
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Whether a basketball player’s movements are standard or not is a key indicator to evaluate a basketball player and a key point for basketball player training. In order to improve the training effect of basketball players, effective and fast accurate recognition of basketball players’ action trajectories is crucial. In order to solve the problems of inadequate extraction of limb action features and loss of detail information due to multiple scales of limb action features caused by traditional recognition algorithms, an action trajectory recognition algorithm based on the improved EfficientDet-D0 is proposed. The algorithm firstly adds a spatial attention mechanism in the backbone network of EfficientDet-D0, where can locate the limb action trajectory features in the image more accurately. Secondly, in the feature fusion network, in order to describe the high-frequency detail information lost by downsampling, the idea of Laplace pyramid is used to fuse the detail feature maps in the top-down fusion path, and cross-level connections are added to make full use of the feature information of different resolutions, so that the acquired high-level feature map information is richer. Finally, the whole network is trained using the migration learning technique and Adam optimizer. The experimental results show that the model achieves a PCP value (percentage correct parts) of 95.6% on the upper limb pose dataset and takes only 5.34 s for 1000 tests. Compared with the traditional algorithm, it has a higher accuracy rate and stronger robustness, with strong practical applicability, realizing the effective and accurate recognition of basketball players’ upper limb action trajectories in real time.
Introduction
In the training process of basketball players, coaches need to make corresponding training plans for different players in order to improve the training effect. The core concept of modern sports training is precision and efficiency (Selvi and Rajendran Citation2019). If coaches can accurately control the athletes’ posture, the training effect can be greatly improved (Russell et al. Citation2021). Therefore, it is a new research direction to collect and analyze the posture data of basketball players, and to accurately identify the posture of sports to improve the training effect of athletes (Lan and Zhou Citation2022).
Basketball players’ upper limb movement trajectory recognition is one kind of human action recognition. Human action recognition and action evaluation are current research hotspots. Action recognition is to analyze and process the input video or 3D action data to determine which category different actions belong to. Action recognition techniques have practical applications in various industries such as human-computer interaction scenarios, surveillance video, gesture recognition (Beddiar et al. Citation2020), rehabilitation training (Buckthorpe Citation2019), robotics and behavior understanding (Yu et al. Citation2019). Movement evaluation, on the other hand, is a judgment of the quality of the completion of a specific movement. It is generally applied among professional fields such as sports, dance, and tai chi, not only to assist judges and coaches in scoring, but also, more importantly, to help people in movement analysis and training.
Movement recognition and movement evaluation are two concepts that are significantly different (Crowell et al. Citation2020). But at the same time, action recognition and action evaluation are also closely related, and the two have a lot in common in terms of technical processes and methods. Action evaluation often needs to be done on the basis of action recognition.
As early as the 1970s, the motion perception experiments of moving light spots proposed in the literature (Gosztolai et al. Citation2021) confirmed that three-dimensional human motion information could be analyzed with the help of a two-dimensional model. This aroused the interest of many researchers in the study of human motion recognition, and subsequent research works on motion recognition proliferated with remarkable results. On the other hand, research on action evaluation is still in its infancy, and although there are some successful cases, such as golf swings (Severin et al. Citation2022), badminton swings (Pardiwala et al. Citation2020) and other actions in sports, the actions that can be handled are mainly single and highly repetitive ones. For more complex movements, such as competitive aerobics, dance (Vidal, Montoya-Herrera, and Cano Citation2022), Tai Chi (Lin, Bao, and Dong Citation2020), and opera (Wang et al. Citation2019), it is not possible to handle them. For these complex movements, we should not only compare the “appearance similarity,” but also make a breakthrough in the deeper “professional similarity.”
As the amount of information in video networks increases dramatically, traditional machine learning methods such as human joint-based, spatio-temporal interest-based, and dense trajectory-based can no longer meet the growing demand for applications, so the focus of action recognition shifts to deep learning based on video data. Convolutional neural network (CNN) (Kattenborn et al. Citation2021) has achieved excellent results in image classification research, providing a large amount of information for video classification tasks. However, compared to images, video also has the problem of temporal dimension, and how to capture the temporal dimension between adjacent frames of video is the focus of research, and the difficulties are mainly due to.
The complexity of scene information. The complexity of scene information mainly affects the accuracy of action recognition. In different angles, different lighting and different perspectives, the information presented by the scene is often different, and the same human action usually produces more obvious differences. In addition, for the human activity scale is large, different human appearance and human body since the masking, part of the object masking and other issues are also the human action recognition in the scene information complexity of the embodiment, on the action recognition accuracy aspects have a great impact.
Uncertainty of action boundary. For an unedited video, which can include multiple actions, and the duration of each action is different and the speed changes quickly, the action boundary cannot be accurately located in time, and the human action cannot be more finely analyzed in the time domain and time sequence range. However, blurred action boundaries largely diminish the accuracy of action recognition and have a great impact on the efficiency of action recognition.
In recent years, scholars both at home and abroad have been conducting research on limb action recognition. Limb action recognition algorithm usually contains three steps: action segmentation, feature extraction and classification recognition. Action segmentation is the basis of action recognition. Color is the most obvious feature of action, so color feature based on color becomes the method of most action segmentation. Feature extraction of limb range directly affects the recognition accuracy of limb action and is the core of action recognition.
In the literature (Ji, Wei, and Lu Citation2019), the classical convolutional neural network is improved by introducing a tiled convolutional network structure, and the captured images are input to the network for training recognition after image binarization processing. Although this method introduces tiled convolutional networks to reduce the parameters for model training, the network depth is shallow and tiled convolutional networks can lead to severe information loss, resulting in inadequate extraction of action features, which affects the recognition rate.
The literature (Yildirim and Çinar Citation2021) improved and optimized the AlexNet structure in CNN into a 13-layer CNN model for action recognition, but the network computes and then fuses different feature maps separately. The convolution kernel only convolves with a certain part of the feature map, and the model generalization ability is reduced. And the network depth deepens to filter out the subtle disparity of action features. With the development of target detection, many scholars have converted the classification problem of action recognition into a target detection problem. Compared with traditional machine learning algorithms and image processing algorithms, target detection networks based on deep learning tend to obtain higher accuracy rates.
The paper “Towards Adaptive Consensus Graph: Multi-view Clustering via Graph Collaboration” proposes a method for multi-view clustering, which leverages graph collaboration to improve clustering performance. The goal of multi-view clustering is to cluster data instances based on multiple sets of features or views, with the assumption that each view captures different aspects of the underlying data structure. The proposed approach addresses the challenge of effectively integrating information from multiple views to obtain a consensus clustering result. It introduces the concept of an adaptive consensus graph, which represents the collaboration between individual view-specific graphs to capture the shared and complementary information.
The adaptive consensus graph approach allows the integration of complementary information from multiple views, resulting in a more robust and accurate clustering. By considering the collaboration between view-specific graphs, it addresses the challenge of capturing shared and distinct structures across different views. The proposed method has the potential to be applied in various domains where multi-view data is available, such as bioinformatics, social network analysis, or image analysis. It enables effective utilization of multiple sources of information for clustering tasks, leading to improved clustering results compared to using individual views in isolation.
The “Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering” is a research work that introduces a method for multi-view binary clustering by combining auto-encoder hashing and graph collaboration techniques. The goal of multi-view binary clustering is to cluster data instances based on multiple sets of binary features or views.
The proposed approach addresses the challenge of effectively integrating information from multiple views to obtain accurate binary clustering results. It leverages the power of auto-encoder hashing, a technique that maps high-dimensional data into compact binary codes, and incorporates graph collaboration to capture the shared and complementary information among views.
The Graph-Collaborated Auto-Encoder Hashing approach enables the integration of multiple binary views in the clustering process. By combining auto-encoder hashing for binary encoding and graph collaboration techniques, it effectively captures the shared information and complementary characteristics across views, leading to improved binary clustering performance.
This method has potential applications in various domains where multi-view binary data is available, such as document clustering, image analysis, or social network analysis. By leveraging the advantages of auto-encoder hashing and graph collaboration, it facilitates the clustering of binary data from multiple sources, resulting in more accurate and comprehensive clustering results.
The “Kernelized Multiview Subspace Analysis by Selfweighted Learning” and “Attribute-Guided Feature Learning Network for Vehicle Re-Identification” are two separate research works that propose methods for vehicle re-identification, a task that involves matching and recognizing vehicles across different cameras or instances.
1. Kernelized Multiview Subspace Analysis by Selfweighted Learning: This work focuses on learning discriminative representations for vehicle re-identification by exploiting multiple views of vehicle images. The method utilizes kernelized multiview subspace analysis, which aims to project the data into a lower-dimensional space while preserving the discriminative information across multiple views. The key contributions of this work include:
Kernelized Multiview Subspace Analysis: The method constructs a kernel matrix for each view and performs subspace learning on each kernel matrix to obtain view-specific subspaces. By employing kernels, the method can capture nonlinear relationships and better preserve the structure of the data.
Selfweighted Learning: A self-weighted learning strategy is introduced to assign adaptive weights to the training samples based on their similarity. This approach helps to alleviate the influence of noisy or irrelevant samples and focuses more on informative samples during the subspace learning process.
By combining kernelized multiview subspace analysis and self-weighted learning, the proposed method aims to improve the discriminative power of the learned representations for vehicle re-identification.
2. Attribute-Guided Feature Learning Network for Vehicle Re-Identification: This work focuses on learning discriminative features from vehicle images using attribute-guided feature learning. It utilizes attributes or semantic descriptions associated with vehicles to guide the feature learning process. The attributes provide additional semantic information about the appearance, shape, or color of vehicles. The main contributions of this work include:
Attribute-Guided Feature Learning: A deep neural network architecture is designed to learn vehicle features guided by the attribute information. The network leverages both the visual appearance and the attribute information to extract discriminative features for vehicle re-identification.
Attribute Attention Module: An attribute attention module is introduced to emphasize the relevant attributes for each vehicle instance. This module helps the network to focus on the most discriminative attributes during the feature learning process.
By incorporating attribute guidance and attention mechanisms, the proposed method aims to enhance the discriminative power of the learned features and improve the accuracy of vehicle re-identification.
Both of these research works address the challenge of vehicle re-identification by proposing methods that can effectively learn discriminative representations from multiple views or utilize attribute information to guide the feature learning process. These methods contribute to the development of more accurate and robust vehicle re-identification systems, which have applications in areas such as surveillance, transportation, and security.
The mainstream algorithmic frameworks for target detection are broadly divided into Twostage and Onestage. twostage algorithms are represented by the RCNN series. onestage algorithms are represented by the YOLO series and SSD algorithms, etc. The literature (Krišto, Ivasic-Kos, and Pobar Citation2020) uses the improved Faster RCNN to achieve the detection and recognition of limb movements, but the Faster RCNN is the TwoStage target detection algorithm. It first goes through the region generation network (RPN) to generate a series of region candidate frames and then enters the classification network. Therefore, although this algorithm has high accuracy, it is computationally intensive, has a large model, and has a slow detection speed. The improved YOLO algorithm was applied to action recognition in the literature (Chen et al. Citation2020) and achieved very good results.
The literature (Liu et al. Citation2021) proposed a limb action recognition method by improving the relevant parameters in the SSD model and training it with the application context of limb action interaction. This method passes through only one network after the input image, and the generated results contain both location and category information. Although this structure is fast, it suffers from inaccurate localization, poor detection of very small objects and objects close to the camera, and its recall is not as good as that of the region generation network-based approach.
Recently, EfficientDet (Mekhalfi, Nicolò, and Bazi Citation2021) overcame these drawbacks and achieved state-of-the-art performance on the object detection task, with a 10-fold improvement in efficiency on the object detection task. In addition, in the process of deepening the number of network layers, the perceptual field of pixel-level features is not enough, which leads to poor BiFPN fusion effect.
To address the above problems, this paper designs and increases the spatial attention mechanism, pays more attention to the multi-scale limb action features, increases the fusion of detailed feature maps in the feature fusion network, and increases the cross-level connectivity.
The highlighted contribution can be summarized as follows:
Proposed Action Trajectory Recognition Algorithm: The contribution lies in the development of an action trajectory recognition algorithm based on the improved EfficientDet-D0. This algorithm aims to address the limitations of traditional recognition algorithms, specifically related to inadequate extraction of limb action features and loss of detail information caused by multiple scales of limb action features.
Spatial Attention Mechanism: The algorithm incorporates a spatial attention mechanism in the backbone network of EfficientDet-D0. This addition allows for more accurate localization of limb action trajectory features within the image. By improving the localization accuracy, the algorithm enhances the ability to recognize and analyze basketball players’ movements.
Laplace Pyramid-based Feature Fusion: To capture high-frequency detail information lost through downsampling, the algorithm utilizes the concept of Laplace pyramid in the feature fusion network. This approach helps fuse the detail feature maps in the top-down fusion path, enabling a more comprehensive representation of the limb action features. Additionally, cross-level connections are introduced to leverage feature information of different resolutions, resulting in richer high-level feature map information.
Training Technique and Optimization: The algorithm utilizes migration learning technique and Adam optimizer to train the entire network. This training approach enhances the network’s ability to recognize and interpret basketball players’ upper limb action trajectories accurately and efficiently.
Experimental Results: The algorithm’s performance is evaluated through experiments. The results demonstrate its effectiveness and practical applicability. It achieves a PCP value of 95.6% on the upper limb pose dataset, indicating a high accuracy rate in recognizing basketball players’ upper limb actions. Furthermore, the algorithm demonstrates real-time capability, with a processing time of only 5.34 seconds for 1000 tests.
Overall, the highlighted contribution focuses on the development of an improved action trajectory recognition algorithm specifically tailored for basketball players. This algorithm offers enhanced accuracy, robustness, and real-time recognition capabilities, making it a valuable tool for evaluating basketball players and improving their training effectiveness.
Methodology
The EfficientDet-D0 algorithm is divided into three main parts. The first part consists of EfficientNet-B0 (Gorji et al. Citation2022) as the backbone feature extraction network. The second part is a bi-directional feature fusion network. It performs multiple top-down and bottom-up feature fusions for the output features of layers 3–7 of the backbone feature extraction network. The third part is the classification prediction network, which performs regression classification of the target. The network structure is shown in .
Figure 1. Network structure diagram.
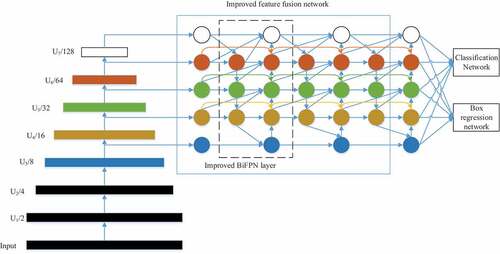
A box regression network, also known as a bounding box regression network, is a type of neural network architecture used in object detection tasks. The purpose of a box regression network is to predict the precise location and size of bounding boxes around objects within an image.
Object detection involves not only identifying the presence of objects but also accurately localizing them within the image. A bounding box is a rectangle that tightly encloses an object, typically represented by four coordinates: the x and y coordinates of the top-left corner and the x and y coordinates of the bottom-right corner.
In a box regression network, the input is an image, and the output is a set of predicted bounding boxes for the objects in the image. The network is typically designed to have both convolutional and fully connected layers, enabling it to extract features from the input image and learn to regress the bounding box coordinates.
During training, the network is provided with a labeled dataset where each image is annotated with the ground truth bounding box coordinates for the objects present. The network learns to minimize the discrepancy between its predicted bounding boxes and the ground truth coordinates using a loss function such as mean squared error or smooth L1 loss.
The architecture of a box regression network can vary depending on the specific object detection framework being used. One common approach is to combine a convolutional neural network (CNN) for feature extraction with additional layers for bounding box regression. The CNN processes the image to extract high-level features, which are then passed through fully connected layers to predict the bounding box coordinates.
Box regression networks are often used in conjunction with other components, such as a classification network, to build a complete object detection system. These systems typically involve a two-stage process: first, a set of regions of interest (RoIs) is proposed using a region proposal network (RPN), and then the box regression network refines the proposed bounding boxes to improve their accuracy.
Overall, box regression networks play a crucial role in object detection tasks by enabling accurate localization of objects within images, making them an essential component of many state-of-the-art object detection systems.
Improved Feature Extraction Network
In the training process of deep learning model, the most common way to improve the accuracy of the model is to expand the network width, deepen the network depth and increase the resolution of the input image.EfficientNet can achieve the appropriate effect on the expansion of the depth, width and resolution of the network, and then obtain good model performance. The calculation formula is.
whererepresents the concatenated multiplication operation. F denotes the base network layer. x denotes the number of network layers.
denotes the network depth. I denotes the input feature matrix.
denotes the height, width and number of channels of I. d is used to scale the depth. m is used to scale the channels of the feature matrix. r is used to scale the resolution. They are denoted separately as follows.
Because the floating point operations per second of regular convolutional operations are proportional to d, m2 and r2. The restriction of Equationequation (2)(2)
(2) is as follows.
The resources can be adjusted according to the model. The parameters are optimally adjusted by Neural Architecture Search (NAS) if the constraints are satisfied.
The EfficientNet backbone is essentially a series of convolutional blocks (MBConv Blocks), as shown in . In this paper, a Spatial Attention Block (Spatial Block) is introduced after the SE Block (Hu and Wang Citation2020) in each MBConv Block. In the action dataset, some of the upper limbs in the dataset account for a small percentage, adding spatial domain attention can more accurately locate smaller upper limb positions and improve the accuracy of detection. The formula for the Spatial Attention Block is shown in EquationEquation (4)(4)
(4) .
Figure 2. Structure of MBConv Block.
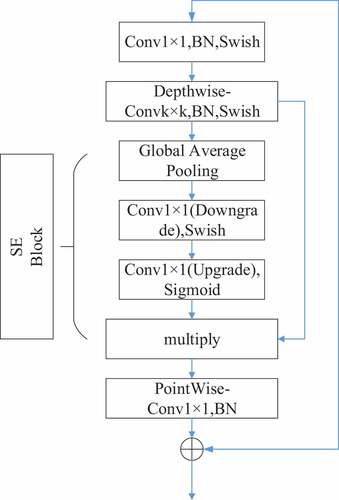
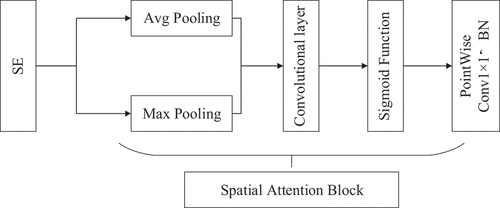
where x denotes the specific spatial domain. denotes the spatial attention feature. σ denotes the Sigmoid function. AvgPool and MaxPool denote the average pooling and maximum pooling operations, respectively.
The implementation of the spatial attention module is shown in . After the Sigmoid function, the spatial attention feature is finally generated, and then the point convolution operation in the original MBConv Block is performed.
Figure 3. Spatial attention module diagram.
Feature Fusion of Laplace Pyramid
The purpose of feature fusion is to merge the original features extracted from the image into one feature that is richer than the input features, thus making the features more discriminative. Most feature fusion in previous detection algorithms used top-down feature pyramid networks (FPNs) (Li, Wei, and Li Citation2020). It has the drawback of unidirectional fusion of information flow. Bi-directional feature fusion network (BiFPN) enables information to flow in top-down and bottom-up directions, using weighted feature fusion to aggregate features at different resolution scales.
The BiFPN is a neural network architecture that aims to capture both local and global context information by fusing features in a bidirectional manner. It is commonly used in computer vision tasks such as image classification, object detection, and semantic segmentation.
The BiFPN architecture consists of two pathways: a forward pathway and a backward pathway. The forward pathway processes the input data in a typical feed-forward manner, extracting features at different levels of abstraction. On the other hand, the backward pathway takes the features from the higher levels and progressively refines them by incorporating contextual information from the lower levels.
The key idea behind the BiFPN is to exploit the hierarchical structure of the features and capture both local and global information. The forward pathway captures low-level details and local context, while the backward pathway incorporates high-level semantic information and global context. By combining features from both pathways, the BFFN aims to achieve a more comprehensive understanding of the input data.
The fusion of features between the forward and backward pathways is typically performed at multiple levels or scales. This allows the network to integrate information from different spatial resolutions and effectively capture both fine-grained details and global contextual cues.
The fusion operation itself can take various forms. One common approach is to concatenate the features from the forward and backward pathways along the channel dimension. This creates a multi-scale feature representation that combines local and global information. The fused features are then further processed by additional layers to make final predictions or generate segmentation maps.
The BiFPN architecture can be customized and adapted to different computer vision tasks. For instance, in object detection, the fused features can be used for region proposal generation or refined bounding box regression. In semantic segmentation, the fused features can be used to produce pixel-wise class predictions.
In the BiFPN, the inputs depend on the specific task or application for which the network is designed. However, in general, the BiFPN takes images or feature maps as inputs.
For image-based tasks such as image classification or object detection, the BiFPN takes raw pixel data as input. The input images are typically represented as multi-channel tensors, where each channel corresponds to a different color channel (e.g., RGB images have three channels). These images are fed into the network, and the BiFPN architecture extracts features from the input images using convolutional layers.
For tasks such as semantic segmentation, where the goal is to assign a label to each pixel in an image, the input to the BiFPN is usually feature maps. Feature maps are intermediate representations obtained from a convolutional neural network (CNN) that processes the input image. These feature maps capture the spatial and semantic information of the image at different levels of abstraction. Each pixel in the feature maps contains a vector of feature values.
In the BiFPN, the feature maps are passed through the forward pathway and the backward pathway to capture local and global context information, respectively. The fusion of features occurs at multiple levels or scales, where the features from the forward and backward pathways are combined or concatenated to create a fused representation. The fused features are then further processed by additional layers to make final predictions or generate segmentation maps.
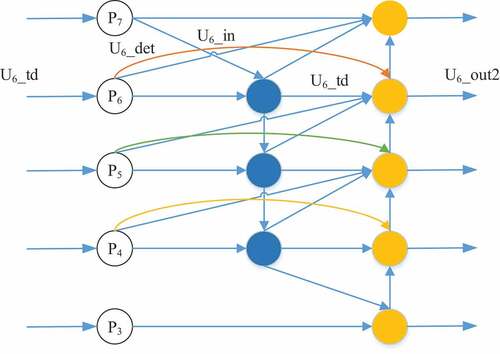
Its output can be used as the input of the next BiFPN. The improved feature fusion network is shown in . Ux is the feature map in the backbone network at resolution 1/2x of the input image. Where U3-U5 is obtained from the backbone network. U6 and U7 are obtained by down-sampling twice. U6_det indicates the obtained detailed feature map.
Figure 4. The improved BiFPN map.
In order to describe these high frequency information, this paper uses the idea of Laplacian Pyramid (LP) to obtain the detail information. The mathematical definition of the x-th layer of Laplacian Pyramid is.
Where, denotes the image of the x-th layer. And the
operation is to map the pixels at position (i, j) in the source image to the (2i + 1, 2j + 1) position of the target image, i.e., to perform up-sampling. The symbol ⊗ denotes convolution and
is a 5 × 5 Gaussian kernel.
In this paper, the top-down fusion path (blue connecting line in ) containing the up-sampling operation is performed as follows. The implementation flow is shown in (taking U6 as an example).
Figure 5. Top-down feature fusion.
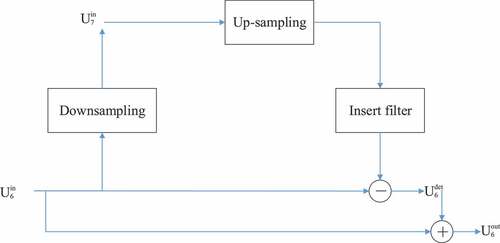
Up-sampling and Gaussian convolution are performed on the previous layer of images.
The image obtained in the previous step is subtracted from the image of the previous layer to obtain a series of detail images.
The detail images are calculated as follows.
(3) Use the previous layer image plus the detail image to get the feature after enhancing the details.
That is, the blue connecting line in is no longer simply up-sampled from the previous layer and then fused with the previous layer; instead, it is up-sampled and Gaussian convolved to calculate the feature difference with the previous layer and then fused with the previous layer. As shown in EquationEqs. (7)(7)
(7) , (Equation8
(8)
(8) ) and (Equation9
(9)
(9) ).
is the output with added detail features, x ∈ (3–7).
where is the
with added weights and activation functions. It is a simple attention mechanism that gives different weights to different parts and represents the output of the intermediate level of the first BiFPN. It is shown in Equationequation (10)
(10)
(10) , which is the solid blue circle in . This part of this paper only uses the output of the sixth layer as an example, and the outputs of other layers are similar.
,
denote the weights of the feature maps. ε is a coefficient set to prevent the denominator from being zero, and is taken as 0.001 in this paper. Upsample denotes upsampling.
In order to make fuller use of the semantic and positional information of different levels, two levels of cross-level connections (purple and green lines in ) are added to the original BiFPN to make full use of the feature information of different resolutions, thus making the acquired high-level feature map information richer. The low-level feature maps of the first two levels are added in each BiFPN downsampling operation. Finally, the obtained high-level feature maps are fed into the classification regression network for prediction. Its calculation formula is shown in Equationequation (11)(11)
(11) .
similarly, as shown in Equationequation (11)
(11)
(11) , denotes the final stage output of the first BiFPN, i.e., the yellow solid circle in , and Downsample denotes downsampling.
Algorithm Optimization Strategy
In deep learning, the knowledge learned by a neural network from one task can be applied to another related independent task. In the treatment of inter-class imbalance problems, migration learning is one approach to machine learning.
Migration learning, also known as domain adaptation or transfer learning, is a machine learning technique that addresses the challenge of leveraging knowledge gained from one domain (source domain) to improve performance on a different but related domain (target domain). It aims to overcome the domain shift problem, where the statistical characteristics of the training data and the test data differ.
In traditional machine learning, models are typically trained and evaluated on data from the same distribution. However, in real-world scenarios, it is common to encounter situations where the training and test data come from different distributions. This can happen due to variations in data collection settings, different sensors, environmental conditions, or other factors.
Migration learning techniques aim to adapt or transfer the knowledge learned from the source domain to the target domain by minimizing the discrepancy between them. The underlying assumption is that although the source and target domains are different, they share some common underlying structure or information.
There are different approaches to migration learning, including:
Feature-based methods: These methods aim to align the feature representations of the source and target domains. They extract domain-invariant features that are robust to domain variations. This can be achieved through techniques like domain adversarial training, where a feature extractor is trained to confuse a domain discriminator while performing a primary task.
Instance-based methods: These methods focus on reweighting or selecting instances from the source domain that are similar or relevant to the target domain. This can involve techniques such as importance weighting, where the source domain instances are weighted based on their relevance to the target domain.
Model-based methods: These methods adapt the model itself to the target domain. They typically involve fine-tuning the pre-trained model on a small amount of labeled data from the target domain. This allows the model to adapt its learned representations to the target domain while leveraging the knowledge from the source domain.
The choice of migration learning approach depends on the specific problem, available data, and the nature of the domain shift. It is crucial to carefully design the adaptation process to ensure effective transfer of knowledge from the source domain to the target domain while avoiding overfitting or underfitting to either domain.
Migration learning has found applications in various domains, including computer vision, natural language processing, and speech recognition. It enables the utilization of existing knowledge to improve model performance in scenarios where collecting labeled data in the target domain may be expensive, time-consuming, or impractical.
Migration learning can be performed on models trained in relatively balanced datasets, and good results have been obtained by removing the last layer of the network of pre-trained models trained on large datasets and transposing the feature vectors extracted from the convolutional layer of the pre-trained models to train the new classifier when training a new model.
Result Analysis and Discussion
The characteristics of basketball players’ upper limb action trajectories pictures can be analyzed with emphasis on the following aspects:
Range of Motion: The upper limb action trajectories of basketball players encompass a wide range of motion. They involve various movements such as shooting, dribbling, passing, blocking, and rebounding. Each of these actions has its own distinct trajectory pattern, which can be captured and analyzed from the pictures.
Dynamic and Fluid Movements: Basketball players’ upper limb actions exhibit dynamic and fluid movements. The trajectories depicted in pictures often show smooth curves or arcs, indicating the continuous flow of motion during actions like shooting or passing. These trajectories reflect the coordinated and agile nature of basketball player movements.
Acceleration and Deceleration: Basketball players frequently engage in rapid acceleration and deceleration during their upper limb actions. This can be observed in the pictures by examining the curvature and steepness of the trajectory. Quick changes in direction or speed can signify explosive movements or changes in momentum during actions like driving to the basket or changing direction while dribbling.
Joint Flexibility: The flexibility of basketball players’ upper limb joints plays a crucial role in their actions. Pictures of upper limb trajectories can reveal the extent of joint flexibility, such as the range of motion in the shoulder, elbow, and wrist. This information can provide insights into the player’s ability to execute different techniques and perform precise movements.
Shot Arc and Release Point: For shooting actions, the trajectory of the ball as it leaves the player’s hand is particularly important. Pictures capturing the upper limb action trajectories can help analyze the shot arc and release point. The arc can vary depending on the shooting technique, distance from the basket, and player’s shooting style, while the release point can indicate the player’s shooting accuracy and consistency.
Body Mechanics and Biomechanics: Upper limb action trajectories pictures can offer insights into the basketball player’s body mechanics and biomechanics. The alignment and positioning of the upper limbs, along with the overall body posture, contribute to the trajectory patterns. Analyzing these trajectories can help identify areas for improvement in terms of technique, balance, and efficiency of motion.
Variation and Adaptability: Basketball players exhibit a wide range of upper limb action trajectories due to the varying game situations and defensive strategies they encounter. Analyzing the pictures can reveal the player’s ability to adapt their upper limb movements to different scenarios, such as adjusting the angle of a pass to avoid a defender or altering shooting techniques based on defensive pressure.
By analyzing these characteristics in basketball players’ upper limb action trajectory pictures, coaches, trainers, and researchers can gain valuable insights into players’ skills, techniques, efficiency, and areas for improvement. This analysis can further aid in developing tailored training programs, refining player performance, and enhancing overall gameplay.
The equipment used for the experiments in this paper is a computer with 8 G RAM and NVIDIA GTX1050-Ti, and the deep learning framework used is tensor flow 1.8.0. The four algorithms used for comparison are shown in .
Table 1. List of compared algorithms.
Experimental Dataset
The first dataset is the LSP (leeds sports pose dataset) dataset. The 2nd dataset is an upper limb pose dataset filtered and organized from AI challenger’s pose estimation dataset. There are 64,304 samples after the screening, and each sample contains the 2D coordinate annotations of eight human bone nodes. These bone nodes are head, neck, left and right wrist, left and right shoulder, and left and right elbow.
Experimental Setup
The LSP contains a total of 2000 images of sports, of which 1000 are used for training and the other 1000 are used for testing. The gradient optimization algorithm used for training is the RMSprop (root mean square propagation) algorithm and mini-batch gradient descent. The global learning rate was set to 1e−3, the decay coefficient to 0.9, and the mini-batch to 30.
For the upper limb pose dataset, a total of 64,304 samples were screened. To meet the training needs, they are divided into three parts, namely, training set, validation set and test set, in the ratio of 8:1:1. The gradient optimization algorithm used for training is RMSprop algorithm and mini-batch gradient descent. The global learning rate was set to 1e−3, the decay coefficient to 0.9, and the mini-batch to 36. PCP (per centage correct parts) criterion is widely used in the evaluation of the accuracy of human pose estimation for evaluation. This criterion is also used as an evaluation index for the experimental results in this section.
Pose Estimation on the LSP Dataset
In this paper, we follow the literature (Li, Wei, and Li Citation2020) to calculate the PCP values for different methods on the LSP dataset. As shown in . The upper arm, forearm, thigh and calf each have two PCP values on the left and right side.
Table 2. PCP values of the components of the four methods on the LSP dataset %.
According to the analysis of the results in , the average PCP value of the proposed method in this paper reached 70.8%, which is 4.7% higher than the PCP value of literature (Cavallari, Golodetz, and Lord Citation2019) (66.1%), but when compared with the other two methods, it can be found that the value is 12.7% less than literature (Wang et al. Citation2019) (83.5%) and 14.5% lower than literature (Silva et al. Citation2019) (85.3%) 14.5%. After analysis, it was found that the reason for this result is that the number of joints provided by the LSP dataset is 14, and the experiment is a single human full-body pose estimation, while the proposed algorithm in this paper has a weak feature extraction capability and shows a weakness for the estimation task with a large number of joints and complex samples of pose.
In addition to the above experiments, the proposed algorithm needs to be experimented and analyzed by the number of parameters and operation efficiency. In this experiment, the number of parameters and the elapsed time of the same sample tested 1000 times are counted for the four methods to perform the pose estimation task on the LSP dataset, and the average value is taken after repeating the experiment five times to ensure the credibility of the experimental results.
According to the results in , the number of parameters of the proposed method is 2,863,370, which is 29.5%, 17.3% and 13.2% of that of literature (Wang et al. Citation2019), literature (Silva et al. Citation2019) and literature (Cavallari, Golodetz, and Lord Citation2019), respectively. The time consumption statistics of Literature (Wang et al. Citation2019) (27.62s) and Literature (Silva et al. Citation2019) (178.30s) are 3.72 times and 24.0 times of the proposed method, respectively. Although these two methods obtain better estimation results, the increased elapsed time of the pose estimation task reduces more performance.
Table 3. Number of parameters and time to test 1000 times for the four methods.
Pose Estimation on the Upper Limb Pose Dataset
Each image of this dataset was processed to retain 2D coordinates of only eight joints of the human upper limbs, which include the head, neck, left and right wrists, left and right elbows, and left and right shoulders. These eight upper limb joint points were divided into seven parts to meet the evaluation criteria of PCP: left upper arm, right upper arm, left lower arm, right lower arm, left shoulder, right shoulder, and head. The experimental results of the four algorithms on this dataset are recorded in .
Figure 6. PCP values of the four methods on the upper limb posture dataset.
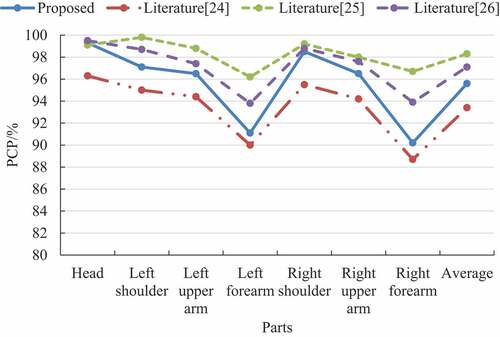
According to the analysis of the results in , it can be seen that the average PCP value of the proposed methods in this paper on the upper limb pose dataset reached 95.6%, which is 1.5% less than literature (Wang et al. Citation2019) (97.1%), 2.7% lower than literature (Silva et al. Citation2019) (98.3%), and 2.2% higher than the average PCP value of literature (Cavallari, Golodetz, and Lord Citation2019) (93.4%). The comparative analysis between and shows that the average PCP values of the pose estimation tasks of the four methods improve when the number of sample nodes performing human pose estimation is reduced from 14 to 8, and the gap between the proposed method and the literature (Wang et al. Citation2019) and literature (Silva et al. Citation2019) methods is further reduced.
The proposed algorithms will be analyzed by the number of parameters and operation efficiency in the following. As shown in , the number of parameters of proposed algorithms is reduced by 43% to 1,636,470 compared with , which is caused by the structure of the model itself, the number of nodes to be estimated is reduced from 14 to 8, and the number of parameters of the proposed method is also reduced exponentially. In terms of time consumption, the time consumption statistics of literature (Wang et al. Citation2019), literature (Silva et al. Citation2019) and literature (Cavallari, Golodetz, and Lord Citation2019) are 5.03 times, 33.25 times and 43.14 times higher than those of this paper, respectively, which are almost the same as the experimental findings on the LSP dataset.
Table 4. Number of participants and time to test 1000 times for the four methods.
The algorithm demonstrates superior performance based on the following indications:
Experimental Results: The paper states that the algorithm’s performance was evaluated through experiments. It achieved a PCP value (percentage correct parts) on the upper limb pose dataset. This high accuracy rate suggests that the algorithm is effective in recognizing and accurately capturing the upper limb action trajectories of basketball players.
Comparison with Traditional Algorithms: The paper indicates that the proposed algorithm outperforms traditional algorithms. While the exact comparison metrics are not specified, the claim of higher accuracy and stronger robustness implies that the proposed algorithm achieves better results in terms of correctly identifying and interpreting the basketball players’ upper limb action trajectories.
Practical Applicability: The algorithm is described as having strong practical applicability. This suggests that it is not only accurate but also performs well in real-world scenarios, implying that it can handle different variations and challenges commonly encountered in basketball player action recognition tasks.
Efficient Processing Time: This indicates that the algorithm is capable of processing a significant number of action trajectory recognition tasks within a short time frame, contributing to its efficiency and suitability for real-time applications.
Overall, the higher accuracy and stronger robustness of the proposed algorithm are reflected through the experimentally achieved high PCP value, its superiority over traditional algorithms, its practical applicability, and its efficient processing time. These indicators suggest that the algorithm offers improved performance in accurately recognizing and analyzing basketball players’ upper limb action trajectories compared to existing approaches.
Conclusion
In this paper, we propose to add spatial attention mechanism based on EfficientDet-D0 model, fuse detailed feature maps in feature fusion network and add cross-level connections, use transfer learning technique and Adam optimizer to achieve basketball player upper limb action trajectory recognition, and prove the effectiveness of the method through experiments. The experiments show that the proposed algorithm can be well applied in the public data set and achieves the research objectives of this paper. This paper proposes a two-dimensional coordinate of joint points from RGB pictures for basketball players’ limb movements recognition algorithm. There are some differences between the dataset used in this paper and the actual measured data in real scenes, which will have some effects on the model training and evaluation. However, compared with traditional algorithms, the algorithm in this paper has higher accuracy and stronger robustness, less computation time consuming, and realizes real-time recognition of basketball players’ upper limb action trajectory.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Beddiar, D. R., B. Nini, M. Sabokrou, and A. Hadid. 2020. Vision-based human activity recognition: A Survey[J. Multimedia Tools & Applications 79 (41):30509–2210. doi:10.1007/s11042-020-09004-3.
- Buckthorpe, M. 2019. Optimising the late-stage rehabilitation and return-to-sport training and testing process after ACL reconstruction[J. Sports Medicine 49 (7):1043–58. doi:10.1007/s40279-019-01102-z.
- Cavallari, T., S. Golodetz, and N. A. Lord. 2019. Real-Time RGB-D Camera pose estimation in novel scenes using a relocalisation cascade[J. IEEE Transactions on Pattern Analysis and Machine Intelligence 42 (10):2465–77. doi:10.1109/TPAMI.2019.2915068.
- Chen, C., T. Wang, D. Li, and J. Hong. 2020. Repetitive assembly action recognition based on object detection and pose estimation[J. Journal of Manufacturing Systems 55:325–33. doi:10.1016/j.jmsy.2020.04.018.
- Crowell, H. L., C. Soneson, P. L. Germain, D. Calini, L. Collin, C. Raposo, D. Malhotra, and M. D. Robinson. 2020. Muscat detects subpopulation-specific state transitions from multi-sample multi-condition single-cell transcriptomics data[J. Nature Communications 11 (1):1–12. doi:10.1038/s41467-020-19894-4.
- Gorji, H. T., S. M. Shahabi, A. Sharma, L. Q. Tande, K. Husarik, J. Qin, D. E. Chan, I. Baek, M. S. Kim, N. MacKinnon, et al. 2022. Combining deep learning and fluorescence imaging to automatically identify fecal contamination on meat carcasses[J. Scientific Reports 12 (1):1–11. doi:10.1038/s41598-022-06379-1.
- Gosztolai, A., S. Günel, V. Lobato-Ríos, M. Pietro Abrate, D. Morales, H. Rhodin, P. Fua, and P. Ramdya. 2021. LiftPose3D, a deep learning-based approach for transforming two-dimensional to three-dimensional poses in laboratory animals[J. Nature Methods 18 (8):975–81. doi:10.1038/s41592-021-01226-z.
- Hu, B., and J. Wang. 2020. Detection of PCB surface defects with improved faster-RCNN and feature pyramid network[J. IEEE Access 8:108335–45. doi:10.1109/ACCESS.2020.3001349.
- Ji, S., S. Wei, and M. Lu. 2019. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery[J. International Journal of Remote Sensing 40 (9):3308–22. doi:10.1080/01431161.2018.1528024.
- Kattenborn, T., J. Leitloff, F. Schiefer, and S. Hinz. 2021. Review on convolutional neural networks (CNN) in vegetation remote sensing[J. ISPRS Journal of Photogrammetry and Remote Sensing 173:24–49. doi:10.1016/j.isprsjprs.2020.12.010.
- Krišto, M., M. Ivasic-Kos, and M. Pobar. 2020. Thermal object detection in difficult weather conditions using YOLO[J. IEEE Access 8:125459–76. doi:10.1109/ACCESS.2020.3007481.
- Lan, T., and W. Zhou. 2022. Improved siamese network-based 3D motion tracking algorithm for athletes[J. Mobile Information Systems 2022:1–9. doi:10.1155/2022/8341442.
- Lin, M., J. Bao, and E. Dong. 2020. Dancing in public spaces: An exploratory study on China’s grooving grannies[J. Leisure Studies 39 (4):545–57. doi:10.1080/02614367.2019.1633683.
- Liu, C., J. Ying, H. Yang, X. Hu, and J. Liu. 2021. Improved human action recognition approach based on two-stream convolutional neural network model[J. The Visual Computer 37 (6):1327–41. doi:10.1007/s00371-020-01868-8.
- Li, M., F. Wei, and Y. Li. 2020. Three-dimensional pose estimation of infants lying supine using data from a kinect sensor with low training cost[J. IEEE Sensors Journal 21 (5):6904–13. doi:10.1109/JSEN.2020.3037121.
- Mekhalfi, M. L., C. Nicolò, and Y. Bazi. 2021. Contrasting Yolov5, transformer, and efficientdet detectors for crop circle detection in desert[J. IEEE Geoscience & Remote Sensing Letters 19:1–5. doi:10.1109/LGRS.2021.3085139.
- Pardiwala, D. N., K. Subbiah, N. Rao, and R. Modi. 2020. Badminton injuries in elite athletes: A review of epidemiology and biomechanics[J. Indian Journal of Orthopaedics 54 (3):237–45. doi:10.1007/s43465-020-00054-1.
- Russell, J. L., B. D. McLean, F. M. Impellizzeri, D. S. Strack, and A. J. Coutts. 2021. Measuring physical demands in basketball: An explorative systematic review of practices[J. Sports Medicine 51 (1):81–112. doi:10.1007/s40279-020-01375-9.
- Selvi, M. S. M., and L. Rajendran. 2019. Application of modified wavelet and homotopy perturbation methods to nonlinear oscillation problems[J. Applied Mathematics and Nonlinear Sciences 4 (2):351–64. doi:10.2478/AMNS.2019.2.00030.
- Severin, C., A. Tackett, S. A, and C. L. Barnes. 2022. Three-Dimensional Kinematics in Healthy Older Adult Males during Golf Swings[J. Sports Biomechanics 21 (2):165–78. doi:10.1080/14763141.2019.1649452.
- Silva, L. J. S., D. L. S. Silva, A. B. Raposo, L. Velho, and H. Côrtes Vieira Lopes. 2019. Tensorpose: Real-time pose estimation for interactive applications[J. Computers & Graphics 85:1–14. doi:10.1016/j.cag.2019.08.013.
- Vidal, A. C., J. Montoya-Herrera, and R. P. Cano. 2022. The ideographic image of Tai Chi Chuan movement score as a training resource for the actor[J. Kepes 19 (25):223–56. doi:10.17151/kepes.2022.19.25.9.
- Wang, R., Z. Cao, X. Wang, Z. Liu, and X. Zhu. 2019. Human pose estimation with deeply learned multi-scale compositional models[J. IEEE Access 7:71158–66. doi:10.1109/ACCESS.2019.2919154.
- Yildirim, M., and A. Çinar. 2021. A new model for classification of human movements on videos using convolutional neural networks: MA-Net[J. Computer Methods in Biomechanics & Biomedical Engineering: Imaging & Visualization 9 (6):651–59. doi:10.1080/21681163.2021.1922315.
- Yu, Z., H. Du, F. Yi, Z. Wang, and B. Guo. 2019. Ten Scientific problems in human behavior understanding[J. CCF Transactions on Pervasive Computing and Interaction 1 (1):3–9. doi:10.1007/s42486-018-00003-w.