
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The role of the stock market in the whole financial market is indispensable. How to obtain the actual trading income and maximize the interests in the trading process has been a problem studied by scholars and financial practitioners for a long time. Deep learning network can extract features from a large number of original data, which has potential advantages for stock market prediction. Based on the Shanghai and Shenzhen stock markets from 2019 to 2021, we use LSTM models, optimized on in-sample period and tested on out-of-sample period, using rolling window approach. We select the right hyperparameters at the beginning of our tests, use RBM preprocessing data, then use LSTM model to obtain expected stock return, to effectively predict future stock market analysis and predictive behavior. Finally, we perform a sensitivity analysis of the main parameters and hyperparameters of the model.
Introduction
For a long time, the prediction of future stock price trend and stock return has been an active research field. All investors and researchers hope to achieve the goal of predicting future stock price trend and stock return (Zhong and Enke Citation2017). The commonly used stock return prediction methods are roughly divided into: fundamental analysis method and technical analysis method. Fundamental analysis method is the most important analysis method that investors preparing for long-term trading should adopt (Zhu et al. Citation2008). This method focuses on the internal value of stocks and believes that the return needs time to realize. Investors focus on the future prospects of the investment company, observe the current economic factors and examine the company’s income, debt, cash flow, and growth rate from the perspective of the company’s long-term development, after forecasting and analyzing and buying stocks at the right time, you do not have to spend too much time and energy to care about the real-time trend of stock price. On the contrary, for short-term investors, fundamental analysis indicators are of little significance in daily transactions. They prefer to use moving averages, which are more time sensitive technical indicators to reflect the market faster and help them make decisions in a shorter time. Technical analysis is usually considered as a method of medium and short-term investment (Li et al. Citation2017).
With the increasing number of high-frequency trading data and the inherent complexity and dynamics of stock market prediction, researchers need to improve the relevant technology of stock market prediction, be able to extract abstract features from the data and identify the hidden relationship. Deep learning can automatically extract features from the original data. In the process of feature selection, it needs the least manual intervention and does not need the professional knowledge of macroeconomic variables and other prediction factors, so it can play a key role in stock market prediction. In addition, the market microstructure noise will lead to temporary market ineffectiveness. Many profit opportunities can be found under high frequency, and it is possible to realize statistical arbitrage. Using high-frequency data can get a large data set, and using deep neural network can overcome the problems of data snooping and over fitting in the process of using data (Bengio Citation2007). Deep neural network can reveal complex patterns and hidden relationships, analyze different indicators and their interactions, so as to predict market behavior and provide solutions that individual investors can’t deal with effectively.
We evaluate the effect of deep learning as a stock return prediction tool and the potential of applying deep learning to broader financial market prediction. There are great differences in the selection of network structure, activation function, and other model parameters. This paper makes a systematic and comprehensive analysis on the application of deep learning. In particular, using stock return as the input data of deep neural network, the overall ability of LSTM neural network to predict future market behavior is tested.
The results show that the prediction performance of deep learning network depends on environmental factors and user determined factors. LSTM deep neural network is effective and can improve the prediction accuracy of stock return. In addition, we also explain how to construct and evaluate the stock return prediction model based on deep learning, which enriches the research of financial prediction market.
Related Research
The stock market changes rapidly, there are many interference factors, and the periodic data are insufficient. Stock trading is a game process under incomplete information. The single objective supervised learning model is difficult to deal with this kind of sequential decision-making problem. Deep learning is one of the effective ways to solve this kind of problem. Traditional quantitative investment is mostly based on technical indicators, with poor adaptability and short investment life. This research aims to introduce the deep learning model into the application of the financial field. Deep learning can process the massive data in the financial market, enhance the ability of data processing and extracting features from the transaction signals to achieve the purpose of stock return analysis (J, S. Z., et al., Citation2012). For example, stock trading is a sequential decision-making method, and deep learning is to learn multi-stage behavior strategies (Yeh et al., Citation2011). This method can determine the best return in a certain state and minimize the transaction cost. Therefore, it has the best practicability in the field of investment.
Because of the great success of deep learning in image classification, natural language processing and various time series problems, people apply deep learning to the field of finance. Deep neural network automatically finds the corresponding representation of low dimension by extracting high-dimensional input data. Its core is to integrate the deviation of responders into the hierarchical neural network structure (Evermann, Rehse, and Fettke Citation2017). Therefore, deep learning has strong ability of perception and feature extraction. Recurrent neural network has recursive feedback connection between neuron cells to form a directed cycle. It can retain and use the information in past data to help predict future events, and can provide a scheme for the construction of cognitive decision-making system of complex system.
Deep neural network provides good stability, universality, and scalability through big data. As candel et al said, “because it performs quite well on many different problems, deep learning is rapidly becoming the preferred algorithm with the highest prediction accuracy (Baranochnikov et al., Citation2022).” The deep neural network will first have an input layer to match the feature space, then multiple nonlinear layers, and finally a linear regression or classification layer to match the output space. Each non-output layer of the network includes a bias unit (Tumminello et al., Citation2010). The output of the whole network will be determined by the weight obtained by connecting neurons and deviation from other neurons (Ballings et al. Citation2015). Therefore, these weights are adjusted to minimize the error on the labeled training data connecting neurons and deviations with other neurons, and fully determine the output of the whole network; When these weights are adjusted to minimize the error on the training data, learning will occur and minimize the loss function of each training instance. Deep learning structure is a model of hierarchical feature extraction, which usually involves multiple levels of nonlinearity (Kijewski and Ślepaczuk Citation2020). It can learn the useful representation of original data and show high performance on complex data.
Long-short term memory (LSTM) neural network can connect the current and previous events, and this structural time series design method has high accuracy and only depends on the previous events. Therefore, combining different methods and technologies is the fundamental to improve the accuracy of prediction. The research of scholars at home and abroad has also proved this. Sharang published a study on the application of deep belief network (DBN), which is composed of stacked restricted Boltzmann machines, coupled with multilayer perceptron (MLP), and uses the long-range logarithmic return of stock price to predict the return higher than the median (Sharang and Rao Citation2015). Xiong applied long-term and short-term memory (LSTM) neural network to model the volatility of S & P 500 index, and used Google stock domestic trend as an index of market volatility for relevant research (Xiong, Nichols, and Shen Citation2015); Fischer and Krauss successfully applied long-term and short-term memory (LSTM) to financial stock market prediction (Fischer and Krauss Citation2017). The research data set is synthesized by the S & P 500 index. The S & P 500 index combines the list into a binary matrix to eliminate bias and effectively applies the optimizer called “rmsprop.” We put forward the robust concept of time series prediction. The main advantage of the research is that it adopts the most advanced in deep learning technology to provide financial market prediction. The performance of LSTM neural network is better than traditional DNN and logistic regression algorithms. Their methods show that LSTM neural network is suitable for financial time series prediction tasks different from short-term price trend prediction (Grudniewicz and Ślepaczuk Citation2021). Therefore, we use the coupling of restricted Boltzmann machine and Long-short term memory (LSTM) neural network, and use the long-range logarithmic return of stock price to predict the return above the median.
Theoretical Model
Deep Learning Framework for Stock Return Prediction
For each stock, we seek a predictor function in order to predict the stock return at time
given the features
extracted from the available information at time
. We assume that
can be decomposed into two parts: the predictable part
=
and the unpredictable part
,
represents the linear transformation or nonlinear transformation of the current information, including
和
The original available information is defined as the past return of the sample stock. Suppose there are n stocks in the sample and g lagged returns are selected, has the following form:
where represents the past earnings of the
th stock in the period
. In the following part, we will use deep neural network to construct prediction function
and conversion function
, and how to use different data representation methods to construct conversion function.
Data Representation Method
The performance of machine learning algorithm largely depends on the choice of data representation method (Gurjar et al. Citation2018). Therefore, converting the original data before input can improve the performance of machine learning task. We use limited Boltzmann machine to process the data (Thawornwong and Enke Citation2004).
Restricted Boltzmann Machine (RBM)
RBM processes input variables and output variables
, defines a function
, and obtains the formula from the joint probability density function of
和
(Hinton Citation2002):
Where is the partition function. In most cases,
is assumed to be a
-dimensional binary variable,
.When
is a binary or real-valued variable (Taylor et al. Citation2006), there is a performance function
where ,
are the model parameter.
set as identity matrix; This makes machine learning easier and simpler with less performance loss (Selvin et al. Citation2017). According to Equationequations (5)
(5)
(5) and (Equation6
(6)
(6) ), the conditional probability distribution is as follows:
where is the sigmoid function,
和
is the row
and column
of
. This RBM is called Gauss Bernoulli restricted Boltzmann machine. Then, the conditional probability distribution is used to represent and reconstruct the input data (Nti, Felix, and Asubam Citation2020). Given an input data set
, the maximum log likelihood learning formula is as follows:
=
is a model parameter. Because it is difficult to calculate the partition function, the learning method of comparative difference is usually used to estimate the model parameters.
Deep Neural Network
The neural network establishes the nonlinear relationship between two variables. The specific relationship formula is as follows:
Among σ is called activation function, which is used to realize the nonlinear transformation of weighted data. The commonly used choices are logistic sigmoid () and hyperbolic tangent () functions, but it is usually different in different network structures. is the weight matrix and
is the offset vector.
Weight matrix
Multilayer neural networks extended by advanced learning methods are usually called deep neural networks. The deep neural network can be expressed by superimposing different levels of features according to the needs of the task, and build a deep structure to identify the patterns and relationships related to the corresponding learning task (Roy et al. Citation2015). Deep neural network operates the high-dimensional original input data, and uses its ability of automatic feature learning to complete the modeling task. The prediction function is constructed by superimposing the network function in the following order (it is the number of layers of the deep neural network):
Given the input data set and objective function
, as well as an error function
. In order to make the output function
=
and the objective function
, the weight of each node can be adjusted and the model parameters of the whole network can be optimized, so the total error
can be minimized. (
)
Select the appropriate , its gradient can be obtained by error back propagation analysis. In this case, the minimization problem in (14) can be solved by the usual gradient descent method. The typical form of objective function is as follows:
Where and
represent Euclidean norm and matrix norm, respectively, the second item is the added “Regularizer.” In Equationequation (15)
(15)
(15) , the second term is regularized to avoid overfitting, and the coefficient is determined at the same time.
LSTM Neural Network
LSTM is a variant of deep neural network, which has the ability to read and interpret sequential data such as text or time series (Babu and Reddy Citation2014). LSTM network has the ability to use storage units and gates to maintain its status information. These gates enable these networks to reject irrelevant information in the past, remember important information in the current state, and capture the input of the system at the current time, so as to generate output as the prediction of the next time. The state vector in the LSTM memory unit performs aggregation of the old information received from the forget gate and the latest information received from the input gate. Finally, the output gate generates output from the network in the current time slot. This output can be regarded as the next predicted value calculated by the model. In short, LSTM neural network is a powerful tool in the field of machine learning. It can extract features, dimensions, and improve data classification. It is a machine language with the ability to learn internal representation and solve complex combinatorial problems.
Model Data and Trend Prediction
We construct a deep neural network using stock returns from the stock returns of Shanghai and Shenzhen stock markets in 2019–2021. First, we choose the top 50 stocks with average income ranking, and keep only the stocks which have a price record over the entire sample period (50 stocks are listed in ) (Tsai and Hsiao Citation2010). The stock return is expressed as , which
means the time difference of five minutes (Castellano Gomez et al. Citation2021). Each stock in the sample has 750 trading days and 37,500 five-minute return data. Data preprocessing and processing is in Python 3.8 based on Numpy and Pandas packages, RBM and LSTM are implemented with tensorflow. In order to evaluate the performance of the model and avoid over fitting in the training process, we used a rolling window approach, the data set is divided into in-sample (training and validation) and into out-of-sample (test), the training set consists of the first 80% of the samples, including 30,000 stock returns, and the validation set consists of the remaining 20%, including 7500 stock returns, the test set uses 3125 stock returns in the next three months to test (Kim and Sayama Citation2017). After making the predictions, the window was moved ahead, by the number of periods equal to test set and the model was retrained from scratch (Saâdaoui and Messaoud Citation2020). Model checkpoint callback function was used to store the best weights (parameters) of the model, based on the lowest loss function value from all trained epochs. These weights were then used for prediction on the test set data. (Jakub Michan´ ków et al. 2022)
Table 1. The sample stocks. They are chosen from the stock returns of Shanghai and Shenzhen stock markets with average return ranking.
Training set: , Test set:
All stock returns are standardized by using the mean and standard deviation
of the training set (Wang et al., Citation2011). The standardized rate of return is:
, and 10 lagged returns of stocks in the sample are used as data input each time:
Evidence of Predictability in the Shanghai and Shenzhen Stock Market
As an example of prediction, we carry out a simple experiment to see whether past returns have predictable power for future returns (Bui and Ślepaczuk Citation2021). We first divide the returns of each stock into two groups according to the mean or variance of 10 lagged returns: if the mean of lagged returns, , is greater than a certain threshold λ, the return is assigned to one group; otherwise, it is assigned to the other group. Similarly, by comparing the variance of lagging returns,
, with a threshold ρ, the returns are divided into two groups.
The classification is carried out in the training set, and the threshold λ and ρ are chosen for each stock so that the two groups have the same size (Rundo Citation2019). These thresholds are then applied to the test set to classify the returns, and the mean and variance of each group are calculated (Yoshihara et al. Citation2014).
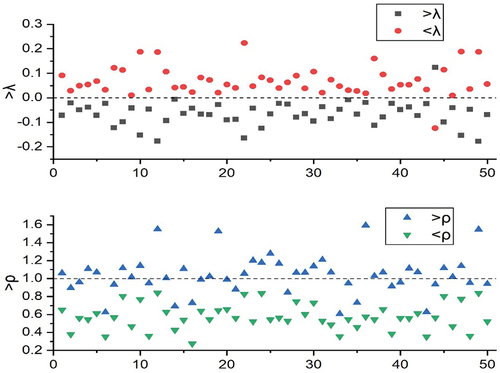
The results are shown in and . It is clear from the first chart that the average rate of return > λ. The prices of all stocks except 44 are lower than those of the other group. Obviously, the average difference between the two groups is significant for all stocks at a 99% confidence interval. Under the 99% confidence interval, the variance difference of all stocks is significant. This shows that the past returns do have a certain prediction ability, which can further use deep feature learning (Zhang et al. Citation2021).
Table 2. Mean and variance of stock returns of each group in the test set. The second and the third columns are mean returns of each group and the fourth column is the p-value of t-test on the mean difference. The last three columns are variances of the returns and the p-value of F-test on the variance difference.
Figure 1. Mean and variance of stock returns of each group in the test set. The figure above shows the average return of each group of stocks defined by the average value of past return. The following figure shows the variance of each group of returns defined by the variance of past returns. The x-axis represents the stock serial number.
Market Representation and Trend Prediction
Restricted Boltzmann machine (RBM) is used to receive the original feature input and generate the output, . and show the prediction accuracy and reference accuracy of each data set through RBM.
Figure 2. Upper figure: prediction accuracy and reference accuracy of each data set. Figure below: difference between test set precision.
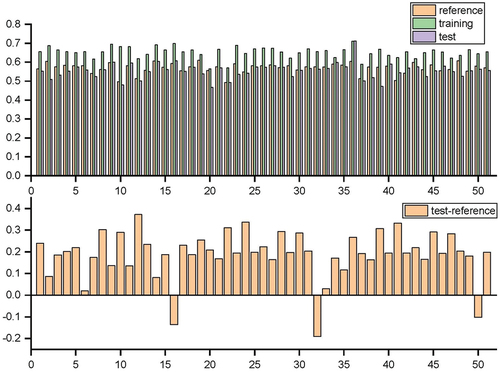
Table 3. Up/Down prediction accuracy of RBM.
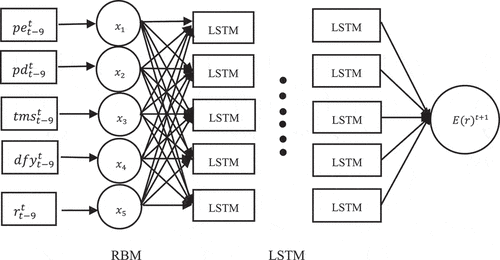
Then, according to the prediction function =
, the LSTM neural network is used to predict its performance (Nguyen and Ślepaczuk Citation2022), and compared with the univariate autoregressive model (AR (10)) with 10 lag returns. Input variable: price/return ratio (PE); Price/dividend ratio (PD); Period difference (TMS); Default spread (dfy); Lagging stock return (R). Output variable: stock return forecast (Thawornwong and Enke Citation2004). Through the RBM input variables, the LSTM network is trained by minimizing the objective function defined in Equationequation (15)
(15)
(15) through 3000 learning iterations, and the 3125 stock returns in the next three months are used as the verification set stopped in advance to avoid overfitting (Chai, Draxler, and Stein Citation2015).(As shown in )
Figure 3. Data processing flow chart.
Hyperparameters Turning
During our research, we conducted detailed hyperparameters tuning to ensure the best possible results from our model (Michańków et al. Citation2022). During the process, we optimized the following parameters:
The number of layers (5) and neurons in each layer (512/256/128).
Dropout rate (0.02) and L2 kernel regularization (0.0005).
The optimizer (Adam variants).
Learning rates (0.005) and momentum values (0.5).
As for the input data, we tuned the training and testing/rolling window sizes, sequence length (2–20), batch size (from 16 to test size) and training process duration, which was set by the number of epochs (10–300), as well as callback functions of early stopping and model checkpoint. Only the first window of data was used for tuning, and the best hyperparameters were then used for the remaining iteration during the walk forward predictions.
Most of the tuning was done using the Tensorflow framework, we could test how changes to several parameters at once would affect the network performance, instead of testing each hyperparameter separately (Srivastava et al. Citation2014). In addition, we also conducted a careful manual sensitivity analysis on the parameters that had the most impact on the results. (Jakub Michan´ ków et al. 2022)
Performance Evaluation
We evaluate the prediction performance using four measures: normalized mean squared error (NMSE), root mean squared error (RMSE), mean absolute error (MAE), and mean absolute directional loss (MADL). (Jakub Michan´ ków et al. 2022)
Normalized Mean Squared Error
Given a set of target returns and their predicted values, , NMSE formula is as follows:
NMSE=
Where var () represents variance and NMSE is the minimum MSE normalization obtained from constant prediction.
Root Mean Square Error
RMSE is the square root of MSE. The RMSE formula is as follows:
RMSE=
Mean Absolute Error
MAE is calculated as follows:
The inequality is applicable to the measurement of RMSE and NMSE, and their size relationship; MAE≤RMSE≤NMAE; Although Mae gives the same weight to all error quantities, RMSE is more sensitive to outliers and more suitable for normal distribution errors (Chai, Draxler, and Stein Citation2015).
Mean Absolute Directional Loss (MADL)
In order to improve the usefulness of forecasting ability of LSTM model in algorithmic investment strategies (AIS), we adopted Jakub Michan´ ków et al.’s Mean Absolute Directional Loss (MADL) that can be calculated using the following formula:
where: MADL is the Mean Absolute Directional Loss, is the observed return on interval
,
is the predicted return on interval
. This way, the value the function returns will be equal to the observed return on investment with the predicted direction, which allows the model to tell if the prediction will yield profit or loss and how much this profit or loss will be. The function of MADL is minimized, so that if it returns the negative values the strategy will make a profit, and if it returns a positive value the strategy will generate a loss. MADL was the main loss function used in hyperparameters tuning and in the estimation of the LSTM model.
Prediction Results
We use classic loss function NMSE, RMSE, MAE and MADL loss function, NMSE, RMSE, MSE were used as our starting point in comparing the performance of LSTM networks, we saw that results based on MADL function are much better in prediction.
shows the performance of LSTM network in NMSE, RMSE, MSE, MADL, MADL-AR. MADL is more accurate than classic loss function prediction. We combine LSTM with AR (10) to enhance predictability. When LSTM is applied to the residuals of AR (10), MADL increases slightly, with little effect, but the characteristics are consistent. Regardless of the feature selection, LSTM improves prediction performance for all representations.
Table 4. Performance of LSTM network in NMSE, RMSE, MSE, MADL, MADL -AR.
Sensitivity
We compute the gradient of each predictor function with respect to the input features to identify the contribution of each feature to the prediction (Cakra and Trisedya Citation2016). We compute a sensitivity matrix from the test set as follows:
where is
of the
th data in the test set. The sensitivities are visualized in . White color represents zero sensitivity and a darker color means a higher sensitivity. It is interesting to note that, for LSTM, the sensitivity of
is particularly high with respect to
for
, and
.
Figure 4. Heat map of the sensitivity matrix. This represents the sensitivity of the predictor functions with respect to the past returns. y-axis represents the prediction function of each stock return, and x-axis represents the past returns of the stocks in the order of ,
, … … ,
,
, … … ,
. Sensitivities to the lagged returns with lag > 5 are omitted as their values are close to 0. White represents zero sensitivity and darker color means higher sensitivity.

Conclusion
Our research suggest that the stock returns are predictable to some extent, a stock market prediction model based on deep feature learning is proposed. From the original level input composed of lagging stock returns, the data are represented by restricted Boltzmann machine, and the LSTM neural network is constructed to predict the future stock returns. The results show that LSTM performs better than linear autoregressive model in the test set. The prediction of stock return is mainly affected by the lag return. By applying LSTM to the residual of autoregressive model, it is found that LSTM can extract additional information and improve the prediction. These research results can help high-frequency traders improve stock returns, predict overall market returns and risks, and can also be used in the trading market of index derivatives such as index futures and options.
One of the main advantages of LSTM neural network is that it can extract features from a large number of original data without relying on the prior knowledge of predictors. This makes deep learning especially suitable for stock market prediction. In stock market prediction, many factors affect stock prices in complex and nonlinear ways. If there are factors with predictable evidence, these factors can be used as part of the input data of in-depth learning to determine the relationship between these factors and stock price.
As one of the studies to test the effectiveness of deep feature learning in stock market analysis and prediction, we provide a direction for the expansion and further research of the advantages of deep learning network. The combination of limited Boltzmann machine and LSTM network function can provide better performance. In addition, the equity risk premium needs to be considered in future research. It is also noted that when the training set is too refined, the risk of overfitting will increase.
Acknowledgments
The work is supported by the following project grants, National Social Science Foundation funded project Research on vulnerability diagnosis and ‘data governance’ model of urban drainage system(17BGL210); Tianjin’s key soft science research project Research on Countermeasures to vigorously promote global science popularization in Tianjin(19ZLZDZF00270).
Disclosure statement
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Data Availability Statement
All employed data will be made available on reasonable request. http://data.cnstock.com/
Additional information
Funding
References
- Babu, C. N., and B. E. Reddy. 2014. A moving-average filter based hybrid ARIMA–ANN model for forecasting time series data. Applied Soft Computing 23 (Complete):27–3927. doi:10.1016/j.asoc.2014.05.028.
- Ballings, M., V. Dirk, N. Hespeels, and R. Gryp. 2015. Evaluating multiple classifiers for stock price direction prediction. Expert Systems with Applications 42 (20):7046–56. doi:10.1016/j.eswa.2015.05.013.
- Baranochnikov, I. Ś. R., 2022, A comparison of LSTM and GRU architectures with the novel walk-forward approach to algorithmic investment strategy, Working papers of faculty of economic sciences, University of Warsaw, WP 21/2022 (397), https://www.wne.uw.edu.pl/application/files/3516/5945/4534/WNE_WP397.pdf.
- Bengio, Y. 2007. Scaling learning algorithms towards ai. Large Scale Kernel Machines 34 (5):1–41. doi:10.1016/j.asoc.2014.05.028.
- Bui, Q., and R. Ślepaczuk. 2021. Applying hurst exponent in pair trading strategies on nasdaq 100 index. Physica A: Statistical Mechanics and Its Applications 592:126784. https://www.sciencedirect.com/science/article/abs/pii/S037843712100964X.
- Cakra, Y. E., and B. D. Trisedya. Stock price prediction using linear regression based on sentiment analysis. International Conference on Advanced Computer Science & Information Systems USA, IEEE, 2016.
- Carreira-Perpinan, M. A., and G. E. Hinton 2005. On contrastive divergence learning. proceedings of artificial intelligence & statistics R5: 33–40 . .
- Castellano Gomez, S., and R. Ślepaczuk, 2021, Robust optimization in algorithmic investment strategies, Working papers of faculty of economic sciences, University of Warsaw, WP 27/2021 (375), https://www.wne.uw.edu.pl/application/files/8616/3847/9793/WNE_WP375.pdf.
- Chai, T., R. Draxler, and A. Stein. 2015. Source term estimation using air concentration measurements and a lagrangian dispersion model – experiments with pseudo and real cesium-137 observations from the fukushima nuclear accident. Atmospheric Environment 106 (apr):241–51. doi:10.1016/j.atmosenv.2015.01.070.
- Evermann, J., J. R. Rehse, and P. Fettke. 2017. Predicting process behaviour using deep learning. Decision Support Systems 100:129–40. doi:10.1016/j.dss.2017.04.003.
- Fischer, T., and C. Krauss. 2017. Deep learning with long short-term memory networks for financial market predictions. European Journal of Operational Research 270 (2):654–69. doi:10.1016/j.ejor.2017.11.054.
- Grudniewicz, J., and R. Ślepaczuk, 2021, Application of machine learning in quantitative investment strategies on global stock markets, Working Papers of faculty of economic sciences, University of Warsaw, WP 23/2021 (371), https://www.wne.uw.edu.pl/files/6216/3603/4435/WNE_WP371.pdf.
- Gurjar, M., P. Naik, G. Mujumdar, and T. Vaidya. 2018. Stock market prediction using ann. International Research Journal of Engineering and Technology 5 (3):2758–61.
- Hinton, G. E. 2002. Training products of experts by minimizing contrastive divergence. Neural Computation, págs1771–1800. doi: 10.1162/089976602760128018.
- J, S. Z. et al. 2012. A review of research on deep learning. Computer Application Research 29 (8):2806–10. doi:10.48550/arXiv.1206.5538.
- Kijewski, M., and R. Ślepaczuk, 2020, Predicting prices of S&P500 index using classical methods and recurrent neural networks, Working papers of faculty of economic sciences, University of Warsaw, WP 27/2020 (333), https://www.wne.uw.edu.pl/application/files/4616/3609/7114/WNE_WP333.pdf.
- Kim, M., and H. Sayama. 2017. Predicting stock market movements using network science: An information theoretic approach. Applied Network Science 2 (1):35. doi:10.1007/s41109-017-0055-y.
- Li, Z. B., G. Y. Yang, Y. C. Feng, and L. Jing. 2017. Empirical test of Fama French five factor model in China’s stock market. Financial Research 6:191–206.
- Michańków, J., P. Sakowski, and R. Ślepaczuk. 2022. The comparison of LSTM in algorithmic investment strategies on BTC and SP500 index. Sensors 22:917. doi:10.3390/s22030917.
- Nguyen, V., and R. Ślepaczuk. 2022. Applying hybrid ARIMA-SGARCH in algorithmic investment strategies on S&P500 Index. Entropy 24 (2):158. doi:10.3390/e24020158.
- Nti, I. K., A. A. Felix, and W. B. Asubam. 2020. A systematic review of fundamental and technical analysis of stock market predictions. Artificial Intelligence Review 53 (4):3007–57. doi:10.1007/s10462-019-09754-z.
- Qiu, M., Y. Song, and F. Akagi. 2016. Application of artificial neural network for the prediction of stock market returns: The case of the japanese stock market. Chaos Solitons & Fractals the Interdisciplinary Journal of Nonlinear Science & Nonequilibrium & Complex Phenomena 85:1–7. doi:10.1016/j.chaos.2016.01.004.
- Roy, S. S., D. Mittal, A. Basu, and A. Abraham. 2015. Stock market forecasting using lasso linear regression model. Springer International Publishing. doi:10.1007/978-3-319-13572-4_31.
- Rundo. 2019. Deep LSTM with reinforcement learning layer for financial trend prediction in fx high frequency trading systems. Applied Sciences 9 (20):4460. doi:10.3390/app9204460.
- Saâdaoui, F., and O. B. Messaoud. 2020.Multiscaled neural autoregressive distributed lag: A new empirical mode decomposition model for nonlinear time series forecasting. International Journal of Neural Systems 30: 2050039.doi: 10.1142/S0129065720500392
- Selvin, S., R. Vinayakumar, E. Gopalakrishnan, V. K. Menon, and K. Soman (2017). Stock price prediction using lstm, rnn and cnn-sliding window model. In 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), USA, pp. 1643–47. IEEE.
- Sharang, A., and C. Rao 2015. Using machine learning for medium frequency derivative portfolio trading. Papers. doi: 10.48550/arXiv.1512.06228.
- Srivastava, N., G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929–58. doi: 10.1016/j.neucom.2015.09.116.
- Taylor, G. W., G. E. Hinton, and S. T. Roweis. 2006. Modeling human motion using binary latent variables. Advances in Neural Information Processing Systems 19, 1345–52.
- Thawornwong, S., and D. Enke. 2004. The adaptive selection of financial and economic variables for use with artificial neural networks. Neurocomputing 56:205–32. doi:10.1016/j.neucom.2003.05.001.
- Ticknor, J. L. 2013. A bayesian regularized artificial neural network for stock market forecasting. Expert Systems with Applications 40 (14):5501–06. doi:10.1016/j.eswa.2013.04.013.
- Tsai, C.-F., and Y.-C. Hsiao. 2010. Combining multiple feature selection methods for stock prediction:Union, intersection, and multi-intersection approaches. Decision Support Systems 50 (1):258–69. doi:10.1016/j.dss.2010.08.028.
- Tumminello, M., F. Lillo, and R. N. Mantegna. 2010. Correlation, hierarchies, and networks in financial markets. Journal of Economic Behavior & Organization 75 (1):40–58. doi:10.1016/j.jebo.2010.01.004.
- Wang, J.-Z., J.-J. Wang, Z.-G. Zhang, and S.-P. Guo. 2011. Forecasting stock indices with back propagation neural network. Expert Systems with Applications 38 (11):14346–55. doi:10.1016/j.eswa.2011.04.222.
- Xiong, R., E. P. Nichols, and Y. Shen. 2015. Deep learning stock volatility with google domestic trends. arXiv preprint arXiv :151204916 2015 .
- Yeh, C.-Y., C.-W. Huang, and S.-J. Lee. 2011. A multiple-kernel support vector regression approach for stock market price forecasting. Expert Systems with Applications 38 (3):2177–86. doi:10.1016/j.eswa.2010.08.004.
- Yoshihara, A., K. Fujikawa, K. Seki, and K. Uehara 2014. Predicting stock market trends by recurrent deep neural networks. In Pacific rim international conference on artificial intelligence. 759–69. doi: 10.1007/978-3-319-13560-1_60.
- Zhang, X., G. Naijie, C. Jie, and Y. Hong. 2021. Predicting stock price movement using a dbn-rnn. Applied Artificial Intelligence 35 (12):876–92. doi:10.1080/08839514.2021.1942520.
- Zhong, X., and D. Enke. 2017. Forecasting daily stock market return using dimensionality reduction. Expert Systems with Applications 67:126–39. doi:10.1016/j.eswa.2016.09.027.
- Zhu, X., H. Wang, L. Xu, and H. Li. 2008. Predicting stock index increments by neural networks: The role of trading volume under different horizons. Expert Systems with Applications 34 (4):3043–54. doi:10.1016/j.eswa.2007.06.023.