:https://doi.org/10.1007/s11045-017-0533-5.
- Pun, C.M., and M.C. Lee. 2003. Log-polar wavelet energy signatures for rotation and scale invariant texture classification. IEEE Transactions On Pattern Analysis And Machine Intelligence 25 (5): 590- 603.
- Qian, X., X.-S. Hua, P. Chen, and K. Liangjun. 2011. PLBP: An effective local binary patterns texture descriptor with pyramid representation. Pattern Recognition 44 (10–11):2502–15. doi:https://doi.org/10.1016/j.patcog.2011.03.029.
- Rassem, T. H., A. A. Alsewari, and N. M. Makbol. 2017. Texture image classification using wavelet completed local binary pattern descriptor (WCLBP), The Seventh International Conference on Innovative Computing Technology, Luton, UK.
- Rocha, A., H. A. X. Costa, and L. M. C. Chaves. 2004. Software for digital security using steganography. REIC - Electronic Journal of Scientific Initiation, SBC v. I, n. Number I, 1–11. FTVL Database: Accessed December 12, 2020. http://www.ic.unicamp.br/~rocha/pub/downloads/tropical-fruits-DB1024x768.tar.gz/
- Safia, A., and D. He. 2013. New Brodatz-based image databases for grayscale color and multiband texture analysis. ISRN Machine Vision, Article ID 87638. ColorBrodatz database: Accessed December 12, 2020. https://multibandtexture.recherche.usherbrooke.ca/colored%20_brodatz_more.html
- Seetharaman, K., and M. Kamarasan. 2014. Statistical framework for image retrieval based on multiresolution features and similarity method. Multimedia Tools and Applications 73 (3):1943. doi:https://doi.org/10.1007/s11042-013-1637-z.
- Shakoor, M. H., and R. Boostani. 2018. Radial mean local binary pattern for noisy texture classification. Multimedia Tools and Applications 77 (16):21481. doi:https://doi.org/10.1007/s11042-017-5440-0.
- Singh, S., and S. Batra. 2020. An efficient bi-layer content based image retrieval system. Multimedia Tools and Applications 79 (25–26):17731–59. doi:https://doi.org/10.1007/s11042-019-08401-7.
- Singh, V. P., and R. Srivastava. 2017. Improved image retrieval using fast Colour-texture features with varying weighted similarity measure and random forests. Multimedia Tools and Applications. doi:https://doi.org/10.1007/s11042-017-5036-8A.
- Singha M., K. Hemachandran, and A. Paul. 2012. Content-based image retrieval using the combination of the fast wavelet transformation and the colour histogram, IET Image Process 6 (9): 1221–1226. DOI:https://doi.org/10.1049/iet-ipr.2011.0453
- Singhal, A., M. Agarwal, and R. B. Pachori. 2020. Directional local ternary co-occurrence pattern for natural image retrieval. Multimedia Tools and Applications. doi:https://doi.org/10.1007/s11042-020-10319-4.
- Srivastava, P., and A. Khare. 2018. Utilizing multiscale local binary pattern for content-based image retrieval. Multimedia Tools and Applications 77 (10):12377–403. doi:https://doi.org/10.1007/s11042-017-4894-4.
- Srivastava, P., N. T. Binh, and A. Khare. 2014. Content-based image retrieval using moments of local Ternary pattern. Mobile Networks and Applications 19 (5):618–25. doi:https://doi.org/10.1007/s11036-014-0526-7.
- Tajeripour, F., E. Kabir, and A. Sheikhi. 2007. Fabric defect detection using modified local binary patterns. EURASIP Journal on Advances in Signal Processing 8:1–12.
- Tan, X., and B. Triggs. 2010. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Transactions on Image Processing 19 (6):1635–50. doi:https://doi.org/10.1109/TIP.2010.2042645.
- Tao, D., X. Li, and S. J. Maybank. 2007. Negative samples analysis in relevance feedback. IEEE Transactions on Knowledge and Data Engineering (TKDE) 19 (4):568–80 Corel-10k Database: Accessed December 12, 2020. http://www.ci.gxnu.edu.cn/cbir/Dataset.aspx
- Tuceryan, M., and A. K. Jain. 1993. Texture analysis. In Handbook pattern recognition and computer vision, ed. C. H. Chen, L. F. Pau, and P. S. P. Wang, 235–76. Singapore: World Scientific.
- Vimina, E. R. 1., and M. O. Divya. 2020. Maximal multi-channel local binary pattern with colour information for CBIR. Multimedia Tools and Applications 79 (35–36):25357–77. doi:https://doi.org/10.1007/s11042-020-09207-8.
- Walia, E., S. Vesal, and A. Pal. 2014. An effective and fast hybrid framework for color image retrieval. Sensing and Imaging 15 (1): Article number: 93. doi:https://doi.org/10.1007/s11220-014-0093-9.
- Yadav, A. R., R. S. Anand, M. L. Dewal, and S. Gupta. 2015. Hardwood species classification with DWT based hybrid texture feature extraction techniques. Sadhana 40 (Part 8):2287–312. doi:https://doi.org/10.1007/s12046-015-0441-z.
- Yang, P., F. Zhang, and G. Yang. 2018. Fusing DTCWT and LBP based features for rotation, illumination and scale invariant texture classification. IEEE Access 6:13336–49. doi:https://doi.org/10.1109/ACCESS.2018.2797072.
- Yang, Y., and S. Newsam. 2010. Bag-Of-Visual-Words and spatial extensions for land-use classification, ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS). San Jose California, 270–279 .
- Zhang, B., Y. Gao, S. Zhao, and J. Liu. 2010. Local derivative pattern versus local binary pattern: Face recognition with high-order local pattern descriptor. IEEE Transactions on Image Processing 19 (2):533–44. doi:https://doi.org/10.1109/TIP.2009.2035882.