
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
As the cryptocurrency trading market has grown significantly in recent years, the number of comments related to cryptocurrency has increased tremendously in social media platforms. Due to this, sentiment analysis of the cryptocurrency-related comments has become highly desirable to give a comprehensive picture of peoples’ opinions about the trend of the market. In this regard, we perform cryptocurrency-related text sentiment classification using tweets based on positive and negative sentiments. For increasing the efficacy of the sentiment analysis, we introduce a novel deep neural network hybrid architecture which is composed of an embedding layer, a convolution layer, a group-wise enhancement mechanism, a bidirectional layer, an attention mechanism, and a fully connected layer. Local features are derived using a convolution layer, and weight values associated with intuitive features are developed using the group-wise enhancement mechanism. After feeding the improved context vector to the bidirectional layer to grab global features, the attention mechanism and the fully connected layer have been employed. The experimental findings indicate that the proposed architecture outperforms the state-of-the-art architectures with an accuracy value of 93.77%.
Introduction
The popularity of trading cryptocurrency coins in trading platforms has increased exponentially in recent years. Cryptocurrency is a blockchain-based digital asset which is used as peer to peer digital exchange units in online payments. This digital currency is basically based on two encryption algorithms, which are elliptic curve encryption and public-private key pairs. Besides, in order to secure online payments, hashing functions are used to provide legitimate and unique transactions (Aslam et al. Citation2022). Bitcoin is the first cryptocurrency coin which is introduced in 2009. It is designed to be an independent digital asset against the currency tracking systems of governments and banks by hiding the information of the sender and the receiver in a payment process (Di Pierro Citation2017). There are well-known cryptocurrencies in the market. Ethereum is one of them which was introduced in 2015 by Vitalik Buterin (Tikhomirov et al. Citation2018). Ethereum enables its users to create smart contracts of their own (Wöhrer and Zdun Citation2018).
In today’s world, there are no more physical boundaries for sharing information. As the usage rates of communication technologies evolve very rapidly, people communicate with each other using social media platforms and microblogging sites such as Twitter, Facebook, Instagram. Here, such platforms play an important role for people to share their comments, feedback, and observations about any kind of topic with a much larger audience. As a result of the popularity of the cryptocurrencies, increasing number of people have started to write articles on trading point view, where the feelings and the thoughts are instantly shared on online platforms with short sentences consisting of a few words rather than long texts. Therefore, sentiment analysis of the comments on cryptocurrency emerges as an important field of study.
The cryptocurrency market is considered to be volatile where the prices of the cryptocurrencies move up and down frequently. These fluctuations in the market provide investors the opportunity to earn money. For this purpose, investors use many tools to forecast the direction of the market. On the other hand, governmental policies and general public opinions have efficacy on the market. In this regard, sentiment analysis can be an effective approach to determine rise and fall of the market since it is considered as a valuable feedback information for cryptocurrency investment these days (Abraham et al. Citation2018; Colianni, Rosales, and Signorotti Citation2015). According to the studies (Lamon, Nielsen, and Redondo Citation2017; Wołk Citation2020), tweets containing sentiments play an important role for influencing investor demands. As a result, analyzing peoples’ sentiments to predict the directions of the cryptocurrency markets has become an important classification task (Chuen, Guo, and Wang Citation2017).
The aim of this study is to contribute Turkish text sentiment analysis studies related to cryptocurrency in the literature by providing a novel supervised learning model which increases the performance of identification of sentiments related to cryptocurrency coins in social media platforms. To do this, a new Turkish cryptocurrency-related dataset is created which is composed of 9,548 tweets in total where 5,907 tweets are labeled as positive and the rest 3,641 tweets are labeled as negative. After that, a new hybrid deep neural network architecture is presented which is based on Convolutional Neural Network (CNN), group-wise enhancement mechanism, Recurrent Neural Network (RNN) and attention mechanism. Local features have been derived using a convolution layer in this scheme. Then, using the group-wise enhancement mechanism, an enhanced context vector was obtained by assigning a higher weight to informative features and a lower weight to uninformative features. The enhanced context vector was then fed into bidirectional Long Short-term Memory (LSTM) architecture to capture global features. Then, the attention mechanism has been employed so that the different weight values can be assigned to global features to reflect the importance regarding the contextual information. Finally, the fully connected layer has been utilized to identify sentiment orientation of text documents. We examined the predictive performance of three different versions of the proposed model. In addition, the prediction performances of the three word embedding schemes were evaluated together with the four basic deep neural networks and the proposed model. The comprehensive empirical analysis on two sentiment classification datasets with the state-of-the-art architectures indicates that the proposed scheme can yield promising results on sentiment analysis tasks. The contributions of the paper can be summarized as follows:
Motivated by the encouraging findings obtained by the hybrid architectures based on CNNs and RNNs on NLP tasks, we introduce a bidirectional CNN-RNN architecture for text sentiment classification, along with the group-wise enhancement and the attention mechanisms.
To the best of our knowledge, this study is the first comprehensive analysis of the state-of-art deep neural architectures for sentiment analysis on cryptocurrency.
In addition to the analysis on fourteen architectures, we also present a hybrid deep neural architecture with high predictive performance. To the best of our knowledge, this is the first hybrid architecture in which group-wise enhancement mechanism in conjunction with attention mechanism.
The remaining sections are arranged as follows: The existing works are presented in the Related Works Section. The Theoretical Foundations Section includes a brief overview of the proposed model’s fundamental components. The next section addresses the proposed model for sentiment analysis. The empirical findings are discussed in the Experiments and Results Section. In the last part, the study is concluded.
Related Works
As the usage rates of social media platforms have grown very rapidly, identifications of sentiments and emotions in text data have become an important research area in the literature (Calefato, Lanubile, and Novielli Citation2017; Haryadi and Kusuma Citation2019; Hasan, Rundensteiner, and Agu Citation2019; Onan Citation2021, Citation2022; Salam and Gupta Citation2018; Shah et al. Citation2019; Tocoglu, Ozturkmenoglu, and Alpkocak Citation2019; Zhang et al. Citation2020). However, identification of sentiments about cryptocurrency trading has not evolved at the same pace since it is a new concept. In the literature, the studies related to cryptocurrency market are generally focused on price prediction problems by examining correlations between price and sentiment values of cryptocurrency coins using machine learning techniques.
In the study, the authors (Mehta et al. Citation2020) used sentiment analysis techniques to make price prediction for Bitcoin cryptocurrency price in real-time using Twitter and news data. To accomplish this goal, they trained their LSTM model with a dataset composed of 1559 tuples where each tuple has date, sentiment values and Bitcoin price data. The suggested model is live on a server where it makes predictions of Bitcoin price continuously. In another study (Raju and Tarif Citation2020), the authors focused on providing informative predictions about future Bitcoin market price by examining the correlation between Bitcoin price and the sentiments of tweets about it. They used LSTM architecture to construct their prediction model.
Şaşmaz and Tek (Citation2021) focused on sentiment analysis of NEO cryptocurrency coin and the correlation of daily sentiment of tweets with the market price of NEO. For this, they first gathered a dataset composed of last five years of daily tweets regarding NEO. Next, the raw dataset was labeled manually for three sentiment categories which are positive, negative and neutral. Sentiment analysis experiments were performed by constructing models using Random Forest and BERT classifiers where the former algorithm outperformed the other. In the study’s second phase, the daily sentiment of tweets was compared to the market price of NEO.
Valencia, Gómez-Espinosa, and Valdés-Aguirre (Citation2019) sought to anticipate the price fluctuations of the cryptocurrencies Bitcoin, Litecoin, Ethereum, and Ripple. To begin, they gathered a dataset of tweets and market price caps for four cryptocurrencies. Then, they compared the predictive performances of several classifiers. In general, the model constructed using multi-layer perceptron algorithm performed the highest result among others.
Pant et al. (Citation2018) concentrated on forecasting the Bitcoin price in the market using sentiment analysis methods. Firstly, they gathered tweets from different news accounts and categorized them manually as positive and negative. Next, they trained a voting classifier model, consists of five algorithms, using the categorized dataset to make daily sentiment percentage predictions. The accuracy value for the voting classifier was achieved as 81.39%. Further, the authors combined the output of the voting classifier with the historical price of Bitcoin and used them to feed the RNN model which predicts Bitcoin price with an accuracy rate of 77.62%.
Köksal et al. (Citation2021) conducted a sentiment analysis using Naïve Bayes and Logistic Regression classifiers with 3,737 tweets related to Bitcoin in the first phase of their study. They labeled the tweets in the dataset for three sentiments which are positive, negative and neutral. As a result, Logistic Regression classifier performed the highest accuracy value. In the second phase of the study, the authors estimated the market closing price of Bitcoin by using opening price of Bitcoin and the rate of daily positive tweets containing the keyword Bitcoin. To do so, they used Linear and Random Forest Regression algorithms.
Çılgın et al. (Citation2020) evaluated the correlation between tweets and Bitcoin price. They first gathered 2,819,784 tweets in English containing the keyword Bitcoin. Then, 1,500 tweets were chosen and labeled as positive, negative and neutral to be used as the training dataset. The authors used several conventional classifiers to construct the sentiment analysis model. In the next step, the rest of the raw dataset was classified by using the trained model. Then, the authors conducted a correlation analysis using the rates of the positive tweets sent for each day and the Bitcoin daily closing prices.
Huang et al. (Citation2021) focused on analyzing the correlation between price movements in the market and sentiments in Chinese social media platform Sina-Weibo for cryptocurrency price prediction. The authors created crypto-based sentiment dictionary and proposed a machine learning approach using LSTM architecture for the prediction of price trend of the cryptocurrency market. The proposed method outperformed the state of the art models in precision and recall by 18.5% and 15.4%, respectively.
The primary goal of the studies discussed above is to predict cryptocurrency market prices rather than conducting sentiment analysis itself. As a result, studies focusing on increasing the performances of sentiment analysis models for cryptocurrencies are limited. For this reason, this study proposes a novel hybrid deep neural network architecture for sentiment analysis on cryptocurrency-related tweets. In the literature, there are few studies which are mainly concentrated on sentiment analysis for cryptocurrency market. For example, Aslam et al. (Citation2022) proposed a stacked deep learning ensemble architecture using LSTM followed by GRU. They used TextBlob and Text2Emotion libraries to categorize the raw tweet dataset. Considering the overall results in the study, the proposed architecture outperformed the compared models. On the other hand, in this study, we focused on enhancing the classification performance of the proposed model by using group-wise enhancement and attention mechanisms to reveal the informative features more precisely.
Theoretical Foundations
The basic elements are briefly described in this section. We summarized Word2vec word embedding scheme, and covered the deep neural network architectures in the following subsections.
Word2vec Model
The Vector Space Model (VSM) is not capable of capturing the semantic relationships between features of the dataset. VSM suffers in performance due to problems of high dimensionality and sparsity. To handle such problems, neural language models have become popular in text mining tasks. In these models, a real-valued vector is generated for each word by encoding words with similar meanings in the vector space. Such representation is called dense vector representation which provides low dimensionality and text documents with semantic properties.
The Word2vec is a neural language model which builds word embeddings using a layered structure in sequence (Mikolov et al. Citation2013; Onan and Toçoğlu Citation2021). By requiring less manual preprocessing of texts with semantic and syntactic features, neural language models provide robust representation. The dense vector representation yields promising results for natural language tasks. The word2vec model is composed of three layers: an input layer, an output layer, and a hidden layer. It is an artificial neural network-based scheme for word embedding (Mikolov et al. Citation2013). It attempts to learn to embed words by calculating the probability that a given word is rooted in other words. The model is composed of two fundamental architectures: the skip-gram (SG) and the continuous bag of words (CBOW). The CBOW architecture defines the target word by using the content of each word as an input; on the other hand, the SG architecture anticipates the words surrounding the target word by using the objective words as an input. The CBOW architecture can function well with a small amount of data (Rasool et al. Citation2021). The SG architecture performs admirably on large datasets. Let we denote a sequence of training words with length T, the objective of skip-gram model is determined based on EquationEquation (1)
(1)
(1) (Mikolov et al. Citation2013):
where C represent the size of training context, represents a neural network with a set of parameters denoted by
.
Deep Neural Network Architectures
In this section, we shared brief overviews of the four well-known deep learning architectures.
Convolutional Neural Networks
The convolutional neural network (CNN) is a specialized deep learning architecture that uses a mathematical operation named convolution to process input data. In text mining techniques, CNN is a well-known multi-layer network employed for identifying local features (Gutiérrez et al. Citation2018; Li and Wu Citation2015).
Recurrent Neural Networks
A recurrent neural network (RNN) is a deep learning architecture which trains on sequential and time-series data (Hochreiter and Schmidhuber Citation1997). In contrast to conventional feedforward neural networks, RNN architecture processes sequences using feedback loops to retain memory over time. Recurrent units in the architecture have generic configurations with no memory units or extra gates. The input length of the RNN architecture was used to calculate the time step size.
Long Short-Term Memory
The LSTM architecture is based on RNN architecture which has feedback connections, unlike conventional RNN (Rojas‐barahona Citation2016). To cope with the vanishing gradient problem of RNN architecture, the LSTM algorithm employs a recurrent unit that contains a cell and input gate, output gate, and forget gate in total. These gates provide LSTM architectures to have the ability to retain long-term memory. Based on the cell structure, the information to be kept has been identified (Chung et al. Citation2014).
Gated Recurrent Unit
The gated recurrent unit (GRU) is a class of RNN architecture that also utilizes a gating mechanism similar to the LSTM model (Cho et al. Citation2014). However, because it only has two gates and requires fewer training parameters than LSTM design, GRU is less complicated.
Proposed Bi-Directional CNN-RNN Architecture (CGWELSTM)
To classify text sentiment, we introduce a new deep neural network architecture (CGWELSTM) in this study. Convolutional layers and large short-term memory are used in the CGWELSTM architecture to extract local and global properties from text sources. shows the outline of the CGWELSTM. The suggested technique is made up of seven main modules: an input layer, an embedding layer, a convolution layer, a group-wise enhancement mechanism, a bidirectional layer, an attention mechanism, and a fully connected layer.
Figure 1. The proposed model.
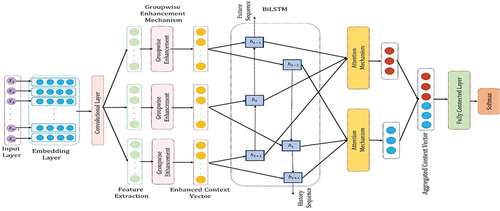
The dense vector representation of text documents was first created by the embedding layer using deep neural language models. To extract useful local characteristics, the proposed technique uses a convolutional layer. The local features acquired by the convolutional layer were subjected to the group-wise enhancement technique to improve the relevant features. In this way, important features have been given greater importance coefficients while decreasing the coefficients associated with the other features. Local features have been split up into several categories in this approach. Bidirectional LSTM has been used to analyze the augmented context feature vector further to extract comprehensive features.
Then, the attention method has been applied to the features, allowing for the assignment of various weights that affect a text’s sentiment. The sentiment orientation of text documents was lastly determined utilizing a fully linked layer and an aggregated context feature set. Details on the CGWELSTM architecture’s parts are presented in the remaining paragraphs of this section.
The Embedding Layer
The embedding layer module generates word embeddings from text using a pre-trained word2vec embedding matrix. We begin by transforming each word in an n-dimensional text document into its corresponding V-dimensional word vector and obtaining the word embedding matrix. In this way, the word embedding matrix has been obtained.
The Convolutional Layer
We apply convolutions on the word embedding matrix in the convolution layer module to extract local features. CNN obtains the local context features on the text documents at this phase. Let corresponds to the filter, with w denoting the size of the sliding window. Concatenating the initial dimensions of the associated vectors yields the following equation, which has been used to derive the local context characteristics for w words:
where f corresponds to the RELU and corresponds to the convolution. Using a succession of identical-sized filters, local CNN architectural features were retrieved from the text file. On enhanced context, the convolution operation was repeated to produce the local feature matrix.
The Group-Wise Enhancement Mechanism
Utilizing feature weighting algorithms on the local features obtained by the convolutional layer in the group-wise enhancement mechanism, informative features were recovered. The spatial group-wise enhancement technique, which was first created for picture classification problems, is a variation of the module that we’re talking about today (Li, Hu, and Yang Citation2019; Onan Citation2022). The mechanism is intended to make weight values for informative features stronger and weaker relative to uninformative feature weight values. Finding suitably distributed feature sets for developing deep neural architecture-based learning models is typically challenging due to the amount of uninformative information. Utilizing all the semantic data in important areas is the goal of the group-wise enhancement process. In this way, semantic vector has been obtained.
The word embedding matrix has V dimensions. Here, n denotes the size of the text. Initially, we divide the representation scheme into M groups, obtaining
, where
, n=V, and k corresponds to the number of groups. The group’s semantic vector has been obtained by using the following equation:
We can then determine the significance of each feature. The following equation determines the significance of features based on the similarity with the global semantic feature and the local feature
using a dot product:
We normalize c over space using the following equations to prevent biased values for samples:
where is a constant (assigned to 1e-5) that has been added for regularization. Moreover,
have been added for each coefficient
:
where the parameter values have been determined empirically (Liu and Guo Citation2019). At the end, the improved vector
was constructed by using the following equation:
The final features , where
have been obtained.
The Bidirectional Layer
In this layer, we have employed a bidirectional LSTM. Bidirectional RNN-based designs can also help in the capture of top-notch features by processing data in two directions. The following equations demonstrate that the context therefore includes both the past and the future:
where denotes the hidden state vector and ct denotes the cell state vector.
The Attention Mechanism
A distribution over the input representations can be produced by combining the attention mechanism with deep neural network topologies in a few natural language processing applications. Using the attention mechanism, one can assign different weights to features. The equations below demonstrate how attention mechanisms can be employed to assign weights to features:
where and
stand for vectors of the LSTM units and v is a trainable parameter.
The Fully Connected Layer
The first two layers of the fully connected layer employs RELU function and the last layer employs the softmax activation function. In this layer, L2-norm regularization has been employed. Here, the regularization coefficient is equal to 0.1 and the dropout parameter is equal to 0.30. The binary cross entropy function has been employed as the loss function.
Experiments and Results
This section contains information about the dataset used in the empirical analysis, the experimental procedure, and the experimental results obtained using deep neural network architectures.
Dataset
In this paper, we collected a raw dataset consists of 25,000 Turkish cryptocurrency-related tweets by using a social networking service scraper named SNScrape library. The tweets are gathered from April 20, 2021 to March 20, 2022. To do so, we fetched the tweets which are tagged to fourteen specific hashtags which are #avax, #avalanche, #bitci, #btc, #bitcoin, #chz, #chiliz, #eth, #ethereum, #solana, #xrp, #crypto, #nft, #defi. In the annotation process of the raw data, each tweet is labeled as positive, negative, neutral and not crypto-related by two annotators. After the annotation process, the size of the dataset declined to 9,548 tweets in total because we eliminated the tweets categorized as neutral and not crypto-related and the tweets which are no consensus on the labeling results of the annotators. As a result, 5,907 tweets are labeled as positive and the rest 3,641 tweets are labeled as negative. Next, we preprocessed the dataset for empirical research. Firstly, we removed tags, usernames and links, which are ineffective and meaningless data for training machine learning models, from each tweet. After that, we converted all letters to lowercase and eliminated numeric characters, extra spaces, and punctuation marks. In the next step, we performed Porter stemmer to normalize the dataset (Pedregosa et al. Citation2011). Lastly, a pre-defined NLTK Turkish stopword list was used to extract stopwords in the dataset. In addition, we assessed the predictive performance of the proposed architecture on a well-known sentiment classification benchmark (i.e., Sentiment140 dataset) in this study. It contains 1,600,000 tweets that have been automatically classified as positive or negative (Go, Bhayani, and Huang Citation2009).
Experimental Procedure
The deep neural network architectures utilized in the empirical investigation have been implemented and trained using Tensorflow and the Keras framework. To improve the predictive effectiveness of each model, we employ hyperparameter optimization. Hyperparameters were optimized using the Gaussian approach, which is based on Bayesian optimization, to achieve this. To ensure exact comparison, the same parameters have been utilized for ABCDM (Basiri et al. Citation2021). The RELU activation function was utilized for the first two layers of the fully connected layer, and the soft-max activation function was employed for the third and final layer of the fully connected layer. The convolution filters’ sizes were set at 4 and 5. The CNN’s hidden layer has a 100 × 100 dimension. For the mini batch, the sample size is 50, and the dropout coefficient is 0.30. To represent text documents, we looked into the word2vec approach with 300 dimensions. In , the hyper parameters for the proposed scheme has been summarized.
Table 1. The hyperparameters for the proposed scheme.
Baseline Models
In this study, we assessed the predictive performance of fourteen cutting-edge deep neural network designs against the architecture. The results were encouraging. The material below condenses the specifics of the underlying models utilized in the empirical analysis:
ABCDM architecture: A bidirectional layer follows an embedding layer in the model’s first stage. Parallel applications of bidirectional LSTMs and bidirectional GRUs were utilized to extract global features from text documents in the bidirectional layer. Convolution and pooling layers are utilized next, and then the attention mechanism (Basiri et al. Citation2021).
AC-BiLSTM architecture: A hybrid deep neural network with an attention mechanism is placed after a one-dimensional convolutional layer made up of varied filter sizes. Finally, the sentiment of review documents was ascertained using the fully connected layer (Liu and Guo Citation2019).
AGCNN architecture: The attention-gated layer followed the convolutional layer in the model’s progression. Maximum pooling was then employed, and then a fully connected layer (Liu et al. Citation2019) came after that.
ARC architecture: The model is made up of five modules: a bidirectional GRU, an attention mechanism, a convolutional layer, a pooling layer, and a fully connected layer (Wen and Li Citation2018).
ATTPooling architecture: An RNN with an attention mechanism based on CNNs makes up the model. The first thing CNN does is describe what makes the area unique. The attention mechanism was then used to weigh the features. Finally, a fully linked layer has been used, followed by an RNN with CNN-based attention (Usama et al. Citation2020).
CAT-BiGRU architecture: Bidirectional GRUs are used in the model to include convolution and attention. Two attention layers and a convolutional input-embedding bidirectional GRU make up this system (Kamal and Abulaish Citation2022).
CNN-GRU architecture: The model consists of a GRU recurrent unit, a max-pooling layer, and an embedding layer that made use of pre-trained vectors from word2vec (Wang et al. Citation2016).
CRNN architecture: The input word vectors are subjected to regional CNN in this model, which treats each phrase as a region. Then, local attributes are diminished via max pooling. Finally, a linear decoder is utilized to determine future valence and excitement while an LSTM layer is employed to identify longer-term dependencies (Yang et al. Citation2016).
HAN architecture: A sequence encoder, a word-based attention mechanism, a sentence-based attention mechanism, and a sentence-based attention mechanism make up the model’s four modules. This technique uses bidirectional GRUs in the sequence encoder and phrase encoder modules (Yang et al. Citation2016).
Improved word vectors (IWV) architecture: Pre-trained sentiment analysis word embedding techniques are more accurate with the help of this model. The model consists of a fully connected layer that is followed by three convolutional layers with maximum pooling (Rezaeinia et al. Citation2019).
SS-BED architecture: This model seeks to extract semantic information from text sources using two simultaneous LSTM layers. To categorize the sentiment of review materials, a fully connected neural network with a single hidden layer was deployed (Chatterjee et al. Citation2019).
Tree bi-LSTM architecture: For text classification, the model used a tree-based bidirectional LSTM architecture (Li et al. Citation2015).
Tree LSTM architecture: The model uses a recursive tree-based architecture in place of the composition layers included in traditional LSTM blocks to understand text documents (Zhu, Sobhani, and Guo Citation2015).
The weighted embedding layer, dropout layer, N-gram convolution layer (with 1-gram, 2-gram, and 3-gram convolutions), max-pooling layer, LSTM layer, and fully connected layer make up the WCNNLSTM architecture (Onan Citation2021).
Model Variations
In addition to the proposed scheme and the fourteen state-of-the-art architectures mentioned in advance, we have also considered three model variants. The following summarizes the details of the model variations used in the empirical analysis:
CGWELSTM-v1 architecture: All the elements of the proposed schemes have been used in this model, except for the group-wise enhancement mechanism. In this manner, the bidirectional layer has been provided directly with the local information that the convolutional layer extracted. The remainder of the plan is identical to the proposed scheme.
CGWELSTM-v2 architecture: All the elements of the proposed scheme have been used in this model, except for the attention mechanism. In this manner, the bidirectional layer’s global feature extractions have been combined, and the fully connected layer has continued processing the combined context vector (without the attention method).
CGWELSTM-v3 architecture: All of the elements of the suggested scheme have been used in this model, with the exception of the bidirectional layer. We have used bi-GRU in the bidirectional layer rather than bi-LSTM. The recommended methodology has been applied to the remaining modules in the same manner.
Experimental Results
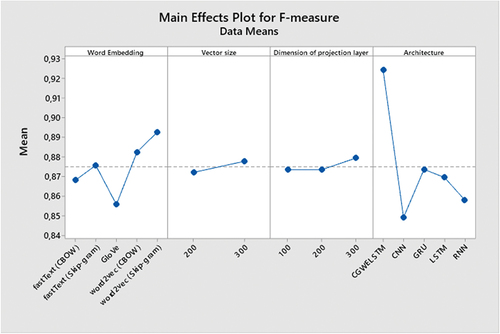
In the empirical analysis, the prediction performance, classification accuracy, precision, recall, of the three-word embedding schemes were evaluated in relation to the five deep neural network architectures (i.e. CNN, GRU, LSTM, RNN, and CGWELSTM) and F-measure. In , accuracies, precision, recall, and F-measure values received with the aid of using comparative schemes are presented, respectively. As may be visible from the empirical outcomes indexed in , the proposed scheme (ie, CGWELSTM) outperforms conventional deep neural architectures based on accuracy. Among the deep neural architectures compared, CNN offers the lowest prediction overall performance even as GRU offers the best prediction overall performance. Regarding the overall performance of word embedding methods, GloVe offers the lowest prediction overall performance and the word2vec (skip-gram) version offers the best prediction overall performance. For the 2 vector sizes taken into consideration with inside the evaluation and the 3 dimensions of the projection layer, the vector length three hundred offers better prediction overall performance, and the excellent overall performance is carried out while the projection layer length is set to three hundred. For other metrics used for predictive overall performance, particularly CGWELSTM, outperform conventional deep neural networks in terms of precision, recall, and F-measure.
Table 2. Classification accuracy values of the conventional architectures and the proposed scheme.
Table 3. Precision values of the conventional architectures and the proposed scheme.
Table 4. Recall values of the conventional architectures and the proposed scheme.
Table 5. F-measure of the conventional architectures and the proposed scheme.
display the summary figures for deep neural architectures. The CGWELSTM architecture achieved the highest average predictive performance.
Figure 2. The summary figure for accuracy.
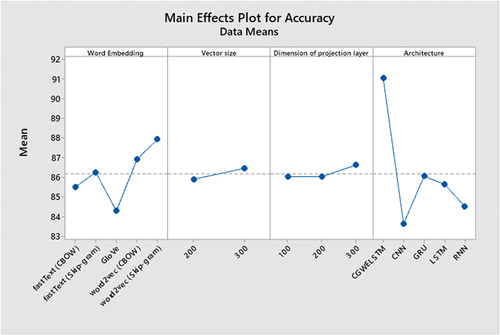
Figure 3. The summary figure for precision.
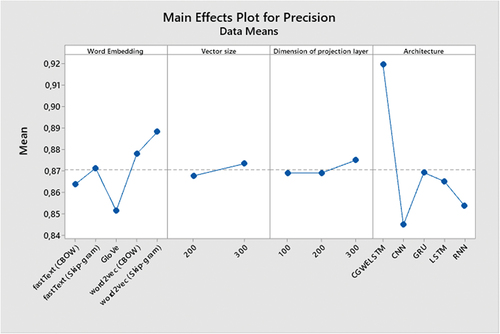
Figure 4. The summary figure for recall.
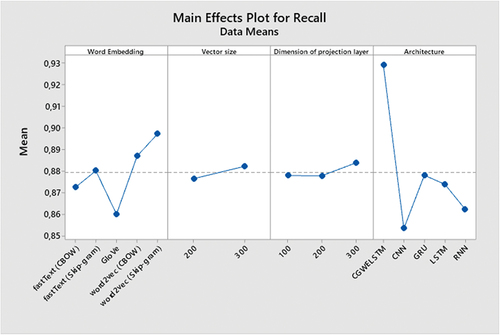
Figure 5. The summary figure for F-measure.
The proposed scheme (specifically, CGWELSTM) is compared with fourteen basic deep neural network architectures and three model variants for classification accuracy, precision, recall, and F-measure values. summarizes the classification accuracy values obtained using the compared architectures. The results show that the proposed scheme (i.e, the CGWELSTM architecture) outperforms the most advanced architectures. The CGWELSTM architecture achieved the best prediction performance on the dataset, with a predictive performance of 93.7777%. The empirical results show that the second highest prediction performance is achieved by the CGWELSTM-v3 architecture with a classification accuracy of 90.9731%. In the CGWELSTM-v3 architecture, a bidirectional gated repetitive unit (bi-GRU) is used in the bidirectional layer instead of bidirectional long short-term memory (bi-LSTM). Therefore, the empirical results show that bi-LSTM outperforms bi-GRU for text classification tasks in benchmarks. The third highest predictive performance was achieved by the ABCDM architecture, followed by the CAT-BiGRU architecture. For the results listed in , tree-LSTM, tree-bi-LSTM and SS-BED architectures give lower prediction performances on the dataset. According to the classification accuracies listed in , the use of CNN with RNN generally outperforms traditional deep neural network architectures. In addition, bidirectional architectures often achieve promising results.
Table 6. Predictive performances by the deep learning models.
The precision, recall, and F-measure metrics from the deep neural network models are also shown in . For the dataset employed in the empirical investigation, CGWELSTM outperformed the other architectures in terms of precision, recall, and F-measures. With a precision of 0.9472, recall of 0.9569, and F-measurement value of 0.9520, CGWELSTM achieved the best prediction performance in the dataset.
Three model variations were taken to evaluate the performance of the CGWELSTM. As can be seen from the results in , the use of group-wise improvement can yield better performance. In addition, bi-LSTM outperforms bi-GRU and the utilization of attention mechanisms can yield better predictive performance.
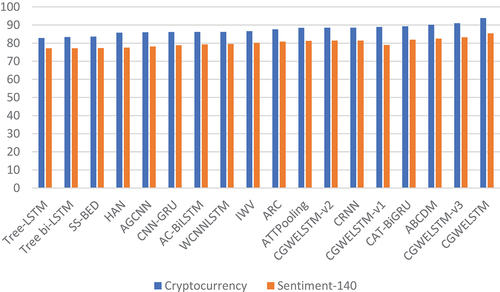
In , the predictive performance values obtained by the deep neural learning models on Sentiment-140 dataset has been presented. The empirical results indicate that the proposed scheme (i.e., CGWELSTM architecture) outperforms the state-of-the-art architectures on Sentiment-140 dataset. CGWELSTM architecture achieved the best predictive performance on the dataset, with a classification accuracy of 85.4001%. The empirical results indicate that the second highest predictive performance has been achieved by CGWELSTM-v3 architecture, with a classification accuracy of 83.9217%. In the CGWELSTM-v3 architecture, bidirectional gated recurrent unit (bi-GRU) has been employed in the bidirectional layer, instead of bidirectional long short-term memory (bi-LSTM). Hence, the empirical results indicate that bi-LSTM outperforms bi-GRU for the text classification tasks on the dataset. The third highest predictive performance has been achieved by the ABCDM architecture, which is followed by CAT-BiGRU architecture. As it can be observed from the results listed in , the tree-LSTM, tree-bi-LSTM, and SS-BED architectures yield lower predictive performances on the datasets. According to the classification accuracy values listed in , the utilization of CNN in conjunction with RNN generally outperforms the conventional deep neural network architectures. In addition, the bidirectional architectures generally obtain promising results.
Table 7. Predictive performances by the deep learning models on Sentiment-140 dataset.
In , the bar-chart for the models based on the classification accuracy values has been presented. As illustrated in , the utilization of groupwise enhancement mechanism improves the predictive performance of the deep neural network architectures. Similarly, by utilizing the attention mechanism, the predictive performance of deep neural network architectures is enhanced. Regarding the predictive performance of RNN-based architectures utilized in the bidirectional layer, the proposed scheme in which bi-LSTM has been utilized outperforms the scheme with bi-GRU (referred as, CGWELSTM-v3 architecture).
Figure 6. The bar-chart for the models based on classification accuracy.
Conclusion
Sentiment analysis (SA) is a rapidly growing branch of natural language processing research. Deep architectures have been widely used in SA due to their high predictive efficiency. RNNs are particularly adept at simulating long-term dependencies and extracting global features. Convolutional neural networks (CNNs) are capable of successfully extracting local features. Hybrid architectures combining RNN, and CNN have been shown to outperform traditional deep neural network architectures. We present a bidirectional CNN-RNN architecture for text sentiment classification in this article, as well as group-wise enhancement and attention mechanisms. Local features are derived using a convolution layer, and the weight values associated with insightful features are enhanced by the proposed scheme. The attention mechanism and the fully connected layer were used after feeding the improved context vector to the bidirectional layer to capture global features. The experimental results indicate that when performing SA tasks, the proposed scheme outperforms state-of-the-art architectures. The empirical results indicate that the proposed scheme (i.e., CGWELSTM architecture) outperforms the state-of-the-art architectures on the dataset taken into consideration in the empirical analysis. CGWELSTM architecture achieved the best predictive performance on the dataset, with a classification accuracy of 93.7737%.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Abraham, J., D. Higdon, J. Nelson, and J. Ibarra. 2018. Cryptocurrency price prediction using Tweet volumes and sentiment analysis. SMU Data Science Review 1 (3):1–3472.
- Aslam, N., F. Rustam, E. Lee, P. B. Washington, and I. Ashraf. 2022. Sentiment analysis and emotion detection on cryptocurrency related tweets using ensemble LSTM-GRU model. IEEE Access 10:39313–24. doi:10.1109/ACCESS.2022.3165621.
- Basiri, M. E., S. Nemati, M. Abdar, E. Cambria, and U. R. Acharya. 2021. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Generation Computer Systems 115:279–94. doi:10.1016/j.future.2020.08.005.
- Calefato, F., F. Lanubile, and N. Novielli. 2017. EmoTxt: A toolkit for emotion recognition from text. Proceedings of the 7th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos, 79–80, San Antonio, TX, USA, 2017 October.
- Chatterjee, A., U. Gupta, M. K. Chinnakotla, R. Srikanth, M. Galley, and P. Agrawal. 2019. Understanding emotions in text using deep learning and big data. Computers in Human Behavior 93:309–17. doi:10.1016/j.chb.2018.12.029.
- Cho, K., B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation ArXiv 2014: 1–15 . .
- Chuen, D. L. K., L. Guo, and Y. Wang. 2017. Cryptocurrency: A new investment opportunity? The Journal of Alternative Investments 20 (3):16–40. doi:10.3905/jai.2018.20.3.016.
- Chung, J., C. Gulcehre, K. Cho, and Y. Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling ArXiv 2014: 1–9.
- Colianni, S., S. Rosales, and M. Signorotti. 2015. Algorithmic trading of cryptocurrency based on twitter sentiment analysis. CS229 Project, Stanford University 1 (5):1–4.
- Çılgın, C., C. Ünal, S. Alıcı, E. Akkol, and Y. Gökşen. 2020. Metin Sınıflandırmada Yapay Sinir Ağları ile Bitcoin Fiyatları ve Sosyal Medyadaki Beklentilerin Analizi. Mehmet Akif Ersoy Üniversitesi Uygulamalı Bilimler Dergisi 4 (1):106–26. doi:10.31200/makuubd.651904.
- Di Pierro, M. 2017. What is the blockchain? Computing in Science & Engineering 19 (5):92–95. doi:10.1109/MCSE.2017.3421554.
- Go, A., R. Bhayani, and L. Huang. 2009. Twitter sentiment classification using distant supervision. CS224N Project, Stanford University 1 (12):1–6.
- Gutiérrez, G., J. Canul-Reich, A. O. Zezzatti, L. Margain, and J. Ponce. 2018. Mining: Students comments about teacher performance assessment using machine learning algorithms. International Journal of Combinatorial Optimization Problems and Informatics 9 (3):26–40.
- Haryadi, D., and G. P. Kusuma. 2019. Emotion detection in text using nested long short-term memory. International Journal of Advanced Computer Science and Applications 10 (6):351–57. doi:10.14569/IJACSA.2019.0100645.
- Hasan, M., E. Rundensteiner, and E. Agu. 2019. Automatic emotion detection in text streams by analyzing twitter data. International Journal of Data Science and Analytics 7 (1):35–51. doi:10.1007/s41060-018-0096-z.
- Hochreiter, S., and J. Schmidhuber. 1997. Long short-term memory. Neural Computation 9 (8):1735–80. doi:10.1162/neco.1997.9.8.1735.
- Huang, X., W. Zhang, X. Tang, M. Zhang, J. Surbiryala, V. Iosifidis, Z. Liu, and J. Zhang. 2021. LSTM based sentiment analysis for cryptocurrency prediction ArXiv 2021: 1–4.
- Kamal, A., and M. Abulaish. 2022. CAT-BiGRU: Convolution and attention with bi-directional gated recurrent unit for self-deprecating sarcasm detection. Cognitive computation 14 (1):91–109. doi:10.1007/s12559-021-09821-0.
- Köksal, B., G. Erdem, C. Türkeli, and Z. K. Öztürk. 2021. Twitter’da Duygu Analizi Yöntemi Kullanılarak Bitcoin Değer Tahminlemesi. Düzce Üniversitesi Bilim ve Teknoloji Dergisi 9 (3):280–97. doi:10.29130/dubited.792909.
- Lamon, C., E. Nielsen, and E. Redondo. 2017. Cryptocurrency price prediction using news and social media sentiment. SMU Data Science Review 1 (3):1–22.
- Li, X., X. Hu, and J. Yang. 2019. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks. ArXiv Preprint ArXiv:1905.09646.
- Li, J., M. T. Luong, D. Jurafsky, and E. Hovy. 2015. When are tree structures necessary for deep learning of representations? ArXiv Preprint ArXiv:1503.00185.
- Liu, G., and J. Guo. 2019. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 337:325–38. doi:10.1016/j.neucom.2019.01.078.
- Liu, Y., L. Ji, R. Huang, T. Ming, C. Gao, and J. Zhang. 2019. An attention-gated convolutional neural network for sentence classification. Intelligent Data Analysis 23 (5):1091–107. doi:10.3233/IDA-184311.
- Li, X., and X. Wu. 2015. Constructing long short-term memory based deep recurrent neural networks for large vocabulary speech recognition. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 4520–24, South Brisbane, QLD, Australia, 2015 April.
- Mehta, T., G. Kolase, V. Tekade, R. Sathe, and A. Dhawale. 2020. Price prediction and analysis of financial markets based on news social feed and sentiment index using machine learning and market data. International Research Journal of Engineering and Technology Technology 7 (6):483–89.
- Mikolov, T., I. Sutskever, K. Chen, G. Corrado, and J. Dean. 2013. Distributed representations of words and phrases and their compositionality Advances in Neural Information Processing Systems 26 3111–3119.
- Onan, A. 2021. Sentiment analysis on product reviews based on weighted word embeddings and deep neural networks. Concurrency and Computation: Practice and Experience 33 (23):e5909. doi:10.1002/cpe.5909.
- Onan, A. 2022. Bidirectional convolutional recurrent neural network architecture with group-wise enhancement mechanism for text sentiment classification. Journal of King Saud University-Computer and Information Sciences 34 (5):2098–117. doi:10.1016/j.jksuci.2022.02.025.
- Onan, A., and M. A. Toçoğlu. 2021. Weighted word embeddings and clustering‐based identification of question topics in MOOC discussion forum posts. Computer Applications in Engineering Education 29 (4):675–89. doi:10.1002/cae.22252.
- Pant, D. R., P. Neupane, A. Poudel, A. K. Pokhrel, and B. K. Lama. 2018. Recurrent neural network based bitcoin price prediction by twitter sentiment analysis. Proceedings of the IEEE 3rd International Conference on Computing, Communication and Security, Kathmandu, Nepal, 128–32, 2018 October.
- Pedregosa, F., G. Varoquaux, A. Gramfort, V. Michel, and B. Thirion. 2011. Scikit-learn: Machine learning in python. Journal of Machine Learning Research 12:2825–30.
- Raju, S. M., and A. M. Tarif. 2020. Real-time prediction of BITCOIN price using machine learning techniques and public sentiment analysis ArXiv 2020 1–14.
- Rasool, A., Q. Jiang, Q. Qu, and C. Ji. 2021. WRS: A novel word-embedding method for real-time sentiment with integrated LSTM-CNN model. Proceedings of the 2021 IEEE International Conference on Real-time Computing and Robotics, 590–95, Xining, China, 2021 July.
- Rezaeinia, S. M., R. Rahmani, A. Ghodsi, and H. Veisi. 2019. Sentiment analysis based on improved pre-trained word embeddings. Expert Systems with Applications 117:139–47. doi:10.1016/j.eswa.2018.08.044.
- Rojas‐barahona, L. M. 2016. Deep learning for sentiment analysis. Language and Linguistics Compass 10 (12):701–19. doi:10.1111/lnc3.12228.
- Salam, S. A., and R. Gupta. 2018. Emotion detection and recognition from text using machine learning. International Journal of Computer Science and Engineering 6 (6):341–45. doi:10.26438/ijcse/v6i6.341345.
- Shah, F. M., A. S. Reyadh, A. I. Shaafi, S. Ahmed, and F. T. Sithil. 2019. “Emotion detection from tweets using AIT-2018 dataset.” Proceedings of the 5th International Conference on Advances in Electrical Engineering, Dhaka, Bangladesh, 2019 September: 575–80.
- Şaşmaz, E., and F. B. Tek. 2021. Tweet sentiment analysis for cryptocurrencies. Proceedings of the 6th International Conference on Computer Science and Engineering, 613–18, Ankara, Turkey, 2021 September.
- Tikhomirov, S., E. Voskresenskaya, I. Ivanitskiy, R. Takhaviev, E. Marchenko, and Y. Alexandrov. 2018. Smartcheck: Static analysis of ethereum smart contracts. Proceedings of the 1st International Workshop on Emerging Trends in Software Engineering for Blockchain, Gothenburg, Sweden 2018 May: 9–16.
- Tocoglu, M. A., O. Ozturkmenoglu, and A. Alpkocak. 2019. Emotion analysis from Turkish tweets using deep neural networks. IEEE Access 7:183061–69. doi:10.1109/ACCESS.2019.2960113.
- Usama, M., B. Ahmad, E. Song, M. S. Hossain, M. Alrashoud, and G. Muhammad. 2020. Attention-based sentiment analysis using convolutional and recurrent neural network. Future Generation Computer Systems 113:571–78. doi:10.1016/j.future.2020.07.022.
- Valencia, F., A. Gómez-Espinosa, and B. Valdés-Aguirre. 2019. Price movement prediction of cryptocurrencies using sentiment analysis and machine learning. Entropy 21 (6):589. doi:10.3390/e21060589.
- Wang, J., L. C. Yu, K. R. Lai, and X. Zhang. 2016. “Dimensional sentiment analysis using a regional CNN-LSTM model.” Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany 2016 August: 225–30.
- Wen, S., and J. Li. 2018. “Recurrent convolutional neural network with attention for twitter and yelp sentiment classification: ARC model for sentiment classification.” Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, Hainan, China 2018 December: 1–7.
- Wołk, K. 2020. Advanced social media sentiment analysis for short-term cryptocurrency price prediction. Expert Systems 37 (2):e12493. doi:10.1111/exsy.12493.
- Wöhrer, M., and U. Zdun. 2018. “Design patterns for smart contracts in the ethereum ecosystem.” Proceedings of the 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data, Halifax, NS, Canada 2018 July:1513–20.
- Yang, Z., D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy. 2016. Hierarchical Attention networks for document classification. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA 2016 June: 1480–89.
- Zhang, X., W. Li, H. Ying, F. Li, S. Tang, and S. Lu. 2020. Emotion detection in online social networks: a multilabel learning approach. IEEE Internet of Things Journal 7 (9):8133–43. doi:10.1109/JIOT.2020.3004376.
- Zhu, X., P. Sobhani, and H. Guo. 2015. Long short-term memory over tree structures. ArXiv Preprint ArXiv:1503.04881.