
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Process mining uses event logs to improve business processes, but such logs may contain privacy information. One popular research problem is the privacy protection of event logs. Publishing logs with differential privacy is one of major research directions. Existing research achieves privacy protection primarily by injecting random noise into event logs, or merging similar information. The former ignores the fact that injecting random noise will produce apparently unreasonable activity traces, and the latter will cause a loss of process information in the process mining perspective. To solve the above problems, this article proposes a differential algorithm based on randomized response to model Petri nets for the original event logs, select the important labels in the logs by the weak sequential relationship of control flow between activities, inject noise into the Petri net model based on the important labels using the randomized response approach, and establish a differential Petri net model. Experiments on public datasets show that the event logs produced by the approach proposed do not contain unreasonable traces. Compared with the baseline approach, the proposed approach performs better on Fitness metrics with consistent privacy requirements and retains more process variants, reducing the loss of original event log process information.
Introduction
Process mining aims to help organizations or individuals to improve the performance, conformance or quality of their relevant business processes. The event logs recorded by information systems are the starting point of process mining (van der Aalst Citation2016), which relies on the event logs of business processes (van der Aalst Citation2012) to obtain information from the event logs to discover, monitor or improve the actual business processes. The process discovery algorithm constructs a process model from the event log in order to define the relationship between activities in the process (Augusto et al. Citation2019).
Event logs contain information about individuals with corresponding cases, and such information may contain private information directly, or private information about specific individuals may be obtained from such information, so that event logs are potentially invasive of personal privacy (Mannhardt, Petersen, and Oliveira Citation2018). For example, for Healthcare Process, an event log may include personal information about the patient receiving the treatment, such as (Stefanini et al. Citation2018) and (Liu et al. Citation2022). (Nuñez von Voigt et al. Citation2020) used individual uniqueness in the event log to quantify the risk of re-identification, and showed that all cases in the event log are likely to be re-identified. In order to protect the private information of individuals in event logs, most countries and regions have restricted the analysis of such event logs by introducing regulations, such as the European General Data Protection Regulation (GDPR), which prohibits the processing of personal data except for specific needs (Voss Citation2016).
In order to circumvent legal restrictions, (Elkoumy et al. Citation2021) proposed privacy-preserving mining that aims to protect personal data while being able to improve business processes. Existing research has focused on implementing privacy-preserving process mining from two different perspectives (Fahrenkrog-Petersen Citation2019): anonymizing the event logs used for process mining (Fahrenkrog-Petersen, van der Aa, and Weidlich Citation2020), or designing process mining algorithms so that their outputs satisfy privacy requirements (Kabierski, Fahrenkrog-Petersen, and Weidlich Citation2021). In this article, we focus on the perspective of anonymizing event logs, and existing research has proposed numerous approaches to anonymize event logs. (Rafiei, von Waldthausen, and van der Aalst Citation2020) proposed the definition of distance metric for traces through embedding of events based on distance metric of feature learning and guided the anonymization of event logs. (Pika et al. Citation2020) evaluated the applicability of privacy-preserving data transformation techniques in the field of data mining for the anonymization of medical process data in the context of medical processes and demonstrated how some of the methods affect the process mining results.
However, anonymization of data only does not effectively protect against differential attacks. For example, in the case of healthcare logs, if an external attacker has prior knowledge that only a particular patient has performed a particular activity, then anonymizing only the relevant information in the data, such as the patient’s name, will not achieve the privacy protection goal. To prevent such attacks, (Dwork Citation2008) proposed the concept of differential privacy. (Mannhardt et al. Citation2019) investigated potential privacy breaches and means of protection from common assumptions about event logs used in process mining. A model for the protection of event data privacy is developed. (Elkoumy, Pankova, and Dumas Citation2021) proposed a differential privacy mechanism that oversamples the cases in the logs and adds noise to the timestamps to ensure that the probability of an attacker identifying any individual in the original logs does not increase beyond a threshold after the anonymized logs are made public. (Rösel et al. Citation2022) incorporated a distance metric based on feature learning to consider activity semantics in the anonymization process. (Fahrenkrog-Petersen, van der Aa, and Weidlich Citation2019) and (Rafiei, Wagner, and van der Aalst Citation2020) combine distance metrics to merge multiple different traces of a process to achieve hiding information about a single process instance, as well as the personal information of the person associated with that instance. (Elkoumy et al. Citation2022) proposed a tool for inter-organizational process mining privacy protection that enables independent parties to perform process mining operations without revealing any data. (Feng et al. Citation2018) proposed a differential privacy collaborative filtering recommendation algorithm based on behavioral similarity. By adding noise obeying Laplace distribution to the behavioral similarity matrix, the privacy of the correlator is effectively protected. (Batista and Solanas Citation2021) proposed an approach based on uniformization of event distribution to protect personal privacy in process mining. (Hou et al. Citation2022) introduced fuzziness into differential privacy to establish fuzzy differential privacy to achieve a more flexible balance between the accuracy of the output and the level of privacy protection of the data.
Privacy protection of personal information in event logs through differential privacy has been a popular direction in recent years, and many researchers have proposed well-established solutions. However, there are several problems with existing research that may have a negative impact on the application of process mining techniques. One of such problems is the introduction of random noise into the event logs, which may produce traces that are not present in the original event logs, or traces with obvious logical errors. For example, in a healthcare process, assuming that in a certain anonymized trace, the patient first performs the activity of “pharmacy medicine pickup” and then the activity of “outpatient consultation,” this is clearly not logical and makes the attacker doubt the authenticity of the trace and choose not to trust this activity trace, reducing the privacy protection performance. The second is to prohibit the publication of infrequent activity traces in the event log, represented by the k-anonymity approach (Sweeney Citation2002), or to merge similar information in the event log, as in (Fahrenkrog-Petersen, van der Aa, and Weidlich Citation2019). From the perspective of process mining, the disadvantage of these approaches is that part of the process information is lost, and the information contained in the original logs is hidden. This obviously has a negative impact on the effectiveness of process mining techniques. The research in this article is based on the above two problems and is summarized in two research questions.
RQ1:
How to avoid the differential mechanism that generates event logs to produce unreasonable activity traces?
RQ2:
How to reduce the loss of process information while ensuring the degree of privacy of the event log?
The goal that this article hopes to achieve is to reduce the loss of the original process information caused by the processing of the event logs, while ensuring the privacy of the processed event logs. In addition, ensure that the resulting new event log does not contain traces that are not present in the original log. Based on this goal, we propose a randomized response-based differential algorithm, an approach that solves the two research problems we have proposed by publishing a differential Petri net model that balances privacy protection performance with data availability while ensuring data security, and validates it through experiments. This approach models Petri nets on the original data by process mining approach, obtains important label sets based on the weak sequential relationships of control flow between activities, builds randomized anonymization structures, and generates differential Petri net models. For RQ1, this article selects the activity labels added as noise based on the weak order relationship of control flow, and the produced traces are all included in the original event log, and will not produce traces that do not exist in the original event log or apparently do not conform to the common sense of life. For RQ2, this article builds a differential Petri net model based on the randomized response approach with the weak sequential relationship between activities to generate a privacy event log and reduce the loss of process information.
Related Knowledge
In this section, we describe the basic concepts involved in this article. section 2.1 introduces the basic concepts of Petri nets and behavioral profile. section 2.2 introduces the concept of differential privacy and its related definitions.
Petri Net
Definition 1 (Petri Net)
Let be a net, Mapping M:P→{0,1,2,⋯} is called the mark of the net N, and the quaternion
is called the marked net i.e. Petri net.
There exists a weak order relation in Petri net PN, i.e., the sequence for the arbitrary activity pair
containing
when
1,2,
1
,
and
,
.
Strict Order Relation
,If and only if
Exclusiveness Relation
Interleaving Order Relation
Definition 2 (Behavioral profile)
(Weidlich et al. Citation2010) Let be a Petri net, For any transition pair
satisfying one of the following relations.
Differential Privacy
Differential privacy is a new definition of privacy proposed for the privacy leakage problem of databases. Mainly by using random noise to ensure that, the result of query requesting publicly visible information does not reveal individual privacy information, and individual characteristics are removed to protect user privacy while preserving statistical characteristics, so to some extent, differential privacy can ensure the availability of the protected data so that it can still be applied in the field of data analysis. Nevertheless, the usability of the data is reduced.
As a real-life example, in the mid-1990s, the state of Massachusetts released anonymized employee medical records for research purposes, and an MIT graduate student was able to decipher the anonymized medical records by matching them with publicly available voter registration records to obtain information about the governor. The purpose of proposing differential privacy is to avoid such breaches of data privacy as much as possible and to reduce data leakage when the data is used for research.
Differential privacy hopes to achieve the goal that, while the publicly available dataset is analyzed for valid data information about groups in the dataset, there is no increase in the knowledge of information about specific individuals in the dataset, and the presence or absence of information about any individual in the dataset does not affect the results of differential privacy. That is, the purpose of differential privacy is to reduce the impact of individual data on the overall query results.
Definition 3 (Neighboring datasets)
Given two different data sets and
,
and
are called neighboring datasets when
and
satisfy that there is and only one data difference.
According to Definition 3, dataset (1) and dataset (2) and dataset (1) and dataset (3) in all constitute neighboring datasets, since they all differ from each other by only one piece of data.
Figure 1. Neighboring datasets.

Definition 4 (Differential privacy)
is a randomized algorithm. The datasets
and
are neighboring datasets.
is an arbitrary subset of all possible outputs of the randomized algorithm
. If there is
. Then the algorithm
is said to be
-differential privacy.
is the privacy budget that controls the degree of privacy protection of the algorithm. the smaller the
, the higher the degree of privacy protection.
Definition 5 (Post-processing immunity)
is a randomized algorithm for differential privacy satisfying ε-differential privacy, and
is an arbitrary randomized mapping, then
is
-differentially private.
The meaning of Definition 5 is that the differential privacy algorithm is independent of post-processing, and the result obtained by combining the differential privacy algorithm with an arbitrary mapping is still consistent with differential privacy, also known as differential privacy post-processability.
Differential Petri Nets
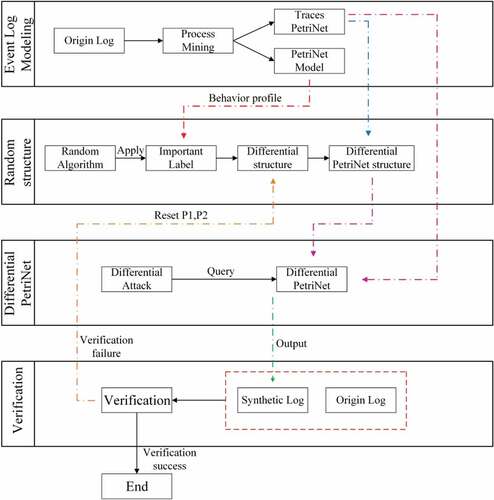
To address the two research questions presented in the first section, this article proposes a differential algorithm based on randomized response that mines the Petri net model of the original event log, selects important labels by weak sequential relationships among activities, adds these labels to the Petri net model as noise, builds the differential Petri net model and publishes it instead of the event log. Since the important labels are present in the original event log, the algorithm does not generate traces or behaviors that are not present in the original event log. The model responds to queries by synthesizing a virtual event log, which is -differentially private according to the post-processing nature of differential privacy. At the same time, the algorithm still keeps the virtual event log data with certain availability. In this section, the algorithm is illustrated in this article with a simple simulated event log as an example. The steps of the algorithm are shown in .
Figure 2. Algorithm process.
Event Log
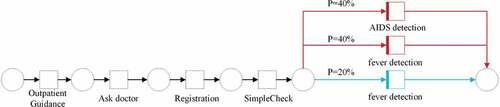
shows the event log of a hospital diagnostic process. Each different kind of event trace corresponds to a different diagnostic process. In this article, we use a process mining algorithm to model this event log as a Petri net and obtain the Petri net model corresponding to the original event log. The process mining approach is a process-oriented modeling and analysis method, the idea of which is to obtain information from event logs to discover, improve or monitor actual business processes. In the past decades, many kinds of process mining algorithms have been proposed, such as -algorithm (van der Aalst, Weijters, and Maruster Citation2004), Inductive algorithm (Leemans, Fahland, and van der Aalst Citation2013), HPNs (Liu et al. Citation2022), MBPM (Liu Citation2022), etc. In this section, we use Inductive algorithm to model the event logs and apply process mining algorithms to each different kind of process variants in the event logs to obtain the corresponding Petri net models. shows the model for one of the classes of traces.
Figure 3. Model of trace.

Table 1. Event log.
Private Label
Business process management has grown in importance over the past few decades. However, event logs often contain users’ personal private information, so many countries and regions restrict data analysis of these event logs. In the hospital diagnosis process presented in this article, the event labels may contain private information about the patient. For example, in the event log shown in , for the activity AIDS detection; whether this patient is eventually diagnosed with AIDS or not, he does not want this information to be disclosed. However, by querying the public event log, it is theoretically possible to know whether a patient has performed a specific activity.
Assuming that Patient A is known to be in a public event log, combine the results of the following two queries “What is the number of people with active AIDS detection in this event log?” and “What is the number of people in this event log who have active AIDS detection other than Patient A?” This type of method of obtaining privacy information through several queries is called differential attack, and in order to defend against this type of attack, it is necessary to introduce some inaccuracy into the event log, i.e., to introduce noise into the event log.
There have been studies on differential privacy protection of event logs by randomly injecting noise, and such methods may produce traces that are not present in the original logs themselves or are obviously not in line with common sense, reducing the effectiveness of differential privacy. The algorithm proposed in this article performs differential privacy protection for event logs by using differential Petri nets instead of traditional event log publication, and in response to queries, differential Petri nets generate virtual event logs that are also differentially private.
Applying noise to event logs leads to a reduction in the availability of event log data, which is required by process analysis algorithms, so we want to be able to protect personal private information while keeping the event log data still available. If all activity tags in the trace are anonymized, the usability of the event log data will be significantly reduced. In fact, not all activity tags contain privacy information; for example, in healthcare scenarios, different medical conditions may have common activity labels, such as blood draw, temperature measurement, etc. Only a few labels, such as AIDS detection, will contain privacy information. Therefore, to ensure data availability, in this article, only activity labels that may contain privacy information are anonymized. We refer to the labels of such activities that contain privacy information as private labels, and in the work done in this paper, the private labels are obtained from a priori knowledge, such as AIDS detection, a private activity in process, which is based on the experience in daily life.
Definition 6 (Sensitive labels)
is a Petri net,
is the transition set of this Petri net, the label of
is a private label, and if
and
, the label of
is a sensitive label in Petri net
.
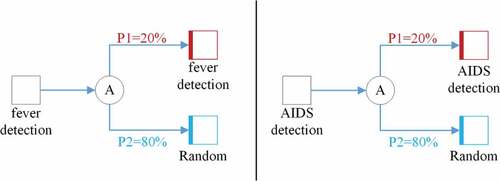
As an example, the event log in is assumed to correspond to a Petri net model in which the privacy label is AIDS detection, and this conclusion is obtained from a priori knowledge. According to the definition of the previous behavioral profile relation and sensitive label, the corresponding sensitive label in this Petri net model can be obtained as fever detection. For the convenience of description, the private label in a Petri net and its corresponding sensitive label are collectively referred to as important labels in this article.
Definition 7 (Important labels)
is a Petri net,
is the transition set of this Petri net,
is the privacy label set,
is the sensitive label set. Then
is the set of important labels, and arbitrary
is a important label.
Randomization Algorithm
According to the concept of differential privacy, in order to achieve the protection of the private information of the case entity, i.e., the patient, in the event log, it is first necessary to randomize the important labels in this Petri net model to achieve anonymity. In this article, a randomized response algorithm is introduced to randomize the important labels. In life, we often encounter the situation that in a survey, when a question involves the privacy of the respondent, it may happen that the respondent does not want to give the true answer, and a solution is to let each respondent add noise to their respective answers. For example, suppose the interviewer asks a sensitive question about right and wrong, the respondent can flip a coin once and answer the true answer if the result of the coin flip is heads, or randomly answer yes or no if it is tails, which is the concept of randomized response. The process of obtaining the differential Petri net corresponding to a case in the event log using the randomized response algorithm is shown in .
Figure 4. Differential Petri nets obtained by randomizing responses.
In this article, we introduce the concept of randomized response into the Petri net model to anonymize the important labels in the model. In Petri nets, we cannot reduce the variation in Petri nets to simple right and wrong questions, and need to make optimization of randomized responses. In the traditional randomized responses algorithm, the algorithm outputs the true value with a certain probability, while the remaining cases are randomly outputted as yes or no answers to achieve privacy protection. Mapping to Petri nets, we specify that for important labels in the model, the randomization algorithm outputs their true labels with a certain probability, while the remaining situations randomly output arbitrary important labels with equal probability of outputting different arbitrary labels, and maintain the as-is output for traces that do not contain private labels. The structure of the optimized randomization algorithm is shown in .
Figure 5. Randomization algorithm for Petri net labels.
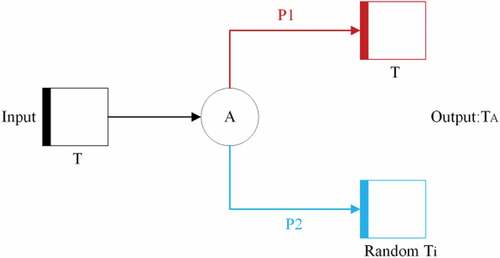
In , T_i is the set of private and sensitive labels in the Petri net model, i.e., the set of important labels. T ∈ T_i is the input of the algorithm, P1 is the true output probability, which represents the probability of outputting the true activity labels, i.e., “occasions when a coin is tossed heads,” and P2 is the noise addition probability, which represents the probability of adding noise to the output activity labels, i.e., “occasions when a coin is tossed tails.” In such scenarios, the algorithm randomly selects the activity label in T_i as the output. It should be noted that the randomization algorithm may still output the true activity label even in the case of “tails of a coin.” After the randomization algorithm, the output label is said to be randomized anonymization. The randomization algorithm is shown in Algorithm 1.
Algorithm 1:
Randomized anonymization

Definition 8 (Randomized anonymization)
is a Petri net,
is the set of important labels in the net
; a randomized anonymous
is a transformation with an input arbitrary transition
and an output transition
.
In order to achieve differential privacy protection against differential attacks on patients’ personal privacy information in event logs, it is necessary to accurately select the true output probability P1 and the noise addition probability P2. In the algorithm of this article, firstly, the initial probabilities of P1 and P2 are set; subsequently, according to Definition 4, the differential privacy mechanism should satisfy Equation (1). Finally, this P1 and P2 are verified using Equation (1) to find the exact values of P1 and P2.
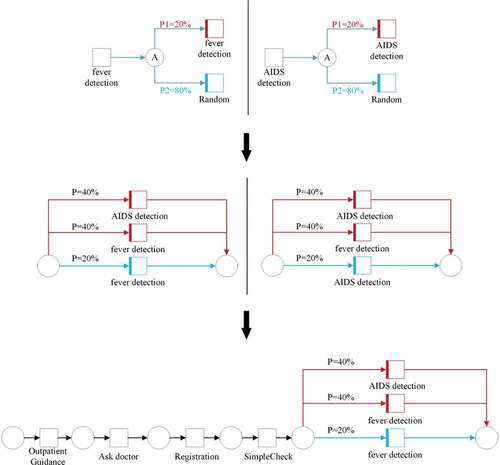
As can be observed from Section 3.2, the Petri net corresponding to the event logs in has the private label of AIDS detection and the sensitive label of fever detection, and we take this Petri net model as an example to illustrate the process of randomized anonymization. We set the privacy budget for differential privacy in this example to 1.05, and the initial probabilities of true output probability P1 and noise addition probability P2 are P1 = 0.2 and P2 = 0.8. According to the Petri net label randomization algorithm structure in , we obtain the randomization algorithm structure of the important labels in the example Petri net model, and according to Definition 8, we perform Randomized anonymization. The structure is shown in .
Figure 6. Randomized anonymization of important labels.
Differential Petri Nets
In section 3.3 the randomized anonymization structure is obtained, which is based on the work done in section 3.2. In this section, the differential Petri net model will be built based on the work done above.
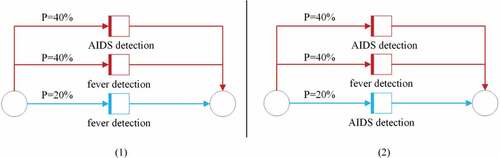
After obtaining the randomized anonymization structure shown in , in order to add this structure to the original Petri net, it is necessary to replace this algorithmic structure with the Petri net structure. According to the definition of randomized anonymization, a randomized anonymization transformation C can be understood as the structure of “place to transition to place” in Petri net, and we use this as the basis for replacing the randomized anonymization structure shown in with the Petri net structure, and the arcs in the Petri net are labeled according to the true output probability P1 and the noise addition probability P2 in , and the replacement structure is shown in . We use different colors to distinguish the occasions of true output from the occasions of noise addition. In the case of outputting the true activity label, the trace is shown as the blue arc in , and when injecting noise into the output activity label, the trace is shown as the red arc in .
Figure 7. Randomized anonymization Petri net structure.
After obtaining the Petri net structure corresponding to the randomized anonymization, we take the Petri net corresponding to the trace in as an example to obtain the differential Petri net. It is observed that this Petri net model contains sensitive label fever detection, so the structure in is used to replace the sensitive label fever detection in the Petri net, and the result is shown in , and the replaced Petri net has the structure of randomized anonymity. According to the concept of differential privacy mechanism, the model can synthesize activity traces with differential privacy protection due to the introduction of noise in the Petri net model, which can achieve differential privacy protection for patient privacy information in the event log, i.e., a differential Petri net model is obtained. Next, we replace the important labels in the Petri nets corresponding to the other activity traces contained in the original logs to obtain the differential Petri nets corresponding to each different activity trace, and these models can generate activity traces with differential privacy, and combine the activity traces corresponding to the differential Petri net model for each trace to obtain the event log with differential privacy protection logs to achieve the protection of patient privacy information in the event logs.
Figure 8. Differential Petri nets.
Differential Privacy Protection Event Log and Its Availability Verification
Section 3.4 obtains the differential Petri net model by introducing the randomized anonymization structure into the Petri net model. According to the concept of differential privacy mechanism, the data generated by this Petri net model are all data with differential privacy, which can achieve differential privacy protection of event logs and avoid the leakage of patient privacy information in event logs by differential attacks. Based on the work in Section 3.4, we replace all the important labels in the Petri net corresponding to each different trace to obtain the differential Petri net model corresponding to each trace, generate the event traces using these models, and combine these activity traces into a new event log that is -differentially private according to the concept of differential privacy.
In this section, the event log of the medical diagnosis process in will be used as an example to show how the differential Petri net proposed in this paper can protect the information of patients in the event log with differential privacy. In particular, in addition to preventing differential attacks and leakage of personal privacy information, it is also necessary to ensure that the algorithm-processed data remains somewhat availability. One of the motivations of this article is to reduce the loss of process information in the processed event log, while the frequency information of the process variants in the original log can be restored. If the availability of the event log data is low after processing by the randomization algorithm, the significance of analyzing the event log is lost. Therefore, after applying the randomization algorithm, the availability of the data is also analyzed in this article. The differential privacy log generation algorithm in this article is shown in Algorithm 2.
Algorithm 2:
Differential privacy log algorithm

In Section 3.4, we obtained the differential Petri net model corresponding to each process variant in the original log, and shows the differential Petri net model corresponding to one variant in the original log. According to the post-processing definition of differential privacy, if a mechanism is satisfying differential privacy, the result obtained is consistent with differential privacy no matter what post-processing is applied to it. Therefore, we can synthesize virtual event logs by differential Petri nets, and these synthesized event logs are all differential privacy compliant. Also, since this article uses the activity labels present in the original logs to replace the important labels, no traces or activities that do not exist in the original logs are generated.
The differential Petri nets corresponding to process variants can generate activity traces with differential privacy protection based on probability, and the activity traces generated by differential Petri nets corresponding to all process variants in the event log are recombined to obtain a virtual event log, which is -differentially private according to the post-processing definition of differential privacy. As shown in . shows a virtual event log synthesized by differential Petri nets, and it should be noted that since there are traces in the original log that do not contain private labels, for such traces we maintain the output as is and do not process them. According to Definition 5, this event log is
-differentially private.
Figure 9. Generate virtual event logs.
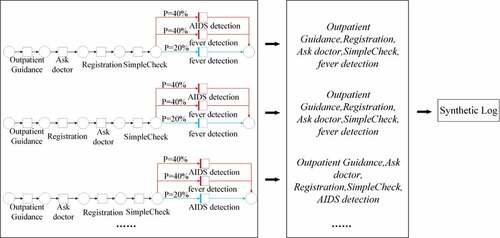
Table 2. Synthetic event log.
To verify the differential privacy performance of this event log, by definition, the verification formula in this example is shown below.
In this example, and
can be regarded as neighboring databases, i.e., the true activity labels of the activities recorded in the event log. This is because in the randomized anonymization structure used in this article, only the label fever detection and the label AIDS detection is performed to replace the original labels, so that no activity traces that do not exist in the original event log or activity traces that are clearly not in line with common sense of life are generated.
represents the probability that the real label in the original log is AIDS detection, while the activity label in the output virtual event log is AIDS detection, hereafter referred to as Pr1.
represents the probability that the real label in the original log is fever detection and the active label in the output virtual event log is AIDS detection, hereinafter referred to as Pr2.
According to Algorithm 2, the initial probabilities set are P1 = 0.2 and P2 = 0.8, which are calculated as Pr1 = 0.6 and Pr2 = 0.4, and the result of the formula is 1.5, i.e., , and the privacy budget
is
1.5, which satisfies
1.5 differential privacy; the actual privacy requirements will limit the value of the privacy budget to ensure the effect of privacy protection. In this example we set the value of the privacy budget to 1.05, and
1.5 < 1.05. According to Algorithm 2, the performance of the differential privacy mechanism can be considered as meeting the requirements, and there is no need to reset the true output probability P1 with the noise addition probability P2 to end the algorithm.
In the work done in this section, we applied the method proposed in this article to the example by setting the privacy budget = 1.05 and obtained the differential Petri net model, as well as the event logs generated by this model, as shown in . Compared with the original event log, the generated event log contains all the variants of the original traces and does not generate traces that do not exist originally.
To verify the performance of the methods in this article to retain process information in the original log, we use k-anonymity as a measure of the degree of privacy of the event log and verify it. To guarantee the k-anonymity of the event log, a simple approach is to remove all traces that violate the privacy requirement according to the k-anonymity requirement, producing an event log with a large loss of process information. We set the value of k to 15, and shows the original event log after processing and shows the synthetic event log after processing. The event log generated by the approach in this article contains more active trace variants when the k-anonymity requirements are the same.
Table 3. Original event log after processing.
Table 4. Synthetic event log after processing.
Restore Frequency Information
The approach used in this article incorporates a randomized response approach, which protects log privacy and reduces the loss of process information, while by reversing the randomized response approach, we can restore the trace frequency information in the original logs through the processed event logs, yielding frequency results that approximate the original logs.
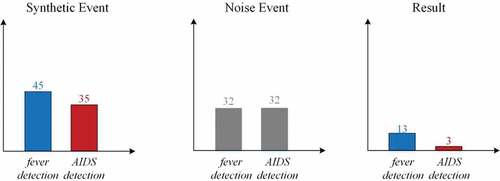
The differential privacy mechanism proposed in this article can ensure that the protected event logs still have data availability. In the randomized anonymization structure proposed in Section 3.3, we set the initial probability to P1 = 0.2 and P2 = 0.8. i.e., each private label AIDS detection or sensitive label fever detection has 80% probability of being injected with noise, corresponding to The part of the red arc in the differential Petri net, and 20% probability of outputting the true label directly, corresponding to the part of the blue arc in .
Therefore, in the event log after processing, there are about 64 important labels in the related cases 80 cases are activity labels outputted after noise injection, and since the label fever detection or label AIDS detection is outputted with the same probability when noise is injected, there are about 32 label fever detection with noise injection and 32 label AIDS detection with noise injection.A total of 45 activity fever detections and 35 activity AIDS detections were recorded in , and it is presumed that the number of activity fever detections output with true labels was 13 and the number of activity AIDS detections was 3. In the processed logs, it can be presumed that about 19% of the patients performed AIDS detection.According to , a total of 65 event fever detections and 15 event AIDS detections were recorded in the original event log, and 23% of the patients performed AIDS detection. It can be concluded that the virtual event log generated by the differential Petri net in this article can approximate the frequency information of the activity traces in the original log, and can provide approximate results with the original log. The calculation process is shown in .
Figure 10. Data availability verification.
Experimental Evaluation
In the previous section, we combined the behavioral profile with the randomized response to ensure that the noise injected into the original logs is the traces that were already present in the logs by selecting the important labels. Thus solving RQ1, which we proposed in Section 1, and in RQ2, we propose to reduce the loss of process information during log processing. To evaluate the performance of the approach in this article in terms of process information reduction, in this section we performed experiments using a public dataset. In the following we refer to the proposed approach as DP-PetriNet. The details of this part are as follows: Section 4.1 presents information on the dataset used for the experiments, section 4.2 describes the experimental settings in detail, section 4.3 discusses the results of the experiments.
Dataset
We verified the algorithm of this article on the open source tool PM4PYFootnote1. We conducted evaluation experiments using a public dataset BPI Challenge 2017 - Offer logFootnote2. According to Algorithm 2, DP-PetriNet processes the eligible activity traces in this event log, while the unqualified ones are left unprocessed. The information of this dataset is shown in . In this experiment, we set P1 = 20%, P2 = 80%, and = 1.05. The information of the event log after processing by the approach in this article is shown in .
Table 5. Event log information.
Table 6. Event log information after processing.
Experimental Settings
We compare the experimental results of DP-PetiNet with a Baseline method. This Baseline method provides privacy guarantees in the following way.
Baseline: Based on the definition of k-anonymity, the traces that appear less than k times in the original log L are removed to ensure the k-anonymity of Baseline log LB.
The degree of privacy of the event log can be measured using k-anonymity as a metric, but guaranteed k-anonymity results in the loss of process information in the original log. To evaluate this, we use the number of variants in the original log retained by the approach as a metric to verify the performance of DP-PetriNet and Baseline in retaining process information in the original log when k takes the same value, respectively. In addition, while reducing the loss of process information, we also hope that the quality of the process models mined from the processed event logs will not be significantly degraded. To verify the quality of the process models, for the event logs processed by DP-PetriNet or Baseline, we use the Inductive approach to discover process models from these logs. Afterward, we measured the quality of the models by the Fitness (Adriansyah, van Dongen, and van der Aalst Citation2011) and Precision (Adriansyah et al. Citation2015) of the discovered models relative to the original event logs L. In addition, we evaluate the effect of different k values on model quality in our experiments.
Results
The experimental results are shown in . shows the retention of process trace variants in the original event log at different k values. It can be found that the number of variants contained in the processed event logs of both DP-PetriNet and Baseline approaches decreases as the value of k increases. However, in most cases, the DP-PetriNet approach retains more variants than the Baseline approach, and only in the case of some k values, for example, when the value of k is taken in the range (500,1000), the number of variants retained by the DP-PetriNet approach is comparable to that of the Baseline approach. This result indicates that the DP-PetriNet approach always retains more or a considerable number of variants compared to the Baseline approach for the same k value, in other words, the DP-PetriNet approach always retains more process information in the original log for the same k value, reducing the loss of process information in the original log.
Figure 11. Number of retained trace variants.
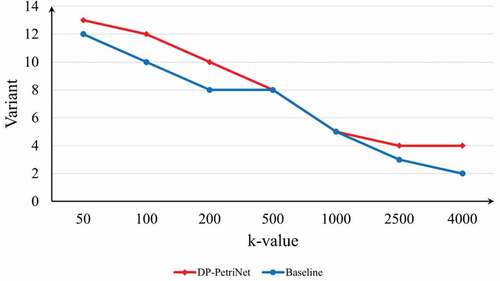
Table 7. Experimental data.
shows the Fitness and Precision between the process model mined from the processed event logs using Inductive approach and the original event logs. Also, we include the results of the model mined from the unprocessed event logs as a comparison. It can be found that, compared with the Baseline approach, the Precision of the DP-PetriNet approach is comparable to that of the Baseline approach when the value of k is taken small, such as k = 50 or k = 100; and when the value of k is taken large, such as k = 2500, the Precision of the DP-PetriNet is 0.8831 at this time. The Precision of Baseline method is 0.9921, and the performance of DP-PetriNet will be slightly lower than that of Baseline approach at this time, which is due to the fact that DP-PetriNet approach retains more kinds of activity traces compared with Baseline approach at k = 2500.
Figure 12. Fitness and precision.
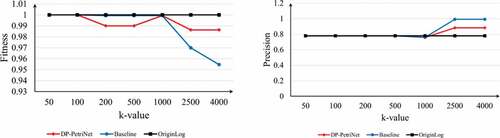
In terms of Fitness measure, compared with Baseline approach, when the value of k is small, the Fitness of DP-PetriNet approach is basically comparable to Baseline approach, for example, when k is 200, the Fitness of DP-PetriNet is 0.99, and the Fitness of Baseline approach is 0.9993; and when k takes a larger value, such as k = 2500, the Precision of DP-PetriNet is 0.9863 and the Precision of Baseline approach is 0.97, and the performance of DP-PetriNet is slightly better than that of Baseline approach.
The experimental results demonstrate that the performance of the DP-PetriNet approach proposed in this article is slightly lower in Precision and higher in Fitness compared to the Baseline approach in terms of Precision and Fitness metrics. This result indicates that for the same k value, the event logs processed by the Baseline approach and the DP-PetriNet approach have their own advantages in terms of quality metrics for the models mined using process mining techniques, such as higher Precision for the Baseline approach and higher Fitness for the DP-PetriNet approach. Overall, the quality of the models mined by both approaches is comparable. Combining the number of variants in the original logs retained by the two approaches, we can conclude that the DP-PetriNet approach can retain more process variants in the original logs compared with the Baseline approach with comparable quality of the mined models, which means that the loss of process information in the original logs is reduced.
Conclusion
In this article, we propose a differential algorithm based on behavioral profile and randomized response to build differential Petri nets that solve the two research questions presented in Section 1. The algorithm is secure provable, performance usable and decision interpretable. It selects the important labels in the event logs by the behavioral profile between activities, injects the important labels as noise into the Petri net model mined from the original event logs through a randomized response approach, and builds a differential Petri net model, which is used to synthesize the processed event logs.
Compared with the existing literature, this article has the following potential innovations: (1) In terms of content, different from the existing works based on the privacy protection perspective alone, this article integrates the knowledge of privacy protection and Petri net domain, combines the behavioral profile theory with the differential privacy approach, and the research perspective is more comprehensive and deeply. (2) In terms of approach, existing research focuses on processing the original logs and obtaining differential privacy event logs by injecting noise or merging similar information. In this paper, we consider the loss of process information in the processed event logs, and propose a approach that balances privacy and process information.In this paper, we consider the loss of process information in the processed event logs, and propose a approach that balances privacy and process information. It provides a supplement to the research in the area of differential privacy protection of event logs.
The differential Petri nets established by this approach are differential privacy compliant. According to the post-processing definition of differential privacy, the synthesized event logs are also differential privacy compliant, and since the important labels as noise injection exist in the original event logs, RQ1 is solved and the traces contained in the processed event logs are all present in the original logs. At the same time, we solve RQ2 by introducing a random response mechanism that retains more process variants of the original log under the same k-anonymity requirement, thus reducing the loss of process information from the original log. In addition, the approach in this article also effectively restores the frequency information of process variants in the original logs. The performance of the approach is experimentally demonstrated on a public dataset.
Acknowledgements
We also gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Disclosure Statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
Notes
References
- Adriansyah, A., J. Munoz-Gama, J. Carmona, B. F. van Dongen, and W. M. P. van der Aalst. 2015. Measuring precision of modeled behavior. Information Systems and E-Business Management 13 (1):37–842. doi:10.1007/s10257-014-0234-7.
- Adriansyah, A., B. F. van Dongen, and W. M. P. van der Aalst. 2011. Conformance checking using cost-based fitness analysis. In 2011 IEEE 15th International Enterprise Distributed Object Computing Conference, 55–64. doi:10.1109/EDOC.2011.12
- Augusto, A., R. Conforti, M. Dumas, M. L. Rosa, F. M. Maggi, A. Marrella, M. Mecella, and A. Soo. 2019. Automated discovery of process models from event logs: Review and benchmark. IEEE Transactions on Knowledge and Data Engineering 31 (4):686–705. doi:10.1109/TKDE.2018.2841877.
- Batista, E., and A. Solanas. 2021. A uniformization-based approach to preserve individuals’ privacy during process mining analyses. Peer-To-Peer Networking and Applications 14 (3):14. doi:10.1007/s12083-020-01059-1.
- Dwork, C. 2008. Differential privacy: A survey of results. In Theory and applications of models of computation, ed. M. Agrawal, D. Du, Z. Duan, and A. Li, 1–19. Berlin Heidelberg: Springer.
- Elkoumy, G., S. Fahrenkrog-Petersen, M. Dumas, P. Laud, A. Pankova, and M. Weidlich. 2022. Shareprom: A tool for privacy-preserving inter-organizational process mining, August 5.
- Elkoumy, G., S. A. Fahrenkrog-Petersen, M. F. Sani, A. Koschmider, F. Mannhardt, S. N. Von Voigt, M. Rafiei, and L. V. Waldthausen. 2021. Privacy and confidentiality in process mining: Threats and research challenges. ACM Transactions on Management Information Systems 13 (1):1–11. doi:10.1145/3468877.
- Elkoumy, G., A. Pankova, and M. Dumas. 2021. Mine me but don’t single me out: Differentially private event logs for process mining. In 2021 3rd International Conference on Process Mining (ICPM), 80–87. doi:10.1109/ICPM53251.2021.9576852
- Fahrenkrog-Petersen, S. 2019. Providing privacy guarantees in process mining, 23–30.
- Fahrenkrog-Petersen, S. A., H. van der Aa, and M. Weidlich. 2019. PRETSA: Event log sanitization for privacy-aware process discovery. In 2019 International Conference on Process Mining (ICPM), 1–8. doi:10.1109/ICPM.2019.00012
- Fahrenkrog-Petersen, S. A., H. van der Aa, and M. Weidlich. 2020. PRIPEL: Privacy-preserving event log publishing including contextual information. In Business Process Management, ed. D. Fahland, C. Ghidini, J. Becker, and M. Dumas, 111–28. Cham, Switzerland: Springer International Publishing.
- Feng, P., H. Zhu, Y. Liu, Y. Chen, and Q. Zheng. 2018. Differential privacy protection recommendation algorithm based on student learning behavior. In 2018 IEEE 15th International Conference on E-Business Engineering (ICEBE), 285–88. doi:10.1109/ICEBE.2018.00054
- Hou, Y., X. Xia, H. Li, J. Cui, and A. Mardani. 2022. Fuzzy differential privacy theory and its applications in subgraph counting. In IEEE Transactions on Fuzzy Systems, 1–1. doi:10.1109/TFUZZ.2022.3157385
- Kabierski, M., S. A. Fahrenkrog-Petersen, and M. Weidlich. 2021. Privacy-aware process performance indicators: Framework and release mechanisms. In Advanced information systems engineering, ed. M. L. Rosa, S. Sadiq, and E. Teniente, 19–36. Cham, Switzerland: Springer International Publishing.
- Leemans, S. J. J., D. Fahland, and W. M. P. van der Aalst. 2013. Discovering block-structured process models from event logs—A constructive approach. In Application and theory of petri nets and concurrency, ed. J.-M. Colom and J. Desel, 311–29. Berlin Heidelberg: Springer.
- Liu, C. 2022. Formal modeling and discovery of multi-instance business processes: A cloud resource management case study. IEEE/CAA Journal of Automatica Sinica 9 (12):2151–60. doi:10.1109/JAS.2022.106109.
- Liu, C., L. Cheng, Q. Zeng, and L. Wen. 2022. Formal modeling and discovery of hierarchical business processes: A petri net-based approach. In IEEE Transactions on Systems, Man, and Cybernetics: Systems, 1–12. doi:10.1109/TSMC.2022.3195869
- Liu, C., H. Li, S. Zhang, L. Cheng, and Q. Zeng. 2022. Cross-department collaborative healthcare process model discovery from event logs. In IEEE Transactions on Automation Science and Engineering, 1–11. doi:10.1109/TASE.2022.3194312
- Mannhardt, F., A. Koschmider, N. Baracaldo, M. Weidlich, and J. Michael. 2019. Privacy-preserving process mining: Differential privacy for event logs. Business & Information Systems Engineering 61 (5):595–614. doi:10.1007/s12599-019-00613-3.
- Mannhardt, F., S. A. Petersen, and M. F. Oliveira. 2018. Privacy challenges for process mining in human-centered industrial environments. In 2018 14th International Conference on Intelligent Environments (IE), 64–71. doi:10.1109/IE.2018.00017
- Nuñez von Voigt, S., S. Fahrenkrog-Petersen, D. Janssen, A. Koschmider, F. Tschorsch, F. Mannhardt, O. Landsiedel, and M. Weidlich. 2020. Quantifying the re-identification risk of event logs for process mining: empirical evaluation paper, 252–67). doi:10.1007/978-3-030-49435-3_16
- Pika, A., M. T. Wynn, S. Budiono, A. H. M. Ter Hofstede, W. M. P. van der Aalst, and H. A. Reijers. 2020. Privacy-preserving process mining in healthcare. Intern-ational Journal of Environmental Research and Public Health 17 (5):1612, Article 5. doi:10.3390/ijerph17051612.
- Rafiei, M., L. von Waldthausen, and W. M. P. van der Aalst. 2020. Supporting confidentiality in process mining using abstraction and encryption. In Data-driven process discovery and analysis, ed. P. Ceravolo, M. van Keulen, and M. T. Gómez-López, 101–23. Springer International Publishing. doi:10.1007/978-3-030-46633-6_6.
- Rafiei, M., M. Wagner, and W. M. P. van der Aalst. 2020. TLKC-privacy model for process mining. In Research challenges in information science, ed. F. Dalpiaz, J. Zdravkovic, and P. Loucopoulos, 398–416. Cham, Switzerland: Springer International Publishing.
- Rösel, F., S. Fahrenkog-Petersen, H. van der Aa, and M. Weidlich. 2022. A distance measure for privacy-preserving process mining based on feature learning 73–85. doi:10.1007/978-3-030-94343-1_6.
- Stefanini, A., D. Aloini, E. Benevento, R. Dulmin, and V. Mininno. 2018. Performance analysis in emergency departments: A data-driven approach. Measuring Business Excellence 22 (2):130–45. doi:10.1108/MBE-07-2017-0040.
- Sweeney, L. 2002. k-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10 (5):557–70. doi:10.1142/S0218488502001648.
- van der Aalst, W. 2012. Process mining: Overview and opportunities. ACM Transactions on Management Information Systems 3 (2):1–17. doi:10.1145/2229156.2229157.
- van der Aalst, W. 2016. Data science in action. In Process mining: Data science in action, 3–23. Berlin Heidelberg: Springer. doi:10.1007/978-3-662-49851-4_1.
- van der Aalst, W., T. Weijters, and L. Maruster. 2004. Workflow mining: Discovering process models from event logs. IEEE Transactions on Knowledge and Data Engineering 16 (9):1128–42. doi:10.1109/TKDE.2004.47.
- Voss, W. G. 2016. European union data privacy law reform: General data protection regulation, privacy shield, and the right to delisting. The Business Lawyer 72 (1):221–34.
- Weidlich, M., A. Polyvyanyy, N. Desai, and J. Mendling. 2010. Process compliance measurement based on behavioural profiles. In Advanced information systems engineering, ed. B. Pernici, 499–514. Springer. doi:10.1007/978-3-642-13094-6_38.