
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In the field of emotion recognition, analyzing emotions from speech alone (single-modal speech emotion recognition) has several limitations, including limited data volume and low accuracy. Additionally, single-task models lack generalization and fail to fully utilize relevant information. To address these issues, this paper proposes a new bi-modal bi-task emotion recognition model. The proposed model introduces multi-task learning on the Transformer architecture. On one hand, unsupervised contrastive predictive coding is used to extract denser features from the data while preserving self-information and context-related information. On the other hand, model robustness against interfering information is enhanced by employing self-supervised contrastive learning. Furthermore, the proposed model utilizes a modality fusion module to incorporate textual and audio information to implicitly align features from both modalities. The proposed model achieved accuracy rates of 82.3% and 83.5% on the IEMOCAP and RAVDESS datasets, respectively, when considering weighted accuracy (WA). When weight is not considered (unweighted accuracy (UA)), the model achieved 83.0% and 82.4% accuracy. Compared to the existing methods, the performance is further improved.
Introduction
In the early stage of emotion recognition, only a single mode is used for speech emotion recognition. The acoustic characteristics, including formant frequency, speech speed, energy characteristics, and time domain characteristics, are used as the identification criteria. Text is also commonly used for speech emotion recognition. Different from acoustic information, text information focuses more on the information contained in the text in the speech. The extracted features include vocabulary, grammar, syntax, and other information related to language structure. For speech data that has been converted to text, such as speech translation and chat conversations, natural language processing (NLP) techniques can be used to analyze the emotional information in the text (Min et al. Citation2023; Samant et al. Citation2022).
With the rapid advancement of deep learning technology, emotion recognition technology is becoming increasingly sophisticated. This progress has also highlighted the limitations of relying on a single modality (like speech) for emotion recognition. While single-mode data is limited, training accurate emotion recognition models requires large amounts of labeled speech data covering a wide range of emotions and speech variations. Moreover, the emotion in speech is usually subjective, and the same emotion shows significant differences when different people use different ways of speech expression. The single-modality emotion recognition model faces difficulty in generalization when dealing with various speech variants. This is where multi-modality becomes a valuable approach. By integrating other modal information, such as facial expression and body language, the emotional state of the speaker can be more holistically captured, improving the accuracy of emotion detection. (Cai, Li, and Li Citation2023; Huang et al. Citation2023)
In the field of mood analysis, multi-task learning has gained significant attention because of its powerful performance. Multi-task learning is a branch of computational learning that utilizes simultaneous learning of multiple related tasks to achieve the goal of enhancing the overall efficiency of the model through the interrelationship between tasks (Yang et al. Citation2023). show the traditional method and the proposed bi-modal bi-task approach, respectively. Specifically, the traditional method solely extracts emotional information from a single modality through a single backbone network. This dependence on a single modality limits the model’s generalization capability. In contrast, the proposed bi-modal bi-task approach further expands the modality range of input information and facilitates the complementary fusion of information between different modalities. This makes the model more robust and adaptable. Furthermore, the joint training of multiple tasks assists in emotion recognition while addressing other tasks further improves the performance of the model.
Figure 1. Comparison between bimodal dual-task emotion recognition methods and traditional methods.
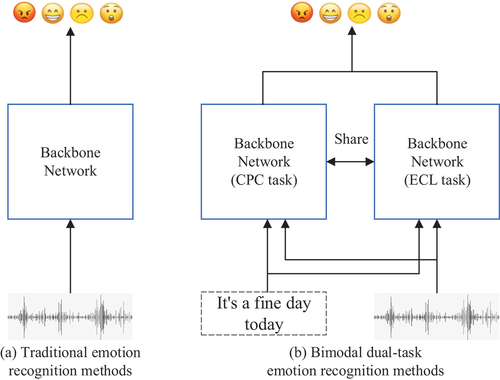
The literature shows that multimodal and multitasking learning techniques in emotion recognition tasks have better results and higher recognition accuracy. This work proposes using self-supervised models for emotion recognition. Sel-supervised learning can utilize the inherent properties or structures of the data for learning, significantly reducing the cost and workload of data annotation. Hence, this approach facilitates the practical deployment of the model. Additionally, self-supervised learning can assist the model in learning richer feature representations from different modalities of data, enhancing the model’s generalization ability and performance. Therefore, this paper proposes a bi-modal bi-task model to analyze emotion more comprehensively and accurately from the aspects of both mode and learning tasks. The main contributions include:
A novel multi-modal emotion analysis model. Inspired by the Transformer architecture, the proposed model utilizes both text and acoustic modes for interaction to obtain more comprehensive emotion information in speech. This approach effectively reduces the bias in sentiment analysis that can occur when relying on a single mode.
The accuracy of emotion recognition can be improved by introducing two auxiliary tasks. The features of relevant data are extracted through Contrastive Predictive Coding (CPC) (Meng and Yolwas Citation2023), enabling the sharing of basic information among different parts of the high-dimensional signal. This approach employs Enhanced Contrastive Learning (ECL) (Wang et al. Citation2023) to improve feature learning. In addition, conditional BERT contextual augmentation (CBCA) and Linear Spectral Adjustment (LSA) are utilized to enrich the input data. By comparing and contrasting data samples, ECL helps the model extract more robust and distinctive features.
Related Work
The development of emotion recognition technology is inextricably linked to the development of various machine learning algorithms. Early machine learning algorithms mainly include Linear Regression (Ribeiro and Schön Citation2023), Logistic Regression, k-nearest neighbor algorithm (Goshvarpour and Goshvarpour Citation2023), decision tree, Naive Bayes and support vector machine. Early neural networks were relatively small due to computational resource constraints. With the evolution of deep learning in recent years, there has been a surge in interest and development in neural networks, leading to advancements in various technologies. In the realm of emotion recognition, algorithms such as convolutional neural networks (Datta and Chakrabarti Citation2022; Feng et al. Citation2023; Sarvakar et al. Citation2023), recurrent neural networks, and long short-term memory networks, have also shown promising performance.
Emotion Recognition Model
In the further deepening of emotion recognition research, multi-modal speech emotion recognition has come into public view. Different from the single feature vector of a single mode, multi-modal speech emotion recognition has a wider range of application scenarios and a stronger generalization ability. Kakuba et al. proposed an attention-based multi-learning approach, utilizing residual dilated causal convolution blocks, dilated convolution layers, and multi-head attention, to learn emotional cues from extracted features (Kakuba, Poulose, and Han Citation2022a). However, further research is still needed for the robustness of multimodal emotion recognition. Subsequently, they found that attention mechanisms still play a significant role in bi-modal speech emotion recognition. Therefore, they proposed the DBMER model to improve the performance of bimodal speech emotion recognition by combining traditional methods (Kakuba, Poulose, and Han Citation2023). Sharafi et al. introduced a novel multimodal neural architecture that integrates both audio and visual data as inputs into a composite network composed of a bidirectional Long Short-Term Memory (BiLSTM) network and a pair of Convolutional Neural Networks (CNNs). Experimental investigations demonstrate that this approach outperforms the existing algorithms in adapting emotion recognition (Sharafi et al. Citation2022). Wen et al. presented a cross-modal dynamic convolution method and experimentally validated its competitive performance and higher efficiency (Wen, You, and Fu Citation2021). Chang et al. defined a multimodal residual perceptron network that learns end-to-end through multimodal network branches. The concept behind this multimodal residual perceptron network has promise for applications beyond just optical and acoustic signal sources (Chang and Skarbek Citation2021). Several studies have also integrated information from different modalities. Lian, Liu, and Tao (Citation2021) proposed the use of a transformer-based structure to model intra-modal and cross-modal interactions among multimodal features (Lian, Liu, and Tao Citation2021). Additionally, they introduced intra-modal interaction modules and cross-modal interaction modules to capture contextual information between different modalities (Lian, Liu, and Tao Citation2022).
Transformer Architecture
The Transformer was first proposed in 2017 by the Google Machine translation team (Vaswani et al. Citation2017). This new architecture revolutionized the field by moving away from traditional RNN and CNN toward a stacked structure. Transformer has achieved a surprising effect in the field of NLP. Various emotion recognition algorithms based on Transformer architecture have been launched. Le et al. (Citation2023) established a Transformer-based fusion and representation learning method to fuse and enrich multi-modal features for emotion recognition in multi-label videos. Experimental results demonstrate that this approach outperforms other robust baseline methods and current techniques in the field of multi-label video emotion recognition (Le et al. Citation2023). MA et al. proposed a Transformer-based self-distillation model that can transfer knowledge of both hard and soft labels to each mode. Experimental results from the dataset indicate that the Single Decision Tree (SDT) surpasses the performance of the previous best baseline model (Ma et al. Citation2023). Xie et al. utilized a Transformer-based cross-modal fusion technique, called the EmbraceNet network architecture, for emotion prediction. The developed model achieved 65% precision, surpassing the single-mode model used for comparison (Xie, Sidulova, and Park Citation2021). Similarly, Kakuba et al. also investigated the importance of multi-level fusion for emotion recognition. They utilized multi-level fusion with the Transformer’s multi-head attention mechanism to concurrently learn spatial, temporal, and semantic feature representations, further enhancing the effectiveness and robustness of the model (Kakuba, Poulose, and Han Citation2022b).
Multi-Task Learning
Emotion recognition usually uses a large pool of labeled data when training models. In multi-task learning (MTL), emotion recognition tasks can be combined with other related tasks to share the same dataset, efficiently utilizing the limited annotated data. Latif et al. proposed an MTL framework for learning generalized representations from augmented data (McL-aug). The semi-supervised nature of the McL-aug makes it possible to leverage large amounts of unlabeled data to further improve the efficiency of identification (Latif et al. Citation2022). Atmaja et al. used two audiovisual data-based affective attribute prediction methods based on MTL and fusion strategies. The use of MTL in single-modal and early fusion methods has shown better results than single-tasking learning, achieving an average Concordance Correlation Coefficient (CCC) score of 0.431 (Atmaja and Akagi Citation2020). Bendjoudi and colleagues proposed a novel context-dependent multi-label multi-task deep learning structure for identifying emotions. The findings from the EMOTIC dataset indicate that the label with a lower frequency outperforms the existing technological standard (Bendjoudi et al. Citation2021).
The above-mentioned studies exhibit the superior results of the Transformer architecture and the positive role of MTL in emotion recognition. Therefore, this paper improves Transformer architecture and incorporates MTL. This allows the model to learn multiple emotional aspects simultaneously, resulting in a more comprehensive understanding of emotions.
Methodology
The overall network framework is divided into two tasks: CPC and ECL. These tasks share parameters within the core parts of the network. In the CPC task, the audio sequences are encoded using wav2vec-2.0, while the text sequences are encoded using DistilBERT. Subsequently, a Cross-Modal coding Block (CCB) is utilized to fuse the representation of different modalities. Then, BiGRU is employed to effectively merge information from different modalities, and finally, the extracted features are used to compute cross-entropy. The process of the ECL task is similar to that of the CPC task, with the difference lying in the input stage, where text and audio are subjected to text enhancement techniques CBCA and spectral enhancement techniques LSA, respectively. In the output stage, unlike the CPC task, the features obtained are used for contrastive loss computation. This article assumes a dataset containing
sentences
and their corresponding labels
. Here, it is assumed that each sentence
has a voice cue
and a text cue
, where
. The task of emotion recognition is converted to assigning each sentence
an emotion label
, which
represents the emotion probability distribution of the first
sentence studied in the dataset.
Feature Extraction Module
Unlabeled speech data was pre-trained on a 960-hour Librispeech using wav2vec-2.0 (Schneider et al. Citation2019) as the original waveform encoder. During pre-training, the wav2vec-2.0 model learned the speech feature representation by reordering random subsequences of inputs into the correct order with predictions. The speech features of each discourse
were fed to the wav2vec-2.0, and feature extraction was performed at the CNN layer of wav2vec-2.0. Frames with a step size of 20 ms and a jump size of 25 ms were extracted.
Text feature coding with DistilBERT. DistilBERT is a compressed and streamlined BERT model proposed by Hugging Face (Sanh et al. Citation2019). Think of distilling a large model into a smaller model like this: the large model acts as a teacher and the smaller model learns everything it can from the teacher’s outputs. The model uses a distillation loss, which is calculated using soft labels. When T is set to 1, the distillation loss becomes similar to the regular loss function used for training. It retains most of the language understanding capabilities of the original BERT model. By learning from the original BERT model, it achieves a significantly smaller size and faster processing speed, making it suitable for running in resource-constrained environments.
Mode Fusion Module
The Modal fusion module (MFM) consists of two CCBs and a BiGRU module. It incorporates a multi-head attention mechanism module (Tsai et al. Citation2019), a residual connection and a feedforward layer. Each CCB is constructed into a common Transformer layer (Vaswani et al. Citation2017), as shown in yellow and green boxes in . Each Transformer layer is made up of a multi-head attention mechanism module (Tsai et al. Citation2019), residual connections, and feedforward layers.
Figure 2. Network architecture diagram.
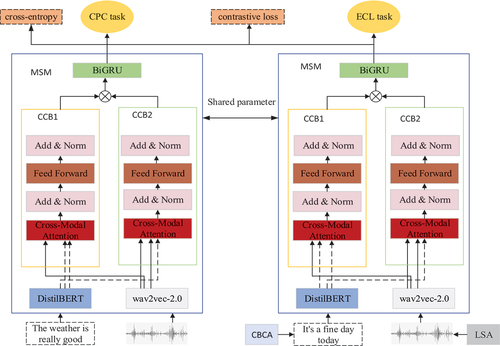
Speech-Aware Text Representation
To enhance token representations in text, associated audio is utilized as guidance for learning. Specifically, during the computation of Cross-Modal Attention, audio features extracted by wav2vec-2.0 serve as queries for embedding, while features extracted by DistilBERT serve as keys and values
for embedding. Here,
,
and
represent the dimensionalities of the audio, text and embedding features, respectively. The output of Cross-Modal Attention in CBB1 is as follows:
Herein, represents the weight matrices of the query, key, and value for the ith attention head, respectively. The final output of CCB1 is denoted as
.
Text-Aware Speech Representation
To enhance the token representations in audio, related text is utilized for guidance in learning. Specifically, during the computation of Cross-Modal Attention, features extracted by DistilBERT are used as queries for text embeddings, while features extracted by wav2vec-2.0 are used as keys and values
for audio embeddings. Here,
,
and
represent the dimensionalities of the audio, text and embedding features, respectively. The final output of CCB2 is
. Phoneme alignment holds a significant research position in speech science and acoustics, allowing each word to allocate weights to the speech embeddings according to their importance.
BiGRU Module
BiGRU is an improved RNN unit that receives output from a CCB as input and models the data through a bidirectional loop structure. It consists of two directional GRUs (Gated Recurrent Units), one responsible for forward sequential processing and the other responsible for reverse sequential processing. Despite the preliminary fusion of information from different modalities by the CCB module, BiGRU still contributes to modeling contextual information in the input data, allowing it to capture contextual relationships between different modalities even when speech and text information have been integrated. Additionally, it effectively learns long-term dependencies in sequential data. Its bidirectional structure allows it to simultaneously analyze information both before and after the current time step, facilitating more detailed modeling of the temporal relationships between speech and text information. Furthermore, BiGRU can extract abstract representations of the input data through hidden layer states, capturing key features in speech and text information.
Multi-Task Learning
The model introduces two emotion recognition learning tasks. This section will introduce the principle of two loss functions and two tasks and the main tasks in emotion recognition.
Cross Entropy Loss
Cross-entropy loss is a commonly used function for training speech emotion recognition (SER) models. When calculating cross-entropy loss with emotional labels, the maximum pooled mp(.) is first used independently on the wav2vec-2.0 speech A and MFM modules on the time step axis. The embeddings are then concatenated to obtain the final embed. The final embedding is passed by the linear transformation and softmax activation function, as shown in formula (2):
where is a single vector representation of each discourse,
is a weight matrix,
represents softmax activation function and
indicates an attention-pooling operation. After this step, the cross-entropy is calculated by
.
N-Pair Loss Function
The N-Pair loss function is used for contrast learning. The input samples are mapped to the feature space by constructing a network of shared parameters, and the similarity between positive and negative samples is maximized by the N-pair loss function. The loss function is defined as:
where and
represent
positive and negative cases, respectively, where
and
belong to the same class, and
belong to
different classes.
Contrastive Predictive Coding
CPC is a self-supervised learning method based on prediction tasks. It works by making the model predict what comes next in a sequence of information and then comparing the predicted results with the actual inputs to learn the input representation. The CPC method predicts contextual information within a modality, which enables the model to learn representations that capture shared semantic information between two modalities. Furthermore, through contrastive loss functions, CPC encourages the model to differentiate representations of semantic information in different modalities. This helps the model learn more universal and generalized feature representations.
Enhanced Contrast Learning
ECL helps the model become more efficient by learning the similarities and differences between samples. This allows the model to develop more robust and discriminative feature representations. Traditionally, emotion recognition focused on classifying emotions based on static features. However, this paper considers multiple modes of input and enhances the original data to enable the model to learn through comparisons across a richer dataset. In the aspect of speech, LSA spectrum enhancement technology is introduced to reduce noise by noise estimation and spectrum modification of input signal. The short-time Fourier transform (STFT) is used to convert the input signal into the time-frequency domain. Noise estimation and gain calculations are then used to determine the region of the spectrum that needs to be modified. Finally, the enhanced signal can be obtained by modifying the frequency spectrum of these regions and performing inverse STFT. In terms of text, text enhancement technology based on context information (Wu et al. Citation2019) (CBCA) is introduced. This approach begins with a pre-trained language model that randomly removes a word from the initial text that requires improvement. The residual text is then fed into the language model. The model’s first k predicted words are utilized to substitute the erased words in the original text, resulting in k new texts. Finally, to optimize the model, the minimum is reduced to: , where
and
are the adjusted hyperparameters.
Experiments
Dataset and Parameter Settings
The proposed model underwent training and assessment using the IEMOCAP and RAVDESS datasets. The IEMOCAP dataset, developed by the University of Southern California’s Speech Analysis and Interpretation Laboratory (SAIL), comprises recordings of 10 actors engaged in two-person dialogs. These recordings are marked with comprehensive details about the actors’ facial expressions and gestures during both scripted and spontaneous conversational scenes. The actors performed scripts specific to certain emotions and improvised hypothetical situations intended to elicit various emotional responses such as joy, anger, sorrow, frustration, and neutral states. The entire collection consists of approximately 12 hours of data. The RAVDESS is an emotion dataset for the study and analysis of emotional expression in speech and song. The dataset was created by the Department of Psychology at Ryerson University in Canada to provide a diverse range of emotional voice and song samples. It contains approximately 1,500 voice and song samples from 24 actors. Each actor performed eight emotional states in the dataset, including surprise happiness, anger, fear, disgust, sadness, calm and neutral. These emotional states are expressed through speech and song.
To accurately evaluate the model’s performance, a 5-fold cross-validation experiment was employed. The steps are as follows: The data was divided into five equally-sized folds, keeping each actor’s session intact. For each experiment, the sessions of one actor were selected as the verification set and the remaining sessions of all other actors were combined to form the training set. In each experiment, the hyperparameters were kept consistent. The training set was utilized for model learning, followed by the validation set for model validation. The above steps were repeated until each actor’s session was tested once as a verification set. The accuracy of each experiment was a weighted average and used as the evaluation index of hyperparameters. The results of evaluation indicators were then used to select the appropriate hyperparameters. Finally, the model was trained with the selected hyperparameters using all the data as the training set and the final model was obtained. This approach allows for a more precise evaluation of hyperparameters, ultimately leading to the selection of the best hyperparameters and their corresponding models.
Both DistilBERT and wav2vec-2.0 use basic architectures. The model was implemented on PyTorch (Paszke et al. Citation2019) and optimized by Adam. The cumulative gradient of training and evaluation with a batch size of 4 and 100 rounds was raised to 4. For an MTL setup, a training model was used where the search was performed between and grid search. The proposed model has approximately 180 M parameters.
Baseline Model
In the early stage, emotion recognition relied on a single mode of speech, and in the later stage, utilized multi-mode for recognizing emotions. This study compares the emotion recognition models with different modes and algorithms in recent years.
Mustaqeem et al. used similarity measures based on radial function network (RBFN) to select key sequence segments and extract discriminant features and significant features from speech spectrograms (Sajjad and Kwon Citation2020). Lu et al. proposed a method to solve speech sentiment analysis, which uses the pre-learned characteristics of the end-to-end automatic speech recognition (ASR) model as inputs for downstream tasks (Lu et al. Citation2020). Wang et al. proposed a new two-layer model to predict emotions based on Mel spectra generated by MFCC features and raw audio signals (Wang et al. Citation2020). Padi et al. developed a neural network-based emotion recognition framework, utilizing transfer learning and fine-tuning models to combine speech and text modal information (Padi et al. Citation2022). Kumar et al. obtained audio and text attributes using attention-based gated loop units (GRUs) and pre-trained BERT, respectively, and then combined these attributes to forecast the ultimate emotional category (Kumar and Mahajan Citation2019). Feng et al. suggested an end-to-end fusion of the voice-word automatic speech recognition (ASR) model and the speech emotion recognition (SER) model (Feng, Ueno, and Kawahara Citation2020). Morais et al. presented a modular end-to-end (E2E) SER system following the upstream + downstream architectural paradigm (Morais et al. Citation2022).
Zeng et al. designed a time-aligned mean-maximum pooling mechanism (Zeng et al. Citation2019). Xu et al. proposed a multi-task model based on deep neural networks (DNN) and used it to simultaneously process multiple audio classification tasks (Xu, Zhang, and Zhang Citation2021). Li et al. proposed a head fusion approach based on a multi-head attention mechanism and established an attention-based convolutional neural network (ACNN) model (Li et al. Citation2020). Singh et al. developed a deep learning-based layered approach (Singh et al. Citation2021). Kakuba et al. proposed a Transformer-based model that further improves the performance by learning multi-level fusion of spatial, temporal, and semantic features (Kakuba, Poulose, and Han Citation2023). Chen et al. proposed an improved pre-trained encoder Vesper, which enhances the performance of speech emotion recognition through emotion-guided masking strategy and hierarchical cross-layer methods (Chen et al. Citation2024).
Comparison with Baseline Model
The evaluation indexes used in the experiments were weighted average accuracy (WA) and unweighted accuracy (UA). The proposed model was evaluated on IEMOCAP and RAVDESS datasets, with the results shown in , respectively. The asterisk * denotes a multi-task model. shows that in the IEMOCAP dataset, multi-modal input improves the overall performance of the model compared with single-modal input (Lu et al. Citation2020; Sajjad and Kwon Citation2020; Wang et al. Citation2020). It is worth noting that there are also models with multi-modal input, but the enhancement effect is not significant, such as in the literature (Feng, Ueno, and Kawahara Citation2020). This may be because multi-modal sentiment recognition requires designing models that work with multiple types of data. The previous multi-modal fusion methods adopted simple linear or splicing methods, ignoring the relevance and importance of different modes. Compared with the model that also chooses speech and text as modal inputs (Kumar and Mahajan Citation2019; Padi et al. Citation2022; Feng, Ueno, and Kawahara Citation2020; Morais et al. Citation2022), the proposed model has outstanding advantages in terms of performance. Padi et al. (Citation2022) used additional tasks, categorical markers, and independent fragment markers for transfer learning. However, the algorithm proposed in this paper still improves WA by 6.4% and UA by 8%. This is because the supervised contrast learning utilized by the proposed model does not require large-scale labeling of datasets and can better handle data scarcity and noise conditions in emotion recognition tasks. Feng, Ueno, and Kawahara (Citation2020) and Morais et al. (Citation2022) use end-to-end models but require a large number of labeled data to train the entire system. When the training data is not enough or there is noise, the accuracy is worse than the proposed model. Sebastian et al. (Citation2019) used the GRU fusion attention mechanism to extract audio features, which shows the applicability of the GRU module in emotion classification. However, the proposed model uses a bidirectional BiGRU module and achieves superior efficiency. Overall, the proposed bi-modal bi-task model demonstrates the best performance, with WA and UA reaching 82.3% and 83.0%, respectively. This achievement is attributed to the synergistic interaction of two key factors. Firstly, a bi-task learning approach is adopted, which allows the model to simultaneously consider different tasks and extract more informative features from the data. Secondly, the CCB module enables the audio and text modalities to perceive each other, facilitating the adaptive alignment of key components between different modalities. Additionally, BiGRU further captures the temporal relationships and long-term dependencies of the data features. The mutual coordination between CCB and BiGRU enables the model to comprehensively understand the input data and enhances the performance and robustness of the emotion recognition task.
Table 1. Algorithm comparison on the IEMOCAP dataset.
Table 2. Algorithm comparison on the RAVDESS dataset.
To test the generalization performance of the proposed model, experiments were conducted on the RAVDESS dataset. The results are presented in . During the testing phase, only the audio information from the dataset was utilized. The results were then compared with five other emotion recognition models that have been tested on the RAVDESS dataset in recent years (Kakuba, Poulose, and Han Citation2023; Li et al. Citation2020; Singh et al. Citation2021; Xu, Zhang, and Zhang Citation2021; Zeng et al. Citation2019). All models were for audio-based single-modal emotion recognition. The results revealed that the proposed model achieved WA and UA of 83.5% and 82.4%, respectively. Despite the absence of interaction between different modalities, CCB still played a critical role. The CCB module incorporated an attention mechanism, enabling the model to effectively capture long-range dependencies between features. Furthermore, BiGRU was still capable of modeling sequential data, which is crucial for handling temporal data like audio. The combination of these two aspects allowed the model to perform remarkably well even with single-modal data. It is worth noting that although the DBMER model proposed by Kakuba et al. achieved better results on single-modal datasets, the proposed model surpasses its performance when dealing with multi-modal datasets. This is because the DBMER model employs multiple deep learning techniques, including CNNs, RNNs, and multi-head attention mechanisms. These techniques enhance the model’s feature extraction capability and exhibit significant advantages on single-modal data. However, on multi-modal data, despite extracting high-quality features, the DBMER model overlooks the alignment of features between different modalities, resulting in semantic misalignment. In contrast, the proposed model maintains feature quality and effectively aligns the semantic information of different modalities through the CBB module and BiGRU when modeling multi-modal.
Visual Analysis
To visually illustrate the effectiveness of the proposed model within and across various emotional categories, the confusion matrices of the model on the IEMOCAP and RAVDESS datasets are displayed in , respectively. It can be observed from the figures that the proposed model performs best in identifying happy and sad emotions with accuracy of 87.5% and 84.8% (IEMOCAP dataset) and 89.5% and 90% (RAVDESS dataset), respectively.
Figure 3. Confusion matrix of the model in the IEMOCAP dataset.

Figure 4. Confusion matrix of the model in the REVDESS dataset.
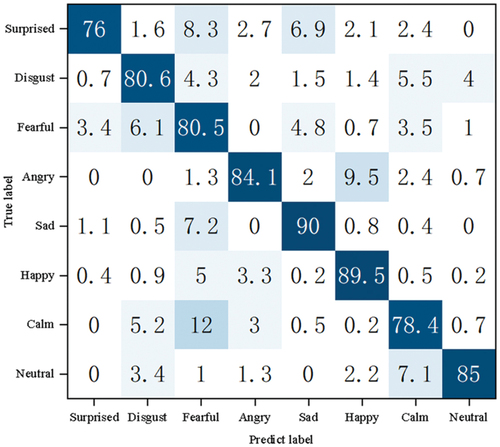
This is because happy and sad emotions often have distinct phonetic and textual features. Happiness is often expressed by high pitch, fast speech speed, bright sound quality, and a greater tendency to use positive sentence structures, such as affirmations and exclamations. Sad feelings are often expressed by low pitch, slow speech speed, heavy voice quality, and a greater tendency to use negative sentence structures, such as negative sentences and questions. The lowest recognition rate of surprise can be seen on the RAVDESS dataset, at only 76%, because surprise can be accompanied by short pauses, sudden changes in pitch, and changes in speech speed. These features can be confused with other emotions, making recognition difficult. Furthermore, it can be noticed from that calmness, an emotion in the middle of the emotional dimension, is also misclassified as other emotions.
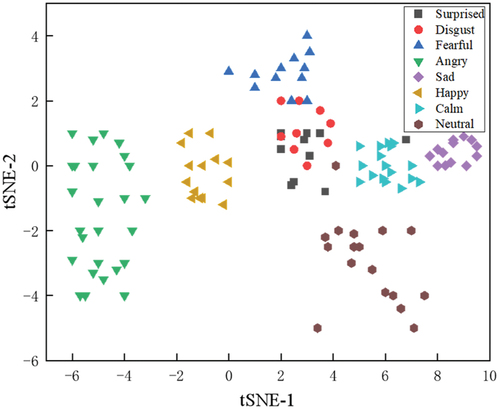
By preserving the final layer results of the model and utilizing the t-SNE visualization method, features can be plotted on a plane for visual analysis. For the IEMOCAP dataset, shows the feature distribution learned using the cross-entropy loss function, while illustrates the positions of deep features learned after incorporating enhanced contrastive learning. Different shapes of points represent features of different categories. It can be observed from that the cross-entropy loss function is capable of separating different emotion features, yet the differences within features remain substantial. However, indicates that after incorporating enhanced contrastive learning and sufficient training, the CCB module seems to better combine information across different modalities, leading to a clearer clustering structure in the t-SNE plot. Additionally, the BiGRU module can extract abstract representations of input data, making the feature points in the t-SNE plot more representative and discriminative. Overall, the introduction of the bi-task model enables the model to learn more about emotion representation. This allows the model to better capture the variations and complexities within the data, subsequently improving feature discriminability and clustering effectiveness. Moreover, parameter sharing and feature learning further enhance the model’s generalization capability and robustness. This is reflected in the t-SNE plot, where the feature points appear more consistent and stable. This visualization analysis provides a comprehensive understanding of the feature distribution learned by the model under different conditions and the influence of different tasks on features.
Figure 5. Feature distribution learned under the supervision of cross-entropy loss function on the IEMOCAP dataset.
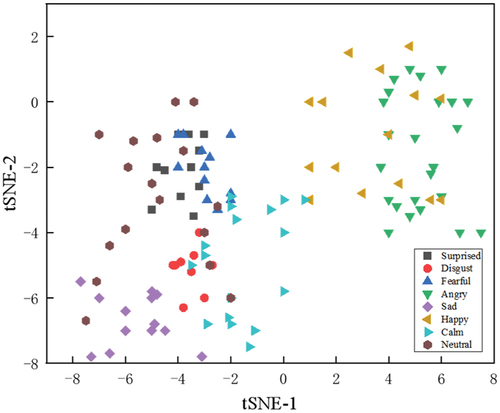
Figure 6. Feature distributions learned under the supervision of both cross-entropy and N-pair loss function on the IEMOCAP dataset.
Ablation Experiment
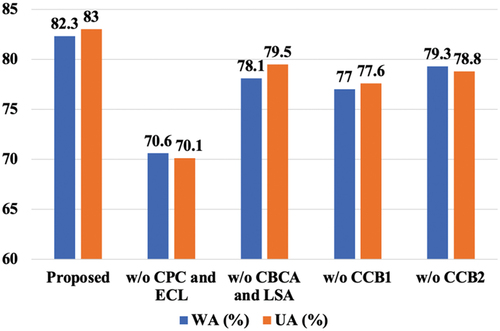
Ablation tests were conducted on the IEMOCAP dataset to evaluate its impact on overall performance by progressively reducing parts of the model. In experiments, other parameters were fixed and only specific parts of the model were modified one by one. The performance of the model was evaluated after each change. This helps validate whether each part is truly necessary for the model to function effectively.
First, the two task modules CPC and ECL were deleted. shows that the model accuracy rate decreases the most in the absence of tasks, WA decreases by 11.7% and UA decreases by 12.9%. The increase in tasks has no significant impact on the number of model parameters, but it impacts the recognition efficiency. This is because, in MTL, two tasks share the model’s parameters. Hence, the parameter count does not increase significantly. The introduction of another task can provide more training data and training signals, speeding up the rate of convergence training efficiency of the model. Secondly, only the original speech and text were used for extraction, and voice and text enhancements were not carried out. At this point, WA was 70.6% and UA was 70.1%. WA and UA were 11.7% and 12.9% lower than the original model, respectively. This is because the enhancement of speech and text data can make the model more robust to changes in diversity factors such as noise, accent, and tone. This ultimately leads to a more accurate and consistent model. Finally, in the model fusion module, only CCB 2 and CCB 1 were used for modal fusion. It can be seen from the figure that the recognition efficiency is reduced. In the fusion phase, CCB 1 uses text-assisted speech, while CCB 2 uses voice-assisted text. The partial accuracy of missing CCB 1 decreases even more significantly, with WA decreasing by 5.3% and UA decreasing by 5.6%. This shows that the effect of audio features is more obvious in the two modes of speech and text, which is also an important reason why speech features are often used to identify emotions in previous single-modal studies. Ablation experiments demonstrate the functions of the model components and evaluate the contribution of each module to the performance.
Figure 7. Ablation experiments based on the IEMOCAP dataset.
Conclusions
This paper presents a novel and innovative bi-modal bi-task model for emotion recognition. The Transformer architecture is improved and a new bi-modal bi-task emotion recognition model is developed. The proposed model first uses wav2vec-2.0 to encode speech features and DistilBERT to encode text. These speech and linguistic features are then fed into the cross-modal coding block respectively for modal fusion. After fusion, the combined features are input into the BiGRU module, whose features and gating unit further extract the information in the features. In addition, contrastive predictive coding and enhanced contrastive learning tasks are added to the model to improve the recognition accuracy. The proposed model is compared with the existing advanced methods. The experimental comparison demonstrates that the proposed model performs the existing methods. To confirm the model’s effectiveness and importance, a range of ablation tests were carried out. These ablation experiments provide an understanding of the role of each part of the model, highlight the key points of performance improvement, and can help in optimizing the model design. It can enhance the model’s effectiveness and offer superior benchmarks and guidance for future research.
However, the proposed method still has some limitations. Firstly, constrained by the modalities of input data, the model can only handle information from two modalities: audio and text. The model is unable to process other types of inputs such as images or videos, which limits the model’s generalization capability. Secondly, there is a high demand for language proficiency, requiring further research on the model’s robustness to different languages, accents, and other interference factors. Lastly, it is crucial to design lightweight models to improve computational efficiency and facilitate the practical deployment of motion recognition technology in real-life scenarios. This means reducing the model parameters as much as possible without compromising accuracy.
Acknowledgements
The authors would like to thank the editor and anonymous reviewers for their contributions toward improving the quality of this paper.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data used to support the findings of this study are included within the article.
Additional information
Funding
References
- Atmaja, B. T., and M. Akagi 2020. Multitask learning and multistage fusion for dimensional audiovisual emotion recognition. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4482–22. doi:10.1109/ICASSP40776.2020.9052916
- Bendjoudi, I., F. Vanderhaegen, D. Hamad, and F. Dornaika. 2021. Multi-label, multi-task CNN approach for context-based emotion recognition. Information Fusion 76:422–28. doi:10.1016/j.inffus.2020.11.007
- Cai, Y., X. Li, and J. Li. 2023. Emotion recognition using different sensors, emotion models, methods and datasets: A comprehensive review. Sensors 23 (5):2455. doi:10.3390/s23052455
- Chang, X., and W. Skarbek. 2021. Multi-modal residual perceptron network for audio–video emotion recognition. Sensors 21 (16):5452. doi:10.3390/s21165452
- Chen, W., X. Xing, P. Chen, and X. Xu (2024). Vesper: A compact and effective pretrained model for speech emotion recognition. IEEE Transactions on Affective Computing. doi:10.1109/TAFFC.2024.3369726
- Datta, S., and S. Chakrabarti. 2022. Integrated two variant deep learners for aspect-based sentiment analysis: An improved meta-heuristic-based model. Cybernetics and Systems 1–37. doi:10.1080/01969722.2022.2145657
- Feng, J., S. Cai, K. Li, Y. Chen, Q. Cai, and H. Zhao. 2023. Fusing syntax and semantics-based graph convolutional network for aspect-based sentiment analysis. International Journal of Data Warehousing and Mining 19 (1):1–15. doi:10.4018/IJDWM.319803
- Feng, H., S. Ueno, and T. Kawahara. 2020. End-to-end speech emotion recognition combined with acoustic-to-word ASR model. In Interspeech, 501–05. doi:10.21437/Interspeech.2020-1180
- Goshvarpour, A., and A. Goshvarpour. 2023. Novel high-dimensional phase space features for EEG emotion recognition. Signal, Image and Video Processing 17 (2):417–25. doi:10.1007/s11760-022-02248-6
- Huang, W., S. Cai, H. Li, and Q. Cai. 2023. Structure graph refined information propagate network for aspect-based sentiment analysis. International Journal of Data Warehousing and Mining 19 (1):1–20. doi:10.4018/IJDWM.327363
- Kakuba, S., A. Poulose, and D. S. Han. 2022a. Attention-based multi-learning approach for speech emotion recognition with dilated convolution. IEEE Access 10:122302–13. doi:10.1109/ACCESS.2022.3223705
- Kakuba, S., A. Poulose, and D. S. Han. 2022b. Deep learning-based speech emotion recognition using multi-level fusion of concurrent features. IEEE Access 10:125538–51. doi:10.1109/ACCESS.2022.3225684
- Kakuba, S., A. Poulose, and D. S. Han. 2023. Deep learning approaches for bimodal speech emotion recognition: Advancements, challenges, and a multi-learning model. Institute of Electrical and Electronics Engineers Access 11:113769–89. doi:10.1109/ACCESS.2023.3325037
- Kumar, Y., and M. Mahajan. 2019. Machine learning based speech emotions recognition system. International Journal of Scientific and Technology Research 8 (7):722–29.
- Latif, S., R. K. Rana, S. Khalifa, R. Jurdak, and B. Schuller 2022. Multitask learning from augmented auxiliary data for improving speech emotion recognition. IEEE Transactions on Affective Computing 14:4. doi:10.1109/TAFFC.2022.3221749
- Le, H., G. Lee, S. Kim, S. Kim, and H. Yang. 2023. Multi-label multimodal emotion recognition with transformer-based fusion and emotion-level representation learning. Institute of Electrical and Electronics Engineers Access 11:14742–51. doi:10.1109/ACCESS.2023.3244390
- Lian, Z., B. Liu, and J. Tao. 2021. Ctnet: Conversational transformer network for emotion recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing 29:985–1000. doi:10.1109/TASLP.2021.3049898
- Lian, Z., B. Liu, and J. Tao (2022). Smin: Semi-supervised multi-modal interaction network for conversational emotion recognition. IEEE Transactions on Affective Computing 14:2415–2429. doi:10.1109/TAFFC.2022.3141237
- Li, H., W. Ding, Z. Wu, and Z. Liu 2020. Learning fine-grained cross modality excitement for speech emotion recognition. arxiv preprint arxiv:2010.12733.
- Lu, Z., L. Cao, Y. Zhang, C. Chiu, and J. Fan 2020. Speech sentiment analysis via pre-trained features from end-to-end asr models. In IEEE ICASSP, Barcelona, Spain, 7149–53. doi:10.1109/ICASSP40776.2020.9052937
- Ma, H., J. Wang, H. Lin, B. Zhang, Y. Zhang, and B. Xu 2023. A transformer-based model with self-distillation for multimodal emotion recognition in conversations. ArXiv, abs/2310.20494.
- Meng, W., and N. Yolwas. 2023. A study of speech recognition for Kazakh based on unsupervised pre-training. Sensors 23 (2):870. doi:10.3390/s23020870
- Min, B., H. Ross, E. Sulem, A. P. B. Veyseh, T. H. Nguyen, O. Sainz, E. Agirre, I. Heintz, and D. Roth. 2023. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Computing Surveys 56 (2):1–40. doi:10.1145/3605943
- Morais, E. D., R. Hoory, W. Zhu, I. Gat, M. Damasceno, and H. Aronowitz 2022. Speech emotion recognition using self-supervised features. arXiv preprint arXiv:2202.03896.
- Padi, S., S. O. Sadjadi, D. Manocha, and R. D. Sriram 2022. Multimodal emotion recognition using transfer learning from speaker recognition and BERT-based models. arXiv preprint arXiv:2202.08974.
- Paszke, A., S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. 2019. PyTorch: An imperative style, high-performance deep learning library. Neural Information Processing Systems 32.
- Ribeiro, A. H., and T. B. Schön. 2023. Overparameterized linear regression under adversarial attacks. IEEE Transactions on Signal Processing 71:601–14. doi:10.1109/TSP.2023.3246228
- Sajjad, M., and S. Kwon. 2020. Clustering-based speech emotion recognition by incorporating learned features and deep BiLSTM. Institute of Electrical and Electronics Engineers Access 8:79861–75. doi:10.1109/ACCESS.2020.2990405
- Samant, S. S., V. Singh, A. Chauhan, and J. Dasarahalli Narasimaiah. 2022. An optimized crossover framework for social media sentiment analysis. Cybernetics and Systems 1–29. doi:10.1080/01969722.2022.2146849
- Sanh, V., L. Debut, J. Chaumond, and T. Wolf 2019. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. ar**v preprint ar**v:1910.01108.
- Sarvakar, K., R. Senkamalavalli, S. Raghavendra, Kumar JS, Manjunath R, Jaiswal S. 2023. Facial emotion recognition using convolutional neural networks. Materials Today: Proceedings 80:3560–64. doi:10.1016/j.matpr.2021.07.297
- Schneider, S., A. Baevski, R. Collobert, and M. Auli 2019. wav2vec: Unsupervised pre-training for speech recognition. ar**v preprint ar**v:1904.05862.
- Sebastian, J., P. Pierucci. 2019. Fusion techniques for utterance level emotion recognition combining speech and transcripts. In Interspeech 2019 51–55. doi:10.21437/Interspeech.2019-3201
- Sharafi, M., M. Yazdchi, R. Rasti, and F. Nasimi. 2022. A novel spatio-temporal convolutional neural framework for multimodal emotion recognition. Biomedical Signal Processing and Control 78:103970. doi:10.1016/j.bspc.2022.103970
- Singh, P., R. Srivastava, K. P. Rana, and V. Kumar. 2021. A multimodal hierarchical approach to speech emotion recognition from audio and text. Knowledge-Based Systems 229:107316. doi:10.1016/j.knosys.2021.107316
- Tsai, Y. H., S. Bai, P. P. Liang, J. Z. Kolter, L. Morency, and R. Salakhutdinov 2019. Multimodal transformer for unaligned multimodal language sequences. In ACL 6558. doi:10.18653/v1/p19-1656
- Vaswani, A., N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. 2017. Attention is all you need. Advances in Neural Information Processing Systems 30.
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. 2017. Attention is all you need. NeurIPS 2017:30.
- Wang, H., X. Li, Z. Ren, M. Wang, and C. Ma. 2023. Multimodal sentiment analysis representations learning via contrastive learning with condense attention fusion. Sensors 23 (5):2679. doi:10.3390/s23052679
- Wang, J., M. Xue, R. Culhane, E. Diao, J. Ding, and V. Tarokh 2020. Speech emotion recognition with dual-sequence LSTM architecture. In IEEE ICASSP, Barcelona, Spain 6474–78. doi:10.1109/ICASSP40776.2020.9054629
- Wen, H., S. You, and Y. Fu. 2021. Cross-modal dynamic convolution for multi-modal emotion recognition. Journal of Visual Communication and Image Representation 78:103178. doi:10.1016/j.jvcir.2021.103178
- Wu, X., Lv S, Zang L, Han J, Hu S. 2019. Conditional BERT contextual augmentation. International Conference on Computational Science. Cham: Springer. doi:10.1007/978-3-030-22747-0_7
- Xie, B., M. Sidulova, and C. H. Park. 2021. Robust multimodal emotion recognition from conversation with transformer-based crossmodality fusion. Sensors 21 (14):4913. doi:10.3390/s21144913
- Xu, M., F. Zhang, and W. Zhang. 2021. Head fusion: Improving the accuracy and robustness of speech emotion recognition on the IEMOCAP and RAVDESS dataset. IEEE Access 9:74539–49. doi:10.1109/ACCESS.2021.3067460
- Yang, E., J. W. Pan, X. M. Wang, H. B. Yu, L. Shen, X. H. Chen, L. Xiao, J. Jiang, and G. B. Guo. 2023. AdaTask: A task-aware adaptive learning rate approach to multi-task learning. Proceedings of the AAAI Conference on Artificial Intelligence 37 (9):10745–53. doi:10.1609/aaai.v37i9.26275
- Zeng, Y., H. Mao, D. Peng, and Z. Yi. 2019. Spectrogram based multi-task audio classification. Multimedia Tools and Applications 78 (3):3705–22. doi:10.1007/s11042-017-5539-3