Abstract
The combination of productivity, dynamics and grounding imposes constraints that require specific architectures for their combined implementation. Grounding of representations can be achieved with specific neuronal assembly structures, which can be distributed over different brain areas. This entails that grounded conceptual representations cannot be copied, transported and pasted to form compositional structures. Instead, grounded conceptual representations have to remain in situ when they are a part of a compositional structure. Thus, each representation of a concept used in a compositional structure is always the same grounded representation of that concept. Compositional connectionist structures based on in situ grounded representations can be formed temporarily by embedding these representations in specific compositional (neural) architectures. Different compositional architectures will be needed for different cognitive processes. They are integrated by the in situ representations embedded in them. Grounded in situ representations could be partly distributed. Compositional architectures could be more distributed or more localist, depending on the specific processes they implement. We will discuss examples of each.
1. Introduction
We discuss the localist/distributed dimension (and related issues) from the perspective of connectionist (neural) architectures that integrate grounding, productivity and dynamics. Grounding refers to the fact that the (conceptual) representations of a cognitive system are determined by the way the system interacts with its environment. In this way, the system obtains representations that have a meaning for the system itself. Productivity refers to the ability to process unlimited amounts of (novel) information and to generate arbitrarily many different forms of behaviour, based on a limited amount of already stored information. Dynamics refers to the real-time processing of information and the ability to interact with the environment. In particular, dynamical processing of information allows the system to keep up with the dynamics of events unfolding in its environment.
Productivity, dynamics and grounding can each be seen as important features of cognition. But, in our view, it is their combination that sets human cognition apart from cognition of animals or present-day artificial systems. For example, dynamical interaction is obviously an important feature of animal cognition, but productivity to the extent of human cognition is not found in animals. On the other hand, productivity can be found in artificial forms of information processing, as given by classical symbol manipulation, but grounding of representations is missing in these systems.
Connectionist (neural) architectures that integrate grounding and productivity differ from cognitive systems that use symbol manipulation to process or create compositional structures. Symbol manipulation depends on the ability to make copies of symbols and to transport them to other locations. Newell Citation(1990) argued that symbols are needed for cognition because only a limited amount of information can be stored physically at a given location, as illustrated in . The symbol token is then needed to obtain more information when that is required for a given process. In Newell's (Citation1990, p. 74) words:
Figure 1. The role of symbols in symbolic architectures of cognition or symbol systems. (a) Symbols are used for access and retrieval of information (based on Newell Citation1990, fig. 2–10). (b) Symbol copies are constituents in complex representations, as in The cat is on the mat.
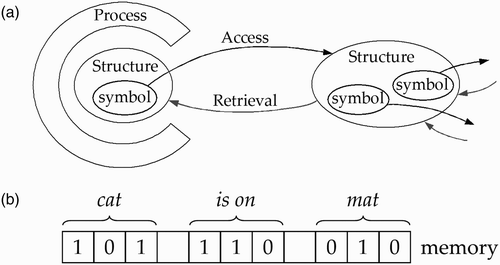
The symbol token is the device in the medium that determines where to go outside the local region to obtain more structure. The process has two phases: first, the opening of access to the distal structure that is needed; and second, the retrieval (transport) of that structure from its distal location to the local site, so it can actually affect the processing. (…) Thus, when processing ‘The cat is on the mat’ (which is itself a physical structure of some sort) the local computation at some point encounters ‘cat’; it must go from ‘cat’ to a body of (encoded) knowledge associated with ‘cat’ and bring back something that represents that a cat is being referred to, that the word ‘cat’ is a noun (and perhaps other possibilities), and so on.
The symbol token is thus needed to obtain more information when that is required for a given process. Symbols can be used to access and retrieve information because they can be copied and transported. For the same reason, symbols can be used to create compositional structures. For example, we could use symbols to create the sentence – The cat is on the mat in the following way (ignoring the). A specific symbol, say 101, represents cat (we can use a string like 101 as a single symbol). Another symbol represents mat (e.g. 010) and yet another (e.g. 110) represents the phrase is on. It is arbitrary which symbol represents which word. The symbol 101 could just as well represent mat or is on, instead of cat. But once a choice is made, we need to use the same symbol throughout.
So, with symbols, it is easy to make constituents like words. Because symbols can be copied and transported, they can be used to create complex compositional structures based on these constituents. What is required is a suitable computational architecture to implement these processes. That is why classical cognitivism saw the Turing machine or the Von Neumann computer as the basic model for this architecture. Of course, the actual symbol architectures would be more complex and refined as these model architectures, but they shared the same feature that knowledge is represented using symbols that can be copied and transported (even over the Internet in the present times), and can be used to create or process complex symbol strings. For example, using the word symbols for cat, is on and mat given above, the symbolic compositional structure of cat is on mat could be represented with 101-110-010 (using – for a blank symbol).
When information is represented using symbols, representing complex compositional (e.g. sentence-like) forms of information is easy. This is why symbolic architectures excel in storing, processing and transporting huge amounts of information, ranging from tax returns to computer games. The capacity of symbolic architectures to store (represent) and process these forms of information far exceeds that of humans. But interpreting information in a way that could produce meaningful answers or purposive actions is far more difficult with these architectures. In part, this is due to the ungrounded nature of symbols, which in turn, is partly due to the fact that symbols are copied and transported into these cognitive systems.
When a symbol token is copied and transported from one location to another, all its relations and associations at the first location are lost. For example, the perceptual information related to the concept cat is lost when the symbol token for cat is copied and transported to a new location outside the location where the perceptual information is processed. At the new location, the perceptual information related to cats is not directly available. Indeed, as noted by Newell in the quote above, a significant role of a symbol is to escape the limited information that can be stored at one site. So, when a symbol is used to transport information to other locations, at least some of the information at the original site is not transported.
The ungrounded nature of symbol tokens has consequences for processing. Because different kinds of information related to a concept are stored and processed at different locations, they can be related to each other only by an active decision to gain access to other locations, to retrieve the information needed. This raises the question of who (or what) in the architecture makes these decisions, and on the basis of what information. Furthermore, given that it takes time to search and retrieve information, there are limits on the amount of information that can be retrieved and the frequency with which information can be renewed.
So, when a symbol needs to be interpreted, not all of its semantic information is directly available, and the process to obtain that information is very time-consuming. And this process needs to be initiated by some cognitive agent. Furthermore, implicit information related to concepts (e.g. patterns of motor behaviour) cannot be transported to other sites in the architecture.
The ungrounded nature of symbol tokens has consequences for learning as well. Because different kinds of information concerning a concept are stored at different locations, the changes that occur at one location have no effect on the information stored at another location, unless again an active process is initiated to transfer the new information to the other locations. Furthermore, new information that is learned in an implicit manner cannot be transferred in this way.
2. Grounded representations
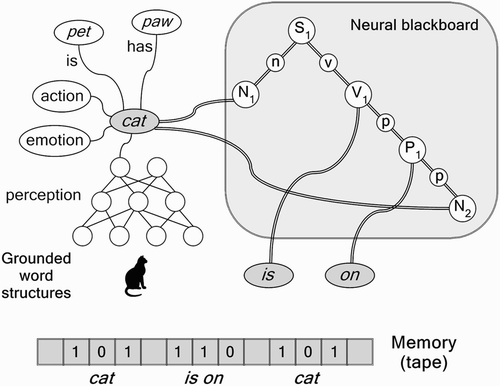
In human cognition, conceptual representations are grounded in experiences (perception, action, emotion) and (conceptual) relations (Harnad Citation1991; Barsalou Citation1999). In the brain, the grounded representation of a concept consists of a network structure distributed over the cortex (and other brain areas). (left) illustrates the grounded structure of the concept cat. It interconnects all aspects related to cats. For example, it includes all perceptual information about cats. It also includes action processes related to cats (e.g. the embodied experience of stroking a cat, or the ability to pronounce the word cat), emotional content associated with cats, and all other information related to or associated with cats, such as the information about the (negative) association between cats and dogs and the semantic information that a cat is a pet or has paws.
Figure 2. Left: The neural representation of cat, grounded in perception, emotion, action, associations and semantic relations. Right: Grounded in situ representations are embedded in several specialised architectures, needed for specific-compositional structures.
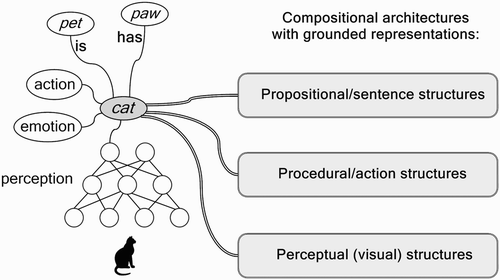
The grounded structure of the concept cat illustrated in consists of a network structure that develops over time in a continuous fashion (i.e. it can and will be adjusted continuously). For example, the network labelled ‘perception’ indicates that networks located in the visual cortex learn to identify cats or learn to categorise them as animals. In the process of learning to identify or categorise cats they will modify their connection structure, by growing new connections or synapses or by changing the synaptic efficacies. Other networks will be located in the auditory cortex, or in the motor cortex or in parts of the brain related to emotions. For these networks as well, learning about cats results in a modified network structure. Precisely because these networks remain located in their respective parts of the cortex, learning can be a gradual and continuous process. Moreover, even though these networks are located in different brain areas, connections can develop over time between them because their positions relative to each other remain stable as well.
The grounded network structure for cat illustrates why grounded concepts are different from symbols. When cat is represented by a symbol like 101, it is clear how copies of the representation of cat can be used to represent different sentences like cat is on the mat or cat chases dog. But when the conceptual representation of cat is embodied in a network structure as illustrated in , it is difficult to see what should be copied to represent cat in sentences like these.
For example, the grey oval in , labelled cat, plays an important role in the grounded representation of the concept cat. It represents a central neural population that could interconnect the neural structures that represent and process information related to cats. However, it would be wrong to see this central neural population itself as a neural representation of cat that could be copied and transported like the symbol 101. As (left) illustrates, the representational value of the central neural population labelled cat derives entirely from the network structure of which it is a part. When the connections between this central neural population and the other networks and neural populations in the structure of cat are disrupted or when the other networks and populations are removed, the central neural population no longer constitutes a representation of the concept cat; for example, because it is no longer activated by the perceptual networks that identify cats. So, when the internal network structure of the central neural population (or its pattern of activation) is somehow copied and transported, the copy of the central neural population is separated from the network structure that represents cat. In this way, it has lost its grounding in perception, emotion, action, associations and relations.
Hence, grounded representations cannot be copied and transported. Instead, they remain in situ. This does not entail that representations cannot become more abstract over time. That is, we can learn a more abstract concept like cat, based on the specific cats we have experienced. The network structure of a more abstract concept (e.g. cat) will also be grounded and in situ, just as the network structure of a specific object (e.g. ‘Felix’). The difference is in the network structure itself. The one for cat will (partly) have different connections compared with the one for ‘Felix’. So, grounded in situ representations do not prevent the development of abstract relations between concepts, which could be important for systematicity of cognition.
3. Grounded representations in compositional structures
The question arises as to how in situ representations can be used to represent compositional structures, which form the basis of the productivity of (human) cognition.
We argue that, because grounded representations always remain in situ, they have to be embedded in specific compositional (neural) architectures to temporarily form compositional structures. We assume that there are specific neural compositional architectures (or ‘neural blackboards’, van der Velde and de Kamps Citation2006) for specific cognitive processes. (right) illustrates three of them: a propositional (or sentence) architecture, to process propositions like The cat is on the mat; a perceptual (visual) architecture, e.g. to perceive and localise a cat on the mat; and a procedural architecture, e.g. to initiate behaviour (e.g. looking for a cat). The grounded in situ representations play a pivotal role in the interactions between these architectures (van der Velde and de Kamps Citation2010).
Indeed, we suggest that each specific kind of compositional structure could depend on a specific neural blackboard. So, next to the blackboards illustrated in , there could be neural blackboards for compositional structures like phonological structures, non-sentence sequences of (pseudo)words (Hadley Citation2008), more elaborate sentence structures, compositional structures used in reasoning or complex motor sequences. This could seem to be overly complex. But complexity is needed to account for human cognition. It will be included in any elaborate architecture of (human-like) cognition. For example, in the case of symbol manipulation executed on a computer, a lot of its complexity is hidden in the underlying machinery provided by the computer. As a model of cognition, this machinery has to be assumed as a part of the model as well.
Furthermore, the use of these different blackboards is a direct consequence of the grounded nature of representations. Because these representations always remain in situ, they have to be connected to architectures like blackboards to form compositional structures and to execute processes on the basis of these structures. suggest that specific blackboards will arise for specific kinds of processes, instead of some general kind of blackboard that could serve for all purposes.
4. Visibility of grounded representations in compositional structures
In one aspect, grounded in situ representations resemble symbols. Like symbols, they are explicit forms of representation, in the sense that they remain accessible or ‘visible’ in compositional structures. In this way, they can remain grounded when they are a part of a compositional structure. Cognitive neuroscience has already begun to show that grounded representations indeed remain visible and grounded in compositional structures (Tettamanti et al. Citation2005). Because grounded representations are visible (accessible), they can influence the compositional structures of which they are a part.
However, unlike symbols, grounded in situ representations as constituents in compositional structures provide both local and global information. As constituents, they can affect the specific (local) compositional structures of which they are a part. But as grounded in situ representations, they retain their embedding in the global information structure of which they are a part (van der Velde and de Kamps Citation2010). That is, as illustrated in , the grounded representations are a part of each specific blackboard architecture in which they are embedded. In this way, they form a link between these architectures. When processes occur in one blackboard, the grounded representations can also induce processes in the other blackboards, which could in turn influence the process in the first blackboard. In this way, an interaction occurs between local information embodied in specific blackboards and global information embodied in grounded in situ representations.
5. Localist versus distributed
Concerning the localist/distributed dimension, the issue in terms of this overall architecture is not whether representations are local or distributed, but whether they are grounded. In particular, the issue is whether representations remain grounded when they are a part of a compositional representation. Given that grounded representations are typically distributed over different brain areas, they could be partly overlapping. Compositional architectures (neural blackboards) could be more or less distributed as well, depending on the specific processes involved. We will illustrate this with two kinds of blackboards: one for ‘spatial’ compositional structures and one for sequential compositional structures.
5.1 A blackboard architecture of compositional visual structures
A visual object elicits activity distributed over the visual cortex and beyond. In the lower areas of the visual cortex, conjunctive processing of visual features like shape, colour, texture, motion and location occurs. But in higher areas, a specialisation of processing occurs. In particular, in the temporal cortex (‘ventral pathway’), the identity of objects (e.g. of its shape or colour) is processed. In the parietal cortex (‘dorsal pathway’), the processing of information related to actions occurs, such as information about the location of an object in space. A visual object is thus encoded by neuronal activity distributed over the visual cortex, combining neurons in the lower areas, ventral pathway and dorsal pathway.
We argue that a neural blackboard architecture can be identified in the visual cortex that processes visual displays in a productive (compositional) manner. illustrates a simplified example, in which two objects are presented in a visual display. The objects consist of a cross on the left and a diamond on the right. Thus, each object has two ‘features’: shape (cross or diamond) and location (left or right). One of the objects (the cross) is selected by a cue (e.g. by using the word cross), and the task is to find the location of the cross in the display (left, in this case). The objects in the display activate neurons in a number of cortical areas distributed over the visual cortex. For convenience, only a selected number of the areas are presented, based on (Felleman and van Essen Citation1991). The objects next to a given area are presented in shades of grey, to indicate the relative strength of activity of the neurons that represent the objects in these areas.
Figure 3. Compositional processing of shape (identity) and location in a neural blackboard architecture based on the ventral and dorsal pathway of the visual cortex. Here, the location of the cross is selected in the dorsal pathway when the shape of the cross is selected in the ventral pathway by a cue (e.g. using the word cross). Shades of grey reflect the relative levels of activation of neurons representing (elementary) features (shape, location) of the cross and diamond. Initial times of activity (latency) are given for each area.
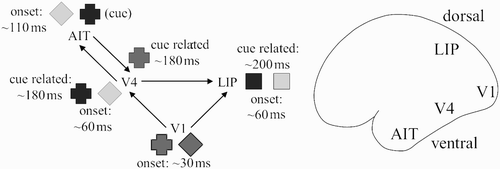
After initial processing of the display in the primary visual cortex (V1), the identity and location of the objects are processed in parallel. Processing proceeds initially in a feedforward manner, going from area V1 to areas V4 (visual area 4) and AIT (anterior inferior-temporal) in the ventral pathway, and from V1 to areas such as LIP (lateral intra-parietal) in the dorsal pathway. Representation is retinotopic (topographic) in V1, V4 and LIP, but it is to a large extent location independent in AIT (Oram and Perrett Citation1994). Animal research has provided information about the time course of the feedforward activation, as illustrated in . The time course is given in onset latency, i.e. the beginning of activation after the onset of the stimulus display. Onset latency in V1 is about 30 ms (Oram and Perrett Citation1994), in V4 about 60 ms (Oram and Perrett Citation1994), in AIT about 110 ms (Chelazzi, Miller, Duncan, and Desimone Citation1993), and in LIP about 60 ms (Gottlieb, Kusunoki, and Goldberg Citation1998).
Feedback activation is also found in the visual cortex, whereas feedforward activation is based on the presence of a stimulus, feedback activation is typically based on cue-related information. For example, the word cross could be used as a cue, or the cross could have been given as a cue stimulus, preceding the object display. Bichot, Rossi, and Desimone Citation(2005) showed that feedback activity interacts with feedforward (display related) activity in monkey area V4, in a way that is selective for cue-related activity. The onset latency of this interaction in V4 is about 180 ms after presentation of the stimulus display. Thus, there is a difference between the onset of stimulus activation in V4 (∼60 ms) and onset of the interaction between cue and stimulus activation in V4 (∼180 ms), even in cases when the cue precedes the stimulus display.
van der Velde Citation(1997) and van der Velde and de Kamps (Citation2001, 2006) argued that the interaction between feedforward activation and feedback activation in the visual cortex, and the timing of that interaction, reflects the structure of a neural blackboard architecture that processes and integrates the features of a visual object in a compositional manner.
Representation is (at least) partly distributed in this architecture. For example, the cross in is represented by retinotopic neuronal activation in the lower areas of the visual cortex. This representation reflects both location and (elementary) identity information. So, objects presented at the same location would also partly activate these neurons, depending on their structural similarity with the cross. In AIT, the identity of the cross is represented by (distributed) activation that is largely location independent. In LIP, the current location of the cross in the visual display is represented by retinotopic neuronal activation. Other objects presented at that location would activate the same neurons in LIP.
Because visual objects are processed in a compositional manner, the different features of an object (here: shape and location) have to be related (bound) to each other. The interaction or binding process illustrated in shows how the identity of the object, represented in one part of the architecture, can influence the location information related to the object, represented in another part of the architecture.
In , the identity of the cross (used as a cue) enhances (selects) cross-related activity in AIT, which results in cross-related feedback activity in the ventral pathway (e.g. from AIT to V4). In V4, the cross-related feedback activity interacts with all stimulus (display)-induced feedforward activity. The interaction is such that the activity related to the cross in V4 is enhanced. Because the representation of the cross in V4 is retinotopic (topographic), the enhanced representation in V4 corresponds to the location of the cross in the display. When the enhanced activity in V4 is transmitted to LIP, it enhances the corresponding topographic representation in LIP. In this way, the location of the cross is selected in LIP (e.g. to be used as the target for an action such as an eye movement). In line with this account, Gottlieb, Kusunoki, and Goldberg Citation(2005) observed a difference in response latency between such cue-related activity (∼200 ms) and onset activity (∼60 ms) in monkey LIP. Similar interactions can select identity information of the object based on spatial information, or one form of identity information (e.g. shape) based on other forms identity information (e.g. colour), or vice versa.
The neural blackboard architecture illustrated in can be used to process compositional visual structures based on features like shape, colour, motion, texture and location, using a similar interaction and binding process as illustrated in this figure (van der Velde and de Kamps Citation2006). As illustrated in , the neural blackboard architecture illustrated in is connected to other compositional architectures by means of the grounded in situ representations involved. For example, cue information in can be given by linguistic information, such as object (shape) or colour names, or spatial prepositions. Thus, for example, the word cross (e.g. used as a cue) could influence the interaction process as illustrated in , which would indicate that neural word representations can influence visual representations in different areas in the visual cortex. In fact, such a neural word representation and the related visual representations in different areas in the visual cortex combine to form a grounded in situ representation of a word, as illustrated in . These grounded in situ word representations will integrate the visual blackboard architecture with the blackboard architectures that represent compositional word structures, as illustrated below.
5.2 A blackboard architecture of compositional propositional structures
illustrates that grounded representations of the words cat, is, on, and mat can be used to create a compositional structure of the sentence The cat is on the mat (ignoring the). The structure is created by forming temporal interconnections between the grounded representations of cat, is, on, and mat in a ‘neural blackboard architecture’ for sentence (propositional) structure (van der Velde and de Kamps Citation2006).
Figure 4. Illustration of the combinatorial structure The cat is on the mat (ignoring the), with grounded representations for the words. The circles in the neural blackboard represent populations and circuits of neurons. The double line connections represent conditional connections. (N, n=noun; P, p=preposition; S=sentence; V, v=verb.)
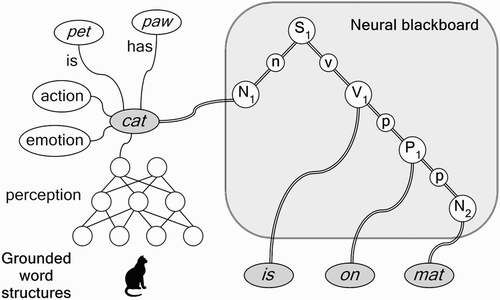
The neural blackboard consists of neural populations that represent syntactical type information such as sentence (S 1), noun phrase (here, N 1 and N 2), verb phrase (V 1) and prepositional phrase (P 1). In the process of creating a sentence structure, the populations representing specific syntactical type information (or syntax populations, for short) are temporarily connected (bound) to word structures of the same syntactical type. For example, cat and mat are bound to the noun phrase populations N 1 and N 2, respectively. In turn, the syntax populations are temporarily bound to each other, in accordance with the sentence structure. So, cat is bound to N 1, which is bound to S 1 as the subject of the sentence, and is is bound to V 1, which is bound to S 1 as the main verb of the sentence. Furthermore, on is bound to P 1, which is bound to V 1 and N 2, to represent the prepositional phrase is on mat.
All bindings in this architecture are of a temporal nature, represented by the double line connections in . Binding is a dynamic process that activates specific connections in the architecture. The syntax populations play a crucial role in this process, because they allow these connections to be formed. For example, each word structure corresponding to a noun has connections to each noun phrase population in the architecture. However, these connections are not just associative connections. Instead, they are conditional connections. That is, they consist of neural circuits that control the flow of activation through the connection. In , these circuits are represented by the small circles in between the syntax populations. For example, the circle labelled n represents the circuit that binds N 1 to S 1 as its subject.
To make a conditional connection active, its control circuit has to be activated. This is an essential feature of the architecture, because it provides control of activation, which is not possible in a purely associative connection structure. In this way, relations instead of just associations can be represented. also illustrates an example of relations. They consist of the conditional connections between the word structure of cat and the word structures of pet and paw. For example, the connection between cat and pet is conditional because it consists of a circuit that can be activated by a query of the form cat is? The is part of this query activates the circuit connection between cat and pet, so that pet is activated as the answer to the query. Thus, in conditional connections, the flow of activation can be controlled. For example, the is and has labels in indicate that information of the kind cat is or cat has controls the flow of activation between the word structures.
Grounded concepts cannot be copied, yet some sentences seem to require copies of words. For example, in the sentence The cat is on the cat, the noun cat has the role of the subject, but also the role of a noun in a prepositional phrase. A symbolic architecture can solve this problem easily. shows a symbolic representation of the sentence cat is on mat, with symbols stored in a memory (tape). shows that all that is required to form cat is on cat is to replace the symbol for mat with a copy of the symbol for cat.
also illustrates how this problem can be solved in an architecture of grounded cognition. Instead of making a copy, the grounded in situ representation of cat is connected twice to the sentence structure of The cat is on the cat in the neural blackboard for sentence (propositional) structures. This can be achieved because the grounded structure for cat is now bound to two noun phrase populations, N 1 and N 2. Because N 1 is bound to S 1, cat is the subject of the sentence. But cat is also the noun in the prepositional phrase because N 2 is bound to P 1. Both representations of cat in the sentence remain grounded and in situ in this way.
Figure 5. Top: the combinatorial structure The cat is on the cat (ignoring the) with grounded representations for the words. Bottom: symbolic representation of cat is on cat, with symbol 101 for cat and 110 for is on.
To avoid confusion between their syntactic roles, and the words they bind to, the syntax populations are localist in this architecture. In the same way, the populations that connect the grounded in situ (word) representations to the neural blackboard are localist also. However, we have not yet investigated what would happen if these populations were more distributed. Furthermore, the grounded in situ representations themselves can (and will) be more distributed, as in the case of representations encoding information processed in the visual architecture.
6. Conclusion
At face value, there seems to be a tension between the grounded nature of human cognition and its productivity. The grounded nature of cognition depends on structures as illustrated in . At a given moment, they consist of a fixed network structure distributed over one or more brain areas (depending on the nature of the concept). Over time, they can be modified by learning or development, but during any specific instance of information processing they remain stable and fixed (in situ). Indeed, it is precisely because they are stable and fixed that they can be modified and can develop over time. When the core of the structure is (relatively) fixed and stable, it forms an anchor to which new information (e.g. new relations) can be connected in a gradual way.
However, compositional structures can be formed on the fly with grounded representations that remain in situ, as illustrated with the visual architecture of and the propositional architecture of and . These architectures differ on the localist/distributed dimension. The visual architecture of is highly distributed, as shown by neuroscience. This may perhaps be due to the spatial nature of visual processing. On the other hand, sequentially operating neural blackboards, as the one illustrated in and , will likely be more localist, given the temporal nature of sequential processing. Examples of such neural blackboards may perhaps also be found in controlling complex movement sequences, consisting of activating and deactivating distinctive muscles in a specific order (e.g. as in piano playing). Indeed, controlling complex movement sequences with muscles that are by nature in situ may be the basis for controlling complex sequences of grounded in situ conceptual representations in cognitive processes.
Acknowledgements
The authors wish to thank an anonymous reviewer for valuable comments on the article.
References
- Barsalou , L. W. 1999 . ‘Perceptual Symbol Systems’ . Behavioral and Brain Sciences, , 22 : 577 – 660 .
- Bichot , N. P. , Rossi , A. F. and Desimone , R. 2005 . ‘Parallel and Serial Neural Mechanisms for Visual Search in Macaque Area V4’ . Science , 308 : 529 – 534 .
- Chelazzi , L. , Miller , E. K. , Duncan , J. and Desimone , R. 1993 . ‘A Neural Basis for Visual Search in Inferior Temporal Cortex’ . Nature , 363 : 345 – 347 .
- Felleman , D. J. and van Essen , D. C. 1991 . ‘Distributed Hierarchical Processing in the Primate Cerebral Cortex’ . Cerebral Cortex , 1 : 1 – 47 .
- Gottlieb , J. P. , Kusunoki , M. and Goldberg , M. E. 1998 . ‘The Representation of Visual Salience in Monkey Parietal Cortex’ . Nature , 391 : 481 – 484 .
- Gottlieb , J. , Kusunoki , M. and Goldberg , M. E. 2005 . ‘Simultaneous Representation of Saccade Targets and Visual Onsets in Monkey Lateral Intraparietal Area’ . Cerebral Cortex , 15 : 1198 – 1206 .
- Hadley , R. F. 2008 . ‘The Problem of Rapid Variable Creation’ . Neural Computation , 20 : 1 – 23 .
- Harnad , S. 1991 . “ ‘The Symbol Grounding Problem’ ” . In Emergent Computation: Self-organizing, Collective, and Cooperative Phenomena in Natural and Artificial Computing Networks , Edited by: Forrest , S. Cambridge, MA : MIT Press .
- Newell , A. 1990 . Unified Theories of Cognition , Cambridge, MA : Harvard University Press .
- Oram , M. W. and Perrett , D. I. 1994 . ‘Modeling Visual Recognition from Neurobiological Constraints’ . Neural Networks , 7 : 945 – 972 .
- Tettamanti . 2005 . ‘Listening to Action-related Sentences Activates Fronto-parietal Motor Circuits’ . Journal of Cognitive Neuroscience , 17 : 273 – 281 .
- van der Velde , F. 1997 . ‘On the Use of Computation in Modelling Behavior’ . Network: Computation in Neural Systems , 8 : 1 – 32 .
- van der Velde , F. and de Kamps , M. 2001 . ‘From Knowing What to Knowing Where: Modeling Object-based Attention with Feedback Disinhibition of Activation’ . Journal of Cognitive Neuroscience , 13 : 479 – 491 .
- van der Velde , F. and de Kamps , M. 2006 . ‘Neural Blackboard Architectures of Compositional Structures in Cognition’ . Behavioral and Brain Sciences , 29 : 37 – 108 .
- van der Velde , F. and de Kamps , M. 2010 . ‘Learning of Control in a Neural Architecture of Grounded Language Processing’ . Cognitive Systems Research , 11 : 93 – 107 .