
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In machine reading comprehension, answers to questions may be found in either text or tables. Previous studies have shown that table-specific pre-trained language models perform well when applied to tables; however, applying such models to input data that consists of both tables and text can be challenging. To address this issue, we introduce the hybrid reader model that can manage both tables and text using a modified K-Adapter architecture for effectively encoding the structured information of tables. The training process infuses knowledge for tabular data into a pre-trained model while retaining its original weights from pre-training. Hence, the pre-trained model is able to learn and utilize table information without sacrificing its previous training. Our proposed hybrid reader model achieved comparable or superior performance to that of a specialized model on the Korean MRC dataset, KorQuAD 2.0, using the provided adapters. Furthermore, we conducted experiments on an additional English MRC dataset and confirmed that our proposed model achieves performance comparable to that of the existing model. Our study indicates that employing a single hybrid model instead of two separate models can require fewer computing resources and less time while achieving comparable or superior performance, especially for techniques that apply projection and adapter.
Introduction
Machine Reading Comprehension (MRC) refers to the ability of a machine to understand and interpret documents and locate and provide specific answers to the given question within the document. When a model finds the answer to a given question in a multi-paragraph input, it goes through the process of selecting the relevant paragraph, processing the selected paragraph, finding an answer span, and choosing the final answer from answer candidates. There are large-scale MRC datasets (Campos et al. Citation2016; Rajpurkar et al. Citation2016b) for this purpose. The development and advancement of pre-trained language models (Devlin et al. Citation2018; Liu et al. Citation2019) has led to considerable performance improvement in MRC tasks.
MRC can be categorized into various types based on the form of the answer, type, or number of input paragraphs. In some MRC datasets, answers are tagged not only in unstructured text but also in structured text, such as tables and lists. In another case, structured texts such as tables and lists could be used as input paragraphs. However, the performance of the model of structured text is worse than that of unstructured text.
A simple way to improve the performance of semi-structured data is by using the extension structure of the model or pre-training on structured data. Here, if the input paragraph has both the table and text, using separate reader models, which are two models trained for each structured and unstructured data, is required to improve performance. However, these separated reader models increase GPU memory usage and are computationally intensive because they use an additional BERT (Bi-directional Transformers) model for tables. Furthermore, all of the MRC processes are in the model pipeline and are independently preceded. However, using separate readers creates extra processes of verifying the final answer because of the inconsistent outputs from the separate readers. The performance of the MRC model may be compromised when faced with inconsistent outputs from each individual model, resulting in a decrease in the accuracy of the final answer.
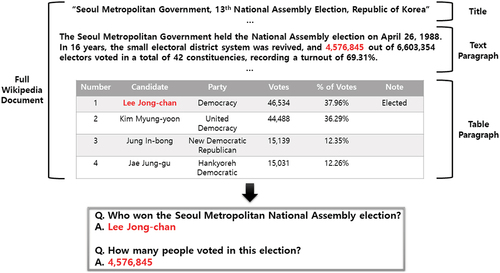
shows an example of a KorQuAD 2.0 dataset (Kim et al. Citation2019). Compared to the KorQuAD 1.0 (Lim, Kim, and Lee Citation2019), which used only short paragraphs as an answer, the KorQuAD 2.0 used a full Wikipedia document that was too long to process at once. The answers are tagged in tables and lists just as in the text. Hence, to find the correct answer in KorQuAD 2.0, the MRC model must read the semi-structured data.
Figure 1. Example of a paragraph from a full Wikipedia document with a title, text paragraph, and a table.
In this paper, we propose a multi-paragraph MRC model, a hybrid reader, with an adapter layer. The adapter layer minimizes the catastrophe of forgetting knowledge from a natural text in pre-training tasks over tables. The hybrid reader uses a unified reader model for both text and tabular data. We will present the extension of the BERT architecture to encode semi-structured data without particular embedding of tabular data in this research.
Related Work
Machine Reading Comprehension
MRC is advanced with large-scale datasets, such as SQuAD (Rajpurkar, Jia, and Liang Citation2018), MS Marco, and Trivia QA (Joshi et al. Citation2017).
In addition to QA datasets focused on machine reading comprehension from text, several QA datasets have been introduced that diverge from traditional QA datasets by necessitating the simultaneous reasoning and extraction of answers from heterogeneous sources, including tables and unstructured texts. HybridQA (Section 2) is a multi-hop question-answering dataset that requires reasoning on tables and texts. This dataset was constructed by utilizing Wikipedia tables and multiple free-form corpora linked with the entities within these tables. TAT-QA (Zhu et al. Citation2021) and FinQA (Z. Chen et al. Citation2021) proposed QA datasets over tables and texts from financial reports, which require numerical reasoning to infer the answer. In TAT-QA, the questions are crafted to aggregate both tabular information and text information. FinQA includes questions that require domain-specific knowledge to infer answers. For the Korean language, there are MRC datasets, such as KorQuAD 1.0, KorQuAD 2.0, NIA MRC dataset,Footnote1 KLUE (Park et al. Citation2021), and (Zhong, Xiong, and Socher Citation2017). KorQuAD 1.0, NIA MRC, and KLUE-MRC utilized text paragraphs as input context. KorWikiTableQuestions used tabular data as input context.
KorQuAD 1.0 is a dataset developed by benchmarking SQuAD 1.1, utilizing Korean Wikipedia documents. KorQuAD 2.0 represents an expansion of the original dataset KorQuAD 1.0 dataset. While KorQuAD 1.0 utilizes short paragraphs as context, KorQuAD 2.0 provides full Wikipedia documents as context. Full Wikipedia documents typically exceed the token limit of 512, commonly used in transformer-based encoder models. Consequently, a process of selecting or ranking specific paragraphs that are likely to contain answers becomes necessary. The answer spans in KorQuAD 2.0 are tagged not only in unstructured text but also in structured text (such as tables and lists) as well.
In early research stages, MRC models with an attention mechanism that allows the model to focus on a specific area within a query-relevant paragraph of text achieved impressive results. The BiDAF (Seo et al. Citation2016) achieved promising results with the MRC model using bi-directional attention between query and context. QA-Net (Yu et al. Citation2018) proposed an MRC model architecture using a convolution neural network and global self-attention without a recurrent neural network to reduce training and inference time. Recently, MRC fine-tuning language models (Zhang, Yang, and Zhao Citation2021) pre-trained with large-scale raw corpus based on transformers achieved state-of-the-art performance. Dong et al. (Citation2023) introduces unified multi-module end-to-end model for multi-passage MRC, which encompasses passage retrieval, answer extraction, and ranking of multiple answer verifications. This model employs an answer verification method that utilizes the attention mechanism to fuse the features of answer candidates, demonstrating improvement in multi-passage MRC tasks. FinBERT-MRC (Zhang and Zhang Citation2022) proposed a novel approach to solving MRC problems by formulating financial named entity recognition. This study employs the FinBERT (Yang, Uy, and Huang Citation2020), a domain-specific pre-trained model, to enhance the capability to identify target entities. Fin-EMRC (Chai et al. Citation2023) proposed a novel MRC model augmented with structured financial domain knowledge. They employed a new query template scheme to improve the MRC framework’s inference efficiency.
TableQA and Semantic Parsing
A semantic parsing task can be viewed as question answering over structured text. In semantic parsing tasks, the language models that were pre-trained with tables achieved state-of-the-art results. TABERT (Yin et al. Citation2020) was proposed as a pre-trained language model that learns joint representations for natural language text and structured text. TAPAS (Herzig et al. Citation2020) extends BERT architecture with additional embeddings for rows, columns, and rankings to capture the tabular structure of tables. TAPAS and TABERT were pre-trained on millions of tables, and their outputs were learned with a masked language model (MLM) objective.
Automatically generated synthetic data is used to inject reasoning skills in pre-training language models. Pruksachatkun et al. (Eisenschlos, Krichene, and Müller Citation2020) proposed an intermediate pre-training task to predict whether statements generated automatically for a table with context-free grammar are positive or negative. GRAPPA (Yu et al. Citation2020) constructed synthetic question-SQL pairs over tables with synchronous context-free grammar (SCFG) and pre-trained language models with MLM and SQL semantic prediction (SSP) objectives.
Previous studies on Korean table Question Answering (QA) have been mainly conducted in the form of span prediction for tables. TabQA (Park et al. Citation2018) proposed an end-to-end neural model to encode table cell features. They constructed table QA datasets consisting of 20,000 tables and 100,000 natural questions related to telephone services. Park et al. (Citation2020) proposed both novice and intermediate Korean TableQA tasks that infer the answer to a question from structured tables to build a question-answering pair. Novice tasks constructed questions with simple rules and templates. In intermediate tasks, they imposed lexical variations and added more complex levels of queries.
HybridQA
In HybridQA, both tabular and text data are used as input context, necessitating aggregating information from both sources to infer answers. W. Chen et al. (Citation2020) a proposed cross-block reader based on sparse attention to aggregate information across top-K text and tabular blocks. TAT-QA (Zhu et al. Citation2021) introduced a novel QA model, TAGOP, for practical reasoning across tabular and textual data. TAGOP employs a sequence tagging approach to extract relevant cells and text spans, then applies symbolic reasoning combined with aggregation operators to process them. UniRPG (Zhou et al. Citation2022) used a semantic parsing-based approach, which consists of a neural programmer and a symbolic program executer. The neural programmer generates programs, which the program executor then directly employs for conducting discrete reasoning over tabular and textual data. Nararatwong, Kertkeidkachorn, and Ichise (Citation2022) proposed a QA model that builds upon TAGOP, integrating explicit tabular structures with a graph neural network. The model consists of an evidence extraction module with GNN and an improved numerical reasoning module. FinMath (Li, Ye, and Zhao Citation2022) proposed the FinMath framework, which enhances the model’s performance on numerical reasoning through multi-step reasoning using a tree-structured neural network.
Adapter
When fine-tuning is performed to inject additional information into a pre-trained model, a catastrophic forgetting problem can occur where knowledge trained during pre-training disappears. K-Adapter (Wang et al. Citation2020) has been developed to mitigate the issue of catastrophic forgetting during fine-tuning. K-Adapter is a neural adapter that can be connected to pre-trained language models like BERT, enabling the utilization of additional knowledge without the risk of losing pre-trained information.
Proposed Methodology
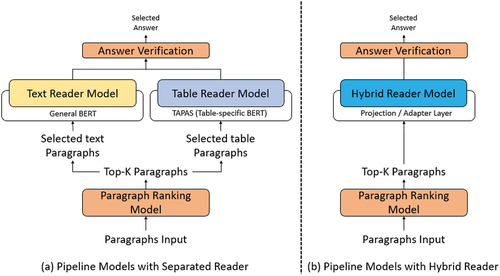
We propose a multi-paragraph MRC system consisting of two main components: a paragraph ranking model and a paragraph reader model. shows the architecture of the proposed MRC system. The paragraph ranking model selects top-k paragraphs from a full Wikipedia document. The paragraph reader model predicts two things: answer spans and whether input paragraphs include answers or not. The Separated Reader model uses separate models for tables and texts, while the hybrid reader Model uses a unified reader model for both tables and texts.
Figure 2. Architecture of (a) pipeline models with a separated reader, (b) pipeline models with hybrid reader.
Paragraph Ranking
An input document is divided into several parts if the number of input tokens exceeds the maximum length that the reader model can process at once. It makes hard to find answers in the splited several paragraphs. Therefore, it is efficient to rank the paragraphs that are likely to have the correct answer. Thus, we trained the paragraph ranking model to predict the probability of whether the correct answer to the question is in the input paragraph. We use heuristic exact matching (HEM) (Eisenschlos, Krichene, and Müller Citation2020) as an auxiliary method for paragraph ranking. The HEM score between the query and paragraph is obtained as follows. First, words in the paragraph are broken down into tokens of morphs. To compare the similarity between query and paragraph, nouns are examined since they undergo fewer morphological changes than other types of part of speech, and importantly they convey crucial semantic information in the context. Using the bi-gram features, we computed the Jaccard coefficient, which serves as a HEM score between query and paragraph:
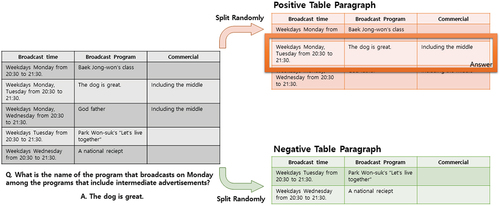
where indicate the tokens in the query and paragraph, respectively. Answer paragraphs and top-k negative paragraphs are sorted out based on the HEM score with in-batch negatives. Tables are flattened by adding commas to separate each cell. If there is no negative table paragraph corresponding to the positive one, we generate a negative table sample to prevent paragraphs with only text from being selected as a negative sample. shows a method for generating a negative table sample by processing the original tables into positive and negative tables. We use this method if the document has no other tables.
Figure 3. Example of generating negative and positive paragraph table from the original paragraph.
In KorQuAD 2.0, there are short answers with answer spans tagged in a part of a sentence and long answers as well, where the answer spans are tagged on an entire paragraph or several paragraphs. Therefore, in this section, our key challenge is to output the probability of short answers, long answers, and no answers in a number of paragraphs for a given question and rank the paragraphs. As mentioned earlier, the model can process at a maximum length at one time. If the input document exceeds the maximum, it is broken down into smaller units of paragraphs.
When inputting paragraphs into the model, a batch is made up of a paragraph with answers and the rest containing no answers. After inputting the vector, we gain three probability values of short answers, long answers, and no answers for each paragraph in the last hidden vector of the [CLS] token. Then, the probability vector is computed using the SoftMax operation.
where is the [CLS] token’s final hidden vector output of BERT.
is the probability of whether the answer is a short answer, a long answer, or unanswerable. We calculate
with cross-entropy between two vectors to see how much the resulting vector deviates from the actual correct answer. We also used titles of documents and paragraphs as input and cross-entropy loss to train the ranking model.
Next, we check whether the derived probability vector output can find the position of the paragraph with the answer. We extract the max values from the probabilities of short answers and long answers and reconstruct them into a single vector. Then,
is the probability of short and long answers of the
-
component of the vector of the [CLS] token mentioned above,
is a
-
vector created by applying the max function of short and long answers in the vector output
. When we apply SoftMax operation to
, the following equation is derived:
indicates a vector that applies SoftMax operation to vector
. Then, we reshaped its result to be the same side as the initial input vector. Cross-entropy is used to compute the
between the correct answer vector and the reshaped vector.
is reshaped to the max probability vector between short answers and long answers.
So far, we have obtained the HEM scores and computed the probabilities of short answers, long answers, and no answers for each paragraph. A score to select the top-k paragraph is computed as illustrated below:
where is the HEM score between a question and a paragraph morph token,
is the final score for paragraph ranking,
is the probability of a short answer, and
is the probability of a long answer.
Finally, paragraphs are sorted based on the final score, and the top-5 paragraphs computed by the ranking model are delivered to the reader models to find the correct answer.
Separated Reader Model
In the Separated Reader Model, different reader models are used depending on whether the input paragraph, selected from the ranking model, is structured text or unstructured text. The BERT model is pre-trained with unstructured corpora and we used it as the backbone model. If a table is in the selected paragraph, the table reader model outputs the answer span; if not, the text reader model outputs the answer span.
For the language model to capture a tabular structure, additional pre-training on structured data and special embeddings for tabular data are required. We used an additional embedding of a column, row, and ranking (TAPAS) and an additional pre-training language model with the Masked Language Model (MLM) and SQL semantic prediction (SSP) objective (GraPPa). The MLM predicts the original token replaced with a special token mask. SSP predicts whether a column occurs in the SQL utterance and which operation is triggered.
In this paper, we extend the SSP task to predict cells, rows, and column heads that occur in the SQL utterance. We extract table-utterance pairs from Korean Wikipedia and Namuwiki, and then generate synthetic data using these tables. MLM loss is computed to optimize the model for natural language utterances and SSP is computed to optimize the model for synthetically generated utterances.
Each reader model is fine-tuned independently with KorQuAD 2.0, depending on whether the answer is tagged in the table or text. For unanswerable questions, we set the answer span to point [CLS] token for both start and end span prediction and used it as no-answer probabilities to verify the final answer. Predictions of the separated model are computed as follows:
are the final hidden states of the language model pre-trained with text data and table data,
and
are the probability of the answer span for start and end. The former probability is selected if a table is in the paragraph otherwise the latter is selected. The term
represents the score of the i-th input to verify the answer among answer candidates. The final answer is selected where the candidate answers are extracted from the input with the highest score.
represents the HEM score, as described in Section 3.1, between the query and i-th input paragraph. It is particularly useful when the verification of answers becomes challenging due to the similarity of input formats, such as in situations where the inputs include monthly match result tables that have the same head data.
Hybrid Reader Model
While the Separated Reader Model uses different reader models for tables and texts, the hybrid reader model uses a unified reader model for data with an adapter structure. We used two approaches: one without additional pre-training over tables, and the other one with additional pre-training of an adapter structure in the hybrid reader Model over tables. We will refer to the two methods that we have employed as the projection method and the adapter method, respectively ().
Figure 4. Architecture of a hybrid reader with projection.
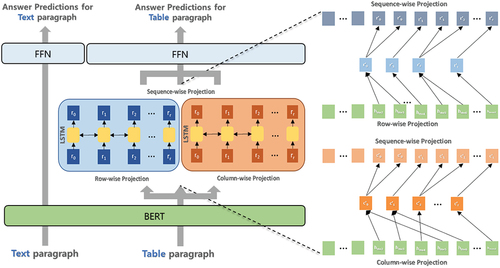
Using the BERT model with additional embedding for tables makes it difficult to use a unified model. Instead, we use a unified pre-trained language model and a separate classification for tables and texts. While we present vector representations of BERT directly to the FeedForward Network (FFN) for the case of text paragraph, we use additional embeddings, such as columns, rows, and rank embedding, to encode semi-structured data and present concatenation of all vectors to FFN.
Additional Embeddings
To acquire column and row representations, we applied a summation operation on the output vectors that corresponded to the same column or row, respectively. Afterward, BERT’s encoder was utilized without any additional alterations. The equation for obtaining column and row embeddings is expressed as follows:
where is the final hidden state of BERT,
and
are row and column vectors that one-hot encoded row and column indexes which indicate the row and column index of input tokens,
is the max row length,
is the max column length. To model the temporal interactions between table cells, we used the bidirectional LSTM (Hochreiter and Schmidhuber Citation1997) on the column and row representations.
As illustrated in the equation above, we obtain the final hidden states in the output layer, where /
is a row/column representation vector from LSTM,
/
is a row/column representation vector at the indexes of each token input, [;] is the vector concatenation,
is the trainable weight matrix, and
is a modified hidden state for structured text.
Attention Restriction
Motivated by (Eisenschlos et al. Citation2021), we restricted the BERT’s attention heads to consider cell representations in the same rows and columns by masking. By attention mask, , a token at the position
can be obtained:
where is a query set,
is the head of columns and rows, and
are the columns and rows at the
-
position.
If the input is a paragraph with a table, only the loss in the table classifier is minimized. Otherwise, only the loss in the text classifier is minimized. Final predictions and losses are computed as:
,
and
,
are the probability of the answer span for start and end, and
is a constant value which indicates whether input paragraph is table or not.
The answer verification is applied using the same approach described in Section 3.2.
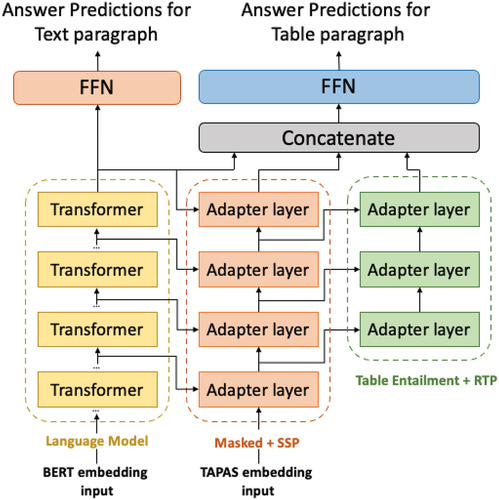
Hybrid Reader with Adapter
For the Unified Reader Model to handle both table and text, we used additional pre-training over tables with an adapter structure. The adapter structure consists of seven adapter layers to capture the tabular structure. Of those adapter layers, four adapter layers obtain input directly from the pre-trained transformer layer and the other three obtain input from previous adapter layers. Motivated by previous work (K-adapter), we added additional transformer layers for pre-training tasks on the table data. As shown in , adapter layers consist of two parts and the pre-training over a table is made up of two phases. In the first phase, only the weights of the four adapter layers, which obtain input directly from transformers, are updated. In the second phase, the weights of all adapter layers including the other three adapter layers are updated. The transformers’ weights are permanently fixed after pre-training from unstructured corpora and each of {0,4,8,12} transformer layers are plugged into each of the four adapter layers.
Figure 5. Architecture of a hybrid reader with adapter.
shows the architecture of the adapter layer. We extend the transformer layer with the projection layer to capture the tabular structure. We compute column and row embeddings by summing the output representations of the transformer layer without modifying the embedding layer of BERT, as shown in the following equations.
Figure 6. Architecture of adapter layer; row-wise, direct, column-wise projection is concatenated and passed to adapter transformer layer.
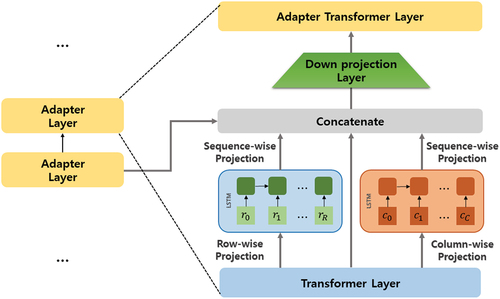
where is the input of
-
Adapter Layer,
is the hidden states from the,
,
-
layer of pre-trained transformer and
is the output of former adapter layer. In the first adapter layer, special embeddings used in (Herzig et al. Citation2020) were used as input instead of the former layer’s output.
We obtained the row and column representation, then concatenate them with the transformer layer’s outputs.
/
is the row/column representation vector of the adapter layer,
/
is the row/column representation vector of index position from the adapter layer, [;] is the vector concatenation,
and
are the trainable weight of down projection layer, and output of down projection layer
is passed to
, transformer layer at
-
adapter layer; then we acquire final hidden states
.
Details of Pre-training Tasks for Adapter
We use the BERT-base (L = 2, H = 768, A = 12) model as the transformer layer and initialize the adapter layer (N = 4, L = 1, H = 1024, A = 8) randomly. There are two phases in pre-training procedures. In the first pre-training phase, we only train four adapter layers that are plugged from transformer layers. In the second pre-training procedure, weights of all the adapter layers are learned, while the original parameters of transformer layers pre-trained on unstructured corpora are fixed in all phases. Following Yu et al. (Citation2018), we generated queries using synchronous context-free grammar with Korean Wikipedia tables and trained the model with masked language model loss and SQL semantic loss using augmented examples.
Using a unified pre-trained model, we cannot add special embedding or additional pre-training for tables in the hybrid reader model. However, with an adapter, we feed input special embeddings of columns, rows, and rankings to the first adapter layer in the adapter layers.
In the first pre-training phase, we train four adapter layers, as shown in the middle of , with MLM and SSP objectives. In the second pre-training phase, we use intermediate (Eisenschlos, Krichene, and Müller Citation2020) pre-training tasks, table entailment with synthetic data generation, and relevant statement prediction to train all the adapter layers. With these pre-training phases, the weight of the transformer is fixed, which is pre-trained from the text at the very begining.
We generate table-dependent synthetic statements using context-free grammars introduced in Pruksachatkun et al. (Eisenschlos, Krichene, and Müller Citation2020) to train entailment recognition tasks. We excluded counterfactual statements because of an insufficient number of tables with statements in the Korean Wikipedia. A relevant statement prediction task is added to improve answer verification in the table reader. Statement() and table(
) pairs present in the same paragraph are collected as positive samples. Statement(
) and table(
) pairs in different paragraphs or documents are collected as negative samples.
We use BERT and adapter’s [CLS] token representations to model the joint probability of the relevance statement prediction and table entailment tasks. We used binary cross entropy loss for the table entailment and relevant table prediction (RTP) tasks described in .
Transformers for Long Sequences with Structured Data
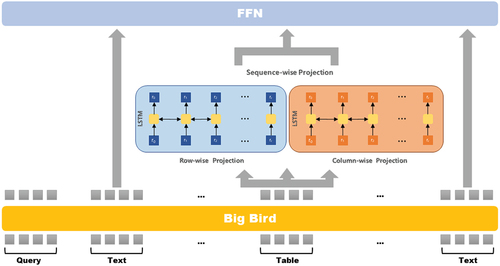
While the previous method uses special embedding for the table on the embedding layer, our model architecture captures the tabular structure with a representation vector from the existing language model and could be applied to long sequence transformers such as Big Bird (Zaheer et al. Citation2020).
shows the hybrid reader model architecture with long sequence transformer. This model takes the top-K paragraph from the Ranking Model and outputs the hidden vectors for each paragraph. From those hidden vectors, we pick the hidden vectors from the table paragraph, and table architectures in the hybrid reader model were applied to the picked hidden vectors. Encoding structural information with projection is applied as an Equationequations 10(10)
(10) –Equation15
(15)
(15) .
Figure 7. The architecture of hybrid reader model with projection using long sequence transformer.
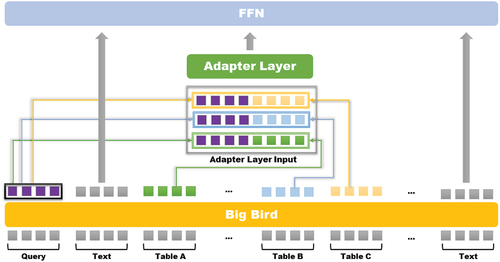
illustrates the architecture of the adapter layer, in which the output vector of the long sequence transformer model and the output of the tokens of the question are concatenated and passed to the adapter layer as input. Encoding structural information with an adapter is applied as an Equationequations 21(21)
(21) –Equation26
(26)
(26) . The vectors from the adapter are projected to sequence-wise projection and concatenated to Big Bird representation, and we acquire the final H.’
Figure 8. The architecture of adapter layer for tables.
Experiments
We used a pre-trained (Zaheer et al. Citation2020) transformer model from Huggingface. The
model is specialized in long sequence lengths and full attention; it is more efficient than the BERT model and can be used while limiting the length of the sequence to 512. To compare our results with those of other models, we implemented the model pre-trained with a masked language model over tables, with additional embedding columns, rows, and ranking following Herzig et al. (Citation2020). Instead of millions of tables used in Herzig et al., we collected 70 thousand tables from Korean Wikipedia.
Dataset
Our model was trained and evaluated using KorQuAD 2.0, a Korean machine reading comprehension dataset that includes both textual and tabular data. The dataset consists of 83,686, 10165, and 9,309 question-answering data for training, development, and testing, respectively. The data is collected from 47,957 documents, including Korean Wikipedia and other web pages. The development dataset comprises 1663, 6877, and 1625 instances of long answers, answers from a text paragraph, and answers from a table, respectively. Since the number of answers from the table is much smaller compared to that of answers from the text, the performance enhancement in a table would not be coupled with the overall performance improvement.
There are two types of answers in KorQuAD 2.0; one is a short answer that is a word or phrase, and the other one is a long answer that tags the whole paragraph as an answer. Answers are tagged not only from the text but also from the table and list. The number of syllables in the long answer is larger than or equal to 240, and 17.8% of KorQuAD 2.0 data are long answers.
In order to conduct experimentation on English QA, four datasets were utilized: SQuAD (Rajpurkar et al. Citation2016a), WikiSQL (Zhong, Xiong, and Socher Citation2017), NQ-Tables (Kwiatkowski et al. Citation2019), and TAT-QA (Zhu et al. Citation2021). SQuAD v1.1 is a reading comprehension dataset comprising 100,000 questions that were generated by crowd workers using information from Wikipedia. WikiSQL is a dataset for text-to-SQL generation. This dataset focuses on translating text to SQL. The dataset was created by converting template-based questions into natural language and was created and vetted by crowd workers. The dataset consists of 80,654 questions and SQL queries from Wikipedia. NQ-tables is a tabular question-answer dataset created from the NATURAL QUESTIONS dataset. It was created by extracting 12,000 data from the NQ dataset, which are cases where the correct answer also exists in the table. Additionally, we conducted experiments on the TAT-QA dataset to explore the task of extracting answers from both tables and text. TAT-QA dataset was constructed based on real financial reports’ text paragraphs and tables, requiring numerical reasoning to extract answers. TAT-QA is composed of three types: table, table-text, and text, depending on the input source type from which the answers are tagged. The model needs to aggregate information from both tables and text to infer the answers from hybrid sources.
Experimental Method
As shown in , we compared the Separated Reader Model and our proposed hybrid reader model. To compare the differences between application methods within these models, we conduct four types of experiments: Vanilla which is the base model (BERT pre-trained on unstructured text), TAPAS, with column-row-wise projection, and with Adapter structure. All experiments are conducted in three types of data: only table, only text, and both table and text.
As there was no publicly available pre-trained TAPAS model for Korean language, we implemented a pre-trained TAPAS model for Korean language by utilizing approximately 100,000 tables from Korean Wikipedia and 500,000 tables from Namu Wiki.Footnote2 This pre-trained model was employed as the table-specific reader model in separated reader model. Since the full Wikipedia document, which serves as the context input for KorQuAD 2.0, exceeds the maximum input token length of 512, it is divided into sub-paragraphs. In the separated model, each sub-paragraph is inputted into different reader models depending on whether it contains tables or not.
In this study, we conducted additional experiments on English QA datasets to prove the universality of our hybrid reader model. To replicate the experimental environment of KorQuAD 2.0 dataset which involves processing both text and table data inputs, we used a mixture of SQuAD v1.1, NQ-tables and WikiSQL datasets. SQuAD v1.1 dataset was used to evaluate the MRC performance on text inputs. NQ-tables and WikiSQL datasets were used to evaluate the MRC performance on tabular inputs. To train the MRC model with WikiSQL, we set the positions of tagged answer cell’s start token and end token to the answer span. We used pre-trained RoBERTa base modelFootnote3 from huggingface as backbone model. We used pre-trained TAPAS base modelFootnote4 for comparison with hybrid model. In the experiment with TAT-QA, we retained the overall architecture of TAGOP model (Zhu et al. Citation2021) and replaced the encoder model of TAGOP with our proposed hybrid reader model.
Training Details
The concatenated vector of the Row-wise Projection, Column-wise Projection, and Transformer Layer in the adapter layer has a size of 768 × 3, and it is projected to the Adapter Transformer layer using a Down projection Layer. The hidden size of the Adapter Transformer Layer is set to 768. The BERT model in and Language Model with a transformer in were optimized with Adam optimizer at a learning rate of 0.0002. The epochs and dropout rate were set to 5 and 0.2, respectively. We applied the same hyperparameters used in the experiments of TAGOP (Zhu et al. Citation2021). We ensured reproducibility by utilizing the code provied in TAGOP code release, with only the encoder part replaced by our proposed model with projection layers and adapter layers.
Result
Experiment Result
We evaluated two different types of readers; a Separated Reader which uses two independent readers for each text and table, and a hybrid reader which has one reader for table and text. shows the main evaluation for KorQuAD 2.0, which is a multi-paragraph machine reading comprehension on the entire HTML Wikipedia document. The evaluation is focused on data types (text, table, or both), additional structures, and the existence of a paragraph ranking model. We experimented on text, table, and both table and text data in KorQuAD 2.0 to see performance change by using table-specialized modifications. Vanilla is a basic BERT model without modifications for tables. TAPAS is a table-specific BERT that uses BERT input embedding with additional embeddings of a row, column, and raking for the table. We implemented additional pre-training with the table and raw text corpus for the TAPAS. Instead, Projection uses only BERT input embeddings by projecting the BERT representation vector to its corresponding row and column(row, column representation). The adapter uses adapter layers for the table with additional pre-training over tables. Using adapter layers with two phases of training, we achieved the best performance by capturing the tabular knowledge in the data without performance loss in text. For the paragraph ranking, we used the top five paragraph outputs from the paragraph ranking model as reader input, which means there could be no answer in the paragraph. For the “oracle” experiment, we gave the paragraph which contains the answer as input context for the reader model. Compared to paragraph ranking, the performance for the table data improved in all metrics by at most 0.11 points in Oracle, because there is always an answer in Oracle, and the model can find the answer span for it.
Table 1. Result comparison between separated model and hybrid model with and without paragraph ranking.
presents the experimental results of applying projection layers and adapter layers to the BirBird model, a long sequence transformer. The model with projection layers showed significant performance improvement on tabular data, yet a decline in performance was observed on text data. While the model with adapter layers improved performance on tabular data, it exhibited a lower increase compared to the model with projection layers and a marginal decline on text data.
Table 2. Result of the new architecture of BigBird model with our modifications.
shows the evaluation results on the three English MRC datasets. Among the three datasets, SQuAD v1.1 and WikiSQL are textual QA datasets, and NQ-Tables is a tabular QA dataset. Vanilla model performed well on the text dataset SQuAD v1.1 but showed low performance on the table dataset NQ-Tables. Conversely, Tapas model showed limited efficacy on the SQuAD v1.1, yet performed well on the NQ-Tables. The models we propose in this study, Projection, and Adapter, have similar performance on the datasets where Vanilla and Tapas perform well. This outcome demonstrates that the proposed hybrid reader model can be effectively applied to datasets in both English and Korean, indicating its potential to achieve universality across multiple languages.
Table 3. Results for experiments using the English MRC dataset, SQuAD 1.1, WikiSQL, and the NQ-Tables on hybrid reader model.
shows the results of the experiment on the TAT-QA dataset. When the encoder model of TAGOP was replaced with the table-specific pre-trained model TAPAS, it showed improved performance on table data but showed lower performance than the baseline model on table-text data and text data. In contrast, when the encoder model of TAGOP was replaced with the hybrid reader model, it showed a slight decline in text data performance and improvements in both table and table-text data. Compared to the baseline model, the model with projection layers showed an improvement of EM 7.08 and F1 7.1, and the model with adapter layers showed an improvement of EM 7.87 and F1 7.75.
Table 4. Result for experiments using TAT-QA dataset.
Ablation Study
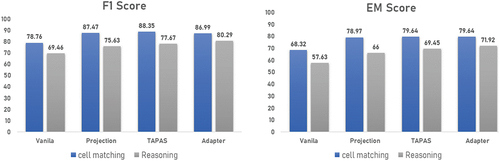
To evaluate the reasoning performance of the language models, we divided the MRC table data into reasoning data and cell-matching data. In reasoning data, there are questions to compare between cells or examine multiple cells to find an answer. In cell-matching data, there are questions paraphrased and require knowledge to answer. shows the comparison of the performance of language models for reasoning data and cell-matching data. Pre-training language models with adversarial training did not have much effect on reasoning data but showed improved performance in cell-matching data.
Figure 9. The performance comparison of each vanilla, projection, TAPAS, and adapter.
Conclusion
In this paper, we propose a hybrid reader model over both tables and text with the adapter structure. The projection layer gets column and row representations with column-wise and row-wise summation of encoder outputs and combines it with encoder outputs. The reader model with projection layers showed improved results on table data, even without additional pre-training on table data. In the experiments with adapter structure, we used weights of the BERT model pre-trained from unstructured texts, fixed in additional pre-training tasks over tables; instead, the weights of BERT in adapter layers are updated by two stages. Adapter layers infuse knowledge from unstructured texts to tasks over structured texts and capture tabular structure. This approach enhanced the performance of question answers over tables and texts. It showed that the hybrid reader model with adapter captures tabular knowledge better than BERT or TAPAS.
In the experiments on TAT-QA dataset, significant performance improvements were observed even when only replacing the encoder model of the baseline model with our proposed hybrid reader model. This demonstrates that our model can be utilized in various research, simply by replacing the encoder model. Thus, in future research, we plan to conduct further experiments by combining our model with other models that have demonstrated good performance on hybrid QA datasets, such as FinMath (Li, Ye, and Zhao Citation2022), UniRPG and TAT-QA (Nararatwong, Kertkeidkachorn, and Ichise Citation2022). Additionally, we will expand our experiments to various hybrid QA datasets.
uaai_a_2367820_sm0155.png
Download PNG Image (63.4 KB){kind=link}
uaai_a_2367820_sm0161.png
Download PNG Image (61.8 KB){kind=link}
uaai_a_2367820_sm0165.png
Download PNG Image (69.3 KB){kind=link}
uaai_a_2367820_sm0152.jpg
Download JPEG Image (20.7 KB){kind=link}
uaai_a_2367820_sm0168.jpg
Download JPEG Image (151.2 KB){kind=link}
uaai_a_2367820_sm0154.cls
Download (23.9 KB)uaai_a_2367820_sm0156.png
Download PNG Image (30.4 KB){kind=link}
uaai_a_2367820_sm0158.png
Download PNG Image (193.5 KB){kind=link}
uaai_a_2367820_sm0157.png
Download PNG Image (62 KB){kind=link}
uaai_a_2367820_sm0167.jpg
Download JPEG Image (202.6 KB){kind=link}
uaai_a_2367820_sm0159.jpg
Download JPEG Image (14.5 KB){kind=link}
uaai_a_2367820_sm0149.bib
Download Bibliographical Database File (6.4 KB)uaai_a_2367820_sm0163.png
Download PNG Image (42.9 KB){kind=link}
uaai_a_2367820_sm0169.eps
Download EPS Image (36.3 KB)uaai_a_2367820_sm0162.jpg
Download JPEG Image (14.8 KB){kind=link}
uaai_a_2367820_sm0166.png
Download PNG Image (31.1 KB){kind=link}
uaai_a_2367820_sm0150.jpg
Download JPEG Image (49.3 KB){kind=link}
uaai_a_2367820_sm0160.eps
Download EPS Image (36.6 KB)uaai_a_2367820_sm0164.sty
Download (44.4 KB)uaai_a_2367820_sm0148.png
Download PNG Image (95.1 KB){kind=link}
uaai_a_2367820_sm0153.bib
Download Bibliographical Database File (15.2 KB)uaai_a_2367820_sm0151.bst
Download (32.4 KB)Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Source codes and dataset used in this paper can be accessed in our github page.Footnote5
Additional information
Funding
Notes
References
- Campos, D. F., T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, L. Deng, and B. Mitra. 2016. Ms marco: A human generated machine reading comprehension dataset. arXiv Preprint arXiv:150302531 2.
- Chai, Y., M. Chen, H. Wu, and S. Wang. 2023. Fin-EMRC: An efficient machine reading comprehension framework for financial entity-relation extraction. Institute of Electrical and Electronics Engineers Access 11:82685–25. doi:10.1109/ACCESS.2023.3299880.
- Chen, Z., W. Chen, C. Smiley, S. Shah, I. Borova, D. Langdon, R. N. Moussa, M. Beane, T. H. Huang, B. Routledge, et al. 2021. FinQA: A dataset of numerical reasoning over financial data. arXiv Preprint arXiv: 150302531 2. https://api.semanticscholar.org/CorpusID:235399966.
- Chen, W., M.-W. Chang, E. Schlinger, W. Yang Wang, and W. W. Cohen. 2020. Open question answering over tables and text. arXiv Preprint arXiv: 150302531 2. https://api.semanticscholar.org/CorpusID:224803601.
- Devlin, J., M.-W. Chang, K. Lee, and K. Toutanova. 2018. Bert: Pre- training of deep bidirectional transformers for language understanding. arXiv Preprint arXiv:1810.04805.
- Ding, J., W. Hu, Q. Xu, and Y. Qu. 2019. Leveraging frequent query substructures to generate formal queries for complex question answering. arXiv Preprint arXiv:150302531 2. https://api.semanticscholar.org/CorpusID:201668424.
- Dong, R., X. Wang, L. Dong, and Z. Zhang. 2023. Multi-passage extraction- based machine reading comprehension based on verification sorting. Computers & Electrical Engineering 106:108576. issn: 0045-7906. https://www.sciencedirect.com/science/article/pii/S0045790623000010. doi:10.1016/j.compeleceng.2023.108576.
- Eisenschlos, J. M., M. Gor, T. Müller, and W. W. Cohen. 2021. MATE: Multi-view attention for table transformer efficiency. Conference on Em- pirical Methods in Natural Language Processing, Punta Cana, Dominican Republic.
- Eisenschlos, J. M., S. Krichene, and T. Müller. 2020. Understanding tables with intermediate pre-training. arXiv Preprint arXiv: 150302531 2. https://api.semanticscholar.org/CorpusID:222090330.
- Herzig, J., P.-L. K. Nowak, T. Müller, F. Piccinno, and J. M. Eisenschlos. 2020. TaPas: Weakly supervised table parsing via pre-training. arXiv Preprint arXiv:2004.02349.
- Hochreiter, S., and J. Schmidhuber. 1997. Long short-term memory. Neural Computation 9 (8):1735–80. doi:10.1162/neco.1997.9.8.1735.
- Joshi, M., E. Choi, D. S. Weld, and L. Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv Preprint arXiv: 1705.03551.
- Kim, Y., S. Lim, H. Lee, S. Park, and M. Kim. 2019. KorQuAD 2.0: Korean QA dataset for web document machine comprehension. Annual Conference on Human and Language Technology, Daejeon, South Korea, 97–102, Human and Language Technology.
- Kwiatkowski, T., J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, et al. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics 7:453–66. doi:10.1162/tacl_a_00276.
- Lim, S., M. Kim, and J. Lee. 2019. Korquad1. 0: Korean qa dataset for machine reading comprehension. arXiv Preprint arXiv:1909.07005.
- Liu, Y., M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. 2019. Roberta: A robustly optimized Bert pretraining approach. arXiv Preprint arXiv:1907.11692.
- Li, C., W. Ye, and Y. Zhao. 2022. FinMath: Injecting a tree-structured solver for question answering over financial reports. International Conference on Language Resources and Evaluation. https://api.semanticscholar.org/CorpusID:252432931.
- Nararatwong, R., N. Kertkeidkachorn, and R. Ichise. 2022. Enhancing financial table and text question answering with tabular graph and numerical reasoning. AACL. https://api.semanticscholar.org/CorpusID:253761979.
- Park, C., M. Kim, S. Park, S. Lim, J. Lee, and C. Lee. 2020. Korean TableQA: Structured data question answering based on span prediction style with S3-NET. ETRI Journal 42 (6):899–911. doi:10.4218/etrij.2019-0189.
- Park, S., S. Lim, M. Kim, and J. Lee. 2018. TabQA: Question answering model for table data. https://api.semanticscholar.org/CorpusID:238431804.
- Park, S., J. Moon, S. Kim, W. Ik Cho, J. Han, J. Park, C. Song, J. Kim, Y. Song, T. Oh, et al. 2021. Klue: Korean language understanding evaluation. arXiv Preprint arXiv:2105.09680.
- Rajpurkar, P., R. Jia, and P. Liang. 2018. Know what you don’t know: Unan- swerable questions for SQuAD. arXiv Preprint arXiv:1806.03822.
- Rajpurkar, P., J. Zhang, K. Lopyrev, and P. Liang. 2016a. SQuAD: 100, 000+ questions for machine comprehension of text. CoRR Abs/1606.05250. arXiv: 1606.05250. http://arxiv.org/abs/1606.05250.
- Rajpurkar, P., J. Zhang, K. Lopyrev, and P. Liang. 2016b. Squad: 100,000+ questions for machine comprehension of text. arXiv Preprint arXiv: 1606.05250.
- Seo, M., A. Kembhavi, A. Farhadi, and H. Hajishirzi. 2016. Bidirectional attention flow for machine comprehension. arXiv Preprint arXiv: 1611.01603.
- Wang, R., D. Tang, N. Duan, Z. Wei, X. Huang, G. Cao, D. Jiang, M. Zhou. 2020. K-adapter: Infusing knowledge into pre-trained models with adapters. arXiv Preprint arXiv:2002.01808.
- Yang, Y., M. C. S. Uy, and A. Huang. 2020. FinBERT: A pretrained language model for financial communications. CoRR Abs/2006.08097 arXiv: 2006.08097. https://arxiv.org/abs/2006.08097.
- Yin, P., G. Neubig, W.-T. Yih, and S. Riedel. 2020. TaBERT: Pretraining for joint understanding of textual and tabular data. arXiv Preprint arXiv:2005.08314.
- Yu, A. W., D. Dohan, M.-T. Luong, R. Zhao, K. Chen, M. Norouzi, and Q. V. Le. 2018. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv Preprint arXiv:1804.09541.
- Yu, T., C.-S. Wu, X. V. Lin, B. Wang, Y. C. Tan, X. Yang, D. Radev, R. Socher, and C. Xiong. 2020. GraPPa: Grammar-augmented pre-training for table semantic parsing. arXiv Preprint arXiv:2009.13845.
- Zaheer, M., G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontañón, P. Pham, A. Ravula, Q. Wang, L. Yang, et al. 2020. Big Bird: Transformers for longer sequences. arXiv Preprint arXiv:150302531 2.
- Zhang, Z., J. Yang, and H. Zhao. 2021. Retrospective reader for machine reading comprehension. Proceedings of the AAAI Conference on Artificial Intelligence 35 (16):14506–14. doi:10.1609/aaai.v35i16.17705.
- Zhang, Y., and H. Zhang. 2022. FinBERT–MRC: Financial named entity recognition using BERT under the machine reading comprehension paradigm. Neural Processing Letters 55 (6):7393–413. https://api.semanticscholar.org/CorpusID:249210021.
- Zhong, V., C. Xiong, and R. Socher. 2017. Seq2SQL: Generating structured queries from natural language using reinforcement learning. CoRR Abs/1709.00103. arXiv: 1709.00103. http://arxiv.org/abs/1709.00103.
- Zhou, Y., J. Bao, C. Duan, Y. Wu, X. He, and T. Zhao. 2022. UniRPG: Unified discrete reasoning over table and text as program generation. arXiv Preprint arXiv:150302531 2 Abs/2210.08249. https://api.semanticscholar.org/CorpusID:252918014.
- Zhu, F., W. Lei, Y. Huang, C. Wang, S. Zhang, J. Lv, F. Feng, and T.-S. Chua. 2021. TAT-QA: A question answering benchmark on a hybrid of tabular and textual content in finance. arXiv Preprint arXiv:150302531 2 Abs/2105.07624. https://api.semanticscholar.org/CorpusID:234741852.