
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, the integration of intelligent industrial process monitoring, quality prediction, and predictive maintenance solutions has garnered significant attention, driven by rapid advancements in digitalization, data analytics, and machine learning. As traditional production systems evolve into self-aware and self-learning configurations, capable of autonomously adapting to dynamic environmental and production conditions, the significance of reinforcement learning becomes increasingly apparent. This paper provides an overview of reinforcement learning developments and applications in the manufacturing industry. Various sectors within manufacturing, including robot automation, welding processes, the semiconductor industry, injection molding, metal forming, milling processes, and the power industry, are explored for instances of reinforcement learning application. The analysis focuses on application types, problem modeling, training algorithms, validation methods, and deployment statuses. Key benefits of reinforcement learning in these applications are identified. Particular emphasis is placed on elucidating the primary obstacles impeding the adoption and implementation of reinforcement learning technology in industrial settings, such as model complexity, accessibility to simulation environments, safety deployment constraints, and model interpretability. The paper concludes by proposing potential alternatives and avenues for future research to address these challenges, including improving sample efficiency and bridging the simulation-to-reality gap.
Introduction
In the context of the Fourth Industrial Revolution, commonly known as Industry 4.0, manufacturing processes are undergoing a transformation toward increasingly digitalized and automated ecosystems. This shift is driven by the development of various technologies, including Cyber-Physical Systems, the Industrial Internet of Things, Cloud Computing, Big Data, and Artificial Intelligence (AI). The revolution is based on the integration of these technologies in industrial processes, enabling the creation of flexible, smart, and autonomous factories, thus offering new opportunities for efficient, advanced, and sustainable production (Lasi et al. Citation2014).
Specifically, the continuous advances in AI and emerging applications in the industry present enormous opportunities to integrate state-of-the-art technologies and address challenges driven by the digital transformation in these environments (Peres et al. Citation2020).
As a sub-field of AI, Machine Learning (ML) algorithms are key elements in Industry 4.0 (Bécue, Praça, and Gama Citation2021). ML models, which are data-driven approaches, provide a set of techniques and methodologies to model and learn patterns from data in machines and computer systems. This smart exploitation of data in the industry has the potential to significantly impact Key Performance Indicators (KPIs) such as productivity, efficiency, quality, environmental footprint, and availability, which are of utmost importance in production systems.
Within the realm of ML, supervised and unsupervised learning methods primarily analyze data patterns for prediction and clustering applications. In contrast, reinforcement learning (RL) excels in decision-making, offering support and control in real-time production settings. RL operates on the principle of goal-directed and interactive learning, guided by a numerical reward signal (Sutton and Barto Citation2018). The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.
RL has demonstrated remarkable success across various domains, including complex games (Silver et al. Citation2018), video games (Lample and Singh Chaplot Citation2017), natural language processing (Uc-Cetina et al. Citation2023), healthcare (Yu et al. Citation2021), finance (Hambly, Xu, and Yang Citation2023), and autonomous driving (Kiran et al. Citation2021), showcasing its significant potential. However, despite these successes, implementing RL in manufacturing processes presents substantial challenges. Consequently, the adoption of RL technologies in industrial settings remains in its early stages.
Despite advances in digitalization, many industrial environments still rely on manual or traditional systems for process and system control and planning. Although extensive research has been conducted to improve these traditional systems (Guzman, Andres, and Poler Citation2022; Tavazoei Citation2012), these models often lack the adaptability and flexibility to respond to environmental changes. RL, however, has the potential to overcome many of these limitations. Given RL’s capabilities, it is essential to analyze the benefits it can provide, identify the primary challenges limiting its industrial applicability, and propose solutions for its controlled and safe implementation.
Relevant research has explored the use of RL in specific fields and tasks, such as robotics (Singh, Kumar, and Pratap Singh Citation2022), power systems (Cao et al. Citation2020), and the semiconductor industry (Stricker et al. Citation2018). Moreover, Nian, Liu, and Huang (Citation2020) conducted a study on the application of RL in industrial control focusing on a specific example of an industrial pumping system, comparing RL with traditional algorithms. However, these studies do not provide a comprehensive perspective across all industry domains.
Our analysis explores various critical industrial applications, such as robotic manipulation, scheduling and routing design, operational performance, production efficiency, and fault diagnosis. To enhance clarity and facilitate comprehension, we categorize these applications according to industry type. Our main focus lies in exploring the benefits of RL and its challenges related to training and implementation, specifically targeting the simulation-to-reality (sim-to-real) gap, safety concerns, and deployment limitations. While acknowledging the existing body of literature, previous studies have not extensively addressed these areas. Through the examination of these challenges, our objective is to offer insights that can enrich the effectiveness of RL applications across various industrial contexts with shared characteristics. Hence, the contributions of this article are outlined as follows:
Analysis of diverse RL applications: Examine the current applications and objectives of RL within industrial domains, including modeling strategies, types of RL technologies utilized, and the level of validation and deployment achieved across various industries.
Identification of advantages and challenges: Identify the primary benefits and challenges associated with implementing RL in industrial settings. Explore potential alternatives to assess RL’s scalability and effectiveness in real-world industrial environments.
We initiate our exploration by elucidating the foundational concepts of RL and surveying the principal algorithms documented in the literature, presenting a taxonomy of these algorithms in Section 2. Proceeding to Section 3, we conduct an extensive review of RL applications within manufacturing, spanning diverse areas such as robot automation, welding processes, the semiconductor industry, injection molding, metal forming, milling processes, and the power industry. Additionally, we emphasize the variety of applications and offer an analysis of the environmental conditions employed in training, along with the current deployment status of each application. In Sections 4 and 5, we delve into a discussion regarding the potential and challenges associated with implementing RL in industrial domains, while also delineating possible avenues for future research. Finally, Section 6 encapsulates the conclusions drawn from our analysis and potential directions for further research.
Reinforcement Learning
This section provides an explanation of the field of RL and presents an overview of the main algorithms that have been applied in the presented articles.
RL provides an efficient framework for solving optimal control and decision-making tasks in stochastic and sequential environments modeled as Markov Decision Processes (MDPs) (Littman, Moore, and Moore Citation1996). Formally, an MDP can be defined by a 6-tuple , where:
is the set of states.
A state, embodying all necessary information to predict system transitions, must adhere to the Markov property in an MDP (Equation 1) (Sutton and Barto Citation2018). This property asserts that, given the present state and action, the subsequent state’s probability distribution depends only on these factors, not on earlier states or actions, indicating that the current state sufficiently predicts future system behavior.
The conventional MDP framework, operating under the Markov property assumption, inherently assumes a fully observable environment. In real-world industrial scenarios, achieving full observability can be challenging, given that a portion of the state remains concealed from the agent (Zhao and Smidts Citation2022). This inherent limitation introduces an additional layer of complexity to the decision-making process. When the Markov property is not met, a pragmatic alternative is the consideration of a Partially Observable Markov Decision Process (POMDP), offering a solution for decision-making in environments where the agent’s perception is restricted to a limited portion of the environment or is subject to noise (Spaan Citation2012).
In the formal definition of a POMDP, encapsulated by the tuple , two pivotal additional elements come into play. Firstly,
comprises the set of observations that the agent can receive, contingent on the transition state
and potentially influenced by the previously executed action
in the environment’s prior state
. Secondly, the probability function
, which, given a pair
, determines the probability
assigned to each observation
, considering the state
and action
. Additionally, the initial observation is sampled from a probability function
. The key distinction of a POMDP from a fully observable MDP lies in the fact that the agent now perceives an observation
, as opposed to directly observing
.
In certain scenarios, external variables can influence the transition model (Ebrie et al. Citation2023). These variables, which are not inherently part of the state, may limit the model’s ability to generalize when directly incorporated (Hallak, Di Castro, and Mannor Citation2015). To address this challenge, the Contextual Markov Decision Process (CMDP) extends the capabilities of a traditional MDP. It achieves this by introducing a context space and a mapping function
. This function associates each context
with a specific set of MDP parameters (Modi et al. Citation2018). Consequently, a CMDP is represented as a tuple
, where
maps any context
to an MDP
. This MDP is defined by the tuple
, wherein
,
,
, and
are specific to context
. In alignment with the stated focus and objectives of this paper, our analysis does not extend to exploring potential applications within the industry domain for this particular extension.
In any of the frameworks, the process is modeled as an agent iteratively interacting with an environment. The agent takes actions in the environment, and subsequently, the environment provides the agent with the system state (or observations in the case of a POMDP) and the reward associated with the previous action and the current state. The agent aims to learn a function that maps states (or observations) to actions, referred to as policy , with the goal of maximizing the expected cumulative future reward. This iterative process within the framework of an MDP is illustrated in .
Figure 1. Schematic overview of reinforcement learning in industrial processes.
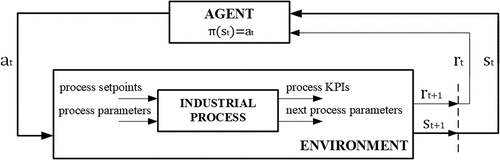
Algorithm 1 introduces a unified iterative reinforcement learning process that seamlessly integrates standard MDPs (and POMDPs) within a finite episode consisting of sequential interaction steps, each lasting for steps. To achieve effective training, it’s essential to engage in numerous interactions with the environment, which in turn necessitates a significant number of episodes. Furthermore, employing specific techniques to explore the state space (Ladosz et al. Citation2022), ensuring efficient sampling (Yu Citation2018), and maintaining training stability are crucial (Nikishin et al. Citation2018). Section 2.1 provides further elaboration on insights into policy updating.
Table
In RL, agents navigate environments with scalar feedback (rewards) guiding them toward optimal actions. These actions, encapsulated within the policy function, are pivotal for shaping control strategies and behavioral policies. A fundamental concept in RL is the deterministic greedy policy, , a strategy that consistently selects actions to maximize the expected cumulative future reward. Presented below is an introductory overview of the fundamental principles and primary functions in RL. All equations presented in this section are based on the formulation from Sutton and Barto (Citation2018).
At any given time step , the expected cumulative future reward is denoted by
, as defined in Equation 2. This value represents the discounted sum of rewards along an episode trajectory, guided by policy
and governed by the discount factor
. Mathematically,
can be expressed recursively: it starts with the immediate reward from the state-action pair
and adds the discounted expected cumulative future reward from time step
, denoted by
.
In assessing the efficacy of a policy, value functions are essential. Specifically, the value function provides an estimation of the discounted expected cumulative future reward
when starting from each state
under the guidance of policy
. This estimation is detailed in Equation 3.
Similarly, the state-action value function, or Q-values, , estimates the value associated with each state-action pair, as defined in Equation 4. This function summarizes the discounted expected future cumulative reward, starting from the state-action pair
, and follows policy
until the end of the episode.
Bellman equations play a crucial role in articulating the recursive relationships within RL. Along with their immediate derivations, they constitute a key mechanism for solving problems in the control theory domain (Sutton and Barto Citation2018). These equations establish a connection between the value of a state or a state-action pair and the values of its successor states and state-action pairs.
Equations 5 and 6 illustrate the Bellman equations for the previously defined value functions, incorporating the recursive nature of as presented in Equation 2. Equation 5 represents the Bellman equation for the state value function
, illustrating how the value of a state is recursively related to the values of its successor states under policy
. Similarly, Equation 6 outlines the Bellman equation for the state-action value function
, showcasing the recursive connection between the value of a state-action pair and the values of its successor state-action pairs under policy
.
Since the objective of RL aims to identify an optimal policy , the goal is to maximize expected rewards, thereby finding the policy that maximizes future trajectory values. Equations 7 and 8 define the Bellman optimality equations characterizing the optimal value functions
and
respectively. These equations introduce the maximization aspect by replacing
with
and
with
.
Solving the Bellman optimality equations to derive the optimal policy stands as a central objective in RL algorithms, aiming to maximize long-term rewards within the environment. Consequently, the optimal policy
is determined by actions that maximize Q-values in each state, as illustrated in Equation 9.
Initially, an agent’s decision policy may be random or based on prior expert knowledge, such as through transfer learning (Nian, Liu, and Huang Citation2020). In decision-making scenarios, where the agent is familiar with the environment dynamics, it leverages this knowledge to enhance its policy through dynamic programming algorithms (Liu et al. Citation2021). However, in pure RL scenarios, where the agent lacks knowledge about the initial environment’s transition probability distribution , exploration strategies come into play during training. Non-deterministic policies are employed to explore unknown states, refining estimates of the value function and learned policies. The data collection process carefully balances random actions (under a random policy) and known actions (under a greedy policy). The RL training process involves iterative refinement, where the agent evaluates actions in the environment to maximize the expected cumulative reward and utilizes these estimations to improve the policy (generalized policy iteration) (Sutton and Barto Citation2018).
Classical Reinforcement Learning Methods
Classical RL methods in the literature can be classified into two major groups: Q-learning, and policy-optimization methods. Most RL algorithms involve learning value functions that estimate how good it is to be in a given state (EquationEquation 3(3)
(3) ), or how good it is to perform a given action in a given state (EquationEquation 4
(4)
(4) ). illustrates this classification into method types along with some relevant examples of specific algorithms found in the reviewed studies.
Figure 2. Taxonomy of classical reinforcement learning approaches.
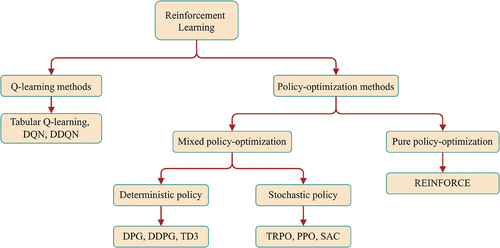
Q-Learning Methods
In Q-learning methods, the RL agent learns a Q-value function, representing the values of state-action pairs used to select actions with higher expected returns. The primary update step in Algorithm 1 for such methods involves adjusting the value of each state-action pair using a learning rate , which integrates the received reward and the estimated value of the subsequent state. This update process is formalized in Algorithm 2 (Watkins and Dayan Citation1992). Consequently, the policy is derived from the learned Q-value function.
Table
In tabular Q-learning methods, the expected future value for each state-action pair is estimated using a tabular format. However, relying on a lookup table may lead to slow convergence, particularly when dealing with a large number of states.
Real-world applications often require learning agents to navigate MDPs featuring large or continuous state and action spaces. The limitations of tabular methods, driven by the curse of dimensionality – where the number of states (or actions) increases exponentially with the growth of the state (or action) space’s dimensions – become apparent in such scenarios. Representing all possible state-action pairs in a lookup table becomes impractical, especially in large state and/or action spaces (Powell Citation2007).
To address this, function approximation becomes essential, allowing the generalization of learned policies from visited states to unknown ones (Xu, Zuo, and Huang Citation2014). These methods facilitate a more efficient computation and are adept at handling problems with high-dimensional spaces. RL employs various function approximators, including linear combinations of features, decision trees, nearest neighbors, neural networks, among others. Deep Reinforcement Learning (DRL) emerges from integrating Deep Neural Networks (DNN) with RL, evolving into a powerful tool for operating and managing large, high-dimensional, and complex continuous systems.
Deep Q-learning (DQN) (Mnih et al. Citation2015) learns the value function using DNNs as a function approximation to enable generalization. A replay buffer is a memory structure used to collect transitions and sample them randomly in batches for training the agent. The replay buffer allows more efficient training with better convergence behavior and stability; and increases sample efficiency, since it efficiently reuses past experiences and helps to decorrelate the training data.
In DQN, two networks with the same architecture are used to represent the value function. The main network updates its weights at every training step, while the target network’s weights are frozen and periodically copied from the main network. In Double Deep Q-learning (DDQN) (Van Hasselt, Guez, and Silver Citation2016), both networks are used when computing target values. The main function is used to select the action, while the target function estimates the value. DDQN addresses the maximization bias from the value function overestimation in Q-learning and DQN, allowing for more stable and faster learning.
Q-learning methods are typically applied to discrete action spaces. Therefore, in continuous domains, it is common to discretize the action space when using Q-learning approaches.
Policy-Optimization Methods
In policy-optimization methods, we can distinguish between pure policy-optimization methods and mixed policy-optimization methods.
Pure policy-optimization methods do not learn value functions; instead, they directly learn the policy. These methods can handle continuous action spaces and learn stochastic policies. In DRL, the weights of a DNN are updated repeatedly for batches of transitions to obtain an estimate of a deterministic or stochastic greedy policy.
For instance, REINFORCE is a Monte Carlo variant within the category of policy gradient methods (Sutton et al. Citation1999). The REINFORCE policy update is outlined in Algorithm 3. Here, governs the policy
undergoing continual learning. The policy parameters, denoted by
, are updated via gradient ascent on
. The update process occurs iteratively for each episode utilizing a learning rate
.
Table
Mixed policy-optimization methods are a hybrid between Q-learning and pure policy-optimization methods. They rely on two functions that work together to accelerate learning, introduce more stability, and improve performance: i) the critic, which estimates the value function, and ii) the actor, which updates the probability distribution of the parametric policy guided by the critic. As the critic network learns which states are better or worse, the actor uses the value estimations to guide the training and learn more efficiently, avoiding undesirable states (Grondman et al. Citation2012). Algorithm 4 delineates the fundamental updates for both the actor and critic in such policy-optimization methods, corresponding to and
updates, respectively. Here,
denotes the actor learning rate, and
represents the critic learning rate.
Table
Some methods consider deterministic policies, such as Deterministic Policy Gradient (DPG) (Silver et al. Citation2014), Deep Deterministic Policy Gradient (DDPG), which combines DPG and DQN, and Twin-delayed deep deterministic policy-gradient (TD3) (Fujimoto, Hoof, and Meger Citation2018), which is an extension of DDPG.
In contrast, others consider stochastic policies, like the Trust Region Policy Optimization (TRPO) method (Schulman et al. Citation2015), which incorporates a regularization term when updating the policy function. This introduces a constraint to minimize changes from the previous policy, avoiding possible divergences or unfavorable modifications. Proximal Policy Optimization (PPO) (Schulman et al. Citation2017) aims to simplify TRPO. It considers a clipped surrogate objective, making it easier to implement while maintaining similar performance. It also incorporates multiple epochs of stochastic gradient ascent at each policy update.
Soft Actor-Critic (SAC) (Haarnoja et al. Citation2018) is another example of a stochastic mixed policy-optimization method. It introduces randomness in the evaluation through an entropy measure that encourages exploration. Thus, there’s a trade-off between the entropy measure and the expected returns, which can be balanced. SAC accelerates learning and prevents the policy from converging too quickly to poor local optima.
Other Reinforcement Learning Methods
The methods discussed in the preceding section fall under the category of online model-free RL methods. In online model-free learning, the RL model or agent engages with an environment, gathering data through its own experiences and refining its understanding through trial and error. This environment can take the form of a real-world setting or virtual simulators. Notably, learning within virtual environments, such as digital twins, has demonstrated significant efficacy (Matulis and Harvey Citation2021). However, there might be a substantial gap between the virtual and the physical environment, which necessitates careful consideration of the transferability of learned behaviors and policies from simulations to real-world applications (Ranaweera and Mahmoud Citation2023). Conversely, learning within physical environments avoids the need for a simulation and the sim-to-real gap but presents other challenges and associated risks, such as the potential for hardware damage, safety concerns, slower learning, and higher costs related to trial-and-error learning in a real-world setting (Dulac-Arnold et al. Citation2021).
Within the literature, two primary types of online learning in RL are distinguished: model-free and model-based. Model-based RL involves the agent learning the dynamics of the environment through interactions and subsequently leveraging these learned dynamics to simulate interactions with the real environment for planning (Moerland et al. Citation2023). Periodically, new real-world experiences are incorporated, contributing to refining the dynamics in the simulated environment and correcting potential deviations. Model-based approaches prove particularly beneficial in environments where interactions are limited or costly, or when there’s a need to expedite the learning process.
On the other hand, offline learning involves the RL model or agent learning from a predefined dataset of accumulated experiences, guided by a behavior policy. This behavior policy can be a combination of various policies. The goal in offline RL is to acquire a robust policy from the predefined dataset that outperforms the behavior policy using data collected from it, without further exploration in the environment (Levine et al. Citation2020). To achieve this, the data collection policy must be sufficiently exploratory and somewhat effective in showcasing desirable states and favorable consequences of action-taking in different states. Moreover, this methodology integrates techniques to address issues related to distribution shift and overestimation challenges in offline RL, arising due to constraints in validating beliefs (Kumar et al. Citation2019).
In this review, our primary focus has centered on model-free online RL applications, representing the predominant approach across various industries. Many of these applications cover training scenarios within virtual environments (Zhong, Zhang, and Ban Citation2023), while some also involve the utilization of real-world systems for training or retraining purposes (Ahn, Na, and Song Citation2023).
Reinforcement Learning Applications
This section reviews selected representative application fields of RL in the manufacturing industry, including robot automation, welding processes, semiconductor industry, injection molding industry, metal forming industry, milling processes, and power industry. These industrial sectors are considered innovative fields with significant potential for RL applications. Moreover, most of the reviewed applications in this work can be easily extended and transferable to different domains because they represent the core manufacturing process for several industries (such as automotive and home appliances). Many productions utilize the same industrial procedures; for instance, welding or part stamping processes are used in the production of car products and mobile phones. Furthermore, an RL algorithm does not require previous information about “how to control a process;” but the possible control points in the system (action space). An RL algorithm can be adaptable and useful for a wide range of tasks as it can learn from experience and adapt to various contexts without relying on particular assumptions. This fact favors adaptation to other similar productions. However, the control agents need previous training before deploying them in a real-world environment. An agent cannot effectively operate within Industry 4.0 without prior expertise, as it may have a detrimental impact on industrial KPIs.
Each field is summarized in a table that provides the reference of each reviewed research, the specific application in the field, the RL algorithm implemented, its classical classification presented in section 2.1, and finally, the type of problem that it is trying to solve. In the tables, QL refers to Q-learning methods, and PO refers to policy-optimization approaches.
The criteria used in the discussion of various applications are based on four principal aspects to guide the development of future similar applications. The considered aspects are:
Objective: This includes the type of task being addressed, the specific industrial application, and categorization into control, planning, or maintenance solutions.
Modeling: This involves the state space, action space, and the modelization of the reward function for each application.
Training strategy: Analysis focuses on identifying relevant algorithms based on specific applications and problem modeling characteristics.
Validation and deployment: Attention is given to evaluation criteria and the extent of deployment for the provided solution.
Robot Automation
In the manufacturing context, the movement of a robotic arm requires a well-designed trajectory for efficient operation. Traditionally, this task has been carried out by researchers or engineers with expertise in the domain. However, recent research has focused on leveraging ML techniques to reduce the reliance on human experts and achieve promising results. Robotic arms are typically used in complex and non-linear environments with uncertainties stemming from disturbances and sensor noise, which require frequent reconfiguration (Pane et al. Citation2019). To address these challenges, RL technology has been explored to increase robustness and provide adaptive and immediate responses. While planning and control processes can be time-consuming, robotic arms must identify an efficient solution for a given task and also adapt in real-time to changing situations.
In this field, Tejer, Szczepanski, and Tarczewski (Citation2024) introduced a Q-learning algorithm tailored for controlling a robotic arm. Its objective is to adeptly choose products from three sources by considering factors such as availability at pickup points, historical data, and future projections. Within this framework, the RL agent garnered positive rewards for executing suitable movements, negative rewards for unsuitable ones, and neutral rewards for opting to wait. Both training and validation were conducted within a simulated environment. Therefore, it’s important to note that this research is in the developmental phase and has yet to be transitioned to real-world implementation.
Meyes et al. (Citation2017) developed a Q-learning algorithm for a six-axis industrial robot. The RL agent was trained to play the wire loop game, using only two dimensions for simplicity. The action space consisted of 6 movement actions to guide the metal loop, while the state space was a three-dimensional matrix containing local information about the robot’s tool center point, the loop’s position relative to the wire and the goal. The algorithm provided positive rewards when the goal was reached and negative ones when any non-desired situation occurred. An experimental setup was used to test the robot, which was able to plan complex motions along continuous trajectories and generalize to new scenarios not seen during the training phase, with successful outcomes.
Similarly, Pane et al. (Citation2019) considered the Actor-Critic algorithm introduced in Bayiz and Babuska (Citation2014) to improve the performance of a controller in tracking an industrial robotic manipulator arm. Two additive compensation methods were employed for this task, using RL algorithms to enable precise movement along a square reference path, a circular reference path, and a trajectory on a three-dimensional surface. The controlled variable was the velocity of the arm, based on its position and current velocity, in order to achieve maximum precision in the reference paths. The reward system was based on the precision joint error in the trajectories. In experimental tests, the proposed methods were successfully benchmarked against other industrial control techniques, including proportional derivative, Model Predictive Control (MPC), and iterative learning control.
Additional methods for controlling industrial robotic manipulator arms have been proposed in the literature. For instance, in Zeng et al. (Citation2020) and in Atae and Gruber (Citation2021), the effectiveness of the DDPG algorithm as a control technique is validated. Furthermore, a SAC approach is utilized in Matulis and Harvey (Citation2021).
Liu et al. (Citation2020) also applied a DDPG approach to a humanoid robotic-arm controller, which was multitasking-oriented and trained using a simulator environment to achieve rapid and stable motion planning. The RL control agent learned to minimize trajectory errors by moving the arm based on given coordinates.
In addition, Beltran-Hernandez et al. (Citation2020) employed a SAC method to instruct robotic agents in precise assembly skills. More specifically, a robotic agent underwent training to perform peg-in-hole tasks with uncertain hole positions. The RL agent was tasked with selecting controller parameters enabling it to reach the goal with minimal contact force. The approach was successfully validated in experimental tests involving a range of concrete tasks, yielding highly promising results.
In the same domain, Ahn, Na, and Song (Citation2023) explored the application of a SAC algorithm for dynamic peg-in-hole tasks within the field of robotics. The proposed assembly approach, integrating both visual and force inputs, endowed the robot with the capability to adapt to diverse assembly piece shapes and hole locations. Pretraining encompassed both force-based and image-based trajectory generators, utilizing human demonstration data and virtual environment training, respectively. Subsequent training took place in the real environment. Experimental validation underscored the efficacy of the strategy in handling a range of peg-in-hole challenges. Their method not only facilitated precise assembly but also demonstrated exceptional performance in the face of substantial orientation or initial position difficulties.
Nguyen et al. (Nguyen et al. Citation2024) proposed harnessing the inherent symmetry of the peg-in-hole task to efficiently train a memory-based SAC agent. Specifically, they demonstrated that various initial configurations of the peg and hole were equivalent due to the symmetry of a round hole, enabling data augmentation. By transforming trajectories initiated in one configuration to generate valid trajectories in others, they streamlined the search space for more sample-efficient learning. The problem was formulated as a POMDP, with the state comprising the relative pose from the peg to the hole coordinate. However, the agent received partial observations, including 3D position, torques, and forces. Actions corresponded to displacements of the arm’s tip. The reward structure was sparse, granted only upon successful peg insertion into the hole. Training was conducted using a simulator, yet leveraging data augmentation and regularization through auxiliary losses to exploit symmetries, enabling efficient training with real robots in minimal time.
The main applications of RL in the field of robot automation involve the control and planning of robotic manipulator arms in two and three-dimensional space, summarized in . The robotic arm plays a crucial role in the field of industrial automation, however, to get high-cost efficiency and provide good quality manufactured products, each task of the industrial robot must be well calibrated. Real-time adaptive supervision is necessary to ensure high accuracy and precision in complex, nonlinear, and uncertain environments. Recent approaches use algorithms to enable robots to deal with environmental variations and autonomously adapt to them. RL satisfies these requirements, but designing the state information passed to the agent for action selection and modeling the reward function, which is central to the learning objective, are complex aspects of these RL solutions.
Table 1. Robot automation RL applications and algorithms.
Policy-optimization methods are the most widely considered algorithms in this field, as they can handle continuous state and action spaces. However, Q-learning methods such as DQN can manage continuous state spaces but not continuous action spaces. In some of the reviewed works, the algorithm has to select from continuous ranges of velocities and movements in a multi-dimensional space. Policy-optimization algorithms respond very well to the needs of the industry by providing high-quality performance on the proposed goals. Several applications have been tested to demonstrate the effectiveness of the learned policies. Although these attempts demonstrate the conceptual usability of the methods, some research still relies on simplified case studies that are hardly scalable to more complex, large-scale, and real-world problems. Since robotics deals with real-world scenarios, unlike other traditional RL applications such as recommendation systems and gaming that deal with simulated ones, computing resource requirements and training time difficulties are more pronounced. The main drawbacks of interacting with real-world environments are:
These environments are frequently complex and dynamic in continuous state and action spaces.
In physical robotic environments, rewards are often sparse and delayed. Although RL algorithms are designed to handle delayed rewards, coping with very sparse rewards remains a challenge in learning efficient policies.
Policies must maximize the future cumulative reward but also avoid risky situations.
Welding Processes
Welding processes are highly complex and nonlinear, with the quality of results dependent on a multitude of variables and environmental conditions. These aspects make an effective system control quite challenging. While traditional controllers, such as proportional-integral (PI) or proportional-integral-derivative (PID) controllers, are commonly used in this industry, they do not solve all the challenges. These controllers typically work within a limited range of parameters and do not respond well enough to the dynamics and uncertainties of the process, since making precise predictions in this domain is difficult. Hence, more adaptive methods are required to achieve the desired welding quality under any dynamic and uncertain environment and to avoid defects in the welds such as porosity, cracking, or poor mechanical properties.
RL methods have been used for control purposes in conjunction with traditional PID controllers, as seen in Jin, Li, and Gao (Citation2019). In this research, an adaptive PID controller based on an Actor-Critic approach was employed to regulate the weld pool width. The RL agent was trained using a simulator to choose an input parameter for the PID controller, in order to minimize the difference between the actual and the desired weld pool width.
RL techniques have found application in the laser welding industry, where laser welding’s advantages, such as speed, high-quality welds, and reduced tool wear, have led to increased popularity. However, ensuring replicability in the produced parts remains a challenge due to dynamic conditions.
Gunther et al. (Günther et al. Citation2014, Citation2016) implemented an Actor-Critic algorithm to control the applied laser power, aiming to achieve the desired weld depth. Their proposed control system architecture integrated three key technologies:
Utilization of a DNN to extract significant variables from sensors, representing the environment’s state.
Application of a Temporal Difference (TD)-Learning algorithm with linear function approximation for real-time nexting (Modayil, White, and Sutton Citation2014) to assess system performance. Incorporated into the reward function, this guided control training toward achieving the target weld depth. TD-Learning predicted relevant features of the system’s sensor data for action selection in the control model.
Implementation of the Actor-Critic algorithm (Degris, Pilarski, and Sutton Citation2012) for laser power control.
Subsequently, a laser welding simulator provided the sensor data necessary for training and testing the control system architecture.
Masinelli et al. (Masinelli et al. Citation2020) proposed a similar control system architecture with the objective of adjusting laser power to control welding quality. The state of the system was captured using acoustic and optical emission sensors. The reward function incorporated welding depth and porosity. The learned control policy underwent testing in a laboratory environment, providing valuable algorithm validation. The control system consisted of:
An encoder based on a convolutional neural network (CNN) for translating sensor values to the environment state, reducing dimensionality.
A CNN classifier to compute the reward for the agent.
Development of two control approaches: a Fitted Q-iteration (FQI) algorithm (Antos, Szepesvári, and Munos Citation2007) and a REINFORCE algorithm.
In Quang et al. (Citation2022), the FQI approach from Masinelli et al. (Citation2020) was tested in two environments at different scales: in a laboratory environment and in a more unpredictable industrial environment. The authors highlighted differences in training time between both environments.
Mattera, Caggiano, and Nele (Citation2024) introduced a novel Stochastic Policy Optimization (SPO) algorithm, a variant of the REINFORCE algorithm, tailored for optimizing gas metal arc welding processes. The primary goal was twofold: achieving a desired penetration depth while minimizing the resulting bead area. The action space was defined by a combination of process parameters that are updated based on their current values, ensuring adaptability to changing conditions. The reward function was designed to leverage the disparity between the model output and the desired reference point. Moreover, penalties were incorporated, correlating with the deviation from the reference point and the bead area. Training of the algorithm was conducted within a simulated environment, showcasing superior computational efficiency and solution performance compared to a genetic algorithm across various scenarios. This work is in an early stage, only considering simulation scenarios.
The applications summarized in this field are detailed in , specifying the algorithm utilized for each.
Table 2. Welding processes RL applications and algorithms.
Significant progress has been made in advancing the control of welding processes. However, implementing these advancements in industrial plants remains challenging. Moreover, exploring additional control parameters, such as velocity and distance, and creating more complex scenarios to train RL agents that accurately reflect the intricacies of current industrial systems are crucial areas to focus on.
While policy-optimization methods are prevalent in the field, especially for control applications, a key challenge lies in translating sensor data into meaningful state and reward functions to properly input into the MDP. This translation is particularly necessary in processes where a large number of sensors capture data. The captured data from the process needs to be translated into simple and concise information required for the RL system. DNN and other RL approaches can be used for this translation task, learning a mapping from the sensor values to the MDP state representation and reward values.
Semiconductor Industry
In the realm of the semiconductor industry, researchers have delved into the application of RL for scheduling tasks. Within the intricate landscape of job shops, conventional production scheduling planning demonstrates inefficiency in addressing uncertainty and lacks the capability to respond promptly to unforeseen changes in scenarios (Yeap Citation2013). An exemplary study by Waschneck et al. (Citation2018) focused on enhancing production scheduling with the objective of improving uptime utilization.
The methodology involved the RL agent’s meticulous selection of each lot position, taking into account the capabilities, availabilities, and setups of the machines, along with the specific properties of the jobs slated for scheduling. The formulation of the reward function was grounded in the uptime utilization within the work centers and the overall factory, incorporating penalties associated with the problem constraints. Validation of the proposed approach was conducted through simulations in a small-scale semiconductor wafer processing factory. The results were then benchmarked against various dispatching heuristics to assess the effectiveness and efficiency of the developed RL-based production scheduling strategy.
Similarly, Stricker et al. (Citation2018) implemented an autonomous and adaptive Q-learning with a DNN system for order dispatching in the semiconductor industry. The RL agent was given information about the waiting and finished batches, the target of the next orders, and the position of the worker. Then, the agent selected what to do with a batch. The reward system was designed to maximize the utilization of all manufacturing equipment and minimize lead time. A TRPO algorithm was implemented for an equivalent task with the same aim in Kuhnle et al. (Citation2019), where the simulation environment represented a real use case in the semiconductor industry. Actions were defined to be the movement of resources based on their locations and relevant information about the order and machines. Moreover, an analogous TRPO approach was presented in Kuhnle, Röhrig, and Lanza (Citation2019) for order dispatching in a complex job shop and exemplified in the semiconductor industry. Later, the methodology was applied for a more complex and robust control system design in the semiconductor industry and evaluated with real-world scenarios (Kuhnle et al. Citation2021). Evaluations in all cases were done by comparison with heuristics in the simulation environments. The RL approach proved to be the best.
In the supply chain field, Tariq et al. (Citation2020) provided a DQN solution for optimal replenishment in a semiconductor complex supply chain collaboration model to mitigate the bullwhip effect. This research was done using a simulator with real use case data from a company. Results were compared with the company operating behavior. The action space was discrete where actions represented different replenishment amounts. The observations were based on the demand and the anticipation of target stock levels. The objective was to minimize penalties related to the positions deviating from the mean value of stock levels.
Similarly, in the semiconductor industry, a DQN was employed to enhance efficiency by optimizing production plan scheduling within an uncertain and dynamic environment (Lee and Lee Citation2022).
The state was defined based on four features per idle machine: the actual setup type, the number of waiting wafers, the relationship between planned and current production quantity, and the degree of production plan fulfillment at that moment.
An action represented the selection of a wafer layer by the agent from among the layers waiting to be processed on each machine.
The reward function gauged how closely the agent’s action selection aligned with the production plan.
Ma and Pan (Citation2024) employed RL algorithms to adjust weights in a run-to-run controller for real-time manufacturing processes, based on observable system states when facing unknown disturbances. The control objective was to ensure quality amidst environmental distortions. They trained DDPG and TD3 agents in a simulated environment and compared them with the control system without real-time weight adjustment. No tests were conducted in real environments due to the sim-to-real gap, which was not addressed in the study.
Previous investigations have shown remarkable results on the application of RL, outperforming traditionally rule-based systems, heuristics, and companies’ decision rules. Both Q-learning and policy-optimization methods with DNN provide valuable solutions for complex and dynamic tasks such as production scheduling, order dispatching, and supply chain management (). These methods help to minimize deviations in expected results, maximize machine utility, reduce production times, and avoid unfeasible or undesired planning. Despite these advantages, training is computationally expensive, and DNNs are considered black-box models, making it difficult to predict how the DRL agents will behave in unknown situations. In the literature, when an ML model is not transparent or interpretable to the user is often referred to as a black-box. This lack of transparency can be problematic if the user wants to justify or authenticate the behavior of the model because is unable to understand how the model derives its results. Further research is required to analyze and understand the performance and, in particular, the learned strategies under more scenarios. While some architectures have been tested with real use cases, they still rely on simulations. Therefore, the models validated by simulations must be transferred and tested in physical environments to confirm their efficacy.
Table 3. Semiconductor industry RL applications and algorithms.
Injection Molding Industry
Injection molding is a highly precise manufacturing process used extensively in the production of plastic products due to its efficiency and ability to produce complex shapes. The consistency of the final product quality largely depends on process variables such as temperature and pressure. Consequently, significant research efforts have been directed toward controlling and stabilizing these variables to achieve the desired quality. Optimal values for these process parameters, such as temperature and pressure, can improve the injection molding process by achieving the desired precision with minimal cost, time, and emissions. Traditionally, domain experts have relied on trial and error methods to determine the optimal process parameters. In order to avoid human errors, domain expert dependency, and streamline decisions, more advanced control and decision-making methods have been applied. However, most of the applied techniques are static with difficulties to react to changes or unforeseen events, anticipating situations, or responding in real-time. Some recent studies have applied RL to overcome the challenges related to the dynamism of the environments and the necessity of real-time responses.
Guo et al. (Citation2019) have developed an Actor-Critic framework for process parameter selection in an injection molding process. The parameters researched are the mold and melt temperatures, packing pressure, and packing time. The state of the MDP was defined by the parameters’ values and part thickness. Finally, the reward aggregated the time spent and the error in the quality indexes. They used a prediction model for training and an online practical environment for validating the results against static optimization.
Similarly, a temperature compensation control strategy under dynamic conditions based on DQN was proposed in Ruan, Gao, and Li (Citation2019). The aim was to achieve temperature stability by increasing, decreasing, or maintaining voltage values. The state was given by the current-voltage value, the sampling temperature, and the temperature error. The RL agent was penalized if the temperature error was too high. To validate the agent an experimental test was done with a modified injection molding machine.
Batch productions have also been considered in this research field. Non-efficient decision-making strategies for the setpoints in the process may cause unsatisfactory quality indexes. To avoid this, Qin, Zhao, and Gao (Citation2018) proposed an Actor-Critic approach to control the product quality in injection molding batch productions. Their objective was to minimize the error between the target quality and the predicted quality using a simulation environment. The controlled variables adjustments were based on the process variables at each moment in time. Similar successful research about RL in injection molding batch production control was presented in Wen et al. (Citation2021), where a Q-learning approach was validated in a simulation environment.
Finally, another Q-learning approach was presented in Li et al. (Citation2022). This approach was developed for fault-tolerant injection speed control to monitor accurately its value and whether the actuator was malfunctioning. It was successfully validated in an injection molding process by comparison with traditional methods. In this article, the algorithm was trained and validated in a simulation environment considering problem simplifications.
The summarized applications within this field are concisely presented in .
Table 4. Injection molding industry RL applications and algorithms.
The quality of results in a plastic injection process hinges significantly on two factors: i) the configuration parameters of the process, and ii) the control system’s capacity to adapt to environmental variations. Furthermore, the overall quality of production batches must be approached comprehensively, taking into account the interdependence of one cycle on the previous one. This intricate interplay of factors underscores the complexity inherent in optimizing industrial processes. It is within this intricate landscape that Dynamic Algorithm Configuration (DAC) becomes particularly pertinent. Adriaensen et al. (Adriaensen et al. Citation2022) introduced DAC as a paradigm within the optimization community, leveraging RL for the fundamental task of parameter selection. In light of this, integrating DAC into parameter selection becomes a pathway to address the dynamic challenges encountered in industrial settings.
In addition to quality optimization, the industry also seeks to minimize carbon emissions while meeting production controls and planning objectives. RL algorithms present an efficient means to achieve these dual objectives. The studies in this field exemplify the convergence and efficacy of these methods through straightforward approaches.
Metal Forming Industry
In the field of metal forming, heavy plate rolling is a very popular sheet deformation process in many industries, including the automotive and maritime industries (Meyes et al. Citation2018). Designing the rolling process is a complex task, as it involves multiple passes that depend on one another to achieve the desired product properties and shape. Traditionally, domain experts have planned the rolling schedule. However, this task involves many objectives, such as minimizing time, adapting velocities, reducing energy consumption, and optimizing machine deterioration, making it challenging to operate efficiently. To address these challenges, more sophisticated techniques have been extensively investigated.
In particular, Meyes et al. (Citation2018) proposed DQN to design a pass schedule for a heavy plate rolling use case to plan the height and grain size of the part per pass. Experiments were successfully validated in a simulation environment.
Similarly, Scheiderer et al. (Citation2020), applied a SAC algorithm to achieve the height and grain size goals of the parts and minimize energy consumption. The action space was based on the next height for the part and the pause time. The state provided to the RL agent was the current height and the grain size of the part at the end of the current pass, the part’s temperature, and the current pass schedule. Finally, the reward function was computed with the deviations from the goals and the energy accumulated. The trained agent performance was benchmarked in a simulation environment against a human domain expert’s behavior.
Concurrently, free-form metal sheet stamping technology integrated DQN to autonomously acquire the optimal stamping path and forming parameters, thereby enhancing control process precision (Liu et al. Citation2020). The DQN agent was specifically utilized to optimize the stamping process with a hammer, defining actions for the hammer, states that include coordinates and calculated stresses, and a reward function based on the desired shape of the next state.
Forging is another widely applied deformation metal process with longer life, higher deformation degree, and higher cost than the rolling one. Therefore, the final geometry of a workpiece is essential, but the final cost of the process is also important to consider. In this context, Reinisch et al. (Citation2021) applied a DDQN approach to design pass schedules in open-die forging processes. The main objectives for the planning were the achievement of the desired geometry in as few passes as possible and taking care of the machines as much as possible. The variables considered in the state space were heights, temperatures, and strain in order to set the height reduction and the bite ratio from discretized values. Finally, a forging experiment was carried out to validate the solution proposed.
Nievas et al. (Citation2022) designed a Q-learning approach for parameter selection in a hot stamping process to minimize the production time of a batch with the desired quality. The product quality was measured with the final temperature of the part. The controlled parameter was the die closing time per each sheet. The action space was based on three actions: increase, decrease, or maintain the previous closing time. The state space considered for action selection was the die temperature, the previous closing time, and the remaining parts of the batch. The training was done with surrogate models of the process and successfully validated against the business-as-usual strategy.
The study conducted by Xian et al. (Citation2024) is centered on alloy compositional design employing DQN. In contrast to many other RL applications, they integrated experimental data to train surrogate models, which are then utilized to simulate rewards during training. This configuration enables the trained agent to collect real-world data, subsequently employed to refine the surrogate model, thus addressing the sim-to-real gap. Within this RL framework, the agent determined the composition of a new component to enhance an alloy, with each state representing a specific alloy composition. The primary objective was to maximize the transformation enthalpy of the alloys. Finally, the study compares the performance of their RL approach with Bayesian global optimization and genetic algorithms.
Flexibility and adaptability to unexpected changes in the environment, along with robustness and economic efficiency, are among the main challenges in the metal forming industry. In this context, RL has shown potential in several subareas: i) pass schedule design to meet quality requirements, ii) free-form metal sheet stamping technology, iii) process variable selection for efficient production while ensuring the material properties of the parts, and iv) determining the combination of elements in an alloy to improve its properties or performance characteristics. The RL applications reviewed in this area, summarized in , have demonstrated their potential for complex tasks through proof-of-concept studies and small experiments. These findings provide a starting point for future research aimed at developing more scalable solutions for larger and more complex environments.
Table 5. Metal forming industry RL applications and algorithms.
Milling Processes
In milling processes, the selection of process parameters and the stabilization of the system has been extensively studied. Moreover, hybrid architectures of RL with other ML technologies have been developed to improve the control of these processes. However, an important concern in milling processes is the occurrence of chatter vibrations, which can negatively affect the final product quality. The occurrence of chatter depends on the process parameters and the dynamics of the system, and it is crucial to detect it as soon as possible.
To maximize productivity and prevent chatter vibration in milling processes, Friedrich, Torzewski, and Verl (Citation2018) applied reinforced k-nearest neighbors (RkNN) for the parameters’ selection during the execution. The algorithm generated the stability lobe diagrams based on the measured data from the process. Validation was done with an environment simulation with analytical benchmark functions.
In addition, Shi et al. (Citation2020) applied an RkNN algorithm for fault diagnosis with the aim of detecting chatter vibrations in these industrial processes. This approach was tested under different cutting conditions with other ML approaches.
Another importantly highlighted particularity of industrial products, and specifically in milling processes, is the demand for increasingly personalized products. Typically, this involves manually adapting production to each customer, increasing final production costs. In this context, to maximize manufacturing KPIs, real-time decisions and adjustments regarding process planning and scheduling must be taken. Moreover, since the environments are unpredictable and dynamic, solutions must be adaptive and flexible.
Mueller-Zhang, Oliveira Antonino, and Kuhn (Citation2021) presented a DQN approach to efficiently schedule and plan productions in milling processes to address changes in the system and the requirement for personalization. The state information for the action selection was the runtime status of products and resources. The agent had to select a service to execute. The evaluation of the proposed solution was done in a virtual aluminum cold milling environment. Future research should consider more complex MDP definitions, modifying the action space definition, to represent a close-to-reality situation. Moreover, benchmarks with current popular control and decision-making approaches could demonstrate the improvements and benefits of applying RL techniques in the field.
Wang et al. (Citation2022) developed two DDQN approaches to control the milling process parameters in order to maximize system efficiency and the quality of the results. They solved a single-objective optimization problem and a multi-objective optimization problem. The first one was used to optimize three internal parameters of a support vector regression considered for surface roughness evaluation based on prediction accuracy. The second one was used to optimize the following machine parameters selection: spindle speed, feed rate, the width of cut, and depth of cut based on the surface roughness evaluation as a quality indicator and the material removal rate as an efficiency indicator. Both models considered the state space as the current parameters’ values and the action space was based on three actions per parameter: increase, decrease, or maintain its setting value between the defined boundaries. The training was done with experimental data and validation with the comparison with other algorithms achieving significantly better results with the DQN approaches. However, the models can be improved in terms of quality, training time, and explainability.
In the sustainable manufacturing field, Lu et al. (Citation2023) proposed a SAC algorithm for improving energy efficiency under changing deformation limits at each pass in a milling process. The environment considered for training was a surrogate model based on an ANN. The definition of the action space was the selection of parameters for each cutting state. Rewards were given considering the energy consumption and penalties associated with machining efficiency. The algorithm proposed was validated against the following alternative solutions: i) by changing the environment (from the surrogate model to an empirical model) and ii) by modifying the selected RL algorithm (from SAC to DDPG). Results showed that the SAC algorithm with the surrogate model environment converged faster and performed better.
Another SAC approach was introduced by Samsonov et al. (Citation2023), aimed at determining the workpiece position and orientation within the workspace of a milling machine. The primary objective was to minimize axis collisions, traveled distances, and accelerations to improve milling efficiency and safety. The proposed solution underwent training and validation in a simulated environment, benchmarked against traditional metaheuristic methods. However, the SAC approach exhibited some limitations compared to metaheuristics in certain scenarios. Notably, the evaluation solely occurs in a simulated environment, lacking real-world validation.
RL approaches, particularly Q-learning methods, are applied in milling processes for planning, scheduling, fault diagnosis, and improving system efficiency (). The works presented in this section have shown promising results. However, the extension of these techniques to more sophisticated environments and problem considerations, such as a more complex action space, represents a significant challenge.
Table 6. Milling processes RL applications and algorithms.
Power Industry
Decision-making and control problems, including energy management, demand response, electricity market, and operational control are crucial research problems in the power system (Zhang, Zhang, and Qiu Citation2019). Achieving each of these objectives contributes to improving the Power Grid’s profitability, which should be maximized while ensuring safety and reliability. Therefore, it is a very powerful field of research that requires efficient and complex decision-making frameworks to overcome uncertainties and challenges in operational conditions. Additionally, this sector is in constant growth due to the increasing energy demand every year. The complexity, uncertainty, and nonlinearity of the power system make it difficult to achieve high-quality and efficient control.
A wide range of methods has been proposed to solve energy and cost minimization problems, including linear programming and dynamic programming, heuristic methods such as Particle Swarm Optimization (PSO), or fuzzy methods that fail to consider online solutions for large-scale, real problems (Mocanu et al. Citation2019). RL has been applied to planning, control, and management under uncertainty with the aim of obtaining a more scalable solution that can ensure power quality, safety, and reliability.
In particular, Rocchetta et al. (Citation2019) have developed a Q-learning approach with DNN to manage the operation and maintenance of Power Grids under uncertainty. The objective of the implementation was to select operational and maintenance actions to maximize revenues and minimize costs. Thus, the cost and incomes related to the DQN actions selection were computed in the reward function. Moreover, other costs, such as the cost of not serving all the demanded energy to some customer, were computed as penalizations in the reward function. Decisions were made based on the degradation mechanism and the setting variables of power sources. Finally, the training and validation was made on simulations.
Purohit et al. (Citation2021) proposed a Q-learning approach with a DNN to control the duty cycle values in a buck power converter to manage the non-linearity. The buck converter was formulated as an MDP where the state space was a discretization of the values for the inductor current and the capacitor voltage. The action space had also been discretized in certain duty cycle values. Finally, the reward function was based on the difference between the desired average output voltage and the achieved one. The system was trained in a simulation environment and validated in an experimental setup. It was benchmarked against a PID controller and a value iteration approach.
Yin, Yu, and Zhou (Citation2018) developed a DQN approach to improve the performance of controllers in a large-scale Power System. In the same domain, the efficiency of Q-learning had been proven before. They proposed a DRL approach to overcome the weaknesses of tabular methods. The reward function considered the performance standard index, the system frequency deviation, and the control errors. Moreover, the performance standard index and the area control errors were provided in the state of the environment to the controller to set the power flow command of the generator. The power flow command of the generation had been discretized for the DQN approach. Training and evaluation were done using a simulator. The proposed approach was compared with PID, Q-learning, and Q()-Learning (Yu et al. Citation2015).
Al-Saffar and Musilek (Citation2019) applied an RL-Monte Carlo Tree Search (MCTS) for the distributed optimal power flow calculation in the electric power industry. The RL approach was used for the selection of distributed energy resource price bids considering the generation output cost that needs to be minimized while ensuring the satisfaction of all the constraints. The power transfer distribution factor was also considered in the state information for the action selection. The control policy trained and evaluated with a simulator was scalable and easily integrated into software for execution.
Predictive maintenance often has the problem of a lack of data in situations of failure or risk. Most of the collected data in the processes are from non-failure operations. Because of this imbalance in the collected data, it is often difficult to train predictive maintenance and fault diagnosis models using supervised learning models. Zhong, Zhang, and Ban (Citation2023) proposed an RL approach based on a DDQN algorithm for fault diagnosis of equipment in nuclear power plants in the cases of imbalanced class data. They used datasets as the MDP environment for training. Given a sample from a dataset, the agent had to select an action. If the selected action corresponded to the diagnosis label from the sample in the dataset, the received reward was positive, and negative otherwise. Higher values were given to minority classes. The DDQN maintenance model was compared with a supervised learning model in different scenarios demonstrating that the RL approach obtained better results in most cases.
Finally, there are several applications in the field of sustainable energy systems. Since renewable energy sources are dependent on weather conditions, their use for electricity generation is variable and unpredictable. The replacement of fossil fuel energy sources with renewable and distributed energies introduces great uncertainty and complexity to the sector to achieve energy efficiency. This requires an understanding of consumption with a deeper vision in order to optimize the allocation of resources in buildings. With this aim, Mocanu et al. (Citation2019) proposed and compared two different RL approaches for smart buildings able to minimize energy consumption and the total cost. A DPG algorithm provided better peak reductions and cost minimizations than DQN algorithms. The training and evaluations were made in a data-driven environment based on a large database. The action space was referred to as the selection of turning on or off an electrical device. This action selection was based on the building’s energy consumption and the price given at every moment in time. To guide the agent’s learning the reward function aggregated the three main components of this problem: the total energy consumption, the total cost, and the electrical device constraints.
Ongoing with the challenge of energy resources management from various renewable sources, Wang et al. (Citation2019) studied a similar problem. They proposed a DQN algorithm to handle the routing energy design under users’ uncertainties and fluctuations in energy generation. The action space was based on the planning of electrical power from different sources. The state space considered for action selection was based on the difference between its supply and its demand. The reward function was defined by aggregating the operating cost, the environmental cost, and the security operation. Finally, the RL approach was validated with simulations.
Renewable energy volatility affects the renewable energy consumption rate. Han et al. (Citation2023) proposed LM-SAC and IL-SAC algorithms based on the Lagrange multiplier method and imitation learning, respectively, to improve the renewable energy consumption rate for the power industry. They used a simulated environment to train the RL agents. The control actions defined were the active power and voltage of generators guided by the operation costs, the load rate, the consumption rate of renewable energy, and constraints to achieve the power balance and prevent undesired situations. They compared the results with other RL algorithms: the traditional SAC, the PPO, and the DDQN. The proposed methods outperformed the others in terms of better robustness and performance.
In the power industry sector, RL has been extensively researched. The papers analyzed are presented in . Planning and control problems have been simulated to prove the efficiency of these methods and their improvements by comparison with more traditional technologies. Valuable results are obtained in this field in addressing uncertainties associated with renewable energy and user demand fluctuations. Furthermore, power network planning becomes exceedingly challenging in complex systems with many buses and generators. In these scenarios, the number of states in the system is very large. Therefore, RL solutions offer an effective means to address these challenges. Although Q-learning methods are the most commonly used algorithms in this field, recent studies (Han et al. Citation2023; Mocanu et al. Citation2019) have shown that Actor-Critic methods outperform Q-learning approaches in sustainable energy consumption planning problems. However, despite much research being conducted in this field, developing a scalable solution for real, nonlinear, complex, and dynamic environments remains a challenge.
Table 7. Power industry RL applications and algorithms.
Application Overview and Analysis
In this section, we present a classification of industry applications based on their types and delve into the specifics of the training environments utilized. Our objective is twofold: first, to identify tasks within industrial environments with the potential for RL application, and second, to assess their level of applicability and transferability to real industrial settings.
The classification of application types and tasks is outlined as follows:
Robotic manipulation: The interaction of a robot with its physical environment for the performance of specific tasks and the manipulation of objects.
Scheduling/routing design: The systematic allocation of resources over time and strategic planning to optimize paths within a system.
Operational performance: The achievement of objectives in a process, considering aspects such as precision, quality, and other indicators of success in task execution.
Production efficiency: The achievement of goals with the least amount of resources possible.
Fault diagnosis: The identification of problems, errors, or malfunctions in a system.
While we have categorized types of applications in RL, it is important to note that multi-objective problems are considered, and as a result, some RL problems may address more than one type of application. For instance, applications falling into both efficiency and performance categories aim to maximize quality while simultaneously optimizing system efficiency (Wang et al. Citation2022). Despite our efforts to classify studies based on their primary objectives, the categorization may not always be absolute.
In the industrial context, an extra challenge lies in developing RL algorithms that not only prove effective in simulated environments during training but also demonstrate robust and efficient generalization to diverse, dynamic, and unpredictable real-world situations. A significant hurdle encountered in dealing with physical environments is the sim-to-real gap (Ranaweera and Mahmoud Citation2023). Zero-shot generalization (ZSG) in DRL becomes particularly relevant when applied to industrial environments facing the sim-to-real gap (Kirk et al. Citation2023) Incorporating ZSG in industrial RL applications has the potential to narrow the sim-to-real gap, enabling models to generalize more effectively across various conditions without an excessive need for real-world data during training.
We indicate whether each reviewed article considers a virtual or simulation environment, if the RL agent is trained and/or validated in a physical environment, and whether solutions are proposed to address the sim-to-real gap.
Summarized results for both perspectives of the study are presented in . The table categorizes articles by application type and provides a simple check mark or cross based on whether they employ simulation environments (sim), train and/or validate in physical environments (real), and address the sim-to-real gap issue. A dash is used in cases where training has been conducted in a real environment, making consideration of the sim-to-real gap irrelevant. This examination aims to illuminate the effectiveness of RL applications in physical domains and their potential for real-world deployment.
Table 8. Type of applications and sim-to-real analysis.
If we contrast this table with the previous tables (), we observe that Robotics is where a greater number of policy-optimization algorithms have been applied. In contrast, in scheduling and fault diagnosis, there are more applications of Q-learning algorithms. Finally, in operational performance and production efficiency applications, there is a greater variety of algorithms, although, in general, Q-learning algorithms have been quite prevalent in the analyzed studies. One plausible explanation for this pattern could be attributed to the simplicity inherent in Q-learning algorithms, particularly given the prevalence of discrete action spaces in many of these industrial applications.
The discussion on the simulation-to-real gap in reveals a notable scarcity in the literature. While the majority of studies rely on simulation environments for training, only a minority consider real or physical settings for validation, typically without implementing strategies to tackle the sim-to-real gap (Guo et al. Citation2019; Lu et al. Citation2023; Reinisch et al. Citation2021). Some researchers propose a hybrid approach, starting with simulated training and transitioning to real-world retraining (Ahn, Na, and Song Citation2023; Beltran-Hernandez et al. Citation2020; Nguyen et al. Citation2024). Yet, this method necessitates online training in real systems, which may be challenging in practical scenarios. Another hybrid strategy, showcased in Xian et al. (Citation2024), refines a surrogate model using experimental data from learned policies. Additionally, certain studies focus on direct online training in real-world contexts (Masinelli et al. Citation2020; Pane et al. Citation2019; Quang et al. Citation2022; Ruan, Gao, and Li Citation2019; Shi et al. Citation2020), underlining the necessity for sample efficiency to facilitate effective learning.
An interesting approach involves cross-domain knowledge transfer and adaptation, leveraging shared characteristics among manufacturing environments, as proposed by Meyes et al. (Citation2018). This strategy has the potential to enhance the efficiency of training methods across various industrial contexts. Additionally, they suggest using real experimental data for RL agent training without performing online training in a physical environment. Combining this with data collected from a simulator can effectively narrow the sim-to-real gap.
We contend that methodologies focused on minimizing the need for extensive real-world interactions during virtual training would significantly improve the adaptability of agents to real-world physical systems. In this context, offline RL techniques present more advanced solutions and are beginning to find applications in specific scenarios (Deng et al. Citation2023; He et al. Citation2023; Wang et al. Citation2023; Zhan et al. Citation2022). Nevertheless, challenges persist in implementing these methodologies, such as model evaluation, and their application in physical environments remains constrained (Prudencio, Maximo, and Luna Colombini Citation2023).
Advantages for Industrial Applications
Data and system control technologies are employed to overcome some critical issues commonly faced by industrial production processes. These issues are related to resources and materials management, machinery efficiency, environmental pollution, energy consumption reduction, and logistics systems (Tang and Meng Citation2021). Processes are becoming more complex due to unpredictable changes in production environments and the need for customization to meet varying demands. Thus, control and planning methodologies should evolve into more efficient and adaptive ones. In these scenarios, RL solutions present valuable advantages. The advantages are summarized in and described below.
Figure 3. Advantages in industrial and manufacturing RL applications.
Speedy Responses
Unlike other methodologies, DRL excels in providing rapid responses, eliminating the need for explicit planning in new scenarios, and enabling direct control in applications requiring real-time adjustments, thanks to its ability to generalize to new states. It is important to note that while the computation time is virtually zero for small NNs, RL might necessitate more complex architectures, and the computation of states should be taken into account. If the required information is readily available, RL does not impose significant overhead. However, in cases where state features introduce specific computational overhead within the RL setting, this becomes a crucial consideration. Despite the potentially lengthy training period, once trained, an RL agent exhibits an immediate response to any state without the need for additional calculations. This attribute proves particularly valuable for applications demanding swift and decisive decision-making.
Effective Generalization
While traditional RL may not be renowned for its generalization ability across diverse environments (Kirk et al. Citation2023), DRL leverages the generalization capacity of NNs to effectively tackle the challenges associated with adapting to unseen states within the same environment in the context of industrial planning and control. Once trained, a DRL agent demonstrates the ability to promptly respond to new states with appropriate actions, eliminating the need for additional training or extensive computation.
However, ensuring the efficient operation of the system and the achievement of its intended goals through accurate responses remain pivotal. Inaccurate responses from the RL agent could lead to costly mistakes or safety risks. To mitigate such risks, continuous monitoring, feedback, and evaluations become imperative. The enhanced generalization capabilities of DRL, facilitated by NNs, contribute to more reliable and adaptable responses in real-world industrial scenarios.
Outperformance of Traditional Methods
RL has the capacity to outperform traditional methods since it can take much more information into account. In particular, RL can take states into account at each iteration step of an industrial process. Supervised or unsupervised learning methods or traditionally hand designed methods struggle with this exponentially large or even infinite space.
The most frequently employed algorithms in the reviewed literature include Q-learning and its deep learning-based counterparts, such as DQN and Actor-Critic methods. In the presented research, these algorithms are frequently validated and tested alongside other control methodologies. Notably, RL surpasses other control methods in terms of online execution time and generalization capacity, making it an efficient choice for real-time planning in dynamic environments.
More specifically, RL algorithms have demonstrated improvements over solutions provided by alternative control and decision-making techniques, including static optimization (Guo et al. Citation2019), heuristics (Kuhnle et al. Citation2021; Waschneck et al. Citation2018), metaheuristics (Mattera, Caggiano, and Nele Citation2024; Xian et al. Citation2024), MPC (Pane et al. Citation2019), PID controllers (Purohit et al. Citation2021; Yin, Yu, and Zhou Citation2018), domain expert and business-as-usual (BAS) strategies (Nievas et al. Citation2022; Scheiderer et al. Citation2020; Tariq et al. Citation2020), and supervised learning models (Shi et al. Citation2020; Zhong, Zhang, and Ban Citation2023).
Ability to Learn without Prior Knowledge
RL agents exhibit the unique capability of controlling a system without the need for any initial policy or domain experience. These models rely solely on the action space provided to them and autonomously deduce the optimal policy function. However, it is crucial to note that specifying the MDP, including the state and action spaces and the reward function, demands a profound understanding of the process and objectives to ensure an accurate definition.
The action space can manifest as either discrete or continuous. In a discrete action space, the RL agent chooses from a predefined set of specific actions. Conversely, in a continuous action space, the agent is presented with a range of values for each control parameter, enabling an infinite number of selections. Regardless of the action space’s nature, whether discrete or continuous, the agent leverages its experience to determine the most suitable values for each parameter in every state.
The learning process unfolds through interaction with the environment, guided by a well-defined reward or objective function within the environment model. Notably, while the environment must be well-established with the correct MDP definition, the agent’s policy can commence from scratch without prior knowledge of the industry or its control task. Nevertheless, an initial policy based on imitation or transfer learning has the potential to expedite the learning process.
Challenges for Industrial Applications
Despite the RL advantages and potentials, it also presents several difficulties and challenges. These challenges are summarized in in four main stages: problem definition, environment for training, training phase, and deployment phase. The main challenges mentioned are presented in more detail below.
Figure 4. Challenges in industrial and manufacturing RL applications.
Problem Modeling
Modeling a problem as an MDP involves meticulous consideration of the state and action spaces, along with the reward function, to ensure the achievement of desired goals. In this context, the involvement of domain experts in the formalization process is crucial to guarantee the inclusion of all relevant and accessible information.
In a fully observable environment, the state should encompass all the information necessary for decision-making. However, real-world scenarios often necessitate decisions to be made without complete information (POMDP). Handling partially observable settings is challenging, typically necessitating the summarization of history. Recurrent learning architectures such as recurrent neural networks (RNNs) and even transformers are commonly employed in such contexts (Nguyen et al. Citation2024).
External variables, which are not part of the environment but play a crucial role in problem modeling (CMDP), may also need consideration. It is essential to recognize the features and constraints of the information available in our environment. This recognition allows us to implement a solution that effectively targets the specific problem at hand.
The action space, depending on the decision-making context, may be discrete or continuous. In many cases, a continuous action space is discretized to simplify the RL learning process. Further research is needed to consider a more complex and realistic action space, as high-dimensional continuous state and action spaces pose challenges for agent training.
Defining the reward function is a crucial step in problem modeling. This function must account for the consequences of each action in each situation, aligning with the system’s objectives and guiding the agent to find an efficient policy based on industrial KPIs. Although most systems have multi-dimensional costs to minimize, agents are trained with a single value metric. Therefore, the global reward function may represent a balance of multiple objectives. If the reward is not well-defined, considering the aims to achieve and trade-offs, the agent may not efficiently learn to manage any process or system.
Environment for Training
RL training in industrial settings often relies on simulations of real-world systems to accelerate learning and reduce the costs and risks associated with undesirable actions. However, there are situations where direct training of these algorithms on real systems is feasible, thereby eliminating the need for simulations or alternative methods and effectively eliminating the sim-to-real gap.
Nevertheless, this direct approach presents its own set of challenges. When training RL algorithms directly on real systems, particularly in online settings, ensuring safe exploration becomes paramount (Wachi et al. Citation2023). Additionally, achieving sample-efficient learning from limited exploration of the state-action space in previous data, as well as bootstrapping from unseen states and actions, is crucial (Nagabandi et al. Citation2018).
When training RL algorithms with simulation environments, the availability of simulation environments that strike a balance between speed and accuracy is essential for facilitating efficient learning during training phases. On one hand, the training process becomes both costly and time-consuming due to the necessity for a large number of interactions to accumulate sufficient experience for effective action selections and generalization. Therefore, minimizing process simulation times is important to enable training convergence toward satisfactory policies. On the other hand, simulators should exhibit sufficient accuracy to allow RL-trained agents to transition seamlessly to real-world environments.
Often, accurate simulation models that can faithfully represent complex environments tend to be too slow for RL training. To navigate this efficiency-quality trade-off, Degrave et al. (Degrave et al. Citation2022), in their application of RL to control a fusion reactor, incorporated the modeling of necessary physics and implemented substantial reward shaping. This approach prevents the RL agent from exploring state spaces where the physics theory was not well-developed, all while maintaining computational efficiency during training.
Moreover, RL has recently emerged as a potent tool for enhancing numerical simulations that rely on computationally intensive equations, which may be impractical or even impossible to solve directly. A notable application is in mesh generation for producing finite element meshes optimally across diverse domains (Foucart, Charous, and Lermusiaux Citation2023; Kim, Kim, and You Citation2024; Pan et al. Citation2023; Yang et al. Citation2023).
However, a new challenge arises when an accurate simulation environment is unavailable for such solutions. Addressing this issue, one potential solution is to explore the offline RL approach (Prudencio, Maximo, and Luna Colombini Citation2023). Instead of training the RL model in a simulation environment, a fixed dataset of previously collected experiences is utilized, eliminating the need for direct interaction with the process. Therefore, having a sufficiently large and comprehensive database is crucial for effective training. Moreover, employing offline RL techniques that address distribution shift and overestimation is essential to reduce the sim-to-real gap.
In the field of robotics, some articles opt for real data instead of simulations when training RL agents (Ahn, Na, and Song Citation2023). Gathering a significant amount of experimental training data is time-consuming, necessitating the exploration of more efficient sampling solutions. Hence, we propose a deeper exploration of model-based RL to address these challenges, following the approach exemplified in Xian et al. (Citation2024). Model-based RL algorithms use a limited number of interactions with the real environment to train a model of that environment. This model is then employed to simulate additional episodes, plan in diverse scenarios, and facilitate exploration (Moerland et al. Citation2023). Subsequent iterations with the real environment are used to refine the environment model. This approach reduces the number of real iterations required by utilizing a simulator that is periodically updated with the collected real data.
An alternative strategy involves leveraging process data to train data-driven models, surrogate models, or Digital Twins (Mocanu et al. Citation2019). In this context, the collection of abundant, high-quality, and diverse data becomes imperative to create accurate simulation environments. This data-driven approach offers a promising avenue for striking the necessary balance between accuracy and computational efficiency in simulation-based training scenarios.
Training and Validation
Training Phase
Based on the problem modeling, action space, and state space definition, the type of algorithms that better fit the problem needs to be selected. Depending on the dimensionality of the action and state spaces and their nature (discrete or continuous), different classes of algorithms can be applied. Moreover, these algorithms have many different parameters that need to be selected, validated, and tested.
It is not straightforward to decide which algorithm is better to use. However, some problem assumptions limit the usability of different types of algorithms. For example, if the state and action space are continuous, tabular algorithms and Q-learning methods are not feasible unless the spaces are discretized. Thus, policy-optimization methods would be more suitable. Generally, control and planning problems in MDPs with many variables are solved using actor-critic algorithms. Actor-critic algorithms are the most complex and frequently require more sophisticated implementation than other algorithms. However, they are the most efficient in high-dimensional spaces. An efficient implementation of a Q-learning approach might not be possible if the action space is discrete but highly dimensional.
Discretizing the state and action spaces is a common technique used to simplify real-world scenarios. In the case of discrete state and action spaces that are manageable in a table, there is no need to use value and policy function approximations, and tabular solutions may be the most appropriate. However, despite working with discrete state and action spaces, it is usually not feasible to work with methods such as classical tabular Q-learning, and methods capable of generalization are needed. Therefore, tabular algorithms are generally not the best option for real-world industrial applications. Nonetheless, they can be an interesting approach for developing a proof-of-concept model. For instance, they can be used to validate the reward function and policy training before implementing more complex algorithms.
Once trained, an RL agent gives immediate responses in a given state. However, the RL agent needs to be previously trained. In some tasks, the learning speed of an RL agent is excessively slow. In those cases, even when the environment is very fast for data collection, techniques to parallelize the agent’s training can be implemented to reduce the training time (Mnih et al. Citation2016). Moreover, in order to increase the learning efficiency, there are other strategies that can be considered such as prioritized experience replay (Schaul et al. Citation2016), transfer learning (Zhu et al. Citation2023), and automated RL (AutoRL) (Parker-Holder et al. Citation2022).
Experience replay reduces the correlation between transitions (state-action-reward-next state) by sampling them randomly, with equal probabilities, from the replay buffer instead of providing consecutive ones. Prioritize experience replay instead uses priorities to assign different probabilities to the collected experiences. The priority measure is computed based on the error between the predicted reward and the actual reward. Unexpected transitions are more probable to be sampled.
Transfer learning is the process of using prior kownledge for the RL training. The prior konwledge can be transferred by giving a pre-trained policy to the agent to help it learn faster or achieve better performance. It makes the training more efficient since the agent is not learning from scratch.
AutoRL refers to a set of methods that automate various aspects of the training process in RL to make it more efficient. It aims to optimize the design of RL algorithms, the configuration of hyperparameters, and the definition of network architectures.
Moreover, it is difficult to guarantee convergence and stability when training RL models. Tabular RL and RL with linear function approximators have convergence guarantees. However, when DNN and other nonlinear functions are used to estimate value and policy functions, convergence is not easy to guarantee (Dai et al. Citation2018).
On the other hand, DRL algorithms may be unstable. This instability can lead to non-desired setpoints, non-secure states, and catastrophic behaviors. During training steps, the learning curve that validates the performance of the learned policies may experience significant fluctuations, even though there is a strictly growing trend. During intermediate training phases, RL agents often experience highly rewarded behaviors. Sometimes, agents struggle to maintain those behaviors over time (Nikishin et al. Citation2018). It may happen because certain behaviors are not utilized frequently enough or due to changes in the environment. Therefore, it is important to select efficient exploration strategies during training phases and monitor and evaluate the performance of RL agents during deployments. Monitoring and evaluation will allow users or operators to identify when RL agents need to update their policies.
Stability in the control field is related to robustness, safety, and reliability. Thus, it must be considered and tested before deploying a control model. Much research is carried out in this direction to minimize the unstable control policy learning (Han et al. Citation2020; Nikishin et al. Citation2018).
Validation Phase
RL actions are rewarded based on performance indicators, and the resulting measure of interest gauges the effectiveness of a policy. However, this measure alone cannot guarantee the optimality of the policy. How can we ascertain that RL agents have acquired an efficient policy? In the existing literature, model validation occurs through two primary approaches:
Current industrial operative strategy and domain expert validation: RL policies undergo evaluation by comparing them to the behaviors exhibited by domain experts and the actual production performance. This validation method ensures alignment with established industry practices and leverages the expertise of professionals in the specific domain.
Benchmarking with other control and decision-making technologies: Various scenarios are explored by applying state-of-the-art control and decision-making techniques, such as heuristics and MPC. These alternative solutions serve as benchmarks against RL policies, allowing for a comparative analysis. Additionally, research endeavors to assess the performance of different RL algorithms, aiming to identify the one that best addresses the specific problem at hand. This benchmarking process contributes to the ongoing refinement and improvement of RL methodologies.
However, the stochastic nature of environments presents a significant challenge in the accurate evaluation and comparison of policies in highly uncertain settings (Parker-Holder et al. Citation2022).
Deployment
In the deployment of RL models in real-world scenarios, a challenge arises when these models are trained using simulators, contributing to the sim-to-real gap. Moreover, considering that industrial environments involve physical processes rather than virtual ones, it is essential to implement robust safety measures to ensure a secure deployment.
Simulation Compared to Real Environment
Despite the potential for generalization in models, there exists a risk of accumulating errors in state prediction along future trajectories. This concern is particularly relevant over an extended time horizon, where the growing disparity between predicted and actual states could become significantly pronounced. The challenges associated with model limitations extend further to certain simulators’ difficulties in generalizing to extreme case situations.
Consider, for instance, a data-driven environment model trained with real data, capturing operational behavior adhering to a specific logic in action selection. However, when the agent explores different policy behaviors not present in the environment’s model training set, predictions from the data-driven environment model may prove inaccurate. These discrepancies can exert a substantial impact on the learning and beliefs of the RL model, potentially leading to incorrect actions and unexpected results in the real environment, incurring a cost of policy failure.
Feedback and Adaptability to Disturbances
Effective monitoring is critical when deploying an RL agent in an industrial setting to detect potential model failures. If the environment is dynamic and significantly different from the environment in which the RL agent was trained, retraining may be necessary. Constant monitoring and evaluation are necessary to identify such deviations. Feedback on the agent’s performance can be obtained through monitoring, which can be done using sensors or other data sources that provide information about the manufacturing process. Additionally, evaluations can be made by domain experts, by comparing the agent’s results with those obtained using other methodologies, or by evaluating industrial KPIs.
An adaptable RL agent is essential to handle unexpected changes or disruptions in the environment. Industrial disturbances can come in various forms, such as changes in raw materials and in production lines, or equipment failures. An adaptable RL agent can quickly learn to adjust its behavior in response to these changes, ensuring system stability and efficiency. However, when the environment experiences substantial changes, the RL agent may need additional training to effectively adapt its policy to new scenarios. In this context, employing strategies that enhance training time and learning efficiency, such as parallelization of training and the implementation of incremental RL approaches, can help to reduce the computational costs associated with retraining in dynamic environments (Liu et al. Citation2023).
Explainable Decisions
When employing an intelligent agent in a real setting, understanding its behavior is one of its most crucial qualities. It entails comprehending how and why it selects what to do. Therefore, transparency and trust are key aspects in the industrial acceptance of a system with a certain autonomy. A simple RL algorithm, such as Q-learning, is straightforward to interpret. However, on the other hand, more complex function approximators such as DNN can be a black box. In this case, the system learns autonomously, and it is hard to understand how its predictions are achieved (Puiutta and Veith Citation2020).
Explainable RL and DRL are still emerging research fields. Due to the rapid increase in the use of these algorithms, the research in explainable RL is also increasing. However, there is still a long way of challenging research to be addressed in this field (Heuillet, Couthouis, and Díaz-Rodríguez Citation2021). The correlations between state features and actions can help identify which state features are the most relevant to the learned policy and how they are weighted. Correlations can reveal important details about the inner workings of the RL agent and also make it possible to identify any potential problem, including biases or mistakes made during the decision-making process.
Safety Restrictions
In industrial applications, there are restrictions in the state and action spaces that need to be considered in order to avoid equipment damage and non-safety situations. All system constraints must be contemplated in the control policies (Dulac-Arnold et al. Citation2021). In this context, the research field Safe RL focuses on the design of RL training that prioritize safe solutions that respect the problem constraints with efficient performance (Garcıa and Fernández Citation2015). This research presents two main approaches. The first approach directly inserts constraints into the RL algorithm. The RL agent can be encouraged to work within the system’s safe operating boundaries by penalizing the reward function (Nievas et al. Citation2022) or restricting the action space. The second approach incorporates external knowledge which can come from backup controllers or monitoring systems. If the RL agent strays too far from the safe operating limits or fails to operate within the predetermined constraints, it may be programmed to take over system control.
Conclusion
Transforming conventional machines into self-aware and self-learning systems to interact with various environments can significantly improve the total performance, quality, efficiency, and maintenance management of assets, among other KPIs. RL solutions have the potential to enhance productivity and reduce costs in industrial processes by providing real-time responses to dynamic environments, outperforming classical optimization techniques. Furthermore, RL algorithms are not domain-specific and can be easily transferred to other fields. This work reviews several research papers that apply RL-based solutions to diverse industrial problems identifying the principal benefits and the current gaps and limitations.
Research on RL applied to the industry has provided advancements in process planning, maintenance, and quality control, which will fuel its growth over the coming few years. The DQN and SAC algorithms are two of the most commonly used RL solutions in the context of Industry 4.0. To accelerate the learning process it is recommended to combine RL with imitation learning and/or transfer learning. The choice of algorithms depends on the specific application and its MDP definition. For instance, DQN requires a discrete action space, making it a suitable solution when the action space is discrete and not highly dimensional. On the other hand, when dealing with high-dimensional or continuous action spaces, an actor-critic solution like SAC may be a better choice.
Despite these advancements, RL is still in its early stages concerning industrial and manufacturing applications, presenting substantial opportunities for further research. Managing and controlling higher-order systems that exhibit unpredictability and non-linearity continues to be a significant challenge. Moreover, the limited existence of rapid and accurate models to simulate complex real-world processes difficult the training of RL agents. High-fidelity simulations or Digital Twins can be very effective, but can also be challenging to obtain, and maintain, and computationally expensive to run.
Typically, the learning process takes place within simulation environments, which differ from the actual operational environments, posing challenges for applying trained RL agents. Consequently, bridging the knowledge transfer gap between simulated and real environments is a crucial research topic in the field of manufacturing RL.
To eliminate this knowledge transfer gap, RL agents can be directly trained in real-world environments. However, this introduces new risks, such as safety restrictions and limited exploration opportunities. Additionally, the training speed is dependent on the actual physical time of the system environment. Therefore, research focused on accelerating the learning process and sample efficiency, ensuring exploration, and maintaining safety restrictions represents areas of ongoing investigation. We propose exploring model-based and offline RL solutions.
Moreover, there are safety restrictions and costs associated with the deployment of this technology. To avoid undesirable situations and negative consequences in physical systems, dangerous actions should be restricted. A reliable RL agent must be capable of generalizing well to new events, adapting to dynamic environments, and preventing catastrophic failures. Research on interpretability and safe RL is essential to ensure the reliable deployment of RL agents in manufacturing systems.
interact.cls
Download (23.9 KB)natbib.sty
Download (44.4 KB)interactapasample.bib
Download Bibliographical Database File (93.5 KB)subfig.sty
Download (20.9 KB)tfcad.bst
Download (32.4 KB)booktabs.sty
Download (6.2 KB)Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplementary Material
Supplemental data for this article can be accessed online at https://doi.org/10.1080/08839514.2024.2383101
Additional information
Funding
References
- Adriaensen, S., A. Biedenkapp, G. Shala, N. Awad, T. Eimer, M. Lindauer, and F. Hutter. 2022. Automated dynamic algorithm configuration. The Journal of Artificial Intelligence Research 75:1633–53. doi:10.1613/jair.1.13922.
- Ahn, K.-H., M. Na, and J.-B. Song. 2023. Robotic assembly strategy via reinforcement learning based on force and visual information. Robotics and Autonomous Systems 164:104399. https://www.sciencedirect.com/science/article/pii/S0921889023000386.
- Al-Saffar, M., and P. Musilek. 2019. Distributed optimal power flow for electric power systems with high penetration of distributed energy resources. 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), 1–5. IEEE, May. https://ieeexplore.ieee.org/document/8861718/.
- Antos, A., C. Szepesvári, and R. Munos. 2007. Fitted Q-iteration in continuous action-space MDPs. Advances in Neural Information Processing Systems 20. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2007/file/da0d1111d2dc5d489242e60ebcbaf988-Paper.pdf.
- Atae, J.-T., and D. P. Gruber. 2021. Reinforcement-learning-based control of an industrial robotic arm for following a randomly-generated 2D-Trajectory. 2021 IEEE International Conference on Omni-Layer Intelligent Systems (COINS), Barcelona, Spain, 1–6. IEEE, August.
- Bayiz, Y. E., and R. Babuska. 2014. Nonlinear disturbance compensation and reference tracking via reinforcement learning with fuzzy approximators. IFAC Proceedings 47 (3):5393–98. doi:10.3182/20140824-6-ZA-1003.02511.
- Bécue, A., I. Praça, and J. Gama. 2021. Artificial intelligence, cyber-threats and industry 4.0: Challenges and opportunities. Artificial Intelligence Review 54 (5):3849–86. doi:10.1007/s10462-020-09942-2.
- Beltran-Hernandez, C. C., D. Petit, I. G. Ramirez-Alpizar, and K. Harada. 2020. Variable compliance control for robotic peg-in-hole assembly: A deep-reinforcement-learning approach. Applied Sciences 10 (19):1–17. doi:10.3390/app10196923.
- Cao, D., W. Hu, J. Zhao, G. Zhang, B. Zhang, Z. Liu, Z. Chen, and F. Blaabjerg. 2020. Reinforcement learning and its applications in modern power and energy systems: A review. Journal of Modern Power Systems and Clean Energy 8 (6):1029–42. doi:10.35833/MPCE.2020.000552.
- Dai, B., A. Shaw, L. Li, L. Xiao, N. He, Z. Liu, J. Chen, and L. Song. 2018. Sbeed: Convergent reinforcement learning with nonlinear function approximation. International Conference on Machine Learning, 1125–34. https://proceedings.mlr.press/v80/dai18c.html.
- Degrave, J., F. Felici, J. Buchli, M. Neunert, B. Tracey, F. Carpanese, T. Ewalds, R. Hafner, A. Abdolmaleki, D. de las Casas, et al. 2022. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 602 (7897):414–19. doi:10.1038/s41586-021-04301-9.
- Degris, T., P. M. Pilarski, and R. S. Sutton. 2012. Model-free reinforcement learning with continuous action in practice. 2012 American Control Conference (ACC), 2177–82. IEEE, June. http://ieeexplore.ieee.org/document/6315022/.
- Deng, J., S. Sierla, J. Sun, and V. Vyatkin. 2023. Offline reinforcement learning for industrial process control: A case study from steel industry. Information Sciences 632:221–31. doi:10.1016/j.ins.2023.03.019.
- Dulac-Arnold, G., N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester. 2021. Challenges of real-world reinforcement learning: Definitions, benchmarks and analysis. Machine Learning 110 (9):2419–68. doi:10.1007/s10994-021-05961-4.
- Ebrie, A. S., C. Paik, Y. Chung, and Y. Jin Kim. 2023. Environment-friendly power scheduling based on deep contextual reinforcement learning. Energies 16 (16):1–12. doi:10.3390/en16165920.
- Foucart, C., A. Charous, and P. F. Lermusiaux. 2023. Deep reinforcement learning for adaptive mesh refinement. Journal of Computational Physics 491:112381. doi:10.1016/j.jcp.2023.112381.
- Friedrich, J., J. Torzewski, and A. Verl. 2018. Online learning of stability lobe diagrams in milling. Procedia CIRP 67:278–83. doi:10.1016/j.procir.2017.12.213.
- Fujimoto, S., H. Hoof, and D. Meger. 2018. Addressing function approximation error in actor-critic methods. International conference on machine learning, Stockholm, Sweden, 1587–96, PMLR.
- Garcıa, J., and F. Fernández. 2015. A comprehensive survey on safe reinforcement learning. Journal of Machine Learning Research 16 (1):1437–80. https://www.jmlr.org/papers/volume16/garcia15a/garcia15a.pdf.
- Grondman, I., L. Busoniu, G. A. D. Lopes, and R. Babuska. 2012. A survey of actor-critic reinforcement learning: Standard and natural policy gradients. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) 42 (6):1291–307. doi:10.1109/TSMCC.2012.2218595.
- Günther, J., P. M. Pilarski, G. Helfrich, H. Shen, and K. Diepold. 2014. First steps towards an intelligent laser welding architecture using deep neural networks and reinforcement learning. Procedia Technology 15:474–83. doi:10.1016/j.protcy.2014.09.007.
- Günther, J., P. M. Pilarski, G. Helfrich, H. Shen, and K. Diepold. 2016. Intelligent laser welding through representation, prediction, and control learning: An architecture with deep neural networks and reinforcement learning. Mechatronics 34:1–11. doi:10.1016/j.mechatronics.2015.09.004.
- Guo, F., X. Zhou, J. Liu, Y. Zhang, D. Li, and H. Zhou. 2019. A reinforcement learning decision model for online process parameters optimization from offline data in injection molding. Applied Soft Computing 85:105828. doi:10.1016/j.asoc.2019.105828.
- Guzman, E., B. Andres, and R. Poler. 2022. Models and algorithms for production planning, scheduling and sequencing problems: A holistic framework and a systematic review. Journal of Industrial Information Integration 27:100287. doi:10.1016/j.jii.2021.100287.
- Haarnoja, T., A. Zhou, P. Abbeel, and S. Levine. 2018. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International conference on machine learning, PMLR, Stockholm, Sweden, 1861–70. July.
- Hallak, A., D. Di Castro, and S. Mannor. 2015. Contextual markov decision processes. http://arxiv.org/abs/1502.02259.
- Hambly, B., R. Xu, and H. Yang. 2023. Recent advances in reinforcement learning in finance. Mathematical Finance 33 (3):437–503. doi:10.1111/mafi.12382.
- Han, M., L. Zhang, J. Wang, and W. Pan. 2020. Actor-critic reinforcement learning for control with stability guarantee. IEEE Robotics and Automation Letters 5 (4):6217–24. https://ieeexplore.ieee.org/document/9146733/.
- Han, X., C. Mu, J. Yan, and Z. Niu. 2023. An autonomous control technology based on deep reinforcement learning for optimal active power dispatch. International Journal of Electrical Power & Energy Systems 145:108686. doi:10.1016/j.ijepes.2022.108686.
- He, H., Z. Niu, Y. Wang, R. Huang, and Y. Shou. 2023. Energy management optimization for connected hybrid electric vehicle using offline reinforcement learning. Journal of Energy Storage 72 (December 2022):108517. doi:10.1016/j.est.2023.108517.
- Heuillet, A., F. Couthouis, and N. Díaz-Rodríguez. 2021. Explainability in deep reinforcement learning. Knowledge-Based Systems 214:106685. doi:10.1016/j.knosys.2020.106685.
- Jin, Z., H. Li, and H. Gao. 2019. An intelligent weld control strategy based on reinforcement learning approach. International Journal of Advanced Manufacturing Technology 100 (9–12):2163–75. doi:10.1007/s00170-018-2864-2.
- Kim, I., S. Kim, and D. You. 2024. Non-iterative generation of an optimal mesh for a blade passage using deep reinforcement learning. Computer Physics Communications 294:108962. doi:10.1016/j.cpc.2023.108962.
- Kiran, B. R., I. Sobh, V. Talpaert, P. Mannion, A. A. Al Sallab, S. Yogamani, and P. Pérez. 2021. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems 23 (6):4909–26. doi:10.1109/TITS.2021.3054625.
- Kirk, R., A. Zhang, E. Grefenstette, and T. Rocktäschel. 2023. A survey of zero-shot generalisation in deep reinforcement learning. The Journal of Artificial Intelligence Research 76:201–64. doi:10.1613/jair.1.14174.
- Kuhnle, A., J.-P. Kaiser, F. Theiß, N. Stricker, and G. Lanza. 2021. Designing an adaptive production control system using reinforcement learning. Journal of Intelligent Manufacturing 32 (3):855–76. doi:10.1007/s10845-020-01612-y.
- Kuhnle, A., N. Röhrig, and G. Lanza. 2019. Autonomous order dispatching in the semiconductor industry using reinforcement learning. Procedia CIRP 79:391–96. doi:10.1016/j.procir.2019.02.101.
- Kuhnle, A., L. Schäfer, N. Stricker, and G. Lanza. 2019. Design, implementation and evaluation of reinforcement learning for an adaptive order dispatching in job shop manufacturing systems. Procedia CIRP 81:234–39. doi:10.1016/j.procir.2019.03.041.
- Kumar, A., J. Fu, G. Tucker, and S. Levine. 2019. Stabilizing off-policy Q-learning via bootstrapping error reduction. Advances in Neural Information Processing Systems (NeurIPS) 32:11784–11794.
- Ladosz, P., L. Weng, M. Kim, and H. Oh. 2022. Exploration in deep reinforcement learning: A survey. Information Fusion 85:1–22. doi:10.1016/j.inffus.2022.03.003.
- Lample, G., and D. Singh Chaplot. 2017. Playing FPS games with deep reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, California USA 31.
- Lasi, H., P. Fettke, H.-G. Kemper, T. Feld, and M. Hoffmann. 2014. Industry 4.0. Business & Information Systems Engineering 6 (4):239–42. doi:10.1007/s12599-014-0334-4.
- Lee, Y. H., and S. Lee. 2022. Deep reinforcement learning based scheduling within production plan in semiconductor fabrication. Expert Systems with Applications 191:116222. doi:10.1016/j.eswa.2021.116222.
- Levine, S., A. Kumar, G. Tucker, and J. Fu. 2020. Offline reinforcement learning: Tutorial. Review, and Perspectives on Open Problems 1–43. http://arxiv.org/abs/2005.01643.
- Li, X., Q. Luo, L. Wang, R. Zhang, and F. Gao. 2022. Off-policy reinforcement learning-based novel model-free minmax fault-tolerant tracking control for industrial processes. Journal of Process Control 115:145–56. doi:10.1016/j.jprocont.2022.05.006.
- Littman, M. L., A. W. Moore, and A. W. Moore. 1996. Reinforcement learning: A survey. The Journal of Artificial Intelligence Research 4:237–85. doi:10.1613/jair.301.
- Liu, C., J. Gao, Y. Bi, X. Shi, and D. Tian. 2020. A multitasking-oriented robot arm motion planning scheme based on deep reinforcement learning and twin synchro-control. Sensors 20 (12):3515–35. doi:10.3390/s20123515.
- Liu, D., S. Xue, B. Zhao, B. Luo, and Q. Wei. 2021. Adaptive dynamic programming for control: A survey and recent advances. IEEE Transactions on Systems, Man, and Cybernetics: Systems 51 (1):142–60. doi:10.1109/TSMC.2020.3042876.
- Liu, S., Z. Shi, J. Lin, and Z. Li. 2020. Reinforcement learning in free-form stamping of sheet-metals. Procedia Manufacturing 50:444–49. https://linkinghub.elsevier.com/retrieve/pii/S2351978920317790.
- Liu, S., B. Wang, H. Li, C. Chen, and Z. Wang. 2023. Continual portfolio selection in dynamic environments via incremental reinforcement learning. International Journal of Machine Learning and Cybernetics 14 (1):269–79. doi:10.1007/s13042-022-01639-y.
- Lu, F., G. Zhou, C. Zhang, Y. Liu, F. Chang, and Z. Xiao. 2023. Energy-efficient multi-pass cutting parameters optimisation for aviation parts in flank milling with deep reinforcement learning. Robotics and Computer-Integrated Manufacturing 81:102488. doi:10.1016/j.rcim.2022.102488.
- Ma, Z., and T. Pan. 2024. DRL-dEWMA: A composite framework for run-to-run control in the semiconductor manufacturing process. Neural Computing & Applications 36 (3):1429–47. doi:10.1007/s00521-023-09112-9.
- Masinelli, G., T. Le-Quang, S. Zanoli, K. Wasmer, and S. A. Shevchik. 2020. Adaptive laser welding control: A reinforcement learning approach. Institute of Electrical and Electronics Engineers Access 8:103803–14. https://ieeexplore.ieee.org/document/9102251/.
- Mattera, G., A. Caggiano, and L. Nele. 2024. Reinforcement learning as data-driven optimization technique for GMAW process. Welding in the World 68 (4):805–17. doi:10.1007/s40194-023-01641-0.
- Matulis, M., and C. Harvey. 2021. A robot arm digital twin utilising reinforcement learning. Computers & Graphics 95:106–14. doi:10.1016/j.cag.2021.01.011.
- Meyes, R., H. Tercan, S. Roggendorf, T. Thiele, C. Büscher, M. Obdenbusch, C. Brecher, S. Jeschke, and T. Meisen. 2017. Motion planning for industrial robots using reinforcement learning. Procedia CIRP 63:107–12. doi:10.1016/j.procir.2017.03.095.
- Meyes, R., H. Tercan, T. Thiele, A. Krämer, J. Heinisch, M. Liebenberg, G. Hirt, C. Hopmann, G. Lakemeyer, T. Meisen, et al. 2018. Interdisciplinary data driven production process analysis for the internet of production. Procedia Manufacturing 26:1065–76. doi:10.1016/j.promfg.2018.07.143.
- Mnih, V., A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. 2016. Asynchronous methods for deep reinforcement learning. International Conference on Machine Learning, PMLR 1928–37. Jun. https://proceedings.mlr.press/v48/mniha16.html.
- Mnih, V., K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518 (7540):529–33. doi:10.1038/nature14236.
- Mocanu, E., D. Constantin Mocanu, P. H. Nguyen, A. Liotta, M. E. Webber, M. Gibescu, and J. G. Slootweg. 2019. On-line building energy optimization using deep reinforcement learning. IEEE Transactions on Smart Grid 10 (4):3698–708. https://ieeexplore.ieee.org/document/8356086/.
- Modayil, J., A. White, and R. S. Sutton. 2014. Multi-timescale nexting in a reinforcement learning robot. Adaptive Behavior 22 (2):146–60. doi:10.1177/1059712313511648.
- Modi, A., N. Jiang, S. Singh, and A. Tewari. 2018. Markov decision processes with continuous side information. In Algorithmic learning theory, ed. F. Janoos, M. Mohri, and K. Sridharan, 597–618. Cambridge, MA, USA: PMLR.
- Moerland, T. M., J. Broekens, A. Plaat, and C. M. Jonker. 2023. Model-based reinforcement learning: A survey. Foundations & Trends in Machine Learning 16 (1):1–118. doi:10.1561/2200000086.
- Mueller-Zhang, Z., P. Oliveira Antonino, and T. Kuhn. 2021. Integrated planning and scheduling for customized production using digital twins and reinforcement learning. IFAC-Papersonline 54 (1):408–13. https://linkinghub.elsevier.com/retrieve/pii/S2405896321007631.
- Nagabandi, A., I. Clavera, S. Liu, R. S. Fearing, P. Abbeel, S. Levine, and C. Finn. 2018. Learning to adapt in dynamic, real-world environments through meta-reinforcement learning. https://arxiv.org/abs/1803.11347.
- Nguyen, H., T. Kozuno, C. C. Beltran-Hernandez, and M. Hamaya. 2024. Symmetry-aware reinforcement learning for robotic assembly under partial observability with a soft wrist. IEEE International Conference on Robotics and Automation, Yohokama, Japan.
- Nian, R., J. Liu, and B. Huang. 2020. A review on reinforcement learning: Introduction and applications in industrial process control. Computers & Chemical Engineering 139:106886. doi:10.1016/j.compchemeng.2020.106886.
- Nievas, N., A. Pagès-Bernaus, F. Bonada, L. Echeverria, A. Abio, D. Lange, and J. Pujante. 2022. A reinforcement learning control in hot stamping for cycle time optimization. Materials 15 (14):4825. https://www.mdpi.com/1996-1944/15/14/4825.
- Nikishin, E., P. Izmailov, B. Athiwaratkun, D. Podoprikhin, T. Garipov, P. Shvechikov, D. Vetrov, and A. G. Wilson. 2018. Improving stability in deep reinforcement learning with weight averaging. Uncertainty in Artificial Intelligence Workshop on Uncertainty in Deep Learning. http://www.gatsby.ucl.ac.uk/balaji/udl-camera-ready/UDL-24.pdf.
- Pan, J., J. Huang, G. Cheng, and Y. Zeng. 2023. Reinforcement learning for automatic quadrilateral mesh generation: A soft actor–critic approach. Neural Networks 157:288–304. doi:10.1016/j.neunet.2022.10.022.
- Pane, Y. P., S. P. Nageshrao, J. Kober, and R. Babuška. 2019. Reinforcement learning based compensation methods for robot manipulators. Engineering Applications of Artificial Intelligence 78:236–47. doi:10.1016/j.engappai.2018.11.006.
- Parker-Holder, J., R. Rajan, X. Song, A. Biedenkapp, Y. Miao, T. Eimer, B. Zhang, V. Nguyen, R. Calandra, A. Faust, et al. 2022. Automated reinforcement learning (AutoRL): A survey and open problems. The Journal of Artificial Intelligence Research 74:517–68. doi:10.1613/jair.1.13596.
- Peres, R. S., X. Jia, J. Lee, K. Sun, A. Walter Colombo, and J. Barata. 2020. Industrial artificial intelligence in industry 4.0 - systematic review, challenges and outlook. Institute of Electrical and Electronics Engineers Access 8:220121–39. doi:10.1109/ACCESS.2020.3042874.
- Powell, W. B. 2007. Approximate dynamic programming: Solving the curses of dimensionality. Hoboken, NJ, USA: John Wiley & Sons. https://books.google.es/books?id=WWWDkd65TdYC.
- Prudencio, R. F., M. R. O. A. Maximo, and E. Luna Colombini. 2023. A survey on offline reinforcement learning: Taxonomy, review, and open problems. IEEE Transactions on Neural Networks and Learning Systems, 1–0. https://ieeexplore.ieee.org/document/10078377/.
- Puiutta, E., and E. M. S. P. Veith. 2020. Explainable reinforcement learning: A survey. International Cross-Domain Conference for Machine Learning and Knowledge Extraction 12279:77–95.
- Purohit, C. S., S. Manna, G. Mani, and A. Alexander Stonier. 2021. Development of buck power converter circuit with ANN RL algorithm intended for power industry. Circuit World 47 (4):391–99. https://www.emerald.com/insight/content/doi/10.1108/CW-03-2020-0044/full/html.
- Qin, Y., C. Zhao, and F. Gao. 2018. An intelligent non-optimality self-recovery method based on reinforcement learning with small data in big data era. Chemometrics and Intelligent Laboratory Systems 176:89–100. doi:10.1016/j.chemolab.2018.03.010.
- Quang, T. L., B. Meylan, G. Masinelli, F. Saeidi, S. A. Shevchik, F. Vakili Farahani, and K. Wasmer. 2022. Smart closed-loop control of laser welding using reinforcement learning. Procedia CIRP, vol. 111, 479–83, 12th CIRP Conference on Photonic Technologies [LANE 2022]. https://www.sciencedirect.com/science/article/pii/S2212827122009532.
- Ranaweera, M., and Q. H. Mahmoud. 2023. Bridging the reality gap between virtual and physical environments through reinforcement learning. Institute of Electrical and Electronics Engineers Access 11:19914–27. https://ieeexplore.ieee.org/document/10054009/.
- Reinisch, N., F. Rudolph, S. Günther, D. Bailly, and G. Hirt. 2021. Successful pass schedule design in open-die forging using double deep Q-Learning. Processes 9 (7):1084. doi:10.3390/pr9071084.
- Rocchetta, R., L. Bellani, M. Compare, E. Zio, and E. Patelli. 2019. A reinforcement learning framework for optimal operation and maintenance of power grids. Applied Energy 241:291–301. doi:10.1016/j.apenergy.2019.03.027.
- Ruan, Y., H. Gao, and D. Li. 2019. Improving the consistency of injection molding products by intelligent temperature compensation control. Advances in Polymer Technology 2019:1–13. doi:10.1155/2019/1591204.
- Samsonov, V., E. Chrismarie, H.-G. Köpken, S. Bär, D. Lütticke, and T. Meisen. 2023. Deep representation learning and reinforcement learning for workpiece setup optimization in CNC milling. Production Engineering 17 (6):847–59. doi:10.1007/s11740-023-01209-3.
- Schaul, T., J. Quan, I. Antonoglou, and D. Silver. 2016. Prioritized experience replay. International Conference on Learning Representations, San Juan, Puerto Rico.
- Scheiderer, C., T. Thun, C. Idzik, A. Felipe Posada-Moreno, A. Krämer, J. Lohmar, G. Hirt, and T. Meisen. 2020. Simulation-as-a-service for reinforcement learning applications by example of heavy plate rolling processes. Procedia Manufacturing 51:897–903. doi:10.1016/j.promfg.2020.10.126.
- Schulman, J., S. Levine, P. Abbeel, M. Jordan, and P. Moritz. 2015. Trust region policy optimization. International conference on machine learning. PMLR, 1889–97. https://proceedings.mlr.press/v37/schulman15.html.
- Schulman, J., F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. 2017. Proximal policy optimization algorithms. https://arxiv.org/abs/1707.06347.
- Shi, F., H. Cao, X. Zhang, and X. Chen. 2020. A reinforced k-nearest neighbors method with application to chatter identification in high-speed milling. IEEE Transactions on Industrial Electronics 67 (12):10844–55. doi:10.1109/TIE.2019.2962465.
- Silver, D., T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, et al. 2018. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 362 (6419):1140–44. doi:10.1126/science.aar6404.
- Silver, D., G. Lever, N. Heess, T. Degris, D. Wierstra, and M. Riedmiller. 2014. Deterministic policy gradient algorithms. International conference on machine learning, PMLR, 387–95, January. https://proceedings.mlr.press/v32/silver14.html.
- Singh, B., R. Kumar, and V. Pratap Singh. 2022. Reinforcement learning in robotic applications: A comprehensive survey. Artificial Intelligence Review 55 (2):945–90. doi:10.1007/s10462-021-09997-9.
- Spaan, M. T. J. 2012. Partially observable Markov decision processes. Adaptation, Learning, and Optimization 12:387–414.
- Stricker, N., A. Kuhnle, R. Sturm, and S. Friess. 2018. Reinforcement learning for adaptive order dispatching in the semiconductor industry. CIRP Annals 67 (1):511–14. doi:10.1016/j.cirp.2018.04.041.
- Sutton, R. S., and A. G. Barto. 2018. Reinforcement learning: An introduction. Cambridge, MA, USA: MIT press.
- Sutton, R. S., D. McAllester, S. Singh, and Y. Mansour. 1999. Policy gradient methods for reinforcement learning with function approximation. Advances in Neural Information Processing Systems 12. https://proceedings.neurips.cc/paper/1999/file/464d828b85b0bed98e80ade0a5c43b0f-Paper.pdf.
- Tang, L., and Y. Meng. 2021. Data analytics and optimization for smart industry. Frontiers of Engineering Management 8 (2):157–71. doi:10.1007/s42524-020-0126-0.
- Tariq, A., S. N.-I. Muhammad, H. Ehm, T. Ponsignon, and A. Hamed. 2020. A deep reinforcement learning approach for optimal replenishment policy in a vendor managed inventory setting for semiconductors. 2020 Winter Simulation Conference (WSC), 1753–64, IEEE, December. https://ieeexplore.ieee.org/document/9384048/.
- Tavazoei, M. S. 2012. From traditional to fractional PI control: A key for generalization. IEEE Industrial Electronics Magazine 6 (3):41–51. doi:10.1109/MIE.2012.2207818.
- Tejer, M., R. Szczepanski, and T. Tarczewski. 2024. Robust and efficient task scheduling for robotics applications with reinforcement learning. Engineering Applications of Artificial Intelligence 127:107300. doi:10.1016/j.engappai.2023.107300.
- Uc-Cetina, V., N. Navarro-Guerrero, A. Martin-Gonzalez, C. Weber, and S. Wermter. 2023. Survey on reinforcement learning for language processing. Artificial Intelligence Review 56 (2):1543–75. doi:10.1007/s10462-022-10205-5.
- Van Hasselt, H., A. Guez, and D. Silver. 2016. Deep reinforcement learning with double Q-learning. Proceedings of the AAAI conference on artificial intelligence, Phoenix, Arizona USA, vol. 30, March.
- Wachi, A., H. Wataru, S. Xun, and H. Kazumune. 2023. Safe exploration in reinforcement learning: A generalized formulation and algorithms. In Advances in neural information processing systems, ed. A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, vol. 36, 29252–72. NY, USA: Curran Associates, Inc.
- Wang, D.-L., Q.-Y. Sun, Y.-Y. Li, and X.-R. Liu. 2019. Optimal energy routing design in energy internet with multiple energy routing centers using artificial neural network-based reinforcement learning method. Applied Sciences 9 (3):3. doi:10.3390/app9030520.
- Wang, X., L. Zhang, Y. Liu, and C. Zhao. 2023. Logistics-involved task scheduling in cloud manufacturing with offline deep reinforcement learning. Journal of Industrial Information Integration 34 (May):100471. doi:10.1016/j.jii.2023.100471.
- Wang, Z., J. Lu, C. Chen, J. Ma, and X. Liao. 2022. Investigating the multi-objective optimization of quality and efficiency using deep reinforcement learning. Applied Intelligence 52 (11):12873–87. doi:10.1007/s10489-022-03326-5.
- Waschneck, B., A. Reichstaller, L. Belzner, T. Altenmüller, T. Bauernhansl, A. Knapp, and A. Kyek. 2018. Optimization of global production scheduling with deep reinforcement learning. Procedia CIRP 72:1264–69. doi:10.1016/j.procir.2018.03.212.
- Watkins, C. J., and P. Dayan. 1992. Q-learning. Machine Learning 8 (3–4):279–92. doi:10.1007/BF00992698.
- Wen, X., H. Shi, C. Su, X. Jiang, P. Li, and J. Yu. 2021. Novel data-driven two-dimensional Q-learning for optimal tracking control of batch process with unknown dynamics. ISA Transactions 125:10–21. https://linkinghub.elsevier.com/retrieve/pii/S0019057821003232.
- Xian, Y., P. Dang, Y. Tian, X. Jiang, Y. Zhou, X. Ding, J. Sun, T. Lookman, and D. Xue. 2024. Compositional design of multicomponent alloys using reinforcement learning. Acta Materialia 274:120017. doi:10.1016/j.actamat.2024.120017.
- Xu, X., L. Zuo, and Z. Huang. 2014. Reinforcement learning algorithms with function approximation: Recent advances and applications. Information Sciences 261:1–31. doi:10.1016/j.ins.2013.08.037.
- Yang, J., T. Dzanic, B. Petersen, J. Kudo, K. Mittal, V. Tomov, J.-S. Camier. 2023. Reinforcement learning for adaptive mesh refinement. International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 5997–6014, PMLR.
- Yeap, G. 2013. Smart mobile SoCs driving the semiconductor industry: Technology trend, challenges and opportunities. IEEE International Electron Devices Meeting, Washington, DC, USA, 1–3.
- Yin, L., T. Yu, and L. Zhou. 2018. Design of a novel smart generation controller based on deep Q learning for large-scale interconnected power system. Journal of Energy Engineering 144 (3). doi:10.1061/(ASCE)EY.1943-7897.0000519.
- Yu, C., J. Liu, S. Nemati, and G. Yin. 2021. Reinforcement learning in healthcare: A survey. ACM Computing Surveys (CSUR) 55 (1):1–36. doi:10.1145/3477600.
- Yu, T., H. Z. Wang, B. Zhou, K. W. Chan, and J. Tang. 2015. Multi-agent correlated equilibrium Q(λ) learning for coordinated smart generation control of interconnected power grids. IEEE Transactions on Power Systems 30 (4):1669–79. http://ieeexplore.ieee.org/document/6913586/.
- Yu, Y. 2018. Towards sample efficient reinforcement learning. International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 5739–43.
- Zeng, R., M. Liu, J. Zhang, X. Li, Q. Zhou, and Y. Jiang. 2020. Manipulator control method based on deep reinforcement learning. Chinese Control And Decision Conference (CCDC), Hefei, China, 415–20. IEEE, August.
- Zhan, X., H. Xu, Y. Zhang, X. Zhu, H. Yin, and Y. Zheng. 2022. DeepThermal: Combustion optimization for thermal power generating units using offline reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence 36 (4):4680–88. doi:10.1609/aaai.v36i4.20393.
- Zhang, Z., D. Zhang, and R. C. Qiu. 2019. Deep reinforcement learning for power system: An overview. CSEE Journal of Power & Energy Systems 6 (1):213–25.
- Zhao, Y., and C. Smidts. 2022. Reinforcement learning for adaptive maintenance policy optimization under imperfect knowledge of the system degradation model and partial observability of system states. Reliability Engineering and System Safety 224 (April):108541. doi:10.1016/j.ress.2022.108541.
- Zhong, X., L. Zhang, and H. Ban. 2023. Deep reinforcement learning for class imbalance fault diagnosis of equipment in nuclear power plants. Annals of Nuclear Energy 184:109685. doi:10.1016/j.anucene.2023.109685.
- Zhu, Z., K. Lin, A. K. Jain, and J. Zhou. 2023. Transfer learning in deep reinforcement learning: A survey. IEEE Transactions on Pattern Analysis & Machine Intelligence 45 (11):13344–62. https://ieeexplore.ieee.org/document/10172347/.