
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Imbalanced classification problems are of great significance in life, and there have been many methods to deal with them, e.g. eXtreme Gradient Boosting (XGBoost), Logistic Regression (LR), Decision Trees (DT), and Support Vector Machine (SVM). Recently, a novel Generalization-Memorization Machine (GMM) was proposed to maintain good generalization ability with zero empirical for binary classification. This paper proposes a Weighted Generalization Memorization Machine (WGMM) for imbalanced classification. By improving the memory cost function and memory influence function of GMM, our WGMM also maintains zero empirical risk with well generalization ability for imbalanced classification learning. The new adaptive memory influence function in our WGMM achieves that samples are described individually and not affected by other training samples from different category. We conduct experiments on 31 datasets and compare the WGMM with some other classification methods. The results exhibit the effectiveness of the WGMM.
Introduction
Imbalanced classification problems often prioritize the minority class, which typically holds more crucial information. Numerous real-world applications encounter imbalanced scenarios, including but not limited to network intrusion detection (Chen et al. Citation2022), cancer detection (Lilhore et al. Citation2022; Seo et al. Citation2022), mineral exploration (Xiong and Zuo Citation2020), illegal credit card transactions (Sudha and Akila Citation2021), bank fraud detection (Abdelhamid, Khaoula, and Atika Citation2014), and Advertisement click-through rate prediction (Zhang, Fu, and Xiao Citation2017). Two main categories of methods are used to address imbalanced classification problems. The first category, known as data-level methods, focuses on transforming imbalanced data into balanced data. This includes oversampling methods (Chawla et al. Citation2002; He and Garcia Citation2009; He et al. Citation2008; Nguyen, Cooper, and Kamei Citation2011; Zheng Citation2020); and undersampling methods (Hart Citation1968; Sui, Wei, and Zhao Citation2015). The second category, algorithm-level methods, adjusts the weights of majority and minority classes within models. Examples include cost-sensitive methods (Bach, Heckerman, and Horvitz Citation2006), kernel adaptation methods (Mathew et al. Citation2017), and hyperplane shifting methods (Datta and Das Citation2015). Including methods such as Logistic Regression (LR) (Luo et al. Citation2019), Cost-Sensitive Decision Trees (Krawczyk, Woźniak, and Schaefer Citation2014), Cost-Sensitive Neural Networks (Krawczyk and Woźniak Citation2015) and Support Vector Machine (SVM), among which the support vector machine algorithm is better at solving imbalanced problems due to the strong generalization ability of SVM.
The SVM, by minimizing the sum of empirical and expected risks, has found extensively used in practical real-world applications, including face recognition (Chaabane et al. Citation2022), cancer detection (Alfian et al. Citation2022; Hussain et al. Citation2011; Seo et al. Citation2022); voice recognition (Harvianto et al. Citation2016) and handwritten character recognition (Hamdan and Sathesh Citation2021; Kibria et al. Citation2020; Kumar, Sharma, and Jindal Citation2011; Nasien, Haron, and Yuhaniz Citation2010). However, the classic SVM cannot always guarantee zero empirical risk, which classifies all training samples correctly. For the SVM, Vapnik proposed a generalization-memorization kernel (Vapnik and Izmailov Citation2021) to correctly classify training samples and have good generalization ability. Subsequently, a generalization-memorization machine (GMM) (Wang and Shao Citation2022) was proposed to account for the mechanism of the generalization-memorization kernel. The GMM enhances memorization by incorporating a memory cost function and improves generalization through a memory influence function. Since the memory influence function is predefined uniformly on the training set, the inessential samples would obtain some larger effects on prediction, especially for imbalance problems.
In this paper, we propose a Weighted Generalization Memorization Machine (WGMM) to deal with the imbalanced classification problem. Our WGMM employs distinct memory cost functions for the majority and minority classes. While preserves zero empirical risk. Furthermore, our WGMM also introduces a self-adaptive memory influence function to adapt to various imbalance problems.
The structure of this paper is as follows: In the next section, a brief overview of GMM and imbalanced classification methods is given. The third part establishes our WGMM model. The last two sections present numerical experiments and conclusions.
Related Works
Imbalanced Classification
There are two primary approaches to deal with imbalanced classification problems: data-level (DL) preprocessing methods (Chawla et al. Citation2002; Hart Citation1968; He and Garcia Citation2009; He et al. Citation2008; Nguyen, Cooper, and Kamei Citation2011; Sui, Wei, and Zhao Citation2015; Zheng Citation2020) and algorithm-level (AL) methods (Bach, Heckerman, and Horvitz Citation2006; Batuwita and Palade Citation2010; Datta and Das Citation2015; Imam, Ting, and Kamruzzaman Citation2006; Iranmehr, Masnadi-Shirazi, and Vasconcelos Citation2019; Mathew et al. Citation2017). Data-level preprocessing methods aim to mitigate class imbalance by adjusting the training data through sample addition or removal to achieve class balance before model training. The oversampling or undersampling is always concerned. Thereinto, oversampling methods rebalance classes by either replicating or generating samples within the minority class. For instance, Random oversampling (ROS) (He and Garcia Citation2009) involves duplicating samples from the minority class, while Synthetic Minority Over-sampling Technique (SMOTE) (Chawla et al. Citation2002) generates artificial samples to balance the training data by linearly interpolating samples from the minority class. Furthermore, other SMOTE variants exist, such as SVM-SMOTE (Nguyen, Cooper, and Kamei Citation2011), Borderline-SMOTE (Zheng Citation2020), Kmeans-SMOTE (Zheng Citation2020) and ADASYN (He et al. Citation2008). Undersampling methods balance the dataset by removing instances from the majority class. For instance, Random undersampling (RUS) (Sui, Wei, and Zhao Citation2015) entails the random removal of instances from the majority class until a specified class balance is achieved.
Algorithm level methods aim to construct a particular classifier to handle imbalanced classification problems. There have been many approaches based on this strategy, such as Fuzzy Support Vector Machines for Class Imbalance Learning (FSVM-CIL) (Batuwita and Palade Citation2010), Cost-sensitive support vector machines (CSSVM) (Iranmehr, Masnadi-Shirazi, and Vasconcelos Citation2019) and z-SVM (Imam, Ting, and Kamruzzaman Citation2006). Introducing fuzzy membership values enables FSVM-CIL to prioritize the minority class while accounting for the majority class, resulting in improved performance on imbalanced datasets. CSSVM assigns distinct misclassification costs to various classes, with a primary focus on prioritizing minority classes. z-SVM embraces a cost-sensitive approach, where it assigns class-specific costs to misclassifications, offering significant value when a class is rare or holds greater importance.
Generalization-Memorization Machine
Recently, the generalization-memorization machine (GMM), the SVM with a new memory mechanism, have been proposed for classification in the n-dimensional real space . Suppose
is the training set, where
is the input sample, and
is the corresponding output. We organize the training set into
and
, where
is the sample matrix composed of
,
is a diagonal matrix composed of labels, and the element on the diagonal is
with
.
GMM considers the optimization problem as
where is
norm,
is a mapping,
and
are positive parameters, and
is a slack variable.
is a column vector composed of
, which is called memory cost and
is called memory impact of
on
.
The goal of this optimization problem is to find a hyperplane that correctly classifies the training datasets and has the largest margin. The first term is half the square of the margin, and by minimizing this term we are trying to maximize the margin. The second term
is the regularization term of the memory cost function, where
control the minimization of the sample memory cost function. Increasing
will increase the penalty on memory cost, thus placing more emphasis on classification accuracy.
is the minimum training sample re-memory terms. In this way, the goal is to control the size and complexity of the model.
is established indicating that each training sample is correctly classified.
For a new sample , outside the training set, it would be classified into positive class if
, and otherwise, it is classified into the negative class.
GMM has been proved that it could obtain zero empirical risk, and its classification performance in numerical experiments is much higher than the SVMs.
Weighted Generalization Memorization Machine (WGMM)
Building upon the foundation of retaining all training samples, one of the advantages of GMM is that it can achieve superior test accuracy than SVM. However, GMM remains susceptible to issues related to sample imbalance. To mitigate this, we have enhanced GMM by optimizing both the memory cost function and the memory influence function, resulting in the development of our WGMM.
Model Formation
We introduce a weighted memory cost function component into the original objective function, with the objective of capturing distinct costs associated with various samples.
The training set includes a positive sample set and a negative sample set
with
. Without loss of generality, consider the positive samples as the minority categories within the imbalanced dataset, with the assumption that the positive sample set
represents the minority class and the negative class sample set
represents the majority class, where
and
represent sample matrix composed of
.
The optimization problem of WGMM can be expressed as follows:
where ,
,
and
are positive parameters,
and
represent the memory cost functions for remembering positive samples and negative samples,
is a column vector consisting of
,
is the memory cost function of the
th positive sample,
is a column vector composed of
,
is the memory cost function of the
th negative sample.
is the memory cost function of the
th positive sample,
is the memory cost function of the
th negative sample.
The objective of formula (2) seeks the large margin with memory costs as lower as possible, and it controls the complexity of the model meanwhile. According to the constraints of formula (2), the memory cost function is a variable, and the memory cost function is split into and
, and multiply them by different parameters. The constraints within the optimization problem are separately defined for the positive and negative classes, allowing for individual control over the memory costs of each class, thus reflecting the importance of each respective class. GMM requires the predefinition of the influence function
. Subsequently, this paper will introduce an adaptive influence function, in alignment with sample adaptation, which will be elaborated on in the following section. The retention of memory for all training samples becomes crucial in compliance with the constraints specified in formula (2).
The decision function of our WGMM is
Formula (3) defines the decision function as a piecewise function. the decision function is a piecewise function. When the input test sample belongs to the training sample, the model employs the first function to make decisions. represents the comprehensive influence of memory training samples on predictions. The function
impacts memory capacity of the model. So
denotes the item re-memorized for the sample, enhancing memory accuracy, thereby guaranteeing a training accuracy rate be 1. Conversely, when the input sample is not part of the training set,
has no practical effect on
. In such cases, the model utilizes the second function as the testing function.
We now delve into the dual problem associated with (2). The original problem (2) can be written in matrix form
where and
are the memory cost functions for remembering positive samples and negative samples,
is a column vector composed of
,
is a column vector composed of
,
with element
,
,
,
are defined similarly to
.
is a vector of one with an
dimension, and
is a vector of one with a
dimension, and elements of
and
are all ones.
In order to solve optimization problem (4), take it as the original optimization problem and apply Lagrangian duality to obtain the optimal solution of the original problem. We construct a LaGrange function
The LaGrange multiplier vectors ,
and
,
are introduced for each inequality constraint. Next, we present the Karush–Kuhn–Tucker (KKT) conditions (Fletcher Citation2000) for (4). The partial derivatives of (5) with respect to variables
,
,
,
and
are
and
(6–11) are calculated mathematically to get
and
Substitute (12–16) into EquationEquation (4)(4)
(4) to get the dual problem
where represents a generalized Gaussian kernel with a parameter
. Furthermore, when examining the solutions for
and
, where
has
non-zero components and
has
non-zero components. From the KKT condition, we can deduce
and
where contains
elements, and
contains
elements. From EquationEquations (18)
(18)
(18) and (Equation19
(19)
(19) ), we can find
New Memory Influence Function
Memorizing different datasets will have an impact on the generalization ability of the model. Therefore, this paper has made the following improvements: An adaptive memory influence function based on Euclidean distance is proposed to adapt different data sets to the model, that is, for each individual example, a distinct memory influence function is introduced.
The memory influence function chosen within GMM is
where is a positive parameter and needs to be selected. However, it lacks the inherent ability to adapt to diverse datasets, potentially impacting the model performance. To address this limitation, we are undertaking improvements. In the Gaussian function, the probability of numerical distribution within
is 0.9974. This insight guides us in defining the influence range of each sample point. We consider the sample as the neighborhood center and designate the radius of the field as half of the Euclidean distance (d) to the nearest heterogeneous point. This approach confines the memory influence function to this specific field. More precisely, we set
, allowing us to calculate
, by substituting it into the Gaussian function, we obtain
At this time, the influence function does not incorporate any parameters; instead, it is calculated based on the characteristics of the sample distribution. Introducing an adaptive memory influence function rooted in Euclidean distance allows for the individual characterization of each sample feature. This adaptation enhances the ability of the model to accommodate various datasets.
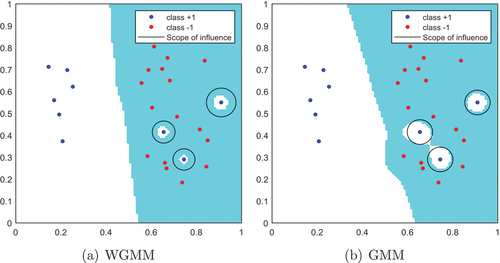
The comparative diagrams for the new influence function we developed and the influence function used in GMM are presented below:
illustrates the influence range of the influence function for both WGMM and GMM. The black circle with the sample as the center is a schematic diagram of the influence range of the sample. provides a schematic depiction of the novel influence function within WGMM. This reveals that diverse samples exhibit varying influence ranges, each with distinct sizes. represents GMM, where the influence ranges for various samples are uniformly sized. During practical model classification, the influence ranges between samples may overlap and converge.
Figure 1. An illustrative example employing synthetic data is used to demonstrate the value range of the memory influence function in linear WGMM and linear GMM. The schematic illustrates classification performance of WGMM when (a) is ,
,
and
utilizing the influence range defined in EquationEquation (22)
(22)
(22) as the memory influence function. (b) is a schematic diagram of the classification performance of GMM when
and
and the influence range of the RBF kernel as a memory influence function.
Finally, we summarize the procedure of our WGMM with the new memory influence function in Algorithm 1.
Table
Experiments
In this section, we describe our experimental study. Section 4.1 lists the datasets and methods used for the experiments. Section 4.2 provides the metrics used to evaluate the performance of all methods, while Sections 4.3 and 4.4 respectively present the specific experiment details and the analysis and summary of the experimental results.
Datasets
Based on 31 datasets obtained from (Rosales-Pérez, Garca, and Herrera Citation2022), our model is evaluated. presents datasets information, including data dimension (n), data volume (m), the size of the positive samples (p), the size of the negative class samples (q), and imbalance ratio (IR) (Lu, Cheung, and Tang Citation2019) represents the ratio of positive samples to negative samples and is arranged in ascending order of IR values, ranging from small to large. Observing the performance of WGMM in different imbalanced growth scenarios is essential.
Table 1. Description of 31 datasets.
Performance Metrics
We employed the Geometric Mean (GM) evaluation index from reference (Luque et al. Citation2019) as the primary evaluation metric in this paper. The evaluation of our model is based on the confusion matrix, as defined in reference (Caelen Citation2017), which helps in computing key parameters: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). Specifically, TP represents the count of correctly classified positive samples, FP represents the count of misclassified positive samples, TN represents the count of correctly classified negative samples, and FN represents the count of misclassified negative samples. According to the insights presented in reference (Luque et al. Citation2019), sensitivity and specificity are
Then the GM is
Reference Methods
The dataset was divided using 10-fold cross-validation. In 10-fold cross-validation, the dataset is randomly separated into 10 distinct subsets. For each fold, one subset is employed as the test set, while the others serve as the training set. Next, 10-fold cross-validation is utilized to select the optimal parameters from within the specified parameter range. Subsequently, these optimal parameters are employed in 20 rounds of 10-fold cross-validation. The number of folds used in each iteration varies, resulting in a total of 200 tests for each dataset.
The comparison methods selected in this paper are LR (LaValley Citation2008), FSVM-CIL (Batuwita and Palade Citation2010), GMM (Wang and Shao Citation2022), SMOTE-SVM (Chawla et al. Citation2002) and RUS-SVM (He and Garcia Citation2009). These methods represent advancements in recent years. Linear experiments involving these methods were conducted on 31 datasets, while 17 datasets were chosen for nonlinear experiments. The experiment presents certain challenges related to hyperparameter selection. For the regularization coefficient, we selected a parameter range represented as . In the case of the kernel function parameters in the nonlinear experiments, the range is
. All these models were implemented on a personal computer equipped with an Intel Core dual-core processor (dual 4.2 GHz) and 32GB of RAM using MATLAB 2017a. The Quadratic Programming Problems for these models were solved using the same algorithm and tolerance.
Experiments Results and Discussion
In this section, we offer a comparative analysis of the performance of WGMM and alternative methods. We conduct experiments using 31 datasets for linear analysis and 17 datasets for nonlinear studies. presents the results of the linearity experiments conducted by each approach. presents a selection of datasets that illustrate the non-linear experimental findings for each method. And illustrates the overall effects of each approach on all datasets. Meanwhile, displays the optimal parameters and
selected by the WGMM method during the experiments. And portrays the model results with different parameters using example data. Additionally, highlights the relationship between data parameters and indicators.
Figure 2. (a) depicts the GM distribution for 31 datasets across 5 linear algorithms. (b) illustrates the GM distribution for 17 datasets using 5 nonlinear algorithms.
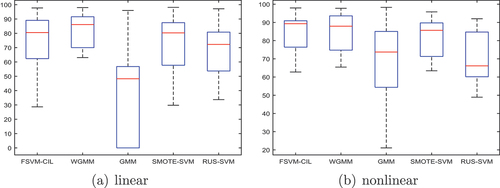
Figure 3. (4) the optimal reference ratio between and
in the formula. (a) is the linear WGMM algorithm. (b) is the nonlinear WGMM algorithm.
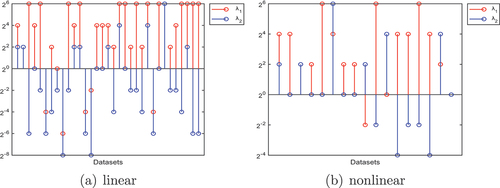
Figure 4. Results of dataset yeast-1-4-5-8, where the and
dimensions are selected.
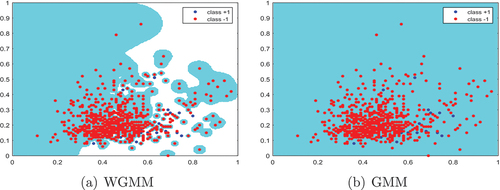
Figure 5. On the datasets of different IR, the GM value of the WGMM method in the selected parameter range. (a)glass0, (b)vehicle2, (c)ecoli1, (d)ecoli3, (e)abalone9–18,(f)winequality-red-4, (g)yeast6,(h)poker-8–9 vs 6, (i)poker-8 vs 6.
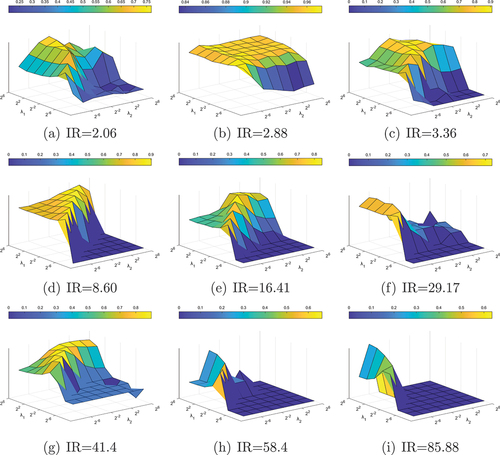
Table 2. GM comparison of linear experiments.
Table 3. GM comparison of nonlinear experiments.
displays the evaluation results for linear models using the GM index. It is evident that WGMM exhibits the best overall performance, particularly when the Imbalance Ratio (IR) is large. Moreover, our method is generally better than LR. In addition, GMM has a GM value of 0.00 on 9 datasets. It can be found that the test accuracy of the minority class on these datasets is 0.00. GMM performs poorly on imbalanced data. In terms of variance, WGMM falls within an acceptable range, and RUS-SVM excels, with variance at 0.00 on most datasets.
presents the evaluation of nonlinear experiments using the GM index. Notably, the FSVM-CIL model performs well on datasets with a small Imbalance Ratio (IR), and WGMM and FSVM-CIL show comparable performance. However, as the IR increases, WGMM emerges as the leading performer, exhibiting significantly superior results compared to other methods.
Comparing , we find:
In , out of the 17 datasets, 11 of them exhibit a distinctive pattern. Under the GM metric, our linear algorithm outperforms the nonlinear model, which can be attributed to the influence of data characteristics.
The datasets ecoli-0-3-4-7 vs 5-6, ecoli-0-1-4-7 vs 2-3-5-6, glass-0-1-6 vs 5, yeast-1-4- 5-8 vs 7 and glass5 exhibited a GM value of 0.00 in the GMM linear experiments. While substantial improvements were observed in the nonlinear experiments, the results remained less than satisfactory.
consists of two boxplots. represents a comparative boxplot of GM values for five methods in the linear experiment. Notably, WGMM exhibits higher median, first quartile, and third quartile values compared to the other methods, with shorter whiskers. This indicates the superior performance of WGMM. Conversely, the GMM method shows a lower box, longer whiskers, and lower outliers, clearly highlighting the subpar performance of unweighted methods in imbalanced experiments. represents the boxplot comparison of the five methods in the nonlinear experiment. Overall, both FSVM-CIL and WGMM methods perform better. Their boxes are short and skewed upward, signifying larger GM values. While the median and first quartile of FSVM-CIL are slightly greater than WGMM, the third quartile of WGMM is larger, and its upper whisker is longer. This suggests that predictive results of WGMM are notably larger.
In formula (4), and
represent the coefficients of the positive and negative class memory cost functions, respectively, with
referring to the positive class. Owing to the imbalance in sample sizes between the positive and negative classes, applying the same weight would introduce bias into performance of the model, favoring the class with more samples. Hence, it becomes essential to define different weights. The weight for the minority class is increased to balance the model’s performance on both types of samples. is the optimal reference comparison diagram for
and
for each dataset in the context of the linear experiment. is the optimal reference comparison diagram for each dataset comparing
and
in the context of nonlinear experiments. Most of the datasets show that
. This implies that greater weight is assigned to the minority samples, thereby achieving data balance through varying weights. In situations of class imbalance, the model attains optimal classification.
selects the 1st and 4th dimensions of the dataset yeast-1-4-5-8 vs 7 for training and testing. represents the optimal parameters, specifically ,
,
and
. shows the result when the weights of the cost memory function are equal, that is,
. It is evident that , the trained classifier exhibits a bias toward the majority class samples, favoring the negative class. This underscores the importance of weighting.
is the linear experimental GM change plot of different datasets for different and
. We can see the following points.
Different datasets correspond to different optimal parameters
and
In many data sets, when
The larger the IR, the fewer parameter groups have a GM value greater than 0.5, and the more parameter groups have a GM value of 0.00.
From the above results, it can be seen that WGMM is a competitive choice.
Conclusions
In this study, our WGMM sets weight parameters for the memory cost functions of positive and negative class samples, respectively. A new adaptive memory influence function is proposed. Implementation samples are described individually without increasing the weight of the entire category. It will not be affected by different training samples and can adapt to different imbalance scenarios. Ensure zero empirical risk while retaining generalization capabilities.
We conduct a comprehensive evaluation of WGMM on 31 imbalanced datasets, benchmarking its performance against alternative methods. Experimental results demonstrate the efficacy of WGMM in tackling imbalanced classification problems and showcasing robust generalization abilities. Notably, in scenarios with a substantial IR, our model exhibits pronounced characteristics and excels across various evaluation metrics.
Regarding the different parameters set for the positive and negative class memory impact functions, experiments found that the optimal parameters of the minority class sample memory impact function are greater than or equal to the optimal parameters of the majority class sample memory impact function. The adaptive memory influence function enables the model to adapt well to different data, and the effect is better than other methods.
These findings strongly affirm WGMM as an effective approach for addressing imbalanced classification challenges. Its superiority in performance and adaptability across different imbalanced datasets without the need for parameter tuning positions WGMM as a potent tool for practical applications.
Future research avenues may involve further optimizing performance of WGMM and exploring its applicability in diverse fields and tasks. In summary, this study provides novel insights and effective solutions for resolving imbalanced classification problems.
glass.eps
Download EPS Image (10.6 MB)xiang.eps
Download EPS Image (18.2 KB)new41.eps
Download EPS Image (1.3 MB)glass0.eps
Download EPS Image (48.4 KB)yeast6.eps
Download EPS Image (45.7 KB)new31.eps
Download EPS Image (1.3 MB)ecoli3.eps
Download EPS Image (46.1 KB)poker-8_vs_6.eps
Download EPS Image (39.8 KB)abalone9-18.eps
Download EPS Image (47.8 KB)vehicle2.eps
Download EPS Image (44.4 KB)xiangfei.eps
Download EPS Image (17.5 KB)glasse.eps
Download EPS Image (5.4 MB)poker-8-9_vs_6.eps
Download EPS Image (39.9 KB)ecoli1.eps
Download EPS Image (47.4 KB)bestno.eps
Download EPS Image (20.1 KB)winequality-red-4.eps
Download EPS Image (41.4 KB)best.eps
Download EPS Image (26.7 KB)Acknowledgements
The authors would like to thank the anonymous reviewers for their valuable suggestions.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data that support the findings of this study are available in [IEEE] at [doi: 10.1109/TCYB.2022.3163974], reference (Rosales-Perez, Garca, and Herrera Citation2022). These data were derived from the following resources available in the public domain: [https://ieeexplore.ieee.org/document/9756639].
Supplementary Material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/08839514.2024.2355424
Additional information
Funding
References
- Abdelhamid, D., S. Khaoula, and O. Atika. 2014. Automatic bank fraud detection using support vector machines. In The International Conference on Computing Technology and Information Management, Dubai, UAE, January.
- Alfian, G., M. Syafrudin, I. Fahrurrozi, N. L. Fitriyani, F. T. D. Atmaji, T. Widodo, N. Bahiyah, F. Benes, and J. Rhee. 2022. Predicting breast cancer from risk factors using SVM and extra-trees-based feature selection method. Computers 11 (9):136. doi:10.3390/computers11090136.
- Bach, F. R., D. Heckerman, and E. Horvitz. 2006. Considering cost asymmetry in learning classifiers. Journal of Machine Learning Research 7:1713–20.
- Batuwita, R., and V. Palade. 2010. FSVM-CIL: Fuzzy support vector machines for class imbalance learning. IEEE Transactions on Fuzzy Systems 18 (3):558–71. doi:10.1109/TFUZZ.2010.2042721.
- Caelen, O. 2017. A Bayesian interpretation of the confusion matrix. Annals of Mathematics and Artificial Intelligence 81 (3–4):429–50. doi:10.1007/s10472-017-9564-8.
- Chaabane, S. B., M. Hijji, R. Harrabi, and H. Seddik. 2022. Face recognition based on statistical features and SVM classifier. Multimedia Tools & Applications 81 (6):8767–84. doi:10.1007/s11042-021-11816-w.
- Chawla, N. V., K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer. 2002. SMOTE: Synthetic minority over-sampling technique. The Journal of Artificial Intelligence Research 16:321–57. doi:10.1613/jair.953.
- Chen, C., X. Xu, G. Wang, and L. Yang. 2022. Network intrusion detection model based on neural network feature extraction and PSO-SVM. In 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, April, 1462–65.
- Datta, S., and S. Das. 2015. Near-Bayesian support vector machines for imbalanced data classification with equal or unequal misclassification costs. Neural Networks 70:39–52. doi:10.1016/j.neunet.2015.06.005.
- Fletcher, R. 2000. Practical methods of optimization. New Jersey, USA: JohnWiley & Sons.
- Hamdan, Y. B., and A. Sathesh. 2021. Construction of statistical SVM based recognition model for handwritten character recognition. Journal of Information Technology and Digital World 3 (2):92–107. doi:10.36548/jitdw.2021.2.003.
- Hart, P. 1968. The condensed nearest neighbor rule (corresp.). IEEE Transactions on Information Theory 14 (3):515–16. doi:10.1109/TIT.1968.1054155.
- Harvianto, H., L. Ashianti, J. Jupiter, and S. Junaedi. 2016. Analysis and voice recognition in Indonesian language using MFCC and SVM method. ComTech: Computer, Mathematics and Engineering Applications 7 (2):131–39. doi:10.21512/comtech.v7i2.2252.
- He, H., Y. Bai, E. A. Garcia, and S. Li. 2008. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, June, 1322–28.
- He, H., and E. A. Garcia. 2009. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering 21 (9):1263–84. doi:10.1109/TKDE.2008.239.
- Hussain, M., S. K. Wajid, A. Elzaart, and M. Berbar. 2011. A comparison of SVM kernel functions for breast cancer detection. In 2011 Eighth International Conference Computer Graphics, Imaging and Visualization, Singapore, August, 145–50.
- Imam, T., K. M. Ting, and J. Kamruzzaman. 2006. z-SVM: An SVM for improved classification of imbalanced data. In AI 2006: Advances in Artificial Intelligence: 19th Australian Joint Conference on Artificial Intelligence, Proceedings, Hobart, Australia, Vol. 19, 264–73.
- Iranmehr, A., H. Masnadi-Shirazi, and N. Vasconcelos. 2019. Cost-sensitive support vector machines. Neurocomputing 343:50–64. doi:10.1016/j.neucom.2018.11.099.
- Kibria, M. R., A. Ahmed, Z. Firdawsi, and M. A. Yousuf. 2020. Bangla compound character recognition using support vector machine (SVM) on advanced feature sets. In 2020 IEEE Region 10 Symposium, Dhaka, Bangladesh, 965–68.
- Krawczyk, B. and M. Woźniak. 2015. Cost-sensitive neural network with roc-based moving threshold for imbalanced classification. In 16th International Conference, Wroclaw, Poland, October 14–16, 2015, Proceedings 16, 45-52.
- Krawczyk, B., M. Woźniak, and G. Schaefer. 2014. Cost-sensitive decision tree ensembles for effective imbalanced classification. Applied Soft Computing 14:554–62. doi:10.1016/j.asoc.2013.08.014.
- Kumar, M., R. K. Sharma, and M. K. Jindal. 2011. SVM based offline handwritten Gurmukhi character recognition. SCAKD Proceedings 758:51–62.
- LaValley, M. P. 2008. Logistic regression. Circulation 117 (18):2395–99. doi:10.1161/CIRCULATIONAHA.106.682658.
- Lilhore, U. K., S. Simaiya, H. Pandey, V. Gautam, A. Garg, and P. Ghosh. 2022. Breast Cancer Detection in the IoT Cloud-based Healthcare Environment Using Fuzzy Cluster Segmentation and SVM Classifier. In Ambient Communications and Computer Systems. Lecture Notes in Networks and Systems, ed. Y. Hu, S. Tiwari, M. C. Trivedi, and K. K. Mishra. Vol. 356. Singapore: Springer.
- Lu, Y., Y. M. Cheung, and Y. Y. Tang. 2019. Bayes imbalance impact index: A measure of class imbalanced data set for classification problem. IEEE Transactions on Neural Networks and Learning Systems 31 (9):3525–39. doi:10.1109/TNNLS.2019.2944962.
- Luo, H., X. Pan, Q. Wang, S. Ye, and Y. Qian 2019. Logistic regression and random forest for effective imb alanced classification. In 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA. 1:916–17.
- Luque, A., A. Carrasco, A. Martin, and A. de Las Heras. 2019. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognition 91:216–31. doi:10.1016/j.patcog.2019.02.023.
- Mathew, J., C. K. Pang, M. Luo, and W. H. Leong. 2017. Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Transactions on Neural Networks and Learning Systems 29 (9):4065–76. doi:10.1109/TNNLS.2017.2751612.
- Nasien, D., H. Haron, and S. S. Yuhaniz. 2010. Support Vector Machine (SVM) for English handwritten character recognition. In 2010 2nd International Conference on Computer Engineering and Applications, Bali Island, 1:249–52.
- Nguyen, H. M., E. W. Cooper, and K. Kamei. 2011. Borderline over-sampling for imbalanced data classification. International Journal of Knowledge Engineering and Soft Data Paradigms 3 (1):4–21. doi:10.1504/IJKESDP.2011.039875.
- Rosales-Pérez, A., S. Garca, and F. Herrera. 2022. Handling imbalanced classification problems with support vector machines via evolutionary bilevel optimization. IEEE Transactions on Cybernetics 53 (8):4735–47. doi:10.1109/TCYB.2022.3163974.
- Seo, H., L. Brand, L. S. Barco, and H. Wang. 2022. Scaling multi-instance support vector machine to breast cancer detection on the BreaKHis dataset. Bioinformatics 38 (Supplement_1):92–100. doi:10.1093/bioinformatics/btac267.
- Sudha, C., and D. Akila. 2021. Credit card fraud detection system based on operational & transaction features using svm and random forest classifiers. In 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 133–38.
- Sui, Y., Y. Wei, and D. Zhao. 2015. Computer-aided lung nodule recognition by SVM classifier based on combination of random undersampling and SMOTE. Computational & Mathematical Methods in Medicine 2015:1–13. doi:10.1155/2015/368674.
- Vapnik, V., and R. Izmailov. 2021. Reinforced SVM method and memorization mechanisms. Pattern Recognition 119:108018. doi:10.1016/j.patcog.2021.108018.
- Wang, Z., and Y. H. Shao. 2022. Generalization-Memorization Machines. arXiv preprint arXiv:2207.03976.
- Xiong, Y., and R. Zuo. 2020. Recognizing multivariate geochemical anomalies for mineral exploration by combining deep learning and one-class support vector machine. Computers & Geosciences 140:104484. doi:10.1016/j.cageo.2020.104484.
- Zhang, S., Q. Fu, and W. Xiao. 2017. Advertisement click-through rate prediction based on the weighted-ELM and adaboost algorithm. Scientific Programming 2017:2938369. doi:10.1155/2017/2938369.
- Zheng, X. 2020. SMOTE variants for imbalanced binary classification: Heart disease prediction. Ann Arbor, Michigan, USA: Los Angeles ProQuest Dissertations Publishing. University of California.