
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The task of providing a natural language description of graphical information of the image is known as image captioning. As a result, it needs an algorithm to create a series of output words and understand the relations between textual and visual elements. The main goal of this research is to caption the image by extracting the features and detecting the object from the image. Here, the object is detected by employing Deep Embedding Clustering. The features from the input image are extracted such as Local Vector Pattern (LVP), Spider Local Image Features, and some statistical features like mean, variance, standard deviation, kurtosis, and skewness. The extracted features and detected objects are given to image captioning which is exploited by Deep Convolutional Neural Network (Deep CNN). The Deep CNN is trained by using the proposed Adaptive Coati Optimization Algorithm (ACOA). The proposed ACOA is attained by the integration of the Adaptive concept and Coati Optimization Algorithm (COA) and thus the image is captioned. The proposed ACOA achieved maximum values in the training data such as 90.5% of precision, 89.9% of recall 89.1% of F1-Score, 90.4% of accuracy, 90.4% of BELU, and 90.9% of ROUGE.
Introduction
A branch of computer vision is image captioning in which its primary goal is to generate gradual or precise text explanations of any kind of situation described in a frame or image. The two major constituents of image captioning are natural language processing (NLP) and computer vision. The contents and information in an image are documented and assumed with the help of computer vision and NLP renovates this semantic data into an expressive sentence (Chang et al. Citation2021). It becomes progressively difficult to extract the semantic data from an image and communicate it in a way that humans can recognize. The image captioning scheme not only offers information but also advanced to show how the two constituents are connected to one another (Al Duhayyim et al. Citation2022). For automatic image indexing, image captioning is employed. Image indexing is employed broadly in web search, biomedicine, business, education, digital libraries, and military since it is essential to Content-Based Image Retrieval which is utilized in many fields. The images may include locations such as a beach or café and most importantly the actions that are happening (Al Duhayyim et al. Citation2022). A wide range of techniques are available for image captioning which connect the visual material with spoken language like providing textual explanations to describe the images (Singh et al. Citation2022).
Image captioning comprises of various uses such as leading people who have disabilities in vision during the travel. In order to enable this, the situation is converted to text, and the text is then transformed into voice messages (Al Duhayyim et al. Citation2022; Balasubramaniam et al. Citation2023). In addition to this, image captioning can be useful in social media to immediately form a description for an image that has been submitted or to define a video (Anderson et al. Citation2018; Xian et al. Citation2022). In some methods, image captioning is done based on the integration of relationship among numerous object regions of images (Chen et al. Citation2022; Xian et al. Citation2022). By changing the image into a description and exploiting the keywords for more correlated searches, automatic captioning can also enhance the Google image search method (Ghandi, Pourreza, and Mahyar Citation2023; Wang and Gu Citation2023). Furthermore, if any doubtful activity is seen, appropriate captions from Closed Circuit Television cameras and alarms can be generated and it can also be engaged in surveillance (Chang et al. Citation2021). The major difficulty with the image captioning method is finding a way to entirely consume image data and provide a humanlike visual description (Choudhury et al. Citation2023; Omri et al. Citation2022). The recognition of scenes in the image or consideration of objects and the capability to examine their states are requirements for the substantial descriptions of higher-level image semantics (Omri et al. Citation2022). Moreover, the furthermost effective technique for image captioning is applying an Encoder–Decoder method (Balasubramaniam and Kavitha Citation2013). It encrypts the images to an advanced level illustration and then decrypts this illustration by means of a language generation approach such as Gated Recurrent Unit (GRU) and Long Short-Term Memory (LSTM) (Al-Malla, Jafar, and Ghneim Citation2022).
In this work, the major involvement is illustrated as follows:
Proposed Deep Convolutional Neural Network (CNN)_Adaptive Coati Optimization Algorithm (ACOA) for image captioning: An effective architecture is recognized for image captioning engaging the technique named Deep CNN_ACOA. The suggested ACOA is accomplished by the integration of the adaptive concept and Coati Optimization Algorithm (COA).
The rest of the paper is arranged as follows: Literature survey and challenges are displayed in section “Motivation”. In section “Proposed Deep CNN_ACOA for Image Caption”, the complete process of the developed approach is described. The result and discussion are deliberated in section “Results and Discussion”, and section “Conclusion” demonstrates the conclusion of the work.
Motivation
The process of converting an image into a textual narration is identified as image captioning. As a result, it associates vision and language in an inspired way which extends from multimodal search engines to support the blind or unsighted people. Hence, it motivates to develop a new technique for captioning the image.
Literature Survey
Thangavel et al. (Citation2023) introduced Mask Recurrent Convolutional Neural Networks (RCNN) and LSTM techniques for predicting the feature of object and to translate the images. Even with intricate input photos, this approach provided very accurate captions and efficiently evaded the result of prior knowledge. Moreover, it needed further retention and it was expensive to compute. The Hybridized Deep Learning (DL) approach was established by Humaira et al. (Citation2021) for captioning the image which involved two embedding layers. Here the overfitting was lessened and appropriate sentences with consequent words were generated by this model. However, the transformer and visual attention were not adjusted to create accurate captions and feature extraction. In Chang et al. (Citation2021), authors developed a DL algorithm to spontaneously produce textual explanations of images. By adding color details and converting the text message into voice, this technique enhanced the quality of the image, even though it had prolonged recognition time. Encoder–Decoder deep architecture was formulated by Al-Malla, Jafar, and Ghneim (Citation2022) to prove the usefulness and utilized two ways of feature extraction. The sentences formed were more significant grammatically and had fewer object mistakes. Furthermore, it did not utilize Meshed-Memory Transformers and failed to enhance the performance. Luo et al. (Citation2023) devised Semantic-Conditional Diffusion Networks framework for image captioning. The cross-modal retrieval framework collected the semantic sentences from every input image and the Diffusion Transformer was utilized for collecting the rich semantics. It achieved good results with minimum computational cost, but the complexity was high. Wang and Gu (Citation2023) established a Joint Relationship Attention Network (JRAN) for effective image captioning. Here, two kinds of relationships were learned by the JRAN. Also, a new feature fusion concept was applied for fusing the features. This was simple and the implementation was easy, but the performance was reduced for the large set of features.
Challenges
The challenges measured by image captioning are labeled as follows:
In Thangavel et al. (Citation2023), the mask RCNN and LSTM approaches upgraded the consequence in the process of image extraction. However, it was still a challenge to syndicate the extracted data from images and to decrease the special effects of unusable information.
In Humaira et al. (Citation2021), the Hybridized DL approach performed better for the datasets of BanglaLekha and Flickr4k-Bn datasets. However, it was challenging to authenticate the information in which image captioning consumes the language in Bengali.
In Chang et al. (Citation2021), the DL approach is employed to extract effects from images which had both distinctive and similar objects. Even though it was challenging for using a Generative Adversarial Network to fill the backdrop of the image and to produce a more precise explanation.
In Al-Malla, Jafar, and Ghneim (Citation2022), Encoder–Decoder deep architecture was well-organized in captioning the image. Still, it faced difficulty in integrating the features of object detection and convolution to form ridiculous object semantic data from caption texts.
Proposed Deep CNN_ACOA for Image Caption
The main intention of this paper is to produce a description for the captioned image by developing the introduced ACOA enabled with Deep CNN. illustrates the block diagram of the proposed Deep CNN_ACOA. Initially, the image is taken as the input in which the input image is concurrently given to object detection and feature extraction. Here objection detection is done using Deep Embedding Clustering (DEC; Xie, Girshick, and Farhadi Citation2016) and the result obtained is noted as output 1. At the same time, the feature extraction is done by using Local Vector Pattern (LVP; Fan and Hung Citation2014), Spider Local Image Features (SLIF; Fausto, Cuevas, and Gonzales Citation2017) and statistical features (Lessa and Marengoni Citation2016) such as mean, variance, standard deviation, kurtosis, and skewness. The result obtained here is noted as output 2. After that, both outputs 1 and 2 are given to caption the image which is done by using Deep CNN in Minarno et al. (Citation2022). The Deep CNN is trained using the proposed ACOA. Here, the proposed ACOA considered is formed by the integration of the Adaptive concept and COA explained in Dehghani et al. (Citation2023), and thus the captioned image is attained which is considered as the final output.
Figure 1. Block diagram of the proposed Deep CNN_ACOA.
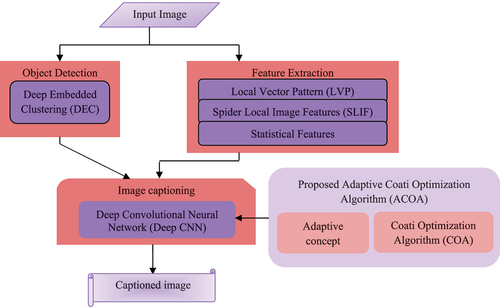
Image Acquisition
An input image obtained from the real dataset in Kim and Bang (Citation2020) is examined to accomplish image caption which is signified as
Here input image is denoted as,
signifies a number of images and
represents
data.
Feature Extraction
Feature extraction aids in decreasing the volume of unwanted data from the data set and here the input is taken as . At this time, feature extraction is attained by changing the input image into a set of features. In order to execute the required task, the features are selected and it extracts the related data from the input image. Here, the features in the input image are extracted which is done by extracting the features such as LVP, SLIF, and statistical features.
LVP Feature
The LVP feature (Fan and Hung Citation2014) calculates the distance between the pixels of neighboring and target pixels. Indeed, LVP is used to extract the required information from the input image. It generates exhaustive discriminatory features from the input and the performance of LVP is robust. The LVP feature is represented as and expressed by the following equation.
where denotes the vector direction, reference pixel is signified as
, count of a neighboring pixel is given as
,
signifies index angle of variation direction, Radius of the neighboring pixel is denoted as
.
SLIF Feature
SLIF feature (Fausto, Cuevas, and Gonzales Citation2017) allocates an equivalent set of feature descriptors by extracting the information from the neighborhood pixel. It calculates exact feature descriptors by utilizing the extracted information from an established illustrative local point. Thus, this feature generates a feature descriptor with a low dimension which is more robust to the alterations and transformations of the normal image. This includes rotation, scaling, bright shifts and changes in the partial viewpoint. Here, the SLIF features are demonstrated as .
Statistical Features
In order to acquire a feature vector, the statistical features (Lessa and Marengoni Citation2016) are applied to the textural feature image. Here the statistical features are mean, variance, standard deviation, kurtosis, and skewness.
Mean
Mean is defined as the average of the total number of pixels in the binary image and it was formulated in Equationequation (3)(3)
(3) . Here
is represented as mean.
Here denotes the probability of
,
signifies a gray level of each image and a total number of gray levels is represented as
.
Variance
The eccentricity value of the gray levels in the image associated with the mean gray level is termed as variance. Variance is denoted as and equation of variance is given in EquationEquation (4)
(4)
(4) .
Standard Deviation
The distribution of the image around the mean is labeled as standard deviation. It offers a reduced or higher similarity in the image. Here signifies standard deviation which is articulated as,
Skewness
The degree of irregularity of a supply of explicit features about the mean is stated as skewness. It has both the values of negative or positive which is mentioned as and was stated as
Kurtosis
The measurement of distribution level in relation to normal distribution is specified as kurtosis. It was illustrated by the below equation which is formulated as
From the above-mentioned extraction features, the feature vector is specified as
Object Detection
Object detection is used to detect the type of objects from an image which is influenced by similarity and dissimilarity. The object in the image is identified by scanning the entire image with several scales. In order to improve the performance of object detection a DEC approach is utilized. The input image is taken as the input of object detection which is done by using DEC (Xie, Girshick, and Farhadi Citation2016). A set of
points
into
clusters is considered. Each cluster is signified by a centroid of
where
. To transform the image instead of image space
a non-linear mapping
is assumed. Here hidden feature space is specified as
and learnable parameters are denoted as
. To avoid the curse of dimensionality, the dimensionality of
is smaller than
. The DEC involves two stages they are optimization and initialization of parameters. Thus, DEC is utilized to detect the object with the obtained output as
.
Image Captioning
Image captioning describes the purpose or intention detected in an image and it has established a substantial amount of consideration. In order to progress, the architecture of Deep CNN is utilized which is employed by the introduced ACOA approach. Moreover, the description and process of ACOA enabled with Deep CNN are demonstrated below.
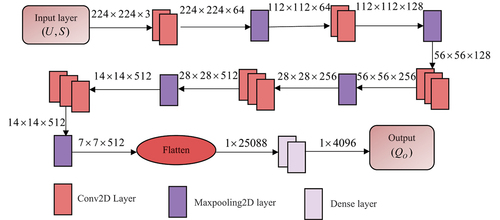
Deep CNN Architecture
The Deep CNN in Minarno et al. (Citation2022) is employed for the development of image captioning. It was most frequently utilized to recognize the configurations in images and video. It includes several layers such as a convolutional two-dimensional layer (Conv2D), max pooling layer, flatten layer and dense layer. Here the output of feature vector and object detection is taken as input of Deep CNN and it is specified as .
Conv2d Layer
For the CNN model to extract features from the image, the convolutional layer becomes the most crucial component. Here conv2D is employed which has parameters like filters, kernel size, and input size are 64,3 × 3 and 224 × 224 × 3, respectively.
Max Pooling Layer
Max-pooling layer determines the maximum value for each input component. This pooling layer helps to decrease spatial input by down-sampling which is essential to lessen the parameters.
Flatten
In order to move the data into subsequent layer, flatten is utilized to transform data from an array of three-dimensional into one-dimensional. It essentially flattens the convolution layer’s output to create a distinct length feature vector.
Dense Layer
Layers that accept input in the form of one-dimensional arrays are stated to as dense layers. Dense units with a unit value signify neurons in their output layer. Here the output is specified as . displays the architecture of Deep CNN.
Figure 2. Architecture of Deep CNN.
Adaptive Coati Optimization Algorithm
In order to improve the performance of image captioning, the optimization of COA is utilized with an integration of the Adaptive concept. This COA approach used in Dehghani et al. (Citation2023) is a recently developed metaheuristic algorithm which imitates the behavior of coati in nature. It delivers accurate solutions to optimization issues by noticing the appropriate stability between exploration and exploitation. Both the adaptive concept and COA are integrated to form a proposed ACOA to enhance the performance. The proceedings of the developed Deep CNN_ACOA are illustrated by the following steps.
Step 1: Initialization
The location of every coati in the search space regulates the standards for result variables. Thus, in COA, the position of coati signifies an applicant’s explanation of the issue. Here the position of coati is arbitrarily initialized at the first stage of COA execution and it is articulated as follows:
Here, the position of coati in search space is signified as
, value of
decision variable is denoted as
, number of coatis is represented as
, number of decision variables is specified as
and the random real number in [0,1] is mentioned as
, lower bound (
) and upper bound (
) are characterized as
decision variable.
The population matrix of coatis in COA is statistically formulated as
Here vector of the gained objective function is denoted as and the value of the objective function in terms of
coati is represented as
.
Step 2: Fitness Measure
Mean Square Error (MSE) is employed for evaluating the fitness and it is expressed as
Here and
denoted as the output of actual and target values, total training samples are designated as
Step 3: Exploration
In exploitation, the finest member of the population is supposed to be the position of iguana. Here the location of the coatis intensifying from the tree is accurately replicated by using the following equation:
for
and
Here is characterized as adaptive. Therefore, the equation of
is articulated as
where is denoted as iteration counter and
signifies parameter constant.
Step 4: Exploitation
In order to simulate the performance, an arbitrary location is created near the spot in which every coati is positioned based on the next equations.
where
Step 5: Reevaluating Fitness Function
The modernized solution of fitness is estimated. From the solution, the lowest value of fitness is measured as an optimal solution.
Step 6: Termination
In this process, the optimal solution weights are formed till the determined iteration is accomplished.
Results and Discussion
The effectiveness of the developed Deep CNN_ACOA is described by employing additional expected methods.
Experimental Setup
The proposed Deep CNN_ACOA is implemented by using the PYTHON tool with Windows 11 OS, 16 GB RAM, 512 GB ROM, and 1.7 Ghz CPU. The experimental parameters of Deep CNN_ACOA are given in .
Table 1. Parameter details.
Dataset Description
The dataset utilized in this research is the Image captioning dataset in Kim and Bang (Citation2020). Here, the dataset contains 1,431 UAV-developed structure site images and 8,601 descriptions relating to the areas of the image. It comprises five kinds of text data on construction properties besides their position and identification information.
Evaluation Metrics
The performance of image captioning is evaluated by using metrics, like precision, Recall, F1 Score, BELU, and ROUGE.
Experimental Results
The experimental results by utilizing images are illustrated in . Here, shows the input 1 1–3 taken from the dataset. The object detected images of those corresponding input 1 1–3 are given in . The LVP feature extracted images of input 1 1–3 are demonstrated in and image captioning images of input 1–3 are shown in .
Figure 3. Experimental results (a) input 1 1, 2, and 3, (b) object detected 1 1–3, (c) LVP extracted 1 1–3, (d) image captioning 1–3.

Comparative Methods
The comparative methods, such as Mask RCNN+LSTM in Thangavel et al. (Citation2023), Hybridized DL in Humaira et al. (Citation2021), DL method in Chang et al. (Citation2021), Encoder–Decoder deep architecture in Al-Malla, Jafar, and Ghneim (Citation2022), and Deep CNN_ACOA without feature extraction are used for evaluation.
Comparative Analysis
The assessment of methods examining proposed Deep CNN_ACOA is calculated with several classes of performance such as training data and k-fold.
Analysis Considering Training Data
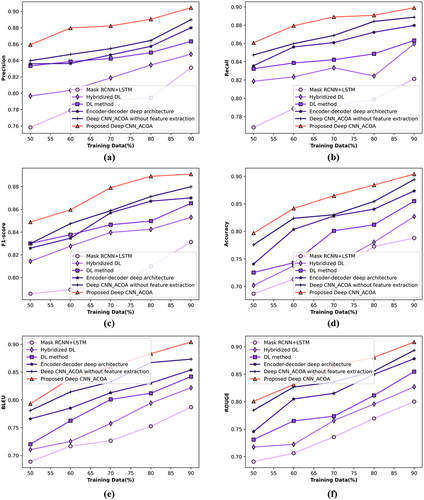
The analysis of Deep CNN_ACOA with training data is illustrated in . In , the graph is drawn between precision and training data of 50%–90%. By considering the training data = 90%, the values of Mask RCNN+LSTM, Hybridized DL, DL method, Encoder–Decoder deep architecture, Deep CNN_ACOA without feature extraction, and proposed Deep CNN_ACOA are 83.1%, 84.8%, 86.3%, 88%, 89.0%, and 90.5%. shows the graph between recall and training data, here 90% of training data is taken into account. The value attained by Mask RCNN+LSTM is 82.1%, Hybridized DL is 86%, DL method is 86.3%, Encoder–Decoder deep architecture is 88%, Deep CNN_ACOA without feature extraction is 88.9%, and proposed Deep CNN_ACOA is 89.9%. demonstrates the graph plotted between F-measure and training data. For 90% of training data, the proposed Deep CNN_ACOA achieved the value of 89.1% while the values of existing methods are 83.1%, 85.3%, 86.5%, 87%, and 88.0%. In the graph is drawn between accuracy and training data of 50%-90%. By considering the training data = 90%, the values of Mask RCNN+LSTM, Hybridized DL, DL method, Encoder–Decoder deep architecture, Deep CNN_ACOA without feature extraction, and proposed Deep CNN_ACOA are 78.8%, 82.7%, 85.5%, 87.4%, 89.4%, 90.4%. shows the graph between BELU and training data; here 90% of training data is taken into account. The value attained by Mask RCNN+LSTM is 78.7%, Hybridized DL is 82.2%, DL method is 84.2%, Encoder–Decoder deep architecture is 85.4%, Deep CNN_ACOA without feature extraction is 87.3%, and proposed Deep CNN_ACOA is 90.4%. demonstrates the graph plotted between ROUGE and training data. For 90% of training data, the proposed Deep CNN_ACOA achieved the value of 90.9% while the values of existing methods are 80.0%, 82.7%, 85.5%, 87.8%, and 89.3%.
Figure 4. Assessment of deep CNN_ACOA by training data with (a) precision (b) recall (c) F1-score, (d) accuracy, (e) BLEU, and (f) ROUGE.
Analysis Considering k-Fold
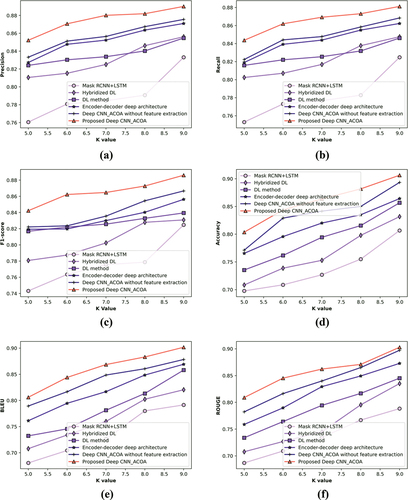
In , the analysis of Deep CNN_ACOA with k-fold is demonstrated. displays the graph between precision and k-fold of 5%-9%. Here 9% of k-fold data is taken into consideration in which the values attained by Mask RCNN+LSTM is 83.3%, Hybridized DL is 85.6%, DL method is 85.5%, Encoder–Decoder deep architecture is 87.1%, Deep CNN_ACOA without feature extraction is 87.6%, and proposed Deep CNN_ACOA is 89%. validates the graph plotted between Recall and k-fold. For 9% of k-fold, the proposed Deep CNN_ACOA attained the value of 88.1% while the values of existing approaches are 82.5%, 84.8%, 84.6%, 86.2%, and 86.8%. In the graph is drawn between F-measure and k-fold. By considering k-fold = 9%, the values of Mask RCNN+LSTM, Hybridized DL, DL method, Encoder−Decoder deep architecture, Deep CNN_ACOA without feature extraction, and proposed Deep CNN_ACOA are 82.5%, 83.1%, 83.9%, 85.6%, 86.7%, and 88.6%. displays the graph between accuracy and k-fold of 5%-9%. Here 9% of k-fold data is taken into consideration in which the values attained by Mask RCNN+LSTM is 80.7%, Hybridized DL is 83.2%, DL method is 85.7%, Encoder–Decoder deep architecture is 86.4%, Deep CNN_ACOA without feature extraction is 89.3%, and proposed Deep CNN_ACOA is 90.6%. validates the graph plotted between BELU and k-fold. For 9% of k-fold, the proposed Deep CNN_ACOA attained the value of 90.2% while the values of existing approaches are 79.1%, 82.0%, 85.8%, 86.9%, and 87.8%. In , the graph is drawn between ROUGE and k-fold. By considering k-fold = 9%, the values of Mask RCNN+LSTM, Hybridized DL, DL method, Encoder–Decoder deep architecture, Deep CNN_ACOA without feature extraction, and proposed Deep CNN_ACOA are 78.8%, 83.5%, 84.5%, 87.3%, 89.7%, and 90.3%, respevtively.
Figure 5. Assessment of deep CNN_ACOA by k-fold with (a) precision (b) recall (c) F-measure, (d) accuracy, (e) BLEU, and (f) ROUGE.
Comparative Discussion
displays the comparative discussion of the methods. The best results are discussed in this table and they are obtained at 90% of training data and k-Fold-9 for various evaluation metrics. The proposed method achieved the highest value of 90.5% precision, 89.9% recall 89.1% F-measure, 90.4% of accuracy, 90.4% of BELU, and 90.9% of ROUGE for 90% training data. Similarly, the proposed method achieved the highest precision of 89.0%, recall of 88.1%, F-measure of 88.6%, accuracy of 90.6%, BELU of 90.2%, and 90.3% of ROUGE for k-Fold-9. The precision of the Deep CNN_ACOA is 90.5, which is 8.18%, 6.30%, 4.64%, 2.76%, and 1.66% improved than the Mask RCNN+LSTM, Hybridized DL, DL method, Encoder–Decoder deep architecture, and Deep CNN_ACOA without feature extraction. Similarly, the highest recall of the Deep CNN_ACOA is 89.9, which is 8.68%, 4.34%, 4%, 2.11%, and 1.11% improved than the conventional methods. Likewise, the Deep CNN_ACOA has the F-measure of 89.1, which is 6.73%, 4.26%, 2.92%, 2.36%, and 1.23% higher than the existing methods. This is due to the effective training of the Deep CNN with the proposed ACOA.
Table 2. Comparative discussion.
Conclusion
Image captioning is a method which permits computers to understand the data in images and make a written text. It has several benefits like guiding blind or low eyesight people in traveling. It is done by changing the situation into text and then transforming it into a voice message. However, the existing methods have limitations in handling large amount of data and obtaining the image’s fine details. In this paper, for image captioning, an image is given as input in which both feature extraction and object detection are done simultaneously. Here, the object is detected using DEC, and the extracted features such as LVP, SLIF and statistical features include standard deviation, mean, kurtosis, variance and skewness. The detected object and extracted features are taken to image captioning which is employed by Deep CNN trained using the proposed ACOA. The ACOA is established by the combination of the Adaptive concept and COA. Thus, the captioned image is obtained from the input. The image is captioned with the introduced Deep CNN_ACOA obtained the enhanced value of precision, recall, F-measure, accuracy, BELU, and ROUGE to 90.5%, 89.9%, 89.1%, 90.4%, 90.4%, and 90.9%, respectively, in training data. However, the accuracy of the model needs to be improved and some important metrics are not considered for the evaluation. In future, further research can be done and the developing approaches can be used in several varieties of external images. Also, more metrics will be considered for the performance evaluation.
Author Contributions Statement
Balasubramaniam S: Conceptualisation, investigation, data curation, formal analysis and writing – original draft, Seifedine Kadry: Project administration and Supervision – Rajesh Kumar Dhanaraj – Review and editing, Satheesh Kumar K – Data curation and Analysis,
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon reasonable request.
References
- Al Duhayyim, M., S. Alazwari, H. A. Mengash, R. Marzouk, J. S. Alzahrani, H. Mahgoub, F. Althukair, and A. S. Salama. 2022. Metaheuristics optimization with deep learning enabled automated image captioning system. Applied Sciences 12 (15):7724. doi:10.3390/app12157724.
- Al-Malla, M. A., A. Jafar, and N. Ghneim. 2022. Image captioning model using attention and object features to mimic human image understanding. Journal of Big Data 9 (1):1–19. doi:10.1186/s40537-022-00571-w.
- Anderson, P., X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang. 2018. Bottom-up and top-down attention for image captioning and visual question answering. IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, Salt Lake City, UT, USA, 6077–6086. doi:10.1109/CVPR.2018.00636
- Balasubramaniam, S., and V. Kavitha. 2013. A survey on data retrieval techniques in cloud computing. Journal of Convergence Information Technology 8 (16):1–15.
- Balasubramaniam, S., M. H. Syed, N. S. More, and V. Polepally. 2023. Deep learning-based power prediction aware charge scheduling approach in cloud based electric vehicular network. Engineering Applications of Artificial Intelligence 121:105869.
- Chang, Y. H., Y. J. Chen, R. H. Huang, and Y. T. Yu. 2021. Enhanced image captioning with color recognition using deep learning methods. Applied Sciences 12 (1):209. doi:10.3390/app12010209.
- Chen, T., Z. Li, J. Wu, H. Ma, and B. Su. 2022. Improving image captioning with pyramid attention and SC-GAN. Image and Vision Computing 117:104340. doi:10.1016/j.imavis.2021.104340.
- Choudhury, A., S. Balasubramaniam, A. P. Kumar, and S. N. P. Kumar. 2023. PSSO: Political squirrel search optimizer-driven deep learning for severity level detection and classification of lung cancer. International Journal of Information Technology & Decision Making 1–34. doi:10.1142/S0219622023500189.
- Dehghani, M., Z. Montazeri, E. Trojovská, and P. Trojovský. 2023. Coati optimization algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems. Knowledge-Based Systems 259:110011. doi:10.1016/j.knosys.2022.110011.
- Fan, K. C., and T. Y. Hung. 2014. A novel local pattern descriptor—local vector pattern in high-order derivative space for face recognition. IEEE Transactions on Image Processing 23 (7):2877–91. doi:10.1109/TIP.2014.2321495.
- Fausto, F., E. Cuevas, and A. Gonzales. 2017. A new descriptor for image matching based on bionic principles. Pattern Analysis and Applications 20 (4):1245–59. doi:10.1007/s10044-017-0605-z.
- Ghandi, T., H. Pourreza, and H. Mahyar. 2023. Deep learning approaches on image captioning: A review. ACM Computing Surveys 56 (3):1–39. doi:10.1145/3617592.
- Humaira, M., P. Shimul, M. A. R. K. Jim, A. S. Ami, and F. M. Shah. 2021. A hybridized deep learning method for Bengali image captioning. International Journal of Advanced Computer Science & Applications 12 (2). doi:10.14569/IJACSA.2021.0120287.
- Kim, H., and S. Bang. 2020. Data for: Context-based information generation from construction site images using unmanned aerial vehicle (UAV)-acquired data and image captioning. Mendeley Data V1. Accessed July 2023. doi:10.17632/4h68fmktwh.1.
- Lessa, V., and M. Marengoni. 2016. Applying artificial neural network for the classification of breast cancer using infrared thermographic images. Proceedings of Computer Vision and Graphics. ICCVG 2016, 10 September 2016, Warsaw, Poland, vol. 9972, 429–438. Springer International Publishing. doi:10.1007/978-3-319-46418-3_38.
- Luo, J., Y. Li, Y. Pan, T. Yao, J. Feng, H. Chao, and T. Mei. 2023. Semantic-conditional diffusion networks for image captioning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 23359–23368. doi:10.1109/CVPR52729.2023.02237.
- Minarno, A. E., Z. Ibrahim, A. Nur, M. Y. Hasanuddin, N. M. Diah, and Y. Munarko. 2022. Leaf based plant species classification using deep convolutional neural network. Proceedings of 10th International Conference on Information and Communication Technology (ICoICT), Bandung, Indonesia, 99–104. IEEE. doi:10.1109/ICoICT55009.2022.9914851.
- Omri, M., S. Abdel-Khalek, E. M. Khalil, J. Bouslimi, and G. P. Joshi. 2022. Modeling of hyperparameter tuned deep learning model for automated image captioning. Mathematics 10 (3):288. doi:10.3390/math10030288.
- Singh, A., J. Krishna Raguru, G. Prasad, S. Chauhan, P. K. Tiwari, A. Zaguia, M. A. Ullah, and S. K. Gupta. 2022. Medical image captioning using optimized deep learning model. Computational Intelligence and Neuroscience 2022:1–9. doi:10.1155/2022/9638438.
- Thangavel, K., N. Palanisamy, S. Muthusamy, O. P. Mishra, S. C. M. Sundararajan, H. Panchal, A. K. Loganathan, and P. Ramamoorthi. 2023. A novel method for image captioning using multimodal feature fusion employing mask RNN and LSTM models. Soft Computing 27 (19):14205–14218.
- Wang, C., and X. Gu. 2023. Learning joint relationship attention network for image captioning. Expert Systems with Applications 211:118474. doi:10.1016/j.eswa.2022.118474.
- Xian, T., Z. Li, Z. Tang, and H. Ma. 2022. Adaptive path selection for dynamic image captioning. IEEE Transactions on Circuits and Systems for Video Technology 32 (9):5762–75. doi:10.1109/TCSVT.2022.3155795.
- Xian, T., Z. Li, C. Zhang, and H. Ma. 2022. Dual global enhanced transformer for image captioning. Neural Networks 148:129–41. doi:10.1016/j.neunet.2022.01.011.
- Xie, J., R. Girshick, and A. Farhadi. 2016. Unsupervised deep embedding for clustering analysis. Proceedings of the 33rd International conference on machine learning, PMLR, New York, NY, USA, vol. 48, 478–487.