
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In this paper, we propose clustering algorithms based on finite mixture and infinite mixture models of exponential approximation to the Multinomial Generalized Dirichlet (EMGD), Multinomial Beta-Liouville (EMBL) and Multinomial Shifted-Scaled Dirichlet (EMSSD) with Bayesian inference. The finite mixtures have already shown superior performance in real data sets clustering using the Expectation–Maximization approach. The proposed approaches in this paper are based on a Monte Carlo simulation technique namely Gibbs sampling algorithm including an additional Metropolis–Hastings step, and we utilize exponential family conjugate prior information to construct their posterior relying on Bayesian theory. Furthermore, we also present the infinite models based on Dirichlet processes, which results in clustering algorithms that do not require the specification of the number of mixture components to be given in advance and selects it in a principled manner. The performance of our Bayesian approaches was evaluated in some challenging real-world applications concerning text sentiment analysis, fake news detection, and human face gender recognition.
Introduction
Clustering count vectors is a challenging task on large data sets considering its high dimensionality and sparsity nature (Jain Citation2010). The bag of words representation for text systematically exhibits the burstiness phenomenon, if a word appears once in a document, it is much more likely to appear again (Church and Gale Citation1995; Katz Citation1996). This phenomenon is not limited to text and can also be observed in images with visual words (Jegou, Douze, and Schmid Citation2009).
Table 1. Experiment results for IMDB movie reviews.
Table 2. Experiment results for Tripadvisor hotel reviews.
It also has a sparsity nature that few words show up with high occurrence and some are less as often as possible or do not appear at all (Margaritis and Thrun Citation2001). Thus, such data are generally represented as sparse high-dimensional vectors, with few thousands of dimensions with a sparsity of 95–99% (Dhillon and Modha Citation2001).
Hierarchical Bayesian modeling frameworks, such as Generalized Dirichlet multinomial mixture model (GDM), Beta-Liouville multinomial mixture model (MBL) and Shifted-Scaled Dirichlet multinomial mixture model (MSSD) (Alsuroji, Zamzami, and Bouguila Citation2018; Bouguila Citation2008; Elkan Citation2006), have shown excellent performance for high-dimensional count data clustering. However, their estimation procedures are very inefficient when the data collection size is large (Zamzami and Bouguila Citation2020a). The exponential family of distributions has a finite-sized sufficient statistics (Brown Citation1986), meaning that we can compress the data into a fixed-sized summary without loss of information (DasGupta Citation2011). Efficient exponential family approximations to the MGD (EMGD), MBL (EMBL) and MSSD (EMSSD) have been previously proposed by Zamzami and Bouguila (Zamzami and Bouguila Citation2020a, Citation2022, Citation2020b). These distributions have shown to address the burstiness phenomenon successfully and to be considerably computationally faster than their original distribution forms especially when dealing with sparse and high-dimensional data (i.e. these exponential approximations are evaluated as functions or non-zero counts only as we will see in the next section).
The main problem in the case of finite mixture models is the estimation of the model parameters (Brooks Citation2001). Expectation–maximization (EM) algorithm is a simple and effective approach for model’s parameters estimation (Emanuel and Herman Citation1987). However, the EM algorithm for finite mixtures has several drawbacks. For example, the occurrence of local maximum and singularities in likelihood function will often cause problems for deterministic gradients method (Robert Citation2007). Moreover, in high dimensional estimation, it will be hard to obtain reliable estimates which possess generalization capabilities to predict the densities at new data points (Cai Citation2010; Dias and Wedel Citation2004). Some Bayesian approaches are based on simulation methods, such as Gibbs sampling, which explore high-density regions (Roeder and Wasserman Citation1997). The stochastic aspect of these simulation methods ensures the escape from local maximum (e.g., Bouguila, Ziou, and Hammoud Citation2009). Tsionas (Citation2004) proposed an estimation approach for multivariate t distribution using Gibbs sampling with data augmentation. Amirkhani, Manouchehri, and Bouguila (Citation2021) presented a fully Bayesian approach within Monte Carlo simulation for Multivariate Beta mixture parameters estimation. Bouguila, Ziou, and Hammoud (Citation2009) successfully adopted a Bayesian algorithm based on Metropolis-within Gibbs sampling for a finite Generalized Dirichlet mixture. Najar, Zamzami, and Bouguila (Citation2019) used Monte Carlo simulation method for exponential family approximation to the Dirichlet Compound Multinomial mixture model (EDCM) parameters estimation and shown excellent results in some real applications. Xuanbo, Bouguila, and Zamzami (Citation2021) successfully proposed a fully Bayesian approach based on Gibbs sampling technique for exponential family approximation to the Multinomial Scaled Dirichlet mixture model (EMSD).
Another challenging aspect when using finite mixture model is usually to estimate the number of clusters which best describes the data without overfitting or underfitting it. For this purpose, many approaches have been suggested. These approaches can be divided into two different strategies for mixture models. The first strategy is the implementation of model selection criteria. The second strategy is resampling from the full posterior distribution with the number of clusters considered unknown. However, the majority of these approaches cannot be easily used for high-dimensional data (Bouguila and Ziou Citation2010). The infinite mixture models based on Dirichlet process (Antoniak Citation1974; Korwar and Hollander Citation1973) have recently attracted wide attention, thanks to the development of MCMC techniques. Dirichlet process mixture (DPM) models resolve the difficulties related to model selection (MacEachern and Muller Citation1998). Rasmussen (Citation1999) successfully applied Dirichlet process on Gaussian mixture model with Gibbs sampling to obtain accurate number of classes. Bouguila and Ziou (Citation2010) also presented a clustering algorithm for Dirichlet process mixture of Generalized Dirichlet distributions with MCMC techniques. Najar, Zamzami, and Bouguila (Citation2020) proposed an infinite mixture of exponential family approximation to the Multinomial Dirichlet Compound mixture model and showed superior experimental results in recognition of human interactions in feature films. Thus, we extend these finite mixture models to infinite mixture models based on Dirichlet process to tackle model selection in the case of sparse high-dimensional vectors.
In this paper, we present clustering algorithms based on finite and infinite mixtures of EMGD, EMBL and EMMSD from Bayesian viewpoint using Gibbs sampling within M–H steps. These distributions have already shown excellent performances in clustering real-world high-dimensional count data sets with deterministic approach. The key contributions of this article are as following: (1) Determination of conjugate priors to EMGD, EMBL and EMSSD by taking into account the fact that these distributions are members of the exponential family, and (2) through challenging applications that concern text sentiment analysis, text fake news detection and human face gender recognition, we show that the proposed algorithms are efficient for clustering sparse high-dimensional count data. The learning of the proposed finite mixtures and their infinite counterparts will be based on MCMC algorithms namely Gibbs sampling and Metropolis–Hastings (M–H) (Favaro and Whye Teh Citation2013).
The rest of this paper is organized as follows. The next two sections, review and develop conjugate prior distributions for the EMBL, EMGD and EMSSD distributions. Then, we present a Bayesian estimation for their finite mixture models parameters using Gibbs sampling, and extend these finite mixture models to infinite mixture models while developing complete clustering algorithms. After we exhibit the abilities of the proposed approaches in text sentiment analysis, text fake news detection, human face gender recognition. The concluding remarks and future work directions are given at the end of the paper.
Exponential Approximation of Distributions for Count Data
In this section, we review the approximations to the MGD, the MBL and the MSSD to bring them to the exponential family of distributions.
Exponential Family
The exponential family of distributions is widely used in machine learning research due to its sufficient property, as the sufficient statistics can give all of needed parameter information by the whole sample data set. For a random variable and a distribution with
parameters in exponential family we have:
where is called the natural parameter,
(X) is the sufficient statistic,
is the underlying measure, and
is called log normalizer used to ensure that the distribution integrates to one (DasGupta Citation2011).
The Exponential Family Approximation to Multinomial Generalized Dirichlet (MGD) Distribution
We define as a sparse count data vector describing a text document, or an image where
corresponds to the frequency of appearances of a word or visual word
. The MGD distribution is defined by (Bouguila Citation2008):
where ,
,
, for
, and
. In count data represented as bag-of-words, Zamzami and Bouguila (Citation2020a) found, experimentally, that
for almost all words
based on different data sets. Moreover, we have for
(Elkan Citation2006):
Then, the exponential family form for MGD can be written as (Zamzami and Bouguila Citation2022):
where is an indicator that represents whether a word
shows up at any entry in the vector
, and
.
The Exponential-Family Approximation to Multinomial Beta-Liouville (MBL) Distribution
If a random vector follows a Multinomial Beta-Liouville distribution, then (Bouguila Citation2011):
where ,
,
, and
.
In several real world applications, the MBL mixture model has provided good high clustering accuracy, comparably to Multinomial Scaled Dirichlet mixture model (MSD) (Zamzami and Bouguila Citation2019), and Multinomial Generalized Dirichlet mixture model (MGD) (Bouguila Citation2008), it also outperforms other widely used mixture models, such as mixtures of Multinomial distributions (MM) and Dirichlet Compound Multinomial (DCM) distributions (Bouguila and Ziou Citation2007; Madsen, Kauchak, and Elkan Citation2005). However, MBL does not belong to the exponential family, and it is not efficient in high-dimensional spaces where many parameters need to be estimated (Zamzami and Bouguila Citation2020a). Approximating MBL to belong to exponential family can reduce the computation cost and improve the efficiency of MBL to model sparse high-dimensional count data (Elkan Citation2006).
Zamzami and Bouguila (Citation2020a) found empirically that and
for real data sets and proposed maximum likelihood method for model parameters estimation. Thus, relying on EquationEquation (3)
(3)
(3) , we have the form of exponential approximation for multinomial Beta-Liouville distribution as:
where , the sufficient static, is an indicator whether the word
appears at least once in the vector
and
.
2.4. The Exponential-Family Approximation to Shifted Scaled Dirichlet Multinomial (MSSD) Distribution
Define a random vector that follows a Shifted Scaled Dirichlet Multinomial Distribution, then:
where ,
and
.
For high dimensional data, Zamzami and Bouguila (Citation2020b) found that the value of parameters are really small which combined with some approximations gave the exponential Multinormial Shifted-Scaled Dirichlet (EMSSD) as:
The Proposed Bayesian Learning Framework
In this section, we propose the algorithms to learn the parameters for finite and infinite mixture models of EMBL, EMGD and EMMSD.
Finite Mixture of Distributions
A finite mixture of distributions with components is defined as (e.g., (Bouguila and Fan Citation2020)):
where the are the mixing weights and
is the components distribution,
is the entire set of parameters to be estimated, where
,
represents the parameters of distribution
, and
is the vector of weight parameters. The
must satisfy:
.
Bayesian Learning for Finite Mixture Weight Parameters
Given a set of independent vectors
described by a finite mixture model, and
is the number of mixture components, supposed to be known, the main problem is to estimate the mixture parameters. In this work, we rely on Bayesian techniques to resolve this problem.
We define an indicator for each in data set
for each class
as:
where and
. In the Bayesian paradigm information brought by the complete data (
), a realization of (
)
is combined with prior information about the parameters
that is specified in a prior distribution with density
and summarized in probability distribution
called the posterior distribution. This can be derived from the joint distribution,
(Nizar, Ziou, and Hammoud Citation2009). Thus, we have:
where is the marginal density of the complete data
. We can directly simulate
with well-known Gibbs sampler rather than directly computing it. Gibbs sampling is widely used in Bayesian mixture model, especially in the case of incomplete data (Train Citation2009; Xuanbo, Bouguila, and Zamzami Citation2021). That is, associate with each observation
a missing multinomial variable
.
In fact, the weight parameter is independent of ,
(Samuel, Balakrishnan, and Johnson Citation2000), and we know that the vector
is defined on the simplex {(
}, then the natural prior distribution for vector
is the Dirichlet distribution, we determine the prior of
(Lee Citation2012) as:
where is the parameters vector of the Dirichlet distribution. Moreover, we have:
where , Having the prior distribution and likelihood distribution in hand, we can obtain the posterior for weight parameters
by the following:
where is Dirichlet distribution with parameters
. We note that the prior and posterior distributions
and
are both Dirichlet distributions. In this case, we say that the Dirichlet is conjugate prior for mixture proportions. Therefore, the weight parameters can be sampled from Dirichlet distribution. We selected
in our experiments.
The Bayesian Learning for Infinite Mixture Weight Parameters
In finite mixture model, we have considered to be fixed finite quantity. In this section, we will explore the limit
and present the conditional posteriors for the indicators and weight parameters based on Dirichlet process. We take
for EquationEquation (11)
(11)
(11) , thus we obtain a simpler form for prior probability of infinite mixture weight parameters:
where we have . From EquationEquation (12)
(12)
(12) , we have the prior distribution for the Z parameter that corresponds to multinomial distribution. Using the standard Dirichlet integral, we could marginalize out the
parameter to get the following probability for the prior directly in terms of the indicators (Rasmussen Citation1999):
Based on Bayes principle, we obtain the conditional posterior distribution for the mixing weight vector:
In order to be able to use Gibbs sampling for the indicators , we need the conditional prior for a single indicator given all the others: this is easily obtained from EquationEquation (17)
(17)
(17) by keeping all but a single indicator fixed (Najar, Zamzami, and Bouguila Citation2020):
where the subscript indicates all except
and
is the number of observations, excluding
, that are associated with component
.
Lastly, we choose inverse Gamma as prior for parameters :
The likelihood for can be derived from EquationEquation (17)
(17)
(17) , which together with the prior from EquationEquation (19)
(19)
(19) gives:
We selected in our experiments. These values were previously used in Bouguila and Ziou (Citation2010), because they allow a diffuse range of values of the number of clusters
(more details and discussions can be found in Escobar and West Citation1995). For the indicators, letting
in EquationEquation (19)
(19)
(19) , the conditional prior reaches the following limits (Rasmussen Citation1999):
Having this prior distribution, we can obtain the conditional posterior by multiplying the model likelihood:
Unfortunately, this integral is not analytically tractable in EquationEquation (23)(23)
(23) , hence, we consider a Monte Carlo sampling approximation.
Learning Algorithm for Finite Mixture Model of EMGD
Define as the prior distribution for the parameters of the EMGD distribution. We use the fact that EMGD belongs to the exponential family. In fact, if a S-parameters density
belongs to the exponential family then we can rewrite it in the exponential form which has been shown in EquationEquation (1)
(1)
(1) .
Writing the EMGD in the exponential form gives:
In this case, a prior of is given by (Lee Citation2012) as:
where , and
are referred as hyperparameters.
The prior for EMGD can be written as following:
Having the prior in hand, the mixture model posterior is (see Appendix A):
According to the posterior hyperparameters, following (Nizar, Ziou, and Hammoud Citation2009), once the sample is known, we can use it to get the prior hyperparameters. Then, we held
and
fixed at:
,
,
,
.
Algorithm 1 Finite EMGD (FinEMGD) learning algorithm
Initialization: Using MOM and K-means method to initialize model parameters
Input: A data set , each is
-dimensional sparse count vector, the number of clusters
output:
for
(1) Generate
(2) Generate weight parameters from EquationEquation 13
(13)
(13)
(3) Generate model from EquationEquation 11
(11)
(11) using M–H algorithm
M–H algorithm:
(1) Generate from
and
(2) compute
(3) if then:
else:
In Algorithm 1, , and we take the K-means (Hartigan and Wong Citation1979) and the method of moments (MOM) (Wong Citation2010) for initializing the model parameters. In the M–H step, the major factor is choosing proposal distribution
(Sorensen and Gianola Citation2002; Train Citation2009). As the model parameters are satisfied
, we choose the Gamma distribution as the proposal distribution for
and
.
The complexity of an algorithm is determined by the size of data set (i.e., number of observations ), and the number of mixture components
. The algorithm computation complexity for one iteration is
where
and
are scale parameters of the Gamma distributions. The complete algorithm for estimating the EMGD parameters using the proposed approach is presented in Algorithm 1.
Learning Algorithm for Infinite Mixture Model of EMGD
We know that the model parameters and
in EMGD satisfy
, then appealing flexible choice as prior is the Beta distribution, with shape parameters:
and
, then:
where ,
.
Then, the conditional posterior distributions for and
are:
In order to have more flexible model, we introduce an additional hierarchical level by allowing the hyperparmeters to follow some selected distributions. The hyperparmeters and
associated with
and
respectively are given Beta distribution and exponential distribution:
For those hyperparameters and
, the prior of
and
is considered as likelihood. Thus, the conditional posterior can be obtained (see Appendix C).
Then, we have the learning algorithm 2 for infinite mixture model of EGDM:
Algorithm 2 Infinite EGDM (InfEGDM) learning algorithm
Initialization: Using MOM to initialize model parameters
Input: a data set , each is W-dimensional sparse count data
output:
for
(1) Generate from EquationEquation (23)
(23)
(23) with Monte Carlo sampling approximation
(2) Update the number of represented components
(3) Generate weight parameters from EquationEquation (20)
(20)
(20) with adaptive reject sampling (ARS)
(4) Generate weight parameters from
(5) Update in M–H algorithm
M–H algorithm:
for in (
):
(1) Generate from
and
(2) compute from EquationEquation (31)
(31)
(31) or EquationEquation (32)
(32)
(32)
(3) if then:
else:
Update the hyperparameters and
with MCMC sampling in their conditional posterior
Learning Algorithm for Finite Mixture Model of EMBL
EMBL also belongs to the exponential family. We define , where
. We can show following EquationEquation (1)
(1)
(1) , that:
Based on EquationEquation (15)(15)
(15) , we have a prior as following:
From Bayesian theory, the posterior can be written as (see Appendix B):
Once the sample is known, the posterior hyperparameters can be fixed, we fix
,
and
(Bouguila, Ziou, and Hammoud Citation2009).
In Bayesian approach, choosing an effective proposal prior distribution is significant factor for the model parameters estimation and convergence time. With many different common proposal distributions attempts, we finally select Beta distribution as proposal distribution for , and inv-Gamma distribution for
.
Algorithm 3 Finite EMBL (FinEMBL) learning algorithm
Initialization: Using the MOM and the K-means method to initialize model parameters
Input: a data set , each is W-dimensional sparse count data, the number of clusters
output:
for
(1) Generate
(2) Generate weight parameters from EquationEquation (13)
(13)
(13)
(3) Generate model from EquationEquation (39)
(39)
(39) using M–H algorithm
M–H algorithm:
(1) Generate from
and
(2) compute
(3) if then:
else:
The complete steps for estimating the EMBL model parameters using the proposed approach are given in Algorithm 3. Note that the proposed Algorithm 3 requires computational cost per step.
Learning Algorithm for Infinite Mixture Model of EMBL
As shown empirically, the values of and
satisfy
and
. Thus, we choose the beta distribution and Inverse Gamma distribution as priors for
and
with hyperparameters
and
, then
Having this prior, the full conditional posteriors for and
are:
In order to reduce the sensitivity of parameters, we give priors for the hyperparmaeters and
, by choosing Beta distribution, exponential distribution and Inverse Gamma distribution, exponential distribution, respectively
For those hyperparameters and
, the prior of
and
is considered as likelihood. Thus, the conditional posterior can be obtained (see Appendix C). The parameter learning algorithm of this infinite model is similar to the infinite mixture model of EGDM, we only need to replace the posterior probability for
and
in M–H steps.
Thus, we have the learning algorithm 4:
Algorithm 4 Infinite EMBL (InfEMBL) learning algorithm
Initialization: Using MOM to initialize model parameters
Input: a data set , each is W-dimensional sparse count data
output:
for
(1) Generate from EquationEquation (22)
(22)
(22) with Monte Carlo sampling approximation
(2) Update the number of represented components
(3) Generate weight parameters from EquationEquation (20)
(20)
(20) with adaptive reject sampling (ARS)
(4) Generate weight parameters from
(5) Update in M–H algorithm
M–H algorithm:
for in (
):
(1) Generate from
and
(2) compute from EquationEquation (43)
(43)
(43) or EquationEquation (44)
(44)
(44)
(3) if then:
else:
Update the hyperparameters and
with MCMC sampling in their conditional posterior
Learning Algorithm for Finite Mixture Model of EMMSD
EMMSD can be written following EquationEquation (1)(1)
(1) , as:
Based on EquationEquation (15)(15)
(15) , we have a prior as following:
From Bayesian theory, the posterior can be written as
Once the sample is known, the posterior hyperparameters can be fixed, we fix
,
and
. Having the posterior in hand, we can propose the algorithm for finite mixture model of EMMSD.
Algorithm 5 Finite EMMSD (FinEMSSD) learning algorithm
Initialization: Using MOM and K-means method to initialize model parameters
Input: a data set , each is W-dimensional sparse count data, the number of clusters
output:
for
(1) Generate
(2) Generate weight parameters from EquationEquation 13
(13)
(13)
(3) Generate model from EquationEquation 11
(11)
(11) using M–H algorithm
M–H algorithm:
(1) Generate from
and
(2) compute
(3) if then:
else:
In Algorithm (5), , and we take the K-means and the method of Moment (MOM) (Wong Citation2010) for initializing model parameters
. We initialize
with a constant proportion vector and
as a vector one. Choosing proposal distribution is significant part in M–H steps (Sorensen and Gianola Citation2002; Train Citation2009). As the model parameters satisfy
and
, we choose the Beta distribution and Gamma distribution as the proposal distributions for
,
and the Inverse Gamma distribution for
.
The algorithm computation complexity for one iteration is
Learning Algorithm for Infinite Mixture Model of EMMSD
We find that taking the prior (EquationEquation (50)(50)
(50) ) and the posterior (EquationEquation (51)
(51)
(51) ) for EMSSD parameters in infinite mixture model, we can obtain a superior performance in real applications. Thus, we directly use them to the infinite mixture model. Then, the complete algorithm can be presented:
Algorithm 6 Infinite EMSSD (InfEMSSD) learning algorithm
Initialization: Using MOM to initialize model parameters
Input: a data set , each is W-dimensional sparse count data
output:
for
(1) Generate from EquationEquation (22)
(22)
(22) with Monte Carlo sampling approximation
(2) Update the number of represented components
(3) Generate weight parameters from EquationEquation (20)
(20)
(20) with adaptive reject sampling (ARS)
(4) Generate weight parameters from
(5) Update in M–H algorithm
M–H algorithm:
(1) Generate from
and
(2) compute
(3) if then:
else:
Experimental Results
In this section, we aim at comparing the proposed algorithms and their corresponding finite mixture models learned in a deterministic way using EM algorithm in different data clustering applications. The first experiment and second one concentrate on textual data for sentiment analysis and fake news detection. The last one considers images data for distinguishing male and female faces. All experiments were conducted using optimized python code on Inter (R) Core (TM) i7-9750 H processor PC with Windows 10 Enterprise Service Pack 1 operating system with a 16 GB main memory. The results that we will present in the following subsections represent the average over 20 runs of the proposed algorithms. For our proposed algorithm, The empirical assessment of MCMC convergence is delicate, especially in high dimensional spaces. In our experiments we applied the widely used one-long run technique as proposed in Raftery and Lewis (Citation1992).
Text Sentiment Analysis
Sentiment analysis, also called opinion mining, involves analyzing evaluations, attitudes, and emotions, expressed in a piece of text, toward entities such as products, services, or movies (Batista and Ratté Citation2014). In our first experiment, we classify whether a whole opinion document expresses a positive or negative sentiment. The challenges in sentiment analysis, as a text clustering application, include that the reviews are usually limited in length, have many misspellings, and shortened forms of words. Thus, the vocabulary size is immense, and the count vector that represents each review will be highly sparse. The experiment used large data set of IMDB movies reviews with two labels: negative and positive, and TripAdvisor Hotel reviews with three labels: negative, neutral and positive. The experimental results are based on comparing recall, precision, and F-measure values. We take 50,000 samples from each IMDB reviews of different labels with 76,340 unique words in total, and we used 5,000 samples from TripAdvisor Hotel reviews with 1,000 unique words. We compare the proposed algorithms with other methods, such as EGDM mixture model (Zamzami and Bouguila Citation2022), EMBL mixture model (Zamzami and Bouguila Citation2020a), EMSSD mixture model (Zamzami and Bouguila Citation2020b) that have been proposed for modeling count data.
The results are shown in . According to the F-measure in these tables, we can note that the proposed approaches outperform other compared models and approaches, and that infinite models show better results, compared with finite mixture models.
Covid-19 Fake News Detection
This data set contains 947 twitters which are related with Covid-19 information, and that have been already divided into two classes, one contains real news and the other contains fake news. In this experiment, we take all samples and select the most frequently used 1,000 unique words as a count data.
From , our proposed algorithms still show excellent performance in the fake news detection task. Compared with other approaches and models, InfEMGD-MCMC yields the best accuracy of 87.45 and FinEMGD-MCMC also reaches 86.48
. Comparing with finite mixture models, the performance of our infinite mixture models show higher accuracy rate.
Table 3. The experiment result for CON-19 fake news detection.
Human Face Gender Recognition
In this experiment, we use two standard and challenging face recognition databases. The first database is the AR face database, which has 4000 color images corresponding to 126 people’s faces (70 men and 56 women). Images feature frontal view faces with different facial expressions, illumination conditions, and occlusions (sunglasses and scarf). The second database is Caltech faces by California Institute of Technology, consists of 450 face images of around 27 unique people (both genders) with different lighting/expressions/backgrounds (sample images are shown in . We apply bag of feature (BOF) for representing the image vectors where SIFT has been used for feature extraction, treating the local image patches as the visual equivalent of individual words.
Figure 1. Sample from face recognition database.

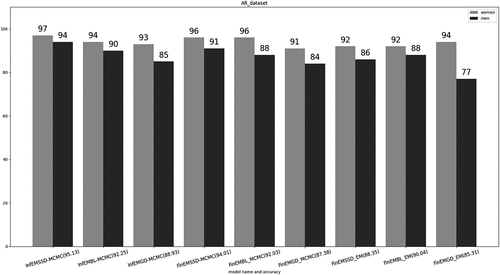
show that our proposed approaches permit good discrimination. The intraclass performance for the AR using proposed approaches is shown in . We note that InfEMSSD-MCMC shows superior performance in distinguishing women class () from men class (
) and InfEMBL-MCMC achieves
in Caltech data set as we can see in . Overall, all of our proposed models and algorithms ensure an accuracy above 85
in this application. Compared with the EM algorithm, our proposed MCMC algorithms show higher accuracy with the corresponding models.
Figure 2. Intraclass accuracy for proposed approaches models in Caltech data.
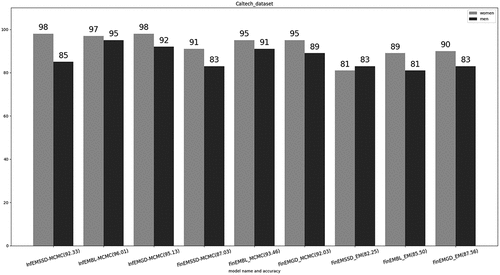
Figure 3. Intraclass accuracy for proposed approaches models in AR data.
Conclusion
In this paper, we have proposed a novel approach for finite mixtures of EMGD, EMBL and EMSSD based on the development of conjugate prior distributions and on the Monte Carlo simulation techniques of Gibbs sampling mixed with a M–H step. Generally, with the help of prior information and the stochastic aspect of the simulation in Gibbs sampling, our proposed algorithms ensure accurate models learning. Moreover, via a Bayesian nonparametric extension based on these mixtures, we show that the problem of determining the number of clusters can be cured and avoided by using infinite mixtures which model well the structure of the data. Our proposed approaches and infinite models offer excellent modeling capabilities as shown in the experimental part, which involves text sentiment analysis, fake news detection and human face recognition, compared to the widely used maximal likelihood approaches in high-dimensional count data. However, our modeling framework still has some drawbacks as follows. First, the high computational complexity of the proposed inference led to slow convergence. A promising future work could be replacing the classical M–H by the Scalable M–H algorithm proposed in Cornish et al. (Citation2019). This scheme is based on combination of factorized acceptance probabilities, procedures of Bernoulli processes, and control variate idea. It can be used to reduce the computational complexity by discovering in advance the sampling points that may be rejected. Second, Gibbs sampling might take a long time to converge. When two or more mixture components have similar parameters, the Gibbs sampling method can get stuck in a local mode, resulting in inaccurate data points clustering. A possible solution that could be investigated is to consider the spilt-merge Markov Chain Monte Carlo procedure for the Dirichlet process as described in Jain and Neal (Citation2004). Finally, the proposed approaches may be sensitive to the choice of the hyperparameters values. A potential future work could be devoted to developing an approach for the automatic selection of these values depending on the data to model.
Acknowledgments
The authors would like the thank the associate editor and the reviewers for their comments and suggestions that helped to improve the paper.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Alsuroji, R., N. Zamzami, and N. Bouguila. 2018. “Model selection and estimation of a finite shifted-scaled dirichlet mixture model.” In 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, December 17-20, edited by M. A. Wani, M. M. Kantardzic, M. S. Mouchaweh, J. Gama, and E. Lughofer, 707–2542. IEEE.
- Amirkhani, M., N. Manouchehri, and N. Bouguila. 2021. Birth-death MCMC approach for multivariate beta mixture models in medical applications. In Advances and trends in artificial intelligence. artificial intelligence practices, ed. H. Fujita, A. Selamat, J. C.-W. Lin, and M. Ali, 285–96. Cham: Springer International Publishing.
- Antoniak, C. E. 1974. Mixtures of dirichlet processes with applications to bayesian nonparametric problems. The Annals of Statistics 2 (6):1152–74. doi:10.1214/aos/1176342871.
- Batista, L., and S. Ratté. 2014. Multi-classifier system for sentiment analysis and opinion mining. In Encyclopedia of social network analysis and mining, ed. R. Alhajj and J. Rokne, 989–98. New York: Springer New York.
- Bouguila, N. 2008. Clustering of count data using generalized dirichlet multinomial distributions. IEEE Transactions on Knowledge and Data Engineering 20 (4):462–74. doi:10.1109/TKDE.2007.190726.
- Bouguila, N. 2011. Count data modeling and classification using finite mixtures of distributions. IEEE Transactions on Neural Networks 22 (2):186–98. doi:10.1109/TNN.2010.2091428.
- Bouguila, N., and W. Fan. 2020. Mixture models and applications. Springer.
- Bouguila, N., and D. Ziou. 2007. Unsupervised learning of a finite discrete mixture: Applications to texture modeling and image databases summarization. Journal of Visual Communication and Image Representation 18 (4):295–309. doi:10.1016/j.jvcir.2007.02.005.
- Bouguila, N., and D. Ziou. 2010. A Dirichlet process mixture of generalized Dirichlet distributions for proportional data modeling. IEEE Transactions on Neural Networks 21 (1):107–22. doi:10.1109/TNN.2009.2034851.
- Bouguila, N., D. Ziou, and R. I. Hammoud. 2009. On Bayesian analysis of a finite generalized dirichlet mixture via a Metropolis-within-Gibbs sampling. Pattern Analysis and Applications 12 (2):151–66. doi:10.1007/s10044-008-0111-4.
- Brooks, S. P. 2001. On Bayesian analyses and finite mixtures for proportions. Statistics and Computing 11 (2):179–90. doi:10.1023/A:1008983500916.
- Brown, L. D. 1986. Fundamentals of statistical exponential families with applications in statistical decision theory. Lecture Notes-Monograph Series 9:100–279.
- Cai, L. 2010. High-dimensional exploratory item factor analysis by a Metropolis–Hastings Robbins–Monro algorithm. Psychometrika 75 (1):33–57. doi:10.1007/s11336-009-9136-x.
- Church, K. W., and W. A. Gale. 1995. Poisson mixtures. Natural Language Engineering 1 (2):163–90. doi:10.1017/S1351324900000139.
- Cornish, R., P. Vanetti, A. Bouchard-Cote, G. Deligiannidis, and A. Doucet. 2019. “Scalable Metropolis–Hastings for exact Bayesian inference with large datasets.” In International Conference on Machine Learning, 1351–60.
- DasGupta, A. 2011. The exponential family and statistical applications. In Probability for statistics and machine learning. edited by Anirban DasGupta, 583–612. New York, NY: Springer.
- Dhillon, I. S., and D. S. Modha. 2001. Concept decompositions for large sparse text data using clustering. Machine Learning 42 (1/2):143–75. doi:10.1023/A:1007612920971.
- Dias, J. G., and M. Wedel. 2004. An empirical comparison of EM, SEM and MCMC performance for problematic gaussian mixture likelihoods. Statistics and Computing 14 (4):323–32. doi:10.1023/B:STCO.0000039481.32211.5a.
- Elkan, C. 2006. “Clustering documents with an exponential-family approximation of the dirichlet compound multinomial distribution.” In Proceedings of the 23rd International Conference on Machine Learning, ICML ‘06, New York, NY, USA, 289–96. Association for Computing Machinery.
- Emanuel, L., and G. T. Herman. 1987. A maximum a posteriori probability expectation maximization algorithm for image reconstruction in emission tomography. IEEE Transactions on Medical Imaging 6 (3):185–92. doi:10.1109/TMI.1987.4307826.
- Escobar, M. D., and M. West. 1995. Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association 90 (430):577–88. doi:10.1080/01621459.1995.10476550.
- Favaro, S., and Y. Whye Teh. 2013. MCMC for normalized random measure mixture models. Statistical Science 28 (3):335–59. doi:10.1214/13-STS422.
- Hartigan, J., and M. Wong. 1979. Algorithm AS 136: A K-Means Clustering Algorithm. Journal of the Royal Statistical Society 28 (1):100–08.
- Jain, A. K. 2010. Data clustering: 50 years beyond K-means. Pattern Recognition Letters 31 (8):651–66. doi:10.1016/j.patrec.2009.09.011.
- Jain, S., and R. Neal. 2004. A split-merge markov chain monte carlo procedure for the dirichlet process mixture model. Journal of Computational and Graphical Statistics 13 (1):158–82. doi:10.1198/1061860043001.
- Jegou, H., M. Douze, and C. Schmid. 2009. On the burstiness of visual elements. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, 1169–76.
- Katz, S. M. 1996. Distribution of content words and phrases in text and language modelling. Natural Language Engineering 2 (1):15–59. doi:10.1017/S1351324996001246.
- Korwar, R. M., and M. Hollander. 1973. Contributions to the theory of dirichlet processes. The Annals of Probability 1 (4):705–11. doi:10.1214/aop/1176996898.
- Lee, P. M. 2012. Bayesian Statistics: An Introduction. Wiley.
- MacEachern, S. N., and P. Muller. 1998. Estimating mixture of dirichlet process models. Journal of Computational and Graphical Statistics 7:223–38.
- Madsen, R. E., D. Kauchak, and C. Elkan. 2005. “Modeling WORD BURSTINESS USING THE DIRICHLET DISTRIBUTION.” In Proceedings of the 22nd International Conference on Machine Learning, ICML ‘05, New York, NY, USA, 545?552. Association for Computing Machinery.
- Margaritis, D., and S. Thrun. 2001. A bayesian multiresolution independence test for continuous variables. In Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, 346–53. Morgan Kaufmann Publishers Inc.
- Najar, F., N. Zamzami, and N. Bouguila. 2019. “Fake news detection using bayesian inference.” In 2019 IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), 389–94.
- Najar, F., N. Zamzami, and N. Bouguila. 2020. “Recognition of human interactions in feature films based on infinite mixture of EDCM.” In 2020 International Symposium on Networks, Computers and Communications (ISNCC), 1–6.
- Raftery, A. E., and S. M. Lewis. 1992. [Practical markov chain monte carlo]: comment: one long run with diagnostics: implementation strategies for markov chain monte Carlo. Statistical Science 7 (4):493–97. doi:10.1214/ss/1177011143.
- Rasmussen, C. E. 1999. The infinite Gaussian mixture model. Advances in Neural Information Processing Systems 12:554–60.
- Robert, C. P. 2007. The Bayesian choice. From decision-theoretic foundations to computational implementation. Springer.
- Roeder, K., and L. Wasserman. 1997. Practical bayesian density estimation using mixture of normals. Journal of the American Statistical Association 92 (439):894–902. doi:10.1080/01621459.1997.10474044.
- Samuel, K., N. Balakrishnan, and N. L. Johnson. 2000. Continuous multivariate distributions. New York: Wiley-Interscience.
- Sorensen, D., and D. Gianola. 2002. Likelihood, Bayesian and MCMC methods in quantitative genetics. Springer.
- Train, K. E. 2009. Discrete choice methods with simulation. 2nd ed. Cambridge University Press.
- Tsionas, E. G. 2004. Bayesian inference for multivariate gamma distributions. Statistics and Computing 14 (3):223–33. doi:10.1023/B:STCO.0000035302.87186.be.
- Wong, T.-T. 2010. Parameter estimation for generalized Dirichlet distributions from the sample estimates of the first and the second moments of random variables. Computational Statistics & Data Analysis 54 (7):1756–65. doi:10.1016/j.csda.2010.02.008.
- Xuanbo, S., N. Bouguila, and N. Zamzami. 2021. “Covid-19 News Clustering using MCMC-Based Learing of finite EMSD Mixture Models.” In Proceedings of the Thirty-Fourth International Florida Artificial Intelligence Research Society Conference, North Miami Beach, Florida, USA, May 17-19, edited by E. Bell and F. Keshtkar.
- Zamzami, N., and N. Bouguila. 2019. A novel scaled Dirichlet-based statistical framework for count data modeling: Unsupervised learning and exponential approximation. Pattern Recognition 95:36–47. doi:10.1016/j.patcog.2019.05.038.
- Zamzami, N., and N. Bouguila. 2020a. High-dimensional count data clustering based on an exponential approximation to the multinomial Beta-Liouville distribution. Information Sciences 524:116–35. doi:10.1016/j.ins.2020.03.028.
- Zamzami, N., and N. Bouguila. 2020b. Probabilistic modeling for frequency vectors using a flexible shifted-scaled dirichlet distribution prior. ACM Trans. Knowl. Discov. Data 14 (6):1–35. doi:10.1145/3406242.
- Zamzami, N., and N. Bouguila. 2022. Sparse count data clustering using an exponential approximation to generalized dirichlet multinomial distributions. IEEE Transactions on Neural Networks and Learning Systems 33 (1):89–102. doi:10.1109/TNNLS.2020.3027539.
Appendix A
Proof of EquationEquation 17 (17) (17)
(17) (17)
Removing the equation parts which is only related with data set , because it does not have an effect on the r calculation in M–H step.
Appendix B
Proof of EquationEquation 21(21) (21)
We remove the equations which are only related with data set .
For the fact that:
So we have this:
Appendix C.
Conditional Posterior of model hyperparmeters
In EMGD, those conditional posteriors becomes:
In EMBL, the form of and
are same in Equation (C1) and Equation (C2). the conditional posterior for
and
, we have: