
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the home entertainment system, karaoke is a popular leisure facility in our daily life. Via the karaoke system, users can sing along with the lyrics based on the recordings of pop songs. However, a lot of karaoke systems can display lyrics semi-automatically. Traditionally, some lyrics are input manually and need to be synchronized with the tonal music stepwise, which is time-consuming. One of the famous musical phrase segmentation theories is a generative theory of tonal music, through which we have implemented a karaoke system in C# programming language. This intelligent system can automatically segment music phrases and use a high-level fuzzy Petri net model to calibrate the lyrics in pop songs. Fifty Chinese pop songs are selected to evaluate its performance. The experimental results have shown that the average calibration precision value (92.78%) and recall value (90.46%) are highly acceptable.
Introduction
In the home entertainment system, karaoke playing has become a popular activity, which is enjoyed by many people. Via a karaoke system, users can sing along with lyrics based on the recordings of pop songs, and receive a score based on their performances (Tsai and Lee Citation2017). When reading the karaoke lyrics on the screen, users can recognize how to adjust their singing intonation to improve their scores, which is really simple and interesting. However, a difficulty in the traditional karaoke lyrics to be calibrated manually is encountered. It takes a large amount of time to segment the musical phrases, which is quite inefficient. Karaoke songs have become more difficult to make and the manufacturing costs are increasing. Thus, the selling price of a karaoke system is harder to be accepted by users.
In recent years, with advances in computer technology, the music albums have gradually been replaced by digital music purchased online. Nowadays, researchers suggest that automatically calibrating karaoke lyrics may be possible. Firstly, the musical phrase segmentation is required. One of the famous music segmentation theories is a generative theory of tonal music (GTTM) (Chan and Hsiao Citation2016; Frankland and Cohen Citation2018), which was conceived by a music theorist, Fred Lerdahl, and a linguist, Ray Jackendoff; and presented in the book with the same title. Grouping preference rules (GPRs) are established in GTTM for the purpose of making a music grouping structure (Goto Citation2016). Quantification and testing of the local grouping rules for four local GPRs are provided (Frankland and Cohen Citation2018). In the approach based on the preference rules, the sound onset detection is applied to find all onsets in the song (Wu and Cao Citation2018).
The high-level fuzzy Petri net (HLFPN) model (Chiang et al. Citation2020; Citation2021; Lin et al. Citation2020a) is now used to perform the music segmentation. It is based on Petri net theory and fuzzy reasoning. Petri net theory, proposed by Dr Carl Adam Petri in 1962, is a graphical and mathematical modeling tool, which is concurrent, asynchronous, distributed, parallel, non-deterministic, stochastic, and so on. It can be used to model and analyze various systems (Sung and Chang Citation2019). However, along with the advances in information system, the description of Petri nets is becoming more and more complex with use of fuzzy production rules (Matsumoto and Hori Citation2019). In general, a fuzzy production rule can be used to describe the fuzzy relationship between antecedent and consequent.
Due to the above reasons and motivation, the goal of this paper is to make a karaoke system which can automatically calibrate karaoke songs with lyrics. A C# program has been designed to implement GTTM and HLFPN model for the purpose of segmenting each musical phrase. Musical phrases are used to automatically calibrate the lyrics that form a database system, and music notes are automatically calibrated for a Chinese character which has only one syllable. Then, an automatic calibration system for Chinese karaoke lyrics is completed.
Problem Statement: Although the karaoke technology has advanced with multi-functions for many years, it still lacks a robust database system for musical analysis. The grouping preference rules are diversified (Frankland and Cohen Citation2018). Also, the technical analysis parameters are hard to make musical decision. Consequently, the original semi-automatic lyrics calibration system needs to be further improved.
The remainder of this paper is organized as follows: Section 2 discusses the literature review of GTTM which is applied to fuzzy reasoning of HLFPN model. The system architecture and music segmentation are described in Section 3. The experimental results are discussed in Section 4. Finally, the conclusion is remarked in Section 5.
Literature Review
First, the background knowledge of a generative theory of tonal music (GTTM) rules and the musical context combination method are described. Second, some basic definitions regarding the HLFPN model, and the related works are presented.
Generative Theory of Tonal Music (GTTM)
The traditional method of musical phrase segmentation is based on psychological perspectives, and their relationship is discovered by psychology in music grouping. In 1920s, German psychologists proposed Gestalt theory to group similar objects. In Gestalt theory, they proposed the cognitive psychological aspects of musical groups, including three basic principles, namely, principle of proximity, principle of similarity, and principle of continuation.
In Gestalt theory, the research work in music grouping, composed of Jackendoff‘s and Lerdale’s ideas, proposed a generative theory of tonal music (GTTM) (Chan and Hsiao Citation2016; Frankland and Cohen Citation2018). GTTM constitutes a formal description of the musical intuitions of a listener who is experienced in a musical idiom. It includes the grouping preference rules (GPRs) defined as follows:
Rule 1: Single Event: “Avoid analyses with very small groups- the smaller, the less preferable.”
Rule 2: Proximity: “Consider a sequence of four notes, n1 – n4, the transition n2 – n3 may be heard as a group boundary if A. Slur/Rest: “the time interval from the end of n2 is greater than that from the end of n1 to the beginning of n2 and that from the end of n3 to the beginning of n4; or if B. Attack-Point: “the time interval between the attack points of n2 and n3 is greater than that between the attack points of n1 and n2 and that between the attack points of n3 and n4.”
Rule 3: Change: “Consider a sequence of four notes, n1 – n4, the transition n2 – n3 may be heard as a group boundary if marked by Register, Dynamics, Articulation, Length, and Timbre,” which are shown in .
Figure 1. Register change.
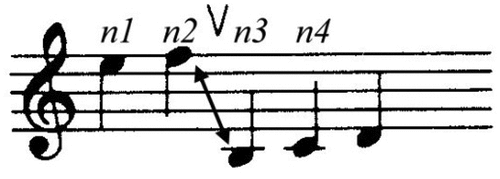
Figure 2. Dynamics change.
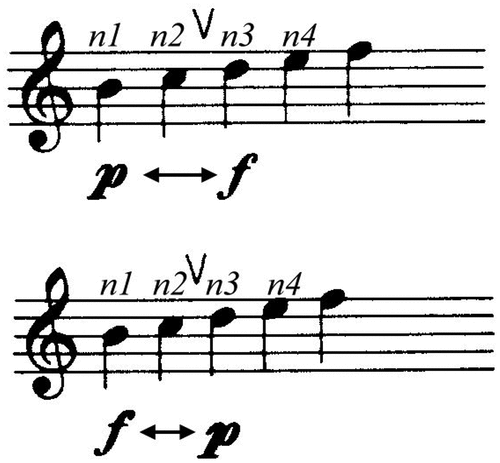
Figure 3. Articulation change.
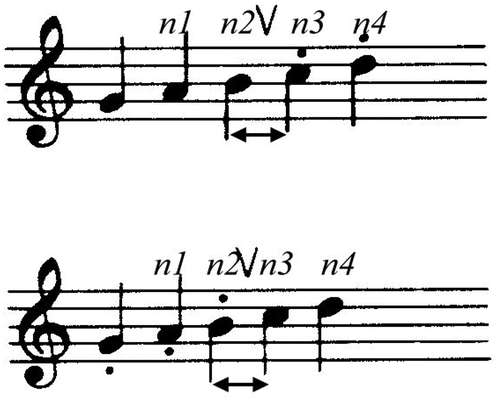
Figure 4. Length change.
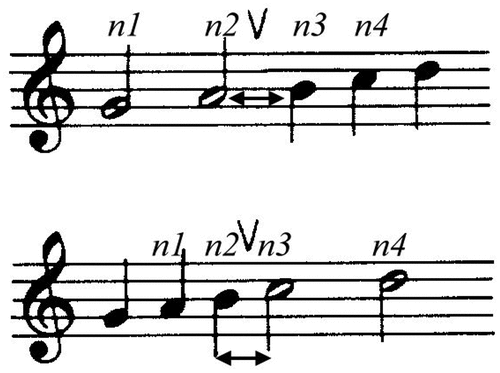
Figure 5. Timbre change.
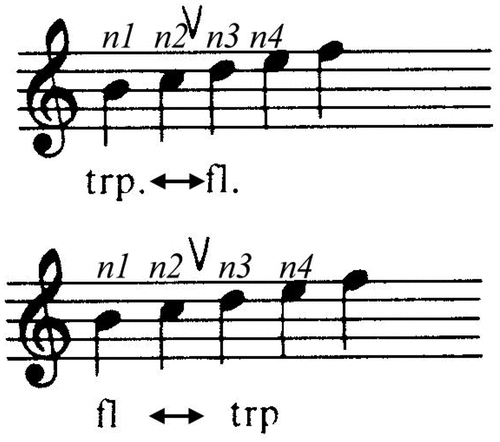
High-Level Fuzzy Petri Net
Based on the original Petri net theory, scholars conduct their research works with evolutionary Petri nets one after another, such as colored Petri nets (Zhang, Zhao, and He Citation2022), timed Petri nets (Lin et al., Citation2020b; Lin et al. Citation2022), fuzzy Petri nets (Chowdhury et al. Citation2019), high-level fuzzy Petri nets (Chiang et al. Citation2020; Lin et al. Citation2020a). The HLFPN model was adopted to make decision on the segmentation of music phrases. It provides the characters of Petri net and fuzzy logic theories, which can be used to model fuzzy production rules and to conduct fuzzy reasoning (Chiang et al. Citation2021). The basic definitions and fuzzy reasoning approach are presented as follows:
Definition 1. The HLFPN is defined as an 8-tuple:
where:
: a finite set of places.
: a finite set of transitions.
: called the flow relation which is also a finite set of arcs, each representing the fuzzy set (i.e. fuzzy term) for an antecedent or a consequent; where the positive arcs (i.e. THEN parts) are denoted by →.
: A finite set of linguistic variables, e.g.
, and
, where
,
,
.
: A finite set of fuzzy truth values known as the fuzzy relational matrix between the antecedent and the consequent of a fuzzy production rule.
: An association function, mapping from places to linguistic variables.
, where
is a set of linguistic variables in the knowledge base (KB) and is the number of linguistic variables in the KB;
: An association function, mapping from the flow relations to the fuzzy truth values between zero and one.
: An association function, mapping from transitions to fuzzy relational matrices.
Definition 2. Input and Output Functions:
: A set of input places of transition
.
: A set of input transitions of place
.
: A set of output places of transition
.
: A set of output transitions of place
.
Definition 3. Membership Function:
The mapping function assigns each place a real value, where
,
represents the degree of membership in the associated proposition and data tokens are available in a set of places
.
Definition 4. Max-Min Compositional Rule:
In the HLFPN model, transition t, V(t) = min (fuzzy sets in I(t));
place p, V(p) = max (fuzzy sets in I(p)). The Max-Min composition operator is denoted by ○.
Definition 5. Input Place, Hidden Place, and Output Place:
In the HLFPN model, place pi
P, if
tj
T, pi
O(tj), then pi is called an input place (IP) of tj. if
tj
T, pi
I(tj), then pi is called an output place (OP) of tj; otherwise, pi is called a hidden place.
Fuzzy Reasoning
For the fuzzy reasoning, fuzzy production rules are used (Lin et al. Citation2020a). In general, a fuzzy production rule is used to describe fuzzy relationship between the antecedent and the consequent. Let R be a set of fuzzy production rules, where . The general form of the i-th fuzzy production rule
is shown as follows:
where denote propositions;
is called the input linguistic variable;
and
are called the output linguistic variables, respectively;
is called the input fuzzy set;
and
are called the output fuzzy sets, respectively; the fuzzy truth values of the propositions “
is
”, “
is
” and “
is
” are restricted to [0, 1];
is the antecedent of a fuzzy production rule Ri; dk and dw denote the consequents of the fuzzy production rule
. Let
represent the fuzzy relational matrix between antecedent and consequent of a fuzzy production rule.
Illustrative Example:
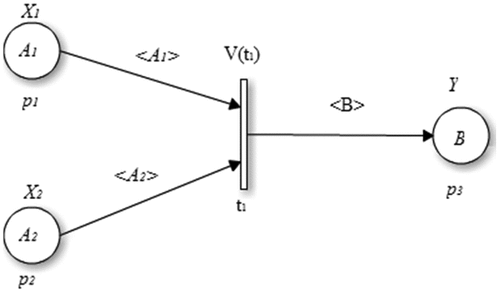
Let us consider the fuzzy production rule shown as follows:
Based on the transformation procedure presented in (Casey et al. Citation2018), the above fuzzy production rule is transformed into the following first-order logic form:
Then, the HLFPN model is shown in .
Figure 6. HLFPN model of illustrative example.
Assume that the fuzzy sets ,
and
are shown as follows:
By the cylindrical extension operations (Lin et al. Citation2020a), that is, a Cartesian product, we can obtain the antecedent fuzzy set A, shown as follows:
Then, the fuzzy relational matrices between antecedent and consequent of the fuzzy production rule
can be obtained, shown as follows:
The most widely used fuzzy reasoning method is the max–min composition inference (Yang et al. Citation2019). Assume that the input fuzzy sets and
are shown as follows:
Then, we can get
Finally, we can obtain
The above description is the fuzzy reasoning process of HLFPN model.
Fuzzy Reasoning Algorithm
In this sub-section, a fuzzy reasoning algorithm (FRA) (Chiang et al. Citation2020) is briefly reviewed to determine whether there exists a fuzzy relational matrix between antecedent and consequent of a fuzzy production rule or not.
INPUT: Input Place (IP), , (or fuzzy set), where
denotes a set of input places.
OUTPUT: Output Place (OP), , (or fuzzy set), where
denotes a set of output places.
Procedure
Step 1:
Initially, assume that only the Degree of Memberships (DOMs) in the propositions operating on input variables are available. Consequently, the initial marking function is shown as follows:
Step 2:
Calculate the fuzzy relational matrices V() of the current transition, and use the input to perform cylindrical extension.
compute
where
denotes a set of transitions;
is a fuzzy relational matrix between the antecedent and the consequent of rule
;
is a fuzzy set of weights in the antecedent;
is a fuzzy set of weights in the consequent; and each element of a fuzzy set is denoted as a fuzzy weight interval.
Step 3:
Input a data pattern to -input.
Step 4:
Fire the enabled transitions and execute Zadeh’s max-min operation. Let be any enabled transition. Then, compute
= the number of data tokens
=
-input
if an ELSE part is available.
Step 5:
Send the results to the output place. For every output variable , its associated membership distribution is
, where
denotes the in-degree of output variable
. Then,
becomes an actual output.
Step 6
Go back to Step 4, while (That is, while the enabled transitions still exist, go to Step 4).
Step 7
The weighted average defuzzification method is applied, and the real operation value is obtained.
Ieee 1599
“Music is much more than listening to audio encoded in some unreadable binary format” (Wick, Hartelt, and Puppe Citation2020). So, we need to integrate each karaoke song, score, information, and musical phrase. The standard is named as IEEE1599 (Baggi Citation2015), proposed by Denis L. Baggi and Goffredo M. Haus in 2009. IEEE 1599 is a standard to encode music with XML symbols. The main distinguished characteristics use blocks to represent music and the concept of layers, as shown in .
Figure 7. All layers in IEEE 1599 (Wick, Hartelt, and Puppe Citation2020).
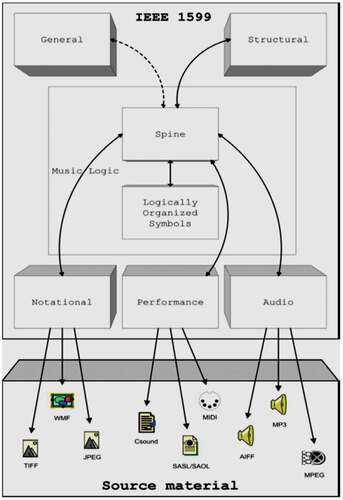
General Layer: The layer provides a general description of the music. It contains the following items: music title, authors, number, data, type, and so on. Structural Layer: The layer stores information of musical structure. Logical Layer: The layer provides music description from a symbolic point and includes scores with symbols, as well as the spine with logically organized symbols, and a sorted list of music events. Notational Layer: The layer includes notations of music, like a great variety of pictures. Performance Layer: The layer contains the information about musical performance, including midi, Csound, etc. Audio Layer: The audio layers including media contents are still available in their original encoding.
Related Works
According to reference (Meier Citation2013; Wu and Cao Citation2018), for the problem of song sentiment classification based on Chinese lyrics, there are two methods that have been widely used at present, namely, a sentiment-dictionary-based method and a machine-learning-based method. The former sentiment dictionary is difficult to expand, while the latter may cause “dimensional disaster” when generating feature vectors. It proposes a song sentiment classification method that combines the advantages of these two ideas. The method obtains the positive and negative tendency values by the process of word segmentation and weight calculation based on sentiment dictionary, which are used as feature vectors. Then, we use Logistic Regression algorithm to carry binary classification of Chinese songs. According to reference (Shen and Chen Citation2014), it was the initial idea to develop this lyrics calibration system, which had lower precision value (71.43%) and no recall values available. More useful parameters and detailed discussions are needed to improve its system performance. The fuzzy reasoning algorithm also needs to be further improved. According to reference (Bilbao et al. Citation2020; Ruangsang and Assawinchaichote Citation2019), as the computational costs for physical modeling synthesis of sound are often much greater than those for conventional sound synthesis methods, most techniques currently rely on simplifying assumptions. They include digital waveguides and modal synthesis methods. However, it can be difficult to approach some of the more detailed behavior of musical instruments.
Proposed Approach
For a karaoke system, it is important to make musical phrases, which are concepts and practices related to grouping consecutive melodic notes in performance and composition. A musical phrase is a unit that has a complete musical sense of its own length, in which a singer or instrumentalist can sing or play in one breath. We have developed a C# program to implement GTTM and HLFPN model to segment musical phrases. Musical phrases are used to automatically calibrate the lyrics that form a database system. And the music notes are automatically calibrated for a Chinese character, which has only one syllable.
Data Preprocessing System
A phrase segmentation technique is highly required because a phrase is the basic unit for organizing and analyzing the music signals. In music scores, it is usually marking a phrase with a slur, as shown in .
Figure 8. A phrase.

For phrase segmentation, as rule 3 in grouping preference, “Consider a sequence of four notes, n1 – n4, the transition n2 – n3 may be heard as a group boundary if marked by register, dynamics and length.” (Haus and Ludovico Citation2017; Haus, Longari Citation2019; Hu, Chen, and Yin Citation2020), the score function (Liu Citation2010) is defined for the grouping preference rule 3 of GTTM as follows:
The register change rule is assumed that the pitches (in cent) of the four music notes n1n2n3n4 are c1c2c3c4. If |c3-c2| > |c2-c1| and |c3-c2| > |c4-c3|, then it is defined as:
else, defined as . It represents that the pitch has not been changed.
Similarly, the dynamics change rule is assumed that the intensities (in dB) of the four music notes n1n2n3n4 are d1d2d3d4. If |d3-d2| > |d2-d1| and |d3-d2| > |d4-d3|, then it is defined as
else, defined as . It represents the intensity not being changed.
Also, the length change rule is assumed that the lengths (in second) of the four music notes n1n2n3n4 are l1l2l3l4 defined as:
First, the membership function can be defined in accordance with the input parameters. The fuzzy reasoning rule and the corresponding HLFPN model can be established. The ,
and
associated with the membership functions for the fuzzifier are input into the HLFPN model. With the characters of fuzzy reasoning, each input parameter is reasoned by the fuzzy rule. Finally, all indices are integrated to make decision on the musical phrase segmentation and to perform automatic calibration of karaoke lyrics (Bastanfard, Amirkhani, and Naderi Citation2020; Chen Citation2021).
HLFPN Model Based on GTTM
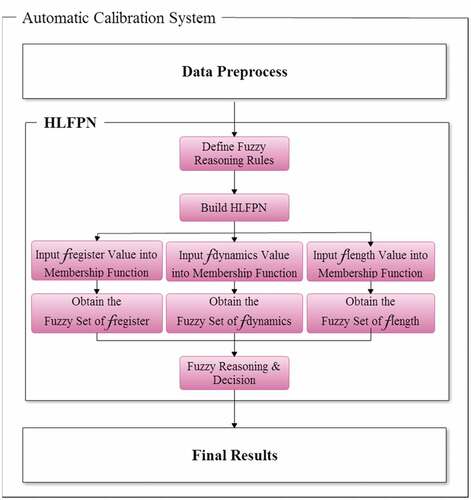
To make more precise in the musical phrase segmentation, it is a good way to implement grouping preference rules of GTTM. The decision based on input parameters uses the calculated values to set the position of segmentation. However, an input parameter needs to be considered as a fuzzy term, high or low. Grouping preference rules of GTTM including three parameters are used to determine where the position of performance or segmentation is. In these unclear, obscure, and ambiguous cases, it is appropriate to use the fuzzy logic theory. Thus, the HLFPN model is applied to make decision (Shen et al. Citation2017), as shown in .
Figure 9. Block diagram of HLFPN model.
Calibration Mechanism in Membership Degrees
According to the corresponding membership functions and fuzzy sets defined, we input each parameter to a fuzzifier and calculate the membership degrees in each set. Based on the size of the input parameter, each parameter is transformed to 「If … then … 」statement and the fuzzy rules are established. In the decision method, three parameters are used, namely, the ,
and
. As a result, each index is defined in membership degrees of Low and High. Then, three sets of technical indices include the S-Type and Z-Type membership degrees, as shown in .
Figure 10. The type of membership degrees for input parameter.
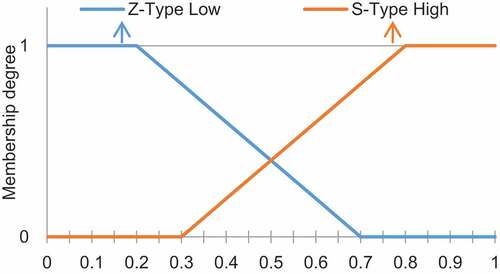
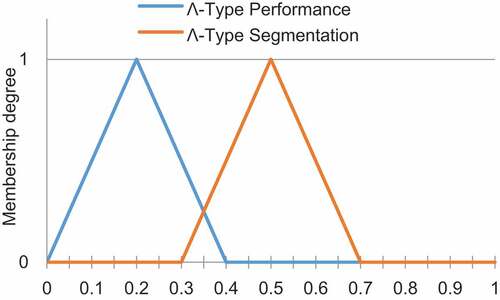
In addition, the decision is also divided into two cases, namely, “Performance” and “Segmentation.” Therefore, two sets of performance and segmentation belong to the Λ-Type of membership degree, as shown in .
Figure 11. The type of membership degrees for technical decision.
In this paper, three input parameters are used, namely, the ,
and
. As a result, the membership functions of “high” and “low” are defined for each input parameter. Therefore, all of them are defined in . The membership degrees of the decision on music performance and segmentation are listed in .
Table 1. Membership degrees of input parameter.
Table 2. Membership degrees of technical decision.
In the analysis, the values of each input parameter are usually set between 0 and 1. When ,
, and
values larger than 0.3 are high, and those values less than 0.7 are low. However, due to the membership degree as defined above, whose scope of a variable is set between 0 and 1. Thus, the values of each input parameter must be converted to the values between 0 and 1 before they are substituted into the calculation of basic rules.
Assume that and
values represent membership degrees of “high” and “low,” respectively. The fuzzification procedure is defined as follows:
Fuzzy Reasoning and Building HLFPN Model
According to fuzzy sets and their corresponding membership degrees as defined previously, each input parameter is imported to a fuzzifier and the technical index is calculated to find its own membership degree. Based on the size of an input parameter, it has been transformed into an「If … then … 」statement in order to establish a rule base. The activity diagram of fuzzy reasoning is shown in .
Figure 12. The activity diagram of fuzzy reasoning.
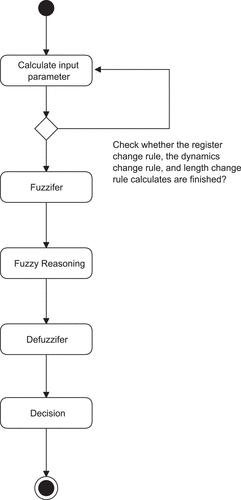
Assume that ,
, and
denote input linguistic variables with fuzzy terms: high (H) and low (L). And assume that the decision (D) is an output linguistic variable with fuzzy terms: strong (S) and weak (W). The fuzzy production rules are defined as follows:
R1: If is H, then D is S.
R2: If is L, then D is W.
R3: If is H, then D is S.
R4: If is L, then D is W.
R5: If is H, then D is S.
R6: If is L, then D is W.
Then, the fuzzy production rules are transformed into the HLFPN model, as shown in , and the parameters are listed in .
Figure 13. The HLFPN model representing six fuzzy production rules.
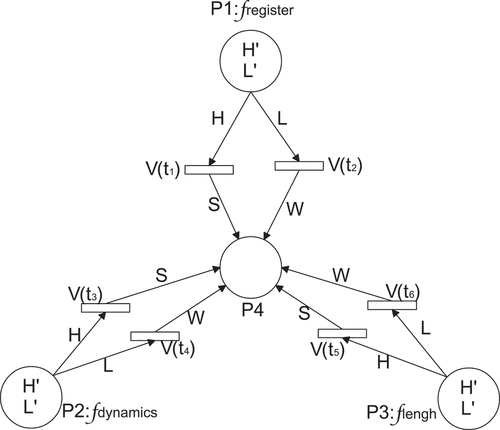
Table 3. Description of parameters.
According to the proposed HLFPN model, the fuzzy inference is performed with the technical indices of a fuzzier and the fuzzy rules in the rule base. Within the process of fuzzy inference, the standard operators for calculations are used. Finally, the crisp outputs are obtained to decide performance or segmentation by the weighted average defuzzification method, and the real operation value of “Decision” can be computed.
Preprocessing Results
However, the music lyrics, score, and other music information are integrated into an automatic calibration system. A new music standard named IEEE 1599 and a software system are used to show the preprocessing results. The IEEE 1599 standard (Baggi Citation2015) is used to encode music with XML symbols. This is an example in IEEE 1599 from a song named “Silence,” composed by Jay Chou, as shown in .
Figure 14. Layers in IEEE 1599.
Figure 15. Description in general layer of IEEE 1599.

Figure 16. The related files in general layer of IEEE 1599.

Figure 17. Layers in IEEE 1599.

Experimental Results
To demonstrate that the proposed HLFPN-based calibration system is feasible, this Section is intended to evaluate the proposed system performance. A fuzzy reasoning algorithm (FRA) (Chiang et al. Citation2020) is used to determine whether a fuzzy relational matrix exists between antecedent and consequent of a fuzzy rule. Then, our proposed approach is applied to the illustrative example.
Example of HLFPN Model for Fuzzy Reasoning
In this sub-section, an example is used to illustrate the viability of the fuzzy reasoning process. Two digits of significant numbers represent the result of each calculation.
Step 1: Initially, assume that only the DOMs in the propositions operating input variables are available. Assume that four fuzzy sets are shown as follows:
,
,
,
Step 2: Compute the fuzzy relational matrices, shown as follows:
Step 3: Input data pattern, shown as follows:
Step 4: Fire the enabled transitions:
Steps 5–6: Finally, the fuzzy reasoning result is shown as follows:
Step 7: If the weighted average defuzzification method is applied, then the real operation value of “Decision” can be computed, shown as follows:
Due to , the decision is made as “Segmentation.”
Main Results
The experimental results illustrate the effectiveness of the proposed system. An automatic calibration system for karaoke lyrics is useful, but its musical phrase segmentation may have a little deviation. The comparison results are shown in .
Figure 18. Deviation in automated system.

Figure 19. The actual score.

According to manual experiments, the automatic music segmentations which are measured by the recall and the precision values defined as follows:
Finally, in the experiment, 50 Chinese pop songs were used. In total, there are 2076 musical phrases manually labeled. As shown in , there are 1463 musical segmentations that are correctly detected by the proposed system. Therefore, the average recall is 90.46% and the average precision is 92.78%.
Table 4. Experimental results.
Functional Comparison
Based on the above experimental results, we have made a functional comparison with each other among different approaches, including ours, Wu’s (Wu and Cao Citation2018), and Bilbao’s (S. Bilbao et al. Citation2020). The results of functional comparison are listed in . In summary, our proposed approach is more feasible and powerful than others.
Table 5. Results of functional comparison.
“ˇ” denotes “Yes” or “Available.”
Conclusion
In this paper, those datasets including karaoke lyrics, songs, titles, and author names downloaded from the Internet have been used, and a database system of Chinese pop songs for automatic calibration has been built. The grouping preference rules of GTTM are adopted to perform the parameter analysis as a basis for determination. The appropriate decisions are made based on the above parameters by applying the reasoning algorithm of HLFPN model. A C# program has been developed to implement this automatic calibration system. Users can use this system to sing a pop song from which the singer’s voices are removed, and the lyrics can be calibrated automatically. The contributions of this paper are stated as follows:
A robust database system with Chinese pop songs has been successfully built, providing a useful environment for musical analysis.
The grouping preference rules of GTTM are easily used to group each song.
The parameters obtained from the register change rule, the dynamics change rule, and the length change rule are all used to easily conduct technical analysis for musical decision.
Through the fuzzy reasoning algorithm of HLFPN model, a fast decision can be made on music performance or segmentation.
This system can provide users with an easy way to sing a pop song and to get the lyrics automatically.
In the future, the learning algorithms of the HLPFN model will be adopted to accurately detect music segmentations. Also, a specific tool of HLFPN model will be created to predict the music segmentation and to make a difference between HLFPN model and GTTM. Since this system is now designed for Chinese karaoke songs only, it has been limited to some users. Therefore, it will be enhanced for English songs or songs in other languages to provide more applications.
Acknowledgments
The authors are grateful to the anonymous reviewers for their constructive comments, which have improved the quality of this paper.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Baggi, D. L. 2015. An IEEE standard for symbolic music. IEEE Computer, 100–3048.
- Bastanfard, A., D. Amirkhani, and S. Naderi. 2020. A signing voice separation method from Persian music based on pitch detection methods, Procs. of 2020 6th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Mashhad, Iran, 1–6.
- Bilbao, S., C. Desvages, M. Ducceschi, B. Hamilton, R. Harrison-Harsley, A. Torin, and C. Webb. 2020. Physical modeling, algorithms, and sound synthesis: The NESS Project. Computer Music Journal 43 (2–3):15–30. doi:10.1162/comj_a_00516.
- Casey, M. A., R. Veltkamp, M. Goto, M. Leman, C. Rhodes, and M. Slaney. 2018. Content-based music information retrieval: Current directions and future challenges. Proceedings of the IEEE more author. 96 (4):668–96. doi:10.1109/JPROC.2008.916370.
- Chan, A. B., and J. H. Hsiao. 2016. Information distribution within musical segments. Music Perception: An Interdisciplinary Journal 34 (2):218–42. doi:10.1525/mp.2016.34.2.218.
- Chen, G.-F. 2021. Music sheet score recognition of Chinese Gong-che notation based on deep learning. Proceedings of 2021 International Conference on Big Data Analysis and Computer Science (BDACS), Kunming, China, 1–6.
- Chiang, D.-L., S.-K. Wang, Y.-N. Lin, C.-Y. Yang, V. R. L. Shen, T. T.-Y. Juang, and T.-Y. Liao. 2021. Development and evaluation of a novel investment decision system in cryptocurrency market. Applied Artificial Intelligence 35 (14):1169–95. doi:10.1080/08839514.2021.1975380.
- Chiang, D.-L., S.-K. Wang, -Y.-Y. Wang, Y.-N. Lin, T.-Y. Hsieh, C.-Y. Yang, V. R. L. Shen, and H.-W. Ho. 2020. Modeling and analysis of Hadoop MapReduce systems for big data using Petri nets. Applied Artificial Intelligence 35 (1):80–104. doi:10.1080/08839514.2020.1842111.
- Chowdhury, J. I., D. Thornhill, P. Soulatiantork, Y. Hu, N. Balta-Ozkam, L. Varga, and B. K. Nguyen. 2019. Control of supercritical organic rankine cycle based waste heat recovery system using conventional and fuzzy self-tuned PID controllers. International Journal of Control, Automation and Systems 17 (4):2969–81. doi:10.1007/s12555-018-0766-6.
- Frankland, B. W., and A. J. Cohen. 2018. Parsing of melody: Quantification and testing of the local grouping rules of Lerdahl and Jackendoff’s a generative theory of tonal music. Music Perception: An Interdisciplinary Journal 21 (4):499–543. doi:10.1525/mp.2004.21.4.499.
- Goto, M. 2016. A chorus-section detecting method for musical audio signal and its application to a music listening station. IEEE Transactions on Audio, Speech, and Language Processing 14 (5):1783–94. doi:10.1109/TSA.2005.863204.
- Haus, G., and M. Longari. 2019. Time-based music description approach based on XML. Computer Music Journal 29 (1):70–85. doi:10.1162/comj.2005.29.1.70.
- Haus, G., and L. A. Ludovico. 2017. Music segmentation: An XML-oriented approach. Lecture Notes in Computer Science 33 (10–1):330–46.
- Hu, D., Z. Chen, and F. Yin. 2020. Passive geometry calibration for microphone arrays based on distributed damped Newton optimization. IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (11):118–31. doi:10.1109/TASLP.2020.3037532.
- Lin, Y.-N., T.-Y. Hsieh, C.-Y. Yang, V. R. L. Shen, T. T.-Y. Juang, and W.-H. Chen. 2020a. Deep Petri nets of unsupervised and supervised learning. Measurement and Control Online. 53 (7–8):1–11. doi:10.1177/0020294020923375.
- Lin, Y.-N., S.-K. Wang, G.-J. Chiou, C.-Y. Yang, V. R. L. Shen, T. T.-Y. Juang, and T.-J. Huang. 2022. Novel deadlock control for smartphone manufacturing systems using Petri nets. International Journal of Control, Automation and Systems 20 (3):877–87. doi:10.1007/s12555-020-0239-6.
- Lin, Y.-N., S.-K. Wang, C.-Y. Yang, V. R. L. Shen, T. T.-Y. Juang, and C.-S. Wei. 2020b. Novel JavaScript malware detection based on fuzzy Petri nets. Journal of Intelligent & Fuzzy Systems Online:1–26.
- Liu, -C.-C. 2010. Automatic phrase segmentation of MP3 songs based on the technique of breath sound detection. Proceedings of IEEE 7th International Conference on Information Technology and Applications, Taipei, Taiwan, 285–90.
- Matsumoto, M., and J. Hori. 2019. Classification of silent speech using support vector machine and relevance vector machine. Applied Soft Computing 20 (1):95–102. doi:10.1016/j.asoc.2013.10.023.
- Meier, W. 2013. eXist: An opensource native XML database. Lecture Notes in Computer Science 2593 (1):169–83.
- Ruangsang, S., and W. Assawinchaichote. 2019. Control of nonlinear Markovian jump system with time varying delay via robust H fuzzy state feedback plus state-derivative feedback controller. International Journal of Control, Automation and Systems 17 (3):2414–29. doi:10.1007/s12555-019-0044-2.
- Shen, V. R. L., and H.-C. Chen. 2014. An automatic calibration system for Chinese karaoke lyrics based on high-level fuzzy Petri nets. Procs. of 2014 International Conference on Machine Learning and Cybernetics (ICMLC), Lanzhou, China, 1–6.
- Shen, V. R. L., R.-K. Shen, C.-Y. Yang, and W.-C. Chen. 2017. A novel fall prediction system on smartphones. IEEE Sensors Journal 17 (6):1865–71. doi:10.1109/JSEN.2016.2598524.
- Sung, W.-T., and K.-Y. Chang. 2019. Health parameter monitoring via a novel wireless system. Applied Soft Computing 22 (1):667–80. doi:10.1016/j.asoc.2014.04.036.
- Tsai, W. H., and H.-C. Lee. 2017. Automatic evaluation of karaoke singing based on pitch, volume, and rhythm features. IEEE Transactions on Audio, Speech, and Language Processing 20 (4):1233–43. doi:10.1109/TASL.2011.2174224.
- Wick, C., A. Hartelt, and F. Puppe. 2020. Lyrics recognition and syllable assignment of medieval music manuscripts, Procs. of 2020 17th. International Conference on Frontiers in Handwriting Recognition (ICFHR), Dortmund, Germany, 1–6.
- Wu, X., and Y. Cao. 2018. Research on song sentiment binary classification based on Chinese lyrics. Proceedings of 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 22–29.
- Yang, S.-H. Y.-N. L., G.-J. Chiou, M.-K. Chen, V. R. L. Shen, H.-Y. Tseng, and H.-Y. Tseng. 2019. Novel shot boundary detection in news streams based on fuzzy Petri nets. Applied Artificial Intelligence 33 (12):1035–57. doi:10.1080/08839514.2019.1661118.
- Zhang, Y., H. Zhao, and C. He. 2022. Robust control design with optimization for uncertain mechanical systems: Fuzzy set theory and cooperative game theory. International Journal of Control, Automation and Systems 20 (2):1377–92. doi:10.1007/s12555-020-0874-y.