
Abstract
Ubiquitin-activating enzyme (E1) is a key regulator in protein ubiquitination, which lies on the upstream of the ubiquitin-related pathways and determines the activation of the downstream enzyme cascade. Thus far, no structural information about the human ubiquitin-activating enzyme has been reported. We expressed and purified the N-terminal domains of human E1 and determined their crystal structures, which contain inactive adenylation domain (IAD) and the first catalytic cysteine half-domain (FCCH). This study presents the crystal structure of human E1 fragment for the first time. The main structure of both IAD and FCCH superimposed well with their corresponding domains in yeast Uba1, but their relative positions vary significantly. This work provides new structural insights in understanding the mechanisms of ubiquitin activation in humans.
Graphical Abstract
Crystal structure of the N-terminal domains of human E1 was determined, which is the first structure of human E1 fragment.
Introduction
Post-translational modification of protein by ubiquitin and ubiquitin-like molecules (UBLs) is very important in many physiological processes, such as protein quality control, innate and adaptive immune response, cell cycle, DNA repair, inflammatory response, and programmed cell death. The malfunction of these molecules leads to particular neurodegenerative diseases, developmental abnormalities, autoimmunity, and cancers.Citation1–4) Ubiquitin-modified proteins are usually destroyed by the 26S proteasome. In recent years, an increasing number of non-traditional functions of this modification have been reported.Citation5,6) Three different kinds of enzymes exist in this activation cascade.Citation7) First, ubiquitin is adenylated through its C-terminal double glycine motif and covalently binds to an ubiquitin activating enzyme (E1); the activated ubiquitin is then transferred to the correlated ubiquitin conjugation enzymes (E2) which are recognized by the ubiquitin-fold domain (UFD) of E1. The activated ubiquitin is then transferred to various downstream ubiquitin ligases (E3) or directly to the substrates through different mechanisms. Given that E1 is the most upstream activator in this cascade, in recent years, studies have developed quickly on the inhibitors of human ubiquitin E1, such as 4[4-(5-nitro-furan-2-ylmethylene)-3,5-dioxo-pyrazolidin-1-yl]-benzoic acid ethyl ester (PYR-41), to find a good medicinal candidate for specific related diseases. This inhibitor is membrane-permeable and demonstrated to be effective for particular tumors by covalently interacting with the active site cysteine residue.Citation8)
Different UBLs have different corresponding E1s. In humans, eight E1s can initiate UBLs conjugation.Citation9) Based on their domain architecture, these E1s are divided into canonical and non-canonical E1s. Canonical E1s include UBA1, UBA6, UBA7, SAE1-UBA2, and NAE2-UBA3, and non-canonical E1s consist of UBA4, UBA5, and Atg7. The E1 for ubiquitin has a molecular weight of about 120 kDa, and encoded by a single open reading frame, whereas the E1s for SUMO and NEDD8 are heterodimeric complexes with comparable overall molecular weights.Citation10–13) The structure of ubiquitin E1 consists of four different domain blocks: First, the inactive adenylation domain (IAD) and the active adenylation domain (AAD), which are composed of two MoeB/ThiF-homology motifs, and AAD is responsible for the binding of ATP and ubiquitin; Second, two conserved catalytic cysteine domains (first catalytic cysteine half-domain [FCCH] and second catalytic cysteine half domain [SCCH]) inserted into the adenylation domains, the latter of which contains the active site cysteine; Third, a four-helix bundle (4HB) that immediately follows the FCCH inserted into the IAD; Fourth, the UFD, lies on the C-terminal of the whole enzyme, and can recognize the coordinate E2s.Citation14) The FCCH and SCCH in E1s vary significantly, not only in sequence, but also in their three-dimensional structures.Citation14–17) For non-canonical E1s, they are very different in molecular weight, domain architecture, structure, and mechanisms for the activation of their corresponding UBLs.Citation18–21)
Given that canonical E1s for UBLs exhibit similar mechanism of activation, in the past decade, structure studies have mainly focused on the NAE1-UBA3 for NEDD8 and SAE1-UBA2 for SUMO. The detailed molecular mechanism of how these UBLs were activated, loaded onto their corresponding E1s, and their transfer into downstream E2s has been elucidated.Citation15–17,22,23) In 2010, Olsen et al. demonstrated an “active site remodeling” model through studying the structures of two SUMO E1 reaction intermediate mimics.Citation24) Yang et al. found that Cys278 in the FCCH domain can affect ubiquitin charging through a change in the structural conformation of mouse ubiquitin E1.Citation25) However, studies on human ubiquitin activating-enzyme are insufficient. Thus far, we only know the crystal structure of mouse SCCH, the NMR structure of mouse FCCH, the crystal structure of Saccharomyces cerevisiae (S. cerevisiae) Uba1 non-convalently bound with ubiquitin, and the crystal structures of Schizosaccharomyces pombe (S. pombe) Uba1/Ub/ATP·Mg alone and in complex with the ubiquitin E2 Ubc4.Citation14,26−28) Although many advances have been presented in understanding the structural basis for ubiquitin E1s activities from other species, no structural information about human ubiquitin E1 is known. Further structure-based drug design also requires the structural elucidation of human ubiquitin E1 and its different complexes with ubiquitin.
In this study, we expressed, purified, and crystallized the N-terminal domains of human ubiquitin-activating enzyme (residues 1–439), and determined their crystal structures at 2.75 Å resolution, which contains the IAD and FCCH domain. The main structures of both IAD and FCCH superimposed well with their homologs in S. cerevisiae Uba1, but their relative positions vary considerably. Our work provides a strong basis for further studies on the structure and function relationship of human ubiquitin-activating enzyme E1.
Materials and methods
cDNA, bacterial strains, and reagents
The cDNA plasmid of human ubiquitin E1 (EC6.3.2.19, NCBI accession No. CAA40296) was kindly provided by Dr Arthur L. Haas (Louisiana State University, Health Sciences Center). Cloning was conducted using the E. coli DH5α strain, and the overexpression of the N-terminal domains of human E1 was carried out with the E. coli BL21 (DE3) strain. The pETDuet-1 (Novagen) expression vector was used for recombinant protein expression. Restriction endonucleases (BglII and KpnI) were purchased from NEB (New England Biolabs). Plasmids were purified using the Plasmid Miniprep Kit from Tiangen. Ni-NTA columns were purchased from Qiagen. Source15Q column was purchased from GE Health Biosciences. The 3C protease (derived from rhinovirus) for cutting the 6 × His tag was expressed and purified in our lab. Gel filtration chromatography was performed with Superdex-200 (10/300 GL) from GE Healthcare Life Sciences. Primers for cloning were synthesized and sequenced by Invitrogen China. The crystallization screen kits were from Hampton. All other chemicals were purchased from Sigma-Aldrich.
Subcloning of human E1 N-terminal domains
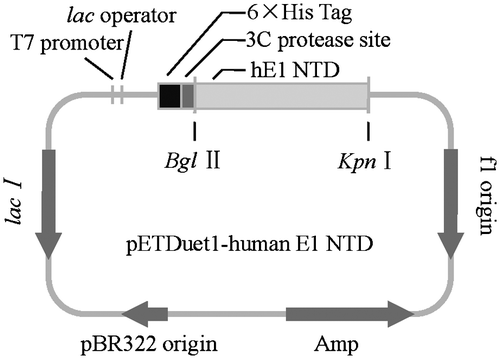
Human E1 N-terminal domains were amplified from the cDNA plasmid by PCR, using a forward primer with the sequence 5′-GAGCATGTCAGATCTATGTCCAGCTCGCCGCTGT-3′, and a reverse primer containing stop codons at the C-termini of the clone (5′-GTGACGTCAGGTACCTCAGCGGATGGTGTATCGGA-3′) were used. The PCR product was digested with restriction endonucleases (BglII and KpnI) and ligated into the vector pETDuet-1. Ligation products were transformed into E. coli DH5α competent cells by heat shock, and then the positive transformants were selected from agar plates containing 100 μg/mL ampicillin. The authenticity of the recombinant plasmids was confirmed by DNA sequencing.
Expression and purification of the recombinant protein
The recombinant plasmid was co-transformed with the plasmid pRare-2 into E. coli BL21 (DE3) competent cells via a heat-shock procedure. The positive transformants were selected from agar plates containing 50 μg/mL chloramphenicol plus 50 μg/mL ampicillin and inoculated into 10 mL of LB (Luria Bertani) media, overnight at 37 °C with agitation. The overnight cell culture was diluted into 1 L of LB, and grown at the same condition to an OD600 of 0.6. Recombinant proteins were induced with 0.2 mM IPTG (isopropyl β-d-Thiogalactoside) at 20 °C for 12 h.
The bacterial cells were harvested by centrifugation and resuspended in lysis buffer (50 mM Tris-HCl pH 8.0, 300 mM NaCl) supplemented with 10 mM MgCl2, 1 mM PMSF, and 200 Units/mL DNaseI, and then disrupted by sonication. Cell lysate was centrifuged at 8000× g at 4 °C for 45 min, and the soluble fractions were loaded onto the Ni-NTA beads (Qiagen). After washed with buffer containing 50 mM Tris-HCl pH 8.0, 500 mM NaCl, the recombinant protein was eluted by elution buffer (50 mM Tris-HCl pH 8.0, 250 mM imidazol). The preliminarily purified proteins were loaded onto source15Q column(GE Health Biosciences) pre-equilibrated with 50 mM Tris-HCl pH 8.0, and then eluted using a linear gradient of 0–1 M NaCl. The 6 × His tag was cleaved by 3C protease (derived from rhinovirus), and removed by reloading the mixture onto a Ni-NTA affinity column. Fractions were then condensed and loaded onto superdex 200 (GE Health Biosciences) column equilibrated with 10 mM Tris-HCl pH 8.0, 150 mM NaCl, and 2 mM Dithiothreitol. Purified protein was analyzed by 12% SDS-PAGE and the protein concentration was determined by ultraviolet absorption at 280 nm (for recombinant human E1 1-439 region, 1 A280 = 2 mg/mL). The purified proteins concentrated to 15 mg/mL were aliquoted, frozen in liquid nitrogen, and stored at −80 °C for crystallization.
Crystallization, data collection, and structure determination
Crystallization of human E1 N-terminal domains was performed at 21 °C via the hanging-drop vapor diffusion method with different crystal screen kits. Thin and clustered plate crystals appeared in drops consisted of 1.5 μL proteins and 1.5 μL reservoir solution containing 0.1 M Na3Citrate pH 5.6 and 3.2 M NH4Ac. Crystals suitable for data collection were obtained after microseeding in 0.1 M Na3Citrate pH 5.6, 3.0 M NH4Ac and 3 days growth. Fresh single crystals were quickly transferred to the cryoprotectant buffer containing the reservoir solution supplemented with 25% (v/v) ethylene glycol and then flash-frozen under a cold nitrogen stream at 100 K. The diffraction data were collected at Shanghai Synchrotron Radiation Facility beamline BL17U with a Mar225 CCD detector and processed by HKL2000.Citation29) Molecular replacement was performed with CCP4 using the N-terminal domain of S. cerevisiae Uba1 (1-424) as the searching model.Citation30) Given that the linker region between the IAD and FCCH exhibit flexibility to a particular extent, we failed to obtain the phase by using the intact yeast Uba1N-terminal domains’ structure as the searching model, but succeeded with the use of IAD and FCCH as two searching models, separately. The program COOT and PHENIX were used for inspection and manual refinement of the model.Citation31,32) PROCHECK was used to analyze the model stereochemistry.Citation33) The coordinates and structure factors of human E1 N-terminal domains were deposited into the RCSB Protein Data Bank with accession code 4P22. All structural representations were prepared with PyMOL software (http://www.pymol.org).
Results and discussion
Cloning of human E1 N-terminal domains
As human ubiquitin E1 lies on the apex upstream of the ubiquitination pathway, and is the potential target for particular structural-based drug designing, detailed structural information about structures of this enzyme, and the mechanisms by which it activates ubiquitin molecules and transfers them to the right downstream E2s are necessary. Human ubiquitin E1 is composed of 1058 amino acids, which contains an IAD and AAD, inserted by the FCCH and SCCH domain, and an UFD domain in its C-terminus (Fig. ). The secondary structure is similar to its yeast homolog with 50% sequence identity. The extreme N-terminal sequence of human E1 has no homologous sequence in yeast. Primers for amplifying the human ubiquitin E1 fragments were designed based on sequence alignment. Different human E1 fragments, including the full-length enzyme, were designed, expressed, and purified, but only the crystals of the N-terminal recombinant proteins were obtained. The sequence alignment analysis indicated that the IAD domain covers from Met1 to Glu204 and Val295 to Ile439 and that the FCCH domain covers from Glu205 to Gln294. The human E1 N-terminal domains were inserted into the pETDuet-1 vector using BglII and KpnI sites with an N-terminal 6 × His tag (Fig. ). This clone was used to express the recombinant protein.
Fig. 1. Domain architectures of human and S. cerevisiae ubiquitin E1.
Notes: A, adenylation domain; CC, cysteine catalytic domain; UFD, ubiquitin-fold domain. C632 and C600 are the active site cysteine residues for human and S. cerevisiae E1, respectively.
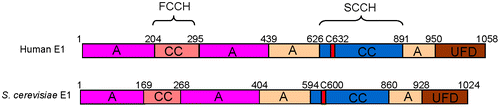
Fig. 2. Cloning of the N-terminal domains of human ubiquitin E1.
Notes: The N-terminal domains of human ubiquitin E1 were amplified and inserted into the pETDuet-1 vector with an N-terminal 6 × His tag for recombinant expression.
Expression and purification of human E1 N-terminal domains
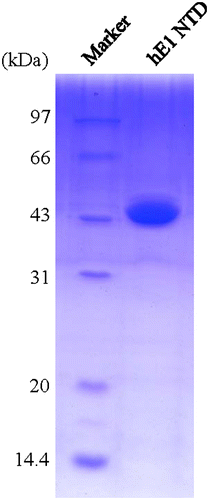
The human ubiquitin E1 N-terminal domains were overexpressed using E. coli BL21 (DE3) as host cells. At the beginning of the experiment, the yield of recombinant protein was relatively high, but always purified with some low-molecular weight contaminant bands. Thus, we analyzed the codons of the DNA sequence and found several rare codons for E. coli BL21 (DE3) strain, two of which are continuous. To solve this problem, we co-expressed the pRare-2 plasmid (which encodes tRNA that recognizes rare codons) with pETDuet-1-human E1 NTD, and finally improved the purity of the recombinant proteins. The human E1 N-terminal domains were primarily purified using a Ni-NTA affinity column and a source 15Q column. Then, to obtain proteins that are more suitable for crystallization, the 6 × His tag was removed by the 3C protease, and the proteins were further purified using a Superdex 200 column. The purities of target proteins were determined to be greater than 95% by SDS-PAGE (Fig. ).
Fig. 3. SDS-PAGE of the purified N-terminal domains of human ubiquitin E1.
Notes: The purified proteins were resolved via 12% SDS-PAGE, stained with Coomassie Brilliant Blue R-250, and then de-stained with an ethanol: acetic acid: water (2:1:7) mixture. The left lane is the protein marker, and the right lane contains 1.5 μL of the purified recombinant proteins.
Overall structure of human E1 N-terminal domains
To obtain molecular and structural information about human ubiquitin E1, and how it activates ubiquitin molecules and transfer them to the right downstream E2s, we conducted crystallization trials of full-length human E1 and its complexes with ubiquitin that are either covalently or non-covalently bound. However, all of the trials failed. Then we built a sequence alignment of human ubiquitin E1 with NAE1-UBA3 and SAE1-UBA2, which are two heterodimeric E1s with known crystal structures, and then generated two new clones (human E1 1-439 and 440-1058) corresponding to their two subunits separately.Citation14) We then successfully obtained the crystals of human E1 N-terminal domains (1-439). At first, the crystals were very thin plates clustered together, and the diffraction is relatively weak (Fig. (A)). Thus, we optimized the crystallization conditions and used the microseeding method to obtain thick crystals with high-quality diffraction (Fig. (B)). The structure was determined at 2.75 Å resolution (Fig. ). The statistics for data collection and structure refinement are summarized in Table . This study presents the fragmental crystal structure of human ubiquitin-activating enzyme E1 for the first time.
Fig. 4. Crystallization of N-terminal domains of human ubiquitin E1.
Notes: (A) Crystals of N-terminal domains of human ubiquitin E1 after three days at room temperature with the reservoir buffer containing 0.1 M Na3Citrate pH 5.6 and 3.2 M NH4Ac. (B) Optimized crystals of N-terminal domains of human ubiquitin E1 by microseeding, after two days growth at room temperature with the reservoir buffer containing 0.1 M Na3Citrate pH 5.6 and 3.0 M NH4Ac.

Fig. 5. Diffraction patterns of the crystal of the N-terminal domains of human ubiquitin E1.
Notes: The crystal diffracted to 2.75 Å resolution. B is the partial enlargement of region in A surrounded by rectangle.

Table 1. Data collection and refinement statistics.
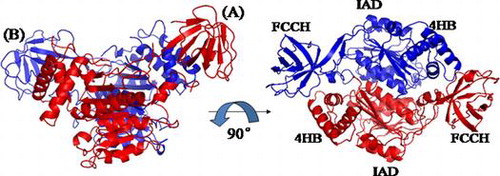
The secondary structure of human E1 N-terminal domains is similar to its yeast homolog, with 50% sequence identity (Fig. ). The extreme N-terminal sequence of human E1 has no homologous sequence in yeast. In this crystal structure, two molecules are present in one crystallographic asymmetric unit, which exhibit almost identical conformations, with an R.m.s.d. (Root mean square deviation) of 0.42 Ǻ over 332 residues (Fig. ). Given that the FCCH of molecule B has a comparatively low b-factor value and better electronic density map than molecule A, we used molecule B for description and comparison, unless noted otherwise. Molecule A and B form a pseudo-dimer, which is very similar to the pattern between the IAD and AAD of yeast Uba1. The structure of human E1 N-terminal domains consists of two domains, namely, IAD and FCCH. No obvious electronic density was found for the first 40 amino acids, which suggests that this region may be flexible and has no fixed structure. A linker region lies between these two domains, which was comprised of two long anti-parallel β-sheets, and demonstrated to have some flexibility between molecule A and B. The overall fold of human E1 N-terminal domains is composed of 12 α-helices and 15 β-strands, and the canonical adenylation domain was inserted by the FCCH and a four-helix bundle region.
Fig. 6. Sequence alignment of the N-terminal domains of human ubiquitin E1 (1-449) and S. cerevisiae E1 (1-424).
Notes: Secondary structures of human ubiquitin E1 (1-439) and S. cerevisiae E1 (1-424) were labeled above and below the amino acid sequence based on the crystal structure (PDB ID: 4P22 and 3CMM).
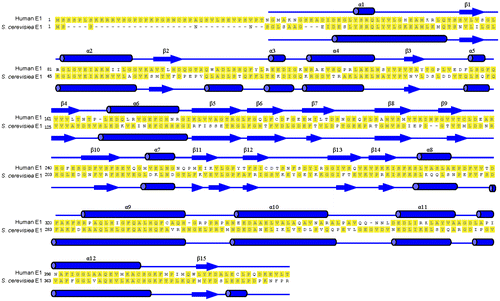
Fig. 7. Overall Structure of N-terminal domains of human ubiquitin E1.
Notes: Schematic diagram of the structure of the N-terminal domains of human E1, and the right figure is the view of the left structure by a 90° rotation around a horizontal axis. A and B are two molecules in the same crystallographic asymmetric unit.
Comparison of human E1 NTD with its yeast homolog
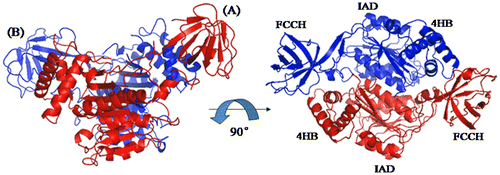
To determine other specific features, we compared the crystal structure of human E1 N-terminal domains with its homologs S. cerevisiae and S. pombe Uba1. As shown in Fig. (A) and (B), the main adenylation domain and the four-helix bundle adopts a very similar three-dimensional structure, whereas the FCCH seems to be considerably dissimilar. The homologs have high-sequence conservation, but differ remarkably in terms of crystal structure. We then considered and compared the FCCH domains. As shown in Fig. (C), FCCH domains, which consist of seven anti-parallel β-strands and a short α-helix, are superimposed very well. The R.m.s.d. value of human E1 FCCH to S. cerevisiae and S. pombe Uba1 FCCH is 1.15 and 1.21 Å. Therefore, the relative position of human E1 IAD and FCCH domain changed considerably compared with its two yeast homologs (Fig. (D–F)). In human E1, the axis of the cylinder surrounded by seven β-sheets of FCCH domain is nearly vertical to α12 helix whereas that in yeast Uba1 is almost parallel. In S. cerevisiae Uba1, a surface that includes Arg202, Gly204, and Glu206 interacts with ubiquitin molecule (circled by dotted line).Citation13) The transposition of human E1 FCCH domain results in the transfer of this region located from near the IAD to outward with the entire molecule.
Fig. 8. Structural Comparison of the N-terminal domains of human ubiquitin E1 with Its Yeast Homologs.
Notes: (A and B) Superimposed N-terminal domains of human ubiquitinE1 (colored blue) with S. cerevisiae Uba1 1-424 (PDB ID: 3CMM, colored pink) and S. pombe Uba1 1-392 (PDB ID: 4II2, colored cyans). (C) Superimposed FCCH domains from human ubiquitin E1 and yeast Uba1 (the same color with A and B). (D, E, and F) The relative position of human, S. cerevisiae and S. pombe ubiquitin E1 FCCH domains with the IAD, the encircled region is the ubiquitin-binding surface.
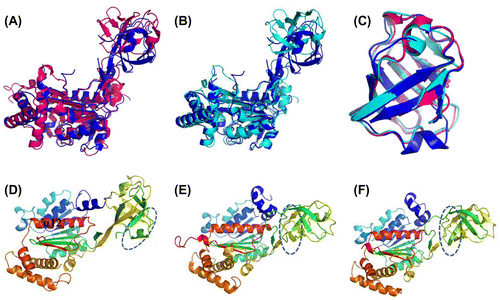
In this structure, human E1 IADs in symmetric molecules form a homodimer (Fig. (A)), and the dimer interface is primarily hydrophobic and mainly composed of an α-helix. Based on the structure of yeast Uba1 and some other related UBL-activating enzymes, such as SAE1-UBA2 and NAE1-UBA3, we know that in canonical E1s, IAD, and AAD form a pseudo-dimer through an interface containing the α12 helix in human E1.Citation17,22,23,34) The pattern of the S. cerevisiae Uba1 IAD and AAD pseudo-dimer is very similar to that in human IAD dimer (Fig. (B)). Adenylation domains of non-canonical E1s, such as Atg7 and Uba5, form a homodimer in the same pattern. Dimerization for Atg7 adenylation domains is necessary, as it was confirmed to catalyze the formation of Atg3-Atg8 intermediate in a trans manner (Fig. (C)).Citation19−21) The interface α-helix for Uba5 is relatively long and contains the active site cysteine (Fig. (D)).Citation18) But why canonical E1s use IAD and AAD to form a pseudo-symmetrical structure instead of using two AADs, is still a riddle.
Fig. 9. Comparison of the dimerization pattern of human ubiquitin E1 IAD with Its homologs in yeast uba1 and non-canonical E1s.
Notes: (A) Cartoon diagram of human E1 IAD dimer in the same crystallographic asymmetric unit. (B) Pseudo-symmetrical dimerization of S. cerevisiae Uba1 IAD and AAD (PDB ID: 3CMM). (C and D) Dimerization of the Atg7 and Uba5 AADs, respectively (PDB ID: 3VH1 and 3H8 V).
The N-terminal domains (IAD and FCCH) aids in constructing the entire structure of UBL-activating enzyme. Although the active site cysteine is not located in this region, the NTD collaborated with the AAD domain and the SCCH to form the two clefts, which were divided by the cross loop and function to hold the two ubiquitin molecules in the activation reaction. In the structure of human E1 NTD, both the IAD and FCCH exist as rigid bodies, but the linker region seems to be flexible. Furthermore, in the E1 homologs, the FCCH domain does not interact with the other region of the entire enzyme. Given that human E1 NTD is not an intact enzyme, and that ubiquitin non-covalently binds to Uba1 and interacts with the FCCH domain in yeast, we propose that FCCH can possibly help E1 to recognize and then recruit ubiquitin to the catalytic cleft through the transposition of the ubiquitin-binding region. Nevertheless, the remarkable change in relative position between IAD and FCCH, as well as their physiological function, still requires further structural and functional studies.
Acknowledgment
We thank Dr Arthur L. Haas for generously providing the cDNA plasmid of human ubiquitin E1.
Funding
This work was supported by the Natural Science Foundation of China [grant number 31070643], [grant number 31130062]; China National Key Basic Research Program [grant number 2011CB910803], [grant number 2013CB530603].
Notes
Abbreviations: AAD, active adenylation domain; E. coli, Escherichia coli; FCCH, first catalytic cysteine half domain; IAD, inactive adenylation domain; Ni-NTA, nickel-nitrilotriaceticacid; NTD, N-terminal domain; SCCH, second catalytic cysteine half domain; UBLs, ubiquitin-like molecules; UFD, ubiquitin-fold domain.
References
- Goldberg AL. Functions of the proteasome: from protein degradation and immune surveillance to cancer therapy. Biochem. Soc. Trans. 2007;35:12–17.
- Hershko A, Ciechanover A. The ubiquitin system. Annu. Rev. Biochem. 1998;67:425–479.10.1146/annurev.biochem.67.1.425
- Mukhopadhyay D, Riezman H. Proteasome-independent functions of ubiquitin in endocytosis and signaling. Science. 2007;315:201–205.10.1126/science.1127085
- Sun L, Trausch-Azar JS, Ciechanover A, Schwartz AL. Ubiquitin-proteasome-mediated degradation, intracellular localization, and protein synthesis of myod and id1 during muscle differentiation. J. Biol. Chem. 2005;280:26448–26456.10.1074/jbc.M500373200
- Hochstrasser M. Origin and function of ubiquitin-like proteins. Nature. 2009;458:422–429.10.1038/nature07958
- Aguilar RC, Wendland B. Ubiquitin: not just for proteasomes anymore. Curr. Opin. Cell Biol. 2003;15:184–190.10.1016/S0955-0674(03)00010-3
- Haas AL, Siepmann TJ. Pathways of ubiquitin conjugation. FASEB J. 1997;11:1257–1268.
- Yang Y, Kitagaki J, Dai RM, Tsai YC, Lorick KL, Ludwig RL, Pierre SA, Jensen JP, Davydov IV, Oberoi P, Li C-CH, Kenten JA, Beutler JA, Vousden KH. Cancer Res. 2007;67:9472–9481.10.1158/0008-5472.CAN-07-0568
- Schulman BA, Wade Harper JW. Ubiquitin-like protein activation by E1 enzymes: the apex for downstream signalling pathways. Nat. Rev. Mol. Cell Biol. 2009;10:319–331.10.1038/nrm2673
- Handley PM, Mueckler M, Siegel NR, Ciechanover A, Schwartz AL. Molecular cloning, sequence, and tissue distribution of the human ubiquitin-activating enzyme E1. Proc. Nat. Acad. Sci. 1991;88:258–262.10.1073/pnas.88.1.258
- Gong L, Yeh ET. Identification of the activating and conjugating enzymes of the NEDD8 conjugation pathway. J. Biol. Chem. 1999;274:12036–12042.10.1074/jbc.274.17.12036
- Desterro JM, Rodriguez MS, Kemp GD, Hay RT. Identification of the enzyme required for activation of the small ubiquitin-like protein SUMO-1. J. Biol. Chem. 1999;274:10618–10624.10.1074/jbc.274.15.10618
- Kanemaru A, Saitoh H. High-yield expression of mouse Aos1-Uba2-Fusion SUMO-activating enzyme, mAU, in a baculovirus-insect cell system. Biosci. Biotechnol. Biochem. 2013;77:1575–1578.10.1271/bbb.130070
- Lee I, Schindelin H. Structural insights into E1-catalyzed ubiquitin activation and transfer to conjugating enzymes. Cell. 2008;134:268–278.10.1016/j.cell.2008.05.046
- Walden H, Podgorski MS, Huang DT, Miller DW, Howard RJ, Minor DL Jr, Holton JM, Schulman BA. The structure of the APPBP1-UBA3-NEDD8-ATP complex reveals the basis for selective ubiquitin-like protein activation by an E1. Mol. Cell. 2003;12:1427–1437.10.1016/S1097-2765(03)00452-0
- Walden H, Podgorski MS, Schulman BA. Insights into the ubiquitin transfer cascade from the structure of the activating enzyme for NEDD8. Nature. 2003;422:330–334.10.1038/nature01456
- Lois LM, Lima CD. Structures of the SUMO E1 provide mechanistic insights into SUMO activation and E2 recruitment to E1. EMBO J. 2005;24:439–451.10.1038/sj.emboj.7600552
- Bacik JP, Walker JR, Ali M, Schimmer AD, Dhe-Paganon S. Crystal structure of the human ubiquitin-activating enzyme 5 (UBA5) bound to ATP: mechanistic insights into a minimalistic E1 enzyme. J. Biol. Chem. 2010;285:20273–20280.10.1074/jbc.M110.102921
- Taherbhoy AM, Tait SW, Kaiser SE, Williams AH, Deng A, Nourse A, Hammel M, Kurinov I, Rock CO, Green DR, Schulman BA. Atg8 transfer from Atg7 to Atg3: a distinctive E1-E2 architecture and mechanism in the autophagy pathway. Mol. Cell. 2011;44:451–461.10.1016/j.molcel.2011.08.034
- Noda NN, Satoo K, Fujioka Y, Kumeta H, Ogura K, Nakatogawa H, Ohsumi Y, Inagaki F. Structural basis of Atg8 activation by a homodimeric E1, Atg7. Mol. Cell. 2011;44:462–475.10.1016/j.molcel.2011.08.035
- Hong SB, Kim BW, Lee KE, Kim SW, Jeon H, Kim J, Song HK. Insights into noncanonical E1 enzyme activation from the structure of autophagic E1 Atg7 with Atg8. Nat. Struct. Mol. Biol. 2011;18:1323–1330.10.1038/nsmb.2165
- Huang DT, Paydar A, Zhuang M, Waddell MB, Holton JM, Schulman BA. Structural basis for recruitment of Ubc12 by an E2 binding domain in NEDD8's E1. Mol. Cell. 2005;17:341–350.10.1016/j.molcel.2004.12.020
- Huang DT, Hunt HW, Zhuang M, Ohi MD, Holton JM, Schulman BA. Basis for a ubiquitin-like protein thioester switch toggling E1–E2 affinity. Nature. 2007;445:394–398.10.1038/nature05490
- Olsen SK, Capili AD, Lu X, Tan DS, Lima CD. Active site remodelling accompanies thioester bond formation in the SUMO E1. Nature. 2010;463:906–912.10.1038/nature08765
- Yang U, Yang HY, Kim JS, Lee TH. The functional role of UBA1 cysteine-278 in ubiquitination. Biochem. Biophys. Res. Commun. 2012;427:587–592.10.1016/j.bbrc.2012.09.102
- Szczepanowski RH, Filipek R, Bochtler M. Crystal structure of a fragment of mouse ubiquitin-activating enzyme. J. Biol. Chem. 2005;280:22006–22011.10.1074/jbc.M502583200
- Olsen SK, Lima CD. Structure of a ubiquitin E1-E2 complex: insights to E1-E2 thioester transfer. Mol. Cell. 2013;49:884–896.10.1016/j.molcel.2013.01.013
- Jaremko M, Jaremko L, Nowakowski M, Wojciechowski M, Szczepanowski RH, Panecka R, Zhukov I, Bochtler M, Ejchart A. NMR structural studies of the first catalytic half-domain of ubiquitin activating enzyme. J. Struct. Biol. 2013;185:69–78.
- Otwinowski ZM, Minor W. Processing of X-ray diffraction data collected in the oscillation mode. Meth. Enzymol. 1997;276:307–326.10.1016/S0076-6879(97)76066-X
- McCoy AJ, Grosse-Kunstleve RW, Storoni LC, Read RJ. Likelihood-enhanced fast translation functions. Acta Crystallogr., Sect D: Biol. Crystallogr. 2005;61:458–464.10.1107/S0907444905001617
- Adams PD, Grosse-Kunstleve RW, Hung LW, Ioerger TR, McCoy AJ, Moriarty NW, Read RJ, Sacchettini JC, Sauter NK, Terwilliger TC. PHENIX: building new software for automated crystallographic structure determination. Acta Crystallogr., Sect D: Biol. Crystallogr. 2002;58:1948–1954.10.1107/S0907444902016657
- Emsley P, Cowtan K. Coot: model-building tools for molecular graphics. Acta Crystallogr., Sect D: Biol. Crystallogr. 2004;60:2126–2132.10.1107/S0907444904019158
- Laskowski RA, Macarthur MW, Moss DS. PROCHECK: a program to check the stereochemical quality of protein structures. J. Appl. Crystallogr. 1993;26:283–291.10.1107/S0021889892009944
- Lake MW, Wuebbens MM, Rajagopalan KV, Schindelin H. Mechanism of ubiquitin activation revealed by the structure of a bacterial MoeB-MoaD complex. Nature. 2001;414:325–329.10.1038/35104586