
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Multimodal sentiment analysis is a technical approach that integrates various modalities to analyze sentiment tendencies or emotional states. Existing challenges encountered by this approach include redundancy in independent modal features and a lack of correlation analysis between different modalities, causing insufficient fusion and degradation of result accuracy. To address these issues, this study proposes an innovative multi-channel multimodal joint learning method for image-text sentiment analysis. First, a multi-channel feature extraction module is introduced to comprehensively capture image or text features. Second, effective interaction of multimodal features is achieved by designing modality-wise interaction modules that eliminate redundant features through cross-modal cross-attention. Last, to consider the complementary role of contextual information in sentiment analysis, an adaptive multi-task fusion method is used to merge single-modal context features with multimodal features for enhancing the reliability of sentiment predictions. Experimental results demonstrate that the proposed method achieves an accuracy of 76.98% and 75.32% on the MVSA-Single and MVSA-Multiple datasets, with F1 scores of 76.23% and 75.29%, respectively, outperforming other state-of-the-art methods. This research provides new insights and methods for advancing multimodal feature fusion, enhancing the accuracy and practicality of sentiment analysis.
Introduction
Through processing and analysis (Riyadh and Shafiq Citation2022; Zhang, Yu, and Zhu Citation2022). Sentiment analysis is a technological way to determine the sentiment tendency or emotional state conveyed in text (Khan et al. Citation2023), photos (Jia et al. Citation2023), voice (Zhao et al. Citation2023), and other information. Multimodal sentiment analysis (Yan et al. Citation2022) is an extended application of sentiment analysis that combines information from multiple modalities. Multimodal sentiment analysis (MSA) methods have potential applications, such as in personalized advertising (Xie et al. Citation2023), where they can provide advertisers with insights into user emotions and enable targeted advertisement placements. Sentiment cross-modal retrieval (Manek and Shenoy Citation2022) allows users to obtain more accurate emotional information through queries in different modalities. In terms of opinion mining (Liu et al. Citation2023), multimodal sentiment analysis helps in the analysis of user emotions expressed across different media, providing businesses or researchers with a comprehensive market feedback. Furthermore, multimodal sentiment analysis provides decision-makers with a comprehensive information foundation in the field of intelligent decision-making (Angamuthu and Trojovský Citation2023), aiding in the formulation of intelligent and personalized decision strategies.
Analysis and processing of information derived from multiple modalities exhibit both advantages and disadvantages over single-modal analysis. Numerous prompt multimodal approaches rely heavily on manually crafted components. However, such features are usually based on restricted human knowledge and lack the ability to completely characterize highly abstract sentiments, which can cause unsatisfactory outcomes. Convolutional neural networks (CNN) were applied to MSA since the advent of deep learning, and exhibited promising results. Nevertheless, the majority of the techniques based on CNN either connect features gathered from various modalities (Guo et al. Citation2021) or enable basic-level comprehension of the relationship across images and text (Gandhi et al. Citation2022). Human sentiments are primarily prompted by certain regions (She et al. Citation2020) in images, and are expressed by specific words in the accompanying commented text. Existing methods for image sentiment analysis still face some outstanding problems that should be solved urgently, e.g., the image regions that the feature extraction networks focus on are not accurate enough, the simple process of feature extraction for independent modalities causes information redundancy, and the semantic correlation between multimodalities is not analyzed and fused sufficiently. This research proposes a multi-channel multimodal joint learning (MMJL) image-text interaction network to overcome the aforementioned problems and improve the performance of MSA. Using cross-modal cross-attention, it extracts multichannel picture and text information and merges them. Three modules make up the suggested network: an adaptive sentiment classification module, a cross-modal fusion module, and a single-modal feature extraction module. The following are the primary contributions of our work:
Vision Transformer (ViT) (Liu, Wu, and Guo Citation2022) and Faster R-CNN (Zhang Citation2022) are combined to propose a new Multi-channel Comprehensive Image Features (MCIF) method, which is employed to comprehensively focus on emotion regions within images. Simultaneously, a novel Multi-channel Syntactic Text Features (MSTF) method based on syntactic features and self-attention mechanisms is utilized to extract global textual emotion features. And apply the proposed MCIF and MSTF methods to extract information from different modalities for MMJL.
Intra-modal interaction modules are designed to remove redundant features. A new Efficient Multimodal Transformer (EMT) fusion module is introduced, which leverages cross-modal attention mechanisms to acquire fused image-text features, and thoroughly explores inherent correlations between two input feature sequences.
A novel Adaptive Multitasking Fusion (AMTF) method is applied to integrate single-modal contextual emotion features with multimodal features, resulting in a more comprehensive multimodal sentiment prediction.
Numerous experiments are carried out on two public datasets, and the outcomes confirm the effectiveness of the proposed MSA method. Furthermore, the proposed method outperforms a number of other advanced MSA techniques.
The rest of the paper is organized as follows: Section 2 carries out a literature review of ViT, BERT, multitask learning and multimodal sentiment classification. The proposed MSA approach is described in Section 3. Section 4 provides the results of MSA experiments on the MVSA-Single and MVSA-Multiple datasets. Section 5 outlines the achievements and limitations of the proposed MSA approach, and future research plans for this topic.
Related Work
Multimodal Sentiment Classification
The integration of verbal and nonverbal data, e.g., visual and acoustic data, has made MSA a significant research topic. Traditionally, researchers concentrated on representation learning and multimodal fusion. Wang et al. (Citation2019) constructed a change embedding network with recurrent change engagement to generate multimodal shifts for the representation learning method. Hazarika, Zimmermann, and Poria (Citation2020) suggested modality-invariant and modality-specific representations for multimodal representation learning. Based on the stage at which fusion is carried out, existing work on multimodal fusion can be separated into two groups: early fusion and late fusion. Early fusion approaches typically employed subtle attention mechanisms for cross-modal fusion. For instance, Tsai et al. (Citation2019) suggested a cross-modal converter to learn cross-modal attention for improving the target modality. After learning the intra-modal representation, post-fusion methods were used to achieve inter-modal fusion using a tensor fusion network. However, this method lacked the ability to interact between multimodal. In order to address this issue, Yan et al. (Citation2021) introduced a multi-tensor fusion method based on cross modal feature extraction. However, this method fused image and text modalities only roughly during the feature fusion stage, and ignored any information exchange within the modalities. Although Yan et al. (Citation2022) introduced a multi-tensor fusion network to model interactions between multiple bimodal pairs, they did not consider the global context of modalities. Additionally, Meena et al. (Citation2023) proposed a hybrid model combining CNN and LSTM, incorporating a knowledge graph to enhance model performance. This approach leverages the local feature extraction capabilities of CNNs and the temporal data memory functions of LSTMs. However, the method relies on the construction of the knowledge graph, and the model may still exhibit instability when dealing with complex linguistic phenomena such as sarcasm and puns.
Our work enhances the ability to extract private and shared information across different modalities and fuse multimodal features at a later stage by using self-supervised and multi-task learning strategies to efficiently learn the information. Moreover, a framework to adaptively combine decision-level and feature-level fusion is designed that significantly improves the sentiment classification accuracy. The proposed method is extensively evaluated on benchmark datasets, demonstrating its effectiveness in extracting and fusing multimodal features.
ViT and BERT
A Transformer is a non-looping sequence-to-sequence architecture (Xu et al. Citation2021), which is employed to model sequential data and can offer superior results, efficiency, and depth compared to cyclic structures. Two models based on the Transformer are ViT and BERT. ViT (Paul and Chen Citation2022; Xie and Liao Citation2023) is a vision model based on the Transformer architecture that achieves impressive performance in computer vision tasks with promising applications. It is based on the principle of segmenting an image into small plots and employing a self-attention mechanism for image feature extraction and modeling. BERT (Bao, Dong, and Wei Citation2021) is a successful application of Transformer for language models, achieving excellent accuracy in various text processing tasks. The open-source pre-trained BERT and ViT models are utilized for obtaining features from text and image data, respectively.
Multi-Task Learning for Multimodal Sentiment Classification
Multi-task learning (MTL) (Gao et al. Citation2022; Tan et al. Citation2023) is a machine learning method that designs a model to simultaneously learn multiple related tasks. It can boost the model’s generalization capacity and efficiency to some extent. Information sharing and interaction between various tasks can be achieved by considering correlation and differences between them via multitask learning for designing an appropriate model architecture and loss function. Multi-task learning uses shared parameters in the backpropagation process, which allows features to be used by other tasks. This provides learning features that can be applied to several different tasks for improving generalization performance across them. The parameters can be shared in two ways: soft sharing and hard sharing.
Multi-task learning (Yang et al. Citation2022; Yu et al. Citation2020; Zhang et al. Citation2023) has been extensively used for MSA. For example, Yu et al. (Citation2020) proposed a multi-task learning framework based on late fusion, which showed state-of-the-art performance on the collected multimodal dataset referred to as CH-SIMS. This framework was used by many researchers as a baseline for research in the multimodal sentiment classification field. Yang et al. (Citation2022) combined pretrained models with multi-task learning strategies to propose a two-stage multi-task sentiment analysis (TPMSA) framework, which improved multimodal sentiment classification performance and achieved good results on multimodal datasets CMU-MOSI and CMU-MOEI. Zhang et al. (Citation2023) proposed a multi-task learning model that integrated cascading and specific scoring, and simultaneously performed inter modal and intra modal interactions to enhance multimodal sentiment representation capabilities. Inspired by these MSA methods based on multi-task learning, we use a hard-sharing approach to share parameters between sub-tasks, and utilize a weight modification strategy for balancing the learning process of each task.
Proposed MSA Approach
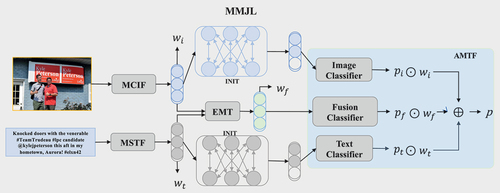
depicts the primary framework of the proposed MMJL network. The MMJL jointly learns a multimodal task, two single-modal subtasks and a joint task, with the aim to develop a rich modal representation and a powerful sentiment classification capability. Its main modules include MSTF, INIT, MCIF, EMT and AMTF. Textual features are primarily extracted through the MSTF module, which uses a BERT-based pre-trained language model for text sequence embedding and Bi-LSTM for capturing hidden states, while considering word dependencies and context. The MSTF introduces a dual-channel mechanism. The first channel extracts syntactic features using a syntactic dependency tree, and the second one uses position encoding and multi-head self-attention for global features, including context and key emotional words. For image features, the MCIF module integrates ViT and Faster R-CNN, where the former extracts global features and the latter detects local target information. The final image feature representation includes concatenated features from both channels.
Figure 1. The main framework of the proposed MMJL network.
MSTF for Multi-Channel Syntactic Text Feature Extraction
depicts the MSTF’s overall network structure whose main objective is to comprehensively extract text features by utilizing multi-channel information, including a BERT-based pre-trained language model, syntactic dependency tree, and global self-attention mechanism. Although its structure is similar to that of the MGGCN (Xiao et al. Citation2022), the MSTF directly utilizes the textual content for GGCN computation that further amplifies the differences between words and sentences, and captures information at different levels. This is unlike MGGCN that shares input data between the GGCN and Bi-LSTM, which introduces additional interference and also extracts redundant features.
Figure 2. Network structure of MSTF.
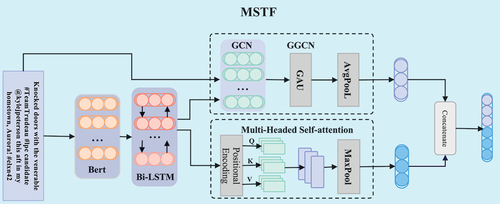
For simplicity, a text sequence with n number of words is defined as . A pre-trained language model based on BERT is employed to extract the text features. First, the sentence is transformed into a word sequence, and the parameters of the BERT model are utilized for word vector feature representation as follows:
In (1), represents the embedding representation of the
-th word for
,
denotes the
-th word, and
represents the BERT model parameters. Second,
is fed into the Bi-LSTM to obtain the hidden state representation of the text, which includes dependencies between adjacent words and contextual information. This process can be expressed as follows:
where and
denote feeding of the word vector representation into the forward and backward LSTM units, respectively.
A total of two channels are used to extract syntactic and global features. The first channel involves construction of a syntactic dependency tree for the text sequence and utilizes the Gated Graph Convolutional Network (GGCN) to extract syntactic features. The output of this channel can be expressed by (3) as follows:
where denotes the aspect words, e.g., food, service, etc., in the text sequence.
The second channel combines positional encoding and a multi-head self-attention mechanism to obtain global features that contain contextual information and key sentiment word information. The output of this channel is shown in (4) as
where MHSA stands for Multiple Self Attention Layer. Last, the obtained syntactic and global features are reduced separately via aspect-word-based local average pooling and global max pooling operations, as shown in (5) and (6), respectively. Subsequently, the final text features are concatenated using (7).
MCIF for Multi-Channel Image Feature Extraction
We utilize ViT and Faster R-CNN to capture both local and global image features. While these components are used for feature extraction by many approaches (Zhang et al. Citation2023), we simplify the network structure by focusing on these two main components. This simplification reduces the complexity and optimizes the features to improve semantic understanding, as shown in . ViT extracts global features by dividing the image into patches and aggregating patch information into a vector. The resulting global feature vector captures the overall semantic information and provides robust support for the subsequent sentiment analysis. Local features are captured by using Faster R-CNN for object detection and region extraction. This framework identifies objects and extracts the corresponding regions, effectively capturing local details and key features. The resulting region features offer a rich representation of local contents in the image.
Figure 3. Network structure of MCIF.
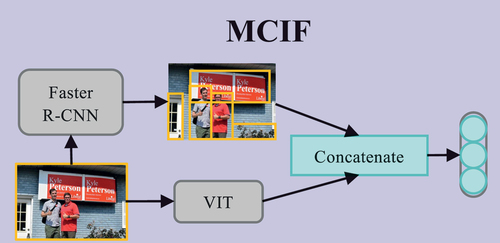
Global and local information is integrated by concatenating the global and local features extracted by ViT and Faster R-CNN, respectively. The resulting fused feature vector is denoted by and combines global and local image information, offering a comprehensive and detailed representation for sentiment classification tasks. This feature vector is used as the input for the final sentiment classification, and is computed according to (8).
Cross-Modal Attention-Based Feature Fusion
We introduce EMT for feature fusion, which enhances multimodal sentiment analysis using a symmetric cross-modal attention MPU to explore correlations between image and text sequences, as shown in 4. This facilitates beneficial information interaction and achieves efficient multimodal fusion. The proposed design reduces redundancy in single-modal features, especially for images. However, we prevent overfitting by balancing the interaction between the global multimodal context and local single-modal features, shown as follows in (9):
Figure 4. Cross-modal feature fusion module EMT, where only the first and Lth layers are shown.
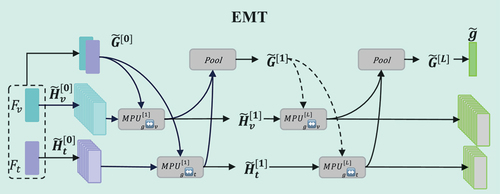
where ,
denotes the l-th layer. In this way, a one-to-many global cross-modal interaction within a single MPU can be captured. The global multimodal context and local unimodal features are refined progressively by stacking multiple MPU modules. After multiple stacking layers, a pooling layer is applied to aggregate sentiment information that facilitates subsequent fusion. The specifics of this operation are illustrated in (10) as follows:
where , and
, and
denote the parameters that can be learned. The entire fusion process can be succinctly described by (11). This process fuses global multimodal context and local unimodal features, ultimately providing the final output of sentiment information.
Sentiment Classification
After image-text feature fusion, the next step is the sentiment classification prediction, as illustrated in . In the single-modal framework, INIT uses the multi-head self-attention mechanism to select sentiment-relevant features, which prevents interference from irrelevant information. A comprehensive integration of single-modal and multi-modal predictions is achieved by feature-level and decision-level fusion using adaptive attention mechanisms, which results in the classification performance optimization. The final sentiment classification combines predictions from textual, image, and multimodal modalities, as shown in (12).
In addition, learnable parameters are designed as shown in (13)-(15) for tuning the final classification results.
The final loss function is defined as follows:
where ,
and
represent the text, image and multimodal classification losses, respectively, and
is the predicted value loss obtained using (15). Furthermore,
is a hyperparameter that modifies the impact of multimodal classification loss on the overall model.
Experiments
Datasets
Two publicly accessible MSA databases, MVSA-Single and MVSA-Multiple, are used to evaluate the model under discussion (Niu et al. Citation2016). 5129 image-text pairings tagged with good, neutral, and negative feelings are included in the former, which is sourced from Twitter and represents actual social media emotions. The latter database contains 19,600 image-text pairs, annotated by three independent annotators for diversity. These datasets pose challenges to sentiment analysis models in real scenarios due to a significant amount of emotional information. Both datasets represent user emotions and offer quality data for advancing multimodal sentiment analysis research and practical applications.
The two datasets are preprocessed following the steps described in (Xu and Mao Citation2017) to remove the image-text pairs whose images are completely different from the text labels. Furthermore, when one modality is labeled as positive (or negative) while the equivalent label of the other modality is neutral, the polarization of the image-text combination sentiment is identified as positive (or negative). displays the statistical information of the preprocessed MSVA-Single and MSVA-Multiple datasets.
Table 1. Statistical table of dataset division.
Implementation Details
All experiments were conducted using the PyTorch framework on an NVIDIA GeForce RTX 4090 GPU with CUDA version 11.8 and torch version 2.0. For data preprocessing, we manually padded and clipped text content to a maximum length of 50 words and resized the images to 224 × 224 pixels. Following data transformation, the dataset was randomly split into training, validation, and test sets in an 8:1:1 ratio, ensuring the original label distribution was maintained. Using a stratified sampling strategy, we further constructed a meta set from the training set, with each dataset containing 256 instances. The Adam optimizer was used, with an initial learning rate of 0.001, which was reduced by a factor of 10 every 10 epochs, and a weight decay set to 1e-5. Based on previous research, the evaluation metrics for this study are accuracy and F1 scores, as described below:
where TP, TN, FP and FN refer to True Positive, True Negative, False Positive and False Negative, respectively.
Baseline Techniques
The proposed image-text sentiment analysis method is compared to a number of conventional and cutting-edge techniques, which are described next. MultiSentiNet (Xu and Mao Citation2017) extracts objects and scenes from images in the form of visual semantic data. After identifying important words through attention using a visual feature-guided LSTM technique, it integrates all of these characteristics to produce the final label. CNN-Multi (Cai and Xia Citation2015) learns visual and textual properties independently using two different CNNs, and then applies the input to a third CNN for sentiment prediction. DNN-LR (Yu et al. Citation2016) uses logistic regression to classify sentiment and makes use of different pre-trained CNNs for text and pictures. The primary contribution and originality of the VAuLT (Chochlakis et al. Citation2022) approach are the utilization of the output representation generated by a prominent language model, such as BERT, to inform the linguistic input of ViLT. This enables the exploitation of the contextual representation capabilities offered by a large language model.
MVAN (Yang et al. Citation2020) is an MSA method that uses memory network modules and multi-view attention networks to repeatedly collect semantic image text characteristics. Zhu et al. (Citation2023) describe ITIN as having a cross-modal alignment module that logs word correspondences between different regions. This approach achieves the present state-of-the-art accuracy by utilizing an adaptive cross-modal gating tool to integrate multimodal data. MultiPoint (Yang et al. Citation2023) designs unified multimodal prompts and introduces probabilistic fusion to reduce discrepancies between modalities and enhance the model robustness, respectively. MLFC (Wang et al. Citation2023) addresses the issue of redundant modal features using a CNN and a Transformer. It leverages supervised contrastive learning to improve the model’s ability for learning standard sentiment features.
Comparison with the State-of-the-Art
provides a comparison of MMJL with several other classical and state-of-the-art methods in terms of accuracy and F1 scores with the MSVA datasets. The following conclusions can be derived:
Table 2. Performance comparison of MVSA dataset.
The MMJL model exhibits optimal performance on both datasets. It provides detailed descriptions of multi-channel text through image feature extraction modules like MCIF, MSTF, and the cross-modal fusion module EMT. This is unlike VAuLT, which mainly focuses on textual input in images and does not fully explore the interaction information. The MMJL model thoroughly explores potential information in image regions and textual words. This exploration achieves cross-modal interaction at both global and local levels that enhances the overall sentiment classification performance.
While ITIN also uses a cross-modal alignment module, it emphasizes local relationships, and faces problem in finding effective connections between images and text. The MMJL model, with its fine-grained interaction, densifies relationships between features that improves its performance. Comparing computational complexity using FLOPs, the MMJL’s multi-channel modules extract information more efficiently, reducing the number of redundant calculations and network complexity. On the MVSA-Single dataset, MMJL achieves 1.79% and 1.26% increase in accuracy and F1 score, respectively, compared to TIIN. Similarly, on the MVSA-Multiple dataset, the proposed model demonstrates performance improvements of 1.80% in both accuracy and F1 score. Compared to the recent MDSE, although its performance is very close to our MMJL, MDSE introduces complex feature learning modules and contrastive loss, increasing the model’s complexity and the number of parameters. Additionally, MDSE overly emphasizes the handling of private features, neglecting the interaction between features across modalities. In contrast, MMJL achieves a balance between intra-modal feature extraction and inter-modal feature interaction, enhancing the model’s understanding of multimodal information and improving its generalization performance.
Ablation Experiments
Ablation experiments are carried out on the MVSA datasets to validate each module’s efficacy in the proposed model. The MHSA and GGCN in text features, Faster R-CNN in image modal features, feature fusion module, intra-modal interaction module, and AMTF module are removed from the MMJL model, respectively. The resulting models without different modules are denoted as “MMJL w/o MCIF only GGCN,” “MMJL w/o MCIF only MHSA,” “MMJL w/o MSTF only ViT,” and “MMJL w/o EMT,” “MMJL w/o INIT” and “MMJL w/o AMTF” in , respectively. We explain this terminology through two examples: 1) “MMJL w/o AMTF” indicates that only simple fusion classifiers are used for prediction while additional loss functions have been removed. 2) “MMJL w/o EMT” denotes simple splicing and dimensionality reduction of multimodal features. provides the outcomes of these studies, which reveal the following key findings: 1) First, the multi-channel feature extraction module improves the model’s comprehension of diverse modalities, which enhances the sentiment classification performance. 2) Second, EMT effectively explores semantic correlations between modalities. This improves the model’s understanding of complex relationships and results in enhanced multimodal sentiment analysis performance: On the MVSA-Multiple dataset, accuracy and F1 scores increase by 3.64% and 3.75%, respectively. 3) Additionally, INIT uses a multi-head self-attention mechanism to select sentiment-relevant features, increasing both accuracy and F1 scores by 0.93% on the MVSA-Multiple dataset. 4)Finally, AMTF improves the model’s ability to integrate information from various modalities, increasing the sentiment classification accuracy: On the MVSA-Multiple dataset, both accuracy and F1 scores increase by 0.93%.
Table 3. Results of ablation studies on the MVSA dataset.
In summary, each module provides distinct information processing features. The integration of these features allows the model to comprehensively capture complex relationships between images and text that improves the multimodal sentiment analysis.
Hyperparameter Study
Adjustment Parameters of Loss Function
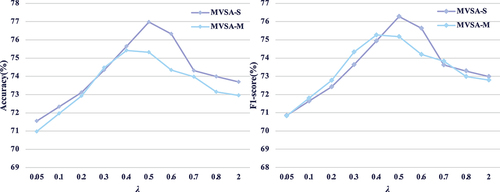
In the experiments, in (16) is considered as a key parameter that affects the prediction performance. Therefore, the values of
are varied to analyze the performance of the proposed method on two MVSA datasets. displays the outcomes of this experiment. When
, the proposed MMJL achieves the best accuracy and F1 scores on the MVSA-Single and MVSA-Multiple datasets. When
is too large, the model excessively emphasizes the fusion of multimodal information and neglects the unimodal features, causing a performance decline. Conversely, if
is too small, the model focuses more on a single modality and ignores the correlation between multimodalities, which also degrades the performance. Therefore, both unimodal and multimodal aspects should be considered for comprehensive sentiment classification. Based on the above analysis,
is used in the proposed MMJL network.
Figure 5. Hyperparameter analysis of different in EquationEquation (16)
(16)
(16) for proposed MMJL.
Initial Learning Rate
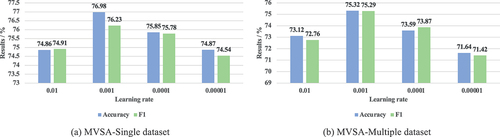
The setting of the initial learning rate significantly affects the sentiment classification performance (An, Zainon, and Hao Citation2023). Therefore, initial learning rates are varied for validation experiments, and the corresponding sentiment classification results are shown in . The figure shows that the model is prone to underfitting for a high initial learning rate. On the other hand, when the initial learning rate is too small, the model is prone to overfitting, which will also increase training costs and reduce the convergence efficiency. Therefore, based on the comprehensive performance analysis of the two datasets, the initial learning rate of the proposed MMJL model is set as 0.001.
Figure 6. The impact of initial learning rate on sentiment classification results.
Cases Analysis
The performance of MMJL is evaluated on six random samples taken from the MVSA-Multiple dataset and used as input to MMJL w/o EMT, MMJL w/o INIT, MMJL w/o AMTF, and MMJL. summarizes the classification results. Out of the six samples, MMJL w/o INIT and MMJL w/o AMTF correctly predict four samples, while MMJL w/o EMT predict only three samples, emphasizing the crucial role of the cross-modal attention fusion module. The MMJL model achieves five correct predictions, showing a 83.33% accuracy rate and indicating the effectiveness of EMT, INIT and AMTF modules in improving the sentiment features. Particularly, their fusion effectively enhances multimodal sentiment classification. However, all models make incorrect predictions for the example (f), possibly due to ambiguous meaning in the text and images that suggests the need to further improve the MMJL.
Table 4. Case analysis results of the proposed MMJL model on the MVSA-Multiple dataset.
Discussion
Different comparison experiments show that the MMJL model demonstrates superior performance in multimodal sentiment analysis compared with other methods. Key findings of the experiments show the effectiveness of different modules included in the model: MSTF and MCIF extract text and image features, EMT introduces global context, INIT facilitates adaptive interactions, and AMTF integrates multimodal information. These modules function collaboratively to enhance the model’s understanding of sentiments in text and images, improving its overall performance. The MMJL model excels in handling global and local image-text correlations, achieving outstanding results in multimodal sentiment analysis.
The MMJL model encounters problems in generating a complete understanding of the emotional content when subtle emotional features in images are not adequately captured by the text. The fine-grained interaction in the MMJL model is limited in such scenarios, as the cross-modal interaction mechanism cannot emphasize the correlation between image regions and text. In the absence of any textual information, the interaction mechanism cannot effectively guide the model, which leads to a heavier reliance on the single-modality information and reduced robustness in multimodal sentiment analysis tasks. To address these issues, it is recommended that future research should focus on the following four aspects to improve the MMJL model’s performance in real-world multimodal sentiment analysis challenges:1) A detailed study of mutual influence between images and text at both global and local levels should be carried out. 2) Existing research should be extended to multimodal continuous sentiment intensity. 3) Consistency between different modalities should be ensured. 4) Methods for enhancing model robustness in challenging scenarios should be explored.
Conclusions
This study introduced the Image-Text Interaction Network (MMJL) with innovative text and image feature extraction modules (MCIF, MSTF) to improve multimodal sentiment analysis. These modules helped in overcoming traditional limitations by capturing latent information from image regions and text words. The Cross-Modal Fusion module (EMT) introduced a global multimodal context for effective cross-modal interactions, while the Adaptive Multitasking Fusion module (AMTF) achieved adaptive fusion of multimodal and single-modal results. The MMJL model consistently outperformed existing methods on public databases, demonstrating significant industrial application value by extracting crucial features from concurrent image and text data in complex environments. A limitation of the proposed model was acknowledged. Future work aims to enhance model robustness by studying mutual influence between images and text to achieve a more comprehensive cross-modal interaction, and exploring multimodal continuous sentiment intensity beyond classification tasks.
Disclosure S tatement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- An, J., W. M. N. W. Zainon, and Z. Hao. 2023. Improving targeted multimodal sentiment classification with semantic description of images. Computers Materials & Continua 75(3):5801–20. doi:10.32604/cmc.2023.038220.
- Angamuthu, S., and P. Trojovský. 2023. Integrating multi-criteria decision-making with hybrid deep learning for sentiment analysis in recommender systems. PeerJ Computer Science 9:e1497. doi:10.7717/peerj-cs.1497.
- Bao, H., L. Dong, and F. Wei. 2021. Beit: Bert pre-training of image transformers. ArXiv, abs/2106.08254.
- Cai, G., and B. Xia. 2015. Convolutional neural networks for multimedia sentiment analysis. In Natural Language Processing and Chinese Computing: 4th CCF Conference, NLPCC 2015, Proceedings 4, Nanchang, China, October 9–13, 2015, 159–167. Springer International Publishing.
- Chochlakis, G., T. Srinivasan, J. Thomason, and S. S. Narayanan. 2022. VAuLT: Augmenting the vision-and-language transformer for sentiment classification on social media. arXiv preprint arXiv:2208.09021.
- Gandhi, A., K. U. Adhvaryu, S. Poria, E. Cambria, and A. Hussain. 2022. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Information Fusion 91:424–44. doi:10.1016/j.inffus.2022.09.025.
- Gao, Q., B. Cao, X. Guan, T. Gu, X. Bao, J. Wu, B. Liu, and J. Cao. 2022. Emotion recognition in conversations with emotion shift detection based on multi-task learning. Knowledge-Based Systems 248:108861. doi:10.1016/j.knosys.2022.108861.
- Guo, W., Y. Zhang, X. Cai, L. Meng, J. Yang, and X. Yuan. 2021. LD-MAN: Layout-driven multimodal attention network for online news sentiment recognition. IEEE Transactions on Multimedia 23:1785–98. doi:10.1109/TMM.2020.3003648.
- Hazarika, D., R. Zimmermann, and S. Poria. 2020. MISA: Modality-invariant and -specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, 1122–1131. https://arxiv.org/abs/2005.03545.
- Jia, L., T. Ma, H. Rong, V. S. Sheng, X. Huang, and X. Xie. 2023. A rearrangement and restore mixer model for target-oriented multimodal sentiment classification. IEEE Transactions on Artificial Intelligence 1–11. doi:10.1109/TAI.2023.3341879.
- Khan, J., N. Ahmad, S. Khalid, F. Ali, and Y. Lee. 2023. Sentiment and context-aware hybrid DNN with attention for text sentiment classification. Institute of Electrical and Electronics Engineers Access 11:28162–79. doi:10.1109/ACCESS.2023.3259107.
- Li, J., C. Wang, Z. Luo, Y. Wu, and X. Jiang. 2024. Modality-dependent sentiments exploring for multi-modal sentiment classification. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7930–7934, IEEE.
- Liu, X., F. Wei, W. Jiang, Q. Zheng, Y. Qiao, J. Liu, L. Niu, Z. Chen, and H. Dong. 2023. MTR-SAM: Visual multimodal text recognition and sentiment analysis in public opinion analysis on the internet. Applied Sciences 13(12):7307. doi:10.3390/app13127307.
- Liu, X., T. Wu, and G. Guo. 2022. Adaptive sparse ViT: Towards learnable adaptive token pruning by fully exploiting self-attention. arXiv preprint arXiv:2209.13802.
- Manek, A. S., and P. D. Shenoy. 2022. Mining the web data: Intelligent information retrieval system for filtering spam and sentiment analysis. In 2022 IEEE International Conference for Women in Innovation, Technology and Entrepreneurship (ICWITE), 1–10. IEEE.
- Meena, G., K. Mohbey, K. Kumar, and K. Lokesh. 2023. A hybrid deep learning approach for detecting sentiment polarities and knowledge graph representation on monkeypox tweets. Decision Analytics Journal 7:100243. doi:10.1016/j.dajour.2023.100243.
- Niu, T., S. Zhu, L. Pang, and A. El-Saddik. 2016. Sentiment analysis on multi-view social data. Conference on Multimedia Modeling 15–27. doi:10.1007/978-3-319-27674-8_2.
- Paul, S., and P. Y. Chen. 2022. Vision transformers are robust learners. Proceedings of the AAAI Conference on Artificial Intelligence 36(2):2071–81. doi:10.1609/aaai.v36i2.20103.
- Riyadh, M., and M. O. Shafiq. 2022. GAN-BElectra: Enhanced multi-class sentiment analysis with limited labeled data. Applied Artificial Intelligence 36(1):2083794. doi:10.1080/08839514.2022.2083794.
- She, D., J. Yang, M. Cheng, Y. Lai, P. L. Rosin, and L. Wang. 2020. WSCNet: Weakly supervised coupled networks for visual sentiment classification and detection. IEEE Transactions on Multimedia 22(5):1358–71. doi:10.1109/TMM.2019.2939744.
- Tan, C. H., A. Chan, M. Haldar, J. Tang, X. Liu, M. Abdool, H. Gao, L. He, and S. Katariya. 2023. Optimizing Airbnb search journey with multi-task learning. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 4872–81. doi:10.1145/3580305.3599881.
- Tsai, Y. H., S. Bai, P. P. Liang, J. Z. Kolter, L. Morency, and R. Salakhutdinov. 2019. Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the Conference. Association for Computational Linguistics Meeting, Florence, Italy, 6558–69. Vol. 2019. NIH Public Access.
- Wang, H., X. Li, Z. Ren, M. Wang, and C. Ma. 2023. Multimodal sentiment analysis representations learning via contrastive learning with condense attention fusion. Sensors 23(5):2679. doi:10.3390/s23052679.
- Wang, H., C. Ren, and Z. Yu. 2024. Multimodal sentiment analysis based on cross-instance graph neural networks. Applied Intelligence 54(4):3403–16. doi:10.1007/s10489-024-05309-0.
- Wang, Y., Y. Shen, Z. Liu, P. P. Liang, A. Zadeh, and L. P. Morency. 2019. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. Proceedings of the AAAI Conference on Artificial Intelligence 33(01):7216–23. doi:10.1609/aaai.v33i01.33017216.
- Xiao, L., X. Hu, Y. Chen, X. Yun, B. Chen, D. Gu, and B. Tang. 2022. Multi-head self-attention based gated graph convolutional networks for aspect-based sentiment classification. Multimedia Tools & Applications 1–20.
- Xie, G. F., N. Liu, X. J. Hu, and Y. T. Shen. 2023. Toward prompt-enhanced sentiment analysis with mutual describable information between aspects. Applied Artificial Intelligence 37(1):2186432. doi:10.1080/08839514.2023.2186432.
- Xie, Y., and Y. Liao. 2023. Efficient-ViT: A light-weight classification model based on CNN and ViT. In Proceedings of the 2023 6th International Conference on Image and Graphics Processing, 64–70. doi:10.1145/3582649.3582676.
- Xu, N., and W. Mao. 2017. MultiSentiNet: A deep semantic network for multimodal sentiment analysis. In Proceedings of the 2017 ACM on Conference on Information & Knowledge Management, 2399–402. doi:10.1145/3132847.3133142.
- Xu, Y., H. Wei, M. Lin, Y. Deng, K. Sheng, M. Zhang, F. Tang, W. Dong, F. Huang, and C. Xu. 2021. Transformers in computational visual media: A survey. Computational Visual Media 8(1):33–62. doi:10.1007/s41095-021-0247-3.
- Yan, X., H. Xue, S. Jiang, and Z. Liu. 2021. Multimodal sentiment analysis using multi-tensor fusion network with cross-modal modeling. Applied Artificial Intelligence 36(1):2000688. doi:10.1080/08839514.2021.2000688.
- Yan, X., H. Xue, S. Jiang, and Z. Liu. 2022. Multimodal sentiment analysis using multi-tensor fusion network with cross-modal modeling. Applied Artificial Intelligence 36(1):2000688. doi:10.1080/08839514.2021.2000688.
- Yang, B., L. Wu, J. Zhu, B. Shao, X. Lin, and T. Liu. 2022. Multimodal sentiment analysis with two-phase multi-task learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing 30:2015–24. doi:10.1109/TASLP.2022.3178204.
- Yang, X., S. Feng, D. Wang, P. Hong, and S. Poria. 2023. Few-shot multimodal sentiment analysis based on multimodal probabilistic fusion prompts. In Proceedings of the 31st ACM International Conference on Multimedia, 6045–6053.
- Yang, X., S. Feng, D. Wang, and Y. Zhang. 2020. Image-text multimodal emotion classification via multi-view attentional network. IEEE Transactions on Multimedia 23:4014–26. 10.1109/TMM.2020.3035277.
- Yin, Z., Y. Du, Y. Liu, and Y. Wang. 2024. Multi-layer cross-modality attention fusion network for multimodal sentiment analysis. Multimedia Tools & Applications 83(21):60171–87. doi:10.1007/s11042-023-17685-9.
- Yu, W., H. Xu, F. Meng, Y. Zhu, Y. Ma, J. Wu, J. Zou, and K. Yang. 2020. CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 3718–27. doi:10.18653/v1/2020.acl-main.343.
- Yu, Y., H. Lin, J. Meng, and Z. Zhao. 2016. Visual and textual sentiment analysis of a microblog using deep convolutional neural networks. Algorithms 9(2):41. doi:10.3390/a9020041.
- Zhang, H., Y. Liu, Z. Xiong, Z. Wu, and D. Xu. 2023. Visual sentiment analysis with semantic correlation enhancement. Complex & Intelligent Systems 1–13.
- Zhang, K. 2022. Faster R-CNN transmission line multi-target detection based on BAM. In 2022 4th International Conference on Intelligent Control, Measurement and Signal Processing (ICMSP), 364–369. IEEE.
- Zhang, S., C. Yin, and Z. Yin. 2023. Multimodal sentiment recognition with multi-task learning. IEEE Transactions on Emerging Topics in Computational Intelligence 7(1):200–09. doi:10.1109/TETCI.2022.3224929.
- Zhang, S., H. Yu, and G. Zhu. 2022. An emotional classification method of Chinese short comment text based on ELECTRA. Connection Science 34(1):254–73. doi:10.1080/09540091.2021.1985968.
- Zhao, Y., M. Mamat, A. Aysa, and K. Ubul. 2023. Multimodal sentiment system and method based on CRNN-SVM. Neural Computing & Applications 35(35):24713–25. doi:10.1007/s00521-023-08366-7.
- Zhu, T., L. Li, J. Yang, S. Zhao, H. Liu, and J. Qian. 2023. Multimodal sentiment analysis with image-text interaction network. IEEE Transactions on Multimedia 25:3375–85. doi:10.1109/tmm.2022.3160060.