
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This research presents a sophisticated model aimed at detecting COVID-19 related misinformation in Traditional Chinese, a critical response to the swift spread of fake news during the pandemic. The model employs an ensemble model of machine learning techniques, such as SVM, LSTM, BiLSTM, and BERT, along with a diverse array of input features including news structure, sentiment, and writing stylistic elements. Testing of the model has shown an impressive 97% accuracy in differentiating factual from fraudulent news. A significant finding is that in-depth content analysis offers more insights compared to mere headline scrutiny, though headlines do aid in marginally increasing accuracy. The integration of sentiment analysis and stylistic nuances further boosts the model’s effectiveness. This study is pivotal in establishing a robust Traditional-Chinese fake news detection mechanism for COVID-19, underscoring the effectiveness of combined machine learning strategies for more consistent and reliable outcomes.
Introduction
In an era where self-media platforms grant individuals unparalleled opportunities to disseminate their ideas and actively participate as content creators (Lazer et al. Citation2018), the deluge of information presents a substantial challenge in discerning reliable sources from those that are fallacious or deceptive (MIT Citation2018). The imperative for individuals to engage in meticulous and critical evaluation of information encountered cannot be overstated.
Particularly during crises or emergencies, there is a tendency among some users to generate additional news and information, often influenced by personal sentiments or perceptions (Meel and Vishwakarma Citation2020; Zhang and Ghorbani Citation2020). This propensity can engender confusion regarding credible information sources, culminating in the propagation of misinformation and spurious news. Such false narratives hold the potential to mislead the public, impacting their perceptions, emotions, and potentially provoking socio-political issues (Allcott and Gentzkow Citation2017; Duffy, Tandoc, and Ling Citation2020; Tandoc, Lim, and Ling Citation2018). Instances where fake news has been manipulated as an instrument to sway public opinion and disrupt democratic processes, including elections, are well-documented.
The dissemination of fake news via social media mirrors viral contagion, with its continuous forwarding and potential to deceive, thereby influencing pivotal decisions, including electoral choices and health-related behaviors (Allcott and Gentzkow Citation2017; Yang, Zhou, and Zafarani Citation2021). Regrettably, fake news often garners more circulation and credence than veritable news (Duffy, Tandoc, and Ling Citation2020). The task of real-time verification of information is formidable, and the resource-intensive nature of fact-checking presents considerable hurdles. Fact-checking entities and individuals grapple with the herculean task of keeping pace with the torrential influx of information, rendering the effective identification and debunking of false or misleading claims increasingly arduous (Bondielli and Marcelloni Citation2019). Consequently, the spread of unverified information and misinformation gains momentum, reaching a wider audience (Zubiaga et al. Citation2018). To differentiate between fake and factual news, researchers have pinpointed various characteristics aiding in the identification process, as outlined in .
Table 1. Characteristics help fake news identification.
In the milieu of the COVID-19 pandemic, detecting fake news, especially in the health domain, has gained critical importance. Health-related misinformation can exacerbate fears and lead to adverse health outcomes. Although previous research predominantly focused on English-language fake news, there has been a dearth of exploration into Chinese fake news during the pandemic. Prior studies on Chinese fake news often overlooked sentiment analysis and contextual features, relying chiefly on machine learning methods or unidimensional features (Shushkevich, Alexandrov, and Cardiff Citation2021; Yang, Zhou, and Zafarani Citation2021).
Related Works
Pandemic Vs Infodemic
The advent of COVID-19 has intensified the ramifications of fake news (Varma et al. Citation2021). The WHO Director-General Tedros has underscored the necessity to combat the “Infodemic” in tandem with the epidemic, emphasizing the dual fight against misinformation and the virus. Throughout the pandemic, there has been a proliferation of conspiracy theories (Brett and Goroncy Citation2020), spurious news (Allcott and Gentzkow Citation2017), and misinformation about the virus, its origins (World Health Organization WHO Citation2020), prevention (Islam et al. Citation2020), and treatment methods. This surge in misinformation poses significant challenges for the public in distinguishing between credible and unreliable sources of information. For instance, during the pandemic, misinformation about a Chinese herbal formula, “Chingguan Yihau,” with incorrect ingredient names, proliferated, leading to potential harmful health outcomes (Al-Rakhami and Al-Amri Citation2020). delineates examples of COVID-related fake news across various domains.
Table 2. Example of COVID fake news about virus, vaccine and treatment topics.
Addressing the spread of COVID-19 related fake news and misinformation necessitates multiple interventions. Providing public access to credible information sources, such as the Taiwan Centers for Disease Control, and leveraging trusted public health organizations and media outlets is crucial. Fact-checking and verification processes to identify and debunk false information (Pennycook and Rand Citation2019a), collaborations with reputable organizations to flag misleading content, and policies by social media companies to limit the spread of such content are essential strategies (Guess, Nagler, and Tucker Citation2019). Government collaboration with social media firms to devise countermeasures against fake news is vital, and these interventions must be rigorously developed and evaluated for efficacy (Bavel et al. Citation2020).
Fake News Detection via Using AI
For fake news detection, AI, in conjunction with NLP (Natural Language Processing), is indispensable. Research is ongoing to enhance AI and machine learning techniques for efficient NLP. From traditional machine learning methods like SVM and Naive Bayes to deep learning models like CNN, RNN, and LSTM, technologies are evolving (Ajao et al. Citation2018). Building on this foundation, recent studies have identified Deep Neural Networks (DNNs) and SVMs as core technologies for detecting fake news. For instance, Lahby et al. (Citation2022) highlighted the prominence of these methods, while Yafooz, Emara, and Lahby (Citation2022) achieved remarkable accuracy using SVM to pinpoint COVID-19 related misinformation in YouTube videos. Additionally, leveraging the capabilities of LSTM and Bidirectional LSTM (BiLSTM) to grasp contextual relationships within texts, Genç and Surer (Citation2023) developed highly accurate models for clickbait detection, achieving 93% accuracy with LSTMs and 97% with BiLSTMs. Furthermore, The Transformer, a deep learning model utilizing attention mechanisms, has been validated for its effectiveness in detecting political platform misinformation (Raza Citation2021).The Bidirectional Encoder Representations from Transformers (BERT), based on Transformer technology, has been validated by Kaliyar, Goswami, and Narang (Citation2021) as effective for social media fake news detection. In a cross-lingual context, Koru and Uluyol (Citation2024) achieved 90% to 94% accuracy in detecting false tweets on social media platforms using the BERT and BERTurk + CNN models. Advancements in AI, particularly through models like SVM, LSTM, and BERT, have significantly enhanced our ability to detect and combat fake news.
On the other hand, NLP techniques, such as word and sentence segmentation, part-of-speech tagging, and sentiment analysis, can identify fake news characteristics. Sentiment analysis, for instance, determines the emotional tone of text and assigns sentiment scores, aiding in fake news detection (Pang and Lee Citation2008). Identifying language patterns in news headlines and articles indicative of fake news, such as sensational or emotive language or the presence of errors, is facilitated by NLP (Shu, Wang, and Liu Citation2019). According to previous studies, analyses focus on content and headlines. While the content is frequently scrutinized, the significance of headlines in fake news dissemination is also notable (Bondielli and Marcelloni Citation2019; Tandoc, Lim, and Ling Citation2018). Moreover, recent studies have incorporated user behavioral characteristics (Khan et al. Citation2021), such as frequency of logging, likes, clicks, and followers, combined with news content (Castillo, Mendoza, and Poblete Citation2011; Yang et al. Citation2018). For example, Al-Rakhami and Al-Amri (Citation2020) extracted user characteristics from Twitter to conclude that account verification, retweet numbers, hashtag usage, mentions, and follow rates are significant indicators.
Despite advancements, Chinese NLP’s complexity surpasses that of English, necessitating a deep understanding of the Chinese language (Zhang Citation2022). However, there remains a gap in research on Chinese fake news during COVID-19, with most studies focusing on English (Shushkevich, Alexandrov, and Cardiff Citation2021) and overlooking sentiment analysis and contextual features in Chinese (Yang, Zhou, and Zafarani Citation2021).
Proposed Method
In addressing the challenge of identifying COVID-19 related fake news, we have developed an ensemble Artificial Intelligence model, as depicted in , which categorizes input news based on their distinct features. This model integrates various discriminative models, including logistic regression, support vector machines (SVMs), and neural networks. These models are extensively applied in diverse fields, such as image classification, sentiment analysis, and natural language processing tasks. To enhance the effectiveness and stability of this discriminative model, an ensemble machine learning strategy is employed, integrating outputs from several distinct models (Durgapal and Vimal Citation2021). Ensemble Learning has been demonstrated to significantly improve predictive accuracy and has been previously applied in contexts such as credit card fraud detection (Tomar, Shrivastava, and Thakar Citation2021) and stock price forecasting (Durgapal and Vimal Citation2021).
Figure 1. Analytics process of the proposed fake news discriminative model.
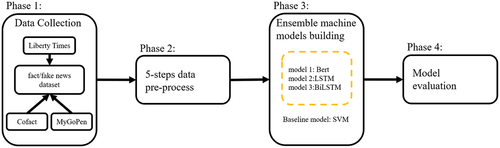
delineates the source dataset of fake news from MyGoPen, Cofact, and Liberty Times, meticulously outlining the dataset source, features, records, and the labeling methodology, as well as categorizing the types of fake news. We strategically employed a variety of dataset sources to guarantee extensive coverage of news, eradicate duplicative information, and authenticate the accuracy of the news content. Furthermore, the utilization of datasets from an array of sources effectively mitigates the issue of data imbalance. Given the inherent time-dependency of news events, our study employs a time-series approach to data segmentation and consequently does not utilize cross-validation. Specifically, we have chronologically divided the dataset into a training set (60%), a test set (20%), and a validation set (20%).
Table 3. Source dataset of fake news from MyGoPen, cofact and liberty times.
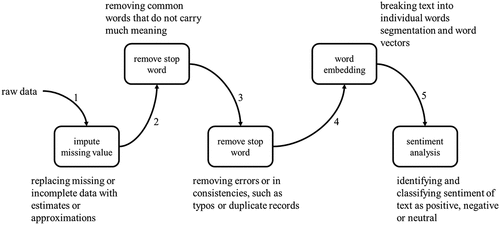
Subsequently, the data pre-processing phase is crucial to assure the quality of data for training and evaluating the discriminative model. As shown in , five data pre-processing steps include imputing missing values, data cleansing, word embedding, stop-word removal, and sentiment analysis. For text segmentation and stop-word removal, the “jieba” tool, an open-source Chinese word segmentation and tokenization tool, was employed. Jieba, available in both Simplified and Traditional Chinese, allows the integration of a custom dictionary. In this study, a specialized dictionary was used to precisely segment terms related to COVID-19, such as “新冠肺炎,” “病毒株,” “境外移入,” “世界衛生組織,” among others. Following word segmentation and tokenization, stop words were removed to enhance search efficiency.
Figure 2. Five steps in data pre-process of phase 2.
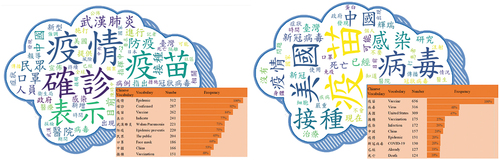
Utilizing word frequencies, word clouds were generated as depicted in . These visual representations contrast authentic (, left) and counterfeit news (, right). Analysis of reveals that terms like “vaccine,” “virus,” “vaccination,” “United States,” “China,” “epidemic,” and “death” appear frequently in both real and fake news analyses. Notably, terms such as “positive test,” “epidemic prevention,” and “command center” were predominantly found in legitimate news sources. This pattern is likely due to authentic news primarily originating from official sources, which is then distributed through various channels. In contrast, terms like “virus origin” and “vaccine policy” are more prevalent in fabricated news, likely reflecting the vaccine scarcity during the data collection period of this study and the varied vaccination strategies across countries. This has led to an influx of conjectures and baseless claims, contributing to the spread of misinformation and online conspiracy theories
Figure 3. Displays word clouds demonstrating the difference between real (left) and fake (right) news.
Experimental Analysis
To rigorously assess the efficacy of our proposed model in distinguishing between factual and counterfeit COVID-19 news, we conducted three distinct experiments. In the first experiment, the focus was on evaluating the effectiveness of three key features: headline, content, and a combination of both headline and content, in the construction of a model capable of discriminating fake news. Additionally, considering the disparity in sentiment scores between genuine and fraudulent news, as illustrated in later, the second experiment aimed to validate the discriminative impact of sentiment scores associated with the news title and body. The third experiment was designed to further investigate the influence of writing style on fake news detection.
Given the intricate nature of the Traditional Chinese language, a significant challenge in NLP research, we meticulously developed a sophisticated model specifically for COVID-19 related fake news detection. This discriminative model is grounded in an ensemble of Machine Learning (ML) methodologies, incorporating algorithms such as Support Vector Machines (SVM), Long Short-Term Memory networks (LSTM), Bidirectional LSTM (BiLSTM), and Bidirectional Encoder Representations from Transformers (BERT). A critical aspect of our approach involved testing various combinations of input features to finely tune the model, ensuring both high explanatory power and robust stability in its results.
The utility of this model extends to its potential application across media platforms, enabling the rapid identification and curtailment of the spread of Chinese fake news. By deploying this model, media platforms can effectively mitigate the dissemination of false information and its consequent impacts. This model stands as a testament to the advancements in AI and NLP, particularly in handling the complexities of the Chinese language, and represents a significant stride in the ongoing battle against the proliferation of fake news.
Study 1: Does the Discriminative Efficacy Differ Across Features of News Architecture?
The structure of a news article typically encompasses three key components: the headline, body, and conclusion, as delineated in . The headline serves as a succinct, compelling introduction summarizing the article’s main point. The body, forming the main content, elaborates on the headline with detailed context, facts, and analyses. The conclusion summarizes and provides closure to the narrative. These components, including text length and style, vary significantly. Therefore, Study 1 investigates the distinct impacts of these features on fake news discrimination.
Figure 4. Architecture of a news article, showing decomposition into three features: headline, body, and tail. (in , an example news article is decomposed in blue.).

Method
To enhance the efficiency of COVID-19 fake news detection, we constructed an ensemble model employing multiple algorithms: SVM, LSTM, BiLSTM, and BERT. Performance tuning was achieved using hyper-parameters from previous studies, including Kernel, cost coefficient, and gamma for SVM; dropout, optimizer, and learning rate for LSTM and BiLSTM; and batch size, learning rate, and epochs for BERT. We conducted a grid search to ascertain the optimal hyper-parameter combinations.
As indicated in , BERT emerged as the superior classifier, achieving an accuracy and F1-score above 92%. For robust results, the ensemble model aggregates outputs from multiple algorithms, using SVM results as a baseline for comparison. Our findings, including a ROC curve displayed in , demonstrate that the ensemble model exhibits superior and stable performance in discriminating fake news.
Figure 5. Experiment results of ROC curve of study 1 (blue line is SVM, red line is LSTM, gray line is bilstm, yellow Bert Model).
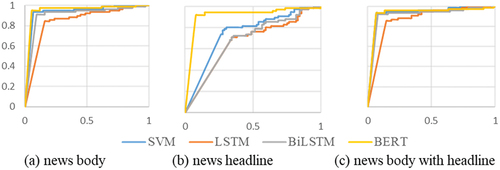
Table 4. The experiment comparisons among classifiers.
In Study 1, our objective was to verify the discriminative capability of the proposed model across three distinct features of a news article: headline, body, and a combination of both headline and body. The analysis of the experimental outcomes, as depicted in , revealed that relying solely on headlines for discerning fake news yielded the lowest accuracy rate, peaking at 92%. This outcome is presumably attributed to the succinct nature of headlines, which inherently restricts the extent of conveyable information. Moreover, in line with our expectations, the inclusion of news content, particularly the initial 500 words, significantly enhanced the precision in distinguishing authentic from spurious news, achieving an accuracy of 94.73%.
Table 5. The experiment results of discriminant effect for fake news among news architectures.
Intriguingly, our initial hypothesis posited that amalgamating news headlines with the content would lead to enhanced accuracy. Contrary to this expectation, the experimental results indicated a minor reduction in accuracy, from 94% to 93%. This phenomenon could be ascribed to the nature of news headlines, which are often crafted to be sensational or at times, entirely divergent from the actual content, aiming to captivate the reader’s attention. Such sensationalism or disconnection could potentially confound the interpretative faculties of the model, leading to a slight decrement in accuracy.
Study 2: Does the Integration of Sentiment Analysis Enhance Fake News Detection?
Sentiment analysis, a pivotal technique in natural language processing, is instrumental in identifying and extracting subjective information from text data. It encompasses the analysis and determination of sentiments expressed in a text, categorizing them as positive, negative, or neutral. Historically, sentiment analysis has played a crucial role in fake news detection. Balshetwar, Rs, and R (Citation2023) utilized sentiment analysis to scrutinize the emotional content in news headlines and text, thereby facilitating the distinction between authentic and counterfeit news. Similarly, Shu, Wang, and Liu (Citation2019) employed sentiment features to capture the emotional tone and polarity in news articles, contributing significantly to the identification of misleading content. Moreover, Tsai (Citation2023) explored how sentiment analysis aids in revealing subjective biases and emotional indicators in fake news articles. The primary objective of sentiment analysis, as outlined by Rezaeinia et al. (Citation2019), is to ascertain individuals’ attitudes toward specific articles. These scholarly works underscore the efficacy of sentiment analysis as a vital indicator in the detection and scrutiny of fake news.
In Study 2, we have incorporated these indicators of sentiment polarity from news content into the outcomes of Study 1. This amalgamation is strategically designed to enhance the proficiency of our model in distinguishing factual news from spurious news with greater efficacy.
Method
To implement sentiment analysis, the proposed model employs two word embedding methods: dictionary-based and machine learning-based approaches. Given the intensive labeling effort required for the machine learning method, we opted for the dictionary-based approach for calculating sentiment scores. We constructed a sentiment dictionary featuring both positive and negative words, drawing inspiration from the National Taiwan University Sentiment Dictionary (NTUSD) and the Chinese Valence-Arousal Words (CVAW4) (Yu et al. Citation2016). In this method, words are classified as either positive or negative. However, the utility of this approach is somewhat constrained by the specific research domain. To counter this limitation, we utilized Semantic Orientation Pointwise Mutual Information (SO-PMI) as a mechanism to expand the lexicon (Turney and Littman Citation2002). For CVAW4, a threshold is set at 5 points: words scoring above this threshold are considered positive, while those below are deemed negative.
Further, the Term Frequency-Inverse Document Frequency (TF-IDF) method is employed to assess the importance of each word in news articles. The top 20 words are selected as candidates for sentiment score computation. These words are then matched against the positive and negative words in the dictionary. A word is counted as positive if it is found in the dictionary’s list of positive words, and negative if it appears in the list of negative words. If a candidate word is not listed in the dictionary, the study utilizes SO-PMI to extend the lexicon (Turney and Littman Citation2002). For each news article, we count the number of positive words (Wpos) and negative words (Wneg), and calculate the sentiment score using Equation (1) below. An article is categorized as positive if its score is above 0, negative if below 0, and neutral if the score is 0. For instance, an article with 14 positive words and 6 negative words would have a sentiment feature of 0.4, suggesting a positive sentiment.
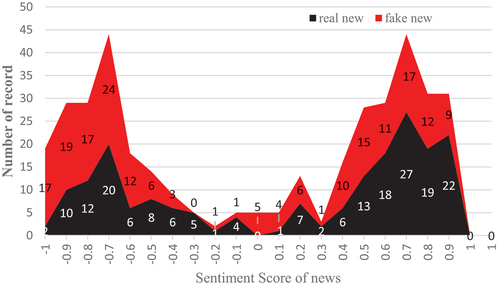
The sentiment scores of our dataset, as depicted in , indicate that fake news frequently uses words with substantial emotional intensity, leaning either toward the positive (approaching 1) or the negative spectrum (approaching −1). Our analysis revealed that the mean sentiment score for genuine news is 0.1675, with a standard deviation of 0.6711, suggesting a more neutral or mildly positive sentiment. In contrast, the average sentiment score for fake news stands at −0.0803, accompanied by a standard deviation of 0.7153, which signifies a predilection for negative wording.
Figure 6. The sentiment score of real and fake new of the dataset.
In Study 2, we incorporated the sentiment scores derived from EquationEquation (1)(1)
(1) as an additional feature for both real and fake news and subsequently retrained our model. The augmented models’ performance is comprehensively outlined in . The experimental outcomes reveal that the feature based on the news body maintained its exemplary performance, achieving an accuracy of 97.37% and a recall rate of 100%. However, the combined feature of news body and headline experienced a notable decline in performance, plummeting from 92% to 81%. This decrease in accuracy can be ascribed to the sensationalist nature of news headlines, which are crafted to capture reader interest and frequently display extreme sentiment scores, either highly positive or negative. Such pronounced sentiment scoring subsequently diminished the original accuracy rate.
Table 6. The experiment results of sentiment analysis for discriminant effect improvement of fake news detection.
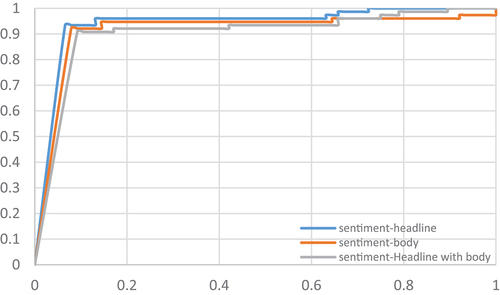
The integration of sentiment scores into the news headline feature led to a marginal improvement in the accurate identification of fake news, showing an increase of around 1%. This slight enhancement is likely a result of the brevity of news headlines, typically ranging from 15 to 20 words, and their pronounced sentiment scores. However, this only had a minor effect on the overall accuracy improvement. Analyzing the ROC curve’s convergence pattern in Study 2, as depicted in , and comparing it with the results from Study 1, it’s evident that the proposed model maintains similar levels of accuracy and convergence across news headline, body, and their combinations. This consistency underscores the stability and reliability of our discriminative model.
Figure 7. Experiment results of ROC curve of study 2.
Study 3: Does Writing Style Vary Between Real and Fake News?
In Studies 1 and 2, we adopt diverse elements within news to differentiate the effects of fake news and incorporated a sentiment analysis metric. However, recent research has begun to recognize the utility of writing style analysis in distinguishing between true and false news. For instance, Zhou and Zafarani (Citation2020) emphasized that effective fake news detection necessitates an analysis of writing style, in conjunction with evaluating the factual accuracy of presented information, scrutinizing the propagation patterns of news, and appraising the credibility of the source. Therefore, in Study 3, we have expanded our methodology to include writing style as a critical factor for ascertaining the authenticity of news pertaining to COVID-19.
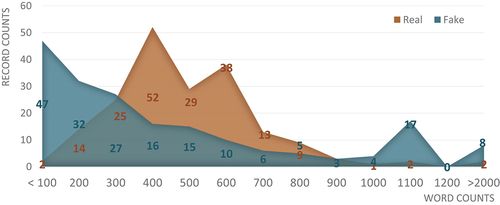
According to , which examines the article length of news, it is observed that the word count of fake news is more extreme, typically either below 100 words or exceeding 100 words, indicating a distinct writing style. Therefore, in Study 3, for writing style analysis, we extract statistical features of the news content, including the word count of characters, the frequency of stop words, and the presence of question marks. These elements serve as indicators for writing style and are utilized to optimize the proposed model.
Figure 8. The sentiment count of real and fake news.
The experimental results from demonstrate that the discriminate effect of writing style for discerning real from false news can yield an impressive 97% accuracy rate, the highest among all studied models. However, incorporating both writing style and sentiment analysis scores into the model does not lead to an improvement in accuracy. This is further evidenced by the convergence pattern of the ROC curve of Study 3 in , which indicates that the proposed model, when combined with considerations of writing style, indeed achieves the most rapid convergence, effectively distinguishing between authentic and fabricated news.
Figure 9. Experiment results of ROC curve of study 3(The blue line is writing style and the orange line is writing style with sentiment score).
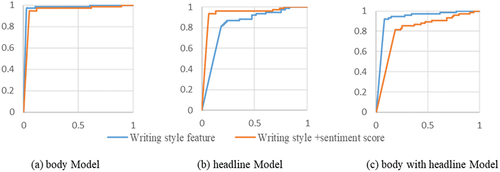
Table 7. The experiment results of discriminant effect for fake news among news architectures.
Discussion
Fake news, characterized as intentionally misleading or fabricated information masquerading as credible news, seeks to sway public opinion or actions. The advent of social media has accentuated its rapid spread and extensive reach, prompting concerns regarding its impact on public dialogue and the ability to distinguish truth from fiction. In our research, we utilized a range of features to differentiate between factual and fake news, scrutinizing the experimental results to understand how these features influence or correlate with the classification process.
Consistent with previous studies (Horne and Adali Citation2017), our model exhibited a commendable average accuracy of 93% in identifying fake news in Study 1. However, Study 2 showed a decline in accuracy with the integration of sentiment analysis. This decline was linked to the tendency of real news to express more positive emotions, in contrast to the broader emotional range observed in fake news, as reflected in sentiment scores. Notably, a slight increase in accuracy for news titles was achieved with sentiment analysis, presumably owing to the prevalent use of emotive language in headlines to draw attention. Impressively, the inclusion of writing style analysis markedly enhanced the accuracy to 97%, particularly when assessing the writing style of the news body. It was observed that combining writing style and sentiment analysis did not produce optimal results.
As outlined in , our findings advocate for the application of sentiment analysis scores in verifying the authenticity of news based on its title. For ascertaining the truthfulness of news content, incorporating a writing style analysis is essential, achieving an accuracy rate of up to 97%. Finally, when evaluating both the content and title of news, the application of our study’s model can attain an average accuracy of 93%.
Table 8. Summary interpretability and explainability of experimental results.
providing insights into analyze results of our ensemble model, we incrementally incorporated features related to sentiment scores and writing styles, examining individual feature impacts on the model’s interpretability and explainability. For illustration, aids in understanding the contribution of each feature to overall model transparency before delving into more intricate patterns. According to our findings indicate that sentiment scores enhance the effectiveness of headline-based models, whereas writing styles have a detrimental effect. This discrepancy likely stems from the necessity of headlines to capture attention and encourage clicks. Further analysis reveals that, in the analysis of the body, “writing style” are more effective than sentiment score at helping the model distinguish fake news. However, combining these features leads to a decrease in accuracy, suggesting an interaction effect. This phenomenon also occurs when analyze news body with headline. It appears that writing style could be pivotal for detecting fake news in longer text passages. Moreover, our results highlight that interactions between different features can adversely affect fake news detection. In textual analysis, selecting appropriate features may be more crucial than merely increasing the number of features.
The model was initially designed with a specific focus on COVID-19 fake news, incorporating distinctive linguistic features pertinent to this context. This specialization raises concerns about potential overfitting. To address this, we increase data variety from initial data source, use a more diverse set of training datasets as shown in that better captures the range of variability in real-world scenarios. In additional, our methodology included a systematic approach to data handling – training, testing, and verification were conducted in strict chronological order. The outcomes across various performance metrics have consistently indicated that overfitting has negligible influence on the model’s effectiveness.
Moreover, in light of the proliferation of large language models (LLMs), researchers have increasingly leveraged their sophisticated language comprehension abilities for detecting fake news (Hu et al. Citation2024; Huang and Sun Citation2023). We have curated pertinent studies that employ LLMs for zero-shot fake news detection, summarized in . Although their efficacy currently falls short of our study’s findings, these investigations highlight the promising research avenues enabled by LLMs.
Table 9. Studies on zero-shot fake news detection with LLMs.
Conclusions
The rapid integration of information technology into everyday life has escalated the issue of fake news, a phenomenon capable of causing significant social and political disruption, intensifying conflicts, and hindering epidemic control efforts (Allcott and Gentzkow Citation2017). The spread of erroneous information about COVID-19, for instance, has been known to erode trust in government and promote ineffective folk remedies, potentially leading to tragic outcomes (Varma et al. Citation2021).
To tackle the challenge of swiftly gathering comprehensive fake news data, we devised an ensemble machine learning algorithm that assesses various combinations of news headlines and content features. Our study’s experimental findings offer several insights into the detection of Traditional Chinese fake news, particularly regarding COVID-19. First, while our model achieved an impressive 93% accuracy in identifying fake news, integrating sentiment analysis led to a slight drop in accuracy, due to the differing emotional expressions in genuine and fake news. Second, the addition of writing style analysis markedly increased accuracy to 97% in content analysis, highlighting its significance in fake news detection. Overall, our holistic approach, combining sentiment analysis and writing style, consistently yielded a high average accuracy of 93% in assessing the authenticity of both news content and headlines, as shown in . These findings are crucial for researchers striving to better understand and effectively detect fake news.
From a practical standpoint, our research holds substantial implications for social media platforms and government agencies. As social media frequently serves as a conduit for fake news, our study provides valuable tools for these platforms to quickly detect and diminish the spread of Traditional Chinese fake news. Additionally, governments can utilize the features and models from our research for rapid identification of fake news in epidemic situations, thus prioritizing public health and medical responses. This study contributes significantly to the field, especially considering the limited research on Traditional Chinese fake news in the context of COVID-19. We have developed a comprehensive analysis pipeline and ensemble method that includes word segmentation tools, word vectors, sentiment dictionaries, and an evaluation of prevalent algorithms, confirming the efficiency of BERT in contexts with limited data. The integration of sentiment and contextual features into our model enables an extensive analysis of text, sentiment, and contextual elements in prevailing fake news narratives.
The outcomes of this study are of great societal importance, particularly during epidemics when the public is highly vulnerable to misinformation. Social media platforms, while facilitating communication, can also become breeding grounds for fake news (Ali et al. Citation2021). Our research can assist these platforms in rapidly countering the spread of Chinese fake news, fostering a safer environment for both users and advertisers. Moreover, these findings are instrumental for governments in addressing public health emergencies, allowing for the swift identification of fake news and the prioritization of essential health measures.
Limitations and Future Research
While our study has made significant strides in establishing analysis pipelines and an ensemble method for Traditional Chinese fake news in the context of COVID-19, it is important to recognize its limitations. One major constraint was the laborious and time-intensive nature of verifying and labeling fake news, resulting in a relatively small dataset. Additionally, the scarcity of labeled Chinese fake news data further limited the scope of our research.
The absence of sender details such as account identifiers and publication timestamps may have impacted the accuracy of our classification model. Future research directions could involve gathering such sender information to further refine the classifier’s effectiveness.
Furthermore, our study primarily utilized the number of words and stop words as contextual features. To enhance classification capabilities, subsequent research could broaden the spectrum of contextual features to include elements like the frequency of punctuation marks, including commas, periods, exclamation points, and at symbols. Integrating these additional features is anticipated to improve the classifier’s ability to more accurately differentiate between authentic and fake news. To extend the applicability of the proposed model post-pandemic to a broader array of misinformation types, not limited to COVID-19, future work should focus on significantly enhancing the model’s generalization capabilities across diverse scenarios. This can be achieved by continuously incorporating different news sources into the proposed model.
Finally, it is important to acknowledge that as societal norms shift, so will the styles and slang prevalent within news media. This evolution poses a substantial challenge in maintaining the model’s accuracy over time. Despite the resource-intensive nature of continuously updating the model to keep pace with these changes, this limitation is an integral part of our ongoing research agenda.
Moreover, while this study does not center on LLMs, and their standalone effectiveness as detectors currently falls short of the results reported here (Hu et al. Citation2024; Huang and Sun Citation2023), LLMs demonstrate remarkable capability in capturing subtle nuances and semantic complexities. Future research could explore strategies such as fine-tuning LLMs (Kareem and Abbas Citation2023) or integrating them with machine learning techniques (Teo et al. Citation2024) to leverage their strengths in semantic understanding and feature extraction, thereby bolstering the efficacy of fake news detection methodologies.
Disclosure Statement
No potential conflict of interest was reported by the author(s).
Data Availability Statement
The data underlying this article will be shared on reasonable request to the corresponding author.
Additional information
Funding
References
- Ajao, O., D. Bhowmik, S. Zargari, A. Gruzd, J. Jacobson, P. Mai, J. Hemsley, K. Hazel Kwon, R. Vatrapu, A. Quan-Haase, et al. 2018. Fake news identification on twitter with hybrid cnn and rnn models. In Proceedings of the 9th International Conference on Social Media & Society, ed, 226–22. Denmark: Copenhagen Business School, Frederiksberg. doi:10.1145/3217804.3217917.
- Al-Rakhami, M. S., and A. M. Al-Amri. 2020. Lies kill, facts save: Detecting COVID-19 misinformation in twitter. Institute of Electrical and Electronics Engineers Access 8:155961–70. doi:10.1109/access.2020.3019600.
- Ali, K., C. Li, K. Zain-Ul-Abdin, and M. A. Zaffar. 2021. Fake news on Facebook: Examining the impact of heuristic cues on perceived credibility and sharing intention. Internet Research 32 (1):379–97. doi:10.1108/INTR-10-2019-0442.
- Allcott, H., and M. Gentzkow. 2017. Social media and fake news in the 2016 election. Journal of Economic Perspectives 31 (2):211–36. doi:10.1257/jep.31.2.211.
- Alonso, M. A., D. Vilares, C. Gómez-Rodríguez, and J. Vilares. 2021. Sentiment analysis for fake news detection. Electronics 10 (11):1–32. doi:10.3390/electronics10111348.
- Balshetwar, S. V., A. Rs, and D. J. R. 2023. Fake news detection in social media based on sentiment analysis using classifier techniques. Multimedia Tools & Applications 82 (23):35781–811. doi:10.1007/s11042-023-14883-3.
- Bavel, J. J. V., K. Baicker, P. S. Boggio, V. Capraro, A. Cichocka, M. Cikara, M. J. Crockett, A. J. Crum, K. M. Douglas, J. N. Druckman, et al. 2020. Using social and behavioural science to support COVID-19 pandemic response. Nature Human Behaviour 4 (5):460–71. doi:10.1038/s41562-020-0884-z.
- Bondielli, A., and F. Marcelloni. 2019. A survey on fake news and rumour detection techniques. Information Sciences 497:38–55. doi:10.1016/j.ins.2019.05.035.
- Brett, M., and J. Goroncy. 2020. Coronavirus, creation and the creator: What the bible says about suffering and evil. ABC religion & ethics. Accessed January 21, 2024. https://www.abc.net.au/religion/coronavirus-creation-and-the-creator-biblical-faith-and-problem/12200508.
- Castillo, C., M. Mendoza, and B. Poblete. 2011. Information credibility on twitter. In WWW’11: Proceedings of the 20th international conference on World wide web, Association for Computing Machinery, ed. S. Sadagopan and K. Ramamritham, 675–84. (NY), NY, United States. doi:10.1145/1963405.1963500.
- Duffy, A., E. Tandoc, and R. Ling. 2020. Too good to be true, too good not to share: The social utility of fake news. Information Communication & Society 23 (13):1965–79. doi:10.1080/1369118X.2019.1623904.
- Durgapal, A., and V. Vimal. 2021. Prediction of stock price using statistical and ensemble learning models: A comparative study. Proceedings of 2021 IEEE 8th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), 1–6. Dehradun, India. November 11–13. doi:10.1109/UPCON52273.2021.9667644.
- Genç, Ş., and E. Surer. 2023. ClickbaitTR: Dataset for clickbait detection from Turkish news sites and social media with a comparative analysis via machine learning algorithms. Journal of Information Science 49 (2):480–99. doi:10.1177/01655515211007746.
- Guess, A. M., J. Nagler, and J. A. Tucker. 2019. Less than you think: Prevalence and predictors of fake news dissemination on facebook. Science Advances 5 (1):eaau4586. doi:10.1126/sciadv.aau4586.
- Horne, B., and S. Adali. 2017. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. In Proceedings of the International AAAI conference on web and social media, ed. M. Winter, A. M, and S. González-Bailón, vol. 11, 759–66. Montreal, QC, Canada. doi:10.1609/icwsm.v11i1.14976.
- Hu, B., Q. Sheng, J. Cao, Y. Shi, Y. Li, D. Wang, and P. Qi. 2024. Bad actor, good advisor: Exploring the role of large language models in fake news detection. Proceedings of the AAAI Conference on Artificial Intelligence 38 (20):22105–13, March. doi:10.1609/aaai.v38i20.30214.
- Huang, Y., and L. Sun. 2023. Harnessing the power of chatgpt in fake news: An in-depth exploration in generation, detection and explanation. arXiv preprint arXiv:2310.05046. doi:10.48550/arXiv.2310.05046.
- Islam, M. S., T. Sarkar, S. H. Khan, A. H. M. Kamal, S. M. Hasan, A. Kabir, D. Yeasmin, M. A. Islam, K. I. Amin Chowdhury, K. S. Anwar, et al. 2020. COVID-19–related infodemic and its impact on public health: A global social media analysis. The American Journal of Tropical Medicine and Hygiene 103 (4):1621–29. doi:10.4269/ajtmh.20-0812.
- Kaliyar, R. K., A. Goswami, and P. Narang. 2021. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimedia Tools & Applications 80 (8):11765–88. doi:10.1007/s11042-020-10183-2.
- Kareem, W., and N. Abbas. 2023. Fighting lies with intelligence: Using large language models and chain of thoughts technique to combat fake news. In Artificial intelligence XL. SGAI 2023. Lecture notes in computer science, ed. M. Bramer and F. Stahl, vol. 14381. Cham: Springer, November. doi:10.1007/978-3-031-47994-6_24.
- Kasprak, A. 2020. The origins and scientific failings of the COVID-19 ‘bioweapon’ conspiracy theory. Accessed April 6, 2023. https://www.snopes.com/news/2020/04/01/covid-19-bioweapon/.
- Khan, S., S. Hakak, N. Deepa, B. Prabadevi, K. Dev, and S. Trelova. 2021. Detecting COVID-19-related fake news using feature extraction. Frontiers in Public Health 9:788074. doi:10.3389/fpubh.2021.788074.
- Koru, G. K., and Ç. Uluyol. 2024. Detection of Turkish fake news from tweets with BERT models. Institute of Electrical and Electronics Engineers Access 12:14918–31. doi:10.1109/ACCESS.2024.3354165.
- Lahby, M., S. Aqil, W. M. S. Yafooz, and Y. Abakarim. 2022. Online fake news detection using machine learning techniques: A systematic mapping study. In Combating fake news with computational intelligence techniques. Studies in computational intelligence, ed. M. Lahby, A. K. Pathan, Y. Maleh, and W. M. S. Yafooz, 1001. Cham: Springer. doi:10.1007/978-3-030-90087-8_1.
- Lazer, D. M., M. A. Baum, Y. Benkler, A. J. Berinsky, K. M. Greenhill, F. Menczer, J. L. Metzger, B. Nyhan, G. Pennycook, D. Rothschild, et al. 2018. The science of fake news. Science 359 (6380):1094–96. doi:10.1126/science.aao2998.
- Meel, P., and D. K. Vishwakarma. 2020. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Systems with Applications 153:112986. doi:10.1016/j.eswa.2019.112986.
- MIT. 2018. Study: On twitter, false news travels faster than true stories. Accessed January 16, 2024. https://news.mit.edu/2018/study-twitter-false-news-travels-faster-true-stories-0308.
- MyGoPen. 2022. WHO raises ‘white flag for COVID-19 vaccine’: It’s all over … vaccines against pneumonia protects you against covid-19. Accessed April 6, 2023. https://www.mygopen.com/2022/01/who-covid.html.
- Pang, B., and L. Lee. 2008. Opinion mining and sentiment analysis. Foundations and Trends® in Information Retrieval 2 (1–2):1–135. doi:10.1561/1500000011.
- Pennycook, G., and D. G. Rand. 2019a. Fighting misinformation on social media using crowdsourced judgments of news source quality. Proceedings of the National Academy of Sciences 116 (7):2521–26. doi:10.1073/pnas.1806781116.
- Pennycook, G., and D. G. Rand. 2019b. Who falls for fake news? The roles of bullshit receptivity, overclaiming, familiarity, and analytic thinking. Journal of Personality 88 (2):185–200. doi:10.1111/jopy.12476.
- Raza, S. 2021. Automatic fake news detection in political platforms-a transformer-based approach. In Proceedings of the 4th Workshop on Challenges and Applications of Automated Extraction of Socio-political Events from Text (CASE 2021), 68–78. Online. August. doi:10.18653/v1/2021.case-1.10.
- Rezaeinia, S. M., R. Rahmani, A. Ghodsi, and H. Veisi. 2019. Sentiment analysis based on improved pre-trained word embeddings. Expert Systems with Applications 117:139–47. doi:10.1016/j.eswa.2018.08.044.
- Salama, S. 2021. World GULF, Saudi Arabia: Sceptics try cupping to remove COVID-19 vaccine. Accessed April 6, 2023. https://gulfnews.com/world/gulf/saudi/saudi-arabia-sceptics-try-cupping-to-remove-covid-19-vaccine-1.82375277.
- Shu, K., S. Wang, and H. Liu. 2019. Beyond news contents: The role of social context for fake news detection. Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, 312–20. doi:10.1145/3289600.3290994.
- Shushkevich, E., M. Alexandrov, and J. Cardiff. 2021. Covid-19 fake news detection: A survey. Computación y Sistemas 25 (4):783–92. doi:10.13053/CyS-25-4-4089.
- Tandoc, E. C., Jr, Z. W. Lim, and R. Ling. 2018. Defining “fake news” a typology of scholarly definitions. Digital Journalism 6 (2):137–53. doi:10.1080/21670811.2017.1360143.
- Teo, T. W., H. N. Chua, M. B. Jasser, and R. T. Wong. 2024. Integrating large language models and machine learning for fake news detection. In Proceedings of 2024 20th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), 102–07. Langkawi, Malaysia. March 1–2. doi:10.1109/CSPA60979.2024.10525308.
- Tibken, S. 2021. CNET, 5G has no link to COVID-19 but false conspiracy theories persist. Accessed April 6, 2023. https://www.cnet.com/tech/mobile/5g-has-no-link-to-covid-19-as-false-conspiracy-theories-persist/.
- Tomar, P., S. Shrivastava, and U. Thakar. 2021. Ensemble learning based credit card fraud detection system. Proceedings of 2021 5th Conference on Information and Communication Technology (CICT), 1–5. Kurnool, India. December 10–12. doi:10.1109/CICT53865.2020.9672426.
- Tsai, C. M. 2023. Stylometric fake news detection based on natural language processing using named entity recognition: In-domain and cross-domain analysis. Electronics 12 (17):3676. doi:10.3390/electronics12173676.
- Turney, P. D., and M. L. Littman. 2002. Unsupervised learning of semantic orientation from a hundred-billion-word corpus. arXiv preprintcs/0212012. doi:10.48550/arXiv.cs/0212012.
- Varma, R., Y. Verma, P. Vijayvargiya, and P. P. Churi. 2021. A systematic survey on deep learning and machine learning approaches of fake news detection in the pre-and post-COVID-19 pandemic. International Journal of Intelligent Computing and Cybernetics 14 (4):617–46. doi:10.1108/IJICC-04-2021-0069.
- Vosoughi, S., D. Roy, and S. Aral. 2018. The spread of true and false news online. Science 359 (6380):1146–51. doi:10.1126/science.aap9559.
- World Health Organization (WHO). 2020. Exposing yourself to the sun or to temperature higher than 25C degrees DOES NOT prevent nor cure COVID-19. Accessed April 6, 2023. https://www.facebook.com/WHO/photos/fact-exposing-yourself-to-the-sun-or-to-temperature-higher-than-25c-degrees-does/3111572302221465/?paipv=0&eav=AfYPBxwjuSYCkDczkRIU-J4glCRFJUUWNOezIqXt8pGdDuThQF3udCO_sOJreHpQSgE&_rdr.
- World Health Organization (WHO). 2021. Alcohol does not protect against COVID-19 and its access should be restricted during lock down. Accessed April 6, 2023. https://www.emro.who.int/mnh/news/alcohol-does-not-protect-against-covid-19-and-its-access-should-be-restricted-during-lock-down.html.
- World Health Organization (WHO). 2020. Coronavirus disease (COVID-19) advice for the public: Mythbusters. Accessed January 16, 2024. https://www.who.int/emergencies/diseases/novel-coronavirus-2019/advice-for-public/myth-busters.
- Yafooz, W. M. S., A. M. Emara, and M. Lahby. 2022. Detecting fake news on COVID-19 vaccine from YouTube videos using advanced machine learning approaches. In Combating fake news with computational intelligence techniques. Studies in computational intelligence, ed. M. Lahby, A. K. Pathan, Y. Maleh, and W. M. S. Yafooz, 1001. Cham: Springer. doi:10.1007/978-3-030-90087-8_21.
- Yang, C., X. Zhou, and R. Zafarani. 2021. CHECKED: Chinese COVID-19 fake news dataset. Social Network Analysis and Mining 11 (1):1–8. doi:10.1007/s13278-021-00766-8.
- Yang, Y., L. Zheng, J. Zhang, Q. Cui, Z. Li, and P. S. Yu. 2018. TI-CNN: Convolutional Neural Networks for Fake News Detection. arXiv preprint arXiv:1806.00749. doi:10.48550/arXiv.1806.00749.
- Yu, L. C., L. H. Lee, S. Hao, J. Wang, Y. He, J. Hu, and X. Zhang. 2016. Building Chinese affective resources in valence-arousal dimensions. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 540–45. San Diego, CA. June 12–17. https://aclanthology.org/N16-1066.pdf.
- Zhang, X., and A. A. Ghorbani. 2020. An overview of online fake news: Characterization, detection, and discussion. Information Processing & Management 57 (2):102025–26. doi:10.1016/j.ipm.2019.03.004.
- Zhang, Y. 2022. Discussion on key problems of computer linguistics based on Chinese NLP. Proceedings of 2022 International Conference on Artificial Intelligence in Everything (AIE), 534–39. Lefkosa, Cyprus. doi:10.1109/AIE57029.2022.00107.
- Zhou, X., and R. Zafarani. 2020. A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Computing Surveys (CSUR) 53 (5):1–40. doi:10.1145/3395046.
- Zubiaga, A., A. Aker, K. Bontcheva, M. Liakata, and R. Procter. 2018. Detection and resolution of rumours in social media: A survey. ACM Computing Surveys 51 (2):1–36. doi:10.1145/3161603.