
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this work, we propose a new approach for face recognition using low-resolution images. By cleverly combining conventional interpolation methods with the state-of-the-art classification approach, i.e. convolutional neural network, we introduce a new approach to efficiently leverage low-resolution images in classification task, especially in face recognition. Besides, we also do experiments on some recent popular methods, our approach outperforms some of them. Additionally, we propose a specific transfer learning strategy based on the preexisting well-known concept dedicated to low-resolution transfer learning. It boosts performance and reduces training time significantly. We also investigate on scalability by applying Bayesian optimization for hyper-parameter search. Therefore, our approach is able to be widely applied in many kinds of datasets and low-resolution classification tasks due to automatically seeking optimal hyper-parameters, which makes our method competitive to others.
Introduction
Image classification problem so far has many applications in the real world. Recently, most attentions focus on problems related to face recognition in business and security. For example, facial emotional recognition helps to investigate user’s behaviors in business (J. Chen et al. Citation2014), facial iris recognition is broadly applied for mobile security (Minaee and Abdolrashidi Citation2019). Besides, face recognition for surveillance is also significantly attractive, many approaches have been proposed which can be divided into learning and unlearning-based ones. In particular, popular methods of the later, including Local Binary Patterns (LBP) (Ojala, Pietikainen, and Maenpaa Citation2002) and Histograms of Oriented Gradients (HOG) (Dalal and Triggs Citation2005), use pre-defined filters to extract features by intention. These approaches were widely applied many years ago until the learning-based methods appear such as Principal Component Analysis (Wold, Esbensen, and Geladi Citation1987), Support Vector Machine (Suykens and Vandewalle Citation1999), and Convolutional Neural Network lately. AlexNet can be seen as the pioneer forming the baseline Convolutional Neural Network (CNN) architecture which surprisingly outperformed in image classification task (Krizhevsky, Sutskever, and Hinton Citation2012). Afterward, other popular CNN-based architectures such as VGG (Simonyan and Zisserman Citation2014), ResNet (He et al. Citation2016), DenseNet (Huang et al. Citation2017), etc, increasingly challenge most ever classification tasks.
Generally, in order to perform well in image classification, it requires a huge amount of high-resolution data. However, most real-world deep-learning-based applications suffer a significant challenge. Since images in the wild are often low-resolution, i.e. the resolution of captured image for inference is lower than training image, due to either far distance or bad quality of device. The problem can be resolved by transforming these images resolution to the original one thanks to conventional interpolation algorithms. However, this can lead to a bad quality result when inference image’s resolution is much lower than the original one (see ). As experiments by Li et al. have shown, small resolution images cause a significant downgrade of accuracy in prediction (Li et al. Citation2018). Additionally, they indicate that images, which resolution are lower than usually being ignored or thrown away. This leads to the waste of data and resources in some cases. Especially in crime tracking and recognition when all relevant data are vulnerable and should be utilized thoroughly.
Figure 1. Same image in different low resolutions (top), and their corresponding bilinear interpolated images (bottom). The recovered images of last two extremely low-resolution cases are nearly indistinguishable. Many works only handle low resolution up to while ours can handle even lower resolution images.

To address the problem, we aim to seek an efficient approach that is robust to low-resolution image classification. The proposed method should preserve the accuracy of it as much as possible. Particularly, given an original CNN-based model already trained on original high-resolution images, our method automatically produces optimal dimensions and CNN architectures, which are able to deal with any resolution. Moreover, we also introduce two optimizations for the problem that (i) accelerate the training time and performance, (ii) adapt various types of data by automatically searching for dedicated hyper-parameters. In summary, our contribution are as follows:
We survey through many existing solutions for low-resolution recognition. These approaches vary from some conventional interpolations such as nearest neighbor, bi-linear, etc. to learning-based methods, i.e. Super Resolution Convolutional Neural Network and many state-of-the-art works.
We propose an approach that significantly surpasses other methods. Our algorithm is a combination of deep learning and typical interpolation guiding the down-sampling process and modification of corresponding architecture.
We further enhance the scalability to practically apply in various real-world problems. Particularly, the training time is reduced thanks to our block transfer learning, and flexible to apply in many different kinds of problems by leveraging Bayesian optimization (Snoek, Larochelle, and Adams Citation2012).
Our work is organized as follows. In Section 2, we survey some popular state-of-the-art approaches which currently handle the problem. In Section 3, our proposed method is introduced in detail. We conduct experiments and discussion in Section 4. Section 5 is the conclusion.
Related Work
To solve the image classification task in high dimension image data, many approaches are divided into manual-based and automated-based. For the manual ones, Local Binary Pattern (LBP) (Ojala, Pietikainen, and Maenpaa Citation2002) and Histograms of oriented gradients (HOG) features (Dalal and Triggs Citation2005) are considered as popular methods. These methods take advantage of pre-defined filters for the feature extraction phase, hence, require specific experiences to acquire good performance but are more computationally efficient instead. On the other hand, automated feature extraction methods represented by CNN-based are recently accounting for significant performance. The increasing complexity of datasets entails the deeper of CNN architecture. For example, the first version of VGG had 16 layers then increased to 19 layers (Simonyan and Zisserman Citation2014), ResNet (He et al. Citation2016), and DenseNet (Huang et al., Citation2017) with the same idea but were even deeper, they appended shortcut layers and a large number of trainable parameters. However, when dealing with low resolution images, the experiments show significant drops in accuracy of those architectures. Surprisingly, shallow models like AlexNet are more vulnerable to low image resolution compared with deep models like ResNet (Koziarski and Cyganek Citation2018). Since the convolved features completely flush out if a model is too deep. We claim that a model can keep performing well on low-resolution images by modifying its architecture based on the original one following our proposed transformation.
On the behalf of low-resolution image classification problem, especially in face recognition, the methods can be divided into two main approaches: interpolation-based and optimization-based.
Interpolation-based Methods
The main idea is to focus on how to preserve and restore from low-resolution image to the original one. In other words, one aims to restore an image with resolution
back to
by an interpolated function
,
is set of parameters that produces
. Hence, the restoration is equivalent to minimize the noise between original image
and interpolated image
by a specific metric
, which is
where
is optimal parameters. The
significantly depends on
. In particular, there are two approaches: conventional interpolation and deep learning enhancement.
Conventional Interpolation
represents as approximation function, which is
, where
denotes convolutional function. These approximation functions are obviously computational, since they pre-define
before applying to interpolation. In fact,
is practically chosen from experiments and fixed. Some popular approximation functions are nearest neighbor, bi-linear, bi-cubic, etc. As a result, they achieve affordable accuracy, but faster in return. shows the results from some conventional approximation functions.
Figure 2. Some well-known conventional interpolation methods. First image is the original, the rest are the interpolated ones.

Deep Learning Enhancement
In recent years, many kinds of research give efforts to overcome the disadvantage of conventional approaches. Unlike conventional interpolation fixing , they integrate deep learning into account, which makes
learnable. Dong et al. are succeeded in taking advantage of CNN and propose Super Resolution CNN (SRCNN) (Dong et al. Citation2015). Generally, the original SRCNN and its relative aim to learn the mapping function from low to high-resolution images. They first up-sample dimension of images to the original one using bicubic interpolation, then apply CNN architecture to learn the mapping function. Their experiments give a significant improvement evaluated on PSNR/SSIM assessments (Wang et al. Citation2004). However, SRCNN has difficulty dealing with extremely low dimension, since up-sampling to the original one with a large range causes vast amount of information leaks. This limitation is observed in .Other architectures, such as Super-FAN (Bulat and Tzimiropoulos Citation2018) and FSRNet (Y. Chen et al. Citation2018), take advantage of GAN-based (Radford, Metz, and Chintala Citation2015) to be more generative when producing high resolution image. However, they are deep and complex. Additionally, GAN-based models are experimentally hard for training due to high computation and time-consuming.
Figure 3. Some interpolation results by SRCNN.

Optimization-based Methods
These works focus on directly optimizing existing low-resolution images without restoring to the original one. So far, neural architecture search (NAS) has much impact. Zoph et al. propose a reinforcement strategy to generate suitable architecture depending on data properties (Zoph and Le Citation2016). However, each kind of resolution requires a specific CNN architecture, which is impractical for applications in the wild.
Recently, there are many state-of-the-art works paying more attention to low resolution face recognition. A significant approach is taken knowledge distillation into account. One consists of two-stream networks denoted as teacher and student models, where the former one is large and deep while the later prefers much simpler and shallower. As a result, the student network can inherit the robust knowledge from the teacher one but still ensure the performance and simplicity. To enhance distilling effectively from robust and discriminative features, Ge et al. consider graph labeling problem based on sparse-connected constructed from face dataset (Ge et al. Citation2018). Their further work employs cross-dataset as a bridge of distillation, where the teacher model is trained on private high-resolution dataset and fine-tuned on the public one to preserve compact and discriminative features. The student model jointly learns to mimic the adapted high-resolution features and face classification on low-resolution dataset (Ge et al. Citation2020). Although these works perform well by inheriting robust knowledge from the teacher model, the student one is independently selected without considering the architecture of the former. Our method, on the other hand, proposes transformation function to construct the models for low-resolution images consistently based on the original one. Besides, other work combines the high and low-resolution images for training and identify discriminative features yet robust to resolution change. For instance, Deep Coupled Resnet consists of a trunk model followed by multi-branches learning three specific resolutions. The authors constrain the distance between high and low-resolution features by Coupled-Mapping loss so that model can learn robust features (Lu, Jiang, and Kot Citation2018). Other work also defines and trains network with many different levels of low resolution called PixelHop++ Y. Chen et al. Citation2020). It is leveraged to either construct successive subspace learning using different color channels (Rouhsedaghat et al. Citation2021b) or build a specific network on top of it, i.e. FaceHop (Rouhsedaghat et al. Citation2021a). We observe that our proposed method can perform well and show a considerably results on lower resolutions comparing to those experiments.
Hence, for the sake of taking advantage of both interpolation and optimization-based, we propose an efficient strategy to wisely produce optimal resolutions and corresponding CNN architectures. Whether the input image’s resolution is high, low, or extremely low, our algorithm can handle direct it to the desired model to achieve the best accuracy.
Method
Hypothesis
Intuitively, we believe that there are optimal resolutions, which come with corresponding optimal CNN architectures varying from high to low resolutions. These optimal resolutions and architectures should be consistent and formulated by our proposed architecture transforming function (ATF) and scale transforming function (STF), respectively.
As a result, our purpose is to form optimal ATF and STF formulas. The STF takes the input resolution, then generates ones varying in a wide range. Besides, the ATF takes the responsibility to generate optimal CNN architectures that satisfy the corresponding resolutions generated by STF. It takes the number of convolutional blocks of the original model, then calculates the optimal one to construct the model architecture for corresponding resolution produced by STF. In particular, the model becomes shallower (i.e. the number of convolutional blocks are decreased) in down-sampling process. After that, the original data are degraded to resulting resolutions and fed to models for training. For the inference phase, given an input image, we define a strategy to interpolate it to the appropriate resolution of trained CNN models.
Problem Definition
Given a single image with corresponding resolution
.
are the height and width of
, respectively. We denote set of data
which contains images
, and corresponding labels
,
is number of training data.
For an identical CNN architecture, we define it based on block unit where a single block is a structure containing some specific layers that repeat sequentially to form the feature extraction. Therefore, we denote a CNN architecture as generated by input image
with resolution
and
blocks. We define STF and ATF as
and
where
and
are the adjusted hyper-parameters, respectively.
Given original data and pre-trained model structured by architecture
. Generally, we aim to produce set of data
where
is pre-defined parameters, which is the number of datasets.
is optimal pair of dataset and model generated by
and
, respectively. Our purpose is to find the optimal
and
that minimize the average loss from each
trained on
as follow:
where and
denote the optimal hyper-parameters and the loss function of the model, respectively.
Training
Heuristically, and
are rarely applied for the original
and
. In fact, we experiment that the original architecture
still gives the best performance, i.e small loss, for some first resolution scales until they reach a specific one, say
, that significantly raises the loss. As a result, it is worth finding
as the input scale of ATF and STF. We would like to propose the algorithm seeking
in Algorithm 1. In particular, our original data are down-sampled to specific resolution scales, and up-sampled again to the original
by any conventional interpolation algorithm such as nearest neighbor, bi-linear, etc (
function). Then they are evaluated by
. The scale which causes the most increasement of loss is marked as
. The process of down-sampling and up-sampling leads to information loss in the image. Hence, we can observe
can preserve the manners until which scale, we then mark
as that one.
Alogrithm 1 Finding
Input:
Output: {Evaluate on specific scales}
While do
Append to
End while
{Get max distance of resulted losses}
While do
Append to
End while
Return
As being mentioned by our assumption, the resolution down-sampling process and modification of model’s architecture is relevant. We experiment that the transformation of resolution and corresponding CNN architecture strictly follow non-linear function, specifically exponential one. We propose the formula of STF and ATF as and
, respectively,
where
and
are hyper-parameters. Those conditions ensure the down-sampling process, i.e output resolution is smaller than the input.
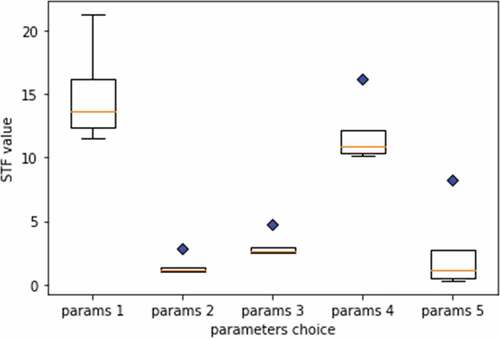
The choice of hyper-parameters of ATF and STF is crucial. Optimal hyper-parameters should help STF and ATF produce value varying in a wide range. For instance, shows the box plot of various parameters of STF. Particularly, the first one (params 1) is most optimal choice since its variance is greater than the rest and has no outlier.
Figure 4. The box plot represents the choices of STF’s hyper-parameters with 5 sets denoted as params 1 to params 5, respectively. The blue diamonds depict the outliers. Param 1 is the most optimal one since it has the largest variance without outlier.
Afterward, our transformation is conducted by and
with given
where
is the set of data at scale
. In particular, we generate
set of data and corresponding models, then the training process is applied. The algorithm is clearly defined in Algorithm 2. It produces sets of models with optimal scale
.
Alogrithm 2 Training
Input:
Output:
{Loop through each dataset}
While do
{Train}
repeat
until converge
Append to
End while
Return
Inference
Our proposed method in the training phase results in set of data with optimal resolutions and corresponding trained models. In the inference phase, we take into account these resulted
dealing with any image resolution. In other words, giving an input image
with resolution
. Since
can be unequal to any dedicated one in
,
should be transformed into a specific optimal one in
which achieves the best accuracy. Let us introduce the strategy in Algorithm 3. We calculate the optimal model where its resolution is closest to one of
using
function. Then a conventional interpolation function
is applied, which takes consider image as input and produces output with the target resolution. Finally, the interpolated image is inferred by the corresponding model.
Alogrithm 3 Inference
Input:
Output: label , probability
Return
Optimization
The proposed method is able to deal with the variance of dimensions. However, there are some significant challenges.
Firstly, it mostly depends on and
especially are hyper-parameters
and
where they have to be pre-defined. In fact, these hyper-parameters are often variant. For instance, ones are effective in the face recognition but behave poorly in the dog vs cat classification with the identical values due to the difference in attribute and distribution of data. To strengthen automation capability, a search strategy is introduced. In general, grid search (LeCun et al. Citation2012) and random search (Bergstra and Bengio Citation2012a) are good choices in common due to their simplicity. However, they are exhaustive search strategies and only work well with a small number of hyper-parameters. Instead, we leverage another search algorithm based on Bayes theory, i.e Bayesian optimization Snoek, Larochelle, and Adams Citation2012), which is highly effective on large-scale number of hyper-parameters.
Secondly, the typical limitation of deep learning problem is exhausted training time. Deep models such as VGG (Simonyan and Zisserman Citation2014), ResNet (He et al. Citation2016), DenseNet (Huang et al. Citation2017) acquire a long training time since they deeply stack convolutional layer to effectively learn complicated features. Fortunately, this problem can be resolved by transfer learning (Weiss, Khoshgoftaar, and Wang Citation2016). For further improvement, we propose an effective transfer learning strategy based on underlying one called block transfer learning.
Bayesian Optimization
Our purpose is to seek optimal hyper-parameters for and
i.e.
and
. Let us denote
as set of hyper-parameters. We then apply bayesian optimization to find optimial
minimizing average loss, or maximizing average accuracy of all models produced by
and
. Formally, the method optimizes on the function level. Instead of directly optimizing an expensive objective function, i.e. hyper-parameters tuning for deep learning model, we define a surrogate model, which is cheaper than the original one that follows the normal distribution (Snoek, Larochelle, and Adams Citation2012). Particularly, the surrogate model defines a prior knowledge over objective function and incorporates it with sampled data to infer a posterior knowledge, which proposes next potential sampling data point. Hence, the global optimum can be quickly identified in minimal steps. We take Gaussian Process
as a popular instance of surrogate model into account (Rasmussen and Williams Citation2005). Besides, we need to define a sampling strategy function for the surrogate model, called acquisition function. This function is denoted as
. Algorithm 4 represents the detail. In particular, bayesian optimization is applied to minimize average loss of resulted model, we note that Expected Improvement
is chosen to be the acquisition function (Snoek, Larochelle, and Adams Citation2012).
Alogrithm 4 Automated searching for optimal by Bayesian Optimization
Input: Observation ,
Output: Optimal
While do
Append to
Append to
End while
Return
Block Transfer Learning
An identical CNN architecture can be decoupled into convolutional-based and fully-connected-based layers. Formally
Where
is the number of layers,
represents the number of layers per block
, including convolutional, sub-sampling, activation layers.
denotes number of fully connected layers. Operator
depicts the stacking of layers.
In conventional transfer learning, given as the transferred model from
. The most popular strategy is to transfer weights starting from the first blocks as
We note that for the conventional case, the transfer process requires the same resolution and dimension, i.e. input shape, of all layers between the source model () and the target model (
), which violates our problem. One can be resolved by down-sampling source layers to fit input shape of the target one, yet obviously, induce leak of information. Instead, we transfer in bottom-up to preserve the original resolution and dimension of the features’ source model. Unfortunately, the dimension is not compatible. Hence,
convolution is added to increase it. The block transfer learning formally can be defined as
where denotes
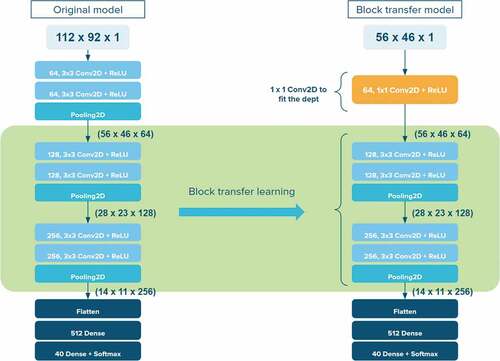
convolution. For better acknowledgment, it can be visualized in .
Figure 5. An example of block transfer learning. The original model has the input shape with
convolutional blocks. The target model has input shape
with
convolutional blocks. The proposed transfer learning method is applied to preserve the knowledge from original model and keep the dedicated input shape of the target model. Then, the identical convolutional layer (
Conv2D) is added to fit the feature depth.
Experiments
In this section, we experiment to compare and evaluate our proposed method. The experiment includes many preexisting methods for the low-resolution image classification, comparing to our proposed method. At first, we introduce two datasets for the experiments. Besides, the pre-processing images, setting up STF, ATF, and original architectures are described. Finally, we provide the experiment results and some evaluations.
Datasets
We carefully choose two identical datasets for the experiments: ORL (ORL FaceDataset, n.d.) and Cybersoft which are small-scale and medium-scale, respectively. The ORL is public and has widely used in many face recognition problems. The Cybersoft contains images captured in multi-devices with various configurations. Besides, those images are illumination diversity. This dataset is much more complex than the first one. Both two identical datasets capture faces from various perspectives, lightning, and emotions, etc. gives detail information about both datasets.
Table 1. Information about ORL and Cybersoft datasets
The datasets are applied some conventional pre-processing methods. In particular, all images are rescaled to range and use mean subtraction. The datasets are randomly split into training set and test set with the ratio
, respectively.
Initialization
Architecture and Scale Transforming Functions
Heuristically, by observation and some experiments, we manually define and
for both datasets at first, which is
and
. Formally,
The initial where one starts to apply
and
for ORL and Cybersoft datasets are
,
, respectively. After that, we apply Bayesian Optimization as being proposed to evaluate and compare to the handcrafted hyper-parameters choice.
Original CNN Architectures
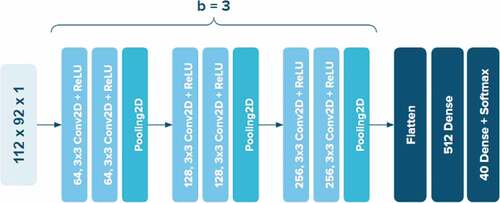
Since VGG-16 (Simonyan and Zisserman Citation2014) is popular for outperforming most classification tasks, we take their architecture into account with some modification. The first layers are used instead of the whole network, we also customize the classifier by using only one intermediate fully connected layer with
neurons. illustrates the detail of our modified architecture, which is set up as
blocks (
) for the feature extraction. This architecture is initialized as the original network for ORL dataset.
Figure 6. The original CNN architecture for training on ORL dataset, which takes first 9 layers from VGG in extraction phase.
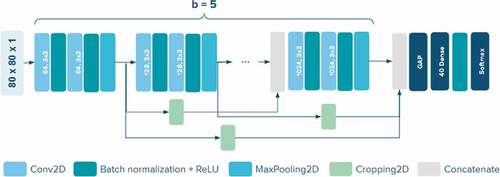
On behalf of the original architecture for the Cybersoft dataset, we take into account a new architecture introduced by Tran et al. called SkippedVGG (Tran et al. Citation2019). The one recently outperforms in the cap bottle classification task but is light weight compared to some well-known CNN models such as VGG, ResNet, DenseNet, etc. illustrates detail of the architecture. Unlike DenseNet which defines skip connection within each block, SkippedVGG employs it among blocks while preserving sequential stacking in each block. It makes the model more scalable and efficient. In addition, to accelerate the training process and avoid gradient vanishing problem, SkippedVGG takes advantage of batch normalization (Ioffe and Szegedy Citation2015). We set up blocks (
) for the feature extraction.
Figure 7. The original CNN architecture for training on Cybersoft. We follow the concept of SkippedVGG.
In the training phase, all corresponding models including two identical original models and ones produced by are minimized their loss function formulated by cross-entropy. The optimizer is Adam (Kingma and Ba Citation2014) with initial learning rate
. All models are trained in
epochs.
Compared Methods and Metric
To get comprehensive observation, we make comparison with other methods arising from conventional-interpolation-based and deep-learning-based methods. Our proposed method includes
settings, which is (i) standalone, (ii) combined with block transfer learning and all layers are frozen, and (iii) combined with block transfer learning but all layers are trainable (fine-tuning). All models are evaluated based on classification accuracy metric. As a result, methods used in experiments can be summarized as follow.
OM – This is the common way when dealing with low resolution images, we keep the same architecture for all CNN models with the input shape that resolutions vary in range scales defined in Algorithm 1. Our purpose is to verify whether this brings better accuracy or not, comparing with dimensions produced by our STF and ATF, i.e
and
NB, BL, BC, BS – These methods are conventional interpolation which up-sample low resolution images back to the original one, such as nearest neighbor, bilinear, bicubic, bspline, respectively, then evaluate on the original model. This is the most popular solution being widely used.
BL+R, BL+T, BL+RT – To strengthen more quality for bilinear interpolation methods, we integrate it with two popular edge-preserving algorithms Ramponi (Ramponi Citation1999) and Taguchi (Taguchi and Kimura Citation2001). In particular, we combine bilinear interpolation with them separately as BL+R, BL+T, respectively, and combine those edge-preserving algorithms together, which is BL+RT.
SRCNN – We induce SRCNN as deep-learning-based method to compare with the others. The SRCNN architecture is designed that respect to the original one from Dong et al. (Dong et al. Citation2015). We build models corresponding to the dimensions produced by our
PM – We purely apply our proposed method, which means that all these models are completely trained from scratch.
PM+TF – Block transfer learning method as being introduced is integrated with our proposed method. Additionally, all layers are frozen except ones in the classifier. This method can be known as feature extraction in transfer learning.
PM+TF+ – The idea is the same as above, but our layers are free to learn during the training. This method is fine-tuning in transfer learning.
Experimental Results
Conventional, Proposed Methods and Block Transfer Learning
Generally, we conducted two separate experiments, ORL (Orl face dataset, Citationn.d.) and Cybersoft datasets using the initialization as being mentioned. and shows the result on ORL. In particular, we compare proposed methods (PM, PM+TF, PM+TF+) with OM, conventional-interpolation-based (NB, BL, BC, BS), those with edge-preserving algorithms (BL+R, BL+T, BL+RT) () and deep-learning-based (SRCNN) (). Meanwhile, the Cybersoft experiment is given in and , the compared methods are the same as those in ORL excepts BS, BL+R, BL+T, BL+RT and SRCNN. We note that low-resolution inputs that are not satisfy to go through the original architecture are denotes as
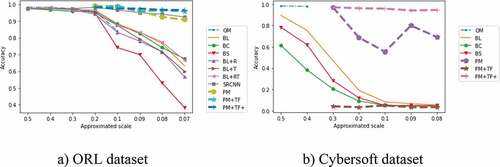
. Since they are completely flushed out before reaching the output. To illustrate the comparison, we visualized the accuracy results in for ORL and Cybersoft experiments, respectively. The PM+TF shows the bad performance on Cybersoft. This is obvious, since the Cybersoft is much more complex and diverse than the ORL. Only extracting the features from the pre-trained extractor without fine-tuning makes those models almost unlearnable. This problem is overcome by PM+TF+, the method gives the highest accuracy comparing with the others.
Table 2. Experiment results on conventional interpolations (ORL Dataset)
Table 3. Experiment results on deep-learning-based interpolations (ORL Dataset)
Table 4. Experiment results on conventional interpolations (Cybersoft Dataset)
Table 5. Experiment results on deep-learning-based interpolations (Cybersoft Dataset)
Figure 8. Accuracy of the methods experiment on ORL (left) and Cybersoft (right) dataset.
Since OM method acquires training which is similar to our method, we plot the training process of OM and our standalone proposed method (PM). Our purpose is to test the hypothesis that whether our proposed transformation functions perform better than conventional resolution scales or not. As shown in , the two first figures show the accuracy and loss in training and validation of OM, the rest figures are the same for PM. It is clear that the OM models significantly drop the accuracy in dimension from scale 0.1. Moreover, they explicitly start over-fitting from the scale 0.2. Our method, on the other hand, tends to outperform where both training and validation accuracy and loss are positively better than OM. Those results complete our hypothesis that the proposed method is more robust.
Figure 9. Training accuracy (solid line) and validation accuracy (dash line) of OM and PM experiments in ORL dataset.

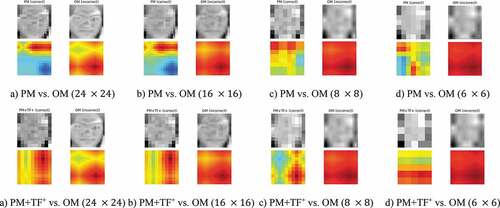
It is worth exploring how CNN models pay attention when dealing with unseen images in various resolutions. By taking advantage of Global Average Pooling (GAP) which is formally introduced in (Lin, Chen, and Yan Citation2013), we implement Class Activation Map (CAM) to visualize the attention of dedicated models (Zhou et al. Citation2016). visualizes the CAMs (i.e. heat maps) between the OM and PM, PM+TF+ on the Cybersoft dataset. According to the results, those CAMs generated by our methods tend to have better robust attention. In other words, these heat maps higher demarcation contrast of cold and hot areas than those of OM, which seem to be confused where to pay attention in low-resolution image. Additionally, when comparing models between PM and PM+TF+, there are significant changes in some cold areas, but still, keep robust to the others. This can be explained as PM+TF+ models are succeeded in transferring knowledge from the original trained model.
Figure 10. Class activation map of PM vs. OM methods (top) and PM+TF+ vs. OM methods (bottom), the dimensions are ,
,
and
, respectively.
Bayesian Optimization
Generally, in many kinds of image classification problems, the parameters in ATF and STF functions are variant. It depends on the attribute, distribution, etc. of dataset. Therefore, parameter optimization is taken into account. We would like to integrate Bayesian-based to our proposed method, which is represented by Gaussian Process (Rasmussen and Williams Citation2005). In this way, it is able to automatically tune the parameters by itself based on the specific kind of dataset. Additionally, we compare with two popular search strategies: random search (Bergstra and Bengio Citation2012b) and random forest (Liaw and Wiener et al. Citation2002).
We experiment 3 search strategies on ORL and Cybersoft datasets. shows the configuration for both. To simplify the search progress, we predefined some parameters such as learning rate, number of epochs, and number of down-sampled datasets produced by ATF and STF. We also keep the original resolution, model’s architecture and as well. The searching is limited by 30 iterations for each strategy.
Table 6. The configuration of parameter optimization for ORL and Cybersoft dataset
and shows the results of ORL and Cybersoft datasets, respectively. The searching provides the optimal that achieves the best average accuracy of down-sampled datasets for each strategy (see Avg.acc column) including the original datasets (ones before
) (see Avg.acc+ column). As a result, Bayesian-based (Gaussian Process) is more effective than the others. Impressively, it beats the result of our manual parameter settings for ORL (0.9760) and Cybersoft (0.9558).
Table 7. Parameters optimization by strategies on ORL Dataset
Table 8. Parameters optimization by strategies on Cybersoft Dataset, including Bayesian-based
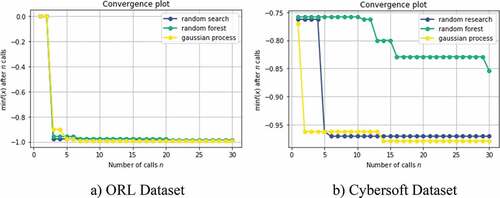
The convergence progress of three search strategies on ORL and Cybersoft are shown in . It minimizes the negative accuracy objective function. As a result, the Gaussian Process practically outperforms the random search and random forest. Since it learns from previous sampling experiences, the convergence is also faster the others.
Figure 11. The convergence of 3 search strategies when optimizing on ORL and Cybersoft Dataset.
Conclusion
In this paper, we proposed a new approach to effectively resolve the low-resolution face recognition problem. The experiments show that the method significantly outperforms some other popular ones. Those methods may perform well on high or affordable low resolution. However, they have difficulty handling extremely low dimension and significantly drop in accuracy. Even being enhanced by deep learning method such as SRCNN, those models only show a trivial improvement.
On the other hand, our approach take advantage of both conventional and deep-learning-based methods, and propose transformation functions. These functions learned to produce the optimal resolutions and corresponding CNN model’s architectures varying in a wide range of scales. As a result, our method can deal with any extremely low resolution, yet keep the high accuracy in classification. Moreover, we also enhance the performance and reduce the training time with our block transfer learning strategy. It guides the models to utilize most useful features from the original one without non-trivial tuning, and learning faster than usual. Besides, our method is scalable with any kind of dataset by automated Bayesian optimization that is successfully integrated.
In the future, we will focus on developing automated deep learning model generator and block transfer learning. Our purpose is to completely release the one-stop solution for low-resolution image classification. We hope our proposed method is feasible to apply to many kinds of real-world problems.
Acknowledgments
This work is done by many supports from our colleges in Intelligent Computing and Image Processing laboratory. We would like to thank Trong Vo for special supports and all involved members. Besides, most of the experiments are conducted on the computing system provided by Kyanon Digital LTD. Our special thanks to Tai Huynh, Hang Tran, and all members of the company. We are grateful for all supports and sponsors.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
References
- Bergstra, J., and Y. Bengio. 2012a. Random search for hyper-parameter optimization. Journal of Machine Learning Research 13 (2):281-305.
- Bergstra, J., and Y. Bengio. 2012b. Random search for hyper-parameter optimization. Journal of Machine Learning Research 13 (2):281-305.
- Bulat, A., and G. Tzimiropoulos 2018. Super-fan: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with gans. Proceedings of the ieee conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 109–1024.
- Chen, J., Z. Chen, Z. Chi, and H. Fu 2014. Emotion recognition in the wild with feature fusion and multiple kernel learning. Proceedings of the 16th international conference onmultimodal interaction, Istanbul Turkey, 508–13.
- Chen, Y., M. Rouhsedaghat, S. You, R. Rao, and -C.-C. J. Kuo 2020. Pixelhop++: A small successive-subspace-learning-based (SSL-based) model for image classification. 2020 IEEE International conference on image processing (ICIP), Abu Dhabi, United Arab Emirates, 3294–98.
- Chen, Y., Y. Tai, X. Liu, C. Shen, and J. Yang 2018. Fsrnet: End-to-end learning face super-resolution with facial priors. Proceedings of the IEEE conference on computer visionand pattern recognition, Salt Lake City, UT, USA, 2492–501.
- Dalal, N., and B. Triggs 2005. Histograms of oriented gradients for human detection. 2005 IEEE computer society conference on computer vision and pattern recognition (cvpr’05), San Diego, CA, USA, vol. 1, 886–93.
- Deng, J., W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei 2009. Imagenet: A large-scale hierarchical image database. 2009 ieee conference on computer vision and patternrecognition, Miami, FL, USA, 248–55.
- Dong, C., C. C. Loy, K. He, and X. Tang. 2015. Image super-resolution using deep convo-lutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (2):295–307. doi:10.1109/TPAMI.2015.2439281.
- Ge, S., S. Zhao, C. Li, and J. Li. 2018. Low-resolution face recognition in the wild via selective knowledge distillation. IEEE Transactions on Image Processing 28 (4):2051–62. doi:10.1109/TIP.2018.2883743.
- Ge, S., S. Zhao, C. Li, Y. Zhang, and J. Li. 2020. Efficient low-resolution face recognition via bridge distillation. IEEE Transactions on Image Processing 29:6898–908. doi:10.1109/TIP.2020.2995049.
- He, K., X. Zhang, S. Ren, and J. Sun (2016). Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 770–78.
- Huang, G., Z. Liu, L. Van Der Maaten, and K. Q. Weinberger (2017). Densely connected convolutional networks. Proceedings of the IEEE conference on computer vision and patternrecognition, Honolulu, HI, USA, 4700–08.
- Ioffe, S., and C. Szegedy (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. International conference on machine learning, Lille France, 448–56.
- Kingma, D. P., and J. Ba (2014). Adam: A method for stochastic optimization.arXiv preprintarXiv:1412.6980.
- Koziarski, M., and B. Cyganek. 2018. Impact of low resolution on image recognition with deep neural networks: An experimental study. International Journal of Applied Mathematics andComputer Science 28 (4):735-744.
- Krizhevsky, A., I. Sutskever, and G. E. Hinton. 2012. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems 25:1097–105.
- LeCun, Y. A., L. Bottou, G. B. Orr, and K.-R. M ̈uller. 2012. Efficient backprop. In Neural networks: Tricks of the trade, 9–48. Lecture Notes in Computer Science, vol 7700. Springer, Berlin, Heidelberg.
- Li, P., L. Prieto, D. Mery, and P. Flynn (2018). Face recognition in low quality images: A survey.arXiv preprint arXiv:1805.11519.
- Liaw, A., M. Wiener . 2002. Classification and regression by randomforest. R News 2 (3):18–22.
- Lin, M., Q. Chen, and S. Yan (2013). Network in network.arXiv preprint arXiv:1312.4400.
- Lu, Z., X. Jiang, and A. Kot. 2018. Deep coupled Resnet for low-resolution face recognition. IEEE Signal Processing Letters 25 (4):526–30. doi:10.1109/LSP.2018.2810121.
- Minaee, S., and A. Abdolrashidi (2019). Deep iris: Iris recognition using a deep learning approach.arXiv preprint arXiv:1907.09380.
- Ojala, T., M. Pietikainen, and T. Maenpaa. 2002. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern analysis and Machine Intelligence 24 (7):971–87. doi:10.1109/TPAMI.2002.1017623.
- Orl face dataset. n.d. http://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html.
- Radford, A., L. Metz, and S. Chintala (2015). Unsupervised representation learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434.
- Ramponi, G. 1999. Warped distance for space-variant linear image interpolation. IEEETransactions on Image Processing 8 (5):629–39. doi:10.1109/83.760311.
- Rasmussen, C. E., and C. K. I. Williams. 2005. Gaussian processes for machine learning(adaptive computation and machine learning). The MIT Press.
- Rouhsedaghat, M., Y. Wang, S. Hu, S. You, and -C.-C. J. Kuo. 2021b. Low-resolution face recognition in resource-constrained environments. Pattern Recognition Letters 149:193–99. doi:10.1016/j.patrec.2021.05.009.
- Rouhsedaghat, M., Y. Wang, X. Ge, S. Hu, S. You, and -C.-C. J. Kuo 2021a. Facehop: Alight-weight low-resolution face gender classification method. International conferenceon pattern recognition, Milano, Italy, 169–83.
- Simonyan, K., and A. Zisserman (2014). Very deep convolutional networks for large-scale image recognition arXiv preprint arXiv:1409.1556.
- Snoek, J., H. Larochelle, and R. P. Adams. 2012. Practical Bayesian optimization of machine learning algorithms. Advances in Neural Information Processing Systems 25:3113–21.
- Suykens, J. A., and J. Vandewalle. 1999. Least squares support vector machine classifiers. Neural Processing Letters 9 (3):293–300. doi:10.1023/A:1018628609742.
- Taguchi, A., and T. Kimura. 2001. Edge-preserving interpolation by using the fuzzy technique. Nonlinear Image Processing and Pattern Analysis Xii 4304:98–105.
- Tran, Q. M., L. V. Nguyen, T. Huynh, H. H. Vo, and V. T. Pham 2019. Efficient CNN models for beer bottle cap classification problem. International conference on future data andsecurity engineering, Nha Trang City, Vietnam, 713–21.
- Wang, Z., A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. 2004. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing 13 (4):600–12. doi:10.1109/TIP.2003.819861.
- Weiss, K., T. M. Khoshgoftaar, and D. Wang. 2016. A survey of transfer learning. Journal of Big Data 3 (1):1–40.
- Wold, S., K. Esbensen, and P. Geladi. 1987. Principal component analysis. Chemometrics and Intelligent Laboratory Systems 2 (1–3):37–52. doi:10.1016/0169-7439(87)80084-9.
- Zhou, B., A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba 2016. Learning deep features for discriminative localization. Proceedings of the ieee conference on computer vision andpattern recognition, Las Vegas, NV, USA, 2921–29.
- Zoph, B., and Q. V. Le (2016). Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578.