
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Artificial intelligence (AI) and big data profoundly impact people’s way of life and way of thinking, and college ideological and political education (IPE) has gradually entered the era of online education. On account of this, this study designs an online education algorithm based on AI technology to help teachers better understand the situation of students’ online IPE teaching and improve the management of IPE in universities. Firstly, the learning features of students are extracted through the Back Propagation Neural Network (BP) model. This model summarizes the shortcomings of feature extraction in machine learning, and can simultaneously obtain depth information from the signals of multiple sensors, thus increasing the overall algorithm classification accuracy. Secondly, combined with the human behavior recognition model, the status and behavior of students’ IPE teaching can be obtained in real-time from students’ listening devices. Finally, the algorithm’s classification performance is evaluated by experiments and compared with the designed model. The results reveal that the recognition accuracy of the designed classification algorithms for the sample students is 98.59%, 98.99%, 99.21%, 100%, 97.10%, 95.61%, and 100%, respectively. In addition, comparing the algorithm with similar recognition algorithms, its index values of accuracy and precision are 97.83% and 97.82%, respectively, which are better than similar classification algorithms. Finally, through the experimental samples, the accuracy of the human recognition model is tested and compared with other recognition models. The results reveal that the designed model has high recognition accuracy. This study is of great significance for improving teachers’ innovative IPE methods and optimizing the management level of online IPE teaching.
Introduction
A country’s future development and progress highly depend on students, who are the primary force. The campus period is crucial for the formation of students’ outlook on life. Since network distance education makes progress continuously, it is significant for teachers to conduct innovative management of college students’ ideological and political education (IPE) classes during online teaching (Zeng Citation2022). IPE has certain ideological and political concepts and moral norms to form ideological and moral standards that meet the needs of society. With the progress of social history, the description and expression forms in IPE are changing, and IPE has social characteristics. In the current changing social environment, people need to constantly adjust their work ideas and plans to adapt to the prospect of continuous development and closely link with social reality (Lin, Wang, and Zhang Citation2022). The combination of artificial intelligence (AI) and education is gradually promoted with continuous development and improvement of AI and social needs (Dai Citation2021). Under the impact and influence of AI, profound changes are taking place in the field of education. AI-supported IPE innovation in colleges has become an urgent and important research topic (Ge Citation2022). Machine learning (ML) and deep learning (DL) technology are adopted by multiple additional sensor functions in smartphones. It can provide a technical path to knowing students’ online learning status and improve the teaching management levels (Zhao and Zhang Citation2021).
With the rapid progress of different types of sensor technology as well as the popularity of smart devices, the use of sensor data for human recognition in smartphones has become the focus of many schools. The signal of the acceleration sensor will also change correspondingly due to different human behaviors. Acceleration can well represent human behavior, so some scholars use a single acceleration to identify human behavior (Zhou et al. Citation2021). Some scholars use triaxial accelerometers and gyroscopes in intelligent devices to recognize human behavior. First, they use appropriate algorithms to rank features. Next, the method of feature selection of the forward selection algorithm is adopted to evaluate the features, and an online behavior recognizer with strong generalization ability is built. In addition to smartphones, which are smart devices carried by the human body, some scholars have also extended the recognition of human behavior by sensors to wearable devices. For example, smartwatches are used to collect the daily life behaviors of the elderly, promote the safety status of the elderly, and prevent them from falling (Novak, Bennett, and Kliestik Citation2021). However, the existing human behavior recognition on the basis of lots of sensors has many problems, like the single type of information for human behavior and too traditional representation and classification algorithm of human behavioral characteristics. The reason for these problems is the single sensor type as well as the feature extraction method (Blasch et al. Citation2021).
Aiming at the shortcomings of the previous research, the Convolutional Neural Network (CNN) model is built for general feature extraction. This model summarizes the shortcomings of ML feature extraction and can obtain depth information from lots of sensor signals, thus increasing the algorithm classification accuracy. The classification performance of the proposed algorithms is compared as well as assessed by experiments. The designed human behavior classification and recognition model can obtain the college students’ learning status and behavior from their listening equipment, and understand their learning situation. This is significant for promoting the online teaching management of IPE teachers.
Methods
The research question underlying the present study is how to improve the management of online IPE teaching using AI technology. While online IPE teaching has become more prevalent, it poses challenges for teachers to monitor and evaluate students’ learning outcomes in real-time, provide personalized feedback and guidance, and promote equitable access to education.
The proposed algorithm aims to address these challenges by using a combination of the BP model and the human behavior recognition model to extract comprehensive learning features and monitor real-time student behavior during IPE teaching. The study seeks to evaluate the algorithm’s classification performance and compare it with similar recognition algorithms.
Thus, the problem that needs solving is how to enhance the effectiveness and efficiency of online IPE teaching management using AI technology, with the ultimate goal of improving students’ learning outcomes and promoting equitable access to education.
Neural networks are a fascinating machine learning model that takes inspiration from the structure and function of the human brain. Essentially, neural networks are made up of interconnected nodes or neurons organized into layers and trained on a dataset to learn patterns and make predictions. This technology has been successfully used in various areas, such as image and speech recognition, natural language processing, and gaming.
One of the advantages of neural networks is their ability to learn from complex and large datasets, making them suitable for tasks where traditional rule-based methods may not be effective. They are also capable of handling noisy and incomplete data, and can automatically extract features from raw data without the need for manual feature engineering.
Another advantage of neural networks is their ability to generalize well to new and unseen data, which is important for many real-world applications. This is achieved through techniques such as regularization and early stopping during training, which help to prevent overfitting.
Overall, neural networks have shown great promise in many fields and are a powerful tool for machine learning and artificial intelligence.
CNN Analysis
ML is not only AI’s core but also the ultimate approach to making computers become intelligent. The machine can be employed to simulate or realize the behavior of human learning. Eventually, new knowledge, as well as techniques, can be acquired, the existing knowledge structure can be reorganized, and its own performance can be continuously improved (Sun and Lei Citation2021). This includes probability theory, statistics, approximation theory, convex analysis, algorithm complexity theory as well as multiple other theories. The Artificial Neural Network (ANN) is a vital algorithm in early ML. It is unnecessary for ANN to decide the mathematical equation of the input and output mapping relationship before. It just learns some rules by its self-training. Then, the result with the least error between the desired output value can be obtained when the input value is given (Song et al. Citation2021). ANN takes algorithms as the core and it is an intelligent system used for information processing.
CNN is a type of ANN. The original ANN has only input, output, and hidden layers. The data of the hidden layer is decided based on the needs. The neurons of each layer are fully connected to the neurons of the next layer, and there is no connection between the same layer and across layers. But CNN not only introduces the concept of the receptive field, that is, local connection. Each neuron is only connected to the part of the neurons in the former layer, and only perceives the part rather than the whole image. At the same time, the concept of weights and multiple convolution kernels is also introduced. In CNN, each neuron can be regarded as a filter, and the same neuron uses a fixed convolution kernel to deconvolve the entire image.
CNN is a type of feedforward neural network. It has a deep structure, in which the convolution calculation is involved, and it is a kind of representative algorithm of DL (Yang et al. Citation2021). CNN can conduct representation learning as well as the translation invariant classification of the input information based on the hierarchical structure. Hence, “translation invariant ANN” can be also used to name it. Firstly, the input signals are sequentially transmitted from the input layer nodes to each hidden layer node. Then, they are transmitted to the output layer nodes. The basic idea of it is the gradient descent method.
When designing a neural network model, selecting the appropriate architecture of neurons is crucial for achieving optimal results. This decision involves considering various factors, such as the complexity of the task, available data, and computational resources. Here are the key steps to follow:
Determine the number of input neurons based on the number of features in the input data.
Determine the number of output neurons based on the type of problem.
Determine the number of hidden layers based on the complexity of the task.
Decide on the number of neurons to use in each hidden layer depending on the task’s complexity and the available data. It’s common practice to start with a few neurons and gradually increase them until the model’s performance no longer improves.
Choose an appropriate activation function, which determines the output of each neuron in the network based on the task at hand.
Consider regularization techniques such as dropout, L1, and L2 regularization to avoid overfitting.
Optimize the model’s performance through techniques such as stochastic gradient descent that are used to minimize the loss function.
It is to adopt the gradient search technology to achieve the goal of minimizing the error mean square deviation between the network’s real and expected output values (Tian et al. Citation2022).
When developing a neural network model, determining the best topology involves considering various factors like the complexity of the task, available data volume and quality, desired accuracy, and computational resources. It is vital to test different topologies and hyperparameters to find the best-performing model for a specific problem.
It’s important to note that the optimal topology may not always be the most complex one, and overfitting should be avoided. To prevent overfitting and improve the model’s generalization performance, regularization techniques such as dropout, L1, and L2 regularization can be applied. The choice of activation function, optimization algorithm, and learning rate can also impact the model’s performance.
To find the best topology, we experimented with various topologies and hyperparameters and conducted model evaluation and validation to assess performance. By comparing the performance of different models, we determined the optimal topology for the given problem.
denotes the structure of CNN:
Figure 1. Structure of CNN.
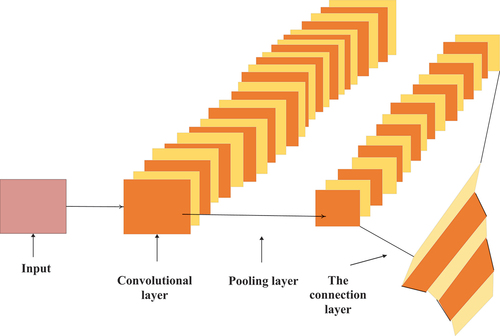
suggests that the multi-dimensional data can be analyzed by the input layer. When related data are input into the network, their time and frequency are unified. The output layer is used for outputting specific problems’ results, classifying the problem surface, and outputting object categories. In the positioning problem, the output is the coordinate data of the object (Li, Sun, and Wang Citation2021). The middle has three layers: convolutional, pooling, as well as fully connected layers.
The training of an initial neural network model involves several steps, including data preparation, model architecture design, and hyperparameter tuning. Below is a general guide on how neural networks are trained for image classification using Convolutional Neural Networks (CNNs):
Data Preparation: The first step is to split the data into training, validation, and test sets. The training set is used to train the model, the validation set is used to evaluate the model’s performance and tune the hyperparameters, and the test set is used to evaluate the final performance of the model.
Model Architecture Design: The next step is to design the neural network model’s architecture. This involves selecting the number of layers, neurons in each layer, activation functions, and optimization algorithm. The architecture should be based on the nature of the problem and the data.
Hyperparameter Tuning: After designing the model architecture, the next step is to tune the hyperparameters to optimize the model’s performance. This involves adjusting the learning rate, batch size, regularization techniques, and other hyperparameters to improve the model’s performance on the validation set.
Training the Model: Once the model architecture and hyperparameters are set, the model is trained on the training set by iteratively adjusting the neural network weights using an optimization algorithm to minimize the error between predicted and actual outputs.
Evaluating the Model: After training, the model is evaluated on the test set to assess its final performance, using metrics like accuracy, precision, recall, and F1-score.
CNNs are a type of deep learning algorithm that is particularly effective for image classification tasks. They use multiple layers of convolutional filters to extract features from the input image, followed by pooling layers that downsample the output of the convolutional layers. The final layers of a CNN combine the extracted features to produce a classification output.
In image classification tasks, a CNN is trained on a large dataset of labeled images, where the network learns to recognize patterns and features associated with specific classes. During training, the weights of the convolutional filters and fully connected layers are adjusted through a process called backpropagation, which uses gradient descent to minimize the error between the predicted class and the true class label.
Once the CNN is trained, it can be used to predict the class label of new, unseen images. The input image is passed through the trained CNN, and the output of the final layer is a probability distribution over the possible classes. The class with the highest probability is chosen as the predicted class label for the input image.
In summary, CNNs are powerful deep-learning algorithms that can be used for image classification tasks. The network is trained on a large dataset of labeled images, and the learned features are used to predict new, unseen images.
CNN’s specific expression is:
The size of the feature map generated after convolution is as follows:
The setting matrix W is the connection weight matrix between the input and the hidden layers (Tian et al. Citation2022).
It can be assumed that the neuron thresholds of the hidden and output layer are as follows:
Then, each layer’s input and output in the network can be expressed as:
The input vector is:
The network input to the hidden layer is written as Equationequation (6):
X refers to the input vector. W represents the connection weight matrix between the input and the hidden layers. α is the neuron threshold of the hidden layer (Zhang et al. Citation2021).
The hidden layer’s network output is exhibited in Equationequation (7):
EquationEquation (8) indicates the network output of the output layer:
V represents the connection weight matrix between the hidden and the output layers; β expresses the neuron threshold of the output layer. means the network output of the hidden layer (Li, Yao, and Xu Citation2021).
When initializing a neural network, the weights of the connections between the neurons are usually initialized randomly. There are different methods for initializing the weights, including:
Random initialization: In this method, the weights are initialized randomly using a uniform or normal distribution. This method is simple but may not be optimal for all types of networks.
Xavier initialization: This method scales the random weights based on the size of the inputs and outputs of each neuron. This can help to avoid the problem of vanishing or exploding gradients, which can occur when the weights are too small or large.
He initialization: This method is similar to Xavier initialization but is optimized for Rectified Linear Units (ReLU) activation functions, which are commonly used in deep learning.
Pretrained weights: In some cases, it may be beneficial to initialize the weights using pretrained weights from a similar network or task. This can help to speed up convergence and improve the performance of the network.
When it comes to initializing a neural network, the method you choose can vary depending on the problem and type of network you are using. Some libraries and frameworks offer standard weight initialization methods, while others enable users to define their own. To determine the most effective initialization method for your particular problem and network, it is essential to test out and compare various options.
EquationEquation (9) signifies the total error of CNN:
d refers to the expected output of CNN; y denotes the network output vector.
The process of calculating the weights of a neural network model during the training phase involves an algorithm called backpropagation. One widely used optimization algorithm in machine learning is backpropagation. It iteratively adjusts the weights of the model to minimize the error between the predicted and actual outputs. Here’s a quick summary of how it works:
Forward Propagation: Input data is fed into the neural network model during the forward propagation step. The output is calculated by applying weights to the input data and passing the result through the activation function.
Calculate the Error: The error between the predicted output and the actual output is then calculated using a loss function, such as mean squared error or cross-entropy loss.
Backward Propagation: During the backward propagation step, the error is propagated backward through the network, and the weights are updated to minimize the error. The chain rule of differentiation is used to calculate the gradient of the loss function with respect to each weight in the network.
Update the Weights: The weights are updated in the direction of the negative gradient of the loss function using an optimization algorithm, such as stochastic gradient descent.
Repeat: Steps 1-4 are repeated for each batch of data in the training set until the model’s performance converges to an acceptable level.
The backpropagation algorithm is an iterative process that trains the neural network model by adjusting its weights to minimize the error between the predicted and actual outputs. Over time, the model learns to make better predictions and improves its performance by updating its weights using the gradient of the loss function.
The convolution kernel plays the most crucial role in the convolutional layer. It can be considered as an element matrix. Various elements will have corresponding weights as well as deviation coefficients. The input data are scanned with specific rules when performing a convolution operation. The pooling layer can be used for deleting useless information in the data acquired from the previous layer. Generally, there are average pool, maximum pool and overlapping pool. The first and second categories have a wide application. The role of the fully connected layer is to classify the information data from the last layer. Under some conditions, the whole parameter value’s average value can be adopted for replacing the last operation to reduce redundant data.
CNN has two main characteristics:
(1) Local connection. Usually, when networks are connected, neurons are connected to each other. It differs from other neural networks in that only part of it is connected. When there is a connection between neurons of layers N-1 as well as N, demonstrates the connection form of CNN:
Figure 2. CNN connection diagram.
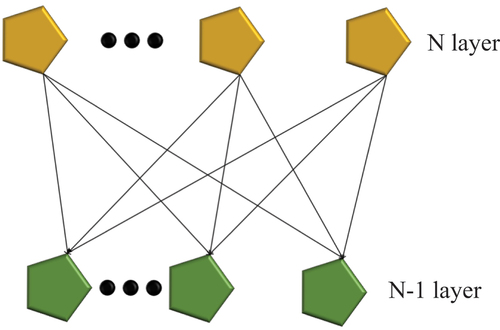
(2) Weight sharing. The convolutional layer’s convolution kernel can be taken as an element matrix. Information is scanned through the convolution kernel in the convolution operation. It is assumed that there are 9 parameters in the 3 × 3 * 1 convolution kernel. Then, an image is input through the convolution kernel for correlation convolution processing, and the whole image will share the nine parameters in the scanning process.
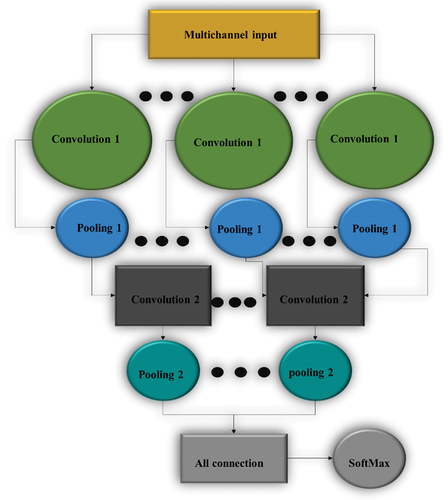
When building a CNN feature extraction model, sensor signal and image signal are different. The gray image pixel of the image signal is usually 28 × 28 pixels. This type of image data is used for the two-dimensional (2D) convolution operation of the previous CNN model. The sensor signal is one-dimensional (1D) and multi-dimensional. It is necessary to convert the sensor data into 2D virtual image data to fit the conventional CNN. This method unilaterally takes the data’s time characteristics into account. If the processed data are input into CNN, the model’s performance will be better than converting it into virtual images. Hence, 1D convolution is adopted for various dimensions of sensor data. The input is a 1D sensor signal in the first convolutional layer. The 1D signal is calculated by translational convolution, and the spatial scale of features is reduced by merging. The data source is the data of three sensors on the smartphone. Sensor data’s temporal and spatial characteristics must be considered when building the model. displays the designed CNN multi-channel feature extraction model.
Figure 3. CNN multi-channel feature extraction model.
It must be noted that it is common in machine learning and data analysis to make assumptions about parameters when conducting calculations. These assumptions may be based on previous studies, domain knowledge, or empirical observations.
In the case of the study being discussed, the assumptions about parameters may include the learning rate, the number of hidden layers and neurons, the activation functions, and the number of training and test samples. These parameters are typically chosen based on previous studies or best practices in the field.
For example, the learning rate is a hyperparameter that controls the step size of the gradient descent algorithm used to optimize the BPNN model. A common practice is to start with a relatively high learning rate and then decrease it gradually over time to help the algorithm converge to a good solution. The choice of the initial learning rate may be based on empirical observations or previous studies.
Similarly, the number of hidden layers and neurons can be chosen based on previous studies or empirical observations. A common practice is to start with a small number of hidden layers and neurons and gradually increase them until the performance of the model on a validation set starts to degrade. The choice of activation functions can also be based on previous studies or empirical observations of their performance on similar tasks.
Finally, the number of training and test samples is typically chosen based on the size of the available data and best practices in the field. A larger number of samples can lead to better generalization performance of the model, but also requires more computational resources to train and test the model.
Overall, the assumptions about parameters in machine learning are typically made based on best practices in the field and previous studies. However, it is important to conduct sensitivity analyses to assess the robustness of the results to changes in these assumptions.
As indicated in , it is essential to conduct preprocessing treatment on the collected three types of sensor data to transform them into multi-channel input samples. Through two convolutions and pooling operations, the characteristic data of human behavior is obtained. The fully connected layer’s output is taken as the extracted signal features. In the process of acquiring model feature data, the correlation between the same dimension of various sensor data is considered. After the first convolution as well as pooling, the data features of the same dimension of the sensor data are merged as well as processed. Deep data features are acquired through two convolutions and pooling.
When the sample data are convolved, it is essential to take the ReLU function as the activation function. It can prevent overfitting and thus improve the model’s performance. A dropout layer is added after the fully connected layer to implement the CNN model, and additional layers can change the layer structure of the CNN. The idea is that some neurons in the fully connected layer are randomly removed, while the input and output neurons do not change (Gong Citation2022). Many different neural networks are trained to optimize the overfitting problem. In the designed model, the probability of deleting a neuron is set to 0.5.
Classification and Analysis of Main Human Behaviors
Generally, AI is the process that computers are adopted to learn new things like human beings. It is to explore the way that computers learn existing knowledge autonomously in the process of continuous learning to get new knowledge, and eventually improve the recognition ability as well as the learning effect (BEINGS] Citation2022). The computer implementation of AI must build a learning machine according to the existing knowledge structure, and use the learning machine to classify as well as forecast unknown information. The prediction results are categorized and the learning machine is optimized.
At present, AI algorithm is usually adopted in two fields: prediction and classification (Yun, Ravi, and Jumani Citation2022). AI algorithm is generally applied in the field of student educational behavior through the classification of student behavior data (Zou, Bo, and Li Citation2021). The acquisition of students’ online learning status data are the data transmitted by smartphone sensors. Generally, when using smartphones, the human body has several actions, as demonstrated in :
Figure 4. Main behaviors of the human body.
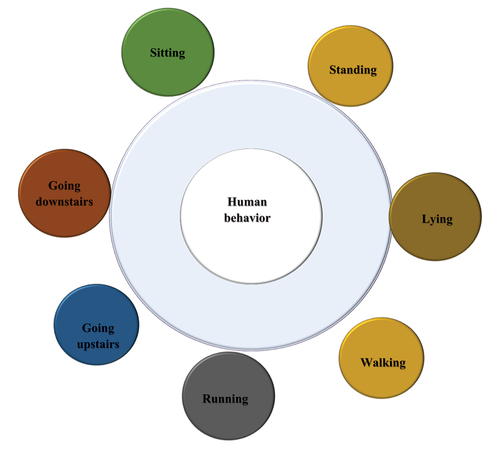
presents some ordinary human behaviors. They are sitting, standing, lying, running, and going upstairs and downstairs. The information data of students’ education are obtained through human posture estimation. The obtained feature values are defined as classification criteria, normalized through feature extraction. Next, they are sent to the learning machine of the classification learning algorithm. At last, through continuous learning data, a recognition model for identifying the identity of students in the online IPE classroom is implemented. Teachers can master students’ learning status from these data and strengthen students’ online management level (Y, Y, and H 2022).
Behavior Recognition on the Basis of Sensor Data
Now, human body recognition receives much attention in AI. Due to the significant progress of sensor technology as well as intelligent equipment, human body recognition technology has obtained much attention from researchers in this field. The following examples can be used for the definition of sensor-based human behavior recognition (Lattanzi and Freschi Citation2021).
If A is set as the predefined behavior of the user, it is in the scope of Equationequation (10):
refers to a typical human behavior. m indicates the human behavior’s type. If the user performs various behaviors, the sensor readings as well as the display mode will be different. Within a specific period of time, the expression of the sensor reading is d,
. dt indicates the sensor reading at time t. EquationEquation (11)
is the expression of the real type of human behavior:
represents actual human behavior. Implementing a human recognition model H by using a learning algorithm and using this newly established model in human behavior prediction are the final objectives of recognizing human behavior.
stands for the type of prediction behavior. In mathematics, building a learning model H through minimized differences between the forecasted behavior type
with the real behavior type
is human behavior recognition’s learning objective. Generally speaking, the sensor reading d is not directly taken as an input by the model H. The sensor readings will be processed before that. ℶ is adopted to represent the processing process (Mantouka, Barmpounakis, and Vlahogianni Citation2021). EquationEquation (12)
expresses the learning goal:
ℶ
portrays the current sensor-based human recognition model process:
Figure 5. Flow chart of ordinary human body recognition.
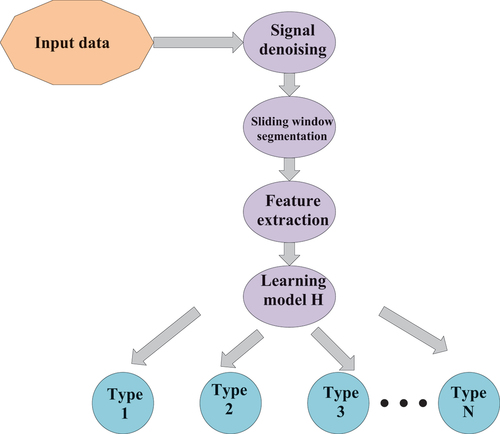
displays that human body recognition has 3 crucial steps. They are sensor data preprocessing, feature extraction as well as model learning. The behavior recognition’s mathematical description is combined with the recognition process to obtain sample d. The characteristic process is sensor reading processing. It means that the learning model H stands for the classification algorithm (Ferrari et al. Citation2021).
Currently, the advanced mobile phone industry makes the competition in this field extremely fierce, and the functions of mobile phones are richer and richer. Many sensors are integrated into the mobile phone. presents several sensors in daily life:
Figure 6. Common mobile phone sensors.
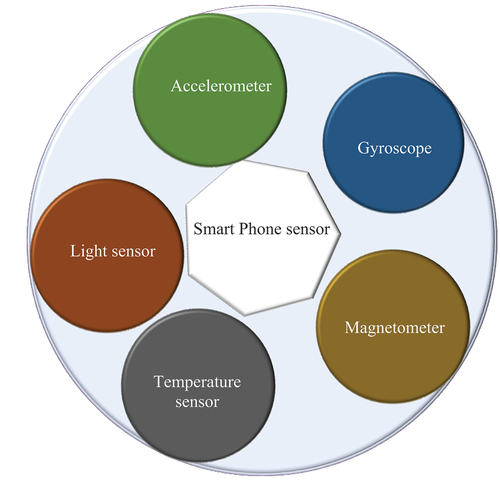
reveals that the sensor connected to the mobile phone can obtain different information about the mobile phone user at the first time. In addition to the built-in sensors that are more exposed daily, some special mobile phones will also add gravity, direction, and rotation sensors. However, these sensors have little to do with human behavior recognition (Xu and Qiu Citation2021). demonstrates the gravity sensor in the mobile phone:
Figure 7. Gravity sensor of mobile phone.
In , the accelerometers, gyroscope sensors and magnetometers inside smartphones are used more frequently. Among them, an acceleration sensor can be applied for the measurement of acceleration. It usually comprises mass blocks, dampers, elastic elements, sensitive elements, as well as adaptive circuits. During the sensor acceleration process, the inertial force on the mass block is measured to obtain the acceleration value based on Newton’s second law. The idea of the gyroscope is that the direction of the rotation axis of a rotating object will not change when external forces do not affect it. People adopt such an idea to keep the orientation. The direction represented by the axis is then read in a variety of methods, and the signal of the data is automatically sent to the control system. However, the data collected by the sensor cannot directly identify the human body, and the collected data usually requires special processing before it can be used (Mekruksavanich and Jitpattanakul Citation2021b).
Sensor Data Collection and Analysis of Smartphones
In order to minimize uncontrollable factors caused by personal reasons, the behaviors of 5 people are collected through sensors. The age of the testers is between 18 and 25 years old. The sampled people reflect the characteristics of college students as much as possible. The weight is controlled at 50-75 kg. There are 3 males and 2 females. The waist is the human body’s gravity center. The human body’s movement information can be well reflected through its changes. Hence, during data acquisition, smartphones are fixed at the waist of the human body. The collected data are used after relevant processing.
During the process of acquiring data, the testers fix the mobile phone at their waist and complete some ordinary human behaviors. These behaviors include walking, going upstairs and downstairs, sitting, standing, lying as well as running. Besides, it is essential to carry out walking, walking up and down, and running all outdoors. When the testers go up and down the stairs with a smartphone in hand, they must make sure that the signal maintains a stable change. The time needed for obtaining the 3 behaviors of sitting, standing, as well as lying will be more than 10 minutes.
In the signal experiment of the mobile phone human behavior sensor, a series of factors such as ambient noise and high-frequency interference will affect the signal. Human breathing can cause behavioral changes, and it may result in changes in sensor signals. Therefore, the collected human behavior data may not be human motion data. With the purpose of improving the recognition model’s robustness and accuracy, data preprocessing is needed. Filtering algorithms, data standardization, and sliding window segmentation are usually used (Sharma and Giannakos Citation2021).
When suitable methods for data preprocessing are adopted, it is essential to extract the feature vectors. Transforming the sensor signal into human behavior’s feature vector is the primary goal of extracting the feature vector. CNN will be used to extract the characteristics of data signals and complete the recognition of human behavior in combination with relevant algorithms (Mekruksavanich and Jitpattanakul Citation2021a).
Experimental Setup
The experiments use multiple sensor data from smartphones to identify human behavior and analyze online course learning. The program running environment uses a personal computer with 4-Gigabyte (GB) running memory. The operating system is Windows 10, the running platform is PyCharm, and the programming language is Python. When implementing a CNN model, Google’s DL framework is applied to establish TensorFlow. The specific experimental setup is revealed in :
Figure 8. Computer equipment used in the experiment.

The experimental samples are 7 human behaviors (walking, going upstairs and downstairs, lying, sitting, standing, as well as running). The training sample quantity is set to 1000, and the number of test samples is set to 500.
The main evaluation indicators of the recognition model are Accuracy, Precision, as well as Recall. Classification accuracy is an indicator to measure the algorithm’s overall performance; Precision is an indicator to measure precision; Recall is an indicator to measure the recall of model data.
Results
The present study proposes an online education algorithm based on AI technology that uses a combination of the Back Propagation Neural Network (BP) model and the human behavior recognition model to extract learning features of students and obtain real-time status and behavior of students’ IPE teaching.
Compared to previous studies, the use of a combination of these two models allows for more comprehensive and accurate feature extraction and recognition of student behavior. The BP model used in this study is known for its ability to simultaneously obtain depth information from the signals of multiple sensors, which increases the overall algorithm classification accuracy. The human behavior recognition model used in this study can capture real-time information about students’ listening behavior, which provides a more accurate understanding of their engagement in IPE teaching.
Moreover, the proposed algorithm is evaluated by experiments, and the results show that the recognition accuracy is high, indicating that the algorithm has a better performance than similar classification algorithms.
In summary, the present study’s combination of two advanced models, comprehensive feature extraction, and real-time recognition, along with rigorous evaluation methods, contributes to its ability to provide more accurate results than previous studies.
Recognition Accuracy of Various Classification Algorithms
The modified CNN model is acquired after training on the basis of 1500 training samples. The recognition accuracy of the proposed recognition model, the CNN- Support Vector Machine (SVM), and CNN- Back Propagation (BP) algorithms for 7 actions in the 500 test sets are denoted in and :
Figure 9. Result chart of recognition accuracy.
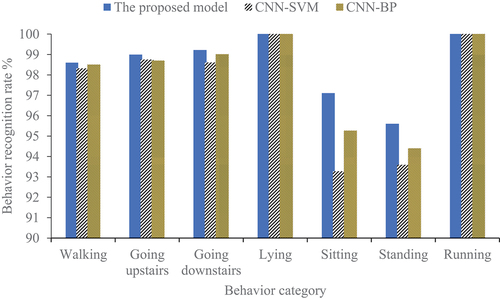
Table 1. Experimental result.
In , the designed classification algorithm has the recognition accuracy of 98.59%, 98.99%, 99.21%, 100%, 97.10%, 95.61%, and 100% for walking, going upstairs, going downstairs, lying, sitting, standing, and running, respectively. The three algorithms’ recognition accuracy is above 95%. Meanwhile, the model algorithm’s recognition accuracy is the highest among the three. Hence, the designed research model performs the best.
Comparison of Indicators of Various Algorithms
To more objectively explore the designed algorithm’s classification performance, the proposed model, CNN-SVM as well as CNN-BP three algorithms are statistically compared with different indicators. The results are illustrated in and :
Figure 10. Reliability and validity analysis results.
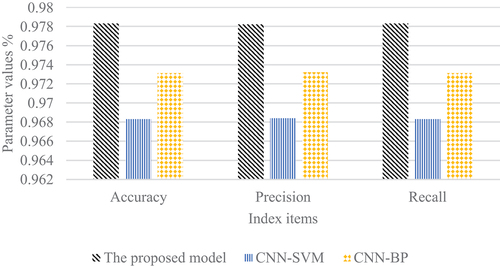
Table 2. Comparison result.
In , the three index values of Accuracy, Precision, as well as Recall of the designed model are 97.83%, 97.82%, and 97.83%, respectively. These three index values of the CNN-SVM algorithm model are 96.83%, 96.84%, and 96.83%, respectively, which are lower than the classification performance of the research model. As a common model for feature extraction, the designed model can be applied well to offline training as well as online recognition. In the process of college students’ IPE online course learning, the constructed DL human behavior recognition model can be obtained from college students’ listening devices to realize students’ learning status and improve the management level of teachers’ online teaching.
Analysis of Simulation Results of Algorithm Model
The simulation experiment of teaching quality evaluation is realized by programming MATLAB2021b. displays the prediction accuracy percentage of the designed convolution algorithm. reveals the sum of squared error (SSE) of the convolution algorithm improved and optimized by big data.
Figure 11. Percentage of algorithm prediction accuracy.
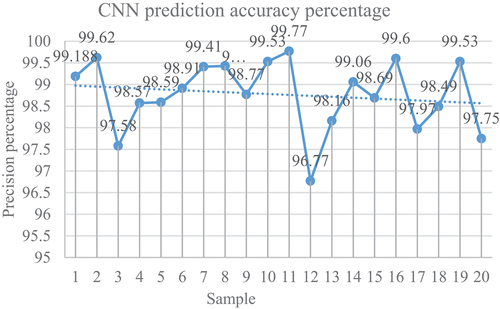
Figure 12. Result of the SSE.Note: Series 1 is the result of the SSE, and series 2 is the minimum SSE
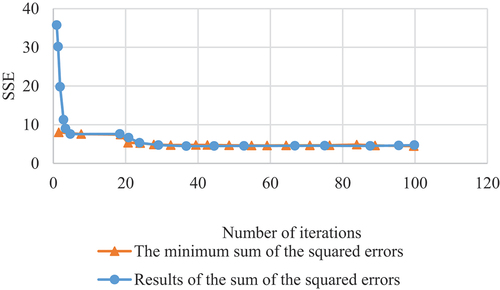
SSE stands for Sum of Squared Errors, which is a commonly used measure of the performance of a machine learning algorithm in regression problems. It measures the difference between the predicted and actual values of the dependent variable, squared and summed across all data points.
In the context of the result plot of the SSE, it is a plot that shows the SSE value as a function of the number of iterations or epochs during the training of a machine learning algorithm. The SSE value decreases as the algorithm iteratively updates its parameters and learns to better fit the training data.
Typically, the plot of the SSE will start with a high value, indicating that the algorithm is initially predicting the target variable poorly. As the number of iterations or epochs increases, the SSE value decreases, indicating that the algorithm is improving its predictions. The plot will eventually converge to a minimum SSE value, indicating that the algorithm has reached its optimal performance and further training will not improve its predictions significantly.
The result plot of the SSE is an important diagnostic tool for evaluating the performance of a machine learning algorithm. It can help identify issues such as overfitting or underfitting, and it can help determine the optimal number of iterations or epochs needed for training the algorithm.
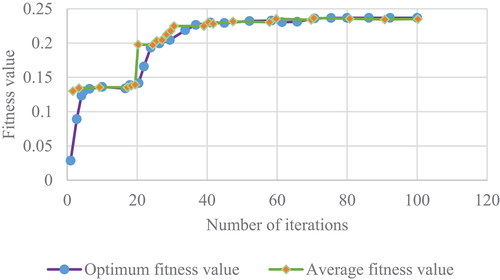
denotes the fitness function curve of the CNN algorithm.
Figure 13. Model fitness function curve.
In , the prediction accuracy of the 20 groups of test samples is above 95%, of which 20 groups have a sample prediction accuracy above 96%. The prediction accuracy of most samples is above 98%, and the prediction accuracy of 9 groups of samples is above 99%. It suggests that the approximation effect of the research model improved by the algorithm is very good. refers that the SSE of the research model optimized by the algorithm is very fast before the 5th iteration, and the convergence rate is relatively stable between the 5th and 20th iterations. The convergence speed is comparatively slow between 20 iterations and 30 iterations. After the number of iterations is 35, the SSE of the BPNN optimized by the genetic algorithm (GA) is stable. This means that the BPNN model improved and optimized by the GA can realize global optimization more quickly.
The performance of a BPNN depends on the choice of its hyperparameters such as the learning rate, the number of hidden layers, and the number of neurons per layer. Selecting optimal hyperparameters can be a challenging task, especially when there are many possible choices to explore.
One way to optimize the hyperparameters of a BPNN is to use a GA. GA is an optimization technique inspired by the process of natural selection, where a population of candidate solutions is evolved over time to find the best solution to a problem.
In the context of optimizing a BPNN with GA, the algorithm works by creating an initial population of candidate hyperparameters, which are represented as chromosomes. The chromosomes encode the hyperparameters as binary strings, and the algorithm evaluates their fitness by training and testing the corresponding BPNN models. The fitness function is typically defined as the performance of the BPNN on a validation set, and it is used to determine the selection of parents for the next generation.
The GA then applies genetic operators such as crossover and mutation to the selected parents to create a new generation of candidate solutions. The process is repeated until a stopping criterion is met, such as a maximum number of generations or a convergence criterion.
By optimizing the hyperparameters of a BPNN with GA, it is possible to find a set of hyperparameters that leads to better performance than manually selected hyperparameters. However, GA can be computationally expensive and may require a large number of training iterations to converge to a good solution.
details that the fitness function of the research model after the algorithm improvement and optimization has a faster convergence rate before the 10th iteration, is relatively smooth between the 10th and 20th iterations, and basically reaches a stable state after the 40th iteration. It illustrates that the adaptive ability of the CNN model improved and optimized by the GA is relatively high.
Conclusion
AI technology is considered to be one of the primary core technological forces driving the progress of modern society. This technology has or is disrupting multiple industries and fields, and education is no exception. With network distance education’s continuous progress, the teaching management of college students’ IPE online courses has become a research hotspot of current IPE innovation. Many additional sensor functions in smartphones, AI, and wireless network technology provide technical support for understanding students’ online learning status and enhancing teaching management. CNN models are built for general feature extraction. The model summarizes the shortcomings of AI technology feature extraction, deeply acquires the signals of multiple sensors, and improves the overall algorithm’s classification accuracy. The designed algorithm’s classification performance is compared and assessed by conducting experiments.
The experimental results manifest that the proposed algorithm has better classification performance than similar classification algorithms. The constructed human behavior recognition model based on AI and big data can collect students’ learning status and behavior data from students’ listening devices to help teachers understand students’ learning state. This is significant for improving the online teaching management level of teachers. This study can provide references and suggestions for the subsequent related design of IPE and the application of AI and big data technology. The deficiency is the short research time and the limited sample size. There are certain deficiencies in the investigation scope and depth, which will be expanded for further research. Furthermore, AI technology is constantly evolving and adapting to new developments, and as such, new technologies will continue to be updated and utilized in the future. The integration of theory and practice will be prioritized, and there will be ongoing efforts to conduct in-depth exploration in this field. Below is a list of the advantages and disadvantages of using AI and machine learning algorithms.
Advantages
Increased accuracy and precision: AI algorithms can often provide more accurate and precise results than traditional methods, especially when dealing with complex or large datasets.
Automation: AI algorithms can automate many tasks that would otherwise require human intervention, saving time and resources.
Learning from data: AI algorithms can learn from data and improve their performance over time, allowing them to adapt to changing conditions and improve accuracy.
Scalability: AI algorithms can often be scaled up to handle large amounts of data and complex tasks.
Disadvantages
Bias: AI algorithms can be biased if they are trained on biased data, leading to unfair or discriminatory results.
Interpretability: Some AI algorithms can be difficult to interpret, making it difficult to understand how they arrive at their conclusions.
Lack of context: AI algorithms may not be able to take into account the broader context of a problem, leading to errors or incorrect conclusions.
Dependence on data quality: AI algorithms depend on high-quality data to achieve accurate results, and low-quality data can lead to poor performance.
While the present study proposes an innovative algorithm for online IPE teaching management using AI technology, there are several areas where the research could be strengthened to address recent developments and research gaps.
Firstly, recent research has emphasized the importance of personalized learning and adaptive teaching approaches. Thus, future research could explore the potential of the proposed algorithm to provide personalized feedback and guidance to students based on their individual learning needs and preferences.
Secondly, recent studies have highlighted the ethical implications of using AI in education, such as data privacy, algorithmic bias, and transparency. Thus, future research could investigate the ethical implications of the proposed algorithm and suggest ways to address these concerns.
Thirdly, the COVID-19 pandemic has accelerated the adoption of online learning and highlighted the digital divide among students. Thus, future research could investigate the potential of the proposed algorithm to bridge the digital divide and promote equitable access to IPE teaching.
Fourthly, while the proposed algorithm focuses on real-time monitoring and evaluation of students’ IPE teaching, there is a need for research on the long-term impact of AI-based online IPE teaching management on students’ learning outcomes and retention.
Finally, while the present study provides a promising approach for online IPE teaching management, there is a need for more studies to replicate the results and test the algorithm’s scalability and generalizability in different settings.
In summary, the present study provides a valuable contribution to the literature on AI-based online IPE teaching management, but future research should address recent developments and research gaps to further advance this area.
Acknowledgements
The study was supported by the teaching reform and Innovation Project of colleges and universities of Shanxi Province: The seedling project: Practice research on the training mode of interdisciplinary innovative talents. (Grant No.J2021324); the teaching reform of postgraduate education (2021): in Shanxi Province:Research on the innovation of “Five-in-one” teaching mode of ideological and political course for postgraduates. (Grant No.2021YJJG202).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- BEINGS], Akmal N.K.I.N.D.S.O.F.T.E.M.P.E.R.A.M.E.N.T.O.F.H.U.M.A.N. 2022. Web of scientist. International Scientific Research Journal 3 (1):321–1929.
- Blasch, E., T. Pham, C. Y. Chong, W. Koch, H. Leung, D. Braines, and T. Abdelzaher. 2021. Machine learning/artificial intelligence for sensor data fusion–opportunities and challenges. IEEE Aerospace and Electronic Systems Magazine 36 (7):80–93. doi:10.1109/MAES.2020.3049030.
- Dai, R. 2021. Research on the innovation and development of ideological and political education in colleges and universities based on computer technology. Journal of Physics 1744 (3):032213. doi:10.1088/1742-6596/1744/3/032213.
- Ferrari, A., D. Micucci, M. Mobilio, and P. Napoletano. 2021. Trends in human activity recognition using smartphones. Journal of Reliable Intelligent Environments 7 (3):189–213. doi:10.1007/s40860-021-00147-0.
- Ge, J. 2022. Multiple influences of intelligent technology on network behavior of college students in the metaverse age. Journal of Environmental and Public Health 1852:032021. doi:10.1155/2022/2750712.
- Gong, X. 2022. The cooperative education mechanism between ideological and political educators and professional course teachers in colleges and universities based on cognitive psychology. Psychiatria Danubina 34 (suppl 1):181–82. doi:10.24869/psyd.2022.181.
- Han, X., and M. MY. 2021. Product modeling design based on genetic algorithm and bp neural network. Neural Computing & Applications 33 (9):4111–17.
- Lattanzi, E., and V. Freschi. 2021. Machine learning techniques to identify unsafe driving behavior by means of in-vehicle sensor data. Expert Systems with Applications 176:114818. doi:10.1016/j.eswa.2021.114818.
- Lin, X., Y. Wang, and R. Zhang. 2022. Ideological and political teaching reform: An introduction to artificial intelligence based on the OBE concept. In 11th International Conference on Educational and Information Technology (ICEIT), Fujisawa, Japan, 23:6–9. IEEE.
- Li, T., J. Sun, and L. Wang. 2021. An intelligent optimization method of motion management system based on BP neural network. Neural Computing & Applications 33 (2):707–22. doi:10.1007/s00521-020-05093-1.
- Li, J., X. Yao, and K. Xu. 2021. A comprehensive model integrating BP neural network and RSM for the prediction and optimization of syngas quality. Biomass & bioenergy 155:106278. doi:10.1016/j.biombioe.2021.106278.
- Luo, Y., C. Cheng, S. Y, and H. Xu. 2022. Human behavior recognition model based on improved EfficientNet. Procedia computer science 199:369–76. doi:10.1016/j.procs.2022.01.045.
- Mantouka, E., E. Barmpounakis, and E. Vlahogianni. 2021. Smartphone sensing for understanding driving behavior: current practice and challenges. International Journal of Transportation Science and Technology 10 (3):266–82. doi:10.1016/j.ijtst.2020.07.001.
- Mekruksavanich, S., and A. Jitpattanakul. 2021a. Biometric user identification based on human activity recognition using wearable sensors: An experiment using deep learning models. Electronics 10 (3):308. doi:10.3390/electronics10030308.
- Mekruksavanich, S., and A. Jitpattanakul. 2021b. Lstm networks using smartphone data for sensor-based human activity recognition in smart homes. Sensors 21 (5):1636. doi:10.3390/s21051636.
- Novak, A., D. Bennett, and T. Kliestik. 2021. Product decision-making information systems, real-time sensor networks, and artificial intelligence-driven big data analytics in sustainable industry 4.0. Economics, Management, & Financial Markets 16 (2):62–72.
- Sharma, K., and M. Giannakos. 2021. Sensing technologies and child–computer interaction: Opportunities, Challenges and ethical considerations. International Journal of Child-Computer Interaction 30:100331. doi:10.1016/j.ijcci.2021.100331.
- Song, S., X. Xiong, X. Wu, and Z. Xue. 2021. Modeling the SOFC by BP Neural Network Algorithm. International Journal of Hydrogen Energy 46 (38):20065–77. doi:10.1016/j.ijhydene.2021.03.132.
- Sun, X., and Y. Lei. 2021. Research on financial early warning of mining listed companies based on BP neural network model. Resources Policy 73:102223. doi:10.1016/j.resourpol.2021.102223.
- Tian, J., Y. Liu, W. Zheng, and L. Yin. 2022. Smog prediction based on the deep belief-BP neural network model (DBN-BP). Urban Climate 41:101078. doi:10.1016/j.uclim.2021.101078.
- Xu, Y., and T. Qiu. 2021. Human activity recognition and embedded application based on convolutional neural network. Journal of Artificial Intelligence and Technology 1 (1):51–60. doi:10.37965/jait.2020.0051.
- Yang, H., X. Li, W. Qiang, Y. Zhao, W. Zhang, and C. Tang. 2021. A network traffic forecasting method based on SA optimized ARIMA–BP neural network. Computer Networks 193:108102. doi:10.1016/j.comnet.2021.108102.
- Yun, G., R. V. Ravi, and A. K. Jumani. 2022. Analysis of the teaching quality on deep learning-based innovative ideological political education platform. Progress in Artificial Intelligence 2022:1–12. doi:10.1007/s13748-021-00272-0.
- Zeng, G. 2022. Analysis of learning ability of ideological and political course based on BP neural network and improved-means cluster algorithm. Journal of Sensors 2022:01239. doi:10.1155/2022/4397555.
- Zhang, Y. G., J. Tang, R. P. Liao, M.-F. Zhang, Y. Zhang, X.-M. Wang, and Z.-Y. Su. 2021. Application of an enhanced bp neural network model with water cycle algorithm on landslide prediction. Stochastic Environmental Research and Risk Assessment 35 (6):1273–91. doi:10.1007/s00477-020-01920-y.
- Zhao, X., and J. Zhang. 2021. The analysis of integration of ideological political education with innovation entrepreneurship education for college students. Frontiers in Psychology 12:610409. doi:10.3389/fpsyg.2021.610409.
- Zhou, Y., M. Shen, X. Cui, Y. Shao, L. Li, and Y. Zhang. 2021. Triboelectric nanogenerator based self-powered sensor for artificial intelligence. Nano Energy 84:105887. doi:10.1016/j.nanoen.2021.105887.
- Zou, Y., L. Bo, and Z. Li. 2021. Recent progress in human body energy harvesting for smart bioelectronic system. Fundamental Research 1 (3):364–82. doi:10.1016/j.fmre.2021.05.002.