
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Named entity recognition (NER) is a crucial step in extracting medical information from Chinese text, and fine-tuning large language models (LLMs) for this task is an effective approach. However, full parameter fine-tuning can potentially damage the model’s original parameters, resulting in catastrophic forgetting. To overcome this challenge, we introduce a novel adapter-based fine-tuning approach. Our adapter is integrated into the first and last transformers of the LLM, operating in parallel to the feed-forward network (FFN), following multi-head attention. It mirrors the FFN’s structure and uses the FFN’s weights for initializing. Additionally, to further enhance performance, we incorporate prefix embeddings into the first and last transformers. Our experiments on the Chinese medical NER benchmark demonstrate that our adapter, combined with prefix embeddings, achieves the highest F1-score of 65.90%, surpassing prompt templates (21.99%), in-context learning (18.65%), P-tuning (63.03%), and the benchmark for the Chinese medical NER task (62.40%). These results indicate that our adapter effectively fine-tunes the LLM for Chinese medical NER while preserving the original parameters.
Introduction
Named entity recognition (NER) is a fundamental task in natural language processing (NLP), and its purpose is to identify and classify entities mentioned in texts. The extracted entities can enhance various subsequent NLP tasks, such as relation extraction, dependency parsing, and syntactic structure parsing (Wei et al. Citation2020; Xia et al. Citation2020). Additionally, NER is a crucial step in identifying Chinese medical entities within text (Li, Zhang, and Zhou Citation2020). By utilizing NER to extract entities such as diseases, treatments, and drugs from Chinese medical texts, researchers can significantly enhance medical research efforts.
Large language model (LLM) often exceeds hundreds of millions of parameters. For example, ChatGPT (Wu et al. Citation2023), LLaMa (Touvron et al. Citation2023), OPT (Zhang et al. Citation2022) and ChatGLM (Du et al. Citation2022) have demonstrated unprecedented performance across various NLP tasks (Hu et al. Citation2023; Qin et al. Citation2023). Therefore, numerous researchers are attempting to use the excellent abilities of LLM to perform medical NLP tasks, including answering medical questions, replying to patient questions (Li et al. Citation2023), conducting drug relationship reasoning, inferencing drug interactions (Ayesha et al. Citation2023), and helping doctors generate medical abstracts (Singh, Djalilian, and Javed Ali Citation2023).
These studies demonstrate the considerably high application value of LLM in medical NLP tasks. In this context, LLM has considerable potential to assist in the Chinese medical NER task.
Currently, the main methods of using LLM to perform NER tasks are in-context learning (ICL) and prompt template (Wei et al. Citation2022). ICL method shows LLM to generate entities under few-shot NER demonstrations (Wang et al. Citation2023). The prompt template uses a series of NER inference templates to guide the LLM to output entities in texts (Ashok and Lipton Citation2023), which can be regarded as zero-shot. Both ICL and prompt template methods do not train the LLM; therefore, the LLM can be rapidly applied to NER. In addition, fine-tuning model parameters is also an effective method (Zhang et al. Citation2023). However, full parameter fine-tuning can lead to the destruction of model parameters, resulting in catastrophic forgetting, and the large parameters of LLM make them expensive to train (Houlsby et al. Citation2019; Hu et al. Citation2023). Catastrophic forgetting presents a significant challenge during model fine-tuning owing to the risk of overshadowing and potential loss of the original knowledge stored within the model, amidst the influx of new task data. This phenomenon can result in a performance decline in the initial tasks, notwithstanding any enhancements achieved on the new task (Zhang and Wu Citation2024).
To this end, researchers have proposed adding a new module that contains trainable parameters to the LLM to adapt downstream tasks, while fixing the existing parameters of the LLM as much as possible, such as adding an adapter module (Houlsby et al. Citation2019). The adapter module is composed of two trainable fully connected networks: one reduces the hidden layer feature dimension to half or less, and the other restores the dimension, which adds to all transformer layers of the pre-trained language model.
In this study, we propose a new adapter for fine-tuning LLM to perform the Chinese medical NER task. Our proposed adapter has a similar structure to the feed-forward network (FFN) of the transformer, which is placed on the first and last transformer layers of LLM and uses the output of multi-head attention as input. To modify the output of transformers to adapt to the Chinese medical NER task, the adapter output is added to the FFN output. A method known as prefix tuning (Zhang et al. Citation2023) has gained widespread attention owing to its advantages in fine-tuning pre-trained models. The prefix comprises several embeddings that do not correspond to real tokens. These virtual tokens can be trained and are designed to guide the language model to adapt to downstream tasks. In this manner, the added prefix is expected to provide additional contextual information to LLMs for specific tasks. Drawing on this, this study utilizes a combination of adapters and prefix embeddings to fine-tune the LLM for the task of Chinese medical NER. In addition, we designed the single-step and stepwise inference format for the Chinese medical NER task based on the text generation of LLM. In the single-step format, the LLM directly generates all the medical entity types and entities. In stepwise format, a series of instructions guide the LLM to gradually generate the medical entity types and entities.
Our approach has the following advantages:
The adapter can preserve the original parameters of the LLM while performing the Chinese NER task. In addition, the adapter mirrors the FFN structure of the transformer and is initialized by the FFN’s weights of the transformer to inherit the knowledge contained in it. In this manner, the adapter can enhance our understanding of knowledge transfer, providing valuable insights for future interpretive research.
The adapter demonstrates competitive performance, outperforming the previous baseline models of the Chinese medical NER task.
This study designed two NER inference methods, namely single-step inference and stepwise inference. Our results indicate that stepwise inference is more effective.
Related work
Studies on Chinese NER
Researchers have conducted numerous studies on the Chinese NER task, focusing on feature design, task logic, and model framework. In feature design, the FLAT model introduced vocabulary information by designing a position vector feature and using transformers to capture long-distance dependence to improve inference efficiency (Li, Yan, et al. Citation2020). Considering the characteristics of Chinese, researchers built a fusion model to combine the features of Chinese characters and words to enhance the performance of the Chinese NER model (Liu et al. Citation2023). From the perspective of task logic, the TNER model (Peng et al. Citation2023) decomposed the Chinese NER task into two-branch tasks constituting entity boundary and type recognition to address the Chinese NER task. Tian, Bu, and He (Citation2023) discovered some noises in the existing word segmentation dictionary that could not represent the Chinese meaning. Therefore, the NER task was divided into two parts: word selection task and NER based on sequence labeling. In the model framework, the researchers focus on making the model framework applicable to Chinese NER tasks, such as based on a handshaking tagging scheme, an end-to-end Chinese knowledge extraction model framework to solve nested entity issues in Chinese sentences (Wang et al. Citation2020; Yang et al. Citation2022). Li et al. (Citation2023) redesigned a new sequence structure, maintaining all the input words as single characters but inserting boundary markers between adjacent words for segmentation. Thus, Chinese words have explicit segmentation markers, such as English words.
These studies suggest that for the Chinese NER task, reasonable task logic and features are essential, and it is emphasized that the model must effectively handle the nested entity. However, these studies are mainly aimed at the sequence structure of BERT (Kenton and Kristina Toutanova Citation2019). Hence, relevant exploration for the Chinese NER task based on generative LLM is scant.
Fine-tuning generative language model for NER Tasks
In research on generative language models for NER tasks, the traditional sequence labeling approach has been innovatively converted into a question-and-answer format (Wang et al. Citation2023). This transformation aligns more cohesively with the inherent task-oriented structure of LLMs. For instance, the LLaMA-7B model can be fine-tuned with full parameters to identify and extract entities from a sentence based on the entity type specified in user queries, such as querying the chemical in a given context (Keloth et al. Citation2024; Zhou et al. Citation2024). Related fine-tuning studies also indicate that fully fine-tuned LLMs demonstrate superior performance in information extraction tasks to their larger, unfine-tuned counterparts, such as ChatGPT-3.5 (Li et al. Citation2024). Furthermore, a study demonstrates that fine-tuning enables LLMs to more accurately meet the expected output of NER tasks, consequently reducing token consumption (Villa et al. Citation2023). When selecting an LLM for fine-tuning, Luo et al. (Citation2024) underscored that, beyond extensive foundational knowledge, LLMs with domain-specific knowledge relevant to the NER task can considerably enhance the model’s performance.
Synthesizing the aforementioned studies, it is evident that selecting an LLM with relevant domain knowledge and fine-tuning it using a question-and-answer format are crucial for enhancing the model’s adaptability to NER tasks within specific domains.
Parameter fine-tuning based on aditive methods
Additive methods are based on existing pre-trained models such as BERT by adding parameters to learn new information, such as adapter modules and soft prompt tuning methods (Lialin, Deshpande, and Rumshisky Citation2023). The adapter modules comprise two fully connected networks (Hu et al. Citation2023), Houlsby et al. (Citation2019) inserted two adapter modules into transformer layers of BERT, wherein one was inserted after the multi-head attention and the other after the FFN. Following this, Pfeiffer et al. (Citation2021) inserted only one adapter after the FFN in the transformer layers of BERT, enabling it to perform downstream tasks effectively. He et al. (Citation2022) inserted the adapter after the FFN of the multi-head attention of the transformer layers in BERT. Subsequently, they combined the output of the adapter with that of the FFN following the multi-head attention process. In addition, a study has shown that inserting an adapter module between transformer layers can also effectively adapt to downstream tasks (Shah et al. Citation2023). In addition to the adapter, soft prompt tuning is a useful additive method, such as P-tuning, which adds a set of tunable vectors to the keys and values of the multi-head attention at all transformer layers (Zhang et al. Citation2023). Currently, P-tuning is often combined with adapters to improve effectiveness, such as mix-and-match (MAM) adapter method (He et al. Citation2022) and S4 method, which combine P-tuning, adapter, and other fine-tuning methods (Chen et al. Citation2023).
These studies based on BERT have inspired us to design an adapter that recognizes Chinese medical entities. Importantly, the proposed adapter’s implementation does not alter the original parameters of the LLM, thus helping to prevent catastrophic forgetting.
In recent years, integrating adapter modules into pre-trained models has emerged as a crucial strategy for enhancing performance across various downstream tasks. This approach has been significantly impactful in the field of text-to-text, such as question answering based on document understanding. Using the multilayer perceptron as a trainable adapter, which makes the base model further learn information about document layout, the quality of the model’s responses can be enhanced (Luo et al. Citation2024). In the domain of text-to-image, such as image generation based on text description, the base model accurately aligns with the desired image by adding the self-attention layer as an adapter to learn image layout features (Qu et al. Citation2023). In the field of image-to-text, such as image question answering, the incorporation of learnable prefix embeddings as adapters has significantly improved models’ response generation, leading to answers that more accurately align with expected results (Zou et al. Citation2024). In addition, in graph-structured tasks, such as question answering based on graph information, using graph neural networks as adapters to encode the context can further optimize models’ accuracy. This provides ideas for the pre-trained model to effectively integrate the graph information (Huang et al. Citation2024). The incorporation of adapter modules aids in adaptation to new tasks and serves to amplify the models’ initial capabilities. For instance, in multilingual question-answering tasks, the integration of adapter modules has empowered models that originally excelled in a single language to extend their competencies across multiple languages (Zhao et al. Citation2024).
These cases demonstrate the effectiveness of the integrated adapter module in extending the base model capabilities to adapt to specific domain tasks without requiring full parameter fine-tuning.
Proposed methods
As illustrated in , we introduced two distinct adapter architectures: a parallel and sequential adapter. Additionally, prefix embeddings are appended to the outputs of the first and last transformers. Similar to P-tuning, these prefix embeddings also require fine-tuning.
Figure 1. Transformers with parallel adapter or sequential adapter. Copy means copying the architecture and weights of the feed-forward network as an adapter. Tunable implies the weights are tunable.
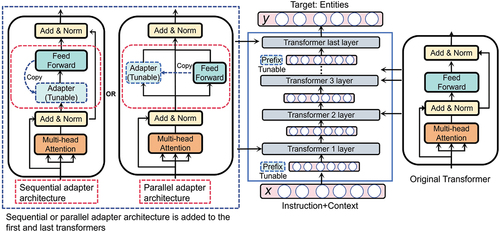
Our proposed parallel adapter is placed solely after the multi-head attention of the first and last transformers, parallel to and structurally identical to the FFN of the transformers. By combining the output of the adapter with the output of the FFN, we modify the transformers’ output to effectively adapt to the Chinese medical NER task.
The sequential adapter is also positioned after the multi-head attention of the first and last transformers, sharing a similar structure with the FFN. In this architecture, the output of the multi-head attention serves as an input to the adapter, and the adapter’s output is then fed into the FFN. This sequential arrangement modifies the FFN’s output to enhance its adaptability to the Chinese medical NER task.
Our adapter module is designed identically to that of the transformer’s FFN and is incorporated into the first and last transformers for fine-tuning. This integration is tantamount to the addition of merely two FFNs. Each FFN layer’s parameters represent 2.8% of ChatGLM2-6B’s total parameters. Consequently, our method requires fine-tuning only 5.6% of the entire parameter set, compared with full-parameter fine-tuning. This indicates that compared with full-parameter fine-tuning, this approach can significantly reduce the algorithm’s complexity.
In the study, we compared the two newly proposed adapter architectures and observed their performance for the Chinese medical NER task.
Base model of adapter
This study used ChatGLM2-6B (Du et al. Citation2022) as the base LLM, which was trained with a Chinese corpus. For the ChatGLM2-6B, the input text sequence is denoted as , which represents word id sequence, and
represents the
-th word in the sequence. For the model, the word vector mapping function is defined as
, which is used to map the text sequence
to the corresponding word vector sequence
, and
is the word vector corresponding to
. According to the output dimension of the base model,
. The feature of the word vector sequence
is subsequently extracted by the transformers of the base model. The
-th (
) multi-head attention of transformer is defined as
, and the output of
can be expressed as
,
. The FFN after the
-th multi-head attention is defined as
, and the output of
can be expressed as
,
. Additionally, the normalization function in each transformer is defined as
.
Based on the above, the transformer encoding process of the base model ChatGLM2-6B can be expressed as:
For the base model ChatGLM2-6B, the above process of multi-head attention can be expressed as:
According to the base model ChatGLM2-6B, , and
, which are the weights of
-th head of multi-head attention, where
in Equation (5). The three weight matrices project inputs to Q, V, and K, representing query, key, and value, respectively. In Equation (6),
is 32, and using the softmax function, we obtain the
. In Equation (7), we concatenate all heads and weigh them to obtain the final output, where
.
In the base model, ChatGLM2-6B contains a SwiGLU active function for FFN and does not contain bias. Therefore, the processing of can be expressed as:
According to the base model ChatGLM2-6B, and
,
.
Adapter function
In the study, we proposed an adapter with an architecture similar to the FFN of the base model; thus, the adapter equation including FFN can be expressed as follows:
Because the adapter is consistent with the FFN, the adapter also has active function, and the weights have the same shape as the FFN of the base model. The weights of the adapter are denoted as
,
, and
.
As shown in , according to the integration method of the adapter and base model, the adapter can be divided into two architectures: parallel and sequential adapters. In this study, we implemented the two adapter architectures to determine their comparative effectiveness.
Parallel adapter
The parallel adapter is placed in the first and last transformers of the base model. Specifically, the input to each adapter comes from the output of the multi-head attention of the transformer. Subsequently, the output of each adapter is summed with the output of the transformer FFN. Based on the above discussion, the output of the first and last transformers combined with the adapter can be expressed as follows:
In the equation, represents the output of the first or last transformer combined with the adapter.
represents the output of multi-head attention in the first or last transformer. The base model ChatGLM2-6B has 28 transformers, so the
.
Sequential adapter
The sequential adapter is also combined with the first and last transformer of the base model. This is distinct from the parallel adapter in that the output of the adapter is the input of FNN, forming a sequential structure. The processing can be expressed as:
Similar to the parallel adapter, ,
represents the output of the first or last transformer combined with adapter.
represents the output of multi-head attention in the first or last transformer.
Experimental dataset and settings
Dataset
The CMeEE dataset was selected for this study. This dataset originates from the Chinese medical NER task (Zhang et al. Citation2022) in the Chinese biomedical language understanding evaluation (CBLUE) benchmark. It widely covers the possible input distribution or situation of medical texts in the real world and effectively reflects the difficulties and complex situations in practical applications. It is the currently used benchmark dataset for the evaluation of Chinese medical NER. Therefore, this dataset can more accurately measure the effectiveness of the model in identifying Chinese medical entities.
In the CMeEE dataset, entities can be words, phrases, sentences, and nested entities. The CMeEE dataset has 15,000 training data, 5,000 validation data, and 3,000 test data, including nine types in the medical field, namely body composition, disease, medical laboratory item, medical department, symptom, medical equipment, medical procedure, drug, and microorganism.
Because LLM outputs the text generatively, we must design the NER task format based on text generation. To this end, we proposed two inference formats for Chinese medical NER: single-step NER and stepwise NER.
Medical entities extraction based on Single-Step inference format
As shown in , in the single-step NER, the input is prompt + Chinese medical context, and the output is all the medical entity types and entities. Based on the inference format, we can prompt the model to output entity types and entities simultaneously.
Table 1. Data example of single-step NER inference format.
Medical entity extraction based on Stepwise Inference format
As shown in , the format of stepwise NER includes two inference formats. One is entity-type inference, and the other is entity inference. For the entity type inference, we asked the model to output the entity types contained in the context. In entity inference, based on the entity types of output, we sequentially asked the model for entities of each entity type.
Table 2. Data example of stepwise NER inference format.
Model and training settings
We used the HuggingFace Transformers library to load the weights of ChatGLM2-6B model. On this basis, we added the structure of our proposed parallel adapter and sequential adapter to ChatGLM2-6B, respectively. The primary hyperparameters encompass the maximum token length, batch size, learning rate, and optimizer. The maximum token length was configured to 512, a value suitable for accommodating all sentence lengths in the study and compatible with our hardware capabilities. Considering our hardware capabilities, the batch size hyperparameter was set at 4. The learning rate was established at 1e-4, utilizing the AdamW optimizer and implementing a cosine learning rate schedule (the learning rate adjustment per epoch ranges from 1e-4 to 1e-5). The application of AdamW alongside this learning rate control scheme prevents the issue of becoming trapped in saddle points by facilitating periodic fluctuations in the learning rate. The model underwent training for 10 epochs, and the iteration yielding the most favorable evaluation results was subsequently selected for testing. All models were trained on Nvidia A100 40 G GPU.
We selected the model that performed best on the validation set for testing. The performance of the models was evaluated using the F1-score. During the training process, we fixed the number of random seeds (12345) to ensure that each model performs the training in the same environment as much as possible.
Baseline models
To evaluate whether our proposed adapter is truly effective for the Chinese medical NER task. We compared our proposed adapter with the benchmark of Chinese medical NER tasks based on various BERT models (Zhang et al. Citation2022), local and global model (Xiang et al. Citation2023), handshaking tagging scheme (HTS) model (Yang et al. Citation2022), and TNER model (Peng et al. Citation2023).
The results of these baseline models can be obtained from the developers of the CMeEE dataset and the models reported by different researchers in recent years. We used the same training and test data for both our models and these baseline models, and the evaluation was completed using the evaluation tools provided by CMeEE, which are consistent with these baseline models. In the model comparison, we compared our results with the best results reported by these baseline models. In addition, we also compared our proposed adapter to P-tuning based on ChatGLM2-6B and prompt templates and ICL based on Baichuai-13B (https://github.com/baichuan-inc/Baichuan-13B) and ChatGLM2-6B. The prompt template and the examples for ICL are similar to stepwise inference.
Results and discussion
Main results
As shown in , based on the stepwise inference, we compared our proposed sequential adapter combined with prefix embeddings (PSA) and parallel adapter combined with prefix embeddings (PPA) to the benchmark based on various BERT models (Zhang et al. Citation2022), local and global models (Xiang et al. Citation2023), HTS model (Yang et al. Citation2022) and TNER model (Peng et al. Citation2023). The results show that our PPA is better than other models, which is 3.50% higher than the best F1-score of benchmark models (MacBERT-large, RoBERTa-wwm-ext-base), 3.88% higher than the local and global model, and 0.93% higher than the HTS model. However, 2.49% is lower than the F1-score of the TNER model. This result is related to the use of an additional entity dictionary in the TNER model (Peng et al. Citation2023). When removing the entity dictionary and relying solely on the TNER model to perform the Chinese medical NER task, the F1-score of the TNER model is 63.55%, 2.35% lower than our F1-score of PPA. These results demonstrate that our proposed adapter has advantages for the Chinese medical NER task.
Table 3. Comparison with other results in Chinese medical NER task.
Additionally, we observed that, compared to our model, although the HTS model has a similar F1-score, the two exhibit distinct entity extraction patterns. The HTS model operates by first identifying the starting tokens of various entities. Subsequently, it searches for the corresponding ending token for each entity based on the identified starting token. Finally, it extracts all the tokens that the entity spans to constitute a complete entity. This method is designed to effectively recognize entity boundaries, thereby accurately extracting entities. Our generative NER design focuses on the output of one entity type at a time and outputs the entities in the sentence in the way of text generation. This task pattern enables the model to focus on the output of one type of entity every time, avoiding omissions caused by concentrating on multiple entity types simultaneously. Therefore, from the perspective of recall rate, our model is 2.83% higher than the HTS model, our proposed method is superior.
Previous studies have indicated that the FFN in the transformer constitutes the memory function and may be utilized to add new knowledge into existing language models (Geva et al. Citation2021). Therefore, our proposed adapter structure is the same as the FFN for storing Chinese medical NER knowledge. Additionally, the relevant studies also highlighted the effectiveness of combining adapter and P-tuning (Chen et al. Citation2023; He et al. Citation2022); therefore, we combined our proposed adapter with prefix embeddings. The results indicate that the Chinese medical NER knowledge can be learned through our adapter method, without full parameter fine-tuning.
Because of our adapter’s ability to learn new knowledge without extensive parameter adjustments, it offers an advantage in avoiding catastrophic forgetting. When the model learns a new NER task, retaining the previously learned knowledge ensures that the model can skillfully perform the previously trained tasks while responding to the NER challenges. Thus, the avoidance of catastrophic forgetting can combine the original abilities of the model with the newly acquired NER abilities. This synergy is particularly valuable for multi-task application scenarios because it allows the model to further interpret or analyze the extracted entity while performing NER tasks, thus enhancing its overall utility and adaptability.
Comparison with prompt template and ICL methods
We further compared our proposed adapter with prompt template and ICL methods, as shown in . According to the results, the highest F1-score of LLMs without fine-tuning is 21.99% achieved by ChatGLM2-6B (prompt template). Compared with our proposed PPA or PSA (), our proposed method demonstrates superior performance. The results indicate that LLMs struggle in directly handling the Chinese medicine NER task, suggesting that training is necessary to improve their performance in the NER task.
Table 4. Results of prompt template and ICL methods based on LLMs.
Comparison of Single-Step inference and Stepwise inference
The Chinese medical NER results of PPA or PSA based on single-step inference are shown in , and further compared to the stepwise inference results, demonstrating that in PPA, the F1-score based on stepwise inference improved by 2.48% compared to single-step inference. For PSA, the F1-score based on stepwise inference improved by 3.17% compared to single-step inference. The results suggest that stepwise inference outperformed single-step inference.
Table 5. Results of parallel or sequential adapter combined with prefix embeddings based on single-step and stepwise inference.
For our proposed two-inference format, single-step inference directs the model to output all entities at once, whereas stepwise inference, similar to the chain of thinking (CoT) (Wei et al. Citation2022), decomposes the NER task and gradually guides the model to output entities step by step. Therefore, the reason for the poor performance based on single-step inference may be that this requires the model to focus on all entity types simultaneously, which inevitably leads to omissions or errors. Conversely, stepwise inference emphasizes that the model only identifies one entity type at once, rather than all entity types. This helps the model focus on what needs to be identified, thereby reducing difficulty and improving performance.
Impact of prefix embeddings on the adapter
In the adapter, we designed, two prefix embeddings are integrated into the first and last transformers, resembling the P-tuning approach. Therefore, we further compare the adapter without prefix embeddings, the adapter combined with prefix embeddings, and P-tuning, to delve into the impact of prefix embeddings.
The outcomes of experiments involving solely the adapter or P-tuning are presented in . The findings reveal that regardless of whether it is single-step or stepwise inference, the parallel adapter outperforms P-tuning. This underscores the effectiveness of our proposed parallel adapter method for the Chinese medical NER task. Specifically, when comparing the PPA results obtained through stepwise inference as presented in , prefix embeddings contributed to a 0.22% enhancement in the parallel adapter. Furthermore, the combination of prefix embeddings with the sequential adapter also yielded a slight improvement, boosting the F1-score by 0.55%. These findings suggest that prefix embeddings can facilitate enhancing the performance of the adapter.
Table 6. Results of parallel or sequential adapter without prefix embeddings.
In the single-step inference, the combination of parallel adapter and prefix embeddings led to the F1-score being 0.27% higher than that using only the parallel adapter. The combination of sequential adapter and prefix embeddings led to the F1-score being 0.73% higher than that of only sequential adapter. The results suggest that the combination of adapter and prefix embeddings is also useful for single-step inference.
According to the above results, we can summarize that the important factors influencing the performance in Chinese medical NER include the architecture of the adapter, whether to use prefix embeddings, and the inference format. Among the three factors, the combination of the parallel adapter with prefix embeddings and the use of stepwise inference is optimal. Furthermore, parallel adapter and stepwise inference are necessary.
Performance of prefix embeddings combined with parallel adapter in different number of training samples
We conducted a comparative analysis of the LLM performance, utilizing both PPA and stepwise inference, across different training sample sizes. As shown in , even with a reduced dataset containing just 75% of the total training samples, the LLM achieved a remarkable F1-score of 62.81%, surpassing the benchmark set in this study. This reflects that our proposed method has good learning ability.
Figure 2. F1-score and different number of training samples in PPA.
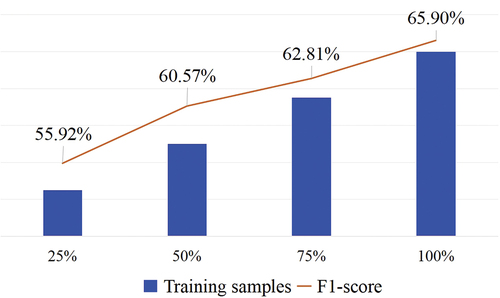
The F1-score of the LLM exhibited a positive correlation with the increasing number of training samples. This trend suggests that the current quantity of training samples has not yet reached the model’s learning capacity ceiling. Consequently, the LLM can benefit from continuously learning more samples. This implies that the upper-performance limit of the model has not been explored, and after recognizing this, we can infer that the performance can be further improved by continuously providing more training samples to the model. However, it should be noted that these improvements occur because the trained samples do not contain repeated input and output, thereby increasing the diversity of entities recognized by LLM. Therefore, the diversity of samples should be considered to improve the model’s performance by increasing samples.
Change in the weights of parallel adapter
In this study, we added the two adapters to the first and last transformers of the ChatGLM 2-6B. Each added adapter contains two FFNs. The FFNs of the adapter have a similar structure as the FFNs in the transformer; therefore, we utilized the FFN’s weights of the transformer to initialize the FFN’s weights of the adapter. This weight initialization is equivalent to inheriting the knowledge of the FFN in the original transformer; thus, we can gain insights into how the adapter adjusts itself to the NER task by observing how the FFN weights in the adapter change after learning the NER task. Specifically, in the two adapters, the adapter located in the first transformer focuses on processing low-dimensional semantic features through its FFNs, while the adapter located in the last transformer processes high-dimensional semantic features through its FFNs. This design allows the adapter to help the model capture and process information at different levels to enhance its adaptability to the NER task. If the FFN’s weights for the low-dimensional semantic features change significantly, the model relies more on the adapter to capture the underlying textual features specific to medical entities. Conversely, if the FFN’s weights of the high-dimensional semantic features change significantly, it may mean that the adapter is helping the model adapt to the NER task by capturing more complex, global semantic patterns. This observation facilitates our understanding of how adapters affect model performance and provides direction for future optimization.
To quantify the weight differences between the FFN’s fully connected network and the adapter after fine-tuning, we employed cosine similarity. As illustrated in , after fine-tuning for the medical NER task, we observe that the similarity of weights between the adapter and FFN in the first transformer layer is lower compared to that in the last layer. This indicates a more significant change in the weights of the adapter in the first layer. These observations suggest that the knowledge within FFN lacks a deep understanding of medical terminology and concepts, particularly in terms of grasping the underlying textual features specific to medical entities. This demonstrates that our proposed adapter can provide new insights into knowledge transfer based on FFN, elucidating whether it primarily focuses on high-level semantic features or underlying textual features.
Figure 3. Cosine similarity between the weights of FFN and adapter in the parallel adapter architecture.
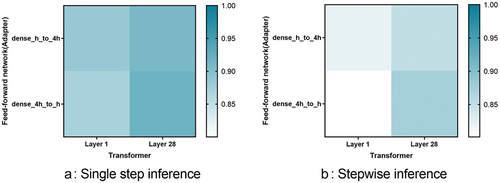
In addition, during training based on the single-step inference format, the adapter makes fewer adjustments to the weights inherited from the FFN. This may suggest that the inference process overly relies on the weights derived from the FFN, thereby restricting its capacity for generalization. Conversely, the stepwise inference format might improve the generalization performance of the LLM through more detailed weight adjustments. It can be seen that our adapter can enhance our understanding of knowledge transfer within the FFN, providing valuable insights for future interpretive research.
Error type analysis
We analyzed the error types based on the evaluation results, as shown in . The analysis of error types includes incorrect entity recognition, entity omission, boundary error, and entity-type error. Among these, incorrect entity recognition (32.97%) and entity omission (30.92%) are the primary sources of errors.
Table 7. Error analysis of the medical NER task.
Incorrect entity recognition refers to the model’s misclassification of non-entities as entities. For instance, the phrase “water in the bottle” was incorrectly recognized as an entity, with its entity type being categorized as a body composition. Entity omission is demonstrated by the model’s failure to identify medical entities within a sentence, such as the omissions of abbreviated entities including HbF (stands for fetal hemoglobin), EGNB (stands for enteric gram-negative bacilli), and cAMP (stands for cyclic adenosine monophosphate). Moreover, entity omissions are caused by incorrect entity recognition, such as the model only outputs “catheter” for the body composition entity “artery catheter” and incorrectly classifies its type as medical equipment. This results in both entity omission and incorrect entity recognition. Additionally, boundary error (26.28%) is an important source of errors, characterized by the correct identification of the entity’s type but with boundary error – causing an overlap with the correct entity. For example, for the body composition entity “thick subcutaneous nerve fibers” the model only recognized “subcutaneous nerve.” These error issues may be because of the model’s lack of training in similar contexts, and the model’s performance could be improved by increasing the number of samples.
Entity type error, which constitutes the smallest category of error (9.84%), refers to the correct identification of an entity’s boundaries but an incorrect assignment of the entity’s type. For instance, the drug entity “antibiotics” is erroneously identified as a microorganism. This issue might be mitigated by incorporating further entity type verification following entity extraction, thereby enhancing the model’s performance.
Limitations
Our adapter is based on the knowledge of LLM further alignment medical NER task. An adapter may fail to achieve the desired effect, if the base model does not have relevant knowledge. Additionally, the study’s approach is also affected by the task design such as single-step inference and stepwise inference; thus, different task design forms must be attempted to select the most effective one.
Conclusion
This study aimed to achieve fine-tuning of LLM to perform a Chinese medical NER task while keeping the original parameters unchanged. To this end, we proposed parallel and sequential adapter architectures for Chinese medical NER. The results suggest that our proposed parallel adapter with prefix embeddings performed better. We found that the performance of LLM in the Chinese medical NER task is related to the inference format; gradually guiding the model to output the medical entities is better than directly letting the model output. This suggests that the inference format of the task affects the performance of LLM; thus, exploring more inference formats that can enhance the performance of NER will be an important study in the future. In addition, our adapter is initialized by FFN’s weights to inherit its knowledge, enabling it to build on FFN’s prior knowledge for new tasks. This approach offers new insights into knowledge transfer, providing a valuable reference for future interpretive studies.
In future work, we plan to further explore the effect of adapter architecture in different locations, to determine a more efficient adapter layout scheme. Additionally, we aim to study different types of prefixes, such as prefix embeddings that are directly added into the input sentence to enhance contextual information. Moreover, extending the current approach to other languages and fields is also the focus of our future research, which not only verifies the generalization ability of the adapter but also enables applications across languages and domains. Through these future explorations, we hope to provide support for addressing a wider range of practical problems.
uaai_a_2385268_sm9653.bib
Download Bibliographical Database File (15.9 KB)uaai_a_2385268_sm9652.bst
Download (33 KB)uaai_a_2385268_sm9654.cls
Download (5.7 KB)Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data that support the findings of this study are available at: https://github.com/bucm-tcm-tool/NewTuning/
Additional information
Funding
References
- Ashok, D., and Z. C. Lipton. 2023. PromptNER: Prompting for named entity recognition. ArXiv abs/2305.15444:1–22. https://api.semanticscholar.org/CorpusID:258887456.
- Ayesha, J., N. Pipil, S. Santra, S. Mondal, J. Kumar Behera, H. Mondal, N. Pipil Sr, S. Santra Sr, and J. K. Behera IV. 2023. The capability of ChatGPT in predicting and explaining common drug-drug interactions. Cureus 15:3. doi:10.7759/cureus.36272.
- Chen, J., A. Zhang, X. Shi, M. Li, A. Smola, and D. Yang. 2023. Parameter-efficient fine-tuning design spaces. ArXiv abs/2301.01821 (16): 1–18. https://api.semanticscholar.org/CorpusID:255440621.
- Du, Z., Y. Qian, X. Liu, M. Ding, J. Qiu, Z. Yang, and J. Tang. 2022. GLM: General language Model pretraining with autoregressive blank infilling. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 320–35.
- Geva, M., R. Schuster, J. Berant, and O. Levy. 2021. Transformer feed-forward layers are key-value memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 5484–95.
- He, J., C. Zhou, X. Ma, T. Berg-Kirkpatrick, and G. Neubig. 2022. Towards a unified view of parameter-efficient transfer learning. International Conference on Learning Representations. https://openreview.net/forum?id=0RDcd5Axok.
- Houlsby, N., A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly. 2019. Parameter-efficient transfer learning for NLP. International Conference on Machine Learning, Long Beach, California, USA, 2790–99.
- Hu, Z., Y. Lan, L. Wang, W. Xu, E.-P. Lim, R. Ka-Wei Lee, L. Bing, and S. Poria. 2023. LLM-Adapters: An adapter family for parameter-efficient fine-tuning of large language models. ArXiv abs/2304.01933:1–21. https://api.semanticscholar.org/CorpusID:257921386.
- Huang, X., K. Han, Y. Yang, D. Bao, Q. Tao, Z. Chai, and Q. Zhu. 2024. GNNs as adapters for LLMs on text-attributed graphs. The Web Conference 2024. https://openreview.net/forum?id=AFJYWMkVCh.
- Keloth, V. K., Y. Hu, Q. Xie, X. Peng, Y. Wang, A. Zheng, M. Selek, K. Raja, C. H. Wei, Q. Jin, et al. 2024. Advancing entity recognition in biomedicine via instruction tuning of large language models. Bioinformatics 40 (4):btae163. doi:10.1093/bioinformatics/btae163.
- Kenton, J. D. M.-W. C., and L. Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. Proceedings of NAACL-HLT, Minneapolis, MN, USA, 4171–86.
- Li, L., Y. Dai, D. Tang, X. Qiu, Z. Xu, and S. Shi. 2023. Markbert: Marking word boundaries improves Chinese bert. CCF International Conference on Natural Language Processing and Chinese Computing, Foshan, China, 325–36.
- Li, X., H. Yan, X. Qiu, and X.-J. Huang. 2020. FLAT: Chinese NER using flat-lattice transformer. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, Washington, USA, 6836–42.
- Li, X., H. Zhang, and X.-H. Zhou. 2020. Chinese clinical named entity recognition with variant neural structures based on BERT methods. Journal of Biomedical Informatics 107:103422. doi:10.1016/j.jbi.2020.103422.
- Li, Y., J. Li, J. He, and C. Tao. 2024. AE-GPT: Using large language models to extract adverse events from surveillance reports-A use case with influenza vaccine adverse events. PLOS ONE 19 (3):1–16. doi:10.1371/journal.pone.0300919.
- Li, Y., Z. Li, K. Zhang, R. Dan, S. Jiang, and Y. Zhang. 2023. ChatDoctor: A medical chat Model fine-tuned on a large language Model Meta-ai (LLaMA) using medical domain knowledge. Cureus 15 (6). doi:10.7759/cureus.40895.
- Lialin, V., V. Deshpande, and A. Rumshisky. 2023. Scaling down to scale up: A guide to parameter-efficient fine-tuning. ArXiv abs/2303.15647:1–21. https://api.semanticscholar.org/CorpusID:257771591.
- Liu, T., J. Gao, W. Ni, and Q. Zeng. 2023. A multi-granularity word fusion method for Chinese NER. Applied Sciences 13 (5):2789. doi:10.3390/app13052789.
- Luo, C., Y. Shen, Z. Zhu, Q. Zheng, Z. Yu, and C. Yao. 2024. LayoutLLM: Layout instruction tuning with large language models for document understanding. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, Washington, USA, 15630–40.
- Luo, L., J. Ning, Y. Zhao, Z. Wang, Z. Ding, P. Chen, W. Fu, Q. Han, G. Xu, Y. Qiu, et al. 2024. Taiyi: A bilingual fine-tuned large language model for diverse biomedical tasks. Journal of the American Medical Informatics Association ocae37. doi:10.1093/jamia/ocae037.
- Peng, H., Z. Zhang, D. Liu, and X. Qin. 2023. Chinese medical entity recognition based on the dual-branch TENER model. BMC Medical Informatics & Decision Making 23 (1):136. doi:10.1186/s12911-023-02243-y.
- Pfeiffer, J., A. Kamath, A. Rücklé, K. Cho, and I. Gurevych. 2021. AdapterFusion: Non-destructive task composition for transfer learning. 16th Conference of the European Chapter of the Associationfor Computational Linguistics, EACL 2021, Online Conference, 487–503.
- Qin, C., A. Zhang, Z. Zhang, J. Chen, M. Yasunaga, and D. Yang. 2023. Is ChatGPT a general-purpose natural language processing task solver? ArXiv abs/2302.06476:1–47. https://api.semanticscholar.org/CorpusID:256827430.
- Qu, L., S. Wu, H. Fei, L. Nie, and T.-S. Chua. 2023. Layoutllm-t2i: Eliciting layout guidance from llm for text-to-image generation. Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, Canada, 643–54.
- Shah, A., S. Thapa, A. Jain, and L. Huang. 2023. Adept: Adapter-based efficient prompt tuning approach for language models. Proceedings of The Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), Toronto, Canada, 121–28.
- Singh, S., A. Djalilian, and M. Javed Ali. 2023. ChatGPT and ophthalmology: Exploring its potential with discharge summaries and operative notes. Seminars in Ophthalmology 38 (5):503–07. doi:10.1080/08820538.2023.2209166.
- Tian, X., X. Bu, and L. He. 2023. Multi-task learning with helpful word selection for lexicon-enhanced Chinese NER. Applied Intelligence 53 (16):19028–43. doi:10.1007/s10489-023-04464-0.
- Touvron, H., T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. 2023. Llama: Open and efficient foundation language models. ArXiv abs/2302.13971:1–27. https://api.semanticscholar.org/CorpusID:257219404.
- Villa, L., C.-P. David, S.-M. Adrián, C. D. Cosmin, and H. Ramón. 2023. Conversational agent development through large language models: Approach with GPT. Proceedings of the 15th International Conference on Ubiquitous Computing & Ambient Intelligence (UCAmI 2023), Riviera Maya, Mexico, ed. J. Bravo and G. Urzáiz Cham, 286–97. Springer Nature Switzerland.
- Wang, S., X. Sun, X. Li, R. Ouyang, F. Wu, T. Zhang, J. Li, and G. Wang. 2023. Gpt-ner: Named entity recognition via large language models. ArXiv abs/2304.10428:1–21. https://api.semanticscholar.org/CorpusID:258236561.
- Wang, Y., B. Yu, Y. Zhang, T. Liu, H. Zhu, and L. Sun. 2020. Tplinker: Single-stage joint extraction of entities and relations through token pair linking. Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 1572–82.
- Wei, J., X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, Louisiana, USA 35:24824–37.
- Wei, Z., J. Su, Y. Wang, Y. Tian, and Y. Chang. 2020. A novel cascade binary tagging framework for relational triple extraction. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online Conference, 1476–88.
- Wu, T., S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y. Tang. 2023. A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA Journal of Automatica Sinica 10 (5):1122–36. doi:10.1109/JAS.2023.123618.
- Xia, C., C. Zhang, T. Yang, Y. Li, N. Du, X. Wu, W. Fan, F. Ma, and P. Yu. 2020. Multi-grained named entity recognition. 57th Annual Meeting of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 1430–40.
- Xiang, Y., W. Liu, J. Guo, and L. Zhang. 2023. Local and global character representation enhanced model for Chinese medical named entity recognition. Journal of Intelligent & Fuzzy Systems 45 (3):3779–90. doi:10.3233/JIFS-231554.
- Yang, N., S. Hang Pun, M. I. Vai, Y. Yang, and Q. Miao. 2022. A unified knowledge extraction method based on BERT and Handshaking tagging scheme. Applied Sciences 12 (13):6543. doi:10.3390/app12136543.
- Zhang, N., M. Chen, Z. Bi, X. Liang, L. Li, X. Shang, K. Yin, C. Tan, J. Xu, F. Huang, et al. 2022. CBLUE: A Chinese biomedical language understanding evaluation benchmark. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, ed. S. Muresan, P. Nakov, and A. Villavicencio, 7888–915. Association for Computational Linguistics. doi:10.18653/v1/2022.acl-long.544.
- Zhang, S., S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, et al. 2022. Opt: Open pre-trained transformer language models. ArXiv abs/2205.01068:1–30. https://api.semanticscholar.org/CorpusID:248496292.
- Zhang, X., and J. Wu. 2024. Dissecting learning and forgetting in language model finetuning. The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=tmsqb6WpLz.
- Zhang, Z., T. Chuanqi, X. Haiyang, W. Chengyu, H. Jun, and H. Songfang. 2023. Towards adaptive prefix tuning for parameter-efficient language Model fine-tuning. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, ed. A. Rogers, J. L. Boyd-Graber, and N. Okazaki, 1239–48, Toronto, Canada, July 9-14, 2023.
- Zhao, Y., W. Zhang, H. Wang, K. Kawaguchi, and L. Bing. 2024. AdaMergeX: Cross-lingual transfer with large language models via adaptive adapter merging. ArXiv abs/2402.18913:1–15. https://api.semanticscholar.org/CorpusID:268063729.
- Zhou, W., S. Zhang, Y. Gu, M. Chen, and H. Poon. 2024. UniversalNER: Targeted distillation from large language models for open named entity recognition. The Twelfth International Conference on Learning Representations, Vienna, Austria. https://openreview.net/forum?id=r65xfUb76p.
- Zou, B., C. Yang, Y. Qiao, C. Quan, and Y. Zhao. 2024. LLaMA-excitor: General instruction tuning via indirect feature interaction. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Washington, USA, 14089–99, June.