
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In response to the shortage of high-quality medical resources, long waiting times, and difficulties finding the right doctor, a smart medical system design scheme is proposed. This system is built on a cloud platform to increase capacity and improve operating speed. It offers intelligent triage, disease diagnosis, intelligent question-and-answer, online doctor diagnosis, online registration, patient-patient communication, doctor-patient communication, online payment, map navigation, and other functions. By using machine learning and deep learning methods, the system analyzes the patient’s disease description, laboratory test sheets, and other medical image materials to diagnose the disease suffered by the patient. The matching degree of the doctor and the patient is calculated based on the doctor’s expertise, patient evaluation, and doctor satisfaction, and doctors are arranged for patients to choose. The system also integrates the diagnosis results made by multiple doctors to help patients understand their illnesses conveniently. Additionally, an intelligent question-and-answer module analyzes the patient’s inquiry intention and gives feedback to the patient’s question. The system’s feasibility and practicability have been demonstrated by experts in the fields of medical treatment, computer, and economic management. Overall, this system has high application value and can effectively solve the problems that exist in the current medical field.
Introduction
Intelligent medical care has been widely discussed by experts, and its essence lies in the creation of a cross-regional medical and health platform using Internet of Things (IoT) technology (Decade of Healthy Ageing: Baseline Report Citation2020). In simple terms, the smart medical system streamlines the traditional medical process by reducing unnecessary offline processes and using IoT technology to automate various tasks. The previous medical model required patients to complete registration, payment, and report collection manually. This often resulted in long queues and extended waiting times, increasing the risk of cross-infection. With the advent of smart medical systems, patients can now make appointments online, pay online, and receive their reports electronically, eliminating the need for physical queues and reducing waiting times significantly. The use of IoT technology has not only improved the efficiency of the medical process but has also made it more convenient and accessible for patients.
The concept of smart healthcare originated from IBM’s Smart Earth initiative, which was presented to US President Obama in 2009. The initiative aimed to create a sustainable and intelligent society that leverages IoT technology to enhance various aspects of daily life, including healthcare. The Smart Earth strategy included six areas, namely Smart Health, Smart Supply Chain, Smart Transportation, Smart Banking, Smart Energy, and Smart City, highlighting the importance of technology in transforming various sectors (Bhosale and Patnaik Citation2022).
The application of smart medical systems is not limited to developed countries; it has been implemented in various developing countries as well. For instance, in rural areas where medical facilities are scarce, telemedicine has been used to provide remote medical consultations, reducing the need for patients to travel long distances to seek medical attention (Baird and Nowak Citation2014). This not only saves time and effort but also reduces healthcare costs significantly.
The benefits of smart medical systems are not restricted to patients alone. Medical professionals also benefit from the system’s ability to provide them with real-time patient data, enabling them to make accurate diagnoses and provide appropriate treatment. Additionally, the integration of patient electronic medical records has made it easier for medical professionals to access and share patient data, leading to improved collaboration among medical teams (Ozdemir, Barron, and Bandyopadhyay Citation2010; Shore et al. Citation2007).
Smart medical systems have transformed the traditional medical process by leveraging IoT technology to automate various tasks, reducing waiting times, and improving efficiency. The implementation of smart medical systems has not only made healthcare more accessible and convenient for patients but has also improved collaboration among medical professionals, leading to better healthcare outcomes (Bhosale, Zanwar, and Ahmed Citation2022; Demertzis et al. Citation2021).
Technologies Involved in Smart Medical Systems
Deep Learning
In 1989, the first convolutional neural network was trained using unsupervised learning algorithm in the new cognitive machine. However, the technology of artificial neural network itself can be traced back much earlier. The initial use of convolutional neural networks was by a Chinese research team using backpropagation for handwritten letter recognition. However, it took nearly three days to perform a training session, making it unsuitable for ordinary applications (LeCun et al. Citation1989). At the same time, shallow structure model algorithms such as support vector machines and naive Bayesian were more popular, challenging the neural network algorithms with simpler structures. Despite the advent of backpropagation algorithms, most experiments with deep artificial neural networks trained by unsupervised learning algorithms failed due to the “vanishing gradient” problem (Hochreiter Citation1991). This problem occurs in both the multi-layer feedforward network and the recurrent neural network. Backpropagation causes the derivative of the overall loss function in the weight of the first few layers to become very small, and the weight update speed of the first few layers is particularly slow. As the number of layers increases, the gradient decreases exponentially, resulting in invalid learning in the training samples.
Deep learning is the intersection of research fields such as neural networks, optimization algorithms, and artificial intelligence. Different experts have provided similar definitions and descriptions of deep learning (Alhussein and Muhammad Citation2018). Deep learning can be summarized as follows: it belongs to the lower branch of machine learning, and it is an algorithm that uses multiple multi-layer transformations to abstract input information. Deep learning is optimized on the basis of simple learning. It simulates a brain nervous system similar to the human brain, constructs a hierarchical model structure similar to the human brain, and gradually extracts input data to generate more abstract attribute classifications or features. Deep learning implements supervised or unsupervised learning to extract and convert features, using multiple nonlinear information processing to describe data such as text, images, and voice. High-level features are defined based on low-level features, and the same low-level concept can define many high-level concepts.
Convolutional Neural Networks
With the advancement and optimization of deep learning algorithms, manual feature extraction methods have been largely replaced by convolutional neural networks for selecting data features. By completing the feature extraction process within the neural network itself, the accuracy of the feature extraction tool is not required. Moreover, convolutional neural networks can extract context along with the information, making it a powerful tool for data feature extraction. Convolutional neural networks have been widely utilized in image processing and speech recognition due to their exceptional ability in feature extraction (Sekhar et al. Citation2021). As the use of convolutional neural networks grows, this technology has now been applied to text classification in natural language processing. Inputting the word embedding vector into the convolutional neural network, features are extracted through convolution and pooling operations, and then the probability of the text on each label is obtained through a fully connected SoftMax layer. This method can also be used to determine the probability of a patient’s disease on each disease label through text classification using convolutional neural networks.
Collaborative Filtering
Collaborative filtering recommendation is a popular technology in information filtering and information systems. Unlike traditional content recommendation based on direct analysis of content filtering, collaborative filtering analyzes user interests and finds similar users with similar interests. The system then synthesizes the evaluation of a certain information by these similar users to generate a prediction of the target user’s liking for this information. Collaborative filtering is the most successful recommender system technology to date, and has been applied in many recommender systems. For example, an e-commerce recommendation system can use collaborative filtering technology to recommend products to target users based on other users’ comments.
Speech Recognition
Speech recognition is a rapidly growing application of artificial intelligence that enables users to control devices through voice commands. This technology has been widely applied in various fields, and the three key factors to its success are data, algorithms, and chips. A large quantity of high-quality data, fast and accurate algorithms, and high-performance speech recognition chips are crucial to improving the quality of speech recognition (Almutairi, Abdlerazek, and Elbakry Citation2020). This system incorporates speech recognition technology into the patient’s condition description stage, allowing patients who are unable or find it inconvenient to type to describe their condition using voice. The system then converts the voice into text using speech recognition technology, making it easy for the system to analyze the patient’s description.
However, there may be occasions when inpatients are unable to talk, which would make speech recognition technology challenging to use in these cases. In situations where patients are unable to speak, healthcare professionals may use alternative communication methods, such as written or visual communication, to gather information about their condition. For example, if a patient is unable to speak due to a medical condition such as a stroke, they may be able to communicate through written notes or gestures.
In cases where speech recognition technology is still feasible, healthcare professionals may use other means to capture a patient’s voice, such as using specialized microphones or voice amplification devices. These tools can help to ensure that the patient’s speech is accurately captured and analyzed, even if they are unable to speak loudly or clearly.
It’s important to note that speech recognition technology should be used as an aid in healthcare diagnosis and treatment and not as a replacement for human interaction and evaluation. Healthcare professionals must consider a wide range of factors when assessing a patient’s condition, including their medical history, physical symptoms, and other diagnostic tests. Speech recognition technology can be a helpful tool in this process, but it should always be used in conjunction with other evaluation methods to ensure the most accurate diagnosis and treatment plan.
Character Recognition Technology
Character recognition technology, also known as optical character recognition (OCR), is a critical component of document digitization. Printed text recognition is the earliest and most mature technology in OCR. German scientist Taushek was granted a patent for OCR in 1929, and since then, European and American countries have been researching Western OCR technology to replace manual keyboard input. After over 40 years of continuous development and improvement, and with the rapid advancement of computer technology, Western OCR technology has become widely used in various fields (Punith, Manish, and Sumanth Citation2021). This has enabled a vast amount of text materials, such as newspapers, magazines, documents, bills, and reports, to be inputted into computers for efficient processing. The “electronicization” of information processing has thus been realized, resulting in significant savings in time, effort, and costs.
Research Purpose and Significance
In response to the challenges faced by patients, such as the need to register as experts even for minor ailments, difficulty in finding the best doctor for their condition, and delayed treatment, a smart medical system is developed in this work. The system is equipped with intelligent guidance and question answering modules, which take advantage of medical resources and create a comprehensive medical service system. The system addresses medical issues, such as long wait times and lack of communication between medical data, that patients commonly face when seeking hospital care. Through the system, patients can easily make appointments or referrals at different medical institutions, depending on the severity of their condition. Minor ailments can be treated in smaller clinics, while more severe conditions can be referred to larger hospitals for specialized care. This approach optimizes the allocation of medical resources and helps patients receive timely and appropriate medical care. By implementing this system, the hospital can effectively address existing problems and establish a sustainable service system for the future.
Systematic Requirements
The system’s functional requirements for patients and doctors are illustrated in a UML use case diagram as presented in .
Figure 1. Diagram of the system’s functional requirements for patients and doctors.
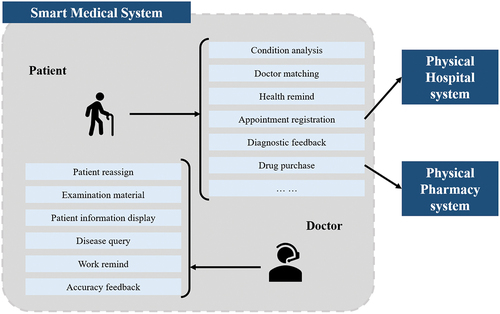
Patients can access the following six representative functions through the system:
Doctor Matching: The system analyzes patient condition descriptions and examination materials to diagnose the patient’s illness and assign them to the appropriate doctor. The system recommends doctors with the highest matching degree to the patient, who can choose one or more doctors from the list for diagnosis.
Health Reminder: Patients can synchronize their health data from their mobile devices, such as the number of steps taken, heart rate, exercise time, and other metrics, which the system will analyze in real-time. If necessary, the system will remind patients to adjust their exercise intensity, for example, if their heart rate is too high or low or if they’ve been inactive for an extended period.
Message Push: The system can push disease prevention information to all system users, including high-incidence disease information, epidemics such as the COVID-19 pandemic (Demertzis, Tsiotas, and Magafas Citation2020), the incidence and geographic distribution of various diseases, and the location of high-risk areas. This information aims to reduce the likelihood of users falling ill.
Wisdom Question and Answer: Patients can interact with the system to receive humanized responses, submit disease descriptions and examination materials for free initial diagnosis, ask for relevant knowledge such as disease introductions and treatment methods.
Appointment and Registration: Patients can register with all hospitals connected to the system for further examination or surgery, significantly reducing queuing times and medical resource waste. The system connects to each hospital’s system via an external interface and performs registration and appointment operations.
Hospital Navigation: The system integrates Baidu map or Tencent map API to enable patients to navigate directly through the system without downloading the Baidu map app, simplifying user operations.
The system offers doctors various functions, including:
Submitting diagnosis results. The system uses algorithm analysis to recommend patients to doctors, who then submit diagnosis results based on their professional judgment. The system then feeds back the results to patients.
Monitoring physical data. The system receives patients’ health data, such as steps taken, heart rate, and blood pressure, from medical equipment and sends it to the doctor for analysis of the patient’s physical condition and rehabilitation progress.
Scheduling reminders. Patients can record important events in the system, which will then remind the doctor to address the matter at the appropriate time.
Medical knowledge inquiry. If a doctor encounters an unfamiliar disease, they can query the patient’s electronic medical records and knowledge base through the system for assistance in diagnosis and treatment.
Feedback on assignments. When the system assigns doctors to patients, patients usually choose the top recommended doctor. However, for rare diseases, the doctor may need to transfer the patient to another doctor, and then report the system’s error to ensure that similar patients are assigned to the correct doctor in the future.
The system’s nonfunctional requirements must also be considered, including:
Reliability: The system must avoid crashes caused by internal or external errors and recover data and functions in case of a crash.
Ease of use: The system’s interface should be optimized for simplicity and clarity. A system assistant should be available to help users navigate, and updates should be easily understandable.
Efficiency: The system should process transactions within 150 ms and maintain a TPS of more than 10.
Software maintainability: The system should quickly identify and locate errors for maintenance personnel to modify without major changes, allowing for stable updates.
Security: The system stores a large amount of sensitive information, including patient and doctor data. Security protocols must be in place, including user account protection, gradually increasing user access rights, advanced firewalls, and adherence to network protocols.
System Design and Implementation
Cloud Platform
Cloud computing is a form of distributed computing that involves breaking down a large data computing program into numerous smaller programs via the “cloud” network. These small programs are then processed and analyzed by a system composed of multiple servers, with the result being returned to the user (Al-Ahmad and Kahtan Citation2018). Initially, cloud computing was simply distributed computing that addressed task distribution and the merging of calculation results, leading to its alternate name: grid computing. Thanks to this technology, thousands of data can be processed in mere seconds, resulting in powerful network services. In today’s era of cloud computing, the “cloud” performs both storage and computing for us. This group of computers includes hundreds of thousands, if not millions, of machines, each of which can be updated at any time to ensure the “cloud” remains immortal. Google, Microsoft, Yahoo, Amazon, and other IT giants all have their own clouds or are currently building them.
In narrow terms, cloud computing refers to the delivery and use of IT infrastructure resources, meaning hardware, platforms, and software can be obtained through the network in an easy-to-expand and on-demand manner. This network, which provides these resources, is called a “cloud.” From a user’s perspective, the resources in the “cloud” can be infinitely expanded and acquired at any time, used on demand, and expanded as needed, with payment based on usage. This feature is often likened to hydropower for IT infrastructure. In a broader sense, cloud computing refers to the delivery and usage of services obtained via the network in an easy-to-expand and on-demand manner. These services may include IT and software, internet-related, or any other service.
This study outlines the construction process of the cloud platform, which can be summarized as follows:
Procuring or leasing servers from companies such as Alibaba Cloud, configuring storage in proportion, and setting up switches for separate management of the platform network, service network, and storage network. Storage can either be independent SAN storage or use the server’s local disk as distributed storage.
Choosing and deploying cloud platform software. shows the structure of the cloud platform built in this study.
Figure 2. The structure of the cloud platform built in this study.
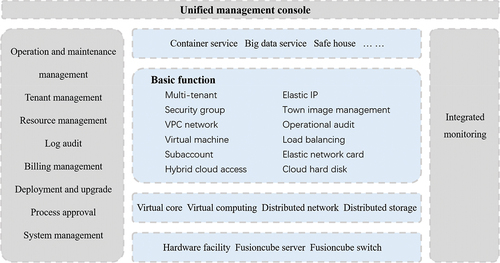
The cloud platform leverages the Hadoop open-source framework to build various components and accomplish diverse functions, such as data acquisition, task management, and workflow coordination, more swiftly and efficiently than traditional approaches. The operation method involves dividing the application program into multiple smaller work units using the Hadoop open-source framework, with each unit capable of running on any node. Additionally, a distributed file system is utilized to improve the data processing speed and boost the bandwidth of the entire cluster.
Big Data Platform
The benefits of big data to the medical industry in terms of health awareness and social impact far outweigh the costs of acquisition and management (Qin Citation2021). By analyzing patient information using big data technology, medical diagnosis can be more accurate and precise, and early targeted countermeasures can be proposed to predict the development of diseases. Moreover, the adoption of data warehouse technology has enriched the analysis dimension of medical information data in hospitals, improved the quality and availability of data, and provided the basic data support for data mining and intelligent applications. The process of building a big data platform is illustrated in :
Figure 3. Flow chart of building a big data platform.

The process of deploying and analyzing data on the big data platform can be broken down into the following steps. Firstly, the Linux operating system is installed with CentOS commonly used as the underlying platform. Secondly, the distributed system and other components are installed. Hadoop series of open-source systems are commonly used as distributed systems, while components like Yarn, Zookeeper, Hive, Hbase, Sqoop, among others, are also installed. Thirdly, data is imported using Sqoop from files or traditional databases to the distributed platform. Fourthly, data analysis is performed where the data is preprocessed, and modeling is done based on the preprocessed data to derive the desired results. Finally, the results are visualized and API outputted. To protect the user’s privacy and security during transmission, the HyperText Transfer Protocol Secure (HTTPS) is used as the protocol for front-end and back-end communication. HTTPS works on port 443 of the TCP/IP protocol, and the software application can directly call the software API.
Functional Module Design
The data preprocessing module is responsible for obtaining data from the network using crawler technology. The data cleaning process involves removing symbols and stop words, segmenting words using tools, identifying new words using statistical methods, and training word embedding vectors through word2vec. This module lays the foundation for subsequent modules.
The disease diagnosis module begins by labeling the data and performing named entity recognition to determine the information contained in the data. This provides training data for the subsequent convolutional neural network. The module then employs a convolutional neural network to diagnose diseases by analyzing medical images such as the text version of the patient’s condition description, the audio version of the condition description, the laboratory test sheet, and the CT film.
Doctor Matching Module: The purpose of this module is to match patients with the most suitable doctors. After analyzing the patient’s disease through the Disease Diagnosis Module, the most likely disease of the patient is obtained. This module uses three aspects for doctor-patient matching: the doctor’s specialty in treating a particular disease, the evaluation of historical patients, and the doctor’s satisfaction with patient allocation. These factors are recorded in the database and used for collaborative filtering.
The doctors themselves mark the diseases they are specialized in treating, and their past experiences with treating patients are evaluated, along with their satisfaction with the allocation of patients. Based on this information, the system recommends the most suitable doctors for the patients to choose from. After the treatment is over, the patients evaluate the suggestions given by the finally selected doctors, and the doctors provide feedback on whether the system correctly assigned the patients they are good at treating.
Recording these evaluations in the database can improve the accuracy of matching similar patients with doctors in the future. The doctor matching process is shown in .
Figure 4. Flowchart of physician matching.
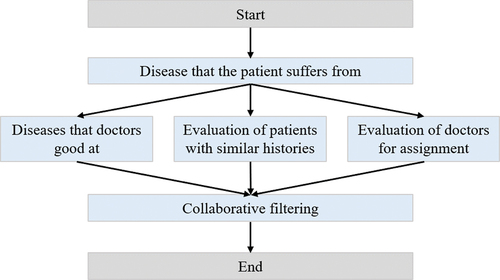
To ensure appropriate doctor-patient matching, the doctors’ fields of expertise must be taken into account. Additionally, when considering potential patients, past patient evaluations (rated on a scale of 1–5) should be considered, along with the doctor’s satisfaction with their previous matches and their ability to successfully treat a patient’s condition.
Using this information, a doctor’s recommendation score (simpq) can be calculated, factoring in a patient’s individual score (pi) and whether the doctor is satisfied with the match allocation (qi).
The Smart Medical Question-and-Answer Module is designed to handle patient inquiries and is categorized into three types: greetings, consultations, and medical knowledge. By extracting tags, the system determines the intention behind the patient’s inquiry. If the patient enters a greeting, the system replies accordingly. If the input is a consultation, the system diagnoses the disease and matches the patient with a suitable doctor. If the patient wants to understand medical knowledge, the system matches the inquiry with crawled medical question-and-answer knowledge using an algorithm, and provides the appropriate response.
Patients often want to know whether their condition is serious before going to the doctor or seek information about their illness, including treatment options, dietary advice, cost of surgery, and medication. In the past, patients had to go to the hospital or search on the Internet, which required registration, payment, and queuing, wasting a lot of time. With this module, patients can easily obtain the medical knowledge they need without leaving their homes. The system matches the inquiry with the appropriate medical question-and-answer knowledge, saving time and providing accurate information to patients who may not understand medical terminology. The Smart Q&A flow chart is shown in .
Figure 5. Flowchart of Smart Q&A.
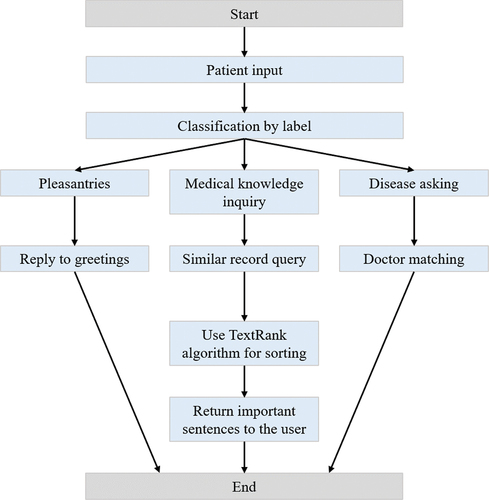
The TextRank algorithm, which is based on the popular PageRank algorithm, is utilized to generate keywords and summaries for text. By utilizing the TextRank algorithm, the system determines the significance of sentences within an article and selects the most important ones in order to provide answers to patients. The original purpose of the PageRank algorithm was to measure the importance of web pages. This algorithm treats a single website as a directed graph, with the links within the webpage serving as the direction between each point. Once the graph is constructed, the PageRank algorithm calculates the importance of the web page through a specific formula:
The importance of web page S(Vi) can be calculated using the PageRank algorithm, with the damping coefficient d typically set at 0.85. In(V) represents the set of all web pages that point to web page i, while Out(Vj) represents the set of all web pages that link to web page j. The TextRank algorithm, a derivative of PageRank, includes the concept of edge weight, which denotes the similarity of the words captured by the two nodes associated with this edge. The standard formula for calculating TextRank algorithm is as follows:
The role of Wij varies depending on the task at hand. In the task of keyword extraction, Wij denotes the similarity between words i and j. On the other hand, in the task of generating a summary, Wij is used to measure the similarity between sentence Z and j.
The BM25 algorithm is used to score all the words in the patient’s questions and the degree of correlation between the words and the systematic response. The formula of the BM25 algorithm is as follows:
Q represents a query, in this work represents a sentence, qi represents a morpheme after Q parsing, represents a word, d represents a document, Wi represents the weight of morpheme qi, R(qi,d) represents the correlation between morpheme qi and the document. In this study, inverse document frequency is used to calculate, and the formula is as follows:
Here, n is the total number of sentences, and n(qi) is the number of sentences containing the word qi. According to the definition of inverse document frequency, given a document set, the more documents containing qi, the lower the weight of qi. R(qi,d) represents the correlation between morpheme qi and the document. The general form of correlation in BM25 algorithm is:
In addition, the system uses the TextRank algorithm to rank all responses according to the patient’s questions. TextRank is a graph-based ranking algorithm used for natural language processing tasks such as text summarization, keyword extraction, and question-answering. It was first introduced by (Mihalcea and Tarau Citation2004) as an extension of the PageRank algorithm used by Google to rank web pages. TextRank represents text documents as a graph of interconnected nodes and uses a random walk algorithm to calculate the importance of each node in the graph.
Here is an overview of the TextRank algorithm:
Preprocessing: The input text is preprocessed by removing stop words, stemming, and other text normalization techniques.
Graph construction: The preprocessed text is represented as a graph, where each node represents a word or a phrase, and each edge represents the relationship between them, such as co-occurrence or syntactic dependency.
Edge weight assignment: Each edge in the graph is assigned a weight based on the strength of the relationship between the nodes it connects. For example, the weight of an edge between two words could be based on their co-occurrence frequency in the text.
Node score initialization: Each node in the graph is assigned an initial score of 1.0.
Iterative score calculation: The TextRank algorithm iteratively calculates the score of each node in the graph based on the scores of its neighboring nodes. The score of a node is updated as a weighted sum of the scores of its neighbors, where the weights are determined by the edge weights. The process is repeated until the scores of the nodes converge to a stable value.
Node ranking: Once the scores of the nodes have converged, they are ranked based on their score, with higher scores indicating greater importance or relevance to the input text.
In the context of the proposed smart medical system, TextRank is used to rank the responses to patient questions based on their relevance and importance. The algorithm constructs a graph of interconnected words and phrases in the patient’s question and the available answers, assigns weights to the edges based on their relationships, and iteratively calculates the importance scores of the nodes. The responses are then ranked based on their scores, with the highest-scoring response being presented to the patient as the most relevant answer to their question.
The analysis process of response generation based on TextRank algorithm is given in .
Figure 6. Diagram of the analysis process using the TextRank algorithm method to generate response.

Database Design
In order to organize the functions of the system, we have designed the following database structures:
Patient information: This includes fields such as name, age, phone number, gender, birthday, and historical data, which are necessary for managing patient records.
Doctor information: This includes fields such as name, age, phone number, and field of expertise, which are necessary for managing doctor records.
Hospital: This includes fields such as hospital ID, hospital name, phone number, and location, which are necessary for managing hospital records.
Clinic: This includes fields such as clinic ID, clinic name, phone number, and location, which are necessary for managing clinic records.
Pharmacy: This includes fields such as pharmacy ID, pharmacy name, drug type, drug name, and phone number, which are necessary for managing pharmacy records.
Condition: This includes fields such as disease ID, disease name, treatment method, and other relevant information, which are necessary for managing disease records.
Checklist: This includes fields such as checklist ID, checklist number, type, and other relevant information, which are necessary for managing medical checklist records.
Medical image: This includes fields such as medical image ID, medical image number, type, and other relevant information, which are necessary for managing medical image records.
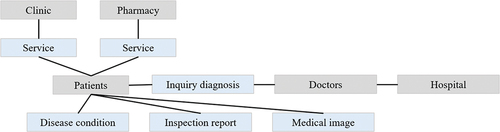
We have used an ER diagram to visually illustrate the relationship between these structures, as shown in .
Figure 7. Diagram of database ER.
Conclusion
This system is a culmination of various cutting-edge technologies such as big data, machine learning, and deep learning. The paper aims to summarize the main aspects of this system, which has been built on a cloud platform to increase its capacity, tolerable pressure, and overall running speed. The system boasts a multitude of functions including intelligent triage, disease diagnosis, intelligent question-and-answer, online doctor diagnosis, online registration, patient-patient communication, doctor-patient communication, online payment, map navigation, and more.
To analyze the patient’s disease description, the system utilizes machine learning methods on various medical materials such as text or voice versions of the disease description, laboratory test sheets, CT films, and other medical images. It then analyzes the disease suffered by the patient and matches them with doctors who have the relevant expertise, good evaluations by patients with the same disease, and a high satisfaction rate for patient allocation. The system calculates the matching degree of the doctor and the patient, and recommends doctors based on their degree of suitability. Patients have the freedom to choose multiple suitable doctors to diagnose their illnesses simultaneously. Additionally, the system can integrate the diagnosis results made by multiple doctors and the system, enabling patients to conveniently understand their illnesses.
Moreover, the system is equipped with an intelligent question-and-answer module that uses label matching to analyze the patient’s inquiry intention and provide relevant feedback using an algorithm. The system is thus well-equipped to cater to patients’ queries and provide them with the necessary information they need.
Despite some potential limitations, the proposed online medical diagnosis system has several practical applications that can benefit patients, doctors, and healthcare systems. The target use case for this system is patients who are seeking a preliminary diagnosis or second opinion for non-emergency medical conditions. Patients can use the system to get a quick and convenient diagnosis, save time, and avoid long wait times in traditional medical settings.
In practical settings, the system can help reduce the burden on healthcare systems, especially in areas where there is a shortage of doctors or where the population is dispersed. The system can provide preliminary diagnoses, which can help doctors prioritize patients and allocate resources more efficiently. Moreover, the system can be useful for patients who are unable to travel to medical facilities due to geographical or physical limitations, such as the elderly or disabled.
However, it is essential to note that the system cannot replace traditional medical settings, and patients must seek medical attention from a healthcare professional for emergency medical conditions or physical examinations. The system’s value contribution lies in providing a preliminary diagnosis and facilitating communication between patients and doctors, thus promoting timely and efficient healthcare delivery.
To ensure the system’s practical value, it is necessary to implement robust security protocols to protect patient data and address technical glitches promptly. The system must also be continuously monitored and evaluated to improve its accuracy and scope and address any limitations.
The current design of the system relies on Baidu map or Tencent map, which are primarily used inside China. To expand the system’s reach and effectiveness on a global scale, it may be necessary to integrate it with global maps systems like Google Maps. Google Maps is a widely used map service that offers comprehensive global coverage, with detailed information about local medical facilities, clinics, and hospitals. By integrating with Google Maps, the proposed system could potentially reach a broader user base, especially those outside of China.
One advantage of integrating with Google Maps is that it could potentially provide more accurate and up-to-date information about medical facilities and healthcare services worldwide. Additionally, Google Maps offers features such as real-time traffic updates and public transit information, which could be useful for patients who need to navigate to healthcare facilities in unfamiliar locations.
Furthermore, by leveraging the power of Google Maps, the proposed system could offer advanced location-based services, such as indoor mapping and real-time location tracking, to help patients find their way inside hospitals or clinics. This could be particularly helpful for patients who are physically impaired or need assistance navigating complex healthcare facilities.
Overall, integrating the proposed system with global maps systems like Google Maps could potentially improve its effectiveness and usability on a global scale. It could also enhance its user experience by providing accurate and comprehensive information about medical facilities and healthcare services worldwide, ultimately benefiting patients who require quality medical attention and care.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Al-Ahmad, A. S., and H. Kahtan. 2018. cloud computing review: Features and issues. 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), 1–1779. doi:10.1109/ICSCEE.2018.8538387.
- Alhussein, M., and G. Muhammad. 2018. Voice pathology detection using deep learning on mobile healthcare framework. IEEE Access 6:41034–41. doi:10.1109/ACCESS.2018.2856238.
- Almutairi, K., H. Abdlerazek, and S. Elbakry. 2020. Development of smart healthcare system for visually impaired using speech recognition. International Journal of Advanced Computer Science and Applications 11 (12):647–54. doi:10.14569/IJACSA.2020.0111275.
- Baird, A., and S. Nowak. 2014. Why primary care practices should become digital health information hubs for their patients. BMC Family Practice 15 (1):1–5. doi:10.1186/s12875-014-0190-9.
- Bhosale, Y. H., and K. S. Patnaik. 2022. Application of deep learning techniques in diagnosis of Covid-19 (coronavirus): A systematic review. Neural Process Lett:1–53. doi:10.1007/s11063-022-11023-0.
- Bhosale, Y. H., S. Zanwar, and Z. Ahmed. 2022. Deep convolutional neural network based Covid-19 classification from radiology X-Ray images for IoT enabled devices. International Conference on Advanced Computing and Communication Systems 5: 1398–402.
- Decade of Healthy Ageing: Baseline Report. 2020. https://www.who.int/publications/i/item/9789240017900.
- Demertzis, K., D. Taketzis, D. Tsiotas, L. Magafas, L. Iliadis, and P. Kikiras. 2021. Pandemic analytics by advanced machine learning for improved decision making of COVID-19 crisis. Processes 9(8):1267. Multidisciplinary Digital Publishing Institute. doi:10.3390/pr9081267.
- Demertzis, K., D. Tsiotas, and L. Magafas. 2020. Modeling and Forecasting the COVID-19 temporal spread in Greece: An exploratory approach based on complex network defined splines. International Journal of Environmental Research and Public Health 17(13):4693. Multidisciplinary Digital Publishing Institute. doi:10.3390/ijerph17134693.
- Hochreiter, S. 1991. Untersuchungen zu dynamischen neuronalen Netzen. Master’s thesis, Institut fur Informatik.
- LeCun, Y., B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. 1989. Backpropagation applied to handwritten zip code recognition. Neural Computation 1 (4):541–51. doi:10.1162/neco.1989.1.4.541.
- Mihalcea, R., and P. Tarau. 2004. TextRank: Bringing order into text. EMNLP 4:404–11.
- Ozdemir, Z., J. Barron, and S. Bandyopadhyay. 2010. An analysis of the adoption of digital health records under switching costs. Information Systems Research 22 (3):491–503. doi:10.1287/isre.1110.0349.
- Punith, A., G. Manish, and M. S. Sumanth. 2021. Design and Implementation of a smart reader for blind and visually impaired people. AIP Conference Proceedings 2317:421–428.
- Qin, B. 2021. Research on the application of intelligent speech recognition technology in medical big data fog computing system. Journal of Decision Systems 1–13. doi:10.1080/12460125.2021.1980943.
- Sekhar, S. R. M., G. Kashyap, A. Bhansali, and K. Singh. 2021. Dysarthric-speech detection using transfer learning with convolutional neural networks. ICT Express 8 (1):61–64. doi:10.1016/j.icte.2021.07.004.
- Shore, J. H., E. Brooks, D. M. Savin, S. M. Manson, and A. M. Libby. 2007. An economic evaluation of telehealth data collection with rural populations. Psychiatric Services 58 (6):830–35. doi:10.1176/ps.2007.58.6.830.