
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Translation serves as a vital link in connecting individuals from diverse cultural backgrounds, assuming greater significance in the context of globalization. With the continued growth of international communication, the importance of effective translation in fostering mutual understanding, exploring new horizons, and building relationships cannot be overstated. However, the persistent language barrier necessitates improvements in translation accuracy and efficiency. In recent years, information technology has facilitated the development of innovative algorithms for English translation. This study aims to investigate correction algorithms for English translation learning, proposing a method that encompasses semantic word similarity calculations, a log-linear model construction, and the selection of appropriate translations using a dependency tree-to-string approach. Our research examines the performance of this system through comprehensive testing, showcasing noteworthy enhancements in the efficacy and precision of the translations in English. By addressing the users’ needs for English translation correction, this work contributes to bridging language gaps and fostering effective cross-cultural communication.
Introduction
Since globalization, with the increased communication between countries, translation has long grown as a substantial instrument to organize relationships between different societies and inspire them to explore the unfamiliar world and witness distinct cultures. Under this trend, language barriers have become a problem that cannot be ignored. Therefore, improving the efficacy and precision of the translation and meeting the needs of people to communicate and understand each other are important issues that research translators need to solve urgently.
A tortuous development process has been witnessed by machine translations. The development of machine translation cannot be separated from electronic computers. The 1940s witnessed the development of the first electronic computer, which could store, modify and transmit a large amount of information and was therefore very suitable for machine translation. Researchers put forward the idea of using computers for language translation (Abby et al. Citation2022).
In the 1950s, the research on machine translation entered the first climax, when it was the special period of the Cold War between the U.S. and the Soviet Union, the U.S. military always wanted to collect Soviet intelligence to grasp Soviet combat operations at any time. Still, because of the shortage of human resources for translation, the U.S. urgently needed a Russian-English automatic translation system, so many U.S. universities, research institutes, and large enterprises began to carry out automatic systems dealing with machine translations. The development of automatic systems dealing with machine translations began to be researched. However, at the beginning of the 1960s, machine translation entered a cold winter. In 1966, the American Advisory Committee on Automatic Language Processing published the ALPAC report (Zhang Citation2022), which guided machine translation to a twenty-year-long downturn because it claimed that machine translation was inefficient, inaccurate, and much more expensive than traditional human translation. It was impossible to develop a machine translation system that could be put into practice in cades or even longer.
Developing machine translation systems that can be applied practically in recent decades or even longer is impossible. So other countries gradually stopped their research on machine translation. Although many people questioned and criticized the ALPAC report, saying that the subject of machine translation is assessed biasedly, an irreparable detriment had already occurred. However, those researchers who love machine translation did not give up exploring and developed some translation systems that can be put into practical use during this period, such as the SYSTRAN system developed by Georgetown University in the United University of Montreal States (Mai Citation2022), TAUMMETEO system developed by Canada (Yuan Citation2022), ARIAN78 system developed by Grenoble University in the University of Texas France (Guejdad et al. Citation2022), US and Siemens in Germany the METAL German-English machine translation system (Xiao Citation2020), etc.
By the mid-seventies, machine translation research came into people’s careers and became prosperous day by day because of the unremitting efforts of these researchers. In the early eighties, the advancements in computers led to emerging of the information age, and the information that needs to be processed in all walks of life grew dramatically. Hence, an urgent need for intelligent information processing translation is an important tool for communication among countries. The efficiency of manual translation is too low to meet people’s needs, so machine translation has regained the attention of several countries, and the second climax was realized in machine translations. Many developed countries have successively invested huge funds to research and make developments on machine translation.
The EURPOTRA multinational translation system of the European Community (Abby et al. Citation2022), the TAUM-METEO system of Canada (Di Giovanni Citation2020), the Mu system (Minsung et al. Citation2022), and the ODA program of Japan (Hassan et al. Citation2022), and the KY-1 (Zou Citation2022) and MT/EC863 English-Chinese machine translation system (Minoru and Nishimjura Citation2022; Ding Citation2022) represented some of the projects researching on machine translations during the era. In addition, people started to focus on studies on machine translation strategies. Besides the methods using traditional rule-based translations, methods utilizing novel ones, such as instance-based and statistical-based were also studied.
Nevertheless, the research on machine translation entered an idle phase one more time in the early 1990s, because researchers in various countries found that even after spending considerable manpower, time, and finance on research, the translation results of machine translation systems still failed to meet expectations since natural languages have both complexities and variabilities. In the current century, as both information technology and algorithms continuously and rapidly develop, the quality of machine translation has enhanced significantly. Especially in recent years, with the development of theories related to neural networks and deep learning, the level of machine translation has made a qualitative leap. Machine translation is widely used in all aspects of people’s production life, and there is a huge demand for language translation in cross-border trade, outbound travel, academic exchange, etc. Machine translation can practically provide much help to people.
Although there have been breakthroughs in machine translation research, there are still many challenges. First, it is very difficult for machine translation to combine specialized background knowledge, for example, translating literary works requires understanding the background of the era, translating current political commentaries requires understanding current affairs and politics, and translating scientific and technical papers requires an understanding professional knowledge and terminology to achieve fluency in translation, which is currently difficult to be achieved by machine translation. Secondly, the training of neural network machine translation system needs more data, and the amount of data and the number of training directly impact the final product of translation. Finally, although the accuracy of machine translation can meet most of the needs at present, both a fluent and beautiful translation with rich words require comprehensive effort. From 1949 when Warren Weaver first proposed the idea of machine translation to today’s widespread use of machine translation, machine translation has gone through a long seventy years, and although machine translation has indeed made many breakthroughs, there is still much room for development.
Machine translation reduces labor costs, improves translation efficiency, and has high application value. Traditional machine translation uses the pipeline traversal method to identify and analyze the input language one by one to obtain syntactic structure, and this method will pass on the errors that occur during the translation process, resulting in lower translation accuracy. To address this problem, this paper investigates the correction algorithm in English translation learning. First, we calculate the semantic similarity between the input sentences to be translated and the vocabulary in the source language in the instance library and construct a log-linear model, then use the dependency tree to string approach to select a suitable translation, implement the dependency structuring process on the source language side to assure the correspondence between Chinese and English, and further proofread the precise translation of English via the data-oriented translation approach. The test results show that the system improves the efficacy and precision of translation in English and can meet the needs of the users concerning English translation correction.
The motivation behind this article is the growing importance of translation in connecting individuals from diverse cultural backgrounds in an increasingly globalized world. As communication between countries continues to expand, there is a need for more accurate and efficient translation methods to promote mutual understanding, explore new perspectives, and build stronger relationships. The language barrier remains a significant challenge, highlighting the necessity to enhance the quality of translation.
The contribution of this article lies in the investigation of correction algorithms for English translation learning. The proposed method involves several innovative techniques, including semantic word similarity calculations, log-linear model construction, and the utilization of a dependency tree-to-string approach for selecting appropriate translations. Through comprehensive testing, the study demonstrates notable improvements in the efficacy and precision of translation in English.
By addressing the users’ needs for English translation correction, the article makes a significant contribution to overcoming language barriers and facilitating effective cross-cultural communication. The research findings provide valuable insights and practical solutions for enhancing translation processes, ultimately enabling better connections between people from diverse linguistic backgrounds.
The remainder of the paper is organized as follows:
Research Background: The necessary context and background information related to the research topic is provided. It may include an overview of the importance of translation in the context of globalization, the challenges posed by the language barrier, and the need for improved translation methods. The section may also include a review of existing literature and studies relevant to correction algorithms for English translation learning.
Materials and Methods: The description of both material and method is given in detail. It outlines the specific steps taken to develop and implement the proposed correction algorithms for English translation learning. This may include a description of the data sources used, such as bilingual corpora or translation datasets. The section also explains the semantic similarity calculations, log-linear model construction, and the dependency tree-to-string approach used in the research. The methodology should be explained thoroughly to ensure transparency and reproducibility.
Results and Discussion: The outcomes derived from the comprehensive testing of the proposed correction algorithms are presented. It includes an analysis and interpretation of the data, showcasing the improvements in efficiency and accuracy achieved compared to existing translation methods. The results may be presented in the form of tables, graphs, or other appropriate visuals. The section also provides a detailed discussion of the findings, highlighting the strengths, limitations, and implications of the research.
Conclusion: The article concludes by summarizing both contributions and key results. It reiterates the significance of the proposed correction algorithms for English translation learning and their impact on bridging language gaps. The conclusion may also discuss potential subjects and developments that can be investigated in the future.
Overall, the article is structured to provide a comprehensive understanding of the research background, the methodology employed, the results obtained, and the implications of the findings. The logical flow of the article helps readers grasp the motivation, method, data, and contribution of the research.
Research Background
The concept of machine translation (Ping) was first introduced by the authors in 1949, with the aim of decoding languages using computers. Warren Weaver proposed that the frequency of letter combinations in various languages follows patterns like Morse code, which could enable machines to interpret languages automatically. Weaver put forth 4 potential approaches to implementing machine translation. The first approach directly substitutes words, while the second method automatically derives language conversions using logical expressions. The third approach views automatic translation as input signals to pass through a channel and to output another signal. In contrast, the fourth method relies on identifying an intermediary language that is translated first before being translated into the target language.
In 1954, Sheridan and Dostert developed the first machine translation system, which accurately translated sixty Russian phrases into English (Research). W. A. Woods introduced the Augmented State Transition Network (Yang Citation2022) in 1970, a natural language grammar parser that uses context-free grammar to analyze grammar (Case Grammer). In 1973, R. F. Simon of the University of Texas built on Woods’ ATN to create the Semantics Networks theory (Wang Citation2022). Peter F. Brown et al. of IBM developed the statistical machine translation model in the early 1990s, which provides methods to predict these models’ parameters when a collection of mutually translated phrase pairs is available (Liu Citation2022).
In 2003, scholars, including Yoshua Bengio, critiqued the statistical machine translation model called Yi (Yi), proposing a new approach that analyzed and generalized the distribution pattern of words. Philipp Koehn then introduced a new phrase-based translation approach and decoding algorithm, which became the standard during the era of statistical machine translation. More recently, in 2014, Dzmitry Bahdanau and Yoshua Bengio proposed a method conducting machine translation based on neural networks (Darren et al. Citation2022), which utilized fixed-length vectors and an attention mechanism to connect the original sequence elements with the output sequence elements.
Di He and other scholars suggested using value networks to enhance the neural machine translation method (Zhao Citation2022). Additionally, Mikel Artetxe et al. developed an innovative method to conduct machine translation based on the training of neural networks in a fully unsupervised manner (Zhang Citation2023), which combined denoising with back translation to train parameters on a monolingual corpus. Test results showed that the velocity and precision of translations in both English-French and English-German were significantly better than machine translations using conventional neural networks.
Materials and Methods
Semantic Translation Model
Before constructing a semantic translation model, it is crucial to establish a clear definition of semantics. Semantics refers to the meaning inherent in data, essentially making data meaningful. Data, in its raw form, is simply a collection of symbols devoid of inherent significance. It is only by assigning meaning to the data and converting it into information that it becomes usable. In this context, semantics can be understood as the representation of the concepts corresponding to real-world entities and the relationships that exist between these meanings.
Domainness emerges as a fundamental characteristic of semantics. The same entity can assume different meanings within distinct domains. Specifically in the realm of translation, a single word or phrase may possess entirely different interpretations depending on the specific context in which it is used.
While semantics pertains to the intrinsic nature of data, syntax encompasses the rules and structural relationships governing the organization of data. In the context of computer systems, data, and its access are obtained by manipulating patterns. Semantics, in this context, refers to the elements that comprise these patterns, while grammar defines the structure of these pattern elements.
The traditional translation system relies on the creation of translation memory and the encoding of Chinese and English texts in XML language, which are stored in separate libraries. These libraries establish a mapping relationship between the code elements, enabling the system to find the corresponding code element based on the input statement’s encoding. By converting the code element into translated text, the translation process is completed. The system’s efficacy depends on the matching between the input utterance and the memory of the translation.
Nevertheless, a limitation of this traditional approach arises from the existence of multiple meanings for a single word, leading to a one-to-many mapping relationship between code elements instead of one-to-one correspondence. Consequently, the system faces difficulties in accurately determining the code element that matches the current context.
To overcome these challenges, the implementation of a semantic translation model proves advantageous. By analyzing the semantic features of the input utterance thoroughly, the semantic translation model facilitates fuzzy mapping. This fuzzy mapping expands the scope of mapping possibilities, resulting in a variety of translations. The model then employs a decision function to evaluate these English language variations. Finally, the translation that best aligns with the intended semantics is selected, effectively achieving an automatic English-to-Chinese translation algorithm.
In summary, the integration of a semantic translation model addresses the limitations of traditional machine translation. Through detailed semantic analysis, fuzzy mapping, and an evaluation process, this approach enhances the accuracy and context awareness of translations, enabling automatic English-to-Chinese translation capabilities.
The special application procedure can be described as follows:
To begin, the input statement was delineated as an assumed one-dimensional array composed of five elements. In this particular case, for illustrative purposes, the array is denoted as G={A, C, H, I, R}. This representation facilitates the explanation of the input statement.
In the given context, an “array” refers to a data structure that allows the storage of multiple values within a single variable. Specifically, a one-dimensional array organizes its elements in a linear sequence.
The array elements A, C, H, I, and R serve as placeholders for specific values. These elements can represent various types of relevant data, such as numbers, characters, or objects, in the actual implementation. However, in the provided example, meaningful placeholders – A, C, H, I, and R – are assigned to the array elements for illustration. The statement establishes the input statement as a one-dimensional array consisting of five elements. The specific values associated with the elements are represented by A, C, H, I, and R.
The fuzzy function’s coefficient becomes a crucial attribution to determine the range of the mapping process. A higher coefficient value leads to a broader mapping range, while a lower coefficient value leads to a narrower mapping range. Choosing the appropriate coefficient carefully is essential to achieve optimal performance in the mapping process.
If the coefficient is set too small, it can create difficulties in finding matching translations. In such cases, the system may fail to identify suitable translations accurately due to the limited range of the mapping process. As a result, the overall effectiveness of the system may be compromised.
On the other hand, if the coefficient is set too large, the system may generate many translation results. This abundance of results can negatively affect the system’s efficiency and make it challenging to identify the most suitable translation option. Consequently, the system’s overall performance may suffer.
Therefore, it’s crucial to strike the right balance when selecting the coefficient value. This involves considering factors such as the specific mapping requirements, the desired level of precision, and the system’s capabilities. The mapping process can be optimized by carefully evaluating and adjusting the coefficient to ensure an efficient and accurate translation system. Here, the fuzzy function’s coefficient is assigned to 0.5, and the fuzzy function of the translation system is assigned to
Fuzzy mapping is a technique used in fuzzy logic systems to map input values to fuzzy sets or linguistic terms. In typical fuzzy logic systems, the range of fuzzy mapping is indeed [0, 1], where no or absence of membership is represented by 0, and complete membership or presence is represented by 1 in a fuzzy set.
Here are the reasons why this study uses the [−0.5, 0.5]:
Symmetrical Membership Functions: Using a range of [−0.5, 0.5] allows for symmetrical membership functions, where the center of the function corresponds to 0. This symmetry can simplify certain computations and make the system more balanced.
Different Scaling: The range is adjusted to [−0.5, 0.5] if the mapped input values have been normalized differently. By aligning the range of the fuzzy mapping with the scaled input range, it can facilitate consistent calculations and comparisons.
Specific Application Requirements: Certain domains have unique requirements for a modified range. Specific considerations within the research implementation drive the choice of [−0.5, 0.5].
English phrases’ frequencies alter, and the structural model is defined based on the English phrases’ distribution rule
To achieve English translation, the input statement is segmented into T-length sections. Semantics are then extracted for analysis, and the covariates required for automated English translation were attained using the fuzzy function technique.
When calibrating the outcomes of machine translation in English by a model called semantic ontology, it is necessary to use decision functions for judgment and evaluation.
The expression (ξ, η) = Δ(min(d(r, a) + ρ * max(Δ), Δ * d(r, a) + ρ * max(Δ))) represents a mathematical relationship between the variables ξ and η.
Here is a breakdown of the components:
ξ and η: These are variables representing unknown quantities or values.
Δ: This symbol represents a specific quantity or a difference.
min(): This function takes two or more arguments and returns the minimum value among them.
d(r, a): This function calculates the distance or difference between r and a.
r and a: These are variables representing specific values.
ρ: This symbol represents a constant or coefficient.
max(): This function takes two or more arguments and returns the maximum value among them.
Δ: This symbol represents a specific quantity or a difference.
The equation computes the value of (ξ, η) based on the calculation of distances, the minimum value, the maximum value, and the constant ρ. The specific values assigned to the variables r, a, and ρ would determine the resulting value of (ξ, η) in the equation.
The translations are ranked according to the assessment outcomes of the decision mapping, and the translation that best matches the semantic features is selected as the result.
The above formula is used to construct a model called semantic ontology translation so that the semantic matching power of translated English can be improved.
Translation Algorithm
Translating complex structures is a challenge for machine translation. It is more difficult to translate sentences and paragraphs than phrases and words because context must be considered to ensure smooth statements. To translate sentences, they are first broken down into phrases and translated. The translations of these phrases are then combined in a specific order, considering semantic features, to produce the final translation results.
The detailed assessment score Q of the result of the English translation is calculated according to the following Eq. 5.
When evaluating the quality of English translations, two factors come into play: the proximity of the translated phrase to the original input, indicated by the distance D, and the relevance of the translation combination, indicated by the combination R. The weight of D and R in determining the composite evaluation value Q differs depending on the number of correlation coefficients x and the detailed assessment coefficient y used in the translation.
To optimize the system of English translation, a user-facing module can be added to the front end, and a translation proofreading module can be affixed to the back end, which can be combined with the software framework. The procedure of proofreading English translation follows rules like those of English translation. The incorrect section of the translation was denoted by W. In contrast, the calibrated, correct translation was denoted by R. The conversion of W to R was the entire procedure of proofreading of English translation, which can be depicted using Eq. (6).
The translation accuracy of this system is represented by M(R). However, due to the relative simplicity of the model, the English translation accuracy is still lacking. To improve accuracy, EquationEquation (6)(6)
(6) can be optimized. During the calibration process, dividing the incorrect segments of the outcomes of English translation into proper lengths is crucial. The calibration module arranges the divided segments correctly to obtain the final calibration result. The calibration module arranges the divided segments correctly to attain the eventual calibration outcome. If the segments are too long, calibration becomes challenging, while too short segments result in too many segments, slowing down the calibration process.
The assessment outcomes of the function used for decision provide a measure of the quality or desirability of each translation option. Higher scores indicate more favorable translations, while lower scores indicate less favorable ones. By ranking the translations according to their evaluation results, the system can prioritize the translations that are the most accurate or appropriate based on the learned model.
The ranking is crucial because it allows for the selection of the translation option that is deemed to be the best choice according to the log-linear model. This ranking process enables the system to output the most suitable translation option based on the assessment of outcomes, enhancing the accuracy and effectiveness of the English translation correction process.
It is common in translation systems to consider semantic features when selecting the final translation. Semantic similarity calculations can be utilized to measure the similarity between words or phrases in the source and target languages. These calculations can help identify translations that capture the intended meaning accurately.
In the context of the log-linear model, semantic features are among the factors considered in the model’s decision function. The log-linear model assigns weights to various features, and semantic features could be included as part of the feature set.
Tree-To-String Model
The Dependency Tree-to-String Model is a technique used in natural language processing and computational linguistics to convert a dependency tree representation of a sentence into a corresponding string or linear sequence of words.
In natural language processing, a dependency tree represents the grammatical structure and relationships between words in a sentence. It consists of nodes representing words (or tokens) and directed edges indicating the syntactic dependencies between them. Each word is associated with a specific syntactic role (e.g., subject, object, modifier) and linked to its governing word or head.
The Dependency Tree-to-String Model aims to transform this dependency tree structure into a linear string representation of the sentence. The process typically involves traversing the dependency tree in a specific order and concatenating the words to form a string.
Here is a general overview of the Dependency Tree-to-String Model:
Traversal Order: The model defines a specific traversal order for visiting the nodes of the dependency tree. Common traversal strategies include preorder, in-order, or post-order traversal.
Word Concatenation: As the model traverses the nodes of the dependency tree according to the defined order, it concatenates the words associated with each node. The concatenation can be performed in a specified manner, such as adding whitespace or punctuation between words to form a coherent string representation.
Handling Dependencies: The model takes into account the syntactic dependencies between words while forming the string representation. It ensures that words governed by a particular node are placed appropriately concerning their governing word.
Additional Processing: Depending on the specific implementation, the Dependency Tree-to-String Model may incorporate additional processing steps. These steps can involve handling special cases, such as multi-word expressions, handling punctuation marks, or applying language-specific rules for word order.
The resulting string representation generated by the Dependency Tree-to-String Model is a linear sequence of words that reflects the original sentence’s grammatical structure. This string representation can be further utilized in several operations related to the processing of natural languages, including machine translation, text summarization, and sentiment analysis.
The model that converts a dependency tree into a string is represented by <D, S, A > .In this translation pair, D represents the dependency tree of the source language, S represents the target word string of the source language, and A identifies the word alignment relationship between D and S.
The branches in the dependency tree D of the source language connect two features: words and lexicality. English words can be classified as nouns, verbs, adjectives, etc. according to their lexical properties. The linkage between two English words is used to describe the dependency relationship between them. This relationship is used to correspond English words to Chinese words one by one. The sentences formed by English words can be regarded as a sequence of strings.
Since different words can express similar meanings, there is a semantic similarity between words. If two words express the same meaning, the similarity is 1; if the meanings of two words are unrelated, the similarity is 0; if the meanings of two words have some similarities, the similarity is between 0 and 1.
Log-Linear Model
A Log-linear model is a model commonly used in machine translation.
It uses a multi-featured thinking judgment method, which can apply the method of multilingual learning to machine translation. The feature functions used in this model are mainly forward and reverse translation probability and translation language approach. The model is highly expandable, and the parameters of this system can be set based on the actual requirements of users for translation quality to obtain the best quality translation (wang Citation2022).
The log-linear model is a statistical model used to estimate the probability distribution of a target variable based on a set of input features. In translation, the log-linear model estimates the likelihood of a particular translation given a source sentence or phrase.
Feature Extraction: Relevant features are extracted from the input data. In translation, these features can include various linguistic and contextual information such as word alignments, language models, part-of-speech tags, and syntactic structures. The implementation of a log-linear model involves the following steps:
Model Parameterization: The log-linear model assigns weight parameters to each feature. These parameters capture the importance or contribution of each feature to the overall translation probability. The parameterization could be mastered from training data utilizing maximum likelihood estimation or gradient-based optimization methods.
Scoring and Translation Selection: Given an input sentence or phrase, the log-linear model calculates a score for each possible translation option based on the weighted sum of the extracted features. The translation option with the highest score is selected as the output translation.
Training and Model Refinement: The log-linear model is trained using a labeled dataset of source sentences and their corresponding translations. The model parameters are optimized to maximize the likelihood of generating the correct translation given the input data. Training typically involves iterative optimization algorithms that adjust the parameter values to minimize a loss function, such as cross-entropy loss.
It is important to note that the specific implementation details of the log-linear model can vary depending on the research or application. The dependency tree-to-string approach suggests that the log-linear model incorporates dependency tree structures as part of the feature extraction process.
Results and Discussion
Experimental Setup
First, a translation memory bank should be constructed. In this experiment, about 120,000 sentences of the English-Chinese parallel corpus were selected from the CWMT 2018 corpus to construct a translation memory bank. In the experiment, the English corpus is randomly selected from the translation memory bank for translation, and the translation quality is checked with the corresponding Chinese.
The crucial component of the translation process is the dependency tree to string model. This model detects the relationship between the source and target languages by analyzing expressions and using that information to translate sentences. It calculates the similarity between the source language and the translated text and replaces the translated text with a higher similarity if it appears. This forms a new dependency tree to the string model, and the corresponding translation is changed accordingly.
In the translation memory, the system calculates the semantic similarity between the input and the translated utterance to find the translated utterance with the highest similarity. This is achieved by matching the target expression to obtain the target translation.
This experiment uses probabilities of forward and backward translations and language models as feature functions to improve translation accuracy. When the word numbers are equal, and more identical words exist between the translated sentences and the translated instances, the forward and backward translation probability produces more accurate translations. The language model function orders the translated words to form a complete utterance. In the research, the target language’s model is employed to determine the translated fragments’ probability in the targeted language.
The next step is to create an English translation correction system. The generic structure of the system is depicted in .
Figure 1. The correction system of translation in English.
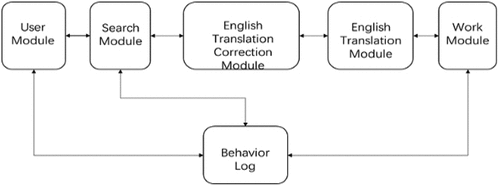
The system is equipped with five modules, each with specific responsibilities. The user module allows users to log in, initiate functions, and retrieve query results. Meanwhile, the search module analyzes input phrases’ lexical and grammatical components. The input phrases are translated into the targeted language by using the module for the translation of English. If necessary, the correction module of English translation fixes issues in the procedure. Finally, the work module receives the outcomes of translation from the module of translation, analyzes the characteristics of each term, and ranks the results according to the input statement’s similarity. The best translation results are then transferred to the user’s module for retrieval.
The English translation correction system is versatile and can be used online and locally. Online users have access to various features, including English translation capabilities and other related operations. The system also notifies users when updates are available so they can download the latest version. Users can connect wirelessly to the network, which interfaces seamlessly with the translation server through the switch and modem, allowing for efficient communication. For users who prefer local usage, our system still offers many features even without online thesauri and search functionality. Users can download a local thesaurus to conduct offline searches and add new words or modify existing word explanations to suit their needs. This feature enhances user convenience and makes retrieving personalized, offline word information easier.
Experimental Results and Analysis
Comparing the different machine translation systems’ performances is often a challenging task for several reasons. Firstly, establishing a standard for translation results, whether generated by machines or humans, is inherently difficult. Unlike questions with clear right or wrong answers, or multiple-choice questions with a single correct option, translation quality is typically evaluated on a scale of “excellent,” “good,” “medium,” and “poor.” However, there is a lack of uniformity in the criteria used to classify translations within each grade. Consequently, the assessment of translation outcomes often suffers objectivity and standardization.
Secondly, the requirements for machine translation vary depending on the user and the specific context. For instance, while product manuals may prioritize readability and comprehension, literary works not only demand accurate translations but also emphasize the use of eloquent language and fluent phrases.
Moreover, the efficiency of machine translation varies across different language structures, such as phrases, sentences, and paragraphs. Translating phrases is generally the easiest task, as it does not require considering the surrounding context. The primary goal is to accurately convey the meaning of the individual phrases. In contrast, translating sentences and paragraphs necessitates contextual understanding, making it more challenging to keep semantic coherence and fluency. Also, the time necessary to translate phrases, sentences, and paragraphs differs significantly.
Considering these arguments, the quality of English translation systems can be evaluated based on the comprehensibility and precision of the translations. The quality of translation is split into 3 classes: A, B, and C. The evaluation instructions of classification can be summarized below:
Category A: The translation correctly states the original text’s meaning while maintaining fluency and naturalness. Alternatively, the translation accurately transmits the original text’s meaning with overall fluency but exhibits minor shortcomings in terms of grammar, word choice, and adherence to Chinese expression conventions. Such translations can be revised to achieve fluency and naturalness without reference to the original text.
Category B: The translation generally conveys the original text’s meaning, although some differences may be present. These differences could be fixed with no referral to the original text. Alternatively, the translation generally conveys the original text’s meaning, but with some divergences that can be corrected by referring to the original text. Another possibility is that certain portions of the translation align with the original text’s meaning, while the entire text is not translated accurately. However, the individual words translated are useful for subsequent manual editing, thus offering some value in the editing process.
Category C: The translation fails to convey the correct meaning, rendering it incomprehensible. However, some sections or individual words may be translated accurately or remain untranslated.
To assess the English translation system’s performance, translation tests are conducted by using a corpus comprising 100 randomly selected phrases, sentences, and paragraphs. We assessed the translation quality of the English translation model based on these tests, conducting separate evaluations for phrases, sentences, and paragraphs. The test results for phrases are depicted in .
Figure 2. Evaluation results.
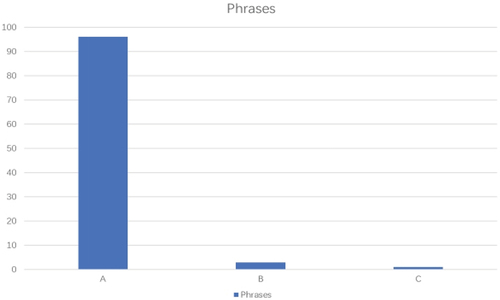
Based on the data presented in , it is evident that the English phrases were translated with high accuracy. Specifically, 96% of the translations were classified as Category A, 3% as Category B, and only 1% as Category C. While there were some difficulties with the more complex phrases, overall, the translations were precise. displays the results of the sentence tests.
Figure 3. Sentence translation results.
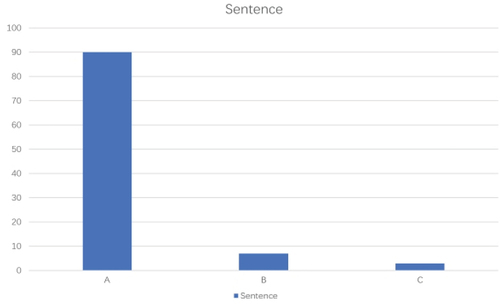
According to the test results on English sentence translations, 90% of the translations were rated as A, 7% as B, and 3% as C. Apart from some phrases that were not fluent enough, all the translations were accurate. While sentences translated by the system were narrowly less than that of phrases regarding quality, the comprehensive impact was still good. depicts the outcomes of paragraph translations.
Figure 4. Paragraph translation results.
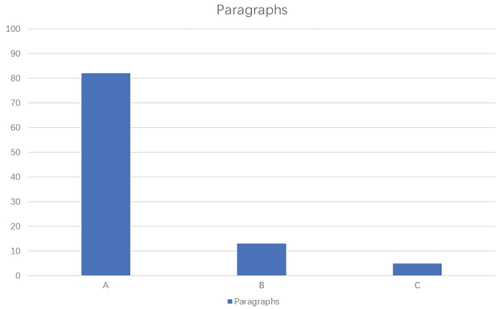
According to the experimental outcomes, 82% of English paragraphs were translated with category A quality, while 13% and 5% reaches category B and C, respectively. Though the system of paragraph translation can satisfy most users’ requirements, its overall quality is not as good as that of phrases and sentences. displays the translation accuracy rates for phrases, sentences, and paragraphs before and after correcting the translation results.
Figure 5. Comparison results.
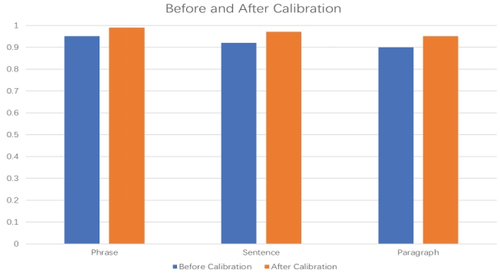
To evaluate the effectiveness of the correction module of the English translation, a comparative analysis was conducted on the translation results before and after correction. The precision ratio for phrases rose to 99%, sentence precision rose to 97%, and paragraph accuracy increased to 95% after correction. These results indicate a significant enhancement in the precision of English translation through the proposed correction method.
The initial experimental results demonstrate that the designed English machine translation correction system is capable of producing accurate English translations, effectively meeting the requirements of most users. However, it is important to acknowledge that certain errors still occur during the translation process. Subsequent analysis identified several primary reasons for these errors:
Insufficient translation memory: The current translation memory possesses a limited scope, resulting in the inability to locate some input words and provide appropriate translations. Consequently, satisfactory translations cannot be obtained for these words.
Fuzzy mapping limitations: As the fuzzy mapping employed in the translation process is not a 1-1 function, it inherently introduces local errors. Optimization of the coefficients used in fuzzy functions is necessary to reduce such errors.
Contextual analysis challenges: The applied correction algorithm struggles to analyze the context effectively, leading to the imperfect articulation of utterances and consequently affecting the overall translation quality.
However, these limitations can be addressed through further improvement in two key aspects: translation memory and the correction algorithm.
To alleviate the impact of insufficient translation memory, efforts should be made to expand and enrich the existing database. Increasing the size and diversity of the translation memory will enable greater coverage of words and phrases, facilitating more accurate translations.
Regarding fuzzy mapping, optimizing the coefficients involved can minimize the occurrence of local errors. Fine-tuning the fuzzy mapping process will lead to better alignment between source and target language expressions, improving the overall translation accuracy.
Additionally, enhancing the correction algorithm’s ability to analyze the context will contribute to improved utterance articulation and subsequent translation quality. By incorporating contextual cues and linguistic features, the algorithm can better understand the intended meaning and produce more accurate translations.
While the preliminary experimental results indicate that the designed English machine translation correction system fulfills the accuracy requirements of most users, there are still areas for improvement. By addressing the limitations related to translation memory and the correction algorithm, the system’s performance can be further enhanced, ensuring more accurate and contextually appropriate English translations.
To overcome limitations that are commonly encountered in translation systems, here are a few strategies that can be employed:
Training Data Expansion: Increasing the size and variety of the training sample can help improve the performance of translation systems. By incorporating a larger and more varied dataset, the system can learn from a wider range of translation examples, leading to better generalization and accuracy. This can involve gathering additional parallel corpora or utilizing techniques like data augmentation and domain adaptation to enhance the training data.
Fine-tuning and Model Optimization: Fine-tuning the system and optimizing the model parameters based on specific evaluation metrics can help address limitations. Techniques like regularization, hyperparameter tuning, and ensemble methods can be employed to improve the model’s performance and robustness. Iterative refinement through experimentation and evaluation can lead to more effective translations.
Incorporating Context and Discourse: Consideration of the broader context and discourse can enhance translation quality. Language is inherently context-dependent, and incorporating information from preceding and succeeding sentences can help resolve ambiguities and improve translation accuracy. Techniques such as neural machine translation with attention mechanisms or transformer models can capture contextual information effectively.
Post-editing and Human-in-the-Loop Approaches: Incorporating human expertise through post-editing can help refine and improve the translations produced by the system. Combining automated translation with human input allows for the correction of errors and the addition of domain-specific knowledge or nuances. Human-in-the-loop approaches, such as interactive translation interfaces or crowdsourcing, can be leveraged to iteratively enhance the translation output.
Continuous Evaluation and User Feedback: Establishing a feedback loop for continuous evaluation and improvement is crucial. Collecting user feedback, analyzing translation quality, and addressing user preferences and specific needs can guide system enhancements. Monitoring and adapting the system based on ongoing evaluation and user input can lead to iterative improvements.
It’s important to note that the specific limitations and corresponding strategies to overcome them would depend on the details of the proposed system and the specific challenges faced in the context of English translation correction.
Conclusion
The traditional machine translation system faces significant challenges in accurately selecting the appropriate translation based on contextual cues, resulting in poor semantic coherence and an inability to meet users’ needs effectively. This research paper presents a design for an English translation correction system to address these limitations. The proposed system incorporates several key components, including a model called semantic translation a translation memory, a fuzzy function of input utterances, a decision function for selecting the correct translation, and calibration for outputting the final translation. These components work together within a system consisting of five modules.
One of the modules allows users to search for word meanings, while the behavior log module enables backend engineers to analyze system behavior data, identify issues, and make necessary improvements. Experimental results demonstrate that the correction system of English translation devised in this research significantly improves the translation results’ accuracy by identifying and correcting erroneous translations. Moreover, compared to traditional machine translation algorithms, this system achieves high translation accuracy and produces smooth and coherent translations.
The system’s effectiveness lies in enhancing the efficacy and precision of English translation correction while reducing the costs associated with manual proofreading. Consequently, it successfully meets the needs of users concerning English translation correction.
Given the advent and advancement of the Internet, there is an increasing urgency to improve machine translation. However, the current machine translation systems still fail to satisfy users’ requirements regarding translation accuracy and coherence fully. Achieving substantial breakthroughs in translation quality remains a significant challenge, and there is a long road ahead before machine translation could satisfy the needs of users. The current proofreading system for English-Chinese machine translation represents an effort to automatically gain useful knowledge from the data of natural language and adapt itself to such data using unprecedented substitutive methods concerning knowledge acquisition in machine translation. As a result, it holds extensive application prospects and long-term research opportunities and importance. Nonetheless, the proofreading system of the implemented English translation has several shortcomings that require additional advancements.
A significant aspect of machine translation is that the translation’s quality improves as the translation memory expands. However, language meaning constantly evolves and enriches over time, leading to the generation of new words and the advent of new meanings for existing words through daily usage. Consequently, timely updating of the translation memory becomes imperative. Therefore, maximizing the translation memory from various resources becomes a crucial issue.
Additionally, managing the translation memory presents another substantial challenge. An efficient system used for translation memory must facilitate fast searches, particularly when dealing with large-scale data. However, when the translation memory grows enormously, the advancement in search velocity becomes constrained and only contributes to overall translation efficiency. To address this, establishing sub-banks within the translation memory to categorize and manage terms provides a viable solution.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abby, H. D., G. Elizabeth, Z. Yvonne, and R. Suzanne. 2022. Realist evaluation of the impact of the research translation process on health system sustainability: A study protocol [J]. BMJ 12 (6):e045172.
- Darren, A., J. Kiniry Stephen, M. Yordanova Martina, V. Baranov Pavel, and P. Morrissey John. 2022. Development of a ribosome profiling protocol to study translation in Kluyveromyces Marxianus.
- Di Giovanni, E. 2020. Reception studies and audiovisual translation. In The Palgrave handbook of audiovisual translation and media accessibility, Łukasz Bogucki and Mikołaj Deckert, ed. Palgrave Studies in Translating and Interpreting, 397–1952. Cham: Springer International Publishing. doi:10.1007/978-3-030-42105-2_20.
- Ding, Y. 2022. A study on title translation of Chinese films and TV plays from the perspective of skopos theory [J]. Open Access Library Journal 9 (05):1–5. doi:10.4236/oalib.1108724.
- Guejdad, K., A. Ikrou, C. Strandell-Laine, R. Abouqal, and J. Belayachi. 2022. Clinical Learning Environment, Supervision and Nurse Teacher (CLES+T) Scale: Translation and validation of the Arabic version. Nurse Education in Practice 63:103374 .
- Hassan, F., N. Alex, K. Joy, K. Dorcas Mwikali, O. Emelda, T. Benjamin, E. Mike, M. Sassy, K. David, and B. Edwine. 2022. Experience of Kenyan researchers and policy-makers with knowledge translation during COVID-19: A qualitative interview study [J]. BMJ 12 (6):e059501.
- Liu, J. X. 2022. On foreign publicity translation from the perspective of Newmark translation theory – a case study of China: democracy that works [J]. Journal of Sociology And, Ethnology 4 (3):74–78.
- Mai, Z. X. 2022. A comparison of appellation translation: A case study of teahouse [J]. International Journal of Education and Teaching 3 (3):390.
- Minoru, N. M., and M. Nishimura. 2022. Dynamics study based on domain wall reorientation and translation in tetragonal Ferroelectric/Ferroelastic Polycrystals [J]. Japanese Journal of Applied Physics 61 (6):061002. doi:10.35848/1347-4065/ac5810.
- Minsung, O. B., L. JiSeon, Y. Dogeon, C. Wook, and S. Il Tae. 2022. A systematic review of translation and experimental studies on internal anal sphincter for fecal incontinence. Annals of Coloproctology 38 (3): 183.
- Wang, P. 2022. A study of an intelligent algorithm combining semantic environments for the translation of complex English sentences [J]. Journal of Intelligent Systems 31 (1):623–31. doi:10.1515/jisys-2022-0048.
- Wang, Q. 2022. An interpretive study of six major models towards translation quality assessments. Studies in Linguistics and Literature 6 (2):p45. doi:10.22158/sll.v6n2p45.
- Xiao, C. 2020. Correction of English Translation Accuracy Based on Poisson Log-Linear Model[C]. Journal of Physics: Conference Series. Vol. 1533. IOP Publishing. doi:10.1088/1742-6596/1533/2/022049.
- Yang, A. M. 2022. RNN neural network model for Chinese-Korean translation learning [J]. Security and Communication Networks 2022:1–13. doi:10.1155/2022/6848847.
- Yuan, Y. 2022. A study on the canonization of Edward Fitzgerald English translation of rubaiyat [J]. International Journal of Education And, Economics 5 (3):203.
- Zhang, L. 2022. A corpus-based comparative study on the translation of the Chinese film Ne Zha from the perspective of toury’s translation norms [J]. International Journal of Education And, Ethnology 3 (2):198.
- Zhang, Y., and Y. Liang. 2023. Norms and Motivation: A Descriptive Study of the English Translations of the Confucian Classic The Great Learning. 2nd International Conference on Education, Language and Art (ICELA 2022). Sanya, China: Atlantis Press.
- Zhao, W. 2022. Historicizing translation as (de)Colonial practices: China’s 1867 debate on learning western sciences as an example. Discourse: Studies in the Cultural Politics of Education 43 (3):367–85. doi:10.1080/01596306.2021.2010012.
- Zou, Z. S. 2022. Study on the C-E translation of the red tourism texts from the perspective of rhetoric persuasion theory [J]. World Scientific Research Journal 8 (6):190–195.