Abstract
While retroactive interference (RI) is a well-known phenomenon in humans, the differential effect of the structure of the learning material was only seldom addressed. Mirman and Spivey (Citation2001, Connection Science, 13: 257–275) reported on behavioural results that show more RI for the subjects exposed to ‘Structured’ items than for those exposed to ‘Unstructured’ items. These authors claimed that two complementary memory systems functioning on radically different neural mechanisms are required to account for the behavioural results they reported. Using the same paradigm but controlling for proactive interference, we found the opposite pattern of results, that is, more RI for subjects exposed to ‘Unstructured’ items than for those exposed to ‘Structured’ items (experiment 1). Two additional experiments showed that this structure effect on RI is a genuine one. Experiment 2 confirmed that the design of experiment 1 forced the subjects from the ‘Structured’ condition to learn the items at the exemplar level, thus allowing for a close match between the two to-be-compared conditions (as ‘Unstructured’ condition items can be learned only at the exemplar level). Experiment 3 verified that the subjects from the ‘Structured’ condition could generalize to novel items. Simulations conducted with a three-layer neural network, that is, a single-memory system, produced a pattern of results that mirrors the structure effect reported here. By construction, Mirman and Spivey's architecture cannot simulate this behavioural structure effect. The results are discussed within the framework of catastrophic interference in distributed neural networks, with an emphasis on the relevance of these networks to the modelling of human memory.
1. Introduction
Retroactive interference (i.e. forgetting of previously learned items when learning new ones) is of great value for the understanding of human memory, and a well-documented phenomenon (e.g. Barnes and Underwood Citation1959, Delprato Citation1970, Shulman and Martin Citation1970, Cofer et al. Citation1971, Bunt and Sanders Citation1972, Izawa Citation1980, Wheeler Citation1995, Bäuml Citation1996). Indeed, the amount of retroactive interference (RI), as a function of the characteristics of the learning material and situation, puts constraints on models of learning and forgetting.
RI is generally investigated in situations involving sequential learning of two lists of items (i.e. associations). The retroactive interference paradigm, commonly used, consists in the following: a first list (L1) is learned and a first test (T1) assesses subjects' memory of the learned associations. Then a second list (L2) is learned, followed by a final test (T2) on both L1 and L2 associations. RI is measured by the drop in performance on L1 between T1 (T
1
L
1) and T2 (T
2
L
1):
![]() Most RI studies have been carried out with meaningful material (e.g. words), mainly in the verbal learning framework. Few studies have both investigated the link between the to-be-learned material and the amount of RI and tried to integrate the results into an explicit, implemented model (but see Chappell and Humphreys Citation1994).
Most RI studies have been carried out with meaningful material (e.g. words), mainly in the verbal learning framework. Few studies have both investigated the link between the to-be-learned material and the amount of RI and tried to integrate the results into an explicit, implemented model (but see Chappell and Humphreys Citation1994).
A notable exception is the recent study by Mirman and Spivey (Citation2001), who investigated the effect of the structure of the learning material on RI with item lists made of meaningless paired associates. Mirman and Spivey (Citation2001) hypothesized that subjects use two different learning strategies according to the nature of the to-be-learned material: a ‘pattern-based’ learning if the items are ‘structured’ (i.e. rule-based associations) and ‘rote memorization’ if the items are ‘unstructured’ (i.e. arbitrary associations). Mirman and Spivey (Citation2001) asked their subjects to learn sequentially either two lists of ‘structured’ items or two lists of ‘unstructured’ items. They found that the amount of RI was higher when two lists of ‘structured’ items were successively learned than when two lists of ‘unstructured’ items were successively learned.
To account for this result, and in accordance with their two learning strategies hypothesis, Mirman and Spivey (Citation2001) argued that memorization in humans is carried out by two different modules according to the nature of the to-be-learned material. They proposed an attractive neural network architecture that accounts for the pattern of results of their behavioural experiment. This architecture, named dual-strategy competitive learner (DSCL), a mixture-of-experts neural network, works on the principle of a competition between two experts, that is, ‘two sub-networks… differentially effective based on the learning task’ (Mirman and Spivey Citation2001: 266): one, distributed, is efficient in learning rule-based items, the other, rather localized (ALCOVE: Kruschke Citation1992), is efficient in learning arbitrary items. A crucial role is devoted to a gating network that ‘is trained to decide which expert is the correct one for a given input; that is, which sub-network's output will be used as the overall output’ (Mirman and Spivey Citation2001: 266).
The critical focus of Mirman and Spivey (Citation2001) is the phenomenon of catastrophic forgetting, or catastrophic interference (CI). CI arises when gradient descent learning procedures are used to train networks in sequential learning tasks. CI is the total destruction of the information about a first set of items previously learned by a network when a second set of items is learned by the network (McCloskey and Cohen Citation1989, Ratcliff Citation1990). This major drawback being unacceptable for models of human learning and memory, numerous authors have studied the CI phenomenon or developed ways to overcome this problem (Hetherington and Seidenberg Citation1989, McCloskey and Cohen Citation1989, Kortge Citation1990, Ratcliff Citation1990, Lewandowsky Citation1991, Citation1994, McRae and Hetherington Citation1993, Lewandowsky and Li Citation1995, McClelland et al. Citation1995, Robins Citation1995, Citation1996, Sharkey and Sharkey Citation1995, Ans and Rousset Citation1997, 2000, French Citation1997, Frean and Robins Citation1998, Robins and McCallum Citation1998, 1999, French et al. Citation2001; for a review, see French Citation1999). As for Mirman and Spivey (Citation2001), they take into account the nature of the learning material when considering CI. Indeed, in the localized part of the DSCL—the part responsible for the storage of the unstructured exemplars—no CI is expected, whereas CI may occur in the distributed module—the one that takes charge of structured information. Thus, the theoretic importance of the proposals of Mirman and Spivey (Citation2001) goes beyond their impact on the understanding of RI, since they offer an original insight into the ‘plasticity–stability’ dilemma, a major problem of neural network models of learning and memory.
The architecture proposed by Mirman and Spivey leads to a pattern of results that qualitatively mirrors that of their behavioural experiment. This is a fact of primary importance since it is a possible argument for the existence of multiple memory systems in humans. In the light of the implications of these findings, it appeared essential to examine the soundness of both the behavioural data and of the simulations. Some features of the behavioural experiment cast doubts on the interpretation that Mirman and Spivey (Citation2001) make of their data. It may well be that the results arise for reasons other than those advocated by these authors. We identify and discuss below two such possible reasons.
In the behavioural experiment of Mirman and Spivey, the rule-based (i.e. the ‘structured’) items were generated with one rule per learning list (e.g. all the items in a list followed the rule ‘when an item's first part is C1VC2, its second part is C2VC1’). It is likely that the subjects found out the ‘rule’ that structures the items after the presentation of as few as two or three items and then did not pay attention any more to the next items. That is to say, the subjects did not necessarily learn the rule-based items at the exemplar level. Indeed, in Mirman and Spivey's (2001: 265) , one may find that on the first test the subjects attempted to give an answer to unlearned items, on average, more than six times out of eight, and this even though they received instructions not to attempt to answer unlearned items. This supports the hypothesis that the subjects did not learn the items at the exemplar level and achieved a 100% correct performance on the first test mainly because they ‘worked out the rule’ and applied it during the recognition test. During the second test the subjects had to choose between something that corresponded to the ‘rule they worked out’ during the learning of the first list (e.g. ‘when an item's first part is C1VC2, its second part is C2VC1’) and something that corresponded to the ‘rule they worked out’ during the learning of the second list (e.g. ‘when an item's first part is CVC, its second part is CV′C, V′ being a if V is o, o if V is a, e if V is i, and i if V is e′). In order to answer correctly, a subject had to remember if the item was part of the first learned list or of the second one, that is to say, the second test was a source memory test for the subjects who learned ‘structured’ items. Failing to remember where he/she encountered a given item, a subject has only a 50% chance to answer correctly. Now, this was not the case for the subjects who learned the ‘unstructured’ items, which by definition are arbitrary and thus, obviously, can only be learned at the exemplar level. Therefore, in this latter condition, the second test did not draw on source memory, that is, there was no need for the subjects to remember where they encountered an item presented at test in order to answer correctly. The requirements of the tests were different in the two conditions to be compared. This lack of similarity makes it difficult to attribute the pattern of results of Mirman and Spivey's (2001) behavioural experiment to the structure of the learning material only.
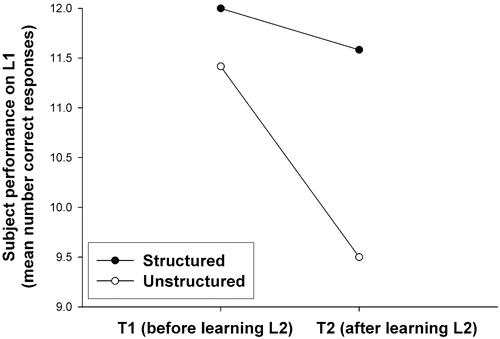
Figure 1. Retroactive interference on list L1 between tests T1 and T2 as a function of the learning material when considering all the subjects (thus letting proactive interference be free to vary between the ‘structured’ and ‘unstructured’ conditions). There is no effect of the structure of the learning material on retroactive interference.
The second aspect concerns the proactive interference (PI) in the experimental paradigm (i.e. retroactive interference paradigm) used by Mirman and Spivey (Citation2001). PI refers to the fact that learning of a second list of items is more difficult after a first list of items has been learned. More precisely, considering that L1 and L2 are of equal difficulty, PI is the difference between the performance on L1 at T1 (T
1
L
1) and the performance on L2 at T2 (T
2
L
2):
![]() It is well known that the retroactive interference paradigm, in addition to RI, also gives rise to PI. Taking into account that RI is the difference between the performance on L1 at T1 and the performance on L1 at T2, one can easily figure out that there is some connection between RI and PI. This is obvious with the following exaggeration as an example: if a subject does not attend to L2 items as L2 is presented (and instead rehearses the items of L1, presented before), RI could be nil (i.e. a performance on L1 as good at T2 as at T1) but PI would be at (or near) its maximum (cf. equation (2)). Thus, proactive interference is to be taken into account and, in concrete terms, to be controlled when one is interested in RI. It is probable that the amount of PI varies with the type of items to be learned (i.e. ‘Structured’ versus ‘Unstructured’). Therefore, when studying the influence of the structure of the learning material per se on RI, the amount of proactive interference should be the same for both conditions (i.e. ‘Structured’ versus ‘Unstructured’). Proactive interference is an issue that was not mentioned in Mirman and Spivey (Citation2001). Thus, the pattern of behavioural results presented by these authors could be due to an amount of PI that varied between the ‘Structured’ and ‘Unstructured’ conditions.
It is well known that the retroactive interference paradigm, in addition to RI, also gives rise to PI. Taking into account that RI is the difference between the performance on L1 at T1 and the performance on L1 at T2, one can easily figure out that there is some connection between RI and PI. This is obvious with the following exaggeration as an example: if a subject does not attend to L2 items as L2 is presented (and instead rehearses the items of L1, presented before), RI could be nil (i.e. a performance on L1 as good at T2 as at T1) but PI would be at (or near) its maximum (cf. equation (2)). Thus, proactive interference is to be taken into account and, in concrete terms, to be controlled when one is interested in RI. It is probable that the amount of PI varies with the type of items to be learned (i.e. ‘Structured’ versus ‘Unstructured’). Therefore, when studying the influence of the structure of the learning material per se on RI, the amount of proactive interference should be the same for both conditions (i.e. ‘Structured’ versus ‘Unstructured’). Proactive interference is an issue that was not mentioned in Mirman and Spivey (Citation2001). Thus, the pattern of behavioural results presented by these authors could be due to an amount of PI that varied between the ‘Structured’ and ‘Unstructured’ conditions.
Concerning Mirman and Spivey's (2001) DSCL simulation, one should notice that the associations that they used did not simply consist of some recoding of the items presented to the subjects. Rather, Mirman and Spivey chose as simulation material some peculiar associations that may suffice to create the expected effect. Indeed, the associations used to simulate the ‘rule-based’ condition are highly incompatible (i.e. auto-associations and inverse associations), which is known to result in maximum catastrophic forgetting (McCloskey and Cohen Citation1989, French Citation1997, experiment 1). As a result, Mirman and Spivey (Citation2001) found a critical 100% forgetting for the ‘Structured’ condition. Since these authors present this simulation to show that RI is higher on the ‘rule-based’ items than on the ‘arbitrary’ items, we cannot but note that this is not the most conservative way to proceed. Furthermore, the RI found on the ‘Structured’ items is in fact true CI.
2. Experiment 1
In order to investigate the influence of the structure of the to-be-learned material on RI thoroughly, we used a retroactive interference paradigm just like Mirman and Spivey (Citation2001) but with modifications that avoid the limitations pointed out above. Just as in Mirman and Spivey's (2001) experiment, the subjects were to learn either ‘Structured’ (i.e. rule-based) or ‘Unstructured’ (i.e. arbitrary) items. The A–B, C–D retroactive interference paradigm was used. The subjects first learned a first list (hereafter L1) of associations (A–B). Immediately after, they performed a forced-choice recognition test (hereafter T1) on the stimuli from L1. Then the subjects learned a second list (hereafter L2) of associations (C–D). Finally, they performed a forced-choice recognition test (hereafter T2) on the stimuli from both L1 and L2. The variable of interest is the amount of forgetting of L1 associations between T1 and T2 (i.e. retroactive interference).
The first modification concerns the number of rules per learning list. It is probable that if only one rule per learning list were used to generate the ‘Structured’ items—as in Mirman and Spivey (Citation2001)—the subjects would ‘work out the rule’ without necessarily learning the items at the exemplar level. Now, the subjects who learn the ‘Unstructured’ items obviously can only learn them at the exemplar level. In order to equate the two conditions, we wanted the subjects presented with ‘Structured’ items to learn these items at the exemplar level as well. Therefore, half of the items of each ‘Structured’ list were derived using one rule, the other half using another rule—with four different rules, two for L1 and two for L2. In this way, even if the subjects are sensitive to the regularities introduced by the rules, they still have to remember which item follows which rule in order to respond correctly at test. In other words, the use of two rules per ‘Structured’ learning list forces the subjects to learn the ‘Structured’ items at the exemplar level, allowing for a fair comparison between their performance and that of the subjects learning ‘Unstructured’ items.
The second modification concerns the control of proactive interference (PI), in order to examine thoroughly the existence of a structure effect on RI per se. Indeed, it could turn out that learning of L2 is more difficult (or easier) following learning of L1 if, say, L1 and L2 are ‘Structured’-item lists than if L1 and L2 are ‘Unstructured’-item lists. A first way to control that PI does not have a differential effect in the two to-be-compared conditions would be to show that there is no such effect, but this solution would have the drawback of relying on the nil hypothesis. A second way to deal with PI would be to use an ANCOVA analysis with PI as a covariate. However, this would not be correct, as RI (the dependent variable) and PI (the covariate) are not independent (see equations (1) and (2)). Finally, we chose a third approach that implies taking into account only the performance of those subjects who exhibited a PI of zero (i.e. equal performances for T 2 L 2 and for T 1 L 1, see equation (2)). With this in mind, more subjects were run than required by the factorial design (see section 2.1.1).
2.1. Method
2.1.1. Participants
Fifty subjects, aged 18–26 years, all undergraduate students at the University of Grenoble, participated in the experiment for extra course credit. They were randomly assigned to one of the four experimental groups (see section 2.1.3) until there were six subjects per group with a PI of zero. To do that, nine subjects were run in the first ‘Structured’ group (S1), 10 subjects in the second ‘Structured’ group (S2), 15 subjects in the first ‘Unstructured’ group (U1) and 16 subjects in the second ‘Unstructured’ group (U2).
2.1.2. Stimuli and apparatus
The items were pairs of letter strings (see the Appendix). Each of the two parts of an item and the item itself are pronounceable and meaningless. To avoid confusion due to phonotactic rules of pronunciation in French only the consonants b c d f g l m n p r t v z and the vowels a e i o were used. The first part (i.e. the left-hand side) of an item is always an alternation of consonants and vowels of the form C1V1C2V2, with C1 differing from C2 and V1 differing from V2. A first part never contained both the vowels a and o, or both i and e. A spacing corresponding to one letter separated the first part of an item from its second part. This latter is equally an alternation of consonants and vowels, again with C1 differing from C2 and V1 differing from V2, but starts with a consonant for half of the items and with a vowel for the remaining items.
The second parts of the ‘Structured’ items were created using one of the following four rules. Supposing C1V1C2V2 is the first part of a ‘Structured’ item, its second part would be C1V2C2V1 if rule one (R1) were applied, V2C1V1C2 if rule two (R2) were applied and V1C2V2C1 if rule three (R3) were applied. If rule four (R4) were applied, the second part would be the same as the first part, except that V1 and V2 would be changed: a would be replaced by o, o by a, e by i and i by e. Starting with 24 different first parts of items, 48 ‘Structured’ items were created.
To create the 48 ‘Unstructured’ items, 48 new and different random second parts of items were created, 24 of them starting with a vowel and 24 starting with a consonant. The same 24 different first parts of items as for the ‘Structured’ items were used, each being paired twice with one of the 48 newly created random second parts.
The experiment was programmed and run using E-Prime 1.1 software on an IBM-compatible computer with a 29 × 39 cm screen. Stimuli were presented on a black background in green uppercase 35-sized bold Arial font characters. During learning of L1 and L2, the items were displayed centred both horizontally and vertically on the screen. During the forced choice recognition tasks, the first part of a learned item was displayed centred horizontally and vertically, and the two choices were displayed about 6.5 cm below it, on the same row, centred horizontally, one on the left, the other on the right, separated by about 16 cm. Subjects responded by pressing either the most left-hand side or the most right-hand side key of an E-Prime Response Box.
2.1.3. Design
We used a between-subjects design, with the ‘Structured’ and ‘Unstructured’ conditions. In the ‘structured’ condition the subjects learned only ‘Structured’ items. In the ‘Unstructured’ condition the subjects learned only ‘Unstructured’ items. In order to check for a possible order effect, there were two groups of subjects per condition (S1 and S2 for the ‘Structured’ condition, and U1 and U2 for the ‘Unstructured’ condition), resulting in four experimental groups.
2.1.4. Procedure
Twenty-four different first parts of items were used. Twelve of them, the same for all the groups, were used as first parts of L1 items. The remaining 12 were used as first parts of L2 items for all groups. All groups learned 12 items as L1 and 12 items as L2.
To create L1 items for group S1, R1 was applied to six L1 first parts and R2 to the remaining possible L1 six first parts. To create L2 items for group S1, R3 was applied to six L2 first parts and R4 to the remaining L2 six first parts. To create L1 items for group S2, R3 was applied to six first parts (three of those used in L1 of S1 with R1, and three of those used in L1 of S1 with R2) and R4 to the remaining L1 six first parts (the remaining three of those used in L1 of S1 with R1, and the remaining three of those used in L1 of S1 with R2). To create L2 items for group S2, R1 was applied to six L2 first parts (three of those used in L2 of S1 with R3, and three of those used in L2 of S1 with R4) and R2 to the remaining L2 six first parts (the remaining three of those used in L2 of S1 with R3, and the remaining three of those used in L2 of S1 with R4). In a similar way, L1 lists for groups U1 and U2 contained the same 12 L1 first parts of items as for the ‘structured’ groups, and different second parts. The same was true for their 12 L2 items (see the Appendix).
For L1 and L2 learning the list of items was presented four times. The four presentations were separated by short pauses. Each item was displayed for 4000 ms and was separated from the next one by a 700 ms pause. Items were presented in random order but with the constraint of no more than two consecutive items created with the same rule. Item order was different for each of the four presentations, but the same for all the subjects.
For L1 learning, all subjects were asked to learn the list of items, without being told anything about the items. They were told they would see the list four times and would be tested just after learning. The nature of the test was kept secret from the subjects.
After learning of L1, subjects were explained the nature of the test and took T1: the beginning of an item was displayed centred horizontally and vertically at the same time as the two choices for its second part were displayed below it (for details, see section 2.1.2), one on the left, the other on the right. Subjects were instructed to answer by pressing the key corresponding to the learned second part of the item, the most left-hand side key if the learned second part of the item was displayed on the left, the most right-hand side key if the learned second part of the item was displayed on the right (i.e. complete stimulus-response compatibility). Care was taken to instruct subjects to take their time before answering, this requirement being presented to them as necessary to avoid haste errors. At T1 each learned L1 item was presented once. Item order in the test list was randomly generated for each subject, with the constraint that the correct answer never occurred more than twice in the same location.
T1 was immediately followed by learning of L2. Subjects were told they were to learn a new list of items, presented to them in the same way as L1. They were informed that this new list contained only items formed of new ‘bits’ (i.e. only new first parts and second parts). Subjects were told that the test they were to complete after learning of L2 was very different from T1. This information was given in order to discourage them from using strategies they did not use during learning of L1 when they were to learn L2. For instance, knowing that they were again to perform a forced choice recognition test, a possible strategy would be to ignore the first parts of the items and to learn only the second parts. A subject adopting this strategy could easily give the expected answer at test on the basis of familiarity with the correct choice. For subjects using this strategy, no performance difference is expected between ‘Structured’ and ‘Unstructured’ lists. Indeed, the distinction between the two lies in the presence or absence of a relationship between the two parts of the items, a relationship that would—obviously—never be detected if the first parts of the items were not attended.
After learning of L2, subjects took T2: the same procedure as for T1 was used, except for the fact that all the learned items (i.e. items from both L1 and L2) were presented in random order but with two constraints. The first constraint was that the correct answer never occurred more than three times in the same location. The second constraint was that no more than three items from the same list (i.e. from L1 or L2) occurred in a row. Subjects were told they had been misled into believing that T2 was different from T1 to prevent them from using encoding strategies due to their previous knowledge of the test nature. Subjects were also reminded that L2 items were actually formed only of new ‘bits’, never presented to them before their learning of L2. Then they were told that T2 consisted of the same kind of test as T1, except that all the learned items (i.e. both those of L1 and those of L2) would be presented. Again, care was taken to instruct subjects to take their time before answering, this requirement being presented to them as necessary to avoid errors due to haste.
2.2. Results
The performance of the six subjects per group who exhibited a PI of zero (i.e. equal performances for T 2 L 2 and for T 1 L 1, see equation (2)) does not depend on PI and thus provides us with unbiased data to test the hypothesis of a structure effect on RI per se. In order to ensure that this selection of subjects does not stem from a selection bias, we first present the results of analyses of the data from all the 50 subjects.
A first analysis (ANOVA) conducted on the number of correct responses to L1 items with the factors Structure and Moment-of-test showed that both main effects are significant: Structure [F(1, 48) = 23.65, p < 0.0001] and Moment-of-test [F(1, 48) = 33.10, p < 0.0001]; the effect of the interaction between these factors is nonetheless not significant [F(1, 48) = 2.68, p = 0.108]. Thus, even if qualitatively RI seems higher in the ‘Unstructured’ condition (see ), this is not confirmed at the statistical level. Nothing can be concluded with regard to the existence of a structure effect on RI.
The second analysis (ANOVA) was conducted to investigate a PI effect and a structure effect on PI. It involved the factors Structure and Proactive interference (One list and Two lists). The One list level refers to the performance on L1 at T1 (T 1 L 1) and the Two lists level refers to the performance on L2 at T2 (T 2 L 2), the difference between the two being the PI (see equation (2)). This analysis revealed that both main effects are significant: Structure [F(1, 48) = 10.90, p < 0.002] and Proactive interference [F(1, 48) = 5.25, p < 0.03]; the effect of the interaction between these factors is not significant [F(1, 48) = 1.93, p = 0.171]. To sum up, this analysis shows an effect of PI and no differential effect of structure on PI.
Taken together, these two analyses suggest that in the absence of a thorough control of PI, this variable could affect the results in a way that is difficult to assess. Is the lack of significance of the structure effect on RI a reflection of the non-existence of this effect, or is it the by-product of a differential structure effect on PI that we missed because of a lack of statistical power? The following analysis will deal with this issue.
The analysis (ANOVA), based on the data from six subjects per group who didn't exhibit PI, was conducted on the number of correct responses to L1 items with the factors Structure and Moment-of-test. It revealed a significant interaction of the two factors [F(1, 22) = 8.78, p < 0.0072]. As one can see from , RI is higher for unstructured items. The analysis also revealed that both main effects are significant: Structure [F(1, 22) = 29.49, p < 0.0001] and Moment-of-test [F(1, 22) = 21.24, p < 0.00014].
Figure 2. Retroactive interference on list L1 between tests T1 and T2 as a function of the learning material for subjects who did not exhibit any proactive interference. Subjects who learned ‘unstructured’ items show a greater RI.
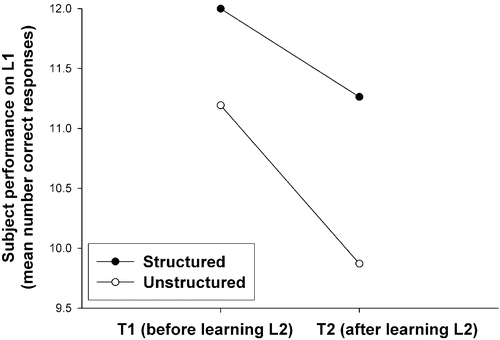
This last analysis showed that in the absence of PI, RI is higher for the ‘Unstructured’ associations. This result is clear-cut and contrasts with that found in the previous analysis, which did not allow for a clear conclusion because of a less well-controlled experimental situation. In conclusion, in the framework of the paradigm used by Mirman and Spivey (Citation2001), when one verifies that the to-be-compared conditions vary only with respect to the variable being manipulated—the structure of the learning material—a higher RI is found for ‘Unstructured’ associations, a result opposite to that of Mirman and Spivey (Citation2001).
2.3. Simulation
We wondered if a model as simple as a three-layer neural network could account for the pattern of RI results obtained in experiment 1. The same items that the subjects learned were used as training material for the networks. These items were made up of the 17 letters: a b c d e f g i l m n o p r t v z. We adopted an orthogonal coding at the letter level: each letter was coded as a 17-bit vector, with a single one and 16 zeros.
Since each item consisted of a four-character first part and a four-character second part, each item the network was trained on was made of a 68-bit input vector and a 68-bit output vector. A three-layer neural network was trained on these items, its task being to associate an input to an output (hetero-association). It consisted of an input layer of 68 units, a hidden layer of 15 units and an output layer of 68 units.
The network was trained using the standard backpropagation learning algorithm (Rumelhart et al. Citation1986) that minimizes a quadratic cost function. Starting with random connection weights—uniformly sampled between − 0.5 and 0.5—the network was trained with a learning rate of 0.2 and a momentum of 0.9. These parameters are the same as those reported by Mirman and Spivey (Citation2001).
The network was trained on L1 items for 30 epochs, then on L2 items for 30 epochs. We ran 20 replications. A replication consisted of training four identical networks (i.e. with exactly the same initial random connection weights): each network was trained on one of the four combinations of item lists L1 and L2 corresponding to groups S1, S2, U1, or U2. Performance on L1 items once the network was trained on them for 30 epochs and performance on L1 items after the network was trained on L2 items for 30 epochs are presented in . As one can see, RI is more severe when the learned associations correspond to ‘Unstructured’ items than to ‘Structured’ items. This is confirmed by a statistical analysis, since the interaction between the factors Structure (‘Structured’ versus ‘Unstructured’) and Moment-of-test (test 1, after training on L1 items versus test 2, after training on L2 items) is significant [F(1,78) = 78.0, p < 0.0001]. The analysis also revealed that both main effects are significant: Structure [F(1, 78) = 91.30, p < 0.0001] and Moment-of-test [F(1, 78) = 5756.93, p < 0.0001].
Figure 3. Retroactive interference in a three-layer network for the items used in experiment 1. The networks trained on ‘Unstructured’ items show a greater RI.
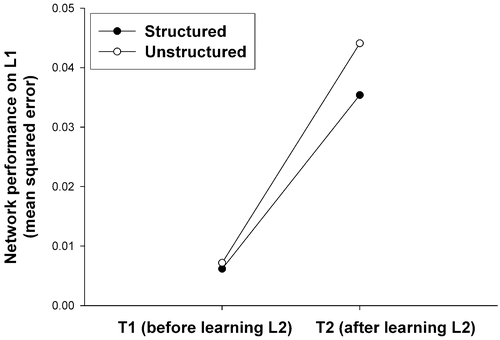
It is noteworthy that this difference is obtained along with a quite good (post-interference) performance in both conditions, not because of a catastrophic drop in performance in just one condition. One cannot speak of CI in the simulations with a three-layer neural network reported here (mean squared error on L1 increases from about 0.007 to about 0.04 when L2 is learned, whereas CI corresponds to a mean squared error of about 0.25). The pattern of results obtained in this simulation mirrors the one obtained in our behavioural experiment (see experiment 1): both for the human subjects and for the network the ‘Structured’ items are more resistant to RI than the ‘Unstructured’ items. At this point it is interesting to notice that we did not conduct the same simulation with the mixture-of-experts neural network architecture proposed by Mirman and Spivey (Citation2001). The reason is simply that this latter architecture was designed to exhibit more RI on ‘Structured’ items, so we know a priori it could not produce the pattern of results we want to simulate, but would yield the opposite one.
3. Control experiments for experiment 1
As previously mentioned, our experiment 1 was aimed at thoroughly testing the relationship between the structure of the to-be-learned material and RI in an experimental design where the subjects of both conditions are forced to learn the items at the exemplar level. Experiment 2 was designed to provide an independent confirmation that subjects in the ‘Structured’ condition actually learn the items at the exemplar level.
On the other hand, experiment 3 was designed to verify that subjects in the ‘Structured’ condition are also able to generalize to novel items.
3.1. Experiment 2
This experiment tested that the subjects who were presented with ‘Structured’ items learned them at the exemplar level.
3.1.1. Method
3.1.1.1. Participants
Eighteen subjects aged 19–26 years, all undergraduate students at the University of Grenoble, participated in the experiment for extra course credit. They were assigned randomly to one of the two experimental groups (see section 3.1.1.3). None of them participated in experiment 1.
3.1.1.2. Stimuli and apparatus
The items were the L1 ‘structured’ items used in experiment 1, plus eight new items, constructed in the same way as the others and used only at test. The new items appear in the Appendix as ‘New’ items.
This experiment was programmed and run with the same apparatus as experiment 1, except for an additional key (the central key), assigned to the answer ‘new’ during test (see section 3.1.1.4).
3.1.1.3. Design
There were two groups of subjects. One group had to learn the L1 items of group S1, the other the L1 items of group S2 (see experiment 1).
3.1.1.4. Procedure
The learning phase was identical to L1 learning of experiment 1. The test was identical to T1 (of experiment 1) except that eight new items were presented among the learned ones. At test, stimuli were presented in a random order but with three constraints: the first was that the correct answer never occurred more than twice in a row in the same location. The second constraint was that no more than three items of the same kind (i.e. ‘learned’ or ‘new’) occurred in a row. The last one was that the correct answer for the ‘learned’ items occurred about the same number of times in a location as in the other location.
After learning L1, the nature of the test was explained to the subjects and they took the test. There was a difference between this test and T1 of experiment 1: the subjects were instructed to answer with the left or right key only if the item had been learned before and to answer with the central key if the item was new (i.e. not a learned item).
3.1.2. Results
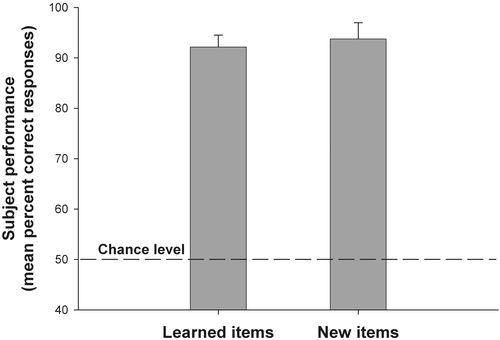
As one can see from , the performance on the learned items was nearly perfect (92.13% correct). More importantly, for the ‘new’ items the expected ‘new’ answer averaged 93.75%. Clearly, the subjects learned the items at the exemplar level, since they were able to detect the new items.
Figure 4. Correct responses on the ‘learned’ items (recognition) and on the ‘new’ items (detection). The subjects are able to distinguish the ‘learned’ items from the ‘new’ items.
3.2. Experiment 3
The aim of experiment 3 was to test that the subjects learning ‘Structured’ items not only learned that material at the exemplar level, but also were sensitive to the rules underlying the to-be-learned material in a way allowing them to generalize. To test generalization, the subjects were asked to give an answer for the learned items, but also for new items presented at test. This experiment was very much like experiment 2, except that there were only two response keys (as in experiment 1) and the subjects were asked to give an answer whatever the stimuli presented at test (i.e. ‘learned’ or ‘new’).
3.2.1. Method
3.2.1.1. Participants
Twenty subjects aged 19–26 years, all undergraduate students at the University of Grenoble, participated in the experiment for extra course credit. They were assigned randomly to one of the two experimental groups (see section 3.2.1.3). None of them participated in experiment 1 or in experiment 2.
3.2.1.2. Stimuli and apparatus
The items were those used in experiment 2. This experiment was programmed and run with the same apparatus as experiment 1.
3.2.1.3. Design
There were two groups of subjects. One group had to learn the L1 items of group S1, the other the L1 items of group S2 (see experiment 1).
3.2.1.4. Procedure
The learning phase was identical to L1 learning of experiment 1. After learning of L1, the nature of the test was explained to the subjects and they took the test.
The test was identical to T1 (of experiment 1) except that eight new items (see experiment 2) were presented among the learned ones. At test, stimuli were presented in a random order but with three constraints: the first constraint was that no more than three items of the same kind (i.e. ‘learned’ or ‘new’) occurred in a row. The second one was that the correct answer for the ‘learned’ items occurred about the same number of times in a location as in the other location. The third constraint was equivalent to the second but concerned the ‘new’ items.
3.2.2. Results
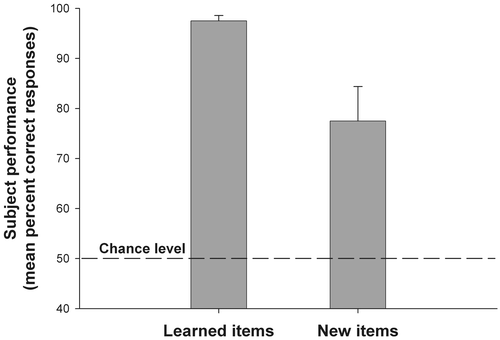
presents the mean performance on the learned items and, more importantly, the mean generalization performance (i.e. the performance on the ‘new’ items). The performance on the learned items is virtually perfect (97.5% correct). The performance on the generalization (i.e. ‘new’) items (77.5% correct) is clearly superior to the chance level [t(1, 19) = 4.0, p < 0.001]. Actually, from the post-experimental debriefing we have reason to think that one of the subjects did not understand the instructions. In fact, she responded correctly for 12 out of the 12 ‘learned’ items, but zero out of eight for the generalization (i.e. ‘new’) items. Without this subject, the mean performance on the generalization items is 81.58% correct and on the learned items 97.37% correct. The subjects learning ‘structured’ items not only learned them at the exemplar level, but also ended up being able to generalize.
Figure 5. Correct responses on the ‘learned’ items (recognition) and on the ‘new’ items (generalization). The subjects are able to generalize to new items.
3.3. Contribution of experiment 2 and experiment 3
Taken together, experiments 2 and 3 confirm that experiment 1 was conducted in a way that allows for a fair comparison of RI between the subjects who learned ‘Structured’ items and the subjects who learned ‘Unstructured’ items. Experiment 2 showed that with our procedure the subjects who learned ‘Structured’ items not only were able to behave according to the rules, but also learned the items at the exemplar level. Experiment 3 showed that the subjects who learned ‘Structured’ items ended up being sensitive to the rules that were used to generate the items and were able to apply these rules to new items, in other words to generalize to items never seen before.
Therefore, the differential forgetting of the items as a function of their structure (i.e. less forgetting on the ‘Structured’ items that on the ‘Unstructured’ items) that we found in experiment 1 is to be interpreted as truly arising because of the structure of the learning material.1
4. Discussion
In this work we have addressed the issue of RI in humans and artificial neural networks (ANNs) as a function of the structure of the learning material. We have shown that a thorough analysis of RI in humans similar to the one proposed by Mirman and Spivey (Citation2001) results in a pattern of data that is compatible with the distributed information viewpoint, but not with the viewpoint advocated by these authors. We have reported on a behavioural experiment—experiment 1—that yielded a pattern of results opposite to that of Mirman and Spivey's (2001): more RI was found for subjects who sequentially learned two lists of ‘unstructured’ items than for subjects who sequentially learned two lists of ‘structured’ items. The same paradigm as in Mirman and Spivey (Citation2001) was used except for differences aimed at eliminating the shortcomings we pointed out in the Introduction. Namely, the material was adapted so as to force the subjects exposed to the rule-based items to encode them at the exemplar level, and PI was controlled a posteriori in order to untangle its effect from the effect of interest, that of the structure of the to-be-learned material on RI. Experiment 2 confirmed that the particular stimuli used in experiment 1 actually forced the subjects exposed to ‘structured’ items to memorize them at the exemplar level. Experiment 3 confirmed that the subjects exposed to ‘Structured’ items ended up using the regularities present in the learning material.
These results shed a new light on the structure effect on RI and stand as a challenge to the multiple system position advocated by Mirman and Spivey (Citation2001) and instantiated in their two-system expert neural network. By construction, Mirman and Spivey's (2001) architecture just cannot produce this pattern of results. In contrast, a single-memory system as simple as a classical three-layer neural network can account remarkably well for the pattern of results obtained in experiment 1. The simulations run with the items used in the behavioural experiment show a significant difference between the ‘Structured’ and the ‘Unstructured’ conditions after the interfering training has been conducted (with more RI in the ‘Unstructured’ condition).
These results speak on the issues of CI in ANNs and of single/multiple human memory system(s). The first issue, both at the ANN level and at the human brain level, concerns the necessity of positing complementary memory systems functioning on radically different neural mechanisms in order to account for the available behavioural results. In their seminal paper, McClelland and Rumelhart (Citation1985) showed that a distributed network, whose functioning was based on only one learning procedure whatever the nature of the information to be learned, could learn general and specific information at the same time. This result produced the ‘revolution’ that we all know about, by opening a new field of research that has been revolving (among other equally interesting topics) around the innovative idea that human memory could be conceived as a single system. Huge amounts of cognitive phenomena have been simulated with parallel distributed processing (PDP) models based on the assumption of a single learning mechanism in a single system.
Of course, in spite of the successes of the connectionist approach, additional evidence from the neurosciences is needed in order to come to a conclusion on the debate of single/multiple memory system(s). For many years now, functional, developmental, psychopharmacological and neuropsychological evidence have been shedding light on the debate on the organization of human memory. Sometimes this evidence is held to be converging in favour of multiple memory systems in humans (e.g. Nyberg and Tulving Citation1996), but sometimes not (e.g. Shanks Citation1997). The debate is still open, and seems far from settled.
A possible complementary argument in the debate may come from the evolution of the connectionist models of human memory as a consequence of the acknowledgement of the phenomenon of CI following the work of McCloskey and Cohen (Citation1989) and Ratcliff (Citation1990). The good, compact, single-learning-mechanism PDP models can learn both general and specific information in a single system and exhibit performance that mimics human behaviour, thus offering a framework for understanding an important number of psychological phenomena; but at the same time they cannot learn new information without permanently losing the previously learned information. A connectionist implementation of human memory has to take into account and solve the problem of CI in ANNs. McClelland et al. (Citation1995), with an analysis of computational constraints as a starting point, concluded that two different systems are required to avoid CI. The solution they proposed relies on two different systems that have to function on radically different bases, with only one of them being distributed (the other one has to be not distributed). It is noteworthy that this solution brings into play a non-distributed network only as a temporary stock, all information types (i.e. general and specific) being finally transferred to and learned by the distributed part of the system. However, this two-system solution does not seem to be mandatory. More recent studies showed that CI could also be eliminated without relying on a non-distributed network, but one or two distributed networks using the same training rules whatever the to-be-learned material (e.g. Robins Citation1995, Ans and Rousset Citation1997, 2000, French Citation1997). Thus, the CI problem in ANNs gave rise to both multiple-system and single-system solutions.
Whereas the different solutions to CI aimed at reducing it to an acceptable level or eliminating it, Mirman and Spivey (Citation2001) went a step further. Their contribution is dramatic, as they propose the idea of two different memory systems that would each take charge of a type of information: a distributed part for general information and a (rather) localized part for specific information. Mirman and Spivey (Citation2001), starting from a fine-grained analysis of the phenomenon of RI in humans, called into question the very idea of a single distributed system that would contain both general and specific information (an idea common to the work of all authors cited earlier).
Mirman and Spivey (Citation2001) reported on behavioural results showing more RI for ‘Structured’ items (rule-based associations) than for ‘Unstructured’ items (i.e. arbitrary associations) and proposed the DSCL neural network model to account for this pattern of results. DSCL is an expert system model that integrates two learning modules working on radically different principles. With this architecture, CI is avoided in the localized part of the system—the part responsible for the storage of unstructured exemplars—whereas the learning of new structured exemplars in the distributed module results in CI on the old learned structured exemplars. Now, going back to the focus of the article by Mirman and Spivey (Citation2001), which is CI, one may question the adequacy of their proposal. First of all, independently of the behavioural result pattern reported in this paper, the proposal of Mirman and Spivey (Citation2001) poses some problems. Indeed, the simulation of the differential forgetting pattern they found in humans with the DSCL model is at the price of catastrophic forgetting of the rule-based associations and of an important forgetting of the arbitrary associations—see Mirman and Spivey's (2001: 268) (0% correct on the ‘pattern-based’ associations and less than 60% correct on the arbitrary associations). Therefore, because it exhibits a very strong RI, the model of Mirman and Spivey (Citation2001) is as questionable as a model of human memory as more traditional single-system connectionist models (see McCloskey and Cohen Citation1989, Ratcliff Citation1990). Moreover, the proposal of Mirman and Spivey (Citation2001) leads to serious qualitative and quantitative problems: concerning the rule-based associations, the DSCL neural network architecture exhibits true CI not mere RI, whereas only mild RI was evidenced in humans.
To sum up, there are no computational characteristics that make mandatory the addition of a complementary system part that would make use of a different working principle in order to avoid CI or to simulate existing differential RI-related behavioural results. Indeed, on one hand, effective solutions to CI have recently been proposed in the all-distributed framework. On the other hand, there are no trustworthy behavioural data that belie the predictions of, or that cannot be simulated by, connectionist systems whose functioning is based on a single learning mode whatever the nature of the information to be learned. In conclusion, the distributed information paradigm introduced by McClelland and Rumelhart (Citation1985) in their seminal paper has not been proven wrong and is not yet out of touch. The results presented in this paper show that this paradigm is still essential to understand and to model human cognition.
Acknowledgements
The authors thank Daniel Mirman for providing them with details on the stimuli and procedure used in Mirman and Spivey (Citation2001). We thank Ronan G. Reilly and the three anonymous reviewers for their helpful comments and suggestions. The authors are indebted to M.-J. Tainturier for various constructive comments that helped to improve the readability of the paper. This research was supported in part by a research grant from the European Commission (HPRN-CT-1999-00065) and by the French Government (CNRS UMR 5105).
Notes
Of course, this conclusion is limited to the between-subjects design that was used in experiment 1, which was chosen to allow for a direct comparison with the work of Mirman and Spivey (Citation2001). However, as suggested by one of the reviewers, real-world cognition rarely affords the total separation of learning of structured and unstructured material. We agree with this idea and we reckon that a within-subjects design resulting in the same outcome would improve the ecological validity of the conclusion based on experiment 1.
References
- Ans , B and Rousset , S . 1997 . Avoiding catastrophic forgetting by coupling two reverberating neural networks . CR Academie Science Paris, Life Sciences , 320 : 989 – 997 .
- Ans , B and Rousset , S . 2000 . Neural networks with a self-refreshing memory: knowledge transfer in sequential learning tasks without catastrophic forgetting . Connection Science , 12 : 1 – 19 .
- Bäuml , K-H . 1996 . Revisiting an old issue: retroactive interference as a function of the degree of original and interpolated learning . Psychonomic Bulletin and Review , 3 ( 3 ) : 380 – 384 .
- Barnes , JM and Underwood , BJ . 1959 . “Fate” of first-list associations in transfer theory . Journal of Experimental Psychology , 58 ( 2 ) : 97 – 105 .
- Bunt , AA and Sanders , AF . 1972 . Some effects of cognitive similarity on proactive and retroactive interference in short-term memory . Acta Psychologica , 36 : 190 – 196 .
- Chappell , MC and Humphreys , MS . 1994 . An auto-associative neural network for sparse representations: analysis and application to models of recognition and cued recall . Psychological Review , 101 ( 1 ) : 103 – 128 .
- Cofer , CN , Faile , NF and Horton , DL . 1971 . Retroactive inhibition following reinstatement or maintenance of first-list responses by means of free recall . Journal of Experimental Psychology , 90 ( 2 ) : 197 – 205 .
- Delprato , DJ . 1970 . Successive recall of list 1 following list 2 learning with two retroactive inhibition transfer paradigms . Journal of Experimental Psychology , 84 ( 3 ) : 537 – 539 .
- Frean MR Robins AV 1998 Catastrophic forgetting and “pseudorehearsal” in linear networks In Proceedings of the Ninth Australian Conference on Neural Networks Brisbane University of Queensland pp. 173–178
- French , RM . 1997 . Pseudo-recurrent connectionist networks: an approach to the ‘sensitivity-stability’ dilemma . Connection Science , 9 ( 4 ) : 353 – 379 .
- French , RM . 1999 . Catastrophic forgetting in connectionist networks . Trends in Cognitive Sciences , 3 : 128 – 135 .
- French RM Ans B Rousset S 2001 Pseudopatterns and dual-network memory models: advantages and shortcomings In R. French and J. Sougné (eds) Connectionist Models of Learning, Development and Evolution London Springer pp. 1–10
- Hetherington P Seidenberg M 1989 Is there ‘catastrophic interference’ in connectionist networks? In Proceedings of the 11th Annual Conference of the Cognitive Science Society Hillsdale NJ Lawrence Erlbaum pp. 26–33
- Izawa , C . 1980 . Proactive versus retroactive interference in recognition memory . The Journal of General Psychology , 102 : 53 – 73 .
- Kortge CA 1990 Episodic memory in connectionist networks In Proceedings of the 12th Annual Conference of the Cognitive Science Society Hillsdale NJ Lawrence Erlbaum pp. 764–771
- Kruschke , JK . 1992 . ALCOVE: an exemplar-based connectionist model of category learning . Psychological Review , 99 ( 1 ) : 22 – 44 .
- Lewandowsky S 1991 Gradual unlearning and catastrophic interference: a comparison of distributed architectures In W. E. Hockley, and S. Lewandowsky (eds) Relating Theory and Data: Essays on Human Memory in Honor of Bennet B. Murdock Hillsdale NJ Lawrence Erlbaum pp. 445–476
- Lewandowsky , S . 1994 . On the relation between catastrophic interference and generalization in connectionist networks . Journal of Biological Systems , 2 : 307 – 333 .
- Lewandowsky S Li SC 1995 Catastrophic interference in neural networks. Causes, solutions, and data In F. N. Dempster and C. Brainerd (eds) New Perspectives on Interference and Inhibition in Cognition New York Academic Press pp. 329–361
- McClelland , JL and Rumelhart , DE . 1985 . Distributed memory and the representation of general and specific information . Journal of Experimental Psychology: General , 114 ( 2 ) : 159 – 197 .
- McClelland , JL , McNaughton , BL and O'Reilly , RC . 1995 . Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory . Psychological Review , 102 : 419 – 457 .
- McCloskey M Cohen NJ 1989 Catastrophic interference in connectionist networks: the sequential learning problem In H. G. Bower (ed.) The Psychology of Learning and Motivation 24 New York Academic Press pp. 109–165
- McRae K Hetherington PA 1993 Catastrophic interference is eliminated in pretrained networks In Proceedings of the 15th Annual Conference of the Cognitive Science Society Hillsdale NJ Lawrence Erlbaum pp. 723–728
- Mirman , D and Spivey , M . 2001 . Retroactive interference in neural networks and in humans: the effect of pattern-based learning . Connection Science , 13 : 257 – 275 .
- Nyberg , L and Tulving , E . 1996 . Classifying human long-term memory: evidence from converging dissociations . European Journal of Cognitive Psychology , 8 ( 2 ) : 163 – 183 .
- Ratcliff , R . 1990 . Connectionist models of recognition and memory: constraints imposed by learning and forgetting functions . Psychological Review , 97 ( 2 ) : 285 – 308 .
- Robins , AV . 1995 . Catastrophic forgetting, rehearsal and pseudorehearsal . Connection Science , 7 : 123 – 146 .
- Robins , AV . 1996 . Consolidation in neural networks and in the sleeping brain . Connection Science , 8 : 259 – 275 .
- Robins , AV and McCallum , S . 1998 . Catastrophic forgetting and the pseudorehearsal solution in Hopfield-type networks . Connection Science , 10 : 121 – 135 .
- Robins , AV and McCallum , S . 1999 . The consolidation of learning during sleep: comparing the pseudorehearsal and unlearning accounts . Neural Networks , 12 : 1191 – 1206 .
- Rumelhart DE Hinton GE Williams RJ 1986 Learning internal representations by error propagation In D. E. Rumelhart and J. L. McClelland (eds) Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Vol. 1. Foundations Cambridge MA MIT Press pp. 318–362
- Shanks , DR . 1997 . Dissociating long-term memory systems: comment on Nyberg and Tulving . European Journal of Cognitive Psychology , 9 ( 1 ) : 111 – 120 .
- Sharkey , NE and Sharkey , AJC . 1995 . An analysis of catastrophic interference . Connection Science , 7 : 301 – 329 .
- Shulman , HG and Martin , E . 1970 . Effects of response-set similarity on unlearning and spontaneous recovery . Journal of Experimental Psychology , 86 ( 2 ) : 230 – 235 .
- Wheeler , MA . 1995 . Improvement on recall over time without repeated testing: spontaneous recovery revisited . Journal of Experimental Psychology: Learning, Memory, and Cognition , 21 ( 1 ) : 173 – 184 .