
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In certain situations, the quality of a process is determined by dependent variables in relation to independent variables, often modeled through a regression framework referred to as a profile. The practice of monitoring and preserving this relationship is known as profile monitoring. In this paper, we propose an innovative approach that uses different machine-learning (ML) techniques for constructing control charts and monitoring generalized linear model (GLM) profiles with three different GLM-type response distributions of Binomial, Poisson, and Gamma, and by examining different link functions for each response distribution. Through our simulation study, we undertake a comparative analysis of different training methods. We measure the charts’ performance using the average run length, which signifies the average number of samples taken before observing a data point that exceeds the predefined control limits. The result shows that the selection of ML control charts is contingent on the response distribution and link function, and depends on the shift sizes in the process and the utilized training method. To illustrate the practical application of the proposed ML control charts, we present two real-world cases as examples: a drug–response study and a volcano-eruption study, to demonstrate how each ML chart can be implemented in practice.
Introduction
Statistical quality control (SQC) is the utilization of statistical tools and techniques to control a product or service’s quality and is used across a range of industries. It can be divided into three main categories: statistical process control (SPC), design of experiments (DOE), and acceptance samplings.
SPC is a quality control method used to monitor and control a process to ensure that it operates within a specified range of variation. The goal of SPC is to detect and correct process variations before they result in defective products or services. By monitoring and controlling processes, organizations can improve quality, reduce waste, and increase efficiency. More details about SQC can be found in Montgomery (Citation2012).
The main tool in SPC is a control chart. In 1924, the first control chart was introduced by Dr. Walter A. Shewhart. At the same time, the concept of statistical process monitoring started developing.
A special case of SPC is profile monitoring, in which we monitor a relationship over time instead of monitoring quality characteristics. Profile monitoring is used to detect changes or shifts in the relationship between the key variables over time, allowing for proactive action to be taken to address any issues or identify opportunities for improvements. Profile monitoring can be characterized as the relationship between one or more response variables and one or more explanatory variables. This functional relationship is in the form of a regression model. If the regression has one explanatory variable, it is called a simple profile; otherwise, it is called a multiple profile. The focus of this paper is solely on the simple profiles. Profile monitoring using control charts is divided into two phases: Phase I and Phase II. In Phase I, a set of historical data points is available, and the main goal of Phase I is evaluating the process stability and estimating the process parameters from the in-control samples. In most of the studies, as well as in ours, it is assumed that the parameters are estimated before the investigation and the study is performed in Phase II to conduct online monitoring and detect shifts.
Kang and Albin (Citation2000) introduced simple linear profiles with two main applications in semiconductor and food manufacturing. They used the memory-less Hotelling´s T2 and memory-type exponentially weighted moving average (EWMA) control charts. A significant development in monitoring simple linear profiles was made by Kim, Mahmoud, and Woodall (Citation2003). Other notable work has been proposed by Zou, Zhang, and Wang (Citation2006). They used a control chart based on a change-point model to monitor linear profiles. More information about different profile types and profile monitoring schemes can be found in Noorossana, Saghaei, and Amiri (Citation2011).
Simple linear profiles are generally used with the assumptions of being quantitative and the normal distribution of the response variable (Amiri et al. Citation2010; Soleimani, Noorossana, and Amiri Citation2009). However, these assumptions can be violated in some applications, and instead, generalized linear models (GLMs) can be used to describe the profiles. We can use a range of distributions and different link functions in GLMs. Koosha and Amiri (Citation2011) investigated the effect of link functions on monitoring logistic regression profiles using the Hotelling’s T2 control chart. The other types of distributions most commonly used other than the Binomial distribution, are the Gamma and Poisson distributions. Amiri, Koosha, and Azhdari (Citation2012) used the Hotelling’s T2-based methods for monitoring Gamma profiles, while Sharafi, Aminnayeri, and Amiri (Citation2013) used the maximum likelihood estimator approach for estimating the time of the step changes in Poisson regression profiles. Koosha and Amiri (Citation2013) considered a generalized linear mixed model for monitoring autocorrelated logistic regression profiles. Shadman et al. (Citation2014) used a change point approach based on the Rao score test for monitoring GLM profiles. Qi et al. (Citation2016) used the weighted likelihood ratio charts for monitoring GLM profiles. Amiri, Sogandi, and Ayoubi (Citation2018) developed some EWMA-based methods for simultaneous monitoring of the multivariate linear and GLM regression profiles.
One strategy would be using machine learning (ML) techniques for process or profile monitoring for different purposes such as dimension reduction, detection, identification, pattern recognition, and diagnosis. The most common ML techniques used for process monitoring are Support Vector Machines (SVM), Random Forests (RF), and Neural Networks (NN) (Apsemidis, Psarakis, and Moguerza Citation2020; Escobar and Morales-Mendez Citation2018; Mohd Amiruddin et al. Citation2020; Yeganeh et al. Citation2022; Yeganeh, Pourpanah, and Shadman Citation2021). In recent years, researchers have combined ML techniques with process monitoring and have used them to construct control charts (Mohammadzadeh, Yeganeh, and Shadman Citation2021; Sabahno and Amiri Citation2023; Sabahno and Niaki Citation2023; Yeganeh et al. Citation2023; Yeganeh, Chukhrova, et al. Citation2023; Yeganeh, Johannssen, et al. Citation2023; Yeganeh, Johannssen, Chukhrova, et al. Citation2023; Yeganeh et al. Citation2024). These studies have shown superior performances of the ML-based control charts over the statistics-based control charts.
Sabahno and Amiri (Citation2023) developed statistical and ML control charts for monitoring GLM profiles. However, they only investigated the Binomilly distributed response and the logit link function. In this paper, for the first time in the literature, we investigate different ML techniques, namely SVM, RF, and NN to build control charts for monitoring different GLM profiles with different link functions. To model profiles, we consider three main distributions: Binomial, Gamma, and Poisson, each with three different corresponding link functions detailed in Section GLM Profiles. We simulate data with fixed parameters and try a variety of training methods to obtain the best ML structures to achieve the desired performance. The performances are evaluated regarding the average run length (ARL) with different shift sizes and types. Run length is the number of samples (subgroups) taken before the chart signals a point beyond the control limit. The main purpose of this paper is to use a range of ML techniques to build the control charts and investigate different response distributions and different link functions as well as different training methods for the ML structures to see which one results in better performance (smaller values of ARL).
This paper is structured as follows. In Section GLM Profiles, we introduce the main theory connected with GLM profiles, explain the differences between profiles for different distributions used in this paper, and briefly describe the theory connected with the link functions. Section Machine Learning Techniques follows with a description of ML techniques. Following the introduction of ML techniques, ML control charts are described in Section Control Charts. In Section Simulation Studies, extensive numerical analyses to evaluate the ML control charts with different distributions, link functions, training methods, and shift sizes and types are performed. After the simulation studies, two different illustrative examples are presented in Section Illustrative Examples. Finally, we summarize the results obtained by this study, state our conclusions, and make some suggestions for future research in Section Concluding Remarks.
GLM profiles
We describe GLM profiles according to Sogandi and Amiri (Citation2017) and Olsson (Citation2002). We assume for the kth profile to have a set of n observations where
is a vector of predictor variables and
represents the jth response variable in the kth profile. We assume that the relationship between the response
and the predictor variables
is defined by generalized linear models (GLM), where
is a vector of q predictor variables (
. As a result, the response variables
have the same distribution for each profile. The predictor variables are combined linearly with the coefficients vector
to define the linear predictor
, where
. We also assume a monotone link function g defined with the following relationship:
where and g is a monotone link function. The link functions will be described in the following section. If the value of
is equal to 1,
is the intercept of the model, and in our study we have
. Most of the studies in profile monitoring assume that the response variable follows the Normal distribution. However, in this paper, we assume that the response variable belongs to the exponential family of distributions and has a Binomial, Poisson, or Gamma distribution, because they are more common in real practices. For the kth profile, the probability distribution belongs to the exponential family if it can be written as:
where and
are some functions, and
is the dispersion parameter.
is the canonical parameter representing some function of the location parameter of the distribution. More information about these functions and parameters for the corresponding distribution can be found in Olsson (Citation2002).
Link functions transform the probabilities of the levels of a categorical response variable to a continuous scale that is unbounded. Link function g represents a relationship between the mean of the response variable and the explanatory variables as:
We also know the canonical link functions. The canonical link functions transform the mean to a canonical location parameter of the exponential family member. For the canonical link function , we have
. So for the Binomial distribution, the canonical link is logit, for the Poisson is log and for the Gamma is negative inverse. There are also some references where the Gamma distribution has different parametrization or the canonical link function (e.g. in Myers et al. Citation2010, it is mentioned that the canonical link function is inverse). The choice of the link function mostly depends on the data type and there are times when the canonical link may not be appropriate. Therefore, we define the most common link functions in the following tables, which are later used for the corresponding distributions. For the Binomial distribution from we have for the cloglog link function
, for the logit link function
and for the probit link function
, where
represents the mean value for the Binomial distribution.
Table 1. Link functions for Binomial distribution.
For the Poisson distribution from we have the identity link function , the log link function
, and the sqrt link function
.
Table 2. Link functions for Poisson distribution.
For the Gamma distribution from we have the identity link function , the inverse link function
, and the log link function
.
Table 3. Link functions for Gamma distribution.
Machine Learning Techniques
We use several ML techniques to build control charts, namely Support Vector Machine (SVM), Random Forest (RF), and Neural Networks (NN), which are briefly described in what follows.
Support Vector Machine
SVM is one of the supervised learning algorithms used for the analysis of data in classification or regression problems. In the case of a regression problem, it is called SVR. The algorithm was first proposed by Boser, Guyon, and Vapnik (Citation1992). The goal of SVM is to transform the input space to a higher dimensional feature space through a mapping function and to construct a separating hyperplane with maximum distance from the closest points, called support vectors.
The kernel functions are used for the transformation of the input space to a higher dimensional feature space. The most commonly used kernel functions are linear, polynomial, sigmoid, and radial basis. The process of training an SVM involves solving a quadratic optimization problem to find the optimal solution. For optimization, in our case, the computer package uses the sequential minimization optimization algorithm. For more information about SVM, we refer interested readers to Stoean and Stoean (Citation2014).
Random Forest
RF is another ML algorithm that is widely used in classification and regression problems. It is a statistical learning method based on the principle of ensemble learning, which combines an ensemble (group of trained models). An RF algorithm consists of many decision trees. We can also call them the building blocks of the RF. Ensemble learning combines predictions (by taking the average in a regression case or choosing the class with the maximum number of occurrences in a classification case) from multiple ML algorithms to make a more accurate prediction than a single model (a decision tree, in the RF case). There are several ways to improve the model. We can specify the maximum depth of the trees, increase or decrease the number of trees, and specify the maximum number of features to be included at each node split. Increasing the number of trees can increase the precision of the prediction. For more information about RF, readers are referred to Breiman (Citation2001).
Neural Networks
The last ML technique used in this paper is NN, whose name and structure are inspired by the human brain. It can be described as a set of algorithms designed to recognize a pattern in a dataset. A NN consists of an input layer, one or more hidden layers, and an output layer.
We will only consider one hidden layer in this research. NNs with more than one hidden layer are called deep learning techniques. Nodes from one layer to another are connected with weight parameters. The problem of an NN is to determine the optimal values of the connection weights and node biases. Node bias refers to a constant input value added to each node, affecting its activation and allowing the network to account for the varying importance of different nodes. In this paper, we use the Broyden-Fletcher-Goldfarb-Shanno optimization method. The most popular NNs are multilayer perceptron, convolutional, and recurrent NNs. More information about NNs can be found in Patterson (Citation1998).
Control Charts
Control charts are the main tool of the SPC and they check whether the process is stable or not (in-control or out-of-control). The values of a measured characteristic (statistic) must be within control limits, otherwise the process is called out-of-control.
Developing control charts involves Phases I and II. In Phase-I, it is necessary to ensure the stability of the process and estimate the in-control values of the process parameters, whereas in Phase II, we monitor the future observations (online monitoring) to detect any shift in the process from the in-control state determined in Phase-I.
Many quality characteristics can be expressed in terms of numerical measurements. We call single measurable characteristics (such as weight, volume, or dimension) variables. That is one type of statistical control charts. Another type of control charts can be for attribute data (such as counts or percentages). More information about variable and attribute control charts can be found in Montgomery (Citation2012).
In the construction of control charts for process monitoring, we consider sample size, sampling interval, and control limits. Usually, sample size and sampling interval are fixed, and the control limit can be obtained with the following algorithm:
Step 1: Set the values of the probability of Type-I error and sample size n.
Step 2: Find a suitable statistic based on the problem at hand.
Step 3: Generate and sort 10,000 in-control samples in ascending order using the statistic from Step 2. The initial value of UCL will be the th value in this set.
Step 4: Run at least 5000 simulations and adjust UCL to obtain .
ML Control Charts
In this paper, we focus on the ML control charts similar to Sabahno and Amiri (Citation2023). We consider three input variables, the estimated slope , intercept
, and sample mean
for all the ML control charts. The output variable is a continuous variable that generates a linear number (regression output). As a result, we call the SVM, support vector regression (SVR), and we call the RF, random forest regression (RFR). An out-of-control signal is triggered provided that
.
UCL is an upper control limit and is obtained using the following algorithm:
Step 1: For each distribution, link function, training method, and regression parameters values, we generate in-control and out-of-control data consisting of the estimated regression intercepts, slopes, and means of the response variables as predictor variables (inputs for the ML structure).
Step 2: Assign 0 to the response variable for the in-control training data and 1 to the response variable for the out-of-control training data.
Step 3: Train the ML structure with the training data in regression form (the training data will be described in Section Simulation Studies).
Step 4: Generate 10 000 samples from the in-control process.
Step 5: Set the value of the probability of Type-I error .
Step 6: Sort ML structure outputs in an ascending order.
Step 7: The initial value of UCL will be the th value in the set.
Step 8: Run at least 5000 simulations and adjust UCL to obtain .
The performance is evaluated with the shifts in the intercept, slope, and simultaneous shifts with the ML structures described in Section Simulation Studies.
Simulation Studies
In this paper, we consider three different training methods. The first training method consists of 2400 profiles, where 1200 are in-control and 1200 are out-of-control. The out-of-control profiles have three types of shifts, namely shifts in the intercept, shifts in the slope, and simultaneous shifts. All types of shifts consist of 400 out-of-control profiles and the shift sizes are equal to 0.1. The second training method consists of 2700 profiles, 1350 in-control profiles, and 1350 out-of-control profiles. The same as the first method, the out-of-control profiles have three types of shifts. In this case, we have three different shift sizes, namely 0.1, 0.5, and 1. We have 150 out-of-control profiles for each size and type. The third training method consists of 1200 in-control and 1200 out-of-control profiles. For the out-of-control profiles, we consider the same types of shifts, but only two shift sizes 0.1 and 1. In this case, we have 200 out-of-control profiles for each type and size. We adopted the first and third training methods from Sabahno and Amiri (Citation2023), and the other one is then proposed with small, moderate, and large shift sizes.
We evaluate the performance of control charts using the ARL for different profiles with corresponding distribution and link functions for each training method and ML technique. The ARL represents the average run length, the average number of samples (subgroups) taken before the chart signals (point beyond the control limits). In addition, we mention the SDRL (standard deviation of run length) as additional information. Changes are made in the profile parameters and a step change of size occurs in the profile parameters, where
and
represent changes in the intercept and slope in terms of its standard deviation, so
and
are the standard deviations of the intercept and slope parameters adopted from different studies to be mentioned. To calculate the ARL and SDRL, we use the following algorithm:

This algorithm is used for the calculation of UCL in the in-control situation with and
as described in Section ML Control Charts. Assuming
= 0.005, the ARL value for the in-control situation is set to 200 for all the control charts. We also use the algorithm for evaluation of the performance and calculation of the ARL and SDRL in the out-of-control situations (
and/or
.
We use similar shift sizes as used in Mohammadzadeh, Yeganeh, and Shadman (Citation2021). For training models, R packages e1071/svm (Meyer Citation2023), randomForest (Liaw and Wiener Citation2022), and nnet (Ripley and Venables Citation2023) are used, in which there are built-in functions for training the corresponding ML techniques. In the case of the SVR, we use the svm() function with default settings, except for the kernel function type. We consider linear, polynomial, radial, and sigmoid kernels to find the best one for each model by considering the performance and the root mean square error (RMSE). For the RFR, we use the randomForest() function by changing the number of trees, other than that, we use the default setting. The same as before, we try to find the best number of trees according to the performance and the RMSE. We use the nnet() function for training the NN. We use the default setting and only vary the number of nodes for the hidden layer and the number of iterations. To be as consistent as possible, we build the NN model with a small number of nodes. We also consider the RMSE and the performance as in previous cases. The obtained RMSEs and the package settings for all the following simulation studies are not reported in this paper to save space but they are available in table formats and can be requested from the corresponding author.
Binomial Profiles
For the Binomial profiles described in Section GLM Profiles, we assume , where
is the number of observations and
represents the probability of success in the kth profile for the jth observation. It is defined by the following relationship with the same simulation setting as in Shadman et al. (Citation2014):
where the in-control parameters are set to . The values of the predictor variable are
with and corresponding link function
. The out-of-control setting is defined for the parameters as
, where
. The covariance matrix of the Binomial regression parameters is
Hence, and
.
For the Binomial distribution with the logit link function in , we investigate different shift sizes of the intercept, slope, and simultaneous shifts using the ARL with different training methods and ML control charts. In the case of the first training method, we obtain the smallest values of ARL with the SVR control chart. We see different results for the second training method. The smallest values of ARL are for the NN control chart with some exceptions under shifts in the slope and simultaneous shifts (see ). For the third training method, we obtain the smallest values of ARL with the SVR control chart, except for the smallest and largest shift sizes in the intercept, slope, and simultaneous shift. In these cases, we obtain the smallest values of ARL with the NN control chart. We can see that the ARL values decrease with increasing shift sizes for all the control charts except for the RFR control chart with the first training method.
Table 4. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Binomial distribution with the logit link function.
Table 5. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the slope for Binomial distribution with the logit link function.
Table 6. ARL (SDRL) values of the SVR, RFR, and NN control charts under different simultaneous shifts for Binomial distribution with the logit link function.
When we compare the overall results, the first training method generally delivers the smallest values of ARL under shifts in the intercept with the SVR control chart except for the smallest shift size. Under shifts in the slope, we obtain the smallest values of ARL with the SVR and NN control charts and the second training method, depending on the shift sizes (see ). Under simultaneous shifts, we can observe a similar trend to the intercept shifts case. We obtain the smallest values of ARL with the SVR control chart and the first training method with some exceptions (see ).
For the Binomial distribution with the probit link function, using the first training method, the smallest values of ARL are obtained with the SVR control chart. For the other two training methods, the smallest values of ARL are obtained with the NN control chart with some exceptions (see ). As mentioned for the logit link function, from a certain value of shift size, the ARL values start to increase as the shift sizes increase, for the RFR control chart and with the first training method.
Table 7. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Binomial distribution with the probit link function.
Table 8. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the slope for Binomial distribution with the probit link function.
Table 9. ARL (SDRL) values of the SVR, RFR and NN control charts under different simultaneous shifts for Binomial distribution with the probit link function.
We mostly obtain the smallest values of ARL with the NN control chart and the second training method under shifts in the intercept. Under shifts in the slope, the SVR control chart delivers the smallest values of ARL with the first training method. The results under simultaneous shifts depend on the shifts in the intercept and slope (see ).
The first training method for the Binomial distribution with the cloglog link function delivers the smallest values of ARL with the SVR control chart, except for the shift size 0.1 in the intercept (see ). For the second training method, we obtain the smallest values of ARL with the NN control chart except for some shift sizes in the slope (see ). The results for the third training method are similar to those obtained for the first one. The smallest values of ARL are for the SVR control charts with some exceptions. Here again, we can observe the increasing values of ARL with the RFR control chart by increasing the shift sizes from a certain value (see ), using the first training method.
Table 10. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Binomial distribution with the cloglog link function.
Table 11. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the slope for Binomial distribution with the cloglog link function.
Table 12. ARL (SDRL) values of the SVR, RFR and NN control charts under different simultaneous shifts for Binomial distribution with the probit link function.
We generally obtain the smallest values of ARL almost for all shift sizes with the SVR control chart and with the first training method under shifts in the intercept. Under shifts in the slope, we obtain the smallest values of ARL with the second training method and the SVR and NN control charts depending on the shift size (see ). Under simultaneous shifts, we obtain the smallest values of ARL with the first training method and the SVR control chart or with the second training method and the NN control chart depending on the shift size (see ).
Poisson Profiles
We use a similar approach for Poisson distribution. We use the same setting as was used in Shadman et al. (Citation2014). The predictor variables are the same as for Binomial profiles and the relationship is defined as:
with and also the covariance matrix of the Poisson regression parameters is
Therefore, and
.
First, we will consider Poisson profiles with the log link function. For the first training method, the SVR control chart delivers the smallest values of ARL under shifts in the intercept and simultaneous shifts with some similar performances to the NN control chart (see ). Under shifts in the slope, the smallest values of ARL are mostly obtained with the NN control chart (see ). For the second training method, we generally obtain the smallest values of ARL with the NN control chart with some similarities to the performance of the SVR control chart under certain shift types and sizes (see ). In the case of the third training method, we obtain the smallest values of ARL with the SVR control chart with some similar performances to the NN control chart.
Table 13. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Poisson distribution with the log link function.
Table 14. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the slope for Poisson distribution with the log link function.
Table 15. ARL (SDRL) values of the SVR, RFR and NN control charts under different simultaneous shifts for Poisson distribution with the log link function.
We obtain the smallest values of ARL mostly with the SVR control chart. The smallest values of ARL are with the first training method under shifts in the intercept and with the third training method under shifts in the slope, with some similar performances to the NN control chart (see ). Under simultaneous shifts, we obtain the smallest values of ARL with the SVR and NN control charts and with all training methods depending on the shift sizes (see ).
Second, we will consider the sqrt link function for the Poisson profiles. We obtain the smallest values of ARL for the first training method with the SVR control charts (see ). For the second and third training methods, we obtain the smallest values of ARL with the NN control chart under shifts in the intercept, and with the SVR control chart under shifts in the slope. However, it is different under simultaneous shifts, in which we obtain the smallest values of ARL with the SVR and NN control charts depending on the shift sizes (see ).
Table 16. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Poisson distribution with the sqrt link function.
Table 17. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the slope for Poisson distribution with the sqrt link function.
Table 18. ARL (SDRL) values of the SVR, RFR and NN control charts under different simultaneous shifts for Poisson distribution with the sqrt link function.
We obtain the smallest values of ARL with the NN control chart and the second training method under shifts in the intercept (see ). Under shifts in the slope, the smallest values of ARL are obtained with the SVR control chart and the first training method (see ). However, the results are slightly different under simultaneous shifts. The smallest values of ARL are mostly obtained with the second training method and the SVR and NN control charts depending on the shift sizes (see ).
Last, we will analyze the Poisson profiles with the identity link function. For the first training method, we obtain the smallest values of ARL with the SVR control chart. However, for the second and third training methods, the smallest values of ARL are obtained with the NN control chart, except for the largest shift sizes in the intercept, slope, and simultaneous shifts (see ).
Table 19. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Poisson distribution with the identity link function.
Table 20. ARL (SDRL) values of the SVR, RFR and NN control charts under different shifts in the intercept for Poisson distribution with the identity link function.
Table 21. ARL (SDRL) values of the SVR, RFR and NN control charts under different simultaneous shifts for Poisson distribution with the identity link function.
We obtain the smallest values of ARL with the first training method and the SVR control chart, except for the two smallest shift sizes in the intercept (see ). Under shifts in the slope, the NN control chart delivers the smallest values of ARL with the second training method, except for the largest shift size (see ). Under simultaneous shifts, we obtain the smallest values of ARL with the NN control chart and the second training method, and from certain values of the shift size, with the SVR control chart and the first training method (see ).
Gamma Profiles
In the case of Gamma distribution, using the same numerical setting as was used in Sogandi and Amiri (Citation2015), we assume different values of the predictor variables, ,
,
and
. Therefore, we assume
and not
which was used in our previous cases. The relationship is
where in-control parameters are and also the covariance matrix of the Gamma regression parameters is:
Hence, are equal to
and
.
Note that, to reduce the paper’s size due to the availability of many tables, we have removed all the tables related to the Gamma analysis from the paper. However, they are provided upon request from the corresponding author.
In the case of log link function, the difference between the RFR and NN control is negligible. Nonetheless, the NN control chart delivers the smallest values of ARL. But for the SVR control chart, we could only obtain the ARL values for the smallest shift sizes under the intercept, slope, and simultaneous shifts , otherwise, the ARL values are extremely large.
The differences between the values of ARL for different training methods and control charts, except for the SVR control chart, are negligible.
For the identity link function, we obtain the smallest values of ARL with the NN control chart, for all training methods.
Under shifts in the intercept, we obtain the smallest values of ARL with the NN control chart and the third training method, except for shift sizes 0.5 and 1. Under shifts in the slope, we obtain different results. We obtain the smallest values of ARL with the NN control chart, but with all the training methods depending on the shift sizes. A similar result can be seen under simultaneous shifts.
In the case of inverse link function, the results are clear for the first and third training methods. We obtain the smallest values of ARL with the SVR control chart in the case of the first training method, and with the NN control chart in the case of the third training method. The second training method, however, delivers the smallest values of ARL for the SVR control chart with some exceptions under the largest shift sizes in the intercept and some shift sizes in the slope.
We obtain the smallest values of ARL for the SVR control chart with the second training method, and for the NN control chart with the third training method depending on the shift sizes in the intercept. We obtain the smallest values of ARL for the smaller values of the shift sizes in the slope with the SVR control chart and the second training method; otherwise, we obtain the smallest values of ARL with the NN control chart and with the third training method. Under simultaneous shifts, we observe similar results.
Illustrative Examples
To illustrate how the developed ML control charts can be implemented in real practice, we present two real cases. Due to the limitations, including the paper size, we only present two examples: i) a drug–response study for Binomial profiles, and ii) a volcano–eruption study for Poisson profiles. Nonetheless, the methodology can also be used for any other practical cases.
A Drug–Response Study
For the Binomial distribution, we adopt an example from Sabahno and Amiri (Citation2023), a drug dose–response study investigating the effect of a new pharmaceutical product. The patient’s response to the drug is the response variable, so that
and the independent variable is the dose of the drug. In-control parameters are set to
and the covariance matrix is
Therefore, and
. For the predictor variables, the drug’s dosage, 13 levels are considered ranging from
to
195, 200, 205, 210, 215, 220, 225, 230, 235, 240) and since each dose of the drug is tested on 50 patients,
. The data for this estimation are available in Myers et al. (Citation2010). To illustrate, how to implement the control charts, we generate 20 profiles from a simulated out-of-control process (a shift
in the intercept). Based on the results of Section Simulation Studies, we design the control charts with the probit link function for the SVR and RFR control charts and the cloglog link function for the NN chart and use the first training method for the SVR control chart, and the second training method for the RFR and NN control charts. The corresponding UCL values by using
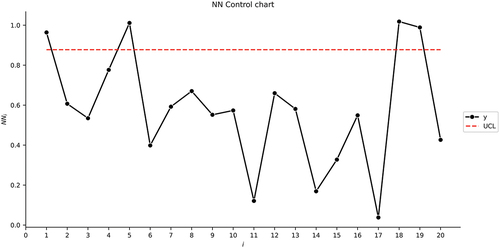
= 0.005 and 5000 simulation runs are obtianed as 0.7686, 0.9644, and 0.8774, respectively, for the SVR, RFR, and NN control charts.
We can see similar behavior in . Four out-of-control samples are detected for each control chart in the same sample numbers: 1, 5, 18, and 19.
Figure 1. The SVR control chart for the first illustrative example.
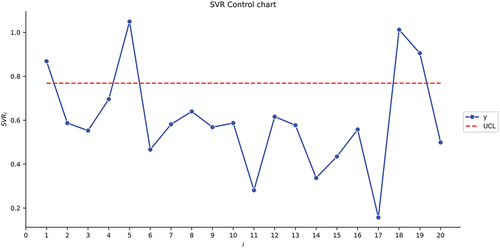
Figure 2. The RFR control chart for the first illustrative example.
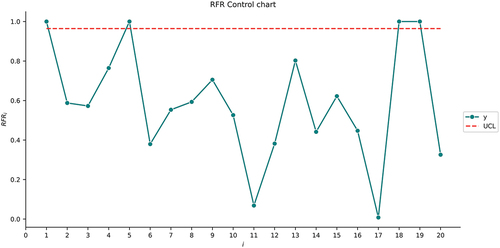
Figure 3. The NN control chart for the first illustrative example.
A Volcano–Eruption Study
For the Poisson distribution, we use the real data from Amiri et al. (Citation2014) which shows Poisson regression profiles with the number of agglomerates that are ejected from a volcano in successive days. Agglomerates are large, coarse, rock fragments associated with a lava flow that are ejected during explosive volcanic eruptions. The response variable is represented by the number of agglomerates and the size of agglomerates is the explanatory variable. The data set is gathered in 68 successive days, and therefore we have 68 Poisson profiles each containing the observations for 20 levels of the explanatory variable. The matrix of the explanatory variables is defined as
The in-control parameters are with covariance matrix:
Therefore, and
. We again generate 20 profiles from the out-of-control process (a shift
in the intercept). Again, based on the results of Section Simulation Studies, we design the control charts with a log link function and the first training method for the SVR and NN control charts and use the third training method for the RFR control chart. Assuming
= 0.005 and with 5000 simulation runs, the UCL values are obtained as 0.4233, 0.9637, and 0.8146, respectively, for the SVR, RFR, and NN control charts.
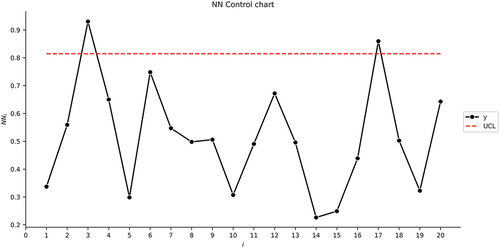
As can be seen in , similar to Section A Drug–Response Study, the SVR and NN control charts behave similarly. However, in this example, only two out-of-control samples are detected for sample numbers 3 and 17. In addition, for the RFR control chart, we detected 2 out-of-control samples but in different sample numbers: 3 and 6.
Figure 4. The SVR control chart for the second illustrative example.
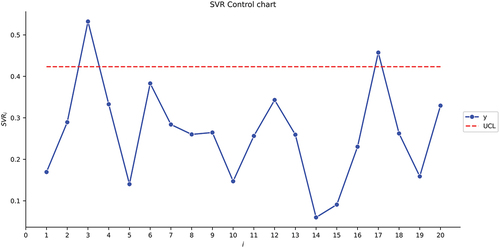
Figure 5. The RFR control chart for the second illustrative example.
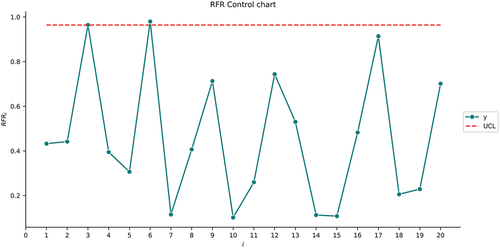
Figure 6. The NN control chart for the second illustrative example.
Concluding Remarks
In this paper, we developed the ML control charts for monitoring GLM-type profiles by considering different training methods, response distributions, and link functions. We first defined the GLM profiles for three main distributions: Binomial, Poisson, and Gamma with their corresponding link functions. Then, we described the ML techniques generally and then we moved on to the statistical and ML-based control charts.
A simulation study followed the theories. We trained the ML models and chose the best training method and ML control chart for the corresponding response distribution and link function. We considered three training methods with different shift sizes. For designing the control charts, we used the SVR, RFR, and NN techniques and compared the results using the ARL values.
In the case of Binomial profiles, for all link functions, we obtained the smallest values of ARL with the SVR and NN control charts and the first and second training methods depending on the shift sizes and types. For the Poisson profiles, with the log link function, the SVR control chart performed mostly the best with all the training methods except under simultaneous shifts. In that case, the NN control chart delivered the smallest values of ARL. For the sqrt link function, the SVR and NN control charts generally performed the best. In the case of shifts in the intercept, it was the NN control chart and the second training method, and under shifts in the slope, it was the SVR control chart and the first training method. Under simultaneous shifts, we also observed the smallest values of ARL with the SVR and NN control charts, and with the second training method. For the identity link function of Poisson profiles, we obtained the smallest values of ARL with the SVR control chart and the first training method, under shifts in the intercept. Under shifts in the slope, the NN control chart delivered the smallest values of ARL with the second training method, and under simultaneous shifts, it was a combination of the NN control chart with the second training method, and the SVR control chart with the first training method. For the Gamma profile with the log link function, the differences between the ARL values were negligible for the RFR and NN control charts. We obtained large values of ARL for almost all shift sizes in the case of the SVR control chart. For the identity link function, the NN control chart and all the training methods delivered the smallest values of ARL. For the Gamma profiles with the inverse link function, we obtained the smallest values with the SVR control chart and the second training method, and with the NN control chart and the third training method, depending on the type or size of the shifts. Furthermore, by approaching the results from a different perspective, it was clear that by keeping the ML technique and training method fixed, for the Binomial profile, using the probit link function emerged as the most effective (the smallest out-of-control ARL value) under most shift sizes and types, and in certain shift scenarios, the cloglog link function demonstrated superior performance, while the logit function proved to be the optimal choice in a few specific cases. For the Poisson profile, the log link function was the best in almost all the cases. For the Gamma profile, the findings exhibited greater diversity. In the case of the RFR and NN charts, the most effective link function was consistently the log link function. However, for the SVR chart, it was observed that the inverse link function predominantly outperformed others, followed by the identity function, and lastly, the log function.
It is important to acknowledge that employing an alternative simulation environment may yield varied results. In this study, we have solely examined outcomes within a singular simulation environment. To implement the proposed control charts in real practice, one may use the same method as we used in Section Simulation Studies to find the best combination of training method, and ML structure for the response distribution and link function to see which one results in better performance and use that control chart to monitor the process thereafter.
Finally, we presented illustrative examples to show how each ML control chart can be implemented in practice. The first example investigated the effect of a new pharmaceutical product in a dose–response study and the second example considered the number of agglomerates that were ejected from a volcano in successive days.
For future research, since in this paper it was assumed that the regression parameters’ values were known, one can consider performing this research in the case their values are unknown and should be estimated. In addition, different control charts can be developed and the results can be compared with the results of this paper.
Acknowledgements
The authors thank the journal’s editorial board and the reviewers for their constructive comments, which have led to significant improvements in the quality of the paper.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data that support the findings of this study are included in the paper.
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
References
- Amiri, A., M. Koosha, and A. Azhdari. 2012. T2 based methods for monitoring Gamma profiles. Proceedings of The International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, 580–30.
- Amiri, A., M. Koosha, A. Azhdari, and G. Wang. 2014. Phase I monitoring of generalized linear model-based regression profiles. Journal of Statistical Computation and Simulation 85 (14):2839–59. doi:10.1080/00949655.2014.942864.
- Amiri, A., M. Mehrjoo, R. Ghajar, and F. Hosseini. 2010. Phase II monitoring of simple linear profiles under decreasing step shifts. Proceedings of The 40th International Conference on Computers & Industrial Engineering, 1–5. doi:10.1109/ICCIE.2010.5668258.
- Amiri, A., F. Sogandi, and M. Ayoubi. 2018. Simultaneous monitoring of correlated multivariate linear and GLM regression profiles in Phase II. Quality Technology & Quantitative Management 5 (4):435–58. doi:10.1080/16843703.2016.1226706.
- Apsemidis, A., S. Psarakis, and J. M. Moguerza. 2020. A review of machine learning kernel methods in statistical process monitoring. Computers & Industrial Engineering 142:1–12. doi:10.1016/j.cie.2020.106376.
- Boser, B. E., I. M. Guyon, and V. N. Vapnik. 1992. A training algorithm for optimal margin classifiers. Proceedings of the fifth annual workshop on Computational learning theory, 144–52. doi:10.1145/130385.130401.
- Breiman, L. 2001. Random Forests. Machine Learning 45 (1):5–32. doi:10.1023/A:1010933404324.
- Escobar, C. A., and R. Morales-Mendez. 2018. Machine learning techniques for quality control in high conformance manufacturing environment. Advances in Mechanical Engineering 10 (2):168781401875551. doi:10.1177/1687814018755519.
- Kang, L., and S. L. Albin. 2000. On-line monitoring when the process yields a linear profile. Journal of Quality Technology 32 (4):418–26. doi:10.1080/00224065.2000.11980027.
- Kim, K., M. A. Mahmoud, and W. H. Woodall. 2003. On the monitoring of linear profiles. Journal of Quality Technology 35 (3):317–28. doi:10.1080/00224065.2003.11980225.
- Koosha, M., and A. Amiri. 2011. The effect of link function on the monitoring of logistic regression profiles. Proceedings of the World Congress on Engineering, London, UK, vol. 1, 326–28.
- Koosha, M., and A. Amiri. 2013. Generalized linear mixed model for monitoring autocorrelated logistic regression profiles. The International Journal of Advanced Manufacturing Technology 64 (1–4):487–95. doi:10.1007/s00170-012-4018-2.
- Liaw, A., and M. Wiener. 2022. randomForest: Breiman and Cutler’s random forests for classification and regression. Accessed March 18, 2024. https://cran.rproject.org/web/packages/randomForest/index.html.
- Meyer, D. 2023. e1071: Misc functions of the department of statistics, probability theory group (formerly: E1071). TU Wien. Accessed March 18, 2024. https://cran.r-project.org/web/packages/e1071/index.html.
- Mohammadzadeh, M., A. Yeganeh, and A. Shadman. 2021. Monitoring logistic profiles using variable sample interval approach. Computers & Industrial Engineering 158:1–12. doi:10.1016/j.cie.2021.107438.
- Mohd Amiruddin, A. A. A., H. Zabiri, S. A. A. Taqvi, and L. D. Tufa. 2020. Neural network applications in fault diagnosis and detection: An overview of implementations in engineering-related systems. Neural Computing and Applications 32 (2):447–72. doi:10.1007/s00521-018-3911-5.
- Montgomery, D. C. 2012. Introduction to statistical quality control, 7th ed. AZ: John Wiley & Sons, Inc.
- Myers, R. H., D. C. Montgomery, G. G. Vining, and T. J. Robinson. 2010. Generalized linear models: with applications in engineering and the sciences, 2nd ed. Hoboken, New Jersey: John Wiley & Sons, Inc.
- Noorossana, R., A. Saghaei, and A. Amiri. 2011. Statistical analysis of profile monitoring. Hoboken, NJ: John Wiley & Sons.
- Olsson, U. 2002. Generalized linear models: an applied approach. Lund, Sweden: Studentlitteratur.
- Patterson, D. W. 1998. Artificial neural networks: Theory and applications, 1st ed. New Jersey, United States: Prentice Hall PTR.
- Qi, D., Z. Wang, X. Zi, and Z. Li. 2016. Phase II monitoring of generalized linear profiles using weighted likelihood ratio charts. Computers & Industrial Engineering 94:178–87. doi:10.1016/j.cie.2016.01.022.
- Ripley, B., and W. Venables. 2023. Nnet: Feed-forward neural networks and multinomial log-linear models. Accessed March 18, 2024. https://cran.r-project.org/web/packages/nnet/index.html.
- Sabahno, H., and A. Amiri. 2023. New statistical and machine learning based control charts with variable parameters for monitoring generalized linear model profiles. Computers & Industrial Engineering 184:1–18. doi:10.1016/j.cie.2023.109562.
- Sabahno, H., and S. T. A. Niaki. 2023. New machine-learning control charts for simultaneous monitoring of multivariate normal process parameters with detection and identification. Mathematic 11 (16):1–31. doi:10.3390/math11163566.
- Shadman, A., C. Zou, H. Mahlooji, and A. B. Yeh. 2014. A change point method for Phase II monitoring of generalized linear profiles. Communications in Statistics - Simulation and Computation 46 (1):559–78. doi:10.1080/03610918.2014.970698.
- Sharafi, A., M. Aminnayeri, and A. Amiri. 2013. An MLE approach for estimating the time of step changes in Poisson regression profiles. Scientia Iranica 20:855–60. doi:10.1016/j.scient.2012.10.043.
- Sogandi, F., and A. Amiri. 2015. Estimating the time of a step change in gamma regression profiles using MLE approach. International Journal of Engineering 28 (2):224–233. doi:10.5829/idosi.ije.2015.28.02b.08.
- Sogandi, F., and A. Amiri. 2017. Monotonic change point estimation of generalized linear model-based regression profiles. Communications in Statistics - Simulation and Computation 46 (3):2207–27. doi:10.1080/03610918.2015.1039132.
- Soleimani, P., R. Noorossana, and A. Amiri. 2009. Simple linear profiles monitoring in the presence of within profile autocorrelation. Computers & Industrial Engineering 57 (3):1015–21. doi:10.1016/j.cie.2009.04.005.
- Stoean, C., and R. Stoean. 2014. Support vector machines and evolutionary algorithms for classification: Single or together. Cham, Switzerland: Springer Publishing Company, Incorporated.
- Yeganeh, A., S. A. Abbasi, F. Pourpanah, A. Shadman, A. Johannssen, and N. Chukhrova. 2022. An ensemble neural network framework for improving the detection ability of a base control chart in non-parametric profile monitoring. Expert Systems with Applications 204:1–18. doi:10.1016/j.eswa.2022.117572.
- Yeganeh, A., S. A. Abbasi, S. C. Shongwe, J.-C. Malela-Majika, and A. Shadman. 2023. Evolutionary support vector regression for monitoring Poisson profiles. Soft Computing 28 (6):4873–97. doi:10.1007/s00500-023-09047-2.
- Yeganeh, A., N. Chukhrova, A. Johannssen, and H. Fotuhi. 2023. A network surveillance approach using machine learning based control charts. Expert Systems with Applications 219:1–17. doi:10.1016/j.eswa.2023.119660.
- Yeganeh, A., A. Johannssen, N. Chukhrova, S. A. Abbasi, and F. Pourpanah. 2023. Employing machine learning techniques in monitoring autocorrelated profiles. Neural Computing & Applications 35 (22):16321–40. doi:10.1007/s00521-023-08483-3.
- Yeganeh, A., A. Johannssen, N. Chukhrova, M. Erfanian, M. R. Azarpazhooh, and N. Morovatdar. 2023. A monitoring framework for health care processes using generalized additive models and auto-encoders. Artificial Intelligence in Medicine 146:102689. doi:10.1016/j.artmed.2023.102689.
- Yeganeh, A., A. Johannssen, N. Chukhrova, and M. Rasouli. 2024. Monitoring multistage healthcare processes using state space models and a machine learning based framework. Artificial Intelligence in Medicine 151:102826. doi:10.1016/j.artmed.2024.102826.
- Yeganeh, A., F. Pourpanah, and A. Shadman. 2021. An ANN-based ensemble model for change point estimation in control charts. Applied Soft Computing 110:1–19. doi:10.1016/j.asoc.2021.107604.
- Zou, C., Y. Zhang, and Z. Wang. 2006. A control chart based on a change-point model for monitoring linear profiles. IIE Transactions 38 (12):1093–103. doi:10.1080/07408170600728913.