
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
With the growing number of insurance purchasers, the sophisticated claim analysis system has become an imperative must for any insurance firm. Claims Analysis can be utilized to better understand the customer strata and incorporate the findings throughout the insurance policy enrollment, including the underwriting and approval or rejection stages. In recent years machine learning (ML) technologies are increasingly being used to claims Analysis. However, choosing the optimal techniques, whether the features selection techniques, feature discretization techniques, resampling mechanisms, and ML classifiers for insurance decision assistance, is difficult and can harm the quality of claim suggestions. This study aims to develop appropriate decision models by combining binary classification, feature selection, feature discretization, and data resampling techniques. We did Extensive tests on three different datasets to evaluate the viability of the selected models. We used multiple assessment metrics besides the statistical significance test from The ANOVA test and the Friedman test to evaluate the ML models. The findings show that the models perform highly better after applying the feature discretization technique, reducing dimensionality using feature selection methods and solving the unbalanced data problem with resampling methods.
Introduction
Insurance is a means of hedging financial loss in the event of a risk occurring. There are two parties involved in insurance: an insurer sells policies, and an insured party receives the policy’s benefits after purchasing it. In exchange for a sum of money known as Premium, the insurer agrees to take on an insured entity’s risk of potential losses (Rawat et al. Citation2021). Where, in the event of an unanticipated incident, the insurer is responsible for paying a claim to the policyholder, which is the benefit amount owed to the beneficiary as defined in the policy agreement. The entire insurance sector is based on the premise of reducing the risk or monetary loss (Barry and Charpentier Citation2020). Where the insurer must protect the insured against any form of monetary loss due to any unanticipated incident, at the same time, the insurance company must manage its transactions to pay claims and earn enough profit to stay in business.
Due to the increase in competitiveness of the insurance industry, customer retention is of particular importance and requires deeper and more accurate knowledge of customers, their buying behavior, and losses. Therefore, if customers are classified, and their losses could be predicted, the insurance company’s profitability can be increased, and insurers can take steps to reduce the loss ratio. The process that assesses the insured’s risk is called underwriting, and the Premium and terms of the insurance contract are determined based on the assessment of the level of risk (Fung et al. Citation1998; Briys and De Varenne Citation2001). Where every insured imposes a different level of risk on the insurance company, thus, to ensure receiving a fair premium, insurers determine the level of risk and place every policyholder in one of the risk classes, which consequently, the higher the risk, the higher the Premium. This is a sound reason for insurers to have their customers’ risks assessed as accurately as possible. Achieving a model for classifying customers into different risk groups has always been considered the most fundamental and challenging issue in the insurance industry. In fact, insurance companies must be profitable and able to survive and continue in the insurance market, and on the other hand, the insurers must establish a fair balance between the level of risk of the insured and the paid premiums. In this context, risk classification means grouping customers with similar risk characteristics that are likely to cause similar losses and placing them in one group.
In the insurance sector, data mining is widely utilized for a variety of purposes, including fraud prevention, claim analysis, marketing analytics, risk analysis, sales forecasting, product development, and underwriting processing (Das, Chakraborty, and Banerjee Citation2020; Das et al. Citation2021). And in this study, an insurance claims analysis will be covered. Where In claim analysis and processing, ML is used to triage claims and automate where possible, decreasing the need for human interaction and making the entire process more convenient. The application of ML algorithms in claim analysis aids the insurers in gaining a better understanding of the claims filing and acceptance patterns, which may be utilized to optimize the entire insurance policy enrollment process flow.
Classification models that play the role of decision models, usually backed by feature selection, feature discretization, and data resampling, are particularly important in risk scoring challenges. When a meaningful feature subset is chosen, the computational cost is reduced, and the model’s efficiency and understandability are significantly improved (Rawat et al. Citation2021). Besides, the risk scoring models may be sensitive owing to dataset imbalance, i.e., the number of positive and negative cases is not evenly distributed; in this scenario, data resampling may improve their overall performance (). Unfortunately, while reviewing the literature studies on risk scoring, there is a shortage of studies that combine all of the strategies mentioned (feature selection, feature discretization, resampling, and classification) into a single processing process creating a classification model.
Classification models that play the role of decision models, usually backed by feature selection, feature discretization, and data resampling, are particularly important in risk scoring challenges. When a meaningful feature subset is chosen, the computational cost is reduced, and the model’s efficiency and understandability are significantly improved (Rawat et al. Citation2021). Besides, the risk scoring models may be sensitive owing to dataset imbalance, i.e., the number of positive and negative cases is not evenly distributed; in this scenario, data resampling may improve their overall performance (Hanafy and Ming). Unfortunately, while reviewing the literature studies on risk scoring, there is a shortage of studies that combine all of the strategies mentioned (feature selection, feature discretization, resampling, and classification) into a single processing process creating a classification model, as shows.
Table 1. Overview of existing techniques
This study used three datasets to analyze claims using four different categorization techniques. And to improve the analysis’s outcomes, we employed the feature discretization method, three different feature selection techniques to lower the data’s dimensionality, and also utilized three different resampling strategies to solve the data’s imbalance problem.
In this study, we will create four alternative binary classification scenarios.
Directly applied the algorithms to the data without discretization, feature selections, or resampling methods.
Investigated the effect of resampling on binary classification outcomes.
Investigated the impact of applying the feature selection followed by data resampling on binary classification outcomes.
Investigated the impact of applying the features discretization method followed by applying the features selection followed by data resampling on binary classification outcomes.
Finally, four widely accepted and trustworthy metrics are used to evaluate and compare the algorithms: Accuracy, sensitivity (Recall), specificity and AUC. And besides the evaluation metrics, we also used statistical analysis to determine the best scenario.
The rest of the paper is organized as follows: The second section examines the literature on the issue. Section 3 includes a discussion of the study’s useful methodologies for ML classification, feature selection, data resampling, features discretization, and established measurements for classification model evaluation. The adopted study process is described and explained in Section 4. Section 5 contains the overall findings of the investigation and the theoretical contributions and implications. The work is summarized in Section 6, with findings and recommendations for future research.
Literature Review
Claim Analysis is a significant part of analytics that predicts the future in the insurance sector because the insurance companies spend around 80% of their premium revenue on claims. As a result, in order to enhance cash flow, a detailed study of claims is required. Also, ML can help automate a variety of mundane procedures to reduce claims cycle time, boost customer delight, prevent fraud, and reduce claim handling costs, which are considered major performance measures for insurance claims (Ringshausen et al. Citation2021; Saggi and Jain Citation2018; Richter and Khoshgoftaar Citation2018).
The study of (Hanafy and Ming) developed models for enhancing the classification efficiency of ML on un-balanced data to predict the occurrence of auto insurance claims. They applied resampling strategies such as oversampling, under-sampling, a mix of the two, and SMOTE. Additionally, they used models such as AdaBoost, XGBoost, C5.0 and C4.5, CART, Random Forest and Bagged CART. The results show the AdaBoost classifier with oversampling, and the hybrid method provides the highest accurate predictions. The study of (Hanafy and Ming Citation2021b) examines how auto insurance firms use ML in their business and looks at how ML models may be used to analyze large amounts of insurance-related data to forecast claim incidence; they use a variety of ML approaches, including logistic regression, XGBoost, random forest, decision trees, nave Bayes, and K-NN. And to solve the imbalanced data issue, they used the random over-sampling technique. Additionally, they assess and contrast the results of various models. The results show that the RF model came out on top of all other methods. The study of (Hanafy and Ming Citation2021c) aims to provide a way that improves the outcomes of ML algorithms for detecting Insurance Claim Fraud. And to address the issue of imbalanced data, they used resampling techniques such as Random Over Sampler, Random Under Sampler, and hybrid methods. According to this paper’s findings, the efficiency of all ML classifiers improves when resampling techniques are used. The results also show that when employing the SMOTE-ENN resampling technique, the Stochastic Gradient Boosting classifier performed the best among all the other models. The main objective for the study of (Hanafy Kotb and Ming Citation2021) is to analyze nine distinct SMOTE family approaches to solving the imbalanced data problem in forecasting insurance premium defaulting. And the performance of the SMOTE family in resolving the unbalanced problem was evaluated using a variety of 13 ML classifiers. The results demonstrate that using approaches from the SMOTE family improved the performance of classifiers significantly. Furthermore, the Friedman test demonstrates that the hybrid SMOTE methods are superior to other SMOTE methods, particularly the SMOTE -TOMEK, which outperforms other methods. Furthermore, the SVM model has produced the best results with the SMOTE- TOMEK among ML methods. The study’s major aim of (Rawat et al. Citation2021) is to use exploratory data analysis and feature selection approaches to find significant and decisive criteria for claim filing and approval in a learning context. In addition, eight ML algorithms (LR, RF, DT, SVM, Gaussian Nave Bayes, Bernoulli Nave Bayes, Mixed Nave Bayes, and K-Nearest Neighbors) are applied to the datasets and assessed using performance measures. Two case studies are included in the analysis: one for health insurance and the other for travel insurance. The results show that the best classifier among all the classifiers for the health insurance sector is the Decision Tree, whereas the best classifier among all the classifiers for the travel insurance dataset is the Random Forest. The study of (Matloob et al. Citation2021) demonstrates the necessity to replace present tactics with methodologies that ensure employees receive need-based healthcare benefits. Where this will not only reduce the likelihood of healthcare fraud/misuse, but it will also improve employees’ sense of health security, regardless of their grades or designations. And by using a ML model based on K means clustering, their proposed methodology generated need-based packages. They were able to calculate the optimal premium amount using this approach. According to the findings, the medical premium amount is optimized by 25% of the present benefit amounts. As a result, if adopted, it will not only enable employers and insurance firms to develop appropriate insurance schemes for the provision of healthcare benefits, but it will also help to avoid long-term financial losses.
The research of (Krasheninnikova et al. Citation2019) examines two distinct ways for carrying out A model-free reinforcement learning system that is used to examine revenue maximization and its effects on customer retention levels. The first is about maximizing revenue while studying the impact on customer retention, while the second is about maximizing revenue while ensuring that customer retention does not go below a certain level. The first scenario has a Markov decision process with a single criterion that must be optimized. The second case is a Constrained Markov decision process with two criteria. The first is related to optimization, and the second is constrained – using a model-free Reinforcement Learning technique. The article of (Dhieb et al. Citation2020) intends to reduce insurance companies’ financial losses by eliminating human involvement, securing insurance processes, alerting and informing about dangerous customers, and detecting fraudulent claims. They propose to employ the XGBoost algorithm for the aforementioned insurance services and compare its performance with DT, KNN, and SVM after presenting the block-chain-based infrastructure to enable secure transactions and data exchange among different inter-acting agents inside the insurance network. When applied to a dataset of vehicle insurance claims, the results reveal that the XGBoost outperformed other models. The study of (Grize, Fischer, and Lützelschwab Citation2020) focuses on technical, analytical applications and shows where ML techniques may bring the most value. They show two real-world examples: first, a comparison of household insurance retention models, and then a dynamic pricing challenge for online automobile insurance. Both instances demonstrate the benefits of using ML technologies in practice.
The research of (Singh et al.) aims to estimate the cost of repair, which will be used to determine the size of an insurance claim. The manual assessment by the service engineer who prepares the damage report, followed by the physical inspection by an insurance company surveyor, makes the life cycle of registering, processing, and reaching a decision for each claim a lengthy process. They propose an end-to-end solution for automating this procedure, which would benefit both the organization and the customer. This system takes photographs of the damaged car as input and delivers pertinent information such as damaged parts and an estimate of the level of damage to each part (no damage, mild, or severe). This serves as a clue to estimate the cost of repair, which would be used to determine the insurance claim amount. The major purpose of the study of (Stucki Citation2019) is to forecast future churn or customer status (stays/churns) for an insurance customer for the next year while acquiring new private insurance such as a vehicle, life, or property insurance. The model should be able to forecast both new and existing customer turnover. Five classifiers were utilized in this study to anticipate the customer’s prospective turnover. These classifiers are LR, RF, KNN, AB, and ANN algorithms. Random forests were shown to be the most effective model in this investigation. The study of (Huang and Meng Citation2019) focuses on the utilization of a large number of driving behavior characteristics in estimating an insured vehicle’s risk likelihood and claim frequency with the following models SVM, RF, XGBoost, and ANN, while Poisson regression is used as a claim frequency model. According to this research, the XGBoost model offers the highest overall prediction accuracy for risk classification tasks. And also, the results show that driving behavior characteristics play an important impact on vehicle insurance prices.
The study of (Pesantez-Narvaez, Guillen, and Alcañiz Citation2019) aims to use telematics data to anticipate the occurrence of accident claims. This research investigated the relative performance of logistic regression and XGBoost approaches. Their findings revealed that logistic regression is an appropriate model because of its potential to be interpreted and predicted, whereas XGBoost needs several model-tuning techniques to match the logistic regression model’s predictive performance and more effort in terms of interpretation. The research of (Sabbeh Citation2018) is on the churn prediction problem makes use of ten distinct types of analytical tools. These tools include Discriminant Analysis, Decision Trees (CART), Support Vector Machines, Logistic Regression, Random Forest, K-NN, Stochastic Gradient Boosting, and AdaBoosting Trees were selected, as well as Nave Bayesian and Multi-layer Perceptron. According to the results, both random forest and AdaBoost outperform all other methods. Three classifiers were developed in the study of (Kowshalya and Nandhini Citation2018) to forecast fraudulent claims and premium amounts as a percentage. The methods Random Forest, J48, and Naive Bayes were chosen for classification. And three test choices are used to record the findings of the classifiers (50:50, 66:34 and 10 Cross-validation). Under all three test choices, On the Insurance Claim dataset, the Random Forest model outperforms the other two algorithms, while Nave Bayes outperforms the other two algorithms on the Premium dataset.
The main aim of the study of (Weerasinghe and Wijegunasekara Citation2016) is to look into data mining approaches for developing a predictive model for vehicle insurance claim prediction and a comparison of them. To create the prediction model, the researchers used Artificial Neural Networks (ANN), Decision Trees (DT), and Multinomial Logistic Regression (MLR); the ANN was shown to be the most accurate predictor. The study of (Hassan and Abraham Citation2016) provides an insurance fraud detection approach. They used the under-sampling method to deal with the unbalanced data problem, and they are employing Decision Tree (DT), Support Vector Machine (SVM), and Artificial Neural Network (ANN) models. The results of the paper show that DT outperforms other competing algorithms. According to the paper of (Sundarkumar and Ravi Citation2015), a unique hybrid strategy is proposed for solving the issue of the data im-balance using k Reverse Nearest Neighborhood and One-Class Support Vector Machine together. The usefulness of the suggested approach was demonstrated using data from two sources: a dataset for detecting auto insurance fraud and another for predicting credit card churn. They applied the following models DT, SVM, LR, Probabilistic Neural Network, Group Method of Data Handling, and Multilayer Perceptron. The results show that with data from the Insurance dataset, the maximum sensitivity is yielded with Decision Trees (DT) and SVM, while Data from the Credit Card Churn Prediction dataset yielded the highest sensitivity with Decision Trees.
The primary aim of the research (Günther et al. Citation2014) is to predict Customer churn using ML classification models. They describe a method for estimating individual consumers’ likelihood of leaving an insurance provider using dynamic modeling. The data is fitted using a logistic longitudinal regression model that includes time-dynamic explanatory factors and interactions. They use generalized additive models to identify nonlinear correlations between the logit and the explanatory variables as a step in the modeling process. The results show that the model performs well in terms of identifying consumers who are likely to leave the organization each month. The study of (Guo and Fang Citation2013) used logistic regression analysis to forecast the likelihood of occurring at least one insurance claim. In this study, the impact of a driver’s personality and unexpected driving accidents were investigated. The results confirmed that driving behavior characteristics are significant in vehicle collision prediction. Vehicle sensor data enables “Pay-As-You-Drive” (PAYD) insurance models that charge premiums based on how much you drive. A classification analysis approach is proposed in the (Paefgen, Staake, and Thiesse Citation2013), where they used LR, NN, and DT classifiers. The results show that while ANN outperforms LR in terms of classification accuracy, also the results demonstrate that LR is better suited to actuarial purposes in various aspects. And the study of (Gramegna and Giudici Citation2020) present an Explainable AI model that may be used to explain why a consumer purchase or cancels a non-life insurance policy. This research suggests that explainable ML models might effectively increase our understanding of consumers’ behavior by applying similarity clustering to the Shapley values acquired by a highly accurate XGBoost predictive classification algorithm. An overview of techniques used in the previous insurance studies is presented in .
shows the recent studies in the field of the application of ML in the insurance industry. And it also shows there are no previous studies that combine all of the strategies that will apply in our study (feature discretization, feature selection, resampling, and classification) into a single process of processing a dataset and creating a classification model. In light of the stated research gap, the question arises as to whether combining the suggested approaches and techniques in the dataset processing process can improve classification model effectiveness. So, the purpose of this paper is to:
Examine the efficacy of several classification models in assisting with insurance decisions.
Construction of decision models using various binary classifiers, feature discretization, feature selection approaches, and data resampling.
Find the best combination of the data science tools that will achieve the best performance.
Evaluation of models using three different datasets comprising real data from insurance claims with four different evaluation metrics besides the statistical analysis.
Materials and Methods
The Data
In this study, we used three separate datasets to do claim analysis. As shows, all three datasets have a categorical target variable. As a result, the analyses are carried out using classification algorithms.
Figure 1. The target variable in the three datasets.
Data Collection
Data collection is the first step in the ML process. Data can be gathered using a variety of sources and methods. The datasets for this study were obtained from Kaggle.com. shows the description of the three datasets that we used in our study.
Table 2. Overview of the three insurance dataset
Data Preparation
In Data Preparation, data is transformed so that an ML algorithm can use it. And it has the potential to have an impact on the model’s performance. Data cleaning, exploratory data analysis (EDA), normalization, encoding, solving the imbalanced data problem, and dimensionality reduction are all part of the process of data preparation.
Data Cleaning
Depending on the dataset, the features that include missing values are either eliminated the whole feature or alter these missing values. In this study, we removed two variables from the third data set because they had the most missing values in the third dataset. Where In the third dataset, we find that around 2.4% of the data are missing values. And the two features we removed have a high percentage of missing values. Following the removal of these two variables, the dataset’s missing values drop to only 0.18%. For the other features in the three datasets, the mode of the column values is used to replace missing values in category and binary variables. In contrast, the mean of the column values is used to fill in missing values in all continuous variables.
Exploratory Data Analysis
Exploratory data analysis is a tool for better understanding data before using an ML algorithm. It is accomplished by visualizing data using various graphs in order to comprehend the various aspects of the data.
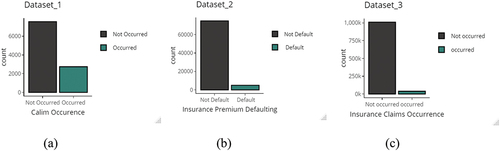
shows the distribution of the target variables in the three datasets. In dataset_1(a) the ratio between the non-occurred and occurred claims is 73% to23%, for the dataset_2(b), the ratio between the not defaulted to default is 94% to6%, and for the dataset_3(c), the ratio between the non-occurred and occurred claims is 96.4% to3.6%. This refers to the datasets suffer from imbalanced data problem especial in the second and third datasets.
Figure 2. The distribution of the binary target variable for the datasets.
Transformation
As most ML algorithms cannot process categorical data, all categorical data is consolidated into an understandable numerical format.
normalization
In the case of categorical data, feature engineering is done using feature encoding techniques. Due to the large number of algorithms used in ML, they only work with factors and continuous features because they’re built on mathematical models and techniques. Besides the encoding, we applied a Normalization for the data. Normalization is a technique for uniformly scaling all of the values in a dataset between 0 and 1. The normalizing formula is as follows:
ML Classifiers
K-nearest Neighbor (KNN)
The K-nearest neighbor (KNN) algorithm is a basic algorithm that predicts each observation based on how similar it is to other observations. KNN is a memory-based algorithm. This means that the training samples are needed at run-time, and predictions are formed based on sample associations. As a result, KNNs are sometimes known as lazy learners (Cunningham and Jane Delany Citation2021).
The Strengths of the KNN Algorithm are as Follows:
The algorithm is very simple to understand.
There is no computational cost during the learning process; all the computation is done during prediction.
It makes no assumptions about the data, such as how it’s distributed.
The Weaknesses of the KNN Algorithm are These:
It cannot natively handle categorical variables (they must be recoded first, or a different distance metric must be used).
When the training set is large, it can be computationally expensive to compute the distance between new data and all the cases in the training set.
The model can’t be interpreted in terms of real-world relationships in the data.
Prediction accuracy can be strongly impacted by noisy data and outliers.
In high-dimensional datasets, KNN tends to perform poorly. This is due to a phenomenon called the curse of dimensionality.
Random Forest (RF)
RF is a commonly used machine-learning model that is based on Breiman et al decision’s theory (Breiman et al. Citation1984). The classification and regression tree (CART) algorithm is used to create trees in this model. If the response variable is a factor, RF will classify it; if the response is continuous, RF will do regression. In the RF model, CART grows a huge tree before pruning it. And according to (Grömping Citation2009), trimming a huge tree rather than growing a limited number of trees increases RF’s prediction accuracy.
The Strengths of the Random Forest are as Follows:
It can handle categorical and continuous predictor variables
It makes no assumptions about the distribution of the predictor variables.
It can handle missing values in sensible ways.
It can handle continuous variables on different scales.
Ensemble techniques can drastically improve model performance over individual trees.
The Weaknesses of Tree-based Algorithms are These:
The main disadvantage can be the loss of interpretability for the trained classifier model.
High computational complexity.
Decision Tree (CART)
The decision tree is a graph or model that looks like a tree. Because it has its root at the top and grows downwards, it resembles an inverted tree. In comparison to other ways, this representation of the data has the advantage of being meaningful and simple to read. Each of the input attributes correlates to one of the tree’s internal nodes. The number of edges on a notional interior node is the same as the number of possible input attribute values. Given the values of the input attributes represented by the path from the root to the leaf, each leaf node represents a value of the label attribute. In the Simple Cart algorithm, decision trees are built by separating each decision node into two separate branches based on various separation criteria (Noori Citation2021).
The Strengths of Tree-based Algorithms are as Follows:
Tree-building has a basic intuition, and each tree is easily interpretable.
Categorical and continuous predictor variables are supported.
There are no assumptions made regarding the predictor variables’ distribution.
It has a logical manner of dealing with missing values.
It is capable of dealing with continuous variables on various scales.
The Weakness of Tree-based Algorithms is This:
Individual trees are prone to overfitting.
Logistic Regression (LR)
The (linear) relationship between a continuous response variable and a set of predictor variables is approximated using linear regression. However, linear regression is not acceptable when the response variable is binary (i.e., Yes/No). Fortunately, analysts can use an approach that is comparable to linear regression in many ways called the logistic regression Faraway (Citation2016).
The Strengths of the Logistic Regression Algorithm are as Follows:
It can handle both continuous and categorical predictors.
The model parameters are very interpretable.
Predictor variables are not assumed to be normally distributed.
The Weaknesses of the Logistic Regression Algorithm are These:
It won’t work when there is complete separation between classes.
It assumes that the classes are linearly separable. In other words, it assumes that a flat surface in n-dimensional space (where n is the number of predictors) can be used to separate the classes. If a curved surface is required to separate the classes, logistic regression will underperform compared to some other algorithms.
It assumes a linear relationship between each predictor and the log odds. If, for example, cases with low and high values of a predictor belong to one class, but cases with medium values of the predictor belong to another class, this linearity will break down.
Feature Selection Methods
The feature selection procedure focuses on detecting and discarding redundant features from a dataset (Ziemba et al. Citation2014). The multidimensionality of the object to be allocated to a given class is one of the most basic concerns in classification tasks. The “dimensional curse” is a severe impediment that reduces the accuracy of classification systems. Reducing the dimensionality of feature space lowers computational and data collection costs, which improves predictions. This also aids in the reduction of execution time. We’ve applied three algorithms:
Relief (RE)
Symmetrical Uncertainty (SU)
Correlation-based Feature Selection (CFS).
Relief Feature Selection Technique
Relief assigns a weight to all the features in the dataset. Once these weights are established, they can be gradually changed (Pronab et al. Citation2021). The goal is to have a high weight for the most critical qualities and a low weight for the less important ones. To determine feature weights, Relief employs methods similar to those found in KNN.
Symmetrical Uncertainty (SU)
SU has been shown to be a good measure for choosing significant traits in a variety of research (Piao and Keun Ho). The SU is a correlation metric for a feature. The following is how to determine the Symmetrical Uncertainty between a feature and a class:
Where IG(F|C) refer to the information gain of a feature F after watching class C. And the entropy of feature F and class C, respectively, is H(F) and H(C). Adjusts for an information gain deviation toward multi-valued attributes and normalizes the final score to the range [0, 1]. ‘1ʹ indicates that we are completely informed based on the at-tribute, allowing us to forecast the object’s class; ‘0ʹ indicates that no information is available after examining the attribute, therefore no prediction is feasible.
Correlation-based Feature Selection (CFS)
CFS evaluates the value of features using a correlation-based heuristic. A well-known feature selector wrapper utilizes a special learning method to direct its search for good features to evaluate CFS’s effectiveness. At first, a matrix of mutual attribute correlation and attribute-class correlation is computed. And the “Best First” method is used for forwarding search (Hall and Smith Citation1999). An important part of the CFS algorithm is an evaluation heuristic for a subset’s value or merit. Individual features’ usefulness in predicting class labels and intercorrelation between them are both taken into account by this heuristic. The heuristic’s hypothesis can be stated as follows: good feature sub-sets contain traits that are highly correlated (predictive of) the class but uncorrelated (not predictive of) each other.
The heuristic is formalized in the following equation:
where is a feature subset’s heuristic “merit”
including
attributes,
is the average correlation between feature classes (
), and
is the average intercorrelation of features. In actuality, EquationEquation 4
(4)
(4) is the Pearson’s correlation, with all variables normalized. The numerator indicates how predictive a set of traits is of the class, while the denominator indicates how much duplication exists among them. Irrelevant traits are ignored by the heuristic because they are given poor predict with the target class.
Resampling Methods
When the number of classes in the training set is uneven, i.e., the target class distribution is significantly unbalanced, ML classifiers develop models that prefer to categorize all objects as belonging to the majority class in order to maximize the overall accuracy of the model. But this leads to low accuracy for the minority class, whose objects are underrepresented in the training set, despite the fact that this minority class is often critical (Pozzolo et al. Citation2015). The techniques of random under-sampling and random oversampling are two of the most prevalent in ML and are also relatively basic. And shows the basis characteristics of each resampling method.
Table 3. Characteristics of the resampling methods
Discretization Methods
By using feature discretization, some classification algorithms increase their performance. Continuous characteristics are separated into ranges or intervals, resulting in numerical data being converted to nominal data. Because continuous data can be discretized in an endless number of ways, the fundamental challenge with feature discretization is suitable to cut point selection. The ideal discretization method would locate a small number of cut points and divide data into appropriate bins. There are two types of discretization techniques: supervised and unsupervised. Because the supervised methods use class distribution to which each object belongs as extra information, the supervised’s results are superior to the second group. A large number of approaches use class entropy, which is a measure of uncertainty in a finite range of classes. And to accomplish discretization, the entropy of different splits is calculated and compared to the entropy of the dataset without divides, and until the search stop requirement is met, it runs recursively (De Sá et al. Citation2013). The Minimal Description Length Principle (MDLP) heuristic approach, for example, can be employed here. If the provided criterion is not met, this approach determines whether or not to accept the current cutoff point candidate, ending the recursion. One of the finest supervised discretization approaches is entropy-based discretization using the MDLP stop criterion. By comparing entropy values, it calculates the information gain score of a feasible cut point. The entropy of the input period is compared to the weighted sum of entropies for two output intervals for each cut point investigated. There are various distinct criteria for MDLP halting conditions. And in our study, we will use The Fayyad criterion (Fayyad and Irani Citation1993).
Evalution Methods
Comparing and determining the optimal model requires evaluating the performance of classifiers. ML algorithms can be measured and checked in a variety of ways. This work employs a variety of evaluation techniques, including prediction accuracy, sensitivity, specificity, and AUC. And for more trustworthy and powerful assessing and comparing, we will also use a statistical assessment technique.
Confusion Matrix
The terms TP, TN, FN, and FP are used to describe Sensitivity (SE), Specificity (SP), and classification Accuracy (AC).
The Sensitivity of a model (also known as the true positive rate) is a metric that evaluates the accuracy of correctly identified positive examples (actual events). While the specificity of a model (also known as the true negative rate) is a metric that quantifies the proportion of correctly identified negative examples (non-actual events). The useful classifier must give highly accurate results for the Sensitivity and the specificity simultaneously.
The accuracy represents the ratio of correct predictions to total samples. While accuracy is simple to realize, it overlooks several important criteria that must be addressed when evaluating a classifier’s performance. When a set of samples of the target class is unbalanced in the data set, the accuracy will be useless because the algorithm forecasts the value of the majority classes for all predictions. In such instances, the AUC is a useful option because it considers the class distribution and is thus less likely to suffer from the data set’s imbalance.
where:
TP refers to the true positives, representing the number of instances the algorithm has predicted the positive class accurately.
FN refers to the false negatives, representing the number of instances the algorithm incorrectly forecasts the negative class.
FP refers to the false positives, representing the number of instances the algorithm incorrectly forecasts the positive class.
TN refers to the true negatives, representing the number of instances the algorithm properly forecasts the negative class.
In ML, evaluating models in the face of rare cases is critical. Despite the fact that Accuracy is the most often used classification assessment metric, it may not be an acceptable solution for unbalanced data sets due to bias toward the majority class. In such instances, the AUC is a useful option because it considers the class distribution and is thus less likely to suffer from the data set’s imbalance (Haixiang et al. Citation2017).
Area Under Receiver Operating Characteristic Curve (AUROC)
The (AUROC) can be used to evaluate the classification’s quality. ROC is a graphic representation of a predictive model’s performance created by sketching the quantitative properties of binary classifiers obtained from such a model using a range of cutoff points. And this shows how the True Positive Rate (TPR) and False Positive Rate (FPR) are related. TPR and FPR can be calculated by the following equations:
The accuracy of the classifier is measured by AUROC. It’s estimated as probability thresholds for the next event – whether the object in question is negative or positive. AUC is the area below the ROC in terms of geometry. The higher the AUROC value, the better the model’s classification outcomes. AUROC less than 0.5 indicates an invalid classifier, i.e., one that is poorer than random, AUROC = 0.5 indicates a random classifier, and AUROC = 1 indicates an ideal classifier (Chawla et al. Citation2002).
Statistical Analysis
Evaluating and comparing the performance of the classifiers is a crucial step. Even though evaluation methods such as sensitivity, specificity, and classification accuracy are simple to implement, the findings they produce can be deceptive. Determining the best model or approach is, therefore, a complex issue. Statistical significance tests will be used to tackle this issue based on the AUC values. A one-way analysis of variance (ANOVA) is a typical statistical test for comparing two or more related sample means. In the ANOVA test, the null hypothesis is that all models perform similarly and that the reported differences are unimportant (Fisher Citation1956). And we also will use the Friedman test (Friedman Citation1937), which is a non-parametric variant of the ANOVA test, which can be used to investigate differences among the methods. The Friedman test’s null hypothesis is that all methods perform equally; however, rejecting this null hypothesis means that one or more approaches perform differently. The Freidman test ranks each method’s data before analyzing the rank values (Friedman Citation1940). As a result, the Friedman test produces a sum of ranks for each approach, which will help us to figure out which method is the most efficient among the others.
Research Procedures
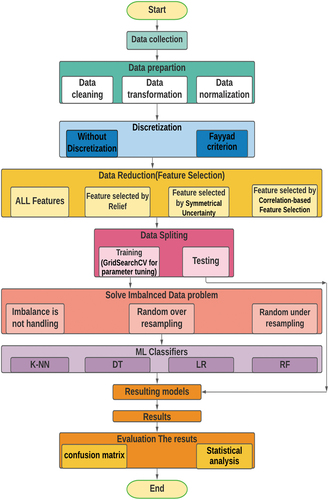
For each dataset, the dataset will divide into two sections: training and testing. 70% of the data is assigned to the training phase, while the remaining 30% is assigned to the testing phase based. In our research topic, there are various combinations will be investigated of filter methods (SU, CFS, Relief), classifier models (LR, DT, KNN, RF), resampling methods (without resampling, random under-sampling, random oversampling) and feature discretization (without discretization, Fayyad criterion).
With the number of methodological approaches studied, each dataset has 60 possible scenarios for each dataset. The research study was divided into four general scenarios, each using the following approach combinations:
Apply the classification algorithms without any resampling or feature selection methods, or feature discretization.
Apply the classification approaches based on only resampling methods.
Apply the feature selection, followed by resampling methods, then the classification algorithms.
Apply the feature discretization followed by features selection methods, followed by resampling methods, then the classification algorithms.
All research scenarios enabled to define:
Examine the effect of data resampling on the performance of ML classifiers.
Examine the impact of features selection methods followed by data resampling approaches on ML classifiers performance.
Examine the impact of the feature discretization method followed by features selection methods, followed by resampling methods on ML classifiers performance.
The research study that was conducted is shown in . We should note that the features selection was made to the training set, and the results were employed in the testing set. This was an important step in ensuring that the training and testing sets were completely consistent. For example, relevant features were chosen from the training set and superfluous features were also purged from the testing set. Data resampling was the only processing method employed only for training and not for testing cases.
Figure 3. Working diagram of proposed model.
Hyperparameter Tuning
To prevent overfitting and underfitting, we must tune model parameters within stable zones where training and validation scores do not change dramatically. The grid search technique, which is a prominent tuning tool in the insurance area, has been used to optimize the model’s parameters. Where In order to achieve the highest ROC values, GridSearchCV was utilized. displays the parameter search ranges and optimum values for the models.
Table 4. The optimal values for several model parameters used in this study
shows the hyper-parameter tuning on the models used in this paper. Where K is the Number of Neighbors, C is the Confidence Threshold, M is the Minimum Instances Per Leaf, cp is the Complexity Parameter and Mtry is the number of Randomly Selected Predictors
Results and Discussion
shows the results of the accuracy, sensitivity, specificity, and AUC values for all ML methods. Accuracy is one of the most widely used methods for assessing an algorithm’s performance. While accuracy is simple to realize, it overlooks several important criteria that must be addressed when evaluating a classifier’s performance. When a set of samples of the target class is unbalanced in the data set, the accuracy will be useless because the algorithm forecasts the value of the majority classes for all predictions. In such instances, the AUC is a useful option because it considers the class distribution and is thus less likely to suffer from the data set’s imbalance.
Table 5. The performance of the ML models on the different datasets
The most important outcome from is the low performance of all algorithms with the initial scenario. Where we should note that algorithms do not get a good AUC-score when using the original data; thus, algorithms do not work well across all classes. The findings show that machine learning algorithms do not produce reliable results and that most classifiers cannot predict all target classes using datasets before utilizing resampling and features selection methods. As a result, resolving the problem of unbalanced data and reducing dimensionality are critical. On the other hand, after applying feature discretization, resampling methods and feature selection methods, The AUC values of all ML models have improved noticeably. For example, in the first dataset, the RF obtained the result of 65.6% with the AUC test using the first scenario, whereas the outcome is improved to the 74% using the FC+SU+RU +RF method in the fourth scenario. And in the second dataset, the LR obtained the result of 56% with the AUC test using the first scenario, whereas the outcome is improved to the 76.5% using the FC+ SU +RU+LR model in the fourth scenario. Furthermore, in the third dataset, the RF achieved the result of 50% with the AUC test with the first scenario, whereas the outcome is improved to the 63% with the FC+ CFS+RU+RF method in the fourth scenario.
shows the performance of the ML models on the different datasets. Where KNN is the K-nearest neighbour model, LR is the logistic regression model, DT is the decision tree model, RF is the random forest model, RO is the random over resampling method, RU is the random under resampling method, RE is the Relief method, SU is the symmetrical uncertainty method, and CFS is the correlation-based feature selection method, and FC is referred to the Fayyad criterion method.
shows the importance of using feature discretization, resampling methods and feature selection methods to increase the accuracy of the ML model performance, where after utilizing feature discretization, various resampling approaches and feature selection methods, the outcomes indicates that algorithms do not overlook any classes. For example, in the third dataset, all ML models in the first scenario are disregard one of the classes. This model, on the other hand, examines all classes with the other three scenarios.
presents the top four classification results for the three datasets based on the AUC scores.
Table 6. Depicts the four top classification results for each dataset
Assuming no resampling or feature selection or discretization are applied, the best classification results were achieved as shows:
Table 7. Depicts the four top classification results for each dataset in first scenario
presents the top classification results for the three datasets based on the ROC-AUC scores for models with the original data.
From , we can note that the first scenario achieved the worst results for all datasets compared to the rest of the scenarios. Obviously, dimensionality reduction and solving the imbalanced problem and applying the discretization technique is necessary in the insurance industry due to the lack of ability to explain classification or the need to collect a great amount of information in order to classify new cases; this means that the dimensionality reduction and also solving the unbalanced data problem in the insurance business and the discretization techniques are obviously required in the insurance industry
Statistical Test Results
Different resampling approaches and feature selection methods produce different data; thus, classifiers perform differently with these different datasets. As a result, determining the optimum approach for achieving the best results is quite difficult. Statistical significance tests such as ANOVA and Friedman tests can help with the difficult task of deciding on the optimal approach. After applying the ANOVA and Friedman test, we found the p-value is less than 0.05 based on the AUC values for the different methods in each dataset as shows. As a result, the null hypothesis is rejected, and we will accept the alternative hypothesis that refers to there is a difference in the performance between the various methods inside each dataset.
Table 8. The ANOVA and the Friedman tests results
shows the p-value for the ANOVA and Friedman test based of the AUC values for the different methods inside each dataset.
Additional Information from Friedman Test Results
shows the results of the Friedman test for the ranks, sum of ranks beside the median of the different methods based on the AUC values for the three datasets. And from , we can conclude the following results:
According to dataset_1, the best results are achieved by the FC+ SU+RU method in the fourth scenario.
According to dataset_2, the best results are achieved by the FC+SU+RU method in the fourth scenario
According to dataset_3, the best results are achieved by the FC+CFS+RO method in the fourth scenario.
According to the three datasets, the first scenario achieves the worst results.
Table 9. Additional information from Friedman test results
The Contributions to Theory and Its Ramifications
It may be argued that incorporating technology like ML into the insurance industry be able to be quite beneficial. It can assist identify and understanding customers in a much more comprehensive way than the insurance industry’s narrow description of their requirements and investing patterns. Where claim analysis can help improve the insurance policies and calculate more sustainable premiums for clients by understanding the claiming patterns and demography of the insureds. The profit ratio of the insurance policies can also be changed by analyzing the insurance company’s acceptance tendencies. In our study, it has been discovered that utilizing feature discretization, feature selection approaches and resampling methods before categorizing data with classification algorithms is really effective. Since not all features are equally important, and also the unbalanced data leads to a bias in favor of the dominant group. By using feature selection strategies, we can pick the best subset of features for the best outcomes. And by using the resampling procedures, we can help overcome the problem of unbalanced data. Also, Feature selection approaches and resampling procedures help reduce data overfitting, improve the algorithm’s accuracy, and shorten computing time. We believe that our work will help insurance economists choose and execute the best predictive models and related methodologies for modeling insurance data to enhance the area of insurance economics.
Conclusion and the Future Work
Insurance Data mining is a powerful analytical tool for uncovering important and relevant knowledge from insurance data. But it can run into issues like imbalanced data and the Dimensions curse. This research aims to demonstrate the impact of resampling strategies for solving the unbalanced data problem and feature selection methods for reducing data Dimensions. It should be noted that three separate insurance databases are employed. In addition, a number of classifiers are used to help draw more accurate conclusions about the different approaches. The results demonstrate that ML classifiers can’t predict some of the classes in the first scenario: While after applying resampling methods, feature selection methods and feature discretization to various data sets, the findings reveal that the performance of most ML classifiers has greatly improved, and all classes are predicted, indicating that the classifiers’ performance is improved. And also, the results show that classifiers perform differently on different data for the three datasets generated by applying the feature discretization, feature selection approaches and resampling methods, making it difficult to choose the optimum strategy. Thus, besides using evaluation measures such as Accuracy, sensitivity, and the AUC measures, the Friedman test was performed in this paper to determine the optimal approach. The findings of this paper confirm the following:
Based on the Friedman test:
For the first data set, the most accurate result is achieved by the FC+SU+RU method in the fourth scenario.
For the second data set, the most accurate result is achieved by the FC+SU+RU method in the fourth scenario.
For the third data set, the most accurate result is achieved by the FC+CFS+RO method in the fourth scenario.
Moreover, the results show also the RF model is the best classifier because it achieved the most accurate AUC results for each dataset:
For the first data set, the RF achieves the best performance with an AUC of 74% with the FC+SU+RU method in the fourth scenario.
For the second data set, FC+SU+RO+LR/ FC+SU+RU+LR/ FC+RE+RU+RF in the fourth scenario achieve the best performance with an AUC of 76.5%.
For the third data set, the RF achieves the best performance with an AUC of 63%with the FC+CFS+RU method in the fourth scenario.
Of fact, the aforementioned heuristics do not cover all aspects of selecting an effective strategy to the risk scoring problem. Where choosing a classification model will essentially entail balancing the inherent characteristics of classifiers.
This research can be developed in the following directions:
For a better comparison and improved performance, new ensemble and hybrid classifiers can be developed, and also other techniques can be applied, such as new feature discretization methods besides new and hybrid resampling methods and new feature selection methods.
Expanding the empirical analysis incorporating XAI (Explainable artificial intelligence) methods. Apply a post-processing technique such as Shapley values or Shapley Lorenz Values as described, for example, in (Giudici and Raffinetti Citation2021; Bussmann et al. Citation2021) to make the models more explainable
Data Availability Statement
Dataset_1: https://raw.githubusercontent.com/heathergeiger/Data621_hw4/master/insurance-evaluation-data.csv
Dataset_2: https://www.kaggle.com/prakharrathi25/premium-default-prediction/data
Dataset_3: https://www.kaggle.com/headsortails/steering-wheel-of-fortune-porto-seguro-eda/data
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Additional information
Funding
References
- Barry, L., and A. Charpentier. 2020. Personalization as a promise: Can big data change the practice of insurance? Big Data & Society 7 (1):2053951720935143. doi:10.1177/2053951720935143.
- Breiman, L., Friedman, J.H., Olshen, R.A., and Stone, C.J. (1984). Classification And Regression Trees (1st ed.). (pp. 368). Routledge. https://doi.org/10.1201/9781315139470
- Briys, E., and F. De Varenne. 2001. Insurance: From Underwriting to Derivatives. In: Jacque L.L., Vaaler P.M. (eds) Financial Innovations and the Welfare of Nations. Springer, Boston, MA, pp 301-314. https://doi.org/10.1007/978-1-4615-1623-1_15, .
- Bussmann, N., P. Giudici, D. Marinelli, and J. Papenbrock. 2021. Explainable machine learning in credit risk management. Computational Economics 57 (1):203–1631. doi:10.1007/s10614-020-10042-0.
- Chawla, N. V., K. W. Bowyer, L. O. Hall, and W. Philip Kegelmeyer. 2002. SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research 16:321–57. doi:10.1613/jair.953.
- Cunningham, P., and S. J. Jane Delany. 2021. k-Nearest neighbour classifiers - A tutorial. ACM Computing Surveys (CSUR) 54 (6):1–25. doi:10.1145/3459665.
- Das, D., C. Chakraborty, and S. Banerjee. 2020. A framework development on big data analytics for terahertz healthcare. In Amit Banerjee, Basabi Chakraborty, Hiroshi Inokawa, Jitendra Nath Roy (eds)Terahertz biomedical and healthcare technologies, 127–43. Elsevier. https://www.sciencedirect.com/science/article/pii/B9780128185568000070
- Das, S., S. Datta, H. Abbas Zubaidi, and I. Ali Obaid. 2021. Applying interpretable machine learning to classify tree and utility pole related crash injury types. IATSS Research.
- De Sá, C. R., C. Soares, A. Knobbe, P. Azevedo, and A. M. Jorge (2013). Multi-interval Discretization of Continuous Attributes for Label Ranking. In: Fürnkranz J., Hüllermeier E., Higuchi T. (eds) Discovery Science. DS 2013. Lecture Notes in Computer Science, vol 8140. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-40897-7_11
- Dhieb, N., H. Ghazzai, H. Besbes, and Y. Massoud. 2020. A secure ai-driven architecture for automated insurance systems: Fraud detection and risk measurement. IEEE Access 8:58546–58. doi:10.1109/ACCESS.2020.2983300.
- Faraway, J. J. 2016. Extending the linear model with R. Generalized linear, mixed effects and nonparametric regression models (2nd ed.). New York: Chapman and Hall/CRC. https://doi.org/10.1201/9781315382722
- Fayyad, U., and K. Irani. 1993. Multi-interval discretization of continuous valued attributes for classification learning. Proceedings of the 13th international joint conference on artificial intelligence, San Francisco, CA, USA; pp. 1022–1027.
- Fisher, R. A. 1956. Statistical Methods and Scientific Inference, Edinburgh: Oliver & Boyd. https://scholar.google.com/scholar_lookup?hl=en&publication_year=1956&author=R.+A.+Fisher&title=Statistical+Methods+and+Scientific+Inference
- Friedman, M. 1937. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association 32 (200):675–701. doi:10.1080/01621459.1937.10503522.
- Friedman, M. 1940. A comparison of alternative tests of significance for the problem of m rankings. The Annals of Mathematical Statistics 11 (1):86–92. doi:10.1214/aoms/1177731944.
- Fung, H.-G., G. C. Lai, G. A. Patterson, and R. C. Witt. 1998. Underwriting cycles in property and liability insurance: An empirical analysis of industry and by-line data. The Journal of Risk and Insurance 65 (4):539–61. doi:10.2307/253802.
- Ghorbani, R., and R. Ghousi. 2020. Comparing different resampling methods in predicting students’ performance using machine learning techniques. IEEE Access 8:67899–911. doi:10.1109/ACCESS.2020.2986809.
- Giudici, P., and E. Raffinetti. 2021. Shapley-Lorenz eXplainable artificial intelligence. Expert Systems with Applications 167:114104. doi:10.1016/j.eswa.2020.114104.
- Gramegna, A., and P. Giudici. 2020. Why to buy insurance? An Explainable Artificial Intelligence Approach’, Risks 8:137.
- Grize, Y., W. Fischer, and C. Lützelschwab. 2020. Machine learning applications in nonlife insurance. Applied Stochastic Models in Business and Industry 36 (4):523–37. doi:10.1002/asmb.2543.
- Grömping, U. 2009. Variable importance assessment in regression: Linear regression versus random forest. The American Statistician 63 (4):308–19. doi:10.1198/tast.2009.08199.
- Günther, C.-C., I. Fride Tvete, K. Aas, G. Inge Sandnes, and Ø. Borgan. 2014. Modelling and predicting customer churn from an insurance company. Scandinavian Actuarial Journal 2014 (1):58–71. doi:10.1080/03461238.2011.636502.
- Guo, F., and Y. Fang. 2013. Individual driver risk assessment using naturalistic driving data. Accident Analysis & Prevention 61:3–9. doi:10.1016/j.aap.2012.06.014.
- Haixiang, G., L. Yijing, J. Shang, G. Mingyun, H. Yuanyue, and G. Bing. 2017. Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications 73:220–39.
- Hall, M. A., and L. A. Smith (1999). Feature selection for machine learning: Comparing a correlation-based filter approach to the wrapper. FLAIRS conference.
- Hanafy Kotb, M., and R. Ming. 2021.Comparing SMOTE family techniques in predicting insurance premium defaulting using machine learning models. International Journal of Advanced Computer Science and Applications (IJACSA) 12 (9):2021. doi:10.14569/IJACSA.2021.0120970.
- Hanafy, M. O. H. A. M. E. D., and R. U. I. X. I. N. G. Ming. 2021c. USING MACHINE LEARNING MODELS TO COMPARE VARIOUS RESAMPLING METHODS IN PREDICTING INSURANCE FRAUD. Journal of Theoretical and Applied Information Technology 99:2819-2833.
- Hanafy, M., and R. Ming. 2021b. Machine learning approaches for auto insurance big data. Risks 9 (2):42. doi:10.3390/risks9020042.
- Hanafy, M., and R. Ming. 2021a. Improving imbalanced data classification in auto insurance by the data level approaches. International Journal of Advanced Computer Science and Applications (IJACSA) 12 (6). doi:10.14569/IJACSA.2021.0120656.
- Hassan, A. K. I., and A. Abraham. 2016. Modeling Insurance Fraud Detection Using Imbalanced Data Classification. In: Pillay N., Engelbrecht A., Abraham A., du Plessis M., Snášel V., Muda A. (eds) Advances in Nature and Biologically Inspired Computing. Advances in Intelligent Systems and Computing, vol 419. Springer, Cham. Berlin/Heidelberg, Germany, pp. 117–127 https://doi.org/10.1007/978-3-319-27400-3_11
- Huang, Y., and S. Meng. 2019. Automobile insurance classification ratemaking based on telematics driving data. Decision Support Systems 127:113156. doi:10.1016/j.dss.2019.113156.
- Hui, L., L. Jia, P-C. Chang, and J. Sun. 2013. Parametric prediction on default risk of Chinese listed tourism companies by using random oversampling, isomap, and locally linear embeddings on imbalanced samples. International Journal of Hospitality Management 35:141–51. doi:10.1016/j.ijhm.2013.06.006.
- Kowshalya, G., and M. N. 2018. Predicting fraudulent claims in automobile insurance. Paper presented at the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT).
- Krasheninnikova, E., J. García, R. Maestre, and F. Fernández. 2019. Reinforcement learning for pricing strategy optimization in the insurance industry. Engineering Applications of Artificial Intelligence 80:8–19. doi:10.1016/j.engappai.2019.01.010.
- Matloob, I., S. Ahmad Khan, F. Hussain, W. Haider Butt, R. Rukaiya, and F. Khalique. 2021. Need-Based and optimized health insurance package using clustering algorithm. Applied Sciences 11 (18):8478. doi:10.3390/app11188478.
- Noori, B. 2021. Classification of customer reviews using machine learning algorithms. Applied Artificial Intelligence 35 (8):567–88. doi:10.1080/08839514.2021.1922843.
- Paefgen, J., T. Staake, and F. Thiesse. 2013. Evaluation and aggregation of pay-as-you-drive insurance rate factors: A classification analysis approach. Decision Support Systems 56:192–201. doi:10.1016/j.dss.2013.06.001.
- Pesantez-Narvaez, J., M. Guillen, and M. Alcañiz. 2019. Predicting motor insurance claims using telematics data—XGBoost versus logistic regression. Risks 7 (2):70. doi:10.3390/risks7020070.
- Piao, Y., and R. Keun Ho. A Hybrid Feature Selection Method Based on Symmetrical Uncertainty and Support Vector Machine for High-Dimensional Data Classification. In: Nguyen N., Tojo S., Nguyen L., Trawiński B. (eds) Intelligent Information and Database Systems. ACIIDS 2017. Lecture Notes in Computer Science, vol 10191. Springer, Cham. Berlin/Heidelberg, Germany, pp. 721–727. https://doi.org/10.1007/978-3-319-54472-4_67
- Pozzolo, D., O. C. Andrea, R. A. Johnson, and B. Gianluca. 2015. Calibrating Probability with Undersampling for Unbalanced Classification, In 2015 IEEE Symposium Series on Computational Intelligence, pp. 159–166.
- Pronab, G., S. Azam, M. Jonkman, F. M. J. M. S. Asif Karim, E. Ignatious, S. Shultana, A. Reddy Beeravolu, F. De Boer, and F. De Boer. 2021. Efficient prediction of cardiovascular disease using machine learning algorithms with relief and LASSO feature selection techniques. IEEE Access 9:19304–26. doi:10.1109/ACCESS.2021.3053759.
- Rawat, S., A. Rawat, D. Kumar, and A. Sai Sabitha. 2021. Application of machine learning and data visualization techniques for decision support in the insurance sector. International Journal of Information Management Data Insights 1 (2):100012. doi:10.1016/j.jjimei.2021.100012.
- Richter, A. N., and T. M. Khoshgoftaar. 2018. A review of statistical and machine learning methods for modeling cancer risk using structured clinical data. Artificial Intelligence in Medicine 90:1–14. doi:10.1016/j.artmed.2018.06.002.
- Ringshausen, F. C., R. Ewen, J. Multmeier, B. Monga, M. Obradovic, R. van der Laan, and R. Diel. 2021. Predictive modeling of nontuberculous mycobacterial pulmonary disease epidemiology using German health claims data. International Journal of Infectious Diseases 104:398–406. doi:10.1016/j.ijid.2021.01.003.
- Sabbeh, S. F. 2018. Machine-learning techniques for customer retention: A comparative study. International Journal of Advanced Computer Science and Applications 9(2), 273-281. http://dx.doi.org/10.14569/IJACSA.2018.090238
- Saggi, M. K., and S. Jain. 2018. A survey towards an integration of big data analytics to big insights for value-creation. Information Processing & Management 54 (5):758–90. doi:10.1016/j.ipm.2018.01.010.
- Singh, R., M. P. Ayyar, T. Venkata Sri Pavan, S. Gosain, and S. Rajiv Ratn. Year. Automating Car Insurance Claims Using Deep Learning Techniques, 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), 2019, pp. 199-207. doi: 10.1109/BigMM.2019.00-25
- Stucki, O. 2019. Predicting the Customer Churn with Machine Learning Methods: Case: Private Insurance Customer Data. Master’s Thesis. LUT University. 2019.
- Sundarkumar, G. G., and V. Ravi. 2015. A novel hybrid undersampling method for mining unbalanced datasets in banking and insurance. Engineering Applications of Artificial Intelligence 37:368–77. doi:10.1016/j.engappai.2014.09.019.
- Weerasinghe, K. P. M. L. P., and M. C. Wijegunasekara. 2016. A comparative study of data mining algorithms in the prediction of auto insurance claims. European International Journal of Science and Technology 5:47–54.
- Ziemba, P., M. Piwowarski, J. Jankowski, and J. Wątróbski (2014). Method of Criteria Selection and Weights Calculation in the Process of Web Projects Evaluation. In: Hwang D., Jung J.J., Nguyen NT. (eds) Computational Collective Intelligence. Technologies and Applications. ICCCI 2014. Lecture Notes in Computer Science, vol 8733. Springer, Cham, Switzerland; pp. 684–693. https://doi.org/10.1007/978-3-319-11289-3_69