Abstract
Androids that replicate humans in form also need to replicate them in behaviour to achieve a high level of believability or lifelikeness. We explore the minimal social cues that can induce in people the human tendency for social acceptance, or ethopoeia, toward artifacts, including androids. It has been observed that people exhibit a strong tendency to adjust to each other, through a number of speech and language features in human–human conversational interactions, to obtain communication efficiency and emotional engagement. We investigate in this paper the phenomena related to prosodic alignment in human–computer interactions, with particular focus on human–computer alignment of speech characteristics. We found that people exhibit unidirectional and spontaneous short-term alignment of loudness and response latency in their speech in response to computer-generated speech. We believe this phenomenon of prosodic alignment provides one of the key components for building social acceptance of androids.
1. Introduction
The purpose of this study is to investigate how prosody, which includes such non-segmental features in voice as intonation and rhythm, affects human–computer interaction. Our research focuses on the nature of voice interaction and the activation of mutual alignment between a human and a computer or android by using the capability of prosody in a computer voice.
The progress made in computer technology has changed the function of robots from a tool for people to use to an interactive partner. This has required robots to attain more social and emotional characteristics toward becoming interactive partners with people. Various review papers have summarized the major findings in this new field (e.g. Duffy Citation2002, Fong et al. Citation2003). As they have mentioned, some research efforts have focused on anthropomorphism to improve the human-like qualities of embodied characters, including robots. Kismit is a typical example of pursuing reality or human-like expressions for social robots (Breazeal Citation1998). On the other hand, some studies have examined the minimal cues needed to induce in users interpersonal behaviour and empathic impressions toward robots in interaction (e.g. Ono et al. Citation2001).
Compared with other social robots, androids have functions that make them more human-like in both appearance and behaviour. Accordingly, people sometimes feel a distinct strangeness about the subtle differences between an android and a real human. This is called the ‘uncanny valley effect’ (Ishiguro Citation2005). At the same time, people sometimes treat computers as real people, even though computers do not display any anthropomorphic features (Reeves and Nass Citation1997). It has also been found that people are apt to interact with artifacts that have very limited anthropomorphic or autonomous functions (e.g. the Eliza effect (Weizenbaum Citation1966)). To minimize the uncanny valley effect, there are two fundamental approaches that android science may take: (1) implementing anthropomorphic appearance/behaviour to give a human-like nature to androids; and (2) examining the minimal social cues needed to induce ethopoeia, which would lead to social acceptance of androids as interactive partners in human society.
Here, we pursue the latter approach to gaining people's social acceptance of robots, including androids, by focusing on the human tendency of ethopoeia to synchronize with the speaking style of an interaction partner, especially at the prosodic level. As Pickering and Garrod Citation(2004) mentioned, people tend to mirror the conversational behaviours used by their partners at multiple levels, from the phonetic representation to the situation level. The communication accommodation theory argues that alignment occurs during conversation in lexical, syntactic and speech signal features between two people (Giles et al. Citation1987). Moreover, some studies have noted the synergetic effect between synchronous behaviour and empathy in interaction among people (Welkowitz and Kuc Citation1973) as well as among wild dolphins (Connor et al. Citation2000).
There have been few studies on this human tendency of alignment at the prosodic level in human–computer interaction, except Coulston et al. Citation(2002), Darves and Oviatt Citation(2002) and Bell et al. Citation(2003). If this human tendency were applied to human–computer voice interaction, it might be an effective strategy for facilitating interpersonal relations between a human and a computer.
In this paper, we describe a simple experiment to examine the prosodic alignment from a human to a computer. We utilize two parameters of voice prosody: (i) voice loudness: vocal intensity in a human or computer voice; and (ii) response latency: pause duration between the end of a human voice and the beginning of a computer voice, or vice versa. Furthermore, the congruence of vocal intensity between two people has been observed in conventional studies (Meltzer et al. Citation1971, Natale Citation1975), as has the congruence of pause duration between two people (Matarazzo and Wiens Citation1967, Jaffe and Feldstein Citation1970, Welkowitz and Kuc Citation1973).
We believe that prosodic alignment can be applied to human–computer interaction, even when the computer slightly changes the prosody in its voice within a short session. We examined whether the user's prosodic features of voice loudness and response latency are influenced by changes in these prosodic features in a system's output voice throughout a session. Our voice system varies voice prosody, i.e. loudness or response latency, within a session in three ways: (a) increasing; (b) constant; and (c) decreasing. We also assessed whether prosodic alignment from a user to a system is bidirectional, both increasing and decreasing, or only unidirectional, either increasing or decreasing, according to prosodic changes in the system's voice.
2. Related works
2.1 Prosodic alignment in human–human interaction
In everyday interpersonal conversation, people may consciously or unconsciously change their own voices to adjust to the prosodic features in a partner's voice. For example, people may talk faster and louder when other participants in the discussion raise their voice, caregivers with infants may speak more slowly and softly, or people may mimic their friend's style of speaking.
Some studies on interpersonal conversation have reported such a synchronous tendency at the prosodic level. For utterance duration, Matarazzo and his colleagues Citation(1963) found a synchronous tendency that increased or decreased the mean speech duration in interviews as well as in conversations between astronauts and ground communicators (Matarazzo et al. Citation1964). Jaffe and Feldstein Citation(1970) stated the congruence of mean response latency interviewers and interviewees, as did Mattarazzo and Wiens (Citation1967). Moreover, Welkowitz and Kuc Citation(1973) examined the congruence of mean response latency in free-style conversation between children as well as between university students. They also found interrelationships between the congruence of switching pause duration and a warm impression felt by the conversation partner. Webb Citation(1972) observed that the mean speech rate of an interviewee adjusted to the change in the interviewer's voice speed. For vocal intensity or voice loudness, Natale Citation(1975) reported the convergence of mean vocal intensity in both interviews and unstructured conversations, while Meltzer et al. Citation(1971) reported the synchrony of voice loudness in simultaneous utterances between two people. Couper-Kuhlen Citation(1996) discussed prosodic repetition between two interlocutors.
From these results of previous studies on human–human interaction, we consider the possibility that prosodic alignment of loudness and response latency can be observed between a human and a computer through interactive sessions.
2.2 Prosodic alignment in human–computer interaction
Prosodic alignment from a user to a spoken dialogue system has been investigated by using the Wizard of Oz method (Coulston et al. Citation2002, Darves and Oviatt Citation2002, Bell et al. Citation2003). These previous studies used animated characters in a computer display as conversational partners, which were implemented to output speech with different prosody, including voice loudness, speech latency and speech rate, as a different voice personality or speaking style. Nass and Lee Citation(2000) found that a user preferred a computer voice with similar prosodic personality traits, for example, extroverted or introverted, as more attractive, credible and informative. This result suggests that the macro-level alignment of speech characteristics contributes to the establishment of good social relationships between humans and computers through the disclosure of personality traits.
Suzuki et al. Citation(2003) found both behavioural and psychological effects of prosodic mimicry when a human user hummed along with a computer's voice in ‘conversation’. They found that the micro-level utterance-wise alignment of speech characteristics contributed to increasing the user's amicable feelings toward the computer. This finding opens up the possibility of exploiting the human capacity of voice prosody alignment within the context of spoken dialogue systems to attain both efficient and emotional engagement in interactions, just as in interpersonal conversations. They also observed that some users returned the mimicry by producing humming voices with prosodic patterns similar to the preceding computer's hummed sound. To exploit fully this mutual alignment of prosody in human–computer interaction, we need to confirm that humans actually exhibit micro-level utterance-wise alignment of speech characteristics in response to computer voices.
To verify further the human tendency to align at the micro level to computer voice prosody, we conducted experiments in which prosodic changes in a computer's voice were systematically manipulated within a single interactive spoken dialogue session.
3. Experimental design
3.1 Hypothesis
We assume that voice prosody in participants’ responses, i.e. voice loudness or response latency, will align in the direction heard from the system within an interactive session. Specifically, it is predicted that the voice amplitude of a participant's responses will be louder after the system asks a question with a louder voice and lower after it asks a question with a lower voice. The same prediction could be applied to the case of response latency.
As noted in the previous section, macro-level prosodic alignment has been observed during different conversational sessions, in both human–human and human–computer interaction. The goal of this experiment was to investigate whether micro-level utterance-wise prosodic alignment can be found within a single conversational session. Bidirectional alignment, that is, the tendency of participants to align their voice prosody in both increasing and decreasing directions, was also examined across slight prosodic changes in the system.
3.2 Conditions
We assigned the following three conditions for different prosody conditions of the system voice, i.e. voice loudness or response latency ():
| • | Increasing: In the first half of a session, the quiz system outputs a question voice with standard voice loudness or standard response latency; then in the second half the system outputs a question voice with slightly higher loudness or after a slightly longer response latency. | ||||
| • | Constant: In both the first and second halves, the system outputs the question voice with standard loudness or standard response latency. In other words, the system outputs the question at a constant loudness or response latency throughout the session. | ||||
| • | Decreasing: In the first half of a session, the quiz system outputs the question voice with a louder vocal intensity or after a longer response latency; then in the second half the system outputs the question voice with standard loudness or standard response latency. | ||||
Figure 1. Conditions: increasing (top); constant (middle); and decreasing (bottom).
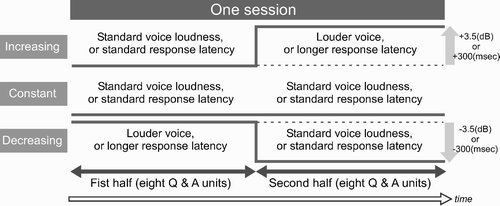
In this experiment, loudness of the system was defined as vocal intensity in the system's voice. Response latency was defined as pause duration between the end of the previous answer from the participant and the beginning of the question voice from the system.
A system's voice with standard loudness denotes the vocal intensity of the original recorded voice, while a louder voice means +3.5 dB louder. This level of the louder voice was set based on the results of a perception test conducted prior to this experiment, which used 20 participants (Suzuki and Katagiri Citation2003). A question voice with a longer response latency denotes a voice with a 300-ms-longer response latency.
3.3 Experimental setting
In this experiment, we conducted one session that included 16 question and answer (Q&A) units. In other words, the first and second halves each consisted of eight Q&A units. The quiz system was constructed as a simple acoustic processing function (programming by Tcl/Tk and snack), without using either speech recognition or the Wizard of Oz simulation function. Response latency manipulation was performed on this acoustic processing function. It automatically output a phrase of a question after detecting sound inputs via a microphone in the subject's headset. illustrates the appearance of the quiz system.
Figure 2. Task: multiple choice question, sample photo of the quiz, and appearance of an interactive experiment.

During data collection, answering voices from participants were recorded on both a hard disc recorder (digidesign: PROTOOLS) and a digital video cassette recorder (SONY: DSR-2000) via a headset (AKG: HSC-200).
The quiz system output recorded speech. The original voices were read by a male Japanese speaker and recorded in a soundproof studio in our laboratory with a digital audio tape recorder. He read six kinds of sentences for questions that were digitized at a sampling rate of 44.1 kHz. Spectral manipulation of the voice was performed by the STRAIGHT technique (Kawahara et al. Citation1999).
summarizes the differences in the speech signal profiles of three conditions, increasing, constant and decreasing, for two parameters, loudness and response latency.
Table 1 Mean acoustic differences under three voice conditions.
3.4 Procedure
Thirty-nine undergraduate and graduate students aged from 18 to 25 years participated as paid volunteers. Before starting a session, each participant practised with an experimenter and received instructions on how to interact in front of a 50-inch plasma display (Pioneer: PDK-50HW2). The participants were simply told that they would be participating in a study of how people work with computers when using their voices to accomplish a task. After the experimenter left, the participants spent approximately 5 min alone in the soundproof room with the quiz system. During this time, participants answered 16 questions (e.g. the system asked ‘Which object does not belong?’ while displaying a sunflower, a tulip and a ladybug on the screen, as shown in ). Each participant was assigned to two sessions, one selected from three different voice loudness conditions and the other selected from three different response latency conditions. During the session, participants wore a headset (AKG: HSC-200); they heard the system's voice from the headphone speakers of the headset and they spoke their answer into the microphone of the headset. These sessions were counter-balanced across three conditions of two parameters to avoid the order effect.
3.5 Analysis
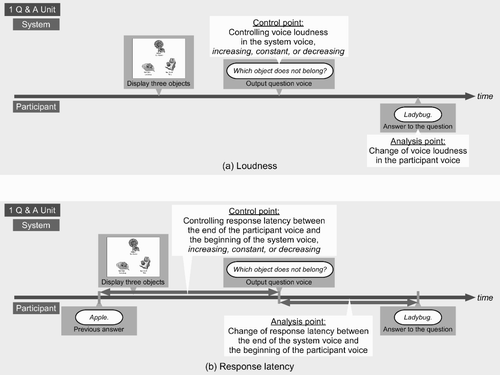
All human–computer interactions were videotaped and digitized. Utterances are transcribed. shows the control and analysis points for each parameter of loudness and response latency. Using Wavesurfer software (Sjolander and Beskow Citation2000), the speech segmentation, or the duration between the end of the system voice and the beginning of the participant voice, was hand-measured after the session. The loudness in the participant voice was also calculated by using the analysis function of this software.
Figure 3. Control and analysis points for each parameter: (a) loudness (upper); (b) response latency (lower).
4. Results
4.1 Voice loudness
compares the average voice loudness in the participants’ responses between the first half and the second half of a session.
Figure 4. Result 1: voice loudness differences among participants.
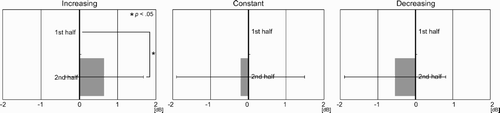
Three paired t-tests using within-subjects analysis were performed for each of the voice loudness conditions of the system's questions (α=0.05). There was a significant difference between voice loudness in participants’ voices in the first half and in the second half under the increasing condition (t=2.30, p<0.05, SD=0.97). However, there was no significant difference in voices between the two halves under the constant (t=0.57, p=0.58, SD=1.25) or decreasing condition (t=1.68, p=0.12, SD=1.12).
While participants may produce louder responses to slight changes in the increasing voice loudness in the system's question voice, participants do not always respond congruently with bidirectional changes, in either the increasing direction or decreasing direction. These results partly support our predictions.
4.2 Response latency
illustrates the average response latency between the computer and participant voices, again comparing the first half with the second half of a session.
Figure 5. Result 2: differences in response latency between computer and participant voices.

Three paired t-tests using within-subjects analysis were performed for each of the response latency conditions used for the system's questions after the participants’ answers (α=0.05). There was a significant difference in response latency between the participants’ voices in the first half and those in the second half under the decreasing condition (t=2.87, p<0.05, SD=0.50). However, there was no significant difference between the two halves under the constant condition (t=0.38, p=0.71, SD=0.14) or the increasing condition (t=0.91, p=0.38, SD=0.30).
While participants may produce responses after a shorter pause duration according to slight changes in the decreasing response latency after the system's question voice, they do not always respond congruently with bidirectional change, in either increasing or decreasing directions. These results also partly support our predictions.
5. Discussion
The preceding results partly support our prediction based on previous studies of prosodic alignment in interpersonal conversations (Matarazzo and Wiens Citation1967, Jaffe and Feldstein Citation1970, Meltzer et al. Citation1971, Welkowitz and Kuc Citation1973, Natale Citation1975) and in human–computer interaction (Darves and Oviatt Citation2002, Coulston et al. Citation2002). In this paper, voice prosody in participants’ responses during interaction did not clearly align bidirectionally to the voice prosody of a computer.
The main reason is due to the parameter settings of the prosody, i.e. voice loudness and response latency, of the computer voice used in this experiment. Both types of variation in the prosodic parameters of the computer voices were too slight to induce bidirectional prosodic alignment from participants. However, users could align to the prosodic changes in the system unidirectionally, which is easy to adjust for people, for either a louder voice or a shorter response latency. In other words, people may align more quickly and strongly to one out of two directions according to the human tendency of making one's replies quicker or louder as time goes on.
There are theoretical and practical implications of these findings for human–android interaction. A theoretical implication is that prosodic alignment by a user toward a computer is powerful and easy to manipulate. Even in a simple form, it might provide a way to induce ethopoeia, the mutual alignment at the prosodic level between people and robots, including androids. In human–human interaction, people, both consciously and unconsciously, express interactive alignment to establish rapport and to feel empathy from such behaviours of their partner. Many studies have found that interactive alignment expresses interest, agreement or understanding of ideas and attitudes. As a typical example, Rogerian psychotherapy uses these mirroring strategies to encourage further communication because it signifies interest and implies an empathic attitude (Rogers Citation1961). In human behavioural science, postural echo is regarded as one of the positive signs of attentiveness, interest or liking, especially with familiar partners (e.g. Morris Citation1977). Welkowitz and Kuc (1972) found interrelationships between temporal congruence and partners’ warmth in human–human interaction. Connor et al. Citation(2000) observed that wild dolphins often swam and dived in precise synchrony with their alliance partners. In human–computer interaction, the authors’ previous work examined the interrelationships between computer-mirrored user intonation by humming and having a familiar impression of the computer (Suzuki et al. 2003a). On the other hand, the results in this paper also suggest that a computer with limited anthropomorphic functions could induce the condition of ethopoeia, through prosodic alignment, from the user. This possibility seems promising for human–android interaction design since it involves enhancing the ethopoeia of people rather than modifying android design itself.
As a practical implication, this research shows that it is possible to achieve more natural human–computer interaction by managing prosody in a user's voice. To the extent that androids, including spoken dialogue systems, can exploit people's prosodic alignment tendencies to enhance their speech as a conversational partner, our approach may provide a simple but effective tool for error management: an android simply monitors prosodic changes by using acoustic processing and outputs speech by adaptively controlling prosody to guide a user's voice to a range of speech recognition coverage. This would help to achieve more sophisticated speech-error management in interaction between people and robots, including androids. An android is not designed to ask users to repeat utterances or to output its failure to understand when it misrecognizes the users’ utterances. In other words, it would also be possible to design easier and more natural voice interaction with androids, especially for young children and elderly people.
6. Conclusions
In this paper, we have focused on a human behavioural tendency, prosodic alignment, as one of the minimal social cues to enhance social acceptance and interpersonal relations between people and androids. To avoid the pitfalls of the uncanny valley, we might explore ethopoeia or human behavioural tendencies as well as anthropomorphism or similarity to human behaviour and appearance. In other words, we can try to examine the design of interaction with androids as well as the design of the androids themselves.
We introduced preliminary results by using a simple experiment to examine the prosodic alignment of people to a system according to slight prosodic changes, i.e. voice loudness or response latency, which were observed in interpersonal conversations. As a result, we found that participants’ speech during interaction with the system aligned at least unidirectionally, even though it was not clearly adapted bidirectionally. While participants produced a louder voice in response to slight increases in the loudness of the system's voice, they did not produce a softer voice in response to slight decreases in loudness of the system's voice. Moreover, while participants produced a shorter response latency in response to a slight decrease in the response latency in the system's voice, they did not produce a longer response latency based on slight increases in the response latency in the system's voice. We confirmed that people tend to align to the system at the prosodic level, even when the system outputs slight prosodic changes within a short session.
As future work, we shall examine the minimal parameter settings that induce bidirectional behaviour in user prosodic alignment, e.g. both louder and softer and both longer and shorter, even without embodied characters. We shall also highlight other prosodic features in voice, such as modulation, rhythms, pitch range and speech rate, to compare the human synchronous tendency in human–computer interaction with that in human–human conversations. We shall further examine the effects of interactiveness or responsiveness on the direction of prosodic alignment from users to embodied characters, including androids. These investigations will permit a comprehensive evaluation of the relationship between the inducement of human behavioural tendencies and the quality of human–android interaction with empathy or intimacy.
Acknowledgements
The authors would like to thank Prof. Hideki Kawahara for permission to use the STRAIGHT system. We also thank Yoshinori Sakane and Takugo Fukaya for their technical help. The research reported here was supported in part by a contract with the National Institute of Information and Communications Technology of Japan (NICT) entitled ‘A study of innovational interaction media toward a coming high functioned network society’.
Related Research Data
References
- Bell , L. , Gustafson , J. and Heldner , M. 2003 . Prosodic adaptation in human–computer interaction . ICPhS2003 , : 2453 – 2456 .
- Breazeal , C. F. 1998 . Early experiments using motivations to regulate human–robot interaction . AAAI Fall Symposium: Emotional and Intelligent. The Tangled Knot of Cognition , : 31 – 36 .
- Connor , R. C. , Wells , R. S. , Mann , J. and Read , A. J. 2000 . “ The bottlenose dolphin: social relationship in a fission-fusion society ” . In Cetacean Societies: Field Studies of Dolphins and Whales , Edited by: Man , J. , Connor , R. C. , Tyack , P. L. and Whitehead , H. 91 – 126 . Chicago : Chicago University Press .
- Couper-Kuhlen , E. 1996 . “ The prosody of repetition: on quoting and mimicry ” . In Prosody in Conversation—Interactional Studies , Edited by: Couper-Kuhlen , E. and Selting , M. 366 – 405 . Cambridge : Cambridge University Press .
- Coulston , R. , Oviatt , S. and Darves , C. 2002 . Amplitude convergence in children's conversational speech with animated personas . ICSLP2002 , : 2689 – 2692 .
- Darves , C. and Oviatt , S. 2002 . Adaptation of users’ spoken dialogue patterns in a conversational interface . ICSLP2002 , : 561 – 564 .
- Duffy , B. R. 2002 . Anthropomorphism and the social robot . IEEE/RSG IROS-2002 ,
- Fong , T. , Nourbakhsh , I. and Dautenhahn , K. 2003 . A survey of socially interactive robots . Robot. Auton. Syst. , 42 : 143 – 166 .
- Giles , H. , Mulac , A. , Bradac , J. and Johnson , P. 1987 . “ Speech accommodation theory: the first decade and beyond ” . In Communication Yearbook , Edited by: McLaughlin , M. L. Vol. 10 , 13 – 48 . Beverly Hills, CA : Sage .
- Ishiguro , H. 2005 . Android science-toward a new cross-interdisciplinary framework- . CogSci2005 Workshop Toward Social Mechanisms of Android Science , : 1 – 6 .
- Jaffe , J. and Feldstein , S. 1970 . Rhythms of Dialogue , New York : Academic Press .
- Kawahara , H. , Masuda-Katsuse , I. and de Cheveigne , A. 1999 . Restructuring speech representations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequency-based F0 extraction: possible role of a repetitive structure in sound . Speech Commun. , 27 : 187 – 207 .
- Matarazzo , J. D. and Wiens , A. N. 1967 . Interviewer influence on durations of interviewee silence . Exp. Res. Personal. , 2 : 56 – 69 .
- Matarazzo , J. D. , Weitman , M. , Saslow , G. and Wiens , A. N. 1963 . Interviewer influence on durations of interviewee speech . Verbal Learn. Verbal Behav. , 1 : 451 – 458 .
- Matarazzo , J. D. , Wiens , A. N. , Saslow , G. , Dunham , R. M. and Voas , R. 1964 . Speech durations of astronaut and ground communicator . Science , 143 : 148 – 150 .
- Meltzer , L. , Morris , W. N. and Hayes , D. P. 1971 . Interruption outcomes and vocal amplitude: explorations in social psychophysics . Personal. Social Psychol. , 18 : 392 – 402 .
- Morris , D. 1977 . Manwatching: A Field Guide to Human Behavior , London : Jonathan Cape .
- Reeves , B. and Nass , C. 1997 . The Media Equation: How People Treat Computers, Televisions, and New Media Like Real People and Places , New York : Cambridge University Press .
- Nass , C. and Lee , K. M. 2000 . Does computer-generated speech manifest personality? . CHI2000 , : 329 – 336 .
- Natale , M. 1975 . Convergence of mean vocal intensity in dyadic communication as a function of social desirability . Personal. Social Psychol. , 32 : 790 – 804 .
- Ono , T. , Imai , M. and Ishiguro , H. 2001 . A model of embodied communications with gestures between humans and robots . CogSci2001 , : 732 – 737 .
- Pickering , M. J. and Garrod , S. 2004 . Toward a mechanistic psychology of dialogue . Behav. Brain Sci. , 27 : 169 – 225 .
- Rogers , C. 1961 . On Becoming a Person , Boston : Houghton Mifflin .
- Suzuki , N. , Takeuchi , Y. , Ishii , K. and Okada , M. 2003 . Effects of echoic mimicry using hummed sounds on human–computer interaction . Speech Commun. , 40 : 559 – 573 .
- Suzuki , N. and Katagiri , Y. 2003 . Prosodic synchrony for error management in human–computer interaction . ISCA Workshop on Error Handling in Spoken Dialogue Systems , : 107 – 111 .
- Sjolander , K. and Beskow , J. 2000 . Wavesurer—an open source speech tool . ICSLP2000 , : 464 – 467 . Available online at: http://www.speech.kth.se/wavesurfer
- Webb , J. T. 1972 . “ Interview synchrony: an investigation of two speech rate measures in an automated standardized interview ” . In Studies in Dyadic Communication , Edited by: Siegman , A. A. and Pope , B. 115 – 133 . Oxford : Pergamon Press .
- Weizenbaum , J. 1966 . A computer program for the study of natural language communication between man and machine . Commun. Assoc. Comput. Machin. , 9 : 36 – 45 .
- Welkowitz , J. and Kuc , M. 1973 . Interrelationships among warmth, genuineness, empathy and temporal speech patterns in interpersonal interaction . Consult. Clin. Psychol. , 41 : 472