
Abstract
Reverse-engineering the brain involves adopting and testing a hierarchy of working hypotheses regarding the computational problems that it solves, the representations and algorithms that it employs and the manner in which these are implemented. Because problem-level assumptions set the course for the entire research programme, it is particularly important to be open to the possibility that we have them wrong, but tacit algorithm- and implementation-level hypotheses can also benefit from occasional scrutiny. This paper focuses on the extent to which our computational understanding of how the brain works is shaped by three such rarely discussed assumptions, which span the levels of Marr's hierarchy: (i) that animal behaviour amounts to a series of stimulus/response bouts, (ii) that learning can be adequately modelled as being driven by the optimisation of a fixed objective function and (iii) that massively parallel, uniformly connected layered or recurrent network architectures suffice to support learning and behaviour. In comparison, a more realistic approach acknowledges that animal behaviour in the wild is characterised by dynamically branching serial order and is often agentic rather than reactive. Arguably, such behaviour calls for open-ended learning of world structure and may require a neural architecture that includes precisely wired circuits reflecting the serial and branching structure of behavioural tasks.
1. Introduction
David Marr's posthumous classic Vision (Marr, Citation1982) began famously with a question: ‘What does it mean, to see?’ Putting such questions up front and centre contributed at the time to a conceptual realignment in the study of natural and artificial neural computation, following which it became accepted that understanding the nature of a problem in cognition is part and parcel of understanding its possible solutions, as well as the actual solution implemented by the brain and used by it to decide how to behave.
But what does it mean, to behave? What computational problems do animals routinely face and solve? Problems that arise ‘in the wild’ are not revealed as such to cognitive scientists (even in the laboratory, what goes on in the subjects’ heads may be not quite what the experimenter intends). To arrive at a reasonable formulation of these problems, we have no choice but to put forward and evaluate hypotheses. These are based on the animal's range of behaviours, which in turn are interdependent with its ecological niche, social habits, body mechanics and physiology, and neural architecture.
Insofar as our hypotheses regarding the problems that animals ostensibly solve are based on abductive reasoning, they are subject to biases. Some of these biases are entirely of our own making. For instance, if an effective algorithmic framework happens to become available for a class of problems, these then tend to loom larger as possible factors in theories of behaviour.Footnote1 As a quick example (to be revisited later), consider the widespread influence exerted on cognitive science by the invention of the back-propagation algorithm for training multilayer perceptrons (Rumelhart, Hinton, & Williams, Citation1986). This made it possible to use a relatively simple (layered and uniformly connected) ‘neural network’ architecture to learn a large and important class of functions for mapping inputs to outputs (Cybenko, Citation1989; Haussler, Citation1989; Hartman, Keeler, & Kowalski, Citation1990; Hornik, Stinchcombe, & White, Citation1989). The resulting spate of connectionist approaches to various cognitive tasks, including visual perception (Mel, Citation1991) and motor control (Mussa-Ivaldi & Giszter, Citation1992), naturally involved the assumption that such tasks can be adequately reduced to mapping inputs to outputs. While rarely stated or defended explicitly (as it was in (Poggio, Citation1990)), this assumption grew to be ubiquitous, quickly spreading even to theories of sequential behaviours such as language (Elman, Citation1990).
To guard against such biases, it makes sense occasionally for us to pause and reevaluate our working hypotheses, including any tacit assumptions, in the broader context of understanding real brains and real behaviour. This paper undertakes such a reevaluation for issues that extend over the three levels of the methodological hierarchy defined by Marr and Poggio (Citation1977; cf. Marr, Citation1982): problem, representation/algorithm and implementation. On each of these levels, I offer a critical look at some common and far-reaching assumptions that are yet rarely discussed.
The remainder of the paper is structured as follows. In Section 2, I discuss the notion that the control of behaviour can be effectively mastered by learning a (possibly very complex) input–output mapping and argue that it is too limited to account for realistic animal behaviour, which is sequential, hierarchically structured, dynamically branching and agentic. Section 3 proposes that the common view of learning as the optimisation of a fixed cost function (over a possibly very complex input/output or state × action space) is likewise too limited to support important sequential behaviours, such as language. In Section 4, I contend that the gross architecture of the mammalian brain can be better understood if we accept that certain tasks in behavioural learning and control are best served not by the common, uniformly connected multilayer networks, but rather by precisely wired circuits, whose topology reflects the connectivity structure of the task space. Section 5 recapitulates the proposed ideas and illustrates them on a case study of a computational model of language acquisition and translation. Finally, Section 6 offers a summary and concluding remarks.Footnote2
2. Behaviour
Parts of this section will appear to reprise a debate that many of us in psychology and neuroscience believe has been long resolved and put to rest: the debate between the behaviourist and situationist approaches on the one hand and interactionist and cognitive approaches on the other (Bowers, Citation1973; Neisser, Citation1967). My intention here is, however, not to revive that debate, but rather to illustrate the extent to which behaviour is still tacitly treated as a series of responses to stimuli, even within theoretical frameworks that are otherwise avowedly cognitive and explicitly computational.
2.1. The S/R assumption
In psychology, the conception of behaviour as a series of responses to stimuli – what I shall call the S/R assumption – appears already in William James (1911, quoted in Phillips, Citation1971):
The structural unit of the nervous system is in fact a triad, neither of whose elements has any independent existence. The sensory impression exists only for the sake of awaking the central process of reflection, and the central process of reflection exists only for the sake of calling forth the final act.
Fifty years later, the S/R assumption still reigned in physiological psychology: the subtitle on the cover of the 1961 Science Editions paperback printing of Donald Hebb's The Organization of Behavior (Hebb, Citation1949) read ‘Stimulus and response – and what occurs in the brain in the interval between them’ (Edelman, Citation2012, p. 1121). Even the subsequent cognitive turn in psychology and neuroscience had little effect on the S/R view of behaviour, which ‘appeals to many psychologists because it seems to be an explicitly causal analysis’ (Bowers, Citation1973, p. 309).
This appeal is still strong. As recently as 2003, a handbook of experimental psychology stated that ‘Learning, like many other central concepts in psychology, is referred to as an intervening variable, that is, an unobservable construct postulated to account for stimulus-response regularities’ (Papini, Citation2003, p. 231). Bowers (Citation1973, p. 316) anticipated such persistence of behaviourism, attributing it to the continued influence of the S/R assumption: ‘So long as cognition is viewed primarily as a response mediating the causal impact of external stimuli, it cannot easily be viewed as initiating, maintaining, or explaining behaviour.’
All this might have been just as well, if the reliance on the S/R assumption in psychology and brain research had been more productive. Arguably, however, it has instead impeded progress. In a recent personal retrospective on several decades of studying the nervous system of the fruit fly, Heisenberg (Citation2014, p. 389) offers the following diagnosis of what he perceives to be a general impasse in this regard: ‘What is the problem with brain research? The problem is the input-output doctrine. It is the wrong dogma, the red herring.’
2.2. A machine learning perspective on the S/R doctrine: function approximation and deep networks
Importantly, the problem with the S/R assumption, or the ‘input-output doctrine’, is not the lack of theoretical understanding of, or practical solutions for, mapping inputs to outputs. On the contrary, as suggested in the introduction, it may be the relative conceptual clarity and computational ease of learning S/R mapping that contributes to its continued dominance in experimental psychology and neuroscience.
In machine learning and artificial intelligence, the problem of mapping stimuli to responses corresponds to function approximation – a well-understood task, which has been extensively studied and for which there exist provably effective algorithmic solutions, amenable to implementation by networks of simple neuron-like computing elements (Hornik et al., Citation1989; Poggio, Citation1990). Among the latter, deep network (DN) architectures have recently been gaining prominence (and media attention) by outperforming competing approaches on many popular benchmarks (Schmidhuber, Citation2015).
Briefly, DNs are uniform, multilayer neural networks that undergo supervised training to serve as generative models.Footnote3 Hinton (Citation2007) summarises their properties by noting that adopting the generative approach reduces the need for labelled data (although given the large size of current models, very large amounts of data are still required), that many hidden layers can be stacked as long as learning is carried out one layer at a time (using Restricted Boltzmann Machines) and that the resulting model can be fine-tuned so as to boost its generative or discriminative performance. Many additional improvements to this general blueprint are possible (e.g. convolutional feature extraction (LeCun & Bengio, Citation1995) and extension to sequential data (Sutskever & Hinton, Citation2007)); see (Hinton, Citation2009) for a concise overview, (Bengio, Citation2009) for a tutorial introduction and (Schmidhuber, Citation2015) for an exhaustive history and references.
Networks with many nonlinear stages are extremely powerful, in that they can express functional relationships of great complexity, in high-dimensional representation spaces. Such power comes at a price, especially in deep, uniform architectures, which present a particularly acute case of the fundamental credit assignment problem (Minsky, Citation1961): how to use supervision data to identify units responsible for each outcome and to modify their parameters to improve performance (Schmidhuber, Citation2015). With the discovery of effective training methods for DNs, it became clear that, for a wide variety of tasks, they are not only much better than traditional networks with one hidden layer, trained by back-propagation (Rumelhart et al., Citation1986), but are also in fact capable of outperforming – on those tasks – any available learning-based method (Schmidhuber, Citation2015).
It is here that the allure of DNs for psychology and neuroscience becomes clear: just as the S/R assumption causes the attention in those disciplines to focus on mapping inputs to outputs (at the expense of a broader conception of behaviour), mapping inputs to outputs is precisely the category of tasks on which DNs excel. As Schmidhuber (Citation2015) concludes in his comprehensive review, what DNs do is ‘learn to perceive/encode/predict/classify patterns or pattern sequences’. It may seem surprising that this category of tasks includes many that arise in language, which involves complex sequential and structural dependencies that extend beyond S/R contingencies (Chomsky, Citation1959). This quandary is resolved if one considers closely the kinds of language task on which DNs do well (e.g. Socher, Lin, Ng, & Manning, Citation2011; Sutskever & Hinton, Citation2007; Sutskever, Vinyals, & Le, Citation2014). Invariably, these involve the mapping of entire structures to entire structures (as in learning to choose the best parse tree for a given input sentence). In other words, DNs can serve as a good model of behaviour only if we pretend that behaviour amounts to one Google (or Watson) query after another.
2.3. A broader view of behaviour: agency, hierarchy, situated dynamics
The view of behaviour as an arc from stimulus to response (perhaps via some thinking or intervening nervous activity) is, however, untenable. To begin with, the problematicity of the very concepts of stimulus and response, discussed at length by Chomsky (Citation1959), had been occasionally acknowledged by B.F. Skinner himself, who complained that ‘It is very difficult to find a stimulus and response which maintain precisely the same properties upon two successive occasions’ (Skinner, Citation1935, quoted in Glenn, Ellis, & Greenspoon, Citation1992). Likewise, in a generally very favourable review of Skinner's legacy, Epstein (Citation1991, p. 362) noted that the concepts of stimulus and response may not apply because behaviour is really continuous: ‘The click of a microswitch suggests, falsely, that a discrete “response” has occurred, but the rat is active continuously, and what occurs is multidimensional and complex.’
Furthermore, behaviour is often agentic or animal-initiated, in a manner that blurs the distinction between a stimulus, which could in reality be an act on the part of the agent, and a response, which could be the resulting snapshot of the environment. Thus, long before Chomsky's (Citation1959) critique of Skinner's attempt to extend the S/R approach to language, John Dewey (Citation1896) wrote:
What we have is a circuit, not an arc or broken segment of a circle. […] The motor response determines the stimulus, just as truly as sensory stimulus determines movement. […] There is simply a continuously ordered sequence of acts, all adapted in themselves and in the order of their sequence, to reach a certain objective end, the reproduction of the species, the preservation of life, locomotion to a certain place. The end has got thoroughly organized into the means.
No external change is a stimulus in and of itself. It becomes the stimulus in virtue of what the organism is already preoccupied with. To call it, to think of it, as a stimulus without taking into account the behaviour that is already going on is so arbitrary as to be nonsensical.
Lashley (Citation1951) concurred, noting that the active role of the animal in shaping its behaviour implies that ‘the input is never into a quiescent or static system, but always into a system which is already actively excited and organized’.Footnote4 Furthermore, Lashley (Citation1951, p. 123) argued, behaviour is serial and, moreover, its control by the brain cannot be a matter of a simply stringing together a series of independent acts or responses:
Certainly language presents in a most striking form the integrative functions that are characteristic of the cerebral cortex and that reach their highest development in human thought processes. Temporal integration is not found exclusively in language; the coordination of leg movements in insects, the song of birds, the control of trotting and pacing in a gaited horse, the rat running the maze, the architect designing a house, and the carpenter sawing a board present a problem of sequences of action which cannot be explained in terms of successions of external stimuli.
In addition to exhibiting a sequential and hierarchical structure, linguistic behaviour is situated and dynamic: speakers and listeners refer to and rely on their physical settings and coordinate their parts of the conversation in an ongoing manner (e.g. Crocker, Knoeferle, & Mayberry, Citation2010; Dale, Fusaroli, Duran, & Richardson, Citation2013; Spivey & Dale, Citation2006). Lessons from ethology, where the S/R approach has been less dominant,Footnote5 suggest that these characteristics are typical of animal sequential behaviour in general.
As an example of a common type of behaviour that is situated, sequentially and hierarchically structured, and in many cases dynamically socially coordinated, we may consider foraging (Galef & Giraldeau, Citation2001; Kamil & Sargent, Citation1981). Many foraging species, including mammals, exhibit the kind of cognitive flexibility and hierarchical real-time control (e.g. Maaswinkel & Whishaw, Citation1999; Sallabanks, Citation1993) that are unlikely to be reducible to S/R learning. For instance, in goat foraging one finds ‘a mixture of influences across a range of spatial and temporal scales’ (Derry, Citation2004, p. 140). More generally, in foraging ‘choices between simultaneously offered goods are relatively rare and foraging is instead dominated by sequential choices between exploiting nearby resources versus exploring elsewhere’ (Cisek, Citation2012, p. 930). Human foraging, in particular, involves complex, dynamic decision-making (Pacheco-Cobos, Rosetti, Cuatianquiz, & Hudson, Citation2010). When foraging is carried out socially, in groups of several people, it is, as one would expect, facilitated by verbal communication (King et al., Citation2011). Indeed, the behavioural needs arising in foraging have been posited as one of the sources of evolutionary pressure that led to the emergence of language (Cangelosi, Citation2001; Kolodny, Edelman, & Lotem, Citation2014).
2.4. The overarching task in complex behaviour
Given that realistic behaviour is agentic, sequentially and hierarchically structured, situated and dynamic, what tasks does it give rise to? In light of the preceding discussion, we would do well to raise our sights and consider the idea that the overarching problem in managing behaviour is deciding what to do next: ‘Briefly, one of the basic problems that must be solved is to resolve which functional system, at any point in time, should be permitted to direct “the final common motor path”, i.e. determine behavioural output’ (Redgrave, Gurney, Stafford, Thirkettle, & Lewis, Citation2013, p. 130).Footnote6
For a realistic behaviour, the problem space associated with deciding what to do next will typically be large, complex, diachronic and open-ended. It is large because of the combinatorics arising from the sequential nature of behaviour and the multiple actions choices available at each step (think of the number of motor degrees of freedom in a typical vertebrate body plan). It is complex because of the interactions among the relevant contextual factors, both external and internal or agentic. It is diachronic because contextual effects extend – and may change – over time. And it is open-ended because of novelty, which can also be external, as in a novel physical or social situation, or internal, as when an opportunity for a novel action arises and needs to be considered.
It is the diachronic effects and open-endedness that are particularly troublesome for the S/R view of behaviour. Action choice typically cannot be reduced to a set of fixed S/R associations or rules; hence the common designation of rigid rule-following behaviours as ‘slavish’ or ‘robotic’ and the notion that ‘rules are there to be broken’. Nor can each action decision be the outcome of choosing a response to an immediately preceding stimulus. These challenges are especially obvious in human behaviour. In the use of language, in particular, the combinatorial space of action choices is both very large (due to the tens of thousands of lexical degrees of freedom) and very complex (due to the intricate syntactic constraints that govern word combination). This complexity, moreover, is not confined to the present moment in time, as a stimulus in the S/R framework is, but rather are spread over time and across multiple time scales: the next word in an utterance may depend in principle on the speaker's entire past life experience, as well as on another word choice that is still in the future.
3. Learning
Setting aside the S/R assumption in favour of the more general, yet arguably more useful, view of the key problem of behaviour as deciding what to do next, we may now descend one level in the Marr hierarchy (keeping in mind, as always, that the levels are interdependent) and ask what algorithms and representations would work for it. Approaching this question rationally (in the sense of Chater (Citation2009)), we may assume that an agent situated in an initially unknown and possibly changing environment would do well to take into account the outcomes of its actions – an assumption that leads to the idea of reinforcement learning (Barto, Citation2013; Sutton & Barto, Citation1981, Citation1998; Woergoetter & Porr, Citation2007).
Reinforcement learning (RL) is an extremely general formalism: Schmidhuber (Citation2015) points out that ‘any task with a computable description can be formulated in the RL framework.’ As such, making it explicit enough to serve as a model of animal behaviour (or an engine of robot behaviour), as well as understanding how it may work in the brain, requires making working hypotheses, or assumptions, about the representations involved and about the manner whereby these are modified by experience. In this section, I examine two types of such assumptions on which RL algorithms are based: those that have to do with what is to be represented and those that pertain to how outcomes affect the representations. I then explore the possible conceptual and practical benefits of modifying these assumptions.
3.1. Common assumptions in RL research
The conceptual roots of RL can be traced back to Thorndike's (Citation1911) Law of Effect, according to which animals tend to repeat actions that are reinforced – followed by positive reward – and refrain from actions that are followed by negative reward or punishment (Barto, Citation2013; Chater, Citation2009). A straightforward formulation of RL thus makes the following assumptions regarding the ‘what’ and the ‘how’ design questions, respectively: (i) representing actions along with their expected rewards in various situations and (ii) choosing at each step the action such that the resulting sequential behaviour maximises cumulative reward (Woergoetter & Porr, Citation2007).
In model-based RL (Doll, Simon, & Daw, Citation2012), the agent builds and maintains a model or representation of the environment, which is used to predict the reward that would ensue from various actions, given the present state of affairs of the agent and of its environment. Such a model typically consists of two components: a mapping that associates state-action pairs with immediate utilities (used to evaluate present reward and to predict future reward from past history) and a mapping from state–action pairs to new states (Chater, Citation2009). The internal model may also focus exclusively on reward structure, without attempting to represent the state of the environment (Nakahara & Hikosaka, Citation2012). In model-free RL, in comparison, reward maximisation is attempted by mapping environment states directly to actions. Furthermore, in either model-free or model-based RL, hierarchical approaches impose structure on behaviour by grouping certain sequences of actions into ‘options’ or subroutines (Botvinick, Niv, & Barto, Citation2009).
Algorithms derived from these assumptions (see Woergoetter & Porr, Citation2007 for a brief overview) are effective when applied to certain practical tasks and are also helpful in elucidating some of the brain underpinnings of RL (to be discussed in Section 4). Both the model-free and model-based approaches do, however, have conceptual problems that stem from the very assumptions that help define them.
On the one hand, because ‘a policy [action] corresponds to a stimulus-response (S-R) rule of animal learning theory’ (Barto, Citation2013, p. 21), model-free RL, which maps inputs directly to actions, inherits the problematicity of the S/R assumption, which has been discussed in Section 2. This observation does not detract from the demonstrated effectiveness of classical model-free RL algorithms: the successes of RL do mean that learning S/R associations can be done well (and even optimally; cf. Pack Kaelbling, Littman, & Moore, Citation1996, p. 240), but they do not make S/R association better suited to explaining or modelling behaviour in general. Model-based RL, on the other hand, is much more powerful in that it aims to construct a potentially sophisticated representation of the environment and to use that to reason about possible actions and their consequences. This power has remained, however, largely unrealised, for several reasons.
3.1.1. The problems with assuming exclusively external reward
The supervised learning algorithms used with the DNs (recall Section 2.2) adjust the network's parameters so as to minimise the total error on a training data-set. The error being defined as a measure of discrepancy between the desired and actual responses to a stimulus, this approach to S/R learning is clearly knowledge-intensive: it requires an external teacher that knows the correct response to every conceivable stimulus. In contrast, RL algorithms are driven merely by the magnitude (or even just the sign) of the reward that the environment, acting as the teacher, apportions to the learner's behaviour.
The difference between error minimisation in DNs and cumulative reward maximisation in RL is very important: ‘Although supervised learning clearly has its place, the RL framework's emphasis on incessant activity over equilibrium seeking makes it essential – in the author's opinion – for producing growth-oriented systems with open-ended capacities’ (Barto, Citation2013, p. 34). The pursuit of external reward by the common RL algorithms is, however, problematic in several respects.
First, although most laboratory studies of RL in human and other animal subjects involve the delivery of a reward at frequent intervals (in some studies, after each trial), in realistic animal behaviour actual environmental reward is rare (think of lions or cheetahs, which may go for days without making a kill). Such sparse rewards are rarely informative enough to allow effective credit assignment (apportioning credit or blame to past actions; cf. Section 2). Moreover, many types of behaviour, such as exploration (as opposed to exploitation; Dayan, Citation2013)Footnote7 or play (Graham & Burghardt, Citation2010), do not by definition carry external reward, yet are important and even crucial for the animal's development and adult functioning.
In ethology, if not in robotics and AI, the ultimate theoretical concern with regard to the sparsity of the external reward has to do with evolutionary viability. On the one hand, much of RL research assumes without questioning that agent behaviour is driven (or, normatively, must be driven) by the pursuit of occasionally rewarding outcomes for its actions. On the other hand, the only outcome that really counts is the final one: the agent's number of offspring.
In one respect, however, the sparsity of external reward in natural ecosystems may be a blessing. If let loose, RL driven by external reward pushes behaviours to extremes of stereotypy, resulting in the emergence of habits and ultimately addiction (Graybiel, Citation2008) and the loss of agency. This suggests that the agent needs to balance the learning of habits (which serve as useful behavioural shortcuts) with preserving agency, so as to promote actions directed at goals that are in some sense the agent's own, rather than the reinforcer's.
3.1.2. The problems with assuming fixed state space and utility
Behaviour by definition unfolds over time and must be managed so by the situated agent, which responds in time to ‘slings and arrows of outrageous fortune’ and initiates and directs the pursuit of its own goals. As the agent executes actions and accrues experience, its state space, which represents the combined system comprising the agent and its environment, may grow. If this growth involves radical novelty, as in the emergence of new dimensions or the addition of new states, a closed-form treatment of the resulting dynamically changing state × utility landscape becomes impossible (cf. Kauffman & Clayton, Citation2006).
The open-endedness of real-world situations renders DN-style supervised learning (e.g. minimising an objective function defined as regularised empirical loss over a training set) ineffective. The difficulty of formulating an objective function that would anticipate the needs of real-time control of behaviour may be intuitively appreciated by considering the infinite regress that ensues if, for instance, an agent attempts to learn a generative model of a certain dynamic aspect of the world. At a minimum, this calls for approximating the joint probability over observable measurement and control variables, possibly along with some posited hidden variables (Körding & Wolpert, Citation2006).
It may seem that in a RL setting, this task might well be undertaken by a DN, with the reward schedule added as another, key dimension to the joint probability distribution. Indeed, a system equipped with a convolutional DN for acquiring the RL action-value function recently achieved human-level performance in learning to play dozens of computer games directly from raw image and running score data (Mnih et al., Citation2015). According to the system's designers, this impressive feat was made possible by ‘harnessing state-of-the-art machine learning techniques with biologically inspired mechanisms’, namely, experience replay (Davidson, Kloosterman, & Wilson, Citation2009) and a sparse (as opposed to continuous) updating of the action values, corresponding to infrequent reward.Footnote8 For a realistic motivated agent, however, the utility of actions is not only subjective, but may depend in complex ways on the agent's entire prior history of interaction with the world, including other agents. Thus, in model-based RL, according to the rational perspective, ‘the model which is being learned might be influenced by all and any knowledge that the agent has’ (Chater, Citation2009, p. 352). Asymptotic convergence of RL (let alone DN) learning in such situations may be too much to expect.Footnote9
3.1.3. The problems with assuming fixed association of states and actions
Even if an agent using RL were to track successfully the changes in the environment and in its own utility function, the assumption that there is a truth of the matter to the question of what to do next – that the mapping from states to actions is fixed for each epoch (albeit initially unknown and possibly changing over time) is overly limiting. In the terminology of Section 2.4, the behaviour of an agent that operates under this assumption is ‘robotic’. Animal behaviour, in contrast, is often flexible. Chater (Citation2009) recounts the extensive evidence from empirical studies, indicating that RL ‘is influenced by a wide range of “cognitive” factors, which are difficult to explain using a mechanistic perspective on reinforcement’.Footnote10
In particular, when the animal's learning objective, as established in a series of trials, is suddenly devalued, or has its valency switched, the learner adjusts its behaviour immediately rather than on the usual RL schedule – a finding that Chater (Citation2009, p. 357) describes as ‘perhaps the most clear-cut case of an apparent contrast between a “reason-based” cognitive viewpoint and putative RL mechanisms’. Thus, gradual modifications posited by RL conflict with observed behaviour, which is ‘to a good approximation, all-or-none […], as if the animal is adopting or rejecting a hypothesis about a putative connection in the environment. Smooth learning curves emerge only from data aggregated across many animals’ (Chater, Citation2009). Likewise, in their recent review of the brain basis of RL, Haber and Behrens (Citation2014) describe such shifts as stemming from ‘clashes between reasons’, noting that the cognitive complexity of behaviour may account for the intricate circuitry that supports it (cf. Section 4.3).
3.2. A broader view of RL: intrinsically motivated learning of the environment
By relaxing the assumptions built into the varieties of RL discussed so far, we can formulate a broader view of learning as it applies to realistic behaviour. The broader formulation of RL should aim to balance reward-driven acquisition of habits with endogenous agency and motivation, should accommodate a changing, open-ended environment and should allow for the growth of the agent's knowledge of it and for the fluidity of the agent's patterns of utility, which determines the meaning of reward. As in the beginning of Section 3, two aspects of the proposed formulation are discussed under separate headings: what to learn, and how to do it.
3.2.1. Learning the world
Briefly, flexible behaviour requires that agents learn as much as possible about the physical and the causal structure of their environment. Ideally, an agent would use this knowledge on the fly to reason about and select among the available actions, or to devise novel actions, given its goals and its best estimate of the current state of the world. With regard to the physical layout of the environment, and in the context of an extremely simple foraging task, this strategy was shown by Kolodny et al. (Citation2014) to be evolutionarily advantageous over several others, including backward chaining of the kind used by some RL algorithms.
More generally, just like learning the layout of a physical space can support smart navigation behaviour such as shortcut-taking (Tolman, Citation1948), so learning the layout of an abstract problem space can support effective and creative problem-solving (see Edelman, Citation2008, ch. 8 for an overview). Finally, the learner may aim to acquire causal dependencies – a feat of which many animal species appear to be capable (Redgrave et al., Citation2010). Causal learning is particularly important for goal-directed as opposed to habitual control, because representations that make causal dependencies explicit afford informed intervention (Chater & Oaksford, Citation2013; Holyoak & Cheng, Citation2011; Pearl, Citation2009). A further discussion of these matters is beyond the scope of this paper.
3.2.2. Intrinsically motivated learning
The idea that an animal would do well to learn the structure of its environment has been around for a long time – and with it the question of the source of its motivation for doing so. According to Barto (Citation2013, p. 29),
Tolman's (1932) theory of latent learning, for example, postulated that animals are essentially always learning cognitive maps that incorporate confirmed expectancies about their environments. But according to Tolman, this learning is unmotivated: it does not depend on reinforcing stimuli or motivational state. This is different from Berlyne's view that surprise engages an animal's motivational systems. Therefore, it is necessary to distinguish between learning from surprise as it appears in supervised learning algorithms and the idea that surprise engages motivational systems.
An algorithmic treatment of surprise and its use in motivating exploration and acquisition of world knowledge can be found, for instance, in the work of Schmidhuber (Citation2009b), who ties surprise to the ability to compress data and to predict novel inputs (cf. Luciw, Kompella, Kazerounian, & Schmidhuber, Citation2013; Wu & Miao, Citation2013). A discussion of the differences between the prediction-based approach and that derived from a computational formulation of competence can be found in the introductory chapter by Barto (Citation2013, p. 31) to a recent volume dedicated entirely to intrinsic motivation in RL (Baldassarre & Mirolli, Citation2013).
A particularly interesting question is whether or not the capacity for purely internal motivation (as opposed to external reward) is evolvable. In a recent evolutionary simulation study, Singh et al. (Citation2010) demonstrated that internal motivation indeed emerges in a population of foraging agents under the right conditions. In two experiments, they showed (i) that ‘evolutionary pressure to optimise fitness captured in the optimal reward framework can lead to the emergence of reward functions that assign positive primary reward to activities that are not directly associated with fitness’ and (ii) that ‘the agent's internal environment […] provides an inverse recency feature’. This, in turn, makes it possible for the agent to single out state-action pairs that it has not recently experienced, enabling exploration.
The key phrase in the preceding paragraph, and possibly in the entire report it quotes from, is internal environment. Reviewing information-seeking and curiosity, Gottlieb et al. (Citation2013, p. 3) remark that ‘the sources of all of an animal's reward signals are internal to the animal.’ Barto (Citation2013, fig. 2), likewise, states that ‘the environment is divided into an internal and external environment, with all reward signals coming from the former’. This observation is true in the simple and immediate sense that the value of any reward is in the eyes of its recipient: water or food are rewarding to me only insofar as I am thirsty or hungry – a truism that is known in economics as the paradox of value and that has been discussed at least since the time of Adam Smith.
More importantly, however, the maxim is also true in a structured sense: to be of use, my internal environment must be sufficiently complex to reflect the layout of the relevant state space – physical layout in case of spatial exploration; abstract topology in case of abstract problem solving. In particular, in the example of Gottlieb et al. (Citation2013), it takes a structured internal environment to support the estimation of recency with respect to states. In other words, our best guess as to what behaving animals do (and what behaving artificial agents should aim to do) is learn to represent their world.
In concluding this section, it is worth noting that the idea that to learn means ultimately to learn to represent the world is as yet by no means a matter of consensus. Of all the chapters in Baldassarre and Mirolli (Citation2013), only one mentions map-learning: ‘Scott and Markovitch (Citation1989) presented a curiosity-driven search method by which an agent's attention was continually directed to the area of highest uncertainty in the current representation, thus steadily reducing its uncertainty about the whole of the experience space’ (Barto, Citation2013).
4. Architecture
With the broader picture in mind of behavioural tasks and of the learning needs that arise from them, we can now have a closer look at some of the popular architectural assumptions that are being made in the cognitive modelling literature. In this section, I discuss two sets of such assumptions, one associated with the DN architecture and the other with RL models.
4.1. The cortex: multiple hierarchies
Practitioners of machine learning often motivate their use of a layered, uniformly connected architecture, such as that of DNs, by claiming a parallel with the hierarchical architecture of the brain.Footnote11 The scope of this analogy is, however, extremely narrow. It is true that a DN may succeed in visual recognition and categorisation tasks insofar as its structure mimics the architecture of the visual cortex (Poggio, Mutch, Leibo, Rosasco, & Tacchetti, Citation2012; Yamins et al., Citation2014). The visual cortex is, however, only one of many areas and circuits that comprise the mammalian brain (for a particularly forceful illustration of this fact, see Cotterill, Citation2001, fig, 7) and is entirely absent in other vertebrate species (e.g. birds) that are, generally speaking, as good at vision as mammals. In any case, the DN–brain analogy is strained even if we limit the consideration to the mammalian cortex.
While hierarchical in some respects (and perhaps surprisingly deep; Hilgetag, O'Neill, & Young, Citation1996), the architecture of mammalian isocortex is generally much more complex than assumed by the standard DN–brain analogy. To begin with, there is a major anatomical and functional division between posterior and frontal cortex (Fuster, Citation2008; Stuss & Knight, Citation2002). Functionally, this division is thought to correspond to a trade-off between, on the one hand, statistical generalisation and semantic association, supported by overlapping distributed representations in the posterior cortex, and, on the other hand, working memory and executive control in the frontal cortex (Atallah, Frank, & O'Reilly, Citation2004). As described next, the posterior and the frontal parts of the cortex have each their own hierarchies (Fuster, Citation2008, p. 339).
The posterior cortex contains three anatomical and functional hierarchies – visual, auditory and somatosensory/motor – whose common apex is situated at the hippocampus, an evolutionarily older allocortical structure that is part of the medial temporal lobe (Merker, Citation2004). The division of labour between posterior cortex and the hippocampus illustrates another memory task-based trade-off. As just noted, the hierarchical converging/diverging connection pattern in the posterior cortex is used for integration of lifetime memory. At the same time, the CA1–CA3 circuit in the hippocampus, which is wired like a crossbar switch between ascending and descending posterior pathways and has recurrent connections, supports episodic memory in the form of sparse representations of current stimuli, which it places in the context of long-term statistical patterns distributed across the entire posterior cortex (Atallah et al., Citation2004; Merker, Citation2004).
The frontal cortex contains distinct ‘stripes’ or columns of neurons capable of sustained firing, which support active short-term maintenance of information or working memory (Atallah et al., Citation2004). The level of processing depends hierarchically on cortical location, with the more rostral regions corresponding to progressively more abstract tasks (Badre, Citation2008; Botvinick, Citation2008). The dynamics of task control across the stripes is, however, neither simply convergent/divergent (as it would be in a purely pyramid-like architecture), nor, indeed, confined to the isocortex.
4.2. Beyond the cortex
Rather than being a largely cortical process, the dynamics of task control by the frontal lobe involves multiple parallel loops that connect frontal and posterior cortical regions with the hippocampus, thalamus, cerebellum and the basal ganglia, a collection of subcortical nuclei long implicated in RL (Graybiel, Citation2008; Redgrave, Vautrelle, & Reynolds, Citation2011). Massive involvement of subcortical structures is equally prominent in the posterior cortex. In the visual pathway, in particular, the ascending retinal connections in the feedforward hierarchy are dwarfed by other influences: in the lateral geniculate nucleus of the thalamus, only 5–10% of the input comes from the retina, the rest descending from layer 6 of various visual cortical areas and ascending from the brainstem (Sherman & Guillery, Citation2002). Another thalamic nucleus, the pulvinar, is plugged into both posterior and frontal cortical hierarchies at every stage, so that ‘often, and perhaps always, when cortical areas have a direct connection, they also have a parallel one through thalamus’ (Sherman, Citation2012). Indeed, the manner and degree of involvement of the thalamus in cortical processing is such that ‘the distinction between so-called “sensory” and “motor” areas of cortex is of limited use’ (Sherman, Citation2012).
We can approach the anatomical complexity of the mammalian brain by trying to interpret it in the context of real behaviour and real learning tasks. Taking as an example foraging, which came up earlier in this paper, one may observe that its brain mechanisms include both cortical and subcortical structures. In primates, in particular, the newly evolved frontal cortical areas have been hypothesised to
reduce foraging errors by generating goals from current contexts and learning to do so rapidly, sometimes based on single events. Among the contexts used to generate these goals, the posterior parietal cortex provides the new prefrontal areas with information about relational metrics such as order, number, duration, length, distance and proportion, which play a crucial role in foraging choices (Genovesio, Wise, & Passingham, Citation2014).
4.3. The basal ganglia: far-reaching, intricate circuits
Many computational models of learning and memory have aimed at interpreting the gross neuroanatomy of the basal ganglia in terms of reward- and prediction-related switching of the so-called direct and indirect pathways that channel the corticostriatal circuits (Botvinick et al., Citation2009; Cohen & Frank, Citation2009; Niv, Citation2009; O'Reilly, Noelle, Braver, & Cohen, Citation2002; O'Reilly & Frank, Citation2006; Redgrave et al., Citation2011). The successes of these models are particularly impressive against the backdrop of the neuroanatomical and functional complexity that remains to be explained.
The main functional challenges are, as already mentioned, to maintain a balance between habit-learning and supporting agentic behaviour, as well as to provide a basis for learning the environment in the form of a structured internal motivation signal. It has been suggested that this is done by distinct circuits passing through the basal ganglia insofar as they instantiate two mechanisms of RL: one driven by internal motives (manifesting agency) and the other by external motives (responding to reward) (Hikosaka & Isoda, Citation2010; Redgrave et al., Citation2010, Citation2013).
With regard to the neuroanatomy, the challenge arises to a large extent from the sheer number of brain areas and structures that seem to be involved in these processes – an extent that is by rights expected from a general framework that encompasses all of behaviour. In this sense, the surging interest in RL has already yielded conceptual dividends for the neural computation community by encouraging theorists to look beyond areas that have long been studied in isolation, such as the sensory cortex or the hippocampus. In addition to their far reach in the brain, however, the circuits in question exhibit also some striking anatomical characteristics.
First, they contain multiple loops running in parallel between distinct corresponding subparts of the areas involved, from the prefrontal cortex (PFC), via the striatum and the thalamus, and back to PFC (Badre, Citation2008; Botvinick, Citation2008; Graybiel, Citation2008). The corticostriatal projection is global in the sense that the entire isocortex is mapped onto the surface of the striatum, in a manner that largely preserves the topography of the originating cortical areas (Redgrave et al., Citation2011). Furthermore, the loops that pass through PFC are organised along the rostro-caudal dimension into distinct stripes (Badre, Citation2008; Fuster, Citation2008), which I mentioned earlier.
Second, along the way the loop circuits are modulated by selective inputs from other parts of the brain (Redgrave et al., Citation2011), forming a pattern of connections that is much more complex than the familiar direct/indirect pathway segregation.Footnote12 For instance, the ventral striatum receives topographically distinct projections not only from isocortical areas in the frontal lobe (in order, from the ventral pole of the striatum, these are: ventromedial, orbitofrontal, anterior cingulate, dorsal prefrontal and premotor cortices), but also from allocortical and periallocortical areas (hippocampus, insula), as well as from the amygdala, ventral tegmental area and substantia nigra (Haber & Behrens, Citation2014. fig. 8). These projections form not a hierarchy but a loose, loopy network (Thompson & Swanson, Citation2010) of highly complex graded associations whose details are still being uncovered (Haber & Behrens, Citation2014).
Third, there are clear and precise internal divisions within the areas connected by the circuits. Just in the striatum, examples include the above-mentioned topography of the projections into the ventral part, the ventral/dorsal gradient (Bornstein & Daw, Citation2011), and the cytoarchitectonic and functional distinctions between striosomes and matrisomes (Amemori, Gibb, & Graybiel, Citation2011).
Is such an elaborate architecture essential for supporting complex sequential behaviour? From the evolutionary standpoint, the answer to this question must be affirmative. Evolution is clearly capable of putting in place highly uniform neural circuits (for instance, in the cerebellar cortex, the sheaf of parallel fibres that run at a right angle to the flat dendritic trees of Purkinje cells, or, in the hippocampus, the crossbar switch implemented by the CA1–CA3 loop, which I mentioned earlier), so what looks like vaunting complexity of some brain circuits is likely there for a reason.Footnote13
4.4. A lesson from the mammalian brain: circuitry matters
The intricate anatomical patterns and distinctions discussed above – which constitute as good an argument as any for the opening sentence of Atallah et al. (Citation2004, p. 253): ‘The brain is not a homogeneous organ’ – are being increasingly used to motivate relatively elaborate functional interpretations. For instance, the striosome/matrisome circuitry has been described functionally in terms of a gated mixture of experts (Amemori et al., Citation2011). Similarly, the ventral basal ganglia (‘the crossroads of space, strategy, and reward’; Humphries & Prescott, Citation2010) are thought to support replay of episodic memory, while tracking reward and implementing action selection by controlling the relative contribution to the current action of the different frontal cortex stripes (Jin, Tecuapetla, & Costa, Citation2014).
The elaborate circuitry and functional anatomy of real brains stands in contrast to the common DN architecture, which is uniform (in that all units in a given layer usually have the same pattern of connections) and distributed (in the usual representational sense). A long-standing concern about modelling the brain with neural networks has been the opaqueness of the representations they learn. With their especially large number of degrees of freedom, DNs are particularly susceptible to this concern: a recent paper by Szegedy et al. (Citation2014) documented and analysed widespread hypersensitivity to perturbations of representations learned by DNs. For these reasons, distributed representations, which characterise DNs, are difficult to put to use in inference (reasoning) and control tasks.
To understand the source of this difficulty, consider again the concept of credit assignment. In any network- or graph-structured representation, it requires that both learning and use cause information to be propagated through the graph. The more complex that representation, the more difficult both temporal and structural aspects of credit assignment become. Using representations that are highly distributed over not just one but many hidden layers (as in DNs), as well as over time (as when serial behaviour needs to be controlled) greatly complicates credit assignment.
While the latest DN algorithms alleviate credit assignment during training, the ‘reuse’ over time of the hidden units remains a problem, whose severity increases as the temporal extent of the behaviour grows. Although attempts are often made to model hierarchically structured sequential behaviour such as language learning and production in shallow uniform distributed architectures (e.g. in Simple Recurrent Networks; Chang, Citation2002; Elman, Citation1990, Citation2009; or Echo State Networks; Tong, Bickett, Christiansen, & Cottrell, Citation2007), such attempts typically only work on toy data or on tasks of limited behavioural relevance, such as learning small artificial grammars or predicting the part of speech of the next word in a sentence. Recurrent varieties of DN, which may also combine deep representations with RL, typically do better, mainly because they do a much better job of credit assignment (Schmidhuber, Citation2015). However, as noted in Section 2, they are limited by their treatment of every problem as an exercise in S/R association – as in mapping entire sentences from one language to another (Sutskever et al., Citation2014), or as in language modelling, which amounts to assigning probabilities to strings of words (Goodman, Citation2001; cf. Schmidhuber, Citation2015, sec 5.20).Footnote14
One way to alleviate the uniform recurrent networks’ problem with extended sequential behaviours is to ‘unfold’ the recurrent architecture, letting space stand for time, so that longer sequences are represented by longer chains of units connected in series (an approach that becomes more attractive if used in conjunction with hierarchical chunking, as suggested already by Lashley (Citation1951); cf. the notion of hierarchical RL with ‘options’ representing chunks of elementary actions (Botvinick et al., Citation2009)).
This implementation-level design choice is supported by a behavioural-level observation: complex sustained sequential behaviour – migration, foraging, courtship rituals, glade skiing, birdsong, language – amounts to navigating through a shifting labyrinth of discrete choices. Every critical point in such a sequence (as in deciding whether to pass to the left or to the right of the next tree down the glade) is a causal nexus, at which one and only one choice must be made; a superposition of alternatives will not do. Thus, it seems natural to insist that the control of such behaviour be serially local, in the sense of relying, for each choice, only on representations that are available locally at the unit that directs the sequence, even if the representations that guide the choice are themselves distributed.Footnote15 Furthermore, if the sequences comprising the behaviour need to be learned (as in birdsong or language, but not in zero-day glade skiing), localist representations of critical control junctures have the extra benefit of easier credit assignment. A design principle for a network architecture based on the above ideas is outlined in the next section.
5. Structured connectionism redux
A straightforward way of making the topology of the network (and not only its connection weights) matter in dealing with sequential behaviour is to have the learner construct incrementally a graph-like localist representation of its sensorimotor experience. I shall illustrate this approach on the problem of learning and using natural language.
Given a sufficiently powerful mechanism for S/R learning, such as DNs, one may try to reduce language acquisition to the minimisation of an appropriately formulated objective function. In computational linguistics, a related idea has been endorsed by the proponents of the ‘new Empiricism’ (Goldsmith, Citation2007) (including an earlier version of the present author). According to this approach, learning proceeds by estimating (perhaps dynamically, using RL), from observed corpus data, a probabilistic language model, which should ideally capture the joint probability distribution over word sequences and context, the latter including both more language (discourse history) and extra-linguistic materials, such as the speaker's motivation, semantic intent and so on. The resulting model can then be used to generate utterances by following the most probable paths through the space of possible word sequences.
We saw, however, that such learning does not seem to be possible in a uniform distributed architecture. In particular, in such an architecture, in which part–whole relationships over sequences are not made explicit, observations of entire utterances may not readily support the acquisition of the representations of their parts. Crucially, language users are typically interested in saying not what the world expects to hear from them, but rather what they intend and mean, and doing so – exhibiting true, agentic productivity – is impossible without being able to manipulate parts of utterances.
This suggests that the learner of language should aim at constructing a generative model that explicitly represent the graph structure of the utterance space, as suggested in the closing paragraphs of Section 4.4. In such a model, language (and other types of complex sequential behaviour, such as spatial exploration; Chrastil, Warren, & Sutherland, Citation2014; Muller, Stead, & Pach, Citation1996) can be generated by injecting activation into a node in the representation graph and letting it spread, as illustrated in Figure for the case of language learning and its use in machine translation (Edelman & Solan, Citation2009). As already noted, the S/R mapping needs of such models, such as recognising when the conditions for activating a localised-representation node are met, can be fulfilled by hierarchical distributed-representation DNs.
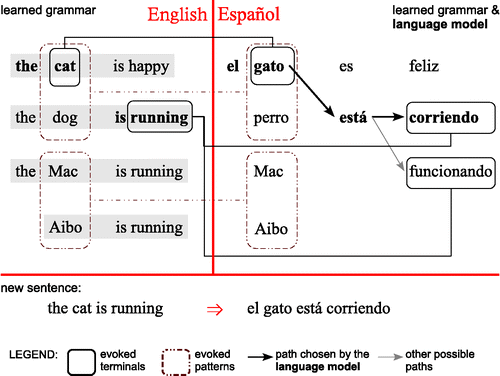
The conceptual roots of this approach, which may be called structured connectionism, include the old-style connectionism (Feldman & Ballard, Citation1982; Feldman, Fanty, Goddard, & Lynne, Citation1988) and the augmented transition network (ATN) methods in natural language processing (Woods, Citation1970). Structured connectionist networks can directly represent sequential order and can support functional abstraction, as indicated, for instance, by the newer work on embodied construction grammar (Chang, Feldman, & Narayanan, Citation2004), where units stand for concept frames such as ‘walk’ and directed connections represent the sequential ordering of units.
A structured connectionist network has been the representation of choice of the ADIOS model of unsupervised language acquisition and production (Solan, Horn, Ruppin, & Edelman, Citation2005), which underlies the example of Figure , and its successor, U-MILA (unsupervised memory-based incremental language acquisition; Kolodny, Lotem, & Edelman, Citation2015). The graph vertices in these models initially represent words (or other symbolic primitives, such as phonemes); edges initially stand for actual observed transitions. With learning, recursive abstraction leads to the emergence of hierarchically structured phrase units and their incorporation into the graph.
Such graph formalisms can be made computationally quite powerful. ATNs, in particular, are equivalent in that respect to Turing machines. Another powerful graph-based representational formalism for structured connectionism is higraphs, introduced by Harel (Citation1988). Intuitively, a higraph is a Venn diagram with a unique blob for every set/state, hyper-edges connecting states and optional composite Cartesian-product states. Importantly, higraphs have been given procedural semantics, in the form of statecharts.Footnote16 A recently developed graphical computational formalism related to statecharts, Live Sequence Charts (Damm & Harel, Citation2001; Harel & Marelly, Citation2003), may be particularly well-suited for modelling complex sequential behaviour, as conjectured by Kolodny and Edelman (Citation2015).
Informally, it seems that the higraph-like representations offer the right primitives for modelling, on one level, complex sequential behaviours, and on another – brain circuits and processes.Footnote17 In particular, the ability of a higraph grammar of behaviour to be in a superposition of states may model the possibility of a brain network having several foci of activity at the same time. The higraph's combination of nested structure with sequential structure may help model certain brain circuits. Finally, higraphs, as any other structured connectionist architecture, allow meaningful activation to be injected into nodes in a targeted manner – something that is difficult, if not impossible, to do in a distributed representation.
6. Conclusions
At the end of the passage on the ‘circuit’ of experience and behaviour quoted in Section 2.3, Dewey (Citation1896) observes that in psychology and brain science the evolved form is indicative of function: ‘The end has got thoroughly organised into the means.’ The idea that understanding behaviour goes hand in hand with understanding how it relates to the fine details of brain circuitry sits well with the less corticocentric among the current theories of how the brain/mind works – e.g. theories of language that consider the entire cortical–BG circuit (Lieberman, Citation2002; Ullman, Citation2001) and theories of birdsong that tie it to theories of language (Bolhuis, Okanoya, & Scharff, Citation2010).
Predictions of such theories are being steadily corroborated. For instance, with regard to the posited role of the basal ganglia in language acquisition and use, an impairment of RL in general appears to accompany developmental language impairment (Lee & Tomblin, Citation2012).Footnote18 Likewise, with regard to the posited involvement of the hippocampus in language acquisition (Edelman, Citation2011), individual differences in hippocampal neuroanatomy in infancy predict language performance a few months later (Can, Richards, & Kuhl, Citation2013). Still, a single overarching framework for integrating such findings with a comprehensive understanding of the brain circuitry – which, as I suggested in Section 4.4, is elaborate, as opposed to uniform – is lacking.
In this paper, I used problem- and representation-level analysis and some neuroanatomical data to argue that the popular DN are in principle unsuited for modelling complex sequential behaviour in animals, or of supporting it in artificial systems, and that RL methods could do so better if extended so as to rely more heavily on intrinsically motivated exploration. These ideas underlie the modest constructive proposal outlined in the preceding section, which offers a complementary, structured connectionist approach to general problem of complex sequential behaviour. Most of the work in developing this proposal remains to be done. This work includes the following:
Making the circuitry of structured connectionist models such as U-MILA (Kolodny et al., Citation2015) more brain-like. This means working out not just an area-level flowchart but also a detailed wiring diagram for specific cell types (as in Wickens, Citation2009, fig. 1) across the areas connected by each proposed circuit.
Making the models more realistic psychologically. The U-MILA model, for instance, lacks a social reinforcement mechanism, which is clearly at work in infant learning (Goldstein et al., Citation2010).
Developing and testing predictions specific to the models. One possible focus for these could be based on the limitations imposed by model architecture and functioning on generalisation and variable binding (cf. Kriete, Noelle, Cohen, & O'Reilly, Citation2013).
Developing better algorithms for training the models. With regard to language learning, existing algorithms for statechart synthesis (Harel, Kugler, & Pnueli, Citation2005) work from abstract scenario-based requirements rather than sample outputs (which is what is available in a language acquisition setting). At the same time, state-of-the-art models in graph-based language learning (Chang, Citation2008; Kolodny et al., Citation2015) employ heuristics, Bayesian or other, in deciding when and how to modify the grammar in the face of new experience. This task may be made easier by resorting to the formal Bayesian methods of Tenenbaum, Kemp, Griffiths, and Goodman (Citation2011).
Acknowledgements
I have benefited from discussing the ideas behind this paper with Björn Merker, Barb Finlay, Oren Kolodny, Arnon Lotem, David Harel, Assaf Marron, Hiroyuki Nakahara, Kazuo Okanoya, Okihide Hikosaka and the participants of the Shonan Workshop on Deep Learning, May 2014. I thank the anonymous reviewers for their comments and suggestions.
Disclosure statement
No potential conflict of interest was reported by the author.
Notes
1. One of the names of this type of bias, which is proverbial in English, is the Law of the Instrument or Maslow's Hammer: ‘I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail’ (Maslow, Citation1966, p. 15).
2. Due to space limitations, each section presents bare arguments and cites only a few select sources. No attempt is made to cover all behaviour or the entire brain.
3. I call a layered network uniform if all units in a given layer have the same pattern of connections (with possibly different weights); cf. Section 4.4. Input-output learning is supervised when driven by an error signal that explicitly refers to the desired output for each input training data point; unsupervised learning relies on some other measure of goodness of the acquired model, such as the input reconstruction error in autoencode r architectures (DeMers & Cottrell, Citation1993) or an information-theoretic measure in MDL- or compression-based approaches (Adriaans & Vitányi, Citation2007; Grunwald, Citation2005; Schmidhuber, Citation2009a). A probabilistic model is generative if it captures the joint probability distribution over the variables of interest; a discriminative model, in contrast, aims to capture the conditional probabilities of class labels for the outputs, given the inputs.
4. This insight has been vindicated by the discovery in the human brain of the default network activity – a complex dynamics that serves as the foundation for, and is modulated by, exogenous stimuli and endogenous goal-oriented thinking (Raichle, Citation2006, Citation2010).
5. Cf. Konishi (Citation1971, p. 60): ‘Ethologists found the explanation of behavioral development in terms of reflex unsatisfactory. They held a strong antireflex view from the beginning.’
6. Cf. ‘All organisms with complex nervous systems are faced with the moment-by-moment question that is posed by life: what shall I do next?’ (Savage-Rumbaugh & Lewin, Citation1994, p. 255).
7. Any good foraging strategy includes both exploitation of resources and exploration of the environment (Kamil & Sargent, Citation1981; Niv, Joel, Meilijson, & Ruppin, Citation2002).
8. Even so, the system's performance remained far below that of human players on games, such as Montezuma's Revenge, that involve complex, hierarchically structured environments.
9. A more formal approach to this issue may be based on the so-called Good Regulator theorem of Conant and Ashby (Citation1970), who proved that, under certain probabilistic assumptions, ‘every good regulator of a system must be a model of that system’. Interestingly, the key assumption on which the proof is based is that the overarching objective in control is homeostasis (not surprising, given Ashby's fame as the inventor of the concept of homeostat (Ashby, Citation1952), which by definition does not leave room for endogenous choice on the part of the agent (the ‘regulator’). Cf. (Barto, Citation2013, p. 32), citing Klopf: ‘homeostasis should not be considered the primary goal of behavior and learning and that it is not a suitable organizing principle for developing artificial intelligence.’ An intriguing conjecture (which I offer here without proof) is that allowing for endogenous choice would lead to infinite regress, severely limiting the applicability of the Good Regulator theorem to realistic animal behaviour.
10. For an evolutionary angle on the question of behavioural flexibility, see Dennett's (Citation1995) notion of ‘The Tower of Generate and Test’ and related ideas, which draw on the classical work of Lorenz (Citation1977).
11. For example:
Whereas most current learning algorithms correspond to shallow architectures (1, 2 or 3 levels), the mammal [sic] brain is organized in a deep architecture with a given input percept represented at multiple levels of abstraction, each level corresponding to a different area of cortex. (Bengio, Citation2009)
12. On one popular account of the basal ganglia function, the action control circuit consists of two pathways – the direct one, which exclusively selects the target action (GO), and the indirect one, which suppresses all other actions (NO–GO). While this idea has led to much excellent modelling work (e.g. Atallah et al., Citation2004; Cohen & Frank, Citation2009; O'Reilly & Frank, Citation2006), it oversimplifies not only the anatomy of the circuit (cf. Redgrave et al., Citation2010, fig. 1), but also its functioning: as shown by Jin et al. (Citation2014), the appropriate action is selected through joint, graded and distributed activity of the direct and indirect pathways.
13. The reason need not be statable in a simple closed form: the complexity may be due to an historical accident such as an accumulation over evolutionary time of ‘strata’ of circuits in a subsumption architecture (Brooks, Citation1986). For an overview of brain evolution, and in particular of the vertebrate brain plan, see Striedter (Citation2005).
14. This remark holds also for the DN-based language model of Collobert and Weston (Citation2008), who used it to map sentences to part-of-speech tags, chunks, named entity tags, semantic roles, semantically similar words and the likelihood that the sentence makes sense (grammatically and semantically); it also holds for the DN-based parser of Hermann and Blunsom (Citation2013), whose tasks were sentiment estimation and phrase similarity ranking.
15. For an outline of distributed control over discrete pathway switching, see Miller and Cohen (Citation2001) and Botvinick et al. (Citation2009, fig. 6).
16. Statecharts is an industrial-strength software specification tool and a predecessor of the UML. See Harel (Citation2007) for a historical perspective and Mehlmann and André (Citation2012) for a recent application of related ideas to multimodal parallel processing for user interaction.
17. Higraphs and related formalisms may thus constitute precisely the kind of tool that computational ethologists are calling for: ‘Given these complexities, it is not surprising that a general, computationally sound approach to describing behaviour using conventional descriptors has not yet emerged, since it is unlikely to be manageable “by hand” (as, for instance, ethograms are)’ (Anderson & Perona, Citation2014, p. 28).
18. Such findings are consistent with the general idea of a brain-wide reach of circuits involved in complex sequential behaviour. This calls for an investigation of ‘the principles by which different computational elements of reinforcement learning are dynamically coordinated across the entire brain’ (Lee, Seo, & Jung, Citation2012).
References
- Adriaans, P., & Vitányi, P. M. B. (2007). The power and perils of MDL. In Proceedings IEEE International Symposium Information Theory (ISIT) (pp. 2216–2220). Nice, France.
- Amemori, K., Gibb, L. G., & Graybiel, A. M. (2011). Shifting responsibly: the importance of striatal modularity to reinforcement learning in uncertain environments. Frontiers in Human Neuroscience, 5, 47. doi:10.3389/fnhum.2011.00047.
- Anderson, D. J., & Perona, P. (2014). Toward a science of computational ethology. Neuron, 84, 18–31. doi:10.1016/j.neuron.2014.09.005.
- Ashby, W. R. (1952). Design for a brain. London: Chapman & Hall.
- Atallah, H. E., Frank, M. J., & O'Reilly, R. C. (2004). Hippocampus, cortex, and basal ganglia: Insights from computational models of complementary learning systems. Neurobiology of Learning and Memory, 82, 253–267. doi:10.1016/j.nlm.2004.06.004.
- Badre, D. (2008). Cognitive control, hierarchy, and the rostro-caudal organization of the frontal lobes. Trends in Cognitive Sciences, 12, 193–200. doi:10.1016/j.tics.2008.02.004.
- Baldassarre, G., & Mirolli, M. (Eds.). (2013). Intrinsically motivated learning in natural and artificial systems. Berlin: Springer.
- Barto, A. G. (2013). Intrinsic motivation and reinforcement learning. In G. Baldassarre & M. Mirolli (Eds.), Intrinsically motivated learning in natural and artificial systems (pp. 16–47). Berlin: Springer.
- Bengio, Y. (2009). Learning deep architectures for AI. Foundations and trends in machine learning, 2(1), 1–127. doi:10.1561/2200000006.
- Bolhuis, J. J., Okanoya, K., & Scharff, C. (2010). Twitter evolution: Converging mechanisms in birdsong and human speech. Nature Reviews Neuroscience, 11, 747–759. doi:10.1038/nrn2931.
- Bornstein, A. M., & Daw, N. D. (2011). Multiplicity of control in the basal ganglia: Computational roles of striatal subregions. Current Opinion in Neurobiology, 21, 374–380. doi:10.1016/j.conb.2011.02.009.
- Botvinick, M. M. (2008). Hierarchical models of behavior and prefrontal function. Trends in Cognitive Sciences, 12, 201–208. doi:10.1016/j.tics.2008.02.009.
- Botvinick, M. M., Niv, Y., & Barto, A. C. (2009). Hierarchically organized behavior and its neural foundations: A reinforcement learning perspective. Cognition, 113, 262–280. doi:10.1016/j.cognition.2008.08.011.
- Bowers, K. S. (1973). Situationism in psychology: An analysis and a critique. Psychological Review, 80, 307–336. doi:10.1037/h0035592.
- Brooks, R. A. (1986). A robust layered control system for a mobile robot. IEEE Journal of Robotics and Automation, 2, 14–23. doi:10.1109/JRA.1986.1087032.
- Can, D. D., Richards, T., & Kuhl, P. (2013). Early gray-matter and white-matter concentration in infancy predict later language skills: A whole brain voxel-based morphometry study. Brain and Language, 124, 34–44. doi:10.1016/j.bandl.2012.10.007.
- Cangelosi, A. (2001). Evolution of communication and language: using signals, symbols, and words. IEEE Transactions in Evolution Computation, 5, 93–101. doi:10.1109/4235.918429.
- Chang, F. (2002). Symbolically speaking: A connectionist model of sentence production. Cognitive Science, 93, 1–43.
- Chang, N. C. (2008). Constructing grammar: A computational model of the emergence of early constructions (Ph. D. thesis). University of California, Berkeley.
- Chang, N. C., Feldman, J. A., & Narayanan, S. (2004). Structured connectionist models of language, cognition, and action. In Proceedings of 9th neural computation and psychology workshop (NCPW9) (pp. 57–67). Singapore: World Scientific Publishing.
- Chater, N. (2009). Rational and mechanistic perspectives on reinforcement learning. Cognition, 113, 350–364. doi:10.1016/j.cognition.2008.06.014.
- Chater, N., & Oaksford, M. (2013). Programs as causal models: speculations on mental programs and mental representation. Cognitive Science, 37, 1171–1191. doi:10.1111/cogs.12062.
- Chomsky, N. (1959). A review of B. F. Skinner' verbal behavior. Language, 35, 26–58. doi:10.2307/411334.
- Chrastil, E. R., Warren, W. H., & Sutherland, R. (2014). From cognitive maps to cognitive graphs. PLoS One, 9, e112544. doi:10.1371/journal.pone.0112544.
- Cisek, P. (2012). Making decisions through a distributed consensus. Current Opinion in Neurobiology, 22, 927–936. doi:10.1016/j.conb.2012.05.007.
- Cohen, M. X., & Frank, M. J. (2009). Neurocomputational models of basal ganglia function in learning, memory and choice. Behavioural Brain Research, 199, 141–156. doi:10.1016/j.bbr.2008.09.029.
- Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning (pp. 1–8). Helsinki, Finland.
- Conant, R. C., & Ashby, R. W. (1970). Every good regulator of a system must be a model of that system. International Journal of Systems Science, 1, 89–97. doi:10.1080/00207727008920220.
- Cotterill, R. M. J. (2001). Cooperation of the basal ganglia, cerebellum, sensory cerebrum and hippocampus: possible implications for cognition, consciousness, intelligence and creativity. Progress in Neurobiology, 64(1), 1–33. doi:10.1016/S0301-0082(00)00058-7.
- Crocker, M. W., Knoeferle, P., & Mayberry, M. R. (2010). Situated sentence processing: The coordinated interplay account and a neurobehavioral model. Brain and Language, 112, 189–201. doi:10.1016/j.bandl.2009.03.004.
- Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2, 303–314. doi:10.1007/BF02551274.
- Dale, R., Fusaroli, R., Duran, N. D., & Richardson, D. (2013). The self-organization of human interaction. In B. Ross (Ed.), Psychology of learning and motivation (Vol. 59, pp. 43–95). Elsevier: Academic Press.
- Damm, W., & Harel, D. (2001). LSCs: Breathing life into message sequence charts. Formal Methods in System Design, 19, 45–80. doi:10.1023/A:1011227529550.
- Davidson, T. J., Kloosterman, F., & Wilson, M. A. (2009). Hippocampal replay of extended experience. Neuron, 63, 497–507. doi:10.1016/j.neuron.2009.07.027.
- Dayan, P. (2013). Exploration from generalization mediated by multiple controllers. In G. Baldassarre & M. Mirolli (Eds.), Intrinsically motivated learning in natural and artificial systems (pp. 73–91). Berlin: Springer.
- DeMers, D., & Cottrell, G. (1993). Nonlinear dimensionality reduction. In S. J. Hanson, J. D. Cowan, & C. L. Giles (Eds.), Advances in Neural Information Processing Systems (Vol. 5, pp. 580–587). San Mateo, CA: Morgan Kaufmann.
- Dennett, D. C. (1995). Darwin's dangerous idea: Evolution and the meanings of life. New York, NY: Simon & Schuster.
- Derry, J. F. (2004). Piospheres in semi-arid rangeland: Consequences of spatially constrained plant-herbivore interactions (Ph.D thesis), The University of Edinburgh.
- Dewey, J. (1896). The reflex arc concept in psychology. Psychological Review, 3, 357–370. doi:10.1037/h0070405.
- Dewey, J. (1931). Conduct and experience. Worcester, MA, US: Clark University Press.
- Doll, B. B., Simon, D. A., & Daw, N. D. (2012). The ubiquity of model-based reinforcement learning. Current Opinion in Neurobiology, 22, 1075–1081. doi:10.1016/j.conb.2012.08.003.
- Edelman, S. (2008). Computing the mind: how the mind really works. New York, NY: Oxford University Press.
- Edelman, S. (2011). On look-ahead in language: Navigating a multitude of familiar paths. In M. Bar (Ed.), Prediction in the brain, Chapter 14 (pp. 170–189). New York, NY: Oxford University Press.
- Edelman, S. (2012). Vision, reanimated and reimagined. Perception, 41(9), 1116–1127. Special issue on Marr's Vision.10.1068/p7274.
- Edelman, S., & Solan, Z. (2009). Machine translation using automatically inferred construction-based correspondence and language models. In B. T'sou & C. Huang (Eds.), Proc. 23rd Pacific Asia Conference on Language, Information, and Computation (PACLIC), Hong Kong.
- Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14, 179–211. doi:10.1207/s15516709cog1402_1.
- Elman, J. L. (2009). On the meaning of words and dinosaur bones: Lexical knowledge without a lexicon. Cognitive Science, 33, 547–582. doi:10.1111/j.1551-6709.2009.01023.x.
- Epstein, R. (1991). Skinner, creativity, and the problem of spontaneous behavior. Psychological Science, 2, 362–370. doi:10.1111/j.1467-9280.1991.tb00168.x.
- Feldman, J. A., & Ballard, D. H. (1982). Connectionist models and their properties. Cognitive Science, 6, 205–254. doi:10.1207/s15516709cog0603_1.
- Feldman, J. A., Fanty, M. A., Goddard, N. H., & Lynne, K. J. (1988). Computing with structured connectionist networks. Communications of the ACM, 31, 170–187. doi:10.1145/42372.42378.
- Fuster, J. (2008). The prefrontal cortex. New York, NY: Elsevier.
- Galef, Jr, B. G., & Giraldeau, L.-A. (2001). Social influences on foraging in vertebrates: Causal mechanisms and adaptive functions. Animal Behaviour, 61, 3–15. doi:10.1006/anbe.2000.1557.
- Genovesio, A., Wise, S. P., & Passingham, R. E. (2014). Prefrontalparietal function: From foraging to foresight. Trends in Cognitive Sciences, 18, 72–81. doi:10.1016/j.tics.2013.11.007.
- Glenn, S. S., Ellis, J., & Greenspoon, J. (1992). On the revolutionary nature of the operant as a unit of behavioral selection. American Psychologist, 47, 1329–1336. doi:10.1037/0003-066X.47.11.1329.
- Goldsmith, J. A. (2007). Towards a new empiricism. In J. B. de Carvalho (Ed.), Recherches linguistiques à Vincennes (Vol. 36)
- Goldstein, M. H., Waterfall, H. R., Lotem, A., Halpern, J., Schwade, J., Onnis, L., & Edelman, S. (2010). General cognitive principles for learning structure in time and space. Trends in Cognitive Sciences, 14, 249–258. doi:10.1016/j.tics.2010.02.004.
- Goodman, J. T. (2001). A bit of progress in language modeling. Computer Speech and Language, 15, 403–434. doi:10.1006/csla.2001.0174.
- Gottlieb, J., Oudeyer, P.-Y., Lopes, M., & Baranes, A. (2013). Information-seeking, curiosity, and attention: Computational and neural mechanisms. Trends in Cognitive Sciences, 17, 585–593. doi:10.1016/j.tics.2013.09.001.
- Graham, K. L., & Burghardt, G. M. (2010). Current perspectives on the biological study of play: signs of progress. The Quarterly Review of Biology, 85, 393–418. doi:10.1086/656903.
- Graybiel, A. M. (2008). Habits, rituals, and the evaluative brain. Annual Review of Neuroscience, 31, 359–387. doi:10.1146/annurev.neuro.29.051605.112851.
- Grunwald, P. (2005). Introducing the minimum description length principle. In Advances in minimum description length: Theory and applications (pp. 3–22). Cambridge, MA: MIT.
- Haber, S. N., & Behrens, T. E. J. (2014). The neural network underlying incentive-based learning: Implications for interpreting circuit disruptions in psychiatric disorders. Neuron, 83, 1019–1039. doi:10.1016/j.neuron.2014.08.031.
- Harel, D. (1988). On visual formalisms. Commun. ACM, 31, 514–530. doi:10.1145/42411.42414.
- Harel, D. (2007). Statecharts in the making: A personal account. In HOPL III: Proceedings of the third ACM SIGPLAN conference on History of programming languages (p. 5–1–5–43). New York, NY: ACM.
- Harel, D., Kugler, H., & Pnueli, A. (2005). Synthesis revisited: Generating statechart models from scenario-based requirements. In Formal methods in software and systems modeling (Vol. 3393, pp. 309–324). Lecture notes in computer science. Berlin: Springer-Verlag.
- Harel, D., & Marelly, R. (2003). Come, let's play: Scenario-based programming using LSCs and the Play-Engine. Berlin: Springer.
- Hartman, E. J., Keeler, J. D., & Kowalski, J. M. (1990). Layered neural networks with Gaussian hidden units as universal approximations. Neural Computation, 2, 210–215. doi:10.1162/neco.1990.2.2.210.
- Haussler, D. (1989). Generalizing the PAC model for neural net and other learning applications. UCSC-CRL 89-30, U. of California, Santa Cruz.
- Hebb, D. O. (1949). The organization of behavior. New York, NY: Wiley.
- Heisenberg, M. (2014). The beauty of the network in the brain and the origin of the mind in the control of behavior. Journal of Neurogenetics, 28, 389–399. doi:10.3109/01677063.2014.912279.
- Hermann, K. M., & Blunsom, P. (2013). The role of syntax in vector space models of compositional semantics. In Proceedings of the 51st annual meeting of the association for computational linguistics (pp. 894–904), Sofia, Bulgaria.
- Hikosaka, O., & Isoda, M. (2010). Switching from automatic to controlled behavior: Cortico-basal ganglia mechanisms. Trends in Cognitive Sciences, 14, 154–161. doi:10.1016/j.tics.2010.01.006.
- Hilgetag, C. -C., O'Neill, M. A., & Young, M. P. (1996). Enhanced perspective: Indeterminate organization of the visual system. Science, 271, 776–776. doi:10.1126/science.271.5250.776.
- Hinton, G. E. (2007). Learning multiple layers of representation. Trends in Cognitive Sciences, 11, 428–434. doi:10.1016/j.tics.2007.09.004.
- Hinton, G. E. (2009). Deep belief networks. Scholarpedia, 4, 5947. doi:10.4249/scholarpedia.5947.
- Holyoak, K. J., & Cheng, P. W. (2011). Causal learning and inference as a rational process: the new synthesis. Annual Review of Psychology, 62, 135–163. doi:10.1146/annurev.psych.121208.131634.
- Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2, 359–366. doi:10.1016/0893-6080(89)90020-8.
- Houghton, G., & Hartley, T. (1996). Parallels models of serial behaviour: Lashley revisited. Psyche, 2(25), Symposium on Implicit Learning.
- Humphries, M. D., & Prescott, T. J. (2010). The ventral basal ganglia, a selection mechanism at the crossroads of space, strategy, and reward. Progress in Neurobiology, 90, 385–417. doi:10.1016/j.pneurobio.2009.11.003.
- Jin, X., Tecuapetla, F., & Costa, R. M. (2014). Basal ganglia subcircuits distinctively encode the parsing and concatenation of action sequences. Nature Neuroscience, 17, 423–430. doi:10.1038/nn.3632.
- Kamil, A. C., & Sargent, T. D. (1981). Foraging behavior: Ecological, ethological, and psychological approaches. New York, NY: Garland.
- Karov, Y., & Edelman, S. (1998). Similarity-based word sense disambiguation. Computational Linguistics, 24, 41–59.
- Kauffman, S. A., & Clayton, P. (2006). On emergence, agency, and organization. Biology and Philosophy, 21, 501–521. doi:10.1007/s10539-005-9003-9.
- King, A. J., Narraway, C., Hodgson, L., Weatherill, A., Sommer, V., & Sumner, S. (2011). Performance of human groups in social foraging: the role of communication in consensus decision making. Biology Letters, 7, 237–240. doi:10.1098/rsbl.2010.0808.
- Kolodny, O., & Edelman, S. (2015). The problem of multimodal concurrent serial order in behavior. Submitted.
- Kolodny, O., Edelman, S., & Lotem, A. (2014). The evolution of continuous learning of the structure of the environment. Journal of the Royal Society Interface, 11, 20131091. doi:10.1098/rsif.2013.1091.
- Kolodny, O., Lotem, A., & Edelman, S. (2015). Learning a generative probabilistic grammar of experience: A process-level model of language acquisition. Cognitive Science, 39, 227–267. doi:10.1111/cogs.12140.
- Konishi, M. (1971). Ethology and neurobiology. American Scientist, 59, 56–63.
- Körding, K. P., & Wolpert, D. M. (2006). Bayesian decision theory in sensorimotor control. Trends in Cognitive Sciences, 10, 319–326.
- Krauzlis, R. J., Bollimunta, A., Arcizet, F., & Wang, L. (2014). Attention as an effect not a cause. Trends in Cognitive Sciences, 18, 457–464. doi:10.1016/j.tics.2014.05.008.
- Kriete, T., Noelle, D. C., Cohen, J. D., & O'Reilly, R. C. (2013). Indirection and symbol-like processing in the prefrontal cortex and basal ganglia. Proceedings of the National Academy of Science, 110, 16390–16395. doi:10.1073/pnas.1303547110.
- Lashley, K. S. (1951). The problem of serial order in behavior. In L. A. Jeffress (Ed.), Cerebral mechanisms in behavior (pp. 112–146). New York, NY: Wiley.
- LeCun, Y., & Bengio, Y. (1995). Convolutional networks for images, speech, and time series. In M. A. Arbib (Ed.), The handbook of brain theory and neural networks (pp. 255–258). MIT Press.
- Lee, D., Seo, H., & Jung, M. W. (2012). Neural basis of reinforcement learning and decision making. Annual Review of Neuroscience, 35, 287–308. doi:10.1146/annurev-neuro-062111-150512.
- Lee, J. C., & Tomblin, J. B. (2012). Reinforcement learning in young adults with developmental language impairment. Brain and Language, 123, 154–163. doi:10.1016/j.bandl.2012.07.009.
- Lieberman, P. (2002). On the nature and evolution of the neural bases of human language. Yearbook of Physical Anthropology, 119, 36–62. doi:10.1002/ajpa.10171.
- Lorenz, K. (1977). Behind the mirror. Mariner Books. German original published in 1973.
- Luciw, M., Kompella, V., Kazerounian, S., & Schmidhuber, J. (2013). An intrinsic value system for developing multiple invariant representations with incremental slowness learning. Frontiers in Neurorobotics, 7, 9. doi:10.3389/fnbot.2013.00009.
- Maaswinkel, H., & Whishaw, I. Q. (1999). Homing with locale, taxon, and dead reckoning strategies by foraging rats: Sensory hierarchy in spatial navigation. Behavioural Brain Research, 99, 143–152. doi:10.1016/S0166-4328(98)00100-4.
- Marr, D. (1982). Vision. San Francisco, CA: W. H. Freeman.
- Marr, D., & Poggio, T. (1977). From understanding computation to understanding neural circuitry. Neurosciences Res Program Bull, 15, 470–488.
- Maslow, A. H. (1966). The Psychology of science. New York, NY: Harper.
- Mehlmann, G., & André, E. (2012). Modeling multimodal integration with event logic charts. In Proc. ICMI’12, Santa Monica, CA.
- Mel, B. (1991). A connectionist model may shed light on neural mechanisms for visually guided reaching. Journal of Cognitive Neuroscience, 3, 273–292. doi:10.1162/jocn.1991.3.3.273.
- Merker, B. (2004). Cortex, countercurrent context, and dimensional integration of lifetime memory. Cortex, 40, 559–576. doi:10.1016/S0010-9452(08)70148-5.
- Miller, E. K., & Cohen, J. D. (2001). An integrative theory of prefrontal cortex function. Annual Review of Neuroscience, 24, 167–202. doi:10.1146/annurev.neuro.24.1.167.
- Minsky, M. (1961). Steps toward artificial intelligence. Proceedings of the Institute of Radio Engineers, 49, 8–30.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518, 529–533. doi:10.1038/nature14236.
- Muller, R. U., Stead, M., & Pach, J. (1996). The hippocampus as a cognitive graph. Journal of General Physiology., 107, 663–694. doi:10.1085/jgp.107.6.663.
- Mussa-Ivaldi, F. A., & Giszter, S. F. (1992). Vector field approximation: a computational paradigm for motor control and learning. Biological Cybernetics, 67, 491–500. doi:10.1007/BF00198756.
- Nakahara, H., & Hikosaka, O. (2012). Learning to represent reward structure: A key to adapting to complex environments. Neuroscience Research, 74, 177–183. doi:10.1016/j.neures.2012.09.007.
- Neisser, U. (1967). Cognitive Psychology. New York, NY: Appleton-Century-Crofts.
- Niv, Y. (2009). Reinforcement learning in the brain. Journal of Mathematical Psychology, 53, 139–154. doi:10.1016/j.jmp.2008.12.005.
- Niv, Y., Joel, D., Meilijson, I., & Ruppin, E. (2002). Evolution of reinforcement learning in uncertain environments: A simple explanation for complex foraging behaviors. Adaptive Behavior, 10, 5–24. doi:10.1177/10597123020101001.
- O'Reilly, R. C., & Frank, M. J. (2006). Making working memory work: A computational model of learning in the prefrontal cortex and basal ganglia. Neural Computation, 18, 283–328. doi:10.1162/089976606775093909.
- O'Reilly, R. C., Noelle, D., Braver, T. S., & Cohen, J. D. (2002). Prefrontal cortex and dynamic categorization tasks: Representational organization and neuromodulatory control. Cerebral Cortex, 12, 246–257. doi:10.1093/cercor/12.3.246.
- Pacheco-Cobos, L., Rosetti, M., Cuatianquiz, C., & Hudson, R. (2010). Sex differences in mushroom gathering: men expend more energy to obtain equivalent benefits. Evolution and Human Behavior, 31, 289–297. doi:10.1016/j.evolhumbehav.2009.12.008.
- Pack Kaelbling, L., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
- Papini, M. R. (2003). Comparative psychology. In S. F. Davis (Ed.), Handbook of research methods in experimental psychology (pp. 211–240). Oxford: Blackwell.
- Pearl, J. (2009). Causal inference in statistics: An overview. Statistics Surveys, 3, 96–146. doi:10.1214/09-SS057.
- Phillips, D. C. (1971). James, Dewey, and the reflex arc. Journal of the History of Ideas, 32, 555–568. doi:10.2307/2708977.
- Poggio, T. (1990). A theory of how the brain might work. Cold Spring Harbor Symposia on Quantitative Biology, LV, 899–910. doi:10.1101/SQB.1990.055.01.084.
- Poggio, T., Mutch, J., Leibo, J., Rosasco, L., & Tacchetti, A. (2012). The computational magic of the ventral stream: sketch of a theory (and why some deep architectures work), CSAIL TR 035 MIT.
- Raichle, M. E. (2006). Neuroscience: the brain's dark energy. Science, 314, 1249–1250. doi:10.1126/science.1134405.
- Raichle, M. E. (2010). Two views of brain function. Trends in Cognitive Sciences, 14, 180–190. doi:10.1016/j.tics.2010.01.008.
- Redgrave, P., Gurney, K., Stafford, T., Thirkettle, M., & Lewis, J. (2013). The role of the basal ganglia in discovering novel actions. In G. Baldassarre & M. Mirolli (Eds.), Intrinsically motivated learning in natural and artificial systems (pp. 129–150). Berlin: Springer.
- Redgrave, P., Rodriguez, M., Smith, Y., Rodriguez-Oroz, M. C., Lehericy, S., Bergman, H., … Obeso, J. A. (2010). Goal-directed and habitual control in the basal ganglia: Implications for Parkinson's disease. Nature Reviews Neuroscience, 11, 760–772. doi:10.1038/nrn2915.
- Redgrave, P., Vautrelle, N., & Reynolds, J. N. J. (2011). Functional properties of the basal ganglia's re-entrant loop architecture: Selection and reinforcement. Neuroscience, 198, 138–151. doi:10.1016/j.neuroscience.2011.07.060.
- Rosenbaum, D. A., Cohen, R. G., Jax, S. A., Weiss, D. J., & van der Wel, R. (2007). The problem of serial order in behavior: Lashley's legacy. Human Movement Science, 26, 525–554.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323, 533–536. doi:10.1038/323533a0.
- Sallabanks, R. (1993). Hierarchical mechanisms of fruit selection by an avian frugivore. Ecology, 74, 1326–1336. doi:10.2307/1940063.
- Savage-Rumbaugh, S., & Lewin, R. (1994). Kanzi: The ape at the brink of the human mind. New York, NY: Wiley.
- Schmidhuber, J. (2009a). Driven by compression progress: A simple principle explains essential aspects of subjective beauty, novelty, surprise, interestingness, attention, curiosity, creativity, art, science, music, jokes. In G. Pezzulo, M. V. Butz, O. Sigaud, & G. Baldassarre (Eds.), Anticipatory behavior in adaptive learning systems, from sensorimotor to higher-level cognitive capabilities, Lecture Notes in AI. New York, NY: Springer.
- Schmidhuber, J. (2009b). Simple algorithmic theory of subjective beauty, novelty, surprise, interestingness, attention, curiosity, creativity, art, science, music, jokes. Journal of SICE, 48, 21–32.
- Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 85–117.
- Scott, P. D., & Markovitch, S. (1989). Learning novel domains through curiosity and conjecture. In N. S. Sridharan (Ed.), Proceedings of the 11th international joint conference on artificial intelligence (pp. 669–674). San Francisco: Morgan Kaufmann.
- Sherman, S. M. (2012). Thalamocortical interactions. Current Opinion in Neurobiology, 22, 575–579. doi:10.1016/j.conb.2012.03.005.
- Sherman, S. M., & Guillery, R. W. (2002). The role of the thalamus in the flow of information to the cortex. Philosophical Transactions of the Royal Society London B, 357, 1695–1708. doi:10.1098/rstb.2002.1161.
- Singh, S., Lewis, R. L., Barto, A. G., & Sorg, J. (2010). Intrinsically motivated reinforcement learning: An evolutionary perspective. IEEE Transactions on Autonomous Mental Development, 2, 70–82. doi:10.1109/TAMD.2010.2051031.
- Skinner, B. F. (1935). The generic nature of the concepts of stimulus and response. The Journal of General Psychology, 12, 40–65. doi:10.1080/00221309.1935.9920087.
- Socher, R., Lin, C. C. -Y., Ng, A. Y., & Manning, C. D. (2011). Parsing natural scenes and natural language with recursive neural networks. In L. Getoor & T. Scheffer (Eds.), Proceedings of 28th International Conference on Machine Learning (pp. 129–136), Bellevue, Washington, USA.
- Solan, Z., Horn, D., Ruppin, E., & Edelman, S. (2005). Unsupervised learning of natural languages. Proceedings of the National Academy of Science, 102, 11629–11634. doi:10.1073/pnas.0409746102.
- Spivey, M. J., & Dale, R. (2006). Continuous dynamics in real-time cognition. Current Directions in Psychological Science, 15, 207–211. doi:10.1111/j.1467-8721.2006.00437.x.
- Striedter, G. F. (2005). Principles of brain evolution. Sunderland, MA: Sinauer.
- Stuss, D. T., & Knight, R. T. (2002). Principles of frontal lobe function. New York, NY: Oxford University Press.
- Sutskever, I., & Hinton, G. (2007). Learning multilevel distributed representations for high-dimensional sequences. In M. Meila & X. Shen (Eds.), Proceedings of eleventh international conference on artificial intelligence and statistics (pp. 544–551), San Juan, Puerto Rico.
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In C. Cortes & N. Lawrence (Eds.), Proceedings of 27th Neural Information Processing Systems Conference (NIPS), Montreal, Canada.
- Sutton, R. S., & Barto, A. G. (1981). Toward a modern theory of adaptive networks: Expectation and prediction. Psychological Review, 88, 135–170. doi:10.1037/0033-295X.88.2.135.
- Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning. Cambridge, MA: MIT Press.
- Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2014). Intriguing properties of neural networks. In Proceedings of International Conference on Learning Representations (ICLR), Banff, Canada.
- Tenenbaum, J. B., Kemp, C., Griffiths, T. L., & Goodman, N. D. (2011). How to grow a mind: statistics, structure, and abstraction. Science, 331, 1279–1285. doi:10.1126/science.1192788.
- Thompson, R. H., & Swanson, L. W. (2010). Hypothesis-driven structural connectivity analysis supports network over hierarchical model of brain architecture. Proceedings of the National Academy of Science, 107, 15235–15239. doi:10.1073/pnas.1009112107.
- Thorndike, E. L. (1911). Animal Intelligence. New York, NY: Macmillan.
- Tolman, E. C. (1948). Cognitive maps in rats and men. Psychological Review, 55, 189–208. doi:10.1037/h0061626.
- Tong, M. H., Bickett, A. D., Christiansen, E. M., & Cottrell, G. W. (2007). Learning grammatical structure with Echo state networks. Neural Networks, 20, 424–432. doi:10.1016/j.neunet.2007.04.013.
- Ullman, M. T. (2001). A neurocognitive perspective on language: the declarative/procedural model. Nature Reviews Neuroscience, 2, 717–726. doi:10.1038/35094573.
- Wickens, J. R. (2009). Synaptic plasticity in the basal ganglia. Behavioural Brain Research, 199, 119–128. doi:10.1016/j.bbr.2008.10.030.
- Woergoetter, W, & Porr, B. (2007). Reinforcement learning. Scholarpedia, 3, 1448. doi:10.4249/scholarpedia.1448.
- Woods, W. A. (1970). Transition network grammars for natural language analysis. Communications of the ACM, 13, 591–606. doi:10.1145/355598.362773.
- Wu, Q., & Miao, C. (2013). Curiosity: from psychology to computation. ACM Computing Surveys, 46(2), 1–26. doi:10.1145/2543581.2543585.
- Wurtz, R. H., McAlonan, K., Cavanaugh, J., & Berman, R. A. (2011). Thalamic pathways for active vision. Trends in Cognitive Sciences, 15, 177–184. doi:10.1016/j.tics.2011.02.004.
- Yamins, D. L., Hong, H., Cadieu, C., Solomon, E. A., Seibert, D., & Dicarlo, J. J. (2014). Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proceedings of the National Academy of Science, 111, 8619–8624.