
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this work we present a knowledge-based system equipped with a hybrid, cognitively inspired architecture for the representation of conceptual information. The proposed system aims at extending the classical representational and reasoning capabilities of the ontology-based frameworks towards the realm of the prototype theory. It is based on a hybrid knowledge base, composed of a classical symbolic component (grounded on a formal ontology) with a typicality based one (grounded on the conceptual spaces framework). The resulting system attempts to reconcile the heterogeneous approach to the concepts in Cognitive Science with the dual process theories of reasoning and rationality. The system has been experimentally assessed in a conceptual categorisation task where common sense linguistic descriptions were given in input, and the corresponding target concepts had to be identified. The results show that the proposed solution substantially extends the representational and reasoning ‘conceptual’ capabilities of standard ontology-based systems.
1. Introduction
Representing and reasoning on common sense concepts is still an open issue in the field of knowledge representation (KR) and, more specifically, in that of formal ontologies. In Cognitive Science evidences exist in favour of prototypical concepts, and typicality-based conceptual reasoning has been widely studied. Conversely, in the field of computational models of cognition, most contemporary concept-oriented KR systems, including formal ontologies, do not allow – for technical convenience – neither the representation of concepts in prototypical terms nor forms of approximate, non-monotonic, conceptual reasoning. In this paper we focus on the problem of concept representation in the field of formal ontologies. Following the approach proposed in CitationFrixione & Lieto (2014a) we introduce a conceptual architecture that, embedded in a larger knowledge-based system, aims at extending the representational and reasoning capabilities available to traditional ontology-based frameworks.
The study of concept representation concerns different research areas, such as Artificial Intelligence, Cognitive Science, Philosophy, etc. In the field of Cognitive Science, the early work of CitationRosch (1975), preceded by the philosophical analysis of CitationWittgenstein (1953), showed that ordinary concepts do not obey the classical theory (stating that concepts can be defined in terms of sets of necessary and sufficient conditions). Rather, they exhibit prototypical traits: e.g. some members of a category are considered better instances than other ones; more central instances share certain typical features – such as the ability of flying for birds – that, in general, cannot be thought of as necessary nor sufficient conditions. These results influenced pioneering KR research, where some efforts were invested in trying to take into account the suggestions coming from Cognitive Psychology: artificial systems were designed – e.g. frames (CitationMinsky, 1975) and semantic networks (CitationQuillian, 1968) – to represent and to conduct reasoning on concepts in ‘non-classical’, prototypical terms (CitationBrachman & Levesque, 1985).
However, these systems lacked in clear formal semantics, and were later sacrificed in favour of a class of formalisms stemmed from structured inheritance semantic networks: the first system in this line of research was KL-ONE (CitationBrachmann & Schmolze, 1985). These formalisms are known today as description logics (DLs) (CitationNardi & Brachman, 2003). In this setting, the representation of prototypical information (and therefore the possibility of performing non-monotonic reasoning) is not allowed,Footnote1 since the formalisms in this class are primarily intended for deductive, logical inference. Nowadays, DLs are largely adopted in diverse application areas, in particular within the area of ontology representation. For example, OWL and OWL 2 formalisms follow this tradition,Footnote2 which has been endorsed by the W3C for the development of the Semantic Web. However, under a historical perspective, the choice of preferring classical systems based on a well defined – Tarskian-like – semantics left unsolved the problem of representing concepts in prototypical terms. Although in the field of logic-oriented KR various fuzzy and non-monotonic extensions of DL formalisms have been designed to deal with some aspects of ‘non-classical’ concepts (CitationBonatti et al., 2006; CitationCalegari & Ciucci, 2007; CitationGiordano et al., 2013; CitationStraccia, 2011), nonetheless various theoretical and practical problems remain unsolved (CitationFrixione & Lieto, 2010).
As a possible way out, we follow the proposal presented in CitationFrixione & Lieto (2014a), that relies on two main cornerstones: the dual process theory of reasoning and rationality (CitationEvans & Frankish, 2009; CitationKahneman, 2011; CitationStanovich & West, 2000), and the heterogeneous approach to the concepts in Cognitive Science (CitationMachery, 2009). This paper has the following major elements of interest: (i) we provide the hybrid conceptual architecture envisioned in CitationFrixione & Lieto (2014a) with a working implementation; (ii) we show how the system implementing such architecture is able to perform a simple form of non-monotonic categorisation that is, vice versa, unfeasible by using only formal ontologies.
The paper is structured as follows: in Section 2 we illustrate the general architecture and the main features of the knowledge-based system. In Section 3 we provide the results of a twofold experimentation to assess the accuracy of the system in a categorisation task. Finally, we conclude by presenting the related work (Section 4) and by outlining future work (Section 5).
2. The system
In the following, (i) we first outline the design principles that drove the development of the system; (ii) we then provide an overview of the knowledge base architecture and of its components and features, based on the conceptual spaces (CSs) framework (CitationGärdenfors, 2000; CitationGärdenfors, 2014) and on formal ontologies (CitationGruber, 2009); (iii) we elaborate on the inference task, providing the detailed control strategy.
Two cornerstones inspiring the current proposal are the dual process theory and the heterogeneous approach to concepts in Cognitive Science. The theoretical framework known as dual process theory postulates the co-existence of two different types of cognitive systems (CitationEvans & Frankish, 2009; CitationKahneman, 2011; CitationStanovich & West, 2000). The systems of the first type (type 1) are phylogenetically older, unconscious, automatic, associative, parallel and fast. The systems of the second type (type 2) are more recent, conscious, sequential and slow, and featured by explicit rule following. We assume that each system type can be composed of many sub-systems and processes. According to the reasons presented in CitationFrixione & Lieto (2012); CitationFrixione & Lieto (2014a), the conceptual representation of our system relies on two major sorts of components, based on:
type 1 processes, to perform fast and approximate categorisation by taking advantage from prototypical information associated to concepts;
type 2 processes, involved in complex inference tasks and that do not take into account the representation of prototypical knowledge.
The two sorts of system processes are assumed to interact, since type 1 processes are executed first and their results are then refined by type 2 processes.
The second theoretical framework inspiring our system regards the heterogeneous approach to the concepts in Cognitive Science, according to which concepts do not constitute a unitary element from a representational point of view CitationMachery (2009). By following this approach, we assume that each concept represented in an artificial system can be composed of several bodies of knowledge, each one carrying a specific type of information.Footnote3
A system has been implemented to explore the hypothesis of the hybrid conceptual architecture. To test it, we have considered a basic inference task: given an input description in natural language, the system should be able to find, even for typicality-based description (that is, most of common sense descriptions), the corresponding concept category by combining ontological inference and typicality-based one. We chose this task as a challenging one. In fact, classical queries for concept retrieval based on lists of necessary and sufficient conditions are commonly handled by standard ontology-based systems, and in general by logic-oriented systems. Conversely, the answer to typicality-based queries – i.e. queries based on prototypical traits –, is almost never addressed by exploiting ontological inference.
2.1. Knowledge base architecture
Our system is equipped, then, with a hybrid conceptual architecture based on a classical component and on a typical one. Each component represents a specific conceptual body of knowledge together with the related reasoning procedures as in the dual process perspective. shows the general architecture of the hybrid conceptual representation.
Figure 1. Architecture of the knowledge base.
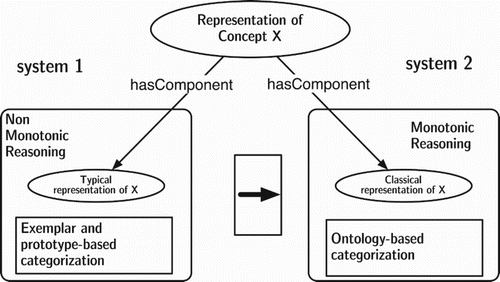
The ontological component is based on a classical representation grounded on a DL formalism, and it allows specifying the necessary and/or sufficient conditions for concept definition. For example, if we consider the concept water, the classical component will contain the information that water is exactly the chemical substance whose formula is H2O, i.e. the substance whose molecules have two hydrogen atoms with a covalent bond to the single oxygen atom. On the other hand, the prototypical facet of the concept will grasp its prototypical traits, such as the fact that water occurring in liquid state is usually a colourless, odourless and tasteless fluid.
The proposed architecture (and in particular its prototypical component) can be useful in tasks such as categorisation. For example, let us consider the question: In which conditions should we say that someone grasps the concept water? In most cases, when we categorise something as water, we do not use its classical representation as chemical substance. Rather, we make use of information that water is usually liquid, colourless and odourless.
The concept water is not exceptional from this point of view. Most of everyday or ‘common sense’ concepts behave in the same way. The problem is not different in the case of artificial systems: generally a system that has to categorise something as water cannot perform chemical analyses, and it must resort to prototypical evidence. The typicality-based categorisation is rooted in the constraints that concern agents with limited access to the relevant knowledge for a given task, and that try to adopt a heuristic approach to problem solving (CitationSimon & Newell, 1971).Footnote4
By adopting the ‘dual process’ notation, in our system the representational and reasoning functions are assigned to the system 1 (executing processes of type 1), and are associated to the CSs framework (CitationGärdenfors, 2000). Both from a modelling and from a reasoning point of view, system 1 is compliant with the traits of conceptual typicality. On the other hand, the representational and reasoning functions assigned to the system 2 (executing processes of type 2) are associated to a classical DL-based ontological representation.Footnote5 Differently from what proposed in CitationFrixione & Lieto (2014a), the access to the information stored and processed in both components is assumed to proceed from the system 1 to the system 2, as suggested by the central arrow in .
We now briefly introduce the representational frameworks upon which system 1 (henceforth ) and system 2 (henceforth
) have been designed.
2.1.1. Formalising CSs and distance metrics
As mentioned, the aspects related to the typical conceptual component are modelled through the CSs (CitationGärdenfors, 2000). CSs are an intermediate level between the symbolic and the sub-symbolic approaches to the knowledge representation relying on geometrical structures, encoded as a set of quality dimensions. In some cases, such dimensions can be directly related to perceptual mechanisms; examples of this kind are temperature, weight, brightness, pitch. In other cases, dimensions can be more abstract in nature. A geometrical (topological or metrical) structure is associated to each quality dimension. The chief idea is that KR can benefit from the geometrical structure of CSs: instances are represented as points in a space, and their similarity can be calculated in terms of their distance according to some suitable distance measure. In this setting, concepts correspond to regions, and regions with different geometrical properties correspond to different kinds of concepts. CSs are suitable to represent concepts in ‘typical’ terms, since the regions representing concepts can have soft boundaries. In many cases typicality effects can be represented in a straightforward way: for example, in the case of concepts, corresponding to convex regions of a CS, prototypes have a natural geometrical interpretation, in that they correspond to the geometrical centre of the region itself. So, ‘when natural properties are defined as convex regions of a CS, prototype effects are indeed to be expected’ (CitationGärdenfors, 2000, p. 9). Given a convex region, we can provide each point with a certain centrality degree, that can be interpreted as a measure of its typicality. Moreover, single exemplars correspond to single points in the space: this allows us to consider both the exemplar and the prototypical accounts of typicality (further details can be found in CitationFrixione & Lieto, 2013, p. 9).
The CS defines a metric space that can be used to compute the proximity of the input entities to prototypes. To compute the distance between two points p1, p2 we apply a distance metrics based on the combination of the Euclidean distance and the angular distance intervening between the points. Namely, we use Euclidean metrics to compute within-domain distance, while for dimensions from different domains we use the Manhattan distance metrics, as suggested in CitationGärdenfors (2000) and CitationAdams & Raubal (2009). Weights assigned to domain dimensions are affected by the context, too, so the resulting weighted Euclidean distance distE is computed as follows
where i varies over the n domain dimensions, k is the context, and wi is the weight associated to the i-th dimension.
The representation format adopted in CSs (e.g. for the concept whale) includes information such as:

that is, the WordNet identifier, the lemma of a given concept, information about its typical dimensions, such as colour (as the position of the instance on the three-dimensional axes of brightness, hue and saturation) and food.Footnote6 All concepts are mapped onto WordNet synsets: WordNet is a lexical resource whose nodes – the synsets – are sets of synonyms, connected through binary relations such as hyponymy/hypernymy and meronymy (CitationMiller, 1995).Footnote7
Each quality in a domain is associated to a range of possible values. To avoid that larger ranges affect too much the distance, we have introduced a damping factor to reduce this effect; also, the relative strength of each domain can be parametrised.
We represent points as vectors (with as many dimensions as required by the considered domain), whose components correspond to the point coordinates, so that a natural metrics to compute the similarity between them is cosine similarity. Cosine similarity is computed as the cosine of the angle between the considered vectors: two vectors with same orientation have a cosine similarity 1, while two orthogonal vectors have cosine similarity 0. The normalised version of cosine similarity (ˆcs), also accounting for the above weights wi and context k, is computed as
In the metric space being defined, the distance d between individuals ia, ib is computed with the Manhattan distance, enriched with information about context k that indicates the set of weights associated to each domain. Additionally, the relevance of domains with fewer dimensions (that would obtain overly high weights) is counterbalanced by a normalising factor (based on the work by CitationAdams & Raubal, 2009), so that such distance is computed as:
(1)
(1)
where K is the whole context, containing domain weights wj and contexts kj, and |Dj| is the number of dimensions in each domain.
In this setting, the distance between each two concepts can be computed as a function of the distance between two regions in a given domain (Formula (1)). Also, we can compute the distance between any two region prototypes, or the minimal distance between their individuals, or we can apply more sophisticated algorithms: in all cases, we have designed a metric space and procedures that allow characterising and comparing the concepts herein.
2.1.2. Ontology
On the other hand, the representation of the classical component is implemented through a formal ontology. As already pointed out, the standard ontological formalisms leave unsolved the problem of representing prototypical information. Furthermore, it is not possible to execute non-monotonic inference, since classical ontology-based reasoning mechanisms contemplate deductive processes. It is known, in fact, in literature (e.g. by referring to the foundational approach in DOLCE) how to model the fact that ‘the rose is red’, that is:
we refer to a given rose (rose# 1 in );
it has a certain colour, expressed via the inherence relation, qtc: this enables us to specify that
;
the particular colour of the rose# 1 has a particular redness at a certain time t: this is expressed via the quale, ql, as the relation:
Figure 2. Connecting concepts to qualities and quality regions in a foundational ontology (taken from CitationMasolo et al., 2003).
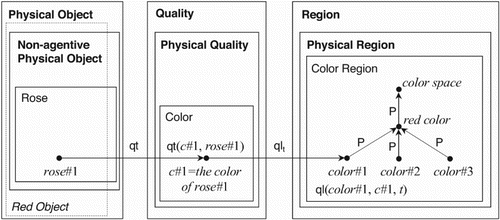
However, in this setting we cannot represent even simple prototypical information, such as ‘A typical rose is red’. This is due to the fact that being red is neither a necessary nor a sufficient condition for being a rose, and therefore it is not possible neither to represent and to automatically identify a prototypical rose (let us assume # roseP) nor to describe (and to learn from new cases) the typical features of the class of prototypical roses. Such aspect has, on the other hand, a natural interpretation by using the CSs framework.
2.2. Inference in the hybrid system
Categorisation (i.e. to classify a given data instance into a predefined set of categories) is one of the classical processes automatically performed both by symbolic and sub-symbolic artificial systems. In our system, the categorisation is based on a two-step process involving both the typical and the classical component of the conceptual representation. These components account for different types of categorisation: approximate or non-monotonic (performed on the CSs), and classical or monotonic (performed on the ontology). Different from classical ontological inference, in fact, categorisation in CSs proceeds from prototypical values. In turn, it is not necessary to specify prototypical values for all individuals in a class: prototypical values can be inherited or overwritten by class individuals, like in structured inheritance networks CitationBrachman & Levesque (2004, Chapter 10). One typical example is the case of birds that – by default – fly, except for special birds like penguins, that do not fly.
The whole categorisation process can be summarised as follows (Algorithm 1). The system takes in input a textual description d and produces in output a pair of categories , the output of
and
, respectively. In particular,
produces in output a list of results, sorted according to a similarity score assessing how similar the input is w.r.t. the available prototypes (Algorithm 1: line 1). All of these elements are then checked by
through the cycle at lines 2–14. If the
system classifies it as consistent with the ontology, then the classification succeeded and the category provided by
(and referred to as
) is returned along with
, the top scoring class returned by
(Algorithm 1: line 8). If
– the class computed by
– is a subclass of one of those identified by
(and referred to as
), both
and
are returned: thus, if
provides more specific output, we follow a specificity heuristics (Algorithm 1: line 11).

A pair of results is always returned, including both the output of and the output of
, thereby providing typically valid answers (through
) that are checked against a logically valid reasoning conducted on the ontological knowledge base (through
). In so doing, we follow the rationale that even though the
output can contain errors, it furnishes approximate answers that cannot be obtained by resorting only to classical ontological inference. On the other hand, the output of
is always returned with the rationale that it is safer,Footnote8 and potentially helpful in correcting the mistakes returned by the
process. If all results in
are inconsistent with those computed by
, a pair of classes is returned including
and the output of
having for actual parameters d and
, the meta class of all the classes in the ontological formalism (Algorithm 1: line 16).
3. Experimentation
We have designed a twofold experimentation on a categorisation task, where the system's results have been studied and compared to state-of-the-art search engines. In the first experiment we tested the system over a restricted domain, and we were mainly interested in assessing the control strategy illustrated in Section 2.2; in the second experiment we tested the system in a broader setting, and we were interested in assessing its robustness and the discriminative features of the component in a multi-domain context.
Two data sets, one composed of 27 ‘common-sense’ linguistic descriptions, and one composed of 56 linguistic descriptions were used, containing two lists of stimuli, including descriptions and their corresponding target categories, such as
The target T is the ‘prototypically correct’ category, and in the following it is referred to as the expected result.Footnote9 The set of stimuli was devised by a team of neuropsychologists and philosophers in the frame of a broader project, aimed at investigating the role of visual load in the concepts involved in inferential and referential tasks. Such input was used for querying the system as in a typicality-based question-answering task. In Information Retrieval such queries are known to belong to the class of ‘informational queries’, i.e. queries where the user intends to obtain information regarding a specific information need. Since it is characterised by uncertain and/or incomplete information, this class of queries is by far the most common and complex to interpret, if compared to queries where users can search for the URL of a given site (‘navigational queries’), or look for sites where some task can be performed, like buying music files (‘transactional queries’) (CitationJansen et al., 2008).
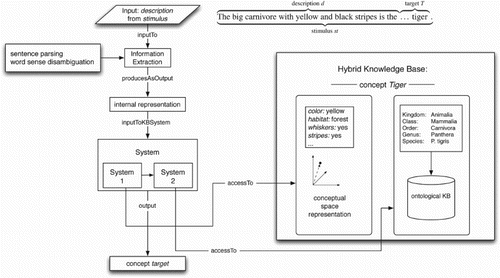
The system is part of a larger software pipeline including the extraction of salient information from the input stimulus, the access to the hybrid knowledge base, and the retrieval of the corresponding concept (). The whole system works as follows: once the linguistic input is given, an internal representation is built by analysing the stimulus, and by looking for matches between the CSs and the input. An Information Extraction step was designed that relies on syntactic analysis. The syntactic structure of sentences is computed through the Turin University Parser (TUP) in the dependency format (CitationLesmo, 2007). Dependency formalisms represent syntactic relations by connecting a dominant word, the head (e.g. the verb ‘fly’ in the sentence The eagle flies) and a dominated word, the dependent (e.g. the noun ‘eagle’ in the same sentence). The connection between these two words is represented by using labelled directed edges (e.g. subject): the collection of all dependency relations of a sentence forms a tree, rooted in the main verb. In this step, phrases containing nouns and their adjectives are mapped onto the CSs. Another fundamental step regards the word sense disambiguation (CitationJurafsky & Martin, 2000), necessary to access concepts representation both in the CSs and in the ontological representation. In the present setting, this Information Extraction step is performed in a supervised fashion.
Figure 3. The software pipeline takes in input the linguistic description, queries the hybrid knowledge base and returns the categorised concept.
3.1. Experiment 1
The evaluation consisted of an inferential task aimed at categorising a set of linguistic descriptions. Such descriptions contain information related to concepts’ typical features. Some examples of common-sense descriptions are: ‘the big carnivore with black and yellow stripes’ denoting the concept of tiger, or ‘the fresh water fish that goes upstream’ denoting the concept of salmon, and so on.
We devised some metrics to assess both the accuracy of the system, by evaluating it against the expected target, and the agreement between and
. The following information was recorded:
how often
the accuracy obtained by
2a. the accuracy of
2b. the accuracy of
how often Google and Bing – used in a question-answering mode – return pages corresponding to the appropriate concepts, given the same set of definitions and target concepts used to test the proposed system. To these ends, we considered the first 10 results provided by each search engine.Footnote10
In the first experiment a formal ontology has been developed describing the animal kingdom. It has been devised to meet common sense intuitions, rather than reflecting the precise taxonomic knowledge of ethologists, so we denote it as naïve animal ontology.Footnote11 In particular, the ontology contains the taxonomic distinctions that have an intuitive counterpart in the way human beings categorise the corresponding concepts. Classes are collapsed at a granularity level such that they can be naturally grouped together also based on their accessibility (CitationSmith & Branscombe, 1988). For example, although the category pachyderm is no longer in use by ethologists, we created a pachyderm class that is superclass to elephant, hippopotamus, and rhinoceros. The underlying rationale is that it is still in use by non-experts, due to the intuitive resemblances among its subclasses. The ontology is linked to DOLCE's Lite version;Footnote12 in particular, the tree containing our taxonomy is rooted in the agentive-physical-object class, while the body components are set under biological-physical-object, and partitioned between the two disjunct classes head-part (e.g. for framing horns, antennas, fang, etc.) and body-part (e.g. for paws, tails, etc.). The biological-object class includes different sorts of skins (such as fur, plumage, scales), substances produced and eaten by animals (e.g. milk, wool, poison and fruits, leaves and seeds).
The results obtained in the first experimentation are presented in .
Table 1 Results of the first experiment.
3.1.1. Discussion
The system was able to correctly categorise a vast majority of the input descriptions: in most cases ()
alone produces the correct output, with considerable saving in terms of computation time and resources. Conversely, none of the concepts (except for one) described with typical features would have been classified through classical ontological inference. It is by virtue of the former access to CSs that the whole system is able to categorise such descriptions. Let us consider, e.g. the description ‘The animal that eats bananas’. The ontology encodes knowledge stating that monkeys are omnivore. However, since the information that usually monkeys eat bananas cannot be represented therein, the description would be consistent to all omnivores. The information returned would then be too informative w.r.t. the granularity of the expected answer.
Another interesting result was obtained for the input description ‘the big herbivore with antlers’. In this case, the correct answer is the third element in the list returned by
; but because of the categorisation performed by
, it is returned in the final output pair (see Algorithm 1, line 8).
Finally, the system revealed to be able to categorise stimuli with typical, though ontologically incoherent, descriptions. As an example of such a case we will consider the categorisation results obtained with the following stimulus: ‘The big fish that eats plankton’. In this case the expected prototypical answer is whale. However, whales properly are mammals, not fishes. In our hybrid system, the component returns whale by resorting to prototypical knowledge. If further details were added to the input description, the answer would have changed accordingly: in this sense the categorisation performed by
is non-monotonic. When then
(the output of
) is checked against the ontology, as described by the Algorithm 1 lines 7–13, and an inconsistency is detected,Footnote13 the consistency of the second result in
(whale–shark in this example) is tested against the ontology. Since this answer is an ontologically compliant categorisation, then this solution is returned by the
component. The final output of the categorisation is then the pair
–
: the first element, prototypically relevant for the query, would have not been provided by querying a classical ontological representation. Moreover, if the ontology recorded the information that also other fishes eat plankton, the output of a classical ontological inference would have included them too, thereby resulting in a too large set of results w.r.t. the intended answer.
3.2. Experiment 2
In order to assess the accuracy of the system in a more demanding experimental setting, we devised a second experimental task, where used the knowledge base OpenCyc.Footnote14 OpenCyc is one of the largest ontologies publicly available, in that it is a huge attempt at integrating many diverse semantic resources (such as, e.g. WordNet, DBpedia, Wikicompany, etc.). Its coverage and depth were therefore its most attractive features (it contains about 230, 000 concepts, 2, 090, 000 triples and 22, 000 predicates). Differently from Experiment 1, we adopted OpenCyc to use a knowledge base independent of our own representational commitments. This was aimed at more effectively assessing the flexibility of the proposed system when using general-purpose, well-known, existing resources, and not only domain-specific ones.
A second data set of 56 new ‘common-sense’ linguistic descriptions was collected with the same rationale considered for the first experiment.Footnote15
The obtained results are reported in .
Table 2. The results of the second experiment.
3.2.1. Discussion
While the previous experiment explores the output of both and
components, the present one is aimed at assessing it with respect to existing state-of-art search technologies: the main outcome of this experiment is that the trends obtained in the preliminary experiment are confirmed in a broader and more demanding evaluation. Despite being less accurate with respect to the previous experiment, the hybrid knowledge-based
system was able to categorise and retrieve most of the new typicality-based stimuli provided as input, and still showed a better performance w.r.t. the general-purpose search engines Google and Bing used in question-answering mode.
The major problems encountered in this experiment derive from the difficulty of mapping the linguistic structure of stimuli containing very abstract meaning in the representational framework of CSs. For example, it was impossible to map the information contained in the description ‘the place where kings, princes and princesses live in fairy tales’ onto the features used to characterise the prototypical representation of the concept Castle. Similarly, the information extracted from the description ‘Giving something away for free to someone’ could not be mapped onto the features associated to the concept Gift. On the other hand, the system shows good performances when dealing with less abstract descriptions based on perceptual features such as shape, colour, size, and with some typical information such as function.
In this experiment, differently from the previous one (e.g. in the case of whale), mostly provided an output coherent with the model in OpenCyc. This datum is of interest, in that although we postulate that the reasoning check performed by
is beneficial to ensure a refinement of the categorisation process, in this experimentation
did not reveal any improvement to the output provided by
, also when this output was not in accord with the expected results. In fact, by analysing in detail the different answers, we notice that at least one inconsistency should have been detected by
. This is the case of the description ‘An intelligent grey fish’ associated to the target concept Dolphin. In this case, the
system returned the expected target, but
did not raise the inconsistency since OpenCyc erroneously represents Dolphin as a subclass of Fish, rather than a subclass of Mammal. Therefore, one of the weaknesses of the overall architecture can be due to ontological misclassifications in the
component.
4. Related work
The presented solution has some analogies with the approach that considers concepts as ‘semantic pointers’ (CitationEliasmith et al., 2012; CitationThagard & Findlay, 2012), proposed in the field of the computational modelling of brain. In such approach, different informational components are supposed to be attached to a unifying concept identifier. The similarity with their approach is limited to the idea that concepts consist of different types of information. However, the mentioned authors specifically focus on the different modalities of the stimuli contributing to conceptual knowledge, and therefore they identify the different components of concepts according to the different information carriers used to provide the information. Their conceptual components are divided in: sensory, motor, emotional and verbal stimuli, and for each type of carriers a mapping function to a brain area is supposed to be activated. On the other side, our focus is on the type of conceptual information (e.g. classical vs. typical information): we do not consider the modality associated to the various sources of information (e.g. visual or verbal, etc.).Footnote16 Rather, we are concerned with the type of information combined in the hybrid conceptual architecture embedded in our computational system.
In the context of a different field of application, a solution similar to the one adopted here has been proposed in CitationChella et al. (1997). The main difference with their proposal concerns the underlying assumption on which the integration between symbolic and sub-symbolic system is based. In our system the CSs and the classical component are integrated at the level of the representation of concepts, and such components are assumed to convey different – though complementary- conceptual information. On the other hand, the previous proposal is mainly used to interpret and ground raw data coming from sensors in a high level symbolic system through the mediation of CSs.
In other respects, our system is also akin to the ones developed in the field of the computational approach to the above mentioned dual process theories. A first example of such ‘dual-based systems’ is the mReasoner model (CitationKhemlani & Johnson-Laird, 2013), developed with the aim of providing a computational architecture of reasoning based on the mental models theory proposed by CitationJohnson-Laird (1980). The mReasoner architecture is based on three components: a system 0, a system 1 and a system 2. The last two systems correspond to those hypothesised by the dual process approach. System 0 operates at the level of linguistic pre-processing. It parses the premises of an argument by using natural language processing techniques, and it then creates an initial intensional model of them. System 1 uses this intensional representation to build an extensional model, and uses heuristics to provide rapid reasoning conclusions; finally, system 2 carries out more demanding processes to searches for alternative models, if the initial conclusion does not hold or if it is not satisfactory. A second system has been proposed by CitationLarue et al. (2012). The authors adopt an extended version of the dual process approach, which has been described in CitationStanovich & West (2000); it is based on the hypothesis that the system 2 is divided in two further levels, respectively called ‘algorithmic’ and ‘reflective’. The goal of Laure and colleagues is to build a multi-agent and multilevel architecture, to represent the emergence of emotions in a biologically inspired computational environment.
Another system that is close to our present work has been proposed by CitationPilato et al. (2011). The authors do not explicitly mention the dual process approach; however, they build a system for conversational agents (chatbots) where agents’ background knowledge is represented using both a symbolic and a sub-symbolic approach. They also associate different sorts of representation to different types of reasoning. Namely, deterministic reasoning is associated to symbolic (system 2) representations, and associative reasoning is accounted for by the sub-symbolic (system 1) component. Differently from our system, however, the authors do not make any claim about the sequence of activation and the conciliation strategy of the two representational and reasoning processes. It is worth noting that other examples of this type of systems can be considered that are in some sense akin to the dual process proposal: for example, many hybrid, symbolic-connectionist systems – including cognitive architectures such as, for example, CLARIONFootnote17 –, in which the connectionist component is used to model fast, associative processes, while the symbolic component is responsible for explicit, declarative computations (for a deeper discussion, please refer to CitationFrixione & Lieto (2014b)). However, to the best of our knowledge, our system is the only one that considers this hybridisation with a granularity at the level of individual conceptual representations.
5. Conclusions and future work
In this work we have presented a knowledge-based system relying upon a cognitively inspired architecture for the representation of conceptual knowledge. The system is grounded on a hybrid framework coupling classical and prototypical representation and reasoning. It aims at extending the representational and reasoning capabilities of classical ontological-based systems towards more realistic and cognitively grounded scenarios, such as those envisioned by the prototype theory. The system has been tested in a twofold experimentation consisting of a categorisation task involving typicality-based queries. In the former case we used an ad-hoc developed domain ontology; whilst in the latter case we used OpenCyc, a publicly available, huge knowledge base. The obtained results show that in the restricted domain of the animal kingdom the proposed architecture is by far more accurate than general purpose systems such as Google and Bing. This advantage is reduced when dealing with an unrestricted context, but the overall results corroborate the hypothesis that matching in CSs can be fruitfully paired with ontological inference. However, the ontological inference would not suffice to categorise the common sense stimuli presented in both experiments, with only one exception.
The –
system can be applied in a task close to that considered in present experimentation: besides informational queries, the system can be employed in the analysis of search engines web logs to investigate whether and to what extent their results match the actual users’ informational needs. A meta-search model can be envisioned, where web engines results are filtered by the system
–
before being returned to the user, so as to retain only relevant (to the ends of informational queries) results.
In the next future we will complete the automatisation of the Information Extraction step from linguistic descriptions, which are currently (in a supervised fashion) mapped onto an internal representation shared by both and
. In particular, we are currently investigating how to exploit information provided by semi-structured sources such as ConceptNetFootnote18 to compute the values required to fill the CSe dimensions. Furthermore, we plan to test the proposed approach in the area of biomedical domain in order to assess disease diagnosis tasks by using in
an ontology such as SNOWMED,Footnote19 and in
CSs representing the typical symptoms of a given disease. Moreover, the CSs information can be globally seen as an effort to provide some portions of the WordNet hierarchy with a CSs annotation. For the next future, we plan to release the CSs resource in open format.
Finally, the obtained results show that this approach may be beneficial to a plethora of NLP tasks where a wide-coverage is required, such as summarisation (also in a multilingual setting), question answering and information retrieval.
Acknowledgements
The authors kindly thank Leo Ghignone, for working to an earlier version of the system; Marcello Frixione, for discussions and advices on the theoretical aspects of this approach; the anonymous reviewers, whose valuable suggestions were helpful to improve the work; Manuela Sanguinetti, for her comments on a previous version of the article. We also thank the attendees of the ConChaMo 4 Workshop,Footnote20 organised by the University of Helsinki, and the participants of the Spatial Colloquium Workshop organised by the Spatial Cognition Center of the University of BremenFootnote21 for their comments and insights to initial versions of this work: in particular, we thank David Danks, Christian Freksa, Peter Gärdenfors, Ismo Koponen, and Paul Thagard. We especially thank Leonardo Lesmo, beloved friend and colleague no longer with us, who strongly encouraged the present line of research.
Funding
This work has been partly supported by the Ateneo-San Paolo project number TO_call03_2012_0046, The role of visual imagery in lexical processing (RVILP). The first author's work is also partially supported by the CNR F.A.C.I.L.E. project ICT.P08.003.001.
Notes
1. This is the case, for example, of exceptions to the inheritance mechanism.
2. For the Web Ontology Language, see http://www.w3.org/TR/owl-features/ and http://www.w3.org/TR/owl2-overview/, respectively.
3. In the present implementation we considered two possible types of informational components: the typical one (encoding prototypical knowledge) and the classical one (encoding information in terms of necessary and sufficient conditions). In particular, although in this case we mainly concentrate on representation and reasoning tenets coming from the prototype theory, the typical component can be considered general enough to encode many other forms of representational and reasoning mechanisms related to a wider spectrum of typicality theories such as, for example, the Exemplars theory (CitationMurphy, 2002).
4. Therefore, the use of prototypical knowledge in cognitive tasks such as categorisation is not a fault of the human mind, as it could be the fact that people are prone to fallacies and reasoning errors (leaving aside the problem of establishing whether recurrent errors in reasoning could have a deeper ‘rationality’ within the general framework of cognition). For the same reason it is also a desired characteristics in the field of intelligent artificial systems.
5. Currently OWL and OWL 2 profiles are not expressive enough to perform the reasoning processes provided by the overall system. However, both language profiles are usable in their DL-safe characterisation to exploit taxonomical reasoning. Extending the expressivity of ontological formalisms and languages would be a long-term desideratum in order to enrich the ontological reasoning with more complex inference. To be more expressive and practically usable, a KR framework should provide an acceptable trade-off in terms of complexity. However, this is an open problem in Fuzzy and Non-Monotonic extensions of standard DLs.
6. Typical traits are selected based on statistically relevant information regarding a given concept, as posited by the Prototype Theory (CitationRosch, 1975). For example, the selection of the information regarding the typical colour of a rose (red) is given by the fact that roses are often red.
7. WordNet information is relevant in our system in that synset identifiers are used by both and
as a lexical ground to access both the conceptual representations.
8. The output of cannot be wrong on a purely logical perspective, in that it is the result of a deductive process. The control strategy tries to implement a tradeoff between ontological inference and the output of
, which is more informative but also less reliable from a formal point of view. However, in next future we plan to explore different conciliation mechanisms to ground the overall control strategy.
9. The expected prototypical target category represents a gold standard, since it corresponds to the results provided within a psychological experimentation. In this experimentation 30 subjects were requested to provide the corresponding target concept for each description. The full list is available at the URL http://www.di.unito.it/radicion/datasets/cs_2014/stimuli.txt.
10. We also tried to extend our evaluation to the well-known semantic question-answering engine Wolfram-Alpha (https://www.wolframalpha.com). However, it was not possible to test the descriptions in that it explicitly disregards considering typicality-based queries. Namely, the only stimulus correctly categorised is that describing the target as ‘The domestic feline.’.
11. The ontology is available at the URL http://www.di.unito.it/radicion/datasets/cs_2014/Naive_animal_ontology.owl
13. This follows by observing that ,
; and
, while
; and mammal and fish are disjoint.
15. The full list of the second set of stimuli, containing the expected ‘prototypically correct’ category is available at the following URL: http://www.di.unito.it/radicion/datasets/cs_2014/stimuli.txt.
16. In our view the distinction classical vs. prototypical is ‘a-modal’ per se, for example both a typical and a classical conceptual information can be accessed and processed through different modalities (that is visual vs. auditory, etc.).
References
- Adams, B., & Raubal, M. (2009). A metric conceptual space algebra. In K. S. Hornsby, C. Claramunt, M. Denis, & G. Ligozat(Eds.), COSIT (pp. 51–68). Lecture Notes in Computer Science, 5756. Berlin: Springer.
- Bonatti, P. A., Lutz, C., & Wolter, F. (2006, June 2–5). Description logics with circumscription. In P. Doherty, J. Mylopoulos, & C. A. Welty(Eds.), Proceedings of the tenth international conference on principles of knowledge representation and reasoning, Lake District of the United Kingdom (pp. 400–410). Palo Alto, CA: AAAI Press.
- Brachman, R. J., & Levesque, H. J. (1985). Readings in knowledge representation. Burlington, MA: Morgan Kaufmann.
- Brachman, R. J., & Levesque, H. J. (2004). Knowledge representation and reasoning. Amsterdam, The Netherlands: Elsevier.
- Brachmann, R. J., & Schmolze, J. G. (1985). An overview of the KL-ONE knowledge representation system. Cognitive Science, 9(2), 171–202. doi: 10.1207/s15516709cog0902_1
- Calegari, S., & Ciucci, D. (2007). Fuzzy ontology, fuzzy description logics and fuzzy-owl. In F. Masulli, S. Mitra, & G. Pasi(Eds.), Applications of fuzzy sets theory (pp. 118–126). Berlin: Springer.
- Chella, A., Frixione, M., & Gaglio, S. (1997). A cognitive architecture for artificial vision. Artificial Intelligence, 89(1–2), 73–111. doi: 10.1016/S0004-3702(96)00039-2
- Eliasmith, C., Stewart, T. C., Choo, X., Bekolay, T., DeWolf, T., Tang, Y., & Rasmussen, D. (2012). A large-scale model of the functioning brain. Science, 338(6111), 1202–1205. doi: 10.1126/science.1225266
- Evans, J. St. B. T., & Frankish, K..(Eds.). In two minds: Dual processes and beyond. Oxford: Oxford University Press.
- Frixione, M., & Lieto, A. (2010, October 25–28). The computational representation of concepts in formal ontologies some general considerations. In J. Filipe & J. L. G. Dietz(Eds.), KEOD 2010 – Proceedings of the international conference on knowledge engineering and ontology development, Valencia, Spain (pp. 396–403). Lisboa, Portugal: SciTePress.
- Frixione, M., & Lieto, A. (2012). Representing concepts in formal ontologies: Compositionality vs. typicality effects. Logic and Logical Philosophy, 21(4), 391–414.
- Frixione, M., & Lieto, A. (2013). Representing non classical concepts in formal ontologies: Prototypes and exemplars. In C. Lai, G. Semeraro, & E. Vargiu(Eds.), New challenges in distributed information filtering and retrieval, Studies in Computational Intelligence, 439 (pp. 171–182). Berlin: Spinger.
- Frixione, M., & Lieto, A. (2014a). Towards an extended model of conceptual representations in formal ontologies: A typicality-based proposal. Journal of Universal Computer Science, 20(3), 257–276.
- Frixione, M., & Lieto, A. (2014b). Formal ontologies and semantic technologies: A dual process proposal for concept representation. Philosophia Scientiae, 18(3), 1–14.
- Gärdenfors, P. (2000). Conceptual spaces: The geometry of thought. Cambridge, MA: MIT Press.
- Gärdenfors, P. (2014). The geometry of meaning: Semantics based on conceptual spaces. Cambridge, MA: MIT Press.
- Giordano, L., Gliozzi, V., Olivetti, N., & Pozzato, G. L. (2013). A non-monotonic description logic for reasoning about typicality. Artificial Intelligence, 195, 165–202. doi: 10.1016/j.artint.2012.10.004
- Gruber, T. (2009). Ontology. In L. Liu & M. Tamer Özsu(Eds.), Encyclopedia of database systems (pp. 1963–1965). Berlin: Springer.
- Jansen, B. J., Booth, D. L., & Spink, A. (2008). Determining the informational, navigational, and transactional intent of web queries. Information Processing & Management, 44(3), 1251–1266. doi: 10.1016/j.ipm.2007.07.015
- Johnson-Laird, P. N. (1980). Mental models in cognitive science. Cognitive Science, 4(1), 71–115. doi: 10.1207/s15516709cog0401_4
- Jurafsky, D., & Martin, J. H. (2000). Speech and language processing: An introduction to natural language processing, computational linguistics and speech. Upper Saddle River, NJ: Prentice Hall.
- Kahneman, D. (2011). Thinking, fast and slow. New York, NY: Farrar, Straus and Giroux.
- Khemlani, S., & Johnson-Laird, P. N. (2013). The processes of inference. Argument & Computation, 4(1), 4–20. doi: 10.1080/19462166.2012.674060
- Larue, O., Poirier, P., & Nkambou, R. (2012). A cognitive architecture based on cognitive/neurological dual-system theories. In F. M. Zanzotto, S. Tsumoto, N. Taatgen, & Y. Yao(Eds.), Brain informatics (pp. 288–299). Berlin: Springer.
- Lesmo, L. (2007). The rule-based parser of the NLP group of the university of Torino. Intelligenza Artificiale, 2(4), 46–47.
- Machery, E. (2009). Doing without concepts. Oxford: Oxford University Press.
- Masolo, C., Borgo, S., Gangemi, A., Guarino, N., & Oltramari, A. (2003). WonderWeb deliverable D18 ontology library (final). Technical report, IST Project 2001-33052 WonderWeb: Ontology Infrastructure for the Semantic Web.
- Miller, G. A. (1995). WordNet: A lexical database for English. Communications of the ACM, 38(11), 39–41. doi: 10.1145/219717.219748
- Minsky, M. (1975). A framework for representing knowledge. In P. Winston(Ed.) The psychology of computer vision (pp. 211–277). New York, NY: McGraw-Hill.
- Murphy, G. L. (2002). The big book of concepts. Cambridge, MA: MIT Press.
- Nardi, D., & Brachman, R. J. (2003). An introduction to description logics. In F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi, & P. F. Patel-Schneider(Eds.), Description logic handbook (pp. 1–40). Cambridge: Cambridge University Press.
- Pilato, G., Augello, A., & Gaglio, S. (2011). A modular architecture for adaptive ChatBots. Proceedings of the IEEE fifth international conference on semantic computing, Palo Alto, CA, USA. New York, NY: IEEE.
- Quillian, R. (1968). Semantic memory (pp. 216–270). Cambridge, MA: MIT Press.
- Rosch, E. (1975). Cognitive representations of semantic categories. Journal of Experimental Psychology: General, 104(3), 192–233. doi: 10.1037/0096-3445.104.3.192
- Simon, H. A., & Newell, A. (1971). Human problem solving: The state of the theory in 1970. American Psychologist, 26(2), 145–159. doi: 10.1037/h0030806
- Smith, E. R., & Branscombe, N. R. (1988). Category accessibility as implicit memory. Journal of Experimental Social Psychology, 24(6), 490–504. doi: 10.1016/0022-1031(88)90048-0
- Stanovich, K. E., & West, R. F. (2000). Individual differences in reasoning: Implications for the rationality debate? Behavioral and Brain Sciences, 23(5), 645–665. doi: 10.1017/S0140525X00003435
- Straccia, U. (2011). Reasoning within fuzzy description logics. Retrieved from arXiv preprint arXiv:1106.0667.
- Thagard, P., & Findlay, S. (2012). The cognitive science of science: Explanation, discovery, and conceptual change. Cambridge, MA: MIT Press.
- Wittgenstein, L. (1953). Philosophische untersuchungen-Philosophical investigations. Oxford: B. Blackwell.