
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Aiming at the problems of difficult data collection and labor-intensive manual annotation, few-shot object detection (FSOD) has gained wide attention. Although current transfer-learning-based detection methods outperform meta-learning-based methods, their data organization fails to fully utilize the diversity of the source domain data. In view of this, Data Resampling (DR) organization is proposed to fine-tune the network, which can be employed as a component of any model and dataset without additional inference overhead. In addition, in order to improve the generalization of the model, a Cross-Iteration Metric-Learning (CIML) branch is embedded in the few-shot object detector, thus actively improving intra-category feature propinquity and inter-category feature discrimination. Our generic DR-CIML approach obtained competitive scores in extensive comparative experiments. The nAP50 performance on PASCAL VOC improved by up to 6.3 points, and the bAP50 performance reached 81.0, surpassing the base stage model (80.8) for the first time. The nAP75 performance on MS COCO improved by up to 1.6 points.
Introduction
With their forceful feature learning and visual perception capability, deep convolutional neural networks (CNNs) show performance beyond human level, achieving great success in computer vision fields such as image classification, object detection, and segmentation (Bochkovskiy, Wang, and Liao Citation2020; He et al. Citation2016; Ren et al. Citation2015; Simonyan and Zisserman Citation2014; Tan and Le Citation2019; Tian et al. Citation2019). However, general object detection algorithms require a large amount of labeled data to generalize well and obtain an effective model, which imposes a heavy workload and is costly (Deng et al. Citation2009; Everingham et al. Citation2010, Citation2015; Lin et al. Citation2014). In cases such as medical applications (Katzmann et al. Citation2021) or rare species (Mannocci et al. Citation2022), it is unrealistic to obtain a large amount of data, while ordinary people quickly learn new concepts from only a few observations, even at early ages (Samuelson and Smith Citation2005). In view of this, it is of great significance to study how to obtain a vision system with good generalization performance using a small number of samples.
Scholars have researched deep learning-based few-shot object detection (Lu et al. Citation2020), which is complicated because it must accurately locate different categories of objects (Köhler, Eisenbach, and Gross Citation2021). If only a small number of novel categories are trained, the detector is prone to nonconvergence or overfitting, resulting in poor generalization (Chen et al. Citation2018), and it cannot correctly detect instances from novel categories.
Some meta-learning-based methods (Finn, Abbeel, and Levine Citation2017; Nichol, Achiam, and Schulman Citation2018; Vinyals et al. Citation2016; Yan et al. Citation2019) effectively learn prior knowledge from multiple subtasks and even learn to learn, so as to learn new tasks with few training examples. The performance of transfer-learning-based FSOD methods (Sun et al. Citation2021; Wang et al. Citation2020) exceeds that of meta-learning-based FSOD methods. Among them, TFA (Wang et al. Citation2020) has a simple and effective two-stage, single-branch structure. By freezing all model parameters except the last layer, the problem of losing source domain knowledge in transfer-learning (Zhuang et al. Citation2020) was solved. In addition, TFA has established a new evaluation protocol and new benchmarks by repeating runs to obtain a stable evaluation. FSCE (Sun et al. Citation2021) adopts the same data division as TFA, where the major cause affecting the AP on novel class (nAP) is the misclassification of novel categories rather than inaccurate positioning. Therefore, a CPE branch is embedded in the RoI feature extractor to improve classification performance, inspired by the successful application of comparative learning in image recognition (Schroff, Kalenichenko, and Philbin Citation2015; Sun et al. Citation2014) and self-supervised representation learning (Khosla et al. Citation2020). However, CPE is slow to increase the differences of feature embeddings of inter-class objects, and a large amount of data is needed for self-supervised learning. Therefore, we apply triple loss, which is considered more appropriate (Schroff, Kalenichenko, and Philbin Citation2015), to actively minimize the distance between the anchor and the positive examples of the same category and to maximize the distance between the anchor and negative examples of different categories. Cross-iteration metric learning is added to increase the feature diversity of metric learning, so as to better solve the problem of misclassification in FSOD.
In addition, it is obvious that current methods based on transfer learning train on the fixed base class and novel class samples, i.e., the training data of each epoch are exactly the same. Although this settles the problem of data imbalance, the diversity of the abundant base data is not fully utilized. As a result, the model still has room to improve its detection performance. In view of the above problems, the main contributions of this paper include the following:
Base data resampling. To fully utilize the diversity of the abundant base data, instead of fixing the base categories samples in the fine-tuning phase, we randomly sample K-shot base category instances for each epoch when maintaining the same partition and fixed novel categories instances as TFA (Wang et al. Citation2020). We believe this is the first application of data resampling organization to transfer-learning-based FSOD;
Cross-iteration metric-learning branch. To deal with the misclassification of novel category instances, we employ a cross-iteration metric-learning branch with triplet loss (Weinberger and Saul Citation2009) in FSOD for supervised learning. We retain object feature embeddings from adjacent iterations to increase the feature diversity of metric learning, so as to actively promote intra-category feature propinquity and inter-category feature discrimination.
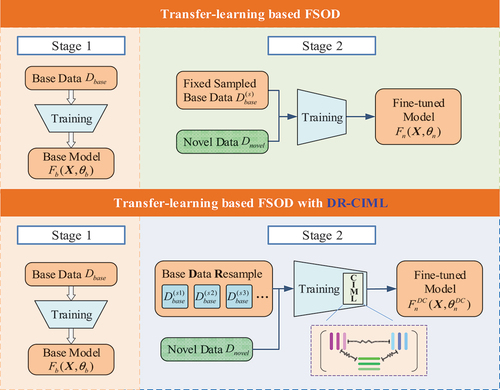
shows the modifications and improvements of transfer-learning-based FSOD via our proposed DR-CIML.
Figure 1. Modifications and improvements of DR-CIML applied to transfer-learning-based FSOD.
In extensive experiments, our generic training scheme obtained the highest novel-categories AP50 (nAP50) almost in three different splits under K-shot settings with K = 1, 2, 3, 5, and 10 on PASCAL VOC (Everingham et al. Citation2010, Citation2015), and the nAP50 performance improved by up to 6.3 points. Furthermore, the proposed method is the first to achieve>80 base-categories AP50 (bAP50) on all shots after fine-tuning on PASCAL VOC, even exceeding the bAP50 performance of the base training stage (80.8) when K > 3. Competitive scores were also achieved on MS COCO (Lin et al. Citation2014) under the K-shot setting with K = 10, 30. The nAP75 performance improved by up to 1.6 points.
The remainder of this paper is organized as follows. Section 2 introduces work related to few-shot object detection. Section 3 introduces our proposed data resampling and cross-iteration metric-learning methods. Section 4 discusses our experimental results and provides a comparative analysis. Section 5 summarizes the paper.
Related Work
Most FSOD methods were developed in the context of few-shot classification (Sun et al. Citation2021). However, it is more difficult than the classification task because it must accurately and simultaneously locate and classify objects (Zhuang et al. Citation2020). Many FSOD approaches are based on meta-learning and feature re-weighting to avoid overfitting and learn to learn (Finn, Abbeel, and Levine Citation2017; Han et al. Citation2022; Karlinsky et al. Citation2019; Li et al. Citation2020; Michaelis et al. Citation2018; Nichol, Achiam, and Schulman Citation2018; Wang, Ramanan, and Hebert Citation2019). Recent transfer-learning-based FSOD methods have shown strong generalization capability (Fan et al. Citation2021; Li et al. Citation2021; Sun et al. Citation2021; Wang et al. Citation2020; Wu et al. Citation2020; Zhang, Wang, and Forsyth Citation2020), surpassing many methods based on meta-learning.
Meta-Learning
Meta-learning aims to learn meta-knowledge through episodic training, so as to quickly learn new concepts through small amounts of labeled data.
In the MAML method (Finn, Abbeel, and Levine Citation2017), the meta-network assigns parameters to each n-way k-shot subtask. The sub-network performs one-step learning and parameter updating on the supply set of the subtask. The query set of the subtask is used to calculate the sub-network loss, and the gradient is calculated to update the meta-network parameters.
Reptile (Nichol, Achiam, and Schulman Citation2018) improves MAML by updating meta-network parameters through the difference between them and sub-network parameters instead of the gradient of subtasks.
With an episodic training scheme, meta-learning inadequately trains existing data, but the model can quickly learn new concepts through a small amount of annotated data. Therefore, meta-learning pays more attention to the future potential of initialization parameters than pre-training, and not the current performance on multitasking
Metric Learning
Metric learning learns feature embedding, where inputs with similar content are encoded in features with small metric distances, while coded features from different types of inputs should be far from each other (Kaya and Bilge Citation2019), so as to obtain better feature representation ability for more accurate classification prediction (Weinberger, Blitzer, and Saul Citation2005; Xing et al. Citation2002). Basic metric distance calculation methods include Euclidean, Mahalanobis, Matusita (Matusita et al. Citation1955), Bhattacharyya (Aherne, Thacker, and Rockett Citation1998), and Kullback Leibler (Elgammal, Duraiswami, and Davis Citation2003). A metric-learning loss function such as triplet loss (Weinberger and Saul Citation2009) or its variant form (Aganian et al. Citation2021) can shorten the distance between the anchor and positive examples, and increase the distance between the anchor and negative examples, and is suitable for few-shot learning tasks. Because the learned feature-embedding network usually has good generalization, the model can make metric-based decisions without further training for unseen objects (Köhler, Eisenbach, and Gross Citation2021). For example, in the inference stage of the classification task, the feature embedding of the test image is compared with those of the novel categories, and the class corresponding to the nearest feature embeddings is the recognized class.
Therefore, metric learning is conducive to the alleviation of the misclassification of novel categories in few-shot object detection.
Meta-Learning-Based Few-Shot Object Detection
Meta-learning-based FSOD includes dual-branch (Han et al. Citation2022; Li et al. Citation2020; Michaelis et al. Citation2018; Yan et al. Citation2019) and single-branch (Karlinsky et al. Citation2019; Wang, Ramanan, and Hebert Citation2019) methods, both of which utilize episodic training.
Dual-branch methods consist of a query branch Q and support branch S, which share the backbone. Q extracts the query RoI features through a region proposal network (RPN) and RoI Align, and S extracts the representative support feature vector of each category. Therefore, the query RoI features and support feature vectors can be aggregated, and these are input to the RoI head for bounding box regression and binary classification. Dual-branch methods vary most in the means of aggregation between RoIs, and support feature vectors are employed. Meta R-CNN (Yan et al. Citation2019) takes channel-wise soft-attention on RoI features to remodel the predictor head when more complicated aggregation approaches are adopted by OSWF (Li et al. Citation2020), OSIS (Michaelis et al. Citation2018), and Meta Faster R-CNN (Han et al. Citation2022). Although dual-branch methods allow the quick learning of new categories without fine-tuning in meta-testing, they demand complex episodic training. As the support category increases, to aggregate separately for each category requires more RAM.
Without Q and S branches, single-branch methods obtain more discriminative features through metric learning or diminish learnable parameters when training novel data. (Karlinsky et al. Citation2019) calculated the similarity between the embedded feature vector of RoI and category-representative vectors, exploiting extra embedding loss to learn discriminative feature embeddings.
Transfer-Learning-Based Few-Shot Object Detection
Compared with meta-learning-based FSOD methods, which require complex episodic training, transfer-learning-based FSOD methods utilize a relatively simple two-stage approach on a single-branch architecture. In the first stage, the detector is trained on all base categories. In the second stage, unfrozen layers on the balanced base and novel categories are fine-tuned, while freezing the other components of the model. There are many modifications based on this.
Modifications of RPN
CoRPN (Zhang, Wang, and Forsyth Citation2020) replaces the single binary classifier in the original RPN with N binary classifiers to avoid missing the foreground RoI from RPN. FSCE (Sun et al. Citation2021) doubles the maximum number of proposals kept after Non-Maximum Suppression (NMS) to avoid abandoning the foreground RoI. RPN parameters are learnable in the fine-tuning stage to benefit novel detection results.
Modifications of FPN
FSCE is based on the assumption that fine-tuning FPN parameters in the second stage performs better than freezing them. MPSR (Wu et al. Citation2020) implements the FPN processing of multiscale positive sample refinement through object pyramids, so as to expand the scale distribution of novel categories and reduce improper negative samples containing a large proportion of positive instances.
Modifications of Loss Function
MPSR applies a refinement branch, adding the extra classification loss of the extracted multiscale positive samples to the RPN loss function and ROI loss function of Faster R-CNN. FSCE employs contrastive proposal encoding (CPE) loss to promote the compactness of intra-class instances. CGDP+FSCN (Li et al. Citation2021) applies additional semi-supervised loss to exploit unlabeled instances, thereby promoting the learning of sparse novel category objects.
Maintaining Performance on Base Categories
Retentive R-CNN (Fan et al. Citation2021) utilizes separate classification heads for novel and base categories to avoid the catastrophic forgetting of base categories.
To sum up, transfer-learning-based FSOD does not need complex episodic training; it achieves state-of-the-art (SOTA) performance by appropriately freezing network components or modifying the loss function.
Nonetheless, existing transfer-learning-based FSOD approaches are trained on fixed base class objects and novel class objects, and it is obvious that the diversity of the abundant annotated base data is not fully utilized. These mean that the model still has room to improve the detection performance. Therefore, we expect that our transfer-learning-based DR-CIML can make full use of base class data.
Method
Our proposed method follows the standard transfer-learning-based FSOD methods (Sun et al. Citation2021; Wang et al. Citation2020). We explore some neglected properties of the abundant base data for fine-tuning. The training scheme has two stages. The first stage is training Faster R-CNN with abundant base data. In the second stage, the metric-learning branch is embedded in the RoI feature extractor, and the base model is fine-tuned with sufficient base data and sparse novel data. In addition, we freeze different components of the model according to particular K-shot tasks. We optimize the model by jointly optimizing the RPN, regression, and classification loss of the standard Faster R-CNN, as well as the cross-iteration metric-learning loss added in the fine-tuning stage. shows the structure of the DR-CIML method.
Figure 2. Structure of DR-CIML method.
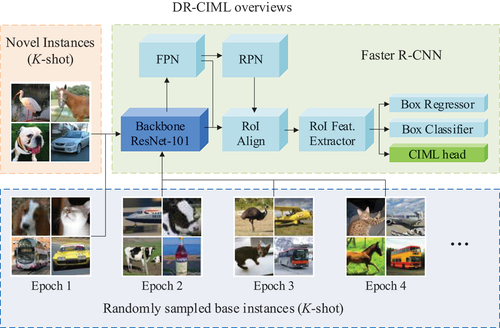
Data Resampling
Standard FSOD methods adopt a unified dataset organization. In the basic training phase, the model is trained on all base data. In the fine-tuning phase, we utilize the fixed-base and novel class samples under the K-shot setting. This dataset organization has the advantage of avoiding the imbalance of base and novel categories, as well as constructing practical few-shot application scenarios. The disadvantage is that a large amount of base-class data is not fully exploited. Hence the data resampling organization technique is proposed. The basic training stage is the same as with the standard FSOD. However, in the fine-tuning stage, novel class data are organized in the same way as Wang et al. (Citation2020), Sun et al. (Citation2021), and Kang et al. (Citation2019), and base-class data
consist of all data that do not contain
, i.e.,
. Because the data volume of
is much larger than that of
, at the beginning of each epoch,
is randomly sampled to construct a balanced sub-dataset under the K-shot setting. Data resampling has two advantages: 1) We have constructed a new balanced sub-dataset that conforms to the FSOD application scenario, so that we can make full use of the base-class data and reduce performance degradation on the base categories; 2) It improves the diversity of sample features, so as to promote the inter-class distance between novel and base categories ().
Figure 3. Overview of cross-iteration metric-learning (CIML) algorithm.
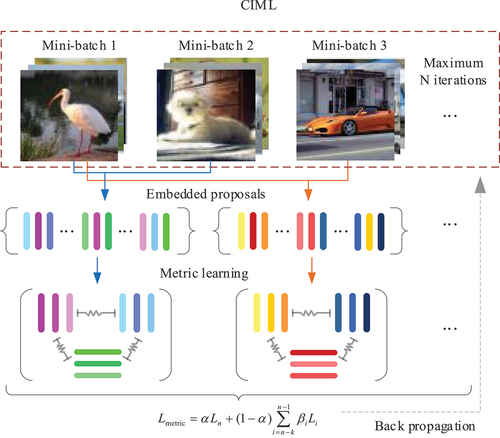
Cross-Iteration Metric-Learning Branch
Standard Faster R-CNN extracts features with its backbone. RPN regresses the bounding box of the predefined anchor and decides whether it is foreground or background. Then region proposals are given by RoI Align. Finally, the regressor of the RoI head fine-tunes the location of region proposals again, and the classifier of the RoI head classifies objects contained in region proposals. Among them, the optimization goal of the classifier is a one-hot vector. In the scenario with large-scale training data, the optimization goal of the classifier is applicable, but it will decrease the robustness of the model while it lacks training data. From this point of view, we embed the metric-learning branch in the RoI feature extractor and calculate the similarity of object features generated by RPN. Specifically, the triple loss (Schroff, Kalenichenko, and Philbin Citation2015) function is applied to increase intra-category feature propinquity and inter-category feature discrimination, so as to reduce misclassification. Our metric loss function is
where embeds a proposal
into a
-dimensional Euclidean space,
is a proposal of a specific object (anchor),
is a proposal of the same class (positive),
is a proposal of any other class (negative), and
is the margin enforced between positive and negative pairs.
However, the quality of region proposals from RPN is uneven, including both high-quality proposals with high IoU with ground truth, and low-quality ones with low IoU with ground truth. Although low-quality proposals with low IoU can be filtered by the IoU threshold , to select an appropriate
is usually problematic. When
is undersized, numerous low-quality proposals containing superfluous backgrounds will be kept, which leads to negative optimization of the model, and when
is too large, few high-quality proposals are preserved, which will make it hard to optimize the model. Therefore, to improve the diversity of features when metric-learning, we consider that adjacent iterations contain features that can be fed into the metric-learning branch to optimize the model. Specifically, we employ a cross-iteration metric-learning branch. Our cross-iteration metric loss function is
where is the current iteration;
denotes the input features of the metric branch of the
th iteration, i.e., the filtered RPN output;
is the weight coefficient of the metric loss of the current iteration; and
is the weight coefficient of the metric loss of all feature embeddings of the current and the
th iterations.
Therefore, the joint optimization objectives of the model are
where utilizes binary cross-entropy loss to generate foreground proposals;
utilizes cross-entropy loss for bounding box classifiers;
utilizes smooth-L1 loss for bounding box regression deltas;
is the metric loss; and
,
,
, and
are the weight coefficients of
,
,
, and
, respectively. Our revised joint loss functions are improved based on the standard Faster R-CNN loss (Ren et al. Citation2015).
Experiments
Comprehensive experiments were conducted on PASCAL VOC and MS COCO, and our proposed method showed competitive scores. We followed the dataset division method of Wang et al. (Citation2020), Sun et al. (Citation2021), and Kang et al. (Citation2019) in order to provide reliable comparative evaluation results. We provide implementation details and results of comparative and ablation experiments, as well as visualization outcomes.
Implementation
Faster R-CNN with ResNet-101 and FPN were employed as our few-shot object detector, and a single Nvidia GeForce RTX 3080 Ti was used to accelerate graphic calculation while loading two images per iteration. Because it would lead to gradient oscillation and non-convergence if the batch were undersized, we adopted the accumulate gradients approach which updates parameters once every batches trained to update the parameters every eight iterations, so as to increase the batch size to 16. The maximum number of iterations was 48,000. The optimizer was SGD, with momentum 0.9 and weight decay 1e-4. The learning rate scheduler adopted linear preheating and cosine attenuation. Multiscale training, random flipping, image mosaic, and other data-enhancement methods were adopted.
Few-Shot Object Detection Benchmarks
Pascal Voc
We used the dataset division of Wang et al. (Citation2020), Sun et al. (Citation2021), and Kang et al. (Citation2019), randomly dividing PASCAL VOC (Everingham et al. Citation2010, Citation2015) into split 1, split 2, and split 3, each containing 15 base categories with abundant instances and five novel categories sampled from training data under the K-shot setting with K = 1, 2, 3, 5, and 10. In the base training stage, the detector was trained on all annotated base categories. In the fine-tuning stage, balanced base category instances and novel category instances were utilized with K-shot, with the modification that the training scheme of data resampling was adopted to fully utilize the diversity of the abundant base data. We evaluated AP50 for novel categories (nAP50) and base categories (bAP50) on the PASCAL VOC2007 test set.
Ms Coco
There are 80 categories in MS COCO (Lin et al. Citation2014), which were divided into 60 base categories and 20 novel categories with K = 10, 30. We report novel AP50–95 and novel AP75 on 5,000 images of COCO2014val.
Few-Shot Object Detection Comparison Results
Results on PASCAL VOC
compares nAP50 between our proposed method and existing methods on PASCAL VOC with three novel splits. Our proposed method reaches the highest nAP50 in different splits under K-shot settings with K = 1, 2, 3, 5, 10, and nAP50 improves by up to 6.3 points, which fully demonstrates the effectiveness of our method. Moreover, for further demonstration the generality of our DR-CIML, we implement them on multiple baselines, as shown in . Both nAP50 and bAP50 have been improved which fully verifies the generalization ability of the DR-CIML for different baselines.
Table 1. nAP50 performance of existing FSOD methods on three PASCAL VOC novel splits with K = 1,2,3,5, and 10. “●” represents meta-learning-based methods. “◊” represents transfer-learning-based methods. “–“represents unreported results of other methods.
Table 2. Apply DR-CIML to different baselines on PASCAL VOC split 1 with K = 3, 5, 10. “◊” represents transfer-learning-based methods. “–“represents unreported results of other methods.
The bAP50 performance on three base splits is shown in . Obviously, the proposed method is the first to achieve>80 bAP50 on all shots after fine-tuning, even exceeding bAP50 of the base training stage (80.8) when K > 3. Besides, its score slightly lower than that of the base training stage when K = 3 mainly because the sampled base class data is insufficient. However, the bAP50 score of the other methods decreased significantly, FSCE reduced by 6.7% and TFA reduced by 2.4%. This shows the strong capacity of DR-CIML to retain base category knowledge in the fine-tuning stage. DR-CIML improves accuracy while incurring no extra inference overhead.
Table 3. bAP50 of existing FSOD methods on three PASCAL VOC base splits. “–“represents unreported results of other methods.
Results on MS COCO
compares the results (nAP50–95 and nAP75) of the proposed and existing methods with K = 10, 30. Our method surpasses many methods, with nAP50–95 and nAP75 improved by up to 1.6 points, which fully verifies the generalization ability of the proposed method for different datasets.
Table 4. Evaluation results of existing FSOD methods on two MS COCO novel splits.
Ablation Research and Visualization
Modifications were implemented in the fine-tuning stage, and the baseline was the standard FSCE (Sun et al. Citation2021) which employs contrastive proposal encoding (CPE) loss to promote instance-level intra-class compactness and inter-class variance. DR-CIML increases instance diversity through base data resampling (DR) to fully utilize source domain data and increases feature diversity of comparative learning through CIML. We performed ablation experiments combining DR, CPE, or CIML components when fine-tuning the model. The ablation results obtained from PASCAL VOC split 1 are shown in .
Table 5. Ablation for data resample organization and cross-iteration metric learning; results gained from PASCAL VOC split 1. “–” represents unreported results of other methods.
Ablation for Base Data Resampling
FSCE fine-tunes on the fixed base categories, so that the diversity of base data is not fully utilized. We promote this by adopting the training scheme of data resampling (DR). The results of (Exp1, E×P3) and (Exp2, E×p4) show that under different metric-learning methods, the DR strategy can improve both nAP50 and bAP50, and even bAP50 surpasses that of the base model (80.8) obtained in the basic training stage, which indicates that DR has a strong ability to maintain base category knowledge.
Ablation for Metric-Learning Branch
We also explored the effect of the cross-iteration metric-learning (CIML) branch. The experimental results of (Exp1, E×p2) show that nAP50 is increased by up to 4.7 points with K = 2, as compared to CPE. (Exp3, E×p4) show that both nAP50 and bAP50 are improved through DR-CIML, which demonstrates that our CIML branch can improve intra-category feature propinquity and inter-category feature discrimination.
To sum up, the experimental results show that the DR and CIML branches can both promote model performance, and only the combined DR-CIML can maximize this. Furthermore, DR-CIML does not lead to extra inference cost, so the inference speed is the same as that of Faster R-CNN.
Visualization for Analysis
shows the visualization results of our method and the standard FSCE. It is found that our proposed DR-CIML method improves misclassification, uncertain recognition, and missed detection. For example, our method would unlikely to recognize dogs and cats as birds or cows, it can also detect the bicycle in while FSCE ignores it. Therefore, DR-CIML learns superior semantic and spatial information.
Figure 4. Visual detection results of our method and standard FSCE.

Conclusion
We explored the deficiencies of transfer-learning-based FSOD methods in data utilization. We are the first to apply data resampling organization and cross-iteration metric learning (DR-CIML) in the transfer-learning-based detection method, so as to make full use of the diversity of base-class data and increase the feature diversity of metric learning. Extensive experiments in PASCAL VOC and MS COCO fully verified the effectiveness of the data resampling method applied to transfer-learning-based FSOD. Our proposed method is independent of models and datasets; hence it can be readily embedded in any object detector without extra inference overhead. FSOD is a challenging task, and we hope our work can inspire more research on FSOD regarding data resampling and visual feature metric-learning. In the future, we will study the effectiveness of data resampling in few-shot segmentation.
Acknowledgements
This work is supported by the National Natural Science Foundation of China, Grant/Award Number: 61973075; Special Funds of the Jiangsu Provincial Key Research and Development Projects, Grant/Award Number: BE2019612; and Jiangsu Provincial Cadre Health Research Projects, Grant/Award Number: BJ17006. We thank LetPub (www.letpub.com) for its linguistic assistance during the preparation of this manuscript.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Aganian, D., M. Eisenbach, J. Wagner, D. Seichter, and H. M. Gross 2021. Revisiting loss functions for person re-identification. In International Conference on Artificial Neural Networks (pp. 30–511). Springer, Cham. doi: 10.1007/978-3-030-86383-8_3.
- Aherne, F. J., N. A. Thacker, and P. I. Rockett. 1998. The Bhattacharyya metric as an absolute similarity measure for frequency coded data. Kybernetika 34 (4):363–68.
- Bochkovskiy, A., C. Y. Wang, and H. Y. M. Liao. 2020. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004 10934. doi:10.48550/arXiv.2004.10934.
- Chen, H., Y. Wang, G. Wang, and Y. Qiao. 2018. Lstd: A low-shot transfer detector for object detection. Proceedings of the AAAI Conference on Artificial Intelligence 32 (1). doi:10.1609/aaai.v32i1.11716.
- Deng, J., W. Dong, R. Socher, L. J. Li, K. Li, and L. Fei-Fei 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248–55). Ieee. doi: 10.1109/CVPR.2009.5206848.
- Elgammal, A., R. Duraiswami, and L. S. Davis 2003. Probabilistic tracking in joint feature-spatial spaces. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Proceedings. (Vol. 1, pp. I–I). IEEE. doi: 10.1109/CVPR.2003.1211432.
- Everingham, M., S. M. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. 2015. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision 111 (1):98–136. doi:10.1007/s11263-014-0733-5.
- Everingham, M., L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. 2010. The pascal visual object classes (voc) challenge. International Journal of Computer Vision 88 (2):303–38. doi:10.1007/s11263-009-0275-4.
- Fan, Z., Y. Ma, Z. Li, and J. Sun 2021. Generalized few-shot object detection without forgetting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4527–36). doi: 10.1109/CVPR46437.2021.00450.
- Finn, C., P. Abbeel, and S. Levine 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International conference on machine learning (pp. 1126–35). PMLR.
- Han, G., Y. He, S. Huang, J. Ma, and S. F. Chang 2021. Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 3263–72). doi: 10.1109/ICCV48922.2021.00325.
- Han, G., S. Huang, J. Ma, Y. He, and S. F. Chang 2022. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 36, No. 1, pp. 780–89). doi: 10.1609/aaai.v36i1.19959.
- He, K., X. Zhang, S. Ren, and J. Sun 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–78). doi: 10.1109/CVPR.2016.90.
- Hu, H., S. Bai, A. Li, J. Cui, and L. Wang 2021. Dense relation distillation with context-aware aggregation for few-shot object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 10185–94). doi: 10.1109/CVPR46437.2021.01005.
- Kang, B., Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell 2019. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8420–29). doi: 10.1109/ICCV.2019.00851.
- Karlinsky, L., J. Shtok, S. Harary, E. Schwartz, A. Aides, R. Feris, and A. M. Bronstein 2019. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5197–206). doi: 10.1109/CVPR.2019.00534.
- Katzmann, A., O. Taubmann, S. Ahmad, A. Mühlberg, M. Sühling, and H. M. Groß. 2021. Explaining clinical decision support systems in medical imaging using cycle-consistent activation maximization. Neurocomputing 458:141–56. doi:10.1016/j.neucom.2021.05.081.
- Kaya, M., and H. Ş. Bilge. 2019. Deep metric learning: A survey. Symmetry 11 (9):1066. doi:10.3390/sym11091066.
- Khosla, P., P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, and D. Krishnan. 2020. Supervised contrastive learning. Advances in Neural Information Processing Systems 33:18661–73. doi:10.48550/arXiv.2004.11362.
- Köhler, M., M. Eisenbach, and H. M. Gross. 2021. Few-shot object detection: A Survey. arXiv preprint arXiv:2112 11699. doi:10.48550/arXiv.2112.11699.
- Li, A., and Z. Li 2021. Transformation invariant few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3094–102). doi: 10.1109/CVPR46437.2021.00311.
- Lin, T. Y., M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, and C. L. Zitnick 2014. Microsoft coco: Common objects in context. In European conference on computer vision (pp. 740–55). Springer, Cham. doi: 10.1007/978-3-319-10602-1_48.
- Li, X., L. Zhang, Y. P. Chen, Y. W. Tai, and C. K. Tang. 2020. One-shot object detection without fine-tuning. arXiv preprint arXiv:2005 03819. doi:10.48550/arXiv.2005.03819.
- Li, Y., H. Zhu, Y. Cheng, W. Wang, C. S. Teo, C. Xiang, and T. H. Lee 2021. Few-shot object detection via classification refinement and distractor retreatment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 15395–403). doi: 10.1109/CVPR46437.2021.01514.
- Lu, J., P. Gong, J. Ye, and C. Zhang. 2020. Learning from very few samples: A survey. arXiv preprint arXiv:2009 02653. doi:10.48550/arXiv.2009.02653.
- Mannocci, L., S. Villon, M. Chaumont, N. Guellati, N. Mouquet, C. Iovan, and D. Mouillot. 2022. Leveraging social media and deep learning to detect rare megafauna in video surveys. Conservation Biology 36 (1):e13798. doi:10.1111/cobi.13798.
- Matusita, K. 1955. Decision rules, based on the distance, for problems of fit, two samples, and estimation. The Annals of Mathematical Statisticss 26 (4):631–40. doi:10.1214/aoms/1177728422.
- Michaelis, C., I. Ustyuzhaninov, M. Bethge, and A. S. Ecker. 2018. One-shot instance segmentation. arXiv preprint arXiv:1811 11507. doi:10.48550/arXiv.1811.11507.
- Nichol, A., J. Achiam, and J. Schulman. 2018. On first-order meta-learning algorithms. arXiv preprint arXiv:1803 02999. doi:10.48550/arXiv.1803.02999.
- Ren, S., K. He, R. Girshick, and J. Sun. 2015. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems 28. doi:10.1109/TPAMI.2016.2577031.
- Samuelson, L. K., and L. B. Smith. 2005. They call it like they see it: Spontaneous naming and attention to shape. Developmental science 8 (2):182–98. doi:10.1111/j.1467-7687.2005.00405.x.
- Schroff, F., D. Kalenichenko, and J. Philbin 2015. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 815–23). doi: 10.1109/CVPR.2015.7298682.
- Simonyan, K., and A. Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409 1556. doi:10.48550/arXiv.1409.1556.
- Sun, Y., Y. Chen, X. Wang, and X. Tang. 2014. Deep learning face representation by joint identification-verification. Advances in Neural Information Processing Systems 27.
- Sun, B., B. Li, S. Cai, Y. Yuan, and C. Zhang 2021. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7352–62). doi: 10.1109/CVPR46437.2021.00727.
- Tan, M., and Q. Le 2019. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (pp. 6105–14). PMLR. doi: 10.48550/arXiv.1905.11946.
- Tian, Z., C. Shen, H. Chen, and T. He 2019. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9627–36). doi: 10.1109/ICCV.2019.00972.
- Vinyals, O., C. Blundell, T. Lillicrap, and D. Wierstra. 2016. Matching networks for one shot learning. Advances in Neural Information Processing Systems 29.
- Wang, X., T. E. Huang, T. Darrell, J. E. Gonzalez, and F. Yu. 2020. Frustratingly simple few-shot object detection. arXiv preprint arXiv:2003 06957. doi:10.48550/arXiv.2003.06957.
- Wang, Y. X., D. Ramanan, and M. Hebert 2019. Meta-learning to detect rare objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9925–34). doi: 10.1109/ICCV.2019.01002.
- Weinberger, K. Q., J. Blitzer, and L. Saul. 2005. An information maximization model of eye movements. Advances in Neural Information Processing Systems 17:18.
- Weinberger, K. Q., and L. K. Saul. 2009. Distance metric learning for large margin nearest neighbor classification. Journal of Machine Learning Research 10 (2).
- Wu, A., Y. Han, L. Zhu, and Y. Yang 2021. Universal-prototype enhancing for few-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9567–76). doi: 10.1109/ICCV48922.2021.00943.
- Wu, J., S. Liu, D. Huang, and Y. Wang 2020. Multi-scale positive sample refinement for few-shot object detection. In European conference on computer vision (pp. 456–72). Springer, Cham. doi: 10.1007/978-3-030-58517-4_27.
- Wu, A., S. Zhao, C. Deng, and W. Liu. 2021. Generalized and discriminative few-shot object detection via SVD-dictionary enhancement. Advances in Neural Information Processing Systems 34:6353–64.
- Xing, E., M. Jordan, S. J. Russell, and A. Ng. 2002. Distance metric learning with application to clustering with side-information. Advances in Neural Information Processing Systems 15.
- Yan, X., Z. Chen, A. Xu, X. Wang, X. Liang, and L. Lin 2019. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9577–86). doi: 10.1109/ICCV.2019.00967.
- Zhang, G., K. Cui, R. Wu, S. Lu, and Y. Tian 2021. Pnpdet: Efficient few-shot detection without forgetting via plug-and-play sub-networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (pp. 3823–32). doi: 10.1109/WACV48630.2021.00387.
- Zhang, W., and Y. X. Wang 2021. Hallucination improves few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13008–17). doi: 10.1109/CVPR46437.2021.01281.
- Zhang, W., Y. X. Wang, and D. A. Forsyth. 2020. Cooperating RPN’s improve few-shot object detection. arXiv preprint arXiv:2011 10142. doi:10.48550/arXiv.2011.10142.
- Zhuang, F., Z. Qi, K. Duan, D. Xi, Y. Zhu, H. Zhu, and Q. He. 2020. A comprehensive survey on transfer learning. Proceedings of the IEEE 109 (1):43–76. doi:10.1109/JPROC.2020.3004555.
- Zhu, C., F. Chen, U. Ahmed, Z. Shen, and M. Savvides 2021. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 8782–91). doi: 10.1109/CVPR46437.2021.00867.