
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Structural and index decomposition analyses allow identifying the main drivers of observed changes over time of energy and environmental impacts. These decomposition analyses have become very popular in recent decades and, many alternative methods to implement them have become available. Several of the most popular methods have been developed earlier in index number theory, a context in which each particular method is defined by adhering to a set of properties. The goal of the present paper is to review the main results of index number theory and discuss its connection to decomposition analyses. By doing so, we can present a decision tree that allows users to choose a decomposition method that meets desired properties. We report as hands-on example an empirical case study of the carbon footprint of the Netherlands in the period 2004–2005.
1. Introduction
In recent decades, many studies have attempted to identify the drivers of observed changes over time of energy and environmental impacts (Hoekstra and van den Bergh, Citation2003; Su and Ang, Citation2012). Such decomposition analyses can fall under two distinct but related categories: index decomposition analysis (IDA), in which the link between impact (energy, environmental, employment or whatever) and production level is explored; and structural decomposition analysis (SDA), in which the link between impact and consumption activities is explored. Hence, SDA is more comprehensive than IDA (since it requires explicitly accounting for the link between production and consumption) but also requires more data. A practitioner who is new in the field of IDA and/or SDA can find much advice in literature, for example Ang (Citation2004), Ang et al. (Citation2009), Su and Ang (Citation2012), Ang (Citation2015) and Wang et al. (Citation2017b). In fact, there are so many possible references that a general overview is tough to disentangle; in other words the new practitioner will have trouble to ‘see the forest for the trees’. Moreover, the mathematics employed and notation used is usually unduly complicated. In this paper, we follow a different route: we go back to the ‘forest’, that is to say to the collective stock of knowledge called index number theory in which the mathematics is usually easily accessed. Then, we turn to IDA and SDA, which – as one of the referees correctly points out- ‘in quite a number of cases proceeds by, knowingly or unknowingly, re-inventing or replicating well-known results from index number theory.’
This paper is structured as follows. In Section 2, we review the relevant properties and formulas of index number theory and, in Section 3, discuss its connection with IDA and SDA. Section 4 deals with the general case of ideal decompositions (index number theory), which leave no residual term (IDA and SDA), of an aggregate change into of n factors. Sections 5 and 6 are devoted to a hands-on example of a decomposition of carbon dioxide emissions of sectors of the Dutch economy into five factors. In the supplementary material, to enable replication we provide in the Appendices D–G our Matlab programs and Excel files used in the hands-on example. Based on theory and empirics we present in Section 7, a decision tree that we hope will help practitioners who seek to select the appropriate decomposition method for their problem at hand. Section 8 concludes.
2. Index number theory
2.1. Historical background
Traditionally index number theory is about the measurement of aggregate price and quantity change. Prominent applications are the consumer price index (CPI), producer price index (PPI), purchasing power parity (PPP) and human development index (HDI.) There is a vast literature on this subject. The oldest price index is attributed to the French economist Dutot (Citation1738) who disposed of data on prices of several commodities in 1515 (base period), under the reign of King Louis XII, and in 1738 (comparison period), under the reign of King Louis XV. He took the arithmetic mean of the prices in the comparison period (1738) and of the prices in the base period (1515) and divided them by each other. According to the price index of Dutot the price level was multiplied by the factor 22. Dutot concluded that Louis XV was worse off, when compared to his ancestor, because his income was only multiplied by the factor 13. The price index of Dutot depends on the units of measurement (the price of, say, salt, can be measured per ounce or per pound) so that the outcome is arbitrary. The Italian economist Carli (Citation1764) constructed the first index free from the units of measurement using price relatives, that is to say he divided the price of, say one ounce of salt, in the comparison period by the corresponding price in the base period, and took the arithmetic mean of the price relatives. The disadvantage of Carli’s approach is that it does not take into account the importance of a commodity in the budget of a consumer who will spend in (say) one year more money on bread than on salt. According to Balk (Citation2008a) the first person who recognized the necessity of introducing weights into a price index was Young (Citation1812). The two most important contributions in the nineteenth century are undoubtedly the ones by Laspeyres (Citation1871) and Paasche (Citation1874). Laspeyres considered a basket of commodities in the base period and computed the total expenditure. He also computed total expenditure of this basket in the comparison period. His price index is the ratio of the total expenditure in the comparison period and the total expenditure in the base period. Laspeyres’ choice of the base period’s basket is arbitrary. Paasche chose the basket of the comparison period. In his seminal book, Fisher (Citation1922) introduced time reversal and the product test as two desirable properties of indices (to be described later in greater detail). Laspeyres and Paasche do not meet time reversal. Fisher proposed as new price (quantity) index the geometric mean of the price (quantity) indices of Laspeyres and Paasche which satisfies time reversal. He proved that from all at that time existing pairs of price and quantity indices only the product of his pair satisfied the product test. That is the reason why he called his pair of indices ‘ideal’. After the contribution of Fisher two other pairs of ideal index numbers were discovered. Montgomery (Citation1929, Citation1937) and, independently, Vartia (Citation1974; Citation1976), proposed a solution, the so-called Montgomery-Vartia index. Another solution was, independently, proposed by Sato (Citation1976) and Vartia (Citation1974; Citation1976), the so-called Sato-Vartia index.
Above, we give a short history of the classical index number problem in which one wants to decompose the ratio value change in expenditure into the product of two factors, called price and quantity ‘indices’ (singular ‘index’). The alternative problem, lesser known but equally old (and more relevant in the context of index and structural decomposition analysis), is the decomposition of the difference between the values of two expenditures as the sum of two parts, the price and quantity ‘indicators’, which measure respectively the changes due to price and quantity differences. The indicators of Bennet (Citation1920) are the additive counterpart of the indices of Fisher. Another pair of ideal indicators was discovered by Montgomery (Citation1929; Citation1937).
The remainder of this section is organized as follows. Section 2.2 is devoted to the notation, problem formulation and properties used to characterize indices and indicators. The following subsections then report specific indices and indicators. For computational purposes these turn out to cluster around two basic methods: Fisher and Bennet methods, which are combinatorial in nature (addressed in Section 2.3), while Montgomery-Vartia, Sato-Vartia and Montgomery involve logarithmic transformations (addressed in Section 2.4). In Section 2.5 we discuss another important contribution, viz. the concept of consistency-in-aggregation. Section 2.6, finally, summarizes the relevant properties and formulas of index number theory for IDA and SDA.
2.2. Notation, problem formulation and properties
2.2.1. Notation
| = | price of commodity | |
| = | quantity of commodity | |
| = | value of commodity | |
| = | total value in base | |
| = | share of value of commodity | |
| = | ratio change in value : | |
| = | price index measuring the price change from the base to the comparison period | |
| = | quantity index measuring the quantity change from the base to the comparison period | |
| = | difference change in value: | |
| = | price indicator measuring the change in prices from the base to the comparison period | |
| = | quantity indicator measuring the change in quantities from the base to the comparison period. |
2.2.2. Problem formulation and properties
We quote from the abstract of Balk (Citation2008b): ‘The index number problem is known as that of decomposing aggregate value change, in ratio or in difference form, into two, ideally symmetric, factors.’ In our notation:
(5)
(5)
and
(6)
(6)
The basic properties (Eichhorn and Voeller, Citation1976, and Eichhorn, Citation1978) on the price and quantity indices in Equation 5 comprise:
global monotonicity: the price (quantity) index is non-decreasing in comparison prices and non-increasing in base prices (quantities);
linear homogeneity in comparison prices (quantities): if all comparison prices are multiplied by a common factor, the price (quantity) index is multiplied by that common factor, as well;
identity: if all comparison prices (quantities) in the comparison period are the same as those in the base period, the price (quantity) index is equal to one;
homogeneity of degree zero in prices (quantities): if all prices (quantities) in comparison and base period are multiplied by a common factor, the price (quantity) index remains the same;
invariance to changes to the units of measurement of the commodities.
A price (quantity) index that satisfies the requirements of ‘linear homogeneity in comparison prices (quantities)’ and of ‘identity’ satisfies a stronger requirement, namely that of
proportionality with respect to prices (quantities). If all the individual price (quantity) relatives are the same, then the price (quantity) index number must be equal to these relatives.
Other desirable properties (Fisher, Citation1922) are:
time reversal (symmetry): the price (quantity) index for the base period relative to the comparison period must be equal to the reciprocal of the price (quantity) index for the comparison period relative to the base period;
product test: it requires that the ratio change in value can be decomposed as product of a price and a quantity index, like in Equation 5;
idealness: a pair of price and quantity indices which, in addition to satisfying the product test, also have the same functional form, i.e. by interchanging prices and quantities the price index turns into the quantity index and vice versa, is called ‘ideal’.
Indicators return monetary values, which may be negative or zero. Therefore the basic properties must be modified a bit (Diewert, Citation2005, Balk, Citation2008a). They comprise: global monotonicity, modified identity (if all comparison prices and quantities in the comparison period are the same as those in the base period, the price (quantity) index is equal to zero); homogeneity of degree 1 in prices (quantities), invariance to changes to the units of measurement of the commodities. Please note that there is no analogue to the property of ‘linear homogeneity in comparison prices (quantities)’, so that there is no analogue of ‘proportionality’ for indicators, as well. Other desirable properties are:
time reversal (symmetry): the price (quantity) indicator for the base period relative to the comparison period must be equal to the opposite of the price (quantity) indicator for the comparison period relative to the base period;
sum test: the sum test requires that the difference change in value can be decomposed as the sum of a price and a quantity index, like in Equation 6;
idealness: a pair of price and quantity indicators which, in addition to satisfying the sum test, also have the same functional form, i.e. by interchanging prices and quantities the price indicator turns into the quantity indicator and vice versa, is called ‘ideal’.
The property of idealness is an important contribution of index number theory to structural and index decomposition analysis since it implies that the decomposition is ‘complete’, that is to say that there is no residual term. We refer to the review of index number theory of Balk (Citation2016) and to Balk’s monograph (Balk Citation2008a) for the mathematical presentation.
2.3. Combinatorial indices and indicators
2.3.1. Introduction
This class consists of the ‘traditional’ indices and indicators of Laspeyres (superscript ), Paasche (superscript
), Fisher (superscript
) and its additive counterpart Bennet (superscript
).
2.3.2. Indices
The indices are defined as:
(7)
(7)
(8)
(8)
(9)
(9)
Hence, Fisher’s price (quantity) index is the geometric mean of the price (quantity) indices of Laspeyres and Paasche. All above-mentioned indices satisfy the basic properties, so that they also satisfy the stronger property of ‘proportionality’ (Balk, Citation2008a; Citation2016). It is easily verified from (7) and (8) that the indices of Laspeyres and Paasche do not possess the property of time reversal. However, the indices of Fisher do possess it. It is also easily verified that:
(10)
(10)
It follows from (10) that the index pair of Fisher is ideal, but that the pairs of Laspeyres and Paasche are not ideal.
2.3.3. Indicators
The Laspeyres and Paasche price and quantity indicators are the additive counterparts of the Laspeyres and Paasche price and quantity indices and defined as:
The additive counterpart of the Fisher indices are the indicators of Bennet (Citation1920) defined as the arithmetic mean of the Laspeyres and Paasche price indicators:
(11)
(11)
(12)
(12)
All above-mentioned indicators satisfy the basic properties (Balk, Citation2008a; Citation2016). It is easily verified that the indicators of Laspeyres and Paasche do not possess the property of time reversal. But Bennet’s indicators do possess it. It is also easily verified that
(13)
(13)
It follows from (13) that Bennet’s indicator pair is ideal, but Laspeyres’s and Paasche’s do not possess that property.
2.3.4. Fisher and Bennet: a combinatorial approach
De Boer (Citation2009b) used the decomposition of the ratio change in value into the ratio changes in two factors (price and quantity) by means of the Fisher indices as a step towards the general case of factors where he used the generalization of Siegel of the Fisher indices. Let
denote a certain aggregate to be decomposed and let
and
denote factors 1 and 2, respectively (in our example ‘price’ and ‘quantity’), then we have:
(14)
(14)
The Fisher index for factor 1 reads:
(15)
(15)
The first term gives the change in factor 1, weighted by the magnitudes of factor 2 in the base period, and the second term the change in factor 1, weighted by the values of factor 2 in the comparison period. The number of duplicates of each term is 1 and the weight of each term is ½. This is summarized by De Boer (Citation2009b) in his Table .
TABLE 1. Summary for the case of two factors.
The Bennet indicator for factor 1 reads:
(16)
(16)
The first term gives the change in factor 1 (prices), weighted by the values of the factor 2 (quantities) in the base period, and the second term the change in factor 1 (prices), weighted by the values of the factor 2 (quantities) in the comparison period. The number of duplicates of each term is 1 and the weight of each term is ½. Consequently, Table can also be used for the Bennet indicators. De Boer (Citation2009b) also supplied the tables with 3–6 factors; the one for 5 factors is used in our empirical application.
2.4. Logarithmic indices and indicators
2.4.1. The logarithmic mean
The indices and indicators that belong to this class are based on the logarithmic mean, which for two positive numbers a and b is defined as:
(17)
(17)
The logarithmic mean is very convenient when switching from a ratio to a difference and vice versa (Balk, Citation2003). It follows straightforwardly from (17) that:
(18)
(18)
(19)
(19)
It is ‘zero value robust’: in practice we can replace zeros by epsilon small positive numbers. (Ang and Liu, Citation2007a). If a and b are both positive, it can still be used. However, if there is a change in sign, that is to say when a is positive (negative) and b is negative (positive), the logarithmic mean (17) is not defined so that it is not ‘change-in-sign robust’. According to Ang and Liu (Citation2007b) the logarithmic mean might handle changes in sign using the so-called ‘Analytical Limit Strategy’. Their procedure has to be applied to each change in sign individually. In practice, this is so cumbersome that in case of the presence of changes in sign we do not advise to use methods based on the logarithmic mean.
2.4.2. The Montgomery indicator and Montgomery-Vartia index
Balk (Citation2003) gave a simple derivation of the indicator of Montgomery (Citation1929; Citation1937) that was used in the application of this indicator to SDA by de Boer (Citation2008). Using, successively, definition (4) of the difference change in value, definition (17) of the logarithmic mean of the value in the comparison and base period
, and the definition (1) of
and
we obtain:
(20)
(20)
in which the first term after the second equality is the definition of the price indicator and the second term of the quantity indicator according to Montgomery.
Using the following definition of the weight for the Montgomery decomposition:
(21)
(21)
the price and quantity indicators read:
(22)
(22)
These indicators exhibit the basic and desired properties of time reversal and being ideal, except the property of monotonicity. But, as argued by Balk (Citation2003, Appendix A.2), this problem is unlikely to be of practical importance.
Using the definition of the logarithmic mean of the value in the comparison period and the base period
and rewriting (19) we obtain:
(23)
(23)
We define the weight according to Montgomery-Vartia decomposition as:
(24)
(24)
Then, the application of (23) to the Montgomery decomposition (20) leads to the Montgomery-Vartia decomposition:
(25)
(25)
The first term after the second equality of (25) is the logarithm of the price index and the second one the logarithm of the quantity index of Montgomery-Vartia. By exponentiation it follows from (25) that:
(26)
(26)
Like the Montgomery indicators, the indices of Montgomery-Vartia do not exhibit the property of global monotonicity, but as argued by Balk (Citation2003, Appendix A.1) this problem is unlikely to be of practical importance. More importantly, contrarily to the Fisher indices, the indices of Montgomery-Vartia fail to exhibit the property of ‘linear homogeneity in comparison prices (quantities)’ and, consequently the property of ‘proportionality’. Fulfilment requires the sum of the weights (24) being equal to one, but, using Jensen’s inequality, Balk (Citation2003) proved that this sum is smaller than one.
2.4.3. The Sato-Vartia index and the Additive Sato-Vartia indicator
Balk (Citation2003) supplied a simple derivation of the indices of Sato-Vartia that was used in the application of this index to SDA by de Boer (Citation2009a). From the logarithmic mean of the value shares of commodity in total expenditure in comparison and base period, i.c.
and
, we derive
. Summation over
results in:
(27)
(27)
where the last equality follows from the adding-up of the shares to one.
From (1) and (2) it follows that and
. Consequently,
(28)
(28)
Substitution of (28) into (27) leads to:
which after defining:
(29)
(29)
can be rewritten to:
(30)
(30)
The first term on the right-hand side of (30) is the logarithm of the price index and the second one the logarithm of the quantity index of Sato-Vartia. By exponentiation it follows from (30) that:
(31)
(31)
Like the indices of Montgomery-Vartia, the indices according to Sato-Vartia do not exhibit the property of global monotonicity, but, as argued by Balk (Citation2003, Appendix A.3), this problem is unlikely to be of practical importance either. More importantly, contrary to Montgomery-Vartia indices, due to the fact that the sum of the weights (29) is equal to one, the indices of Sato-Vartia exhibit the property of ‘proportionality’.
The additive counterparts of the Sato-Vartia indices do not exist in index number theory. Therefore we call them ‘Additive Sato-Vartia’. It was introduced in energy and environmental studies by Ang et al. (Citation2003, Appendix B) under the name ‘Additive LMDI II’. We rewrite (23) to:
(32)
(32)
Substitution of (30) into (32) and defining the weight of the Additive Sato-Vartia decomposition as:
(33)
(33)
we arrive at:
so that the price indicators according to Additive Sato-Vartia are:
Like the other logarithmic indices and indicators, it will not exhibit the property of global monotonicity, either. But this problem is unlikely to be of much practical importance, as well.
2.5. A contribution of index number theory: consistency-in-aggregation
All indices (indicators) that we discussed above are one-stage indices (indicators). In practice, the computation of price and quantity indices might also be performed via a multistage process. As an example, Balk (Citation2016) gives the computation of the price index of Laspeyres in two stages. The set of commodities is partitioned into
disjoint subsets
, that is to say:
with
for
. In the first stage, the Laspeyres price index is computed for each subset
. In the second stage the Laspeyres price index of all first stage indices is computed. Balk (Citation2016) proves that the Laspeyres index according to (7) is equal to Laspeyres index computed in the two-stage process. If at each stage the same type of index is used the index called ‘consistent-in aggregation’ (CIA). Consequently, the indices of Laspeyres are CIA. As Balk (Citation2016, p. 7) states: ‘However, this is the exception rather than the rule. For most indices, two-stage and one-stage variants do not coincide. Put otherwise, most indices are not consistent-in-aggregation.’
Balk (Citation1996) formalized consistency-in-aggregation of a particular price index and proved that the ‘pseudo Montgomery’ price index (nowadays named ‘Montgomery-Vartia’) is CIA. Balk (Citation2008a) reproduced this canonical form and the proofFootnote1 in his section 3.7.2. The proofs that the indicators of Bennet and MontgomeryFootnote2 are CIA are given in his section 3.10.3. In Appendix A of the supplementary material, we give a numerical example from which it is immediately clear that the one-step indices according to Fisher and Sato-Vartia are not equal to the corresponding two-step indices. The same applies to the one- and two-step indicators according to the Additive Sato-Vartia indicator. As a consequence, ‘Fisher’, ‘Sato- Vartia’ and ‘Additive Sato-Vartia’ are not CIA.
2.6. Summary of relevant properties and formulas for IDA and SDA
2.6.1. Relevant properties
All pairs of indices and indicators share the properties of ‘identity’, ‘linear homogeneity of degree zero in prices (quantities)’, invariance to changes in the units of measurement’, ‘time reversal’ and being ‘ideal’. In Table we summarize those theoretical properties, which are met with or not.
TABLE 2. Fulfilment of relevant properties of ideal indices and indicators.
It follows from Table that no ideal index meets all the three desired properties simultaneously. Fisher’s is the only one that meets the property of monotonicity; Montgomery-Vartia is the only one that meets consistency-in-aggregation; whereas Fisher and Sato-Vartia both meet the requirement of proportionality, but not Montgomery-Vartia. With respect to the ideal indicators Additive Sato-Vartia is the only one that does not meet the requirement of consistency-in-aggregation so that it not advisable to use it in practice.
2.6.2. Summary of formulas
The relevant formulas of index number theory are summarized in Table . From the empirical point of view they are as easily implemented. But remember that index number theory deals with only two factors. In Section 4, we present the generalization to factors. We find that methods based on the logarithmic mean are easier to implement than the combinatorial ones (Fisher and Bennet). But knowing that these two factors only take on nonnegative numbers means that changes-in-sign cannot occur. In the practice of SDA, however, they might.Footnote3
TABLE 3. Decomposition of change in value into price and quantity effect of ideal methods.
3. Correspondence between index number theory and IDA and SDA: overview of literature
3.1. Combinatorial indices
3.1.1. Index decomposition analysis
Sun (Citation1998) derived a complete additive decomposition model for n factors by a refinement of the Laspeyres’s method. In it he assures that the residuals due to interactions are distributed equally among the main effects based on the principle of ‘jointly created and equally distributed principle’ (Sun, Citation1998, p. 88, citing Sun, Citation1996). Albrecht et al. (Citation2002) used the Shapley value from noncooperative game theory to derive a complete additive decomposition model. Ang et al. (Citation2003) proved that Sun’s approach is equivalent to using the Shapley value and, hence, named the method ‘Sun-Shapley’. But it was just the Bennet indicator applied to n factors. Ang et al. (Citation2004) applied the multiplicative analogue of the Shapley value to the four-factor decomposition model of Chung and Rhee (Citation2001). In their Appendix A they presented the decomposition formula using Shapley’s (Citation1953) generic formula. They called it the ‘Generalized Fisher’ method. Siegel (Citation1945) had already supplied the resulting decomposition formula in his generalization of the two-factor Fisher index.
3.1.2. Structural decomposition analysis
Dietzenbacher and Los (Citation1998) decomposed additively the change in labor costs of 214 sectors in the Netherlands between 1986 and 1992 into four components: the effects of a change in the labor cost per unit of output; the effects of technical change; the effects of changes in the final demand mix; and the effects of the changes in the final demand levels. They computed the arithmetic mean of all elementary decompositions and of the two polar decompositions, and concluded that both means were rather close to each other. In the framework of the same example Dietzenbacher et al. (Citation2000) gave a multiplicative decomposition and computed the geometric mean of all 24 elementary decompositions and of the two polar decompositions and reached the same conclusion as before. De Haan (Citation2001) collected the duplicates of the additive decomposition of Dietzenbacher and Los and gave, in his Table , the weights attached to each of the eight combinations. These weights are equal to those given in Siegel (Citation1945) for the multiplicative analogue. The formula used by de Haan is nothing but the Bennet indicator. Seibel (Citation2003) extended De Haan’s ‘Dutch approach’ and illustrated it for the five-factor case. But his approach is the same as Siegel’s, which we show via application in Appendix B. In Appendix C we apply Shapley’s approach and show the equivalence of the two approaches. De Boer (Citation2009b) proved that the geometric mean of all elementary decompositions is equivalent to Siegel’s generalization of the index of Fisher to n factors. Since Bennet’s indicator is the additive counterpart of Fisher’s index (Balk, Citation2003), De Boer’s proof implies that the arithmetic mean of all elementary decompositions is equivalent to the Siegel’s (Citation1945) generalization of Bennet’s indicator.
To summarize: all the approaches described above are either generalizations of the Fisher index or of the Bennet indicator applied to a decomposition into factors. The generic formulae used are either Siegel’s or Shapley’s.
3.2. Logarithmic indices and indicators
3.2.1. Index decomposition analysis
Boyd et al (Citation1987) introduced their so-called ‘Divisia index approach’, by assuming all variables are continuous and each is a function of time. The resulting equation is differentiated with respect to t, integrated over the time interval 0 to T, and the integral path is approximated using the arithmetic mean weight function. It resulted in the so-called AMDI method (‘Artihmetic Mean Divisia Index’.) In the theory of indices and indicators, this method is called the ‘Törnqvist index’ (Törnqvist and Törnqvist, Citation1937), which is defined as the geometric mean of the Geometric Laspeyres and Geometric Paasche indices (Balk, Citation2008a). Boyd and Roop (Citation2004) explicitly introduced the Fisher ideal index for the decomposition of structural change in energy intensity into two factors (‘structure’ and ‘intensity’) and compared the results with those obtained by application of AMDI. Since the latter is not an ideal index we do not consider it in this paper. Ang and Choi (Citation1997) introduced ‘a refined Divisia index method’ by replacing the arithmetic mean by the logarithmic mean weight scheme proposed by Sato (Citation1976). Ang and Liu (Citation2001) renamed it the LMDI-II method but is clearly equivalent to the Sato-Vartia index. Ang et al. (Citation1998) proposed ‘a refined Divisia index method based on decomposition of a differential quantity’. This method is nothing but Montgomery’s indicator. Ang and Liu (Citation2001) proposed a so-called LMDI-I method, which is equivalent to the Montgomery-Vartia index. They also rename the method proposed by (Ang et al. Citation1998) to (additive) LMDI-I. The mathematical derivations of the multiplicative LMDI-I and LMDI-II methods and of the additive LMDI-I method (which are, respectively, the Montgomery-Vartia and Sato-Vartia indices, and the Montgomery indicator) are mathematically complicated. As shown in Section 2, Balk (Citation2003) supplied far simpler derivations. The additive LMDI-II method is introduced in Ang et al. (Citation2003, Appendix B). As noted earlier, this method is unknown in the theory of indices and indicators.
3.2.2. Structural decomposition analysis
De Boer (Citation2008) showed the correspondence between the theory of indices and indicators and SDA. He applied the Montgomery indicator to the additive decomposition of the example of Dietzenbacher and Los (Citation1998), replicated their results and showed that the Montgomery decompositions were very close to the arithmetic mean of all elementary decompositions. De Boer (Citation2009a) applied the index of Sato-Vartia to the multiplicative decomposition in the framework of the same example (Dietzenbacher et al., Citation2000). He replicated their results and showed that the Sato-Vartia decompositions were very close to the geometric means of all elementary decompositions. reports the equivalence between names of methods in index number theory and in index/structural decomposition analysis.
3.3. Summary of names of methods
TABLE 4. Summary of names of methods.
4. Ideal methods for decomposition: the case of n factors
4.1. Introduction
In Section 2, we decomposed the aggregate change in a variable , i.e. value, into two factors: price and quantity. The decomposition took on two different forms: a ratio change
(multiplicative decomposition), or a difference change
(additive decomposition.) We considered pairs of price and quantity indices (indicators) that are ideal, i.e, the decomposition is complete or, in other words, there is no residual term.
In this section, we deal with the decomposition of an aggregate change into factors which can be written asFootnote4:
(34)
(34)
where
: aggregate to be decomposed;
: set of summation indices;
: factor
.
The multiplicative decomposition reads:
with
: ratio change of factor
and the additive decomposition:
with
: difference change of factor
4.2. Fisher and Bennet
4.2.1. The generic formula of Siegel (1945)
For the multiplicative decomposition, Siegel (Citation1945) reduced, by collecting duplicates, the calculation of permutations (in SDA called ‘elementary decompositions’) to the calculation of
combinations. Then, he proposed to take the weighted geometric mean of all combinations, the fraction of the number of duplicates in the total number of elementary decompositions being the exponent. This is, of course, equal to the geometric mean of all elementary decompositions.
The generic formula for the geometric mean is given in Appendix B, in which it is applied to the case of five factors. It amounts to the calculation of combinations, whereas the number of elementary decompositions is equal to
, which constitutes a considerable decrease in the number of computations. The Bennet decomposition is the additive counterpart to the Fisher decomposition (Balk, Citation2003). It is the weighted arithmetic mean with the same combinations, the weights being the same as the exponents of the Fisher decomposition.
4.2.2. The generic formula of Shapley (1953)
Although independent of Siegel,Footnote5 Shapley (Citation1953) followed an identical route for the additive decomposition. He reduced permutations to combinations and proposed taking the weighted arithmetic mean of all combinations, the divisor being again the fraction of the number of duplicates in the total number of permutations. In Appendix C we give the generic formula of Shapley and apply it to the case of five factors, as well. We present a table in which we prove that Siegel and Shapley yield exactly the result.
4.3. Logarithmic indices and indicators
Consider Equation 34 and define:
(35)
(35)
and
(36)
(36)
The four methods are summarized in (compare Table ).
It follows from Table that all methods are a weighted mean of the logarithm of the relatives, i.e. the value of a factor in the comparison period relative to its value in the base period; the only difference being the weighting factor. It is easy to verify that the Montgomery-Vartia decomposition can be derived from Montgomery’s using the transformation (cf. (18)):
(37)
(37)
and that the Additive Sato-Vartia decomposition can be derived from Sato-Vartia’s using the transformation (compare (19)):
(38)
(38)
Equations 37 and 38 are used in the Matlab program given in Appendix E.
TABLE 5. Name of the method, the weight, the effect of a factor and the decomposition.
5. A hands-on toy model of decomposition of an aggregate change into five factors
5.1. The toy model and its decompositions
In our expository toy model we only deal with emissions of carbon dioxide of sectors of the Dutch economy and ignore the direct emissions of households. We dispose of two input–output tables and of the sectoral carbon dioxide emissions. The number of sectors is denoted by N and the number of final demand categories by m.
We define the following vectors and matrices:
:
vector of sectoral emissions of carbon dioxide;
:
vector of sectoral outputs;
:
vector of sectoral emissions per unit of output;
:
diagonal diagonal matrix with
on the main diagonal;
:
matrix of input–output coefficients
measuring the input from sector i in sector j, per unit of sector j’s output;
:
matrix of bridge coefficients
measuring the fraction of final demand in category k that is spent on products from sector j;
:
vector of shares
of final demand category k in total final demand; and
: total final demand.
We consider the model:
of which the solution is:
(39)
(39)
with:
the Leontief inverse.
In sum notation (39) reads:
(40)
(40)
Consequently, the aggregate to be decomposed,
in (34), is ‘carbon dioxide emissions of sector
’ (
), the set of summation indices is
; and the factors are:
(‘emission coefficients’,
);
(‘production techniques’,
);
(‘final demand mix’,
);
(‘demand structure’,
); and
(‘size of economy’,
), respectively. We want to decompose the change in carbon dioxide emissions from the base period, denoted by the superscript 0, to the comparison period, denoted by the superscript 1, into the changes of these five factors.
5.1.1. Multiplicative (ratio) decomposition
The ratio change in carbon dioxide emissions of sector i is defined to be:
From (40) we obtain:
(41)
(41)
We want to decompose (41) into the ratio changes in emission coefficients (
), production techniques (
), final demand mix
, demand structure (
) and size of the economy (
), i.e.:
5.1.2. Additive (difference) decomposition
The difference change in carbon dioxide emissions of sector i is defined to be:
From (40) we obtain:
(42)
(42)
We want to decompose (42) into the difference changes in emission coefficients (
), production techniques (
), final demand mix
, demand structure (
), and size of the economy (
), i.e.:
5.1.3. One- and two-step decomposition
Due to the presence of two common factors, the multiplicative decomposition (41) can easily be rewritten to a two-step procedure (de Boer, Citation2009b):
(43)
(43)
In the first step we compute the simple index numbers of the factors ‘emission coefficients’ and ‘size of the economy’ and in the second step the composite index numbers of the factors ‘production techniques’, ‘final demand mix’ and ‘demand structure’. The decompositions according to Fisher and Sato-Vartia possess the property of proportionality. Then, the one-step decomposition (41) and the two-step (43) yield the same results for the simple index numbers of the factors ‘emission coefficients’ and ‘size of the economy’. They are used as a assure that the Matlab programs performing the computation of multiplicative and additive decomposition at the same time are correct. The decomposition according to Montgomery-Vartia does not exhibit proportionality, so that the one- and two-step decompositions do not yield the same results. Unfortunately, such a simple device of two-step decomposition does not exist for additive decompositions. Evidently, Equation 42 cannot be rewritten to the sum of the two simple indicators for ‘emission coefficients’ and ‘size of the economy’ and the composite indicators of ‘production techniques’, ‘final demand mix’ and ‘demand structure’. Moreover, there is no analogue of ‘proportionality’ for indicators.
5.2. The Fisher and Bennet decompositions
In Appendix B we use Siegel’s generic formula, and in Appendix C Shapley’s generic formula to arrive at the following summarizing table. In a different format it is also given in De Boer (Citation2009b).
In the first row of Table , we give the combination with the values that the other four other factors take on in the base period. In SDA literature this is called the Laspeyres perspective. There are 24 duplicates so that on the 120 elementary decompositions the first polar decomposition has a weight of 1 over 5. In the last row we give the combination with the values of the four other factors in the comparison period, the Paasche perspective. The weight of the second polar decomposition is also 1 over 5. If the mean of the two polar decompositions is taken the combinations given in the rows (A.2) up to and including (A.5) are neglected and the weights are increased to 1 over 2. For a small number of factors you may expect it to be close to the mean of all decompositions.
TABLE 6. Summary for the case of five factors.
From Table we can derive the decomposition formulae for each of the five factors. For factor 1Footnote6, ‘ratio change in emission coefficients’, it results in:
(44)
(44)
In the very same way, we use Table for the Bennet decomposition. For factor 1, ‘difference change in emission coefficients’, we obtain:
(45)
(45)
In Appendix D the Matlab program is given that performs the Siegel and Bennet decompositions at the same time. As noted earlier, the results of the simple index numbers for the factors ‘emission coefficients’ and ‘size of the economy’ were used to check that the program yields the correct result for Siegel, so that the result according to Bennet is correct, as well.
5.3. Decompositions based on the logarithmic mean
According to Equations 35 and 40, we have
(46)
(46)
so that the weight of the Montgomery decomposition (cf. Table ) is equal to:
(47)
(47)
Using the transformation (37), and the fact that the variable to be decomposed
in Equation 34 is the emission of carbon dioxide of sector
,
, we arrive at the weight of the Montgomery-Vartia decomposition (cf. Table ):
(48)
(48)
According to Equation 36 we have:
Consequently, the weight of the Sato-Vartia decomposition (cf. Table ) is:
(49)
(49)
Using the transformation (38) we derive from (49) that the weighting factors of the additive Sato-Vartia decomposition (cf. Table ) read:
(50)
(50)
In Table , we summarize the formulas for the decompositions of the methods based on the logarithmic mean.
TABLE 7. Formulas for the methods based on the logarithmic mean.
We use just one Matlab program to perform all four decompositions at the same time. It is given in Appendix E. As said earlier, we used the results of the simple index numbers for the factors ‘emission coefficients’ and ‘size of the economy’ to check that the program yields the correct result for Sato-Vartia, so that the results according to Montgomery-Vartia, Montgomery and Additive Sato-Vartia are correct, as well.
6. Empirical results
6.1. DatasetFootnote7
The dataset consists of two Excel files. In the ‘Base period’ the emissions of carbon dioxide (in million kg) are given for 60 sectors of the Dutch economy in 2004, together with the 60 × 60 matrix of intermediate deliveries (in million €) and the 60 × 5 matrix of final deliveries (consumption, government consumption, investments, change in stocks, and exports.) In ‘Comparison period’ the same data are given for 2005, the matrices of intermediate and final deliveries are recorded in prices 2004.
In the last row of Table , we give the percentages of the five largest emitters in the total economy. Together they count for 68 % of the emissions while their share in total final demand is 10.4 %. Between brackets we give the percentages in the total economy of the largest emitter. Not unsurprisingly for the Netherlands it is sector number 25 ‘Electricity and gas supply’. It accounts for about one third of total emissions whereas its share in total final demand is only 1.3%. From the column ‘DCO2’ we gather that the largest emitter accounts for 51.8% of the reduction of carbon dioxide emissions from 2004 to 2005.
TABLE 8. Carbon dioxide emissions (million kg), ratio and difference change, and total final demand (million €) for the five largest emitters and for the total economy.
6.2. Empirical implementation of the decompositions based on the logarithmic mean
As stated before, the logarithmic mean is ‘zero value robust’. That is to say, in practice we can replace zeros by epsilon small positive numbers (Ang and Liu, Citation2007a). In the Matlab program (Appendix D) is used. But it is not ‘change-in-sign robust’. We cannot apply the decompositions on our data set because of the presence of the final-demand category ‘change in stocks’. As argued by De Boer (Citation2008), however, this is not a genuine final-demand category. A correct treatment is the following: the final-demand matrix should include a column with the (nonnegative) ‘addition to stocks’ and the input–output table should have a row with the (nonnegative) ‘depletion of stocks’. Due to problems of data collection, national account statisticians only include the balancing item ‘change in stocks’. De Boer (Citation2008) solved the problem of changes in sign for stocks by splitting them over the other items of a row according to the pertinent shares in total output. The column sums are no longer equal to total output, so he added a row (that plays no role in decompositions) in which he recorded the adjustment for the stocks. We applied this procedure to our example. As a consequence, the number of final-demand categories is reduced from five to four.
6.3. Results for the multiplicative decompositions
As we conclude from Table the decompositions are very close to each other. From an empirical point of view the split of ‘change in stocks’ over the other items of the pertinent row had no effect. If ‘change-in-sign robustness’ is required we need to apply the Fisher decomposition, but if it is not required, like in this example, we advise to use either the Montgomery- Vartia or the Sato-Vartia decomposition since the latter two are easier to program than Fisher’s.
TABLE 9. Results of the multiplicative decompositions.
The decompositions according to Fisher and Sato-Vartia (cf. Table ) satisfy ‘proportionality’, which implies that for all sectors the effect of the factor ‘size of the economy’ in six decimal places, is equal to 1.020135. Because Montgomery-Vartia does not satisfy this property
.020135. For the abovementioned sectors 25, 13, 12, 36 and 34, we find 1.011939, 1.020128, 1.020125, 1.020129, and 1.020130, respectively, which are all very close to the upper bound. For all 60 sectors the minimum effect is equal to 1.019438; the maximum to 1.020134; while the mean effect is equal to 1.020098 with a standard deviation of 0.000119. If in this example we desire to have consistency-in-aggregation, we can easily take the nonfulfilment of ‘proportionality’ for granted and apply Montgomery- Vartia either as one-step decomposition or as a two-step one. If not, we advise to use Sato-Vartia since it satisfies ‘proportionality’.
6.4. Results for the additive decompositions
Obviously, the results for the additive decompositions, presented in , show the same picture as those of the multiplicative decompositions with the same conclusion that the three methods yield the same results so that the split of ‘change in stocks’ over the other items of a row had no effect either. In subsection 2.6.1, we did not recommend the use of the Additive Sato-Vartia decomposition because it does not possess the theoretical property of consistency-in-aggregation. From the empirical point of view there is another serious drawback as pointed out by Ang et al. (Citation2009). They provide a numerical example of an industry which is the aggregate of two sectors. At the aggregate level (industry) the decomposition is complete (‘no residual term’), but that at the disaggregated level (sectors) the decomposition is not complete since the residuals are unequal to zero. It can be shown that in the framework of this example the decompositions according to Bennet and Montgomery are not only complete at aggregate level, but also at disaggregate level so that the use of one of these methods is recommended. If ‘change-in-sign robustness’ is required we need to apply Bennet’s decomposition, but if it is not required, as in this example, we advise the use of Montgomery’s decomposition because it is easier to program than Bennet’s decomposition.
TABLE 10. Results of the three additive decompositions.
7. Summary of methods, their properties and our recommendations
In Table below we summarize the various methods and their properties. Since the nonfulfilment of monotonicity of the methods based on the logarithmic mean plays no role of importance in practice (Balk, Citation2003) we do not list its fulfilment in Table .
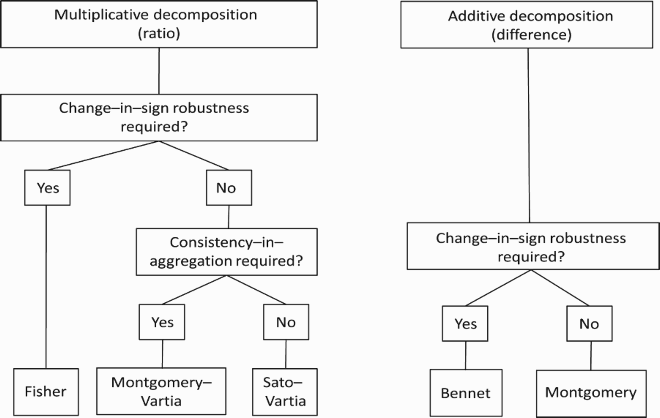
In the following picture we summarize our recommendations:
TABLE 11. Summary of methods and of their relevant properties.
8. Concluding remarks
In this paper, we pay attention to six widely used decomposition methods, all of which share the properties of time reversal and of being ideal. On the basis of theoretical and empirical considerations we show when to use which method.
8.1. Multiplicative decomposition
We considered:
Fisher (SDA) is zero-value and change-in-sign robust, satisfies proportionality, but is not consistent-in-aggregation;
Montgomery-Vartia (multiplicative LMDI-I) is zero-value robust, but not change-in-sign robust, is consistent-in-aggregation, but does not satisfy proportionality; and
Sato-Vartia (multiplicative LMDI-II) is zero-value robust, but not change-in-sign robust, satisfies proportionality, but is not consistent-in-aggregation.
If there are changes in sign in the data set that cannot be resolved, so the only method that can be applied is Fisher. If the data set is ‘change-in-sign robust’ we can apply all three methods. If we wish to apply a method that is ‘consistent-in-aggregation’, we have to apply the Montgomery-Vartia decomposition and take the nonfulfilment of proportionality for granted. If we are not interested in consistency-in-aggregation, we can either apply Sato-Vartia or Fisher, both of which satisfy proportionality. Since the first method is simpler to implement than the latter, we recommend using Sato-Vartia.
8.2. Additive decomposition
We considered:
Bennet (SDA): consistent-in aggregation (CIA), zero-value and change-in-sign robust, and complete at aggregate and disaggregate level;
Montgomery (additive LMDI-I): CIA, zero-value robust, but not change-in-sign robust. It is complete at aggregate and disaggregate level;
Additive Sato-Vartia (additive LMDI-II): not CIA. It is zero-value robust, but not change-in-sign robust; and it is complete at aggregate level, but not at disaggregate level. These are the two reasons why we do not recommend this method.
If there are changes in sign in the data set which cannot be resolved, only Bennet can be applied. Otherwise, we can use either Montgomery or Bennet, but since the first method is simpler to implement we recommend the use of Montgomery.
8.3. Hands-on toy model
We applied all methods to an example in which the change from 2004 to 2005 in sectoral carbon dioxide emissions of the Netherlands are decomposed into five factors: emission coefficients, production techniques, final-demand mix, demand structure and size of the economy. The data set is not change-in-sign-robust because of the presence of ‘change in stocks’ which, as argued by de Boer (Citation2008), is not a genuine final-demand category. It was resolved by spreading the change in stocks over the other items of the pertinent row in the input–output table. We applied the methods of Fisher and Bennet to the full data set, i.e. including the change in stocks, and the other methods which are based on the logarithmic mean to the data set where the number of final demand categories is reduced to four.
8.4. Multiplicative decomposition
From Table it followed that all decompositions are very close to each other so that the split of ‘change in stocks’ over the other items of the pertinent row had no effect. We advise using either the Montgomery-Vartia or the Sato-Vartia decomposition since the latter two are easier to program than is Fisher’s. The effect of the factor ‘size of the economy’ for the Montgomery-Vartia decomposition turned out to be very close to the effect according to the decompositions of Fisher and Sato-Vartia, both of which satisfy ‘proportionality’. In the framework of this example, we can safely take its nonfulfillment for granted and apply, if desired, the two-step decomposition. In general, if one wishes to adopt a method that is consistent-in-aggregation Montgomery-Vartia should be applied, if not, Sato-Vartia is recommended since it satisfies ‘proportionality’.
8.5. Additive decomposition
From Table it followed again that the split of ‘change in stocks’ over the other items of a row had no effect. We advise to use the Montgomery decomposition because it easier to program than Bennet’s.
Supplemental Material
Download PDF (371.1 KB)Acknowledgements
This is a revised version of the paper presented at the 26th International Input Output Conference in Juiz de Fora (Brazil), June 2018, under the title ‘Energy and environmental studies: When to use which method of decomposition?’. We are indebted to Bert Balk for the numerous discussions on index number theory and decomposition analysis and to the chairperson, Mike Lahr, for his encouraging and stimulating comments. The revised version greatly benefitted from remarks of anonymous reviewers.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
João F. D. Rodrigues http://orcid.org/0000-0002-1437-0059
Notes
1 Without using the canonical form of Balk (1996, Citation2008a), Ang and Liu (Citation2001) gave a direct proof that Montgomery-Vartia is CIA.
2 Without using the canonical form of Balk (1996, Citation2008a) Ang and Wang (Citation2015) give a direct proof that Montgomery is CIA.
3 To give but one example: in the seven-sector decomposition model of Chung and Rhee (Citation2001) the sector ‘petroleum, coal and town gas’ has a negative value for final demand in the base period, but a positive one in the comparison period. Methods based on the logarithmic mean cannot be used, but the combinatory ones are applicable.
4 In applied research there are often two-step decompositions, such as the decomposition of the Leontief matrix (Xu and Dietzenbacher, Citation2014; Zhang and Lahr, Citation2014) and multiplicative attribution analysis (Choi and Ang, Citation2012; Su and Ang, Citation2014; Su and Ang, Citation2015; Wang et al. Citation2017a; Yan et al., Citation2018). In all these cases (34) is the first step. Such two-step decompositions are beyond the scope of the present paper.
5 In IDA and SDA literature the generic formula of Siegel has not as yet been presented. De Boer (Citation2009b) used Siegel’s formula but only gave a verbal description. Su and Ang (2014, Appendix B) use Shapley’s generic formula but erroneously attribute it to Siegel.
6 The same formulae are used for the other factors.
7 The authors are indebted to Sjoerd Schenau of Statistics Netherlands for putting these two tables at their disposal.
References
- Albrecht, J., D. François and K. Schoors (2002) A Shapley Decomposition of Carbon Emissions Without Residuals. Energy Policy, 30, 727–736. doi: 10.1016/S0301-4215(01)00131-8
- Ang, B.W. (2004) Decomposition Analysis for Policymaking in Energy: Which is the Preferred Method? Energy Policy, 32, 1131–1139. doi: 10.1016/S0301-4215(03)00076-4
- Ang, B.W. (2015) LMDI Decomposition Approach: A Guide for Implementation. Energy Policy, 86, 233–238. doi: 10.1016/j.enpol.2015.07.007
- Ang, B.W. and K.H. Choi (1997) Decomposition of Aggregate Energy and Gas Emissions Intensity for Industry: A Refined Divisia Index Method. Energy Journal, 18, 59–73. doi: 10.5547/ISSN0195-6574-EJ-Vol18-No3-3
- Ang, B.W. and F.L. Liu (2001) A New Energy Decomposition Method: Perfect in Decomposition and Consistent in Aggregation. Energy, 26, 537–548. doi: 10.1016/S0360-5442(01)00022-6
- Ang, B.W., F.L. Liu and E.P. Chew (2003) Perfect Decomposition Techniques in Energy and Environmental Studies. Energy Policy, 31, 1561–1566. doi: 10.1016/S0301-4215(02)00206-9
- Ang, B.W., F.L. Liu and H.-S. Chung (2004) A Generalized Fisher Index Approach to Energy Decomposition Analysis. Energy Economics, 26, 757–763. doi: 10.1016/j.eneco.2004.02.002
- Ang, B.W., H.C. Huang and A.R. Mu (2009) Properties and Linkages of Some Index Decomposition Analysis Methods. Energy Policy, 37, 4624–4632. doi: 10.1016/j.enpol.2009.06.017
- Ang, B.W. and N. Liu (2007a) Handling Zero Values in Logarithmic Mean Divisia Index Decomposition Approach. Energy Policy, 35, 238–246. doi: 10.1016/j.enpol.2005.11.001
- Ang, B.W. and N. Liu (2007b) Negative-value Problems of the Logarithmic Mean Divisia Index Decomposition Approach. Energy Policy, 35, 739–742. doi: 10.1016/j.enpol.2005.12.004
- Ang, B.W. and H. Wang (2015) Index Decomposition Analysis with Multidimensional and Multilevel Energy Data. Energy Economics, 51, 67–76. doi: 10.1016/j.eneco.2015.06.004
- Ang, B.W., F.Q. Zhang and K.-H. Choi (1998) Factorizing Changes in Energy and Environmental Indicators Through Decomposition. Energy, 23, 489–495. doi: 10.1016/S0360-5442(98)00016-4
- Balk, B.M. (1996) Consistency-in-Aggregation and Stuvel Indices. Review of Income and Wealth, 42, 353–363. doi: 10.1111/j.1475-4991.1996.tb00187.x
- Balk, B.M. (2003) Ideal Indices and Indicators for Two or More Factors. Journal of Economic and Social Measurement, 28, 203–217. doi: 10.3233/JEM-2003-0223
- Balk, B.M. (2008a) Price and Quantity Index Numbers: Models for Measuring Aggregate Change and Difference. Cambridge UK, Cambridge University Press.
- Balk, B.M. (2008b) Searching for the Holy Grail of Index Number Theory. Journal of Economic and Social Measurement, 33, 19–25. doi: 10.3233/JEM-2008-0295
- Balk, B.M. (2016) A Review of Index Number Theory. Wiley StatsRef: Statistics Reference Online.
- Bennet, T.L. (1920) The Theory of Measurement of Changes in the Cost of Living. Journal of the Royal Statistical Society, 83, 455–462. doi: 10.2307/2340960
- Boyd, G.A., J.F. McDonald, M. Ross and D.A. Hanson (1987) Separating the Changing Composition of U.S. Manufacturing Production From Energy Efficiency Improvements: A Divisia Index Approach. Energy Journal, 8, 77–96. doi: 10.5547/ISSN0195-6574-EJ-Vol8-No2-6
- Boyd, G.A. and J.M. Roop (2004) A Note on the Fisher Ideal Index Decomposition for Structural Change in Energy Intensity. Energy Journal, 25, 87–101. doi: 10.5547/ISSN0195-6574-EJ-Vol25-No1-5
- Carli, G.R. (1764) Del Valore et Della Proporzione ‘de Metalli Monetati. Reprinted in: G.G. Destefanis (1804). Scrittori Classici Italiani di Economia Politica, Vol. 13. Milan, Opere Scelte di Carli, Milano, 297–366.
- Choi, K. and B.W. Ang (2012) Attribution of Changes in Divisia Real Energy Intensity Index – an Extension to Index Decomposition Analysis. Energy Economics, 34, 171–176. doi: 10.1016/j.eneco.2011.04.011
- Chung H.S. and H.C. Rhee (2001) A Residual-free Decomposition of the Sources of Carbon Dioxide Emissions: A Case for the Korean Industries. Energy, 26, 15–30. doi: 10.1016/S0360-5442(00)00045-1
- De Boer, P.M.C. (2008) Additive Structural Decomposition Analysis and Index Number Theory: An Empirical Application of the Montgomery Decomposition. Economic Systems Research, 20, 97–109. doi: 10.1080/09535310801892066
- De Boer, P.M.C. (2009a), Multiplicative Structural Decomposition Analysis and Index Number Theory: An Empirical Application of the Sato-Vartia Decomposition. Economic Systems Research, 21, 163–174. doi: 10.1080/09535310902937638
- De Boer, P. (2009b) Generalized Fisher Index or Siegel-Shapley Decomposition? Energy Economics, 31, 810–814. doi: 10.1016/j.eneco.2009.03.003
- De Haan M. (2001) A Structural Decomposition Analysis of Pollution in the Netherlands. Economic Systems Research, 13,181–196. doi: 10.1080/09537320120052452
- Dietzenbacher, E. and B. Los (1998) Structural Decomposition Techniques: Sense and Sensitivity. Economic Systems Research, 10, 307–324. doi: 10.1080/09535319800000023
- Dietzenbacher, E., A.R. Hoen and B. Los (2000) Labor Productivity in Western Europe 1975–1985: An Intercountry, Interindustry Analysis. Journal of Regional Science, 40, 425–452. doi: 10.1111/0022-4146.00182
- Diewert, W.E. (2005) Index Number Theory Using Differences Rather Than Ratios. The American Journal of Economics and Sociology, 64, 311–360. doi: 10.1111/j.1536-7150.2005.00365.x
- Dutot, C.F. (1738) Réflections Politiques sur les Finances et le Commerce, Volume I (les Frères Vaillants et N. Prevost, The Hague). Édition Intégrale Publiée Pour la Première Fois par Paul Harsin (1935) Bibliothèque de Faculté de Philosophie et Lettres de l’Université de Liège, Fascicule LXVII, Paris- Liège.
- Eichhorn, W. (1978) Functional Equations in Economics, Reading, MA, Addison-Wesley.
- Eichhorn, W. and J. Voeller (1976) Theory of the Price Index. Lecture Notes in Economics and Mathematical Systems, 140, Berlin, Springer-Verlag.
- Fisher, I. (1922) The Making of Index Numbers. Boston, Houghton Mifflin.
- Hoekstra, R. and J.C.J.B. van den Bergh (2003) Comparing Structural and Index Decomposition Analysis. Energy Economics, 25, 39–64. doi: 10.1016/S0140-9883(02)00059-2
- Laspeyres, E. (1871) Die Berechnung Einer Mittleren Waarenpreissteigerung. Jahrbücher für Nationalökonomie und Statistik, 16, 296–314.
- Montgomery, J.K. (1929) Is There a Theoretically Correct Price Index of a Group of Commodities? Rome, International Institute of Agriculture.
- Montgomery, J.K. (1937) The Mathematical Problem of the Price Index. London, P.S. King & Son.
- Paasche, H. (1874) Ueber die Preisentwicklung der Letzten Jahre Nach den Hamburger Börsennotierungen. Jahrbücher für Nationalökonomie und Statistik, 23, 168–178.
- Sato, K. (1976) The Ideal Log-Change Index Number. The Review of Economics and Statistics, 58, 223–228. doi: 10.2307/1924029
- Seibel, S. (2003) Decomposition Analysis of Carbon Dioxide Emission Changes in Germany: Conceptual Framework and Empirical Results. European Commissions Working Papers and Studies, THEME 2 Economy and finance, EUROSTAT publications, Luxemburg.
- Shapley L. (1953) A Value for n-Person Games. In: H.W. Kuhn and A.W. Tucker (eds.) Contributions to the Theory of Games, vol. 2. Princeton, Princeton University, 307–317.
- Siegel, I.H. (1945) The Generalized ‘Ideal’ Index-Number Formula. Journal of the American Statistical Association, 40, 520–523.
- Sun, J.W. (1996) Quantitative Analysis of Energy Consumption, Efficiency and Savings in the World. Turku School of Economics and Business Administration, Technical Report Series A-4.
- Sun, J.W. (1998) Changes in Energy Consumption and Energy Intensity: A Complete Decomposition Method. Energy Economics, 20, 85–100. doi: 10.1016/S0140-9883(97)00012-1
- Su, B. and B.W. Ang (2012) Structural Decomposition Analysis Applied to Energy and Emissions: Some Methodological Developments. Energy Economics, 34, 177–188. doi: 10.1016/j.eneco.2011.10.009
- Su, B. and B.W. Ang (2014) Attribution of Changes in the Generalized Fisher Index with Application to Embodied Emission Studies. Energy, 69, 778–786. doi: 10.1016/j.energy.2014.03.074
- Su, B. and B.W. Ang (2015) Multiplicative Decomposition of Aggregate Carbon Intensity Change Using Input-Output Analysis. Applied Energy, 154, 13–20. doi: 10.1016/j.apenergy.2015.04.101
- Törnqvist, L. and E. Törnqvist (1937) Vilket är Förhållandet Mellan Finska Markens och Svenska Kronans Köpkraft? Ekonomiska Samfundets Tidskrift, 39, 1–39. doi: 10.2307/3438106
- Vartia, Y.O. (1974) Relative Changes and Index Numbers. Licentiate Thesis, University of Helsinki, (The Research Institute of the Finnish Economy, Helsinki, 1976).
- Vartia, Y.O. (1976) Ideal Log-Change Index Numbers. The Scandinavian Journal of Statistics, 3, 121–126.
- Wang, H, B.W. Ang and B. Su (2017a) Multiplicative Structural Decomposition Analysis of Energy and Emission Intensities: Some Methodological Issues. Energy, 123, 47–63. doi: 10.1016/j.energy.2017.01.141
- Wang, H, B.W. Ang and B. Su (2017b) Assessing Drivers of Economy-Wide Energy Use and Emissions: IDA Versus SDA. Energy Policy, 107, 585–599. doi: 10.1016/j.enpol.2017.05.034
- Yan, J., B. Su and Y. Liu (2018) Multiplicative Structural Decomposition and Attribution Analysis of Carbon Emission Intensity in China, 2002–2012. Journal of Cleaner Production, 198, 195–207. doi: 10.1016/j.jclepro.2018.07.003
- Xu, Y. and E. Dietzenbacher (2014) A Structural Decomposition Analysis of the Emissions Embodied in Trade. Ecological Economics, 101, 10–20. doi: 10.1016/j.ecolecon.2014.02.015
- Young, A. (1812) An Inquiry Into the Progressive Value of Money in England as Marked by the Price of Agricultural Products. Hatchard, Piccadilly.
- Zhang, H. and M.L. Lahr (2014) China’s Energy Consumption Change From 1987 to 2007: A Multi-regional Structural Decomposition Analysis. Energy Policy, 67, 682–693. doi: 10.1016/j.enpol.2013.11.069