
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Our research objective was to develop a model that calculates the affinity between candidates and job descriptions. We focused specifically on the fields of data science and software development. This endeavor addressed the challenge posed by the need for a systematic method for its evaluation. To overcome these obstacles, we adopted a mixed-methods design. This approach enabled us to identify two findings. Firstly, the essential elements that must be included in CVs to render them a valuable information source. Secondly, a comprehensive and systematic benchmark for human-level performance. We studied the candidate selection processes. The above involved the participation of professionals in these fields who, as part of their routine duties, are responsible for identifying, evaluating, and selecting job candidates for their teams. Subsequently, we designed a binary candidate-job matching model using Siamese networks in conjunction with the Choquet integral. This model’s original architecture combines a data-driven learning method with one for representing expert knowledge in decision-making. We assessed the effectiveness of this model against the established human-level performance. Our study highlights the challenges in effectively capturing professional preferences and biases in the candidate selection process. It provides insights into the complexities of integrating expert judgment into automated recruitment tools.
Introduction
Recruitment and hiring are crucial processes for the functionality and success of modern organizations. One improvement area in these processes is related to the disconnection between the precise needs of the position to be filled and its interpretation during the profiling phase. In addition, these activities are even more complicated when they are focused on highly technical or specialized positions.
The variety of roles and titles of professionals involved in some stage of the hiring process can vary significantly among companies, encompassing Recruiters, Hiring Managers, Talent Acquisition Specialists, Recruitment Consultants, Headhunters, HR (Human Resources) Managers, Sourcing Specialists, Team Leads, Technical Recruiters, Managers, CEOs, among others. In this study, the generic term “hiring personnel” is adopted to include all those involved in the comprehensive process of identifying, evaluating, and selecting candidates for job positions.
Specifically, in companies with employees in the STEM sector (an acronym for Science, Technology, Engineering, and Mathematics), hiring challenges (or recruitment challenges) arise from the technical specialization required for positions and the rapid evolution of demanded skills. The US Bureau of Labor Statistics reported, in March 2022, a figure of 9,778,200 professionals in STEM fields.Footnote1 This growing base of professionals, along with the specificity of requested competencies, adds a layer of complexity to the selection process.
In this context, the analysis by Fayer, Lacey, and Watson (Citation2017) highlights that, as of May 2015, the most numerous occupations in STEM were primarily found in the information and technology sector. Roles such as software application developers, technical support specialists, computer systems analysts, network and systems administrators, and IT managers were among the most in demand.
Considering the diversity of hiring approaches in various STEM subsectors, our study analyzes the resume review process performed by hiring personnel on candidates in software development and data science-related areas. We aim to systematically integrate the expert perspective of hiring personnel into a model. This model will enable individuals, with less specialization in the area, to identify suitable candidates for a specific position, optimizing time and resources in the selection process and serving as an auxiliary tool to standardize resume evaluation. This approach bridges the gap between expert knowledge and practical application in recruitment, making the process more efficient and accessible to a broader range of professionals involved in the hiring process.
The main contributions of our research are:
Development of a human-level performance: we introduced a human-level performance methodically developed using mixed methods, serving as a benchmark for assessing and comparing the performance of automated personnel selection systems.
Systematic analysis of hiring preferences: we systematically identified the minimal structure of a curriculum vitae preferred by hiring personnel, providing a framework for understanding an effective CV in the eyes of software and data science professionals.
Insights into cognitive biasesFootnote2 in hiring: our research documented the presence and impact of cognitive biases in the resume evaluation process in software and data science areas.
Empirically designed classification model for automatic profiling using fuzzy measures: our experimental approach, grounded in our methodological design, incorporated a neural network, specifically Siamese networks, along with the Choquet integral. This combination allowed us to leverage synthetically generated and real data effectively for learning purposes. Through this process, we could discern and understand the criteria used by hiring professionals. Our design enabled the expression of these criteria as decisions based on either knowledge or preferences. These preferences and knowledge-based decisions are naturally better modeled using fuzzy logic (see, e.g., Yu and Xu (Citation2020); Guillaume, Houé, and Grabot (Citation2014); Dumnić et al. (Citation2022)). As a result, we were able to design a more comprehensive function for candidate-job affinity, taking into account a broader range of factors and interactions in the evaluation process.
The resources used in this research are openly available at https://github.com/Maleniski/Empirical-JobModel-HLP.
Background
This section consists of three parts. The first part compiles and presents recent research on profiling processes and models proposed for automation in recent literature. The second part addresses challenges in modeling and evaluating machine learning-based systems that emulate human behavior. Finally, the third part articulates our research objective.
HR Profiling and Selection: Model Design and Research
The analysis, definition, and implementation of solutions and research on profiling and selection of human resources have been the subject of study in the academic literature from the perspectives of psychology within the field of decision theory and machine learning.
In decision theory, various statistical and economic models attempt to capture human behavior and reasoning complexities. According to Ajzen (Citation1996), expected subjective utility and expectancy-value models focus on how individuals develop expectations and value potential outcomes in uncertain contexts. According to these models, individuals evaluate alternatives based on the expected utility and subjective values assigned to different outcomes. However, Ajzen notes limitations in these models, highlighting that human decisions vary even under identical conditions. Specifically, context and motivation influence the degree of systematization in human reasoning, leading to rigorous analysis, whereas intuitive approach prevails in others, with less scrutiny and reliance on heuristics or cognitive biases.
In the field of personnel selection, Linos and Reinhard (Citation2015) highlights certain cognitive biases, such as the tendency to judge a candidate’s suitability on the basis of industry stereotypes, the influence of memories of previous employees when evaluating new candidates, and the impact of first impressions of a CV, on subsequent judgments. These cognitive shortcuts can manifest themselves throughout the selection process. Therefore, introspection and critical analysis of performance and failures in these processes are fundamental for understanding and mitigating their occurrence (Pitz and Sachs Citation1984).
In the context of this theory, some academic literature includes the analysis of decision processes in personnel selection. Although only a few studies directly address the analyses conducted by recruiters when reviewing CVs, the studies conducted by Proença and de Oliveira (Citation2009) and Zide, Elman, and Shahani-Denning (Citation2014) are noteworthy.
Proença and de Oliveira (Citation2009) results revealed that, although recruiters often refer to the internal policies of their respective companies during interviews, during the experiment, they sometimes resort to ambiguous or previously unmentioned criteria. Additionally, some CV characteristics were valued positively by some recruiters and negatively by others, pointing to the influence of previously unmentioned personal criteria in the evaluation. Therefore, the authors could not conclude criteria systematically present during the study among all participants, in addition to reporting the occurrence of cognitive biases during the experiment.
On the other hand, Zide, Elman, and Shahani-Denning (Citation2014) aimed to identify specific criteria that recruiters analyze in a LinkedIn social network profile when evaluating candidates. Through qualitative analysis of semi-structured interviews with human resources professionals and subsequent coding of the results, they identify 21 variables in candidate profiling. These include gender, ethnicity, grammatical errors within the profile, the accessibility and formality of the e-mail, education, and the type of photograph. Grammatical errors and an informal e-mail emerged as the main factors for discarding a candidate, followed by a profile picture that could be considered inappropriate.
Concerning the current context of human resource profiling and selection, a report from the Chartered Institute of Personnel and Development (CIPD Citation2022) provides insights into the trends in these processes. The study involved collaboration from 1,000 organizations in the United Kingdom that employ human resources professionals in their operations. This report provides descriptive statistics on talent acquisition strategies, selection methods, retention challenges, and strategic human resource planning. According to the report, work experience was the most common criterion for candidate selection, with 77% of surveyed companies confirming its use, followed by curriculum vitae review at 61%, and academic degrees at 59%. Regarding recruitment challenges, the attraction of talent for senior-level positions (58%), the attraction and hiring for operational roles (39%), and the hiring of candidates with limited experience (26%) were most frequently mentioned. These figures indicate human resource professionals’ preferences and challenges in the job market.
In the field of machine learning, recent works (2018 to present) dealing with the analysis and design of solutions for personnel profiling include the research conducted by Bondielli and Marcelloni (Citation2021); Barducci et al. (Citation2022); Barrak, Adams, and Zouaq (Citation2022); Mohamed et al. (Citation2018); Reusens et al. (Citation2018); Ong and Hui Lim (Citation2023). These studies explore various methods related to personnel profiling based on specific job positions.
The study conducted by Bondielli and Marcelloni (Citation2021) includes the analysis of different methods for the automatic summarization of CVs. This study concluded that Sentence-BERT is the most computationally efficient technique compared to a methodology based on BERT and -means. On the other hand, Barducci et al. (Citation2022) proposes a specific procedure for identifying personal information, skills, and work experiences in curricula vitae. This procedure is based on Name Entity Recognition techniques and implementing a BERT model adjusted explicitly for this task.
Concerning resume recommendation systems based on job descriptions, contributions by Ong and Hui Lim (Citation2023) and Mohamed et al. (Citation2018) were identified. Ong and Lim presents a system for skill recommendation based on job title descriptions, designed using BERT and FastText models, trained with data from job descriptions, job titles, and associated skills. On the other hand, Mohamed et al. introduce a solution that uses semi-automatically maintained ontological structures, as this system requires manual input of new skills identified in CVs for its maintenance.
Regarding studies that address the ethical and legal implications of automated personnel profiling, Bogen and Rieke (Citation2018) discuss the use, limitations, and identified opportunities of algorithms used in personnel recruitment as of 2018. Among the conclusions of this report, the authors mentioned that although these systems lack decision-making capability, they automate rejections. Furthermore, it also highlights the ease with which biases can be replicated. The solution to this does not solely lie in eliminating protected classesFootnote3 during the solution’s definition. Additionally, it has been suggested that these tools may amplify insignificant qualities, and there is no standardized framework for validating these systems. Moreover, the report evaluates some tools available at that time for matching job positions and candidates, concluding that systems based on recommender models propagated recruiter biases.
In terms of identifying and characterizing emerging biases in hiring processes, Linos and Reinhard (Citation2015) present affinity biases (preference for people with familiar characteristics), status quo biases (inclination toward candidates similar to those previously hired), endowment effect (valuation of current staff qualities without considering future needs), and halo effect (conclusions based on first impressions), as some of the biases identified in the literature that can be present in personnel recruitment processes. A reported case of an automated system that propagated bias within recruitment processes was the one designed by Amazon in 2014. This model was based on data from the majority group of their employee population at that time, which consisted of white males. The model discriminated against candidates whose curriculum vitae included the word women (Dastin Citation2022).
Challenges in Machine Learning Models Related to Human Behavior and Expert Knowledge Extraction
The analysis of the use of artificial intelligence to support social issues has been a growing area of interest for researchers. The lack of empirical studies validating the coherence and use of these models, as well as the lack of justification in decisions automated by machine learning models, create a gap between theoretical contributions and reality (Lai et al. Citation2021, 7–10). For example, Blodgett et al. (Citation2020) conducted a study analyzing the motivations and justifications of NLP contributions for bias mitigation. Their review concludes that the solutions must systematically justify their motivations and precisely define bias and its detriment. Furthermore, this study reports a disconnection between the techniques used and the contributions motivations, as well as the need for conceptual frameworks outside of the NLP field.
Regarding empirical studies quantifying the impact of using profiling systems in hiring, Peng et al. (Citation2022) presents a quantitative study using specially prepared software for the analysis. This study required participants to classify the possible occupation of a person described in a curriculum vitae summary, including the use of personal pronouns. The study assessed whether there were differences in participant responses when the software displayed a suggested occupation inferred from NLP models. The results were varied. While some occupations, such as surgeon and teacher, showed a general improvement in classification, errors increased when classifying women in the occupation of lawyer, for example. The scientific community acknowledges the necessity for more qualitative scientific studies to determine methodologies that address the use of machine learning. This is due to social science researchers’ unfamiliarity with machine learning tools and models (Chen et al. Citation2018).
In the current context, achieving human-level performance through expert knowledge, that includes qualitative and subjective factors inherent in recruitment and profiling tasks, is a significant challenge. To the best of the authors’ knowledge, this process has not been systematically addressed. The extraction of expert knowledge in specific tasks is intrinsically linked to the characteristics of the methodology implemented in this process, the quality of the instructions provided, and the specific profile of the individuals involved in the assessed tasks (Cowley et al. Citation2022). Insufficient control of these factors impedes the accurate validation of data used for comparison with a system (Cowley et al. Citation2022). Additional elements such as fatigue, stress, and cognitive overload can also be considered in capturing human performance (Gunda, Gupta, and Kumar Singh Citation2023).
In order to achieve the use of methodologies that effectively quantify factors associated with the analysis of qualitative elements, it is necessary to implement methodological designs that allow for the systematic integration of these elements. Mixed methods constitute methodological designs that combine qualitative and quantitative procedures, intending to overcome the limitations inherent in the exclusive use of a single research method (Quinn Citation2014, 478–479). These designs are typically structured in sub-studies, whether qualitative or quantitative, facilitating the exploration of how the information obtained from each of them is interrelated. This allows for addressing difficulties associated with these types of experimental designs, such as the juxtaposition of ideas rather than their integration (Kelle and Buchholtz Citation2015).
Research Objective
This research aimed to design a system using resumes and job descriptions that classifies candidates, as suitable or not, for job positions in software development and data science-related areas. The approach involved identifying and modeling recruitment processes conducted by hiring personnel, which is applicable in the automatic profiling of personnel.
Our study employed mixed methods to establish human-level performance, focusing on how hiring personnel classify resumes for specific job positions. Then, we compared this benchmark to the classification model’s performance to assess its accuracy.
Our research questions were: What are the predominant criteria and attributes used by hiring personnel when profiling and evaluating resumes for software development and data science-related positions? What is the minimum structure required for a resume to be considered viable in a hiring process? How can human profiling rules and criteria be translated into an automatic similarity calculation function?
Methodology
This section outlines the methodological procedure we adopted to achieve the research objectives. This methodological design included the acquisition and analysis of both qualitative and quantitative data, through mixed methods. This approach aimed to achieve a rigorous human-level performance assessment, enabling the identification of characteristics within the CV review process conducted by hiring personnel. Simultaneously, it sought to capture and isolate the inherent subjectivity in hiring processes and identify biases associated with the task of a CV review. To the best of our knowledge, the design we use is innovative in machine learning research that focuses on models for task automation. The methodology incorporates practices that have been reported to be beneficial in machine learning comparison studies (see, e.g., Cowley et al. (Citation2022)).
Building upon this methodological foundation, which we will explain in detail below, we faced specific challenges in the practical execution of our study that were decisive in the design of our methodology. Specifically, these challenges were related to data availability for model design, identifying only a few public data sources for research purposes. We attributed this scarcity possibly to the private nature of information in CVs. To address this, we devised a procedure to synthetically generate resume information using OpenAI’s GPT-3.5 API and extracted job descriptions through web scraping from an employment portal. The synthetic generation of CVs prompted considerations about which sections to generate, their structure, and the reasons for these choices. Additionally, generating irrelevant or inadequate information in synthetic CVs would unnecessarily increase API usage costs. As stated in Background section, the literature provided few references to support this task.
Our study aimed to develop a model based on the abstraction and generalization of hiring personnel practices and to evaluate it systematically. For this, we needed to conduct two complementary studies, named Human Expert Information Extraction and Model for Job-Candidates Matching, respectively (see ).
Figure 1. General methodological diagram.
The flowchart is divided into three main sections, each represented by a different background color. CV Preference of Human Experts (light blue background), Human Level Performance Determination (light green background) and Model for Job-Candidates Matching (light red background).
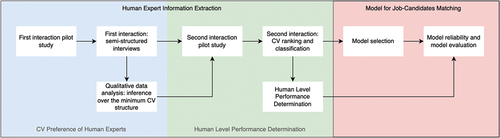
The Human Expert Information Extraction section comprised two phases. The initial phase focused on characterizing and generalizing hiring personnel’s norms during CV analysis. The goal was to identify the essential sections CVs must contain to be valid information sources. The second phase involved an experiment in classifying and ranking CVs, where participants assessed the CVs based on their relevance to a specific job description, categorizing them as suitable or unsuitable. This process established a benchmark for human-level performance.
The Model for Job-Candidates Matching section focused on designing a model incorporating the criteria and rules identified in the Human Expert Information Extraction section. The aim was to create a system capable of classifying CVs as suitable or unsuitable based on their affinity with a specific job description, comparing it to the established human-level performance. The remainder of this section details each of these studies.
Human Expert Information Extraction
In the first section, we defined two primary objectives (see blue and green regions). The first sought to discern hiring personnel’s criteria during resume reviews through semi-structured interviews. This analysis would enable us to identify essential elements a CV must incorporate. The second objective aimed to establish human-level performance through an evaluation experiment.
This phase’s structure focused on creating a synthetic database of CVs. This database needed to reflect rich and well-structured information based on the criteria of the participating hiring personnel. This approach prevented the generation of potentially irrelevant synthetic information and allowed us to examine whether cognitive biases influenced some criteria identified during interviews. Detecting biased criteria was of particular interest to us, as incorporating them into the classification model could inadvertently propagate them.
Based on the inferred CV structure, we designed an experiment. This experiment involved evaluating a series of candidate CVs for a specific position, given a job description. This experiment considered different common scenarios identified from the semi-structured interviews. The task required ranking candidates from most to least affinity for the position, indicating whether candidates below a certain threshold should be excluded from the selection process. This methodology provided a binary classification (suitable and unsuitable) for evaluating the subsequently developed system. Additionally, the generated ranking would complement the criteria established during the interviews, aligning with findings from previous studies (see Proença and de Oliveira (Citation2009)), which suggest discrepancies between criteria verbally declared and those effectively applied in the selection and classification process.
Due to the potential influence of cultural factors in the selection process criteria, we restricted the study to Mexican professionals who volunteered and met the appropriate profile. These participants either worked for companies in Mexico or remotely in Mexico for U.S.-based companies. All participants signed an informed consent form at the beginning of the first interview. As an incentive for participation, we offered them a certificate of participation and a report summarizing the general results of the initial interviews. We conducted all the interviews in Spanish and designed the instruments originally in this language.
CV Preference of Human Experts
In order to identify the CV preferences of human experts, we employed semi-structured interviews as our methodology approach. This strategy necessitated several key components. Firstly, developing an interview protocol, meticulously revised by an experienced specialist in semi-structured techniques, was imperative. Furthermore, in this study was essential the participation of hiring personnel coming from companies whose characteristics were representative of the target population. This methodology required qualitative analytical techniques, enabling a detailed and contextual interpretation of the collected data. Such an approach ensured a comprehensive and nuanced understanding of the underlying trends and patterns in recruitment preferences.
Procedure
To establish the criteria and key characteristics that hiring personnel prioritize when evaluating resumes in candidate profiling processes, we adopted a qualitative methodology focusing on analyzing semi-structured interviews and, to select our sample we used a maximum variation sampling method. This non-probabilistic sampling method, as described by Quinn (Citation2014, 428), considers the primary qualities of the target population, maximizing the heterogeneity within the sample. The goal was to capture the variety of profiles among hiring personnel and thereby identify prevalent patterns.
Years of experience and the number of employees in the current companies of participants served as heuristics to characterize the study population. Experience was categorized into three segments: 0 to 10 years, more than 10 to 20 years, and over 20 years. Company size categories included 2 to 99 employees, 100 to 999, and 1000 or more employees. We analyzed whether these segmentations resulted in an equitable sample distribution.
The analysis involved data from the Stack Overflow 2023 Developer Survey,Footnote4 which annually gathers information from software development and data science professionals. This database, selected for its relevance and updated content, provided the necessary information for the proposed analysis.
We downloaded and filtered the annual survey data for respondents currently employed in Mexico. We applied an additional filter from the 605 extracted records to identify positions potentially linked to personnel involved in the hiring process. The selected categories were Project manager, Engineering manager, Senior Executive, C-Suite, VP, etc., Academic researcher, and Product manager. This selection process resulted in 31 records, classified according to the predefined categories for maximum variation sampling (see ).
Table 1. Distribution of respondents working in Mexico according to data from the Stack Overflow 2023 Developer Survey in segmentation used for maximum variation sampling.
The evaluation of respondent distribution across the defined segmentations ensured the study reflected equitable representation of professionals in each one of the categories. This assessment determined the suitability of the employed stratification for maximum variation sampling in characterizing the population of interest (see ).
Table 2. Number of professionals to sample according to maximum variation technique through segmentation criteria of years of experience and number of employees in their current company.
Using information from the Stack Overflow 2023 Developer Survey also enabled us to adopt terminology related to current occupational titles in software development and data science-related fields. This adoption in the research originated from the lack of a standardized naming convention across companies, for employee positions. Consequently, determining which specific occupations to select and their denominations was a non-trivial task that influenced the generation of synthetic CVs and web scraping extraction. We chose the terminology for occupations over other existing classifications, such as the one used by the U.S. Bureau of Labor Statistics in the 2010 Standard Occupational Classification (Jones Citation2014), because we considered that Stack Overflow terminology accurately reflects the current trends in occupations within the fields of software development and data science-related fields.
Instruments
We devised a protocol for conducting semi-structured interviews, initially including 13 questions. These questions addressed the strategies and considerations hiring personnel employ during the candidate selection process. Topics covered included identifying frequently recruited roles, preferences for and usage of recruitment platforms, evaluation of competencies and work experiences, the influence of candidates’ digital presence, and methods for differentiating among candidates in final decision-making.
We conducted all the interviews remotely to interact with professionals in various regions of Mexico in order to standardize the interview process. All sessions underwent video recording for subsequent analysis.
Pilot Test
In August 2023, we conducted a pilot study to test the clarity of the instrument’s questions. The interviewee was a professional with 12 years of experience in recruitment within the software sector and possessed a bachelor’s degree in Administrative Computer Science. This pilot test revealed the need to modify the wording of question number 12 and to add a question. The revised question 12 asked, “When you come across a resume that seems overqualified for a position, what is your procedure or criteria for evaluating it and deciding whether to continue in the selection process? And for one who does not meet all the qualifications?.” On the other hand, the new question established “Have you ever had difficulty identifying potential candidates due to the volume of applicants for a position?.” The final protocol is available in Appendix A.
A journalist with five years of experience who has served as a reporter for a local television station reviewed the video-recorded pilot test. This review aimed to verify the appropriateness of the questions, the tone, and the execution of the interview. This second review revealed no need for additional changes.
Sample Selection Process
During August and September 2023, Mexicans specializing in software or data science, who were deemed to meet the criteria of maximum variation, were invited via LinkedIn and various professional networks. This process resulted in 16 individuals who agreed to participate in the study. We conducted 16 interviews, with a minimum and maximum duration of 35 and 120 minutes, respectively.
Since only nine professionals were needed from the total sample, sixteen were required (see ), so we had some over-representation of some profiles (see ).
Table 3. Number of interviewed professionals organized according to the criteria of the maximum variation sample.
In order to obtain the final sample of nine professionals, the tie-breaking criterion we considered was selecting the professional with the most years of experience, specifically in tasks related to profiling personnel.
Participant Characteristics
Following the maximum variation sampling criteria, we selected a subsample of nine individuals who met the pre-established criteria. This subsample encompassed five professionals from software development (specifically, front-end, back-end, and full-stack development), three data science specialists, and one embedded software expert. The group included only one female participant. Regarding academic background, four participants held bachelor’s degrees, another four had master’s degrees, and one had a Ph.D. degree. The study fields of all participants spanned engineering, mathematics, artificial intelligence or data science, information technologies, and computer science. Professional positions within the subsample were four CEOs, two managers, two technical leaders, and one recruiter. Age-wise, three professionals ranged from 26–32 years old, while the others ranged from 40–57 years old.
Qualitative Data Analysis
After transcribing the video-recorded interviews, the first two authors of this study manually coded the transcriptions using ATLAS.ti software. They performed a cross-review of the assigned codes to reach a consensus.
Human-Level Performance Determination
In this stage, our methodology involved several steps to ascertain human-level performance. In the initial phase, we synthesized CVs based on structural insights gleaned from the first segment of our study. Before deployment, these CVs underwent a thorough expert review to validate their appropriateness for the experiment. Subsequently, we utilized randomization tools to allocate these CVs for evaluation, ensuring that they were anonymized with non-descriptive identifiers to maintain impartiality. The core of our experiment relied on the participation of pre-selected hiring personnel, who were tasked with evaluating various work scenarios and candidates. This process necessitated specialized software for the seamless presentation of the CVs and the intricate analysis of the ranked data and classification. Through this comprehensive approach, we aimed to emulate real-world hiring conditions and accurately determine Human-Level Performance.
Procedure
The second phase of the study, conducted between November and December 2023, was intended to determine human-level performance for subsequent model evaluation and to further explore the preferences and criteria expressed in the initial interviews.
This phase involved the nine selected participants evaluating four different scenarios. Each scenario corresponded to a specific job description and included six candidates applying for the position. The design of these scenarios reflected everyday situations in profiling and personnel hiring processes, identified from the participants’ statements in the preliminary interviews. All the resumes for each job description were synthetically generated based on the structure derived from the interviews.
Given that our study was conducted in Mexico with Mexican participants, we adjusted the procedure for obtaining human-level performance to take into account the specific cultural characteristics of the region. In particular, we decided to exclude certain information from the evaluated CVs. Specifically, the synthetically generated resumes omitted any information that could reveal the candidate’s gender, geographic location, or names of real institutions or companies. Our decision was based on a literature review, that revealed the prevalence of classism in Mexican society, often linked to racism based on skin tone, as well as the high levels of poverty in some areas of the country (Lopez Citation2019; Moreno-Figueroa and Saldvar-Tanaka Citation2016; Garza-Rodriguez et al. Citation2021). Additionally, considering that both poverty and classism can influence university education, such as access to opportunities during higher education (see Adams, Anne Bell, and Griffin (Citation2007, 309)), we opted to exclude these categories to avoid possible biases that are difficult to identify and could potentially add noise to the evaluation of the final model.
Regarding the above, each CV received a key name for candidate identification during the evaluation. In order to avoid difficulties for the participants, we decided that these names should not be in Spanish, but should be phonetically similar to it. These names themed each of the evaluation scenarios: Greece, Trees, Constellations, and Fruits (see ). This approach ensured easy referencing of candidates without revealing sensitive information.
Table 4. Key names of the CVs used in the different sets of the evaluation experiment.
Regarding each case (also called evaluation set):
The Greece case aimed to evaluate candidates who were all suitable for the position, and had a strong semantic similarity between each of them and the job description.
The purpose of the Trees case was to evaluate candidates who were suitable for the position and those who were not suitable because they were from unrelated areas to the job description.
In the case of Constellations, the goal was to evaluate candidates suitable for the position and those who were not precisely suitable but had some relevant experience related to the job description. Examples of candidates with these characteristics include professionals making a career transition and recent university graduates.
The Fruits case aimed to evaluate candidates suitable for the position and those with profiles that might be considered suitable but with an equivalent profile.
Each resume for the evaluated cases needed specific characteristics, as detailed in . Since the nine evaluating professionals came from different occupational areas, the study designed three versions for each evaluation set, adapted to software development, data science, and embedded software.
Table 5. Description of the features that each of the CVs used in the evaluation experiment had to meet.
To ensure the comparability of the results, it was essential to standardize specific characteristics among analogous CVs across different areas. For instance, the “Delta” CV in the Greece case needed to present the same highest level of education and years of experience in all its versions, whether in software development, data science, or embedded software. This approach looked for a uniform and comparative evaluation across the various professional profiles and occupational areas involved in the study.
To facilitate the participants’ visualization of each set for remote evaluation, the study displayed these sets using FlipHTML5,Footnote5 and conducted the evaluation process through a survey on Qualtrics.Footnote6
To address potential fatigue during the evaluation process, we used the Qualtrics randomized item option in the order of the evaluation sets. The participants had to perform two tasks in each case:
Ranking of the CVs: For each job description, participants needed to order the CVs from the most to the least suitable for the position, where 1 indicated the most suitable and 6 the least suitable.
Identification of ranking cutoffs or discards: Participants indicated at what ranking value they considered candidates ineligible to continue in the selection process.
We derived the Human-Level Performance used in the final phase of this research from the binary classification of candidates as suitable or unsuitable, based on the cutoff points identified within the evaluators’ rankings.
Instruments
The need for external validation arose for the evaluation sets in embedded software and software development areas, as these fields were beyond our expertise. Consequently, collaboration with experts in embedded software and software development became essential to ensure the accuracy and relevance of the content of the resumes and job descriptions.
These specialists reviewed the coherence in the wording of each CV and job description. They ensured that the inclusion of tools and technologies in the work experiences detailed in the CVs was congruent with the time frame of their emergence and popularity in the sector.
Pilot Study
Before the selected group of nine professionals began their evaluation, a pilot test was conducted with three individuals from the initial interviews who were not part of the group of nine. These individuals represented the areas of data science, software development, and embedded software, respectively. The purpose of the pilot test was to evaluate the wording of the instruments and the clarity in presenting the evaluation sets for each occupational area. It also aimed to verify the understandability and manageability of the evaluation process, which included using FlipHTML5 to view job descriptions and CVs, followed by ranking through Qualtrics. This pilot study led to minor changes in the software development Greece evaluation set.
Analysis of Quantitative Results
We conducted the descriptive analysis of the rankings to complement the criteria established in the first interview using the pmr package in R, following the procedures outlined in Lee and Yu (Citation2013).
Model for Job-Candidates Matching
In the last stage of this research (see red region), we undertook the task of modeling the rules used by hiring personnel for reviewing resumes in the candidate selection process. The objective was to provide a model that classifies CVs as suitable or not suitable for a position given a job description. This modeling process incorporated data obtained from the ranking process during the evaluations.
The strategy adopted was to use a Siamese network to train a sentence embedding model. This model could embed CVs and job description texts and link them as part of different occupational areas. A significant challenge was overcoming the lack of available data for model training.
We used OpenAI’s GPT-3.5 API to address this limitation, developing a bot that generated synthetic CVs. The bot was programmed to create CVs reflecting the minimum acceptable structure, derived from the interviews conducted in the first phase of the research. In addition, we extracted job descriptions through web scraping. The occupations selected for generating synthetic CVs and the web scraping process focused on those used in the Stack Overflow 2023 Developer Survey, as described in CV Preference of Human Experts section.
This section will detail the procedures to perform the above-mentioned tasks.
Data extraction, generation, and processing
A bot constructed using the GPT-3.5 API generated 300 CVs for each of the following occupational areas: Blockchain Engineer, Business Analyst, Cloud Infrastructure Engineer, Data Engineer, Data Scientist, Database Administrator, DevOps, Developer QA, Embedded Developer, Game Developer, Hardware Engineer, Product Manager, Project Manager, Sales Professional, Senior Executive, Site Reliability Engineer, System Administrator, Technical Lead, Back-end Developer, Desktop Developer, Front-end Developer, Full-stack Developer, and Mobile Developer. The synthetic generation of this information used the prompt available in Appendix B, using the structure that the hiring personnel mentioned as appropriate for a CV. We adhered to the best practices for prompt design established by OpenAI.Footnote7
Some issues emerged during the use of this bot, such as the tendency to generate CVs for candidates with more work experience in specific occupational areas. For example, the bot tended to produce CVs for candidates with more experience (generally older individuals) in embedded software, and candidates with less experience (younger individuals) in areas like data science. Additionally, the bot encountered difficulties in generating CVs with varied semantic vocabulary richness, often returning similar or, in some cases, identical CVs. We removed these identical CVs to obtain a dataset of unique resumes.
We obtained job descriptions via a well-known professional social network using web scraping, employing the same occupational terminology as in CV generation. Many of these job descriptions were lengthy, complicating the model training process. Consequently, we summarized and anonymized these job descriptions using Chat GPT-3.5.
The dataset of job descriptions and resumes we obtained was unbalanced across occupational areas. Therefore, we removed from the study areas with fewer than 100 CVs and job descriptions. The remaining occupational areas included Business Analyst, Cloud Infrastructure Engineer, Data Engineer, Data Scientist, DevOps, Embedded Developer, Game Developer, Project Manager, System Administrator, Technical Lead, Back-end Developer, Desktop Developer, Front-end Developer, Full-stack Developer, and Mobile Developer.
For job descriptions with fewer than 150 entries, we duplicated records randomly up to 150, and for those with more than 150, we selected a random subsample to reach 150. Similarly, given that the minimum CV quantity per area resulted in 150, we randomly duplicated resumes in areas with less than 200 to reach 200. For those with more than 200, we selected a random subsample to reach 200. This procedure resulted in a balanced database that we divided into training and test sets.
Model Architecture
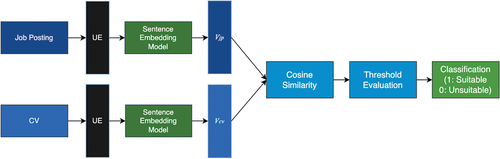
In this research, we designed two distinct approaches for developing the classification model: a baseline model and an experimental model. The baseline classification model (see ) categorized resumes and job descriptions as suitable (1) or unsuitable (0), by using cosine similarity calculated from a sentence embedding of a candidate’s CV and job description to surpass a determined threshold. Cosine similarity in this context serves as a measure of the affinity between the candidate and the job description.
Figure 2. Baseline model architecture. The represents embedding vectors. Possible values of
are
(job posting), and
(curriculum vitae). The acronym UE stands for “Universal encoder”.
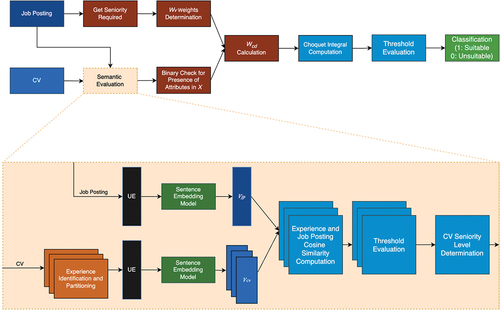
For the second model, we incorporated an affinity calculation function based on the Choquet integral and the same sentence embedding model as the baseline model (see ), designed using interview data and the evaluation experiment.
Figure 3. Experimental model architecture. The represents embedding vectors. Possible values of
are
(job posting), and
(curriculum vitae). The acronym UE stands for “Universal encoder”.
The experimental model considers seniority requirements, semantic evaluation, and Choquet integral computation.
We exhaustively established the threshold, by defining the affinity classification (1 for suitable and 0 for unsuitable) in both models. In a later section, we will present specific details on how we determined this threshold and the criteria for its establishment.
The Choquet integral offers a comprehensive framework for decision process modeling, providing notable advantages over conventional methods (Grabisch and Labreuche Citation2010). The integration of fuzzy measures into the integral is a key feature, enabling modeling interactions and dependencies among decision criteria. This inclusion allows for a representation of decision processes that potentially align more closely with real-world scenarios. Additionally, fuzzy measures facilitate the elicitation of preferences directly from decision-makers. This aspect contributes to a modeling process that is not only transparent, but also more aligned with the intuitive understanding of those involved in the decision-making process.
We chose the Choquet integral for its ability to represent the rules expressed by study participants. This integral allows the determination of a factor space relevant to the problem being modeled, and assigns weights to these factors, reflecting their relevance and interactions. Below, we present the definition of a fuzzy measure and the Choquet integral.
Let , a fuzzy measure is a set function
which is monotonic (i.e.,
if
) and satisfies
and
. Thus,
can represent the importance of the qualities indexed by
.
Let be a set of qualities, each evaluated typically in
. The Choquet Integral computed from a fuzzy measure
is given by:
where is a permutation on
such that
, and
. The design of the fuzzy measure allows for the assignment of importance to all possible criteria groups, thus offering greater aggregation flexibility.
Sentence Embedding Model
We used a Siamese neural network to train the baseline and experimental model’s sentence embedding model (see ). This training integrated the universal sentence encoder (Cer et al. Citation2018) with a dense neural network (see ). We specifically designed the network’s configuration for the context of occupational areas. In this scheme, the network’s anchor was a job description from a specific occupational area. The corresponding positive element was a resume from the same occupational area, and the negative element was a CV from a different occupational area.
Figure 4. Siamese network architecture used for training the sentence embedding model. The represents embedding vectors. Possible values of
are
(the job anchor),
(the positive example), and
(the negative example). The acronym UE stands for “Universal encoder”.
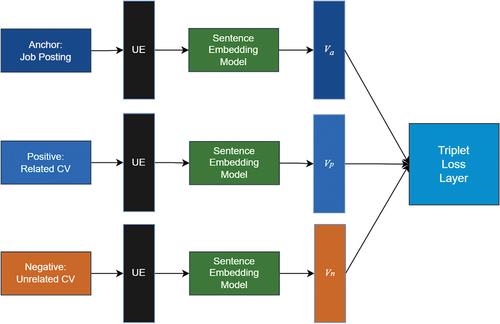
Figure 5. Sentence embedding model architecture.
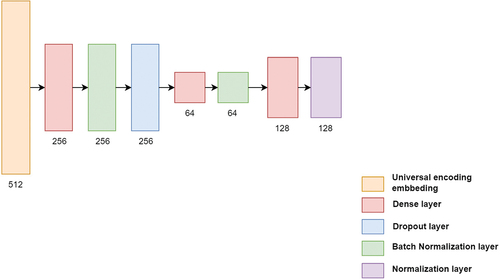
This design allowed the sentence embedding model to effectively capture the specific linguistic variations of each occupational area. We aimed to ensure that the model could accurately discern and relate the relevance between job descriptions and corresponding CVs, distinguishing them from those in other occupational areas.
Model Reliability
Once the Siamese network train was completed, we extracted the resulting sentence embedding model from this architecture. Considering the interpretability challenge of understanding the criteria under which an embedding model encodes data, we decided to perform sentence embedding on the test set of CVs and job descriptions. Subsequently, this information was visually represented by reducing the dimensionality to two dimensions using t-SNE on the performed sentence embeddings (see ).
Figure 6. t-SNE 2-dimensionality reduction of the test set’s sentence embeddings with CVs and job descriptions hue by occupational areas.
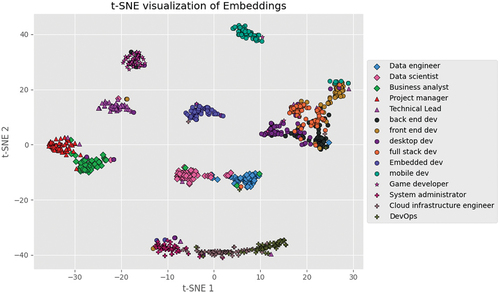
Dimensionality reduction revealed clusters that demonstrated the model’s ability to group information by occupational areas. It also showed that the model could maintain close groupings of related occupational areas, such as data science and data engineering, as well as front-end, back-end, and full-stack development. Conversely, areas like game development and embedded development were placed in more distant and exclusive clusters. In some instances, the model captured the evolution of occupations. For example, it identified the relationship between system administrators, cloud infrastructure engineers, and DevOps.
Consequently, we concluded that the sentence embedding model obtained through the training of the Siamese network was suitable for in the final design of the classification system.
Affinities Using the Choquet Integral
The procedure for calculating affinity using the Choquet integral in the experimental model involved the following methodology (see ): we defined a space of attributes or qualities evaluated in a CV during the profiling process, identified through the interviews and evaluation experiment. To this factor space
, we assigned a regular fuzzy measure
manually. This assignment considered the relevance and interactions of the factors as stated in the interviews and the evaluation experiment, allowing for a more nuanced and representative evaluation of the criteria used in the job selection process. The specific attributes used for the space
were a result of previous studies, so they will be presented in the following section.
Next, we established categories of possible work experience in a job description: junior (denoted by ), mid-level (denoted by
), and senior or higher (denoted by
). We assigned specific weights to each experience level to determine the relevance of certain attributes from the set
being present in job positions. For instance, if
includes attributes like “Has a university degree,” “Is overqualified,” and “Has the appropriate years of experience for the position,” the assigned weights for a job description could be
for a junior level and
for a senior level. Thus, we have
with
,
and
.
Subsequently, to determine the affinity level between a candidate CV, , and a job description,
, we used a script according to the following procedure:
– First, it identified, based on the job description , whether it corresponded to a junior, mid-level, senior (or higher) position, which determined the associated set of weights
.
– Second, it was binary determined which qualities from the set of attributes were met by
, based on the information provided by it and the job description. For instance, if
included “Has a university degree,” it was verified whether
mentioned having university studies, assigning values of 1 or 0 as applicable. For factors like “Has the appropriate years of experience for the position,” the script used the sentence embedding model to determine the presence of relevant experience in the CV concerning the job description using cosine similarity with 0.5 threshold. This resulted in a set of binary values
with
and
.
–Third, it was calculated the product , keeping only the weights of the job description
that are met by the candidate
based on the qualities of
.
– Lastly, it was used the fuzzy measure and the weights
to compute the Choquet integral, representing the level of affinity between the candidate
and the job description
.
Model Evaluation
We conducted an exhaustive process to determine the necessary threshold for binary classification in both, the baseline and experimental models. This process was done for each evaluation case: Greece, Trees, Constellations, and Fruits. We used the Human-Level Performance obtained from the binary evaluations (suitable and unsuitable) from the evaluation experiment, as described in Human-Level Performance Determination section. In both models, we tested various thresholds within the interval and calculated the resulting classification for each threshold.
For each judge and evaluation set, we measured these thresholds’ resulting precision and recall. Then, to develop a general model using an optimal threshold for these evaluation metrics, we calculated the mean precision and mean recall of all judges for each evaluation case.
We selected the threshold that provided the best possible mean precision and mean recall in all four cases. The details and results of this analysis will be presented in the results section.
Results
In this section, we present the findings acquired through our methodological approach. We provide an exhaustive description of the essential characteristics that CVs should embody, as identified by hiring personnel. These elements were declared, by hiring personnel, as crucial for the CVs to represent candidates’ experiences accurately. Furthermore, we expound upon the data analysis outcomes conducted using the evaluation experiment. This experiment provided significant insights into the hiring professionals’ preferences. We conclude by presenting the results obtained from both baseline and experimental models.
This section is divided into two parts. The first one, divided in two, corresponds to the results of the procedures presented in CV Preference of Human Experts and Human-Level Performance Determination sections. The second corresponds to the results of the methodology explained in Model for Job-Candidate Matching section.
Human Expert Information Extraction Results
CV Preference of Human Expert Results
The coding analysis revealed patterns in the characteristics that interviewees deemed essential in candidates’ resumes and attributes that, while not consistently mentioned by all, were frequently highlighted. Common codes across all interviews included clarity in the description of previous work experiences, technical competencies or hard skills, and soft skills with an emphasis on communication. Also, alignment between the technologies or concepts mentioned by the candidate and those used in the company, the relevance of years of experience in similar roles, and the importance of the resume being written in English. Each of these aspects is discussed in more detail below:
Structuring of job descriptions: Participants expressed that vague or overly broad narratives did not provide a clear understanding of the candidate’s main responsibilities, their specific role in previous projects, or the impact of their contribution.
Technical competencies or hard skills: There was a preference for a delineated section in the resume that detailed these skills and provided a context for evaluating the described professional experiences.
Interpersonal competencies or soft skills: Communication skills were unanimously valued for their ability to facilitate collaboration and problem-solving, and were sometimes valued above technical skills.
Technological relevance: Participants mentioned the importance of candidates handling technologies and concepts that are current in the company, arguing that this minimizes the learning curve and facilitates integration into the team.
Relevant work experience: Emphasis was placed on the value of professional experience directly linked to the role the candidate aspires to, focusing on relevant experience rather than general experience. All interviewees agreed that candidates’ proficiency with technologies that he/she had not used for years was not seen as a negative factor, as they believed that even if there was a considerable period when the candidate did not use a specific tool or technology, this skill could be quickly regained due to their prior experience.
Aspects such as the candidate’s online visibility, professional networking profiles like LinkedIn, tertiary education, and the length of resumes were recurring themes, though not dominant in the interviews. Four out of nine interviewees viewed an active presence on LinkedIn positively, considering it a valuable complement to the content of the resume. Regarding tertiary education, opinions varied, with only five of the nine interviewees considering this data crucial in the CV. On the other hand, three out of nine considered a resume exceeding two pages as an unfavorable factor.
Another relevant aspect among the responses of the interviewees was the tendency not to automatically discard resumes that appeared overqualified in the initial screening stage. However, these candidates were often excluded after the first interview, generally due to budgetary limitations.
The above led us to conclude that a resume with a higher likelihood of being positively evaluated as a high-quality source of information on a candidate’s professional trajectory should consist of:
A contact information section, including the candidate’s full name, e-mail address, phone number, and LinkedIn profile.
A section dedicated to education.
A single section for stating professional experience and project involvement. Each item should detail the job or project title, start and end dates, technical competencies, or hard skills acquired. It should also include a descriptive narrative that showcases the main challenges faced, strategies or actions implemented to resolve them, and the impact of those actions. We identified that adopting the STAR formatFootnote8 (Situation, Task, Action, Result), used by Amazon in their interviews, can optimize the clarity and effectiveness of these descriptions. This structured approach can facilitate the presentation of previous work experiences in a way that highlights the candidate’s contributions and achievements.
A section highlighting soft skills.
A section stating the languages the candidate speaks.
Cognitive Biases
According to Korteling and Toet (Citation2022), cognitive biases are universal, systematic tendencies, inclinations, or dispositions that distort information processing in ways that result in inaccurate, suboptimal, or outright erroneous outcomes, and generally do not adhere to the principles of logic, probabilistic reasoning, and plausibility.
Throughout the interview process and subsequent coding, we observed various cognitive biases in the resume reviews by seven of the nine participants. We used deductive coding based on the cognitive biases that Linos and Reinhard (Citation2015) identified as frequent in recruitment processes. This approach allowed for the identification of biases such as confirmation, halo effect, attribute substitution, affinity, and cognitive load. Confirmation bias and the halo effect were the most prevalent.
Participants often linked confirmation bias to preconceptions about various resume aspects, such as the number of courses listed, whether someone referred the candidate, the types of hobbies mentioned, the candidate’s programming speed, future aspirations, duration in previous jobs, motivations behind their career choice, and marital status.
Regarding the halo effect, interviewers inferred multiple aspects of a candidate’s personality from specific characteristics observed during the hiring process. For instance, they associated quick responses to questions with a solid conceptual understanding, the length of the resume with organizational skills, and the style of the photograph in the resume with the individual’s personality.
Interview Process
Although the questions in the semi-structured interview protocol were not explicitly designed to explore interview dynamics within the selection process, all interviewees mentioned this phase. Most interviewees declared that their hiring process was structured in two or three stages, always including a qualitative interview. However, two of the nine interviewees reported that they did not include a technical assessment in their procedure.
During the interviews, several participants highlighted the significance of teamwork and leadership skills in a candidate. However, two interviewees acknowledged the absence of a set of questions to evaluate these competencies. When asked about using tools like rubrics or checklists to evaluate qualitative aspects, only four of the nine professionals confirmed having established systems to identify specific responses or behaviors demonstrating such skills in candidates. One interviewee mentioned having a technical test, but without a concrete evaluation method.
Evaluation Experiment Results
In the evaluation analysis, we were only able to reconvene with seven of the original nine professionals. Among these seven professionals, five specialized in software development, and two in data science.
The information from the rankings was used to perform a dimensionality reduction to two dimensions for each evaluation case, applying the singular value decomposition technique. This analysis aimed to identify preference patterns among the participating professionals (see ). Through this process, we observed proximities between some professionals, suggesting similar preferences. Additionally, we detected CVs closer to specific evaluators.
Figure 7. Ranking data’s 2-dimensional singular value decomposition for every set evaluation.
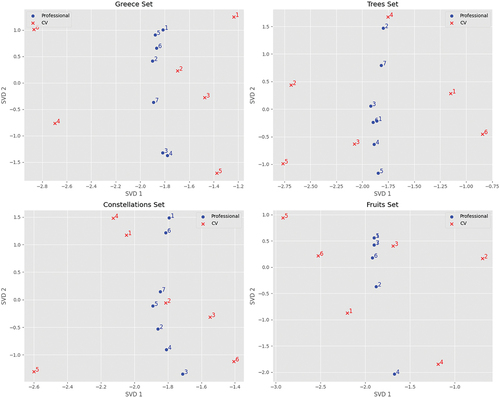
We computed descriptive statistics for the ranked data to deepen our understanding of the emerging patterns in the professionals’ rankings. Specifically, we calculated paired frequencies and marginal distributions. We present this data in , and for complementary information necessary for interpretation, see .
Table 6. Descriptive statistics for analysis of ranking evaluation data. On the top: pair CV frequencies used on the different evaluation sets. On the bottom: marginal frequency distribution for each CV used on the different evaluation sets (RP stands for “Relative Position”).
Based on the descriptive statistics, we observed the following general trends in the evaluated cases:
Greece Evaluation Set: A preference for candidates mentioning education was noted. Overqualified profiles that did not state education were ranked lower, while those with similar qualifications but did mention education occupied the top positions. CVs with lengthy job descriptions or insufficient experience for the position were consistently ranked lower.
Trees Evaluation Set: CVs unrelated to the occupational area of the position were ranked lower. Regarding education, in profiles with adequate experience, there was a preference for those not mentioning education, though both maintained priority positions.
Constellations Evaluation Set: the ranking of CVs was positively influenced by doctoral studies and project experience, while those with a doctorate but little experience and indeterminate basis positions were ranked lower. In some cases, recent bachelor’s graduates with completed projects during their studies outperformed those with doctoral studies and projects. CVs of candidates transitioning between occupational areas did not show a clear preference, occupying various positions in the ranking.
Fruits Evaluation Set: Candidates who included education in their CVs were preferred over those who did not, even when they had similar profiles and experiences. The profile with little experience and a master’s degree related to the position was less favored. The CV of a candidate who had not changed jobs and did not mention education was well ranked, but surpassed by the CV with frequent job changes and who mentioned education.
Baseline and Experimental Model Results
We conducted a detailed analysis of the qualitative interviews and evaluation rankings to integrate the Choquet integral into the experimental model. This analysis led us to deduce that the factor space for the Choquet integral should include qualities in the CVs such as “Sufficient years of experience in roles related to the position”, “Include descriptions of roles unrelated to the position”, “Has undergraduate studies”, “Has postgraduate studies”, and “Is overqualified”. We detail the justification for including these qualities in the factor space in . This approach ensures that the Choquet integral bases itself on factors that are relevant and consistent with the reality of the CVs used in the evaluation, thereby providing a more representative analysis of the preferences and criteria professionals use in the selection process.
Table 7. Qualities of the factor space and the reason behind its inclusion.
It is worth noting that we did not consider some qualities frequently mentioned in the interviews for the factor space. These include elements like the STAR structure in the description of experiences, the candidate’s online presence, and the CV being written in English. This was due to the fact that the evaluated CVs were synthetically generated, and none of them had an online presence. Additionally, all synthetic CVs followed the STAR writing structure and were written in English (see Appendix B).
In the interviews, professionals also mentioned other relevant CV qualities, including technologies and concepts aligned with the company and a section on hard skills related to the job description. While we did not explicitly include these characteristics in the factor space, we considered them to be implicitly covered in both the baseline and experimental models. The above is due to both models using the sentence embedding model, which semantically captures these dimensions (see ).
After establishing the necessary weights for the Choquet integral, we conducted an exhaustive process to determine the optimal classification threshold (see Model for Job-Candidates Matching section).
We observed that applying different thresholds sometimes resulted in mean precision and recall levels equal to 1. However, these thresholds generally behaved irregularly (see ), which we attribute to the diverse preferences of professionals during the evaluation (see Evaluation Experiment Results section). Specifically, in the baseline model, we noted that relying exclusively on cosine similarity could allow for higher thresholds in specific evaluation scenarios (see , Fruits case), expanding the range of admissible thresholds. This might be because cosine similarity captures semantic similarities through sentence embedding but does not explicitly consider other critical factors in CV review, like sufficient experience for the position, overqualification, or the presence of tertiary education.
Figure 8. Mean precision and mean recall for the CVs classification as suitable or unsuitable, using baseline and experimental models, for every set evaluation.
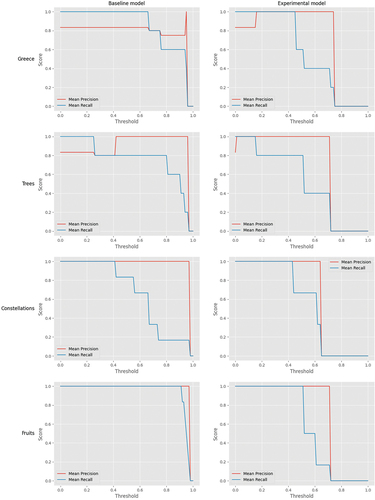
In our analysis of the experimental model, we observed a reduction in the number of viable threshold values compared to the baseline model. We interpret this as a reflection of the Choquet integral’s ability to regulate the affinity scale. The high values of this integral indicate that the candidate more fully meets the criteria of factor space and its interaction values beyond the simple semantic relationship between the job description and the candidate’s CV. This suggests that the Choquet integral provides a more nuanced and comprehensive measure of affinity.
From our inspection analysis of , we consider that a threshold between 0.0 and 0.2 for the baseline model and 0.2 and 0.4 for the experimental model yields appropriate mean precision and mean recall values. These thresholds achieve rates above 0.8 for mean precision and 1 for mean recall for both the baseline and experimental models.
Conclusion
Throughout the various phases of this research, we identified notable aspects of each stage. During the initial phase, focusing on the preferences of the experts regarding resumes, we noted differences compared to the findings of Zide, Elman, and Shahani-Denning (Citation2014), who identified key characteristics that recruiters consider when reviewing LinkedIn profiles. Their study highlighted aspects such as gender, ethnic origin, hobbies, grammatical errors, and e-mail style. We attribute these differences to cultural and temporal elements and the differing participant profiles in each study. In our study, we considered not only recruiters but also managers, business owners, and technical leaders involved in the comprehensive process of identifying, evaluating, and selecting job candidates. These professionals formed the majority of our interviewees and represented a significant portion of our study sample.
Moreover, although job analysis techniques often lead to the creation of taxonomies for homogenizing criteria and competencies sought in candidates (see Bratton and Gold (Citation2012, 217)), we found that such structures were infrequently declared among our interviewees. There are significant opportunities for standardizing and systematizing processes in the profiling and personnel selection phases carried out by professionals.
Constructing questions to determine the skills expected from the candidate and incorporating checklists or rubrics with associated achievements during non-technical interviews, could significantly improve the detection of interpersonal competencies necessary for the team. Furthermore, we highlighted the adoption of systematic methods for evaluating technical tests as an area for improvement, which clarifies the anticipated achievements of the candidate in such evaluations. It is our conjecture that this would reduce some of the cognitive biases identified and increase the reliability and validity of their selection processes, understanding reliability as the extent to which a selection technique achieves consistency over repeated use and validity as the ability of the technique to measure what it intends to measure (Bratton and Gold Citation2012, 229).
In our analyses of the evaluation processes conducted by study participants, we observed different preference clusters among professionals, leading to the conclusion that there is significant diversity in ranking CVs from most to least suitable. During the preliminary phase of designing the classification model, we explored the feasibility of creating a general model that respected the rankings established by hiring personnel. This task presented considerable challenges due to capturing the wide range of identified preferences. We found that developing a general ranking model that effectively reflects these diverse preferences is complex. This requires additional qualitative analyses and larger sample sizes to identify specific characteristics defining the preferences of the professionals involved in the study. A more detailed qualitative analysis would improve our understanding of the factors influencing the profiling process, such as corporate culture.
However, we determined that designing a binary system for matching candidates and job positions using the Choquet integral is feasible. This approach provides a highly interpretable model that adequately reflects the participants’ general preferences and demonstrates the Siamese network’s capacity to create sentence-embedding models. Despite the limited data, these models successfully differentiated and correlated resumes and job descriptions across various occupational areas. Implementing this design, however, required empirical research to ensure the model closely aligns with the reality of the profiling process carried out by the hiring personnel.
Building on this foundation, our experimental model and baseline model had an architecture that incorporated a sentence embedding model based on Siamese networks and the Universal Sentence Encoder. A strategic consideration of resource allocation and model complexity informed this decision. We decided to retain the Universal Sentence Encoder in our final architecture, instead of integrating more complex and resource-intensive sentence encoding models such as BERT or RoBERTa. Although BERT and RoBERTa offer potentially greater accuracy due to their sophisticated architectures, their resource demands and complexity did not align with our system’s requirements for efficiency and simplicity. The Universal Sentence Encoder, by contrast, provided a more streamlined and resource-effective solution while still delivering the necessary level of performance for our application.
Nevertheless, it is crucial to highlight certain limitations in the use of this model. The lack of availability of real resumes prevented a deeper analysis of the model’s behavior in realistic scenarios, highlighting a lack of authentic data for validation, which likely led to changes in the Choquet integral formulation. Additionally, this study did not address challenges related to the cleaning and preprocessing of data from resumes and job descriptions, as exposed in previous works (see, e.g., Barducci et al. (Citation2022)). Challenges include handling various document formats (PDF, Word, plain text), heterogeneity in writing dates, the use of special characters (for example, in programming languages like C# or C++), and the identification of key information blocks (education, experience, skills, certifications). These aspects add complexity to the modeling process, and we excluded them from the scope of this research.
Among the analyses we were unable to perform due to the reduced sample size of professionals in the evaluation experiment, was a hypothesis test to determine if ranking assessments resulted from a randomized evaluation process (see Finch (Citation2022)). We believe that such a test could have provided more information for defining the Choquet integral by identifying potentially arbitrary assessments made by professionals. This could help to reduce the erratic behavior of these metrics observed in the threshold analysis.
Finally, we examined the efficacy of the GPT-3.5 API in generating synthetic resumes for different job sectors. We observed an interesting trend: the model tended to generate resumes for more experienced candidates in older sectors (e.g., embedded software) and younger candidates in emerging fields (such as data engineering). This observation suggests that GPT-3.5 can gather, synthesize, and contextualize relevant information, reflecting historical and evolutionary trends in the job market.
In general, our methodology enabled a systematic identification of the minimal resume structure in software and data science-related areas and established human-level performance benchmarks. This process provided significant insights into the expectations of the hiring personnel participants. These findings are highly relevant for analyzing and developing future automated personnel selection systems, aiming to improve their reliability and interpretability. Recognizing the intrinsic subjectivity within hiring processes is paramount, especially considering its implications for designing automated recruitment models. The inherent challenges in evaluating these models demand attention, particularly given their potential impact on businesses, work teams, and candidates who may be assessed and potentially overlooked based on ambiguous criteria or unrecognized cognitive biases.
Future Research
In this study, we have identified several areas for future inquiry, focusing on creating a valid and precise data preference collection instrument. This tool aims to simplify the identification of preferences within corporate recruitment teams. Developing such a tool promises to facilitate the integration of a comprehensive model into existing commercial recruitment software. Furthermore, this type of tool ensures that the development aligns closely with the practical needs of the domain and enhances the interpretability of the underlying rules used in profiling methodologies. For instance, this tool would have allowed us to speed up the design of the Choquet integral for computing affinities.
Regarding the Choquet integral, although we consider that the integral used in this research provides a high level of explainability by design, we believe that further analysis can be made to examine the acquisition and relevance of the features and weights used in the integral. Specifically, we believe a future area of research is to incorporate additional techniques from explainable AI for the Choquet Integral (see, e.g., Murray et al. (Citation2020)).
Another area of future research involves incorporating graph approaches into our design. For example, ontologies could facilitate the analysis of candidates and their connections (see, e.g., Gugnani, Kasireddy, and Ponnalagu (Citation2018)), and graph databases could be utilized in the automation step to extract features from job descriptions and resumes (see, e.g., Giabelli et al. (Citation2021)).
On the other hand, in our experiment aimed at determining human-level performance, we considered the preferences explicitly declared in interviews and the cultural context of the participants. This approach was intended to mitigate potential noise in the evaluation by reducing the possibility of hard-to-identify biases. Nevertheless, further investigations are warranted to examine the data types that can introduce bias in determining human-level performance, considering the cultural context and its interrelation with the model architecture.
Finally, the preferences of professionals regarding CV structure and writing style provide an opportunity for further research. Studies replicating these findings in other STEM fields or different countries could provide insights into recurring patterns. This could highlight, for instance, the influence of cultural factors in hiring processes.
Acknowledgements
We gratefully acknowledge the following people for their valuable contributions to our work:
• Ph.D. Cipriano Arturo Santos-Borbolla and MBA Francisco Enrique Andrade-López from the Operations Artificial Intelligence group (Oper.ai) at the Instituto Tecnológico y de Estudios Superiores de Monterrey (México);
• Evelyn Mercedes Medina-García from the Master’s Program in Social Sciences at the Universidad de Sonora (México);
• Ph.D. Ramón Soto de la Cruz and Francisco Alejandro Bernal-Cañez from the Department of Mathematics at the Universidad de Sonora (México);
• M.Sc. Irenisolina Antelo-López from the Doctoral Program in Sciences with a specialization in Educational Mathematics at the Universidad de Sonora (México);
• Computer Scientist, Luis Fernando Sotomayor-Samaniego.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data that support the findings of this study are openly available in figshare at https://doi.org/10.6084/m9.figshare.25127627 and https://doi.org/10.6084/m9.figshare.25127564.
Additional information
Funding
Notes
1. https://www.bls.gov/oes/2022/may/stem_2022.xlsx. Accessed: 12/08/2023
2. In this text, we employ the term “cognitive biases” as defined by Korteling and Toet (Citation2022).
3. According to the Cornell Law School Dictionary (https://www.law.cornell.edu/wex/protected_class, Accessed: 2023-05-31), a protected class is a “class of individuals to whom Congress or a state legislature has given legal protection against discrimination or retaliation.” In machine learning, this category typically refers to data related to sex, gender, religious beliefs, nationality, and race.
4. https://www.kaggle.com/datasets/stackoverflow/stack-overflow-2023-developers-survey. Accessed: 10/08/2023
7. These practices can be consulted at https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/.
8. https://www.amazon.jobs/en/landing_pages/in-person-interview. Accessed: 15/09/2023
References
- Adams, M., L. Anne Bell, and P. Griffin. 2007. Teaching for diversity and social justice, vol. 2. New York: Routledge.
- Ajzen, I. 1996. The social psychology of decision making, 297–41. New York: Guilford Press.
- Barducci, A., S. Iannaccone, V. La Gatta, V. Moscato, G. Sperl, and S. Zavota. 2022. An end-to-end framework for information extraction from Italian resumes. Expert Systems with Applications 210:118487. doi:10.1016/j.eswa.2022.118487.
- Barrak, A., B. Adams, and A. Zouaq. 2022. Toward a traceable, explainable, and fairJD/Resume recommendation system. arXiv preprint. doi:10.48550/arXiv.2202.08960.
- Blodgett, S. L., S. Barocas, H. Daumé III, and H. Wallach. 2020. Language (technology) is power: A critical survey of “bias” in nlp. arXiv preprint. doi:10.48550/arXiv.2005.14050.
- Bogen, M., and A. Rieke. 2018. Help wanted. An examination of hiring algorithms, equity, and bias. Washington, DC: Technical Report. Upturn.
- Bondielli, A., and F. Marcelloni. 2021. On the use of summarization and transformer architectures for profiling résumés. Expert Systems with Applications 184:115521. doi:10.1016/j.eswa.2021.115521.
- Bratton, J., and J. Gold. 2012. Human resource management: Theory and practice. London: Palgrave Macmillan.
- Cer, D., Y. Yang, S. Yi Kong, N. Hua, N. Limtiaco, R. St. John, N. Constant. 2018. Universal sentence encoder. arXiv preprint. doi:10.48550/arXiv.1803.11175.
- Chen, N. C., M. Drouhard, R. Kocielnik, J. Suh, and C. R. Aragon. 2018. Using machine learning to support qualitative coding in social science. ACM Transactions on Interactive Intelligent Systems 8 (2):1–20. doi:10.1145/3185515.
- CIPD. 2022. Resourcing and talent planning report 2022 (London: Chartered Institute of Personnel and Development). https://prod.cipd.org/globalassets/media/knowledge/knowledge-hub/reports/resourcing-and-talent-planning-report-2022-1_tcm18-111500.pdf.
- Cowley, H. P., M. Natter, K. Gray-Roncal, R. E. Rhodes, E. C. Johnson, N. Drenkow, T. M. Shead, F. S. Chance, B. Wester, and W. Gray-Roncal. 2022. A framework for rigorous evaluation of human performance in human and machine learning comparison studies. Scientific Reports 12 (1):5444. doi:10.1038/s41598-022-08078-3.
- Dastin, J. 2022. Amazon scraps secret AI recruiting tool that showed bias against women. In Ethics of data and analytics: concepts and cases, 296–99. New York: Auerbach Publications. doi:10.1201/9781003278290.
- Dumnić, S., K. Mostarac, M. Ninović, B. Jovanović, and S. Buhmiler. 2022. Application of the choquet integral: A case study on a personnel selection problem. Sustainability 14 (9):5120. doi:10.3390/su14095120.
- Fayer, S., A. Lacey, and A. Watson. 2017. STEM occupations: Past, present, and future. Spotlight on Statistics 1:1–35.
- Finch, H. 2022. An introduction to the analysis of ranked response data. Practical Assessment, Research & Evaluation 27 (1):7.
- Garza-Rodriguez, J., G. A. Ayala-Diaz, G. G. Coronado-Saucedo, E. G. Garza-Garza, and O. Ovando-Martinez. 2021. Determinants of poverty in Mexico: A quantile regression analysis. Economies 9 (2):60. doi:10.3390/economies9020060.
- Giabelli, A., L. Malandri, F. Mercorio, M. Mezzanzanica, and A. Seveso. 2021. Skills2Job: A recommender system that encodes job offer embeddings on graph databases. Applied Soft Computing 101:107049. doi:10.1016/j.asoc.2020.107049.
- Grabisch, M., and C. Labreuche. 2010. A decade of application of the choquet and sugeno integrals in multi-criteria decision aid. Annals of Operations Research 175 (1):247–86. doi:10.1007/s10479-009-0655-8.
- Gugnani, A., V. K. R. Kasireddy, and K. Ponnalagu. 2018. Generating unified candidate skill graph for career path recommendation. In 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 328–33, IEEE.
- Guillaume, R., R. Houé, and B. Grabot. 2014. Robust competence assessment for job assignment. European Journal of Operational Research 238 (2):630–44. doi:10.1016/j.ejor.2014.04.022.
- Gunda, Y. R., S. Gupta, and L. Kumar Singh. 2023. Assessing human performance and human reliability: A review. International Journal of System Assurance Engineering & Management 14 (3):817–28. doi:10.1007/s13198-023-01893-5.
- Jones, J. 2014. An overview of employment and wages in science, technology, engineering, and math (STEM) groups. Beyond the Numbers: Employment & Unemployment. U.S. Bureau of Labor Statistics. https://www.bls.gov/opub/btn/volume-3/an-overview-of-employment.htm.
- Kelle, U., and N. Buchholtz. 2015. The Combination of Qualitative and Quantitative Research Methods in Mathematics Education: A “Mixed Methods” Study on the Development of the Professional Knowledge of Teachers. Approaches to Qualitative Research in Mathematics Education: Examples of Methodology and Methods, vol. 1, 321–61. New York: Springer, Dordrecht. doi:10.1007/978-94-017-9181-6_12.
- Korteling, J. E., and A. Toet. 2022. Cognitive biases. Encyclopedia of Behavioral Neuroscience, 610–19. Netherlands: Elsevier. doi:10.1016/B978-0-12-809324-5.24105-9.
- Vivian Lai and Chacha Chen and Q Vera Liao and Alison Smith-Renner and Chenhao Tan. 2021. Towards a science of human-AI decision making: A Survey of Empirical Studies. arXiv preprint. doi:10.48550/arXiv.2112.11471.
- Lee, P. H., and P. L. Yu. 2013. An R package for analyzing and modeling ranking data. BMC Medical Research Methodology 13 (1):1–11. doi:10.1186/1471-2288-13-65.
- Linos, E., and J. Reinhard. 2015. A head of hiring: the behavioural science of recruitment and selection. London: Chartered Institute of Personnel and Development.
- Lopez, A. C. 2019. Positionality and Social Class. In Y tú ¿qué hora traes?: Unpacking the privileges of dominant groups in México, 1–16. Netherlands: Brill.
- Mohamed, A., W. Bagawathinathan, U. Iqbal, S. Shamrath, and A. Jayakody. 2018. Smart talents recruiter-resume ranking and recommendation system. In 2018 IEEE International Conference on Information and Automation for Sustainability (ICIAfS), Sri Lank, 1–5, IEEE.
- Moreno-Figueroa, M. G., and E. Saldvar-Tanaka. 2016. ‘We are not racists, we are Mexicans’: Privilege, nationalism and post-race ideology in Mexico. Critical Sociology 42 (4–5):515–33. doi:10.1177/0896920515591296.
- Murray, B. J., M. Aminul Islam, A. J. Pinar, D. T. Anderson, G. J. Scott, T. C. Havens, and J. M. Keller. 2020. Explainable ai for the choquet integral. IEEE Transactions on Emerging Topics in Computational Intelligence 5 (4):520–29. doi:10.1109/TETCI.2020.3005682.
- Ong, X. Q., and K. Hui Lim. 2023. SkillRec: A data-driven approach to job skill recommendation for career insights. In 2023 15th International Conference on Computer and Automation Engineering (ICCAE), Sydney, 40–44, IEEE.
- Peng, A., B. Nushi, E. Kiciman, K. Inkpen, and E. Kamar. 2022. Investigations of performance and bias in human-AI teamwork in hiring. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, vol. 36, 12089–97.
- Pitz, G. F., and N. J. Sachs. 1984. Judgment and decision: Theory and application. Annual Review of Psychology 35 (1):139–64. doi:10.1146/annurev.ps.35.020184.001035.
- Proença, M. T. V. C., and E. T. de Oliveira. 2009. From normative to tacit knowledge: CVs analysis in personnel selection. Employee Relations 31 (4):427–47. doi:10.1108/01425450910965469.
- Quinn, M. 2014. Qualitative research evaluation methods, 4th ed. US: Sage publications.
- Reusens, M., W. Lemahieu, B. Baesens, and L. Sels. 2018. Evaluating recommendation and search in the labor market. Knowledge-Based Systems 152:62–69. doi:10.1016/j.knosys.2018.04.007.
- Yu, D., and Z. Xu. 2020. Intuitionistic fuzzy two-sided matching model and its application to personnel-position matching problems. Journal of the Operational Research Society 71 (2):312–21. doi:10.1080/01605682.2018.1546662.
- Zide, J., B. Elman, and C. Shahani-Denning. 2014. LinkedIn and recruitment: How profiles differ across occupations. Employee Relations 36 (5):583–604. doi:10.1108/ER-07-2013-0086.
Appendix A Semi-structured Interview Protocol
Date: __________ Time: __________
Interviewee (Name, Age, Gender, Position):__________
Introduction. Provide the interviewee with a general description of the project, including its purpose, the reason for their selection, and the use of collected data. Explain that the interview will be recorded for analysis and record-keeping to ensure accurate and appropriate use of the information provided.
Characteristics of the Interview. This is a semi-structured interview, for which an informed consent document was previously designed and will be provided to the interviewee at or days before the interview.
Questions.
1. What types of positions do you do the most interviews for?
2. Do you use different selection criteria depending on the type of position you are looking to fill? If so, could you give me an example?
3. What platforms or websites do you most frequently use during the recruitment process? Why do you prefer those platforms?
4. Does your platform preference vary based on the type of position you are recruiting for?
5. When you first review a resume, what sections or details immediately capture your attention?
6. What elements of a resume do you consider to be clear indicators of a strong candidate? Conversely, what do you consider as red flags or points of concern?
7. When considering candidates for a specific position, what competencies, skills, or experiences do you value most? And which are less favorable?
8. If a candidate does not have a public online profile or digital presence, how does that influence your perception or evaluation of them?
9. Is there any type of information or detail not commonly found in resumes that you would like to see? Why do you think it would be useful?
10. Once you have selected candidates based on their resumes, how do you proceed with their further evaluation? What other criteria or methods do you use to refine your selection?
11. If you have two candidates with similar skills and experience, how do you decide which one is better suited for the job?
12. When you come across a resume that seems overqualified for a position, what is your procedure or criteria for evaluating it and deciding whether to continue in the selection process? And for one who does not meet all the qualifications?
13. When assessing a candidate’s work experience, do you consider the time elapsed since the skills or competencies were acquired in previous jobs?
14. Have you ever had difficulty identifying potential candidates due to the volume of applicants for a position?
Observations. Close by thanking the interviewee and reiterating confidentiality.
Appendix
B Synthetic CV GPT-5 Prompt
You are a bot that generates the curriculum vitae of candidates with {profession} profile in JSON format. You will use the following steps to generate a CV.
- Step 1: Generate the “experience” key. The nested keys of experience must include the keys “initial_date” in format MM/YYYY, “final_date” in format MM/YYYY,“position” (position_name), “position_description” and “hard_skills” (the associates’ hard skills). You can choose to add 1 up to 5 different jobs. For the “position_description” use AMAZON STAR (situation, task, action, result) for the structure of the position_description.
- Step 2: Generate the “education” key. The education must include “degree_name” (BA, Master, PhD and followed by the name of the degree). You can choose to add 1 up to 4 different educations.
- Step 3: Generate “soft_skills” key.
- Step 4: Generate the “languages” key. These are the languages that the candidate knows.
Return in your response only the JSON and no other information.
The profession variable could take the values Blockchain engineer, Business analyst, Cloud infrastructure engineer, Data engineer, Data scientist, Database administrator, DevOps, Developer QA, Embedded developer, Game developer, Hardware engineer, Product manager, Project manager, Sales professional, Senior executive, Site reliability engineer, System administrator, Technical Lead, Back-end developer, Desktop developer, Front-end developer, Full-stack developer, Mobile developer.