
Abstract
Solving a finite Markov decision process using techniques from dynamic programming such as value or policy iteration require a complete model of the environmental dynamics. The distribution of rewards, transition probabilities, states and actions all need to be fully observable, discrete and complete. For many problem domains, a complete model containing a full representation of the environmental dynamics may not be readily available. Bayesian reinforcement learning (RL)\ is a technique devised to make better use of the information observed through learning than simply computing Q-functions. However, this approach can often require extensive experience in order to build up an accurate representation of the true values. To address this issue, this paper proposes a method for parallelising a Bayesian RL technique aimed at reducing the time it takes to approximate the missing model. We demonstrate the technique on learning next state transition probabilities without prior knowledge. The approach is general enough for approximating any probabilistically driven component of the model. The solution involves multiple learning agents learning in parallel on the same task. Agents share probability density estimates amongst each other in an effort to speed up convergence to the true values.
Introduction
The solution of a Markov decision process (MDP) using methods from dynamic programming (DP) requires a complete and fully observable environmental model. When a complete model is available, i.e. the set of states, actions, transition probabilities and rewards are known, then the process reduces to a planning problem and can be solved using DP methods such as policy or value iteration. However, often in the real world, complete models governing the next state probabilities and distribution of rewards are not known or readily available. Reinforcement learning (RL) (Kaelbling, Littman, & Moore Citation1996) is a technique which is effective at solving these types of problems. The technique involves observing responses to actions by operating either directly within the environment or offline via a simulator. By calculating Maximum likelihood estimates based on past returns observed, the technique can achieve optimal or near optimal solutions in a wide variety of problems.
RL methods can broadly be defined by two categories, model-based RL and model-free RL. Model-free learners attempt to approximate the control policy through direct environmental interactions and averaging rewards through successive iterations of the learning task. Through knowledge exploitation, e.g. by greedily choosing actions which maximise the average or discounted returns achievable from the current state, a good control policy mapping actions to states can be discovered. However, the purely greedy policy approach proves to be sub-optimal if there is any uncertainty in the reward structure (Strens Citation2000) with a high likelihood of convergence to a local minimum. The conventional approach to mitigating against this problem is to introduce a small probability of exploration each time, i.e. select a non-greedy action every once in a while. Techniques from temporal difference learning have predominated this category, with algorithms such as Q-learning, SARSA and TD(λ) all prevalent in the area. However, one of the frequent criticisms of these techniques is that they do not exploit the environmental observations to their full potential (Dutreilh, Rivierre, Moreau, Malenfant, & Truck Citation2010), as they focus solely on approximating Q-function estimates. An alternative approach to model-free methods is to retain a notion of uncertainty in the model parameters and make decisions according to hypotheses over the true model parameters as opposed to just averaging returns from actions. This is known as model-based RL and is theoretically as justifiable a technique as model-free learning. Bayesian RL is a model-based RL approach proposed by Strens (Citation2000) which combines Bayesian inference and RL to compute the posterior probability over the model parameters and integrate observations within this framework.
Typically large RL tasks suffer from curse of dimensionality problems, where the state space grows exponentially with each additional state variable added. Many techniques have been proposed aiming at addressing this problem but particular emphasis has been focussed on function approximation methods (Baird 1995, Melo, Meyn, & Ribeiro 2008, Sutton, McAllester, Singh, &Mansour 1999). Function approximation techniques reduce the problem space by generalising over states and actions not yet visited based on their proximity to ones that have. The learner does not have to directly experience every state in order to learn a policy. These methods greatly enhance the range of domains that RL can realistically be deployed, particularly for large real-world problems.
The increase in availability of parallel computing resources through cloud and utility computing paradigms has facilitated an alternative approach to solving for large state and actions spaces. Known as parallel learning methods (Kretchmar 2002), these approaches can potentially offer effective solutions when dealing with large agent learning tasks (Chu et al., Citation2007). To date, a number of approaches have been developed for parallelising learning algorithms including stochastic gradient descent (Zinkevich, Weimer, Smola, & Li Citation2010), SARSA (Grounds &Kudenko 2008) and the DP techniques, value iteration and policy iteration (Chu et al., Citation2007). Within this domain, two main approaches towards the parallelisation of learning techniques have been predominated thus far. The first approach involves de-constructing the learning task into subtasks, with each agent learning on a specific part of the problem (Littman 1994). The second approach involves agents learning on the same task and sharing their learning experiences with one another (Kretchmar 2002).
This paper focusses on the second approach where agents learn in parallel on the same task. We propose a parallel Bayesian RL approach in which agent learners share estimates of probability density functions with one another in an effort to speedup the approximation of the true model parameters. In this scenario, aspects of the model are missing and through sharing their experiences the agents build up an approximation of the missing parts. However, in order to correctly approximate this, large amounts of environmental experience is required. By parallelising the model learning process, the length of time taken to approximate the model is reduced substantially. To facilitate information sharing whilst learning on the specified task, we use the Kullback–Leibler divergence (KLD) metric to calculate the relative distance between a learners own estimates and that of a global representation. Individual agents compare their estimates with the global estimate and only share their experience if theirs deviates from the global estimate, above a pre-determined threshold. The approach is highly scalable, given that the amount of information shared amongst the agents reduces over time as a function of the distance between its distribution and that of the global estimate. This paper demonstrates this technique by learning transition probabilities estimates through Bayesian model updates with no prior knowledge. The approach is also general enough to approximate other probabilistic components of the model.
The rest of this paper is structured as follows: Related research provides an overview of relevant work in this field. MDPs and Bayesian learning details the theory of MDPs, and outlines Bayesian inference and its application to RL. Learning in parallel outlines our parallel learning approach to RL. Experimental results empirically examines the performance of the approach, leading finally to Conclusions.
2. Related research
Previous work by Kretchmar (2002) demonstrated the convergence speedups made possible by applying a parallel RL approach to action value estimations. He demonstrated this empirically using multi-armed bandit tasks. In this work, the agents share action-value estimates for the different arms while operating on the same bandit task. Each agent has a unique learning experience due to the stochastic nature of the reward distribution. Learning in parallel, the agents share information amongst each other and update their knowledge based on their own observations and the global observation. The results clearly demonstrate that the convergence time leading to the discovery of optimal actions is reduced as the number of agents is increased.
Grounds and Kudenko (2008) developed an approach for solving a single-agent learning task using parallel hardware. The algorithm focusses on sharing value function estimates represented by linear function approximators. Using the Message Passing Interface, agents asynchronously transmit messages containing their learned weight values over the previous time period. This paper demonstrated that parallel computing resources applied to a single learning task reduced the time taken to compute good policies over a range of problem domains.
Kushida, Takahashi, Ueda, and Miyahara (2006) published a comparative study of three parallel implementation models for RL. Two of them utilise Q-learning and one utilises fuzzy Q-learning. Their results compared each algorithms performance against one another and showed an improvement in convergence over the course of the experiments.
Building upon the successes with machine learning and data mining, Li and Schuurmans (Citation2012) designed a number of parallel learning algorithms which utilise the MapReduce paradigm and execute in parallel. They presented solutions for both classical DP methods and also for parallelising temporal difference and gradient temporal difference methods.
To the best of our knowledge, this is the first attempt aimed at parallelising a Bayesian RL technique. Previous approaches have focussed on sharing value estimates or linear function approximation representations and combining the results to learn better policies in a shorter time period. One of the benefits of Bayesian RL is that it naturally balances exploration and exploitation, as it considers the effect that each action will have on both its knowledge and the returns achievable. As the distance between the two distributions (learned and true) begin to converge the KLD drops to 0, reducing in tandem the information shared between learners. This limits the quantity of information passed between learners, ensuring that only required information, i.e. where the divergence is great, is transmitted. This paper demonstrates that through learning in parallel, superior approximations on the hidden parameters can be discovered when compared to a single-agent case. Combining this with an appropriate sampling method leads to the discovery of better policies.
3. MDPs and Bayesian learning
3.1 Markov decision processes
MDPs are a particular mathematical framework suited to modelling decision-making under uncertainty. An MDP can typically be represented as a four tuple consisting of states, actions, transition probabilities and rewards.
S, represents the environmental state space;
A, represents the total action space;
p(.|s, a), defines a probability distribution governing state transitions
;
q(.|s, a), defines a probability distribution governing the rewards received
S the set of all possible states represents the agent's observable world. For many problems, the agent learning experience is broken up into discrete time periods. At the end of each time period t, the agent occupies state st∈S. The agent chooses an action , where A(st) is the set of all possible actions within state st. The execution of the chosen action, results in a state transition to st+1 and an immediate numerical reward R(st, at). The state transition probability
governs the likelihood that the agent will transition to state st+1 as a result of choosing at in st. The numerical reward received upon the arrival at the next state is governed by
and is indicative as to the benefit of choosing at whilst in st.
The solution of a MDP results in the output of a policy π, denoting a mapping from states to actions, guiding the agent's decisions over the entire learning period.
As stated previously in the specific case where a complete environmental model is known, i.e. (S, A, p, q) are fully observable, the problem reduces to a planning problem Nau, Ghallab, &Traverso (2004) and can be solved using traditional DP techniques such as value iteration. However, if there is no complete model available, then one must either attempt to approximate the missing model (model-based RL) or directly estimate the value function or policy (model-free RL). Model-based techniques involve the usage of statistical techniques in order to approximate the missing model Grzes & Kudenko (2009). In this paper, we adopt a model-based learning approach known as Bayesian model learning which attempts to approximate the missing model.
3.2 Bayesian RL
Bayes theorem is a mathematical framework which allows for the integration of ones observations into ones beliefs. The posterior probability P′(X=x | e), denoting the probability that a random variable X has a value equal to x given experience e can be computed via
Bayesian RL algorithms combine Bayesian inference (Bayes rule) with RL to generate a model-based RL solution. Model-based reinforcement learners can approximate the underlying missing model, whilst interacting directly with that environment, choosing actions, etc. By incorporating prior knowledge in this manner, the learner can avoid the costly exercise of repeating steps in the environment (Dearden, Friedman, & Andre 1999).
Strens (Citation2000) describes a Bayesian RL approach for representing the MDP model parameters as a posterior distribution strictly for the probabilistic model components, the transition and reward distributions. Using a hierarchal version of the Dirichlet formalism proposed by Friedman andSinger (1999) as the prior probability, Strens applies Bayesian inference to compute posterior distributions over the parameters in an iterative manner. By limiting the sampling of the posterior distribution to a sample size of 1 each time, Strens generates hypotheses in an unbiased manner. In comparison with an action selection policy such as ε-greedy, this approach is a much more a natural way of moving from a purely exploratory policy to a more exploitative one as the posterior probabilities begin to converge to the true values. Bayesian methods can optimally trade-off exploration and exploitation (Pourpart, Vlassis, Hoey, & Regan 2006) offering an advantage over model-free learning methods such as Q-learning (Watkins Citation1989).
In a real-world problem, different aspects of the model may be hidden from the learning agent, these can range from a partial or hidden state space, to transition probabilities or the distribution of rewards. Partially observable Markov decision processes (POMDPs) are a particular framework for modelling environments where one only has a partial or limited view of the state space. POMDPs are solved by maintaining a distribution of belief states, a multinomial distribution over a collection of real-world states. Through observations, the learner adjusts its beliefs accordingly and computes the likelihood of being in one particular state over another. A finite POMDP will only have a finite number of belief states. Since the process is Markovian b′, the next belief state can easily be determined as a function of the previous belief state b, the action a and the observation o, similar to how next states s′ are determined in a standard MDP (T(s, a, s′)). Bellmans equation can be modified to incorporate the belief structure over the state space and is given as
The approach to updating the multinomial distribution governing the transition function is similar to what was proposed previously by Spiegelhalter, Dawid, Lauritzen, & Cowell (Citation1993) and further extended by Doshi, Goodwin, Akkiraju, and Verma (Citation2005). It uses a modified Bayes rule, where all that is required to compute the posterior probability is an initial prior probability and subsequent environmental experience. The approach involves maintaining an experience counter Expc for each state variable. To explain how the probabilities are calculated we focus on one aspect of the missing MDP model, the transition probabilities T. Each time the RL agent chooses an action a within state s and observes the next state s′, the experience associated with the transition is incremented by 1. Knowledge is accumulated iteratively over time for each action selected within a state. Through observing the responses, the agent builds up a model of the underlying dynamics. Equations (3) and (4) define the update rules for approximating the transition probabilities from experience.1
4. Learning in parallel
Our approach to learning in parallel involves agents sharing estimates of probability densities over time in order to speedup convergence to the true transition probabilities. The agents attempt to approximate the transition probabilities independently of one another. The approach only works when simulated offline or when guarantees preventing the agents from affecting each others experience are upheld. In other words, the transitions between states cannot be affected or interfered with, by the decisions of the other agents learning in parallel. Each agent maintains a local posterior probability estimate P′ and has access to a global estimate G representing the collective knowledge of all other learning agents. This allows the learners to separate their own personal experience, from that of all others.
In order to facilitate learning in parallel the learners need some measures of the relative difference between their estimate of a given model parameter and the global estimate. The KLD, sometimes referred to as information gain or relative entropy is a technique capable of measuring the distance between two probability distributions. Given two probability distributions P and Q, the KLD is given by
RL maintains action value estimates of states and actions Q(s, a) observed. Q(s, a) for the MDP model is specified by

Algorithm 1 depicts the steps involved in our parallel Bayesian RL approach. First, the prior probability P is defined as equi-probable across all possible next states. This is equivalent to assigning probabilities according to a Dirichlet distribution, which has previously been demonstrated viable as an incremental parametric posterior for multinomial probabilities (Friedmanand Singer 1999). The global estimate G is also initialised as equi-probable. P forms the initial prior for the Bayesian update rules defined in Equations (3) and (4). The communications arrays commsin and commsout are set to ∅.
We repeat the process for each time step of the learning episode. At the end of each time step, the learning agent occupies a state s and chooses an action a according to its selection strategy. With Bayesian RL, determining the appropriate action to select within each state requires the generation of a hypothesis each time. To generate hypotheses over the posterior distribution, we employ a simple unbiased sampling method based on the approach defined by Strens (Citation2000). To ensure a natural balance between exploration and exploitation, we obtain a sample of size 1 over the posterior distribution. This ensures that all actions will be selected some of the time, particularly in the beginning and will slowly reduce as the underlying model parameters are revealed. Producing a sample requires mapping the multinomial posterior probability to a Cumulative Distribution Function (CDF) via numerical integration and generating a random number from the corresponding CDF.
The learner receives a scalar reward r upon execution of the action and transitions to the next state s′ with an unknown probability. The agent, observing the next state, computes the posterior probability using Equations (3) and (4) in light of the new experience.
A single learner computes the global posterior from all the other learners by combining their experiences to generate a combined posterior T which becomes the transition function estimate to update Q(s, a), Equation (6). It is important that the learner always maintains its own separate distribution P′ and experience counter P′Expc′ to allow for more accurate repeated integration of the vector of posterior probabilities between learners. This can be illustrated by means of a simple example; assume that a single learner has observed based on two transitions to state s upon selecting action a. The combined experience of all the other learners stands at
based on six transitions from s to s′ when selecting a. To integrate the probabilities, we weight them according to the experience, resulting in the integrated combined estimate for
. Thus, T is now based on eight separate experiences and is a much better estimate of the true transition function. However, whilst it is useful to compute value function estimates using the experience of all learners, it is not useful to assign T as the next prior and Expc′ to 8. The reason for this is that estimates will continue to accumulate indefinitely as the learners share information even though this could be based on only a small number of actual experiences. This will lead to large inaccuracies in T and reduce the efficacy of the approach. By maintaining separate experience counters for each learner's own experience, we can mitigate against this problem and ensure an effective integration solution.
The KLD between T and G gives the learner a measure of the distance between the two distributions. If this distance is greater than a pre-determined threshold θ (a very small number), then it adds P′ to the outgoing communications array commsout to be shared with the other learners. This information can then be incorporated by the other learning agents to improve their own estimates. Finally, all information received from other agents is accessed via the commsin array and during each learning step, the agent integrates this information into the global estimate value.
5. Experimental results
To demonstrate the effectiveness of our parallel learning method, we validate our approach using a stochastic GridWorld example (Sutton & Barto Citation1998) and a virtual resource allocation problem supporting both cost and quality constraints. The focus is to reduce convergence time, improve approximations of the underlying model and ultimately discover better policies. In the stochastic GridWorld problem, the transition probabilities belong to a discrete distribution. However, in the resource allocation task, the underlying model has a higher degree of complexity where the transition probabilities are affected by a number of variables such as performance/user requests and cannot be easily inferred. In addition, we introduce model changes at specific time instances causing shifts in the transition probabilities and analyse the effects on learning.
5.1 Stochastic GridWorld
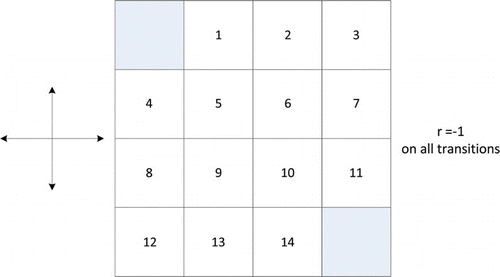
The Stochastic GridWorld pictured in consists of a fixed number of discrete environmental states represented by the cells of the grid. In each state, the learner can choose from a set of four possible actions (up, down, left, right). Each chosen action has a probability of 0.6 moving the learner one step in that direction and a probability of 0.2 moving the learner at right angles to the chosen direction. The reward on each transition is 0 and the learner can only occupy one position on the grid at any moment in time. An action that takes the learner off the grid leaves its state unchanged but incurs a negative reward of −1. A number of special states are dispersed randomly throughout the grid, the number of which depends on the overall size of the GridWorld. Once the agent enters a special state, it is deterministically transported to a corresponding state somewhere else on the grid and receives a large numerical reward. The learner must choose actions repeatedly in order to maximise overall return. The GridWorld we use for our experiments is a 5×5 grid, 25 possible states with two special states resulting in a reward of 10 and 5 if visited.
Fig. 1. Stochastic GridWorld.
5.1.1 Analysis of selection strategies
Every RL algorithm has an action selection strategy denoting the action to choose whilst in a particular state. This is known as its policy and is critical as to the agents’ performance within the system. A wide variety of action selection strategies for RL have been devised but for the purpose of our results, we focus on three of them, including the unbiased sampling approach proposed by Strens (Citation2000).
ε-greedy – Choose the greedy (best) action the majority of the time, but with a small fixed probability of ε choose a non-greedy random exploratory action. This ensures that a fixed quotient of exploratory actions are always executed, preventing convergence to a local minimum.
Softmax selection – Actions are selected as a graded function according to their values, thus the better the action values, the more likely they are to be chosen. Gibbs or Boltzmann distributions are commonly used to choose actions based on the action value estimates (Sutton & Barto Citation1998).
Unbiased sampling – Generates unbiased samples from the posterior distribution of the model parameters. It then chooses actions based on these samples, as learning progresses the approach converges towards the greedy strategy (Strens Citation2000).
These selection strategies possess advantages and disadvantages depending on a number of factors such as the specific problem, the information available and whether or not we are learning online or offline (via simulation). The question we address is, in a parallel learning context how do these strategies compare in terms of performance.
(a) plots the KLD between the combined (global) transition probability distribution of parallel learners against the true transition probabilities, over 400 trials of learning. The action selection strategy is an ε-greedy policy where ε is fixed at 0.15 and the number of learners is varied from a single learning agent up to ten agents. Clearly as additional learners are added, the distance between the learned transition function and the true function reduces. Interestingly from (a) we also see diminishing returns as the number of learners increases. The improvement from 1 to 2 learners is much larger than the improvement from 5 learners to 10. Thus, a threshold exists between the computational overhead incurred and the improvement arising from additional learners, which limits the number of learners it is practical to have within the system.
Fig. 2. The effects of model changes on the action selection strategies for multiple agents learning in parallel: (a) ε-greedy;=0.15, (b) softmax selection, and (c) unbiased sampling.
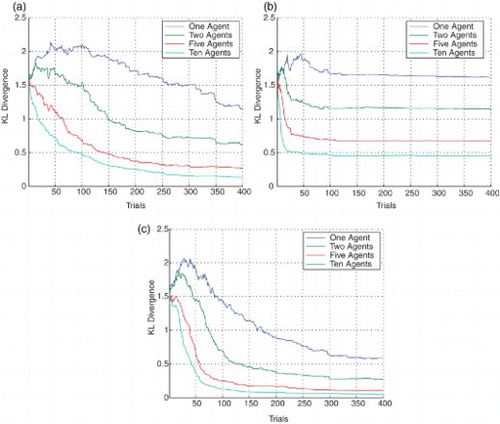
(b) plots the KLD between the transition functions approximated by increasing numbers of agent learners and the true transition probabilities. The learners employ the action selection strategy softmax which chooses actions according to Equation (7).
Softmax selection chooses non-greedy actions proportionately to their value estimates. This is in contrast to ε-greedy which is equally likely to choose the worst action as the next best action. Thus as learning progresses, softmax selection focusses on a smaller subset of the action space than ε-greedy. Not choosing the worst actions some of the time reduces the knowledge of the model parameters, which eventually results in a higher KLD divergence from the true model parameters. Interestingly, the performance gain from 2 learners to 5 does not diminish as rapidly as it does with the ε-greedy strategy ((a)). However, it does not achieve the same proximity to the true transition functions as that of the ε-greedy strategy. It is clear that the softmax selection strategy achieves a greater improvement from parallel learning overall, but does not approximate the model as closely as the ε-greedy policy.
The third sampling approach we examine is the unbiased sampling solution proposed by Strens(Citation2000). (c) plots the KLD between the learners approximation of the model and the actual true values. Unbiased sampling ensures a greater balance between exploration and exploitation, as it considers the effect each action will have on its knowledge and the cumulative discounted reward. It achieves the closest approximation of the true model and also generates the greatest cumulative reward when compared with the other selection strategies. Unbiased sampling does not achieve the same level of improvement as a result of parallel learning, when compared with softmax selection. This is because the single-agent learner employing unbiased sampling has already achieved a very good approximation of the transition probabilities, the equivalent of five agents learning with softmax in parallel. Notwithstanding all of this, (c) still demonstrates significant improvements over the single-agent learner as additional learners are added to the system.
(a) compares the selection strategies for five agents learning in parallel over 400 trials. We alter the ε-greedy strategy by varying the ε parameter which controls the selection of non-greedy actions from 5% to 25%, where the lower the value of ε the more greedy the strategy becomes. Determining an optimal setting for ε requires some domain knowledge and some degree of experimentation. This is one of disadvantages with this type of selection strategy. The best performing strategy for 5 agents learning in parallel is unbiased sampling, achieving a KLD value of 1.8 after only 100 trials of learning and overall achieving a much lower KLD value than the nearest ε-greedy strategy (). However, with RL the goal is also to achieve large amounts of discounted reward over the course of interaction with the environment.
Fig. 3. A high level comparison detailing the KLD between the distributions (learned and true) and the Q-values for agent learners in parallel: (a) comparison of selection strategies for five agent learners and (b) average Q values for five agent learners with varying selection strategies.
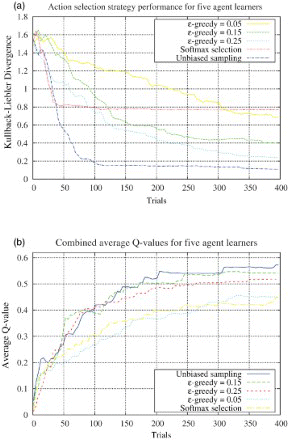
(b) compares the average Q-values over 400 trials for each strategy, again with 5 agents learning in parallel. The unbiased sampling technique outperforms the other strategies as it naturally exploits the closest approximation of the underlying model to achieve a high value policy. It is interesting to note that the ε-greedy policy with has a higher average Q-value than the
strategy. Although as can be seen from (a), the
strategy achieves a closer approximation of the underlying model, it does not exploit this knowledge to good effect and is outperformed by the more exploitative
strategy. Determining the optimal setting for ε would require extensive sensitivity analysis over the entire range of parameter settings. However, this work is not concerned with determining the optimal setting of this parameter, but instead the improvements that are achievable through parallel methods utilising these strategies as a whole, which we have demonstrated empirically.
5.1.2 The effects of underlying model changes
This section investigates the parallel learning performance of the various action selection strategies, when underlying model parameters are non-stationary and shift periodically. This type of scenario would frequently occur in a real- world setting, such as in application deployments where the addition of a software patch, an operating system update or variance in user request characteristics could lead to model changes. We simulate it in the Stochastic GridWorld by varying the transition function over all states and actions.
The model is altered at fixed points over the entire learning episode. The initial values of the transition probabilities are set to having a 90% chance of moving in the direction of your choice and 5% chance of moving at right angles to that choice. For every 100 trials, the probability of moving at right angles is increased by 5% for each direction. Thus, after 100 trials of learning choosing action up will have an 80% chance of moving you up, a 10% chance of moving you left and a 10% chance of moving you right. This continues for every 100 trials for a total of 300 trials at which point it stops and remains at that level for further 300 trials.
This experiment examines the vulnerability of selection strategies to fundamental shifts and changes in the underlying model parameters. Some strategies reduce the number of random actions as learning begins to converge, choosing instead to exploit their knowledge once they have a decent grasp of the workings of the system. However, a sudden shift in the model parameters renders this strategy sub-optimal as it will not pursue any exploratory actions to enable it to learn about this change in the model. From a parallel learning perspective, we wish to study the effects that this technique has on the chosen selection strategies.
(a)–(c) details the performance of the ε-greedy strategy with ε varying from 0.05 to 0.25 and model changes for every 100 trials until the last change at trial 300. Clearly, the strategy with the greatest degree of exploration () outperforms the others as it still pursues non-greedy actions 25% of the time, helping it to cope more easily with changes in the model. Again even in this circumstance, executing multiple instances in parallel and updating using our method realises substantial improvements over the single learner case. (d) analyses how the unbiased sampling method performs in an environment where the underlying model parameters are non-stationary. It again demonstrates convergence speedups with the KLD between the true probabilities and learned approximations reducing substantially as learning progresses.
Fig. 4. The effects of model changes on the action selection strategies for multiple agents learning in parallel: (a) ε-greedy selection (ε=0.05), (b) ε-greedy selection (ε=0.15), (c) ε-greedy selection (ε=0.25), (d) unbiased sampling, and (e) comparison of the performance of the selection strategies for 10 agents in parallel.
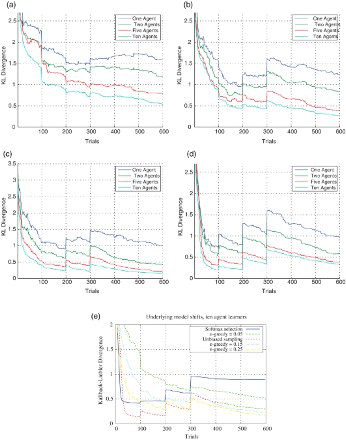
All the experiments show that some degree of improvement upon model change but (e) compares their performance over 600 trials with 10 agents learning in parallel. This time the best-performing selection strategy with 10 agents sharing information is the ε-greedy=0.25 strategy followed by the ε-greedy=0.15 and unbiased sampling in third. The two worst performing ε-greedy=0.05 and softmax selection represent the least exploratory of the approaches and do not perform as well as they do not engage in sufficient exploratory behaviours to discover the new transition function.
5.2 Virtual machine allocation
Our second learning task examines performance in a real-world setting using data traces gathered from virtual servers in the cloud. The focus is on allocating resources to support application deployments, responding to variable user requests and performance. Multiple learners are deployed in parallel to decrease the time taken to learn good policies. The experiment uses real http response time data sets and an open loop queueing user request model to simulate a cloud resource allocation problem.
5.2.1 Data traces for simulations
To generate a realistic simulation for our real-world resource allocation problem, we utilise response time data provided to us from real cloud deployments by Cedexis. Cedexis are specialists in multi-cloud deployment strategies which are inferred through the analysis of real-time cloud performance data (bandwidth, response time, availability). Cedexis measures cloud performance from disparate geographical locations across multiple cloud providers observed from real end users. This enables their customers to get up to the minute performance measures of how particular clouds are performing to requests, localised to specific geographical locations and regions. Using this information, customers can then load balance and scale their applications to ensure the highest levels of service possible. Cedexis value their real-time data the most and are thus happy to open up their historical data to the research community for experimental and simulation purposes.
Customers of Cedexis agree to the placement of a script on a busy page in their website, i.e. http://www.bbc.co.uk. When users visit this page, the script is automatically downloaded and runs client side.2 The script contains a list of URLs pointing to applications hosted in different cloud regions. The client randomly chooses one or many URLs each time to measure the performance from the client to the cloud.
Each URL points to a location which contains one of two possible objects, a 50 byte object and a 100 kbyte object. Requests for the 50 byte object are executed twice in quick succession, this is useful as the difference between the response times can determine the delay from domain name server lookup or secure socket layer negotiation. Importantly, a dynamic application is used to service the requests and not a static object. This is to prevent caching and edge servicing via content delivery networks which will skew the results. In this manner, actual server response times can be observed from a variety of locations.
The http response time parameter measures the length of time it takes the server to respond to the request. It is a close approximation of server round trip time from the client to the virtual server. This technique offers a more holistic view of response time performance from the user's perspective. For the purposes of our simulations, we sample from a much smaller data set consisting of 350k+ data points recorded over a single day (11 March 2013) focussing on a single cloud provider, Amazon EC2. (c) details http response time over a single day across six separate regions of EC2. We split up the response times observed into buckets of 0−100 ms, 100−200, etc. meaning a response of 50 ms will be placed in the first bucket and so on. We then count the number of tests observed within each bucket and visualise them as a histogram. The histogram shows that the best-performing regions (0−100) are Europe (Ireland) followed by US East (Northern Virginia), with Asia Pacific (Tokyo) in third.
Fig. 5. Data traces provided by Cedexis measuring application response time, total requests per country and total requests per region all over a single day: (a) number of requests per country, (b) number of requests satisfied per region, and (c) application response time performance histogram by region (Amazon EC2).
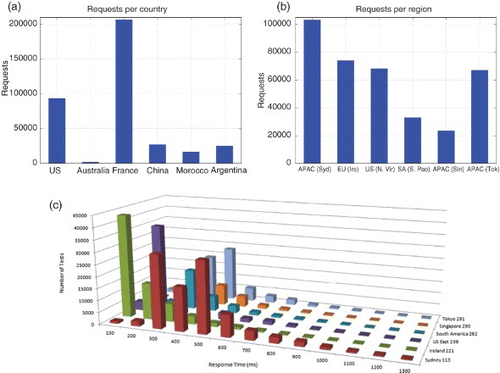
(a) shows the number of requests executed on a per country basis. Currently, Cedexis's biggest customers are large French media sites which result in a disproportionate number of requests from the France, 206, 702 in total. Requests serviced by EU (Ireland) EC2 region originating from France would likely experience reduced latency due to lower physical distances from client to provider. Likewise for the US region (93, 701), the portion of requests handled by US East (Northern Virginia) would have also had reduced distances to travel when compared with a region such as Asia Pacific (Sydney). As Cedexis gain greater presence worldwide, more holistic results from a global perspective will be possible.
(b) details the number of requests handled per region, interestingly the Asia Pacific (Sydney) region handled the most requests followed by EU (Ireland) and the US East (Northern Virginia). It is important to understand that the apparent poor performance observed by the Asia Pacific (Sydney) region is in part due to the physical distances which must be travelled as opposed to the actual IaaS cloud suffering performance difficulties itself. It is obviously not a good idea to host your applications/services in Australia if the majority of your requests originate in Europe and the Americas.
To use this data for the purposes of our simulations, we sample each time using a simple random sampling method with replacement. The distribution of the data allows us to model response times according to region and locale, generating performance models most suited given our simulation configuration each time. This allows for a much more realistic and accurate modelling of the actual variations observed from the end user offering a more detailed simulation model than ever before.
5.2.2 MDP formalism
To facilitate agent learning for a cloud resource allocation problem, we define a simple-state action space formalism. The state space S consists of two state variables .
q is the average http response time for the service over the period under consideration. This is indicative as to the quality of the service and is defined in the service level agreement (SLA).
v is the total number of Virtual Machines (VMs) currently allocated to the application.
The learners action set A is to an n number of (VMs) each time. Rewards are determined based on a defined SLA which is directly related to performance. The overall reward allocated per time step is given by the following equations:
Cr is the cost of the resource, this is variable depending on the type, specific configuration and region. Vi represents an individual virtual machine instance, with Va representing the specific virtual machine allocated, deallocated or maintained as a result of action a. H is the overall penalty applied as a result of violating the specified SLA. represents a defined penalty constant incurred through violation of the SLA. The SLA comprises a guaranteed level of service response time agreed between the service provider and consumer. The total reward R(s, a) for choosing action a, in s is the combination of the cost of execution and any associated penalties.
User requests are generated via an open-loop poisson process with an adjustable mean inter-arrival rate. The origin of the requests are restricted to the six countries detailed in (a). The application response time is proportionally sampled with replacement, as a function of the number of incoming requests and the number of (VMs) currently supporting the application. This value governs the number of user requests that can be handled prior to significant performance degradation. The application response time is split into 50 separate bins, similar to the histogram in (c). The maximum number of VMs allocated to the application at any given time is restricted to 10.
(a) plots the global KLD between ‘ground truth’ and the learned probability estimates over 1000 trials. The results are averaged over 10 runs with the learning agent numbers increasing from 2 to 10 agents. As the number of agents increases, there is a marked improvement in the distance between the true model parameters and the learned parameters.
Fig. 6. Performance of the parallel learning architecture, demonstrating improvements as additional learners are added: (a) Virtual resource allocation, unbiased sampling, multiple agent learners, learning in parallel. (b) A single run of unbiased sampling for 300 trials.
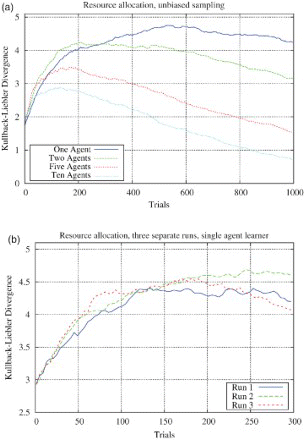
Due to the size and nature of this task, the learning challenge is much greater than the previous Stochastic Gridworld problem. (a) highlights the sizeable adjustments with respect to the approximation of the underlying transition function as the number of agents increase. Clearly, parallel learning has a significant impact for this type of real-world problem which presents a much more challenging and dynamic environment for the agent learner. As the model approximations improve so too do the policies derived from this information. This is a validation of our hypothesis that a parallel learning mechanism is capable of reducing policy times considerably as additional agents are added to the system.
(b) shows the KLD for three individual runs for a single agent attempting to approximate the true transition probabilities. The variation in learning experience can clearly be seen as each agent observes different responses to its actions and adjusts its estimates accordingly. This demonstrates that whilst the agents are learning on the same problem each agent's experience is unique and is what makes learning in parallel so effective.
6. Conclusions and future work
This paper presents an approach which successfully parallelises a Bayesian RL algorithm. The approach is based on learning agents sharing information with one another in an effort to approximate the true model parameters and learn good policies. This paper has shown empirically using a stochastic GridWorld example and a cloud resource allocation problem, that convergence speedups can be achieved through the described parallel learning approach. Although this paper details the approach by learning transition distributions, the approach is general enough to approximate any probabilistically driven component of the model.
Acknowledgements
The authors would like to gratefully acknowledge the continued support of Science Foundation Ireland. The authors also wish thank Marty Kagan & Cedexis for the use of their historical performance data for the purposes of this research.
References
- Baird, L. (1995, July 9–12). Residual algorithms: Reinforcement learning with function approximation. Proceedings of the 12th international conference on machine learning, Tahoe City, CA.
- Chu, C.-T., Kim, S. K., Lin, Y.-A., Yu, Y. Y., Bradski, G., Ng, A. Y., et al. (2007). Map-reduce for machine learning on multicore. In B. Schölkopf, J. C. Platt, & T. Hoffman (Eds.), Advances in neural information processing systems (pp. 281–288). Cambridge, MA: MIT Press.
- Doshi, P., Goodwin, R., Akkiraju R., & Verma, K. (2005). Dynamic workflow composition using Markov decision processes. International Journal of Web Services Research, 2, 1–17. doi: 10.4018/jwsr.2005010101
- Dearden, R., Friedman, N., & Andre, D. (1999, July). Model based Bayesian exploration. Proceedings of the fifteenth conference on uncertainty in artificial intelligence (pp. 150–159). Stockholm, Sweden.
- Dutreilh, X., Rivierre, N., Moreau, A., Malenfant, J., & Truck, I. (2010). From data center resource allocation to control theory and back. In S. S. Yau & L.-J. Zhang (Eds.), 2010 IEEE 3rd international conference on cloud computing (CLOUD) (pp. 410–417). Miami, FL: IEEE.
- Friedman, N., & Singer, Y. (1999). Efficient Bayesian parameter estimation in large discrete domains. In Advances in neural information processing systems 11: Proceedings of the 1998 conference, Vol. 11, p. 417, The MIT Press. Retrieved from http://books.google.co.in/books?id=bMuzXPzlkG0C&printsec=frontcover&source=gbs_ge_summary_r&cad=0#v=onepage&q&f=false
- Grounds, M., & Kudenko, D. (2008, May 12–16). Parallel reinforcement learning with linear function approximation. Adaptive agents and multi-agent systems III. Adaptation and multi-agent learning. Estoril, Portugal.
- Grounds, M., & Kudenko, D. (2009). Learning shaping rewards in model-based reinforcement learning. Proc. AAMAS 2009 workshop on adaptive learning agents, Budapest, Hungary.
- Kaelbling, L. P., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
- Kawaguchi, K., & Araya, M. (2013). A greedy approximation of Bayesian reinforcement learning with probably optimistic transition model. Proc. AAMAS 2013 workshop on adaptive learning agents, Saint Paul, Minnesota, USA.
- Kretchmar, R. M. (2002, July 14–18). Parallel reinforcement learning. The 6th world conference on systemics, cybernetics, and informatics, Orlando, FL.
- Kushida, M., Takahashi, K., Ueda, H., & Miyahara, T. (2006, December). A comparative study of parallel reinforcement learning methods with a PC cluster system. Proceedings of the IEEE/WIC/ACM international conference on intelligent agent technology, pp. 18–22, Hong Kong, China.
- Li, Y., & Schuurmans, D. (2012). MapReduce for parallel reinforcement learning. In S. Sanner & M. Hutter (Eds.), Recent advances in reinforcement learning (pp. 309–320). New York: Springer Berlin Heidelberg.
- Littman, M. L. (1994, July 10–13). Markov games as a framework for multi-agent reinforcement learning. Proceedings of the 11th international conference on machine learning, New Brunswick, NJ.
- Melo, F. S., Meyn, S. P., & Ribeiro, M. I. (2008, July 5–9). An analysis of reinforcement learning with function approximation. Proceedings of the 25th international conference on machine learning, Helsinki, Finland.
- Nau, D., Ghallab, M., & Traverso, P. (2004) Automated planning: Theory & practice. San Francisco, CA: Morgan Kaufmann.
- Poupart, P., Vlassis, N., Hoey, J., & Regan, K. (2006). An analytic solution to discrete Bayesian reinforcement learning. In W. W. Cohen & A. Moore (Eds.), Proceedings of the 23rd international conference on machine learning (pp. 697–704). New York, NY: ACM.
- Russell, S. J., Norvig, P., Canny, J. F., Malik, J. M., & Edwards, D. D. (1995). Artificial intelligence: A modern approach (Vol. 2). Englewood Cliffs, NJ: Prentice Hall.
- Spiegelhalter, D. J., Dawid, A. P., Lauritzen, S. L., & Cowell, R. G. (1993). Bayesian analysis in expert systems. Statistical Science, 8, 219–247. doi: 10.1214/ss/1177010888
- Strens, M. (2000). A Bayesian framework for reinforcement learning. ICML, (pp. 943–950). Stanford, CA.
- Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction (1st ed., Vol. 1). Cambridge, MA: Cambridge University Press.
- Sutton, R. S., McAllester, D. A., Singh, S. P., & Mansour, Y. (1999). Policy gradient methods for reinforcement learning with function approximation, In Advances in Neural Information Processing Systems, Denver, Colorado, USA, Vol. 99, pp. 1057–1063. Retrieved from http://webdocs.cs.ualberta.ca/sutton/papers/SMSM-NIPS99.pdf
- Watkins, C. (1989). Learning from delayed rewards. England: University of Cambridge.
- Zinkevich, M., Weimer, M., Smola, A., & Li, L. (2010). Parallelized stochastic gradient descent. Advances in neural information processing systems, (Vol. 23, pp. 2595–2603), Lake Tahoe, Nevada, USA.