Abstract
Learning the meanings of words requires coping with referential uncertainty – a learner hearing a novel word cannot be sure which aspects or properties of the referred object or event comprise the meaning of the word. Data from developmental psychology suggest that human learners grasp the important aspects of many novel words after just a few exposures, a phenomenon known as fast mapping. Traditionally, word learning is viewed as a mapping task, in which the learner has to map a set of forms onto a set of pre-existing concepts. We criticise this approach and argue instead for a flexible nature of the coupling between form and meanings as a solution to the problem of referential uncertainty. We implemented and tested the model in populations of humanoid robots that play situated language games about objects in their shared environment. Results show that the model can handle an exponential increase in uncertainty and allows scaling towards very large meaning spaces, while retaining the ability to grasp an operational meaning almost instantly for a great number of words. In addition, the model captures some aspects of the flexibility of form-meaning associations found in human languages. Meanings of words can shift between being very specific (names) and general (e.g. ‘small’). We show that this specificity is biased not by the model itself but by the distribution of object properties in the world.
1. Introduction
One of the greatest challenges in acquiring a lexicon is overcoming the inherent referential uncertainty upon hearing a novel word. This is because linguistic symbols embody a rich variety of perspectives – speakers use different words to draw the attention of the hearer to different aspects of the same object or event. Some of these contrasts are generality–specificity (‘thing’, ‘furniture’, ‘chair’, ‘desk chair’), perspective (‘chase–flee’, ‘buy–sell’, ‘come–go’, ‘borrow–lend’) and function (‘father’, ‘lawyer’, ‘man’, ‘American’) or (‘coast’, ‘shore’, ‘beach’) (Langacker Citation1987). Just from perceiving an object and hearing a word that supposedly describes that object, a word learner cannot know the intended meaning of the word. This problem is commonly related to the term ‘referential indeterminacy’. Quine Citation(1960) presented an example picturing an anthropologist studying the – unknown to him – language of a tribe. One of the natives utters the word ‘gavagai’ after seeing a rabbit. How can, even after repeated uses of this word, the anthropologist ever come to know the meaning of ‘gavagai’? It could mean rabbit, an undetached rabbit part, food, running animal or even that it is going to rain. Children are very good at dealing with this problem. From the age of around 18 months to the age of 6 years, they acquire on average nine new words a day (or almost one per waking hour). They can infer usable word meanings on the basis of just a few exposures, often without explicit training or feedback – a phenomenon that is known as fast mapping (Carey Citation1978; Bloom Citation2000).
Word learning is commonly viewed as a mapping task, in which a word learner has to map a set of forms onto a set of pre-established concepts (Bloom Citation2000). The implicit assumption is that learners have access to a number of potential meanings and they need to choose (or guess) the correct one. Building on this assumption, several solutions to the problem of referential uncertainty have been theorised. One proposal is that the learner is endowed with several word-learning constraints (or biases) that guide him towards the right mapping (Gleitman Citation1990; Markman Citation1992). Although the problem of referential uncertainty is acknowledged in this approach, it is also largely circumvented by claiming that learners are able to almost instantaneously establish a mapping between a novel word and its meaning. Another suggestion proposes that learners enumerate all possible meanings the first time they are confronted with a novel word and prune this set in subsequent communicative interactions that involve the same word. This approach, while taking into account the problem of referential uncertainty, does not explain fast mapping. Smith, Blythe and Vogt Citation(2006) have shown that under the assumption of atomic word meanings, large vocabularies are learnable through cross-situational learning. But the time needed to grasp a usable meaning far exceeds the number of exposures as observed in children, especially when scaling to high-dimensional meaning spaces. This is why often these two proposals go together: word learners use constraints to make a limited list of initial mappings and rule out all except one hypothesis later on.
Instead of characterising a child as identifying the meaning of a word from a set of plausible possibilities, Bowerman and Choi Citation(2001) envision the child as constructing and gradually shaping word meanings. The hypothesis is that ‘\dots the use of words in repeated discourse interactions in which different perspectives are explicitly contrasted and shared, provide the raw material out of which the children of all cultures construct the flexible and multi-perspectival – perhaps even dialogical – cognitive representations that give human cognition much of its awesome and unique power’ (Tomasello Citation1999, p. 163). Although in this view learners also make guesses at the meanings of novel words, they are different in nature. Children cannot have at hand all the concepts and perspectives that are embodied in the words of the language they are learning – they have to construct them over time through language use. ‘For example, many young children overextend words such as dog to cover all four-legged furry animals. One way they home in on the adult extension of this word is by hearing many four-legged furry animals called by other names such as horse and cow’ (Tomasello Citation2003, pp. 73–74). Moreover, the enormous diversity found in human natural languages (Levinson Citation2001; Haspelmath, Dryer, Gil and Comrie Citation2005) and the subtleties in word use (Fillmore Citation1977) suggest that language learners can make few a priori assumptions, and even if they could, they still face a towering uncertainty in identifying the more subtle aspects of word meaning and use.
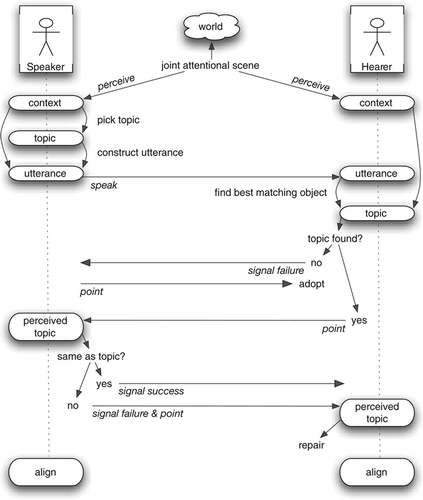
The problem of referential uncertainty differs depending on which of the above views on word learning is followed. In this article, we present a computational model to deal with referential uncertainty that does not rely on enumerations of possible meanings or word-learning constraints. Instead, we argue for truly flexible representations of meanings and mechanisms for shaping these word meanings through language use. We implemented the model in physical robotic agents that can perceive the world through their cameras and have mechanisms to engage in communicative interactions with other robots. Populations of these robots play language games (Wittgenstein Citation1967; Steels Citation2001) about objects in their shared environment (). These games are routinised interactions in which a speaker tries, using language, to draw the attention of a hearer to a particular object in a shared scene. The speaker and hearer give each other feedback as to whether this was successful, and point to the intended object in cases of failure. This allows the population, over the course of many interactions, to self-organise a language to talk about physical objects. Note that agents are implemented such that they do not have access to internal representations of other agents – there is no meaning transfer, telepathy or central control.
Figure 1. Sony QRIO humanoid robots play a language game about physical objects in a shared scene.

A long history of experiments already exists on the emergence of communication systems in the language game paradigm, both in simulated worlds and with robots interacting in real environments. Since the early 1990s, complexity has steadily increased in the agents’ communicative task, and thus also in the nature of the coupling between form and meaning. One of the first models of lexicon formation was the Naming Game (Steels Citation1995), in which simulated agents have to agree on names for pre-conceptualised individual objects. Technically, they had to establish one-to-one mappings between words and (given) symbolic representations without internal structure as illustrated in . The problem of referential uncertainty does not appear in the naming game – when a speaker points to an object, it is immediately clear for the hearer which individual concept to associate with a novel word. The main focus in the naming game was on the problem of how to reach lexical conventions and coherence in a population of interacting agents. Since each agent can invent new words, different words with the same meaning (synonyms) spread in the population, which poses a problem for reaching coherence. In a default naming game implementation agents keep different hypotheses about the meaning of a word in separate one-to-one mappings between names and individuals. Each mapping is scored and synonymy damping mechanisms, mainly based on lateral inhibition acting on these scores, were proposed to cope with the problem of incoherence.
Figure 2. Increasing complexity in the nature of the coupling between form and meaning. Hypothetical example lexicons of one agent are shown for four different models of lexicon formation. Line widths denote different connection weights (scores). (a) One-to-one mappings between names and individuals in the naming game. There can be competing mappings involving the same individual (synonyms). (b) One-to-one mappings between words and single features in guessing games. In addition to synonymy, there can be competing mappings involving the same words (homonymy). (c) Many-to-one mappings between sets of features and words. In addition to synonymy and homonymy, words can be mapped to different competing sets of features that partially overlap each other. (d) Associations as proposed in this article. Competition is not explicitly represented but words have flexible associations to different features that are shaped through language use.
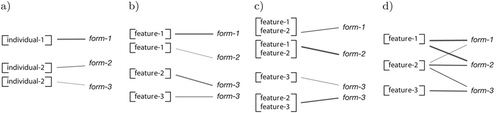
When objects in the world are not represented as holistic symbols but, instead, different conceptualisations for the same object are possible, the problem of referential uncertainty appears. For example, in Guessing Games such as the Talking Heads experiment (Steels and Kaplan Citation1999), agents establish scored one-to-one mappings between words and perceptually grounded categories (or features, see . Hearers need to guess which sensory quality (size, colour, position, etc.) a word is about and then choose an appropriate feature for that quality. In addition to synonymy, agents can adopt mappings to different features for the same word (homonymy). The amount of referential uncertainty, as measured by the number of different hypotheses, equals the number of different features of an object representation. One proposed mechanism to overcome this uncertainty is a word-learning constraint: agents choose the sensory quality that is most salient in the scene (the difference between the topic and other objects in a scene is the highest for that quality). More prominently, cross-situational learning (Siskind Citation1996; Smith Citation2005; De Beule, De Vylder and Belpaeme Citation2006; Smith et al. Citation2006; Vogt and Divina Citation2007) has been shown to successfully solve the problem. In this approach, agents enumerate all possible meanings upon hearing a novel word and gradually refine this set by memorising co-occurrences between forms and meanings. After many interactions, the mapping with the highest co-occurrence wins over the others and is used as the meaning of the word.
In natural language, words may refer to more than just single features such as (red) or (small). One of the first models that allowed mappings between words and combinations of features as illustrated in was introduced by Van Looveren Citation(1999). It was shown to work when the number of object features is low. Since the meaning of a word can be any subset of the features of an object, referential uncertainty increases exponentially, as opposed to linearly in the guessing games outlined above. Suppose an object is represented by 60 features. The number of all possible subsets of these 60 features is 1.152921 × 1018. Cross-situational approaches as outlined above become truly unfeasible since an agent cannot enumerate the long list of hypotheses, which would be necessary to memorise co-occurrence relations. De Beule and Bergen Citation(2006) have shown that when there is competition between specific (many features) and general (one feature) words, general words will win over the specific ones because they are used more often – resulting again in a one-to-one mapping such as that in .
In the model presented in this article, uncertainty is captured in the representation of word meaning itself (. Instead of competing mappings that connect different sets of features to the same word, words have flexible connections to different features that are constantly shaped by language use. The model can be seen as an extension of cross-situational learning, with the key difference that there is no enumeration of competing hypotheses, and therefore the model can scale to very high-dimensional hypothesis spaces. Learners do not make guesses, or choose from enumerations of possible meanings because the uncertainty is simply too great. The remainder of this article is structured as follows. In the next section, we outline the experimental set-up that we use to test our approach. The model itself is explained in Section 3. Experimental results are presented in Section 4 and discussed in Section 5.
2. Interacting autonomous robots
The robotic set-up used in this experiment is similar to other experiments that investigate the cultural transmission of language in embodied agents (e.g. Steels and Kaplan Citation1999; Steels and Loetzsch Citation2008; see Steels Citation2001 for an overview). The experimental set-up requires at least two robots with the ability to perceive physical objects in a shared environment using their cameras, to track these objects persistently over time and space and to extract features from these objects. The robots must establish joint attention (Tomasello Citation1995) in the sense that they share the same environment, locate some objects in their immediate context, and know their mutual position and direction of view. Finally, there have to be non-linguistic behaviours for signalling whether a communicative interaction was successful and, in case of failure, the robots need to be able to point to the object they were talking about.
In this experiment, we use QRIO humanoid robots (Fujita, Kuroki, Ishida, and Doi Citation2003) to test our model. The robots are about 60 cm high and weigh 7.3 kg. They have a wide variety of sensors, including two cameras in the head, a microphone, and sensors in each motor joint to monitor posture and movement. Two QRIO robots are placed in an office environment that contains a set of geometric and toy-like coloured objects (). Based on a software developed for robotic soccer (Röfer et al. 2004), we developed a real-time visual object recognition system that can detect and track objects in image sequences captured by the built-in camera at the rate of 30 frames per second (Spranger Citation2008). The robots maintain continuous and persistent models about the surrounding objects using probabilistic modelling techniques. As a result, each agent has a representation of every object in the scene, including estimated position, size, and colour properties (). From each such model, values on 10 continuous sensory channels are extracted. In this experiment, these channels are the position of the object in an egocentric co-ordinate system (x and y), the estimated size (width and height), the average brightness (luminance), average color values on a green/red and a yellow/blue dimension (green-red and yellow-blue), and finally the uniformity of the brightness and colour values within the object (as the standard deviation of all pixels within the object region in the camera image; stdev-luminance, stdev-green-red and stdev-yellow-blue). Note that the language model (see next section) does not depend on the choice of these 10 channels. Any other quality such as shape, texture, weight, sound, softness, etc. could be used, requiring techniques to construct it from the sensorimotor interaction with the environment. Channel values are scaled between 0 and 1. This interval is then split into four regions, a technique that could be compared to discrimination trees (Steels Citation1997; Smith Citation2001). One out of four Boolean features is assigned to an object for each channel according to the intervals of each channel value. For example, the green/red value for obj-506 in is 0.88, so the assigned feature is green-red-4. We refer to the list of objects with their associated features as sensory context.
Figure 3. Visual perception of an example scene for robots A and B. On the top, the scene as seen through the cameras of the two robots and the object models constructed by the vision system are shown. The coloured circles denote objects, the width of the circles represents the width of the objects and the position in the graph shows the position of the objects relative to the robot. Black arrows denote the position and orientation of the two robots. At the bottom, the features that were extracted for each object are shown. Since both robots view the scene from different positions and lighting conditions, their perceptions of the scenes, and consequently the features extracted from their object models, differ. Those features that are different between the two robots are denoted in italics.

As mentioned earlier, populations of software agents play a series of language games. All agents start with empty lexicons and have never before seen any of the physical objects in their environment. Since we have only two physical robots available and wish to model population sizes greater than two, they have to be shared. In each interaction two agents, randomly drawn from the population, embody the two robots to perceive their physical environment. At the start of the interaction, a human experimenter modifies the scene by adding/removing objects or by changing the position/orientation of objects. The agents establish a joint attentional scene (Tomasello Citation1995) – a situation in which both robots attend to the same set of objects in the environment and register the position and orientation of the other robot. Once such a state is reached, the game starts. One of the agents is randomly assigned to take the role of the speaker and the other the role of the hearer. Both agents perceive a sensory context (as described above) from the joint attentional scene. The speaker randomly chooses one object from his context to be the topic of this interaction – his communicative goal will be to draw the attention of the hearer to that object. For this he constructs an utterance, inventing new words when necessary and eventually uttering these words (these mechanisms are described in detail in the following section). The hearer interprets the utterance using his own lexicon and tries to find the object from his own perception of the scene that he believes to be most probable, given the utterance. It could happen, however, that the hearer is confronted with a novel word or that his interpretation does not match any of the objects in his context. In this case, the hearer signals a communicative failure (by shaking his head). The speaker then points to the object he intended. When the hearer did understand the utterance, he points to the interpreted topic. The speaker then compares this object with the topic that he intended and signals either a communicative success (by nodding his head) or a communicative failure (by pointing to his intended topic). Finally, at the end of each interaction both agents modify their lexicons slightly, based on the sensory context, the topic and the words used (alignment).
Since conducting thousands of such language games with real robots would be more time-consuming and also because we wanted repeatable and controlled experiments, we recorded the perceptions of the two robots (as in ) for 150 different scenes, each containing between two and four different objects of varying position and orientation out of a set of 10 physical objects. A random scene from this collection is then chosen in every language game and the two different perceptions of robots A and B are presented to the two interacting agents. In these simulations, agents point to objects by transmitting the x and y co-ordinates of the objects (in their own egocentric reference system). The agent receiving these co-ordinates can transform them into a location relative to its own position using the offset and orientation of the other robot.
3. A flexible model of word learning
As explained in the previous section, the vision system represents objects as sets of Boolean features. Though we are aware that such a representation lacks the richness needed to capture many interesting phenomena of human language and cognition, we believe this representation is sufficient for investigating the problem of referential uncertainty. Our language model itself is agnostic to the origins of the features. Using such a straightforward representation of objects and allowing the meaning of a word to be any subset of those features, the actual hypothesis space scales exponentially in the number of features. The first step towards a solution is to include uncertainty in the representation of word meaning itself. This is achieved by keeping an (un)certainty score for every feature in a form-meaning association instead of scoring the meaning as a whole. This representation is strongly related to both fuzzy set theory (Zadeh Citation1965), with the degree of membership interpreted as the degree of (un)certainty, and prototype theory (Rosch Citation1973). Although this representation is identical to a fuzzy set, in what follows, we refer to the representation as a weighted set to avoid confusion since we will redefine many set-theoretic operations.
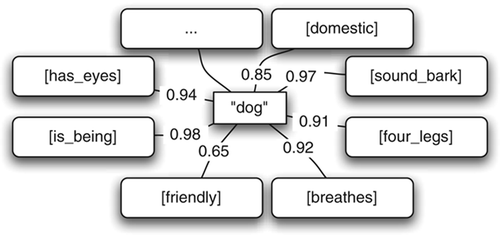
By allowing the certainty scores to change, the representation becomes adaptive and the need to explicitly enumerate competing hypotheses disappears. Thus, in contrast to most cross-situational learning models it is not necessary to maintain and update a set of competing hypotheses. It follows that during production and interpretation (detailed in the following section) there is no need to choose between competing hypotheses since there is only a single hypothesis. As an example, the meaning of the word ‘dog’ in is the complete set of scored associated features. Of course the features coming from the vision system in our experiment are much more basic than those depicted in .
Figure 4. A possible representation for the word ‘dog’ in English. Every feature associated with the form ‘dog’ is scored separately.
3.1 Language use in production and interpretation
It is possible to define a weighted similarity measure for the above representation, taking the certainty scores as weights. Given two weighted sets of features as input, the measure returns a real number between −1 and 1, respectively, denoting disjunction and equality. This weighted similarity measure lies at the core of the model and requires detailed elaboration, but we first need to define some additional functions. Assume a function Features(A) that takes as input a weighted set A and returns the normal set B containing only the features from A, and another function CertaintySum(A) that takes as input a weighted set A and returns a real number representing the sum of all the certainty scores. We can define the following operations as slight modifications of those of the fuzzy set theory:

Note that the function Intersection is not commutative in contrast to its definition in fuzzy set theory because it returns all shared features between A and B but takes the certainty scores from A. In what follows we will also use the union operation on fuzzy sets as defined in Zadeh Citation(1965). It takes the normal union of the two feature sets, but when a feature appears in both A and B it takes the score with greater certainty.
Given these definitions we can define the weighted similarity measure as follows:

Given two weighted sets A and B, Similarity first takes all shared features and all disjoint features from A and B. By using the CertaintySum function we allow the certainty scores to weigh in. It is clear that sharing features is beneficial for the similarity while the opposite is true for features that are not shared. Intuitively, Similarity(A,B) will be high when A and B share many features with high certainty scores. Correspondingly, the result will be low when A and B have many disjoint features with high certainty scores. Some examples:
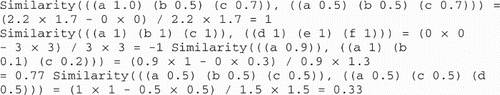
We now have the elements to describe production and interpretation which both rely heavily on this similarity measure. As illustrated in the speaker, after choosing a topic, must find an appropriate utterance to indicate the topic as clearly as possible. This process is called production and is implemented as follows:

Figure 5. Flow of one language game. A speaker and a hearer follow a routinised script. The speaker tries to draw the attention of the hearer to a physical object in their shared environment. Both agents are able to monitor whether they reached communicative success and thus learn from the interaction by pointing to the topic of the conversation and giving non-linguistic feedback. Populations of agents gradually reach consensus about the meanings of words by taking turn being speaker and hearer in thousands of such games.
The ForEach loop will fill productionScores with a score for each unused word in the lexicon not just denoting its similarity to the topic but taking into account its similarity to the rest of the context. For example, if the topic is a red object, but all other objects in the context are also red it does not really help much to use the word ‘red’. The bestNewWord is thus the word with the highest score in productionScores. If the productionScore for bestNewWord improves the average of the productionScores for the utterance built so far, it gets added to the utterance. If not, the search stops. At the end, utterance is that subset of the lexicon that strikes the optimal balance between being most similar to the topic and being most distant from the other objects of the context. This results in context-sensitive multi-word utterances and involves implicit, on-the-fly discrimination using the lexicon.
The most important effect of using a similarity measure is the great flexibility in word combination, especially in the beginning when the features have low certainty scores. Owing to this flexibility, the agents can use (combinations of) words that do not fully conform to the meaning to be expressed, resembling what Langacker Citation(2002) calls extension. The ability to use linguistic items beyond their specification is a necessity in high-dimensional spaces to maintain a balance between lexicon size and coverage (expressiveness).
Interpretation amounts to looking up the meaning of all the uttered words, taking the union of their (fuzzy) feature sets and measuring the similarity between this set and every object in the context. The hearer then points to the object with highest similarity.

3.2 Learning: invention, adoption and alignment
After finding the best possible combination of words to describe the topic, the speaker first tries to interpret his own utterance. In this process – which is called re-entrance (Steels Citation2003) – the speaker places himself in the role of the hearer and thus can check for potential misinterpretations, allowing him to rephrase or remedy the utterance. When re-entrance leads the speaker to a different object than his own, which means that no combination of words can discriminate the topic in the current context, refinement of the lexicon is needed. The speaker invents a new form (a random string) and associates to it, with very low initial certainty scores, all features of the topic that have not yet been expressed in the utterance. Because word meanings can shift, it might not be necessary to introduce a new word. Chances are that the lexicon just needs a bit more time to develop. Therefore high similarity between the meaning of the utterance and the topic translates to a lower likelihood of introducing a new word. In pseudocode the above process can be operationalised as follows:

When the hearer encounters one or more novel words in the utterance, he needs a way to associate an initial representation of meaning with the novel forms. First, the hearer interprets the words he knows and tries to play the game without adopting the novel forms. At the end of the game, when he has knowledge of the topic (), the hearer associates all unexpressed features with all the novel forms. Just as with invention, the initial certainty scores start out very low, capturing the uncertainty of this initial representation. Excluding the features of the already-known words is the only constraint shaping the initial representation. Note that there is no explicit enumeration of competing interpretations:

Flexible word use entails that in a usage event some parts of the meanings are beneficial (the shared parts) and others are not (the disjoint parts). If all features of the used meanings are beneficial in expressing the topic, it would not be extension but instantiation, which is rather the exception than the rule. As Langacker Citation(2002) puts it, extension entails ‘strain’ in the use of the linguistic items, which in turn affects the meanings of these linguistic items. This is operationalised by slightly shifting the certainty scores every time a word is used in production or interpretation. The certainty score of the features that raised the similarity are incremented and the others are decremented. This resembles the psychological phenomena of entrenchment, and its counterpart semantic erosion (also referred to as semantic bleaching or desemantisation). Features with a certainty score less than or equal to 0 are removed, resulting in a more general word meaning. In failed games the hearer adds all unexpressed features of the topic, again with very low certainty scores, to all uttered words, thus making the meanings of those words more specific:

Combining similarity-based flexibility with entrenchment and semantic erosion, word meanings gradually shape themselves to better conform with future use. Repeated over thousands of language games, the word meanings progressively refine and shift, capturing frequently co-occurring features (clusters) in the world, thus implementing a search through the enormous hypothesis space, and capturing only what is functionally relevant.
4. Experimental results
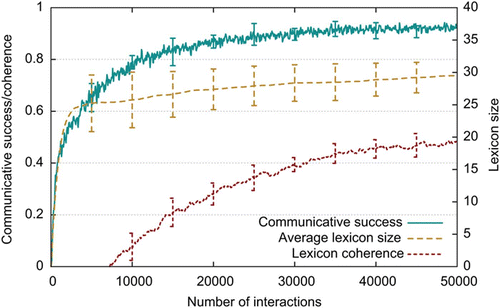
We tested our model by letting populations of 25 agents play repeated series of 50,000 language games. After only a few thousand games the agents reach their final lexicon size of 25–30 words (). Also from very early on (at around interaction 10000), the agents communicate successfully in more than 80% of the cases. On average each of the 25 agents takes part in only 800 out of 10,000 interactions and thus plays only 4000 games in total. Although the agents can communicate successfully almost from the start, coherence is low (even negative) in the beginning, which means that the agents associate very different feature sets to each word form. Coherence continuously increases over the course of the following interactions, and after 50,000 games, communicative success has risen to 95%, indicating that the agents progressively align their word meanings.
Figure 6. Dynamics of the language games in a population of 25 agents averaged over 10 runs of 50000 interactions. Values are plotted for each interaction along the x-axis. Communicative success: for each successful interaction (the hearer understands the utterance and is able to point to the object that was chosen as topic by the speaker), the value 1 is recorded, for each failure, 0. Values are averaged over the last 100 interactions. Average lexicon size: the number of words each agent knows is averaged over the 25 agents of the population. Lexicon coherence: this is a measure of how similar the lexicons of the agents are. For each word form known in the population, the similarity function described in Section 3.1 is applied to all pairs of words known by different agents and the results are averaged. The value 1 means that all 25 agents have identical lexicons,−1 means that they are completely different (each agent associates completely different feature sets to each word form), and the value 0 means that the number of shared and non-shared features in the words of different agents is equal. Error bars are standard deviations across the 10 different experimental runs.
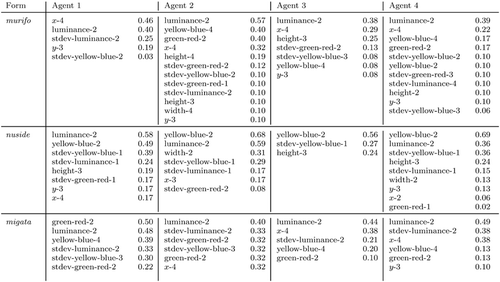
To explain the very low initial lexicon coherence, lists the meanings of the first three words of agent 1 after 10,000 interactions (communicative success ≈ 80%) and compares them with the meanings that agents 2, 3, and 4 connect to these forms. For each word, the features associated to it and the scores of the association are shown (sorted by score). It is immediately clear why lexicon coherence is so low in the population: each agent indeed associates drastically different feature sets of highly varying size to the same word forms. For example, all four agents associate different height information to the word ‘murifo’: agent 1, none; agent 2, height-4 and height-3; agent 3, height-3; and agent 4, height-2. The number of features connected to the word ‘nuside’ ranges from three (agent 3) up to nine (agent 4). For nearly every word form, each agent associates at least one feature that no other agent connects to the same form. Words can even be associated to multiple features on the same sensory channel. For example, agent 4 has the features yellow-blue-2 and yellow-blue-4, as well as stdev-yellow-blue-2 and stdev-yellow-blue-3 in its feature set for the word ‘murifo’. The agents could not, however, communicate successfully if word meanings were not (at least) partially shared. Despite all the differences, the meanings of the three words in start to emerge: (almost) all agents associate x-4, y-3, luminance-2 and yellow-blue-4 to the word ‘murifo’, giving it the meaning ‘far, left, uniformly dark, and blue’. For ‘nuside’, the features yellow-blue-2, luminance-2, height-3, and stdev-luminance-1 are shared, meaning ‘high and uniformly yellow’. The third word ‘migata’ is associated by most of these four agents with green-red-2, luminance-2, yellow-blue-4, and x-4 (‘far and turquoise’). This level of coherence is already enough for the agents to communicate successfully in many different contexts. Coherence continuously increases during the remaining 40,000 interactions (), allowing the agents to communicate successfully in 95% of the cases after 50,000 interactions.
Figure 7. The meanings of the first three words of agent 1 (out of a population of 25 agents) and the corresponding meanings in the lexicons of agents 2, 3, and 4 after 10,000 interactions. The numbers on the right side are scores of the association to the feature.
In order to understand how the agents are able to align their initially very different lexicons, we looked at how the meanings of single words in one agent evolve over time. Not surprisingly, word meanings are extraordinary flexible and shift constantly. gives four examples of the changing association of word forms to different features. A word that constantly changes its dominant meaning is shown in . It is invented or adopted at around interaction 6000 and subsequently undergoes many meaning shifts. Over time, the highest association scores are to height-3 (interaction 7000), yellow-blue-2 (interaction 16,000), width-2 (21,000 – 36,000), and luminance-2 (40,000). Despite that, many other features become temporarily associated with the word, but are immediately discarded. The situation stabilises towards the end, giving the word its final meaning ‘narrow, dark, yellow’. In contrast, is an example of a rather unsuccessful word. The initial meanings disappear quite soon and at around interaction 5000, a stable set of three features arises. This meaning does not seem to spread over the population, and the word loses all its features after 22,000 interactions. Thereafter, the agent does not himself use the word in production, but other agents in the population still use it, leading to new associations with features, which also ultimately remain unsuccessful.
Figure 8. Examples of flexible word meanings. A population of 25 agents played 50,000 language games. Each graph shows, for one particular word in the lexicon of agent 1, the strength of the association to different features. In order to keep the graphs readable, the agents have access only to a subset of the 10 sensory channels (width, height, luminance, green-red, yellow-blue).
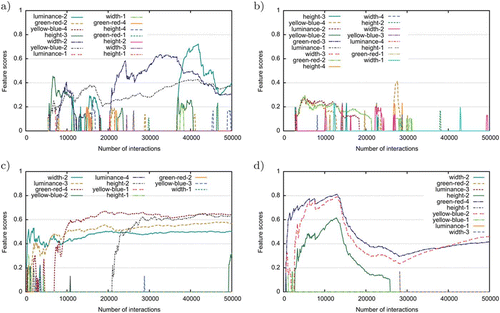
In our model, words can be associated with any number of features. They can be very general, connected to only one feature (words such as ‘red’ or ‘small’). They can also be very specific, similar to names, with connections to many features. And they can shift from general to specific and back. Despite some other associations that disappear very quickly, the word in is initially only connected to width-2. Over the course of many interactions, more and more features are associated (luminance-3 at around interaction 3000, green-red-4 at interaction 7000, and finally height-2 at interaction 22000). So, this word changed from being very general (‘thin’) to very specific (‘thin, low, bright, and red’). The word in is an example of the opposite. It starts very specific, with connections to green-red-4, yellow-blue-2, height-2, width-2, luminance-3 (‘orange, small, and bright’). It loses most of these features, becoming very general (‘orange’) towards the end.
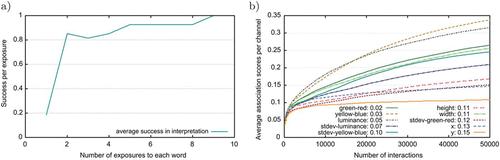
As mentioned earlier, human learners can infer usable meanings for a novel word after only a few exposures. The graph in does not give us any insight into this issue, as it is about a population in the process of bootstrapping a lexicon. To investigate whether our model performs comparably with fast mapping, we added a new agent to a population that had already conventionalised a shared lexicon. The new agent only takes the role of a hearer, resembling a child born in a population that speaks a fairly stable language. The results, as depicted in , show that by the time of the second exposure 85% of the novel words lead to a successful interpretation. Further exposures gradually improve this result and by the 10th exposure all words result in a successful interpretation. This is even more surprising, given that the other members of the population are unaware that they are talking to a new agent, and thus use multi-word utterances, making it harder for the new agent to grasp the meanings of the words. In 20% of the cases, the new agent successfully interprets the utterance on the very first exposure to a new word because he understands enough of the other words to be able to point correctly.
Figure 9. (a) The interpretation performance of one new agent that is added to a stabilised population. For each word this agent adopts, the communicative success at the first, second, third, etc. exposure is measured and averaged over all the words in the lexicon of that agent. (b) The impact of the different perceptions on the lexicon: for each sensory channel, the average association score for channel features is shown, given all words in the population. In the legend, for each channel the average difference between the perception of robots A and B for all scenes in the data set is shown.
When agents are embodied in physical robots, they have to deal with perceptual noise. The two robots view the scene from different angles and under different lighting conditions, leading to different perceptions of the same physical objects. However, the similarity in perception varies depending on the sensory channel. The average distance between the perception of a physical object between robots A and B on each sensory channel is shown in the legend of . This distance is computed by iterating over all objects of all scenes in the data set and for each sensory channel averaging the distances of the sensory values between the two robots. From the result we see that the most reliable sensory channels are green-red (average distance 0.02), yellow-blue (0.03), and luminance (0.05). The most varied channels show a very high level of difference, which makes them less suitable for successful communication: y (0.15), x (0.13), and stdev-green-red (0.12). The quality of a sensory channel is reflected in the agents’ lexicons. shows the strength with which features are associated, for each sensory channel. This average score is computed for each channel by iterating over all the words in the population and averaging the scores of connections to features on that channel. The highest average scores are for features on the yellow-blue, luminance, and green-red channels, the lowest for features on y, x, and stdev-green-red. This corresponds perfectly to the average sensory differences on these channels, showing that the agents cope with perceptual differences by relying less on unreliable channels.
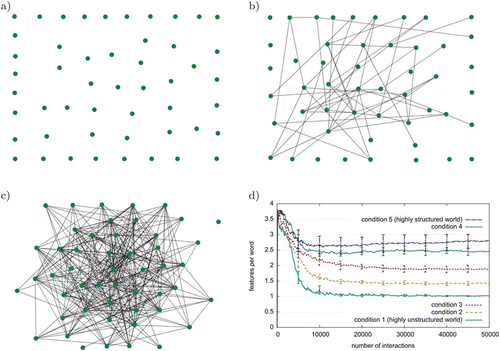
The world in which the robots interact ‘is structured because real-world attributes do not occur independently of each other. Creatures with feathers are more likely also to have wings than creatures with fur, and objects with the visual appearance of chairs are more likely to have functional sit-on-ableness than objects with the appearance of cats. That is, combinations of attributes of real objects do not occur uniformly. Some pairs, triples, or n-tuples are quite probable, appearing in combination sometimes with one, sometimes another attribute; others are rare; others logically cannot or empirically do not occur’ (Rosch, Meruis, Gray, Johnson, and Boyes–Braem Citation1976, p. 383). For example, objects that are yellow also tend to be bright, tall objects are often also wide, and so on. This structure in the world is also reflected in the structure of the lexicons. Features that co-occur often will co-occur in the meanings of words. Since we cannot control the distributional properties of the object features in our previously recorded embodied data, we ran our model on a simulated world where such control is possible. We represented 50 features as nodes of a directed graph as shown in –10c. Each node from index 1 to 50 was assigned a linearly decreasing probability for being attached to an edge. For different experimental conditions, a varying number of edges were added to the graph by connecting nodes randomly depending on their attachment probabilities. In each interaction, a sensory context similar to those in and consisting of five objects, each represented by five features is generated. Features were drawn by randomly selecting a node and taking also its neighbours having lower indices, until five features were chosen. The amount of structure in the world was controlled by the number of edges added to the graph: no edges in condition 1 (highly unstructured world, see , 20 in condition 2, 50 in condition 3 (, 100 in condition 4, and 400 in condition 5 (highly structured world, see . We then ran series of 50,000 language games with populations of 25 agents that are identical to those in the experiments above, except that they use perceptions from the five differently structured simulated worlds, and compared the emerging lexicons as shown in . In condition 1, features co-occur completely randomly, making any attempt to capture re-occurring patterns in the world useless. This is clearly reflected in the lexicons of the agents. After about 10,000 interactions, the words become essentially direct mappings of one feature to one form. On the other hand, objects in condition 5 show very high regularity, allowing the agents to create very specific words for specific objects. As a result, the average number of features covered in condition 5 is 2.75. The values for conditions 2–4 are between these extremes. This shows that in our model the specificity of words is not biased by the model itself but is a direct function of the structure in the world.
Figure 10. The effect of the amount of structure in a simulated world on the structure of the emerging language. Features are represented as nodes in a directed graph and feature nodes that are connected by edges will occur together in simulated perceptions of the world. (a)–(c) The co-occurrence graph used in conditions 1 (highly unstructured world), 3 and condition 5 (highly structured world). (d) The average number of features associated to each word for conditions 1–5. Values are averaged over all words in the population. Error bars are standard deviations over 10 repeated series of 50,000 language games each.
5. Discussion and conclusion
In this article, we introduced a new model of word learning to deal with the problem of referential uncertainty. It does not rely on the simplifying assumptions made in previous models and instead builds on the idea that in order to tackle the uncertainty one must embrace it. We therefore argue for an adaptive representation of meaning that captures uncertainty at its core. This representation needs to be accompanied by a flexible manner of language use, captured in our model by defining a similarity measure. From this flexible use it follows that some parts of a meaning are beneficial, and others are not, opening the possibility for entrenchment and semantic erosion effects. Combining these ideas and repeating their effects over thousands of interactions results in a highly adaptive communication system with properties resembling some aspects also found in human languages. We tested the model in populations of physical robotic agents that engage in language games about objects in the real world. The results show that the model performs remarkably well, despite the difficulties arising from embodiment in robots and the high population size of 25 (compared with similar experiments).
In most previous experiments on lexicon formation, words are mapped to single components of meaning (individuals, categories, or other features). Even in models where words can map onto sets of features, the dynamics are such that the agents finally arrive at one-to-one mappings between words and features (De Beule and Bergen Citation2006). This is due to the assumption that general words and specific words compete (against each other). Suppose there is a word ‘yellow’ for the meaning [yellow], ‘fruit’ for [fruit] and ‘banana’ for [yellow, fruit]. When there are other objects in the world that are also [yellow] or [fruit], the words ‘yellow’ and ‘fruit’ will win the competition over ‘banana’ because they are used more often. But in natural languages, different perspectives on the same object such as ‘yellow’ and ‘banana’ are clearly not competing but instead contribute richness. The model presented in this article does not have a bias towards one-to-one mappings between features and forms – words acquired by the agents can have any number of features associated to them. And pairs of words that share features such as ‘yellow’ and ‘banana’ do not compete because they are successfully used in different communicative situations. Finally, we showed that structure in the world, and not the model itself, biases the structure of language and the specificity of words.
Although there is clear value in investigating the emergence of communication systems in simulated environments, we opted for an experimental set-up using situated robots. Presenting physical robots with a non-trivial communicative task in a rich and open-ended world prevented us from making unrealistic assumptions that were required in other models. For example, common scaffolding techniques such as direct meaning transfer between agents, or pre-conceptualised meanings, are not possible when robotic agents perceive real-world objects with initially unknown properties through cameras. Furthermore, not only the exponential uncertainty but also the complexity of our robotic set-up forced us to endow the agents with more flexible meaning representations and learning mechanisms. Both robots perceive the same scene from different angles, and so they can have drastically different views of the same object (for example the red block in has a much smaller width for robot A (obj-506) than for robot B (obj-527)). This makes guessing the meaning of a novel word even more difficult, because the intended meaning of the speaker might not even be among the different hypotheses constructed by the hearer. We argue that instead of trying to identify the meaning of a word by enumerating possible meanings, learners have to make an initial and necessarily uncertain representation that becomes refined over time. We showed that this actually happens in our model – different agents associate very different sets of features to the same words in the early interactions and then gradually reshape word meanings to reach coherence.
This ‘shaping of meanings’ may make our model appear to be yet another variant of the cross-situational learning techniques as discussed above. But again we want to make very clear that there is a fundamental difference between structured (sets of features) and atomic (single feature) word meaning. We are not aware of any cross-situational learning model that allows meaning to be non-atomic or otherwise coping with exponential uncertainty. Smith et al. Citation(2006) wrote: ‘Firstly, and most importantly, we have considered both words and meanings to be unstructured atomic entities’ (p. 41). Furthermore, the agents in our language game experiments give each other non-linguistic corrective feedback, i.e. the speaker either confirms that the topic pointed at by the hearer was intended or points to the right topic. Lieven Citation(1994) has shown that children are able to learn many, and sometimes all, of their words without such social scaffolds. Vogt and Coumans Citation(2003) have demonstrated that more natural ‘selfish games’ which do not involve such a feedback are more difficult, albeit viable when tackled with cross-situational learning techniques. We did not test our model in such kind of interaction scenarios, but we speculate that the uncertainty stemming from missing feedback is of a lesser magnitude than that resulting from exponentially scaling hypothesis spaces.
Finally, we want to clear some potential misunderstandings. First, we are not unsympathetic to the idea of word-learning constraints, but we believe that constraints only seem crucial when word learning is viewed as a mapping. In this article, we tried to show that by trading the mapping view for a more organic, flexible approach to word learning the constraints become less necessary. Secondly, some developmental psychologists emphasise human proficiency in interpreting the intentions of others (Tomasello Citation2001) and our endowment with a theory of mind (Bloom Citation2000) as main forces in word learning. While being supportive of these ideas and even taking some for granted in our experimental set-up, it is important to understand that intention reading is not telepathy. These abilities might help in dealing with referential uncertainty, but they do not entirely solve the problem. Thirdly, we do not take a position regarding the relation between the terms ‘word meaning’ and ‘concept’. Some researchers use these synonymously (Bloom Citation2000), others advocate that they cannot be one and the same (Levinson Citation2001). In this experiment we did not investigate the subtle interplay between language, cognition, and conceptual development but, instead, implemented a straightforward process from sensory experiences of objects to feature sets. This leads to the last point: since in our model agents have no other task but communicating, and therefore have no other internal representations besides word meanings, we cannot make any claims (pro or contra) regarding Whorf's thesis (Whorf and Carroll Citation1956).
Acknowledgements
The authors are grateful to Masahiro Fujita and Hideki Shimomura of the Intelligent Systems Research Labs at Sony Corp, Tokyo, for graciously making it possible to use the QRIO robots for our experiments. We thank Michael Spranger for his indispensable help with the robotic set-up. This research was carried out at the Artificial Intelligence Laboratory of the Vrije Universiteit Brussel and the Sony Computer Science Laboratory in Paris and Tokyo with additional support from FWOAL328 and the EU-FET ECAgents project (IST-2003 1940). Experiments are done in the Babel 2 framework, which can be freely downloaded from http://www.emergent-languages.org.
References
- Bloom , P. 2000 . How Children Learn the Meanings of Words , Cambridge, MA : MIT Press .
- Bowerman , M. and Choi , S. 2001 . “ Shaping Meanings for Language: Universal and Language-specific in the Acquisition of Spatial Semantic Categories ” . In Language Acquisition and Conceptual Development , Edited by: Bowerman , M. and Levinson , S. C. 132 – 158 . Cambridge : Cambridge University Press .
- Carey , S. 1978 . “ The Child as Word Learner ” . In Linguistic Theory and Psychological Reality , Edited by: Wanner , E. , Maratsos , M. , Halle , M. , Bresnan , J. and Miller , G. 264 – 293 . Cambridge, MA : MIT Press .
- De Beule , J. and Bergen , B. K. On the Emergence of Compositionality,” in . Proceedings of the 6th International Conference on the Evolution of Languag , Edited by: Cangelosi , A. , Smith , A. and Smith , K. pp. 35 – 42 . London : World Scientific Publishing .
- De Beule , J. , De Vylder , B. and Belpaeme , T. A Cross-situational Learning Algorithm for Damping Homonymy in the Guessing Game . Artificial Life X: Proceedings of the Tenth International Conference on the Simulation and Synthesis of Living Systems . Edited by: Rocha , L. M. , Yaeger , L. S. , Bedau , M. A. , Floreano , D. , Goldstone , R. L. and Vespignani , A. pp. 466 – 472 . Cambridge, MA : MIT Press .
- Fillmore , C. J. 1977 . “ Scenes-and-frames Semantics ” . In Linguistic Structures Processing , Edited by: Zampolli , A. 55 – 81 . Amsterdam : North Holland Publishing .
- Fujita , M. , Kuroki , Y. , Ishida , T. and Doi , T. T. Autonomous Behavior Control Architecture of Entertainment Humanoid Robot sdr-4x . Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) . October 2003 , Las Vegas, Nevada. pp. 960 – 967 .
- Gleitman , L. 1990 . The Structural Sources of Verb Meanings . Language Acquisition , 1 : 3 – 55 .
- Haspelmath , M. , Dryer , M. , Gil , D. and Comrie , B. 2005 . The World Atlas of Language Structures , Edited by: Haspelmath , M. , Dryer , M. , Gil , D. and Comrie , B. Oxford : Oxford University Press .
- Langacker , R. W. 1987 . Foundations of Cognitive Grammar. Volume 1 , Stanford : Stanford University Press .
- Langacker , R. W. 2002 . “ A Dynamic Usage-based Model ” . In Usage-based Models of Language , Edited by: Barlow , M. and Kemmer , S. 1 – 63 . Chicago : Chicago University Press .
- Levinson , S. C. 2001 . “ Language and Mind: Let's Get the Issues Straight! ” . In Language Acquisition and Conceptual Development , Edited by: Bowerman , M. and Levinson , S. C. 25 – 46 . Cambridge : Cambridge University Press .
- Lieven , E. 1994 . “ Crosslinguistic and Crosscultural Aspects of Language Addressed to Children ” . In Input and Interaction in Language Acquisition , Edited by: Gallaway , C. and Richards , B. J. 56 – 73 . Cambridge : Cambridge University Press .
- Markman , E. M. 1992 . “ Constraints on Word Learning: Speculations About Their Nature, Origins, and Domain Specificity ” . In Modularity and Constraints in Language and Cognition: The Minnesota Symposium on Child Psychology , Edited by: Gunnar , M. and Maratsos , M. Vol. 25 , 59 – 101 . Hillsdale, NJ : Erlbaum .
- Quine , W. 1960 . Word and Object , 299 Cambridge, MA : MIT Press .
- Rofer , T. , Brunn , R. , Dahm , I. , Hebbel , M. , Hoffmann , J. , Jungel , M. , Laue , T. , Lotzsch , M. , Nistico , W. and Spranger , M. German Team . RoboCup 2004: Robot Soccer World Cup VIII Preproceedings, extended version , http://www.germanteam.org/GT2004.pdf
- Rosch , E. 1973 . Natural Categories . Cognitive Psychology , 7 : 573 – 605 .
- Rosch , E. , Mervis , C. B. , Gray , W. D. , Johnson , D. M. and Boyes-Braem , P. 1976 . Basic Objects in Natural Categories . Cognitive Psychology , 8 : 382 – 439 .
- Siskind , J. M. 1996 . A Computational Study of Cross-situational Techniques for Learning Word-to-meaning Mappings . Cognition , 61 : 39 – 91 .
- Smith , A. D.M. Establishing Communication Systems Without Explicit Meaning Transmission . Proceedings of the Sixth European Conference ECAL 2001 Vol. 2159 of Lecture Notes in Artificial Intelligence . Advances in Artificial Life , Edited by: Kelemen , J. and Sos’ı k , P. pp. 381 – 390 . Berlin : Springer Verlag .
- Smith , A. D.M. 2005 . The Inferential Transmission of Language . Adaptive Behavior , 13 : 311 – 324 .
- Smith , K. , Smith , A. D.M. , Blythe , R. A. and Vogt , P. Cross-situational Learning: a Mathematical Approach . Symbol Grounding and Beyond: Proceedings of the Third International Workshop on the Emergence and Evolution of Linguistic Communication , Edited by: Vogt , P. , Sugita , Y. , Tuci , E. and Nehaniv , C. pp. 31 – 44 . Berlin/Heidelberg : Springer .
- Spranger , M. 2008 . “ World Models for Grounded Language Games ” . Humboldt-Universit at zu Berlin . Diploma thesis
- Steels , L. 1995 . A Self-organizing Spatial Vocabulary . Artificial Life , 2 : 319 – 332 .
- Steels , L. 1997 . The Origins of Ontologies and Communication Conventions in Multi-agent Systems . Journal of Agents and Multi-agent Systems , 1 : 169 – 194 .
- Steels , L. 2001 . Language Games for Autonomous Robots . IEEE Intelligent Systems , 16 : 16 – 22 .
- Steels , L. 2003 . Language Re-entrance and the Inner Voice . Journal of Consciousness Studies , 10 : 173 – 185 .
- Steels , L. and Kaplan , F. Situated Grounded Word Semantics . Stockholm, Sweden. Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence (IJCAI’99) , Edited by: Dean , T. pp. 862 – 867 . Morgan Kaufmann .
- Steels , L. and Loetzsch , M. 2008 . “ Perspective Alignment in Spatial Language ” . In Spatial Language and Dialogue , Edited by: Coventry , K. R. , Tenbrink , T. and Bateman , J. A. Oxford University Press (in press) .
- Tomasello , M. 1995 . “ Joint Attention as Social Cognition ” . In Joint Attention: Its Origins and Role in Development , Edited by: Moore , C. and Dunham , P. J. Hillsdale, NJ : Lawrence Erlbaum Associates .
- Tomasello , M. 1999 . The Cultural Origins of Human Cognition , Harvard : Harvard University Press .
- Tomasello , M. 2001 . “ Perceiving Intentions and Learning Words in the Second Year of Life ” . In Language Acquisition and Conceptual Development , Edited by: Bowerman , M. and Levinson , S. C. 132 – 158 . Cambridge : Cambridge University Press .
- Tomasello , M. 2003 . Constructing a Language: A Usage Based Theory of Language Acquisition , London, , UK : Harvard University Press .
- Van Looveren , J. Multiple Word Naming Games . Proceedings of the 11th Belgium-Netherlands Conference on Artificial Intelligence (BNAIC ’99) . Maastricht, The Netherlands.
- Vogt , P. and Coumans , H. 2003 . Investigating Social Interaction Strategies for Bootstrapping Lexicon Development . Journal of Artificial Societies and Social Simulation , 6
- Vogt , P. and Divina , F. 2007 . Social Symbol Grounding and Language Evolution . Interaction Studies , 8 : 31 – 52 .
- Whorf , B. and Carroll , J. 1956 . Language, Thought, and Reality , Cambridge, MA : MIT Press .
- Wittgenstein , L. 1967 . Philosophische Untersuchungen , Frankfurt : Suhrkamp .
- Zadeh , L. A. 1965 . Fuzzy Sets . Information and Control , 8 : 338 – 353 .