Abstract
Natural human speech contains a large amount of variation which poses difficulties for contemporary applications of speech technology. Following Lindblom's theory of hyper- and hypospeech, variation in speech is governed by a general principle, which is to optimise the ratio of information throughput to the energy invested. Even though such a relation is often implicitly assumed by researchers, it has never been quantified in terms of actual energy consumption. This is due to the difficulty of measuring speech energetics in humans. This paper introduces an animatronic model of the vocal tract – ‘AnTon’ – which has been designed to quantify energy relations in human speech production. Experiments are reported that demonstrate the animatronic tongue's ability to imitate basic human speech gestures.
1. Introduction
Modern speech technology has evolved up to a point where many beneficial applications have come within reach (Bailly, Campbell and Möbius Citation2003; Gilbert, Knight and Young Citation2008). State-of-the-art techniques rely heavily on statistical modelling, which treats any variation as fundamentally random. The advantage is that any hidden set of dependencies that might be responsible for such variation can be described by a quantitative model. The flexibility of this approach has led to a significant improvement of speech technology in recent years. A fundamental drawback of statistical modelling in general purpose speaker independent applications, however, is the great amount of variation that occurs naturally in speech. This leads to the need for larger and larger databases to estimate the parameters of the models which, even then, still struggle when presented with the natural variation inherent in everyday speech (Moore Citation2003). It can be hypothesised that, in order to handle such variation effectively, it is necessary to understand its underlying sources better. This paper addresses these issues and, in particular, focuses on the relation between the variation in human speech and the energy invested by speakers during its production.
The following section reviews a range of possible sources of variation in speech, giving special attention to the ‘Lombard reflex’ (Lombard Citation1911) and its relationship with the ‘H&H’ theory of hyper- and hypospeech (Lindblom Citation1990). The Lombard reflex is a very well-documented phenomenon in speech, whereby a speaker alters his/her vocal output as a function of his/her communicative environment. This is an effect that is often implicitly associated with speech energetics, but which has not yet been quantified experimentally. The H&H theory provides a plausible framework to explain speech variation in general, but it, too, has not been formulated in quantitative terms. The reason for this lack of quantitative data in both these cases lies mainly in the difficulties associated with acquiring data from human subjects about the energetics of speech production.
One possible solution is to employ an artificial speech generator, and Section 3 elaborates on the decision process that led to the rejection of using conventional speech synthesis techniques in favour of the construction of an animatronic model of a human tongue and vocal tract – ‘AnTon’. What makes this approach unique is that AnTon's construction is guided by vocal anatomy rather than functional efficiency. This position is based on a conviction that functionality should emerge from the incorporation of human physiology in a robotic model, i.e. a ‘biomimetic’ solution (Bar-Cohen Citation2006).
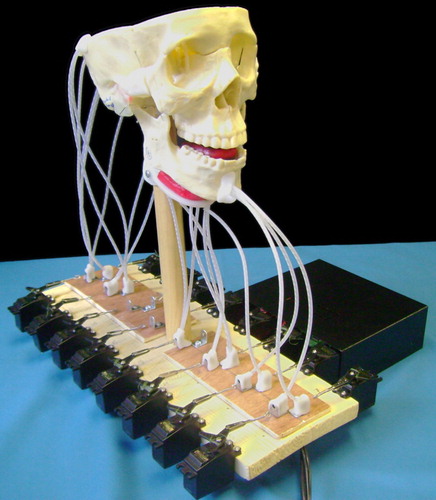
Section 4 describes AnTon in its present stage of development, comprising a tongue and a movable jaw that are activated by five and four sets of muscles, respectively (see ). The current model is capable of adopting a range of articulatory positions that demonstrate its adequacy as a tool for the research objectives identified above.
Figure 1. AnTon, the animatronic tongue and vocal tract model.
2. Variation in natural speech
2.1. Sources of variation
Variation seems to be inevitable in natural speech production. Although some might be random (even under controlled experimental conditions, it would be most unlikely for a subject to produce exactly the same waveform twice), a large part does carry important information about the speaker, the listener and their communicative environment (Benzeghiba et al. Citation2007). This information can easily be extracted by human listeners and it supports the communication process (Moore Citation2007). Sources of systematic intra-speaker variation in natural speech include the following:
| • | The ‘Lombard reflex’ which is treated in detail in Section 2.2. | ||||
| • | Emotion: speech production is strongly influenced by the emotional state of the speaker; see, e.g. Barra et al. Citation(2006), de Gelder Citation(2003), Juslin and Laukka Citation(2003), Lee, Yildirim, Kazemzadeh and Narayanam Citation(2005) and Scherer Citation(2003). | ||||
| • | Coarticulation: individual speech sounds within an utterance influence each other in fluent speech, see e.g. Borden, Harris and Raphael (Citation2003, pp. 188ff), Denes and Pinson (Citation1993, chap. 8) and Hura, Lindblom and Diehl Citation(1992). | ||||
| • | Social pragmatics: speech varies depending on the social relation between the dialogue partners; see, e.g. Dalton-Pfeffer and Nikula Citation(2006) and Eslami-Rasekh Citation(2005). | ||||
| • | Parentese: speech directed to infants is modified to aid them in the language learning process; see, e.g. Barinaga Citation(1997), Kuhl et al. Citation(1997) and Thiessen Citation(2005). | ||||
| • | Speaker physiology: age (Benjamin Citation1982) and medical condition (Palmer, Enderby and Cunningham Citation2004; Parker, Cunningham, Enderby, Hawley and Green Citation2006). | ||||
| • | Errors: speakers prevent or correct errors using specific strategies; see, e.g. Clark Citation(2002), Howell Citation(2002) and Levelt Citation(1983). | ||||
The variety of these sources constitutes a multi-dimensional problem for any modelling attempt. Therefore, in order to make progress, it is beneficial to factorise the number of free parameters. In AnTon, the multi-dimensional space has been reduced to a single governing principle, derived from the H&H theory (see Section 2.3).
2.2. The Lombard reflex
In the presence of noise, subjects consistently increase their articulatory and vocal effort in order to remain intelligible. This is an automatic reaction governed by the auditory feedback that speakers use to judge the intelligibility of their speech, see e.g. Junqua Citation(1996) and Garnier, Bailly, Dohen, Welby and Loevenbruck Citation(2006). The reflex functions even when the noise is played over headphones and the speakers are aware that they would not need to raise their voices in order to be understood by a listener.
Among the sources of variation listed above, the Lombard reflex is one of the most documented. This is probably due to the relative straightforwardness of setting up repeatable experimental conditions and collecting data. In the context of the research reported here, the reflex is useful in three respects:
| • | The assumption of energy optimisation is a necessary part of any theory that sets out to explain the Lombard effect. | ||||
| • | The Lombard reflex is conditioned on a well-defined and controllable external source, thereby facilitating the establishment of an objective relation between source and variation. | ||||
| • | Meaningful experiments can be conducted employing single speech sounds (rather than complex sequences of sounds). | ||||
2.3. The H&H theory
2.3.1. Concept
The H&H theory claims that speakers vary their speech production along a continuum from hypo- to hyperarticulated speech in order to adapt to various environmental and other influences. The control mechanisms that determine the position of a given utterance along the H&H continuum are called output-oriented and system-oriented motor control. The output-oriented side tries to maximise the clarity of the speech signal to aid the listener in the interpretation of the speech. The system-oriented side tries to minimise the energy used to produce the speech signal. These two competing constraints form a feedback control loop, where speakers monitor the intelligibility of their own output and control the effort that goes into its production. Corrections are made whenever it is judged that the perceived clarity does not match that which was intended. Similar control loops for governing behaviour in general are suggested by Powers Citation(1974) in his Perceptual Control Theory (PCT).
Working with the H&H theory reduces the multi-dimensional problem of speech variation to a much simpler optimisation task with two competing parameters: energy consumption in terms of articulatory effort, and intelligibility. This principle is depicted in . H&H does not explain specific reactions to specific influences, it rather constitutes a general principle that should govern all kinds of variation.
Figure 2. The H&H theory simplifies attempts to quantify speech variation by reducing the number of relevant dimensions.
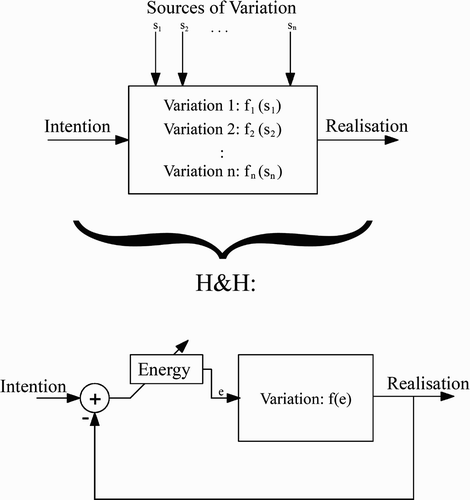
A similar view is stated by Boersma Citation(1998). Boersma uses a strict ranking of constraints rather than a continuum (the higher ranked constraint governs behaviour totally), but the basic ideas are similar: ‘The speaker will minimise her articulatory and organisational effort’ and ‘… will minimise the perceptual confusion between utterances with different meanings’ (p. 3). Boersma also cites Passy, who formulated a principle of economy and a principle of emphasis as early as 1891.
2.3.2. Evidence
The Lombard reflex is a prominent piece of evidence for the output-oriented side of H&H theory, for example subjects try actively to maintain intelligibility under noisy conditions by speaking louder. For the system-oriented side, Garnier et al. Citation(2006) show that such speech is not just louder, but articulatory movements tend to be larger. If the speech rate is maintained, larger movements mean both further and faster displacement of the articulators, and as articulators have a certain mass, this necessarily requires extra energy.
Although articulatory movements might be the most obvious energy drain, there are certainly others. About 20% of a human's resting energy is consumed by the brain (Laughlin, de Ruyter van Steveninck, and Anderson Citation1998). In comparison, talking might seem to be a relatively effortless task, but it can be argued that talking (and listening) seems to require a considerable amount of the brain's resources, leaving less to perform other tasks at the same time (Howell Citation2002).
Apart from the brain and the articulators, the lungs also need energy, both to produce an air stream, and to control the magnitude of the air stream properly. Moon and Lindblom Citation(2003) found that both vocal effort and speech rate have a measurable influence on the amount of oxygen consumed by a speaker. They inferred that increased loudness or speech rate requires more energy to produce.
2.3.3. Quantification
Although there is abundant evidence in favour of energy efficiency and information throughput as a general principle governing speech variation, it is very hard to quantify it. This is due to the difficulty of measuring energy consumption reliably and ethically in human subjects. Although muscle activation can be measured using electromyography (EMG), it is difficult to separate functions of neighbouring muscles (Koolstra Citation2002), or even to record some muscles because of their location in the body (Vatikiotis-Bateson and Ostry Citation1999). Other approaches include electrical stimulation of muscles (Zwijnenburg, Lobbezoo, Kroon and Naeije Citation1999) and electro-magnetic excitation of motor regions of the brain (McMillan, Watson and Walshaw Citation1998). All these methods require electrodes to be inserted into the investigated muscle, either for measurement or excitation, and are potentially dangerous for test subjects. The scientific goal of the AnTon project is to overcome these difficulties, using an artificial representation of the human speech production system to provide the necessary experimental data.
It is important to point out that the notion of speech energetics is not limited to just the speech production process, but also to speech perception. Speech is often a matter of two people communicating with each other in a dialogue, where the roles of speaker and listener change frequently. Assuming that listening uses resources as well, for example by the allocation of attention, it is very likely that two people can minimise their joint conversational effort by spending more energy for their speech output than would be absolutely necessary for the respective listener to reconstruct the meaning. This concept of two parties co-ordinating their behaviour to maximise their overall profit is well known in game theory (Sorin Citation2002). The only prerequisite is that the gain of energy on the listener's side is greater than the loss on the speaker's side. This is in line with the view recently put forward by Moore Citation(2007) that the speech process should be seen as a communicative loop, where both speaker and listener are actively involved in the process, rather than as the traditional speech chain from speaker to listener (Denes and Pinson Citation1993). This aspect of conversational energetics will be an important and novel feature of future research using AnTon.
3. Modelling speech variation
3.1. Artificial speech production
The first models of human speech production were functional physical models. As early as 1771 (Riskin Citation2003, pp. 105f) Erasmus Darwin reported that he had built a machine that could pronounce ‘mama’, ‘papa’, ‘map’ and ‘pam’ (Darwin Citation1825, p. 98). Other physical speaking machines were constructed during the late eighteenth century by Mical (1778), Kratzenstein (1779) and Von Kempelen (1791) (Flanagan Citation1972, pp. 204–210; Riskin Citation2003, pp. 105–108). Probably the most sophisticated speaking machine that exists today is the ‘Waseda Talker’ (Fukui et al. Citation2005, Citation2007).
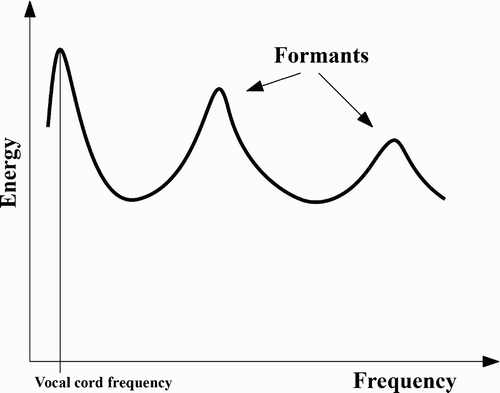
During the second half of the nineteenth century, interest turned away from imitating the human vocal apparatus physically to modelling speech production using just the acoustic properties of the vocal tract. Scientists discovered that they could produce vowels by combining energy at certain frequencies: the resonant frequencies of the vocal tract – known as ‘formants’ (see ). Helmholtz used a set of tuning forks to synthesise vowels; other designs, e.g. by Miller and Stumpf, used organ pipes for a similar effect (Flanagan Citation1972, pp. 207ff). Software formant synthesisers were the state-of-the-art until the middle of the 1990s.
Figure 3. Spectral cross section of a speech sound. The formants are resonances that result from the vocal tract shape associated with the sound.
Contemporary speech synthesisers use libraries of pre-recorded sound segments that are concatenated to form utterances (e.g. Portele, Höfer and Hess Citation1997; Holmes and Holmes Citation2001, ch. 5), and this has led to some increase in the perceived naturalness of synthesised speech (Carlson Citation1995). The main focus of interest in speech synthesis research has consequently shifted away from the underlying principles of speech production towards the manipulation of the recorded speech segments (e.g. Conkie and Isared Citation1997).
In parallel with these mainstream developments, speech production research has concentrated on ‘articulatory synthesis’ since the 1970s (Mermelstein Citation1973; Maeda Citation1979, Citation1988). These techniques are not defined by the method of sound production, but by a control interface that represents a more or less accurate model of the human articulatory system. Control parameters relate to human physiology instead of acoustic properties of the vocal tract, for example the position of certain articulators or the states of muscles controlling the articulators. There are two ways to generate the speech waveform from such articulatory models: using formant frequencies computed from the vocal tract geometry (Carré Citation2004); or air stream modelling to calculate the behaviour of the vibrating air in the vocal tract. In the first case, the articulatory synthesiser is really just a formant synthesiser with an added layer of control elements. The second approach is often considered impractical because of the vast computational cost involved. Also, the fluid dynamics of air streams in the vocal tract are still under experimental investigation (Barney, Shadle and Davies Citation1999; Shadle, Barney and Davies Citation1999; Zhang, Mongeau, Frankel and Thomson Citation2004). The most advanced models that are being developed today use finite element models (FEM) of the articulators (Engwall 1999; Birkholz, Jackel and Kröger Citation2006), some of which are actuated by realistic muscle configurations (Gérard, Wilhelms-Tricarico, Perrier and Payan Citation2003; Fels et al. Citation2006; Vogt et al. Citation2006).
3.2. Model selection
The different speech production solutions discussed in the previous section were evaluated with respect to their usability for the intended research. Following the line of arguments given above, the most important prerequisites are an inherent representation of speech production energy and the possibility to operate the model using a feedback control loop. Another important factor is a close resemblance to the human vocal system. This is necessary to compare the working model with human behaviour.
In selecting a suitable model, some attributes would be beneficial but not essential, for example:
| • | Real time behaviour would facilitate the use of evolutionary algorithms and babbling experiments to train the speech generator – such approaches require the generation of large amounts of data, which constitutes a problem with slower algorithms. | ||||
| • | A large range of speech sounds would increase the range of possible experiments. | ||||
| • | The ease of simulation of physical vocal tract deformations would make it possible to research the effects of physiologically induced speech disorders. | ||||
The last point is particularly interesting in the context of clinical speech research, because, instead of just comparing ‘normal’ human speech with the behaviour of the model, speech produced by clinical patients could be compared with an H&H model working under similar constraints.
shows a decision matrix that evaluates the different methods of artificial speech production with respect to the given criteria. It is clear that concatenative synthesisers do not fulfil most of the criteria, i.e. it is hard to find suitable parameters that allow the implementation of a control loop; neither is there a relation to the energy used in speech production, nor a relation to human physiology. Likewise, formant synthesisers fall short of the requirements, i.e. they do not include the necessary constraints of a human physiology; and there is no straightforward method for linking their behaviour with speech energetics. Of all the software methods shown in , articulatory synthesis is the only one that provides the necessary representation of the human system and the possibility to implement controls that relate to speech energetics. A model using air stream simulation for sound production would be preferable to one using formants derived from the vocal tract shape.
Table 1. Decision matrix evaluating the possible tools to research human speech energetics.
Apart from software solutions, a robotic approach was considered. The subcategory of robotics that concentrates on the animation of life-like models is called ‘animatronics’. An animatronic model was rated to be similar to an articulatory synthesiser with respect to its resemblance to the human physiology and the possibility to introduce physical sources of speech disorder. Although it would probably be easier to build a control loop with an articulatory synthesiser (because of the lack of hardware interfaces), a robot has an inherent representation of energetics in the amount of energy required by its motors. Also, an animatronic model has the ability to operate close to real time as all of the movements, deformations and sound production occur in the real world, rather than having to be calculated. This offers the possibility of creating the large amounts of data needed for babbling experiments and optimisation by evolutionary algorithms.
These advantages are in direct contrast to the behaviour of FEM models. For example, in one of their recent publications, the development team of ArtiSynth claimed that calculating tongue movements in their model required 10 s of calculation time per second of simulated movement (Vogt et al. Citation2006). Although this is reported to be 60 times faster than other state-of-the-art systems, it is clear that real time FEM simulations of the entire vocal tract remain well out of reach. Air stream modelling in a three-dimensional model is even more time intensive. For example, in Praat (Boersma Citation2001), a two-dimensional articulatory model with air stream modelling requires around 12 s to generate an utterance of half a second on a modern computer.
might give the wrong impression that the animatronic model was chosen mainly because it is closer to real time performance, whereas, in fact, the ratings of articulatory synthesis refer to an ideal articulatory synthesiser, which incorporates the best properties of several existing models. Important elements such as realistic muscle configuration, air stream modelling, or the availability of a complete vocal tract are in practice only realised in different implementations.
4. The animatronic tongue and vocal tract model: AnTon
4.1. Animatronic modelling
4.1.1. Design principle
The main guideline in the development of AnTon has been human anatomy. Functional considerations have only been taken into account where it has been impossible to mimic the biological system with materials and technology that are currently available. For example, the realistic reproduction of biological muscle tissue is still a significant research area in biomimetic materials engineering (e.g. Bar-Cohen Citation2003). AnTon's ability to mimic typical human speech gestures derives solely from the implementation of a human-like animatronic anatomy. The reason to copy anatomy rather than functionality is that the human vocal tract has to fulfil multiple functions, of which vocalisation is not the most important one compared with mastication and breathing (Palmer Citation1993; Seikel, King and Drumright Citation1997, chap. 8). A model incorporating the specific vocal tract functionality required for speech would probably be more energy efficient than an anatomical model (and a human speaker), thereby undermining the main scientific questions pertaining to speech energetics.
The biomimetic approach is what sets AnTon apart from the Waseda Talker, currently under development at Waseda University, Japan. Interestingly, the Waseda project uses a functional approach (e.g. the tongue mechanics described in Fukui et al. Citation2007) but, for some crucial elements, they have started to apply biomimetic methods to find a solution, for example in the production of the vocal cords and the lips (Fukui et al. Citation2005). AnTon is conceptually the opposite, using functionality only where it is not technically feasible to copy the biological prototype. For example, the Waseda Talker actuates a tongue surface by underlying pistons, whereas AnTon comprises a complete anatomical model of a tongue and more realistic muscle configurations. The Waseda Talker represents a functional approach to generate specific tongue shapes, whereas AnTon represents a biomimetic approach, concentrating on anatomical likeness.
4.1.2. Components
Actuation.
Artificial muscles do not currently exist that function like real biological muscle cells, and can be integrated to form a complex structure like the human tongue. Research that might lead to such muscles in the near future includes work on shape changing polymers (Carpi, Migliore, Serra and De Rossi Citation2005) and artificial muscle cells (Takemura, Yokota and Edamura Citation2007). Although future versions of AnTon will take advantage of improved technology that will become available, the best solution of existing actuation methods is servo motors.
The servo motors are connected to filaments (0.16 mm Dyneema® fishing line) that run through shafts to respective places in the animatronic model. The principle is similar to that of a Bowden cable, except that the shafts are incised spirally to make them more flexible. This is necessary so that the shafts that run to movable parts of the model interfere as little as possible with the movement of these parts. Friction and other losses that occur in the transmission of force from motors to model are not a problem, as calibration measurements will be used to relate the motors’ energy consumption to the force on the model directly. For example, it does not matter whether a muscle force of 5 N requires a motor to draw a current of 100 mA or 250 mA (given a constant supply voltage), as long as the relation is known.
Bone tissue.
The skull that forms the basis of the animatronic model is a plastic cast of a male human skull. The density of the material was measured to be 1 g cm−3; the density of living jaw bone is 1.85 g cm−3 (Yang, Chiou, Ruprecht, MacPhail and Rams Citation2002). The volume of the jaw model is 75 cm3, so a weight of 63.75 g had to be added to imitate living bone density.
Tongue and skin tissue.
A very soft silicone (Smooth-On Ecoflex™) was used to model the tissue of the tongue and the skin. This material was originally developed to imitate human skin and flesh for special effects in TV/film production and for medical prosthetics. The silicone is available in several degrees of hardness that can be adjusted further by additives. The human tongue consists mainly of muscle fibres (Kier and Smith Citation1985), which are reported to have a density of 1.04 g cm−3 (Gandhi, Lazzi and Furse Citation1996). The silicone that forms the model tongue comes very close to this value with a density of 1 g cm−3.
All the layers of tissue, from the bone up to the skin, that form the surface of the face are imitated by a single silicone ‘skin layer’. The biological tissue is a mixture of muscles, fat, collagen and skin, each with different physical properties. The density of fat is 0.91 g cm−3 (Curry, Dowdey, and Murry Citation1990), while for muscle it is 1.04 g cm−3. With 0.95 g cm−3, the density of the silicone component chosen for the skin layer lies in the middle and it matches the density measured for human thigh flesh (VanIngen-Dunn, Hurley and Yaniv Citation1993).
4.2. Control
The same biomimetic principle used to design the physical part of AnTon also governs its control structure. Maps of artificial neurons that represent speech and speech-related motor regions of the human brain (Rizzolatti and Arbib Citation1998; Rizzolatti and Craighero Citation2004) are the basis of the DIVA model of speech production (Guenther, Ghosh and Nieto-Castanon Citation2003; Guenther Citation2006). DIVA is a very recent and successful model that can explain many speech phenomena as a result of its neural structure. It is currently used to control an articulatory software synthesiser. As motor commands to articulators are an inherent part of DIVA, modifying it to control AnTon will be straightforward.
The sounds produced by the artificial vocal tract will be recorded with a microphone and form a feedback stream to the control structure. Such auditory feedback is an integral part of DIVA (Guenther, Nieto-Castanon, Ghosh and Tourville Citation2004). Another feedback stream supported by DIVA is tactile feedback, which could be provided in later versions of AnTon.
Learning in DIVA consists of a babbling stage, where the relation between motor commands and auditory feedback is formed, and a mimicking stage, where the model tries to imitate given speech utterances. A recent trend in language research puts more emphasis on the role of a caregiver that supports children in language acquisition (Yoshikawa, Asada, Hosoda and Koga Citation2003; Messum Citation2007). A learning phase involving additional feedback from a caregiver could also be part of AnTon's initial training.
As the DIVA model simulates actual neural processes in the human brain, the amount of neural activity could be used to infer energetics at the control level of language production.
4.3. Experiments
Experiments with the animatronic vocal tract model will be carried out in three main stages: babbling, mimicking of speech sounds and adaptation to disturbances in the environment.
4.3.1. Babbling stage
AnTon will start by producing a wide range of articulatory gestures G i and corresponding sounds S i to map out the range of sounds possible and the energy costs involved in their production. If M describes the whole articulatory model with its m j muscle filaments, then each articulatory gesture G i consists of a set of parameters g i, j controlling the respective muscles. The result of the babbling stage will be an articulatory to sound mapping with the amount of energy E i used to produce the gesture associated to every gesture–sound pair:
4.3.2. Mimicking stage
The next step will be to mimic human speech sounds. To do so, AnTon will use the data collected during the babbling stage and compare gesture–sound pairs from its repertoire with the target sound S t . A cost function will be used to determine the best solutions G n , n∈i within the repertoire. The cost c i associated with a gesture–sound pair will depend on its closeness to the target sound (e.g. the confidence value of a speech recogniser for the specific sound) and the energy consumption of the gesture:
4.3.3. Adaptation stage
In the adaptation stage, noise will be introduced into the auditory feedback path, as described above for Lombard reflex experiments with human test subjects. The noise is expected to reduce the perceived closeness of the sounds derived from the mimicking stage to the target sounds. To regain the required closeness, AnTon will have to search for new solutions which, according to H&H theory, should require more energy.
At the end of each stage, AnTon's performance will be compared with human behaviour. If the animatronic model proves to be able to imitate natural human articulation within a defined tolerance, then the quantitative energetics relationships derived from the experiments will in turn be used to predict human behaviour. The range of experiments could also be extended to include the imitation of well known speech disorders, providing another range of options to evaluate AnTon and to quantify H&H theory.
4.4. State of development
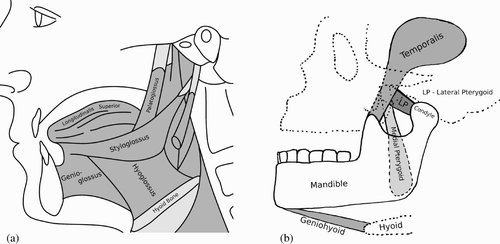
In its present stage, AnTon consists of a soft silicone tongue body, a movable jaw, a skull, a hard palate and a hyoid bone. The whole model is actuated by 11 servo motors that are operated by a controller board connected to the USB port of a standard PC. In the current setup, up to 16 motors could be controlled. Muscles are represented by filaments that run along realistic lines of action (Koolstra, von Eijden, van Spronsen, Weijs and Valk Citation1990) for the jaw, and follow the muscle fibre orientation of the biological antetype inside the tongue body (Takemoto Citation2001; Saito and Itoh Citation2003). There are currently 18 muscle filaments connected to the servo motors, individually or in pairs. Actuation takes place symmetrically: filaments that represent symmetric pairs of muscles (one on the left and one on the right) are connected to the same motor. In the future, it would be possible to actuate these muscles individually by allocating more motors. illustrates the muscles that have currently been implemented.
Figure 4. (a) Muscles of the tongue implemented in AnTon. The palatoglossus will be included as soon as the soft palate is in place; (b) The four muscles of the jaw implemented in AnTon.
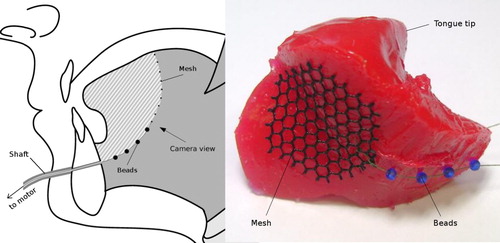
The tongue comprises 11 different muscle filaments that attach to meshes embedded in the soft silicone body. These meshes solve two problems: they serve as attachment points, and they distribute the force applied to them over a larger volume of the tongue body. Glass beads guide the filaments along the curved paths of the biological muscle fibres within the tongue and prevent them from cutting into the silicone. One of those meshes, representing the middle part of the genioglossus muscle, is illustrated in .
Figure 5. The attachment and force distribution mesh for the middle part of the genioglossus as it is put into place during the production process. Glass beads are embedded to prevent the filaments from cutting into the silicone body. The sketch on the left hand side clarifies the camera viewpoint as well as the tongue part depicted.
The jaw is actuated by seven muscle filaments that represent muscles associated with jaw movement during speech production (Vatikiotis-Bateson and Ostry Citation1999). The jaw joints (temporomandibular joints, TMJ) consist of plastic capsules that enclose the condyles of the mandible, leaving enough room for some movement in all degrees of freedom. The ligaments that surround the TMJ in the biological system were not modelled, as they do not seem to influence jaw movement much during normal movement with symmetrical muscle activation (Koolstra Citation2002). shows the muscles and their representation in the model. The hyoid bone that supports the tongue is fixed in its position, somewhat restricting the tongue's upward and downward movement in the current model.
Table 2. Muscles implemented in the current version of AnTon: tongue (top) and mandible (bottom).
4.5. AnTon's current capability
Even at this early stage of its development, AnTon is able to mimic a range of oral gestures and functionality. The model demonstrates realistic co-ordinated jaw opening and tongue movements when driven by appropriate commands from the controlling software.
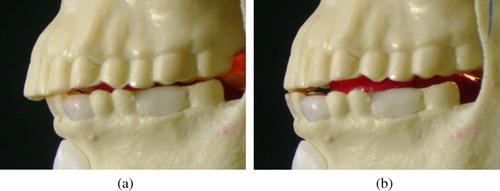
One particularly advanced feature in AnTon is that, as in the human, the condyle of the mandible slides forward within the TMJ during the jaw opening gesture (Norton Citation2007). This behaviour emerges naturally from AnTon's biomimetic construction, rather than being enforced (as in a functional solution). shows a jaw opening gesture initiated by activation of the geniohyoid and relaxation of the medial pterygoid and temporalis muscles. The centre of gravity of the mandible and the configuration of the muscles involved in the movement are obviously enough to produce a realistic movement quite naturally. demonstrates AnTon's ability to produce retruded and frontal jaw closures. The former is usually associated with a voluntary full closure of the mouth, whereas the latter is a more relaxed closure where only the front teeth meet.
Figure 6. AnTon's temporomandibular joints (TMJ) produce a natural forward sliding motion during jaw opening. The markers show that in (b), the condyle has clearly moved forward within the joint capsule.
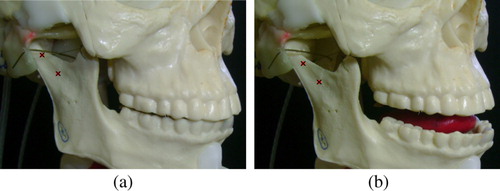
Figure 7. (a) Retruded and (b) frontal closures produced by AnTon.
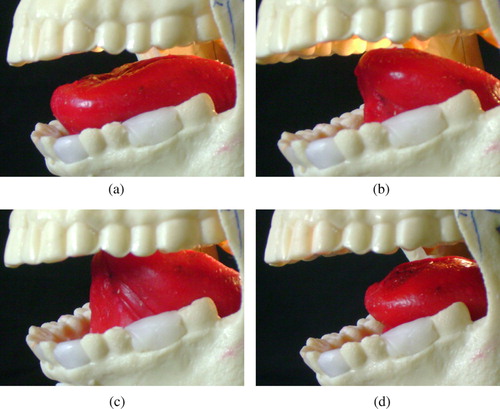
The tongue is capable of producing a variety of forward and backward movements. illustrates the basic gestures generated by individual muscles: down and forward using the genioglossus; back and down using the hyoglossi; a retroflex motion using the longitudinalis superior; and back and up using the styloglossi. All these basic gestures can be performed to various degrees, from slight to full muscle activation, and several muscle groups can be combined in order to increase further the variety of possible movements. A demonstration video can be downloaded from the AnTon project website (http://www.dcs.shef.ac.uk/∼robin/anton/anton.html).
Figure 8. (a) Frontal position, genioglossus pulling forward; (b) hyoglossus pulling the posterior part of the tongue back and downwards; (c) retroflex motion initiated by longitudinalis superior; (d) styloglossus producing backward movement.
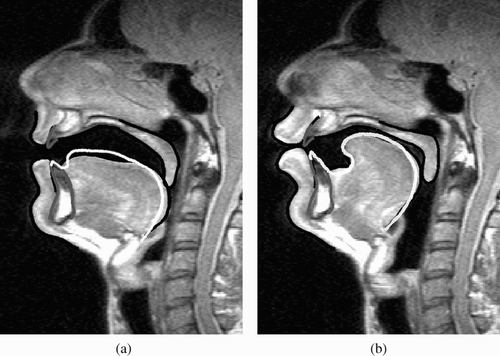
Experiments were carried out to determine whether the animatronic tongue can mimic actual human speech gestures. The tongue positions for two vowel sounds previously recorded by magnetic resonance imaging (MRI) (Badin and Serrurier Citation2006) were imitated by AnTon. Extracting the tongue shape from the model was a slow manual process and constrained the stepwise convergence towards the target. shows the results for both vowels after three successive approximation steps. For the /u/ sound this yielded a very close match, as the gesture could be imitated using the styloglossus muscle pair alone. The /a/ sound was not imitated as closely, because multiple muscles work together to produce the shape. A closer match would have required more steps of convergence.
Figure 9. Comparison of MRI data (black contour) with AnTon (white contour) in pre-vocalisation experiments: (a) vowel/a/; (b) vowel/u/. MRI data by courtesy of Badin and Serrurier Citation2006.
4.6. Further potential applications
Apart from investigating energetics in human speech, an animatronic tongue and vocal tract model could be applied in many other areas:
| • | General speech research: AnTon could be used to address a range of speech-related research issues, e.g. the acoustic cues produced by emotional facial expressions (Aubergé and Cathiard Citation2003) or how language is acquired (Yoshikawa et al. Citation2003). | ||||
| • | Education: illustrating vocal tract functionality to students of phonetics, speech technology, or anatomy (less complex models are being used already, e.g. Arai Citation2006). | ||||
| • | Speech therapy: visualisation of articulatory movements to support patients with speech disorders (Palmer Citation2005). | ||||
| • | Medicine: both as a means for pathological research and to improve the quality of oral prostheses (e.g. existing tongue prostheses do not have the ability to move (Bredfeldt Citation1992; Bova, Cheung and Coman Citation2004). | ||||
| • | Robotics: the construction of AnTon might yield valuable lessons for robotics, e.g. in the fields of applying soft materials in robotics (Trimmer et al. Citation2006; Takemura et al. Citation2007) or efficiently co-ordinated muscle control (Northrup, Brown, Parlaktuna and Kawamura Citation2001). | ||||
5. Conclusion and future research
An animatronic model of a human tongue and vocal tract was designed in order to investigate speech energetics. Experiments with AnTon in its present state of development have demonstrated the model's ability to mimic oral gestures realistically. This behaviour emerges naturally from the biomimetic design principle applied.
At the next stage, the vocal tract will be completed by adding soft palate and pharynx models. Also, the hyoid bone will be improved to allow for vertical movement. The oral cavity will then be sealed off by a facial skin, so that speech sound production by a loudspeaker, an air stream, or a combination of both will become possible. Active lip movement remains a further option for future improvement.
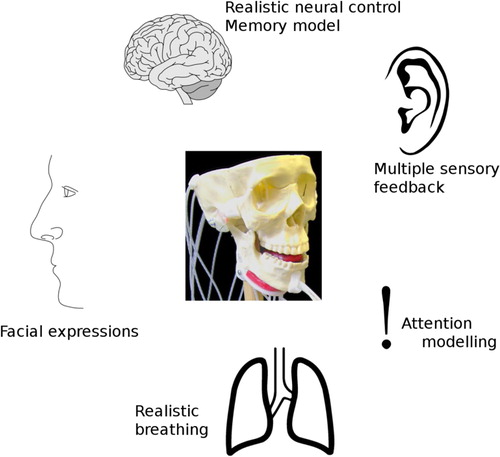
The long-term vision for AnTon is to make it available as a general platform for speech research. The soft parts are moulded from readily available silicone, so that existing moulds can be used to fabricate tens of models for distribution to partners. Production of larger numbers would require an automated process and could be managed by a spin-off company. The model can also be expanded successively to match the human vocal system more and more closely. Each step towards a comprehensive representation of speech production and cognition offers new insights. illustrates possible modules that could be added to AnTon. Multiple sources of sensory feedback could improve articulatory control, e.g. touch or intraoral pressure sensors. Binaural auditory feedback and simulation of acoustic bone conduction are further ways to approximate the human system. Lungs and/or facial muscles would yield the possibility of investigating a wider range of physiological influences on speech production, e.g. being out of breath, reduced lung capacity, or emotional expressions such as smiling. Realistic neural control structures, such as DIVA, memory modelling and attention allocation, could be used to research energy requirements on the cognitive level of speech communication.
Figure 10. The vision of AnTon as a comprehensive model of speech production and cognition. Each of the modules shown would significantly enhance its value as an experimental tool.
Acknowledgements
The authors would like to thank Pierre Badin, CNRS, Grenoble for providing the MRI images that have been used in the tongue shape imitation experiments.
References
- Arai , T. 2006 . Lung Model and Head-shaped Model with Visible Vocal Tract as Educational Tool in Acoustics . Acoustical Science & Technology , 27 : 111 – 113 .
- Aubergé , V. and Cathiard , M. 2003 . Can We Hear the Prosody of Smile? . Speech Communication , 40 : 87 – 97 .
- Badin , P. and Serrurier , A. Three-dimensional Linear Modeling of Tongue: Articulatory Data and Models,’ . Proceedings of the 7th International Seminar on Speech Production, ISSP7 . Edited by: Yehia , H. , Demolin , D. and Laboissiére , R. pp. 395 – 402 . Ubatuba, SP, UFMG, Belo Horizonte .
- Bailly , G. , Campbell , N. and Möbius , B. 2003 . ISCA Special Session: Hot Topics in Speech Synthesis . EUROSPEECH 2003 , : 37 – 40 .
- Barinaga , M. 1997 . Speech Development: New Insights Into How Babies Learn Language . Science , 277 : 641
- Barney , A. , Shadle , C. H. and Davies , P. O.A.L. 1999 . Fluid Flow in a Dynamic Mechanical Model of the Vocal Folds and Tract. I. Measurements and Theory . Journal of the Acoustical Society of America , 105 : 444 – 454 .
- Barra , R. , Montero , J. M. , Macias-Guarasa , J. , D'Haro , L. F. , San-Segundo , R. and Cordoba , R. Prosodic and Segmental Rubrics in Emotion Identification . IEEE International Conference on Acoustics, Speech and Signal Processing . pp. 1085 – 1088 .
- Bar-Cohen , Y. Biologically Inspired Intelligent Robots Using Artificial Muscles . International Conference on MEMS, NANO, and Smart Systems . pp. 2 – 8 .
- Bar-Cohen , Y. 2006 . Biomimetics – Using Nature to Inspire Human Innovation . Bioinspiration & Biomimetics , 1 : 1 – 12 .
- Benjamin , B. J. 1982 . Phonological Performance in Gerontological Speech . Journal of Psycholinguistic Research , 11 : 159 – 167 .
- Benzeghiba , M. , De Mori , R. , Deroo , O. , Dupont , S. , Erbes , T. , Jouvet , D. , Fissore , L. , Laface , P. , Mertins , A. , Ris , C. , Rose , R. , Tyagi , V. and Wellekens , C. 2007 . Automatic Speech Recognition and Speech Variability: A Review . Speech Communication , 49 : 763 – 786 .
- Birkholz , P. , Jackel , D. and Kröger , B. J. Construction and Control of a Three-dimensional Vocal Tract Model . IEEE International Conference on Acoustics, Speech and Signal Processing . pp. 873 – 876 .
- Boersma , P. 1998 . “ Functional Phonology ” . Netherlands Graduate School of Linguistics .
- Boersma , P. 2001 . Praat, A System for Doing Phonetics by Computer . Glot International , 5 : 341 – 345 .
- Borden , G. J. , Harris , K. S. and Raphael , L. J. 2003 . Speech Science Primer: Physiology, Acoustics, and Perception of Speech , 4 , Philadelphia : Lippincott Williams & Wilkins .
- Bova , R. , Cheung , I. and Coman , W. 2004 . Total Glossectomy: Is it Justified? . ANZ Journal of Surgery , 74 : 134 – 138 .
- Bredfeldt , G. W. 1992 . Tongue Prosthesis for Total Glossectomy Patient . Journal of Prosthodontics , 1 : 131 – 133 .
- Carlson , R. Models of Speech Synthesis . Proceedings of the National Academy of Sciences USA . Vol. 92 , pp. 9932 – 9937 .
- Carpi , F. , Migliore , A. , Serra , G. and De Rossi , D. 2005 . Helical Dielectric Elastomer Actuators . Smart Materials and Structures , 14 : 1210 – 1216 .
- Carré , R. 2004 . From an Acoustic Tube to Speech Production . Speech Communication , 42 : 227 – 240 .
- Clark , H. H. 2002 . Speaking in Time . Speech Communication , 36 : 5 – 13 .
- Conkie , A. D. and Isard , S. 1997 . “ Optimal Coupling of Diphones ” . In Progress in Speech Synthesis , 293 – 304 . Berlin : Springer .
- Curry , T. S. , Dowdey , J. E. and Murry , R. E. 1990 . Christensen's Physics of Diagnostic Radiology , 4 , Philadelphia : Lippincott Williams & Wilkins .
- Dalton-Pfeffer , C. and Nikula , T. 2006 . Pragmatics of Content-based Instruction: Teacher and Student Directives in Finnish and Austrian Classrooms . Applied Linguistics , 27 : 241 – 267 .
- Darwin , E. 1825 . “ The Temple of Nature; Or, The Origin of Society ” . In The Botanic Garden , 3 , 1825 London : Jones & Company .
- Denes , P. and Pinson , E. 1993 . The Speech Chain: The Physics and Biology of Spoken Language , New York : Worth Publishers .
- de Gelder , B. 2003 . Perceiving Emotions by Ear and by Eye . Eurospeech 2003 ,
- Engwall , O. 2002 . “ Tongue Talking-Studies in Intraoral Speech Synthesis ” . Stockholm : Royal Institute of Technology, KTM . Doctoral Dissestation
- Eslami-Rasekh , Z. 2005 . Raising the Pragmatic Awareness of Language Learners . ELT Journal , 59 : 199 – 208 .
- Fels , S. , Vogt , F. , van den Doel , K. , Lloyd , J. , Stavness , I. and Vatikiotis-Bateson , E. 2006 . “ ArtiSynth: A Biomechanical Simulation Platform for the Vocal Tract and Upper Airway ” . Columbia : Computer Science Dept., University of British . Technical Report TR-2006-10
- Flanagan , J. L. 1972 . Speech Analysis Synthesis and Perception , Berlin : Springer .
- Fukui , K. , Ishikawa , Y. , Sawa , T. , Shintaku , E. , Honda , M. and Takanishi , A. New Anthropomorphic Talking Robot having a Three-dimensional Articulation Mechanism and Improved Pitch Range . Proceedings of the 2007 IEEE Conference on Robotics and Automation . pp. 2992 – 2997 .
- Fukui , K. , Nishikawa , K. , Kuwae , T. , Takanobu , H. , Mochida , T. , Honda , M. and Takanishi , A. Development of a New Human-like Talking Robot for Human Vocal Mimicry . Proceedings of the 2005 IEEE International Conference on Robotics and Automation . pp. 1449 – 1454 .
- Fukui , K. , Nishikawa , K. , Ikeo , S. , Shintaku , E. , Takada , K. , Takanobu , H. , Honda , M. and Takanishi , A. Development of a Talking Robot with Vocal Cords and Lips Having Human-like Biological Structure . IEEE/RSJ International Conference on Intelligent Robots and Systems . pp. 2526 – 2531 .
- Gandhi , O. P. , Lazzi , G. and Furse , C. M. 1996 . Electromagnetic Absorption in the Human Head and Neck for Mobile Telephones at 835 and 1900 MHz . IEEE Transactions on Microwave Theory and Techniques , 44 : 1884 – 1897 .
- Garnier , M. , Bailly , L. , Dohen , M. , Welby , P. and Loevenbruck , H. 2006 . An Acoustic and Articulatory Study of Lombard Speech: Global Effects on the Utterance . Interspeech 2006 , : 2246 – 2249 .
- Gérard , J. M. , Wilhelms-Tricarico , R. , Perrier , P. and Payan , Y. 2003 . A 3D Dynamical Biomechanical Tongue Model to Study Speech Motor Control . Recent Research Developments in Biomechanics , 1 : 49 – 64 .
- Gilbert , M. , Knight , K. and Young , S. 2008 . Spoken Language Technology . IEEE Signal Processing Magazine , 25 : 15 – 16 .
- Guenther , F. H. 2006 . Cortical Interactions Underlying the Production of Speech Sounds . Journal of Communication Disorders , 39 : 350 – 365 .
- Guenther , F. H. , Ghosh , S. S. and Nieto-Castanon , A. A Neural Model Of Speech Production . Proceedings of the 6th International Seminar on Speech Production . Sydney . pp. 85 – 90 .
- Guenther , F. H. , Nieto-Castanon , A. , Ghosh , S. S. and Tourville , J. A. 2004 . Representation of Sound Categories in Auditory Cortical Maps . Journal of Speech, Language, and Hearing Research , 47 : 46 – 57 .
- Howell , P. 2002 . “ The EXPLAN Theory of Fluency Control Applied to the Treatment of Stuttering by Altered Feedback and Operant Procedures ” . In Clinical Linguistics: Theory and Applications in Speech Pathology and Therapy , Edited by: Fava , E. 95 – 115 . Amsterdam : John Benjamins .
- Holmes , J. and Holmes , W. 2001 . Speech Synthesis and Recognition , 2 , Oxford : Taylor & Francis .
- Hura , S. L. , Lindblom , B. and Diehl , R. L. 1992 . On the Role of Perception in Shaping Phonoligical Assimilation Rules . Language and Speech , 35 : 59 – 72 .
- Junqua , J. C. 1996 . The Influence of Acoustics on Speech Production: A Noise-induced Stress Phenomenon Known as the Lombard Reflex . Speech Communication , 20 : 13 – 22 .
- Juslin , P. N. and Laukka , P. 2003 . Emotional Expression in Speech and Music Evidence of Cross-modal Similarities . Annals New York Academy of Sciences , 1000 : 279 – 282 .
- Kier , W. M. and Smith , K. K. 1985 . Tongues, Tentacles and Trunks: The Biomechanics of Movement in Muscular-hydrostats . Zoological Journal of the Linnean Society , 83 : 307 – 324 .
- Koolstra , J. H. 2002 . Dynamics of the Human Masticatory System . Critical Revies in Oral Biology and Medicine , 13 : 366 – 376 .
- Koolstra , J. H. , von Eijden , T. M.G.J. , van Spronsen , P. H. , Weijs , W. A. and Valk , J. 1990 . Computer-assisted Estimation of Lines of Action of Human Masticatory Muscles Reconstructed in vivo by Means of Magnetic Resonance Imaging of Parallel Sections . Archives of Oral Biology , 35 : 549 – 556 .
- Kuhl , P. K. , Andruski , J. E. , Chistovich , I. A. , Chistovich , L. A. , Kozhevnikova , V. L.R. , Stolyarova , E. I. , Sundberg , U. and Lacerda , F. 1997 . Cross-language Analysis of Phonetic Units in Language Addressed to Infants . Science , 277 : 684 – 685 .
- Laughlin , S. B. , de Ruyter van Steveninck , R. R. and Anderson , J. C. 1998 . The Metabolic Cost of Neural Information . Nature Neuroscience , 1 : 36 – 41 .
- Lee , S. , Yildirim , S. , Kazemzadeh , A. and Narayanam , S. 2005 . An Articulatory Study of Emotional Speech Production . Interspeech 2005 , : 497 – 500 .
- Levelt , W. J.M. 1983 . Monitoring and self-repair in speech . Cognition , 14 : 41 – 104 .
- Lindblom , B. 1990 . “ Explaining Phonetic Variation: A Sketch of the H&H Theory ” . In Speech Production and Speech Modelling , Edited by: Hardcastle , W. J. and Marchal , A. 403 – 439 . Dordrecht : Kluwer Academic .
- Lombard , E. 1911 . Le sign de l’élévation de la voix . Ann. Maladies Oreille, Larynx, Nez, Pharynx , 37 : 101 – 119 .
- Maeda , S. 1979 . An Articulatory Model of the Tongue Based on a Statistical Analysis . Journal of the Acoustical Society of America , 65 : S22
- Maeda , S. 1988 . Improved Articulatory Model . Journal of the Acoustical Society of America , 84 ( Sup. 1 ) : S146
- McMillan , A. S. , Watson , C. and Walshaw , D. 1998 . Transcranial Magnetic-stimulation Mapping of the Cortical Topography of the Human Masseter Muscle . Archives of Oral Biology , 43 : 925 – 931 .
- Mermelstein , P. 1973 . Articulatory Model for the Study of Speech Production . Journal of the Acoustical Society of America , 53 : 1070 – 1082 .
- Messum , P. R. 2007 . “ The Role of Imitation in Learning to Pronounce ” . London : University College London . Ph.D Thesis
- Moore , R. K. A Comparison of the Data Requirements of Automatic Speech Recognition Systems and Human Listeners . Proceedings of EUROSPEECH’03 . pp. 2582 – 2584 .
- Moore , R. K. 2007 . Spoken Language Processing: Piecing Together the Puzzle . Speech Communication , 49 : 418 – 435 .
- Moon , S. J. and Lindblom , B. Two Experiments on Oxygen Consumption During Speech Production: Vocal Effort and Speaking Tempo . The 15th International Congress of Phonetic Sciences . pp. 3129 – 3132 .
- Northrup , S. , Brown , E. E. Jr. , Parlaktuna , O. and Kawamura , K. 2001 . Biologically-inspired Control Architecture for an Upper Limb, Intelligent Robotic Orthosis . International Journal of Humanfriendly Welfare Robotic Systems , 2 : 4 – 8 .
- Norton , N. S. 2007 . Netter's Head and Neck Anatomy for Dentistry , Philadelphia : Saunders Elsevier .
- Palmer , J. M. 1993 . ANATOMY for Speech and Hearing , Philadelphia : Lippincott Williams & Wilkins .
- Palmer , R. 2005 . “ An Evaluation of Speech and Language Therapy for Chronic Dysarthria: Comparison of Conventional and Computer Approaches ” . Sheffield , , UK : University of Sheffield . Ph.D Thesis
- Palmer , R. , Enderby , P. and Cunningham , S. 2004 . The Effect of Three Practice Conditions on the Consistency of Chronic Dysarthric Speech . Journal of Medical Speech-Language Pathology , 12 : 183 – 188 .
- Parker , M. , Cunningham , S. , Enderby , P. , Hawley , M. and Green , P. 2006 . Automatic Speech Recognition and Training for Severely Dysarthric Users of Assistive Technology: The STARDUST Project . Clinical Linguistics & Phonetics , 20 : 149 – 156 .
- Portele , T. , Höfer , F. and Hess , W. J. 1997 . “ A Mixed Inventory Structure for German Concatenative Synthesis ” . In Progress in Speech Synthesis , 263 – 277 . Berlin : Springer .
- Powers , W. T. 1974 . Behavior: The Control of Perception , London : Wildwood House .
- Riskin , J. 2003 . Eighteenth-century Wetware . Representations , 83 : 97 – 125 .
- Rizzolatti , G. and Arbib , M. A. 1998 . Language Within our Grasp . Trends in Neuroscience , 21 : 188 – 194 .
- Rizzolatti , G. and Craighero , L. 2004 . The Mirror-Neuron System . Annu. Rev. Neurosci. , 27 : 169 – 192 .
- Saito , H. and Itoh , I. 2003 . Three-dimensional Architecture of the Intrinsic Tongue Muscle, Particularly the Longitudinal Muscle, by the Chemical-maceration Method . Anatomical Science International , 78 : 168 – 176 .
- Seikel , J. A. , King , D. W. and Drumright , D. G. 1997 . Anatomy and Physiology for Speech and Language , San Diego : Singular Publishing Group .
- Scherer , K. R. 2003 . Vocal Communication of Emotion: A Review of Research Paradigms . Speech Communication , 40 : 227 – 256 .
- Shadle , C. H. , Barney , A. and Davies , P. O.A.L. 1999 . Fluid Flow in a Dynamic Mechanical Model of the Vocal Folds and Tract. II. Implications for Speech Production Studies . Journal of the Acoustical Society of America , 105 : 456 – 466 .
- Sorin , S. 2002 . “ Bluff and Reputation ” . In GameTheory and Economic Analysis , 57 – 73 . London : Routledge .
- Takemoto , H. 2001 . Morphological Analyses of the Human Tongue Musculature for Three-Dimensional Modeling . Journal of Speech, Language, and Hearing Research , 44 : 95 – 107 .
- Takemura , K. , Yokota , S. and Edamura , K. 2007 . Development and Control of a Micro Artificial Muscle Cell Using Electro-conjugate Fluid . Sensors and Actuators A , 133 : 493 – 499 .
- Thiessen , E. D. 2005 . Adults and Baby Talk . Pediatrics for Parents , 22 : 5
- Trimmer , B. A. , Takesian , A. E. , Sweet , B. M. , Rogers , C. B. , Hake , D. C. and Rogers , D. J. Caterpillar Locomotion: A New Model for Soft-bodied Climbing and Burrowing Robots . 7th International Symposium on Technology and the Mine Problem .
- VanIngen-Dunn , C. , Hurley , T. R. and Yaniv , G. Development of a Humanlike Flesh Material for Prosthetic Limbs . Engineering in Medicine and Biology Society, 1993. Proceedings of the 15th Annual International Conference of the IEEE . pp. 1313 – 1314 .
- Vatikiotis-Bateson , E. and Ostry , D. J. Analysis and Modeling of 3D Jaw Motion in Speech and Mastication . 1999 IEEE International Conference on Systems, Man, and Cybernetics . Vol. 2 , pp. 442 – 447 .
- Vogt , F. , Lloyd , J. E. , Buchaillard , S. , Perrier , P. , Chabanas , M. , Payan , Y. and Fels , S. S. Investigation of Efficient 3D Finite Element Modeling of a Muscle-activated Tongue . Proceedings of ISBMS 06 in Springer LNCS 4072 . pp. 19 – 28 .
- Yang , J. , Chiou , R. , Ruprecht , A. , MacPhail , L. and Rams , T. 2002 . A New Device for Measuring Density of Jaw Bones . Dentomaxillofacial Radiology , 31 : 313 – 316 .
- Yoshikawa , Y. , Asada , M. , Hosoda , K. and Koga , J. 2003 . A Constructivist Approach to Infants’ Vowel Acquisition Through Mother–Infant Interaction . Connection Science , 15 : 245 – 258 .
- Zwijnenburg , A. , Lobbezoo , F. , Kroon , G. and Naeije , M. 1999 . Mandibular Movements in Response to Electrical Stimulation of Superficial and Deep Parts of the Human Masseter Muscle at Different Jaw Positions . Archives of Oral Biology , 44 : 395 – 401 .
- Zhang , Z. , Mongeau , L. , Frankel , S. H. and Thomson , S. 2004 . Sound Generation by Steady Flow Through Glottis-shaped Orifices . Journal of the Acoustical Society of America , 116 : 1720 – 1728 .