
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Automated decision-making techniques play a crucial role in data science, AI, and general machine learning. However, such techniques need to balance accuracy with computational complexity, as their solution requirements are likely to need exhaustive analysis of the potentially numerous events combinations, which constitute the corresponding scenarios. Intuition is an essential tool in the identification of solutions to problems. More specifically, it can be used to identify, combine and discover knowledge in a “parallel” manner, and therefore more efficiently. As a consequence, the embedding of artificial intuition within data science is likely to provide novel ways to identify and process information. There is extensive research on this topic mainly based on qualitative approaches. However, due to the complexity of this field, limited quantitative models and implementations are available. In this article, the authors have extended the evaluation to include a real-world, multi-disciplinary area in order to provide a more comprehensive assessment. The results demonstrate the value of artificial intuition, when embedded in decision-making and information extraction models and frameworks. In fact, the output produced by the approach discussed in their article was compared with a similar task carried out by a group of experts in the field. This demonstrates comparable results further showing the potential of this framework, as well as artificial intuition as a tool for decision-making and information extraction.
Introduction
Problem-solving skills have enabled the human race to thrive throughout the centuries. Despite clear evidence that animals exhibit such skills, only humans have managed to perfect them, which have led to the establishment of several sciences. Rational thinking is one of the main components of science, as logical and methodical approaches have identified new solutions in a replicable and rigorous manner. However, not all discoveries have been solely guided by rationality. Intuitive thinking allows us to find novel ideas, which would not be possible to achieve by using rational approaches.
The ability of identifying alternative paths to new solutions is an important aspect that have been often demonstrated to be crucial in several scientific endeavors Xiaolong et al. (Citation2019), Ray et al. (Citation2018)
As a consequence, artificial intuition is drawing increasing attention from the computational sciences communities, as it is likely to lead to efficient decision-making approaches (Johnny, Trovati, and Ray Citation2020, Shao et al. Citation2017, Trovati et al. Citation2019). Loosely speaking, artificial intuition can be defined as the ability to evaluate a problem within a specific context and discover new connections to enable the automation of decision-making processes (Trovati, Johnny, and Polatidis Citation2022). Moreover, intuition depends on prior knowledge and experiences, which can be used to identify solutions otherwise difficult to discover via ordinary logical process (Dundas and Chik Citation2011).
Artificial intuition and artificial creativity are usually associated with different, but overlapping research areas, where the former aims to discover novel solutions related to specific problems. The objective of the latter, on the other hand, is to achieve “artistic” beauty. Artificial creativity tends to utilize specific machine learning methods by identifying data patterns which constitute beautiful and appealing products. Alternatively, artificial intuition focuses on pinpointing innovative problem-solving solutions. Since the context of the corresponding problems needs to be taken into consideration, their semantic properties must be investigated and assessed.
This article aims to expand and further discuss the approach to artificial intuition introduced in Trovati, Johnny, and Polatidis (Citation2022). In particular, a more comprehensive evaluation will be introduced to demonstrate its applicability and efficiency, based on multi-disciplinary research on how to optimize innovation in organizations (Cullen and De Angelis Citation2021); Bolton, Green, and Kothari (Citation2016) More specifically, the evaluation consists of a real-world case scenario focusing on business innovation. Companies capitalize on new ideas and technologies via different business models. While there are specific channels for exploring and assessing new ideas and technologies, they tend to have limited ability to identify innovative processes to discover new knowledge related to their business models (Chesbrough Citation2010).
In Thomas and Autio (Citation2019), the concept of “innovation ecosystem” is introduced to define the complexity related to the different components of business innovation. More specifically, the authors emphasize that the dynamics of such ecosystem poses challenges in the full understanding and prediction of the most relevant parameters and trends. A a consequence, many information identification steps and decision-making processes are influenced by individual knowledge, as well as intuitive thinking, which is also defined as the gut feeling.
The intrinsic complexity in the identification and analysis of the main parameters which define business innovation demonstrates that this is a valuable and non trivial area to investigate to demonstrate the potential of the approach discussed in this article.
This work is structured as follows: in Section 2, the relevant background is discussed, and Section 3 introduced the core concepts of this work. Sections 4, 5 and 6 discuss the main components of the approach, and their implementation. The evaluation is discussed in Section 7, and finally, Section 8 concludes this work and prompts future research directions.
Figure 1. The overall architecture of this approach. All steps and phases are detailed in Sections 4, 5 and 6.
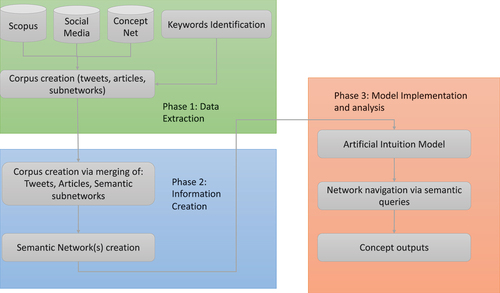
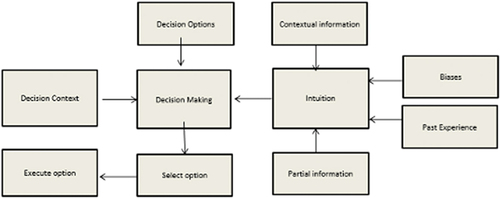
Figure 2. Overview of entrepreneur decision-making process.
Background
The computational and application aspects of intuition have been the focus of extensive multi-disciplinary research.
In Johnny, Trovati, and Ray (Citation2020), the authors introduce a computational model of artificial intuition based on the assumption that specific data patterns can be extracted form prior knowledge related to the domain of the problem. One of the applications of such framework has been identified by Bolton and Cullen (Citation2022) to extract information related to small-medium enterprises (SMEs). SMEs play a crucial global economic role, and in particular the UK economy heavily relies on a healthy ecosystem created by the wealth, opportunities and knowledge generated, shared and augmented by SMEs.
In Simon (Citation1987), the authors discuss managerial decision-making approaches which focus on how intuition is used. In particular, real-time information integrated with intuition can lead to proactive behaviors with respect to the environment, as depicted in .
In Kahneman and Frederick (Citation2002), two fundamental and distinct intuition modes are introduced. These are defined as System 1 (intuition) and System 2 (logic-based reasoning) (Stanovich and West Citation2000). More specifically, System 1 is related to (automatic) thought processes, which require limited attention and is based on prior knowledge. System 2 is a strenuous and controlled type of thinking. Despite System 1 is usually defined by pattern recognition approaches, System 2 requires rational analysis to exhaustively select the most suitable choice.
Clinical decisions are another example of a System 1 approach that consist of the inductive reasoning experiences (Payne Citation2015). However, System 1 approaches might be subject to bias-induced errors when unusual data patterns might occur. According to Liu and Ping (Citation2019), suitable environments and experiences are significant to the learning process, suggesting that past experiences play a crucial role.
In Roger (Citation2003), intuition is defined as the subconscious pattern recognition process where prior knowledge and experience are crucial for the accuracy of any intuition based decision-making process. In Dundas and Chik (Citation2011), the authors present an implementation of human-like intuition where relational relationships connecting experience with associated attributes are implemented. In Srdanov et al. (Citation2017), the authors present an artificial intuition approach via random based optimal path searches. According to Diaz-Hernandez and Gonzalez-Villela (Citation2017), intuition consists of three stages: inputs, processing, and outputs. The authors implement such steps via data collection extracted from human abilities facilitate by intuition; implicit intuitive performance analysis; integration and simulation of intuitive action/reaction steps.
Applications of Artificial Intuition
In this section, an overview of applications of artificial intuition is presented.
Intuition in Clinical Settings
Intuition in clinical practice enables the rapid identification of links between collected information and pattern recognition to unconsciously assess data trends (Billay et al. Citation2007). In Lyneham, Parkinson, and Denholm (Citation2008), the authors argue that intuitive decision-making process within clinical settings exhibit three stages: cognitive, transitional, and embodied intuition. The cognitive stage stems from the integration of experience with clinical knowledge and experience. The transitional intuition stage is the result of cognitive and embodied intuition, and finally the embodied intuition stage is the effect of clinical practitioners’ confidence on their experience and knowledge.
Intuition and Business Decision
There is strong evidence from research that intuition has significant applications in strategic business decision making (Simon Citation1987). In Miller and Ireland (Citation2005), the authors present a study based on behavioral decision-making approaches, and business modeling. The authors argue that executives extensively and consistently employ intuition in their decision making. However, they also argue that intuition can lead to the erroneous conclusions, if not properly utilized and interpreted.
Player’s Intuition in Games
Remembering prior data patterns and quickly superimposing them to relevant scenarios is a crucial feature of artificial intuition. For example, subsequent to completing a game, the most relevant moves tend to be remembered and captured as mental models and represented as semantic networks to capture the mutual (semantic) relationships. In Silver et al. (Citation2016), the authors suggest that the experience of intuitive thinking based on prior knowledge is a likely candidate to a successful model representation.
General Definitions
Intuition involves the identification of new semantic paths, during the process of discovering potential solutions related to a specific problem. Such problems, or queries, consist of mutually connected semantic entities, as defined below.
Definition 3.1
(Definition of Query (Trovati, Johnny, and Polatidis Citation2022).) A query is a group of semantically equivalent concepts, which describes a problem objectives. The solution of a query is defined as the paths joining the query with specific concepts.
The concepts related to a query are defined as the query leaf nodes.
As introduced in Trovati, Johnny, and Polatidis (Citation2022), in this work we shall consider three types of knowledge.
Existing knowledge which is the information related to prior knowledge
Intuitive knowledge, which is linked with general (intuitive) knowledge, and finally
Contextualized knowledge, which is related to individual experience.
Definition 3.2.
We define three types of knowledge:
Network Theory
Let be an undirected network, where
is the set of nodes and
is the set of edges. Many real-world systems are modeled by networks and in particular, by weighted networks, that is networks where each edge
has a weight
. Two nodes are said to be adjacent if they have a common edge and incident edges have a common node. We define a path
between
and
as a sequences of incident edges
joining the two nodes. A network is said to be cyclic if more than a single path can occur between any two nodes.
Semantic networks are specific networks where nodes are defined by concepts, and their mutual edges, as directed binary relations (Brasethvik and Gulla Citation2001). Semantic networks have been widely applied within artificial intelligence, machine learning and natural language processing techniques, as they provide a declarative graphical representation that can be utilized to model and reason about knowledge.
Concepts are associated with other concepts so that prior knowledge can be connected with new one.
In this article, as per Definition 3.2, we define a network defined by the union of three following (typically overlapping) networks
where and
are related to existing, intuitive and contextualized knowledge, respectively.
Each node is defined by a concept and the network topology of the network controls how information is shared.
Phase 1: Data Extraction
As discussed above, in this article we will focus on a specific context, namely innovation in business ecosystems. Innovation is, by definition, the process that allows to discover new and impactful solutions, concepts and their mutual connections depicts the overall architecture of the framework proposed in this article. Usually, it involves “thinking outside the box,” which is based on more than objective and quantifiable knowledge. The gut feeling some individuals might exhibit with respect to specific areas, can lead to novel solutions and ideas. The motivation of using innovation as a test case, also originates from its intrinsic multi-disciplinary definition, which makes it difficult to pinpoint it in a very quantitative manner. In particular, intuitive thinking has been demonstrated to successfully understand and address inconsistent growth in SMEs (Bolton and Cullen Citation2022). This work is also motivated by the attempt to automate such insights.
In this section, the main data extraction process is introduced and discussed. In Trovati, Johnny, and Polatidis (Citation2022), an initial evaluation was described, which suggested the model suggested by the authors could provide an effective approach to a systematic implementation of artificial intuition. In this work, a more comprehensive analysis is introduced based on various large textual datasets, whose integration generates large fragments of semantic networks.
ConceptNet Dataset
The first dataset considered in this article is ConceptNet, which consists of common sense knowledge encompassing various aspects of everyday life. Information used to created ConceptNet has been extracted from multiple sources, such as expert created resources as well as the Open Mind Common Sense corpus, which is a crowd-sourced knowledge project (Liu Citation2004).
In this work, ConceptNet is utilized to find semantic networks as per the following steps:
Identify query concepts
Establish the appropriate network
Integrate it with any other one previously created
Assess the network(s) to enable knowledge discovery pertaining to the query.
An important point to consider, when defining a knowledge graph from ConceptNet, is which (semantic) nodes should be represented, due to the related implications on the network and its use. Furthermore, this has also significant effects on any other resources which might be linked, as well as any corresponding representation (Liu 2004a). Furthermore, statements contain (semantic) concepts, which are connected by a positive or negative weight, where higher (positive) values suggest more reliable corresponding assertions, and negative weights may imply unreliable assertions (Liu 2004a).
Wikipedia, Scopus and Twitter Datasets
ConceptNet still has limited data capture and semantic information and relationships. To augment and complement ConceptNet, Wikipedia was also used, which is a multilingual online encyclopedia (McNeill Citation1994). It is widely utilized in numerous AI and machine learning tasks due to its extensive and free content. To further extend the (textual) dataset used in this work, Scopus (https://www.scopus.com/home.uri) was queried to identify academic articles via based on the following keywords:
Business innovation
Risk
Revenue
Opportunity
Margin
All the above keywords were combined and permuted, and the corresponding synonyms and lexical variants were also considered. This allowed to extract over 500 abstracts, which were subsequently analyzed to extract relevant concepts and dependence relations as described in Trovati et al. (Citation2017).
Text analysis was carried out via SpaCy (https://spacy.io), which included tokenization, lemmatization, POS tagging, Named Entity Recognition (NER) and subsequent syntactic relation extraction. See Trovati et al. (Citation2017) for more details used in this article. Once the textual analysis identified the different concepts and mutual relationships, this naturally defined a graph representation of knowledge (Choi, Tetreault, and Stent Citation2015).
Finally, the same keywords were utilized to extract data from Twitter, which created approximately 600 tweets, via the Twitter Developer API (https://developer.twitter.com/en), which was accessed on 20/12/2023. The authors are aware that Twitter only offers limited data from social networks. In fact, a free account was utilized, restricted capabilities. Furthermore, tweets usually include partial information that could be used to extract precise temporal information to identify a definite timeline. Finally, an in-depth analysis based on social networks should also incorporate information from other platforms, such as LinkedIn, Facebook, as well as general blogs. However, the motivation to use Twitter was to initialize and partially simulate intuitive knowledge, which, by definition, may not have a framework as rigorous and well- developed as other types of knowledge (??).
The tweets were downloaded as a CSV file and subsequently, they were manually pre-processed to remove any inconsistent or redundant tweet, as well as any duplicated one. Furthermore, any non-ASCII characters were removed to allow the creation of a new CSV text file, suitable for the subsequent text analysis. A similar textual analysis as per above was conducted. The different knowledge graphs created a single (overlapping) network, whose nodes and connections were labeled depending on their source, that is ConceptNet, Scopus, Wikipedia and Twitter, respectively.
The rationale behind the choice of the above data sources was to simulate the three types of knowledge introduced in Definition 3.2. Namely, Twitter data was associated with intuitive knowledge, Wikipedia and ConceptNet with existing knowledge, and academic articles (extracted via Scopus) with contextualized knowledge. The authors acknowledge that other (perhaps, even better) datasets could have been selected. However, based on their availability, suitability and wide usage within the AI and machine learning research community, the above data sources were deemed to be sufficiently justified and appropriate.
The above steps generated a large of amount of textual data, which had to be pre-processed and analyzed to ensure the format is fully compatible and integrated. This is discussed in the following section.
Phase 2: Information Creation
As discussed above, the data identified in Section 4, consists of fragments of texts, pairs of concepts linked by semantic relationships, as well as further keywords. In order to generate a navigable network, the different concepts had to be linked by suitable semantic relations which, if not explicitly defined, had to be identified from the different textual fragments.
A group of keywords (and corresponding synonyms) related to semantic relations was manually identified, which include (but not limited to):
Cause
Depend (on)
Based (on)
Influence
Impact
Induce
Stimulate
Count (on)
Act (on)
Regulate
Affect
The identified text fragments (containing relevant concepts and/or relational links) were pre-processed and lemmatized to ensure they were uniform and spurious words and punctuation were removed. The concepts identified were coupled, which naturally define edges, based on whether they were linked by a relational link or whether they occurred in the same sentence. More details can be found in Trovati et al. (Citation2017).
The presence of any of the above relations linking paris of concepts (nodes) would entail a stronger relation type (being explicitly linked by a dependency relation) compared to the latter, which only depends on co-occurrence properties. The strength of each edge also depends on how many times such couples occur in the texts. As mentioned above, the different networks from the datasets described in this section had their nodes and edges labeled accordingly to identify their origin for the algorithm implementation as per Section 6. The resulting network had edges and
nodes and a single connected components. depicts its degree distribution. In particular,
Figure 3. The network and degree distribution of the network defined in Section 5.
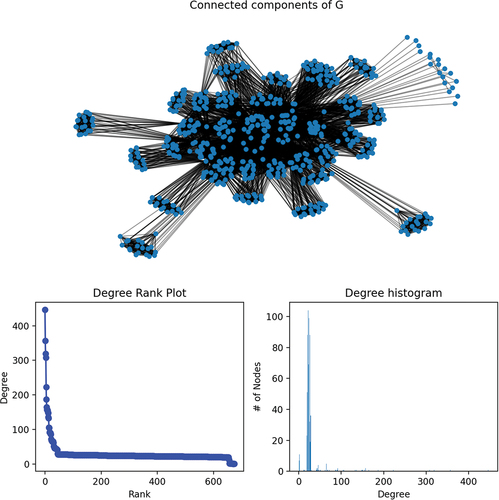
Average Degree: 26.161
Diameter: 4
Average Path length: 2.1068
Density: 0.075, which suggests a sparse graph
In the next section, the model initially introduced in Trovati, Johnny, and Polatidis (Citation2022) is implemented to analyze and assess the approach discussed in this work.
Phase 3: Model Implementation and Analysis
The model initially introduced in Trovati, Johnny, and Polatidis (Citation2022) is based on some definitions and results which will be discussed in this section. First of all, edges have an activation value , measuring the influence between
and
. Every node
has a probability of occurrence
. This is combined with the information propagation to define the post node probability of
with respect to its neighbor
as
The topology of the network can be assessed by algebraically combine the edge attributes via the disjoint, joint and information independence relationships (Trovati, Johnny, and Polatidis Citation2022). More specifically, for ,
is defined as
where
Similarly, is defined as
A path can be written as
. Definition 5 in Trovati, Johnny, and Polatidis (Citation2022), introduces the innovation index between
and
linked by the path
is defined as
where and
refer to the sets of edges in
the edges in
for a path
, respectively. The overall innovation index between
and
, based on the assumption that there are
paths linking them is
Algorithm 1. Solution Assessment Algorithm
Algorithm 1 is subsequently used to identify suitable solutions to a specific query, where
is the propagation index, and the (overall) entropy from is defined as
for all the paths from
.
In particular, can be utilized to explore the query space by allowing to identify:
Whether, from a given network, it is possible to identify one or more solutions based on a query, and
The depth of the network (in terms of the number and lengths of paths originating from the query/concepts) required to reach a feasible solution.
Evaluation of the Model
The evaluation aimed to compare the results of our approach with Bolton and Cullen (Citation2022) to assess whether the same “intuition” could have been replicated using the method discussed in this work. Artificial intuition is a new research area, and as a consequence there are very limited evaluation benchmarks or comparison tests. Furthermore, the multidisciplinary nature of artificial intelligence does not easily allow the use of existing (or new) datasets. Therefore, in this work the experimental evaluation has been independently assessed by a group of experts to understand whether the method introduced in this article yields comparable results with respect to manual assessment.
It is, however, not suggested that this method replicates intuition as such a claim would need to be substantiated by a series of large scale experiments, capturing different concepts and spanning across different topics and contexts. Such endeavor would, in fact, require the creation of large and more sophisticated semantic networks and corresponding models. The discussion included in this article is hopefully leading the general effort in that direction.
Computational intuition can also be viewed as the discovery of new knowledge, which cannot be directly extracted from given data. In other words, the semantic network defined above needs to be assessed based on the algorithm defined in Section 6, to discover semantic connections linking specific concepts. It is important to emphasize that such discovery process needs to identify novel information, which is not trivially identified from the given data. depicts some concepts that have been recently identified in Bolton and Cullen (Citation2022) as important factors linked to business productivity. It is important to point out that the mutual relationships have either not been published, or not included in the articles used in Section 4. As a consequence, any relation discovered via the method introduced in this work is not immediately discoverable.
Table 1. Research Variables Detailed as per (Bolton and Cullen Citation2022), which were used to inform the creation, query and analysis of the data introduction and discussed in Sections 4, 6 and 5.
As a consequence, the concepts in were used to assess the method introduced in this article with respect to business productivity. More specifically, the concepts which are non trivially related to it include clear objectives and priorities; data collection; technology adoption; business age; performance assessment and reactive strategic innovation, as shown in .
Table 2. The experimental results as discussed in Section 7.
All these concepts were normalized and grouped into semantically equivalent nodes to ensure they were captured by the network created. For example, clear objectives and priorities were simplified as objective and priority. This query pre-processing was carried out automatically and subsequently manually verified to ensure that the identified nodes were semantically and lexically as close to the original concept as possible.
Despite a relatively small set of relations described in , the overall process was based on extensive textual analysis and investigation, which was manually assessed and evaluated by a group of approximately 25 experts, including business practitioners, researchers and analysts (including the authors of (Bolton and Cullen Citation2022), who routinely complement their practical and academic research with intuitive thinking to identify data trends and insights, which are often hidden in the data. These individuals are part of the Edge Hill University Productivity Innovation Research Center (https://www.edgehill.ac.uk/departments/support/e3i/supporting-business/pic/), which aims to identify, assess, and facilitate business innovation across UK SMEs. The members of this center (who include some of the authors, as well as business practitioners and academics in various disciplines) collect and digitalize data produced by the center’s activities.
The results were also manually evaluated by experts to assess whether they were aligned with the findings inBolton and Cullen (Citation2022). A notable instance is business age, as it is not a trivial association with business productivity. This was reflected by a relatively high innovation index, suggesting an “intuitive solution” with respect to the overall knowledge.
The experimental evaluation, based on a much more comprehensive data from various sources compared to Trovati, Johnny, and Polatidis (Citation2022) has again demonstrated the potential of this method. The evaluation was also performed on innovative research, which has been carried out within business productivity. The aim was to enable a scientifically sound and academically justified evaluation, which was independently confirmed by experts.
Discussion and Conclusions
Artificial intuition has been demonstrated to have significant potential in automated decision-making approaches. However, the development, implementation and ultimately the evaluation of artificial intuition frameworks have several challenges due to the novelty and multidisciplinary nature of this area. This work has been motivated by Trovati, Johnny, and Polatidis (Citation2022), which is supported by the experimental evaluation discussed in this article and it further motivates more research in this area. depicts how the proposed intuition framework can be mapped to current and future research. In particular, subsequent research efforts will focus on the creation and analysis of suitable dynamic semantic knowledge network. This will be only partially manually maintained and augmented as novel “data-evolutionary” algorithms would model the natural data stages, via suitable dynamical changes. These would enable an efficient and agile data creation system to create a knowledge system mimicking a “collective intelligence” system. Furthermore, there is scientific evidence that collective intelligence (e.g. created by an ant colony) is used by the individual components (e.g. individual ants) to self-organize and regulate their common maintenance and survival.
Figure 4. The research motivation.
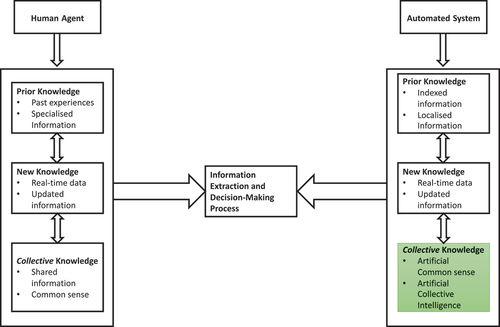
This will enable an agile, adaptive and accurate data structure model that not only would it enhance artificial intuition but it would also improve the state-of-the-art technology in data science and AI.
Disclosure statement
No potential conflict of interest was reported by the author(s).
References
- Billay, D., F. Myrick, F. Luhanga, and O. Yonge. 2007. A pragmatic view of intuitive knowledge in nursing practice. Nursing Forum 42 (7:326–32):147–2304. doi:10.1111/j.1744-6198.2007.00079.x.
- Bolton, S., and U. A. Cullen. 2022. Data driven assessment of inconsistent growth in SMEs. In Progress.
- Bolton, S., L. Green, and B. Kothari. 2016. Optimize the contribution of design to innovation performance in Indian SMEs–what roles for culture, tradition, policy and skills? South Asian Popular Culture 14 (3):199–217. doi:10.1080/14746689.2017.1294803.
- Brasethvik, T., J. A. Gulla. 2001. Natural language processing and information systems”, natural language analysis for semantic document modeling. Berlin Heidelberg: Springer. doi:10.1007/3-540-45399-7_11.
- Chesbrough, H. 2010. Business model innovation: Opportunities and barriers. Long Range Planning 43 (2–3):354–63. Elsevier. doi:10.1016/j.lrp.2009.07.010.
- Choi, J. D., J. Tetreault, and A. Stent. 2015. It depends: Dependency parser comparison using a web-based evaluation tool. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Association for Computational Linguistics 22 (4):387–96.
- Cullen, U. A., De Angelis, R. 2021. Circular entrepreneurship: A business model perspective. Resources Conservation & Recycling 168:463–72. Elsevier. doi:10.1016/j.resconrec.2020.105300.
- Diaz-Hernandez, O., and V. J. Gonzalez-Villela. 2017. Analysis of human intuition towards artificial intuition synthesis for robotics. Mechatronics and Applications: An International Journal (MECHATROJ) 1 (1). doi:10.2139/ssrn.3427647.
- Dundas, J., and D. Chik. 2011. Implementing human-like intuition mechanism in artificial intelligence. CoRR abs/1106.5917. http://arxiv.org/abs/1106.5917.
- Johnny, O., M. Trovati, and J. Ray. 2020. Towards a computational model of artificial intuition and decision making. In Advances in intelligent networking and collaborative systems, 463–72. Springer International Publishing.
- Kahneman, D., and S. Frederick. 2002. Representativeness revisited: attribute substitution in intuitive judgment. In Heuristics & biases: The psychology of intuitive judgment, 49–81. New York: Cambridge University Press.
- Liu, S., and H. Ping. 2019. Artificial Intuition Reasoning System (AIRS) and application in criminal investigations. Journal of Physics Conference Series 1302 (7:326–32):032032. Cambridge University Press. doi:10.1088/1742-6596/1302/3/032032.
- Liu, H., and P. Singh. 2004. ConceptNet — a practical commonsense reasoning tool-kit. BT Technology Journal 22 (4):211–26. Kluwer Academic Publishers. doi:10.1023/B:BTTJ.0000047600.45421.6d.
- Lyneham, J., C. Parkinson, and C. Denholm. 2008. Explicating benner’s concept of expert practice: Intuition in emergency nursing. Journal of Advanced Nursing 64 (7:326–32):380–87. doi:10.1111/j.1365-2648.2008.04799.x.
- McNeill, A. 1994. A corpus of learner errors: Making the most of a database. ed. Flowerdew and A. Tong, 114–25.
- Miller, C., and R. Ireland. 2005. Intuition in strategic decision making: Friend or foe in the fast-paced 21st century? Engineering Management Review, IEEE 33 (2):30–30. doi:10.1109/EMR.2005.26745.
- Payne, L. K. 2015. Intuitive decision making as the culmination of continuing education: A theoretical framework. International Journal of Offshore and Polar Engineering 46 (7):326–32. NCambridge University Press. doi:10.3928/00220124-20150619-05.
- Ray, J., O. Johnny, M. Trovati, S. Sotiriadis, and N. Bessis. 2018. The rise of big data science: A survey of techniques, methods and approaches in the field of natural language processing and network theory. Big Data and Cognitive Computing 2 (3):22. doi:10.3390/bdcc2030022.
- Roger, F. 2003. Herbert Simon. Artificial intelligence as a framework for understanding intuition. Journal of Economic Psychology 24:265–77. Cambridge University Press. doi:10.1016/S0167-4870(02)00207-6.
- Shao, Y., M. Trovati, Q. Shi, O. Angelopoulou, E. Asimakopoulou, and N. Bessis. 2017. A hybrid spam detection method based on unstructured datasets. Soft Computing 21 (1):233–43. doi:10.1007/s00500-015-1959-z.
- Silver, D., A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, et al. 2016. Mastering the game of go with deep neural networks and treesearch. Nature 529 (7587):484–89. doi:10.1038/nature16961.
- Simon, H. A. 1987. Making management decisions: The role of intuition and emotion. Academy of Management Perspectives 1 (1):57–64. doi:10.5465/ame.1987.4275905.
- Srdanov, A., D. Milovanovi, S. Vasi, and N. Ratković Kovačević. 2017. The application of simulated intuition in minimizing the number of moves in guessing the series of imagined objects. Proceedings.
- Stanovich, K. E., and R. F. West. 2000. Individual differences in reasoning: Implications for the rationality debate? Behavioral and Brain Sciences 23 (5):645–65. Cambridge University Press. doi:10.1017/S0140525X00003435.
- Thomas, L. D., and E. Autio. 2019. Business model innovation: Opportunities and barriers. Available at SSRN 3476925.
- Trovati, M., J. Hayes, F. Palmieri, and N. Bessis. 2017. Automated extraction of fragments of bayesian networks from textual sources. Applied Soft Computing 60:508–19. doi:10.1016/j.asoc.2017.07.009.
- Trovati, M., O. Johnny, and N. Polatidis. 2022. A new model for artificial intuition. In Artificial neural networks and machine learning – ICANN 2022 463–72. Springer International Publishing. doi:10.1007/978-3-031-15919-0_38.
- Trovati, M., H. Zhang, J. Ray, and X. Xu. 2019. An entropy-based approach to real-time information extraction for industry 4.0. IEEE Transactions on Industrial Informatics 16 (9):6033–41. doi:10.1109/TII.2019.2962029.
- Xiaolong, X., H. Nan, L. Tao, M. Trovati, F. Palmieri, G. Kontonatsios, and A. Castiglione. 2019. Distributed temporal link prediction algorithm based on label propagation. In Future generation computer systems, vol. 93, 627–36. Elsevier. doi:10.1016/j.future.2018.10.056.