Abstract
Connectionist language modelling typically has difficulty with syntactic systematicity, or the ability to generalise language learning to untrained sentences. This work develops an unsupervised connectionist model of infant grammar learning. Following the semantic boostrapping hypothesis, the network distils word category using a developmentally plausible infant-scale database of grounded sensorimotor conceptual representations, as well as a biologically plausible semantic co-occurrence activation function. The network then uses this knowledge to acquire an early benchmark clausal grammar using correlational learning, and further acquires separate conceptual and grammatical category representations. The network displays strongly systematic behaviour indicative of the general acquisition of the combinatorial systematicity present in the grounded infant-scale language stream, outperforms previous contemporary models that contain primarily noun and verb word categories, and successfully generalises broadly to novel untrained sensorimotor grounded sentences composed of unfamiliar nouns and verbs. Limitations as well as implications to later grammar learning are discussed.
1. Introduction
One of the most remarkable aspects of language is its acquisition. From exposure to only a small fraction of utterances, infants are able to progressively abstract and represent the underlying components of language while developing a system capable of generating an astronomically large number of utterances only in their first few years of life. Using explicit formal computational models and simulation, we can examine the mental representations infants might possess in order to support language, their representational structure, the processes that construct and make use of these representations, and the design of a computational-representational system capable of supporting these linguistic representations and processes. This paper presents a new approach to connectionist computational accounts of human language learning based on the ideas of sensorimotor grounding, which displays strong syntactic systematicity in generalising from old to new language items.
1.1. Systematicity in language processing
One of the criticisms of connectionist models as viable models of cognition came from Fodor and Pylyshyn Citation(1988). Much like Brachman (Citation1977, Citation1979) and Woods Citation(1975) had identified over a decade earlier for network models, Fodor and Pylyshyn argued that connectionist models were too often being specified at the level of symbol manipulation and cognitive architecture, which was inappropriate for a model based on low-level neural functioning. While from a reductionist perspective brains certainly implement cognitive systems, and as such cognition can ultimately be grounded in neural systems, connectionist models of language were using this low-level formalism to explain too high a level of functioning, and ignoring critical aspects of the problem of language. Fodor and Pylyshyn Citation(1988) argued that connectionist models failed to exhibit systematicity in language processing, which is the property of being able to generalise or extrapolate from a set of numerous specific instances into a set of few general properties or rules. Where connectionist models could successfully process the exact sentences they had seen before, they were unable to successfully demonstrate processing even minor but untrained variations of those sentences, or generalising to novel sentences or words. Further, even if a single demonstration of systematicity in a connectionist system was developed, this would be insufficient – systematicity is a general property of cognition (Fodor and McLaughlin Citation1990) and should also be a broad property of any model of cognition.
Hadley Citation(1994) divided systematicity into what he called weakly and strongly systematic behaviour. A network that is said to be weakly systematic must not only be able to acquire representations of a set of trained sentences, but also be able to accept novel sentences composed piecewise of words that occurred across trained sentences, with the caveat that these words occur at the same location in novel sentences as they were presented in familiar ones. For example, given training on the sentences “the cat ran” and “a mouse slept”, the network must demonstrate the capability of also accepting the sentence “a cat slept”. Because “cat” occurred as the second word in sentence 1, the network should also be able to generalise and accept it as a valid substitution for the second word in sentence 2. Strong systematicity requires that a network be able to acquire knowledge of word categories (noun, verb, adjective, etc.), as well as knowledge of valid sets of sequences of word categories (sentence structures), and to successfully demonstrate accepting valid novel sentences composed of familiar words and sentence structures across syntactic positions. For example, a system exhibiting strong systematicity must accept the novel sentence “the mouse chased the cat” as valid and grammatical, given previous exposure to the sentences “the mouse slept”, and “the cat chased the ball”. This requires that a network be able to ascribe a grammatical category to each word in a sentence, as well as to parse each sentence structure into its component grammatical categories, and accept novel combinations of words in familiar sentence structures that do not violate grammatical category boundaries. Hadley Citation(1994) further specified that for a network to be considered strongly systematic, it must also be able to acquire grammatical categories across sentence structures that include embedded clauses, such as “the dog saw the cat who chased the mouse” (a right-branching clause), or “the cat who the dog saw chased the mouse” (a centre-embedded clause).
1.2. Contemporary approaches to modelling systematicity
Elman Citation(1990) extended the three-layer feed-forward architecture described by Rumelhart and McClelland Citation(1986a) with recurrent connections in the hidden layer of a three-layer feed-forward network. These recurrent connections could be used to supply the hidden layer with information processed in a previous time-step, and through this mechanism provide the network with a “temporal context” of processing. The simple recurrent network (SRN) became a standard tool for language modelling, and increased the ability to model language beyond the level of the single word towards sequences of words and full sentences – with demonstrations including models of grammatical structure (Elman Citation1991) and the lexicon (Elman Citation1995), to name only a few.
The ability of the SRN to display systematicity was evaluated by Marcus Citation(1998), who demonstrated that the networks that Elman used to simulate the acquisition of grammatical knowledge were unable to generalise beyond their training set, even for simple tasks. The pattern of results was consistent with a network that was acquiring specific instances, rather than general processes, and echoed Prasada and Pinker's (1993) evaluation of earlier connectionist models of English past-tense based on the architecture of Rumelhart and McClelland Citation(1986b). Similarly, Van der Velde, van der Voort van der Kleij, and de Kamps Citation(2004) evaluated the potential of SRNs to display strong systematicity, and concluded that the networks were generally incapable of demonstrating even weak systematicity.
Frank Citation(2006) suggested that the failure of Van der Velde et al. Citation(2004) to produce systematicity in the SRN may have been a function of the properties of the simulation, rather than a general property of the network architecture. Frank Citation(2006) proposed a number of further simulations, using both the SRN, as well as a related variant, the echo state network (ESN; Jaeger Citation2003). Where the recurrent connections in the hidden layer of the SRN are complete (and potentially available for training), the corresponding recurrent connections of an ESN are sparse, lossy, and of relatively low weight. In this way, where the SRN must learn a process of “dimensionality reduction” to generalise grammatical category from a broad set of instances, the pattern of activation transferred by the sparse recurrent connections of the ESN contains much less information, and may have a more general or abstract character. As such, the ESN may capitalise on these abstract patterns of activation, and be more amenable to displaying systematic behaviour.
Frank Citation(2006) trained both networks on the benchmark training set of Van der Velde et al. Citation(2004), consisting of simple, right-branching, and centre-embedded clausal structures, with a variable-sized and vastly expanded vocabulary of nouns and verbs. Using a more graded metric of systematicity, both the SRN and ESN models showed some evidence of strongly systematic performance. The ESN model generally performed better than the SRN model in measures of systematicity, although substantial degradation in the performance of both the models was evident in grammatically difficult situations. This was taken as evidence that these recurrent connectionist architectures, while not demonstrating a general property of strong systematicity, were exhibiting behaviour that is substantially above the level of behaving entirely unsystematic, and at a level where at least some concept of generalisation was present. Brakel and Frank Citation(2009) demonstrated that this aspect of systematicity is a general property of SRNs across a variety of training circumstances, and that the SRN is likely learning to produce similar internal representational states for words of similar grammatical category, which the network can then use as a mechanism to behave strongly systematically within and across sentence structures. This general property of SRNs across a variety of circumstances was taken as a demonstration contra Fodor and Pylyshyn Citation(1988), in that connectionist architectures have the potential to behave systematically, at least to a certain degree.
Extending the study of Frank Citation(2006), Farkaš and Crocker Citation(2008) constructed an unsupervised model of systematicity in language processing in an effort to extend the results of Frank Citation(2006) by demonstrating systematic processing across very different connectionist architectures. Where the SRN and ESN models of Frank Citation(2006) made use of the backpropagation of error learning algorithm (Rumelhart and McClelland Citation1986a), a supervised error-driven learning algorithm that often requires constant input from a trainer or “oracle” during training (though not for the next-word prediction task, as the target outputs are presented in the input stream), Farkaš and Crocker Citation(2008) used an unsupervised architecture based on the self-organising map (SOM; Kohonen Citation1982, Citation1995). The SOM is an architectural abstraction of the topographic organisation observed in perceptual cortex, and combines unsupervised forms of both cooperative and competitive learning. Because Kohonen's Citation(1995) specification of the SOM describes an architecture that is particularly capable of representation and categorisation, but almost completely incapable of processing with that information, Farkaš and Crocker Citation(2008) presented and made use of a derivative architecture, the RecSOMsard, that incorporates temporal sequence-processing capabilities using recursive methods similar to the SRN (Elman Citation1990).
The RecSOMsard model was trained on the benchmark grammar of Van der Velde et al. Citation(2004) using a similar vocabulary size and training proportion to the models of Frank Citation(2006). While mean performance was indicative of a network with a high probability of demonstrating strong systematicity, specific performance at each grammatical transition across all sentence structures fluctuated dramatically, with substantially reduced performance as grammatical prediction difficulty increased. Overall, this pattern of performance was very similar to Frank's Citation(2006) ESN model and demonstrates that systematic behaviour can be observed across a variety of very different connectionist architectures, at least to a certain degree.
1.3. Representational grounding in language learning
While not specifically addressing the issue of systematicity in connectionist systems, others have investigated whether the expressivity of the input set might influence performance in grammar learning. Jean Mandler has extensively studied the conceptual world of even very young infants, and describes (Mandler Citation2004) the rich conceptual representations of pre-linguistic infants that have been uncovered across a variety of experimental paradigms, including habituating to familiar concepts, looking preferences, and differed imitation. To investigate whether the availability of conceptual information would influence grammar learning, Howell, Jankowicz, and Becker Citation(2005) constructed a database of sensorimotor conceptual representations consisting of 352 nouns and 89 verbs across 97 and 84 developmentally plausible perceptual and kinaesthetic noun and verb feature dimensions that 8- to 28-month old infants are likely to be sensitive to, such as “is red” or “involves mouth motion”. Howell et al. Citation(2005) showed that while an SRN was capable of acquiring a simple grammar of N–V–N sentences using only abstract symbolic lexical representations, sensorimotor grounded conceptual representations greatly improved performance, suggesting that the affordances the world has to offer may help to guide the infant in early grammar learning.
It is often argued that a critical aspect of grounding is the ability to have direct access to input from and the potential to affect changes to the world – a perspective known as embodiment (e.g. Clark Citation2008; see also Searle Citation1980; Harnad Citation1990). The concept of embodied cognition is pervasive across the study of intelligent systems, from approaches that propose extreme levels of embodiment with virtually no internal representation in cognitive robotics (e.g. Brooks Citation1991), to others that suggest that most aspects of thought and representation occur not centrally in either the mind or the world, but across a continual exchange between the two (e.g. the extended mind hypothesis; Clark Citation2008). In either case, it seems likely that the world supplies us with at least a vast amount of the information that we use to learn about it, and that computational models that are sensitive to grounded information can potentially capitalise on the benefits it has to offer.
1.4. Goals
While contemporary modelling of grammar acquisition and systematicity have had considerable success using SRNs, ESNs, as well as SOMs in concert with trained perceptrons, in the present study, we wish to examine the capacity of entirely unsupervised architectures to display strong systematicity in such a way that systematic behaviour is observed across grammatical class and sentence structure acquisition, irrespective of relative difficulty. This goal is driven in part by examining grammar learning from a developmental perspective, where one might argue that infants have not yet become sensitive to error signals in their environments, and must rely on other processes (such as correlational learning) to bootstrap their earliest knowledge of language. As such, we wish to concurrently address the problem of representational grounding (Harnad Citation1990), such that the network could be argued to possess grounded and developmentally plausible conceptual representations that it makes use of to acquire its knowledge of the combinatorial structure of language.
A further criterion imposed upon this work is that in addition to the model's performance on a next-word prediction task, we are also interested in examining the model's internal representations to see if they reflect an underlying process of abstraction. In this way, the architecture of the neural model presented here will be expanded somewhat for the sake of inspection, and use more layers than is in principle required for good performance on the next-word prediction task. We hope to expand each level of processing in the model, and have separate layers that contain explicit representations of conceptual knowledge, semantic category, and valid grammatical sentence structures.
The structure of the paper is as follows: Section 2 describes the low-level details of the SOM and presents the Chimaera framework – a parallel tool for easily constructing multi-layer SOM simulations that can pick-and-choose a variety of features from popular SOM variants for each layer. Section 3 discusses representational grounding, selecting suitable sensorimotor grounded language data for simulations, and the problems with using Euclidian metrics for determining grammatical category from sensorimotor representations through similarity. It introduces the semantic feature co-occurrence function, and shows how this function is a more natural method of evaluating similarity in a semantic space. Section 4 experimentally verifies the utility of the semantic co-occurrence activation function in distilling the grammatical category of nouns and verbs from sensorimotor representations in the first of two simulations, then experimentally applies the semantic co-occurrence function in a larger architecture capable of acquiring separate representations of sensorimotor concepts, grammatical category, as well as valid grammatical sentence structures. Two measures of systematicity are presented – grammatical prediction error (GPE), as well as the abstraction percentage, where it is shown that the architecture produces nearly zero GPEs and a near-perfect abstraction of representational states when using sensorimotor grounded input compared with ungrounded input. Section 5 discusses these results in the context of contemporary models of adult grammar learning, the limits of the semantic co-occurrence metric and semantic bootstrapping as one transitions from infant towards adult grammar learning, and the biological plausibility of the semantic co-occurrence activation function in neural models.
2. Model description
The SOM was originally formulated by Kohonen Citation(1982) as an unsupervised analogue to the topographic organisation found in perceptual cortex (e.g. Cansino, Williamson, and Karron Citation1994). The SOM typically consists of a single layer n-dimensional spatial array of nodes, each of which can be thought of as capable of representing a b-dimensional data vector in the weights to that node. Representing data vectors in an SOM is explicit, both in that each node represents a given vector, and that the learning rule explicitly modifies a subset of these nodes’ representations to more closely represent a given input vector. In this way, a single-layer SOM can be thought of both as a substrate for data-vector representation and classification, yet without extensions (such as recurrent or multilayered SOMs), it is unable to represent associative processes or temporal sequences. The SOM architecture has been applied to a diverse set of phenomena, including grammatical and semantic feature classification (Ritter and Kohonen Citation1989; Howell et al. Citation2005), acquiring phonetic categories (Behnke and Whittenburg 1996), and visual contour integration (Choe and Miikkulainen Citation2004).
Since its development, the SOM has experienced a proliferation of architectural extensions that add the ability to represent temporal sequences of data through a variety of mechanisms (see Mozer Citation1994, for a review of approaches to temporal representation). Architectures such as the temporal Kohonen map (TKM; Chappell and Taylor Citation1993) make use of leaky integrators that allow the learning rule to factor recently winning nodes into subsequent best-matching node calculations. Other contemporary approaches, such as the RecSOM (Voegtlin Citation2002), SOM for structured data (SOMSD; Hagenbuchner, Sperduti, and Tsoi Citation2003), and Merge SOM (Strickert and Hammer Citation2003) use a scheme where the weight vector representation of each element in a sequence is a combination of (i) the features that make up that representation (e.g. the RGB values in the case of a colour), and (ii) the “context” or position of that data vector in a sequence. These context values can take the form of a recurrent activation map from a previous epoch, the spatial coordinates of a best-matching node at the previous epoch, or other methods that supply some unique temporal context input.
Here, we describe the use of a Chimaera SOM model. The Chimaera framework and parallel simulation toolbox was developed by Jansen Citation(2010) as a means of easily specifying and simulating multi-layer SOM models. Each layer in a Chimaera network is able to selectively include one or more features of popular SOM variants, including recurrence (as in the RecSOM), intralayer Hebbian association, and specialised activation functions. As such, any given layer (or entire multi-layered model) may look like a blend, or Chimaera, of existing SOM architectures. While strictly speaking some of these features are functionally similar, and some may be preferable in certain cases. For instance, a given layer may include RecSOM-style recurrence in the form of previous activation maps being used as input vectors. This technique is particularly amenable to storing long sequences of temporal information, but not for generating predictions as to which input vectors may come next. For such a prediction, temporal Hebbian association between nodes within a layer can be used. Nodes activated by an input vector presented at time t will learn to preferentially associate with nodes that tend to be activated at time t+1, and “flow” some of their activation towards those future nodes, generating a mechanism of prediction. This flow can then be analysed, and used to describe the network's performance on a temporal prediction task.
2.1. Formal description
The SOM is typically described as a set of nodes i, where , each of which has a corresponding weight vector
between that node and an input vector
x
(
t
). At a given epoch t, the weights of a subset of the nodes in the network are modified based on a given node's spatial proximity to a “best-matching” node of index k, defined as the node that minimises the quantisation error E
i
between the input and weight vectors, typically evaluated in terms of the Euclidian distance |·|2 between these vectors, such that:
2.1.1. The Chimaera model
In a given epoch, the SOM learning rule typically searches for the best-matching node in the network based on the principle of minimising the Euclidian distance between an input vector and a given node's weight vector. The Euclidian distance is also often used to compute an energy or activation map. Here,
2.1.2. An activation map and inter-node Hebbian association
While the Chimaera framework supports SOM layers that compute activation straight from Euclidian distance, it also supports several other types of SOMs, including those whose activation maps include temporal Hebbian associations. To describe the activation of an associative SOM layer, we make use of the concept of flow. The flow into a node is a weighted contribution of Euclidian activations s j (t) of the network, given by:
When this Hebbian association is enabled for a given layer, the associative weights between nodes are updated at each epoch. The association weight update rule is essentially straight Hebbian learning (Hebb Citation1949), but includes a scaling factor to mediate the modification of weights over time, as well as a condition to preferentially associate from previously active nodes to currently active nodes (but not vice versa). In addition, the associative weights are only updated if the activation of each node exceeds a minimum ‘noise’ threshold:
Temporal sequences are represented using this Hebbian association mechanism acting over time. As a series of input vectors are serially presented to the network, specific nodes corresponding to those vectors will highly activate. When the input vector x at time t in some sequence is presented, the activation caused by the presentation of the input vector at t−1 will progressively decay to zero at a rate mediated by the k d decay parameter. Similarly, specific nodes corresponding to weight vectors representing x ( t ) will activate. As such, at any given point in a sequence, the region representing x ( t ) will be highly activated, where regions representing the input vectors x ( t - m ), where m is some positive integer, will have significantly less activation as m increases (i.e. the earlier an input vector is in a sequence, the less activation the region representing it will have at some arbitrary point in that sequence). This decay profile is similar to other leaky-integrator activation extensions of the SOM, including SARDNET (James and Miikkulainen Citation1995).
This simultaneous activation of multiple network regions corresponding to temporally close portions of the input vector sequence allows the Hebbian learning rule to associate these regions. Specifically, the associative weights between nodes corresponding to input vectors and
x
(
t
) will associate. As a result of the preferential association direction condition in EquationEquation (8)
, only the associative weights in the temporal direction from
to
x
(
t
) will strengthen, as a consequence of the nodes for the input vector at time t−1 having just recently been highly activated on the previous epoch. Over time, as the weights between regions preferentially increase in the direction of larger t, the flow of activation between nodes will cause activation of the nodes representing
x
(
t
) to also significantly activate the nodes representing
. This form of prediction-over-time is similar in form to a Synfire chain (Herrmann, Hertz, and Prugel-Bennett Citation1995).
2.1.3. Recurrence through input vectors
While the associative temporal mechanism described in section 2.1.2 is capable of generating predictions, for cases where the input set contains repeated elements, those predictions can be ambiguous. For instance, for the input sequence sets A–B–C and X–B–Y, when presented the input vector B, the network would generate predictions for both C and Y, regardless of whether A or X previously followed B in the input. The mechanism is unable to resolve sequences with ambiguous transitions among elements shared across sequences.
To address this, the Chimaera framework also supports selectively enabling RecSOM-style (Voegtlin Citation2002) recurrent temporal sequence processing for specific layers. If enabled for a given layer, that layer will recurrently feed back its activation map at time t−1, and use these activation values as a subset of that layer's input vector at time t. This has the effect of creating unique representations in that layer for even deep sequences. Coupled with the temporal association mechanism described in section 2.1.2, a given network can then have mechanisms to both represent deep sequences as well as to make unambiguous predictions for the next transition in those sequences.
3. Representational grounding
While many contemporary models have approached grammatical learning by attempting to distil general underlying structure from no more than a large corpus of ungrounded symbolic instances (e.g. Van der Velde 2004; Frank Citation2006; Farkaš and Crocker Citation2008), others (e.g. Howell et al. Citation2005) have approached the problem from the perspective of symbol grounding (Harnad Citation1990) and embodied cognition (e.g. Clark Citation2008). From this perspective, a young infant learning language is greeted not with simply a unique number (or a symbol) to represent a word, but rather a symbolic label that can be paired with an already rich pre-linguistic conceptual representation that shares similarities with other conceptual representations. It is these semantic commonalities and distinctions that allow the infant to tease initial broad category knowledge from their linguistic stream, and enable their initial acquisition of grammatical knowledge – a perspective known as semantic bootstrapping (Pinker Citation1984).
One of the difficulties in transitioning from abstract symbolic input vectors to those that have some grounded character is the task of generating such an input set. In their effort to determine the effects of grounded representations on grammar learning in SRNs, Howell et al. Citation(2005) constructed a database of developmentally plausible sensorimotor concept vectors containing rich feature representations of 352 nouns and 89 verbs across 97 noun-feature and 84 verb-feature dimensions. Howell et al. took great care to ensure that these feature dimensions were human-generated, non-artificial, developmentally plausible, and well-controlled and normed. Beginning with the thousands of human-generated semantic features of McRae, de Sa, and Seidenberg Citation(1997), Howell et al. extracted noun features describing explicitly perceptual knowledge, then had these feature dimensions independently rated for the plausibility that an 8- to 28-month infant would be sensitive to them. Similarly, verb features were generated by undergraduate participants, then later teased apart to arrive at 84 verb feature dimensions that were largely kinaesthetically themed (such as “requires head motion”), or described changes of state (as in “decreases hunger”). A total of 352 concrete nouns were selected from the MacArthur Communicative Development Inventory (MCDI; Fenson et al. Citation2000) and rated across the 97 feature dimensions by undergraduate participants, while 89 early and/or prototypical verbs from the MCDI as well as Goldberg Citation(1999) were similarly rated. Participants were asked to ascribe the likelihood of a given word to contain a given feature dimension, and assign this likelihood a value between 1 and 10. These values were averaged, then later normalised to arrive at a scalar probability for each feature across all words. Their cluster analysis showed very good overall categorical agreement within nouns and verbs at 88% and 70%, respectively, where chance performance was 9.1% for nouns and 11.1% for verbs. Here, we use this grounded input database to test our Chimaera model's ability to abstract strongly systematic grammatical representations from sensorimotor-grounded input.
3.1. Co-occurrence-based activation function
From the perspective of a self-organising neural network, how might one acquire broad categorical knowledge from semantic representations? One possible method comes from the notion of semantic similarity – already a low-level property of the activation function of a Chimaera network. At a given epoch, the Chimaera network generates an activation map that contains positive activation for nodes whose data vector representations are within a defined Euclidian distance from the input vector. By simply increasing the range of this Euclidian distance, the activation function might be made to produce positive values of activation for all data vectors that are similar to a given input vector – and using this broad signal as input, we might have a measure of category. But first, we must consider how we define similarity. Consider the set of input vectors in .
Table 1. Sample input vectors representing semantic co-occurrence.
Were a Chimaera network fully trained on these input vectors, then presented with the third input vector and asked to activate all similar representations (defined as all representations out to some Euclidian distance), the activation function would much sooner activate vector 2 () than vector 1 (
) despite vectors 2 and 3 having no commonalities aside from the relative intensities of their respective features – but sharing no features themselves in common. One might argue that semantically, vectors 1 and 3 are much more similar than vectors 2 and 3 because they share the same feature, with one vector simply being a less-intense version of the other – the difference is of degree, and not of kind. As such, Euclidian distance seems to be a poor measure of semantic similarity and cross-category activation is almost certain to occur.
We might define a metric for the semantic similarity of concepts expressed as feature vectors as follows: (i) two vectors are increasingly similar as the number of features they have in common increases, and (ii) two vectors are increasingly similar the closer their values match on a given feature dimension. In essence, this definition of similarity is based on semantic feature co-occurrence, rather than mathematically on Euclidian distance.
One might choose to express a semantic co-occurrence activation function in terms of something like a percentage difference, or a scalar product between
x
(
t
) and . Through pilot simulations we had success with both of these methods, but report here only on a normalised scalar product. The semantic co-occurrence score m is defined as:
The semantic co-occurrence activation function m′ i (t) is defined on (0,1), where negative values are clipped to 0, and the closer a value is to 1, the greater the semantic feature co-occurrence between two vectors. Note that in the case where two vectors share none of the same features, the resulting similarity value based on co-occurrence will be 0. Intuitively, this makes a lot of sense – while we could define a metric that might fall back to another measure of distance should co-occurrence not yield a match, from the perspective of semantic similarity it would not be meaningful to ascribe (for example) whether vector 2 from was closer to a vector that was describing something malleable, versus something that was sweet in taste. This is a critical difference between the semantic feature co-occurrence function and Euclidian distance, and the crux of our argument. While Euclidian metrics make sense for defining distance in a geometric space, they seem to be a poor measure for defining a distance analogue (such as similarity) in a semantic space. The scalar product method used here also strongly resembles the scalar product of Hebbian learning and common activation functions, which offer natural and biologically plausible implementation mechanisms.
4. Simulations
Here we present two sets of simulations that make use of the semantic co-occurrence activation function in grammar learning. The first group of simulations examine the utility of the semantic co-occurrence activation function to extract broad semantic category information from the Howell et al. Citation(2005) sensorimotor concept vector database, and do not involve any temporal or sentence processing. Building upon these first simulations, the second group of simulations construct a larger architecture based on the semantic co-occurrence activation function capable of processing sentences of sensorimotor concept vectors, and compare the performance of this architecture on both grounded and localist input sets.
In the following simulations, the formal description of the Chimaera network activation Equation(7) and flow Equation(6)
are altered slightly to include the use of the semantic co-occurrence activation function m′
i
(t) in place of a standard Euclidian activation function s
i
(t):
4.1. Simulation 1: Semantic Categories
Simulation 1 functioned to test the semantic co-occurrence activation function, and attempt to distil broad semantic category information from a large collection of sensorimotor grounded conceptual representations. The architecture of simulation 1 consists of a two layer network, with each layer making use of the semantic co-occurrence activation function for both activation and best matching node calculations.
The design of simulation 1 is as follows. Input vectors representing sensorimotor grounded nouns and verb concepts (25 each of nouns and verbs) along 181 real-valued feature dimensions drawn from the Howell et al. Citation(2005) database served as input. The network contained two layers, both 20×20 nodes in size. Layer 1 served as an input layer, and accepted 181-dimensional sensorimotor input vectors whose values ranged between 0 and 1 on each feature dimension. Each Layer 2 unit received the entire activation map of Layer 1 as input, reformatted from a 2D 20×20 array into a 400 dimensional real-valued vector. On a given epoch, a single sensorimotor vector was chosen and presented as input to the first layer of the network. Following the description in Section 2, the best-matching node for this vector was found, and the weights of all nodes out to a monotonically decreasing learning radius σ centred about the best matching node k were modified to more closely resemble the input vector. This process was repeated until all 50 of the sensorimotor input vectors had been presented to the network, when σ would decrease by one, and the process of presenting input vectors to the network would begin anew. This continued until σ decreased from its initial size (the size of the network, or 20) to 0. Layer 1 of the network was then considered trained, and training on Layer 2 began.
Layer 2 was trained identically to Layer 1, with the exception that the network's input was not sensorimotor vectors, but rather the activation patterns of Layer 1 in response to those sensorimotor vectors. At a given epoch, a sensorimotor concept vector would be presented to Layer 1 (as before), but instead of training the network, this vector would be used to generate a 20×20 activation map using the semantic co-occurrence activation function. This map then served as input to Layer 2. Training similarly proceeded from an initial learning radius σ of 20 until 0, linearly decreasing by 1 after each set of 50 epochs from each of the 50 sensorimotor concept vectors.
Where Layer 1 was designed to acquire explicit representations of the 181-dimensional sensorimotor grounded concepts, the broad patterns of activation produced by the semantic co-occurrence activation function were designed to provide a very broad signal of semantic category as input to Layer 2. As such, after self-organisation Layer 1 should contain representations of individual sensorimotor concepts, where Layer 2 should contain representations that signify two broad semantic categories – either that of “objects” (populated by the nouns in the Howell et al. data set), or “actions” (populated by the verbs). In this way, this two layer network could be thought of as a “semantic low-pass filter” that transduces the high-dimensional conceptual feature representations into a signal representing either “object” or “action”. Appendix 1 includes further details on the network parameters used in this simulation.
4.2. Simulation 1 Results
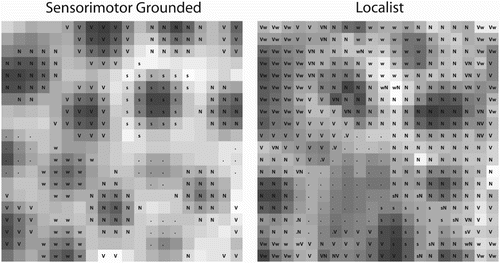
Activation maps for a subset of the 50 input vectors are displayed in (top). After 40 sets of 50 epochs, the network is fully trained and contains distinct sensorimotor representations for each of the 50 nouns and verbs in the input set in Layer 1. The activation maps of the input layer show broad non-overlapping spatial patterns of activation for noun and verb sensorimotor concepts. While a given sensorimotor conceptual representation (such as “OWL”) will be represented by only a few nodes in the 20×20 network, the similarity scaling (τ) parameter of Layer 1 is set to 1.0, causing all vectors that share at least one feature dimension in common – essentially, most nouns – to activate to at least some degree. As such, with these settings, while a pattern of activation will be unique for a given sensorimotor concept, many of these patterns of activation will be similar for semantically similar concepts, and nearly all nouns or verbs will tend to produce non-zero activation for the same nodes, even if the specific value of activation for each node is different.
Figure 1. A subset of activation maps after training for Simulations 1A and 1B. (Top) Where Layer 1 acquires unique sensorimotor representations for each concept, Layer 2 acquires representations of semantic category (object, or action). (Bottom) Adjusting the semantic similarity scaling parameter τ allows finer semantic categories to emerge. Here, in Layer 3, separate categories for “NOUN_FOOD” (LOLLIPOP, POTATOCHIP, GUM), “NOUN_AGENT” (OWL, DADDY, MOMMY), and “NOUN_OBJECT” (TRICYCLE, BUCKET) are evident.

Because the activation of a given node in Layer 1 can be thought of as mapping to a unique feature dimension in the input to Layer 2, and because nouns and verbs are activating many of the same nodes in Layer 1 (though with different values), the semantic co-occurrence activation function in Layer 2 tends to act as a “semantic low-pass filter” and produce only two patterns of activation – one for all nouns, and one for all verbs presented to Layer 1. In this way, the semantic co-occurrence activation function has distilled the semantic category of these early conceptual representations, either “object” or “action”, and because of the young-infant scope of the dataset, these semantic categories can be used to infer grammatical category – either noun or verb.
This demonstration is extreme, in that the semantic co-occurrence activation function is barely dampened by the τ parameter, and is thus providing very coarse signals of semantic category. This need not be the case. Simulation 1B is shown in (bottom), and is identical to Simulation 1A with the exception that the similarity scaling parameter has been moderately dampened from 1.0 to 0.3 (and an extra layer has been added onto the semantic low-pass filter). Here, again, Layer 1 represents specific sensorimotor concepts, and a given sensorimotor concept (such as “OWL”) is represented by only a few nodes. When a sensorimotor input vector is presented, the semantic co-occurrence activation function activates similar concepts in Layer 1 – but here, the sensorimotor concepts have to be far more similar to be activated.
Traversing to Layer 3 of Simulation 1B, the activation pattern for “noun” from Simulation 1A is no longer present. Instead, the network has distinct patterns of activation clusters for food items (including LOLLIPOP, POTATOCHIP, and GUM), animates (including OWL, DADDY, and MOMMY), and several non-self-animate objects (including TRICYCLE and BUCKET). In this way, the semantic scaling parameter allows us to modulate the intensity of the semantic low-pass filter, and the number of and specificity of grammatical categories that we may wish to pass on to a subsequent grammar learning network (such as “noun” versus “noun_animate”, “noun_inanimate”, “noun_food”, etc.). Note here that this process is not perfect or as straightforward as simply extracting broad “noun” or “verb” semantic category information from the dataset. The sensorimotor verbs in this dataset appear to have stronger intercategory feature agreement than the nouns, and as such would require a lower semantic scaling parameter to separate out distinct categories. The process is also not perfect – some nouns that intuitively should belong to a broader category (e.g. APPLESAUCE) tend to cluster with counterintuitive semantic categories, or form their own categories. This may be an artefact of some small inconsistencies in the sensorimotor database, or a more complicated representational issue that necessitates a more complex semantic activation function.
4.3. Simulation 2: grammatical sequences and predictions
Where Simulation 1 successfully demonstrated the abstraction of semantic category based on semantic feature co-occurrence, Simulation 2 aimed to incorporate this function into a broader model able to acquire both grammatical category information from sensorimotor conceptual representations (as in Simulation 1), as well as a broader knowledge of the grammatical combinations of parts of speech (or word categories, such as “determiner”, “noun”, “verb”, etc.) that form valid sentences. As such, this simulation aimed to take serially presented sequences of grounded sensorimotor conceptual representations as input, and to acquire a knowledge of both the part of speech of a given sensorimotor concept, as well as a knowledge of grammatical combinations of words such that a grammatical prediction could be successfully generated for the next-word prediction task. Note here that the input to the network is not a lexical representation (as in the word “cat”), but rather continues to be sensorimotor conceptual representations (such as a 181-dimensional semantic feature describing the features of a cat to which a young infant would be sensitive). As such, this model is not simulating grammar acquisition directly from the level of the word, although this is not a theoretical limitation. In principle, one could easily construct a 2-layer feed-forward associative network that binds words to 181-dimensional feature representations. Here, to bring focus on the importance of the role of the sensorimotor grounded conceptual representations, this step is omitted.
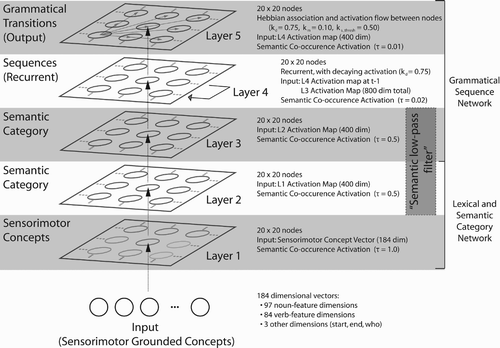
The architecture of the network was optimised to promote the best possible grammatical prediction performance, and as such, functioned at the broad grammatical category scale of Simulation 1A rather than the more specific categories of Simulation 1B. The network layout was very similar to the two-layer semantic category distillation architecture of Simulation 1A, where here these two initial layers serve as input to a recurrent network that learns grammatical sequences. The topology of this sequence learning network resembles an SRN, with input, recurrent, and output layers, though this network is composed of Chimaera networks with different temporal features enabled. This architecture is depicted in . Each layer makes use of the semantic co-occurrence activation function, with progressively decreasing semantic scaling values for higher layers. The output activation map of the semantic low-pass filter at Layer 3 served as input to Layer 4, a recurrent SOM layer that served to acquire not individual sequence elements such as noun or verb as in previous layers, but rather grammatical sequences of these elements. As Layer 4 was recurrent, one half of its input vector at a given epoch consisted of its own activation map from the previous epoch (at time t−1), while the remaining half consisted of the output activation map from Layer 3. Finally, the output activation of Layer 4 served as input to Layer 5, a layer with intralayer temporal Hebbian association enabled. Where Layer 4 functioned to acquire distinct representations for grammatical sequences, Layer 5 served as a global output layer. Here, output patterns were designed to contain a single highly active region representing a given transition in the grammar, while the temporal prediction mechanism would generate predictions for grammatical transitions that the next sequence element could take. In this way, the output layer resembled a finite state automata representation of the grammatical states (the representational clusters), as well as the grammatical transitions (the associative temporal predictions), distilled from the input sentences.
Figure 2. The network architecture used in Simulation 2. Layers 1 and 2 represent the subset that is identical to Simulation 1, where a recurrent grammar-learning network has been appended to acquire valid sequences of parts of speech distilled from Layer 2.
4.4. Input set and training
The input set was divided into a training set of nine sentences, and a test set of 30 sentences. The structure of these sentences took the form of equal numbers of simple (N – V – N), right-branching (N – V – N – Who – V – N), and centre-embedded sentence structures (N – Who – N – V – V – N), similar to the sentence structures used by Van der Velde et al. Citation(2004), as well as Frank Citation(2006) and Farkaš and Crocker Citation(2008). The nine training sentences contained a total of 24 unique nouns and 15 unique verbs, where the test sentences were randomly generated and contained 80 instances of nouns and 50 instances of verbs from the remaining 402 sensorimotor concepts. That is, the test and training sets contained zero overlapping nouns or verbs. Examples from both the training and test sets are found in . To ascribe vector representations to the start marker, end marker, and “who” clause marker, arbitrary independent input vectors were created that did not share any feature dimensions with either the sensorimotor nouns and verbs, or each other.
Table 2. Example sentences used in both training (top) and test (bottom) sets, across simple, right-branching, and centre-embedded sentence structures.
While the model in Simulation 2 was developed to be sensitive to the semantic regularities in the input stream, it is possible that the model's performance is due to the network architecture itself rather than the coupling of the network with grounded representations. As a control condition, a localist dataset was also prepared. The localist input set consisted of binary feature vectors with unique binary representations for each word. Specifically, each lexical vector is 42-bit long, and consists of a single “on” bit in a unique location for each word. The training set similarly consisted of the nine training sentences (three each of simple, right-branching, and centre-embedded clauses) described in . The test set was modified from the sensorimotor grounded dataset, and consisted of 30 randomly generated sentences whose nouns and verbs were familiar and drawn from the training set (rather than novel nouns and verbs, as were used in the sensorimotor test dataset). This modification was made to make the localist test case easier, as it was unlikely that the network would be able to extract semantic category from a set of completely novel localist representations.
Training proceeded in a stage-like fashion similar to Simulation 1, where the preceding layer was completely trained before training on a subsequent layer commenced. At the beginning of a set of epochs, a sentence was chosen from the training set. A sequence of sensorimotor concepts as well as input vectors representing start, end, and “who” markers were then serially presented to the input layer of the network in the order they appeared in the sentence. Training for a given layer proceeded after each word in a sentence, and until the radius of learning for all layers had decreased from initial values representing the size of their respective layers to 0. For Layer 5, the temporal Hebbian association training began after the SOM weight portions of this layer had been trained, and continued for 20 complete presentations of all the sentences in the training set.
4.5. GPE and analysis metrics
Network performance in the next-word-prediction task is often evaluated by measuring the GPE (Christiansen and Chater Citation1999), or the probability of the network to generate an erroneous and ungrammatical prediction for a transition from a given part-of-speech to the next part-of-speech in a parse. Because the Chimaera does not include a single output unit for a given part of speech, but rather the possibility for a cluster of units representing a given grammatical transition, the GPE measure had to be adapted to fit the output of the network.
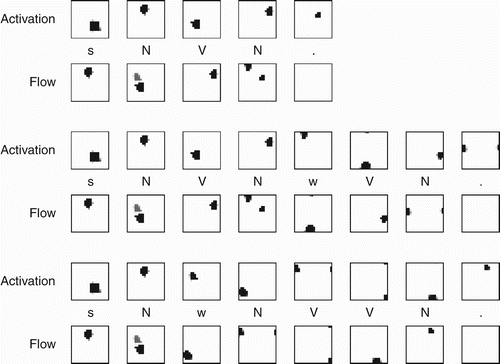
To obtain a measure of network performance, we used an automated algorithm to tag the involvement of each node in the activation map of the output layer, and then used this information to quantify the predictive activation present in the flow maps for each sequence element. The tagging algorithm proceeded as follows. At the end of training, the network was again serially presented each sentence in the training set. For each word in the training sentence, the 184-dimensional input vector representing that word (either a specific sensorimotor-grounded feature representation of a noun, verb, or a start, end, or “who” marker) was presented to the network. The activation of the output layer was separated into three different maps (these maps can be seen in ) – Equation(1) activation caused solely by the presentation of an input vector, (2) decaying activation from time t−1, and Equation(3)
predictive activation for nodes the network anticipates to be active at time t+1. Using the first of these maps, any node in the 20×20 map whose activation was greater than a certain noise threshold was tagged as representing the part-of-speech of the input vector (one of start, end, noun, verb, or who). In this way, the network did not ascribe a part of speech tag to an entire pattern of activation, but rather for each active node in a given pattern of activation. Allowing for the possibility that a given output node might be active for more than one part-of-speech, this tagging continued for each word across all of the training sentences, until a final 20×20 map key was constructed that described what part-of-speech each of the nodes in the output layer represented. Two examples of tagged map keys are shown in .
Figure 3. The results of Simulation 2 (sensorimotor input set) for a novel centre-embedded sentence, “NAPKIN – WHO – SUN – BRING – WISH – APPLE”. Here, the similarity map represents a scaled relative difference in the Euclidian distance of the weight vectors contained in nearby nodes, out to some small radius (where black represents very similar representations in adjacent nodes, and white represents dissimilar adjacent nodes). The input layer (Layer 1) represents sensorimotor conceptual information, where layers 2 and 3 represent semantic category. The output layer (Layer 5) generates unique grammatical predictions for each transition. The activation patterns in Layers 2–5 are nearly identical to those in the case of any given familiar centre-embedded sentence, indicative of a network that is strongly systematic. (Note that this example simulation was run at a network size of 32×32 for all layers to generate higher resolution images for visualisation.)

Figure 4. Example tagged activation map keys automatically generated from the activation patterns of one sensorimotor and one localist training run. Clusters representing the transitions of a finite-state automation representing the Van der Velde et al. grammar are clearly evident in the sensorimotor grounded map, with (for example) two clusters representing the two possible transitions to the “Who” marker, three clusters representing the three possible transitions to an “End” marker, four transitions to a “Verb”, and five transitions to a “Noun”. Topographic organisation in the localist key is less clear, and some nodes display involvement for multiple transitions.
To obtain a measure of GPE, each sentence from the test set was serially presented to the network as in training, where now the flow map of the output network – representing the predictive activation for possible transitions to the next part-of-speech – was analysed using the tagged activation map key for part-of-speech. For each output node in the flow map, if that node was above a small noise threshold, the node would be categorised as generating a prediction for any tag(s) associated with that node in the map key. The proportion of nodes generating predictions for each of the five possible tags was then calculated for each transition in a given sentence structure, generating a probability distribution for each part-of-speech to be predicted as the next transition for a given location in the parse. To further increase the sensitivity of this measure, as well as mediate any effects of association magnitude across the dataset (which can be caused by relative presentation frequency, as observed in pilot simulations of the Chimaera's temporal prediction mechanism), each flow map was scaled to between 0 and 1 before analysis.
Using this information, average GPE was calculated for each transition across the three sentence structures. Following Christiansen and Chater Citation(1999), GPE was defined as the proportion of nodes that predict transitions that are not represented or deviate from the grammar:
4.6. Simulation 2: results
Mean GPE is displayed in for 10 runs of Simulation 2 for each of the sensorimotor grounded and localist datasets, where mean GPE for each transition across each sentence type (simple, right-branching, and centre-embedded) is displayed in . The results show impressive performance across all transitions for sensorimotor-grounded input vectors, where mean GPE across all sentence types was 1.9%. shows very minor contributions of self-association to error – that is, the errorful predictions that do exist tend to be restricted to a given part-of-speech occasionally weakly predicting itself as the next transition – with otherwise excellent performance predicting each possible grammatical transition. Further, a single sensorimotor simulation run failed to learn one of the two early transitions in the grammar (“<Start> – <N> – V”), and this omission comprises nearly the entire GPE of the sensorimotor runs, and is the cause of the small rise in GPE for the second transition in each sentence type. Mean GPE was generally poor across the control localist input vectors at 43.1%, and the network failed to generate responses in approximately 7.7% of test cases largely comprising the latter transitions in the centre embedded structure. Still, while substantially errorful, clearly the network is still making some successful abstractions from the localist training set.
Figure 5. Mean and best-average GPE for each transition in the van der Velde et al.’s grammar for both the sensorimotor grounded and localist test sets of Simulation 2, averaged across 10 simulations. Replacing the sensorimotor grounded sensorimotor input set with ungrounded representations greatly increases GPE, particularly for deep transitions in the right-branching and centre-embedded structures.
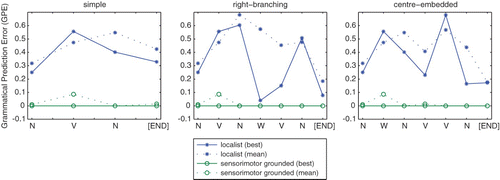
Figure 6. Mean transitional prediction values across each possible transition in the Van der Velde et al. grammar averaged across 10 simulations using the sensorimotor grounded input set. The network displays excellent performance across all transitions. Ungrammatical transitions are marked with an asterisk.
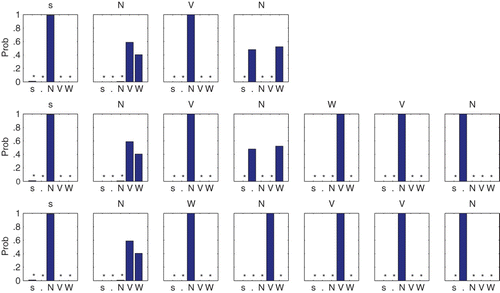
Table 3. Mean GPE for Simulation 2 across simple, right-branching, and centre-embedded sentence structures for both sensorimotor grounded and localist input sets. Values in parentheses represent the mean of the standard deviations across all transitions in a given set.
shows the activation patterns across the network for a novel randomly generated centre-embedded test sentence, where shows exemplary activation and predictive flow patterns of the output layer across sentence types. Across the grammatical sequence learning network of layers 3 through 5, virtually no difference in the activation patterns between familiar and novel sentences was present for the sensorimotor input set (within a given sentence structure), suggesting that the grammatical category distillation mechanism of layers 1 and 2 is operating effectively, and delivering broad part-of-speech information to the superordinate layers. Overall, this pattern of qualitative representational clustering and quantitative grammatical prediction performance is consistent with a network that has distilled both a broad knowledge of grammatical category and an excellent knowledge of the grammatical sequences into which these parts of speech can combine. The network is then generally able to use this knowledge to generate predictions for possible grammatical transitions from a given word in a sentence with near-perfect accuracy.
Figure 7. Exemplary activation inthe output layer of the Chimaera model (Layer 5) after training for simple, right-branching, and centre-embedded sentence structures on sensorimotor input. Predictive flow maps are also included, showing the Chimaera's prediction mechanism successfully flowing activation to the next grammatical transition in each sentence structure. Here, all maps are scaled to activation values between 0 (white) and 1 (black).
4.7. Abstraction percentage
If a network is truly abstracting from a set of exemplars to a common structure shared in those instances, then one might argue that the output of the network should be the same for any given instance of a common structure. In terms of sentence processing, this argues that the output of a network should be the same for all simple sentences, the same for all right-branching sentences, and so forth, regardless of the specific nouns and verbs used in any particular sentence. Because the output of the network is a 2D array of activations rather than a labelled series of nodes clearly specifying the sentence type and next part-of-speech element, here we define a measure to determine the agreement between two sets of activation maps. The abstraction percentage (AP) between two output activation maps y(t) and y(T)is defined as:
For example, to test the AP for the right-branching sentence structure, one would iteratively present the network a series of right-branching test sentences, then calculate the AP between each of the activation maps for a given syntactic position. If the network was presented with 10 test sentences, there would be (102−10) AP comparisons for each of the six positions (eight including start and end markers) of the right-branching sentence. These AP values can then be averaged within-position to show the average abstraction performance for each position in the sentence, or averaged across all positions to arrive at a mean AP for a given sentence type.
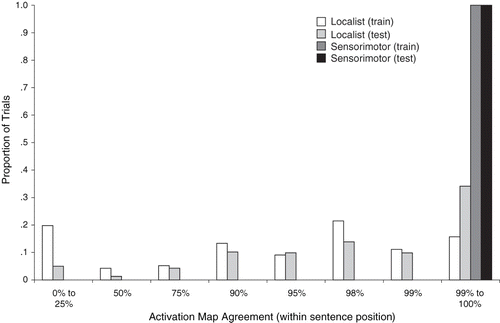
To obtain a measure of representational abstraction in Simulation 2, the abstraction percentages for both sensorimotor-grounded and localist input vectors were compared across all sentence types. The histogram in shows AP performance for grounded and localist input sets grouped into eight approximately logarithmic bins. The sensorimotor input set shows a clear tendency towards abstraction, where activation maps for a given transition were nearly identical and differed by only 0.02%, on average. Conversely, AP performance on the localist input set is mixed. In the test set, only 58% of output activation maps were nearly identical (), although notably 78% of maps had APs of greater than 75%, suggesting that many similar regions were activated. Interestingly, on the localist training set, nearly 20% of activation maps had entirely distinct representations and strongly favoured an instance-based representation scheme, while this number decreases to only 5% for the test set, indicating a greater abstraction in test versus training sets. This suggests that in the case of localist input, the architecture sometimes favours representing specific instances of training sentences, but may also be somewhat capable of finding a common middle-ground when tested on familiar words in novel positions.
Figure 8. Histogram of proportions of abstraction percentages across simple, right-branching, and centre-embedded sentences for sensorimotor grounded and ungrounded localist input sets. Histogram bins represent trials with abstraction percentages equal to or less than the label value, but greater than the next smallest bin label. Proportions add to 1.0 for each of the four datasets, with the exception of the localist test set, where failed response trials are not included in any bin. Values towards 0% signify that the network has represented a given transition in some sentence type using different activation maps, and is favouring an instance-based representation scheme (i.e. a given sentence structure produces different patterns of activation in the output layer when different words are used in that sentence structure). Conversely, values towards 100% signify that the network is representing a given transition in some sentence structure using the same activation map, regardless of the specific words used in that sentence. Abstraction percentages near 100% are indicative of strongly systematic behaviour. The sensorimotor grounded dataset displays strong systematicity, where the ungrounded localist dataset includes a mix of values between strongly systematic and instance-based.
5. Discussion
5.1. Comparison with Frank (2006) and Farkaš and Crocker (2008)
The recurrent sensorimotor Chimaera model exhibits impressive performance on the next part-of-speech prediction task, generating ungrammatical predictions only 1.9% of the time, on average. This mean performance is approximately 3% better than the best-performing unsupervised RecSOMsard model of Farkaš and Crocker Citation(2008), while near or above the performance of the best-performing SRN and ESN models of Frank Citation(2006) – though Frank uses an alternate measure of grammatical performance, so the measures are not entirely alignable.
The analysis of a network's performance beyond the GPE is difficult. Frank Citation(2006) argued that GPE, a measure of grammatical prediction performance, is a poor measure of grammatical systematicity in that it lacks a baseline measure, as a given transition may be more or less difficult than another, requiring differing depths of temporal look-back (and the systematic abstraction of lexical items required to obtain that look-back). In light of this, Frank Citation(2006) introduced an alternate measure of performance (later independently coined Frank's Generalisation Performance, or FGP) that evaluated grammatical prediction performance against a bigram statistical model that functions as a baseline. The issue with using a bigram model as a performance baseline is that the Van der Velde et al. Citation(2004) benchmark grammar contains ambiguities easily visible to hand-inspection that are deeper than first order, and as such, are deeper than what a bigram model can detect. Brakel and Frank Citation(2009) later transitioned to using a performance metric of systematicity based on network performance surpassing the best available n-gram Markov model that the experimenter could generate. However, this n-gram Markov model performance metric still does not seem to be an adequate measure of systematicity. Fodor and Pylyshyn Citation(1988) described systematicity as a defining property of a cognitive system, and being more systematic than an alternative model does not necessarily mean that one is being generally systematic, or that systematicity is a general property of the system one is examining.
To determine the difficulty of each transition in the Van der Velde et al.’s (2004) grammar, a recursive depth parser was implemented, where for each transition in each of the three sentence structures in the Van der Velde et al.’s grammar, the algorithm determined the maximum depth of lookback required in order to successfully generate an unambiguous prediction for that transition. This provides a more accurate measure of the relative difficulty of each grammatical prediction. The results of this analysis are included in Appendix 3. As a side effect of this process is to determine all the transitions present in the grammar for each depth, and whether they are ambiguous transitions or not (i.e. they require looking back more elements to resolve their ambiguities), these data are included as well.
The analysis shows that the Van der Velde et al.’s grammar contains several second-order ambiguities, specifically at the fourth transition in the right-embedded grammar (“<Who> – V”), and the fourth transition in the centre-embedded sentence (“<V> – V”). These transitions correspond to the worst mean FGP performance on both the ESN model at approximately 0.4 out of a possible 1.0 (Frank Citation2006), as well as approximately 0.65 out of a possible 1.0 for the RecSOMsard model (Farkaš and Crocker Citation2008), while all three models tended to show decreased performance leading up to these transitions. Additionally, both the ESN and RecSOMsard models show a substantial dip in FGP performance to 0.6 and 0.75, respectively, for the first transition in both simple and right-branching sentences (“N—V”), while showing top performance on this transition in centre-embedded sentences (“N—Who”). While this transition is not ambiguous in that it does not depend on the context (the transition is in fact free, and either way is valid), the networks handle this transition with a substantial decrease in performance.
This analysis suggests that for difficult grammatical transitions – transitions that require deep lookback – the previous models including the SRN, ESN, and RecSOMsard network are unable to successfully acquire one or both of the generalised part of speech information (distilled from statistical co-occurrence), or deep grammatical sequence information. The performance of both the ESN and RecSOMsard models on the free transition in both the simple and right-branching sentence structures further suggests that these models have difficulty acquiring a grammar that allows multiple transition paths, either in the aspect of this acquisition that involves distilling part of speech, or in the simultaneous pairing of this distillation process with storing grammatical sequence information.
In comparison with the supervised SRN and ESN models of Frank Citation(2006), and the unsupervised RecSOMsard model of Farkaš and Crocker Citation(2008), the current Chimaera model generates nearly completely correct predictions across all transitions in the network, including these deeply ambiguous predictions. In this way, the performance distribution of the Chimaera model reflects a different process than is present in the previous models – where the SRN, ESN, and RecSOMsard models generally show decreased performance in areas where difficulty increases, the Chimaera's performance distribution is functionally flat, and does not show any significant performance degradation across any transition in the network. This performance distribution reflects what one would expect from a network exhibiting general strong syntactic systematicity across virtually all inputs.
This conclusion is further reinforced by the difference in test sets used in the Chimaera model versus the previous models. Frank Citation(2006) and Farkaš and Crocker Citation(2008) have taken care to assemble training data with specific instances of nouns and verbs that appear in only a single sequential location in the parse, where they then check to see if that word is also accepted in untrained locations during the test set – for example, the word “bottle” might only ever appear as a direct object in the training set, where it would then be tested in a subject position in the training sentences. The test set of the recurrent Chimaera model has taken this one step further – the words themselves, represented by unique sensorimotor concept representations, are novel. That is to say, the model is not testing the transfer of one word instance to other positions that share that word category – the model is testing the general acquisition of two separate types of knowledge – word category, and grammatical sequence learning – and seamlessly transferring the two to novel instances of words.
One might argue that the networks are performing different tasks, and as such the performance comparison is not entirely accurate. This is true. The models of Frank Citation(2006) and Farkaš and Crocker Citation(2008) are attempting to ascribe grammatical category to completely ungrounded symbolic input, and are further attempting to learn the grammatical sequence structures present in that input. In this case, it is not the problem that has been over constrained, but the input to the problem. Indeed, Frank and Cernansky Citation(2008) showed that when the input to their ESN model was changed from unique symbolic vectors representing each word to vectors that represented the syntactic co-occurrence statistics between words, their models performed extremely well on the next-word prediction task. A further analysis of their network's representational states by Frank and Jacobsson Citation(2010) showed that this co-occurrence input provided the network generalised syntactic information that it could use to construct a compact finite state representational space representing the generalised grammar. Stochastic methods have seen remarkable success across a variety of domains in language processing (Cristianini Citation2010), and indeed both the previous models as well as the Chimaera model are using stochastic methods based on co-occurrence to ultimately distil grammatical category information from a language stream, whether those be from syntactic or semantic representations. However, the poverty of the stimulus in the symbolic case is extreme – with no referent information available for the symbols, each lexical representation contains no useful information to generalise its part of speech, or any other property for that matter. Fodor and Pylyshyn Citation(1988) did not intend for their description of systematicity to apply to an algorithm operating on a set of unrelated numbers – they were describing the behaviour of human cognitive systems – and when we supply our networks with a subset of the same conceptual knowledge that young infants who are beginning to learn language have access to (Mandler Citation2004), the network acquires a general behaviour of syntactic systematicity. Following the logic of the semantic bootstrapping hypothesis (Pinker Citation1984), we might posit that systematicity is not a property of the cognitive system alone, but rather (in terms of Fodor and Pylyshyn) it can be a property of the pairing of an appropriately sensitive computational/representational system with an informative input set, which further is specifically informative at each level of representation to which one wishes to be systematically sensitive.
While care was taken in choosing the Howell et al. Citation(2005) sensorimotor grounded dataset for its feature-rich, empirically gathered, and developmentally plausible noun and verb representations, it amounts to a substantial amount of preprocessing. Some of this is preprocessing that the world itself has to offer an infant, in that objects (or nouns) tend to share specific perceptual features, and that those features also tend to differ from those of actions (or verbs). In this way, grounding gives the model the access to a very different kind of input than a localist representation, and simplifies the problem of abstracting semantic category, and subsequently grammatical category, from an input stream.
However, this grounded dataset is still artificial in a number of ways and oversimplifies the problem. For example, with 97 noun and 84 verb sensorimotor feature dimensions that are entirely independent from one another, the dataset currently does not accurately capture nouns and verbs with overlapping features, such as the noun “to go on a walk” versus the verb “to walk”. Inasmuch as the first handful of nouns and verbs an infant learns have non-overlapping features, the current dataset may be a more faithful model of bootstrapping the very earliest grammatical knowledge – but certainly as an infant's lexicon and conceptual library grow, the Howell et al. Citation(2005) dataset becomes less representative of the increasingly complicated grammar learning problem the infant has to solve.
In a related sense, to what extent is the abstraction and strong systematicity displayed by the model due to the Chimaera network architecture, and to what extent is it dependent upon the structure of the sensorimotor input? While the simulation using ungrounded binary feature vectors suggests that the model architecture does display some abstraction whether grounded or ungrounded representations are used, the critical aspect to displaying strong systematicity appears to be the use of grounded representations in concert with an activation function that is sensitive to the statistics of the semantic components of those representations.
5.2. Perceptual symbol systems and grounding
Perceptual Symbol Systems theory (Barsalou Citation1999) is a modal description of cognitive knowledge representation with an increasing body of empirical support (e.g. Richardson, Spivey, Barsalou, and McRae Citation2003; Pecher, Zeelenberg, and Barsalou Citation2004; Solomon and Barsalou Citation2004) suggesting that the knowledge stored in brains is stored not amodally, but rather specifically localised in the perceptual modality where that information was acquired. These individual, modal representations are joined together in conceptual integration areas that allow (for example) the cuing of the concept of a “dog” to invoke these perceptual representations stored across the cortex, and in general subserves cognitive performance, for example, semantic property verification (Solomon and Barsalou Citation2004). In this context, it seems probable that at least some subset of the sensorimotor information contained within the Howell et al. Citation(2005) input set is not only available to infants, but is also the kind of information that they are actively acquiring and using to think about and represent their worlds.
In the terms of Barsalou Citation(1999), the input layer of the recurrent Chimaera model is acting as a “conceptual integration area”, where perceptual features across a variety of modalities converge into a single coherent representation. While the model does not contain separate modality-specific networks sensitive to particular aspects of perception – such as colour, shape, or auditory frequency – or have any mechanisms to implement anything like the simulation described in perceptual symbol systems, the current model is not incompatible with these ideas, and indeed, the model begins to look something like the architectural sketches Barsalou describes with only a few additions. The model might be modified to include modality-specific networks for the categories of perceptual features found in the Howell et al. Citation(2005) input set, where the output of these networks would then converge upon the current integration area, creating – at least partially – an architecture similar to that described by perceptual symbol systems. Van der Velde and de Kamps (Citation2008, 2011) describe some of the broader implementational issues in constructing a grounded representational system in a neural architecture.
5.3. The limits of grounding and semantic bootstrapping
While we have demonstrated that grounded sensorimotor conceptual representations can greatly aid an unsupervised process of determining the grammatical category of an infant-scale lexicon of nouns and verbs, how useful might this technique be for acquiring more complex natural language grammars? Language can generally be divided into classes of words that can be grounded in the world, including parts of speech such as nouns and verbs, as well as adjectives (such as “blue”) and adverbs (such as “quietly”), as well as into classes of words that are not easily concretely grounded, such as pronouns or conjunctions, that function to convey structural relationships in event representations. This class of “function” words cannot be easily specified in terms of sensorimotor representations, and are instead thought to be acquired through the relationships they convey between agents (Bates and Goodman Citation1997).
In terms of the current model, the model would be unable to acquire parts of speech that could not be naturally specified in terms of distinct, non-overlapping feature representations. This is already the case for the “who” clause marker in the input set of Simulation 2, where this marker was artificially assigned an arbitrary value on a single non-overlapping feature dimension to ensure its categorisation as a unique part of speech. Where semantic bootstrapping suggests that sensorimotor concept representations may enable the initial acquisition of grammatical knowledge, it is likely that this process is incomplete as a full specification of grammatical category learning, and must soon migrate to other methodologies – either purely stochastic, as in the case of Frank Citation(2006) or Farkaš and Crocker Citation(2008), or a combination of stochastic and segregation methods working to ground higher level knowledge of events with symbolic labels, perhaps through a process of self-supervised error-driven learning based on expectation failure (Schank Citation1982).
While function words require a higher level knowledge of event structure, the semantic co-occurrence metric begins to lose utility much sooner, potentially when children begin to acquire adjectives. Adjectives are perceptual modifiers, further specifying the features of a noun, as in the case of a “cuddly cat” or a “sour apple”. Because adjectives work to specify a specific aspect of a noun – or, in terms of the sensorimotor concept set of Howell et al. Citation(2005), provide a specific value along a given noun feature dimension – the current semantic co-occurrence metric would be unable to distinguish between nouns and adjectives. One might imagine that the current metric might be adjusted to include not only semantic co-occurrence, but also feature diversity, such that adjectives – containing a value on only a single feature dimension – might be teased apart from nouns or verbs, which tend to contain values across many sensorimotor feature dimensions. While the perceptual act of “notice” has been suggested as a method of acquiring conceptual information (Mandler Citation2004), and taking stock of a difference does tend to focus our attention on a single aspect of a stimulus that disagrees with our expectations, it is not clear that this is the mechanism young infants learn to acquire a knowledge of adjectives, or that this method might be usefully extended to acquiring other parts of speech, and as such, is left for future work.
That being said, the utility of semantic bootstrapping does not have to end with acquiring early grammatical knowledge, and may extend to populating sensorimotor conceptual representations for newly encountered or ambiguous words. For example, a slightly more complicated Chimaera model that is sensitive to finer semantic categories (of the type demonstrated in Simulation 1B) might acquire a set of semantically specified grammar rules – say, “NOUN_AGENT – VERB – NOUN_OBJECT” rather than “N – V – N”. When encountering a novel sentence, for example “bleeb ate lollipop”, it could then in principle begin to acquire an underspecified representation of the noun “bleeb”, including that a bleeb likely contains many of the sensorimotor conceptual features of an agent (such as being self-animate). This process of semantic grammar refinement could continue to progressively greater depths, where a semantically specified grammar might further suggest that a verb with gustatory semantic features is often followed by a food item, and that in the utterance “bleeb ate zoxe”, a zoxe is likely an edible food item.
5.4. Applicability to other models and architectures
In spite of the ultimate limitations of the semantic co-occurrence metric in terms of acquiring functional parts-of-speech, the technique itself of using a variety of non-Euclidian energy functions is a general property of SOM architectures (e.g. Heskes Citation1999). As such, this specific technique is not limited to the recurrent Chimaera model presented here, but rather is broadly applicable to virtually any recurrent SOM variant capable of transferring the information contained within an activation map generated using the semantic co-occurrence metric to superordinate processing layers. Further, this technique might be adapted to supervise architectures as well.
This brings to light a key difference between the current model and typical SRN models of grammar learning. These SRN models often attempt to acquire both a process of generalising grammatical category information, as well as a knowledge of deep grammatical structure, concurrently in the same three-layer network. At the heart of the matter is whether a given network (or subset of a network) is capable of acquiring more than one type of computational process. Recent supervised models of psycholinguistic production have had particular success taking a “dual-representational” approach, separating a knowledge of words and grammar into separate supervised networks (Chang, Dell, and Bock Citation2006), and the Chimaera model presented here does something very similar. Layer 1 functions to acquire grounded sensorimotor conceptual representations, whereas Layer 2 works to distil the commonalities in the representations of Layer 1 into semantic categories, and layers 3–5 undertake a process of sequence learning that makes use of this semantic category information to arrive at a knowledge of grammar. The issue with the performance of the supervised models of Frank Citation(2006) may simply be that too many processes are being ascribed to a single network, where devoting a separate network to each level of representation present in the task of grammar acquisition from lexical sentence representations might see these supervised networks reach a level of performance similar to the Chimaera model presented here.
5.5. Unsupervised models and plausibility of the semantic co-occurrence metric
From the perspective of developmental plausibility, there is something appealing about an unsupervised model that achieves particularly good performance at the task of grammar learning. Because co-occurrence learning depends upon the activation level of a given set of neurons, as well as whether they are interconnected, and not upon a mechanism whereby the weights of neurons are sensitive to error signals (or even capable of propagating these error signals to train deep-layered networks, e.g. Rumelhart and McClelland Citation1986a), the technique is unsupervised. In this sense, the semantic co-occurrence activation metric introduced here is also unsupervised, and as such the sensitivity of the infant to the systematicity in the language stream is brought about by a nativist sensitivity to co-occurrence. But as unsupervised techniques do not necessarily imply biological or developmental plausibility, in what sense might this metric be considered cognitively plausible?
Semantic priming (Meyer, Schvaneveldt, and Ruddy Citation1975) is generally considered a classic finding in cognitive psychology, and is the behavioural observation that humans tend to be faster at processing information across a variety of tasks when the information they are presented at a given trial is semantically related to information they have previously seen on a recent trial. Semantic priming can be contrasted to associative priming (Meyer and Schvaneveldt Citation1971) or stimulus-response binding, in that where associative priming is purely correlational and can produce priming effects over repeated exposures of unrelated stimuli, semantic priming occurs specifically between semantically related stimuli, and occurs untrained, suggesting that it is a low-level property of the representational structure of the brain (e.g. Collins and Quillian Citation1969; Collins and Loftus Citation1975). As such, the semantic co-occurrence activation function could be argued to use the very same semantic priming mechanism that we know occurs naturally in cognitive systems, albeit at a much higher rate of gain than conventional semantic priming. The semantic co-occurrence metric produces non-zero activation for any representation that shares semantic features with another, and in this sense, the intensity of the function is much higher than is traditionally ascribed in network models of semantic priming. While the difference in degree between the two may be a function of gain, it is also possible that the representationally coarse conceptual categories of the young infant (e.g. Eimas and Quinn Citation1994) may make the handful of nouns and verbs they have acquired by age 2 (e.g. Nelson Citation1973) seem far more similar than were their mental lexicon to contain the estimated 60,000 words of an average young adult (Bloom Citation2000). As such, as a bootstrapping mechanism to begin to acquire semantic categories, semantic priming and the semantic co-occurrence metric may in fact be functionally the same process, with the differences in degree an artefact of considering semantic priming on the scale and diversity of an adult conceptual system.
5.6. Plausibility as a temporal model of acquisition
While the current model achieves an impressive performance on the grammar learning task, the model makes several artificial assumptions about the temporal time-course of learning, and as such, is a poor model of how infants acquire grammatical knowledge over time. The training of the model assumes that infants acquire a complete knowledge of their sensorimotor-grounded conceptual representational space before first beginning to distil a knowledge of grammatical category. Further, the model then assumes that this knowledge of grammatical category must be complete and stable before beginning to acquire a knowledge of the valid grammatical sequences of parts-of-speech present in the input set, indicative of the grammatical rules of the sample language. Were any one of these assumptions not met, or the representations at any level modified after their initial training, the network would be unable to function. This temporal profile is of course dramatically different from that of infants acquiring language, where their knowledge of vocabulary begins initially quite slowly before reaching a sudden spurt where the young infant begins to frequently and rapidly acquire new words (Bates and Carnevale Citation1993). Concurrently, infants’ knowledge of grammar and morphosyntax steadily increases in a more-or-less predictable fashion (Brown Citation1973), where a knowledge of regular plurals tends to be acquired by 30 months of age, and before a knowledge of possessives at 34 months, which itself tends to be followed by a knowledge of regular past-tense at around 40 months old. This limit in the temporal profile of learning is not limited to the current model, but rather is a general limitation of virtually all contemporary neural network learning rules.
6. Summary
A computational method of distilling part-of-speech from semantic co-occurrence was developed, where it was shown that operating on a corpus of grounded sensorimotor conceptual representations can greatly aid the unsupervised process of learning the grammatical category of nouns and verbs in an infant-scale lexicon. Using an unsupervised Chimaera model, it was shown that a near-complete knowledge of the Van der Velde et al. Citation(2004) grammar can be acquired from sequences of grounded sensorimotor representations arranged in grammatical sentence structures, in support of the semantic bootstrapping hypothesis of grammar acquisition (Pinker Citation1984). This unsupervised model paired with an input set of developmentally plausible sensorimotor grounded conceptual representations outperformed previous contemporary supervised and unsupervised models (Frank Citation2006; Farkaš and Crocker Citation2008), and further displayed a functionally different pattern of results broadly across all transitions in the input set – namely, the general acquisition of the syntactic systematicity present in the grounded language stream. While the model exhibits impressive performance when serving as a bootstrap mechanism for the earliest grammatical knowledge, the semantic bootstrapping mechanism presented here quickly falls short as infants begin to acquire more complicated grammars that contain words with overlapping semantic categories or words that are not easily expressed in terms of sensorimotor grounded features. Where adult-level grammatical knowledge is almost certainly acquired through a combination of semantically-grounded representations and statistical co-occurrence between semantic and syntactic representations, developing more complete, capable, and biologically plausible methods of distilling semantic co-occurrence in neural systems will enable future connectionist models of semantic bootstrapping and grammar acquisition in young infants.
Acknowledgements
This research was supported by Natural Sciences and Engineering Research Council of Canada (NSERC) Grant 327454 to S.W., and an Ontario Graduate Scholarship to P.A.J., and in-kind donations of compute time by the Shared Hierarchical Academic Research Computing Network (SHARCNET) for earlier simulations and development work. We thank Karin Humphreys, Lee Brooks, Mark Hahn, members of McMaster University's Cognitive Science Laboratory, and three anonymous reviewers for useful comments and assistance, as well as Steve Howell and Stefan Frank for generously sharing input vectors from their work.
References
- Barsalou , L. 1999 . Perceptual Symbol Systems . Behavioural and Brain Sciences , 22 : 577 – 660 .
- Bates , E. and Carnevale , G. 1993 . New Directions in Research on Language Development . Developmental Review , 13 : 436 – 470 .
- Bates , E. and Goodman , J. C. 1997 . On the Inseparability of Grammar and the Lexicon: Evidence from Acquisition, Aphasia and Real-Time Processing . Language and Cognitive Processes , 12 : 507 – 584 .
- Bloom , P. 2000 . How Children Learn the Meanings of Words , Cambridge , MA : MIT Press .
- Brachman , R. J. 1977 . What's in a Concept: Structural Foundations for Semantic Networks . International Journal of Man-Machine Studies , 9 : 127 – 152 .
- Brachman , R. J. 1979 . “ On the Epistemological Status of Semantic Networks ” . In Associative Networks: Representation and Use of Knowledge by Computers , Edited by: Findler , N. 3 – 50 . New York : Academic Press .
- Brakel , P. and Frank , S. Strong Systematicity in Sentence Processing by Simple Recurrent Networks . Proceedings of the 31st Annual Conference of the Cognitive Science Society , Edited by: Taatgen , N. and van Rijn , H. pp. 1599 – 1604 . Austin , TX : Cognitive Science Society .
- Brooks , R. 1991 . Intelligence without Representation . Artificial Intelligence , 47 : 139 – 159 .
- Brown , R. 1973 . A First Language: The Early Stages , Cambridge , MA : Harvard University Press .
- Cansino , S. , Williamson , S. J. and Karron , D. 1994 . Tonotopic Organization of Human Auditory Cortex . Brain Research , 663 : 38 – 50 .
- Chang , F. , Dell , S. and Bock , K. 2006 . Becoming Syntactic . Psychological Review , 113 : 234 – 272 .
- Chappell , G. and Taylor , J. 1993 . The Temporal Kohonen Map . Neural Networks , 6 : 441 – 445 .
- Choe , Y. and Miikkulainen , R. 2004 . Contour Integration and Segmentation with Self-Organized Lateral Connections . Biological Cybernetics , 90 : 75 – 88 .
- Christiansen , M. H. and Chater , N. 1999 . Toward a Connectionist Model of Recursion in Human Linguistic Performance . Cognitive Science , 23 : 157 – 205 .
- Clark , A. 2008 . Supersizing the Mind: Embodiment, Action, and Cognitive Extension , Oxford , , UK : Oxford University Press .
- Collins , A. M. and Loftus , E. F. 1975 . A Spreading Activation Theory of Semantic Memory . Psychological Review , 82 : 407 – 428 .
- Collins , A. M. and Quillian , M. R. 1969 . Retrieval Time from Semantic Memory . Journal of Verbal Learning and Verbal Memory , 8 : 240 – 247 .
- Cristianini , N. 2010 . Are we there yet? . Neural Networks , 23 : 466 – 470 .
- Eimas , P. and Quinn , P. 1994 . Studies on the Formation of Perceptually Based Basic-Level Categories in Young Infants . Child Development , 65 : 903 – 917 .
- Elman , J. 1990 . Finding Structure in Time . Cognitive Science , 14 : 179 – 211 .
- Elman , J. 1991 . Distributed Representations, Simple Recurrent Networks, and Grammatical Structure . Machine Learning , 7 : 195 – 224 .
- Elman , J. 1995 . “ Language as a Dynamical System ” . In Mind as Motion: Dynamical Perspectives on Behaviour and Cognition , Edited by: Port , R. and van Gelder , T. 195 – 225 . Cambridge , MA : MIT Press .
- Fenson , L. , Pethick , S. , Renda , C. , Cox , J. , Dale , P. and Reznick , J. 2000 . Short Form Versions of the MacArthur Communicative Development Inventories . Applied Psycholinguistics , 21 : 95 – 115 .
- Farkaš , I. and Crocker , M. 2008 . Syntactic Systematicity in Sentence Processing with a Recurrent Self-Organizing Network . Neurocomputing , 71 : 1172 – 1179 .
- Fodor , J. and Pylyshyn , Z. 1988 . Connectionism and Cognitive Architecture: A Critical Analysis . Cognition , 28 : 3 – 71 .
- Fodor , J. and McLaughlin , B. 1990 . Connectionism and the Problem of Systematicity: Why Smolensky's Solution Doesn't Work . Cognition , 35 : 183 – 204 .
- Frank , S. 2006 . Learn More by Training Less: Systematicity in Sentence Processing by Recurrent Networks . Connection Science , 18 : 287 – 302 .
- Frank , S. L. and Cernansky , M. Generalization and Systematicity in Echo State Networks . Proceedings of the 30th Annual Conference of the Cognitive Science Society , Edited by: Love , B. C. , McRae , K. and Sloutsky , V. M. Austin , TX : Cognitive Science Society .
- Frank , S. L. and Jacobsson , H. 2010 . Sentence-Processing in Echo State Networks: A Qualitative Analysis by Finite State Machine Extraction . Connection Science , 22 : 135 – 155 .
- Goldberg , A. 1999 . “ The Emergence of Argument Structure Semantics ” . In The Emergence of Language , Edited by: MacWhinney , B. 197 – 213 . New Jersey , , USA : Lawrence Erlbaum Associates .
- Hadley , R. 1994 . Systematicity in Connectionist Language Learning . Mind and Language , 9 : 247 – 272 .
- Hagenbuchner , M. , Sperduti , A. and Tsoi , A. C. 2003 . A Self-organizing Map for Adaptive Processing of Structured Data . IEEE Transactions on Neural Networks , 14 (3) : 491 – 505 .
- Harnad , S. 1990 . The Symbol Grounding Problem . Physica D , 42 : 335 – 346 .
- Hebb , D. O. 1949 . The Organization of Behaviour: A Neuropsychological Theory , New York : Wiley .
- Herrmann , M. , Hertz , J. and Prugel-Bennett , A. l . 1995 . Analysis of Synfire Chains . Network: Computation in Neural Systems , 6 : 403 – 414 .
- Heskes , T. 1999 . “ Energy Functions for Self-Organizing Maps ” . In Kohonen Maps , Edited by: Oja , E. and Kaski , S. 303 – 315 . Amsterdam , , The Netherlands : Elsevier .
- Howell , S. , Jankowicz , D. and Becker , S. 2005 . A Model of Grounded Language Acquisition: Sensorimotor Features Improve Lexical and Grammatical Learning . Journal of Memory and Language , 53 : 258 – 276 .
- Jaeger , H. 2003 . “ Adaptive Nonlinear System Identification with Echo State Networks ” . In Advances in Neural Information Processing Systems , Edited by: Becker , S. , Thrun , S. and Obermayer , K. Vol. 15 , 593 – 600 . Cambridge , MA : MIT Press .
- James , D. and Miikkulainen , R. 1995 . “ SARDNET: A Self-Organizing Feature Map for Sequences ” . In Advances in Neural Information Processing Systems , Edited by: Tesauro , G. , Touretzky , D. S. and Leen , T. K. Vol. 7 , 577 – 584 . Cambridge , MA : MIT Press .
- Jansen , P. 2010 . “ A Self-Organizing Computational Neural Network Architecture with Applications to Sensorimotor Grounded Linguistic Grammar Acquisition ” . Hamilton , , Canada : McMaster University . unpublished Ph.D. dissertation
- Kohonen , T. 1982 . Self-Organized Formation of Topologically Correct Feature Maps . Biological Cybernetics , 43 : 59 – 69 .
- Kohonen , T. 1995 . Self-Organizing Maps , Berlin : Springer .
- Mandler , J. 2004 . The Foundations of Mind: The Origins of Conceptual Thought , New York : Oxford University Press .
- Marcus , G. 1998 . Can Connectionism Save Constructivism? . Cognition , 66 : 153 – 182 .
- McRae , K. , de Sa , V. and Seidenberg , M. 1997 . On the Nature and Scope of Featural Representations of Word Meaning . Journal of Experimental Psychology: General , 126 : 99 – 130 .
- Meyer , D. and Schvaneveldt , R. 1971 . Facilitation in Recognizing Pairs of Words: Evidence of a Dependence between Retrieval Operations . Journal of Experimental Psychology , 90 : 227 – 234 .
- Meyer , D. , Schvaneveldt , R. and Ruddy , M. 1975 . “ Loci of Contextual Effects on Visual Word-Recognition ” . In Attention and Performance V , Edited by: Rabbitt , P. 98 – 118 . London : Academic Press .
- Mozer , M. 1994 . “ Neural Net Architectures for Temporal Sequence Processing ” . In Predicting the Future and Understanding the Past , Edited by: Weigend , A. and Gershenfeld , N. 243 – 264 . Redwood City , CA : Addison-Wesley Publishing .
- Nelson , K. 1973 . Structure and Strategy in Learning to Talk . Monographs of the Society for Research in Child Development , 38 : 1 – 135 .
- Pecher , D. , Zeelenberg , R. and Barsalou , L. 2004 . Sensorimotor Simulations Underlie Conceptual Representations: Modality-Specific Effects of Prior Activation . Psychonomic Bulletin and Review , 11 : 164 – 167 .
- Pinker , S. 1984 . Language Learnability and Language Development , Cambridge , MA : Harvard University Press .
- Prasada , S. and Pinker , S. 1993 . Generalization of Regular and Irregular Morphological Patterns . Language and Cognitive Processes , 8 : 1 – 56 .
- Richardson , D. , Spivey , M. , Barsalou , L. and McRae , K. 2003 . Spatial Representations Activated during Real-Time Comprehension of Verbs . Cognitive Science , 27 : 767 – 780 .
- Ritter , H. and Kohonen , T. 1989 . Self-Organizing Semantical Maps . Biological Cybernetics , 62 : 241 – 254 .
- Rumelhart , D. and McClelland , J. 1986a . Parallel Distributed Processing: Explorations in the Microstructure of Cognition , Vol. I , Cambridge , MA : MIT Press .
- Rumelhart , D. and McClelland , J. 1986b . “ On Learning the Past Tenses of English Verbs ” . In Parallel Distributed Processing: Explorations in the Microstructure of Cognition , Edited by: Rumelhart , D. and McClelland , J. Vol. II , 216 – 268 . Cambridge , MA : MIT Press .
- Schank , R. 1982 . Dynamic Memory: A Theory of Reminding and Learning in Computers and People , New York : Cambridge University Press .
- Searle , J. 1980 . Minds, Brains, and Programs . Behavioural and Brain Sciences , 3 : 417 – 457 .
- Solomon , K. and Barsalou , L. 2004 . Perceptual Simulation in Property Verification . Memory and Cognition , 32 : 244 – 259 .
- Strickert , M. and Hammer , B. Neural Gas for Sequences . Proceedings of the Workshop on Self-Organizing Neural Networks (WSOM) , Edited by: Yamakawa , T. pp. 53 – 58 . Kyushu, Japan, Orlando , FL : Elsevier .
- Van der Velde , F. and de Kamps , M. A Neural Architecture for Grounded Cognition: Representation, Structure, Dynamics and Learning . June 1–8 , Piscataway , NJ . Proceedings of the International Joint Conference on Neural Networks (IJCNN 2008), (IEEE World Congress on Computational Intelligence) , pp. 961 – 968 .
- Van der Velde , F. and de Kamps , M. 2011 . Compositional Connectionist Structures Based on In Situ Grounded Representations . Connection Science , 23 : 97 – 107 .
- Van der Velde , F. , van der Voort van der Kleij , G. and de Kamps , M. 2004 . Lack of Combinatorial Productivity in Language Processing with Simple Recurrent Networks . Connection Science , 16 : 21 – 46 .
- Voegtlin , T. 2002 . Recursive Self-Organizing Maps . Neural Networks , 15 : 979 – 991 .
- Woods , B. 1975 . “ What's in a Link: Foundations for Semantic Networks ” . In Representation and Understanding: Studies in Cognitive Science , Edited by: Bobrow , D. and Collins , A. 35 – 82 . New York : Academic Press .
Appendix 1
The two-layer Chimaera network of Simulation 1A consisted of the following parameters – both layers: 2D spatial array, size 32×32, torus topologies. All layers initialised to pseudorandom values; 181 data dimensions (Layer 1, from sensorimotor input) or 1024 data dimensions (Layer 2, from spatial activation map of Layer 1); no associative flow or decay was required for this simulation; learning rate, γ=0.75; initial SOM learning radius-of-effect: 32 (network size), decreased by 1 at the beginning of each series of epochs, where subsequent layers began their SOM training after their input layer ended training. SOM Similarity map: radius of 3. Neighbourhood function h ij took the form of a linearly tapered window. Simulation 1B extended Simulation 1A with one additional layer, while also dampening the semantic similarity scaling parameter (τ) from 1.0 and 0.5 (Simulation 1A) to 0.3 for each of the three layers of Simulation 1B.
Appendix 2
The parameters for Simulation 2 were similar to Simulation 1, only extended to a number of additional layers. Network sizes were reduced to 20×20 nodes to reduce computation time. Layers 1 and 2, as Simulation 1. Layer 3 as Layer 2; τ=0.50. Layer 4, size = 20; recurrent with 800 data dimensions (400 contributed from the activation map of Layer 3, the remaining 400 from Layer 4); τ=0.02; activation decay between epochs ; no flow. Layer 5,
; input was 400 data dimensions (from Layer 4); τ=0.01; temporal dynamics enabled: k
d=0.75; total activation for a given node clipped to a maximum of: 1.0; k
m: 0.10;
; noise threshold: 0.1 (nodes would not associate if their activation was below this threshold); association changes scaled by 0.01 to prevent rapid changes in the association map and promote long-term learning. Noise threshold for tagging and analysis: activation of 0.10 or greater. Note that the localist input set failed to produce significant output using the above parameters, and the τ parameter was adjusted until the network produced meaningful output (τ=1.00 for Layer 1, 0.50 for all other layers).
Appendix 3: Recursive-dependency analysis
This analysis displays each of the transitions in the Van der Velde et al.’s (2004) grammar, as well as the depth of each transition, and whether a given transition is ambiguous/contained across multiple sequences. (Note: The end marker is not included in this analysis.)
