Abstract
Fodor and Pylyshyn [(1988). Connectionism and cognitive architecture: A critical analysis. Cognition, 28(1–2), 3–71] famously argued that neural networks cannot behave systematically short of implementing a combinatorial symbol system. A recent response from Frank et al. [(2009). Connectionist semantic systematicity. Cognition, 110(3), 358–379] claimed to have trained a neural network to behave systematically without implementing a symbol system and without any in-built predisposition towards combinatorial representations. We believe systems like theirs may in fact implement a symbol system on a deeper and more interesting level: one where the symbols are latent – not visible at the level of network structure. In order to illustrate this possibility, we demonstrate our own recurrent neural network that learns to understand sentence-level language in terms of a scene. We demonstrate our model's learned understanding by testing it on novel sentences and scenes. By paring down our model into an architecturally minimal version, we demonstrate how it supports combinatorial computation over distributed representations by using the associative memory operations of Vector Symbolic Architectures. Knowledge of the model's memory scheme gives us tools to explain its errors and construct superior future models. We show how the model designs and manipulates a latent symbol system in which the combinatorial symbols are patterns of activation distributed across the layers of a neural network, instantiating a hybrid of classical symbolic and connectionist representations that combines advantages of both.
1. Introduction
More than 20 years ago, Fodor and Pylyshyn Citation(1988) rebuffed proponents of the burgeoning connectionist movement, stating that ‘when construed as a cognitive theory, [\ldots] Connectionism appears to have fatal limitations’ (p. 48). Central to their argument was the idea that classical theories of cognition perform systematically due to the embedded combinatorial symbol systems, which connectionist models seemed to lack. They argued that, practically by definition, a combinatorial symbol system – one in which entities can be combined and composed according to rules – is the only way to tractably describe systematic behaviour on the level that humans exhibit it. Faced with the work of the connectionists of their time, Fodor and Pylyshyn interpreted the movement as an attempt to replace classical cognitive theory with neural networks that, on the face of it, lacked the ability to operate on symbols systematically. They concluded that the only way neural networks could behave systematically was to directly implement a combinatorial symbol system. This would, in their view, relegate connectionism to an explanatory level below – and unlikely to be relevant to – cognition.
In response to Fodor and Pylyshyn's assertions, many connectionists proposed neural network models demonstrating highly systematic behaviour. For example, Hadley and Hayward Citation(1997) and Hadley and Cardei Citation(1999) advanced related models that took simple sentences as input and produced something like a propositional representation of each sentence's meaning as output. The models were largely connectionist in form, consisting primarily of simple processing elements and trainable weighted connections between them, as well as in training, utilising Hebbian learning methods as well as self-organising maps (Kohonen, Citation1990). However, the models’ output layers possessed a ‘primitive, but combinatorially adequate conceptual scheme prior to verbal training’ (Hadley & Hayward, Citation1997, p. 33). This built-in conceptual scheme consisted of single-node representations of each atomic symbol as well as nodes for thematic roles and bindings of the two into semantic compounds. The neural architecture of these models included all of the atomic symbols and, crucially, only and exactly the potential bindings between symbols that the system would need. As a result, the system was only able to generate valid propositions as output, though it did have to learn which propositions corresponded to a given input. This led to a system with a clear disposition to combinatorial operation over a pre-defined and a priori restricted symbol space. Indeed, the stated goal of these models was to ‘demonstrate that semantic systematicity is theoretically possible when connectionist systems reflect some classical insights’ (Hadley & Hayward, Citation1997, pp. 10–11). Seeing as these models implemented a classical symbol system in the most literal way possible – as part of the neural architecture itself – it is hard to hold them up as counterexamples to the claims of Fodor and Pylyshyn.
At the other end of the spectrum is a more recent neural network model by Frank, Haselager, and van Rooij Citation(2009), consisting of a simple recurrent network (SRN; Elman, Citation1990; Jordan, Citation1986) that learned to map an input sentence to a ‘situation vector’ – an analogical representation of the network's beliefs about possible states of the world. The situation vector that the model produced in response to a given sentence was not directly interpretable, as a symbolic output would be. However, by comparison with other exemplar vectors, Frank et al. were able to quantify the network's level of belief in any particular state of the world. To explain their model's systematic behaviour, Frank et al. Citation(2009) said that it ‘comes to display systematicity by capitalizing on structure present in the world, in language, and in the mapping from language to events in the world’ (p. 358). Frank et al. claimed that their model, though completely distributed and purely connectionist in nature, possesses the same combinatorial properties as a classical symbol system, countering Fodor and Pylyshyn's assertion. But these combinatorial properties are largely what defines such a symbol system, leading directly to the suspicion that Frank et al.’s model may in fact function as a symbol system, even though, on the surface, it is far from obvious how it might do this.
We hypothesise that purely connectionist models like that of Frank et al. may instantiate a combinatorial symbol system in a much more interesting way than in the structure of the neural network. Instead of an innate, hard-wired neural symbol system like the one present in Hadley and Hayward's model, we suspect that models like Frank et al.’s may instantiate, through learning, latent neural symbol systems.
When we speak of a latent symbol system emerging in a neural network, we mean that the symbol system is not enforced as part of the structure of the network. Rather, it exists entirely as part of the learned internal representations of the network. In other words, the symbols are latent from our perspective as outside observers, though they are easily accessed, manipulated, and inspected by the system itself. This idea requires the network to learn distributed representations that it can manipulate in combinatorial ways, thus gleaning the systematicity benefits of classical cognitive symbol systems while preserving the distributed, incremental nature, content-addressibility, and graceful degradation of connectionist representations. Neural network learning methods then provide a natural avenue for the creation and integration of new symbols, assigning each a novel representation created through weight changes in the network, without requiring structural changes such as new nodes to represent newly acquired symbols. Such a system represents symbols both in the patterns of activation of collections of neural units and in the weights between them. The former property allows a properly trained network to freely manipulate symbols – even novel symbols or combinations – online in the temporary memory that the activation values provide. As a result, stored symbols become available for processing into higher level cognitive structures.
Our conception of a latent symbol system is a marriage between classical and connectionist representations that owes much to previous work on compositional representation schemes suitable for use with neural associative memories (e.g. Gayler, Citation1998; Kanerva, Citation1996; Plate, Citation1997; Smolensky, Citation1990). These are systems for storing and manipulating symbols, where each individual symbol is represented as a large vector of low-precision numbers. In contrast to both classical symbolic representation schemes and localist neural representations, these systems – the so-called Vector Symbolic Architectures (VSAs; Levy & Gayler, Citation2008) – do not ascribe a priori meaning to individual elements of the representation vector. Instead of being able to directly inspect the contents of a symbol, one must rely upon arithmetic transformations of symbols and vector-similarity judgements between symbols to interpret their meaning. Plate Citation(1995) showed how these transformations can be used to store arbitrary and recursive compositions of symbols in an associative memory while keeping vector size fixed. Despite their complexity, such encoded structures can be addressed by content and transformed holistically – often without resorting to decomposition and recomposition (Neumann, Citation2002). Such a representation system is a natural way to conceptualise how a neural network would learn to encode and manipulate symbols internally. Gayler Citation(2003) provides an overview of how VSAs provide a complete basis for cognitive representation.
Frank et al. have not, to our knowledge, analysed their model's internal representations in ways that would reveal or refute the presence of a latent symbol system, making it difficult to know if our hypothesis – that their model contains a latent symbol system – is true. To examine the possibility of the emergence of a latent symbol system through training in a neural network, the remainder of this paper presents a neural model of our own design that learns to understand simple English sentences in terms of a scene. We then present a pared-down implementation of the model which reveals, though its structure, that it learns to perform as a VSA that utilises the multiply–add–permute (MAP) encoding studied by Gayler Citation(1998). Through appropriate training, our model learns not only to store and retrieve familiar patterns, but also to process novel symbol compositions based on what it has seen before. In Section 3.3, we describe the structure of our model's memory at each computational step, appealing to the MAP framework of vector-based associative memory operations to detail the sorts of representations that our model learns. First, however, we discuss the model's task and neural network architecture.
2. Methods
Our neural network model has two parallel, temporal input streams representing a scene and an auditory sentence. It is tasked with interpreting the sentence it hears in the context of the relational information describing the scene. For example, if the model hears the sentence ‘The blue pyramid is on the green block’, it needs to map the objects and properties being spoken about (a blue pyramid, a green block, a relation called ‘on’) to actual objects and relations it observes in the scene. Put differently, the network needs to identify the intended referents and relations described in a given sentence. We can test the model's knowledge by prompting it to produce different pieces of its interpretation of the sentence, which will contain unique internal identifiers for each of the scene's objects.
During training, the network learns to segment the input sentence, which is presented at the phoneme level. It develops efficient working memory representations of the objects in the scene. It learns to map both singular and plural noun phrases onto a referent or referents in the scene. Crucially, the model generalises to sentences and scenes never before encountered. By way of explaining this behaviour, we will provide a detailed analysis of the internal representations learned by the network which suggests that it manipulates these representations combinatorially, consistent with a learned implementation of a symbol system. We will then present a pared-down implementation of the model which explains, though its structure, how manipulation of the learned latent symbols takes place.
2.1. Task description
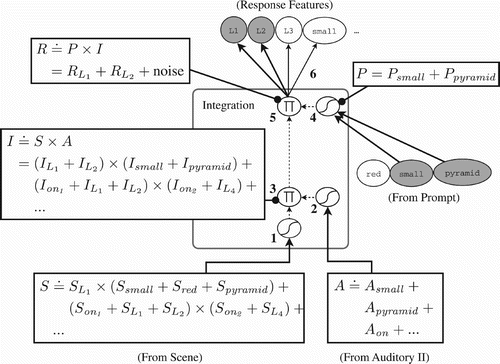
By way of explaining the task, this section describes in turn each type of input that the model must integrate in order to form a coherent representation of each trial's scene and sentence. depicts the general structure of the inputs and outputs of the task and serves as a full example trial that is explained in detail in Section 2.1.4.
Figure 1. An example of the inputs and outputs that comprise the task. The model receives high-level inputs (1) that specify a scene and auditory inputs (2) that specify a sentence describing that scene. The model must integrate these inputs in its working memory and then respond to a variety of prompts (3), with these responses (4) demonstrating its knowledge of the meaning of the sentence in terms of the scene.
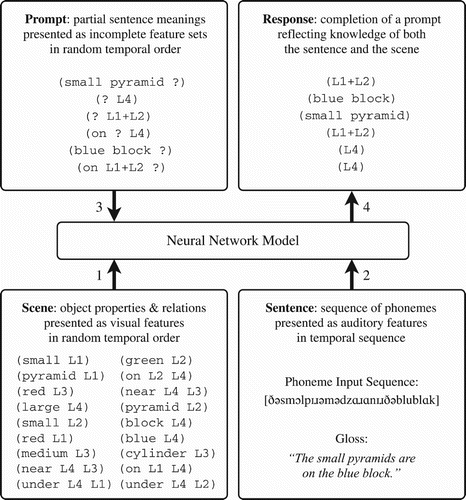
2.1.1. Scene input
Each trial in our task involves a randomly generated scene. A scene, for our purposes, is an abstract representation of a collection of between two and four objects, each of which have three properties: a shape (block, pyramid, or cylinder), a colour (red, green, or blue), and a size (small, medium, or large). Thus 27 distinct objects are possible. Each of the objects appearing in a given scene is assigned a unique label, which can be thought of as its identity in the human object-tracking system and is useful in cases where the scene contains objects that are not distinguishable in terms of their other properties. The main purpose of these labels is to bind properties to objects and, by extension, to each other. Since the object labels do not exist in the auditory modality, the model learning to use them will also serve as proof that it effectively combines auditory information with scene data obtained from another modality.
Since it is not our intention to precisely model human visual perception and its underlying neurobiological pathways, we do not concern ourselves with providing a retinotopic representation of the scene input stream. Instead, we assume a more abstract object representation that could be constructed by higher level visual regions in response to sensory input. We present a scene as a temporal sequence of scene-level features rather than as a single aggregate neural activity pattern for a variety of reasons. First, a temporal presentation simulates shifts in attention within the scene, which is more realistic than requiring a system to take in a scene in its entirety all at once. Second, it allows us to vary the number of objects, which is important in light of research on the capacity limitations of human working memory (see Cowan et al., Citation2005, for a review). Working memory research seems to show that, while there are practical limits on the number of object representations an individual can maintain simultaneously, these limits are not hard and fast. A static array of object input units would provide this capacity limit a priori, while with our temporal representation, network dynamics determine the capacity limitations for the model's equivalent of working memory. This same approach underlies our choice of temporal input for phonemes as discussed in the next section.
The model receives input that specifies the scene as a randomly ordered temporal stream of scene feature sets, using the neural coding shown in . Each set in this sequence denotes a property and the label of an object with that property. We denote these properties and labels in the text using a fixed-width font. For example, if the input scene contains a large red block with label L2, the model will receive the following three feature sets at random positions in the scene input stream: (large L2), (red L2), and (block L2). If the scene consists of four objects, the model will receive a total of 12 such feature sets.
Figure 2. Two examples of featural representations of properties and relationships, which are used for scene and prompt input as well as prompt response output. Circles and ovals represent individual neural units, each assigned to a feature. Units are considered activated when darkened. On the left is an example of the assignment of a property to an object label, (blue L3), by the activation of the property unit blue and the primary label unit L3 from the first label column. One could apply a property to multiple objects simultaneously by activating multiple label units simultaneously. On the right is an example of a relationship between objects; here, we represent the fact that objects L1 and L2 are on top of object L4 using (on L1+L2 L4). This is represented as a temporal sequence of two input patterns. In the first, the unit on-1 is active to represent the first argument to the on relation, along with two active label units for L1 and L2. This is followed by another pattern where on-2 indicates that L4 is the second argument to on.
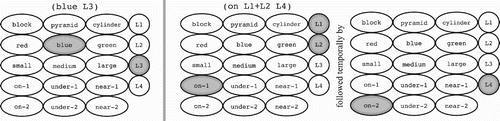
In addition to the intrinsic properties of objects, the scene input also includes sets of features describing the relative locations of objects using the three simple relations near, on, and under. For example, if the object labelled L2 is underneath object L3, the scene input would contain another set of features corresponding to (under L2 L3), where the order specifies the direction of the relation. Location properties are encoded using the neural representation shown at the right side of , and they are inserted into the scene input sequence at random positions.
While one may object to the use of localist units for scene input (and, as we shall see, prompt input and response output), it is important to note that their use here is chiefly for computational expediency and ease of our later analysis. On the other hand, the auditory input representation, presented in the next section, departs from this paradigm by using a sparse auditory feature encoding instead of localist units. Such an encoding could, with few additions, represent speech from any human language. Given enough computational resources, our localist encodings could be replaced with similarly generative schemes, such as a retinotopic representation of the scene input and/or natural language prompts and responses (the latter of which are used in Monner & Reggia, Citation2012a).
The scene input is presented in its entirety before the presentation of the auditory input begins. This is because we require the model to build a full working memory representation of a scene before hearing a sentence about that scene. This forces the model to consult its memory to interpret the sentence, as opposed to consulting the external scene directly. Thus, in order to perform well on the task, the model must learn to maintain the important attributes of the scene in working memory using an efficient scene representation – one which can simultaneously encode several objects, maintaining the bindings between individual objects and their (likely overlapping) attributes, and which the network can later match against the auditory input. We will show in Section 3.3 how the network learns and uses such a representation.
2.1.2. Sentence input
After experiencing the scene input, the network hears a sentence involving some of the objects in the scene. Sentences are generated from a simple, mildly context-sensitive toy grammar () that truthfully describes objects from the scene and relations between them. The grammar allows many ways to refer to any particular object. For example, a (small blue pyramid) could be described as a ‘small blue pyramid’, a ‘blue pyramid’, a ‘small pyramid’, or simply a ‘pyramid’. Notably, the grammar allows plural references to groups of objects, such that our pyramid from above might be paired with a (large blue pyramid) to be collectively referred to as the ‘blue pyramids’; or our original pyramid could be grouped with a (small green cylinder) to be collectively described as the ‘small things’ because of their one common property. Examples of complete sentences that the grammar can generate are ‘the large pyramids are green’, ‘the blue things are under the small red blocks’, and ‘the small green pyramid is on the large red cylinder’.
Figure 3. The toy grammar used to generate the sentences. Terminals begin with a lowercase letter while non-terminals are in boldface and begin with an uppercase letter. The symbol ‘|’ separates alternative derivations, and terms in brackets are optional. *The evaluation chosen for the Is non-terminal must agree in number with its subject NP. **The object NP of ‘on’ will never be a pyramid since, in our simulated world, pyramids cannot support other objects due to their pointy tops. Similarly, the subject NP preceding ‘under’ will never be a pyramid. In other words, nothing will ever be ‘on’ a pyramid, and a pyramid will never be ‘under’ anything.

Each word in an input sentence is transcribed into a sequence of phonemes; these sequences are then concatenated, creating a single unsegmented sequence of phonemes representing the entire sentence and serving as the auditory input to the model. For example, the sentence ‘the large cylinder is green’ is encoded as the sequence ![]() . Each phoneme in such a sequence is input to the network as a set of auditory phonetic features that are known to be used for identification by human learners (Weems & Reggia, Citation2006). Since we are not trying to model the entire auditory pathway, we take it as granted that feature-based phonetic representations similar to the ones used here are available at some higher level in the human auditory system. It should also be noted that the toy grammar employed here is, by design, a vast simplification of human language grammars; it is not our intent to claim that our model learns important aspects of natural language beyond the existence of words that reference specific objects, properties, and relationships.
. Each phoneme in such a sequence is input to the network as a set of auditory phonetic features that are known to be used for identification by human learners (Weems & Reggia, Citation2006). Since we are not trying to model the entire auditory pathway, we take it as granted that feature-based phonetic representations similar to the ones used here are available at some higher level in the human auditory system. It should also be noted that the toy grammar employed here is, by design, a vast simplification of human language grammars; it is not our intent to claim that our model learns important aspects of natural language beyond the existence of words that reference specific objects, properties, and relationships.
During training, the auditory pathway learns to segment the auditory stream into words, for which boundaries are not included. The model must also hold a representation of the full sentence in working memory so it can respond to prompts which probe its understanding of the correspondence between the sentence and the scene, as discussed next.
2.1.3. Prompts and responses
After receiving both the scene and sentence inputs, the model is given a series of prompts, in random order, to which it must respond. These prompts take the form of incomplete bits of knowledge about the environment that the model must complete, in the same style as the model by St. John and McClelland Citation(1990). For example, the prompt (small pyramid ?) will follow any sentence in which a small pyramid, or a group of small pyramids, was mentioned. The model must identify the objects in the scene to which the sentence referred, producing a response like (L1+L2) for a case where the scene contained exactly two small pyramids with those labels. Other prompts ask about the properties of objects with given labels, or the relations between objects. The neural coding for prompts and responses is the same as that used for scene feature sets (). It is important to note that this representation for the prompts and responses, while it does specify the full symbol set, does not a priori restrict the network to producing well-formed responses; the model must discover for itself what constitutes a well-formed and appropriate response to a given prompt.
After receiving the inputs for a trial, we interrogate the model with two to six prompts, based on the complexity of the input sentence. We generate these prompts automatically for each trial based on individual objects and relations from the sentence. For each object, such as (blue block L4), we create a prompt with the object label removed, as (blue block ?), and another prompt with the object properties removed, (? L4). For each relation in the sentence, like (on L1+L2 L4), we create a prompt by removing the first argument to the relation, as in (on ? L4), and another by removing the second argument, as (on L1+L2 ?). The correct response to these prompts is the information that we removed in each case. It is very important to note that the manner in which we test the model leaves it incapable of remembering previous prompts or responses, even those from the same trial; as such, it is impossible for one prompt to provide the model with information about the correct response to a subsequent prompt. On each trial, the model must respond to all prompts that we can create in this way. The model must answer all prompts correctly in order to be scored as processing the trial successfully. To do this, the model must integrate its scene and auditory working memories into a representation suitable for answering arbitrary questions about what it has seen and heard, using each prompt to decode this representation into a suitable response.
2.1.4. Example trial
In order to illustrate the input and output descriptions given above, depicts a full example trial of the language task – a complete specification of related scene and auditory input streams as well as the prompts and the model's response outputs. The scene in this example consists of four objects, which in order of label number are a small red pyramid, a small green pyramid, a medium-sized red cylinder, and a large blue block. The scene also specifies that the two small pyramids rest on top of the block, and that the cylinder is near the block, as well as the inverse relationships. The feature sets specifying these properties are presented to the model in random order. The auditory input, meanwhile, corresponds to the sentence ‘the small pyramids are on the blue block’ and is presented as a temporally ordered phoneme sequence. The sentence in this case refers to a spatial relationship which involves three of the four objects in the scene, making the red cylinder a distractor object on this trial. The model processes the scene and auditory inputs into its working memory and then integrates these into a coherent combined representation of the trial. The model is then subjected to six prompts, being allowed to respond to each before the next is presented. Each prompt is a sort of question about the scene and sentence just observed. For example, the prompt (? L4) asks how the speaker described the object denoted internally as L4. In this case, the model should respond with (blue block), meaning that object L4 was referred to as a ‘blue block’; note here that the model should not include the property large, since it was not present in the sentence. Similarly, (on ? L4) asks which object(s) are on L4, with the answer being (L1+L2). Each correct response demonstrates a relationship that the model has understood by integrating information from both modalities.
2.2. Model description
With the structure of the task firmly in mind, we describe the model itself in this section. We first give an overview of the type of recurrent neural network that comprises the model, followed by a description of the model's neural architecture and connectivity.
2.2.1. Long short-term memory
Our model is a neural network based on the long short-term memory (LSTM) architecture (Gers & Cummins, Citation2000; Hochreiter & Schmidhuber, Citation1997), trained with the LSTM-g algorithm (Monner & Reggia, Citation2012b), which is a form of error back-propagation. Such training regimes are widely considered to be biologically implausible because no mechanism has been identified for backward propagation of information in networks of biological neurons. However, there is theoretical evidence to suggest a rough equivalence, in terms of weight changes produced, between back-propagation of errors and more biologically plausible Hebbian training methods (Xie & Seung, Citation2003). Setting aside that issue, LSTM-g makes use of only spatially and temporally local information, leaving it comparatively more plausible than many popular methods of training recurrent neural networks, such as back-propagation through time (Werbos, Citation1990) and real-time recurrent learning (Williams & Zipser, Citation1989). Since this study is primarily concerned with the nature of the representations that the network uses, rather than via what process it came to use them, we do not believe that the biological implausibility of back-propagation is a significant defect.
LSTM networks have previously been shown to learn and manipulate internal representations such as counters and feature-detectors (Gers & Schmidhuber, Citation2000, Citation2001; Graves, Eck, Beringer, & Schmidhuber, Citation2004). LSTM networks differ from similar recurrent networks like SRNs primarily because they use layers of units called memory cells instead of conventional stateless neural units. Each memory cell maintains a unit-level context by retaining its state from one time step to the next – or, equivalently, utilising a self-recurrent connection with a fixed weight of 1. This contrasts with the layer-level context that an SRN utilises. Additionally, memory cells are allowed to have multiplicative gates controlling their input, output, and self-connection; these are called input gates, output gates, and forget gates, respectively. A typical memory cell, drawn to match its computational structure, is depicted in . Each memory cell can be thought of as made up of simpler units: sigma (additive) units, pi (multiplicative) units, and units where a squashing function – here, the hyperbolic tangent function or tanh – is applied. From a mathematical perspective, a layer of memory cells, under an arbitrary ordering, corresponds to a vector of activation values. The network can perform element-wise vector addition at Σ-junctions and element-wise multiplication at Π-junctions, as well as range restriction via the tanh function. The network can retain these activation vectors across time steps because of the memory cell's self-connection. Taken together, these abilities make a layer of LSTM memory cells an excellent building block for creating complex, learnable associative memories, using an operational scheme that we will described in Section 3.2. This scheme makes use of correspondences between the operations performed by layers of LSTM memory cells and the vector operations used by certain VSAs to store complex symbolic data structures. In particular, we will show that interactions between collections of memory cells and their gates naturally correspond to the operations of the MAP architecture (Gayler, Citation1998).
Figure 4. Diagram of a single LSTM memory cell. Each oval represents a locus of computation within the cell. Solid arrows represent trainable weighted links into or out of the memory cell, while dashed arrows represent non-weighted input/output relationships among the cell-internal components. Like traditional neural network units, the memory cell forms a weighted sum of its inputs (1). The input gate similarly aggregates its own inputs and squashes the result with a tanh function (2), putting it in the [0, 1] range. The resulting input gate activation multiplicatively modulates the input coming into the memory cell (3), allowing none, some, or all of the input to enter. The state of the cell from the previous time step is retained (4) and modulated by the activation of the forget gate (5). The resulting state is added to the current input to form the new state (6), which is then passed through a tanh function (7). The memory cell's outward-facing activation is calculated by multiplying in the activation of the output gate (8). The resulting activation can be passed downstream to other units via further weighted connections. Envisioning an entire layer (vector) of memory cells working together, we can view the vector of activations in homologous parts of each memory cell as patterns to be manipulated by associative memory operations (see Section 3.2). The layer of memory cells receives four distinct patterns as input – one pattern for the memory cells themselves and an additional pattern for each of the three gates. The memory cell (1) and input gate (2) patterns are multiplied (3) – an encode or decode operation. The previous pattern held by the memory cell layer (4) is multiplied – encoded or decoded – with the pattern from the forget gates (5). These two new patterns are superposed (6) and range restricted (7) before being encoded or decoded with the pattern on the output gates (8). In this way, a layer of memory cells can, over several time steps, form complex combinations of patterns, making it a powerful component with which to build a learnable associative memory.
![Figure 4. Diagram of a single LSTM memory cell. Each oval represents a locus of computation within the cell. Solid arrows represent trainable weighted links into or out of the memory cell, while dashed arrows represent non-weighted input/output relationships among the cell-internal components. Like traditional neural network units, the memory cell forms a weighted sum of its inputs (1). The input gate similarly aggregates its own inputs and squashes the result with a tanh function (2), putting it in the [0, 1] range. The resulting input gate activation multiplicatively modulates the input coming into the memory cell (3), allowing none, some, or all of the input to enter. The state of the cell from the previous time step is retained (4) and modulated by the activation of the forget gate (5). The resulting state is added to the current input to form the new state (6), which is then passed through a tanh function (7). The memory cell's outward-facing activation is calculated by multiplying in the activation of the output gate (8). The resulting activation can be passed downstream to other units via further weighted connections. Envisioning an entire layer (vector) of memory cells working together, we can view the vector of activations in homologous parts of each memory cell as patterns to be manipulated by associative memory operations (see Section 3.2). The layer of memory cells receives four distinct patterns as input – one pattern for the memory cells themselves and an additional pattern for each of the three gates. The memory cell (1) and input gate (2) patterns are multiplied (3) – an encode or decode operation. The previous pattern held by the memory cell layer (4) is multiplied – encoded or decoded – with the pattern from the forget gates (5). These two new patterns are superposed (6) and range restricted (7) before being encoded or decoded with the pattern on the output gates (8). In this way, a layer of memory cells can, over several time steps, form complex combinations of patterns, making it a powerful component with which to build a learnable associative memory.](/cms/asset/c628377d-4a52-4ba1-8402-6729155c57f5/ccos_a_798262_o_f0004g.gif)
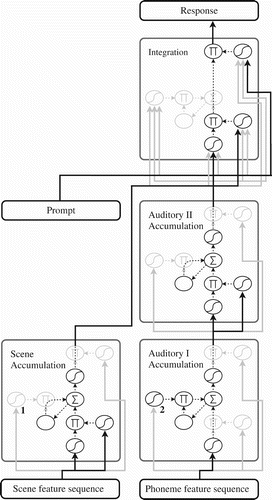
2.2.2. Network architecture
The specific network architecture of our model is depicted in . The network has a scene processing pathway that begins on the bottom left of the figure, comprised an input layer for scene features followed by a scene accumulation layer. The latter is a collection of memory cells which self-organise during training, gaining the capability to integrate the temporal scene input stream into a flexible representation of an entire scene.
Figure 5. High-level view of the architecture of the network. Boxes represent layers of units (with number of units in parentheses) and straight arrows represent banks of trainable connection weights between units of the sending layer and units of the receiving layer, though generally not all possible connections are present. Layers of memory cells are denoted with a curved self-connecting arrow, abstractly representing the self-recurrence of each unit in these layers. For a zoomed-in view that depicts all computational components of the architecture, refer to .
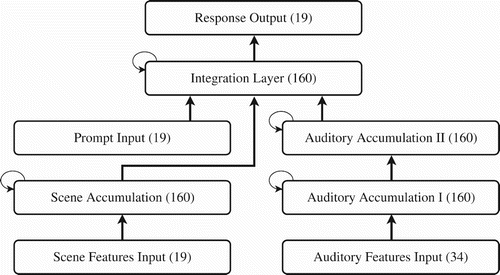
The network's auditory pathway is set up much the same way and begins on the bottom right of the figure with an input layer for auditory phoneme features followed by two auditory accumulation layers in series. To see why the auditory side needs two layers of memory cells instead of one, notice that the network has to perform multiple levels of segmentation in this modality, turning phonemes into morphemes and words, and combining those into phrases that make up the sentence. Section 3.3 explains in more detail the computational utility of each memory cell layer.
To create a combined representation of the trial useful for responding to prompts, the network integrates the sentence representation and the scene representation in another layer of memory cells called the integration layer. The network uses each incoming prompt to decode this integrated representation and produce a valid response.
3. Results
3.1. Experimental evaluation
We trained 20 independent instances of the model, where each instance began with its own set of random initial connection weights. For pairs of layers that shows as connected, individual pairs of units were connected with a probability of.7, leading to networks with 640 internal memory cells and approximately 250,000 trainable weights. The learning rate parameter was set to 0.01. Each input scene was constructed by uniformly choosing a scene size of 2, 3, or 4 objects and then randomly assigning properties and relations between objects, and each sentence was generated by following random transitions from the grammar of while adhering to the constraints of the scene. Each model instance was allowed to train on 5 million scene–sentence pairs, selected randomly with replacement. While this may seem at first like an extensive training period, one must consider that there are more than 10 billion possible scene configurations, each of which admits tens to hundreds of sentences. Since these estimates of the training space do not even account for the random ordering of scene inputs, the model is exposed to a tiny fraction of a percent of the problem space during training (conservatively, 5*106 trials/(1010 scenes * 10 sentences)=0.005% coverage ).
For each pair of test inputs, the model must be able to correctly interpret a sequence of as many as 40 phonemes and a scene having as many as 20 properties, and use this information to correctly respond to as many as 6 distinct prompts, each of which was designed to test a different aspect of its understanding of the trial. The model must respond correctly to all prompts to be scored as successful on the trial.
In order to verify that our model learns to perform the task, we tested each of the 20 instances on a set of 100 novel trials both before and after training. Before training, no model instance was able to produce even a single correct prompt-response, let alone an entire correct trial; this is consistent with chance performance because of the large size of the potential output space. The trained model instances, on the other hand, did quite well on the novel test trials. The average accuracy of the models on novel test trials is shown over the course of training in (darker line). On average, the fully trained model was able to respond to 95 of the 100 novel trials correctly, with its responses showing that it understood every aspect of the scene and the sentence. Overall, the model correctly responded to almost 98% of prompts, showing that even in the cases where the model failed our strict definition of a correct trial, it was able to correctly answer many of the prompts for that trial and thus was not completely lost.
Figure 6. The black line shows accuracy results during training, averaged over 20 independent runs of the model, on test sets of 100 novel trials; error bars denote the standard error of the mean. The grey line shows the same for the minimal model (see Section 3.3). The two models converge on the same level of performance as measured by a two-proportion z-test on post-training test-set accuracies (the 20 original model runs totalled 1903/2000 correct trials, while the minimal model runs scored 1895/2000, giving p=.6132). The minimal model leads the original model early in training (after 10% of training, achieving 1801/2000 correct versus the original model's 1370/2000, p<10−15) presumably because it does not have to learn which pieces of its network architecture to ignore for this task.
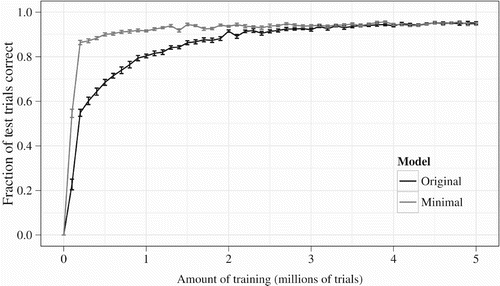
Figure 7. Comparison of the two versions of the model: the original model (everything shown) and the minimal model (non-greyed-out elements). The original model (cf. ) is shown with each memory cell layer expanded to expose its computational structure, in the style of ; this model has 4 layers of memory cells, 12 layers of gates, and more than 350,000 weighted connections in 25 different weight matrices. Examining the black layers and connections only we see the minimal model, which has 3 layers of memory cells, 5 layers of gates, and fewer than 130,000 connections in only 9 weight matrices. Where removing layers from the original model disrupted connectivity, we have used black dashed lines to indicate shortened versions of the original pathways that bypass the removed layers. The architecture of the minimal model lays bare the associative memory operations that it uses to complete the task. The two numbered areas are explained in detail in the main text.
These results demonstrate that our trained model is capable of learning to use language by combining information from two modalities, as required by the task. To provide insight into how this occurs, we investigated the relationship between our network's operation and that required by VSAs, which provide a method of symbolic computation in distributed vectorial representations. Before describing how our network implements a latent symbol system in a VSA framework, we provide more details on VSAs in the next section.
3.2. Latent symbol systems
To show the existence of a latent symbol system in our model, we must first have a formalism describing how such a system would operate. As we discussed in Section 1, there have been several previous characterisations of systems – the so-called VSAs – that encode symbols in distributed activation patterns over collections of neurons in a network. Of these, Gayler's Citation(1998) MAP encoding is perhaps the closest existing match for our model. In what follows, we briefly review the basic operations of VSAs in general and comment on the specifics for MAP. For a full explanation of the mathematics underlying the operations discussed here, see Plate Citation(1994); Kanerva Citation(2009) also provides an accessible introduction. In Section 3.3, we will show how a minimal version of our model utilises the MAP encoding to solve the task.
In VSA representation schemes, a pattern is set of activations across a layer of neural units. In MAP specifically, these neural unit activations are real numbers ranging between −1 and +1. Each such pattern may correspond to a symbol or combination of symbols. No given component of a symbol's pattern can be said to stand for some particular property of that symbol; the patterns are holistic, rendering any symbol-internal structure impervious to casual inspection (though not inaccessible, as we will soon see). This is one sense in which these types of representations produce ‘latent’ symbols: without some knowledge of a symbol's expected structure, one cannot hope to retrieve components of this structure.
Mathematically, a symbol's pattern is just a real-valued vector whose elements are, at least at first, randomly assigned. A memory trace is any pattern that the associative memory is holding at any given time. The simplest traces are just the patterns corresponding to single symbols, but more generally they can be combinations of patterns for many symbols.
To create complex traces, the memory scheme requires only three operations – encoding/decoding to construct or deconstruct associations between objects; a method of embedding, often implemented by permuting the elements of a pattern, to allow multiple copies of a given pattern to be bound together non-destructively; and superposition to allow a single pattern to hold multiple associations simultaneously. We describe each of these operations in greater detail below.
The first of these operations, encoding, is represented here by the × symbol. As input, the operation takes two patterns – which we will often call the key K and value V, though they are interchangeable – and combines them to form a new joint pattern T where key and value are bound together:
Encoding's inverse operation is decoding (⊗), where a pattern called the decoding key K¯ combines with a trace to recover the value V bound to a related encoding key K. In algebraic terms, the decoding key cancels out the encoding key, allowing recovery of the value:
In some VSAs, the decoding operation is identical to the encoding operation, and the decoding key is equivalent to the encoding key. In the MAP framework, both operations are implemented with element-wise vector multiplication. In this setting, an encoding key can be used as its own decoding key, because high-dimensional patterns can be identified primarily based on the signs of their components. Multiplying a pattern by itself produces a new pattern with all positive components, which acts as an identity in this case, resembling the multiplicative identity vector in terms of component signs, if not necessarily in magnitudes. Thus, for MAP we could just as easily write
A second main operation, embedding, can be used to protect multiple bound copies of a pattern from cancelling each other out, as they did in the previous example of decoding. This operation can be useful in building recursively generated bindings that might contain the same pattern more than once, such as embedded sentence structures in natural language. In MAP, the embedding operation is implemented as a systematic rearrangement or permutation of the components of a pattern, which is easily inverted by an un-embedding operation that restores the original pattern. While this operation is crucial for the completeness of VSAs as a potential cognitive substrate, our task does not require its use, so we omit further discussion of it in the interest of brevity. We refer the reader to Gayler Citation(2003) for further explanation.
The final operation is superposition (+), in which two or more patterns are held in the same memory simultaneously. In MAP, as in most VSAs, the superposition operation is implemented as simple vector addition. Using superposition, we can have our associative memory trace T hold both an association between patterns A and B as well as another association of patterns X and Y:
By analogy to the conventions for depicting multiplication in equations, we will sometimes show the multiplication-like encoding operation as adjacency (e.g. A×B is the same as AB) and repeated encoding as exponentiation (e.g. A×A×A is the same as A 3), where convenient. As with their scalar counterparts, the encoding/decoding operator takes precedence over superposition.
With only these three operations, an associative memory has the ability to store complex combinations of symbols (Kanerva, Citation1997; Plate, Citation1994). An ordered list, for example, can be represented with the help of an arbitrary, fixed pattern P that is used to indicate position. To represent the list [A, B, C, D], we create the trace
Armed with this formalism for analysing a latent symbol system, we next show how our model uses these operations to develop and operate on structured, compositional distributed representations.
3.3. A minimal model
Inspired by the model's strong performance on its task, we began manual inspections of the learned representations at each locus of computation in the model. These loci are depicted in , which is a detailed view of the model's neural architecture with two important loci numbered for reference throughout the following. We noticed, for example, that the forget gates in the scene accumulation layer (1) developed strong bias inputs and weak external inputs, leading to activations at (1) that were very close to 1 on every step of every trial. A constant value of 1 on the forget gates is mathematically equivalent to having no forget gates at all. In essence, the model learned that its best interest was not served by utilising these forget gates, so it developed a method of ignoring them. Similarly, each forget gate in the model's first auditory accumulation layer (2) learned to ignore its external inputs almost entirely, each developing a nearly constant activation less than 1 for every step of every trial. This implied that these external inputs were not necessary for the model. This learned constant pattern over the forget gates enables the model to construct ordered lists, as we will explain shortly.
Given these observations, we embarked on the task of paring the model down to the minimal network architecture required to perform the task, with the expectation that a minimal architecture would reveal the structure of the computations that the original model learned to perform. Based on observations like those described above, we began removing individual gate layers and banks of learnable weights between layers. When those versions of the model could still learn the task from scratch, we continued methodically removing components from the model and testing the resulting smaller model. We arrived at the reduced network architecture obtained by removing greyed-out layers and connections from , which is one possible minimal version of the model – minimal in the sense that removing any component of the network causes the model's performance to drop precipitously. Each layer of memory cells in the original model had some essential components, but we found that many of these could be removed without detriment to the model's performance. Our minimal model is approximately one-third the size of the original in terms of the number of gate units, number of weight matrices, and total number of trainable connections. Despite this, its final performance after the completion of training is indistinguishable from that of the original model, as shown in . In fact, the minimal model reaches its maximum level of performance much faster than the original model, further suggesting that the extra network structure in the latter made training more difficult.
The architecture of the minimal model illustrates how the network is able to learn to perform this complex task. The model, through training, becomes a complex, multi-stage associative memory capable of building structured symbolic representations in terms of activation patterns, using the vector operations of encoding, decoding, and superposition detailed in Section 3.2. As we will see in the remainder of this section, the minimal model's network structure defines a set of superposition and encoding operations – precisely those used in the MAP memory scheme – that create the network's structured, integrated representation for a trial. We then show via an analysis of the network's learned representations that it interprets this representation using a close relative of MAP's decoding operation coupled with recognition via a learned clean-up memory.
Beginning in the next section, we work through an example trial to illustrate the model's use of its latent symbolic representations. Throughout the example, we will use fixed-width font, such as small or L1, to refer to input or output units corresponding to certain objects or properties; these are to be distinguished from our notation for the patterns representing these symbols, which will be shown as X
small or in italic font, with the identity of X changing to denote different representations of small or L1 over different layers in the network. In the interest of notational brevity, we will sometimes define – using the ˙eq symbol – a new pattern variable in terms of a combination of previously seen patterns.
3.3.1. Representation building
In this section, we show, step by step, how the minimal model's network architecture implements associative memory operations that result in a final integrated representation for each trial that has a predictable structure. Looking back at , recall that each junction represents a layer of neural units, or equivalently, a vector of activation values – a pattern in VSA terms. The Π-junctions take two inputs and multiply them element-wise, thus instantiating the encoding or decoding operation from MAP. The Σ-junctions perform the element-wise vector addition that underlies the superposition operation. Superposition is generally followed by a pass through the hyperbolic tangent function, as indicated by squashing junctions in , to restrict the range of the output to a predictable (−1, 1) range, which is important so as not to over-saturate links in the network when many patterns have been superposed. With these basic correspondences in mind, we can step through how the network processes the trial from to see a representative example of the symbolic representations it creates.
The minimal model first receives the input scene. The scene accumulation layer will process the scene as a sequence of sets of related scene features, binding related features using the encoding operation, and finally storing them all in a superposed representation that will later be integrated with the auditory input. The details of this process follow.
Each set of scene features arrives in sequence on the scene accumulation layer, shown in detail in . Each feature in each of these sets corresponds to a property of an object or a relation between objects. For example, if a scene feature set describes an inherent property of some object, as in , it will consist of one active unit corresponding to the property and another corresponding to the label of the object to which it applies – for example, two input units representing small and L1 will be activated. For each input unit x, the model learns weights that drive a distinct pattern corresponding to x on either the memory cell inputs – the junction labelled (1) in – or the input gates (2), depending on the connectivity. In the case of the minimal model, all object property units are directed via weights to (2); we will call the pattern that small generates there S
small. Similarly, the object label L1 generates a pattern we will call at (1). Then, at (3), the two patterns are encoded, forming
.
Figure 8. Examples of representations generated by the scene accumulation layer in response to inputs, in which each square box shows an example representation stored on the layer indicated by the connected black dot. In (a), the shaded input units representing (small L1) are active, leading to the activation of learned patterns at (1) and S
small at (2). The Π-junction at (3) encodes these to produce
. This term is superposed at (5) with the previously stored trace from (4) to form the new trace at (6). In (b), the input feature set describes the relationship (on L1 L4). Both (1) and (2) contain superposed patterns, with the former denoting that L1 is the first argument of the relation on and the latter specifying L4 as the second argument. These are bound with each other at (3), with the new term being subsequently superposed with the previous trace as above.
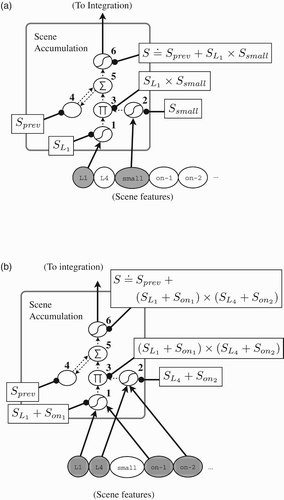
As a more complex example, the input feature set may also describe a relationship between two objects, such as (on L1 L4). In , layers (1) and (2) now each have two active input units driving their activations. The result is that both layers contain superpositions of two patterns. Layer (1) has , which designates L1 as the first argument of the on relation. Similarly, the trace on layer (2),
, indicates that L4 is the second argument of on. These two superpositions are bound with each other at the Π-junction at (3) to produce
.
Once any input feature set is encoded at (3) as described above, the memory cell layer takes its previous trace, stored at (4), and uses the Σ-junction at (5) to superpose it with the new incoming trace from (3). Thus, after the network has received all the scene input, the entire sequence of encoded scene patterns is superposed at the memory cell layer (5). Since vector addition is commutative, the randomised order of the scene feature sets does not have any impact on the final representation. Because the representation consists of many patterns in superposition, the actual activation values at (5) may be quite large; as such, the representation is passed through a tanh function (6) to restrict the activation values again to (−1, 1). Since it encodes the entirety of the scene input, we call this final representation over the scene accumulation layer (6) the scene database S. The scene database in our example trial can be expressed as:
The network processes auditory input in two stages, each having its own layer. It uses the first layer to aggregate incoming phoneme sequences into word representations, using the subsequent layer to collect and remember all the words spoken. Somewhat surprisingly, the network does not appear to utilise the order in which the words themselves appear. While this is clearly problematic for a model of human language comprehension, it turns out that word order is rather unimportant in our toy problem, and as a result the model learns to ignore it. Word order is not wholly irrelevant, however, and we shall see examples in Section 3.4 of how the network learning to ignore syntax causes its representation to break down.
The input to the first auditory accumulation layer () is a sentence divided up into a sequence of phonemes. Each phoneme in the sequence is made up of auditory features, with each feature corresponding to an active input unit. Via the weight matrix coming into (1), each of these features is associated with its own pattern by a learned weight vector. The entire phoneme, then, is a superposition of these features, created at (1). For example, the phoneme is the superposition of learned patterns representing the features:
Figure 9. Example representations generated by the first auditory accumulation layer, after presentation of the phoneme u in the word ‘blue’. Learned patterns corresponding to each active auditory input feature combine to form a phoneme representation of u at (1). The previously stored trace at (2) represents the first two phonemes of the word ‘blue’, stored as an ordered list where older phonemes are multiplied by larger powers of the constant pattern F, which resides at (3). F again multiplies this previous trace at (4), to which the u from (1) is added to create the final representation for blue at (6).
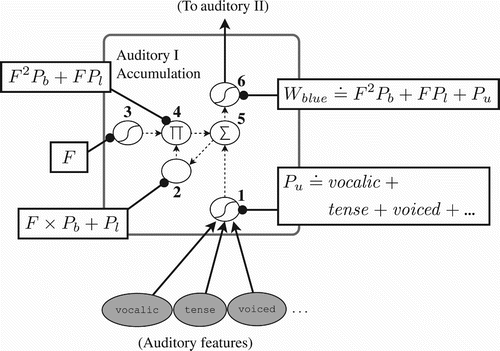
Combining phonemes to form words is not as simple as combining features to make phonemes. At the most basic auditory level, one might expect a word representation to begin as an ordered sequence of phonemes. The network indeed creates such a sequence, using the method for constructing an ordered list that was presented in Section 3.2. We can see this directly in the structure of the minimal model. Notice that the forget gates (3) in do not have any external inputs other than individual bias weights for each unit, which are not shown. As a consequence, the tanh units (4) always contain the same learned pattern throughout every step of a trial. If we call this pattern F and observe how it interacts with the current phoneme trace at (1) and the trace from the previous step saved at (2), we can see that the pattern for a word like ‘blue’ (phonetically, ) is built out of phoneme patterns as
The next layer in series is the second auditory accumulation layer (), where incoming word representations are superposed into a single representation defining the whole of the input sentence. An incoming pattern from the previous layer representing word ‘blue’ is transformed via weight matrices into two distinct patterns, at (1) and
at (2), which are then encoded with each other at (3). The result is two patterns for the same word w, ‘blue’ in this case, bound to each other, for which we will define a shorthand variable:
Figure 10. Example representations generated by the second auditory accumulation layer. The incoming word representation W
blue is transformed by weight matrices into two separate patterns, and
. To prevent their constituent phoneme lists from interfering with each other, these are encoded with each other at (3) to define A
blue before being added to the superposition of previously heard words at (5).
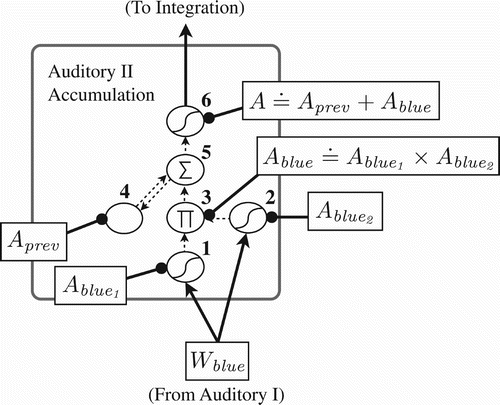
The final result is a superposition of bindings, with each binding representing a word in the sentence. We call this the auditory representation A of the input sentence, at (6). In our example, the sentence ‘the small pyramids are on the blue block’ can be expressed as
With both the scene database S and auditory representation A complete, the integration layer (shown in detail in ) is tasked with combining the two modalities – that is, determining which scene objects correspond to those the speaker intended. To do this, the model simply encodes the scene database (2) with the auditory representation (1). The key to making this strategy work is the network's choice of decoding keys used to interpret this integrated representation.
Figure 11. Example representations generated by the integration layer, and the decoding of those representations by prompts. The S and A traces from upstream (shown abbreviated here) are integrated by encoding them together. Terms that include an I
f
˙eq S
f
×A
f
have a chance of being decoded by the prompts, and all other terms become noise. When the model is prompted to produce an output, prompt input units for small and pyramid are activated, producing the learned decoding key P at (4) which corresponds to the prompt. This key decodes I at (5), producing as the response to the prompt. The weights at (6) form a clean-up memory that calculates the dot product similarity between the pattern at (5) and each output unit, with the most similar units becoming active.
To keep our notation brief, we introduce a new variable I f to refer to a binding between sub-patterns of S and A that both represent a given feature f. This binding exists between the representation of a property S f in the scene database and the word representations A f from the auditory representation. All properties that exist in both the scene and the auditory input will have such a representation, and it will turn out that all properties that do not have such a representation will never be decoded at the end of the task, and so will simply add noise to the decoding process. We define
Encoding S and A gives us many spurious encoded pairs which do not meet the criteria for I x representations above. As we will see, such pairs will never be decoded, and so we collect them all into a single noise term to keep our notation concise. Given the above definitions, the integrated representation I can be expressed as
Up until this point, the representations built by the minimal model – perhaps modulo our repeated redefinitions to maintain clarity of notation – are a straightforward consequence of its network structure. The key to the network's success is in learning how to decode this representation to produce useful information for performing its task. This entails learning to altogether ignore many of the terms in I – those we have collected under the noise term – while correctly decoding the others. While the structure of I would be much more complex in the original model than it is here, it is undeniable that the minimal model's I is a subset of the original model's version; the latter simply includes more terms that turn out to be noise in this task. This helps explain why the minimal model had an easier time achieving peak performance () – it had to deal with less internally generated representational noise.
Though we have shown how the model's I representation can be construed to have a symbolically meaningful VSA-style structure, such a structure is of no practical use unless the model can learn to utilise it in performing its task of responding appropriately to prompts concerning the scene and sentence. We explain next how the network symbolically interprets this structure using MAP-like decoding and a learned clean-up memory, presenting mathematical analyses to support our assertions.
3.3.2. Representation decoding and recognition
To test the model's knowledge about what it has seen and heard, we prompt it to produce a symbolic output representing part of its integrated representation of the trial. Each prompt creates a pattern on the integration layer's output gates – junction (4) of . One of the prompts tested for this example would be the equivalent of asking the model to provide the labels of the objects referred to as ‘small pyramids’ in the sentence. This is done by activating a two-unit prompt input (small pyramid ?), which, it should be noted, does not reveal that there is more than one answer. The prompt layer generates a pattern P on (4) which is used to decode the model's integrated representation into a response R:
The final weight matrix at (6) acts as a learned clean-up memory and thus helps to remove the noise in the result R. To see how this works, note that we can view such a matrix as a set of response recognition vectors R
x
, one attached to each output unit x. Multiplying the response R by the weight matrix corresponds to activating each output unit x in proportion to R·R
x
. Recalling from Section 3.2 that comparison of two vectors with the dot product is a robust measure of their similarity, we see that the output unit(s) whose weight vectors are most similar to R will be the most active. Thus, in keeping with the normal MAP decoding scheme, we would expect the network to learn an output weight matrix consisting of response recognition vectors R
x
corresponding to I
x
for each output unit – in other words, the clean-up memory would learn to directly recognise the I
x
representations used in the integration layer. Note that if R corresponds to superposed patterns, as in this example where , the resulting trace is similar to both constituents, and so in this case the output units for L1 and L2 will both be active. Conversely, any patterns combined multiplicatively via the encoding operation will not be similar to either of the originals (Plate, Citation1994). This property prevents, with high probability, any terms we have labelled as noise from activating an output unit.
An observable consequence of the MAP-style decoding scheme described above is that both the prompt patterns P x and the response recognition patterns R x should be nearly identical to the integrated layer representations I x , for all x. Unfortunately, individual I x patterns are not observable, as they only exist in I in a state where they are bound to other patterns. On the other hand, the P x are directly observable by activating individual prompt input units x, and the R x are defined as the weights attached to each output unit x. To test the hypothesis that P x and R x are approximately equal for all x, we use the standard VSA measure of pattern similarity – the dot product. To say that P x is approximately equal to R x , it must be the case that P x is more similar to R x than any other response pattern, and vice versa. More formally,
We tested this condition for all 19 prompt and output units, with the results shown in . It is clear from this test that generally P x ¬≈ R x , implying that the network is not using the normal MAP decoding process described above. But how, then, do we account for the network's success in recovering the correct outputs for a variety of novel patterns? In the next section, we explore an alternate form of symbolic decoding for MAP-like representations and provide evidence that the network uses this scheme.
Figure 12. Dot product comparisons between all prompt patterns P x (rows) and all response recognition patterns R x (columns) for a randomly chosen run of the minimal model. The cell where the row and column for two patterns intersect displays their dot product, with larger (more similar) values shown darker than smaller (less similar) values. Were it true that P x ≈ R x for all x, we would see the darkest values in each row and column occurring on the diagonal from the upper left to the lower right. In actuality, only about 26% (10/38) of these values occur on the diagonal, implying that, generally, P x ¬≈ R x .

3.3.3. A more general decoding operation
The assumption underlying the MAP memory scheme is that we know, a priori, the patterns associated with each basic concept. We not only use these patterns as building blocks to construct complex representations, but we also use them for decoding the representations and recognising the results with a clean-up memory. The same patterns for each concept are used in all three tasks.
The case for our network is a bit different than this ideal. As we have seen, patterns corresponding to individual symbols vary based on where they occur in the network, though the patterns for the various symbols remain distinct from each other at each location. The network evolves these patterns through learning, with no innate requirements that the same set of symbols needs to be used for constructing representations, decoding them, and recognising them. In particular, the network has no restriction that requires the equality of the response recognition vectors R x , the prompt patterns P x , and the integrated patterns I x .
With this requirement removed, the problems of decoding a recognition would seem to be much harder. However, VSA principles allow for a more general method of decoding and recognition using P x and R x patterns that are not equivalent to the corresponding I x , but merely related to it. Consider the simple case where we have a pattern I x ×I y from which we wish to retrieve I y , and we have independent control of both the decoding key P x and the response retrieval vector R y . In other words, we wish to have P x ×(I x ×I y ) ≈ R y . In MAP, we would simply set P x =I x and R y =I y , giving us
For this scheme to work, the chosen C does not need to be the same for every symbol, but it must be constant across classes of interchangeable items. For example, consider the following, where we momentarily assume that our constant vectors might differ for red and blue:
We can test this interpretation of the network's learned decoding scheme using observable properties of the network. In particular, given the requirements derived for the P x and R x patterns above, for all features f and labels l:
As mentioned in Section 3.3.2, the P
x
and R
x
patterns are easily observable, and thus bound pairs like P
f
×R
l
are trivial to construct for testing. Unlike the original case, we can also observe pairs of bound integration-layer patterns like I
f
×I
l
, which naturally exist in superposition in I. To gather these patterns, we provided the network with the appropriate inputs to form a particular integrated representation I
f, l
=I
f
×I
l
for all 36 combinations of the 9 basic colour/shape/size features and the 4 object labels. For example, to create the integrated representation , we presented the network with a scene consisting of just a cylinder labelled L3, along with auditory input consisting of the phoneme sequence for the word ‘cylinder’. We recorded the resulting integrated layer representation for each combination of feature and identifier. We similarly computed J
f, l
˙eq P
f
×Z
l
and K
f, l
˙eq Z
f
×P
l
directly using the network's post-training weight vectors corresponding to each feature and label. We thus obtained 36 sets of three patterns – an I
f, l
, J
f, l
, and K
f, l
for each of the 36 combinations of f and l – that should be approximately equivalent. We tested this as in Section 3.3.2, with the VSA similarity measure of dot product. For example, to demonstrate the equivalence of some pattern I
x
with the corresponding pattern J
x
, it must be the case that the dot product I
x
·J
x
is larger than all other dot products I
x
·J
y
and I
y
·J
x
for all y≠x. Formally,
We computed all such comparisons; the results, shown in the left column of , confirm that over 98% of possible pairwise equivalences hold. This provides compelling evidence that the minimal model learns to perform the generalised decoding operation as described in this section.
Figure 13. Dot product comparisons between the I x , J x , and K x patterns for a randomly selected run of the minimal model (left column), in the style of . That the darkest cells lie on the diagonal implies, for example in (a), that I x ≈ J x for all x (72/72 cases). In (b) we see that I x ≈ K x for all x (72/72 cases). This is true in (c) as well for over 94% of cases (68/72). In total, the minimal network's learned representations obey the expected equivalences in 212/216 cases (98%). In the right column ((d)–(f)) we see the same tests performed on a randomly selected run of the original model; the results are noisier (169/216 overall) but appear to follow the same pattern.
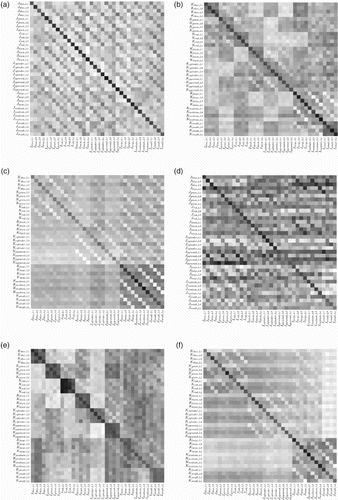
Finally, we performed the same suite of tests on the learned representations in the original model. The results, in the right column of , are, unsurprisingly, substantially noisier than the equivalent results in the original model. Here, the expected equivalences between various products of the original model's representations hold 78% of the time – a substantial amount, though less often than in the minimal model. In the cases where the equivalences do not hold – those where the darkest cell in a row or column is not on the diagonal – the desired cell is generally quite close to being the darkest, as evidenced by the fact that strong dark diagonals are evident. The level of consistency on this test, coupled with the fact that it was performed in conditions which are out of the model's normal context (i.e. single-object scenes and single-word input, neither of which ever occur naturally in the task), suggests that the original model learned to operate using the same general VSA principles as the minimal model.
3.4. Representational deficiencies for the task
The examples and analysis from the previous section show in detail the latent symbol system that the model devises. A side effect of understanding the model's latent symbol system is that we can now readily identify and characterise the situations in which the model will fail at its task. As we alluded to earlier, the model's learned representational scheme is not entirely foolproof. Indeed, on some trials the integrated representation can include some extra terms that are part of the scene but unrelated to the sentence. If we start with our example from and modify it so that the sentence is instead ‘the red pyramid is on the blue block’, the model's auditory representation changes so as to cause an unwanted term in the integrated representation:
So while these unwanted terms are not problematic most of the time because of the constraints of our task, errors do sneak through in some rare cases. Starting from our original example, if we modify the scene input so that the large blue block (object L4) is instead small, the network makes a similar mistake that causes it more trouble. The unchanged auditory representation A matches all terms in S where S
small is bound with any object. With our modified S, this means an extra property is retrieved for in I:
After discovering the above weakness of the model's representational scheme, we combed the training records for trials similar to the above. We found that both the minimal model and the original model routinely produce this type of error when given a trial that has been constructed in precisely the wrong way, as we have here.
We also observed experimental evidence of another class of error that stems from the model's flawed representation scheme. Starting again from our original example, if the scene input contained an additional on-relation (on L3 L4), our integrated representation would include an unwanted term in two places because of the lax restrictions imposed by A:
The representation scheme the model devised was highly successful for our toy task, but ultimately not perfectly suited to it, and is certainly not well suited to more complex tasks such as natural language comprehension. This should not, however, be taken as evidence that appropriate representations for more complex tasks are impossible as VSAs can construct arbitrarily complex representations, including role-filler models and recursive data structures.
Our model learned to use its flawed representation for two reasons. First, the inadequacies of the representation are very rare, occurring in only a small percentage of the trials that the model encountered. As a result of seeing few errors, it had little incentive to abandon this representation. Second, the original model does not have the appropriate computational machinery to build, using VSA operations, a more workable auditory representation that takes word order into account while still remaining easily integrable with the scene representation. The insight provided by the latent symbol system analysis, however, leads to a situation where we can address problems like this more directly than is generally possible with neural models. Were one to construct a robust representation scheme for this task, one could easily work backward from that scheme to obtain a neural network capable of utilising it directly. However, the extent to which complex representation schemes can be readily learned from examples by neural networks remains an open question for future work.
4. Discussion
The representations learned by our minimal model comprise an implementation of a latent combinatorial symbol system in a neural architecture. The symbols on which the model operates are learned vector representations that can be bound and superposed to create diverse structures. This type of VSA representation naturally combines the advantages of symbolic and connectionist representations in several ways. It is compositional, thus capable of giving rise to systematic behaviour. It is fully distributed, lending the benefits of content-addressibility and graceful degradation that neural networks exhibit. Further, our results suggest that it can emerge through learning, potentially even in networks like our original model which are more complex than the representation requires. In general, this suggests that recurrent sigma-pi neural networks, such as those built with the LSTM paradigm, are a fertile test bed for complex memory tasks. Such architectures are capable of modularly encapsulating the needed associative memory operations and simultaneously capable of learning to ignore those operations that are not useful for building a latent symbol system in service of their task.
By calling the learned symbol system ‘latent’ we imply that our model is not hardwired or otherwise predisposed to learning the symbolic representation necessary for its task. It is true that the network architectures of both the original and the minimal models are directly responsible for the composite representations each constructs. Even in the case of the minimal model, however, the resulting patterns involve many useless terms and few useful ones, and the network must learn which represent the signal and which the noise. There are myriad possible representation systems that any such a network could learn. That our model had to choose one of these for its particular task proves that this representation was in no way in-built.
It is worth taking a step back to compare this network's operation to the VSA representation schemes discussed earlier, especially in regard to learning. The architecture of the minimal model clearly shows that it performs the basic VSA operations and, in so doing, constructs composite symbolic representations using the MAP scheme. That said, our model's learned behaviour differs from normal MAP in terms of decoding. Since the network's weight adjustment rules do not naturally enforce the MAP notion that identical patterns should be used for construction, decoding, and recognition, the network instead learns to use a closely related decoding and recognition scheme that utilises patterns that are different from, but related to, those used to construct the composite representations initially. Our model's learned behaviour, which lacks the simple one-to-one pattern-to-concept correspondence found in MAP and most VSAs, is perhaps more closely related to representations in biological neural networks, where representation is naturally bound to location in the network. Such a scheme leaves the model free to learn to recognise patterns that are useful at the level of the task, even if those patterns are composite and emergent rather than basic in some sense. Our model does this when recognising words that are combinations of many phoneme patterns, themselves combinations of auditory features.
An interesting side effect of our model's decoding scheme is the implicit creation of classes of concepts that can only be bound to other concepts of certain other classes. We saw in Section 3.3.3 that the constants modifying the prompt and response patterns, C f and C l , implicitly defined two concept classes – features and labels. These learned classes prevent the model from decoding any nonsensical combinations of concepts that might exist in I, such as the colour concept red bound to green. If a new concept such as purple was added to the task after the model was trained, the existing prompt and output weight patterns would quickly force the new symbol into the feature concept class. This useful property could potentially help explain the human ability to quickly categorise novel stimuli based on a single encounter, though this question is best left for future investigations.
One of the main benefits often attributed to VSAs is that no learning is necessary – one begins with a set of base symbols and associated patterns, and need only use the basic operations to construct or take apart whatever composite patterns one requires. Of course, to recover patterns from a VSA, one needs to ‘teach’ a clean-up memory the base set of symbols and the patterns that correspond to each. The learning performed by our model serves a similar purpose: it trains the output weights, which act as the clean-up memory, which puts it on the same footing as VSAs in this regard. In the same way that VSAs can immediately generalise to new concepts by adding the requisite pattern to the repertoire of inputs available for constructing composite representations and to the clean-up memory, so too can our model generalise by learning appropriate weights attached to input and output units for the new concept. Of course, in our model, weight training encompasses all the internal network weights in addition to the input and output weights. Seeing as we are dealing with a much smaller pattern space than most VSA implementations – hundreds of units/dimensions here versus the thousands or tens of thousands of dimensions normally used – learning serves as a way for the network to force the various patterns it uses to be distinct enough to be mutually recognisable, which VSAs normally accomplish through sheer size combined with randomness. This property, while potentially a boon for reducing representation size, may also require the alteration of previously tuned patterns to accommodate additional patterns for newly learned concepts. More study is necessary to determine if these two features of these models interact in any significant way.
Our symbolic explanations of our model's behaviour may come across as a reinforcement of one of Fodor and Pylyshyn's main points, namely that connectionist networks, to be truly systematic, must implement a symbol system. Frank et al.’s insistence that their model was symbol-free may not apply to the type of latent symbols we describe, potentially leaving our explanations compatible. While we are unsure whether Fodor and Pylyshyn meant to include emergent latent symbol systems as a potential means of satisfying their requirement, we think that their comment, viewed in this inclusive way, is essentially accurate. That said, we disagree with Fodor and Pylyshyn on their corollary assertion that connectionist networks, as implementers of classical cognitive theories, have nothing new to provide to cognitive science. Gayler Citation(2003) has previously identified situations where VSAs have advantages that traditional symbol systems lack. A practical example of this is the ability to perform complex operations on structured representations without first decomposing them, as our model does in its integration of its scene and auditory working memories. A theoretical advantage that pertains to our model specifically is that the representations are grounded in, and indeed defined by, the neural circuitry in which they exist; this is in contrast to classical symbol manipulation, in which symbols can be wantonly copied and pasted in a way that ignores the context in which they appear. Even setting aside the question of whether a neural–symbolic representation is more powerful than a classical symbolic one, there are other facets that connectionist principles help address. Classical symbolic theories often entirely ignore the issues of how symbols are represented in the brain, how they form through learning, or how they break down under load or because of deterioration from age or injury. Connectionist representations are poised to address these issues and, in doing so, provide valuable developmental insights to cognitive researchers.
A union between symbols and distributed representations is both mathematically possible and neurocognitively necessary. This work demonstrates how a system can realise this marriage by learning to develop and manipulate latent symbols which are hidden in plain view as distributed patterns of neural activity. Barring a fundamental shift in our understanding of how the brain processes information, this unified view is a necessary step in relating the brain's structure to the mind's function.
References
- Cowan , N. , Elliott , E. M. , Scott Saults , J. , Morey , C. C. , Mattox , S. , Hismjatullina , A. and Conway , A. R. A. 2005 . On the capacity of attention: Its estimation and its role in working memory and cognitive aptitudes . Cognitive Psychology , 51 ( 1 ) : 42 – 100 . (doi:10.1016/j.cogpsych.2004.12.001)
- Elman , J. L. 1990 . Finding structure in time . Cognitive Science , 14 : 179 – 211 . (doi:10.1207/s15516709cog1402_1)
- Fodor , J. A. and Pylyshyn , Z. W. 1988 . Connectionism and cognitive architecture: A critical analysis . Cognition , 28 ( 1–2 ) : 3 – 71 . (doi:10.1016/0010-0277(88)90031-5)
- Frank , S. L. , Haselager , W. F. G. and van Rooij , I. 2009 . Connectionist semantic systematicity . Cognition , 110 ( 3 ) : 358 – 379 . (doi:10.1016/j.cognition.2008.11.013)
- Gayler , R. W. 1998 . “ Multiplicative binding, representation operators, and analogy ” . In Advances in analogy research: Integration of theory and data from the cognitive, computational, and neural sciences , Edited by: Holyoak , K. , Gentner , D. and Kokinov , B. 181 – 191 . Sofia : New Bulgarian University .
- Gayler , R. W. Vector symbolic architectures answer Jackendoff's challenges for cognitive neuroscience . Proceedings of the ICCS/ASCS international conference on cognitive science. pp. 133 – 138 . Sydney , , Australia : University of New South Wales .
- Gers , F. A. and Cummins , F. 2000 . Learning to forget: Continual prediction with LSTM . Neural Computation , 12 ( 10 ) : 2451 – 2471 . (doi:10.1162/089976600300015015)
- Gers , F. A. and Schmidhuber , J. Recurrent nets that time and count . Proceedings of the international joint conference on neural networks . Edited by: Amari , S.-I , Lee Giles , C. , Gori , M. and Piuri , V. Vol. 3 , pp. 189 – 194 . IEEE .
- Gers , F. A. and Schmidhuber , J. 2001 . LSTM recurrent networks learn simple context-free and context-sensitive languages . IEEE Transactions on Neural Networks , 12 ( 6 ) : 1333 – 1340 . (doi:10.1109/72.963769)
- Graves , A. , Eck , D. , Beringer , N. and Schmidhuber , J. Biologically plausible speech recognition with LSTM neural nets . Proceedings of the international workshop on biologically inspired approaches to advanced information technology. Edited by: Ijspeert , A. J. , Murata , M. and Wakamiya , N. pp. 127 – 136 . Berlin : Springer .
- Hadley , R. F. and Cardei , V. C. 1999 . Language acquisition from sparse input without error feedback . Neural Networks , 12 ( 2 ) : 217 – 235 . (doi:10.1016/S0893-6080(98)00139-7)
- Hadley , R. F. and Hayward , M. 1997 . Strong semantic systematicity from Hebbian connectionist learning . Minds and Machines , 7 ( 1 ) : 1 – 37 . (doi:10.1023/A:1008252408222)
- Hochreiter , S. and Schmidhuber , J. 1997 . Long short-term memory . Neural Computation , 9 ( 8 ) : 1735 – 1780 . (doi:10.1162/neco.1997.9.8.1735)
- Jordan , M. I. Attractor dynamics and parallelism in a connectionist sequential machine . Proceedings of the conference of the cognitive science society. pp. 531 – 546 . Hillsdale , NJ : Lawrence Erlbaum Associates .
- Kanerva , P. Binary spatter-coding of ordered K-tuples . Proceedings of the international conference on artificial neural networks. Edited by: von der Malsburg , C. , von Seelen , W. , Vorbrüggen , J. C. and Sendhoff , B. pp. 869 – 873 . Berlin : Springer .
- Kanerva , P. Fully distributed representation . Proceedings of the Real World Computing Symposium , pp. 358 – 365 .
- Kanerva , P. 2009 . Hyperdimensional computing: An introduction to computing in distributed representation with high-dimensional random vectors . Cognitive Computation , 1 ( 2 ) : 139 – 159 . (doi:10.1007/s12559-009-9009-8)
- Kohonen , T. 1990 . The self-organizing map . Proceedings of the IEEE , 78 : 1464 – 1480 . (doi:10.1109/5.58325)
- Levy , S. D. and Gayler , R. W. Vector symbolic architectures: A new building material for artificial general intelligence . Proceedings of the first conference on artificial general intelligence . Edited by: Wang , P. , Goertzel , B. and Franklin , S. Amsterdam : IOS Press .
- Monner , D. and Reggia , J. A. 2012a . Neural architectures for learning to answer questions . Biologically Inspired Cognitive Architectures , 2 : 37 – 53 . (doi:10.1016/j.bica.2012.06.002)
- Monner , D. and Reggia , J. A. 2012b . A generalized LSTM-like training algorithm for second-order recurrent neural networks . Neural Networks , 25 : 70 – 83 . (doi:10.1016/j.neunet.2011.07.003)
- Neumann , J. 2002 . Learning the systematic transformation of holographic reduced representations . Cognitive Systems Research , 3 : 227 – 235 . (doi:10.1016/S1389-0417(01)00059-6)
- Plate , T. A. 1994 . Distributed representations and nested compositional structure , Toronto : University of Toronto . (PhD Dissertation).
- Plate , T. A. 1995 . Holographic reduced representations . IEEE Transactions on Neural Networks , 6 ( 3 ) : 623 – 641 . (doi:10.1109/72.377968)
- Plate , T. A. 1997 . “ A common framework for distributed representation schemes for compositional structure ” . In Connectionist systems for knowledge representation and deduction , Edited by: Maire , F. , Hayward , R. and Diederich , J. 15 – 34 . Brisbane , AU : Queensland University of Technology .
- Smolensky , P. 1990 . Tensor product variable binding and the representation of symbolic structures in connectionist systems . Artificial Intelligence , 46 : 159 – 216 . (doi:10.1016/0004-3702(90)90007-M)
- St. John , M. F. and McClelland , J. L. 1990 . Learning and applying contextual constraints in sentence comprehension . Artificial Intelligence , 46 ( 1–2 ) : 217 – 257 . (doi:10.1016/0004-3702(90)90008-N)
- Weems , S. A. and Reggia , J. A. 2006 . Simulating single word processing in the classic aphasia syndromes based on the Wernicke–Lichtheim–Geschwind theory . Brain and Language , 98 ( 3 ) : 291 – 309 . (doi:10.1016/j.bandl.2006.06.001)
- Werbos , P. J. 1990 . Backpropagation through time: What it does and how to do it . Proceedings of the IEEE , 78 ( 10 ) : 1550 – 1560 . (doi:10.1109/5.58337)
- Williams , R. J. and Zipser , D. 1989 . A learning algorithm for continually running fully recurrent neural networks . Neural Computation , 1 ( 2 ) : 270 – 280 . (doi:10.1162/neco.1989.1.2.270)
- Xie , X. and Seung , H. S. 2003 . Equivalence of backpropagation and contrastive Hebbian learning in a layered network . Neural Computation , 15 ( 2 ) : 441 – 454 . (doi:10.1162/089976603762552988)