
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Aiming at the problem that the Levenberg-Marquardt (LM) algorithm can not train online radial basis function (RBF) neural network and the deficiency in the RBF network structure design methods, this paper proposes an online self-adaptive algorithm for constructing RBF neural network (OSA-RBFNN) based on LM algorithm. Thus, the ideas of the sliding window method and online structure optimization methods are adopted to solve the proposed problems. On the one hand, the sliding window method enables the RBF network to be trained online by the LM algorithm making the RBF network more robust to the changes in the learning parameters and faster convergence compared with the other investigated algorithms. On the other hand, online structure optimization can adjust the structure of the RBF network based on the information of training errors and hidden nodes to track the non-linear time-varying systems, which helps to maintain a compact network and satisfactory generalization ability. Finally, verified by simulation analysis, it is demonstrated that OSA-RBFNN exhibits a compact RBF network.
Introduction
RBF neural network has been extensively applied to industrial control, pattern classification, signal processing, modeling of non-linear systems and other areas, as it has the ability of strong non-linear fitting, faster convergence, strong robustness, and is not easy to lead to local minima (Gao Citation2022; La Rosa Centeno et al. Citation2018; Zhang et al. Citation2020; Zhou, Oh, and Qiu Citation2022). Structure constructing methods and parameters tuning algorithms are the keys to construct RBF neural networks (Gu, Tok, and Yu Citation2018). Structural constructing is the strategy used to determine the number of hidden nodes in the RBF network; Parameter tuning is how to adjust three parameters in this network (Kadakadiyavar, Ramrao, and Singh Citation2020).
In recent years, considerable advancement has been proposed in the structural construction of the RBF network. The first algorithm dynamically adapts the weights of the participating kernels using the gradient descent method thereby alleviating the need for predetermined weights (Khan et al. Citation2017). The second method realizes online modeling by combing the advantages of the sliding window strategy and clustering algorithm (Jia, Li, and Qiao Citation2022). The novel algorithm provides better performance such as faster convergence rate, better local minima, and resilience against leading to poor local minima. It is a multi-kernel radial basis function neural network in which every base kernel has its weight (Atif et al. Citation2022).
Regarding architectural optimization for RBF neural networks, the most classic online algorithms are resource-allocating network (RAN), minimal resource allocating network (MRAN), and generalized growing and pruning radial basis function (GGAP-RBF). The principles mentioned above of algorithms both design the network online to meet the accuracy requirements, maintain a compact structure, and improve its generalization performance (Meng, Zhang, and Qiao Citation2021). Therefore, it is important to design an online neural network. However, these algorithms have deficiencies in networks.
John Platt (Platt Citation1991) presented RAN to test each training sample continuously. When the new training sample meets the ”‘novelty’,” a new node is allocated to the training sample. However, once the hidden nodes are added, they will not be pruned in the algorithm. Therefore, redundant hidden nodes will inevitably appear in this network for complex online learning tasks, affecting the network’s generalization performance.
To address the mentioned problems, Lu Y W et al. (Lu, Sundararajan, and Saratchandran Citation1997) proposed that MRAN is improved by RAN. On the one hand, if the deviation of the current network for multiple consecutive training samples is too large, add a hidden node; if several consecutive training samples cannot activate a hidden node, prune the node (Jia, Li, and Qiao Citation2022). To a certain extent, MRAN can obtain a compact network model. On the other hand, it also has blindness with adding nodes, because the center of the kernel function is determined randomly. Thereby it results in the poor robustness and generalization performance of the algorithms (Arif, Ray Chaudhuri, and Ray et al. Citation2009).
Based on the poor performance of the MRAN network. In (Li, Chen, and Huang Citation2006), GGAP-RBF neural network links the required learning accuracy to the significance of neurons in the learning algorithm to realize a compact RBF network. But the neural network needs to initialize the network parameters based on all samples, thus it is difficult to realize an optimal online algorithm for the RBF network.
The RAN, MRAN, and GGAP-RBF algorithms use the gradient descent method for the parameters learning algorithm. The gradient descent method is the first-order algorithm. The main problem of the first-order algorithm is slow convergence, and it is easy to lead to the local minimum of the curved error surface. In these situations, second-order algorithms are superior. The Levenberg-Marquardt (LM) algorithm (Houcine Bergou, Diouane, and Kungurtsev Citation2020) is a second-order algorithm, which is a mix of the Steepest Gradient Method and Gauss–Newton method. When the gradient of the error surface is small, the LM algorithm is similar to the Steepest Gradient Method. When the gradient of the error surface is large, the LM algorithm is similar to the Gauss–Newton method. LM can estimate the learning rate of each gradient under the curved error surface according to the Hessian matrix. The LM algorithm is efficient for training neural networks compared to the first-order algorithm (Wilamowski and Yu Citation2010).
The error correction (ErrCor) algorithm (Hao et al. Citation2014) applies the LM algorithm to train the RBF network, and after each iteration, it turns out that a much better learning ability of the RBF network can be obtained when adding a new RBF node at the location of the highest error peak or lowest error valley. This algorithm has strong robustness and can design a compact network (Xi et al. Citation2018). However, it is an offline design and difficult to apply to non-linear time-varying systems.
Based on previous research, according to the above-mentioned problems, we propose an online self-adaptive algorithm for the RBF network based on the LM algorithm. The algorithm builds a sliding window and uses the LM algorithm to train the RBF network. During the training process, it can add, prune or merge hidden nodes according to the training error information and the relevant information of each hidden node, which makes the RBF network structure compact in the learning process, and then ensures the generalization performance of the RBF network. Using the sliding window method can achieve the online application of the LM algorithm and make the RBF network more robust to changes in learning parameters and easier to converge. Finally, the performance of OSA-RBFNN is verified by simulation experiments.
The remainder of this paper is organized as follows. Section 1 introduces RBF network briefly. In Section 2, an online self-adaptive optimal algorithm for the RBF network is proposed in detail. Section 3 evaluates OSA-RBFNN through simulation analysis. Finally, the study is concluded in Section 4.
Materials and Methods
RBF Network
The RBF network comprises three feedforward network layers: the input layer, the hidden layer, and the output layer. The weight connection from the input layer to the hidden layer is fixed at 1. Without loss of generality, set the RBF network structure is I-H-1, that is I input nodes, H hidden nodes, and one output node. The structure is given in .
Figure 1. Structure of RBF networks.
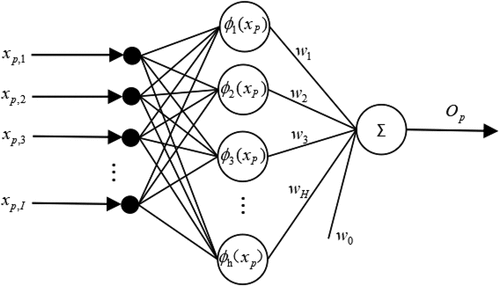
Set is the pth I dimensional sample in the RBF network, the output of the hth hidden node is as EquationEquation (1)
(1)
(1) :
Whereand
are the center vector of the hth RBF node and its width, respectively,
denotes Euclidean distance.
The output of the network for the pth sample is as EquationEquation (2)(2)
(2) :
wheredenotes the weight connecting between the hth hidden node and the output node,
is bias.
LM Algorithm
The LM algorithm is a second-order algorithm successfully applied to the back propagation (BP) network. In terms of the LM algorithm training RBF network, the paper (Wilamowski and Yu Citation2010) improved the LM algorithm. On this basis, the paper (Hao et al. Citation2014) proposed an error correction (ErrCor) algorithm to construct the RBF network structure based on the peak of error training. This algorithm belongs to the growth algorithm and can design a compact RBF network structure.
When the LM algorithm trains the RBF network, the parameter update rule is as EquationEquation (3)(3)
(3) .
Wheredenotes tuning parameter in RBF network (including centers c, widths σ, and the output weights w); Q denotes Quasi-Hessian matrix; I is the identity matrix;
is the learning coefficient; g is the gradient vector.
The training erroris calculated as the desired output
and actual output
, it is shown in EquationEquation (4)
(4)
(4) .
The elementof the nth row of the Jacobian matrix can be calculated by EquationEquation (5)
(5)
(5) .
Where n is three tuning parameters in this RBF network.
The gradient vector g is calculated through the sum of sub-vector in EquationEquation (6)
(6)
(6) .
and sub-vector is calculated as EquationEquation (7)
(7)
(7) .
Where is the row of Jacobian matrix and
is calculated as EquationEquation (4)
(4)
(4) .
The calculation of quasi-Hessian matrix Q is transformed to the sum of sub-matrices in EquationEquation (8)(8)
(8) .
For a given p training sample, and considering the tuning parameter, and
under the RBF network, the Jacobian row elements is calculated by EquationEquation (9)
(9)
(9) .
Integrating EquationEquations (1)(1)
(1) , (Equation2
(2)
(2) ), and (Equation4
(4)
(4) ), with the differential chain rule, the Jacobian row of the pth training sample in (6) can be rewritten as EquationEquations (10)
(10)
(10) ~Equation(12)
(12)
(12) .
Integrating EquationEquations (10)(10)
(10) ~(Equation12
(12)
(12) ), all the elements of Jacobian row of the jth can be calculated. For all input samples, all elements of the Jacobian matrix can be calculated. Quasi-Jacobian matrix Q and gradient vector g are obtained by EquationEquations (6)
(6)
(6) ~(Equation8
(8)
(8) ). To apply the update EquationEquation (3)
(3)
(3) for parameter adjustment.
Online Self-Adaptive Optimal Algorithm for RBF Network(OSA-RBFNN)
Although the LM algorithm is a effective algorithm for training neural networks at present, the LM algorithm can only be used in batch processing when training the RBF network. Hence, the ErrCor algorithm is an offline algorithm for designing the RBF network structure and cannot be performed online, it is not easy to apply to non-linear time-varying systems. In addition, since the RAN, MRAN, and GGAP-RBF online algorithms all use the latest single sample to train the RBF network, it leads to a poor local optimum, and if it has a sample noise impact on learning, it will result in the poor accuracy of learning. For online modeling, the reasonable method is to use the latest multiple samples to dynamically adjust the network parameters during the learning process (Arif, Ray Chaudhuri, and Ray et al. Citation2009).
The mentioned problems can be worked out by the using sliding window method in this paper (Pedro and Ruano Citation2009). The sliding window is a “FIFO” (First In First Out) queue of a fixed length. The elements of the queue are the online input sample by the entry window in chronological order. Sets online input sample is, thus the elements in the sliding window of the length of L denotes
When a new sample arrives, the sample in this window are updated by including the latest sample and eliminating the oldest. All the samples in the sliding window are the RBF network training sample.
As above, when using the sliding window method, and applying the LM algorithm to training the RBF network, the target function of RBF network learning is as EquationEquation (13)(13)
(13) .
Where L is the length of the sliding window;and
denotes desired outputs and actual outputs of the ith sample in the sliding window;
is a forgetting factor, and it can be shown as EquationEquation (14)
(14)
(14) .
Based on EquationEquations (13)(13)
(13) and (Equation14
(14)
(14) ), the latest sample has a large amount of information from online learning, the weighting coefficients of the latest sample of the sliding window are more significant than under the old sample, its weighting coefficients are small.
The online self-adaptive optimal algorithm for the RBF network in this paper has three options: adding, pruning, and merging network hidden nodes.
Adding the hidden nodes. For the process of online training, the maximum error of the samples in each sliding window is detected and recorded. Therefore, one hidden node is added to the hidden layer and regarded with its kernel function center as the training sample corresponding to the currently recorded maximum training error when the RBF network is trained to a certain step, and the root mean square error (RMSE) of the training samples in the sliding window does not reach the target value. The RMSE of the training sample in the sliding window is shown in EquationEquation (15)(15)
(15) .
Pruning the hidden nodes. If such inactive hidden nodes can be detected and removed as learning progresses, it will mean that the hidden node will lose the ability of learning. The criterion for judging whether the hidden node is activated is in EquationEquation (16)(16)
(16) (Lu, Sundararajan, and Saratchandran Citation1997).
whereis the output of the hth hidden node at time k,
is the weight connecting from hidden node h to output node at k time.
is the normalized output of the hth hidden nodes at time k,
is the value of the largest absolute value among the outputs of all hidden nodes at k time. For multiple consecutive training samples, if
is less than a threshold
, it will be pruned.
Merging the hidden nodes. In the process of learning, if the distance of the center and the width are close significantly between the two hidden nodes under the RBF network, according to the characteristics of the local response characteristics of the hidden nodes of the RBF network, the function of the two nodes is almost identical. Thus, we will merge the two hidden nodes into one. This operation will not only simplify the RBF network structure but make no difference to the learning performance of the current network. The relevant parameters can be set as EquationEquation(17)(17)
(17) .
Using the sliding window method can achieve the online application of the LM algorithm and make the RBF network more robust to changes in learning parameters and faster convergence. The structure optimization algorithm combines the advantages of RAN, MRAN, and GGAP-RBF, and it also overcomes their shortcomings. One hidden node is added to the hidden layer and regarded as its kernel function center as the training sample corresponding to the currently recorded maximum training error. It can not only reduce the training error but avoid adding hidden nodes randomly.
Considering the aforementioned problems, an online self-adaptive optimal algorithm for the RBF network can be obtained and it is shown in .
Table 1. Algorithmic depiction of OSA-RBFNN.
Results and Discussion
Computational Complexity Analysis
In the subsection, we compare the computation complexity of the traditional RBF neural network algorithm with OSA-RBFNN.
To build a compact RBF neural network structure, we adopt the sliding window method based on the LM algorithm to optimize the structure by adjusting parameters continuously. RAN, MRAN, and GGAP algorithms all use the gradient descent method, while OSA-RNFNN uses the LM algorithm for training optimization. Let m denote the number of iterations required to reach the object training error, and s denote the training step.
The gradient descent method has the characters of slow convergence and a large number of iterations, the time complexity of one iteration can be approximated as. Thus, the computational complexity of training can be approximated as
. While the LM algorithm has fast convergence and a small number of iterations, and one iteration time complexity is
, the computational complexity can be approximated as
. For the above-mentioned computational complexity, it is shown that the gradient descent method is better than the LM algorithm. However, for the RBF neural network structure, the LM algorithm can calculate the learning rate of each gradient under the curved error surface according to the Hessian matrix to obtain the optima compared to the gradient descent method. It will reduce the number of iterations largely. And OSA-RBFNN based on the LM algorithm uses the latest single sample to adjust parameters dynamically, it can reduce the training step and the training iterations to reach the object training error. Thus, the computational complexity of the LM algorithm is superior to the gradient descent method for OSA-RBFNN.
Non-Linear Function Approximation
We proposed OSA-RBFNN for constructing minimal RBF structure. According to EquationEquation (1)(1)
(1) , we build a non-linear function in EquationEquation (18)
(18)
(18) which consists of six exponential Gaussian functions (Yingwei, Sundararajan, and Saratchandran Citation1997). The function is the summation of six Gaussian exponential functions; thus, the RBF network should have six nodes with Gaussian functions in its hidden layer. In , “△” indicates the true positions of hidden unit centers from non-linear function, and the circles represent the estimated positions of centers obtained from the minimal RBF network.
Figure 2. The attribution of the true and estimated centers.
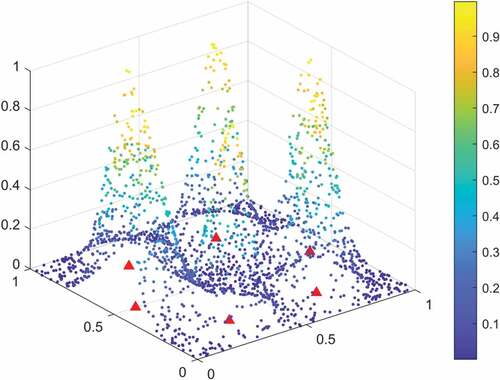
The aim is to construct a minimal RBF network using the method to approximate the function with small error. For this approximation, 2000 training sampleswere generated randomly,
and y present input and output,
And set the length of sliding window L is equal to 20.
Because of the randomness of the training results, we try running the experiment 20 times independently. The algorithm generated six hidden nodes, similar to the non-linear function, by training 16 times. In other times, we got seven hidden nodes. From , the centers, widths, and output weights for the non-linear function in the hidden nodes are quite close to the true values. Thus, OSA-RBFNN can accurately approximate the nonlinear function with minimal network size.
Table 2. Performance comparison of true and estimated value on object function.
Non-Linear Time-Varying System Identification
We choose a benchmark problem Mackey-Glass (MG) chaotic time series (Harpham and Dawson Citation2006; Jiang et al. Citation2022) generated by the differential delay EquationEquation (19)(19)
(19) to test the ability of OSA-RBFNN for non-linear time-varying system identification.
And we use the input vector to predict the output vector
. EquationEquation (19)
(19)
(19) is a static chaotic time series under the condition that τ is constant. We set τ equal to 17, 30, 50, and 100 separately to test the ability of an online self-adaptive algorithm for the RBF network to build time-varying systems. And the chaotic behavior of the system increases with the delay coefficients. shows how the delay between x(t) and x(t + 50) becomes more chaotic as τ increases.
Figure 3. Chaotic behavior of x(t) and x(t + 50).
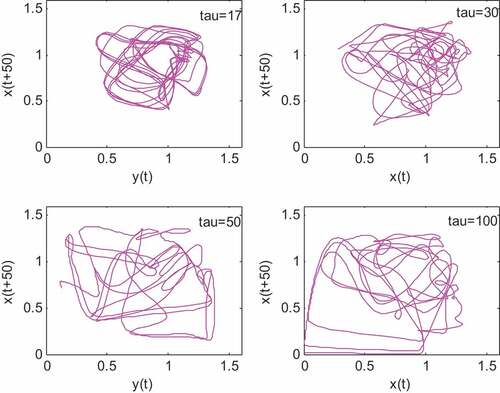
To build a time-varying system, mixing the static MG sequences with delay coefficients of 17, 30, 50, and 100 were used, and the mixing method is shown according to EquationEquations (20)(20)
(20) and (Equation21
(21)
(21) ).
By mixing four static MG sequences, i.e. τ = 17→30, τ = 30→50, τ = 50→ 100, τ = 100→50, τ = 50→30, τ = 30→17. Each changing process has 500 data. Thus, we obtain a total of 3000 samples, the first 2500 samples were selected as training samples and the last 500 samples for testing. Set the length of sliding window L is equal to 200.
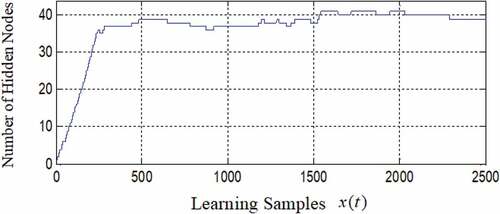
In , at the beginning of learning, the training error is large, but it is suppressed quickly by adding hidden nodes. It shows that OSA-RBFNN models the actual output well. shows the training RMSE is large at the beginning of learning and it has a small fluctuation when constructing the network, but the overall trend tends to converge. presents that when t is equal to 241, the hidden nodes reach 36, which completes the construction of the network by adding nodes. In the whole process of learning, the maximum number of hidden nodes reach 41, and the nodes reaches 39 at the end of the training.
Figure 4. The performance of online learning.
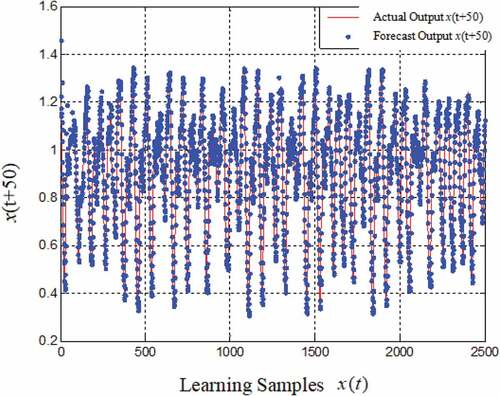
Figure 5. The performance of RMSE.
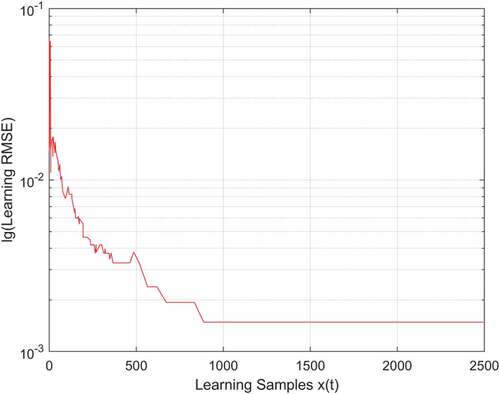
Figure 6. The change in hidden nodes.
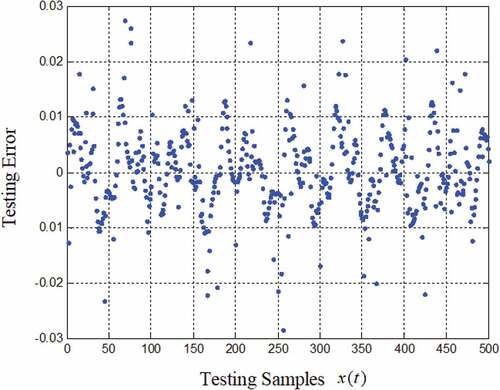
In , the maximum error is within 0.03, and the average error of 500 testing samples is 0.0072. For this experiment, we did 20 independent experiments and set the length of the sliding window L equal to 100, 150, and 200, respectively. The results show that the number of hidden nodes was between 39 and 45, and the average error of 500 testing samples was also 0.0072 ~ 0.0136, which is a stable result.
Figure 7. The testing error of 500 samples.
To further verify the effectiveness of the proposed method, we compare OSA-RBFNN with RAN and MRAN. indicates that the training RMSE and testing error of OSA-RBFNN on the MG series is lower than the other algorithms.
Table 3. The performance of comparison of different algorithms.
The reasons are that we combine the advantages of RAN and MRAN. RAN can modify the parameters of the node when adding a new one; thus, it will improve the learning speed, but the node cannot be pruned once it is added to the RBF network. MRAN can prune inactive hidden nodes to decrease the redundant hidden nodes of the RBF network. We also choose the LM algorithm to estimate the learning rate of each gradient under the curved error surface according to the Hessian matrix. Thus, the learning ability of the RBF network will be improved compared to RAN and RAN. Moreover, we employ a sliding window method to use the latest sample to adjust parameters, it can enhance the accuracy of learning and make the network more stable.
eTS (Rong, Sundararejan, Huang, and Saratchandran Rong et al. Citation2006)
OSAMNN (Qiao, Zhang, and Bo Citation2012)
Conclusion
Aiming at the deficiencies that the LM algorithm can not train online RBF network, we propose OSA-RBFNN based on the LM algorithm. We combine the sliding window method with the LM algorithm to build an online self-adaptive network. We also adopt the operations of adding, pruning, and merging hidden nodes to optimize the RBF network structure. Moreover, the hidden nodes are directly added to the training sample with the maximum training error, which can effectively suppress the training error of the current network and avoid adding hidden nodes randomly. Pruning and merging hidden nodes can reduce the impact on the RBF network performance and simplify the network structure. Finally, we have simulation analyze on non-linear function approximation and non-linear time-varying system identification, the results demonstrate that the proposed OSA-RBFNN realizes online modeling with a compact and stable structure. It has a generalization ability with a minimal structure.
Code Availability
Sample code is available on Github (https://github.com/YLiu000222/OSARBFNN)
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Arif, J., N. Ray Chaudhuri, S. Ray, et al. 2009. Online Levenberg-Marquardt algorithm for neural network based estimation and control of power systems. 2009 International Joint Conference on Neural Networks. Atlanta, GA, USA, 199–3809. IEEE.
- Atif, S. M., S. Khan, I. Naseem, R. Togneri, and M. Bennamoun. 2022. Multi-kernel fusion for RBF neural networks. Neural Processing Letters. doi:10.1007/s11063-022-10925-3.
- Gao, X. 2022. A nonlinear prediction model for Chinese speech signal based on RBF neural network. Multimedia Tools and Applications 81:5033–49. doi:10.1007/s11042-021-11612-6.
- Gu, L., D. K. S. Tok, and D.L. Yu. 2018. Development of adaptive p-step RBF network model with recursive orthogonal least squares training. Neural Compution and Applications 29 (5):1445–54. doi:10.1007/s00521-016-2669-x.
- Hao, Y., P. D. Reiner, T. Xie, T. Bartczak, and B. M. Wilamowski. 2014. An incremental design of radial basis function networks. IEEE Transactions on Neural Networks and Learning Systems 25 (10):1793–803. doi:10.1109/TNNLS.2013.2295813.
- Harpham, C., and C. W. Dawson. 2006. The effect of different basis functions on a radial basis function network for time series prediction: A comparative study. Neurocomputing 69 (16–18):2161–70. doi:10.1016/j.neucom.2005.07.010.
- Houcine Bergou, E., Y. Diouane, and V. Kungurtsev. 2020. Convergence and complexity analysis of a Levenberg–Marquardt algorithm for inverse problems. Journal of Optimization Theory and Applications 185 (3):1–18. doi:10.1007/s10957-020-01666-1.
- Jia, L., W. Li, and J. Qiao. 2022. An online adjusting RBF neural network for nonlinear system modeling. Application Intelligence. Advanced online publication. doi: 10.1007/s10489-021-03106-7.
- Jiang, Q., L. Zhu, C. Shu, and V. Sekar. 2022. An efficient multilayer RBF neural network and its application to regression problems. Neural Computing & Applications 34 (6):4133–50. doi:10.1007/s00521-021-06373-0.
- Kadakadiyavar, S., N. Ramrao, and M. K. Singh. 2020. Efficient mixture control chart pattern recognition using adaptive RBF neural network. International Journal of Information Technology 12 (4):1271–80. doi:10.1007/s41870-019-00381-z.
- Khan, S., I. Naseem, R. Togneri, and M. Bennamoun. 2017. A novel adaptive kernel for the RBF neural networks. Circuits Systems and Signal Processing 36 (4):1639–53. doi:10.1007/s00034-016-0375-7.
- La Rosa Centeno, L., F. C. C. De Castro, M. C. F. De Castro, C. Müller, and S. M. Ribeiro. 2018. Cognitive radio signal classification based on subspace decomposition and RBF neural networks. Wireless Networks 24 (3):821–31. doi:10.1007/s11276-016-1376-y.
- Li, S., Q. Chen, and G.-B. Huang. 2006. Dynamic temperature modeling of continuous annealing furnace using GGAP-RBF neural network. Neurocomputing 69 (4–6):523–36. doi:10.1016/j.neucom.2005.01.008.
- Lu, Y. W., N. Sundararajan, and P. Saratchandran. 1997. A sequential learning scheme for function approximation using minimal radial basis function neural networks. Neural computation 9 (2):461–78. doi:10.1162/neco.1997.9.2.461.
- Meng, X., Y. Zhang, and J. Qiao. 2021. An adaptive task-oriented RBF network for key water quality parameters prediction in wastewater treatment process. Neural Computing & Applications 33 (17):11401–14. doi:10.1007/s00521-020-05659-z.
- Pedro, M. F., and A. E. Ruano. 2009. Online sliding-window methods for process model adaptation. IEEE Transactions Instrumentation and Measurement 58 (9):3012–20. doi:10.1109/TIM.2009.2016818.
- Platt, J. 1991. A resource-allocating network for function interpolation. Neural computation 3 (2):213–25. doi:10.1162/neco.1991.3.2.213.
- Qiao, J., Z. Zhang, and Y. Bo. 2012. An online self-adaptive modular neural network for time-varying systems. Neurocomputing 125:7–16. doi:10.1016/j.neucom.2012.09.038.
- Rong, H.-J., N. Sundararajan, G.-B. Huang, and P. Saratchandran. 2006. Sequential adaptive fuzzy inference system (SAFIS) for nonlinear system identification and prediction. Fuzzy Sets Systems 157 (9):1260–75. doi:10.1016/j.fss.2005.12.011.
- Wilamowski, B. M., and H. Yu. 2010. Improved computation for Levenberg-Marquardt training. IEEE Transactions on Neural Networks 21 (6):930–37. doi:10.1109/TNN.2010.2045657.
- Xi, M., P. Rozycki, J.-F. Qiao, and B. M. Wilamowski. 2018. Nonlinear system modeling using RBF networks for industrial application. IEEE Transactions on Industrial Informatics 14 (3):931–40. doi:10.1109/TII.2017.2734686.
- Yingwei, L., N. Sundararajan, and P. Saratchandran. 1997. Identification of time-varying nonlinear systems using miniman radial basis function neural networks. IEEE Proceedings-Control Theory Applications 144 (2):202–08. doi:10.1049/ip-cta:19970891.
- Zhang, Y., D. Kim, Y. Zhao, and J. Lee. 2020. PD control of a manipulator with gravity and inertia compensation using an RBF neural network. International Journal of Control, Automation, and Systems 18 (12):3083–92. doi:10.1007/s12555-019-0482-x.
- Zhou, K., S.K. Oh, and J. Qiu. 2022. Design of ensemble fuzzy-RBF neural networks based on feature extraction and multi-feature fusion for GIS partial discharge recognition and classification. Journal of Electrical Engineering & Technology 17:513–32. doi:10.1007/s42835-021-00941-z.