Abstract
Highly recurrent neural networks can learn reverberating circuits called Cell Assemblies (CAs). These networks can be used to categorize input, and this paper explores the ability of CAs to learn hierarchical categories. A simulator, based on spiking fatiguing leaky integrators, is presented with instances of base categories. Learning is done using a compensatory Hebbian learning rule. The model takes advantage of overlapping CAs where neurons may participate in more than one CA. Using the unsupervised compensatory learning rule, the networks learn a hierarchy of categories that correctly categorize 97% of the basic level presentations of the input in our test. It categorizes 100% of the super-categories correctly. A larger hierarchy is learned that correctly categorizes 100% of base categories, and 89% of super-categories. It is also shown how novel subcategories gain default information from their super-category. These simulations show that networks containing CAs can be used to learn hierarchical categories. The network then can successfully categorize novel inputs.
1. Introduction
Cell Assemblies (CAs), groups of neurons that form reverberating circuits, were initially proposed as the neural basis of concepts (Hebb Citation1949) and thus of symbols. So, research into CAs can give insights into human symbolic processing. There is evidence that words consistently activate particular distributed areas in the brain and different words activate different areas (Pulvermuller Citation1999), so neural representations of these symbols are distributed. One answer to the question how do we think? is we use our neurons; another consistent answer is that we use our CAs; and yet another is that we use symbols (Newell Citation1990). So, CAs provide a bridge between the more traditional answers.
What do we gain by modelling cognition with networks of neurons with CAs? CAs answer many questions, which a theory that focuses solely on neurons cannot: short-term persistence of memory (Hebb Citation1949, Horn et al. Citation1998), long-term persistence of memory (Hebb Citation1949, Horn et al. Citation1998), categories (Hebb Citation1949, Calvin Citation1995), figure-ground separation (Hebb Citation1949, Jahnke et al. Citation1995, Freeman Citation2000), completion effects (Hebb Citation1949, Fu Citation2003), ambiguity resolution (Huyck Citation2000, Fu Citation2003), cognitive maps (Chown Citation1999, Freeman Citation2000), and, as is shown in this paper, hierarchies.
A neural network can contain many CAs and the long-term dynamic of the neural network can be seen as a process of CA growth, modification and fractionation all achieved by unsupervised learning derived from sensory information. Initially, a CA will form and grow by increasing intra-CA synaptic strength. Uncommitted neurons, weakly committed neurons, or strongly related neurons (via synaptic strength) may be recruited into a CA even though they are never directly stimulated by the senses. Once formed, a CA may break into two or more sub-CAs through a process called fractionation (Hebb Citation1949, Rochester et al. Citation1956).
A network of neurons that has learned CAs is a categorizer. An instance is presented to the net, and the CA that represents the category to which the instance belongs is ignited and remains active. Categorization via CA ignition is the short-term dynamic.
A well-known facet of human memory is that we categorize things hierarchically (e.g. Rosch and Mervis Citation(1975)), so that a particular instance, say a sighting of an animal, might activate several categories, say Lassie, Collie, Dog, Mammal, Animal and Thing. A complete model of memory would need to account for this, so a model of memory must either handle hierarchy or defer to another mechanism. Fortunately networks that contain CAs can both learn and use hierarchical categories.
The model of hierarchical CAs proposed in this paper is based on overlapping sets of neurons. A CA for a super-category contains many of the neurons that are contained in the CAs that represent its subcategories. Moreover, this hierarchy of categories can be learned in an unsupervised manner. The model and simulations described in this paper are consistent with work in attractor nets (Amit Citation1989). However, CAs can move beyond the single, stable states of attractor nets and as such this work provides a conceptual bridge between attractor nets and the long history of CA research.
This paper first discusses neural models, presents a background of prior work in CAs, defends their biological and computational plausibility, and gives a brief background of hierarchies. Section 3 describes a neural model that forms a basis for CAs, and a Hebbian learning algorithm, the compensatory learning algorithm. Section 4 describes the results of simulations to learn two simple hierarchies from presentations of instances of the basic categories; the use of these hierarchies for default reasoning is also described. In section 5 the importance of this result is discussed. The paper concludes with a brief discussion of ongoing and future CA work.
2. Background
To appropriately discuss hierarchical categories in neural networks with CAs, some introduction to related areas is necessary. Below, a discussion of which neural models might be appropriate for modelling CAs is presented. This is followed by a discussion of CAs and their properties. Finally, some background on subcategorization hierarchies and how they are modelled in connectionist systems is presented.
2.1 Neural models
All models are wrong; some models are useful George Box
We think it is essential to develop models that come closer to mammalian neural functioning to improve understanding of that function. While the scientific community's understanding of biological neural functioning is incomplete, it is detailed. It is widely agreed that the long-standing Hodgkin–Huxley equations (Hodgkin and Huxley Citation1952) form a sound basis for modelling the processing of a neuron. However, these equations take into account conductance delays, different gating channels, refractory periods and more. Precise simulators exist (e.g. Bower and Beeman Citation(1995)), but are computationally expensive and thus are too complex to simulate large numbers of neurons over a long period of simulated time.
Since these complex models are too computationally expensive to simulate CAs that consist of a large number of simulated neurons, what other options exist? At the other extreme, connectionist models such as multi-layer perceptrons (Rumelhart and McClelland Citation1986) and self-organizing maps (Kohenen Citation1997) are inspired by neural processing. These have good known computational properties and can be easily simulated on computers. Unfortunately, it is not clear what they tell us about biological processing.
It is important to understand the computational properties of the model, but also understand how the model relates to neuro-biology. In this section, several existing neural models are described. The descriptions move from models whose computational theory is well understood but have major flaws as biological models, to models that are more biologically accurate, but whose computational properties are less well understood.
2.1.1 Popular attractor nets
Attractor networks have patterns of neural activation presented to them. Depending on the particular algorithm, activation is propagated through the system with each unit (neuron) acting only on its inputs. Eventually they settle into a stable state, known as an attractor state, with each unit remaining unchanged. The more initial patterns that settle into a given state, the larger the size of the attractor basin.
There is a large number of attractor networks; the Hopfield Citation(1982) model is probably the most widely used. An excellent review of Hopfield-like attractor networks for brain modelling was written by Amit Citation(1989). Another widely known model is the interactive activation model (Rumelhart and McClelland Citation1982), and another popular model is the Boltzmann machine (Hinton and Sejnowski Citation1983).
The standard Hopfield model is based on integrate and fire units that are well-connected via bidirectional weighted connections. When a unit fires, it sends activation to each unit proportional to the connection weight to that unit. A unit fires if it has enough activation to surpass its threshold. This model is well understood and a wide range of variants have been explored. The model is derived from spin-glass models and takes advantage of energy functions, and statistical mechanics to explore the capacity of the network and the size of attractor basins.
Boltzmann machines (Ackley et al. Citation1985) are similar to the Hopfield model. Like the Hopfield model, units collect activation and are well-connected via bidirectional weighted connections. Boltzmann units fire probabilistically based on the amount of activation they currently have; the higher the activation, the more likely the unit is to fire.
Unfortunately the standard Hopfield model and Boltzmann machine are not biologically accurate. Firstly, neural connections, synapses, are not bidirectional but uni-directional. Secondly, the brain is not well connected, with each neuron having synapses to only a 1000 or so other neurons out of the 1011 neurons (Lippmann Citation1987). Thirdly, units in the standard synchronous Hopfield model and Boltzmann machine do not retain any activation at the end of the cycle.
Certainly theoretical research has addressed some of these issues to a greater or lesser extent. For example, there has been work on sparsely connected Hopfield nets (e.g. Athithan Citation(1999)), but this usually deals with the ellision of a percentage of the connections.
It is possible to have attractor nets with uni-directional connections. Why then do the most widely-used models have bidirectional connections? Bidirectional connections are a prerequisite for the existence of a Hamiltonian, energy function, and thus are needed to use statistical mechanics (Roudi and Treves Citation2004). When statistical mechanics can be applied, a range of precise results are available. For instance, a Hopfield net can store 0.138 N-bit patterns (Hertz et al. Citation1991).
While this bidirectionality of connections allows the system to be analysed using the powerful techniques of statistical mechanics, it eliminates certain possibilities. For example, it eliminates the analysis of a system that moves from state to state. It also eliminates the possibility of compensatory learning like the one used in the experiments below (see section 3.2).
2.1.2 LIF neurons and fatiguing LIF neurons
Recently there has been a great deal of interest in networks of Leaky Integrate and Fire (LIF) neurons (Maas and Bishop Citation2001). Like Hopfield nets, these integrate activity, but if the neuron does not fire, some activity leaks away at the end of the cycle and some remains. The addition of leakage to the model makes LIF neurons a better approximation of biological neurons than Hopfield units.
The SRM model (Gerstner Citation1995) is a variant of the LIF model. The firing threshold varies with time since the last spike was emitted. This enables a simple modelling of absolute and relative refractory periods.
The LIF model has been used to display the repetitive firing behaviour of biological neurons. Including refractory periods in the model can improve the fit to biological data (Stevens and Zador Citation1998).
Computationally, LIF neurons can be used for a variety of tasks such as multiplication (Tal and Schwartz Citation1997). Some other applications and models of biological neural processing tasks are described in Maas and Bishop Citation(2001).
One particular issue that LIF neurons address is synchronous firing. Neurons fire synchronously if they fire at roughly the same time. Groups of neurons can also fire synchronously. The leakage helps integrate and fire neurons to synchronize. Some evidence for the existence of CAs in the brain is synchronous firing of neurons in behaving monkeys (Abeles et al. Citation1993). Synchronous firing can also be used as a form of variable binding (see Sougne Citation(2001) described in section 2.1.3); two CAs are bound if their neurons both fire synchronously.
In the brain and neural-CA nets, the network needs to move on to other tasks, so it needs to move from a stable state; consequently attractor nets alone are an insufficient model of neural processing. Fatigue, also called accommodation, is part of the solution to this problem (Horn and Usher Citation1989). Neurons fatigue, so the state of an ignited CA is not entirely stable. A CA is pseudo-stable firstly because neurons in the CA are firing in one cycle but not the next due to fatigue. Secondly, the overall fatigue in the CA may build until it actually shuts down the CA (Kaplan et al. Citation1991), thus freeing the network to process another input. Other researchers (Dalenoort Citation1985) feel fatigue alone may not be responsible for shutting off a CA; another CA may need to ignite to shut down the first.
LIF neural nets are amenable to analysis by statistical mechanics when there is a Hamiltonian (e.g. Amit and Brunel Citation(1997)). However, when bidirectionality is removed, statistical mechanics is no longer applicable. The theoretical properties of these types of nets are not well understood. This lack of theoretical understanding makes it much more difficult to engineer useful systems with these networks.
2.1.3 Neural models for CAs
Neural and connectionist systems can be used for a range of tasks. One set of tasks centres around simulating CA behaviour.
There is a long history of systems using simulated neurons to simulate CA behaviour. Rochester et al. Citation(1956) worked with 512 neurons almost 50 years ago, but failed in their goal of developing sequences of CAs. Two important properties of CAs (described more formally in section 2.2.1) are persistence and completion. A CA persists if its neurons continue to fire indefinitely; it completes if the firing of a small number of initial neurons activates all the neurons in the CA. The CAs described by Rochester et al. did persist but completion was not measured.
Hetherington and Shapiro Citation(1993) used neurons with synapses that had continuous valued output, instead of spiking neurons; their system formed CAs that had pattern completion and persistence.
More biologically realistic models of neurons have been used to simulate CAs. Fransen et al. Citation(1992) have used conductance-based models of neurons to simulate CAs. Modelling tens of neurons, pattern completion and persistence were shown.
Amit and Brunel Citation(1997) have used statistical mechanics and a simulation of LIF neurons to model, in effect, CAs; the model includes sophisticated time integration of activity and spontaneous neural activity. Attractor states are formed over time by Hebbian learning though this is not related to environmental input, but is instead based on spontaneous activation. This neural model is less sophisticated than Fransen's because it treats each neuron as a unit instead of as a series of compartments. Amit and Mongillo Citation(2003) have used a model similar to Amit and Brunel Citation(1997) that forms persistent CAs.
Brunel Citation(1996) has used a similar model to Amit and Brunel Citation(1997) but added Hebbian learning rules that adhere to some current neurophysiological theory. This model has inhibitory and excitatory neurons, along with four types of synapses with only excitatory–excitatory synapses being plastic. This learns CAs for input patterns, and later can learn to activate neurons that are in CAs that are consistently presented after the current stimuli, in effect showing priming. Crucially, none of these CA simulations have used overlapping CAs (see section 2.2.1).
Sougne Citation(2001) has developed a simulator based on a complex spike timed neural model to simulate variable binding of CAs. This model uses an amplifying connection in addition to the typical excitatory and inhibitory connections, and neurons can have all three types of connections. There is a specific subnet topology, but CAs are overlapping. Base symbols are not learned, but are instead calculated. When these networks are measured, a CA is not active unless its neurons fire in close synchrony.
Knoblauch et al. Citation(2004) have used a LIF model with absolute and relative refractory periods, noise and distance-dependent synaptic delays. The task they simulate is separating different input patterns that are presented simultaneously via synchrony. Again patterns are not learned.
All of the above report persistence results, but only Fransen et al. Citation(1992) and Hetherington and Shapiro Citation(1993) report completion results. So, it is not clear to what degree the CAs have pattern completion.
This section has shown that there are a range of biological neural behaviours that are simulated. These include a range of biologically plausible topologies, activation leak, neural fatigue, types of neurons, refractory periods and synaptic delay.
Since there has been a wide range in the biological faithfulness of models, there is no definitive neural model. The computational properties of individual neurons are not well understood, and the emergent properties of a large number of neurons are even less understood. There is a trade-off between biological faithfulness and computational efficiency. It is important that a range of models and tasks are explored to see which models can effectively achieve which tasks.
Cell assemblies
CAs were proposed by Hebb Citation(1949) as the neural basis of concepts. A CA is a set of neurons that have high mutual synaptic strength; when a sufficient number of the neurons fire at roughly the same time, a cascade of neural firing is begun. This is CA ignition and it is a form of pattern completion. The initial neurons activate other neurons in the CA that complete the pattern. The neurons in the CA will continue to fire at a high rate indefinitely (Kaplan et al. Citation1991) unless shut down by an external mechanismFootnote†. This indefinite firing is a form of persistence that enables the CA to persist even after external stimulus has ceased.
CAs are based on neurons and represent concepts. The neurons can be activated via input from the environment providing a sensory basis for concepts. CAs thus can resolve the symbol grounding problem (Fodor Citation2000). Thus research into CAs may provide a solution to this fundamental problem.
Neurons in CAs will have more synapses between them, and the synaptic weights will be larger than the synapses to neurons outside the CA. CAs can be detected by measuring these weights or by detecting firing patterns when the CA is active. Neural membership in a CA is not strictly binary and some neurons may be more central to the CA than others.
CA ignition is a form of attractor dynamics. CA theory introduces a critical threshold of activity (Hebb Citation1949, Kaplan et al. Citation1991). Some neurons may fire and others have sub-firing activity, without making the CA persist. When there is enough firing and activity to pass the threshold, a cascade of activation occurs with many more neurons firing. Typically, it is assumed that the sub-threshold neurons are the same neurons that are involved in the persistent CA. The persistently firing neurons define an attractor state or limit cycle.
Hebb did not define a neural model and many different models have been used for a neural-CA net. It is an open question which neural model is best (see section 2.1). The neural model used in this paper is the fatiguing leaky integrate and fire neuron (see section 3).
2.2.1 Formal properties of CAs
Though CAs have been discussed for over 50 years, formal results are scarce. Consequently, there is no widespread agreement about the formal properties of CAs. One set of formal properties comes from Sakurai Citation(1998).
-
(i) Persistence. Neurons in a CA remain active for a substantial number of time steps after external stimulation is removed. Neurons do not need to fire in each step.
-
(ii) Completion. Activating a sufficient number of neurons in a CA is enough to ignite the CA.
-
(iii) Sparse Coding. Each CA contains a minority of the cells in the entire network.
-
(iv) Overlapping set coding. Neurons can be a member of more than one CA.
-
(v) Dynamic Construction. CAs can be learned by adapting the connection strengths between neurons.
Formally, persistence can be measured in a synchronous model using Pearson's product moment correlation described in Equationequation (1). This is a dynamic measurement and shows CA persistence based on the pattern of neural firing. Firing is a binary state, and is measured across the discrete cycles. f(x) refers to neuron x firing in the first network, while g(y) refers to neuron y firing in the second network. M
x
and M
y
are the mean values of the first and second network respectively.
Persistence is measured by comparing the state of a network at different periods. The network is presented with an input pattern and this pattern is presented for several cycles. After several cycles the input is removed. Persistence is shown if there is a large ρ at different periods. For instance, one would expect a large ρ between the last cycle of presentation and 50 cycles after the last presentation. Of course the ρ should remain large when comparing a range of different cycles. Note that the duration of CA activity absent of other influences is under debate with some stating that they stop after a period on their own (Kaplan et al. Citation1991) and others saying an external influence is need to stop a CA (Dalenoort Citation1985). This debate is not particularly relevant to this paper as the network categorizes one input at a time, and is then reset for the next input.
Completion allows for a large number of presentations to be linked to the same CA. For instance, in a CA trained to recognize dogs, presentation of the front of a dog or the back will both ignite the CA, though different neurons are initially stimulated. Completion can also be measured using Pearson's product moment correlation. Two different initial input patterns are used. The first pattern is presented and the simulation is allowed to run for several steps. A second pattern of the same type is presented and allowed to run for several steps. The two nets are compared and if ρ is large both complete; they both activate the same CA and are both elements of the same category.
Sparse coding means that a CA consists of a small number of neurons in a large network of neurons. This is easy to measure, by merely counting the number of neurons in a CA. This is in contrast with stored patterns in a Hopfield net, and most other attractor nets where patterns have a large percentage of the neurons on. That is, a Hopfield net of N neurons stores N-bit patterns; typically about half of the neurons are on in any pattern. Others have worked on sparser patterns (e.g. Athithan Citation(1999)), but have always based patterns on a percentage of active neurons. This contradicts the idea of sparse coding.
A CA consists of a set of neurons, but the size of this set is independent of the size of the neural net. So, as the net grows, the number of neurons firing when one CA is active tends toward zero percent of the entire set of neurons, even though the absolute number remains relatively constant.
Overlapping CAs occur when neurons are members of more than one CA, as opposed to orthogonal CAs that occur when neurons are members of at most one CA. Work has been done in studying overlapping CAs (Wickelgren Citation1999), but this was based on biologically implausible neurons with, for example, synapses that had uniform strength and spiked exactly twice. Earlier work (Huyck Citation2004) has shown that biologically plausible networks can be used to learn and store overlapping CAs.
2.2.2 Learning
Hebb is better known for Hebbian learning than for CAs. The Hebbian learning rule states that two neurons that frequently co-fire tend to have the strength between them increased. The high mutual synaptic strengths between neurons in a CA are formed by Hebbian learning. The Hebbian rule can be combined with an anti-Hebbian rule, which reduces strength when one neuron fires and the other does not. When combined, the rules define the long-term behaviour of a synapse based solely on the behaviour of the neurons it connects.
When learning is used, neural-CA nets usually use some type of Hebbian learning. Similarly, the common Boltzmann machine learning algorithm (Ackley et al. Citation1985) is a form of Hebbian learning. Hopfield nets usually have their connection weights calculated. All of the patterns that are going to be stored are used to determine all the weights at one time; this is, somewhat confusingly, also frequently called Hebbian learning. This calculation tends toward the Hebbian values, but a dynamic calculation will have recency and frequency effects that are not present in the Hebbian calculation.
It has been known for at least 100 years that the brain requires at least two types of dynamics: short-term dynamics and long-term dynamics (James 1982). These dynamics are correlated to long-term and short-term memory, the dual trace mechanism (Hebb Citation1949). Short-term dynamics are needed to recognize things. Neurons are activated from the environment via senses; these neurons in turn activate other neurons leading to the ignition of a particular CA. The item that caused the external activation is categorized as belonging to the class of items that the ignited CA represents. This short-term dynamic is rapid and recognition usually occurs in less than a second (Kieras et al. Citation1997).
Long-term dynamics are needed to build these CAs; they represent semantic categoriesFootnote† and the CAs are learned by having many instances of the category presented to the network. These long-term categories are things that are central to human behaviour; once formed, signi-ficant changes are rarely made. For instance, one's category for Dog rarely if ever changes significantly after the age of five. Presumably, once formed, the CA for Dog rarely changes significantly. Over many presentations, Hebbian learning causes synaptic weights within a category to increase. This eventually leads to a CA that is a short-term attractor state. If a stimulus is presented that is within the basin of attraction, the CA will ignite. The ignited CA is an attractor state that many initial states lead to, so all of these initial states will be categorized as the same CA.
Learning has only been briefly explored in attractor net theory, with most work focusing on the short-term dynamics. Our interest in neural-CA networks includes this short-term dynamic, but extends to the use of a long-term dynamic based on learning.
In the untrained simulated networks described in this paper, no CAs are activated (see sections 4.1 and 4.2). As the network is modified through synaptic change based on external stimulation, CAs are learned. This dynamic takes many presentations but it may take days, months, or even years to form a concept in a mammal (James Citation1892, Riesenhuber and Poggio Citation2003). However, when any of a range of stimuli are presented to the trained net, a CA will ignite.
2.3 Subcategorization hierarchies
The type of hierarchical relationship discussed in this paper is the subcategorization relationship, typically labelled IS-A. The categories are related in a type of semantic net (Quillian Citation1967). In this case, a particular item is a member of a class, but every member of this class is also a member of another class. For example, Lassie is a member of the Collie class, and all Collies are members of the Dog class; of course all Retrievers are also members of the Dog class, and all Dogs and Cats are members of the Mammal class.
Subcategorization is a very powerful technique, allowing a huge range of generalizations to be made. For instance, you may never have seen Lassie, but knowing Lassie is a Dog, you know that Lassie almost certainly barks; knowing Lassie is a Mammal and a Female you know that Lassie feeds her children with milk. This gives a great deal of representational efficacy. Subcategorization is so powerful that it is a hallmark of Object Oriented Programming where inheritance is subcategorization.
2.3.1 Psychological foundations of categories and hierarchies
There has been a great deal of research on categorization from machine learning and psychological perspectives. An example of this research is Shepard et al. Citation(1961) who show it is easier for humans to learn categories that differ by only one feature; however, they can learn categories that are not linearly separableFootnote†.
A great deal of machine learning work has been done developing symbolic and statistical algorithms for supervised and unsupervised category formation. For example, Hanson and Bauer Citation(1989) have developed clustering techniques based on feature similarity and difference within and between categories. This work is explicitly linked with human categorization data. More recently, subcategorization has been used to improve a machine learning algorithm (Cardie Citation1992).
One factor, explored by Hanson and Bauer, is that concepts are polymorphic, or natural. That is, they are not usually defined by necessary and sufficient conditions. This problem was discussed by Wittgenstein Citation(1953), and the result is that categories are more like family resemblances. Polymorphic categories are well suited for neural networks to learn by unsupervised training because they can store relations between features that frequently co-occur in a category in their synaptic weights.
Research on categorization has shown that humans form hierarchical categories. The original idea of semantic nets was developed by Quillian Citation(1967) to account for human categories. It has been shown that a spreading activation model based on semantic nets can account for a range of experimental results (Collins and Loftus Citation1975).
Rosch and Mervis Citation(1975) have made a detailed exploration of hierarchical categories and have found that humans have basic level categories. These are the most important categories, are the first learned, are more salient, and this effect is generally cross-cultural. These effects are still used in current psychological research (Erickson and Kruschke Citation1998).
2.3.2 Other connectionist systems for hierarchies
Since hierarchy is crucial to categorization and memory, there has been a great deal of work on connectionist systems that model hierarchy. One common approach is to use standard feed forward networks but to add recurrent connections. Another approach is to use a more biologically plausible network model such as Adaptive Resonance Theory (ART) networks (Grossberg Citation1987). The approach described in this paper is similar to that used in attractor networks.
Several researchers have looked into hierarchy formation using feed forward networks with recurrent connections. For example, Pollack's RAAM and infinite RAAM systems (Pollack Citation1990, Levy et al. Citation2000), Elman's Citation(1990) work, and Hanson and Negishi's Citation(2002) work, have all used this class of model. They use standard feed forward networks with supervised learning but add extra back connections or extra layers with connections. These extra layers are not part of the standard feed forward mechanism, but take output from the system and feed it back in as input. So in any given time step there is input from the environment and from the system.
As Elman Citation(1990) points out, this has the benefit of adding memory to the system. This memory enables these recurrent neural networks to handle sequences, and to some extent develop hierarchies and rules. These systems are useful in understanding how distributed memory representations function and how neurons can combine transduction with memory.
ART (Grossberg Citation1987) has neural plausibility as one of its goals and can account for hierarchical categorization. There is a layered architecture and a node for each category. If an input is not associated with an existing category, a new node is allocated for it. Hierarchy is handled by a change in vigilance, which controls the range of patterns that are deemed to be classified together before recruiting a node to encode a new class. Vigilance is gradually decreased so that new nodes account for larger categories. A new node may then account for several old nodes and will thus be a super-category.
The ART work is excellent but violates the scientific community's understanding of coding in neural populations. Clearly for many concepts, one neuron cannot account for the concept or we would lose that concept if the neuron died (Palm Citation1990). Excellent evidence for the group coding of many concepts exists (e.g. Barlow Citation(1972) and Pulvermuller Citation(1999)). However, this model may approximate the behaviour of groups of neurons, and thus meets its goal of neural plausibility.
A final approach is to use attractor networks (see section 2.1). This is the approach taken in this paper and the one that is used by Feigelman and Ioffe Citation(1987). Their approach is to use categories that activate a large percentage of the neurons. Hierarchically related sub-categories are then derived by modifying the neurons from the super-category by a significant but prescribed amount. This is computationally similar to our approach, though it does require the neurons to be strongly connected and the patterns to be dense.
3. The model
This section describes the model used in this paper. This model is a relatively simple neural model trading off computational simplicity with biological plausibility. Learning is very important to the model, and this section also describes the compensatory learning rule, a Hebbian rule that stabilizes total synaptic strength of a neuron.
3.1 Model description
A model has been developed and a computer implementation of it has been engineered to enable simulation of a network that contains CAs. Like all models, it is a simplification, but we hope that it includes the essential computational properties of neurons. The simulator has been used to explore categorization (Huyck and Orengo Citation2005), ambiguity resolution (Huyck Citation2000), and other phenomena. The simulator has remained largely unchanged over several years accounting for a range of resultsFootnote†. The model attempts to mimic mammalian cortical neural function while remaining computationally efficient.
Mammalian neurons work in continuous time, but this is expensive to simulate in a digi-tal computer. In this model, time is broken into discrete cycles that ignore synaptic delay and refractory periods assuming both are accounted for within one cycle. This leads to an efficient simulator.
The basis of the model is fatiguing leaky integrate and fire neurons. Biological neurons integrate activation from incoming synapses, activation leaks away if the neurons do not fire, and when neurons fire they send activation to the synapses leading from them (Churchland and Sejnowski Citation1992).
In our model, neurons collect activation and fire if activation is above a threshold θ. If neurons do not fire in a given time step, some but not all of the activation leaks away.
If neurons do fire, all activation is lost; in Equationequation (2), d=∞. Activation (or inhibition) equivalent to the synaptic weight is sent from the firing pre-synaptic neuron to all of its post-synaptic neurons.
Neurons also fatigue so that the more steps they fire the more difficult it becomes for them to fire. This is modelled by increasing the activation threshold if a neuron fires as described by Equationequation (3):
Neurons may be inhibitory or excitatory, but they obey Dale's principle (Eccles Citation1986) so that a neuron cannot have both inhibitory and excitatory synapses leading from it. In the experiments described in this paper, the ratio is 80/20 excitatory/inhibitory as in the mammalian cortex (Bratenberg Citation1989).
Each neuron has a small number of synapses from it to other neurons, and a small number of synapses from other neurons to it. Inhibitory synapses are randomly assigned with initial weights near 0. Like the mammalian brain, excitatory neurons are likely to connect to neurons that are nearby. In the simulations described in this paper, excitatory neurons also have one long distance axon with several synapses. So a neuron connects to nearby neurons and to neurons in one other area of the net. These connections are assigned randomly, so each new net is different from other nets with the same number of neurons. Since distance is relevant, the overall network was toroidal to avoid edge problems. EquationEquation (5) is used for connectivity. It is initially called for each neuron with D (distance) of one for three adjacent neurons. It is subsequently called recursively on all four adjacent neurons with distance increasing by one on each recursive call. The recursion is stopped at distance 5. r is a random number. The long-distance axon uses the same process though starts with distance 2.
When learning, the simulations use Hebbian learning rules. Synaptic weight is changed based solely on the properties and firing of the pre- and post-synaptic neurons.
3.2 Learning rule
Our model commits us to a Hebbian learning rule. However, Hebbian learning only commits us to basing the synaptic weights on properties of the pre- and post-synaptic neurons. This leaves a wide range of options including the, poorly named, anti-Hebbian learning rule. As there is a wide range of possibilities, we would like to be directed by neurophysiological data. There is neural evidence for the Hebbian learning rule (Tsodyks et al. Citation1998); unfortunately the precise nature of the Hebbian learning rule is still not known.
A combination of the standard Hebbian rule (Equationequation (6)) and anti-Hebbian (Equationequation (7)
) rule sets the weight of a synapse to approximate the likelihood of the connected neurons co-firing. What is needed is a way of reducing the synaptic strength of neurons that frequently co-fire with many connected neurons, and increasing the strength of those that rarely co-fire with connected neurons. Reducing the synaptic strength of highly correlated neurons allows these neurons to participate in more stable states without these states merging together. Increasing the strength of weakly correlated neurons allows these neurons to participate in stable states. The compensatory learning rule (Huyck Citation2004) does this.
The compensatory learning rule is related to the compensatory factor (Horn et al. Citation1993), which redistributes synaptic weight when a synapse dies. In the simulations described in this paper, the compensatory learning rule is applied at each cycle.
Compensatory learning considers the total synaptic strengths of the pre-synaptic neurons as well as the firing behaviour of both pre- and post-synaptic neurons. Like standard correlational learning, when both neurons fire, the synaptic weight is increased, and when the pre-synaptic neuron fires and the post-synaptic neuron does not fire the weight is decreased. However the changes are multiplied by a compensatory modifier. If the total strength of all synapses leaving a neuron (afferents) is greater than the goal weight, W B, then the increase is multiplied by a positive modifier less than one, and the decrease is multiplied by a modifier greater than one. Similarly, if the total strength is less than the goal weight, increases are multiplied by a modifier greater than one, and decreases are modified by a modifier less than 1. The compensatory modifier forces the total synaptic weight towards the constant W B because there is more of an increase when the current total synaptic weight is less than W B, less of an increase when the total is greater, and a parallel decrease and increase when the anti-Hebbian rule is used.
This is similar to Sanger's Citation(1989) Generalized Hebbian algorithm and the Oja Citation(1982) learning rule. However, these are both based on continuously valued outputs of neurons, where the compensatory rule is based on binary outputs (spikes). Consequently, the compensatory rule should lead to the synaptic weights reflecting principal components like these other rules.
Compensatory learning is biologically plausible because the overall activation (or inhibition) a neuron can emit is limited. Since a neuron is a biological cell, it has limited resources, and synaptic efficiency may well be one such resource.
The compensatory learning rule combines a standard correlatory rule with a strong compensatory modifier. The correlatory Hebbian learning rule is based on the increase of Equationequation (6) where R is the learning rate. In the simulations below, the learning rate was 0.1. The anti-Hebbian learning rule is based on the decrease of Equationequation (7)
. These learning rules alone force the weight toward the correlation percentage; that is, how likely is the post-synaptic neuron to fire when the pre-synaptic neuron fires?
The compensatory rule modifies the standard learning rules to include a goal total synaptic weight W
B. EquationEquation (8) is the compensatory increase rule and Equationequation (9)
is the compensatory decreasing rule; that is, Equationequation (8)
is a Hebbian rule and Equation(9)
an anti-Hebbian rule, W
B is a constant which represents the average total synaptic strength of the pre-synaptic neuron, and W
i
is the current total synaptic strength. So, when the two neurons co-fire there is an increase in synaptic weight corresponding to Equationequation (9)
. If the pre-synaptic neuron fires and the post-synaptic neuron does not fire, the weight is decreased according to Equationequation (9)
. Note that the only difference between Equationequations (6)
and Equation(8)
is the final term of Equationequation (8)
; similarly the only difference between Equation(7)
and Equation(9)
is the final term. The final terms are the compensatory modifiers:
In the simulations, W B was 21 so that the sum of all of the synapses leaving a neuron was near 21 after learning. In the simulation described below, and other simulations (Huyck Citation2004), the combination of the exponential function and total synaptic strength of 21 enables neurons with low correlation weights to have enough synaptic strength to participate in reverberating circuits. It also prevents neurons that are frequently present in external stimuli from having very large weights. This in turn prevents simulated epilepsy (Connolly and Reilly Citation2005), the condition when all, or almost all, of the neurons fire in a given step.
There are parallel rules for inhibitory neurons. The correlatory weights reflect the value probability-1, so that neurons that frequently co-fire have little inhibition, but those that rarely co-fire have a great deal of inhibition; for instance if the correlatory probability is 0.2 the correlatory weight is −0.8. The compensatory modifier prevents inhibitory neurons from having too great an effect and encourages CAs to form.
4. Simulation of learning a hierarchy
Humans learn hierarchical categories. To fulfil our goal of using CAs as a basis for an intermediate level of cognition (see section 6), neural-CA nets need to be able to form hierarchical categories. Below, how the system represents these categories is described. It is then shown how the system can learn these categories from presentations of items in the categories, including learning the super-category with only presentation of items from the base categories. Then a larger hierarchy is learned and exhibits default reasoning.
4.1 Hierarchical categories from overlapping CAs
In the simulated networks, CAs consist of neurons; a particular CA usually consists of a significant subset of the neurons in the network. The CA is active when many of its neurons are firing.
Four categories are represented in this simulation; for expository convenience the base categories are called Dog, Cat and Rat, and the super-category is Mammal. The network is divided into neurons that recognize 10 types of features. Again for expository convenience features 0 to 2 refer to features that a specific animal has, with 0 referring to features that dogs have but cats, rats, and all other mammals do not, 1 to features cats have, and 2 to features rats have with restrictions as before. Features 3 and 4 refer to features all mammals have. 5 to 7 refer to features that relate to the tails of animals; 5 to tails that wag, 6 to fluffy tails, and 7 to furless tails. Neurons 8 and 9 refer to features relating to what the animals eat, 8 refers to omnivores, and 9 to carnivores.
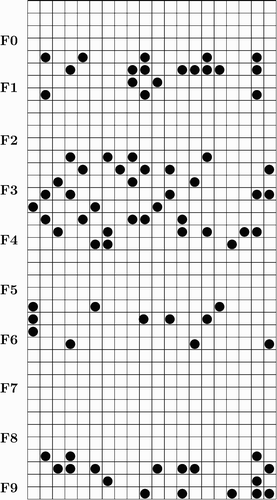
A given instance of a Cat will have some of the 1, 3, 4, 6 and 9 features. These are represented by activating some of the neurons associated with the features. The simulation uses a 40×20 network of neurons connected toroidally as described in section 3. Each feature is made up of all the neurons in four adjacent rows. For example feature one consists of neurons in rows five through eight. is an instance of a Cat. All of the features come from rows associated with features 1, 3, 4, 6 and 9.
Figure 1. 80 Neurons in the cat pattern.
To form hierarchical categories, overlapping CAs are used. Both Dog and Rat are closely related to Cat so they will have some features, and thus neurons, in common. The supercategory Mammal will have features that are common to most of the base categories. The 0, 3, 4, 5 and 8 features are Dog features; 2, 3, 4, 7 and 8 are Rat features; and 3, 4 and 8 are Mammal features.
shows the correlation values when all of the neurons of a given pattern are active. This shows that Cat is quite different from Dog and Rat because they differ on the Eat features. Dog and Rat are also closer to the Mammal supercategory. Pearson's measurements (see section 2.2.1) are used below to gauge similarity of CA networks. The higher the correlation value, the closer the firing patterns.
Table 1. Correlations between fully activated CAs.
4.2 Training and testing of the network
The untrained network is a 40×20 network connected in a distance biased fashion. Initial synaptic weights were random and low (between 0.01 and 0.02). During the training phase, the network was presented instances of the three basic patterns. There was an average of 60 synapses per neuron with 15 of those on the long distance axon. There was an 80/20 ratio of excitatory/inhibitory neurons.
The firing threshold was set to 4 for all neurons so it takes several neurons to cause another neuron to fire. The fatigue rate was 0.4, and the fatigue recovery rate was 0.8. The decay rate was set to 1.2. These parameters were determined by a relaxation and modification process derived from initial Hopfield weights (Huyck and Mitchell Citation2002).
The network was trained by presentations of instances of the subordinate categories. A given instance had 80 of the 400 neurons randomly selected (e.g. ). Each instance was presented for one cycle and a total of 800 instances were presented. Learning occurred in each step, fatigue and activity were reset, and the next training instance was presented.
In the testing phase, learning was turned off, and a randomly selected instance of 80 neurons of a category was presented for 5 cycles. Input neurons were stimulated according to Equationequation (10).
External input continued for five more cycles, a total of 10, and then the net was allowed to run for 40 more cycles. An average of the Pearson's correlations from cycles 15 through 40 was also calculated; this provided a measurement comparing the stable states after external input had ceased. After 50 cycles, the net was reset for the next input pattern by setting all fatigue and activation to zero.
4.3 Results
shows a network 5 cycles after the presentation of a Cat pattern; this is the externally activated pattern that is shown in . The same neurons are used for input and output measurement. During output measurement, more neurons are on, typically several hundred.
Figure 2. An active cat CA.
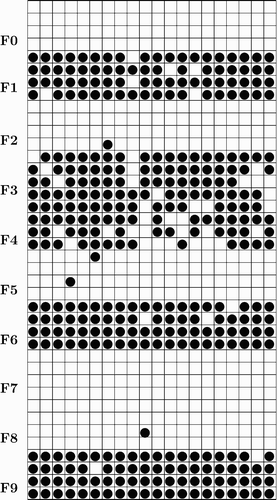
Note that in , some neurons outside the Cat pattern fire. For example two neurons from feature 5, and one neuron from feature 2 and 8 fire. In comparing Dog and Cat patterns, two of the four features are present in both, two are present in neither, and six are present in only one of these two patterns.
For one network, the Pearson's product moment correlations are shown in and . The first measurement in each cell shows the Pearson's measurement at cycle five, and the second shows the Pearson's average between cycles 15 and 40.
Table 2. Correlations between CA runs on one net.
Table 3. Correlations between superordinate and subordinate CA runs.
shows the correlations between subordinate categories. Based on the measurement at cycle five, all patterns are correctly categorized. For instance, the Dog2 item is correctly categorized as a Dog because it is most similar to Dog3 with ρ=0.74. On the average measurement, all but one item is correctly categorized. The Rat3 item is incorrectly categorized as a Dog because the highest value is ρ=0.49 for the correlation with Dog2.
shows the result when the superordinate category is presented. In this case only 48 neurons are externally stimulated, since the pattern is 60% of the size of the superordinate categories. In this case the Mammal patterns are clearly distinct from the subordinate categories.
and are an example of one network. The same process was repeated on a total of 10 networks. For each net, the subcategory patterns were compared with the other patterns. The closest pattern was found using Pearson's measurements, and this formed the basis of the categorization. So, if a given pattern was nearest to a Dog, it was categorized as a Dog. Using the correlation after five cycles, each pattern was correctly classified. Using the average correlations between cycles 15 and 40, 86 of 90 cases or 96% of the base level cases were correctly categorized. Every time the Mammal category was presented during testing it was correctly categorized by both measurements.
The average Pearson's measurement between categories was also calculated. As expected, patterns of the same category were highly correlated and different categories were less correlated. shows these correlations.
Table 4. Correlations between base categories.
It should be noted that Dog and Rat are much closer than other categories. This is of course because they share the omnivore feature. Similarly, Cat is less similar to Mammal because it does not share the omnivore feature.
The result, after 5 cycles, is a sound basis for categorization. Unfortunately, it does not appropriately reflect the behaviour of a CA. The average result is closer to what we would expect, in essence measuring the stable state of activation after presentation has ceased. The average measures involving Cat are good. However, the average measures between Dog and Rat are very close. This is more than would be expected from the inputs. In essence, these two CAs are very close to each other. Fortunately, as the results based on this categorization show, the average measures are still sufficiently different to categorize correctly almost all of the time.
Another measurement that is instructive is average excitatory weight between features. This is described in where F0 refers to a neuron of feature 0, F1 feature 1 etc.
Table 5. Average synaptic weight from one feature to another.
As expected, weights between mutually exclusive features like 0-1 or 0-6 are low, usually about 0.01. Inhibitory weights (not shown here) are also closer to −1 between these mutually exclusive features, while co-occurring features have inhibitory weights much nearer 0. So, exclusive features inhibit each other.
The weights from features 3 and 4 are weighted toward co-occurrence. Weights to each other are around 0.45, and to all others around 0.2. Weights to 3 and 4 are quite large, between 0.4 and 0.5; this is the effect of the compensatory modifier. These neurons have more strength to give, so they activate 3 and 4 while getting comparatively less activation back. This is the basis of the hierarchical effect. The features of the Mammal category are activated by the lower level categories, but send comparatively less activation back, so Mammal can remain active without activating, for instance, Dog. The lower level categories support their own unique features and the higher level categories. Feature 8 falls somewhere between 3 and 4, and the other features sending more activation than 3 and 4 to those it activates but less than the others. Note that these asymmetric weights contradict the bidirectionality constraint needed for statistical mechanics.
4.4 A larger hierarchy
This mechanism is extensible to larger subcategorization hierarchies. In the interest of exploring its extensibility, the simulation was recreated with a larger set of inputs including birds.
The network took 16 input features including all of the above features and six new features. Features 0 to 2 were as before, and there were three additional features, 3 to 5, for bears, geese and pigeons; the old features 3 and 4 were moved to 6 to 7 and are now called warm-blood and fur; a new feature, feathers 8, was added; the old tail features, 6 to 8, were moved to 9 to 11, and a new feature, short tails 12, was added; the old eating features, 8 and 9, were moved to 13 to 14, and a new feature, herbivorous 15, was added.
The system was trained on instances of the five basic level patterns, Dog consisted of features 0, 6, 7, 9, 13; Cat 1, 6, 7, 10, 14; Rat 2, 6, 7, 11, 13; Goose 4, 6, 8, 12, 15; and Pigeon 5, 6, 8, 12, 13. The topology was a 32×40 net with each feature consisting of two complete rows. Presentation was just the same as the earlier experiment, but lasted 1400 cycles to account for the extra basic categories. Note that as the network gets larger, the categories stay the same size. In this simulation, base categories use 5/16 of the neurons, while in the earlier simulation base categories used 5/10 of the neurons. This shows that larger CA nets use sparse coding.
Testing was also the same as the prior experiment. Ten networks were tested and each basic category was presented three times for testing. All 15 inputs were categorized by comparison with the other nets at cycle five. Using the measurement after five cycles, all 150 were correctly categorized, and using the average measure 146, 97%, were correctly categorized.
These inputs lead to a three level subcategorization hierarchy including Mammals consisting of features 6, 7 and 13 as before; Birds consisting of features 6, 8 and 12; and Animals consisting of features 6 and 13. Five instances of each of these were also presented to each of the ten networks. 90% were correctly categorized using the five cycle measurement and 77% were correctly categorized using the average measurement.
4.5 Default reasoning
One of the key advantages of subcategorization hierarchies is the ability to use default reasoning. If a new basic category is presented, the system can use the features of its supercategory to deduce properties about the new category.
The trained net was presented with an instance of a Bear. As it had not seen any before, the behaviour was of interest. The bear consisted of the features 3 (bear), 6 (warm-blooded) and 7 (fur). No neurons were presented for the bear's eating habits (features 12–14). The question then was what did the system have to say about the bear's eating habits. In other words, did it have some form of default reasoning?
The networks were tested at cycle five after presentation and the number of neurons that fired in the Omnivore, Carnivore and Herbivore features was counted. Ten different instances were presented to each of the ten networks. In total 738 Omnivore neurons were fired, 31 Carnivore neurons fired and no Herbivore neurons fired.
With no other information, the system had guessed that bears were omnivores. This information comes from the mammal supercategory. So, the system engaged in default reasoning.
5. Discussion and future work on hierarchies
These simulations show a hierarchy of categories emerging via Hebbian learning. The subcategory CAs emerge as prior work in categorizing with networks of CAs would suggest. Additionally, super-categories also emerge containing the most common features in the subcategories. The super-categories emerge despite never being explicitly presented.
This paper shows how a neural-CA system could account for hierarchies. Others (e.g. Wickelgren Citation(1999)) discuss how hierarchical CAs might be modelled, but none actually develop a neural simulation.
The neural model is relatively simple, but unlike more sophisticated models that learn CAs (Fransen et al. Citation1992, Brunel Citation1996, Amit and Brunel Citation1997, Amit and Mongillo Citation2003), it learns overlapping categories. As overlapping categories are essential to this type of subcategorization hierarchy, this is a unique neural model. Other attractor nets can store hierarchies (e.g. Feigelman and Ioffe Citation(1987)) but these are based on patterns over the whole set of neurons. These may also be inconsistent with pattern completion as none of the initial neurons may be in the final set. So, even as a simple attractor net, this model is a novel mechanism for hierarchical categorization.
The model is at a good level between computational simplicity and biological realism. It enables exploration of simulations of complex categorization problems, and allows the system to move onto new stable states (see section 6).
Hierarchy allows a more flexible categorizer. If a new member of a new subordinate category is presented (say a Bear), the superordinate category will be activated. Eventually, the new subordinate category may be learned. Similarly, default reasoning was used for the new Bear subordinate category. In the absence of any evidence, the system guessed that the new item is an Omnivore because it is a Mammal.
The compensatory learning rule is essential to this process of hierarchical category formation. In addition to providing flexible categories, it forces a neuron to concentrate on the most important neurons with which it interacts. This limits simulated epilepsy, but also supports the formation of the superordinate stable states.
There is a wide range of further work to be done on categorization and hierarchies using neural-CA networks. CA nets can be used for current AI tasks like classification. CA networks have been used for some standard classification tasks (Huyck and Orengo Citation2005) from a standard repository (Blake and Merz Citation1998). There has also been work on information retrieval (IR) tasks that has been successful (Huyck and Orengo Citation2005). Both the IR and classification tasks involved natural polymorphic categories. This work is far from complete and we hope to extend to more complex tasks, including linearly inseparable categories and highly interleaved categories. It is likely that a greater understanding of CA dynamics is needed before CAs can be applied to the full range of current data-mining problems.
Other types of hierarchical relationships exist. An obvious one is the part-of relationship where an object, such as a steering wheel, is part of another object, such as an automobile.
We are hoping to use hierarchical CAs as a part-of system that learns words by associating text with sensory input. This involves the understanding of the semantics of the verb, noun and prepositional phrases in a sentence like I saw the girl with the telescope. (Hindle and Rooth Citation1993). We are hoping that hierarchical categories of these phrases can be used to learn the semantic relationships used in selecting the correct attachment.
More worrisome is the biologically implausible nature of the training regime used for the simulations of section 4. During training, each pattern was presented for only one cycle. If a more plausible mechanism is used, presenting it for 10 cycles and allowing run on, only one CA is formed in the Mammal experiment. It is the superordinate category including the features of all subordinate categories. This is theoretically legitimate, but is not the desired result.
We plan on exploring this problem next. One aspect of the problem is that once a sub-ordinate neuron is fired by the superordinate CA, it is rapidly recruited into it. The problem has occurred in earlier experiments and has been solved by reducing the learning rate (Huyck Citation2004) preventing the subcategories being recruited by the super-categories. A neural fatigue mechanism where neurons recover proportionally to their total fatigue has also been promising in solving this problem (Huyck Citation2002, Huyck and Ghalib Citation2004). Perhaps a better mechanism would allow the superordinate category to form first, but then allow the subordinate CAs to fractionate off.
This problem relates to the long-term dynamics of recruitment and fractionation. The theory of CA development is currently being formulated. This will be related to the theory of attractor nets but will include learning dynamics and biologically plausible topologies.
Further in the future, we are hoping to explore basic level effects, and to use our model to simulate timing data in psychological categorization tasks. We stand by Hebb's original idea that CAs are the basis of human concepts. Consequently, we would like to develop neural models that implement CA networks to account for the full range of categorization data.
6. Ongoing and future work, and conclusion
We have proposed CAs as a good level to model cognition (Huyck Citation2001), and have shown among other things that a neural-CA system can form hierarchies. However, to be the basis of cognition, CAs must form many other structures.
Hierarchies are related to associative memory. We are currently working on associative memory including the related task of priming. In the next few years, we hope to move from theoretical work to more practical data-mining and psychological simulation tasks involving categorization, associative memories and hierarchies.
A related question is how CAs grow into unstimulated regions. In biological systems, stimulus only comes from the environment and most neurons in the mammalian brain are not directly connected to the environment. Large initial weights may help, but we have begun exploration of spontaneous neural activity to drive neural recruitment (Huyck and Bowles Citation2004). There is evidence (Abeles et al. Citation1993, Bevan and Wilson Citation1999) that neurons spontaneously fire without external input; our work relates to Amit and Brunel's Citation(1997). When combined with a compensatory learning mechanism, this allows unstimulated neurons to be recruited into CAs. This process is related to category formation and relationships between categories allowing the growth of CAs in regions that are not directly stimulated by senses.
We are also interested in learning sequences of CAs. Once primitive CAs are learned, it should be possible to use inter-CA connections to support sequences of CAs. If the network has learned ABCDE, presentation of ABC should lead to the ignition of D then E. A CA can ignite, the neurons can fatigue, and a new CA can ignite. This takes us beyond single stable state attractor net theory.
Until recently, we have directly stimulated neurons to simulate external activity, but recently, we have begun to explore how simple sensors can be integrated into the system. Our current work is on numbers for data-mining (Huyck and Orengo Citation2005). In one experiment we use multiple neurons to represent binary values for a categorization task (Blake and Merz Citation1998), and in another we use individual neurons to represent words in an information retrieval task. We plan on developing more sophisticated sensory nets and draw hope from the extensive neurophysiological work on vision and other sensing. Similarly, we would also like to integrate actuators into the model.
Finally, this associative memory can be combined with variable binding to form a signi-ficantly different computational model. The neural model described above has been used to bind CAs (Huyck Citation2005, Huyck and Belavkin 2006) using spontaneous activation and synaptic weight change. Similar models (e.g. Knoblauch and Palm Citation(2001) and Sougne Citation(2001)) have been used to bind using synchronous neural activity. Other connectionist models (e.g. Sun Citation(1995)) have been used for this task, but the model described in this paper is a much closer approximation to biological systems.
A neural-CA system that implemented rules would be Turing complete because rules can be used to define arbitrarily complex functions, but this system would be based more on mammalian processing. Different subsystems could vary certain parameters, but the basic network with a neural-CA architecture could be used to develop a more complete cognitive architecture, which is the ultimate goal of this work. In the long run, we hope that our model is close enough to mammalian neurons to solve problems, like the Turing test (Turing Citation1950), that only mammalian neural systems are currently capable of solving. Hierarchy is obviously an early step in this process.
Acknowledgements
This work was supported by EPSRC grants GR/R13975/01 and EP/D059720. Thanks to Marius Usher for comments on a draft of this paper.
Notes
†Global inhibition is an example of an external mechanism for stopping an active CA.
†The CAs that we are discussing in this work are long-term categories. It is clear that memories can be learned from a single presentation; this episodic memory is not the topic of this paper.
†Linearly separable categories are separated by a line with two inputs or a plane or hyper-plane at higher levels. Exclusive-or is an example of a linearly inseparable problem with two inputs.
†It can be found at http://www.cwa.mdx.ac.uk/cant20/CANT20.html; the simulations from this paper and other simulations are available there.
References
- Abeles , M. , Bergman , H. , Margalit , E. and Vaadia , E. 1993 . “Spatiotemporal firing patterns in the frontal cortex of behaving monkeys” . J. Neurophysiol. , 70 : 1629 – 1638 .
- Ackley , D. , Hinton , G. and Sejnowski , T. 1985 . “A learning algorithm for Boltzmann machines” . Cognitive Sci. , 9 : 147 – 169 .
- Amit , D. 1989 . Modelling Brain Function: The World of Attractor Neural Networks , Cambridge : Cambridge University Press .
- Amit , D. and Brunel , N. 1997 . “Model of global spontaneous activity and local structured activity during delay periods in the cerebral cortex” . Cerebral Cortex , 7 : 237 – 252 .
- Amit , D. and Mongillo , G. 2003 . “Spike-driven synaptic dynamics generating working memory states” . Neural Computat. , 15 : 565 – 596 .
- Athithan , G. 1999 . “Associative memory of low activity patterns with the problem of spurious attractors” . Current Sci. , 76 : 540 – 547 .
- Barlow , H. 1972 . “Single units and sensation: a neuron doctorine for perceptual psychology?” . Perception , 1 : 371 – 394 .
- Bevan , M. and Wilson , C. 1999 . “Mechanisms underlying spontaneous oscillation and rhythmic firing in rat subthalamic neurons” . J. Neurosci. , 19 : 7617 – 28 .
- Blake , C. and Merz , C. 1998 . “ UCI repository of machine learning databases [http://www.ics.uci.edu/∼mlearn/mlrepository.html] ” . Irvine, CA : University of California, Department of Information and Computer Science .
- Bower , J. and Beeman , D. 1995 . The Book of GENESIS , Berlin : Springer-Verlag .
- Bratenberg , V. 1989 . “Some arguments for a theory of cell assemblies in the cerebral cortex” . In Neural Connections, Mental Computation , Edited by: Nadel , L. Cambridge, MA : MIT Press .
- Brunel , N. 1996 . “Hebbian learning of context in recurrent neural networks” . Neural Computat. , 8 : 1677 – 1710 .
- Calvin , W. 1995 . “Cortical columns, modules, and Hebbian cell assemblies” . In The Handbook of Brain Theory and Neural Networks , Edited by: Arbib , M. Cambridge, MA : MIT Press .
- Cardie , C. “Using cognitive biases to guide feature set selection” . Proceedings of the 14th Annual Conference of the Cognitive Science Society . pp. 743 – 748 .
- Chown , E. 1999 . “Making predictions in an uncertain world: environmental structure and cognitive maps” . Adapt. Behav. , 7 : 1 – 17 .
- Churchland , P. S. , Churchland , T. J. and Sejnowski . 1992 . The Computational Brain , Cambridge, MA : MIT Press .
- Collins , A. and Loftus , E. 1975 . “A spreading-activation theory of semantic processing” . Psychol. Rev. , 82 : 407 – 428 .
- Connolly , C. and Reilly , R. “A proposed model of repetition blindness” . Modelling Language, Cognition and Action: Proceedings of the 9th Neural Compuation and Psychology Workshop . Edited by: Cangelosi , A. , Bugmann , G. and Borisyuk , R. pp. 279 – 288 . World Scientific .
- Dalenoort , G. 1985 . “The representation of tasks in active cognitive networks” . Cognitive Syst. , 1 : 253 – 272 .
- Eccles , J. 1986 . “Chemical transmission and Dale's principle” . Prog. Brain Res. , 68 : 3 – 13 .
- Elman , J. 1990 . “Finding structure in time” . Cognitive Sci. , 14 : 179 – 211 .
- Erickson , M. and Kruschke , J. 1998 . “Rules and exemplars in category learning” . J. Exp. Psychol.: Gen. , 127 : 107 – 140 .
- Feigelman , M. and Ioffe , L. 1987 . “The augmented models of associative memory asymmetric interaction and hierarchy of patterns” . J. Mod. Phys. B , 1 : 51 – 68 .
- Fodor , J. 2000 . The Mind Doesn't Work That Way: the Scope and Limits of Computational Psychology , Cambridge, MA : MIT Press .
- Fransen , E. , Lanser , A. and Liljenstrom , H. 1992 . “A model of cortical associative memory based on Hebbian cell assemblies” . In Connectionism in a Broad Perspective , Edited by: Niklasson , L. and Boden , M. 165 – 171 . Berlin : Ellis Horwood Springer-Verlag .
- Freeman , W. 2000 . “Mesoscopic neurodynamics: from neuron to brain” . J. Physiol. , 94 : 303 – 322 .
- Fu , L. L. 2003 . “An analysis of Hebb's cell assembly as a mechanism for perceptual generalisation” . Ann Arbor : University of Michigan . PhD thesis
- Gerstner , W. 1995 . “Time structure of the activity in neural network models” . Phys. Rev. E , 51 : 738 – 758 .
- Grossberg , S. 1987 . “Competitive learning: from interactive activation to adaptive resonance” . Cognitive Sci. , 11 : 23 – 63 .
- Hanson , S. and Bauer , M. 1989 . “Conceptual clustering, categorization, and polymorphy” . Machine Learning , 3 : 343 – 372 .
- Hanson , S. and Negishi , M. 2002 . “On the emergence of rules in neural networks” . Neural Computat. , 14 : 245 – 268 .
- Hebb , D. O. 1949 . The Organization of Behavior , New York : J. Wiley & Sons .
- Hertz , J. , Krogh , A. and Palmer , R. 1991 . Introduction to the Theory of Neural Computation , Cambridge, MA : Perseus Books .
- Hetherington , P. and Shapiro , M. 1993 . “Simulating Hebb cell assemblies: the necessity for partitioned dendritic trees and a post-net-pre LTD rule” . Network: Computat. Neural Syst. , 4 : 135 – 153 .
- Hindle , D. and Rooth , M. 1993 . “Structural ambiguity and lexical relations” . Computat. Linguist. , 19 : 103 – 120 .
- Hinton , G. and Sejnowski , T. “Optimal perceptual inference” . Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . pp. 448 – 453 .
- Hodgkin , A. and Huxley , A. 1952 . “A quantitative description of membrane current and its application to conduction and excitation in nerve” . J. Physiol. , 117 : 500 – 544 .
- Hopfield , J. 1982 . “Neural nets and physical systems with emergent collective computational abilities” . Proc. Nat. Acad. Sci. USA , 79 : 2554 – 2558 .
- Horn , D. , Levy , N. and Ruppin , E. 1998 . “Memory maintenance via neuronal regulation” . Neural Computat. , 10 : 1 – 18 .
- Horn , D. , Ruppin , E. , Usher , M. and Herrmann , M. 1993 . “Neural network modeling of memory deterioration in Alzheimer's disease” . Neural Computat. , 5 : 736 – 749 .
- Horn , D. and Usher , M. 1989 . “Neural networks with dynamical thresholds” . Am. Phys. Rev. , 40 : 1036 – 1044 .
- Huyck , C. 2000 . “Cell assemblies for rapid recognition and disambiguation” . EmerNet: Third International Workshop on Current Computational Architectures Integrating Neural Networks and Neuroscience ,
- Huyck , C. 2002 . “Cell assemblies and neural network theory: from correlators to cell assemblies” . London : Middlesex University . Technical report
- Huyck , C. 2004 . “Overlapping cell assemblies from correlators” . Neurocomputing , 56 : 435 – 439 .
- Huyck , C. “Variable binding of cell assemblies with binding areas and spontaneous neural activation” . Proceedings of the Twenty Second Workshop of the European Society for the Study of Cognitive Systems .
- Huyck , C. R. 2001 . “Cell assemblies as an intermediate level model of cognition” . In Emerging Neural Architectures Based on Neuroscience , Edited by: Wermter , S. , Austin , J. and Willshaw , D. Berlin : Springer .
- Huyck-Belavkin , C. , Huyck , R. and Belavkin . “Counting with neurons: rule application with nets of fatiguing leaky integrate and fire neurons” . Proceedings of the Seventh International Conference on Cognitive Modelling .
- Huyck , C. and Bowles , R. 2004 . “Spontaneous neural firing in biological and artificial neural systems” . J. Cognitive Syst. , 6 : 31 – 40 .
- Huyck , C. and Ghalib , H. “Improving cell assembly categories by fatigue” . Proceedings of the Ninth Neural Computation and Psychology Workshop .
- Huyck , C. and Mitchell , I. “Cell assemblies, self-organising maps and Hopfield networks” . Proceedings of the Sixth International Conference on Cognitive and Neural Systems .
- Huyck , C. and Orengo , V. 2005 . “Information retrieval and categorisation using a cell assembly network” . Neural Comput. Appl. , 14 : 282 – 289 .
- Jahnke , A. , Roth , U. and Klar , H. “Towards efficient hardware for spike-processing neural networks” . Proceedings of the World Congress on Neural Networks . pp. 460 – 463 .
- James , W. 1892 . Psychology: The Briefer Course , Notre Dame, Indiana : University of Notre Dame Press .
- Kaplan , S. , Sontag , M. and Chown , E. 1991 . “Tracing recurrent activity in cognitive elements (trace): a model of temporal dynamics in a cell assembly” . Connect. Sci. , 3 : 179 – 206 .
- Kieras , D. , Wood , S. and Meyer , D. 1997 . “Predictive engineering models based on the epic architecture for a multimodal high-performance human-computer interaction task” . ACM Trans. Comput. Human Interact. , 4 : 230 – 75 .
- Knoblauch , A. , Markert , H. and Palm , G. “An associative model of cortical langauage and action processing” . Proceedings of the Ninth Neural Computation and Psychology Workshop .
- Knoblauch , A. and Palm , G. 2001 . “Pattern separation and synchronization in spiking associative memories and visual areas” . Neural Networks , 14 : 763 – 780 .
- Kohenen , T. 1997 . Self-Organizing Maps , Berlin : Springer .
- Levy , S. , Melnik , O. and Pollack , J. “Infinite RAAM: a principled connectionist basis for grammatical competence” . Proceedings of the 20th Annual Conference of the Cognitive Science Society .
- Lippmann , R. 1987 . “An introduction to computing with neural nets” . IEEE ASSP Mag. , 4 : 4 – 22 .
- Maas , W. and Bishop , C. 2001 . Pulsed Neural Networks , Cambridge, MA : MIT Press .
- Newell , A. 1990 . Unified Theories of Cognition , Cambridge, MA : Harvard University Press .
- Oja , E. 1982 . “A simplified neuron model as a principal component analyzer” . J. Math. Biol. , 15 : 267 – 273 .
- Palm , G. 1990 . “Cell assemblies as a guideline for brain research” . Concepts Neurosci. , 1 : 133 – 147 .
- Pollack , J. 1990 . “Recursive distributed representations” . Artif. Intell. , 46 : 77 – 105 .
- Pulvermuller , F. 1999 . “Words in the brain's language” . Behav. Brain Sci. , 22 : 253 – 336 .
- Quillian , M. 1967 . “Word concepts: a theory of simulation of some basic semantic capabilities” . Behav. Sci. , 12 : 410 – 430 .
- Riesenhuber , Riesenhuber M. and Poggio , T. 2003 . How Visual Cortex Recognizes Objects: The Tale of the Standard Model , Cambridge, MA : MIT Press .
- Rochester , N. , Holland , J. , Haibt , L. and Duda , W. 1956 . “Tests on a cell assembly theory of the action of the brain using a large digital computer” . RE Trans. Informat. Theory , : 80 – 93 . IT-2
- Rosch , E. and Mervis , C. 1975 . “Family resemblances: studies in the internal structure of categories” . Cognitive Psychol. , 7 : 573 – 605 .
- Roudi , Y. and Treves , A. 2004 . “An associative network with spatially organized connectivity” . J. Stat. Mech.: Theory Exp. , 7 : 7 – 32 .
- Rumelhart , D. and McClelland , J. 1982 . “An interactive activation model of context effects in letter perception: Part 2. the contextual enhancement and some tests and extensions of the model” . Psychol. Rev. , 89 : 60 – 94 .
- Rumelhart , D. and McClelland , J. 1986 . Parallel Distributed Processing , Cambridge, MA : MIT Press .
- Sakurai , Y. 1998 . “The search for cell assemblies in the working brain” . Behav. Brain Res. , 91 : 1 – 13 .
- Sanger , T. 1989 . “Optimal unsupervised learning in a single-layer linear feedforward neural network” . Neural Networks , 2 : 459 – 473 .
- Shepard , R. , Hovland , C. and Jenkins , H. 1961 . “Learninng and memorization of classifications” . Psychol. Monographs , 75 : 517
- Sougne , J. 2001 . “Binding and multiple instantiation in a distributed network of spiking neurons” . Connect. Sci. , 13 : 99 – 126 .
- Stevens , C. and Zador , A. “Novel integrate-and-fire-like model of repetitive firing in cortical neurons” . Proceedings of the Fifth Symposium on Neural Computation .
- Sun , R. 1995 . “Robust reasoning: integrating rule-based and similarity based reasoning” . Artif. Intell. , 75 : 241 – 95 .
- Tal , D. and Schwartz , E. 1997 . “Computing with the leaky integrate-and-fire neuron: logarithmic computation and multiplication” . Neural Computat. , 9 : 305 – 318 .
- Tsodyks , M. , Pawelzik , K. and Markram , H. 1998 . “Neural networks with dynamic synapses” . Neural Computat. , 10 : 821 – 35 .
- Turing , A. 1950 . “Computing machinery & intelligence” . Mind , 59 : 433 – 460 .
- Wickelgren , W. 1999 . “Webs, cell assemblies, and chunking in neural nets” . Canad. J. Exp. Psychol. , 53 : 118 – 131 .
- Wittgenstein , L. 1953 . Philosphical Investigations , Oxford : Blackwell .