
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Localization of video caption plays an important role in information retrieval in multimedia applications. In this work, we present and evaluate a novel method for localizing video captions using visual rhythms, which enable the representation and analysis of a specific feature throughout the time. We build visual rhythms from the text location maps produced by general text localization methods that are far more common in the literature than caption-oriented ones. Then, we process the maps properly to keep only the captions, generating caption localization masks. To meet the need for a standardized and large dataset, we constructed a new one, where captions with thirteen different scripts are added to the video frames, generating a total of 221 videos with ground truth. Experiments demonstrate that our method achieves competitive results when compared to other literature approaches.
Introduction
Texts present in videos can be categorized into scene texts and captions (Zedan, Elsayed, and Emary Citation2016). Scene texts occur naturally in video content, whereas captions are artificially embedded into the video frames. In this work, we are particularly interested in localizing video captions, which are usually static, that is, fixed in the same position in some consecutive frames. However, captions can also be scrolled, such as the vertical scrolling in video credits.
Several recent works have investigated different tasks related to video captions, whose development can assist the task of video content analysis (Valio, Pedrini, and Leite Citation2011). We define detection as the task that aims to verify whether there is a caption in a given frame. The localization problem, in turn, returns a bounding box for the caption of each frame. The script recognition problem aims to recognize the script of the text in order to facilitate the task of text recognition. At last, the text recognition aims to determine the words that are written in the text.
The majority of text localization methods proposed in the literature were not focused on captions. However, they can be used as baseline for methods addressing this specific problem, provided that additional steps are proposed to distinguish the two types of text. Thus, the main objective of our work is to propose a new method for caption localization based on general text methods.
As a first contribution of this work, we propose and evaluate a novel method for localizing video captions based on the visual rhythm. Visual rhythm (Souza et al. Citation2020) is a spatiotemporal representation that summarizes relevant information present in a video. It is defined as the concatenation of a predefined feature extracted from each frame or small groups of neighboring frames. Initially, we apply a text localization method in the video frames that results in binary maps in which white pixels indicate text regions. Then, we build visual rhythms from the text location maps. The components of these rhythms are properly processed to keep only the captions. Finally, caption localization masks are retrieved from processed rhythms. We can use any text localization method in the first step, including those for natural text. The remaining process aims to transform the initial text localization into caption localization. This is completely deterministic and does not use or require any learning-based technique.
Similar to specific methods, there is also a lack of large datasets containing the necessary annotation to evaluate the methods. Since the methods do not usually employ a standardized and public dataset, it is difficult to compare their results and generalize their findings. For this reason, our second contribution is a new multi-script dataset with ground truth for video caption tasks. In order to build this database, we collected 17 distinct videos from YouTube with subtitles and under the Creative Commons license. Each subtitle was obtained in English and then translated in such a way that we get 11 different scripts. Subtitles are added to videos according to pre-set settings as font color and size. By including 11 types of subtitles in each of the 17 different videos, we built a dataset with 221 unique videos. Concerning the number of frames, our dataset has 87,789 frames from the original videos and more than 1 million frames with subtitles. Since the detection and localization are performed in the frames and not in the video, it can be considered a large dataset. To the best of our knowledge, there is no similar dataset in the literature. Experiments demonstrate that the proposed method achieves superior results when compared to the method used as a baseline. We believe that our results can be even better in future work if we improve the performance of the caption detection step.
This text is organized as follows. This section presents a brief introduction with some relevant concepts. Related work is described in Section 2. Section 3 presents the proposed method for video caption localization. The description of the proposed dataset and its construction is provided in Section 4. Section 5 reports and discusses the obtained results. Final considerations and directions for future work are outlined in Section 6.
Background
This section presents a brief review of the literature related to the topic investigated in this work. Methods for text localization in still images are presented in Subsection 2.1. Methods for text detection and localization in videos are described in Subsection 2.2.
Text Localization in Images
Long, He, and Ya (Citation2018) conducted a detailed literature review, categorizing the works based on traditional image processing and deep learning techniques. Prior to the advent of deep learning techniques, methods mainly used connected component and sliding window strategies. Some of these works are described as follows.
Wu, Hsieh, and Chen (Citation2008) presented an algorithm for localization of text regions in images based on mathematical morphology techniques. First, an average filter is applied to smooth the image. Then, the difference between the opening and closing operations of the smoothed image is calculated. A closing operation is applied to the image of the differences to merge the characters into a single component. The image is binarized and the components are labeled. Since texts can still be divided into several small segments of different orientations, the orientation of the text is estimated based on statistical moments. From the texts and their rotation angles, their properties are used to select the candidate texts. The nearby text segments are joined. Then, an -projection technique is used to extract features from the candidate texts and verify them.
Epshtein, Ofek, and Wexler (Citation2010) proposed an operator to find the stroke width value for each image pixel, and applied it to the text detection problem. Initially, each pixel is set to an infinite value. Edges are computed using the Canny algorithm (Canny Citation1987). For each edge pixel, its gradient direction is used to find the next one, which is expected to be in the opposite edge of the same stroke. Each intermediate pixel in this path receives the value of the distance between the two edge pixels, if it is smaller than the current value. Based on these distances, pixels with similar values are clusterized, making them candidates for letters, which are filtered according to their size. The letters are finally grouped into lines of text.
Neumann and Matas (Citation2010) proposed localizing text in images using Maximally Stable Extremal Regions (MSER). Each of the localized regions is classified by the Support Vector Machine (SVM) into characters and non-characters using features such as aspect ratio and compactness. From similarity and spatial proximity features, the characters are joined in lines.
Zhang et al. (Citation2016) used a fully convolutional network (FCN) to detect text blocks. The network has five convolutional stages based on the 16-layer VGG model. A deconvolution layer is added at the end of each stage. The fusion of the result of each feature map produces the salience map for text detection. Several other neural network architectures have been proposed for text detection, localization, and recognition in images (Arafat and Iqbal Citation2020; Citation2017b; He et al. Citation2017a; Jiang et al. Citation2020, Citation2017; Katper et al. Citation2020; Liao et al. Citation2018; Liu and Jin Citation2017; Shi, Bai, and Belongie Citation2017; Villamizar, Canévet, and Odobez Citation2020).
Text Localization in Videos
Yin et al. (Citation2016) investigated the most relevant approaches to detection, tracking and recognition of texts in videos. High-pass filters were used for text detection in videos (Agnihotri and Dimitrova Citation1999). Other works used the coefficients of the Discrete Cosine Transform (DCT) in the Moving Picture Expert Group (MPEG) domain, in order to perform text detection in compressed videos with low computational cost (Zhang and Chua Citation2000; Zhong, Zhang, and Jain Citation2000).
Khare, Shivakumara, and Raveendran (Citation2015) proposed a new descriptor for text localization in videos with the invariance of rotation, scaling, font type, and font size. For each frame, the proposed descriptor finds the orientations with the second-order geometric moments. Text candidates are obtained from the analysis of the dominant orientations of the connected components. Candidates of text with constant speed and uniform direction, verified by optical flow analysis, are finally considered as text.
Searching for captions on all video frames can be computationally expensive. In order to reduce the cost, visual rhythm representation (Chun et al. Citation2002; Concha et al. Citation2018; Moreira, Menotti, and Pedrini Citation2017; Pinto et al. Citation2012, Citation2015; Souza Citation2018; Souza et al. Citation2020; Tacon et al. Citation2019; Torres and Pedrini Citation2018; Valio, Pedrini, and Leite Citation2011) can be used to detect frames in which captions are present. Thus, localization techniques can only be applied to the appropriate frames. Chun et al. (Citation2002) proposed the visual rhythm for the frame detection problem. The visual rhythm is constructed by concatenating the vertical, main and secondary diagonal rhythms. Prewitt filter is applied to the visual rhythm to highlight the horizontal edges. Caption is detected based on the analysis of certain properties such as duration.
Lyu, Song, and Cai (Citation2005) proposed a method for detection, localization and extraction of texts in videos. Text detection is done through edge detection and local thresholding. Text localization is performed through a coarse-to-fine analysis. Text extraction is done by adaptive thresholding, followed by labeling and padding steps.
Lee et al. (Citation2007) detected captions in videos based on the assumption that caption holds in many consecutive frames. Initially, they identify the frames in which new captions start with a strategy based on decreasing the frame rate. Twelve wavelet features are extracted from the region, which are used as input to a classifier that determines whether that region refers to a caption.
Valio, Pedrini, and Leite (Citation2011) addressed the problem of caption detection with rotation invariance through visual rhythms. Initially, the visual rhythm is calculated and segmented. Captions are then determined based on some predefined rules. Visual rhythms are calculated in a zigzag scheme. Different scales were considered, which demonstrated a trade-off between efficiency and efficacy.
Zedan, Elsayed, and Emary (Citation2016) proposed a method for caption detection and localization in videos. The method is based on edge features and the integration of multiple frames. Initially, the edges are computed using the Canny method (Canny Citation1987), only at the lower part of the frame. Horizontal lines are detected through the number of edge pixels in each row of the frame. The captions localization are determined from an analysis of these horizontal lines. Finally, the frames are clusterized. From the clustering, the authors classified the captions as static and with horizontal or vertical scrolling.
Chen and Su (Citation2018) performed caption localization in videos using visual rhythms. Vertical and horizontal rhythms are extracted from the video. Then, vertical lines in horizontal rhythm and horizontal lines in vertical rhythm are defined using the Sobel filter and the Hough transform. Vertical and horizontal rhythms are extracted in different positions in order to obtain a rhythm that contains a barcode pattern. Localization is also estimated from visual rhythms. Vertical and horizontal projection techniques are finally used to refine the location of captions.
Sravani, Maheswararao, and Murthy (Citation2021) extracted video text using a hybrid method of MSER through morphological filtering. A 2D discrete wavelet transform was employed to remove noise from background and to enhance the text contrast. The method is also combined with traditional text extraction approaches based on edge dependent and connected components to produce better results.
Valery and Jean (Citation2020) developed a method for detecting and localizing embedded subtitles in video streams based on the search for static regions in the video frames. Connected components are extracted from the background via a Gaussian mixture model (GMM), generating binary image masks. Heuristic rules are used to identify the subtitles in the video stream.
Most approaches available in the literature, either in videos or images, localize the scene texts and not caption texts. In this sense, the method proposed in this work can be used to extend such methods to the problem of caption localization in videos. This aspect is interesting due to the scarce development of methods specific to caption texts.
Approaches that address video captioning tasks do not employ a standardized, large-numbered dataset, making it difficult to compare the methods. The dataset proposed in this work can be used to compare the results of the methods to solve these problems. The vast majority of approaches in the literature use their own sets of videos and do not make them publicly available, so it is not possible to compare different methods in the same videos in these cases. For example, Zhang and Chua (Citation2000) employed six television news videos, while Chun et al. (Citation2002) used three long videos (7–59 minutes). Chen and Su (Citation2018) evaluated their method with a set of five videos. Valery and Jean (Citation2020) presented only qualitative results in a small set of videos.
Caption Localization
The method proposed in this work for caption localization applies a scene text localization approach as a baseline, followed by a visual rhythm analysis, which uses the spatio-temporal information of rhythms to maintain only the captions from all scene texts. We use this approach due to the large number of literature methods for the localization of scene texts. The visual rhythm was employed because of its ability to summarize the spatio-temporal information of a video into a single image (or few images), allowing the employment of classic image processing techniques.
presents a diagram with an overview of our method, which has the captioned video as input. Each of the frames has its captions located separately. Then, the horizontal and vertical visual rhythms are constructed from the caption localization masks. Visual rhythms are processed to correct the estimation of caption locations. Finally, we reconstruct the masks across the regions defined by the visual rhythms. The following subsections explain each step of the method.
Figure 1. Overview of the proposed video caption localization method based on visual rhythms.

The core of the Frame Text Localization step can be done by any third-party text localization method (in our case, the method proposed by Epshtein, Ofek, and Wexler (Citation2010)), which can use any technique, such as deep learning. In turn, the other steps use a deterministic algorithm based on classical image processing techniques without any learning-based approach, which tends to have a lower computational cost, in addition to not requiring a training stage.
Frame Caption Localization
Initially, we localized the text of each frame independently. Several methods in the literature, such as those discussed in Section 2, could be used in this step. In this work, we apply the method proposed by Epshtein, Ofek, and Wexler (Citation2010), motivated by the quality of the results obtained with this method, and the availability of its code.Footnote1 presents an example of caption localization obtained through this method.
Figure 2. Example of a caption localization mask.

In our context, we are interested in the regions surrounding the caption. Since the baseline method generates a segmentation result, we perform a post-processing that obtains the caption localization from the segmentation. In addition, since caption texts are often present either at the top or bottom of the frames, we assume that they are not in the central region and we keep only the top and bottom estimates. These estimates are used to generate the mask illustrated in . To do so, a new image of the same size is initialized with zeros. For each row of the localization mask, we identify the first and the last non-black pixels in the corresponding row of the segmentation image. Every pixel between these two (including them) becomes a white pixel in the mask image.
Although we use a specific method for this step, any other method that finds text in images could be applied. We conjecture that the final performance may be superior when a better method is used to find text in the frames. Nevertheless, the focus of the method proposed in this work is described in the following subsections, where visual rhythms are employed to refine the localization from temporal information.
Visual Rhythm Construction
After computing the localization mask for all frames, we built the visual rhythms in the vertical and horizontal directions. Visual rhythm Souza et al. (Citation2020) is an image that summarizes information from a video. Inspired by the idea of building visual rhythms from the average of rows and columns (Souza and Pedrini Citation2020), we use the standard deviation of rows and columns.
Visual rhythms were formally defined by Souza et al. (Citation2020). Let a video be defined as the set , where each
,
is a
frame represented in matrix form. Let
be an arbitrary operation that maps each
into an
column vector
. A visual rhythm (VR) is defined as the
image given by:
In our case, the operation is the standard deviation. To compose the
-th vertical rhythm column, the standard deviation of each row of the mask is calculated for the
-th frame of the video. Similarly, to construct the
-th column of the horizontal rhythm, the standard deviation of each column of the
-th frame mask is calculated. By concatenating the information from each frame into columns, the vertical rhythm will have dimensions
, whereas the horizontal rhythm will have dimensions
, where
and
, respectively, correspond to the frame height and width, and
is the number of frames in the video.
The standard deviation was chosen empirically, as we noticed that the average would have problems since the caption usually has a very small size compared to the frame size, which becomes worse in extreme cases. Since the input frame has only values 0 and 1, the standard deviation will give us the information we need: which rows and columns have the most variation. Moreover, horizontal and vertical directions are more suitable for our context (for instance, in comparison with zigzag scheme (Valio, Pedrini, and Leite Citation2011)) since they match the usual caption direction.
presents examples of visual rhythms, where captions are defined as rectangles. The rectangles are larger at the horizontal visual rhythm because the horizontal dimension of the caption is typically larger than its vertical dimension. We also observed, especially at the horizontal visual rhythm, that the rectangles have discontinuities and are not regular. This is due to text detection failures, which we intend to correct in the next step.
Figure 3. Examples of visual rhythms extracted from mask videos.

Visual Rhythm Processing
Errors that occur in frame-by-frame text localization can be corrected by incorporating temporal information. From the visual rhythms, we can analyze the temporal information regarding the location of caption from the analysis of adjacent columns. Since we assume that the caption remains fixed in the same position for a certain period of time, it is expected that the corresponding columns should contain uniform rectangles. Thus, in this step we use image processing techniques to make the noisy rectangles from the previous step more uniform.
presents a diagram with the steps of processing visual rhythms. In processing, we consider the binary images of the visual rhythms. To obtain such images, we define as positive any pixel above a constant threshold , empirically chosen.
Figure 4. Steps of the visual rhythm processing. Initially, each visual rhythm has its connected components detected. They are then filtered by a subcomponent analysis. Caption positions are retrieved from final visual rhythms.
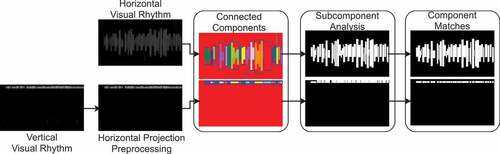
We preprocess the vertical rhythm based on the horizontal projection as shown in Algorithm 1, in which we determine which rows of vertical visual rhythm will be kept according to an analysis of the projection. In summary, we try to keep consecutive rows with positive pixels (white pixels). This is done in order to calculate the vertical position of the captions, which can be either top or bottom. This preprocessing is done only at the vertical rhythm since the vertical positions of the captions in the frames do not have significant changes throughout the video. In some real-world scenarios, captions may appear at both the top and the bottom, such as in sound effect captions. However, this does not appear in our dataset, and we consider it beyond the scope of our work. Since the caption is predominantly present in a same frame region, false positives can be filtered from the frequency with which estimates appear in a given region. Thus, we calculate the horizontal projection of the vertical rhythm, which consists of a histogram, where the -th value is the sum of the pixels of the
-th row. From this histogram, we define a range of rows that represent the location of the captions, so that rhythm rows that fall outside this range are set to null.
The desired range of the histogram is one that has high values. These values can be represented by one or more nearby peaks. Thus, we calculate the differences in consecutive values, described as
where is the
-th value of the histogram. To avoid problems with border values, the zero value is added at the beginning and end of
, before this calculation.
The histogram rows we are looking for are defined as a range based on an analysis of the values. We assign the first index
as the beginning of the range, where
is the first value greater than the
parameter, and assign the last index
as the end of the range, where
the last value that is less than the
parameter. To define the values of
and
, we consider the initial values, chosen empirically, respectively as 0.45 and −0.38. The final values are chosen separately, checking if there is at least one value in
that satisfies these restrictions. If it does not exist for the
parameter, it will be decremented by
, while for the
parameter it will be incremented by the same value.
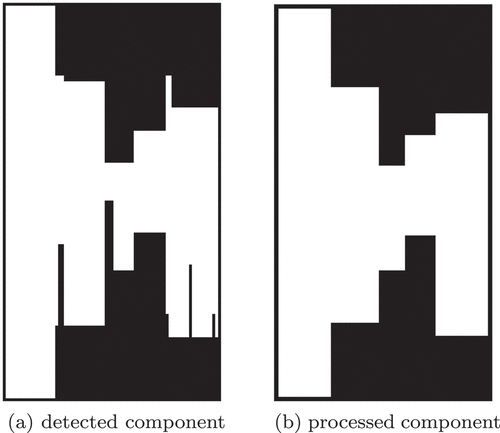
We compute the connected components of the horizontal rhythm and of the preprocessed vertical rhythm. We consider that two pixels belong to the same component if they are connected by an 8-neighborhood and are both positive. Only components that have a minimum width are considered, that is, captions that are in a minimum number of consecutive frames. Since a caption can end in one frame and another start in the next frame, two or more captions can be connected in the same component. provides an example of this case. Thus, for each of the detected components, we analyze and separate their subcomponents. It is possible to observe that the components are separated by entirely black columns indicating non-captioned frames.
Figure 5. Example of detected and processed components.
We perform the subcomponent analysis by comparing the component columns. We start with a column set . To consider adding a new column in
, we verify the first and last pixel that there is a positive value in that column. We called these pixels as boundary pixels (superior and inferior). The current column
is added to the set
if at least one of the following conditions are satisfied.
(1) a threshold value is equal or greater than the difference between (a) the position of the boundary pixels in the column and (b) the averages of the positions of the boundary pixels of all columns currently present in the set
, for at least one of two boundary pixels. In this work, the threshold empirically was chosen as 10 for the horizontal rhythm and 5 for the vertical rhythm;
(2) at least of the next
columns have at least one of two boundary pixels close enough to the average to be part of the set
;
(3) is the last column of this component.
When none of the previous conditions are valid, the end of a subcomponent is determined. This subcomponent starts at the first and ends at the last column added to . Assuming that the frame text localization method generally gets the right result, the upper and lower bounds given by the first and last rows in which positive pixels exist are computed, respectively, as the mode of the first and last rows of the columns in the set
. Then, if the current column is not the last column of the component, it will be added to the set
and the process continues to the last column. The result of processing a component from subcomponents can be seen in , where we can observe that the irregularities present in the component have been corrected.
Irregularities within a component, as shown in , mean that the location of a specific caption changed over the seconds. However, this contradicts our premise that each caption that appears throughout the video is fixed in the same position and with the same delimitation. If two consecutive subcomponents have close values for both the first and last rows, they are joined so that all columns between them are part of a single component. Finally, to reduce the number of possible failures, we check the correspondence of the localized components of two rhythms, so as to maintain only the intersections of the components of both rhythms. presents the visual rhythms obtained at the end of the process.
Figure 6. Examples of visual rhythms after processing.

Video Caption Localization
As we use the rhythms in the vertical and horizontal directions, we can retrieve the caption localization from the positive pixel coordinates. The positive pixels in the -th column of the vertical rhythm indicate the rows of the
-th frame that should be positive. That is, if the
-th pixel of the
-th column is active at the vertical rhythm, the
-th row of the mask of the
-th frame must become active. Similarly, positive horizontal rhythm pixels indicate which columns should be active in the mask. Masks are constructed so that a given pixel is active only if its row and column are active.
Dataset
There is a lack of public data, both in terms of quantity and quality, to evaluate related literature approaches. Thus, we propose a dataset that contains videos with caption and the necessary information for its detection, localization, segmentation, script recognition and text recognition.
To create the dataset, seventeen videos were collected from YouTube. Three criteria were established for a video to be inserted into the dataset: (i) be marked as a Creative Commons license, which gives the right to reuse and edit the video to anyone; (ii) have separate caption in raw text, providing a subtitle file with the format.srt; (iii) has no or little text already embedded in the video.
Preprocessing was done to deal with cases where the video had few frames with embedded text, leaving only frames without embedded text. Thus, it was possible to create a dataset if we had information related to the location of captions in all frames of the video. presents information for each of the collected videos. It is possible to observe that the videos were taken at different frame rates per second (FPS), at high resolution and with different durations.
Table 1. Information from videos collected from YouTube to compose the dataset. All videos were tagged with creative commons license.
presents a frame of each of the videos. Videos #1, #7, #8, #10 and #12 feature plenty of camera shake and cuts in different scenarios, such as music and sports clips. Videos #2, #3, #13, #14, #15, #16 and #17 have either a fixed camera or slow motion. Videos #4 and #5 are animations. Some other scenarios were also considered, such as indoor environments in videos #6 and #11 and slightly darker surroundings as in video #9.
Figure 7. Frames from each of the videos collected from YouTube.

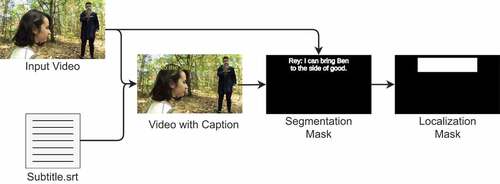
To add the captions to the videos, different characteristics were considered, namely: position, size, color and script. illustrates the process of inserting captions and creating ground truth. Each video and script pair results in a captioned video. As thirteen scripts were considered, 221 captioned videos were obtained.
Figure 8. Representation of text insertion in video and creation of ground-truth information.
For each captioned video, the ffmpeg tool was used to insert the caption into the video. Position, color, and size of captions are randomly chosen, all with equal probability, within predefined options. The settings were selected to include the most common conditions found in real cases. Captions were positioned either below or above in the video frames. Font sizes were chosen from small, medium and large, respectively, 12, 24 and 36. White, yellow, and red colors were considered for captions.
After inserting captions on videos that did not have embedded text, we can calculate the mask for caption segmentation from the differences between the frames of the original video and the frames with the added text
, expressed as
where indexes video frames over time. In addition,
and
index, respectively, the rows and columns of the frame. Pixel
is active in segmentation mask of the
-th frame if, and only if,
is nonzero. If there is at least one nonzero value in
, there will be a caption in the
-th frame. By analyzing
rows and columns where there is at least one non-zero value, we can calculate the rectangle surrounding the segmentation mask obtaining the location mask.
As mentioned previously, thirteen different scripts were considered. For this, each of the captions, originally in English, were translated into each of the scripts, presented in . The scripts adopted are of different types and emerged at different times. For each script, we consider its official language. In the case of Roman, English language was used. illustrates the same sentence in different scripts. The used scripts have substantial variation, which can hamper the development of a system that supports them all. In addition, there is a great similarity between some of the scripts, especially those of the same type, which can make their automatic recognition a hard task.
Table 2. Different scripts considered in this work.
Figure 9. Same sentence for different scripts considered.

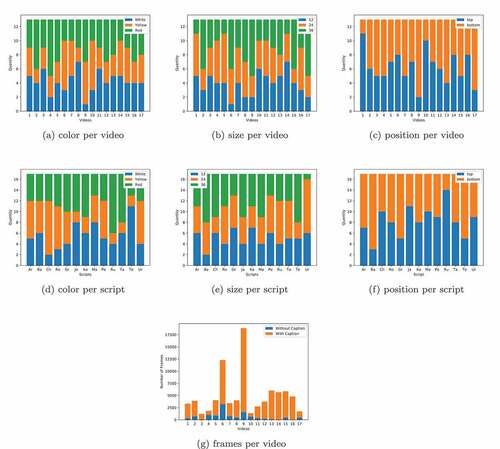
shows statistics about captions added to the videos. The graphics illustrate the number of videos in which captions were added with a certain color, size or position, relative to the seventeen videos collected () or the thirteen scripts (). From these statistics, it is possible to observe the dataset profile. For example, for the Urdu script, the added texts were distributed almost equally over position and color. However, few large texts (36) were added. Sub shows the number of frames with and without text per video, where it is possible to see which videos have text on most of their frames. Video #6 has the largest number of frames without text, whereas video #4 is the video with the highest percentage of videos with text.
Figure 10. Statistics for the built dataset.
Evaluation Metrics
Although we propose a method for caption localization without an earlier step for explicit frame caption detection, we evaluated which video frames a caption was localized and compared it with detection methods available in the literature using the proposed dataset.
Let TP, FP and FN be true positive, false positive, and false negative, respectively. In the detection problem, positive indicates a frame with a caption. Precision and recall metrics are used for caption detection evaluation and can be described respectively as
Precision evaluates the number of frames that have captions over all the frames that have captions. A lower precision value indicates that fewer frames estimated as captioned frames are incorrect. Recall evaluates the number of frames that are estimated to have captions, within all frames that have captions. A lower recall value indicates that fewer captioned frames were estimated.
The ratio between the intersection area and the union area of the estimation of caption location and the mask can be used for evaluating the caption localization, expressed as
where is the estimate and
the mask of the caption location. Values close to zero are obtained when the estimate differs from the mask, either by size or location, whereas values close to one occur when the estimate and mask are similar. From the intersection over the union, we define the accuracy used in localization as
where is the total number of frames in the video, and
Experiments and Discussions
This section presents the experiments conducted on our dataset with the method proposed in this work and different literature approaches. Subsection 5.1 presents the results obtained for the detection of frames with caption. Subsection 5.2 describes and discusses the results obtained for the caption localization task. We compared the results of our method to those proposed by Valio, Pedrini, and Leite (Citation2011) and Epshtein, Ofek, and Wexler (Citation2010). The method proposed by Valio, Pedrini, and Leite (Citation2011) performs caption detection, while the one proposed by Epshtein, Ofek, and Wexler (Citation2010) performs text localization. The experiments presented in Subsection 5.1 compare our method with them. These experiments are preliminary in relation to those presented in Subsection 5.2 and show an aspect in which our method can be improved in future work. These methods were chosen due to their good results and code availability. It is important to highlight the difficulty in making a comparison with other methods in the literature, because, in addition to the lack of available codes, the datasets were not, until this work, standardized for these tasks, in such a way that each literature work used its own set of a few videos.
Caption Frame Detection
The following experiments aim to present the results of frame detection methods in the proposed dataset, in addition to verifying and comparing the results obtained by determining which frames had a caption found by the localization methods. In order to do so, we analyzed the information of the generated masks, in such a way that it was possible to make a comparison with the method proposed by Valio, Pedrini, and Leite (Citation2011). The results obtained with our method and with the approach developed by Epshtein, Ofek, and Wexler (Citation2010) are calculated by assigning true when the sum of the caption mask is greater than zero, and false otherwise. The experiments of this subsection refer only to detection of frames with captions, which is important to eventually determine the methods drawbacks. By improving the quality of the methods at this step, the final results (localization) also tend to be improved.
presents the average results obtained for each source video. For the method proposed by Valio, Pedrini, and Leite (Citation2011), the recall values obtained are above 90% for almost all videos, which shows that this method rarely erroneously disregards frames with a caption. In terms of precision, most videos have values above 90%, however, videos #4, #6 and #10 have low values, with 49.4% in the worst case.
Table 3. Results obtained for detecting frames with captions for the different videos in the dataset.
The results of the method proposed by Epshtein, Ofek, and Wexler (Citation2010) show a better balance between recall and precision, with recall values above 90% for almost all videos, and precision below 80% only for video #10. For our method, we can observe that the precision values were above 90% for almost all videos, outperforming the low results of the method proposed by Valio, Pedrini, and Leite (Citation2011). The precision value for video #10 was also higher than the value of the method proposed by Epshtein, Ofek, and Wexler (Citation2010). On the other hand, recall values are lower, especially for videos #5, #6, #7 and #11. This shows that our method may have trouble finding captions in some frames, but almost does not erroneously find captions in frames that do not have them. This result also indicates that our method removes true-positive frames from the estimation, which affects its final results. Possibly, the poor performance of all methods in the video #10 may be explained by their high rate of smaller and yellow captions located mainly at the top, where the colors of objects in the scene, such as yellowed dry leaves, can cause methods to confuse captions with the background.
presents the average results calculated for each script. We can observe that the values obtained for the different scripts are very close for all the metrics to the results obtained by Valio, Pedrini, and Leite (Citation2011). This was expected since this method considers information independent of the characters used, which shows script invariance. Similar results can be seen for different caption font characteristics, presented in .
Table 4. Results obtained for detecting frames with captions for different scripts.
Table 5. Results obtained for detecting frames with captions for different caption characteristics.
The method proposed by Epshtein, Ofek, and Wexler (Citation2010) shows superior results for precision rate, with recall above 90%. For our method, high precision was obtained, but in some scripts, such as Arabic, Bangla, and Telugu, we achieved lower recall values. Similarly to the results obtained by Valio, Pedrini, and Leite (Citation2011) and Epshtein, Ofek, and Wexler (Citation2010), the values obtained with our method showed invariance for different characteristics of the caption font. These results can be seen in .
Caption Localization in Frames
In the following experiments, we present the final results for the caption localization. presents the average accuracy for each video for our method and the method based on the stroke width operator proposed by Epshtein, Ofek, and Wexler (Citation2010). Additionally, the accuracy rate was also computed only in frames where there was a caption according to the ground truth (correct frames). This was done so that we could also evaluate the results with a lower impact of the errors on non-caption frames by isolating the assessment of error location in false positive detection. In this case, we do not modify our method to take into account only the correct frames, but only calculate the evaluation metrics in those frames.
Table 6. Average accuracy achieved for video caption localization.
For twelve of the seventeen videos, our method had better accuracy, with the most noticeable improvement for videos #2, #6 and #9. On the other hand, the results of the other five videos were slightly lower, with negative highlighting for video #14.
For results considering only correct frames, there was an improvement for all videos, except video #14, with the most evident improvement on videos #2, #6, #7 and #9. These results show that our method achieved better results than the method proposed by Epshtein, Ofek, and Wexler (Citation2010) mainly due to the improved localization of captions in frames that had already been detected. However, the final result is not as good as it could be, because our method erroneously disregarded some true positives, such as video #7, which has a low recall on detection, as shown in .
presents the average accuracy in caption localization for each script. Our method obtained better results than those achieved by Epshtein, Ofek, and Wexler (Citation2010) for all scripts, especially Arabic, Bangla, Malayalam, Persian, and Tamil, where their method obtained low accuracy, probably due to the character formats of these scripts. Since our method considers temporal information, without analyzing the character format, we possibly solved problems that occurred in the caption localization due to the nature of the script.
Table 7. Average accuracy obtained for caption location for each script.
shows the average accuracy in caption localization for different font characteristics. Regarding the font size, our method was superior for larger fonts, maintaining good results for videos with smaller fonts, while both methods were invariant to position and color of the captions. From the results obtained, we believe that the method by Epshtein, Ofek, and Wexler (Citation2010) had problems in dealing with very large fonts, and this reflected the better performance of our method.
Table 8. Average accuracy obtained for caption localization with different characteristics.
presents examples of results for frames where scene texts and captions are shown together. In an overview, our method performed a good caption localization (despite some misalignments) and ignored scene texts. In the first case, the scene text is present in the center of the frame, a region that is disregarded by our method. In the second example, the scene text appears on the opposite side of the captions. The success of our method, in this case, is associated with considering only captions in the same region of the frame, and the scene text is eliminated through temporal analysis. The third example also uses temporal analysis to succeed. In this case, the caption and scene texts are presented in the same region and the method separated them. Finally, the last example shows that our method is also capable of disregarding large scene texts.
Figure 11. Results for frames with scene and caption text.

Conclusions
The contributions of this paper are twofold. We presented a novel method for localizing video captions using visual rhythms for temporal analysis of frame-by-frame location estimates. A new dataset was created with seventeen initial videos. For each video, we added captions with thirteen distinct scripts to obtain a total of two hundred and twenty one videos with ground truth.
Experiments were performed on the proposed dataset to compare our results against two other methods. It is worth mentioning that a more extensive comparison would be a very difficult task due to the lack of available codes and annotated public datasets. In this sense, the dataset built in this work may provide an opportunity for other authors to evaluate their methods. Experimental results demonstrated that our method can considerably improve results for most videos, with improvement being evident in some specific videos. However, our method could still be improved in order to reduce the great number of false positives, which would mitigate the obtained results.
As directions for future work, we intend to evaluate the results of our method considering frame-by-frame localization made by a deep machine learning approach, such as convolutional neural networks. We will also improve the comparative analysis of the literature on the dataset proposed in this paper.
Acknowledgments
The authors are thankful to São Paulo Research Foundation (FAPESP grant #2017/12646-3), National Council for Scientific and Technological Development (CNPq grant #309330/2018-1), Coordination for the Improvement of Higher Education Personnel (CAPES) and Minas Gerais Research Foundation (FAPEMIG) for their financial support.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Agnihotri, L., and N. Dimitrova (1999). Text detection for video analysis. In IEEE Workshop on Content-Based Access of Image and Video Libraries, Fort Collins, CO, USA, 109–2214. IEEE.
- Arafat, S. Y., and M. J. Iqbal. 2020. Urdu-text detection and recognition in natural scene images using deep learning. IEEE Access 8:96787–803. doi:10.1109/ACCESS.2020.2994214.
- Canny, J. 1987. A computational approach to edge detection. In Readings in Computer Vision, 184–203. San Francisco, CA, USA: Elsevier.
- Chen, L.-H., and C.-W. Su. 2018. Video caption extraction using spatio-temporal slices. International Journal of Image and Graphics 18 (2):1850009. doi:10.1142/S0219467818500092.
- Chun, S. S., H. Kim, K. Jung-Rim, S. Oh, and S. Sull (2002). Fast text caption localization on video using visual rhythm. In International Conference on Advances in Visual Information Systems, Hsin Chu, Taiwan, 259–68. Springer.
- Concha, D. T., H. A. Maia, H. Pedrini, H. Tacon, A. S. Brito, H. L. Chaves, and M. B. Vieira (2018). Multi-stream convolutional neural networks for action recognition in video sequences based on adaptive visual rhythms. In 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 473–80. IEEE.
- Epshtein, B., E. Ofek, and Y. Wexler (2010). Detecting text in natural scenes with stroke width transform. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 2963–70. IEEE.
- He, D., X. Yang, C. Liang, Z. Zhou, A. G. Ororbi, D. Kifer, and C. Lee Giles (2017a). Multi-scale FCN with cascaded instance aware segmentation for arbitrary oriented word spotting in the wild. In IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 3519–28.
- He, P., W. Huang, T. He, Q. Zhu, Y. Qiao, and X. Li (2017b). Single shot text detector with regional attention. In IEEE International Conference on Computer Vision, Venice, Italy, 3047–55.
- Jiang, D., S. Zhang, Y. Huang, Q. Zou, X. Zhang, M. Pu, and J. Liu. 2020. Detecting dense text in natural images. IET Computer Vision 14 (8):597–604. doi:10.1049/iet-cvi.2019.0916.
- Jiang, Y., X. Zhu, X. Wang, S. Yang, W. Li, H. Wang, P. Fu, and Z. Luo (2017). R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv preprint arXiv:1706.09579.
- Katper, S. H., A. R. Gilal, A. Waqas, A. Alshanqiti, A. Alsughayyir, and J. Jaafar. 2020. Deep neural networks combined with STN for multi-oriented text detection and recognition. International Journal of Advanced Computer Science and Applications 11 (4):178–85. doi:10.14569/IJACSA.2020.0110424.
- Khare, V., P. Shivakumara, and P. Raveendran. 2015. A new histogram oriented moments descriptor for multi-oriented moving text detection in video. Expert Systems with Applications 42 (21):7627–40. doi:10.1016/j.eswa.2015.06.002.
- Lee, -C.-C., Y.-C. Chiang, H.-M. Huang, and C.-L. Tsai (2007). A fast caption localization and detection for news videos. In Second International Conference on Innovative Computing, Information and Control, Kumamoto, Japan, 226–226. IEEE.
- Liao, M., Z. Zhu, B. Shi, G.-S. Xia, and X. Bai (2018). Rotation-sensitive regression for oriented scene text detection. In IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 5909–18.
- Liu, Y., and L. Jin (2017). Deep matching prior network: Toward tighter multi-oriented text detection. In IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 1962–69.
- Long, S., X. He, and C. Ya (2018). Scene text detection and recognition: The deep learning era. arXiv preprint arXiv:1811.04256.
- Lyu, M. R., J. Song, and M. Cai. 2005. A comprehensive method for multilingual video text detection, localization, and extraction. IEEE Transactions on Circuits and Systems for Video Technology 15 (2):243–55. doi:10.1109/TCSVT.2004.841653.
- Moreira, T. P., D. Menotti, and H. Pedrini (2017). First-person action recognition through visual rhythm texture description. In International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 2627–31. IEEE.
- Neumann, L., and J. Matas (2010). A method for text localization and recognition in real-world images. In Asian Conference on Computer Vision, Queenstown, New Zealand, 770–83. Springer.
- Pinto, A., H. Pedrini, W. Schwartz, and A. Rocha (2012). Video-based face spoofing detection through visual rhythm analysis. In 25th Conference on Graphics, Patterns and Images (SIBGRAPI), Ouro Preto, MG, Brazil, 221–28. IEEE.
- Pinto, A., W. R. Schwartz, H. Pedrini, and A. Rocha. 2015. Using visual rhythms for detecting video-based facial spoof attacks. IEEE Transactions on Information Forensics and Security 10 (5):1025–38. doi:10.1109/TIFS.2015.2395139.
- Shi, B., X. Bai, and S. Belongie (2017). Detecting oriented text in natural images by linking segments. In IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 2550–58.
- Souza, M. R. (2018). Digital video stabilization: Algorithms and evaluation. Master’s thesis, Institute of Computing, University of Campinas, Campinas-SP, Brazil.
- Souza, M. R., and H. Pedrini. 2020. Visual rhythms for qualitative evaluation of video stabilization. EURASIP Journal on Image and Video Processing 2020:1–19. doi:10.1186/s13640-020-00508-4.
- Souza, M., H. Maia, M. Vieira, and H. Pedrini. 2020. Survey on visual rhythms: A spatio-temporal representation for video sequences. Neurocomputing 402:409–22. doi:10.1016/j.neucom.2020.04.035.
- Sravani, M., A. Maheswararao, and M. K. Murthy. 2021. Robust detection of video text using an efficient hybrid method via key frame extraction and text localization. Multimedia Tools and Applications 80 (6):9671–86. doi:10.1007/s11042-020-10113-2.
- Tacon, H., A. S. Brito, H. L. Chaves, M. B. Vieira, S. M. Villela, H. de Almeida Maia, D. T. Concha, and H. Pedrini (2019). Human action recognition using convolutional neural networks with symmetric time extension of visual rhythms. In International Conference on Computational Science and Its Applications, Saint Petersburg, Russia, 351–66. Springer.
- Torres, B. S., and H. Pedrini. 2018. Detection of complex video events through visual rhythm. The Visual Computer 34 (2):145–65. doi:10.1007/s00371-016-1321-1.
- Valery, G., and S. Jean (2020). Detection and localization of embedded subtitles in a video stream. In International Conference on Computational Science and Its Applications, Cagliari, Italy, 119–28. Springer.
- Valio, F. B., H. Pedrini, and N. J. Leite. 2011. Fast rotation-invariant video caption detection based on visual rhythm. In Iberoamerican Congress on Pattern Recognition, ed. César San Martin and Sang-Woon Kim, 157–64. Springer.
- Villamizar, M., O. Canévet, and J.-M. Odobez. 2020. Multi-scale sequential network for semantic text segmentation and localization. Pattern Recognition Letters 129:63–69. doi:10.1016/j.patrec.2019.11.001.
- Wu, J.-C., J.-W. Hsieh, and Y.-S. Chen. 2008. Morphology-based text line extraction. Machine Vision and Applications 19 (3):195–207. doi:10.1007/s00138-007-0092-0.
- Yin, X.-C., Z.-Y. Zuo, S. Tian, and C.-L. Liu. 2016. Text detection, tracking and recognition in video: A comprehensive survey. IEEE Transactions on Image Processing 25 (6):2752–73. doi:10.1109/TIP.2016.2554321.
- Zedan, I. A., K. M. Elsayed, and E. Emary (2016). Caption detection, localization and type recognition in Arabic news video. In 10th International Conference on Informatics and Systems, Giza, Egypt, 114–20. ACM.
- Zhang, Y., and T.-S. Chua. 2000. Detection of text captions in compressed domain video. In ACM Workshops on Multimedia, 201–04. New York, NY, USA: ACM.
- Zhang, Z., C. Zhang, W. Shen, C. Yao, W. Liu, and X. Bai (2016). Multi-oriented text detection with fully convolutional networks. In IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 4159–67.
- Zhong, Y., H. Zhang, and A. K. Jain. 2000. Automatic caption localization in compressed video. IEEE Transactions on Pattern Analysis and Machine Intelligence 22 (4):385–92. doi:10.1109/34.845381.