
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Nowadays, mobile robots are being widely employed in various settings, including factories, homes, and everyday tasks. Achieving successful implementation of autonomous robot movement largely depends on effective route planning. Therefore, it is not surprising that there is a growing trend in studying and improving the intelligence of this technology. Deep reinforcement learning has shown remarkable performance in decision-making problems and can be effectively utilized to address path planning challenges faced by mobile robots. This manuscript focuses on investigating path planning problems using deep reinforcement learning and multi-sensing information fusion technology. The manuscript elaborates on the significance of path planning, providing comprehensive research encompassing path planning algorithms, deep reinforcement learning, and multi-sensing information fusion. Also, the fundamental theory of deep reinforcement learning is introduced, followed by the design of a multimodal perception module based on image and lidar. A semantic segmentation approach is employed to bridge the gap between simulated and real environments. To enhance strategy, a lightweight multimodal data fusion network model is carefully developed, incorporating modality separation learning. Overall, in this paper, we explore the use of a deep reinforcement learning architecture for conducting path planning experiments with mobile robots. The results obtained from these experiments demonstrate promising outcomes.
Introduction
The development of intelligent robots is one of the key endeavors in the current century. Robot technology has a strategic position in industrial development, and countries around the world also attach great importance to robot technology. As one of the important technologies to develop new industries in the new era, the development level of robotics can be used as a reflection of a country’s technological level and the level of high-end industries Wang, Tao, and Liu (Citation2018). Today, the largest robot market exists in China, and various industries are changing production methods, gradually replacing labor-intensive industries with intelligent manufacturing industries. Therefore, robotics technology has great potential in China, and my country has also elevated the development of robotics to a national strategic position. And based on the comprehensive promotion and implementation of the strategy of manufacturing in a strong country, it strongly supports the intelligent robot technology to be developed in China (Yun et al. Citation2016. With the development of AI, the types of robots have been gradually subdivided, the structure of robots has become more complex, and the level of intelligence has become higher. Various intelligent robots with special functions also appeared, such as mobile robots, industrial robots, micro-robots, diving robots, service robots, etc. Among them, mobile robots have become one of the hotspots of current research due to their advantages of wide application scenarios and strong reliability.
Diverse fields have been utilizing mobile robots. In addition to the most common tasks in the fields of modern industrial automation and outdoor risk elimination, they are also widely used in construction, medical care, services, and agriculture (He, Li, and Chen Citation2017). In this era of rapid technological development, mobile robot is no longer a distant word, it has already been integrated into modern society. From simple sweeping robots, and handling robots, to complex autonomous driving, the application fields of mobile robots are rapidly expanding. One of the important reasons why mobile robots are so widely used is path planning. Path planning refers to starting from the initial starting point in a specific scene and reaching the set target endpoint while avoiding all obstacles. And this path is optimized according to some criteria. Since complex implementations and different operation conditions are required, mobile robots are required to have strong environmental adaptability (Lin et al. Citation2022). At this stage, most scholars are researching traditional PP approaches, such as the neural network approach, APF approach, genetic algorithm, fuzzy logic algorithm, etc. However, the mentioned PP approaches completely rely on the environment’s cognition. As the robot is required to conform to unfamiliar surroundings in practical applications, the utilization of mentioned approaches is limited greatly. Today, devising a path for a mobile robot to move safely between the initial and final points without colliding in real-time concerning the unknown environment is still a very big challenge (Yu, Su, and Liao Citation2020).
In unknown surroundings, the mobile robot lacks an understanding of the environment, and the environment may change all the time. Therefore, mobile robots need to have the ability to perceive, learn, make decisions, and act in unknown environments and also need to have the ability to explore and learn. The mobile car needs to continuously perceive information in a dynamic environment, make decisions, perform actions, repeat the learning, and finally obtain a safe path that adapts to dynamic changes. Therefore, it is particularly important to design a method that enables mobile robots to learn autonomous path planning in unknown environments (Ge and Cui Citation2000). In recent years, DRL methods with autonomous learning ability can effectively resolve the PP issue of mobile robots in unfamiliar surroundings. DRL is a decision control method that is different from traditional ML algorithms. Through DRL, the agent can adapt to the environment through online learning and continuous trial and error without any guidance signals in an unknown environment. Due to the significance of DRL through training and achieving the target effect, several scholars investigated it broadly and DRL has also been applied in real life (Song and Liu Citation2012). However, in the actual process, DRL in complex environments still has some problems to be solved and optimized, such as long exploration periods, sparse rewards, and convergence stability.
The mobile robot’s control accuracy relies on the precision of the external environment information obtained by the robot and the state information of its system, which depends on the sensors closely related to the robot (Gao et al. Citation2020). When sensor data is collected, due to the uncertainty of external environment information, the inaccuracy of robot mechanical structure data, and the measurement error of the sensor system itself. This results in a certain deviation between the data obtained by the sensor and the real value, so it is not accurate enough to use one sensor alone to determine the robot information. MSIF technology is to analyze and processes the data obtained by various sensors, which could enhance the accuracy of individual sensor data, thereby improving the control accuracy of mobile robots (Li et al. Citation2022; Xu Citation2019). Therefore, the study investigating avoiding obstacles and PP of mobile robots utilizing MSIF is very meaningful and has application value.
In the manuscript, the DDPG approach was used for the PP experiment of mobile robots, and the TensorFlow DL framework is used to build the DNN structure of the DRL algorithm. The APF approach was suggested to define the DRL’s RF, and finally complete the mobile robot’s PP. In terms of perception, a multi-modal perception module based on image and lidar is designed, and a semantic segmentation model is used to decrease the discrepancy between the simulation and the real environment. In terms of strategy, we carefully design a lightweight multimodal data fusion network model and introduce modality separation learning.
The motivation behind this study stems from the widespread use of mobile robots in various domains, ranging from industrial settings to everyday tasks in homes. To enable autonomous robot movement, efficient route planning is crucial. However, achieving successful implementation of autonomous navigation poses significant challenges. Therefore, there is a strong motivation to enhance the intelligence of mobile robots by leveraging advancements in deep reinforcement learning and multi-sensing information fusion.
This manuscript makes several significant contributions to the field of mobile robot path planning:
Comprehensive Research: The study provides a comprehensive exploration of path planning by examining various aspects, including path planning algorithms, deep reinforcement learning, and multi-sensing information fusion. By consolidating these research areas, the manuscript offers valuable insights into the development of intelligent path planning systems.
Enhanced Deep Reinforcement Learning: The manuscript introduces a novel approach that utilizes deep reinforcement learning techniques, specifically the DDPG algorithm, for mobile robot path planning. By employing the TensorFlow Deep Learning framework, the authors construct a deep neural network structure that facilitates efficient decision-making for the robots.
Multi-Sensing Information Fusion: The study incorporates multi-sensing information fusion, combining image and lidar data, to enhance perception capabilities. A lightweight multimodal data fusion network model is carefully designed, incorporating modality separation learning. This fusion of sensory inputs improves the robots’ understanding of their environment and aids in accurate decision-making.
Improved Performance: The proposed approach demonstrates superior performance compared to existing methods. By utilizing the artificial potential field method to construct the reward function, the manuscript achieves faster convergence of the neural network and higher success rates in mobile robot path planning tasks. These outcomes highlight the effectiveness and practicality of the proposed approach.
In summary, this manuscript’s contributions lie in the comprehensive research of path planning, the application of deep reinforcement learning and multi-sensing information fusion, and the development of an efficient and effective path planning system for mobile robots. These findings contribute to advancing the field and provide valuable insights for researchers and practitioners working in the domain of autonomous mobile robotics.
The rest of the structure of the article incorporate the sections 2. Related Work, 3. Method, 4. Experiment and Analysis and 5. Conclusion. Specifically, in the “Related Work” section, the manuscript discusses prior research and studies related to mobile robot path planning, deep reinforcement learning, and multi-sensing information fusion. It provides an overview of existing approaches, algorithms, and techniques employed in these areas. The section highlights the limitations and challenges of previous methods, emphasizing the need for improved path planning techniques and intelligent decision-making frameworks. By reviewing and analyzing the related work, the manuscript positions its research within the existing literature and identifies the unique contributions it aims to make.
The “Method” section details the proposed approach for mobile robot path planning using deep reinforcement learning and multi-sensing information fusion. It starts by presenting the underlying theory of deep reinforcement learning, explaining concepts such as the DDPG algorithm and its relevance to path planning. The section then outlines the design and implementation of the multimodal perception module, incorporating image and lidar data fusion. It describes the semantic segmentation approach utilized to bridge the gap between simulated and real environments. Additionally, the section elaborates on the development of a lightweight multimodal data fusion network model, highlighting the incorporation of modality separation learning. The section provides a comprehensive overview of the entire methodology, explaining each step in detail and showcasing the integration of deep reinforcement learning and multi-sensing information fusion for effective path planning.
In the “Experiment and Analysis” section, the manuscript presents the experimental setup and methodology used to evaluate the proposed approach. It describes the specific scenarios, environments, and datasets utilized for conducting the experiments. The section outlines the evaluation metrics employed to assess the performance of the path planning system, such as success rate and convergence speed. It then presents the experimental results, showcasing the effectiveness of the proposed approach through quantitative and qualitative analysis. The section includes comparisons with baseline methods or state-of-the-art approaches, highlighting the advantages and improvements achieved by the proposed methodology. The analysis also discusses any limitations or challenges encountered during the experiments and provides insights for potential future enhancements.
The “Conclusion” section summarizes the key findings, contributions, and implications of the research. It restates the motivation behind the study and emphasizes the significance of the proposed approach for mobile robot path planning. The section briefly recaps the methodology, highlighting the integration of deep reinforcement learning and multi-sensing information fusion. It discusses the experimental results and their implications for the field, reinforcing the superior performance and advantages of the proposed approach. The section also addresses any limitations or potential areas for further investigation. Finally, the conclusion concludes by highlighting the broader impact of the research and its potential applications in real-world scenarios, concluding with a compelling call-to-action for future research and development in the field of mobile robot path planning.
Related Work
PP has been one of the important tasks in mobile robots’ control intelligence. The purpose of PP is to make the robot receive environmental information through its sensors and automatically generate a safe and optimal path. Reference (Li et al. Citation2022) proposed a PRM graph search algorithm, which can draw a roadmap between the initial and the final points through optimization rules under certain constraints and solve some path planning problems in high-dimensional complex spaces. RRT is a tree-based incremental sampling search method. RRT randomly picks points in the environment space from the starting point without any parameter tuning. Taking the initial point as the root node, according to the constraints of the path planning, the next node is expanded and stored in the search tree until the search tree fills the entire space to find the endpoint (Noreen, Khan, and Habib Citation2016a). Reference (Wang et al. Citation2020) proposed an improved RRT algorithm, which introduced a search for newly generated nodes and neighboring nodes and optimized the path cost.
The approach’s convergence was strengthened, and the asymptotic optimal solution of the algorithm is ensured. Reference (Raja et al. Citation2020) proposed the idea of combining the RRT approach and the rolling PP method for the RRT approach. The robot uses the sensor to obtain information in a limited range, finds the intermediate point as a local PP, and finally forms a global PP to reach the target endpoint with multiple intermediate points. Reference (Bakdi et al. Citation2017) proposed a PP method concerning mobile robots with a high degree of freedom based on RRT. The joints involved in the robot are selected according to the complexity of the environment. By sampling the adaptive dimension and introducing the adaptive RRT algorithm, the robot can perform RRT planning in a three-dimensional space environment. Reference (He et al. Citation2017) proposed the combination of RRT and APF method, firstly planning the initial path by APF method, and then using RRT for local path planning when encountering obstacles. The problem that RRT will cause a local minimum is solved and the efficiency of path planning is improved.
Reference (Wang et al. Citation2021) achieved better motion effects by adding optimization criteria to make the potential field function adjustable. Reference (Chen et al. Citation2016) improves the potential field method of local navigation so that the smart car can seek the optimal path according to the gradient descent of the potential field. Reference (Kovács et al. Citation2016) suggested an optimal PP approach concerning robots with a multi-degree of freedom based on the improved APF method. Compared with the conventional approach, the selected path has better optimality and is less time-consuming. Reference (Azzabi and Nouri Citation2019) solves the local minimum point problem into which robots fall. The predicted distance is provided concerning the trap area to a certain extent. The planned virtual point is set reasonably since the issue of the AFP method easily falls into the trap area and the local minimum is aimed to be resolved.
Reference (Noreen, Khan, and Habib Citation2016b) proposed the concept of fuzzy logic. Because it is hard to construct an approach concerning a mobile robot path planning and obstacle avoidance, fuzzy control has strong robustness. The application of fuzzy control in path planning forms a mode of perception and decision-making, which avoids the high dependence of traditional path planning on the environment. Reference (Hentout, Maoudj, and Aouache) designed a fuzzy controller to fuzzify the obstacle and target information obtained from the sensor. Path planning and obstacle avoidance are realized by using fuzzy rules, and the experimental results are better than the APF method. Reference (Song and Liu Citation2012) combines fuzzy control with the improved APF method, enables the robot to safely avoid obstacles in path planning through behavior switching, and designs a fuzzy control to solve the trap problem in path planning. DRL is an important machine learning method whose purpose was to find an optimal scheme to achieve the objective in the current environment so that the strategy can get the maximum reward.
Reference (Zhao et al. Citation2020) proposed the Q-learning approach, which utilizes a Q table to keep the Q value corresponding to the action taken in each state. By interrelating with the surroundings to obtain evaluation and solve the Q-score function, Q-learning has received extensive attention in the field of RL since it was proposed. Reference (Yang, Li, and Peng Citation2020) combined DL and RL, and proposed a DQN algorithm, which successfully solved the problem of the curse of dimensionality. The agents it trains also far exceed the level of human game experts in multiple games. Reference (Zhang et al. Citation2022) improved DQN and proposed a DDQN algorithm with a competitive network structure. The algorithm combines the state score and the advantage function to accelerate the approach’s convergence velocity.
Reference (Yu, Su, and Liao Citation2020) proposed the A3C method, which realizes the asynchronous learning method of the agent interrelating with the surroundings under multi-threading and solves the problem that the training data are highly correlated. Reference Kim et al. (Citation2020) proposed a deep deterministic policy gradient algorithm, which implements control in a continuous action space and outperforms DQN in dozens of control tasks. Reference (Wang et al. Citation2021) studied the mobile robots’ PP issues for logistics scenarios. Through the DDPG and PPO algorithms, the feedback of the manipulator is used by the mobile robot to reach the target final point that meets the work requirements. Reference (Jiang et al. Citation2020) applies DRL to the jumping rover and can perform path planning in the case of irregular surface heights. Methods based on multimodal perception are a hot research topic in recent years. Especially in unstructured and complex scenes, sensor data fusion can better perceive the surroundings and enhance the system’s generalization and robustness.
Based on this, reference (Nie et al. Citation2020) proposes a DL framework for the multimodal fusion of image and lidar data simultaneously. It discusses that converting raw images into semantic segmentation maps and processing lidar data into polar grid maps can enable the system to achieve the best performance. Reference (Patel, Choromanska, and Krishnamurthy 2019) proposes a specialized sensor dropout technique using Dropout related theory. The strategy is robustly learned through MSIF and trained with a DRL algorithm, which finally makes the strategy more robust to local sensor failures.
The motivation behind this research paper is driven by the increasing utilization of mobile robots in various domains, ranging from industrial settings to everyday tasks in homes. These robots are designed to perform autonomous movement, which heavily relies on effective path planning. However, achieving successful implementation of autonomous navigation presents significant challenges, necessitating the development of intelligent systems to tackle these issues.
The research aims to address this motivation by leveraging two key areas of study: deep reinforcement learning (DRL) and multi-sensing information fusion (MSIF). Deep reinforcement learning has demonstrated exceptional performance in decision-making problems, making it a promising technique for path planning. By incorporating DRL, the research aims to enhance the intelligence and decision-making capabilities of mobile robots.
Moreover, the integration of multi-sensing information fusion is crucial to improve the perception capabilities of the robots. By combining information from multiple sensors, such as images and lidar data, the robots can better understand and interpret their surroundings. This fusion of sensory inputs plays a vital role in accurate decision-making and successful path planning, particularly in scenarios where there is a disparity between simulated and real environments.
The research is motivated by the need for advanced path planning techniques that can overcome the limitations of existing approaches. By leveraging the power of deep reinforcement learning and multi-sensing information fusion, the aim is to develop a more efficient, intelligent, and reliable path planning system for mobile robots. The research strives to contribute to the advancement of the field by providing novel insights, methodologies, and experimental evidence to demonstrate the effectiveness and practicality of the proposed approach.
Overall, the research motivation is driven by the desire to enhance the intelligence and decision-making capabilities of mobile robots, addressing the challenges faced in achieving autonomous navigation. By combining deep reinforcement learning and multi-sensing information fusion, the research aims to push the boundaries of path planning and pave the way for more sophisticated and efficient mobile robot systems in various applications and domains.
Method
Path Planning Utilizing DDPG Deep Reinforcement Learning
In recent years, with the rapid development of computer hardware such as GPU, ML theories such as DL have been widely used. In particular, the DRL method combining DL and RL has received great attention. In mobile robot path planning, DRL has achieved good results. Although DRL has good generality, it can be used as a model to control robots. To use the DRL method in the robot’s PP, the mobile robot needs to have an experimental environment for the mobile robot and establish the corresponding RF and state space. In the article, the DDPG approach was used for the PP experiment of mobile robots, and the TensorFlow DL framework is used to build the DNN structure of the DRL algorithm. The APF was suggested to construct the DRL’s RF, and finally complete the mobile robot’s PP.
Fully Connected Neural Network
An FCNN is a feedforward ANN, also known as a multilayer perceptron (MLP), which maps input data to a set of output results through nonlinear operations. depicts that it mainly consists of 3 parts: the input, hidden, and output layers. The leftmost layer called the input receives the input information vector, the multiple hidden layers in the middle abstract the input at multiple levels, and the right output layer outputs the prediction result.
Figure 1. Fully connected neural network architecture.
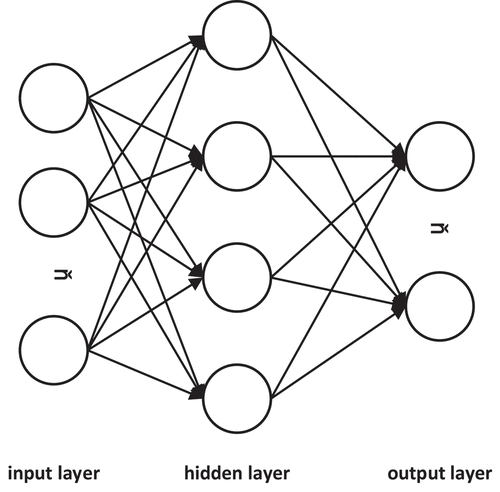
Each layer consists of multiple neurons, where a single neuron is shown in .
Figure 2. Basic structure of a neuron.
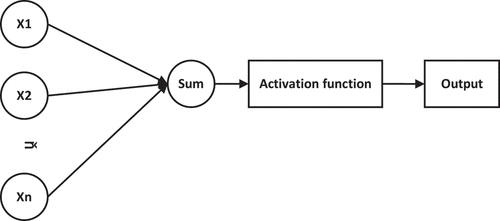
Each neuron usually has multiple inputs , each of which is multiplied by its corresponding weight and then added together. Finally, add the bias and obtain the output y of the neuron through the activation function, which is formulated as:
where represents the weight corresponding to its ith input,
represents the corresponding bias of the neuron, and
represents the activation function used.
If the network applies to no activation functions, each layer’s output of the network is a linear function of its input. Any multi-layer MLP can be viewed as a linear combination of input data, like a more complex single-layer network. Therefore, a nonlinear activation function must be included in the neural network to improve its expressive capacity.
The corresponding formula of the sigmoid function is:
The function restricts the output to a range of 0 ~ 1, but its gradient is very small when the absolute value of the input is large. This leads to slow parameter updates. Currently, this function is generally only used in the output layer.
The corresponding formula of the Tanh function is:
When the output value range of the function is (−1, 1), it is larger than the S function, and the mean value of the output is zero, which is similar to the normalization effect on the input. However, there are also cases where the gradient is very small when the absolute value of the input is large and the parameter update is slow.
The corresponding formula of the ReLU function is:
It is the most widely used activation function at present. It does not limit the output to a fixed range. The form is simple, the calculation is much faster than the above two, and it can better solve the gradient disappearance of the above two. In addition, the sparse expression ability brought by its unilateral suppression enables the network to better mine relevant features.
DDPG Algorithm
Deep reinforcement learning methods such as DQN are essentially value-based RL methods and therefore cannot output actions in a continuous space. The policy-based DRL method DDPG can well select actions on continuous actions such as path planning. DDPG is a DRL method based on the Actor-Critic (AC) approach architecture. Based on the AC framework, DDPG draws on the successful experience of the DQN algorithm. Its overall structure is shown in .
Figure 3. DDPG algorithm structure.
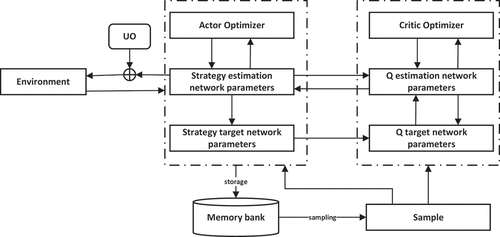
The neural network of DDPG mainly includes a policy network part and a Q network part, each of which contains two neural networks composed of the same structure: the estimation and the target networks. In the Actor part, the policy estimation network can output immediate actions to the Critic, and the policy target network could update the Q target network in the Critic. In the Critical part, both the Q estimation and the Q target networks are used to output the current state’s score. The difference is that the Q estimation network’s input is the action output by the policy estimation network. The update of the Q network can be calculated by defining the loss function.
For the update of the policy network among the actors, the policy gradient of the policy can be determined by computing:
where behavior strategy δ adopts the OU process, the purpose is to introduce random noise, to explore the potential optimal strategy. is the strategy neural network parameter,
is the deterministic behavior strategy, and
is the distribution function of the data in the experience playback pool of the agent according to the strategy δ.
When randomly sampling from the memory playback pool, EquationEquation (5)(5)
(5) can be rewritten as:
The difference is that the target parameters in the DQN use a hard update, while in the DDPG algorithm, the target network parameter update method is a soft update. Its formula is as follows:
Although the step-by-step update method of formula (7) has a larger amount of calculation, due to the complexity of the DDPG structure, better stability can be obtained by adopting this method.
Structure of Deep Reinforcement Learning
Building Diagram of Actor Neural Network
The actor neural network architecture in this study consists of two identical neural networks: a policy target network and a policy estimation network. These networks play a crucial role in the deep reinforcement learning framework for path planning of mobile robots.
The policy network receives the state input, denoted as S, which represents the current state in which the robot finds itself. This input is fed into the input layer of the policy network. The middle layer of the policy network consists of three hidden layers, all of which are fully connected layers (FCLs). The first and second hidden layers contain 100 neurons each, while the third hidden layer has 200 neurons. The activation function used in all these hidden layers is the Rectified Linear Unit (ReLU) function, which is commonly employed in neural networks to introduce non-linearity.
The output layer of the policy network is responsible for generating the action that will be selected by the neural network. The activation function used in the output layer is the hyperbolic tangent (Tanh) function. The Tanh activation function maps the output to the range [−1, 1], allowing the neural network to produce continuous action values within this range.
It is worth noting that the use of two identical neural networks, namely the policy target network and the policy estimation network, is a common approach in deep reinforcement learning algorithms such as DDPG (Deep Deterministic Policy Gradient). The policy target network is periodically updated to match the parameters of the policy estimation network, allowing for more stable and consistent training of the neural network.
By specifying the neural network architecture, including the number of hidden layers, the number of neurons in each layer, and the activation functions used, the study ensures that the actor neural network can effectively process the input state and generate appropriate action outputs for the mobile robot’s path planning task.
The numbers 100 and 200 refer to the number of neurons or units present in the respective hidden layers of the policy network. In neural networks, neurons or units are interconnected computational elements that process and transmit information.
In the given context, the policy network consists of three hidden layers, with the first and second hidden layers containing 100 neurons each, and the third hidden layer containing 200 neurons. These numbers determine the capacity and complexity of the neural network model.
The choice of the number of neurons in a layer depends on various factors, including the complexity of the problem being addressed, the amount and nature of the available data, and the desired model capacity. Generally, increasing the number of neurons in a layer allows the neural network to capture more intricate patterns and representations from the input data, potentially leading to higher model performance. However, excessively large numbers of neurons can increase the computational complexity and may lead to overfitting if the model is not properly regularized.
In the case of the policy network, the selection of 100 neurons in the first and second hidden layers, and 200 neurons in the third hidden layer, indicates a relatively moderate-sized network. This configuration strikes a balance between capturing complex relationships in the input data and maintaining computational efficiency. The specific choice of these numbers are optimized based on empirical experimentation and performance evaluation on the path planning task for mobile robots.
Construction of Critic Neural Network
The critic also consists of two identical neural networks, the Q-target, and the Q-estimator networks. In the Q network, the input to the input layer represents the state S and the robot’s action. The middle layer contains 3 hidden layers, all of which are fully connected. The FCL layer l contains a total of 100 neurons, of which 100 neurons are connected to the state S of the input layer, and 100 neurons are connected to the action a. The FCL layer 2 contains 200 neurons, the FCL layer 3 contains 200 neurons, and the activation functions of all the above FCLs are represented by Relu functions. The output layer is the Q value obtained under the input S and A.
Design of Reward and Punishment Function and State Space
State and Action Space Design
The approach for planning routes is simplified by assuming the robot always travels at the same pace. In other words, the robot moves the same length in each time step, therefore the machine’s steering angle serves as the space for actions, and its dimension equal one. Since the DRL is trained to make a robot reach the planned point while avoiding obstacles, the state space of the robot must reflect the robot’s positional connection with those objects.
The robot’s state space is defined by
where (x, y) and denote the position and the robot’s orientation in the current map, and s is the standardization coefficient.
and
denote the length of the robot to the closest hurdle and target point.
and
denote the length information of the robot from the closest hurdle and target, respectively.
Design of Reward Function Utilizing Artificial Potential Field Method
In the RL process, the characteristic of the RF impacts the entire RL consequence. According to the RL’s fundamental structure, the agent assesses the action’s quality based on the feedback that the environment provides. By selecting the action that could attain the highest after learning, the RF’s logical construction has a key step toward the RL. If the robot’s current length from the goal is taken into account as a reward value, then the nearer the robot is to the goal, the higher the reward gained in each step of movement. But the way where the RF is set does not take into account the alterations in robots and obstacles. A negative reward score was provided only as an obstacle is hit by the robot and the information about the distance between the robot and the hurdle is not continuous.
If the robot performs each action, a fixed value is given as a reward according to approaching or moving away from obstacles, approaching or moving away from the planned point. The distance between the robot and the planned point was not regarded, namely, the nearer the robot is to the target point, the larger the reward value should be. Given the existing issues of constructing the RF in the above methods, this paper proposes to use the APF approach to construct the RF.
1) Introduction to APF. The APF method is a virtual force method. In an APF, the mobile robot will be attracted by the final planned point, while the obstacles would repulse it. The superposition of the 2 forces is used as a control force to move it. A path is planned by the mobile robot to reach the final point when the control force is acted. As the robot approaches the end point, the gravitational force it receives will increase. If a hurdle is approached by the robot, the repulsive force would increase. In the conventional APF, the gravitational potential field mapping is expressed as:
where is the constant of the gravitational field coefficient, and
.
is the length between the robot and the planned point.
The gravitational potential energy of at the target and the endpoint would be the smallest, and the gravitational mapping could be attained by taking the negative derivative of EquationEquation (9)
(9)
(9) :
The repulsion field function is expressed as:
where is the repulsion field coefficient constant,
.
is the distance represented by a straight line from the robot to the planned point.
is the highest effect range of the hurdle.
When is greater than
, it is not impacted by the obstacle. The repulsive potential energy at the obstacle reaches the largest score, and the negative derivative of EquationEquation (11)
(11)
(11) can be obtained:
2) RF design. Pay the robot a certain amount of money when it achieves the goal or when it encounters any barriers or walls. The APF specifies a two-part value for the reward when the robot has not yet reached the objective or contacted a barrier. In both cases, the length information between the robot and the closest barrier has a minus reward score, while the length information between the robot and the goal location has a positive reward value. The total value of the rewards the robot receives for each action is the sum of the individual reward values.
Therefore, the Rf for the robot action is:
To verify the validity of the Rf set by the APF method in this paper, the Rf set only by the target point information is selected as the comparison in this paper:
Multimodal Perception Module of Path Planning System
Binarized Semantic Segmentation Perception
If the RGB image received by the sensor is directly used as the policy input, the policy table learned by the robot in the simulation environment is difficult to be directly applied to the real scene, which is affected by the lighting conditions, scene structure, and sensory properties. The semantic segmentation graph solution suggested in the manuscript was to provide an abstract view as a mid-level visual representation. Semantic segmentation ignores some interfering factors in images and eliminates the differences between images from different scenes.
Specifically, our method uses pixel binarization semantic segmentation as part of the output of the perceptual module in the path planning framework to divide the original RGB image into “feasible” and “infeasible” regions according to pixels. It abstracts lights, textures, shadows, and weather, leaving only a few variables: the geometry of the road, the geometry of obstacles, the camera pose, etc. Overall, this binary semantic segmentation abstract representation not only supports generalization across different scenarios but also contains important visual information required for planning and control.
We train a pixel binarized semantic segmentation network in a supervised training manner, and its function is expressed as:
where indicates that the unmanned ground vehicle receives the original RGB image observed by the sensor at time t, and
indicates its corresponding binarized semantic segmentation map.
represents the binarized semantic segmentation network model, and
is the parameter of the network model.
Lidar Depth Information Perception
Although the color camera sensor can provide rich visual information about the scene, it still lacks the perception of the depth information of the surrounding environment. Lidar sensors have played an increasingly important role in autonomous driving in recent years. Known for its physical ability to perceive distance information from the environment, it works well in a variety of natural lighting conditions. To obtain better perceptual properties than using color camera sensors alone, we additionally introduce depth measurement information from the lidar in the perception module. Since the operation of the lidar sensor is not affected by conditions such as illumination, there is no essential difference between the real scene and the simulated scene, and there is no generalization problem from the simulation to the real scene.
The preprocessing steps for incorporating depth measurement information from the lidar sensor into the perception module can involve the following:
Data Alignment: Ensure that the color camera and lidar sensor data are properly synchronized and aligned. This step ensures that the corresponding depth information from the lidar sensor is correctly associated with the visual information from the color camera.
Data Calibration: Calibrate the lidar sensor and color camera to ensure accurate depth measurements and proper geometric alignment between the two sensor modalities. This calibration process helps rectify any systematic errors or misalignments between the sensors.
Depth Fusion: Fuse the depth measurements from the lidar sensor with the visual information from the color camera. This fusion process combines the depth perception capabilities of the lidar with the rich visual information provided by the color camera, enhancing the overall perceptual properties of the system.
Normalization: Normalize the data to a consistent range or scale. This step ensures that the input data is within a standardized range, which can facilitate the learning and generalization capabilities of the subsequent neural network models.
Preprocessing Image Data: Apply standard image preprocessing techniques to the color camera images, such as resizing, cropping, or normalization, to enhance the quality and compatibility of the visual input data.
Feature Extraction: Extract relevant features from the fused data, such as edges, corners, or object keypoints. Feature extraction helps reduce the dimensionality of the data and highlights salient information that can aid in subsequent decision-making processes.
Data Augmentation (optional): Perform data augmentation techniques, such as random cropping, rotation, or mirroring, to increase the diversity and robustness of the training data. Data augmentation helps prevent overfitting and improves the generalization capabilities of the model.
These preprocessing steps ensure that the depth measurement information from the lidar sensor is properly integrated with the visual information from the color camera, providing a comprehensive and perceptually rich input for subsequent processing and decision-making algorithms. Additionally, by leveraging the depth information from the lidar sensor, the system is not affected by illumination conditions, allowing for improved performance and generalization from simulated to real scenes.
We simply normalize the radar data in the perception module and then superimpose the last three frames of information:
where represents the normalized lidar depth information at time t, and
represents the depth after stacking.
Robot Motion State Information Perception
The real-time motion indicators of the robot are also critical to vehicle decision-making, so we additionally introduce the angular velocity and linear velocity motion indicators , which are fed back by the vehicle odometer in real-time, in the perception module. It represents the speed and direction of its movement.
Integrated Multimodal Perception Module
Combining the perceptual data obtained in the above three parts obtains the real-time output of the multimodal perception module. The multimodal perception module we designed for the local path planning system extracts the abstract visual information of complex scenes through the semantic segmentation model and then perceives the distance information of objects in the surrounding scene through lidar. Combined with the vehicle motion indicators fed back by the odometer, it provides a more complete representation of the environmental information required for planning and the representation of the vehicle’s motion state for the subsequent strategy module and fully considers the real-time requirements of real robots.
Teacher-Student Model
In theory, we should use a deep semantic segmentation network model like GSCNN, which achieves a pioneer semantic segmentation on the urban road benchmark dataset cityscapes. GSCNN-related papers mainly propose a new two-stream CNN architecture, which uses a separate network branch to extract shape-related information of objects in images. It is combined with the classic semantic segmentation model branch to jointly produce a segmentation effect with clear boundaries.
However, such a deep network model is computationally expensive, and the inference speed cannot meet the real-time requirement of the computing device onboard a real robot. Another option is to use a shallow real-time semantic segmentation model like ERFNet, which mainly utilizes residual connections and decomposed convolutions to design a novel network layer. It better balances the inference speed and segmentation accuracy, and can meet the real-time requirements.
However, without a large amount of training data, such shallow semantic segmentation models often have poor generalization ability in complex test scenarios. Based on the above considerations, we specially designed a teacher-student model, which embeds the deep network teacher model into the training process of the shallow real-time student network model, in which GSCNN is used as the teacher model and ERFNet is used as the student model. Specifically, the following steps are included.
Train the teacher model GSCNN using a labeled public dataset of urban roads, Cityscapes.
Control the robot to drive normally in the real scene while recording the RGB images collected by the camera sensor.
Input the above image into the trained teacher model, and output the corresponding segmentation map prediction results as its semantic segmentation label.
Train the student network model with the raw RGB data of the real scene and its labels obtained above, as well as other labeled data.
Although the above ERFNet trained by the teacher-student model will have a little noise when performing scene segmentation. To make our local path PP model have better robustness and better generalization from simulation to real scenes. When training the local PP scheme in the simulation environment, we still use the above-mentioned ERFNet trained by the teacher-student model as the segmentation model instead of directly using the accurate segmentation semantic segmentation map that comes with the simulation environment.
Experiment and Analysis
Dataset and Semantic Segmentation Model Experiment
Semantic segmentation models are designed to obtain passable and impassable regions. First, train the teacher model GSCNN, and then use the trained model to convert the real scene dataset into binary segmentation map labels. Finally, the student model ERFNet is trained in combination with the public dataset Cityscapes and the simulation dataset. In , we report the average IoU performance evaluation of GSCNN and ERFNet in simulation and real test scenarios when trained on different datasets and the inference frames per second of different models on Jetson TX2. The OS in the training set here represents the datasets we collected from the simulation and the real environment.
Table 1. Average IoU performance and inference frames per second.
It should be noted that both the simulation and the real environment are tested on datasets that have not been trained. Although GSCNN has good image segmentation ability for real outdoor scenes, its segmentation efficiency is not high. In contrast, the ERFNet network model achieves an inference rate of 18 frames per second. Furthermore, it can be seen that the ERFNet model trained only on the Cityscapes dataset has the worst segmentation performance in the real scene. Our proposed model significantly improves the performance of ERFNet in both simulation and real environments.
On the other hand, since our policy model also adopts ERFNet during simulation training, the improved segmentation effect brought by GSCNN will also help policy training.
Path Planning Experimental Environment Construction
The dynamic experimental environment is designed to plan the robot’s course from any starting place and any starting orientation angle to the desired destination. The robot’s starting position, initial orientation angle, and final destination should all be created at random as part of the dynamic environment’s first step. Among them, the first point and the planned point should be located outside the obstacle and the wall, and the initial point should have a certain distance from the obstacle object, to assure that the robot could turn thrivingly. After setting the initial state and target point of the movement, you need to add motion rules to it. Set the robot’s highest steering angle to 30°, that is, the selection interval for each action is [-π/6, π/6].
The step size l of each cycle is 20, and the smallest turning radius of the robot is the same. According to the robot’s current position, the current orientation angle , the steering angle α and the step size l, the position
and orientation
of the robot at the next time can be obtained.
While simplifying the environment, considering that the robot itself should have a certain volume, the influence range of obstacles is set to 40. That is as the length between the robot center and the hurdle is denoted by , the impact range of the robot clashing with the hurdle is 60. That is, when
, the influence of obstacles on the mobile robot is not considered.
Experiment and Result Analysis
Experiment Parameter Setting and Process
After both the neural network and the environment are built, the neural network’s relevant parameters are set by using , and run the test environment according to the program.
Table 2. Parameter settings of the neural network.
Analysis of Experimental Results
The DRL was trained by using the Rf constructed by the APF method used in this paper and the RF is constructed by only utilizing the length information of the mobile robot to the planned point. The reward value and the rate of alteration tendency during training are plotted in . shows the alteration inclination of the reward score obtained by the neural network in each round.
Figure 4. The trend of total reward value per round.
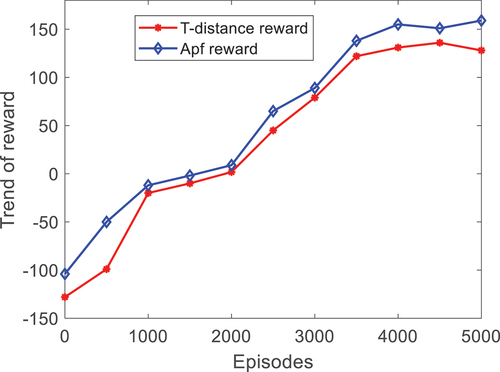
Figure 5. Overall success rate trends.
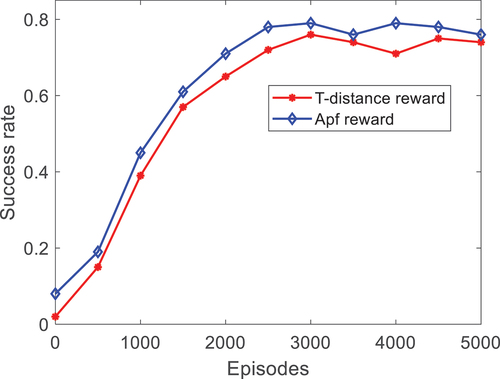
Figure 6. Trend of synthetic power per 200 cycles.
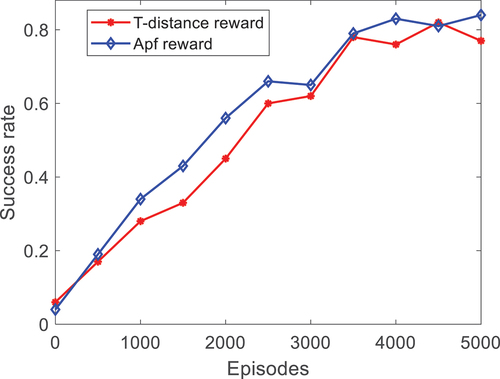
depicts the alternating inclination of the total success ratio of the robot with the increase in training times. shows the alteration tendency of the success ratio per 200 training sessions.
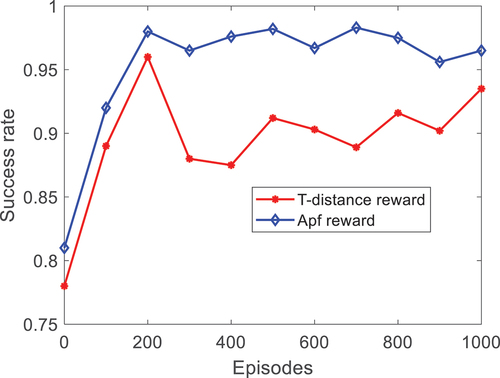
When compared with the method that only uses the mobile robot and the planned point as the RF, the RF set by the APF method in this paper converges faster. The success ratio is higher, and it presents a further ability to approach the target and avoid obstacles when the times of the training are the same. is the alternating inclination of the total success ratio attained after reloading the trained neural network parameters and running the environment. The success rate of using the AFP approach as the Rf is higher.
Figure 7. Training final success rate.
Conclusion
Mobile robots’ PP has been a current research hotspot. In the future, how to make them autonomously master perception and decision-making in unknown environments is an essential key technology. Based on the theoretical knowledge of DRL, this paper integrates DRL and MSIF technology into mobile robot path planning. This empowers the robot to continuously master autonomously by running a trial-and-error approach like humans, and finally acquire the ability to sense the environment and make decisions to complete the PP task.
The proposed method in this study aims to address the current research hotspot of mobile robot path planning (PP) by integrating deep reinforcement learning (DRL) and multi-sensing information fusion (MSIF) technology. The goal is to enable mobile robots to autonomously master perception and decision-making in unknown environments, which is a crucial key technology for their effective operation.
The study starts by highlighting the significance of mobile robot PP and provides an in-depth examination of the research status in terms of path planning algorithms, DRL, and MSIF. By integrating these key components, the proposed method offers a comprehensive framework for enhancing the capabilities of mobile robots.
The paper introduces the basic theory of DRL and presents a multimodal perception module that combines image and lidar data. To bridge the gap between simulated and real environments, a semantic segmentation approach is utilized. Additionally, a lightweight multimodal data fusion network model is carefully designed, incorporating modality separation learning strategies. This architecture enables effective integration of information from different sensors and enhances the perception capabilities of the mobile robot.
The DDPG algorithm is employed for the PP experiments of mobile robots, and the TensorFlow DL framework is used to build the deep neural network (DNN) structure of the DRL algorithm. The artificial potential field (APF) is suggested to construct the DRL’s reward function (RF), which aids in achieving successful PP. The outcomes of the experiments indicate that the proposed approach leads to faster convergence of the neural network and higher success rates in completing the PP task.
The key findings of the study demonstrate the effectiveness of integrating DRL and MSIF in mobile robot PP. By autonomously learning and adapting through a trial-and-error approach, the robot acquires the ability to sense the environment and make informed decisions for successful path planning in unknown scenarios. This research contributes to the advancement of mobile robot technology by providing a novel framework for enhancing their perception and decision-making capabilities.
The proposed method offers several advantages. Firstly, it addresses the challenge of enabling mobile robots to autonomously navigate unknown environments, which is a crucial requirement for their widespread deployment. Secondly, by incorporating DRL and MSIF, the method leverages the strengths of both approaches, enabling the robot to effectively fuse information from different sensors and make intelligent decisions based on a comprehensive understanding of its surroundings. Thirdly, the experimental results demonstrate that the proposed approach outperforms existing methods, achieving faster convergence and higher success rates in PP tasks.
In summary, the study makes significant contributions by proposing an integrated approach that empowers mobile robots with autonomous perception and decision-making capabilities in unknown environments. The method combines DRL and MSIF, introduces a multimodal perception module, and utilizes the DDPG algorithm with an APF-based reward function. The outcomes showcase improved performance in terms of convergence and success rates, highlighting the potential of the proposed approach for real-world applications in mobile robot PP.
The findings and contributions of this study provide a solid foundation for future research and development in the field of mobile robot path planning. Building upon the proposed method, there are several potential directions for further exploration and improvement:
Advanced Reinforcement Learning Algorithms: While the study utilizes the DDPG algorithm for mobile robot path planning, there are numerous other advanced reinforcement learning algorithms that could be investigated. Algorithms such as Proximal Policy Optimization (PPO), Trust Region Policy Optimization (TRPO), or Soft Actor-Critic (SAC) could be explored to further enhance the performance and learning capabilities of the mobile robot in unknown environments.
Adaptive Learning and Transfer Learning: Investigating techniques for adaptive learning and transfer learning can contribute to the generalization of the mobile robot’s learned knowledge across different environments. Adapting the model’s policy to new or changing conditions and transferring knowledge gained from one environment to another could enable the robot to quickly adapt and perform effectively in novel scenarios.
Multi-Agent Systems: Extending the research to incorporate multi-agent systems can enable collaborative path planning among multiple mobile robots. Investigating cooperative decision-making and communication protocols between robots can lead to more efficient and coordinated navigation in complex environments.
Real-Time Perception and Planning: Exploring real-time perception and planning strategies can further improve the responsiveness and efficiency of the mobile robot. Investigating techniques such as online sensor calibration, adaptive perception, and fast planning algorithms can enable the robot to handle dynamic and time-sensitive environments.
Integration of Additional Sensor Modalities: While the study focuses on integrating color camera and lidar data, future work could explore the integration of other sensor modalities such as radar, sonar, or infrared sensors. Incorporating additional sensors can provide complementary information and enhance the robot’s perception capabilities.
Robustness and Safety: Addressing the robustness and safety aspects of mobile robot path planning is crucial for real-world applications. Future research can focus on developing techniques to handle uncertain or noisy sensor data, handling dynamic obstacles, and ensuring collision avoidance to enhance the overall safety and reliability of the mobile robot.
Real-World Deployment and Validation: Conducting extensive experiments and validations in real-world environments can further validate the effectiveness and applicability of the proposed method. Evaluating the performance of the mobile robot in diverse and complex scenarios, including various terrains, lighting conditions, and obstacles, can provide valuable insights and practical guidance for real-world deployment.
By exploring these future directions, researchers can continue to advance the field of mobile robot path planning, making significant contributions to autonomous navigation and decision-making in unknown and dynamic environments.
Data Availability Statement
The dataset of this study is available from the corresponding author upon request.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
References
- Azzabi, A., and K. Nouri. 2019. An advanced potential field method proposed for mobile robot path planning [J]. Transactions of the Institute of Measurement and Control 41 (11):3132–2286. doi:10.1177/0142331218824393.
- Bakdi, A., A. Hentout, H. Boutami, A. Maoudj, O. Hachour, and B. Bouzouia. 2017. Optimal path planning and execution for mobile robots using genetic algorithm and adaptive fuzzy-logic control [J]. Robotics and Autonomous Systems 89:95–109. doi:10.1016/j.robot.2016.12.008.
- Chen, Y., G. Luo, Y. Mei, J.-Q. Yu, and X.-L. Su. 2016. UAV path planning using artificial potential field method updated by optimal control theory [J]. International Journal of Systems Science 47 (6):1407–20. doi:10.1080/00207721.2014.929191.
- Gao, J., W. Ye, J. Guo, and Z. Li. 2020. Deep reinforcement learning for indoor mobile robot path planning [J]. Sensors 20 (19):5493. doi:10.3390/s20195493.
- Ge, S., and Y. J. Cui. 2000. New potential functions for mobile robot path planning [J]. IEEE Transactions on Robotics and Automation 16 (5):615–20. doi:10.1109/70.880813.
- He, W., Z. Li, and C. L. P. Chen. 2017. A survey of human-centered intelligent robots: Issues and challenges[J. IEEE/CAA Journal of Automatica Sinica 4 (4):602–09. doi:10.1109/JAS.2017.7510604.
- He, C., H. Z, Y. L, and B. Zeng. 2017. Obstacle avoidance path planning for robot arm based on a mixed algorithm of artificial potential field method and RRT [J]. Industrial Engineering Journal 20 (2):56.
- Jiang, J., X. Zeng, D. Guzzetti, and Y. You. 2020. Path planning for asteroid hopping rovers with pre-trained deep reinforcement learning architectures [J]. Acta Astronautica 171:265–79. doi:10.1016/j.actaastro.2020.03.007.
- Kim, S., M. Han, D. K, and J. H. Park. 2020. Motion planning of robot manipulators for a smoother path using a twin delayed deep deterministic policy gradient with hindsight experience replay [J]. Applied Sciences 10 (2):575. doi:10.3390/app10020575.
- Kovács, B., G. Szayer, F. Tajti, M. Burdelis, and P. Korondi. 2016. A novel potential field method for path planning of mobile robots by adapting animal motion attributes [J]. Robotics and Autonomous Systems 82:24–34. doi:10.1016/j.robot.2016.04.007.
- Li, A., J. Cao, S. Li, Z. Huang, J. Wang, and G. Liu. 2022. Map construction and path planning method for a mobile robot based on multi-sensor information fusion[J]. Applied Sciences 12 (6):2913. doi:10.3390/app12062913.
- Lin, X., J. Wu, A. K. Bashir, J. Li, W. Yang, and M. J. Piran. 2022. Blockchain-based incentive energy-knowledge trading in IoT: Joint power transfer and AI design [J]. IEEE Internet of Things Journal 9 (16): 14685–14698. doi:10.1109/JIOT.2020.3024246.
- Li, Q., Y. Xu, S. Bu, and J. Yang. 2022. Smart vehicle path planning based on modified PRM algorithm [J]. Sensors 22 (17):6581. doi:10.3390/s22176581.
- Nie, J., J. Yan, H. Yin, L. Ren, and Q. Meng. 2020. A multimodality fusion deep neural network and safety test strategy for intelligent vehicles [J]. IEEE Transactions on Intelligent Vehicles 6 (2):310–22. doi:10.1109/TIV.2020.3027319.
- Noreen, I., A. Khan, and Z. Habib. 2016a. A comparison of RRT, RRT*, and RRT*-Smart path planning algorithms [J]. International Journal of Computer Science and Network Security (IJCSNS 16 (10):20.
- Noreen, I., A. Khan, and Z. Habib. 2016b. Optimal path planning using RRT* based approaches: A survey and future directions [J]. International Journal of Advanced Computer Science & Applications 7 (11). doi:10.14569/IJACSA.2016.071114.
- Raja, G., A. Ganapathisubramaniyan, S. Anbalagan, S. B. M. Baskaran, K. Raja, and A. K. Bashir. 2020. Intelligent reward-based data offloading in next-generation vehicular networks[J. IEEE Internet of Things Journal 7 (5):3747–58. doi:10.1109/JIOT.2020.2974631.
- Song, Q., and L. Liu. 2012. Mobile robot path planning based on dynamic fuzzy artificial potential field method [J]. International Journal of Hybrid Information Technology 5 (4):85–94.
- Wang, J., W. Chi, C. Li, C. Wang, and M. Q.-H. Meng. 2020. Neural RRT*: Learning-based optimal path planning [J]. IEEE Transactions on Automation Science and Engineering 17 (4):1748–58. doi:10.1109/TASE.2020.2976560.
- Wang, M., T. Tao, and H. Liu. 2018. Current researches and future development trend of an intelligent robot: A review [J]. International Journal of Automation & Computing 15 (5):525–46. doi:10.1007/s11633-018-1115-1.
- Wang, N., H. Xu, C. Li, and J. Yin. 2021. Hierarchical path planning of unmanned surface vehicles: A fuzzy artificial potential field approach [J]. International Journal of Fuzzy Systems 23 (6):1797–808. doi:10.1007/s40815-020-00912-y.
- Wang, J., T. Zhang, N. Ma, Z. Li, H. Ma, F. Meng, and M. Q.-H. Meng. 2021. A survey of learning‐based robot motion planning [J]. IET Cyber‐Systems and Robotics 3 (4):302–14. doi:10.1049/csy2.12020.
- Xu, R. 2019. Path planning of mobile robot based on multi-sensor information fusion [J]. EURASIP Journal on Wireless Communications and Networking 2019. 1(1):1–8. doi:10.1186/s13638-019-1352-1.
- Yang, Y., J. T. Li, and L. L. Peng. 2020. Multi‐robot path planning based on a deep reinforcement learning DQN algorithm [J]. CAAI Transactions on Intelligence Technology 5 (3):177–83. doi:10.1049/trit.2020.0024.
- Yun, J., J. H. Won, D. K, and E. S. Jeong. 2016. The relationship between technology, business model, and market in autonomous car and intelligent robot industries [J]. Technological Forecasting & Social Change 103:142–55. doi:10.1016/j.techfore.2015.11.016.
- Yu, J., Y. Su, and Y. Liao. 2020. The path planning of mobile robots by neural networks and hierarchical reinforcement learning [J]. Frontiers in Neurorobotics 14:63. doi:10.3389/fnbot.2020.00063.
- Zhang, X., X. Shi, Z. Zhang, Z. Wang, and L. Zhang. 2022. A DDQN path planning algorithm based on experience classification and multi steps for mobile robots [J]. Electronics 11 (14):2120. doi:10.3390/electronics11142120.
- Zhao, M., H. Lu, S. Yang, and F. Guo. 2020. The experience-memory Q-Learning algorithm for robot path planning in the unknown environment [J]. IEEE Access 8:47824–44. doi:10.1109/ACCESS.2020.2978077.