
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The study presents a systematic review of 232 studies on various aspects of the use of artificial intelligence methods for identification of financial distress (such as bankruptcy or insolvency). We follow the guidelines of the PRISMA methodology for performing the systematic reviews. The study discusses bankruptcy-related financial datasets, data imbalance, feature dimensionality reduction in financial datasets, financial distress prediction, data pre-processing issues, non-financial indicators, frequently used machine-learning methods, performance evolution metrics, and other related issues of machine-learning-based workflows. The study findings revealed the necessity of data balancing, dimensionality reduction techniques in data preprocessing, and allow researchers to identify new research directions that have not been analyzed yet.
Introduction
Predicting the possibility of bankruptcy is considered as one of the key issues of current economic and financial research. The growing importance of corporate bankruptcy prediction as a research subject has been confirmed in recent years by the appearance of various thorough reviews in the literature with the goal of summarizing the important findings of previously published studies (Chen, Ribeiro, and Chen Citation2016; Matenda et al. Citation2021). Analysing financial distress and its various forms (insolvency, bankruptcy, etc.) is important because of its essential role in society and economy (Aljawazneh et al. Citation2021; Chen, Chen, and Shi Citation2020; Zelenkov and Volodarskiy Citation2021), energy sector (Ayodele et al. Citation2019) and social security (Okewu et al. Citation2019). The prediction of”company survival” is a challenging task due to many numbers of factors, which have to be considered (Veganzones, Séverin, and Chlibi Citation2021). Relationships (obvious and hidden) between these factors make the task even more difficult (Mora García et al. Citation2008). Financial distress predictions have become an essential key indicator for decision-makers, such as financial market players, fund managers, stockholders, employees, etc. (Azayite and Achchab Citation2018; Zelenkov and Volodarskiy Citation2021). For these reasons, in empirical and computational finance, the prediction of financial distress has been widely researched, especially in the past decades (Ye Citation2021; Zelenkov and Volodarskiy Citation2021), and a large number of academic scholars from across the world have been constructing business bankruptcy prediction models using diverse modeling methodologies.
This study extends previous literature reviews (Bhatore, Mohan, and Reddy Citation2020; Le Citation2022; Shi and Li Citation2019) and we hope will help to under-explored new research fields for further topic development. Previous systematic reviews identified credit risk determinants for conventional and Islamic banks based on 120 research articles from Web of Science (WoS) and SCOPUS (Rosli, Abdul-Rahman, and Amin Citation2019), analyzed the individuals’ financial behavior associated with credit default based on 108 studies (Çallı and Coşkun Citation2021), analyzed 30 studies published between 1999 and 2006 in which the authors use neural networks to recognize failing firms (Perez Citation2006), and analyzed statistical and machine-learning bankruptcy prediction models based on 49 journal articles published between 2010 and 2015 (Alaka et al. Citation2018). Only the systematic reviews of (Perez Citation2006) and (Alaka et al. Citation2018), analyzed the use of artificial intelligence (AI) and machine-learning methods, but the latest study of (Alaka et al. Citation2018) covered the paper published until 2015. Since then, many new studies have appeared fueled by the explosive growth of AI applications, thus underscoring the need to perform a new systematic review in this research field.
This study seeks to bring knowledge and key insights for further researchers by filling the gaps discussed in previous literature reviews, such as: definitions of “failure,” “bankruptcy,” “insolvency,” “default,” “liquidation” and related terms (Matenda et al. Citation2021); cost-sensitive learning (Chen, Ribeiro, and Chen Citation2016); deep learning methods (Bhatore, Mohan, and Reddy Citation2020); dynamic model applications (Chen, Ribeiro, and Chen Citation2016; Matenda et al. Citation2021); financial accounting ratios, e. g. macroeconomics, industries, etc. (Chen, Ribeiro, and Chen Citation2016; Matenda et al. Citation2021); AI and machine-learning algorithms (Shi and Li Citation2019); binary and multi-class classification (Chen, Ribeiro, and Chen Citation2016); performance validation metrics (Chen, Ribeiro, and Chen Citation2016; Shi and Li Citation2019); curse of dimensionality and feature selection methods (Bhatore, Mohan, and Reddy Citation2020); data preprocessing methods (Bhatore, Mohan, and Reddy Citation2020); models for private corporations, small-medium enterprises (SMEs), and public corporates (Matenda et al. Citation2021); tools suitable for different domains of datasets analyses (Bhatore, Mohan, and Reddy Citation2020); and expert knowledge integration in black-box models (Chen, Ribeiro, and Chen Citation2016).
This systematic review contributes toward understanding of the role of the AI methods in financial distress identification and prediction, while detailing various elements of the AI based workflow.
The remaining parts of this article are organized as detailed further. Section 2 presents the details of the methodological procedure used for the systematic review. Section 3 presents the analysis of the identified articles identified from the search with keywords: “Bankruptcy” or “Financial distress,” which included 335 articles. The section is further continued with the analysis of the specific problems related to the use of AI methods for bankruptcy prediction, e. g. dimensionality curse, class imbalance, anomaly, etc. The limitations of this study are discussed in Section 4, while the conclusions are presented in Section 5.
Review Methodology
Procedure of the Systematic Review Based on the PRISMA Methodology
The main aim of this study is to identify the context of “Financial distress” and its usage of machine-learning methods, including additional aspects related to it, such as imbalance, dimensionality, etc. Therefore, the systematic review technique is implemented in this study. We gathered relevant studies based on a search query using databases such as Science Direct, Springer, IEEE, Google Scholar, etc. following the guidelines of the preferred reporting items for systematic reviews and meta-analyses (PRISMA) (Page et al. Citation2021).
Inclusion and Exclusion Criteria
The topic”Financial distress” and”Bankruptcy” is widely analyzed in the literature; therefore, this article seeks to extend and supplement existing systematic reviews (Bhatore, Mohan, and Reddy Citation2020; Chen, Ribeiro, and Chen Citation2016; Matenda et al. Citation2021; Shi and Li Citation2019) by more relevant context. The inclusion criteria are as follows: (1) The studies that are found with keywords: “Bankruptcy” or “Financial distress;” (2) The studies from 2017 till 2022 February; (3) The studies are published in English; (4) The full text is accessible.
The exclusion criteria selection is related to financial distress barometer creation for SME. The exclusion criteria are: (1) The studies with no companies/enterprises bankruptcy or financial distress data. (2) The studies with no indication of the used data set. (3) The studies with macroeconomic research. (4) The studies analyzing financial sector: banks, insurance, etc. (5) Research with only one class analysis. (6) The traditional Altman method implementation without any new variables or methods comparison. Additional inclusion criteria is selected due to the need of wider analysis in the context of sentiment analysis, dimensionality reduction, imbalance, and outliers. This wider analysis seeks to create knowledge of the variety of methods, their taxonomy, and then the use cases in”Financial distress” context. The additional inclusion criteria are: (1) The necessity of a return to primary sources. (2) The additional techniques theoretical analyses sources and their usage in “Bankruptcy” or “Financial distress” context.
Search Query and the Results
The main search keywords for the specific issue are: “dimensionality reduction,” “feature selection,” “feature extraction,” “anomaly,” “outlier,” “class imbalance,” “imbalance data sets,” and “sentimental analyses,” etc. The boolean model with “and” operator was used for information retrieval with the analyzed topic. The search strategy is based on the keywords “Financial distress” and “Bankruptcy.” Other similar keywords “credit risk,” “credit score,” and “default” have given studies about creditworthiness for customers or risk valuation in the bank sector, due to these reasons, these keywords are not implemented in the main search strategy. If a database search for”financial distress” yields a result with the phrase”credit risk” in the title, this article is examined. Nevertheless, from 2021 the phrase “Financial distress” is used not only in the context of firms but also in the context of human health, so these studies are not included in the analysis. The search query led to Scopus (4455), Web of Science (4049), ScienceDirect (1366), SpringerLink (1148), Emerald (712), IEEE (28), ACM (18), EBSCO (247), Wiley (101), Sage(9), Taylor & Francis (81), Other (58) articles found in databases. Analysis with inclusion and exclusion criteria led to 232 studies (). Distribution of articles in different databases is presented in .
Figure 1. The procedure of the systematic review.
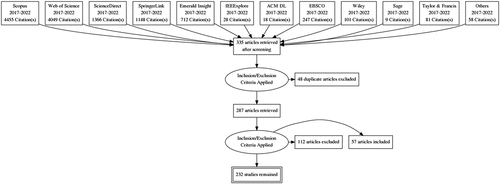
Table 1. Distribution of studies.
Domain Taxonomy and Research Questions
After studying previous systematic research in the financial distress and bankruptcy context, we have made a domain taxonomy (), which is the guideline for this study and is related to these research questions:
Figure 2. Domain research taxonomy.
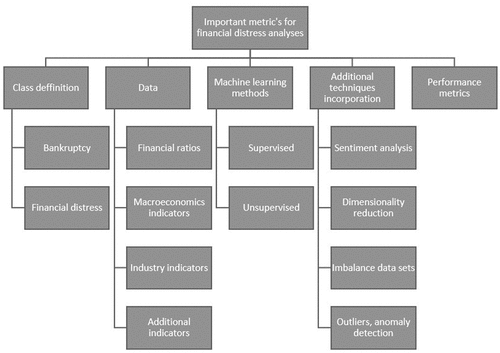
RQ1:
What is the difference between Financial Distress, Insolvency, and Bankruptcy?
RQ2:
What indicators are used as financial distress predicators? Its suitability for SMEs.
RQ3:
What data sources are used?
RQ4:
What data normalization techniques are used?
RQ5:
What non-financial indicators for financial distress prediction are included?
RQ6:
What machine-learning models are used?
RQ7:
What the addition techniques are important for machine-learning algorithms and which of them are used in financial distress context?
RQ8:
What performance metric is used for machine-learning algorithms evaluation in financial distress context?
Analysis of Studies
Conceptual Analysis of Domain Terms: Financial Distress, Insolvency, and Bankruptcy
The concept of financial distress in scientific literature is often related to bankruptcy, insolvency, probability of default, and failure patterns. The common definition of financial distress is a condition of a firm that has difficulties fulfilling its financial obligations (Farooq, Jibran Qamar, and Haque Citation2018; Yazdanfar and Öhman Citation2020). In scientific literature is different use cases (interpretation views) of the same financial distress definition. For example, one point of view is financial distress = bankruptcy, and the second point of view is financial distress bankruptcy.
A common view is that financial distress differs from bankruptcy, it is a distress situation of the company that leads to two possible states: 1) recovery state to become healthy again; 2) bankruptcy state, making reorganization or liquidation of the organization. Bankruptcy is the legal status of the company when creditors take legal actions, so the company cannot repay its debt (du Jardin Citation2018; Farooq, Jibran Qamar, and Haque Citation2018; Salehi and Davoudi Pour Citation2016; Veganzones and Severin Citation2020). In the context of bankruptcy, the words failure and default can be used as synonyms (Letizia and Lillo Citation2019; Salehi and Davoudi Pour Citation2016), contrary to the word insolvency. Insolvency is the middle stage between financial distress and bankruptcy. The main difference between financial distress and insolvency is that in first terminology companies have difficulties paying, or in insolvency used expression is being unable to pay. After insolvency, if legal action is taken, the insolvent firm is declared bankrupt (Farooq, Jibran Qamar, and Haque Citation2018). Two types of bankruptcy are identified (Lukason and Vissak Citation2017):
A gradual failure (“chronic”): The financial situation is incrementally declining for the firm some years before its bankruptcy.
An acute failure (“sudden”): The financial situation of the firm rapidly collapses, and sudden bankruptcy occurs. From a year before bankruptcy declared financial statement, there are no indicators about possible companies’ failure.
Most researchers make a separation of the financial distress and bankruptcy concepts. The main difference is that financial distress leads to bankruptcy, which means that firms can recover or become bankrupt. Therefore, there are two classes in bankruptcy, while in the subject of financial distress the researchers choose not only the number of classes but also the method by which the classes will be identified. The choice of class identification method selection is based on the quantity of the available data and the types of firms (public, nonpublic).
Data Sources
Data researchers commonly choose publicly available, e.g. public companies or open data sets. This is evident from the distribution of the data sources from the analyzed articles, which is presented in . The Private and Other sections are similar due to summarizing different data sources. Nevertheless, the Private section combines data sources, which researchers have given access to data from private sources or specific banks, while the Other section is data sources with a higher probability for other researchers to access such data, e. g. Orbis, Retriever, Thomson Reuters, etc. The Other section summarizes data sources used by the researchers, which are mentioned in the analyzed studies 2.
Table 2. Distribution of data sources used in studies.
If a private database is chosen, researchers choose to analyze public companies and combine more different databases (Compustat, LoPucki’s Bankruptcy Research, New Generation Research, Center for Research in Security Prices, etc. (Darrat et al. Citation2016)). Eventually, the concepts of bankruptcy and financial distress are important for diverse parties: shareholders, investors, creditors, partners, etc. Furthermore, the beginning of bankruptcy prediction is considered the late sixties with Beaver (Citation1966) and Altman’s (Citation1968) works (Joshi, Ramesh, and Tahsildar Citation2018; Shen et al. Citation2020). These authors concentrated on financial indicators as the main historical information holders of the firm. The main of Beaver’s (Beaver Citation1966) research idea is “finding optimal cutoff point” among healthy and bankrupt firms. The author established that is relevant to use no more than five years’ windows before bankruptcy due to differences between the ratio classes distribution (Beaver Citation1966). In addition to this, (Altman Citation1968) created a z-score model, which is used today.
Expanding research on this topic was understood that financial ratios distribution differs from a normal distribution, and covariance matrices in groups are not equal, which leads to logistic regression use in analyses (Wagner Citation2008). Furthermore, additional features are added to research on financial distress or bankruptcy topic due to technical improvements (software, algorithms functions) and data availability (Chollet Citation2018). These reasons may lead to better model accuracy and the creation of a more universal model.
Using data normalization or standardization in studies is not common, the information that was applied provided about 16% of analyzed studies. Commonly used functions are normalization: “max-min” with [0,1] (Antunes, Ribeiro, and Pereira Citation2017; Cheng, Chan, and Sheu Citation2019; Chou, Hsieh, and Qiu Citation2017; Hu Citation2020; Huang and Yen Citation2019; Letizia and Lillo Citation2019; Ouenniche, Pérez-Gladish, and Bouslah Citation2018; Qian et al. Citation2022; Salehi and Davoudi Pour Citation2016; Xu, Fu, and Pan Citation2019) or with [−1,1] (Letizia and Lillo Citation2019; Salehi and Davoudi Pour Citation2016; Sun et al. Citation2020; Wang et al. Citation2017; Zelenkov, Fedorova, and Chekrizov Citation2017), also function of standardization: Z-score (AghaeiRad, Chen, and Ribeiro Citation2017; Cheng, Chan, and Sheu Citation2019; Doğan, Koçak, and Atan Citation2022; Le et al. Citation2018, Citation2018, Citation2019; Letizia and Lillo Citation2019; Lin and Hsu Citation2017; Perboli and Arabnezhad Citation2021). The authors who have applied normalization indicate that it’s necessary for the financial distress prediction model efficiency assurance (Qian et al. Citation2022) and feature weights alignment for the classification part (Antunes, Ribeiro, and Pereira Citation2017). Authors (Antunes, Ribeiro, and Pereira Citation2017) in the data pre-processing part before normalization firstly logarithmized the features due to data distribution uncertainty reduction.
Research on the financial distress and bankruptcy topic is developing in the context of big data, where new features (indicators) are added for greater model accuracy. This leads to higher-dimensional space, which causes the need for data dimensionality reduction before a machine-learning algorithm are used.
Dealing with High Data Dimensionality
The curse of dimensionality claims that the machine-learning algorithm’s cost is exponentially related to dimensions (Kuo and Sloan Citation2005). The data becomes more sparse when a new feature (dimension) is added. This reason leads to challenges in achieving better model accuracy. There is a common belief that more data is better than less (Altman and Krzywinski Citation2018). Data pre-processing step is one of the most important tasks for data analytics, which leads not only to simplified model design, but also to the creation of more efficient models. The main problems caused by dimensionality are:
Data sparsity, e.g. it is used Euclidian distance as a similarity measurement, then a new feature appearance leads to greater dissimilarity, due to increasing distance between classes (points) (Altman and Krzywinski Citation2018),
Multiple testing (also known as signal to noise ratio problem), e.g. the ability of pattern detections decreases of the essence inadequate features (Millstein et al. Citation2020). • Multicollinearity, e.g. if several samples are less than features, this situation leads to redundant feature creation (linear algebra) (Altman and Krzywinski Citation2018).
Overfitting (lower model interpretability (Xu et al. Citation2019)).
Dimensionality reduction methods can be separated to feature selection and feature extraction (). Regardless of the method, it is important to perform data preparation techniques such as:
Feature cleaning: remove features with high missing value ratio, low variance, or select only one feature from two highly correlated features.
Feature normalization or standardization.
Figure 3. Dimensionality reduction methods.
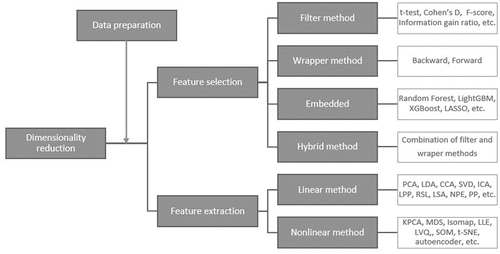
The feature selection approach is used to find a narrow subset of appropriate features from the initial wide range (Al-Tashi et al. Citation2020). This approach consists of three steps: method selection, evaluation, and stopping criteria (Wang et al. Citation2018).
The feature selection approach can be divided into filter, wrapper, embedded, and hybrid models. The first bankruptcy concept researcher - Beaver (Citation1966) used the filter selection technique for healthy and bankrupt firm separation, by comparing the different class ratio distributions. Now in practice are used t-test (Kim, Mun, and Bae Citation2018), Cohen’s D, , F-score, information gain ratio, Correlation Feature Selection (CFS), ReliefF, etc. The filter method assumes that features are independent of each other (Wang et al. Citation2018). The main advantages of this method are a fast, scalable, simple design, easier understanding for other researchers, and working independently from the classifier (Li, Li, and Liu Citation2017). The last advantage can become a disadvantage if an interaction with the classifier could lead to better performance of the model or could save costs.
The wrapper method uses a classifier in evaluating the features al-(Al-Tashi et al. Citation2020). This method analyzes features using forward or backward techniques, e.g., forward – begins with one feature subset and adds a new one if accuracy is better than this feature is left in the analysis, otherwise removed, backward – begins with all features subsets and removes by one, if the accuracy is better before removal, the feature is returned to a subset of feature, both algorithms continue until is analyzed all the subset of features. For feature, evaluation is often used accuracy rate or classification error (Cai et al. Citation2018). Comparing filter and wrapper feature selection methods for the classificational task, the wrapper method tend to have better performance results (Al-Tashi et al. Citation2020), but needs much more computational power and time (Cai et al. Citation2018). The main wrapper methods advantages are: simplicity, interaction with classifier, model features dependencies, disadvantages: overfitting risk, less variety of the classifier which are used, and intensive computation (Li, Li, and Liu Citation2017). The embedded feature selection method differs from others due to feature selection and classification methods integration into a single process, feature selection becomes a part of the classifier (Wang et al. Citation2018), e.g., Random Forest, lightGBM, XGBoost, LASSO, and others. This method is less complicated than the wrapper method (Li, Li, and Liu Citation2017). The hybrid approach combines filter and wrapper methods, firstly using the filter method for primary feature selection, then applying the wrapper method, this combination makes balances the accuracy rate and intensive computation (Wang et al. Citation2018).
Feature extraction transforms high-dimensional data into a new lower-dimensional space, which has maximum information from the initial data set (Ayesha, Hanif, and Talib Citation2020). This approach is used not only for mapping but also for class visualization in 2-dimensional or 3-dimensional space, in which the essential data is visualized (Ye, Ji, and Sun Citation2013). This mapping approach can be divided into linear and non-linear methods. Linear methods attempt to reduce dimensionality by linear functions implementations, which forms new lower dimension feature set (Ayesha, Hanif, and Talib Citation2020), e.g. Principal component analyses (PCA), Linear discriminant analyses (LDA), Canonical correlation analysis (CCA), Singular Value Decomposition (SVD), Independent component analysis (ICA), Locality Preserving Projections (LPP), Neighborhood preserving embedding (NPE), Robust subspace learning (RSL), Latent semantic analysis (LSA) (for text), Projection Pursuit (PP), etc. Every technique is oriented in some information extraction, for example, PCA extracts global information, LPP extracts local information, and LDA merges the information of classes to the feature set, which means that other information of data is lost (Wang, Liu, and Pu Citation2019). Nonlinear feature extraction methods have greater performance results than linear due to the reality of the real-world data, which has a higher probability to be nonlinear, than linear (van der Maaten, Postma, and Herik Citation2007). Nonlinear methods are auto-encoders, Kernel principal component analysis (KPCA), Multidimensional Scaling (MDS), Isomap, Locally linear embedding (LLE), Self-Organizing map (SOM), Learning vector quantization (LVQ), T-Stochastic neighbor embedding (t-SNE) (Ayesha, Hanif, and Talib Citation2020), etc.
Financial distress and bankruptcy concepts tend to expand analyzing indicators for greater model accuracy and new important patterns foundation. This leads to dimensionality reduction issues: data sparsity, multiple testing, multicollinearity, and overfitting, which are solved by feature selection or extraction approaches. In the context of bankruptcy or financial distress this feature extraction technique is used: 1) linear: PCA (Acharjya and Rathi Citation2021; Adisa et al. Citation2019; Jiang et al. Citation2021; Succurro, Arcuri, and Costanzo Citation2019; Wang, Liu, and Pu Citation2019; Štefko, Horváthová, and Mokrišová Citation2021), LDA (Huang et al. Citation2017; Nyitrai Citation2019; Veganzones and Séverin Citation2018; Wang, Liu, and Pu Citation2019), LPP (Wang, Liu, and Pu Citation2019), NPE (Wang, Liu, and Pu Citation2019), RSL (Wang, Liu, and Pu Citation2019) 2) nonlinear: MDS (Khoja, Chipulu, and Jayasekera Citation2019; Mokrišová and Horváthová Citation2020; Štefko, Horváthová, and Mokrišová Citation2021), tSNE (Zoričák et al. Citation2020), SOM (Mora García et al. Citation2008) and autoencoder (Soui et al. Citation2020). Instead of feature extraction, researchers use feature selection, due to achievable knowledge of the feature’s importance. Frequently used feature selection techniques are: 1) Filter: CFS (Faris et al. Citation2020; Séverin and Veganzones Citation2021), ReliefF (Faris et al. Citation2020; Kou et al. Citation2021), (Azayite and Achchab Citation2018; Kou et al. Citation2021); Gain ratio (Kou et al. Citation2021), information gain ratio (Faris et al. Citation2020; Kou et al. Citation2021), Kruskal – Wallis (Séverin and Veganzones Citation2021), t-tests (Séverin and Veganzones Citation2021), 2) Wrapper: Backward (Faris et al. Citation2020; Perboli and Arabnezhad Citation2021; Tsai et al. Citation2021; Zelenkov, Fedorova, and Chekrizov Citation2017); 3) Embedded: LASSO (Du et al. Citation2020; Huang et al. Citation2017; Li et al. Citation2021; Volkov, Benoit, and Van den Poel Citation2017), XGBoost (Ben Jabeur, Stef, and Carmona Citation2022; Du et al. Citation2020), Tree-based (Azayite and Achchab Citation2018; Du et al. Citation2020), Logistic regression (LR) (Doğan, Koçak, and Atan Citation2022), stepwise LR (Ben Jabeur, Stef, and Carmona Citation2022), stepwise DA (Ben Jabeur, Stef, and Carmona Citation2022), partial least squares DA (Ben Jabeur, Stef, and Carmona Citation2022); CatBoost (Jabeur et al. Citation2021), f_classif (Du et al. Citation2020), L1-based (Du et al. Citation2020), PDC-GA (Al-Milli, Hudaib, and Obeid Citation2021); and 4) Hybrid (Lin and Hsu Citation2017; Veganzones, Séverin, and Chlibi Citation2021). Authors tend to apply 3–5 different feature selection techniques to find the best feature set.
Dealing with Bias and Imbalance
The class imbalance occurs when one class’s number of instances is much greater than the other, which is common in real-data set analysis (Le et al. Citation2018; Lin et al. Citation2017; Liu, Zhou, and Liu Citation2019). In the context of financial distress or bankruptcy, the financially successful number of firms is higher than distressed (Sun et al. Citation2020), which can be expressed as a range of proportion from 100:1 to 1000:1 (Veganzones and Séverin Citation2018). A firm’s activity sector influence a higher or lower probability of default, e. g. financial distress is more common in the manufactory industry than in transportation (Shen et al. Citation2020). The most prevailing solution is to add more instances of the minority class. The class imbalance problem is generally related with:
Lack of minority data (cannot be found feature patterns due to limited amount of minority class examples);
Overlapping or class separability (class examples are mixed up between each other in the feature space);
Small disjuncts (intervenes of small groups from minority class in majority classes feature space) (Fernández et al. Citation2018; Lin et al. Citation2017).
These problems lead to difficulties in creating an effective machine-learning classification model. In addition to this, researchers dealing with imbalanced data set issue accuracy metrics to consider as inappropriate evaluation measures due to the dominating classes effect, e. g. the classifier can achieve 99% of accuracy without correctly classifying rare examples (Weng and Poon Citation2008). This measurement is replaced with Precision, Recall, F-scored, the area under the ROC curve (AUC), G-mean, or balanced accuracy metrics (Fernández et al. Citation2018; Kotsiantis, Kanellopoulos, and Pintelas Citation2005; Veganzones and Séverin Citation2018; Weng and Poon Citation2008).
Class imbalance reduction methods are used for binary classification issues, however not all methods can be used for multiclass imbalance issues. To use them researchers apply One-vs-One (OVO), and One-vs-All (OVA) strategy schemes, in which multiclass imbalance issue converts to a binary one (Fenández et al. Citation2018). Methods dealing with class imbalance issues can be separated into data level, algorithm level, and hybrid approach (). The data level approach is directly related to changes in the data set, it is rebalancing data that its distribution of the classes becomes more equivalent. On the other hand, the algorithm level approach is modifying the classifier to the bias of prioritizing minority classes learning (Fernández et al. Citation2018; Kotsiantis, Kanellopoulos, and Pintelas Citation2005; Lin et al. Citation2017). The combination of these two approaches forms hybrid methodology, which makes changes to the data and the classifier for specific problem solvation.
Figure 4. Class imbalance reduction methods.
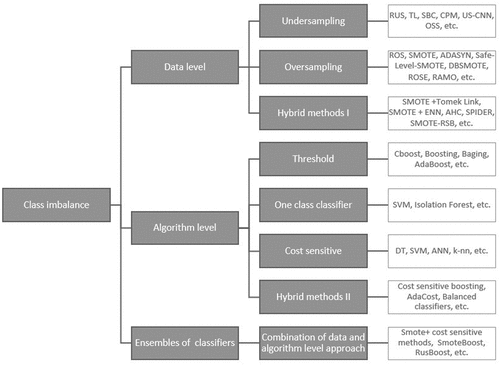
The main advantage of the data-level approach is independent process creation, which is made separated from the sampling and classifier training process (Lin et al. Citation2017). From a data modification perspective, there are three possibilities to make modifications: 1) to reduce the majority class, 2) to increase the minority class, or 3) hybrid to combine majority class reduction with minority class increase. Hence, the data level approach consists of undersampling, oversampling, and hybrids methods. From the undersampling and oversampling methodology perspective the simplest way is to make a random reduction of majority class instances (RUS – random undersampling) or increase of minority class instances (ROS – random oversampling) (Liu, Zhou, and Liu Citation2019). These random methods are not very efficient due to information loss or overfitting (Kotsiantis, Kanellopoulos, and Pintelas Citation2005). For this reason, is developing new undersampling models which use clustering, for instance, identification in feature space and majority class instance elimination due to redundancy, distance from the decision border, etc., such as Tomek Links (TL), Undersampling Based on Clustering (SBC), Class Purity Maximization (CPM), Condensed Nearest Neighbor Rule (US-CNN), One-Sided Selection (OSS), colony optimization Sampling (ACOSampling), etc. (Fernández et al. Citation2018). Synthetic Minority Over-sampling Technique (SMOTE) is the most often used oversampling method (Lin et al. Citation2017), which generates synthetic instances by using the interpolation method dependent on the required balance of the classes. SMOTE interpolating technique use k-nearest neighbor logic, close examples in the feature space are selected forming a line area in which new synthetic instances are created (Ashraf and Ahmed Citation2020). The main advantage of SMOTE technique is the improvement of the capacity generalization to the classifier, which leads scientists to create more than 85 different SMOTE technique extensions: Borderline-SMOTE, ADASYN, Safe-Level-SMOTE, DBSMOTE, ROSE, MWMOTE, MDO, etc. (Fernandez et al. Citation2018). In addition to this, the highest performance of the classifier can be achieved by the combination of the undersampling and oversampling techniques, as hybrid methods I creation: SMOTE +Tomek Link, SMOTE + ENN, AHC, SPIDER, SMOTE-RSB (Fernández et al. Citation2018). This method maintains weaknesses of both methods: the possibility of important information loss and overfitting.
The algorithm level approach can be divided into the threshold, one-class classifier, cost-sensitive, and ensembles of the classifier’s methods. The threshold method also known as “decision threshold” or “discrimination threshold” makes better classifier label prediction by moving the default threshold (0.5 probability) upper or lower for better special class identification (Zhou and Liu Citation2006). For example, the financial institution can save costs if the threshold of good credits is 0.8, which means it saves 2 out of 10 cases for creditworthiness tests. The main idea of using this method is to know the boundary that leads to one prior class label identification (Chen et al. Citation2006). If classes are highly overlapping threshold boundary can not be achieved. Another algorithm level method is one class classifier also known as recognition based learning, this method uses only one specific class example in the training set (Lin et al. Citation2017), this method is used when there are small disjuncts or noisy instances in the data and can be deviated into 3 types: 1) learning from minority class; 2) learning from majority class; 3) output combination after learning on both approaches (Fernández et al. Citation2018). The method applications lead to a decrease in specificity metrics, one of the methods dealing with this issue is the one-class classifier combination approach (Fernández et al. Citation2018). Since one-class classifier is trained only on one class instance, other instances are treated as outliers, for this reason, this method is used as one of the outlier’s detection approaches. The cost-sensitive method uses a cost matrix for misclassification of unequal cost between classes creation (Kotsiantis, Kanellopoulos, and Pintelas Citation2005), it is a penalty treatment for the classifier. In literature two different views are assigning a cost-sensitive method to the class imbalance approach, for one author it is a direct branch of the class imbalance approach (Fernández et al. Citation2018; Lin et al. Citation2017; Sisodia and Verma Citation2018), for others, it is a subclass of the Algorithm level approach (Kotsiantis, Kanellopoulos, and Pintelas Citation2005; Liu, Zhou, and Liu Citation2019; Wang et al. Citation2020). The cost-sensitive method depends on the selected cost, incorrect cost selection leads to impair results of the classifier (Fernández et al. Citation2018). The main idea of Hybrid method II is to combine different classifier outputs for more accurate final decision creating and this method can involve different algorithm level method combinations (Zhou and Liu Citation2006). The main difference from the third type of class imbalance – Ensembles of the classifier’s approach, is that the Hybrid methods II do not mix data level and algorithm level approaches outputs. Ensembles of the classifier’s approach allow researchers not only to use a combination of data level and algorithm level approaches but also make their ensembles learning classifiers.
In the financial distress and bankruptcy context class imbalance reduction techniques are used contradictory. The authors (Huang and Yen Citation2019; Inam et al. Citation2019; Kanojia and Gupta Citation2022; Mselmi, Lahiani, and Hamza Citation2017; Perboli and Arabnezhad Citation2021; Zelenkov, Fedorova, and Chekrizov Citation2017) do not use any class imbalance technique instead they chose majority instances depending on the number of minority instances. For example, the authors (Huang and Yen Citation2019) have 32 financially distressed firms and select 32 non-distressed firms from the same industry. Conversely, authors who adopted class imbalance reduction methods. The commonly used is SMOTE (Al-Milli, Hudaib, and Obeid Citation2021; Aljawazneh et al. Citation2021; Angenent, Barata, and Takes Citation2020; Choi, Son, and Kim Citation2018; Faris et al. Citation2020; Jiang et al. Citation2021; Kim, Cho, and Ryu Citation2021; Le et al. Citation2018; Letizia and Lillo Citation2019; Roumani, Nwankpa, and Tanniru Citation2020; Sisodia and Verma Citation2018; Sun et al. Citation2021; Veganzones and Séverin Citation2018; Vellamcheti and Singh Citation2020; Wang et al. Citation2018; Zelenkov and Volodarskiy Citation2021; Zhou Citation2013), then other oversampling techniques except SMOTE (Aljawazneh et al. Citation2021; Le et al. Citation2018; Sisodia and Verma Citation2018; Smiti and Soui Citation2020; Veganzones and Séverin Citation2018; Wang et al. Citation2018; Zelenkov and Volodarskiy Citation2021; Zhou Citation2013), undersampling (Angenent, Barata, and Takes Citation2020; Le et al. Citation2019; Sisodia and Verma Citation2018; Veganzones and Séverin Citation2018; Vellamcheti and Singh Citation2020; Wang et al. Citation2018; Zelenkov and Volodarskiy Citation2021; Zhou Citation2013), ensembles classifiers approaches (Aljawazneh et al. Citation2021; Roumani, Nwankpa, and Tanniru Citation2020; Shen et al. Citation2020; Sun et al. Citation2020; UlagaPriya and Pushpa Citation2021; Wang et al. Citation2020), Hybrid I (Aljawazneh et al. Citation2021; Le et al. Citation2018; Le et al., Citation2018; Le et al. Citation2019), cost-sensitive (Angenent, Barata, and Takes Citation2020; Chang Citation2019; Ren, Lu, and Yang Citation2021; Wang et al. Citation2018), and threshold (Wang et al. Citation2018). It is noted that authors (Aljawazneh et al. Citation2021; Angenent, Barata, and Takes Citation2020; Le et al. Citation2018; Sisodia and Verma Citation2018; Veganzones and Séverin Citation2018; Vellamcheti and Singh Citation2020; Wang et al. Citation2018; Zelenkov and Volodarskiy Citation2021; Zhou Citation2013) who use techniques other than SMOTE perform a comparative analysis of these techniques, and compared them with SMOTE. Further, SMOTE is one of the common data preparation steps. Authors (Veganzones and Séverin Citation2018) have noticed, that the efficiency of the classifier decreases with class imbalance increases, especially if one class instance is less than 20%. This assumption was made only on data level approach application in the research methodology and the maximum performance of the classifier was achieved after SMOTE techniques implementation. Using one classifier technique the class imbalance problem can be seen as anomaly or outlier detection, which is also applied to concepts of financial distress and bankruptcy (Gnip and Drotár Citation2019; Zoričák et al. Citation2020).
Looking from Outliers’ Perspective
The anomaly is understood as a strong outlier, which is significantly dissimilar to other data instances, on the contrary, a weak outlier is identified as the noise of the data (Aggarwal Citation2017). It is important to understand, that outlier exists in approximately every real data set due to: malicious activity, change in the environment, system behavior, fraudulent behavior, human error, instrument error, setup error, sampling errors, data-entry error, or simply through natural deviations in populations (Chandola, Banerjee, and Kumar Citation2009; Hodge and Austin Citation2004; Wang, Bah, and Hammad Citation2019). Authors are using different approaches (terminologies), such as outlier detection, novelty detection, anomaly detection, noise detection, deviation detection, or exception mining (Hodge and Austin Citation2004), which all lead to the same outlier identification problem. The first step to solving this issue is a precise description of normality, but finding the boundary between normality and nonnormality is often fuzzy due to the instances (data points) which are between the boundary, which can be treated as normal or vice versa (Chandola, Banerjee, and Kumar Citation2009). We identified three types of anomaly/outliers:
Point anomaly or Type I outlier occurs when is used technique, which is analyzing an individual instance with the rest of the data (Ahmed, Naser Mahmood, and Hu Citation2016; Chandola, Banerjee, and Kumar Citation2009). For example, if a person spends three times more than they used to.
Context anomaly or Type II occurs when it is a structure in the data, for example, seasonality of spending Christmas period. For this type is needed two sets of attributes are: 1) contextual attributes (location, time, etc.); 2) behavioral attributes (noncontextual characteristics of the instance: time interval between purchases) (Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009).
Collective anomaly or Type III outlier occurs when is analyzed the sequence of events, in which a separate event is not an anomaly, but the collection of similar events behave anomalously, for example, the sequence of transactions (Aggarwal Citation2017; Ahmed, Naser Mahmood, and Hu Citation2016; Chalapathy and Chawla Citation2019).
We categorize the anomaly detecting methods into six approaches according to literature reviews (Aggarwal Citation2017; Ahmed, Naser Mahmood, and Hu Citation2016; Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009, Citation2009; Hodge and Austin Citation2004; Wang, Bah, and Hammad Citation2019) in the context of anomaly/outlier detection ():
Figure 5. Anomaly detection methods.
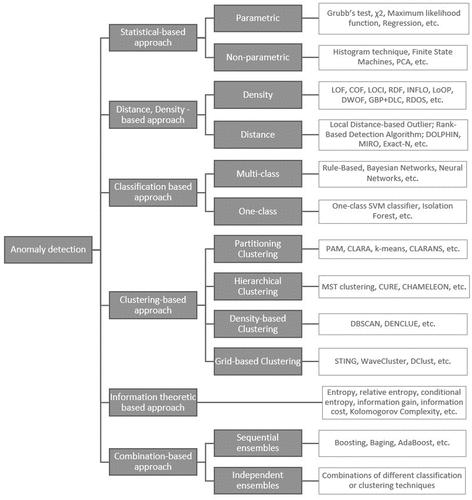
Statistical-based approach is the first algorithms group used for outlier detection (Hodge and Austin Citation2004), which is splinted into parametric and non-parametric methods. The fundamental idea of this approach is the identification of new instance dependencies to the distribution model (Wang, Bah, and Hammad Citation2019), e. g. instances are declared as anomalies if has a low probability to be generated from the learning model (Bhuyan, Bhattacharyya, and Kalita Citation2014). Parametric models use hypothesis testing, if the hypothesis is rejected instance is declared as an anomaly, for hypothesis testing is used
, Grubb’s test, etc. Of course, assuming that data is generated from a Gaussian distribution (Bernoulli (if categorical), etc.) maximum likelihood function can be used as well, where the threshold is applied for the anomaly identification as a distance measure from the mean (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009). A regression model can be applied too. Non-parametric models do not have priory assumption about data distribution, it uses existing data, for example, kernel functions estimate probability density function (pdf) for the data, where instances lying in low probability area are announced as anomalies (Chandola, Banerjee, and Kumar Citation2009; Wang, Bah, and Hammad Citation2019). Other often-used non-parametric models are histogram technique, Finite State Machines, PCA, etc. (Chandola, Banerjee, and Kumar Citation2009). The main advantages of the Statistical based approach are easy implementation, fast processing time, however, this approach has a strong weakness, which is: a) assumption about the density of the data, b) difficult applicability for multidimensional data, c) some methods (e. g. Histogram technique) can not capture the interactions between different attributes (Chandola, Banerjee, and Kumar Citation2009; Wang, Bah, and Hammad Citation2019).
Distance, Density-based approach otherwise known as a Nearest neighbor-based approach due to regularly k-NN technique application. The main idea of this approach is that normal data points instance occurs in more dense or nearby neighborhoods, while anomalies are more distant and may form their local dense groups (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009; Wang, Bah, and Hammad Citation2019). The main advantages of this method are that: a) it can be used during unsupervised learning, b) it is easily scalable in a multidimensional space, c) has efficient computation, d) does not have a prior assumption about data distribution (Chandola, Banerjee, and Kumar Citation2009; Wang, Bah, and Hammad Citation2019). This method is sensitive to parameter settings, which include k-neighbors identification. Also, it relies on the analyzed data, if it is scattered or does not have enough similar normal instances, that leads to a high false-positive rate (Chandola, Banerjee, and Kumar Citation2009). Method performance decreases due to the course of dimensionality, and it is not suitable for the data stream (Wang, Bah, and Hammad Citation2019).
Classification-based approach uses binary classification algorithms to divide instances into the classes: normal instance or anomaly, in which classification boundary can be non-linear (Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009). Depending on the availability of data in the testing set of different classes it are used multi-class or one class-based classification technique (Chandola, Banerjee, and Kumar Citation2009). The main advantages of this approach are a) adoptable threshold setting, and b) flexible pretraining and testing incorporating new information (Bhuyan, Bhattacharyya, and Kalita Citation2014). The main disadvantages of the model are that: a) the performance of the model depends on the assumptions made by the classifier, b) the new unseen instance is often misclassified, and c) a need for more computational power (Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009).
A clustering-based approach can be used during unsupervised learning, hence pre-label class instances do not require (Ahmed, Naser Mahmood, and Hu Citation2016). The main method assumption is that normal data instance belongs to the cluster, while anomalies do not or form their own – smaller cluster (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009). Author (Zhang Citation2013) clustering-based outlier detection algorithms distinguish into seven major categories: Partitioning Clustering methods; Hierarchical Clustering methods; Density-based clustering methods; Grid-based clustering methods. The main advantages of using clustering are a) stable performance, b) no prior knowledge about data distribution is needed, c) adaptable for different data types and data structures d) incremental clustering (supervised) methods are effective for fast response generation (Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009). Some cluster categories have additional advantages, for example partitioning clustering is approximately simple and scalable, hierarchical based methods “maintain a good performance on data sets containing non-isotropic clusters and also produce multiple nested partitions that give users the option to choose different portions according to their similarity level” (Wang, Bah, and Hammad Citation2019). The main clustering-based approach’s main disadvantages are a) dependence on proper cluster algorithm selection that could capture the structure of normal instances, b) high sensitivity for initial parameters, e.g. clustering is optimized for a prior number of cluster creations not for anomaly detection, hence, identifying the proper number of clusters for normal instances and anomalies is challenging (Bhuyan, Bhattacharyya, and Kalita Citation2014; Chandola, Banerjee, and Kumar Citation2009; Wang, Bah, and Hammad Citation2019).
The information theoretic-based approach’s main assumption is to find out irregularities in the information content, which are caused by anomalies in the data set (Chandola, Banerjee, and Kumar Citation2009). The information content is analyzed using different information-theoretic measurements. e. g. entropy, relative entropy, conditional entropy, information gain, information cost, (Ahmed, Naser Mahmood, and Hu Citation2016; Chandola, Banerjee, and Kumar Citation2009). The main advantages of this approach are that it can be used during unsupervised learning and does not have a prior assumption about data distribution. The main weaknesses are a) performance dependence on the information-theoretic measurement selection; b) date sets application limitation: in most cases used for sequential or spatial data, c) computation time and power resources grow exponentially in more complex data sets, d) it is difficult the information-theoretic measurement output connects with anomaly score or label (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009, Citation2009).
The combination-based approach otherwise known as Ensemble-based, which the main idea to use several machine-learning algorithms results and combine them using weighted voting, and majority voting techniques (Bhuyan, Bhattacharyya, and Kalita Citation2014; Wang, Bah, and Hammad Citation2019). Author (Aggarwal Citation2017) ensemble-based outlier detection algorithms distinguish into two categories: sequential and independent ensembles. The main idea of sequential ensembles is that is formed sequential algorithms are used dependent on the data, while independent ensembles use a combination of different algorithms voting outputs. The main advantages of this method are a) performance is more efficient, b) predicts results are more stable, and c) applicable for high dimension data, and streaming data. It is difficult to: a) obtain real-time performances, b) select classifiers in the ensemble, and c) interpret a result, which was get during unsupervised learning (it could lead to robust decision making) (Bhuyan, Bhattacharyya, and Kalita Citation2014; Wang, Bah, and Hammad Citation2019).
Anomaly detection techniques generate the output, which can be one of two types:
Labels. Output technique, which assigns labels, e.g. a normal instance or outlier. It generally uses a threshold for conversion from probability score to binary labels (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009).
Scores. Output technique, which uses direct algorithm outputs as probability score for the outlier, which is ranked (Aggarwal Citation2017; Chandola, Banerjee, and Kumar Citation2009).
Machine-Learning Methods
Machine-learning is the study of computer algorithms, which have the capability to learn and improve automatically through experience (Helm et al. Citation2020; Huang and Wang Citation2019). The machine-learning techniques can be classified into four main groups.
Supervised machine-learning methods are based on useful information with labeled data (Liu and Lang Citation2019). It is called the Task-driven approach due to it uses a sample of input-output pairs to convert an input to an output (van Engelen and Hoos Citation2020). Depending on provided data it can be a regression (continuous data) or classification (discrete data) task (Sarker Citation2021).
Unsupervised machine-learning methods do not have any provided output and their main task is to map similar inputs to the same class (van Engelen and Hoos Citation2020). This Data-Driven approach is widely used for feature extraction, clustering, association rules detection, density estimation, anomaly detection, etc. (Sarker Citation2021).
Semi – supervised machine-learning methods combines Supervised and Unsupervised methods, which seek to improve performance in one of these two tasks by using data that is commonly linked with the other. For example, clustering can benefit from knowing some data points provided output, further classification can be added to additional data points without any output (van Engelen and Hoos Citation2020). Often used in text classification, fraud detection (Akande et al. Citation2021; Awotunde et al. Citation2022), money laundering prevention, data labeling, etc.
Reinforcement machine-learning methods is based on long-term rewords maximization, which is obtained by imitation of human behavior to take environmental action (by reward or penalty learning).
In financial distress and bankruptcy context, the authors most often apply supervised machine-learning methods, especially popular methods are Logistic regression, Artificial neural network (ANN), and Support vector machine (SVM). Logistic regression is the most popular method due to several reasons: 1) one of the first methods applied in a bankruptcy context (Altman’s z-score model is based on LR); 2) popular in social science for the evaluation of analyzed variables; 3) one of the main method used in the efficiency comparison with other machine-learning methods. However, LR method performance results is lower comparing with other Machine-learning methods (SVM, Xgboost, ANN, Random Forest, etc.). For this reason, authors extend their research by implementing new methodology for”Financial distress” classification and other machine-learning issues solving such as: dimensionality reduction, imbalance, etc.
A few unsupervised machine-learning methods are applied: One class SVM, Isolation forest (IF), Least-Squares Anomaly detection (LSAD), K-means, and from deep learning methods group – Auto-encoder. For each method, a more detailed description is given in .
Table 3. Machine-learning methods applied in the context of financial distress.
Performance Metrics
The effectiveness of the methods is evaluated by a comparison of different methods’ performance results. In this study, we are interested in evaluating performance metrics suitable for labels. Most of them begin with the confusion-matrix (Altman Citation1968). In the case of class imbalance, the minority class is presented as negative (Fernández et al. Citation2018). In the case of financial distress, classes would be presented as follows for positive: Non-Financial DistressNon-Bankrupt, and for negative: Financial Distress
Bankrupt.
Based on the confusion matrix, many performance measurements can be constructed. For more accurate evaluation of the methods, researchers use three to five measurements. The shows that 30.9% of studies used one evaluation metric. The authors use other evaluation metrics, such as or Log-loss, in the regression analyses; therefore, it is common to use 3–5 evaluation metrics. The common evaluation matrix is accuracy and the area under the ROC curve (AUC), then recall, specificity, and type I error (). Comparing AUC and ACC ratios, it is observed that studies closer to the present period tend to choose AUC metrics. For AUC calculation is needed ROC curve identification. ROC (the receiver operating characteristic) curve is a graphical evaluation method (Fernández et al. Citation2018) for the binary classification problems, also called a two-dimensional space coordinate system (Wang et al. Citation2018), in which Sensitivity (TPR) is plotted on the Y-axis and 1-Specificity (FPR) is plotted on X-axis (Zhou Citation2013). There is a point in the ROC space for each potential threshold value conditional on the values of FPR and TPR for that threshold (Fernández et al. Citation2018). Linear interpolation is used to construct the curve. AUC is an average performance metric that helps analysis to compare and contrast different models (García, Marqués, and Sánchez Citation2019).
Figure 6. Quantity and number of studies of evaluation metrics used in studies.
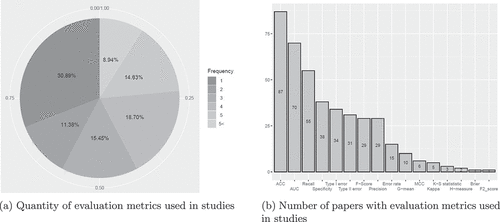
Kolmogorov – Smirnov statistic (K-S), Matthews correlation coefficient (MCC), H-measure, and Brier score (BS) have a low number of studies from 1 to 6. The application of these methods in the financial distress context was found only in 2021–2022 studies.
Discussion
The scope of this study is limited to the period 2017–2022 February, which helps to identify under-explored research fields in financial distress and bankruptcy context. The separation between ”Financial Distress” and”Bankruptcy” can be addressed as the ”gray” area due to unclear ”Financial distress” class indicator. For this reason, author’s results comparison is problematic, because the main class indicator is different. In contrast, the concept”Bankruptcy” has the same understanding as class indicator, but it is too late indication for decision-makers. Analyzing the used data source’s it is noticeable the researchers choose open data sources (Stock exchange, Polish data set). Unfortunately, the authors do not provide data pre-processing steps or present them succinctly, e.g. data were pre-processed, data were normalized, five feature selection methods were used, etc. This information limits ability to identify common data pre-processing steps in Financial distress and bankruptcy context. Therefore, it is needed further analysis in this context.
”Financial distress” topic is challenging for artificial intelligence experts due to existing issues with high data dimensionality, imbalance, sentiment analysis, outliers. These problems author’s analyses separately by combining the most appropriate methodology for their analyzed data. However, at least dimensionality and imbalance pragmatic’s have to be addressed in each study in order to get comparable results.
This study seek to bring knowledge and key insights for further researchers by filling the gaps discussed in previous literature reviews. However, further work can be developed in the directions named by other authors, which were not discussed in this article: dynamic models applications (Chen, Ribeiro, and Chen Citation2016; Matenda et al. Citation2021); switching from binary classification (Chen, Ribeiro, and Chen Citation2016); the tools suitable for different domains of datasets analyses (Bhatore, Mohan, and Reddy Citation2020); users knowledge integration in black-box models (Chen, Ribeiro, and Chen Citation2016).
Finally, one of the main literature analysis limitations is the lack of dynamic view incorporation in the used methods analysis. For example, to know a timeline, which methods are now at peak, or which are less applicable. Another interesting direction of literature review would be the analysis of ensembles. Studies have shown that the author’s design ensembles of classifiers. In further financial distress scope review would be interesting to know, which methods or their modifications usually fall into voting ensembles.
Conclusion
The main aim of this study is to identify the context of “Financial distress” and its usage of machine-learning methods, including additional aspects related to it, such as imbalance, dimensionality, etc. This study analyzed 232 articles, which most of which are Financial distress and Bankruptcy content research from the period 2017 to 2022 February using the guidelines of the PRISMA methodology.
Our main findings are as follows:
Data researchers commonly choose publicly available datasets, e. g. public companies or open data sets such as Polish, Spanish, or Japanese. Consequently, the results of the study are difficult to compare due to the different analysis periods and the inclusion of new data (indicators, sources, etc.) in the analysis.
Data pre-processing steps in financial distress and bankruptcy context are often forgotten or succinctly present. Information on data normalization provided about 14% of analyzed studies. The commonly used functions are normalization and Z-score.
The authors used 27 supervised and 5 unsupervised methods, of which 8 belong to of Deep learning methods subgroup. The most popular method remains in the Logistic regression for the following reasons: 1) one of the first methods applied in the bankruptcy context (Altman’s z-score model is based on LR); 2) popular in social science for the evaluation of analyzed variables; 3) one of the main method used in the efficiency comparison with other machine-learning methods. Other commonly used algorithms are ANN, SVM, Decision tree, Random forest, Boosting (AdaBoost, XGBoost), etc.
The most popular data preprocessing are dimensionality reduction and data balancing, which are becoming essential data pre-processing steps. However, each of these topics contains under-explored research fields for future development.
Lastly, we analyzed evaluation performance metrics suitable for labels. For better evaluation of the methods, researchers use three to five metrics. The common evaluation matrix is accuracy and AUC, then recall, specificity, type I error, etc. The application of K-S, MCC, H-measure, and BS methods in the financial distress context was detected only in 2021-2022 studies.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Aalbers, H., J. Adriaanse, G.-J. Boon, J.-P.V.D Rest, R. Vriesendorp, and F. V. Wersch. 2019. Does pre-packed bankruptcy create value? An empirical study of postbankruptcy employment retention in the Netherlands. International Insolvency Review 28 (3):320–3571. doi:10.1002/iir.1353.
- Abdi, A., S. M. Shamsuddin, S. Hasan, and J. Piran. 2019. Deep learning-based sentiment classification of evaluative text based on Multi-feature fusion. Information Processing & Management 56 (4):1245–59. doi:10.1016/j.ipm.2019.02.018.
- Abdullah, M. 2021. The implication of machine learning for financial solvency prediction: An empirical analysis on public listed companies of Bangladesh. Journal of Asian Business and Economic Studies 28 (4):303–20. doi:10.1108/JABES-11-2020-0128.
- Acharjya, D. P., and R. Rathi. 2021. An extensive study of statistical, rough, and hybridized rough computing in bankruptcy prediction. Multimedia Tools and Applications 80 (28–29):35387–413. doi:10.1007/s11042-020-10167-2.
- Adisa, J. A., S. O. Ojo, P. A. Owolawi, and A. B. Pretorius. (2019). Financial distress prediction: principle component analysis and artificial neural networks. In 2019 International Multidisciplinary Information Technology and Engineering Conference (IMITEC), Vanderbijlpark, South Africa, pp. 1–6.
- Aggarwal, C. C. 2017. Outlier Analysis. Cham: Springer International Publishing.
- AghaeiRad, A., N. Chen, and B. Ribeiro. 2017. Improve credit scoring using transfer of learned knowledge from self-organizing map. Neural Computing & Applications 28 (6):1329–42. doi:10.1007/s00521-016-2567-2.
- Ahmad, A. H. 2019. What factors discriminate reorganized and delisted distressed firms: evidence from Malaysia. Finance Research Letters 29:50–56. doi:10.1016/j.frl.2019.03.010.
- Ahmadi, Z., P. Martens, C. Koch, T. Gottron, and S. Kramer. (2018). Towards bankruptcy prediction: deep sentiment mining to detect financial distress from business management reports. In 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, pp. 293–302.
- Ahmed, M., A. Naser Mahmood, and J. Hu. 2016. A survey of network anomaly detection techniques. Journal of Network and Computer Applications 60:19–31. doi:10.1016/j.jnca.2015.11.016.
- Akande, O. N., S. Misra, H. B. Akande, J. Oluranti, and R. Damasevicius. (2021). A Supervised Approach to Credit Card Fraud Detection Using an Artificial Neural Network, Volume 1455 CCIS of Communications in Computer and Information Science.
- Al-Milli, N., A. Hudaib, and N. Obeid. 2021. Population diversity control of genetic algorithm using a novel injection method for bankruptcy prediction problem. Mathematics 9 (8):823. doi:10.3390/math9080823.
- Al-Tashi, Q., S. J. Abdulkadir, H. M. Rais, S. Mirjalili, and H. Alhussian. 2020. Approaches to multi-objective feature selection: a systematic literature review. IEEE Access 8:125076–96.
- Alaka, H. A., L. O. Oyedele, H. A. Owolabi, V. Kumar, S. O. Ajayi, O. O. Akinade, and M. Bilal. 2018. Systematic review of bankruptcy prediction models: Towards a framework for tool selection. Expert Systems with Applications 94:164–84. doi:10.1016/j.eswa.2017.10.040.
- Alam, N., J. Gao, and S. Jones. 2021. Corporate failure prediction: An evaluation of deep learning vs discrete hazard models. Journal of International Financial Markets, Institutions and Money 75:101455. doi:10.1016/j.intfin.2021.101455.
- Ali, S., R. Ur Rehman, W. Yuan, M. I. Ahmad, and R. Ali. 2021. Does foreign institutional ownership mediate the nexus between board diversity and the risk of financial distress? A case of an emerging economy of China. Eurasian Business Review 12 (3):553–81. doi:10.1007/s40821-021-00191-z.
- Aljawazneh, H., A. M. Mora, P. Garcia-Sanchez, and P. A. Castillo-Valdivieso. 2021. Comparing the performance of deep learning methods to predict companies’ financial failure. IEEE Access 9:97010–38. doi:10.1109/ACCESS.2021.3093461.
- Almaskati, N., R. Bird, D. Yeung, and Y. Lu. 2021. A horse race of models and estimation methods for predicting bankruptcy. Advances in Accounting 52:100513. doi:10.1016/j.adiac.2021.100513.
- Altman, E. I. 1968. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance 23 (4):589–609. doi:10.1111/j.1540-6261.1968.tb00843.x.
- Altman, N., and M. Krzywinski. 2018. The curse(s) of dimensionality. Nature Methods 15 (6):399–400. doi:10.1038/s41592-018-0019-x.
- Andreano, M. S., R. Benedetti, A. Mazzitelli, F. Piersimoni, and D. Di Fatta. 2018. How interconnected SMEs in business cluster survive the economic crisis. Kybernetes 50 (7). doi:10.1108/K-06-2018-0282.
- Angenent, M. N., A. P. Barata, and F. W. Takes. (2020). Large-scale machine learning for business sector prediction. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, SAC ’20, New York, NY, USA, pp. 1143–46.
- Antunes, F., B. Ribeiro, and F. Pereira. 2017. Probabilistic modeling and visualization for bankruptcy prediction. Applied Soft Computing 60:831–43. doi:10.1016/j.asoc.2017.06.043.
- Ashraf, S., and T. Ahmed. 2020. Machine learning shrewd approach for an imbalanced dataset conversion samples. Journal of Engineering and Technology 11 (1):9.
- Ashraf, S., E. G. S. Félix, and Z. Serrasqueiro. 2021. Does board committee independence affect financial distress likelihood? A comparison of China with the UK. Asia Pacific Journal of Management 39 (2):723–61. doi:10.1007/s10490-020-09747-5.
- Awotunde, J. B., S. Misra, F. Ayeni, R. Maskeliunas, and R. Damasevicius. (2022). Artificial Intelligence Based System for Bank Loan Fraud Prediction, Volume 420 LNNS of Lecture Notes in Networks and Systems.
- Awwad, B., and B. Razia. 2021. Adapting Altman’s model to predict the performance of the Palestinian industrial sector. Journal of Business and Socio-Economic Development 1 (2):149–64. doi:10.1108/JBSED-05-2021-0063.
- Ayesha, S., M. K. Hanif, and R. Talib. 2020. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Information Fusion 59:44–58. doi:10.1016/j.inffus.2020.01.005.
- Ayodele, E., S. Misra, R. Damasevicius, and R. Maskeliunas. 2019. Hybrid microgrid for microfinance institutions in rural areas – a field demonstration in west africa. Sustainable Energy Technologies and Assessments 35:89–97. doi:10.1016/j.seta.2019.06.009.
- Azayite, F. Z., and S. Achchab. (2018). Topology design of bankruptcy prediction neural networks using Particle swarm optimization and backpropagation. In Proceedings of the International Conference on Learning and Optimization Algorithms: Theory and Applications, LOPAL ’18, New York, NY, USA, pp. 1–6.
- Balasubramanian, S. A., G.S. Radhakrishna, P. Sridevi, and T. Natarajan. 2019. Modeling corporate financial distress using financial and non-financial variables: The case of Indian listed companies. International Journal of Law and Management 61 (3/4):457–84. doi:10.1108/IJLMA-04-2018-0078.
- Barboza, F., H. Kimura, and E. Altman. 2017. Machine learning models and bankruptcy prediction. Expert Systems with Applications 83:405–17. doi:10.1016/j.eswa.2017.04.006.
- Beaver, W. H. 1966. Financial ratios as predictors of failure. Journal of Accounting Research 4:71. doi:10.2307/2490171.
- Behr, A., and J. Weinblat. 2017. Default prediction using balance-sheet data: A comparison of models. The Journal of Risk Finance 18 (5):523–40. doi:10.1108/JRF-01-2017-0003.
- Ben Jabeur, S. 2017. Bankruptcy prediction using partial least squares logistic regression. Journal of Retailing and Consumer Services 36:197–202. doi:10.1016/j.jretconser.2017.02.005.
- Ben Jabeur, S., N. Stef, and P. Carmona. 2022 Bankruptcy prediction using the XGBoost algorithm and variable importance feature engineering . Computational Economics. doi:10.1007/s10614-021-10227-1.
- Bhatore, S., L. Mohan, and Y. R. Reddy. 2020. Machine learning techniques for credit risk evaluation: A systematic literature review. Journal of Banking and Financial Technology 4 (1):111–38. doi:10.1007/s42786-020-00020-3.
- Bhuyan, M. H., D. K. Bhattacharyya, and J. K. Kalita. 2014. Network anomaly detection: methods, systems and tools. IEEE Communications Surveys & Tutorials 16 (1):303–36. doi:10.1109/SURV.2013.052213.00046.
- Boubaker, S., A. Cellier, R. Manita, and A. Saeed. 2020. Does corporate social responsibility reduce financial distress risk? Economic modelling 91:835–51. doi:10.1016/j.econmod.2020.05.012.
- Bravo-Urquiza, F., and E. Moreno-Ureba. 2021. Does compliance with corporate governance codes help to mitigate financial distress? Research in International Business and Finance 55:101344. doi:10.1016/j.ribaf.2020.101344.
- Cai, J., J. Luo, S. Wang, and S. Yang. 2018. Feature selection in machine learning: A new perspective. Neurocomputing 300:70–79. doi:10.1016/j.neucom.2017.11.077.
- Çallı, B. A., and E. Coşkun. 2021. A longitudinal systematic review of credit risk assessment and credit default predictors. SAGE Open 11 (4):215824402110613. doi:10.1177/21582440211061333.
- Cenciarelli, V. G., G. Greco, and M. Allegrini. 2018. Does intellectual capital help predict bankruptcy? Journal of Intellectual Capital 19 (2):321–37. doi:10.1108/JIC-03-2017-0047.
- Chalapathy, R., and S. Chawla. 2019. Deep learning for anomaly detection: a survey arXiv. :1901.03407 [cs, stat].
- Chandola, V., A. Banerjee, and V. Kumar. 2009. Anomaly detection: A survey. ACM Computing Surveys 41 (3):1–58. doi:10.1145/1541880.1541882.
- Chang, H. (2019). The application of machine learning models in company bankruptcy prediction. In Proceedings of the 2019 3rd International Conference on Software and e-Business, ICSEB 2019, New York, NY, USA, pp. 199–203.
- Charalambous, C., S. H. Martzoukos, and Z. Taoushianis. 2022. Estimating corporate bankruptcy forecasting models by maximizing discriminatory power. Review of Quantitative Finance and Accounting 58 (1):297–328. doi:10.1007/s11156-021-00995-0.
- Chen, Z., W. Chen, and Y. Shi. 2020. Ensemble learning with label proportions for bankruptcy prediction. Expert Systems with Applications 146:113155. doi:10.1016/j.eswa.2019.113155.
- Chen, Y.-S., C.-K. Lin, C.-M. Lo, S.-F. Chen, and Q.-J. Liao. 2021. Comparable studies of financial bankruptcy prediction using advanced hybrid intelligent classification models to provide early warning in the electronics industry. Mathematics 9 (20):2622. doi:10.3390/math9202622.
- Chen, N., B. Ribeiro, and A. Chen. 2016. Financial credit risk assessment: A recent review. Artificial Intelligence Review 45 (1):1–23.
- Chen, J. J., C.-A. Tsai, H. Moon, H. Ahn, J. J. Young, and C.-H. Chen. 2006. Decision threshold adjustment in class prediction. SAR and QSAR in Environmental Research 17 (3):337–52. doi:10.1080/10659360600787700.
- Cheng, C.-H., C.-P. Chan, and Y.-J. Sheu. 2019. A novel purity-based k nearest neighbors imputation method and its application in financial distress prediction. Engineering Applications of Artificial Intelligence 81:283–99. doi:10.1016/j.engappai.2019.03.003.
- Cheng, C.-H., C.-P. Chan, and J.-H. Yang. 2018. A seasonal time-series model based on gene expression programming for predicting financial distress. Computational Intelligence & Neuroscience 2018:1–14. doi: 10.1155/2018/1067350
- Chiou, K.-C., M.-M. Lo, and G.-W. Wu. (2017). The minimizing prediction error on corporate financial distress forecasting model: An application of dynamic distress threshold value. In 2017 IEEE 8th International Conference on Awareness Science and Technology (iCAST), Taichung, Taiwan, pp. 514–17.
- Choi, H., H. Son, and C. Kim. 2018. Predicting financial distress of contractors in the construction industry using ensemble learning. Expert Systems with Applications 110:1–10. doi:10.1016/j.eswa.2018.05.026.
- Chollet, F. 2018. Deep learning with python, ocn982650571. Shelter Island, New York: Manning Publications Co. OCLC.
- Chou, C.-H., S.-C. Hsieh, and C.-J. Qiu. 2017. Hybrid genetic algorithm and fuzzy clustering for bankruptcy prediction. Applied Soft Computing 56:298–316. doi:10.1016/j.asoc.2017.03.014.
- Cleofas-Sánchez, L., V. García, A. Marqués, and J. Sánchez. 2016. Financial distress prediction using the hybrid associative memory with translation. Applied Soft Computing 44:144–52. doi:10.1016/j.asoc.2016.04.005.
- Cooper, E., and H. Uzun. 2019. Corporate social responsibility and bankruptcy. Studies in Economics and Finance 36 (2):130–53. doi:10.1108/SEF-01-2018-0013.
- Crosato, L., J. Domenech, and C. Liberati. 2021. Predicting SME’s default: Are their websites informative? Economics Letters 204:109888. doi:10.1016/j.econlet.2021.109888.
- Da, F., C. Peng, H. Wang, and T. Li. 2022. A risk detection framework of Chinese high-tech firms using wide & deep learning model based on text disclosure. Procedia computer science 199:262–68. doi:10.1016/j.procs.2022.01.032.
- Darrat, A. F., S. Gray, J. C. Park, and Y. Wu. 2016. Corporate governance and bankruptcy risk. Journal of Accounting, Auditing & Finance 31 (2):163–202. doi:10.1177/0148558X14560898.
- Doğan, S., D. Koçak, and M. Atan. 2022. Financial distress prediction using support vector machines and logistic regression. In Advances in econometrics, operational research, data science and actuarial studies: techniques and theories, contributions to economics, ed. M. K. Terzioğlu, 429–52. Cham: Springer International Publishing.
- du Jardin, P. 2017. Dynamics of firm financial evolution and bankruptcy prediction. Expert Systems with Applications 75:25–43. doi:10.1016/j.eswa.2017.01.016.
- du Jardin, P. 2018. Failure pattern-based ensembles applied to bankruptcy forecasting. Decision Support Systems 107:64–77. doi:10.1016/j.dss.2018.01.003.
- du Jardin, P. 2021a. Dynamic self-organizing feature map-based models applied to bankruptcy prediction. Decision Support Systems 147:113576. doi:10.1016/j.dss.2021.113576.
- du Jardin, P. 2021b. Forecasting bankruptcy using biclustering and neural network-based ensembles. Annals of Operations Research 299 (1–2):531–66. doi:10.1007/s10479-019-03283-2.
- du Jardin, P. 2021c. Forecasting corporate failure using ensemble of self-organizing neural networks. European Journal of Operational Research 288 (3):869–85. doi:10.1016/j.ejor.2020.06.020.
- Du, X., W. Li, S. Ruan, and L. Li. 2020. CUS-heterogeneous ensemble-based financial distress prediction for imbalanced dataset with ensemble feature selection. Applied Soft Computing 97:106758. doi:10.1016/j.asoc.2020.106758.
- Dumitrescu, A., M. El Hefnawy, and M. Zakriya. 2020. Golden geese or black sheep: Are stakeholders the saviors or saboteurs of financial distress? Finance Research Letters 37:101371. doi:10.1016/j.frl.2019.101371.
- Escribano-Navas, M., and G. Gemar. 2021. Gender and bankruptcy: a hotel survival econometric analysis. Sustainability 13 (12):6782. doi:10.3390/su13126782.
- Fan, S., G. Liu, and Z. Chen. (2017). Anomaly detection methods for bankruptcy prediction. In 2017 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, pp. 1456–60.
- Faris, H., R. Abukhurma, W. Almanaseer, M. Saadeh, A. M. Mora, P. A. Castillo, and I. Aljarah. 2020. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: A case from the Spanish market. Progress in Artificial Intelligence 9 (1):31–53. doi:10.1007/s13748-019-00197-9.
- Farooq, U., M. A. Jibran Qamar, and A. Haque. 2018. A three-stage dynamic model of financial distress. Managerial Finance 44 (9):1101–16. doi:10.1108/MF-07-2017-0244.
- Fernández, A., S. García, M. Galar, R. C. Prati, B. Krawczyk, and F. Herrera. 2018. Learning from Imbalanced Data Sets. Cham: Springer International Publishing.
- Fernandez, A., S. Garcia, F. Herrera, and N. V. Chawla. 2018. SMOTE for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. The Journal of Artificial Intelligence Research 61:863–905. doi:10.1613/jair.1.11192.
- Freitas Cardoso, G., F. M. Peixoto, and F. Barboza. 2019. Board structure and financial distress in Brazilian firms. International Journal of Managerial Finance 15 (5):813–28. doi:10.1108/IJMF-12-2017-0283.
- García, C. J., and B. Herrero. 2021. Female directors, capital structure, and financial distress. Journal of Business Research 136:592–601. doi:10.1016/j.jbusres.2021.07.061.
- García, V., A. I. Marqués, and J. S. Sánchez. 2019. Exploring the synergetic effects of sample types on the performance of ensembles for credit risk and corporate bankruptcy prediction. Information Fusion 47:88–101. doi:10.1016/j.inffus.2018.07.004.
- Gnip, P., and P. Drotár. (2019). Ensemble methods for strongly imbalanced data: Bankruptcy prediction. In 2019 IEEE 17th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, pp. 155–60.
- Hájek, P. 2018. Combining bag-of-words and sentiment features of annual reports to predict abnormal stock returns. Neural Computing & Applications 29 (7):343–58. doi:10.1007/s00521-017-3194-2.
- Helm, J. M., A. M. Swiergosz, H. S. Haeberle, J. M. Karnuta, J. L. Schaffer, V. E. Krebs, A. I. Spitzer, and P. N. Ramkumar. 2020. Machine learning and artificial intelligence: definitions, applications, and future directions. Current reviews in musculoskeletal medicine 13 (1):69–76. doi:10.1007/s12178-020-09600-8.
- Hernandez Tinoco, M., P. Holmes, and N. Wilson. 2018. Polytomous response financial distress models: The role of accounting, market and macroeconomic variables. International Review of Financial Analysis 59:276–89. doi:10.1016/j.irfa.2018.03.017.
- Hodge, V., and J. Austin. 2004. A survey of outlier detection methodologies. Artificial Intelligence Review 22 (2):85–126. doi:10.1023/B:AIRE.0000045502.10941.a9.
- Horak, J., J. Vrbka, and P. Suler. 2020. Support vector machine methods and artificial neural networks used for the development of bankruptcy prediction models and their comparison. Journal of Risk and Financial Management 13 (3):60. doi:10.3390/jrfm13030060.
- Hosaka, T. 2019. Bankruptcy prediction using imaged financial ratios and convolutional neural networks. Expert Systems with Applications 117:287–99. doi:10.1016/j.eswa.2018.09.039.
- Hu, Y.-C. 2020. A multivariate grey prediction model with grey relational analysis for bankruptcy prediction problems. Soft Computing 24 (6):4259–68. doi:10.1007/s00500-019-04191-0.
- Huang, C., and X. Wang. (2019). Financial innovation based on artificial intelligence technologies. In Proceedings of the 2019 International Conference on Artificial Intelligence and Computer Science, AICS 2019, New York, NY, USA, pp. 750–54.
- Huang, J., H. Wang, and G. Kochenberger. 2017. Distressed Chinese firm prediction with discretized data. Management Decision 55 (5):786–807. doi:10.1108/MD-08-2016-0546.
- Huang, C., Q. Yang, M. Du, and D. Yang. 2017. Financial distress prediction using SVM ensemble based on earnings manipulation and fuzzy integral. Intelligent Data Analysis 21 (3):617–36. doi:10.3233/IDA-160034.
- Huang, Y.-P., and M.-F. Yen. 2019. A new perspective of performance comparison among machine learning algorithms for financial distress prediction. Applied Soft Computing 83:105663. doi:10.1016/j.asoc.2019.105663.
- Inam, F., A. Inam, M. A. Mian, A. A. Sheikh, and H. M. Awan. 2019. Forecasting Bankruptcy for organizational sustainability in Pakistan: Using artificial neural networks, logit regression, and discriminant analysis. Journal of Economic and Administrative Sciences 35 (3):183–201. doi:10.1108/JEAS-05-2018-0063.
- Jabeur, S. B., C. Gharib, S. Mefteh-Wali, and W. B. Arfi. 2021. CatBoost model and artificial intelligence techniques for corporate failure prediction. Technological Forecasting and Social Change 166:120658. doi:10.1016/j.techfore.2021.120658.
- Jiang, C., X. Lyu, Y. Yuan, Z. Wang, and Y. Ding. 2021. Mining semantic features in current reports for financial distress prediction: Empirical evidence from unlisted public firms in China. International Journal of Forecasting 38 (3):1086–99. doi:10.1016/j.ijforecast.2021.06.011.
- Jindal, N. 2020. The impact of advertising and R&D on bankruptcy survival: a double-edged sword. Journal of Marketing 84 (5):22–40. doi:10.1177/0022242920936205.
- Jones, S. 2017. Corporate bankruptcy prediction: A high dimensional analysis. Review of Accounting Studies 22 (3):1366–422. doi:10.1007/s11142-017-9407-1.
- Joshi, S., R. Ramesh, and S. Tahsildar. (2018). A bankruptcy prediction model using random forest. In 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, pp. 1–6.
- Kamalirezaei, H., A. A. A. Rostamy, A. Saeedi, and M. K. V. Zaghard. 2020. Corporate social responsibility and bankruptcy probability: Exploring the role of market competition, intellectual capital, and equity cost. Journal of Corporate Accounting & Finance 31 (1):53–63. doi:10.1002/jcaf.22417.
- Kanojia, S., and S. Gupta. 2022. Bankruptcy in Indian context: Perspectives from corporate governance. Journal of Management and Governance. doi:10.1007/s10997-022-09630-z.
- Keya, M. S., H. Akter, M. A. Rahman, M. M. Rahman, M. U. Emon, and M. S. Zulfiker. (2021). Comparison of different machine learning algorithms for detecting bankruptcy. In 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, pp. 705–12. IEEE.
- Khoja, L., M. Chipulu, and R. Jayasekera. 2019. Analysis of financial distress cross countries: Using macroeconomic, industrial indicators and accounting data. International Review of Financial Analysis 66:101379.
- Kim, H., H. Cho, and D. Ryu. 2021. Corporate bankruptcy prediction using machine learning methodologies with a focus on sequential data. Computational Economics 59 (3):1231–49. doi:10.1007/s10614-021-10126-5.
- Kim, S., B. M. Mun, and S. J. Bae. 2018. Data depth based support vector machines for predicting corporate bankruptcy. Applied Intelligence 48 (3):791–804. doi:10.1007/s10489-017-1011-3.
- Kim, S. Y., and A. Upneja. 2021. Majority voting ensemble with a decision trees for business failure prediction during economic downturns. Journal of Innovation & Knowledge 6 (2):112–23. doi:10.1016/j.jik.2021.01.001.
- Kotsiantis, S., D. Kanellopoulos, and P. Pintelas. 2005. Handling imbalanced datasets: A review. GESTS International Transactions on Computer Science and Engineering 30:25–36.
- Kou, G., Y. Xu, Y. Peng, F. Shen, Y. Chen, K. Chang, and S. Kou. 2021. Bankruptcy prediction for SMEs using transactional data and two-stage multiobjective feature selection. Decision Support Systems 140:113429. doi:10.1016/j.dss.2020.113429.
- Kovermann, J. H. 2018. Tax avoidance, tax risk and the cost of debt in a bank-dominated economy. Managerial Auditing Journal 33 (8/9):683–99. doi:10.1108/MAJ-12-2017-1734.
- Kristianto, H., and B. Rikumahu. (2019). A cross model telco industry financial distress prediction in Indonesia: multiple discriminant analysis, Logit and Artificial Neural Network. In 2019 7th International Conference on Information and Communication Technology (ICoICT), Kuala Lumpur, Malaysia, pp. 1–5.
- Kumar, G., and S. Roy. (2016). Development of hybrid boosting technique for bankruptcy prediction. In 2016 International Conference on Information Technology (ICIT), Bhubaneswar, India, pp. 248–53.
- Kuo, F. Y., and I. H. Sloan. 2005. Lifting the curse of dimensionality. Notices of the AMS 52 (11):9.
- Le, T. 2022. A comprehensive survey of imbalanced learning methods for bankruptcy prediction. IET Communications 16 (5):433–41. doi:10.1049/cmu2.12268.
- Le, T., L. Hoang Son, M. Vo, M. Lee, and S. Baik. 2018. A cluster-based boosting algorithm for bankruptcy prediction in a highly imbalanced dataset. Symmetry 10 (7):250. doi:10.3390/sym10070250.
- Le, T., M. Lee, J. Park, and S. Baik. 2018. Oversampling techniques for bankruptcy prediction: novel features from a transaction dataset. Symmetry 10 (4):79. doi:10.3390/sym10040079.
- Le, T., B. Vo, H. Fujita, N.-T. Nguyen, and S. W. Baik. 2019. A fast and accurate approach for bankruptcy forecasting using squared logistics loss with GPU-based extreme gradient boosting. Information Sciences 494:294–310. doi:10.1016/j.ins.2019.04.060.
- Letizia, E., and F. Lillo. 2019. Corporate payments networks and credit risk rating. EPJ Data Science 8 (1):21. doi:10.1140/epjds/s13688-019-0197-5.
- Liang, D., C.-F. Tsai, A.-J. Dai, and W. Eberle. 2018. A novel classifier ensemble approach for financial distress prediction. Knowledge and Information Systems 54 (2):437–62. doi:10.1007/s10115-017-1061-1.
- Li, L., and R. Faff. 2019. Predicting corporate bankruptcy: What matters? International Review of Economics & Finance 62:1–19. doi:10.1016/j.iref.2019.02.016.
- Li, Y., T. Li, and H. Liu. 2017. Recent advances in feature selection and its applications. Knowledge and Information Systems 53 (3):551–77. doi:10.1007/s10115-017-1059-8.
- Li, C., C. Lou, D. Luo, and K. Xing. 2021. Chinese corporate distress prediction using LASSO: The role of earnings management. International Review of Financial Analysis 76:101776. doi:10.1016/j.irfa.2021.101776.
- Li, S., W. Shi, J. Wang, and H. Zhou. 2021. A deep learning-based approach to constructing a domain sentiment lexicon: a case study in financial distress prediction. Information Processing & Management 58 (5):102673. doi:10.1016/j.ipm.2021.102673.
- Lin, K. C., and X. Dong. 2018. Corporate social responsibility engagement of financially distressed firms and their bankruptcy likelihood. Advances in Accounting 43:32–45. doi:10.1016/j.adiac.2018.08.001.
- Lin, S.-J., and M.-F. Hsu. 2017. Incorporated risk metrics and hybrid AI techniques for risk management. Neural Computing & Applications 28 (11):3477–89. doi:10.1007/s00521-016-2253-4.
- Lin, W.-C., C.-F. Tsai, Y.-H. Hu, and J.-S. Jhang. 2017. Clustering-based undersampling in class-imbalanced data. Information Sciences 409-410:17–26. doi:10.1016/j.ins.2017.05.008.
- Liu, B., T. Ju, M. Bai, and C.-F.J Yu. 2021. Imitative innovation and financial distress risk: The moderating role of executive foreign experience. International Review of Economics & Finance 71:526–48. doi:10.1016/j.iref.2020.09.021.
- Liu, H., and B. Lang. 2019. Machine learning and deep learning methods for intrusion detection systems: a survey. Applied Sciences 9 (20):4396. doi:10.3390/app9204396.
- Liu, H., M. Zhou, and Q. Liu. 2019. An embedded feature selection method for imbalanced data classification. IEEE/CAA Journal of Automatica Sinica 6 (3):703–15. doi:10.1109/JAS.2019.1911447.
- Lu, Y., J. Zhu, N. Zhang, and Q. Shao. (2014). A hybrid switching PSO algorithm and support vector machines for bankruptcy prediction. In 2014 International Conference on Mechatronics and Control (ICMC), Jinzhou, China, pp. 1329–33.
- Lukason, O., and T. Vissak. 2017. Failure processes of exporting firms: Evidence from France. Review of International Business and Strategy 27 (3):322–34. doi:10.1108/RIBS-03-2017-0020.
- Mai, F., S. Tian, C. Lee, and L. Ma. 2019. Deep learning models for bankruptcy prediction using textual disclosures. European Journal of Operational Research 274 (2):743–58. doi:10.1016/j.ejor.2018.10.024.
- Matenda, F. R., M. Sibanda, E. Chikodza, and V. Gumbo. 2021. Bankruptcy prediction for private firms in developing economies: A scoping review and guidance for future research. Management Review Quarterly. doi:10.1007/s11301-021-00216-x.
- Mathew, S., S. Ibrahim, and S. Archbold. 2016. Boards attributes that increase firm risk – evidence from the UK. Corporate Governance 16 (2):233–58. doi:10.1108/CG-09-2015-0122.
- Millstein, J., F. Battaglin, M. Barrett, S. Cao, W. Zhang, S. Stintzing, V. Heinemann, and H.-J. Lenz. 2020. Partition: A surjective mapping approach for dimensionality reduction. Bioinformatics 36 (3):676–81. doi:10.1093/bioinformatics/btz661.
- Mokrišová, M., and J. Horváthová. 2020. Bankruptcy prediction applying multivariate techniques. Scientific Journal of the Faculty of Management of University of Presov in Presov 12: 52–69 .
- Mora García, A. M., P. A. Castillo Valdivieso, J. J. Merelo Guervós, E. Alfaro Cid, A. I. Esparcia-Alcázar, and K. Sharman. (2008). Discovering causes of financial distress by combining evolutionary algorithms and artificial neural networks. In Proceedings of the 10th annual conference on Genetic and evolutionary computation, GECCO ’08, New York, NY, USA, pp. 1243–50.
- Mousavi, M. M., and J. Lin. 2020. The application of PROMETHEE multi-criteria decision aid in financial decision making: Case of distress prediction models evaluation. Expert Systems with Applications 159:113438. doi:10.1016/j.eswa.2020.113438.
- Mselmi, N., A. Lahiani, and T. Hamza. 2017. Financial distress prediction: The case of French small and medium-sized firms. International Review of Financial Analysis 50:67–80. doi:10.1016/j.irfa.2017.02.004.
- Nyitrai, T. 2019. Dynamization of bankruptcy models via indicator variables. Benchmarking: An International Journal 26 (1):317–32. doi:10.1108/BIJ-03-2017-0052.
- Nyitrai, T., and M. Virág. 2019. The effects of handling outliers on the performance of bankruptcy prediction models. Socio-Economic Planning Sciences 67:34–42. doi:10.1016/j.seps.2018.08.004.
- Okewu, E., S. Misra, J. Okewu, R. Damaševičius, and R. Maskeliūnas. 2019. An intelligent advisory system to support managerial decisions for a social safety net. Administrative Sciences 9 (3):3. doi:10.3390/admsci9030055.
- Olsen, B. C., and C. Tamm. 2017. Corporate governance changes around bankruptcy. Managerial Finance 43 (10):1152–69. doi:10.1108/MF-09-2015-0257.
- Ouenniche, J., K. Bouslah, B. Perez-Gladish, and B. Xu. 2021. A new VIKOR-based in-sample-out-of-sample classifier with application in bankruptcy prediction. Annals of Operations Research 296 (1–2):495–512. doi:10.1007/s10479-019-03223-0.
- Ouenniche, J., B. Pérez-Gladish, and K. Bouslah. 2018. An out-of-sample framework for TOPSIS-based classifiers with application in bankruptcy prediction. Technological Forecasting and Social Change 131:111–16. doi:10.1016/j.techfore.2017.05.034.
- Oz, I. O., and C. Simga-Mugan. 2018. Bankruptcy prediction models’ generalizability: Evidence from emerging market economies. Advances in Accounting 41:114–25. doi:10.1016/j.adiac.2018.02.002.
- Oz, I. O., and T. Yelkenci. 2017. A theoretical approach to financial distress prediction modeling. Managerial Finance 43 (2):212–30. doi:10.1108/MF-03-2016-0084.
- Page, M. J., J. E. McKenzie, P. M. Bossuyt, I. Boutron, T. C. Hoffmann, C. D. Mulrow, L. Shamseer, J. M. Tetzlaff, E. A. Akl, S. E. Brennan, et al. March. 2021. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. PLoS medicine 18(3):e1003583. doi: 10.1371/journal.pmed.1003583.
- Park, S., H. Kim, J. Kwon, and T. Kim. 2021. Empirics of Korean shipping companies’ default predictions. Risks 9 (9):159. doi:10.3390/risks9090159.
- Pavlicko, M., M. Durica, and J. Mazanec. 2021. Ensemble model of the financial distress prediction in visegrad group countries. Mathematics 9 (16):1886. doi:10.3390/math9161886.
- Perboli, G., and E. Arabnezhad. 2021. A Machine Learning-based DSS for mid and long-term company crisis prediction. Expert Systems with Applications 174:114758. doi:10.1016/j.eswa.2021.114758.
- Perez, M. 2006. Artificial neural networks and bankruptcy forecasting: A state of the art. Neural Computing & Applications 15 (2):154–63. doi:10.1007/s00521-005-0022-x.
- Pham Vo Ninh, B., T. Do Thanh, and D. Vo Hong. 2018. Financial distress and bankruptcy prediction: An appropriate model for listed firms in Vietnam. Economic Systems 42 (4):616–24. doi:10.1016/j.ecosys.2018.05.002.
- Ptak-Chmielewska, A. 2021. Bankruptcy prediction of small- and medium-sized enterprises in Poland based on the LDA and SVM methods. Statistics in Transition New Series 22 (1):179–95. doi:10.21307/stattrans-2021-010.
- Putri, H. R., and A. Dhini. (2019). Prediction of financial distress: analyzing the industry performance in stock exchange market using data mining. In 2019 16th International Conference on Service Systems and Service Management (ICSSSM), Shenzhen, China, pp. 1–5.
- Qian, H., B. Wang, M. Yuan, S. Gao, and Y. Song. 2022. Financial distress prediction using a corrected feature selection measure and gradient boosted decision tree. Expert Systems with Applications 190:116202. doi:10.1016/j.eswa.2021.116202.
- Rahayu, D. S., and H. Suhartanto. (2020). Financial distress prediction in indonesia stock exchange’s listed company using case based reasoning concept. In 2020 IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA), Bangkok, Thailand, pp. 1009–13.
- Rasmussen, C. E., and C. K. I. Williams. 2006. Gaussian processes for machine learning, Cambridge, Massachusetts Institute of Technology. London, England: The MIT Press.
- Ravula, S. 2021. Bankruptcy prediction using disclosure text features. arXiv:2101.00719 [cs, q-fin]. 10.1111/ijcp.14016
- Regenburg, K., and M. N. B. Seitz. 2021. Criminals, bankruptcy, and cost of debt. Review of Accounting Studies 26 (3):1004–45. doi:10.1007/s11142-021-09608-6.
- Ren, T., T. Lu, and Y. Yang. (2021). Improved data mining method for class-imbalanced financial distress prediction. In 2021 7th International Conference on Computing and Artificial Intelligence, Tianjin China, pp. 308–13.
- Richardson, G., R. Lanis, and G. Taylor. 2015. Financial distress, outside directors and corporate tax aggressiveness spanning the global financial crisis: An empirical analysis. Journal of Banking & Finance 52:112–29. doi:10.1016/j.jbankfin.2014.11.013.
- Rosli, N. F., A. Abdul-Rahman, and S. I. M. Amin. 2019. Credit risk determinants: A systematic review for islamic and conventional banks. International Journal of Business and Management Science 9 (3):481–505.
- Roumani, Y. F., J. K. Nwankpa, and M. Tanniru. 2020. Predicting firm failure in the software industry. Artificial Intelligence Review 53 (6):4161–82. doi:10.1007/s10462-019-09789-2.
- Salehi, M., and M. Davoudi Pour. 2016. Bankruptcy prediction of listed companies on the Tehran Stock Exchange. International Journal of Law and Management 58 (5):545–61. doi:10.1108/IJLMA-05-2015-0023.
- Salehi, M., M. Mousavi Shiri, and M. Bolandraftar Pasikhani. 2016. Predicting corporate financial distress using data mining techniques: An application in Tehran Stock Exchange. International Journal of Law and Management 58 (2):216–30. doi:10.1108/IJLMA-06-2015-0028.
- Sarker, I. H. 2021. Machine learning: algorithms, real-world applications and research directions. SN Computer Science 2 (3):160. doi:10.1007/s42979-021-00592-x.
- Sayari, N., and C. S. Mugan. 2017. Industry specific financial distress modeling. BRQ Business Research Quarterly 20 (1):45–62. doi:10.1016/j.brq.2016.03.003.
- Séverin, E., and D. Veganzones. 2021. Can earnings management information improve bankruptcy prediction models? Annals of Operations Research 306 (1–2):247–72. doi:10.1007/s10479-021-04183-0.
- Shahwan, T. M., and A. M. Habib. 2020. Does the efficiency of corporate governance and intellectual capital affect a firm’s financial distress? Evidence from Egypt. Journal of Intellectual Capital 21 (3):403–30. doi:10.1108/JIC-06-2019-0143.
- Shen, F., Y. Liu, R. Wang, and W. Zhou. 2020. A dynamic financial distress forecast model with multiple forecast results under unbalanced data environment. Knowledge-Based Systems 192:105365. doi:10.1016/j.knosys.2019.105365.
- Shi, Y., and X. Li. 2019. A bibliometric study on intelligent techniques of bankruptcy prediction for corporate firms. Heliyon 5 (12):e02997. doi:10.1016/j.heliyon.2019.e02997.
- Sisodia, D. S., and U. Verma. 2018. The impact of data re-sampling on learning performance of class imbalanced bankruptcy prediction models. International Journal on Electrical Engineering & Informatics 10 (3):433–46. doi:10.15676/ijeei.2018.10.3.2.
- Smith, M., and F. Alvarez. 2022. Predicting firm-level bankruptcy in the Spanish economy using extreme gradient boosting. Computational Economics 59 (1):263–95. doi:10.1007/s10614-020-10078-2.
- Smiti, S., and M. Soui. 2020. Bankruptcy prediction using deep learning approach based on borderline SMOTE. Information Systems Frontiers 22 (5):1067–83. doi:10.1007/s10796-020-10031-6.
- Son, H., C. Hyun, D. Phan, and H. Hwang. 2019. Data analytic approach for bankruptcy prediction. Expert Systems with Applications 138:112816. doi:10.1016/j.eswa.2019.07.033.
- Soui, M., S. Smiti, M. W. Mkaouer, and R. Ejbali. 2020. Bankruptcy prediction using stacked auto-encoders. Applied Artificial Intelligence 34 (1):80–100. doi:10.1080/08839514.2019.1691849.
- Stef, N., and E. Zenou. 2021. Management-to-staff ratio and a firm’s exit. Journal of Business Research 125:252–60. doi:10.1016/j.jbusres.2020.12.027.
- Štefko, R., J. Horváthová, and M. Mokrišová. 2021. The application of graphic methods and the DEA in predicting the risk of bankruptcy. Journal of Risk and Financial Management 14 (5):220. doi:10.3390/jrfm14050220.
- Succurro, M., G. Arcuri, and G. D. Costanzo. 2019. A combined approach based on robust PCA to improve bankruptcy forecasting. Review of Accounting and Finance 18 (2):296–320. doi:10.1108/RAF-04-2018-0077.
- Sun, J., H. Fujita, P. Chen, and H. Li. 2017. Dynamic financial distress prediction with concept drift based on time weighting combined with Adaboost support vector machine ensemble. Knowledge-Based Systems 120:4–14. doi:10.1016/j.knosys.2016.12.019.
- Sun, J., H. Fujita, Y. Zheng, and W. Ai. 2021. Multi-class financial distress prediction based on support vector machines integrated with the decomposition and fusion methods. Information Sciences 559:153–70. doi:10.1016/j.ins.2021.01.059.
- Sun, J., H. Li, H. Fujita, B. Fu, and W. Ai. 2020. Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Information Fusion 54:128–44. doi:10.1016/j.inffus.2019.07.006.
- Süsi, V., and O. Lukason. 2019. Corporate governance and failure risk: Evidence from Estonian SME population. Management Research Review 42 (6):703–20. doi:10.1108/MRR-03-2018-0105.
- Tobback, E., J. Moeyersoms, M. Stankova, and D. Martens. 2017. Bankruptcy prediction for SMEs using relational data. Decision Support Systems 102:69–81. doi:10.1016/j.dss.2017.07.004.
- Tsai, C.-F., K.-L. Sue, Y.-H. Hu, and A. Chiu. 2021. Combining feature selection, instance selection, and ensemble classification techniques for improved financial distress prediction. Journal of Business Research 130:200–09. doi:10.1016/j.jbusres.2021.03.018.
- Tsai, M.-F., and C.-J. Wang. 2017. On the risk prediction and analysis of soft information in finance reports. European Journal of Operational Research 257 (1):243–50. doi:10.1016/j.ejor.2016.06.069.
- Udin, S., M. A. Khan, and A. Y. Javid. 2017. The effects of ownership structure on likelihood of financial distress: An empirical evidence. Corporate Governance: The International Journal of Business in Society 17 (4):589–612. doi:10.1108/CG-03-2016-0067.
- UlagaPriya, K., and S. Pushpa. (2021). A comprehensive study on ensemble-based imbalanced data classification methods for bankruptcy data. In 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, pp. 800–04. IEEE.
- van der Maaten, L., E. Postma, and H. Herik. 2007. Dimensionality reduction: a comparative review. Journal of Machine Learning Research - JMLR 10: 66–71 .
- van Engelen, J. E., and H. H. Hoos. 2020. A survey on semi-supervised learning. Machine Learning 109 (2):373–440. doi:10.1007/s10994-019-05855-6.
- Veganzones, D., and E. Severin. 2020. Corporate failure prediction models in the twenty-first century: A review. European Business Review 33 (2):204–26. doi:10.1108/EBR-12-2018-0209.
- Veganzones, D., and E. Séverin. 2018. An investigation of bankruptcy prediction in imbalanced datasets. Decision Support Systems 112:111–24. doi:10.1016/j.dss.2018.06.011.
- Veganzones, D., E. Séverin, and S. Chlibi. 2021. Influence of earnings management on forecasting corporate failure. International Journal of Forecasting S0169207021001503. doi:10.1016/j.ijforecast.2021.09.006.
- Vellamcheti, S., and P. Singh. (2020). Class imbalance deep learning for bankruptcy prediction. In 2020 First International Conference on Power, Control and Computing Technologies (ICPC2T), Raipur, India, pp. 421–25.
- Volkov, A., D. F. Benoit, and D. Van den Poel. 2017. Incorporating sequential information in bankruptcy prediction with predictors based on Markov for discrimination. Decision Support Systems 98:59–68. doi:10.1016/j.dss.2017.04.008.
- Wagle, M., Z. Yang, and Y. Benslimane. (2017). Bankruptcy prediction using data mining techniques. In 2017 8th International Conference of Information and Communication Technology for Embedded Systems (IC-ICTES), Chonburi , Thailand, pp. 1–4.
- Wagner, N. (2008). Credit Risk: Models, Derivatives, and Management. CRC Press. Google-Books-ID: phgyv2TlguUC.
- Wang, H., M. J. Bah, and M. Hammad. 2019. Progress in outlier detection techniques: a survey. IEEE Access 7:107964–8000. doi:10.1109/ACCESS.2019.2932769.
- Wang, G., G. Chen, and Y. Chu. 2018. A new random subspace method incorporating sentiment and textual information for financial distress prediction. Electronic Commerce Research and Applications 29:30–49. doi:10.1016/j.elerap.2018.03.004.
- Wang, M., H. Chen, H. Li, Z. Cai, X. Zhao, C. Tong, J. Li, and X. Xu. 2017. Grey wolf optimization evolving kernel extreme learning machine: Application to bankruptcy prediction. Engineering Applications of Artificial Intelligence 63:54–68. doi:10.1016/j.engappai.2017.05.003.
- Wang, H., D. Liu, and G. Pu. 2019. Nuclear reconstructive feature extraction. Neural Computing & Applications 31 (7):2649–59. doi:10.1007/s00521-017-3220-4.
- Wang, G., J. Ma, G. Chen, and Y. Yang. 2020. Financial distress prediction: Regularized sparse-based Random Subspace with ER aggregation rule incorporating textual disclosures. Applied Soft Computing 90:106152. doi:10.1016/j.asoc.2020.106152.
- Wang, D., Z. Zhang, R. Bai, and Y. Mao. 2018. A hybrid system with filter approach and multiple population genetic algorithm for feature selection in credit scoring. Journal of Computational and Applied Mathematics 329:307–21. doi:10.1016/j.cam.2017.04.036.
- Weng, C. G., and J. Poon. (2008). A new evaluation measure for imbalanced datasets. In Proceedings of the 7th Australasian Data Mining Conference-Volume 87 Adelaide, Australia, pp. 27–32.
- Xu, W., H. Fu, and Y. Pan. 2019. A novel soft ensemble model for financial distress prediction with different sample sizes. Mathematical Problems in Engineering 2019:1–12. doi: 10.1155/2019/3085247
- Xu, X., T. Liang, J. Zhu, D. Zheng, and T. Sun. 2019. Review of classical dimensionality reduction and sample selection methods for large-scale data processing. Neurocomputing 328:5–15. doi:10.1016/j.neucom.2018.02.100.
- Yang, Y., and C. Yang. (2020). Research on the application of GA improved neural network in the prediction of financial crisis. In 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Phuket, Thailand, pp. 625–29.
- Yazdanfar, D., and P. Öhman. 2020. Financial distress determinants among SMEs: Empirical evidence from Sweden. Journal of Economic Studies 47 (3):547–60. doi:10.1108/JES-01-2019-0030.
- Ye, Z. (2021). A data slicing method to improve machine learning model accuracy in bankruptcy prediction. 2021 5th International Conference on Deep Learning Technologies (ICDLT), Qingdao China, pp. 32–39.
- Ye, J., S. Ji, and L. Sun. 2013. Multi-label dimensionality reduction. London, United Kingdom: CRC Press LLC.
- Zelenkov, Y. (2020). Bankruptcy prediction using survival analysis technique. In 2020 IEEE 22nd Conference on Business Informatics (CBI), Antwerp, Belgium, Volume 2, pp. 141–49.
- Zelenkov, Y., E. Fedorova, and D. Chekrizov. 2017. Two-step classification method based on genetic algorithm for bankruptcy forecasting. Expert Systems with Applications 88:393–401. doi:10.1016/j.eswa.2017.07.025.
- Zelenkov, Y., and N. Volodarskiy. 2021. Bankruptcy prediction on the base of the unbalanced data using multi-objective selection of classifiers. Expert Systems with Applications 185:115559. doi:10.1016/j.eswa.2021.115559.
- Zhang, J. 2013. Advancements of outlier detection: a survey. ICST Transactions on Scalable Information Systems 13 (1):e2. doi:10.4108/trans.sis.2013.01-03.e2.
- Zhang, Y., R. Liu, A. A. Heidari, X. Wang, Y. Chen, M. Wang, and H. Chen. 2021. Towards augmented kernel extreme learning models for bankruptcy prediction: Algorithmic behavior and comprehensive analysis. Neurocomputing 430:185–212. doi:10.1016/j.neucom.2020.10.038.
- Zhang, R., Z. Zhang, D. Wang, and M. Du. 2021. Financial distress prediction with a novel diversity-considered GA-MLP ensemble algorithm. Neural Processing Letters 54 (2):1175–94. doi:10.1007/s11063-021-10674-9.
- Zhao, S., K. Xu, Z. Wang, C. Liang, W. Lu, and B. Chen. 2022. Financial distress prediction by combining sentiment tone features. Economic modelling 106:105709. doi:10.1016/j.econmod.2021.105709.
- Zhou, L. 2013. Performance of corporate bankruptcy prediction models on imbalanced dataset: The effect of sampling methods. Knowledge-Based Systems 41:16–25. doi:10.1016/j.knosys.2012.12.007.
- Zhou, Z.-H., and X.-Y. Liu. 2006. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Transactions on Knowledge and Data Engineering 18 (1):63–77. doi:10.1109/TKDE.2006.17.
- Zoričák, M., P. Gnip, P. Drotár, and V. Gazda. 2020. Bankruptcy prediction for small- and medium-sized companies using severely imbalanced datasets. Economic modelling 84:165–76. doi:10.1016/j.econmod.2019.04.003.