
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Model-based clustering technique is an optimal choice for the distribution of data sets and to find the real structure using mixture of probability distributions. Many extensions of model-based clustering algorithms are available in the literature for getting most favorable results but still its challenging and important research objective for researchers. In the model-based clustering, many proposed methods are based on EM algorithm to overcome its sensitivity and initialization. However, these methods treat data points with feature (variable) components under equal importance, and so cannot distinguish the irrelevant feature components. In most of the cases, there exist some irrelevant features and outliers/noisy points in a data set, upsetting the performance of clustering algorithms. To overcome these issues, we propose a fuzzy model-based t-clustering algorithm using mixture of t-distribution with an regularization for the identification and selection of better features. In order to demonstrate its novelty and usefulness, we apply our algorithm on artificial and real data sets. We further used our proposed method on soil data set, which was collected in collaboration with and the assistance of Environmental laboratory Karakoram International University (GB) from various point/places of Gilgit Baltistan, Pakistan. The comparison results validate the novelty and superiority of our newly proposed method for both the simulated and real data sets as well as effectiveness in addressing the weaknesses of existing methods.
Introduction
The most common obstacle in machine learning and pattern recognition is to divide intrinsic structure of given data set into similar group, which is famously known as clustering (Jain and R, Citation1988; Mcnicholas, Citation2016). Cluster analysis, also known as unsupervised learning, is one of the most significant and successfully employed techniques that has noteworthy application in various areas such as wireless networking and Remote Sensing (Abbasi and Younis, Citation2007; Gogebakan and Erol, Citation2018), computational biology (Gogebakan, Citation2021; Yang and Ali, Citation2019), imaging processing (Chuang et al., Citation2006), soft computing (Gogebakan, Citation2021), data segmentation (Gogebakan and Hamza Citation2019), agriculture (Kadim and Wirnhardt, Citation2012), ecology (Rasool et al., Citation2016), data mining (Agrawal et al.,Citation2005) and economics (Garibaldi et al., Citation2006) etc. There are two major areas of clustering algorithms, namely, model-based clustering and nonparametric approach (McLachlan and Basford, Citation1988). For nonparametric approach, clustering methods are based on objective functions where K-Mean, Fuzzy C-mean and Possibilistic C mean are most common. In model-based clustering approach, we consider that the data points follow a mixture of probability distribution (Banfield and Raftery, Citation1993) where the EM (Expectation-Maximization) algorithm proposed by Dempster et al. (Citation1977) is the most common and famous approach using maximum-likelihood estimation for inferring mixture models (Biernacki and Jacques, Citation2013; Lee and Scott,Citation2012; Melnykov and Melnykov, Citation2012; Yang et al., Citation2012). A large number of algorithms have been proposed in model-based clustering, among them Yang and Ali (Citation2019), Banfield and Raftery (Citation1993), Yang, Chang-Chien, and Nataliani (Citation2019), Yang et al. (Citation2014), Fraley andRaftery (Citation2002), Lo and Gottardo (Citation2012) are most famous methods. Feature selection is not only the important technique in clustering but also challenging for researchers to get most relevant features. Due to the presence of irrelevant features in data sets, many complexities arise during clustering. Among those first is, clustering without relevant feature selection may fail to find the real structure of data and provide a minimum accuracy rate. Secondly, for high-dimensional data sets, clustering is computationally infeasible in the presence of irrelevant features. Thirdly, the presence of irrelevant features may also cause an appropriate model selection criterion problem. In addition, removing non-informative features may largely enhance interpretability (Pan and Shen, Citation2007; Xie et al., Citation2007). In this connection, Tibshirani (Citation1996) introduced the idea of Lasso regularization to cope up with sparsity in the context of regression analysis. Zadeh (Citation1965) presented the idea of fuzzy set which is useful in many areas.
In 2014, Yang et al. (Citation2014) have presented the idea of robust fuzzy classification maximum likelihood using multivariate t-distribution (FCML-T). Although this method is simple and applicable for noisy points and/or outliers in data sets but not applicable for irrelevant features selection. In 2019, Yang and Ali (Citation2019) have presented the idea of fuzzy Gaussian mixture model for feature selection using Lasso regularization but we are familiar that due to shorter tail of normal distribution in many cases, it is not an appropriate choice for clustering. Furthermore, it does not provide us robust results specially when the data sets have outliers or noisy points. To overcome these issues (due to outliers and/or noisy points), we extended the fuzzy classification maximum likelihood t-distribution using Lasso regularization and we called it F-MT-Lasso clustering algorithm. To show the novelty and usefulness of our proposed algorithm (F-MT-Lasso), we use simulated as well as real data sets and compare the performance of our proposed algorithm F-MT-Lasso with that of fuzzy model-based Gaussian clustering (F-MB-N) (Yang, Chang-Chien, and Nataliani Citation2019), FCML-T (Yang et al.,Citation2014) and Fuzzy Gaussian Lasso algorithm (Yang and Ali, Citation2019) algorithms. Results show the significance and upper hand of our proposed F-MT-Lasso algorithm. The rest of paper is organized as follows. In section 2, we discuss our proposed model fuzzy t-clustering Lasso algorithm. Section 3 elaborates the comparative analysis of our proposed method with some of existing schemas using simulated and real data sets. In section 4, we apply our algorithm on a real data set from field of biosciences. Section 5 details the application of our algorithm on real data set regarding soil which was collected from various placed of Gilgit-Baltistan, Pakistan in collaboration with of Karakoram International University Gilgit-Baltistan, Pakistan. We summarized our conclusions in section 6.
Fuzzy T-Distribution Lasso Clustering
Let a p-dimensional random variable X follows multivariate t-distribution with probability density function. Where
,
, and
are mean, covariance and degree of freedom, respectively. The multivariate t-distribution is as follows:
, where
is mahalonobis square distance between data points
and the mean
,is the covariance matrix, and
is the Gamma function with
. In 1965 Zadeh (Citation1965) presented the idea of fuzzy set and Yang et al., (Citation2014) proposed the idea of fuzzy classification maximum likelihood clustering (FCML-T) and the objective function is as follows:
. Here we consider
. In the objective function
,
is fuzziness index,
and
are fixed constants and
are mixing proportions and must satisfying
while sum to one. We extend the fuzzy classification maximum likelihood proposed by Yang et al., (Citation2014) with multivariate t-distribution using Lasso penalty term using common diagonal variances. As we know that mixture of multivariate t-distribution is considered as a scale mixture of normal distributions. Suppose Y is latent variable then
with
,where the gamma density function is defined as;
and
So we can write the objective function as
.
We further extend fuzzy classification maximum likelihood clustering algorithm proposed by Yang et al., (Citation2014) into a new method of multivariate t-distribution by adding the term. Thus, we propose a new F-MT-Lasso objective function as follows:
where is tuning parameter that manage the amount of shrinkage and mean parameter. When the value of tuning parameter
is sufficiently large, some of the cluster centers
to be exactly zero and we discard the features when
.We use common diagonal covariance
, and
.To get the necessary conditions for minimizing the F-MT-Lasso objective function, we use the lagrangian as follows:
The necessary conditions ofto maximize
are as follows:
Differentiate with respect to the fuzzy membership function,
, we obtain the updating equation for the membership function as follows:
Differentiate w.r.t
we obtain the value of mixing proportion
For the degree of freedom, we differentiate with respect to
.We obtain the following equation:
where is the digamma function
, We used decreasing learning parameter
as:
To get the updating equation of we differentiate
with respect to
we obtain the estimated value of
With having
where is the maximum likelihood estimator (MLE) of the FCML-T clustering and
is common diagonal variance. When the value of
is sufficiently increase in Eq. (6), it should have some
= 0, otherwise it has the quantity
of shrinkage. Consequently, when we found, if
, then we consider
= 0, and
features supposed to be uninformative and discarded it from further clustering results; otherwise, cluster center will be
=
. To drive the updating equation of
, we use the F-MT-Lasso objective function
.Differentiate
with respect to
,we obtain the following form:
. Set
= 0, after simplification we obtain;
. In mathematics, we know that some functions are not necessarily differentiable so,
is not differentiable at
= 0. Sub-derivative is defined as a set of all sub-gradients of a convex function
at
is called the sub-differential of
at
. In order to solve this problem, we use sub derivative as a substitute for the derivative. Suppose we have the absolute value function
at x, is the
where sign function is defined as;
. The absolute function
and its sub-differential
is shown in
Figure 1. Sub-differential of .
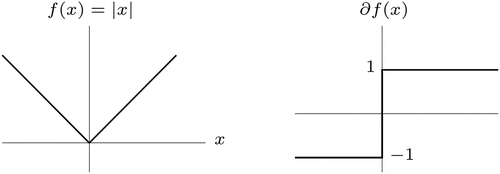
Using this concept of sub-derivative or sub-gradient, we obtained the updating EquationEquation 7(7)
(7) equation (6) for
. We have considered common diagonal covariance matrix which is suitable for high dimensional data sets and good choice for feature selection in our algorithm which is explain as follows:
we differentiate objective function with respect to
we get the updating equation of common diagonal covariance matrix.
Thus, we have summarized our proposed F-MT-Lasso algorithm as follows:
Algorithm F-MT-Lasso clustering algorithm
Step 1: Fix,
and
. Give initials
=1,
,
,
,
.
and
Step 2: Compute with
,
,
,
and
by Eq. (2)
Step 3: Compute with
and
using Eq. (7).
Step 4: Compute using Eq. (5).
Step 5: Compute with
busing Eq. (3).
Step 6: Compute with
,
and
by (8).
Step 7: Update with
,
,
and
using Eq. (2).
Step 8: Compute with
and
using Eq. (4).
Step 9: Compute with
,
and
using Eq. (1).
Step 10 : Update with
and
using Eq. (7).
If,stop .Else t=t+1 and return to step 3
Step 11: Update with
,
and
using Eq. (8)
Step 12: Update with
,
and
using Eq.(6), that is,
If then let
=0.
Else
Step 13: Increase and return to Step 3, or output results.
Numerical Comparisons
Here, we demonstrate the novelty of our proposed algorithm FMT-Lasso using synthetic and real data sets by using accuracy rate define as where
is the number of points in
that are also in
in which
is the set of c clusters for the given data set and
is the set of c clusters generated by the clustering algorithm. We compare our algorithm with F-MB-N (Yang et al. 2019b), FCML-T (Yang et al., Citation2014) and FG-Lasso (Yang and Ali Citation2019).The details of used datasets are presented in .
Table 1. Tabular repsentation of the synthetic and real data sets used.
Example 1.
In this example, a two-cluster data set with 1250 data points generated from a Gaussian mixture model with the parameters
and
,
. Two features, namely,
have been added with 350 noisy points and shown in . Since our objective is to identify relevant features, we extend the data set from two features
up to three features
by adding a 3rd feature
,generated from uniform distribution over intervals [−2,2]. It implies that the third added feature
,is considered as irrelevant feature. We demonstrate F-MB-N, FCML-T, FG-Lasso and F-MT-Lasso by different initializations and record the average of 30 random initials. The clustering results of F-MB-N, FCML-T and FG-Lasso are shown in . The final result of our proposed method F-MT-Lasso has shown in . Due to having irrelevant feature
with d = 3, clustering results from different methods are highly affected and shown poor average accuracy rates, as shown in . On the other hand, our proposed method F-MT-Lasso discard non-informative feature
and provide best average accuracy rate (AR = 0.921). The details of discarded feature through FG-Lasso and F-MT-Lasso with different values of
are shown in . When we increase the value of
from 50 to 135, we observed that FG-Lasso discard important feature
,
and
becomes zero. Similarly, when the value of
is increasing up to 135, we observed that proposed method F-MT-Lasso discard
and
while FG-Lasso discards important component
. It is clearly seen that F-MT-Lasso works better and discarded third irrelevant feature
.After discarding irrelevant feature
F-MT-Lasso shows best results, this shows the novelty of our method.
Figure 2. (a) the original 2-cluster Gaussian data set; (b) F-MB-N clustering results; (c) FCML-T clustering results; (d) FG-Lasso clustering results; (f) F-MT-Lasso clustering results.
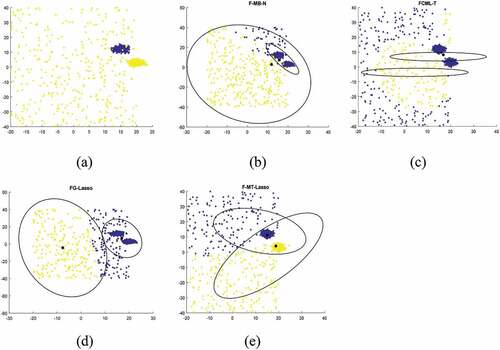
Table 2. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Table 3. Feature reduction pattern based on values.
Example 2.
In this example, we consider a data set consists of 3 clusters with 950 data points generated from the Gaussian mixture (GM) distribution having parameters
,
and
, with two feature
. We added 100 noisy points to features
using uniform distribution over the intervals [−5,5] and [0, 1], and the sample size will be 1050 points. Result is shown in . Since our objective is to identify relevant features, we extended the data set from 2 features
up to four features
by adding two additional features
and
, both have been generated from uniform distribution over intervals [−1,1] and [−5, 5],it implies that the third and four added features
and
, are considered to be irrelevant features. The 3-D plots of
and
have shown in . We demonstrate F-MB-N, FCML-T, FG-Lasso, and F-MT-Lasso under different initializations and record the average of 30 random initials.The clustering results of F-MB-N, FCML-T and FG-Lasso are shown in . The final result of our proposed method F-MT-Lasso has shown in . Due to having irrelevant feature
and
with d = 4, clustering results from different methods have been highly affected and shown poor average accuracy rates, as shown in . While our proposed method F-MT-Lasso discard non-informative features
and
,as a result it provides us best average accuracy rate (AR = 0.989). The details of discarded features through FG-Lasso and F-MT-Lasso for different values of
are shown in . When we increase the value of
to 30, we observed that both Algorithms completely discarded irrelevant feature
. Similarly, when the value of
is increased from 60 to 111 another irrelevant feature
also discarded by both methods and their results have been shown in . It is clearly seen that after discarding irrelevant features
and
our proposed algorithm shows best results.
Figure 3. (a) the original 3-cluster Gaussian data set; (b) 3-D plot representation ; (c) 3-D plot representation
; (d)f-MB-N clustering results; (e)fcml-T clustering results; (f)fg-Lasso clustering results; (g)f-MT-Lasso clustering results.
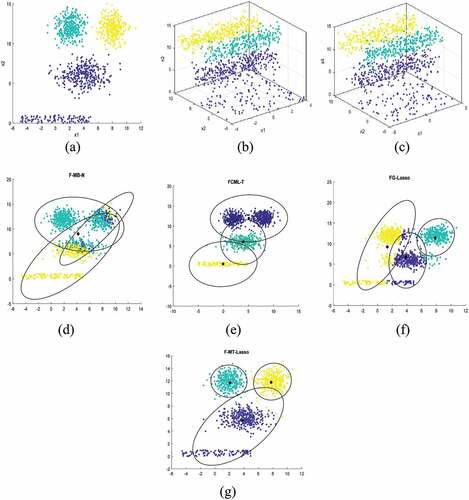
Table 4. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Table 5. Feature reduction pattern based on values.
Example 3.
In this example, we consider a data set consists of five clusters with 400 data points generated from the Gaussian mixture (GM) distribution having parameters
Figure 4. (a) 3-D plot representation ; (b) F-MB-N clustering results; (c) FCML-T clustering results (d) FG-Lasso clustering results;(e) F-MT-Lasso clustering results.
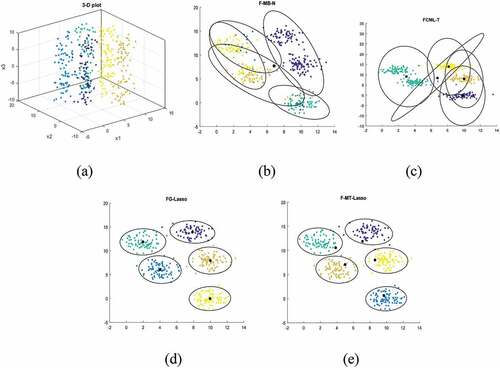
in . However proposed method F-MT-Lasso discard non-informative feature and as a results, it provided us with best average accuracy (AR = 1.00). The details of discarded feature through FG-Lasso and F-MT-Lasso against different values of
are shown in . When we increase the value of
to 50, we observed that both Algorithms completely discarded irrelevant feature
and the obtained results have been shown in . It is clearly seen that after discarding irrelevant feature
our proposed algorithm shows best results, that is the advantage and novelty of our method.
Table 6. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Table 7. Feature reduction pattern based on values.
Application in the Field of Biosciences
Variable selection and dealing with outliers/noisy points in biological studies are challenging and important task. Due to having outliers and irrelevant features/genes in biological data sets, estimated parameters would be biased, insufficient and inconsistent. In order to demonstrate the effectiveness and real applicability of proposed method F-MT-Lasso we applied it in the following five sets of biological real data; seeds, Pima Indian, prostate cancer, breast cancer and soil data set. Soil data set have been collected from Gilgit-Baltistan, Pakistan in collaboration with Karakoram International University GB, Pakistan. Comparisons of the proposed F-MT-Lasso algorithm with F-MB-N, FCML-T and FG-Lasso have also been made in the following.
Example 4.
In this example, we consider the real data set of seeds from (Das, Citation2014). This data set consists of 7 real-valued continuous attributes, namely; area, perimeter, compactness, length of kernel, width of kernel, asymmetry coefficient and length of kernel groove. This data set comprised of three different varieties of wheat and Samples were labeled by numbers: 1–70 first variety of wheat “Kama wheat variety,” 71–140 for the “Rosa wheat variety,” and 141–210 for the “Canadian wheat variety.” 70 elements each, randomly selected for the experiment. To collect this data set, high quality visualization of the internal kernel structure was detected using a soft x-ray technique. This sort of technology is very familiar and famous because it is nondestructive and considerably cheaper. When the proposed F-MT-Lasso algorithm is applied to the data set, F-MT-Lasso and FG-Lasso both methods identified that 6th feature is irrelevant one among a total of seven features. When the value is increased up to 162, according to FG-Lasso we get
and consider features six as irrelevant and removed it from further clustering. After discarding this irrelevant feature, the average accuracy rate with 30 different initializations, we obtain (AR = 0.859) from FG-Lasso, (AR = 0.593) from F-MB-N, and (AR = 0.628) using FCML-T. When we increase the value of
= 200 we observed that
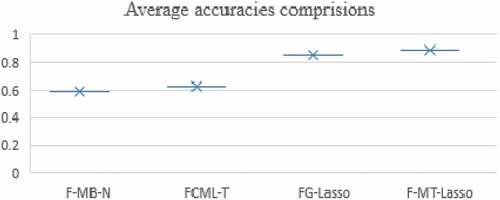
. Our proposed F-MT-Lasso algorithm discards feature six “asymmetry coefficient.” After discarding this feature from data, we execute our proposed F-MT-Lasso algorithm and get better average accuracy (AR = 0.891) with 30 different initializations. The comprision of each average accuracy rate has been shown is and graphical comprision have been shown in . This reveals that, the proposed F-MT-Lasso algorithm is significant and effective for relevant feature selection on the seeds data set.
Table 8. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Figure 5. Box and whisker plot of average accuracies from different methods.
Example 5.
In this example, we consider the real data set of Pima Indian (Citationundefined). This data set consists of 8 predict variables and one response variable. The variables are named as pregnant, plasma, blood pressure (mm Hg), triceps skin fold thickness (mm), insulin (mu U/ml), body mass index (weight in kg/(height in m)^2), diabetes pedigree function, and age (years). While response variable is (1: diabetes, 0: not). The data set has two classes. Diabetes mellitus is very common and severe disease in many populations of the world including American Indian tribe and Indian. There are many risk factors of this disease and some well-known of those are parental diabetes, genetic markers, obesity, diet (Das, Citation2014). When the proposed FG-Lasso algorithm is applied to the Pima Indian diabetics data set, it identified that when we are increasing the value of up to 50 using FG-Lasso, we get
, feature five “insulin” as irrelevant feature and after removing it, from further clustering we obtain (AR = 0.653) from FG-Lasso, (AR = 0.544) from F-MB-N, (AR = 0.5083) using FCML-T with the average of 30 different initializations. Our proposed method F-MT-Lasso also discards feature five “insulin” against the value of
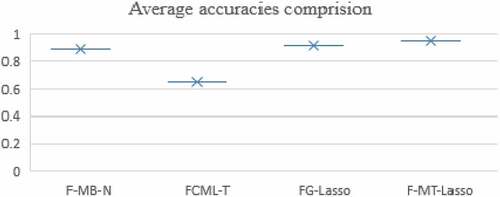
= 150 and we get better average accuracy rate (AR = 0.720) with 30 different initializations. The comprision of each average accuracy rate has been shown is , while graphical comprision have been reflected in . This confirms that, the proposed F-MT-Lasso algorithm is also significant for relevant feature selection on the Pima Indian data set.
Table 9. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Figure 6. Box and whisker plot of average accuracies from different methods.
Example 6
(Breast Cancer (UCI, Citation2019)) Breast cancer is one of the severe and commonest cause of death in women worldwide. It is frequently found in Australia/New-Zealand, United Kingdom, Sweden Finland, Denmark, Belgium (Highest rate), the Netherlands and France. According to the findings of World health organization, common causes of breast cancer are tobacco use, use of alcohol, dietary factors including lack of fruit and vegetable consumption, overweight,obesity, physical inactivity, chronic infections from helicobacter pylori, hepatitis B virus, hepatitis C virus and some type of human papilloma virus, environmental and occupational risks including ionizing and non-ionizing radiation (Bray et al., Citation2018; Siegel et al., Citation2019). In this example, we consider real data set regarding breast cancer that consist of eight features namely; clump thickness, uniformity of cell size, uniformity of cell shape, marginal adhesion, bare nuclei, bland chromatin, normal nucleoli, mitoses and one output variable class having 699 samples. When the proposed FG-Lasso algorithm is applied on this breast cancer data set, it has been observed that when we increase the value of to 400, four features namely; clump thickness, marginal adhesion, normal nucleoli and mitoses are identified to be irrelevant features. So, after removing these four features from further clustering, we obtained (AR = 0.911) from FG-Lasso, (AR = 0.892) from F-MB-N, and (AR = 0.850) using FCML-T on the average, for 30 different initializations. On the other hand, our proposed method F-MT-Lasso discards only feature seven “normal nucleoli” against the same value of
= 400 and we get even more better average accuracy (AR = 0.962) with 30 different initializations. The comprision of each average accuracies are shown is and graphical representation is shown in . This reveals that, the proposed F-MT-Lasso algorithm is more significant and effective for relevant feature selection regarding breast cancer data set.
Table 10. Comparison of F-MT-Lasso with F-MB-N, FCML-T and FG-Lasso.
Figure 7. Box and whisker plot of average accuracies from different methods.

Example 7
(Prostate cancer Saifi, Citation2018)) Prostate cancer is second major common type of cancer and fifth leading cause of death among men worldwide and occurs over the age of 70 years (Bray et al., Citation2018).This kind of cancer starts, when cells in the prostate gland start to grow out of control. The most leading countries in this domain are Australia, America, New Zealand, Norway, Sweden and Ireland (Bray et al., Citation2018). Here we consider a real prostate cancer data set consists of 100 patients of prostate cancer having eight features namely; radius, texture, perimeter, area, smoothness, compactness, symmetry, fractal dimension and one categorical parameter diagnosis results (benign tumors = 38 and malignant tumors = 68). When FG- Lasso algorithm is applied on the prostate cancer data set, this identified that when we are increasing the value of up to 60, we observed the features like radius, texture, perimeter, and area as irrelevant features. After removing these irrelevant features, we obtain (AR = 0.617) from FG-Lasso, (AR = 0.517) from F-MB-N, and (AR = 0.635) using FCML-T after taking the average of 30 different initializations. When the proposed F-MT-Lasso algorithm is applied to the prostate cancer data set, it has been noticed that 4th feature “area” became irrelevant feature against
= 78, and consequently has been discarded. Hence we found that after discardng it, we get better average accuracy rate (AR = 0.807) with 30 different initializations. The comprision of each average accuracy rate, are shown is and graphical comparisons are shown in . This shows that, the proposed F-MT-Lasso algorithm is more significant and effective for relevant feature selection of the prostate cancer data set.
Table 11. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
Figure 8. Box and whisker plot of average accuracies from different methods.

A Real Application of Soil Data from the Region of Gilgit-Baltistan, Pakistan
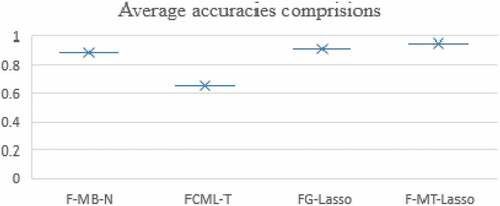
Finally, we apply our proposed F-MT-Lasso algorithm on real data set regarding soil which consists of thirty samples, ten samples in each cluster. The soil samples have randomly been taken from 0 to 15 cm depth with the help of small spade and hand trowel from three region (clusters) of Gilgit-Baltistan namely; Damote Sai (located in Hindukush range), Bunji (located in Himalya) and Jalalabad (located in Karakorum Range) with the collaboration of Karakoram international university Giglit-Baltistan. The purpose of taking samples from three different locations is to compare soil fertility status of regions. The samples have been dried and Sieved through a 2 mm sieve for further laboratory investigation. PH was measured through a pH probe by 1:1 (soil: water) suspension with OAKTON PC 700 meter (Mclean, Citation1983). EC was measured by 1:5 (Soil: water) with Milwaukec EC meter (SM 302) (Rayment and Higginson, Citation1992). Fertility status of soil NO3-N, P, K was determined by (AB- DTPA) extractable method (Jones, Citation2001). In all the samples of three regions, Nitrogen was detected as defecient or low range and our both methods FG-Gauss and F-MT-Lasso have suggested to discard the Nitrogen from soil data to improve the accuracy as shown in . Hussain et al., (Citation2021) conducted research on soil fertility of two villages from lower Karakorum Range and the quantity of nitrogen was in range within marginal or medium range from both orchard and agricultural land. Whereas Babar et al. (Citation2004) stated/reported the deficiency of nitrogen (0.08% only) in the soil of Gilgit region.
Table 12. Comparison of F-MB-N, FCML-T, FG-Lasso with F-MT-Lasso based on reduced feature and average AR.
In the following we show scatter plots for all possible combinations of soil parameters in while graphical comprision have shown in .
Figure 9. Scatter plots for all possible combinations of PH, EC, N, P and K.
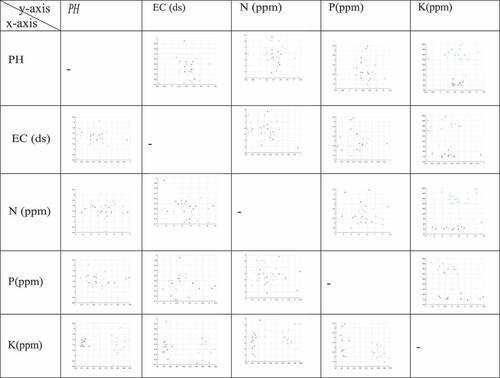
Figure 10. Box and whisker plot of average accuracies from different methods.
Conclusion
In model-based clustering many proposed methods are based on EM algorithm to overcome its sensitivity and initialization issues. However, these methods treat data points with feature (variable) components with equal importance, and so it cannot distinguish the irrelevant feature components. In most of the cases, there exist some irrelevant features and outliers/noisy points in a data set that adversely affect the performance of clustering algorithms. To identify and discard those irrelevant features or to handle the problems due to those outliers/noisy points, multivariate t-distribution is more efficient and effective than multivariate normal distribution due to its heavily. It is therefore we proposed a fuzzy model-based t-clustering schema using mixture of t-distribution with an regularization for the better identification and selection of significant features and to improve the performance of algorithm against the sparsity exists in the data.
We have applied our proposed F-MT-Lasso algorithm on simulatd data sets as well as real data sets including seeds, pima, prostrate cancer, breast cancer and soil data data to show its effectivenss and usefulness.It has been seen from comparative analysis that the proposed F-MT-Lasso algorithm is a robust choice and provides better results with higher accuracy rates as compared to the existing methods for variouse larger values of threshold. However, our question is, which value of the threshold
would be the optimal value for better feature selection in the F-MT-Lasso algorithm? That is, to find a good estimate for the threshold parameter
is very important and would be our further topic in our future research.
Disclosure statement
We have no conflicts of interest to disclose.
References
- Abbasi, A., and M. Younis. 2007. A survey on clustering algorithms for wireless sensor networks. Computer Communications 30 (14–15):2826–492. doi:10.1016/j.comcom.2007.05.024.
- Agrawal, R., J. Gehrke, D. Gunopulos, and P. Raghavan. 2005. Automatic subspace clustering of high dimensional data for data mining applications. Data Mining and Knowledge Discovery 11 (1):5–33. doi:10.1007/s10618-005-1396-1.
- Babar, K., R. A. Khattak, and A. Hakeem. 2004. Physico-chemical characteristics and fertility status of Gilgit soils. Journal of Agricultural Research 42 (3–4):305–12.
- Banfield, J. D., and A. E. Raftery. 1993. Model-based Gaussian and non-Gaussian clustering. Biometrics 49 (3):803–21. doi:10.2307/2532201.
- Biernacki, C., and J. Jacques. 2013. A generative model for rank data based on insertion sort algorithm. Computational Statistics & Data Analysis 58:162–76. doi:10.1016/j.csda.2012.08.008.
- Bray, F., J. Ferlay, I. Soerjomataram, R. L. Siegel, L. A. Torre, and A. Jemal. 2018. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer Journal for Clinicians 68 (6):394–424. doi:10.3322/caac.21492.
- Chuang, K. S., H. L. Tzeng, S. Chen, et al. 2006. Fuzzy c-means clustering with spatial information for image segmentation. Computerized Medical Imaging and Graphics. 30(1):9–15. doi:10.1016/j.compmedimag.2005.10.001.
- Das, R. N. 2014. Determinants of diabetes mellitus in the pima indian mothers and Indian medical students. The Open Diabetes Journal 7 (1):5–13. doi:10.2174/1876524601407010005.
- Dempster, A. P., N. M. Laird, and D. B. Rubin. 1977. Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B (Methodological) 39 (1):1–22. doi:https://doi.org/10.1111/j.2517-6161.1977.tb01600.x.
- Fraley, C., and A. E. Raftery. 2002. Model-based clustering, discriminant analysis, and density estimation. doi:10.1198/016214502760047131.
- Garibaldi, U., D. Costantini, S. Donadio, et al. 2006. Herding and clustering in economics: The Yule-Zipf-Simon model. Computational Economics. 27(1):115–34. doi:10.1007/s10614-005-9018-y.
- Gogebakan, M. 2021. A novel approach for Gaussian mixture model clustering based on soft computing method. IEEE Access 9:159987–60003. doi:10.1109/ACCESS.2021.3130066.
- Gogebakan, M., and H. Erol. 2018. A new semi-supervised classification method based on mixture model clustering for classification of multispectral data. Journal of the Indian Society of Remote Sensing 46 (8):1323–31. doi:10.1007/s12524-018-0808-9.
- Gogebakan, M., and E. Hamza. 2019. Mixture model clustering using variable data segmentation and model selection: A case study of genetic algorithm.Mathematics letters. Mathematics Letters 5 (2):23–32. doi:10.11648/j.ml.20190502.12.
- Hussain, A., H. Ali, F. Begum, A. Hussain, M. Khan, Y. Guan, J. Zhou, S. Din, and K. Hussain. 2021. Mapping of soil properties under different land uses in lesser karakoram range, Pakistan. Polish Journal of Environmental Studies 30 (2):1181–89. doi:10.15244/pjoes/122443.
- Jain, A. K., and C. R. 1988. Dubes: Algorithms for clustering data. New Jersey: Prentice Hall.
- Jones, J. B. 2001. Laboratory guide for conducting soil tests and plant analysis (No. BOOK). CRC press.
- Kadim, T., and C. Wirnhardt. 2012. Neural network-based clustering for agriculture management. EURASIP Journal on Advances in Signal Processing 2012 (1):1–13. doi:10.1186/1687-6180-2012-200.
- Lee, G., and C. Scott. 2012. EM algorithms for multivariate Gaussian mixture models with truncated and censored data. Computational Statistics & Data Analysis 56 (9):2816–29. doi:https://doi.org/10.1016/j.csda.2012.03.003.
- Lo, K., and R. Gottardo. 2012. Flexible mixture modeling via the multivariate t distribution with the box-cox transformation: An alternative to the skew-t distribution. Statistics and Omputing 22 (1):33–52. doi:10.1007/s11222-010-9204-1.
- McLachlan, G. J., and K. E. Basford. 1988. Mixture models: Inference and applications to clustering. vol. 38 New York: M. Dekker.
- McLean, E. O. 1983. Soil pH and lime requirement. Methods of soil analysis: Part 2 chemical and microbiological properties. 9:199–224.
- Mcnicholas, P. D. 2016. Model-based clustering. Journal of Classification 33 (3):331–73. doi:10.1007/s00357-016-9211-9.
- Melnykov, V., and I. Melnykov. 2012. Initializing the em algorithm in Gaussian mixture models with an unknown number of components. Computational Statistics & Data Analysis 56 (6):1381–95. doi:https://doi.org/10.1016/j.csda.2011.11.002.
- Pan, W., and X. Shen. 2007. Penalized model-based clustering with application to variable selection. Journal of Machine Learning Research 8 (5).
- Rasool, A., X. Tangfu, F. Farooqi, et al. 2016. Arsenic and heavy metal contaminations in the tube well water of Punjab, Pakistan and risk assessment: A case study. Ecological engineering 95:90–100. doi:10.1016/j.ecoleng.2016.06.034.
- Rayment, G. E., and F. R. Higginson. 1992. Australian laboratory handbook of soil and water chemical methods. Inkata Press Pty Ltd.
- Saifi, S. Prostate cancer dataset. https://www.kaggle.com/sajidsaifi/prostate-cancer
- Siegel, R. L., K. D. Miller, and A. Jemal. 2019. Cancer statistics, 2019. CA: A Cancer Journal for Clinicians 69 (1):7–34. doi:https://doi.org/10.3322/caac.21551.
- Tibshirani, R. 1996. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B (Methodological) 58 (1):267–88. doi:10.1111/j.2517-6161.1996.tb02080.x.
- UCI Machine Learning Repository. 2019. World health statistics. Geneva. https://archive.ics.uci.edu/ml/index.php
- Xie, B., W. Pan, and X. Shen. 2007. Variable selection in penalized model-based clustering via regularization on grouped parameters. Biometrics 64 (3):921–30. doi:10.1111/j.1541-0420.2007.00955.x.
- Yang, M. S., and W. Ali. 2019. Fuzzy Gaussian Lasso clustering with application to cancer data. Mathematical Biosciences and Engineering 17 (1):250–65. doi:10.3934/mbe.2020014.
- Yang, M. S., Y. C. T. And, and Y. C. Lin. 2014. Robust fuzzy classification maximum likelihood clustering with multivariate t-distributions. International Journal of Fuzzy Systems 16:566–76.
- Yang, M. S., S. J. Chang-Chien, and Y. Nataliani. 2019. Unsupervised fuzzy model-based Gaussian clustering. Information Sciences 481:1–23. doi:10.1016/j.ins.2018.12.059.
- Yang, M. S., C. Y. Lai, and C. Y. Lin. 2012. A robust em clustering algorithm for Gaussian mixture models. Pattern recognition 45 (11):3950–61. doi:10.1016/j.patcog.2012.04.031.
- Zadeh, L. A. 1965. Fuzzy sets. Information and Control 8 (3):338–53. doi:https://doi.org/10.1016/S0019-9958(65)90241-X.