
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Neural machine translation (NMT) is applied to generate a more reliable and accurate translation practice as the most cutting-edge technology. In recent years, NMT has achieved gratifying results. However, the main obstacle for market-oriented NMT application systems appears to suffer from weak translation quality that fails to meet users’ needs. This paper focuses on the machine translation of political documents and implements six dominant NMT application systems in the market to evaluate their translation quality. The evaluation process further employs both BLEU and NIST technical evaluation algorithms and re-verifies the results with the manual evaluation method called the “Score Ranking System” to compare the performances of the six NMTs in Chinese-English translations of political documents. Through diagnosis and evaluation of the problems and errors in NMTs, the paper eventually proposes the “Cue Lexicon+” model to remedy prominent problems. Besides, the “NMT+ Lexicon Intelligent Translation Assistant” soft is developed and the “Cue Lexicon+” is integrated into the NMT application systems to further improve the translation quality, providing a reference and research basis to increase the performance and update the NMT application systems.
Introduction
Neural network technologies help machine translation to increasingly mature. NMT application systems are widely used and have yielded huge benefits. Several major technology companies have started to develop their own NMT practical systems (Zhou et al. Citation2016). In 2013, Baidu (Sun and Kumar Citation2022) began to research NMT; in 2015, it took the lead in adopting the deep neural network in the machine translation system. Afterward, the machine translation quality was significantly improved (Sun and Kumar Citation2022). In 2017, Google proposed the Transformer model. Many excellent pre-trained language models and machine translation models were developed, such as the BERT and the GPT series, which constantly refreshed the ability level of many natural language processing tasks (Wu et al. Citation2016). In 2019, Volctrans proposed LightSeq. The first open-source engine could fully support the high-speed inference of various models such as Transformers and GPT in the industry. In LightSeq, the Transformer-based sequence feature extractor (Encoder) and autoregressive sequence decoder (Decoder) were further optimized.
In the 2020 Conference on Machine Translation (WMT20), Volctrans won the championship in the “Chinese-English” language translation contest with a significant advantage among 39 participating teams (Wu et al. Citation2020). Also, the DeepL which is known as the most accurate translation artifact in the world was presented on its official website (Yulianto and Supriatnaningsih Citation2021). The continuous improvement of the performance of NMT application systems is inseparable from the research on the evaluation of machine translation quality. Ultimately, the evaluation of machine translation quality is a linguistic issue of comparing sentences; therefore, scholars must combine machine translation with linguistic research (Guzmán et al. Citation2017). At present, most scholars focus on the evaluation of English Chinese machine translation. However, there are still few papers on the overall quality performance. Especially, Chinese-English t of political documents are rare.
Therefore, the manuscript utilizes six dominant NMT application systems (Google, DeepL, Amazon, Baidu, Volctrans, and IFLYTEK), and carries out comparative research on machine translations and manual translations by combining quantitative evaluation with qualitative evaluation. It analyzes the problems and errors in machine translations and puts forward targeted improvement schemes based on technical evaluation and manual evaluation. Moreover, this paper will shed light on the choice of the relatively best NMT application system for political documents and the improvement steps in the performance of NMT application systems.
The Design of the Research
Selection of Research Objects
Aiming to investigate the overall quality performance of NMT application systems in the Chinese-English translation of political documents, the paper chose the first and second volumes of “Xi Jinping: The Governance of China” as source language texts (STs) (see ) according to the following principles: (1) Reality: to choose only authentic natural STs to investigate the natural text processing abilities of major NMT application systems; (2) Moderate difficulty: to exclude text materials that were too simple or difficult because they could not correctly reflect the actual levels of the NMT application systems; (3) Single style: to research only political documents represented by “Xi Jinping: The Governance of China” to ensure their representativeness; (4) Official standard translations: to evaluate the translation quality of the six NMT application systems by referring to the comparative translations.
Table 1. List of texts in the source language.
Research Evaluation Methods
The translation quality evaluation is an essential step in improving the performance of translation systems. The qualitative and quantitative evaluations of translation quality are two aspects to assess translation quality. The former is the basis and principle of the latter, while the latter is the objective and digital result of the former. To rephrase, they are inseparable (Duh Citation2008). In this section, quantitative evaluation and qualitative evaluation will be combined to ensure that the score obtained can truly reflect the translation quality level, and to provide a translation quality evaluation scheme for NMT application systems.
Technical Evaluations of BLEU and NIST
In the machine translation field, technical evaluation is the usual method. The evaluation system compares the machine-translated text automatically with the reference translation. A final score is generated. The dominant evaluation methods are called BLEU and NIST.
BLEU evaluation index: BLEU (Bilingual Evaluation Understudy) is an evaluation index for evaluating machine translation results, and its value ranges from 0 to 1. The closer it is to 1, the closer the machine translation result is to the reference translation; the closer it is to 0, the more the machine translation result deviates from the reference translation (Mathur, Baldwin, and Cohn Citation2020). BLEU uses accuracy to measure the length of the machine translation result approaching reference translation. When calculating the accuracy, the number of n consecutive sequence matches between the machine translation results and the reference translation must be first known. More matches indicate a higher BLEU value, which means that the machine translation result is more like the reference translation. Eq. (1) presents the number of n consecutive matches,
where denote n consecutive sequences;
represents the total number of
occurrences in the machine translation result;
denotes the total number of
occurrences in the reference translation;
denotes the number of matches between the numbers of occurrences of n consecutive sequences in the machine translation and the reference translation.
After obtaining the number of consecutive matches, the translation accuracy can be calculated. The Eq. (2) presents the precision,
where denotes the number of occurrences between the numbers of occurrences of n consecutive sequences in the machine translation result and the reference translation;
represents the total number of occurrences of n consecutive sequences in the machine translation.
Since the length of the machine translation is less than the length of the reference translation, the BLEU score will be affected. In this case, a penalty factor will be introduced to control the issue. Therefore, a length penalty factor (Brevity penalty factor) is introduced. Eq. (3) presents the BP,
where denotes the total length of the reference translation;
denotes the total length of the machine translation result;
represents the penalty factor.
The BLEU evaluation index is shown in Eq. (4) as follows:
where N represents the maximum order of n continuous sequences; represents the weight coefficient.
Since the overall translation accuracy gradually decreases with the increase of N, N generally is set to 4. However, the BLEU has its setbacks. To be specific, it focuses on the details of the sentences but neglects the coherence of the overall translation.
NIST evaluation index: NIST is an improvement based on the principles of BLEU. It adds weights to different words in sentences to emphasize the translation of key semantics. The index adds more weights to word sequences containing more information. Eq. (5) presents the computation of weights used in the NIST evaluation index,
where denotes the number of occurrences of n-1 consecutive word sequences in the reference translation;
represents the number of occurrences of n consecutive word sequences in the reference translation;
denotes the final weight of n consecutive word sequences.
The NIST evaluation index can be modified further based on the BLEU evaluation index, which is shown in Eq. (6),
where denotes the number of occurrences between the numbers of occurrences of n consecutive word sequences in the machine translation result and the reference translation;
represents the total number of occurrences of n consecutive word sequences in the machine translation result;
denotes the final weight of the n consecutive word sequences.
The final NIST evaluation index is shown in Eq. (7) as follows:
where denotes the penalty factor;
represents the translation accuracy.
Evaluation of Manual Score Ranking
The high-reliability manual scoring is the key to building an automatic scoring system for Chinese-English translation. The paper follows the Chinese-English translation principles of “Fidelity” and “Fluency” (Feng et al. Citation2020) and adopts the manual scoring criteria in China’s 863 program in machine translation evaluation mentioned by Reiss (Reiss and Rhodes Citation2014). The criteria offered a framework for evaluating the machine translation quality of this paper. Both fidelity and fluency are the primary criteria of the evaluation system throughout the research, which has six evaluation levels and a scale changing from 0 to 5 (corresponding to scores 0 through 5). The evaluation results were recorded up to the second digit after the decimal point to ensure objectivity. The scoring criteria for fidelity and fluency are shown in :
Table 2. The fidelity and fluency scoring criteria for manual evaluation of machine translations.
The machine translation quality is always evaluated with a real number score. However, different understandings of the evaluation criteria and scales for manual translation quality may result in poor consistency and instability of the evaluation results (Ghorbani et al. Citation2021). The ranking method was more reliable than the scoring method for evaluating the quality of multiple machine translations was generally proposed (Shapran et al. Citation2021).
The research underwent meticulous designs in the scoring mechanism and operations to obtain high-reliability scoring results and ensure the quality of comparative research on translations. The “Score Ranking System” evaluation method was designed to ensure effective statistics and analysis on all scores, further, ranking was performed by researchers based on the scores to avoid the distortion of results due to the differences in raters’ scores. The raters consisted of nine graduates with a master’s degree in translation and possessed a Level II certificate from China Accreditation Test for Translators and Interpreters (CATTI). The raters were divided into three groups with three persons in each group. The 300 segments sampled were equally divided into three groups, each of which contained 100 segments. The 100 segments of each group were scored and ranked by the raters in each group. The six NMT application systems were ranked from 1st to 6th based on their translation quality. They were presented in , which are ranking statistics. So, more objective, and fair results were achieved using the ranking method (the implementation steps of Case 2 are the same as above). Afterward, the descriptive statistics of the scores and rankings were carried out with SPSS 23 version. The raters were required to strictly follow the scoring rules and to take notes of the translation segments that appeared problematic to ensure objectivity and consistency in the formal scoring process. The implementation process of the “Score Ranking System” evaluation method is presented in .
Figure 1. Flow chart of evaluation method called “Score Ranking System.
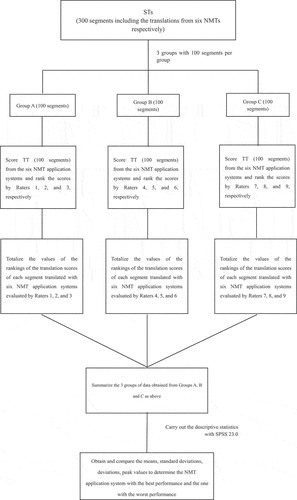
Table 3. Ranking statistics.
Table 4. Statistics of the totalized data of rankings made by raters by segment.
The Steps of Specific Research
Research steps (see ): STs and their official reference translations (RTTs) were converted into the Chinese-English text segments concurrently (see ). The STs were imported into the NMT application systems of Google, DeepL, Amazon, Baidu, Volctrans, IFLYTEK to generate target language texts (TTs). STs and the corresponding TTs were copied into WORD documents. Numbers were given, and documents were archived (see ). The technical evaluation, which was subject to the quantitative analysis, mainly adopted BLEU and NIST to evaluate the TT quality of the six NMT application systems. The manual evaluation, which was subject to the qualitative analysis, verified the technical evaluation results for the second time and adopted the “Score Ranking System” to evaluate the TT quality of the six NMT application systems.
Figure 2. The flow chart of the research steps.
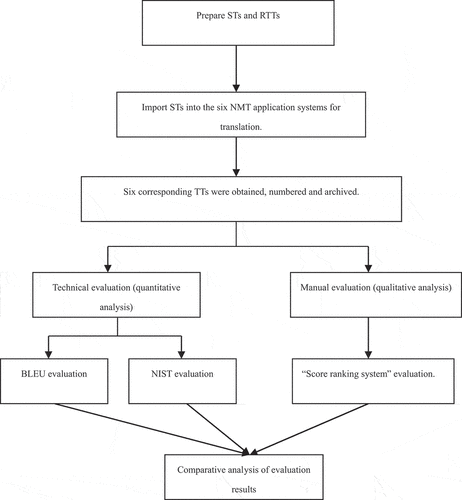
Figure 3. Segment-by-segment contrast version between ST and RTT.
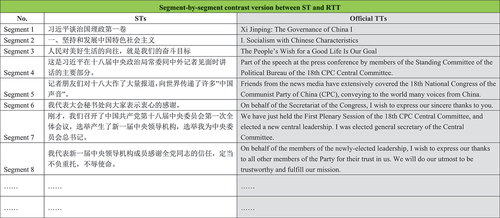
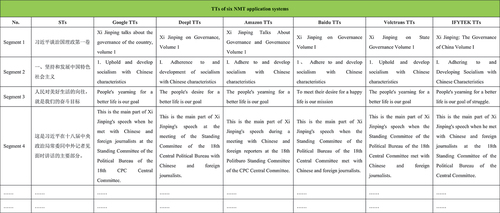
Figure 4. Tts of six NMT application systems.
Evaluation and Result Analysis
Case 1: Quality Evaluation Results of Machine Translations of Xi Jinping: The Governance of China I
Technical Evaluation Scores
The Result of the BLEU Evaluation
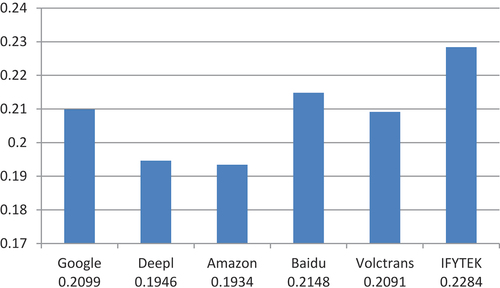
The BLEU scores of the six NMTs appeared from high to low, which is IFYTEK>Baidu>Google>Volctrans>DeepL>Amazon (see ). The TT scores of IFYTEK appeared 0.5391 in 1-gram, 0.3868 in 2-gram, and 0.2798 in 3-gram. All are higher than the other five NMT application systems. Namely, the machine translation of IFYTEK had the highest matching degree of N-grams with the reference translation. All words in the translation had the greatest contribution to the meanings, and the translation was more fluent and readable, while the Amazon translation was the opposite.
Figure 5. BLEU evaluation scores of TTs translated with six NMTs.
The Result of the NIST Evaluation
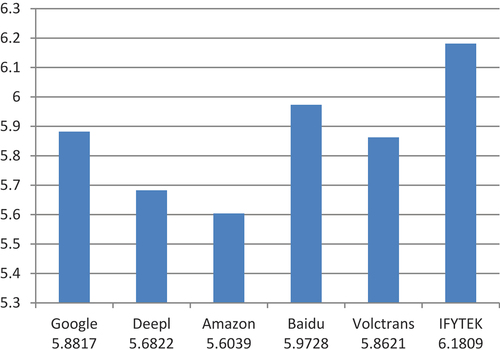
The order of NIST scores from high to low is presented as follows: IFYTEK>Baidu>Google>Volctrans>DeepL>Amazon (see ). Since NIST is the total amount of the information obtained divided by the number of n-gram segments in the entire translation, the weight of the keywords with low occurrence frequency could be increased, that is, the key words had low occurrence frequency. The 1-gram score was 4.3414, the 2-gram was 5.6736, the 3-gram was 6.0477, and the n-gram had higher accuracy in the IFYTEK translation system. So, the scores for correct consecutive translations were also higher than those in the other five NMT application systems, that is, IFYTEK’s TTs contained more information for each sentence, and had the highest overall translation quality. The results obtained from the two machine translation evaluation technologies were found to be consistent. While the highest score was given to IFYTEK, the lowest one was given to Amazon.
Figure 6. NIST evaluation scores of TTs translated with six NMTs.
The Result of Manual Evaluation
After ranking the scoring results of each segment in the 300 segments sampled from the TTs generated by the six NMT application systems with the “Score Ranking System,” the overall descriptive statistics were calculated with SPSS 23 version. presents them.
Table 5. Descriptive statistics of scores of six NMTs.
According to the comparison of the sums and the means of the TT scores of the six NMT application systems, the order was found to be IFYTEK<Baidu<Google<Volctrans<DeepL<Amazon. Thus, the smaller the value, the higher the ranking, that is, IFLYTEK ranked first, with a mean of about 6.81 and a standard deviation of 2.63; Amazon ranked last, with a mean of about 8.02 and a standard deviation of 2.99. It was seen that the ranking values of Amazon were more polarized, so its overall performance was more unstable leading to the relatively worst translation quality.
In conclusion, the results of BLEU, NIST, and manual evaluations of TTs translated with the six NMT application systems were completely consistent. IFLYTEK had the best evaluation result and overall translation quality.
Case 2: Quality Evaluation Results of Machine Translations of Xi Jinping: The Governance of China II
Technical Evaluation Scores
The Result of the BLEU Evaluation
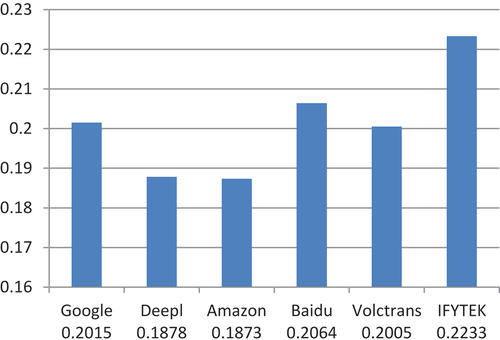
The BLEU scores were presented from high to low as follows: IFYTEK>Baidu>Google>Volctrans>DeepL>Amazon (see ). The TT scores of IFYTEK appeared 0.5387 in 1-gram, 0.3833 in 2-gram, and 0.2879 in 3-gram. All are higher than those of the five NMT application systems. Namely, the TTs and RTTs of IFYTEK had the highest matching degree of N-grams, the words, the syntax, and segments were the most similar, while Amazon translations were found to be the opposite.
Figure 7. BLEU evaluation scores of TTs translated with six NMTs.
The Result of the NIST Evaluation
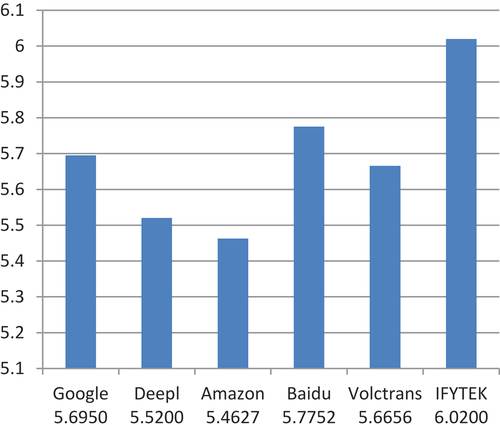
The NIST scores were presented from high to low as follows: IFYTEK>Baidu>Google>Volctrans>DeepL>Amazon (see ). It was seen that the TT scores of IFYTEK appeared 4.3108 in 1-gram, 5.5873 in 2-gram, and 5.9159 in 3-gram, and n-gram had higher accuracy in IFYTEK translation system, with higher scores for correct consecutive translations than those of the five NMT application systems, that is, IFYTEK’s TTs contained more information for each sentence, and had the highest overall translation quality. The results obtained from the two machine translation evaluation technologies were consistent, with the highest score being given to IFYTEK and the lowest score to Amazon.
Figure 8. NIST evaluation scores of TTs translated with six NMT application systems.
Manual Evaluation Scores
After ranking the scoring results of each segment in the 300 segments sampled from the TTs generated by the six NMT application systems with the “Score Ranking System,” the overall descriptive statistics are computed with SPSS 23 version. depicts the outcomes.
Table 6. Descriptive statistics of scores of six NMTs.
According to the comparison of the means of the TT scores of the six NMT application systems, the order was found to be IFYTEK<Baidu<Google<Volctrans<DeepL<Amazon. Namely, IFLYTEK ranked first, with a mean of about 7.93 and a standard deviation of 2.38; Amazon ranked last, with a mean of about 9.08 and a standard deviation of 2.77. It was seen that the ranking values of Amazon were more polarized, so its overall performance was more unstable, with the worst translation quality.
In conclusion, the results of BLEU, NIST, and manual evaluations of TTs translated with the six NMT application systems were completely consistent. IFLYTEK had the best evaluation result and overall translation quality.
Summary of Quality Evaluation
The results of technical evaluation and manual evaluation on Cases 1 and 2 are completely consistent and mutually verified. Concluded that IFLYTEK has the best performance in the evaluations. Therefore, IFYTEK possesses the best translation quality among the six NMT application systems in terms of Chinese-English translations of political documents.
Discussions
To further analyze the problems with machine translation, a manual ranking of scores was performed covering all segments (10,323 segments) of Cases 1 and 2 that were categorized and annotated based on types of problems by counting and inferring the percentages of each type of error. The types of machine translation errors identified in the comparison process were classified regarding the secondary classification system. The generalization of the error categories framework was adopted using the research by Lu and Li (Luo and Li Citation2012). The error types involved were added or deleted by combining them with the actual case text comparison. The errors in machine translations were classified into three types first-order errors based on lexicon, syntax, and so on. The first-order errors were further classified into second-order ones according to the characteristics of specific errors shown in . The error rates of different machine translations in were counted after a segment-by-segment comparison between the translations of NMT application systems and human translations, as well as error annotation. The translation error refers to at least one type of error in machine translations listed in . The error rate is one-tenth of the result of the total number of segments of faulty machine translations divided by the total number of segments of machine translations. The errors of the same type, for instance, improper use of words that occurred repeatedly in the same segment were annotated and counted only once, and errors of different types in the same segment were annotated and counted separately. Errors in machine translations found in the comparative analysis will be described later.
Table 7. Types of errors in machine translations.
Table 8. Percentages of errors in the machine translations of the six NMT application systems.
Lexical Error
Words are the basic elements that constitute a sentence, and vocabulary translation has a crucial influence on the quality of translations (Catford Citation1978). depicts that the rate of lexical errors is much higher than that of other types of errors, up to 69.28% as many sentences are composed of the most basic element of vocabulary. In the type of high-frequency lexical errors, the error rate of terminology tops the list, accounting for 63.14% of 600 machine-translated sentences. This indicates the major linguistic feature of using many terminologies in political documents. The error rate for the wrong part of speech or tense is 4.41%, while that of improper use of words or collocation is 1.7%, accounting for the minimum percentage.
Terminology error. ST: “照此说来,博鳖亚洲论坛正处在一个新的起点上,希望能更上一层楼。” In this sentence, “博鳖亚洲论坛” was translated differently in different databases. It was translated into “the Bodie Forum for Asia,” “the BoF,” “the Bo Turtle Asia Forum,” “the Bo Bie Asia Forum,” “the Bobian Asia Forum,” and “the Boyi Asia Forum” by Google, DeepL, Volctrans, IFLYTEK, Baidu, and Amazon respectively. The translation would be closer to the ST and more accurate if “the Boao Forum for Asia” was included in the machine translation databases.
Wrong part of speech or tense. ST: “阿拉伯谚语说’金字塔是一块块石头垒成的’。” IFLYTEK TT: An Arab proverb says, “A pyramid is made of stones.” Amazon TT: The Arabic proverb says, “A pyramid is a block of stone.” The ST does not mean one pyramid or one stone. Therefore, the part-of-speeches are used incorrectly in the translations. The plurals are better, that is, “Pyramids were built by piling one stone block upon another,” which can reflect the hardships of building pyramids.
Improper use of words or collocation errors. Polysemous words are frequently used in Chinese political documents to express specific meanings in certain contexts. For example, ST: “要坚持系统治理、依法治理、综合治理、源头治理 … … .” DeepL TT: “To adhere to systemic governance, governance by law, comprehensive governance, governance at source … .” Google, DeepL, and IFLYTEK used “governance” indiscriminately for the polysemous word “治理.” None of them carried out interpretative translations as the official translation, leading to the identification error in the polysemous words. This is noteworthy in English translations. It is also one of the difficulties faced in machine translations. To take another example, ST: “健全完善立体化社会治安防控体系 … … ” Amazon TT: “improve and improve the three-dimensional social security prevention and control system … .” The problem with Amazon’s translation is “improve and improve,” that is, repetition of words. Therefore, the score of the translation is the lowest.
Syntactic Error
The error rate of syntactic errors in the machine translations is much lower than that of lexical errors, accounting for 23.44% of the total number of sentences. English is characterized by hypotaxis, which is realized mainly through syntax, the means to organize individual words into sentences. Major syntactic errors may result in disorder and ambiguity of sentences. Therefore, the analysis of syntactic errors and the study of syntactic formalization have been major projects in machine translation (Koponen Citation2010).
Errors in the segmentation of long difficult sentences. ST: “要把人民健康放在优先发展的战略地位,以普及健康生活、优化健康服务、完善健康保障、建设健康环境、发展健康产业为重点,加快推进健康中国建设,努力全方位、全周期保障人民健康,为实现‘两个一百年’奋斗目标、实现中华民族伟大复兴的中国梦打下坚实健康基础.” Google TT: People’s health should be given priority to the strategic position of development, focusing on popularizing healthy life, optimizing health services, improving health protection, building a healthy environment, and developing healthy industries, accelerating the construction of a healthy China, and striving to ensure people’s health in an all-round and full-cycle manner, laying a solid and healthy foundation for realizing the “two centenary goals” and realizing the Chinese dream of the great rejuvenation of the Chinese nation. The major problem with Google Translation is that there is no sentence segmentation. The translation pursues unduly mechanical formal equivalence to the ST, failing to follow the English way of expression.
Error in non-subject sentences. ST: “空气、水、土壤、蓝天等自然资源用之不觉、失之难续.” Google TT: Air, water, soil, blue sky, and other natural resources are unknowingly used and difficult to sustain. The subject of “用之不觉、失之难续” should be a person. Without a subject, the sentence should be translated in the way translates subject-prominent language, that is, with “we” as the subject, to highlight the fact that it is people rather than resources that cannot survive without natural resources. Both Google and DeepL translations fail to handle the non-subject sentence correctly.
Disordered structural relationship. ST: “大道至简,实干为要.” Amazon TT: The road is simple, and practical work is essential. Without giving the implied logical relationship, the translation treats the two parts as parallel structures and expresses an irrelevant meaning. For the sake of correctness, the translation should be “Great visions can be realized only through actions.”
Other Types of Error
There are also other types of errors in the translations of political documents, which account for 16.9% of the total errors in machine translations. The low error rate is highly correlated with the occurrence of the words themselves in the sentence. The followings are examples of errors in the machine translations.
Improper cohesion and coherence. ST: “新世纪以来 … … ” Amazon TT and DeepL TT: “Since the new century … .” Without “the beginning of,” both translations are incohesive and incoherent in the context.
Errors in capital and small letters. ST: “坚持亲、诚、惠、容的周边外交理念” DeepL TT: Adhere to the peripheral diplomacy concept of affinity, sincerity, benefit, and tolerance. This headline is not capitalized in the machine translation as it is unidentified.
Omission. ST: “中国同周边国家贸易额由1000多亿美元增至1.3万亿美元 … … ” “Trade” is not described in the translations. “Trillion US dollars,” instead of “trillion-worth,” is expressed in the translations of the six NMT application systems. The translation of “额” in the Chinese context is omitted. It is known from the machine translations of sentences scored “0” that Baidu fails to translate some sentences, e.g., “这是习近平在十八届中央政治局常委同中外记者见面时讲话的主要部分,” “这是习近平在主持十八届中央政治局第一次集体学习时的讲话.”
Scheme for Improving the Translation Quality of NMT Application Systems
It is a fact that the mistranslation of specific words is more prominent in the translations of NMT application systems. Once a certain word is mistranslated, the translation of the whole paragraph or even the whole text will deviate greatly from the intended meaning of the source text. This would have a great impact on the overall quality of the translation. To resolve this prominent problem, this paper proposes a “Cue Lexicon+” model that integrates “machine translation and translation memory.”
A high-quality Chinese-English translation memory (lexicon) is introduced into the NMT application systems to further examine and proofread certain words such as proper nouns, terms, etc. in the translation results. By doing so, the standard translation of words will be identified and matched, thus improving the translation quality of sentences and passages.
Building a “Cue Lexicon”
To generate a high-quality Chinese-English translation memory (lexicon), a “Cue Lexicon” of political documents that includes the political Chinese-English texts over the past 20 years has been built, with a total of 10 million characters having been included by far. The method is as follows:
Content selection. The selected materials are all Chinese-English text materials published by authoritative Chinese institutions to ensure the high quality of the Chinese and English materials, i.e., Chinese political documents since 2000, including speeches and addresses by state leaders of China at international events, news from the website of the Ministry of Foreign Affairs, and reports on the work of the Chinese government.
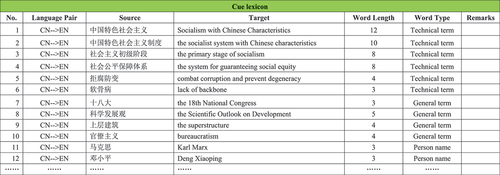
Generating a corpus and extracting terms. The bilingual texts collected were aligned to make a parallel corpus using the Aligner (See ). At the same time, specific words and corresponding translations were extracted from the glossary of political news based on word frequency to make a cue lexicon (See ). In addition, categorical attributes were added to the cue lexicon, namely, general terms, technical terms, organization names, place names, and person names, for finer management and expansion of the cue lexicon in the future.
Figure 9. Corpus of political documents.

Figure 10. Cue lexicon.
Implementation of the Scheme
This study proposes the “Cue Lexicon+” model (See ) to perform three functions based on the above design: (1) Importing the cue lexicon to match specific words in the text to be translated automatically by reference to the lexicon. The specific words are tagged (i.e., labeled with hidden tags) so that they are automatically regarded as phrases in the process of machine translation, ensuring the integrity and specificity of phrases; (2) Connecting and fusing the six NMT application systems to translate the tagged texts automatically; (3) Making intelligent comparisons among specific lexical expressions in the translations of the NMT application systems.
Figure 11. “Cue Lexicon+” model.
They would be replaced and updated if the expressions are inconsistent with those in the lexicon, and a final translation will be generated at last. An application named “NMT + Lexicon Intelligent Translation Assistant” (See ) has been constructed based on this model. The process flow chart is shown in .
Figure 12. NMT+ Lexicon intelligent translation assistant.
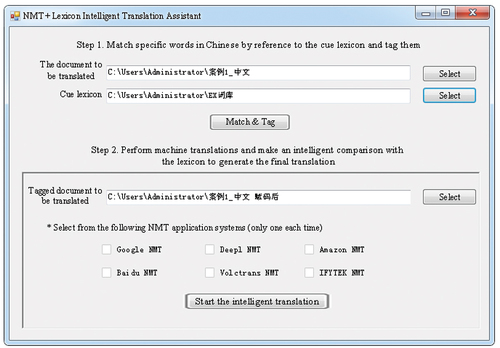
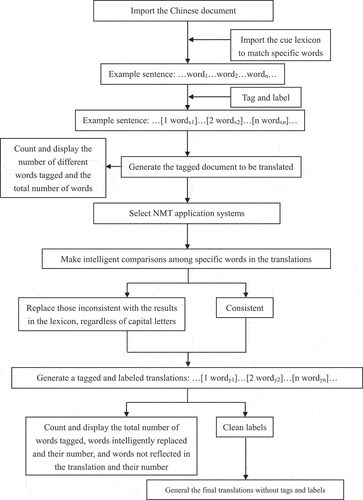
Figure 13. Process flow chart of “Cue Lexicon+.
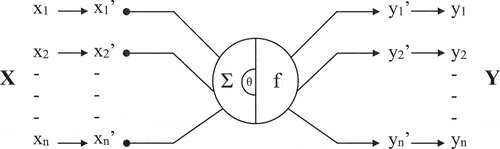
In this model, X denotes ST; x1, x2, xn denote terms in the cue lexicon; x1,’ x2’ and xn’ denote tagged terms; Σ and f denote pre- and post-translation, respectively; θ denotes the comparison of the machine-translated term with the reference translation in the cue lexicon; y1,’ y2,’ yn’ denote the translated terms (with labels); y1, y2 and yn denote the terms after cleaning the labels; Y denotes TT.
The proposed method is expressed as follows: In the first stage, a Chinese text is uploaded. Cue lexicon is imported. A matching process is conducted between reference and cue lexicon to find matched words and they are tagged. A tagged document is generated to be translated. All different tagged words are counted and shown concerning tagged words. In the second stage, all six translation applications are utilized. Comparisons of translated words are conducted intelligently resulting in tagged and not tagged translations. The number of all tagged words, the number of words replaced intelligently, and the number of words not matched with proper translations are counted and shown in the output.
Test Checkout
By reference to the official Chinese-English texts of Cases 1 and 2, 3,298 specific words were extracted from the glossary of political news based on word frequency to make a Chinese-English cue lexicon. Then, the Chinese texts of Cases 1 and 2 were imported into the “NMT + Lexicon Intelligent Translation Assistant,” and the cue lexicon was imported as well to give matched words to be tagged. The texts were subsequently translated with the six NMT application systems to generate final translations (TTnews). The following is the number of words replaced and updated intelligently by the software in the process of translation (See ):
Table 9. Number of words intelligently replaced and updated by “NMT + Lexicon intelligent translation assistant” in the six TTnews.
After further BLEU and NIST evaluation of the six TTns of Cases 1 and 2, the following results were obtained.
According to the results of technical evaluations, the scores of the six TTnews of Cases 1 and 2 have increased significantly (See , , ). The overall quality of the translations processed by “NMT+ Lexicon Intelligent Translation Assistant” has been greatly improved has been shown.
Table 10. Comparison among BLEU scores of six TTnews and TTs of case 1.
Table 11. Comparison among NIST scores of six TTnews and TTs of Case 1.
Table 12. Comparison among BLEU scores of six TTnews and TTs of Case 2.
Table 13. Comparison among NIST scores of six TTnews and TTs of Case 2.
Conclusion
This paper made a comparative study on the performances of six mainstream NMT application systems in the Chinese-English translations of political documents by employing technical and manual evaluations. After comparing and analyzing the translations of the six NMT application systems with the standard translations, this paper concludes problems in the machine translations and builds targeting prominent problems in the “Cue Lexicon+” model and a method called the “NMT+ Lexicon Intelligent Translation Assistant” is proposed, which can greatly resolve the problem of the mistranslation of specific words in the English translation generated by NMT application systems. The results of BLEU, NIST, and manual evaluations of TTs translated with the six NMT application systems were found to be completely consistent. Therefore, TTnew generated after intelligent processing resulted in better translation quality.
The research results showed that after the proposed method, the overall quality of machine translation had a qualitative breakthrough. Found that IFLYTEK had the best performance among the six NMT application systems in actual communication.
The research findings may give readers a reference in selecting a machine translation system for political documents and provide a research basis for improving the translation performance of NMT application systems. In addition, the research proposes a way to build an online corpus platform (http://miaohua.021misn.com) on which the corpus and cue lexicon of political documents are available. Researchers and developers of the NMT application system are welcome to use them for reference.
Disclosure Statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Catford, J. C. 1978. A linguistic theory of translation, Vol. 79. Oxford: Oxford University Press.
- Duh, K. 2008. Ranking vs. regression in machine translation evaluation[C]//Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, Ohio, USA, 191–1531.
- Feng, Y., W. Xie, S. Gu, C. Shao, W. Zhang, Z. Yang, and D. Yu. 2020. Modeling fluency and faithfulness for diverse neural machine translation. Proceedings of the AAAI Conference on Artificial Intelligence 34 (01): 59–66.
- Ghorbani, B., O. Firat, M. Freitag. 2021. Scaling laws for neural machine translation. arXiv Preprint arXiv: 210907740
- Guzmán, F., S. Joty, L. Màrquez, and P. Nakov. 2017. Machine translation evaluation with neural networks. Computer Speech & Language 45:180–200. doi:10.1016/j.csl.2016.12.005.
- Koponen, M. 2010. Assessing machine translation quality with error analysis. Electronic proceeding of the KaTu symposium on translation and interpreting studies.
- Luo, J. M., and M. Li. 2012. Error analysis of machine translation. Chinese Translators Journal 5:84–89.
- Mathur, N., T. Baldwin, and T. Cohn. 2020. Tangled up in BLEU: Reevaluating the evaluation of automatic machine translation evaluation metrics. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. doi:10.18653/v1/2020.acl-main.448.
- Reiss, K., and E. F. Rhodes. 2014. Translation criticism–the potentials and limitations: Categories and criteria for translation quality assessment[M]. Routledge.
- Shapran, N. V., S. V. Novoseletska, E. K. Koliada, T. I. Musiichuk, and K. V. Simak. 2021. Communicative-functional components of discourse. Linguistics & Culture Review 5 (S4):1325–39. doi:10.21744/lingcure.v5nS4.1784.
- Sun, Y., and V. Kumar. 2022. Analysis of Chinese machine translation training based on deep learning technology. Computational Intelligence and Neuroscience 2022:1–14. doi:10.1155/2022/6502831.
- Wu, L., X. Pan, Z. Lin. 2020. The volctrans machine translation system for wmt20. Proceedings of the 5th Conference on Machine Translation (WMT), 2020 November 19–20, 305–312.
- Wu, Y., M. Schuster, Z. Chen. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv Preprint arXiv: 160908144
- Yulianto, A., and R. Supriatnaningsih. 2021. Google translate vs. DeepL: A quantitative evaluation of close-language pair translation (French to English). AJELP: Asian Journal of English Language and Pedagogy 9 (2):109–27.
- Zhou, J., Y. Cao, X. Wang, P. Li, and W. Xu. 2016. Deep recurrent models with fast-forward connections for neural machine translation. Transactions of the Association for Computational Linguistics 4:371–83. doi:10.1162/tacl_a_00105.