
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, the rapid progress of mobile internet technology has revolutionized how data is transmitted and shared wirelessly, making it possible to deliver information in real-time to users anywhere. This technological advancement has created new research opportunities, particularly in teaching quality evaluation in colleges and universities using mobile applications. Teaching quality is a crucial evaluation index at the university level, and accurately assessing it is a complex task due to numerous influencing factors. Therefore, there is a need to develop a model that can effectively evaluate the teaching quality to address this challenge. To this end, this paper proposes a teaching quality evaluation model based on data mining algorithms that consist of four parts: evaluation model, evaluation method, evaluation procedure, and practice optimization. This model aims to improve the accuracy of teaching quality evaluation in colleges and universities. Moreover, this study suggests that virtual simulation experiment systems can positively affect the effectiveness of teaching environmental courses. The paper recommends incorporating virtual simulation experiments into the curriculum to enhance students’ learning experience. In conclusion, the progress in mobile internet technology has opened up new research opportunities, and data mining algorithms can improve the accuracy of teaching quality evaluation. Additionally, integrating virtual simulation experiments in environmental course teaching can enhance students’ learning experience.
Introduction
In today’s information age, which is also a knowledge economy age, talent should receive a lot of attention because it is one of the most active and crucial factors. Universities should pay more attention to the quality of talent training as a foundation for producing high-caliber talent, providing high-caliber talent for various construction projects in Chinese society, and realizing the high-caliber development of the Chinese economy (Janani and Vijayarani Citation2019). The talent battle is at the heart of the increasingly ferocious international struggle between nations. Strengthening skills development is necessary if we wish to hold a more favorable position in the international arena (Sun, Cui, and O Citation2019) Education is necessary for the development of skills, and the caliber of instruction has a significant impact on this process. By the first half of 2014, there were more than 2000 General Colleges and universities (excluding independent colleges) in China, including 400 private general colleges and universities; There are more than 300 adult colleges and universities countrywide, including one private adult college. Also, the number of students and the scale of enrollment in higher education in my country continue to rise. To ensure that the teaching at colleges and universities satisfies the needs of students’ growth, colleges and universities should thoroughly understand the significance of teaching quality, implement efficient techniques to enhance teaching quality, and monitor and assess it (Hansen and Kelley Citation1973). Most of the research on machine learning algorithms involves predictive learning of data, with the aim of estimating correlations from known data to better predict the future (Costin and Menges Citation1973).
In recent years, learning algorithms based on neural network, flexible statistics and statistical mechanics have made some progress, and put forward some new concepts and methods. On the surface, these concepts and methods are related to each other, but there are still many differences between them. People urgently need a complete theoretical system of predictive learning algorithms (Huang Citation2018). Data mining technology has steadily been employed in the field of education over the past several years with its continued development and reasonably advanced use, which is a clear manifestation in the administration of university teaching quality. College and university administrators employ data mining technologies to thoroughly mine a variety of teaching quality-related data, then extract useful information based on a thorough study of these data to help administrators manage the present teaching quality in colleges and universities (Mccormack, Citation2010; Manikandan and Venkataramani Citation2011; Zhang, Chen, and He Citation2010). According to relevant materials, data mining technology has achieved great research results in the commercial field, while in the field of education, data mining technology is still in the primary stage of development. In particular, there is still a large gap between China and developed countries in the level of data mining technology in the field of education (Sánchez, R, and Castejón Citation2020). In view of this situation, relevant personnel of Chinese universities should pay attention to the research of data mining technology, make it organically integrated with the teaching evaluation system of Chinese universities, and make accurate evaluation of the teaching quality of Chinese universities, so that relevant personnel of universities can have a more targeted approach when improving the teaching quality (Minamishima and Takahashi Citation2017).
This paper systematically separates the target conditions of deep learning for college students and the new requirements for classroom instruction in colleges and universities, combining them with the actual conditions of college students and the internal logic of deep learning and classroom teaching. It also enriches the related theoretical research of learning theory and offers theoretical support and assessment tools for college students to assess their learning level.
Τhe paper focuses on exploring how virtual simulation experiment systems can be utilized in teaching environmental courses. The paper aims to examine the impact of virtual simulation experiments on teaching environmental courses’ effectiveness and suggest ways of incorporating these experiments into the curriculum. By analyzing and discussing the role and method of virtual simulation experiment systems, the paper seeks to provide insights into how this technology can enhance students’ learning experience.
Related Work
Firstly, through reading and studying a large number of related literatures, according to the theory of the corresponding evaluation principles, this paper analyzes that SVM is suitable for the quality evaluation of university teaching results.
Du proposed an English teaching quality evaluation method based on fuzzy comprehensive evaluation, constructed an English teaching quality evaluation index system model, and highly realized the accurate evaluation and prediction of English teaching quality. This method is simple and practical, but when the amount of data increases, it will be more difficult to construct the judgment matrix, and the accuracy of the results will also decrease (Yang and Marxism Citation2018). (Lin Citation2011) made a theoretical summary based on the experience of Guangzhou University Town in the exploration Practical teaching, from the importance Practical teaching, the new model Practical teaching, the content Practical teaching, the organization, implementation and guarantee Practical teaching, and the assessment and evaluation Practical teaching (L. M. A). In the study of teaching quality evaluation, Hao applied association algorithm to construct item sets, obtained association relations between data, and then obtained strong association rules that are helpful to students and teachers and can guide teaching, so as to provide powerful help to teachers in teaching (Wang Citation2014). Ekwong C evaluates the quality of vocational education by classifying the unstructured data using the hierarchical classification model of support vector machine according to the specified standards of education quality. However, traditional data mining and analysis methods are difficult to deal with the problems of data reading difficulty and operation timeliness in the case of large data volume, so the algorithm needs to be improved in order to apply it to big data analysis (X). (Zhao Citation2011) believes that the construction of the teaching evaluation system of courses in colleges and universities needs to be implemented according to certain principles, such as comprehensiveness, orientation and hierarchy (D). JiangF applied SVM to the teaching design of text classification, and achieved good results (Jiang and F Citation2015; Sieveking and Savitsky Citation2010). Aiming at some problems in classroom TQA in SievekingNA, SVM is used to solve them. generalization (S. N. A and C 2010). When LekwaAJ used SVM to classify samples, he didn’t consider that there might be inseparable regions in samples, or that the number of classifiers constructed would increase as the number of categories of samples increased (Lekwa et al. Citation2018). Ottopb Through the research, it is pointed out that “evaluation is mainly the process of evaluating the teaching effect. In this process, it is necessary to clarify the completion of teaching objectives, and also to reflect the teaching ideas and teaching methods involved in the teaching process. (Otto and Schuck Citation2010) Douglas studied practical teaching indicators earlier. He mentioned in his article that “the evaluation indicators Practical teaching should be designed from two levels of classroom-based and topic-based. C. Starting from the classroom, clarify the evaluation indicators, mainly including several indicators (Clements et al. Citation2013) .”
According to the domestic research situation described above, numerous academics have studied the effective evaluation system of university teaching, including the origins and evolution of the evaluation system concept, the foundational principles and standards, the implementation strategies and countermeasures, etc. The research has a broad reach and touches on several levels. However, there are few generalizations regarding the impact of teaching and the teaching process.
The choice of whether to use non-linear neural networks or linear models for comparative studies depends on the nature of the problem being studied and the research question being addressed. If the problem is highly complex and requires the detection of non-linear relationships between variables, then non-linear neural networks may be necessary. However, if the problem is relatively simple and has linear relationships between variables, then linear models may be sufficient and more efficient.
In some cases, it may be beneficial to compare the performance of non-linear neural networks and linear models on the same problem to determine which approach is more effective. However, this comparison should be done with caution and should take into account factors such as the size and quality of the data, the availability of computational resources, and the goals of the study.
Therefore, it is feasible and sometimes required to use non-linear neural networks instead of linear models for comparative studies, but the choice should be made based on the nature of the problem and the research goals.
This paper developed a simulation model of teaching achievement evaluation of colleges and universities based on a data mining algorithm to improve the accuracy of teaching quality evaluation of colleges and universities as the goal. It then analyzed the benefits of the teaching quality model of colleges and universities through practical examples. The findings demonstrate that the proposed model’s error is significantly lower than the general approaches currently in use.
Methodology
Analysis of Ideology Teaching Based on Improved SVM Algorithm of Deep Learning
Through the mapping ability of SVM algorithm, designing an algorithm suitable for a large number of samples has become an important content in the research of SVM. The calculation of usage degree function is mainly done by neural network technology. Up to now, some progress has been made in theory and practice, and some effective training algorithms and practical software have appeared.
Optimization Method
SVM is a special kind of optimization problem, which has some very good characteristics. These methods need to store the kernel matrix in memory, which means that the spatial complexity of the algorithm is the square of the number of samples. A major advantage of these techniques is that they are easy to understand, and there is a large amount of commercial and free software, some of which are directly available. A widely used software package is MINOS, from Stanford University’s Optimization Laboratory, which uses a hybrid strategy. Another more commonly used software package is LOQO, which uses the primal-dual interior point method to solve optimization problems.
Improved SVM Algorithm for the Calculation Process of University Teaching
The quality of teachers: Mandarin level, words and deeds, appearance. (2) Teaching attitude: lateness, early departure and absence from class, tutoring and correction of homework, emphasis on students’ feedback, and teaching attitude. (3) Teaching content: scientific, advanced and practical knowledge, cultivation of learning ability, penetration of emotional attitude and values.
Aiming at the low utilization rate of kernel function cache, we propose a new training algorithm of SVM.
Evaluation and Optimization of Deep Teaching Based on Improved SVM Algorithm
Five viewpoints and three characteristics are primarily involved in the important research findings of the teaching achievement evaluation system in colleges and universities, upon which the fundamental assessment of the research status is based. Since teaching is a social activity, this study chose Engstrom’s human activity structure diagram to build the evaluation model of teaching work in colleges and universities. By doing so, it addressed the weaknesses of earlier studies and conducted a thorough investigation of network teaching work. As a result, we must make use of a variety of indications when building the evaluation system. To promote the scientific, standardized, and effective development of college course teaching, it is necessary to objectively and thoroughly evaluate the teaching effect and process to provide accurate feedback, make teachers and students aware of the shortcomings and problems in the course teaching process of colleges and universities, and continually implement relevant improvement measures.
SVM (SVM) is a new machine learning algorithm based on statistical theory. F. The principle of structural risk minimization usually has countermeasures when dealing with compromising empirical risk and confidence risk, based on the principle of evaluation index system, combined with the actual situation of classroom teaching quality in colleges and universities, an ideal index evaluation system is formulated, the accuracy and effectiveness of teaching evaluation can be improved. The expression form of evaluation index system can generally be divided into tower structure and linear structure. In the research of classroom TQA, the tower structure index system is usually used, which is decomposed into several levels according to the requirements of specific problems. As shown in , the more levels are divided, the more specific the indicators are divided:
Figure 1. Tower structure of big data analysis and evaluation index system.
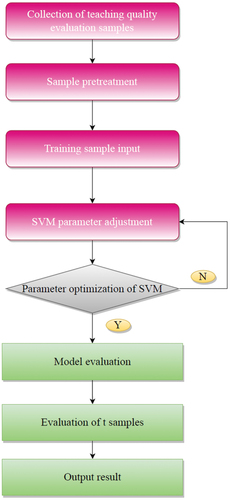
In order to deal with the defects of several methods such as analytic hierarchy process universities, after actively discussing the complete teaching process and evaluation system framework in colleges and universities, this paper establishes a multi-class model based on DBT-SVM. The TQA system model of classification method, which uses the generative strategy of approximate complete binary tree and several definitions of class distance in clustering, and combines the idea of multiple binary tree SVM classifiers together. The flow chart of DBT-SVM ideology classroom TQA model is shown in :
Figure 2. Flow chart of ideology TQA model.
Universities and schools that specialize in the environment offer very practical coursework. In the teaching system of environmental specialization, practical instruction is significant. Its ability to impart knowledge is highly correlated with the caliber of professional talent development. Many courses feature experimental projects, many of which have intricate process flows and long development times. Even with numerous simplifications, the course experiment using two class hours as a unit cannot get the desired results. More importantly, virtual simulation experiments can be seamlessly embedded into online courses, g. Combining “Internet +” and “cloud technology” gives learners great freedom of learning and real experimental experience. Deep learning is different from general learning methods. As the core concept of deep learning, high-order thinking and the development of high-order thinking ability should be taken as important reference factors for evaluating students’ deep learning.
In view of the defects of the above multi-class classification methods, some scholars have put forward improved algorithms on this basis. For example, SVM multi-class classification method based on Directed Acyclic Graph (DAG) is based on the idea of two-class classification. By referring to the idea of OVO algorithm, M (m-1)/two binary classifiers are constructed for M-class training samples, and then these classifiers form the shape of a directed acyclic graph. And the number of leaf nodes is m and the number of intermediate nodes is m(m-1)/2. Taking the 4-classification problem in as an example, after any unknown sample is input, the next output path of the sample should be decided by the output value of the root node classifier, and so on, until the leaf node is reached, and the category of the leaf node reached is the category of the sample. As shown in .
Figure 3. Schematic diagram of SVM algorithm.
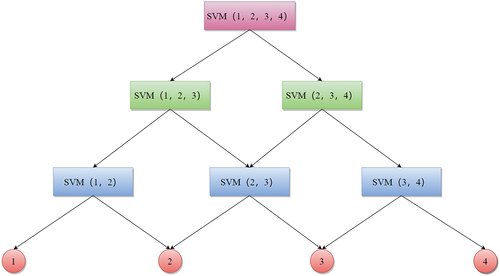
Because this method is based on the idea of ovo algorithm, the number of classifiers constructed is the same as that constructed by ovo algorithm. However, the directed acyclic graph strategy only needs m − 1 classifiers to determine the category of the samples to be tested in the test phase. Therefore, this method has higher classification speed than the first two methods. The location distribution of sub-classifiers in a different sequence, however, results in a different classification path, which significantly impacts the performance of the entire classifier. Due to the storage and computing requirements, these algorithms frequently produce subpar results when applied to real-world issues. In actuality, the training set’s kernel matrix must be stored by these algorithms, and the memory needed to do so grows exponentially with the square of the training set’s sample count. When there are many samples, a lot of memory is needed, which cannot be provided. The “algorithm” can substantially speed up operation when the number of support vectors is much less than the number of training samples. The working sample set will get steadily larger as the algorithm’s iterations go up, but if the total number of support vectors is already quite high, the process will still become quite complex. The fixed working sample set method differs from the block selection algorithm in that the block algorithm’s objective function only includes samples from the current working sample set. In contrast, the fixed working sample set method’s objective function includes samples from the entire training sample set. However, the optimization variables only include working samples because the multiplier of the sample Lagrange outside the working sample set is fixed due to the previous iteration, ensuring that the results are consistent.
Improved Binary Tree SVM Multi Class Classification Algorithm
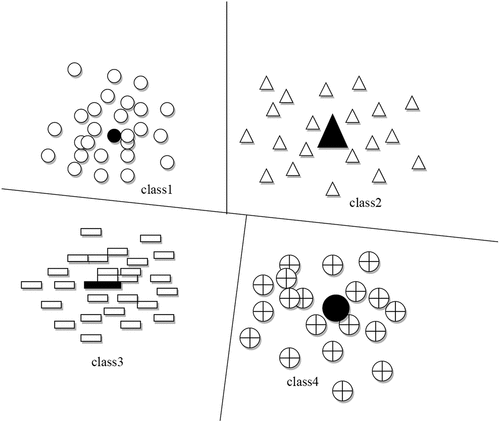
Although the SVM multi-class classification algorithm based on binary tree has achieved certain research results, the structure of the tree is directly related to the performance of the algorithm, and in practice, due to the limited number of samples, training samples are usually used to estimate the ease of use of all categories. degree. As shown in .
Figure 4. Schematic diagram of DBT-SVM multi-class algorithm.
Let X be a sample set including K categories, and Xi represent the training sample set of category I. The existing definition is as follows: Formula (1) The Euclidean distance of the nearest sample between category I and category J is:
The sample center of type I in EquationEquation (2)(2)
(2) is:
Where n is the number of samples of class I.
EquationEquation (3)(3)
(3) If
and
are the sample centers of class i and class j, respectively, then the Euclidean distance between the centers of class i and class j is:
The following uses a specific example to explain the process of constructing a binary tree: Suppose the matrix composed of five types is as follows:
During LIBSVM training, I and J of the working set are selected as the samples that violate KKT conditions at the maximum, which can be obtained from the feasible direction:
Among them, and are:
The definitions of and in the nuclear cache are:
Without losing generality, first calculate A2 and use it to calculate A1.
First define two variables:
The key reason why it is difficult to evaluate the achievements of higher education lies in the lack of evaluation index system, because through previous studies, we know that some current research achievements are mainly qualitative research, while quantitative research is seriously insufficient. There has been more research into general principles than into specific operations. The majority of academics also exercise their “independence” and select a variety of research institutes and perspectives, which produces a wide range of research findings. The evaluation system’s selection of assessment objects should adhere to the principle of diversity, which states that the evaluation objects should be chosen from a variety of viewpoints to evaluate teachers and pupils. When students are evaluated, it helps them to reflect on their learning, and when teachers are evaluated, it can help them develop better teaching strategies. The ability to conduct scientific research is a skill that education professionals should continue to develop. Education professionals have significant theoretical and practical problems in teaching research listed in the national education science and the humanities and social science research projects. A handful of high-level practical teaching research outcomes will be made public after professional evaluation and inspection. To encourage teachers to engage in scientific research, colleges and universities actively may also create particular areas of “practical teaching research.”
It must be noted that the non-linear deep neural networks (NN) and linear matrix transformation are two different approaches to solving complex problems, including those related to teaching quality evaluation in colleges and universities. The key differences between these two approaches are:
Complexity: Non-linear deep neural networks are more complex and can learn complex non-linear relationships in data, whereas linear matrix transformation can only handle linear relationships.
Training time: Non-linear deep neural networks may require longer training times due to their complexity and the need to adjust many parameters, whereas linear matrix transformation can be trained more quickly due to its simplicity.
Accuracy: Non-linear deep neural networks can achieve higher accuracy than linear matrix transformation, particularly when dealing with complex data. However, linear matrix transformation can still provide useful results in many cases.
Interpretability: Non-linear deep neural networks can be difficult to interpret, whereas linear matrix transformation is more straightforward to interpret and understand.
Performance: Non-linear deep neural networks are typically better at handling large amounts of data and more complex problems, whereas linear matrix transformation may struggle with these challenges.
In summary, non-linear deep neural networks and linear matrix transformation approaches have strengths and weaknesses. The choice between them depends on the problem at hand, available resources, and the desired level of accuracy and interpretability.
Result Analysis and Discussion
Adult datasets are widely used to test SVM training algorithms. After the discretization of the data, each sample in the data set has 123 0–1 characteristics. Our purpose is to predict whether a family’s income exceeds US $million according to these 123 characteristics. The data set is divided into eight groups. See for the sample number of each group.
Table 1. The number of data samples in each group of the adult dataset.
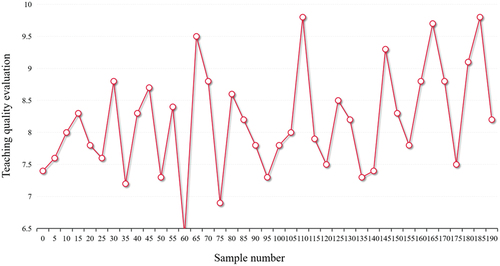
In order to compare the fitting effect of each model intuitively, the fitting effect diagram of each model to the learning sample and the prediction sample is given. As shown in .
Figure 5. Multivariate linear regression.
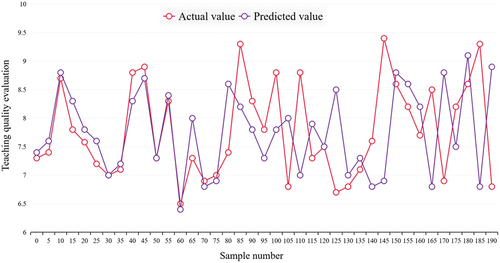
Figure 6. Neural network model.
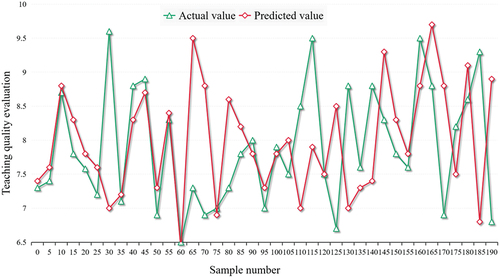
Figure 7. SVM model.
The purpose of this study is to investigate college students’ mobile phone use and vocabulary deep learning. Because the current vocabulary mobile learning is mainly a kind of independent learning, and its relevance to the curriculum is low in classroom teaching. TThe neural network has the ability to approximate nonlinear functions, which improves the solution accuracy of nonlinear functions, but its shortcomings are also obvious: first, the solution is complicated and takes the longest time. From , it can be seen that the neural network model takes as 2∙9s, which are more than 100 times that of the multivariate linear model, more than 3 times that of the partial least squares regression, and 12 times that of the SVM model; secondly, the model is unstable, and local optimization is performed when the neural network model is solved. It’s not the only one, it’s even very different. As shown in .
Table 2. Prediction results of each model.
In order to verify whether students’ deep learn ing level has been improved in the college classroom mode, this study conducted pre-and posttest tests on students’ deep learning status and deep learning ability. From , it can also be seen intuitively by comparing , the average error is less than 2%, and the CPU time is only 0 ¤ 234s. The topology of SVM is determined by a few support vectors, which makes the model simple and speeds up the solution. SVM performs global optimization to ensure that the solution is the only optimal solution. In most training algorithms, after optimizing the current working set, it is necessary to traverse the whole training set again to select a new working set. If we record these samples, it is very convenient to select the working set at the next iteration, which hardly needs to traverse the active set again. If we can remember the two most severe violations of the current samples and their degree of violation, we can reduce the working set by checking and updating these two samples at a small cost in each joint optimization. update cost. After the joint optimization of the current working set is completed, SSMO will enter the set update algorithm, and then SSMO will correct all the samples with incorrect set state. This ensures that the selection of working set used in the next joint optimization is correct. Because the training set is divided, the severity of each set violating KKT conditions becomes a known quantity. Therefore, it is not necessary to find the samples that violate KKT most severely after the joint optimization is completed. It is only necessary to select any one from sets I and J. This reduces the number of times to traverse the training set, thus improving the efficiency of the algorithm.
This work has several obvious advantages:
Innovative approach: Using mobile applications and data mining algorithms for teaching quality evaluation is a novel and innovative approach. This study explores new ways of using technology to improve teaching quality evaluation in colleges and universities.
Practical implications: The proposed teaching quality evaluation model based on data mining algorithms has practical implications for improving teaching quality in colleges and universities. The model can assist teachers and administrators in identifying areas for improvement and making data-driven decisions.
Valuable insights: This paper provides valuable insights into using virtual simulation experiment systems in environmental course teaching. The findings can help instructors to design effective teaching strategies that incorporate virtual simulations, resulting in a better learning experience for students.
Comprehensive analysis: This work comprehensively analyzes the role and method of virtual simulation experiments and the challenges in teaching quality evaluation in colleges and universities. The paper examines various factors that affect teaching quality and proposes a model that addresses these challenges.
Conclusions
University teaching quality and a variety of factors related, has become a current research hot spot, in order to obtain better teaching quality evaluation results, the introduction of the depth of the data mining technology and improved learning vector machine (SVM) algorithm to establish simulation model of university teaching achievement evaluation, the results show that this model is a kind of high precision, high efficiency of the teaching quality evaluation model, It has a wide range of application value.
In the subject of education, raising the caliber of instruction in the classroom is a perennial concern. The process of teaching is not complete without classroom instruction. The assurance for the advancement of teaching and learning is a scientific and reasonable evaluation of the quality of classroom instruction. To assess the effectiveness of classroom instruction, it is important to look at more than just the teachers’ content knowledge, instructional strategies, and pedagogical practices.
Data Availability Statement
The labeled dataset used to support the findings of this study are available from the corresponding author upon request.
Disclosure Statement
No potential conflict of interest was reported by the author.
Additional information
Funding
References
- Clements, D. H., J. Sarama, C. B. Wolfe, and M. E. Spitler. 2013. Longitudinal evaluation of a scale-up model for teaching mathematics with trajectories and technologies: Persistence of effects in the third year[J]. American Educational Research Journal 50 (4):812–1024. doi:10.3102/0002831212469270.
- Costin, F., and G. Menges. 1973. Evaluation of teaching student ratings of college teaching: reliability, validity, and usefulness[J]. The Journal of Economic Education 5 (1):51–53. doi:10.1080/00220485.1973.10845382.
- Ding, L. X. 2012. On university students’ education work[J]. Journal of Social Work 72 (347):85–24.
- Hansen, W. L., and A. C. Kelley. 1973. Evaluation of teaching political economy of course evaluations[J]. The Journal of Economic Education 5 (1):10–21. doi:10.1080/00220485.1973.10845376.
- Huang, B. 2018. The evaluation of college teachers’ teaching ability: Reflection and construction[J]. Educational Research 2018 (8):10–34.
- Janani, B., and M. S. Vijayarani. 2019. Artificial bee colony algorithm for feature selection and improved support vector machine for text classification[J]. Interlending & Document Supply 47 (3):154–70. doi:10.1108/IDD-09-2018-0045.
- Jiang, F., and W. F. Mccomas. 2015. The effects of inquiry teaching on student science achievement and attitudes: Evidence from propensity score analysis of PISA data[J]. International Journal of Science Education 37 (3):554–76. doi:10.1080/09500693.2014.1000426.
- Lekwa, A. J., L. A. Reddy, C. M. Dudek, and A. N. Hua. 2018. Assessment of teaching to predict gains in student achievement in urban schools. School Psychology Quarterly 34 (3):100–20. doi:10.1037/spq0000293.
- Lin, M. A. 2011. Discussion on school social work from the perspective of the education of college students[J]. Journal of Social Work 20 (00):082–4787.
- Manikandan, J., and B. Venkataramani. 2011. Evaluation of multiclass support vector machine classifiers using optimum threshold-based pruning technique[J]. IET Signal Processing 5 (5):506–13. doi:10.1049/iet-spr.2010.0311.
- Mccormack, A. J. 2010. Effects of selected teaching methods on creative thinking, self‐evaluation, and achievement of students enrolled in an elementary science education methods course[J]. Science Education 55 (90):238–378.
- Minamishima, E., and T. Takahashi. 2017. The influence of the usage of teaching materials and teachers’ teaching behavior toward students’ achievement[J]. Frontiers in Psychology 8 (2): 895–09. doi:10.3389/fpsyg.2017.00895.
- Otto, B. P., and R. F. Schuck. 2010. The effect of a teacher questioning strategy training program on teaching behavior, student achievement, and retention[J]. Journal of Research in Science Teaching 20 (6):521–28. doi:10.1002/tea.3660200603.
- Sánchez, T., R. Gilar-Corbi, J. L. Castejón, J. Vidal, and J. León. 2020. Students’ evaluation of teaching and their academic achievement in a higher education institution of Ecuador[J]. Frontiers in Psychology 11 (5): 5594–44. doi:10.3389/fpsyg.2020.00233.
- Sieveking, N. A., and J. C. Savitsky. 2010. Evaluation of an achievement test, prediction of grades, and composition of discussion groups in college chemistry. Journal of Research in Science Teaching 6 (70):85–40.
- Sun, L., G. Cui, and A. O. Marxist. 2019. On the construction of evaluation system of education for college students in TCM universities [J]. The Review of Higher Education 22 (57):007–463.
- Wang, Q. 2014. Establishing the mechanism of education of college students under the new situation[J]. Intelligence 89 (58):315–57.
- Yang, J., and D. O. Marxism. 2018. Using micro-video to improve teaching effects of theory course[J]. The Review of Higher Education 4 (32):399–77.
- Zhang, X., X. Chen, and Z. He. 2010. An ACO-based algorithm for parameter optimization of support vector machines[J]. Expert Systems with Applications 7 (85):10–558.
- Zhao, D. W. 2011. Preliminary discussion on the introduction of casework in education of the elderly[J]. Journal of Social Work 738 (80):480–377.