
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Artificial neural networks are efficient models in pattern recognition applications, but their performance is dependent on employing suitable structure and connection weights. This study used a hybrid method for obtaining the optimal weight set and architecture of a recurrent neural emotion classifier based on gravitational search algorithm (GSA) and its binary version (BGSA), respectively. By considering the features of speech signal that were related to prosody, voice quality, and spectrum, a rich feature set was constructed. To select more efficient features, a fast feature selection method was employed. The performance of the proposed hybrid GSA-BGSA method was compared with similar hybrid methods based on particle swarm optimisation (PSO) algorithm and its binary version, PSO and discrete firefly algorithm, and hybrid of error back-propagation and genetic algorithm that were used for optimisation. Experimental tests on Berlin emotional database demonstrated the superior performance of the proposed method using a lighter network structure.
1. Introduction
Human emotions recognition is one of the interesting applications in recent years that can be performed using speech or (and) image signals. Note that there are two important information sources in the speech signal: (a) an explicit source which contains the linguistic content, and (b) an implicit source which carries the paralinguistic information about the speaker. In the last four decades, several methods focused on developing automatic speech recognition systems to extract linguistic information. Although decoding the paralinguistic information such as emotion needs more research efforts (Jaywant & Pell, Citation2012; Kamaruddin, Wahab, & Quek, Citation2012; Mariooryad & Busso, Citation2014; Origlia, Cutugno, & Galatà, Citation2014; Schuller, Batliner, Steidl, & Seppi, Citation2011). The emotion recogniser is an effective tool in human-computer interfacing applications such as lie detecting, developing learning environments, consumer relationships, computer tutorial, call-center, and in-car boards (Ai et al., Citation2006; Devillers & Vidrascu, Citation2006; Javidi & Fazlizadeh Roshan, Citation2013; Khanchandani & Hussain, Citation2009; Polzehl, Sundaram, Ketabdar, Wagner, & Metze, Citation2009; Tian et al., Citation2014).
In recent years, research on emotion recognition from speech focused on extracting reliable informative features, selecting appropriate feature set, and combining powerful classifiers to improve the performance of emotion detection systems in real-life applications (Chen, Mao, Xue, & Cheng, Citation2012; Fernandez & Picard, Citation2011; Gharavian, Sheikhan, Nazerieh, & Garoucy, Citation2012; López-Cózar, Silovsky, & Kroul, Citation2011; Milton & Tamil Selvi, Citation2014; Sheikhan, Bejani, & Gharavian, Citation2013; Vlasenko, Prylipko, Böck, & Wendemuth, Citation2014).
Several features have been employed for emotion recognition from speech such as the following sets listed below:
Pitch frequency (F0), log energy (LE), formant frequencies, and Mel-frequency cepstral coefficients (MFCCs) (Arias, Busso, & Yoma, Citation2014; Kao & Lee, Citation2006),
F0, LE, formant frequencies, MFCCs, vocal tract cross-section areas (Ak), and speech rate (Gharavian & Sheikhan, Citation2010; Ververidis & Kotropoulos, Citation2006),
Linear prediction coefficients (LPCs) and MFCCs (Pao, Chen, Yeh, & Chang, Citation2008),
F0, LE, MFCCs, and LPCs (Altun & Polat, Citation2009),
Zero crossing rate, LE, F0, and harmonics-to-noise ratio (Gajšek, Struc, & Mihelič, Citation2010),
Harmony features based on the psychoacoustic harmony perception known from music theory (Yang & Lugger, Citation2010),
Statistics of MFCCs computed over three phoneme types (stressed vowels, unstressed vowels, and consonants) (Bitouk, Verma, & Nenkova, Citation2010),
Jitter, shimmer, LPCs, linear prediction cepstral coefficients (LPCCs), MFCCs, derivative of MFCCs (dMFCCs), second derivative of MFCCs (ddMFCCs), log frequency power coefficients, and perceptual linear prediction coefficients (Yeh, Pao, Lin, Tsai, & Chen, Citation2010), and
Modulation spectral features using an auditory filter-bank and a modulation filter-bank for speech analysis (Wu, Falk, & Chan, Citation2011).
Similarly, different classification methods were employed in this field such as k-nearest neighbour (Fersini, Messina, & Archetti, Citation2012; Pao et al., Citation2008; Väyrynen, Toivanen, & Seppänen, Citation2011), decision trees (El Ayadi, Kamel, & Karray, Citation2011; Mower, Busso, Lee, Narayanan, & Lee, Citation2011; Rong, Li, & Chen, Citation2009), Bayesian networks (El Ayadi et al., Citation2011), optimum path forest (Iliev, Scordilis, Papa, & Falcão, Citation2010), hidden Markov models (Kockmann, Burget, & Černocky, Citation2011), Gaussian mixture models (GMMs) (Gharavian, Sheikhan, & Pezhmanpour, Citation2011), support vector machines (SVMs) (Chandaka, Chatterjee, & Munshi, Citation2009), artificial neural networks (ANNs) (Ahmed Hendy & Farag, Citation2013; Caridakis, Karpouzis, & Kollias, Citation2008; Gharavian et al., Citation2012; Sheikhan, Safdarkhani, & Gharavian, Citation2011), and hybrid models (Gharavian, Sheikhan, & Ashoftedel, Citation2013; López-Cózar et al., Citation2011).
The present study used a hybrid heuristic method for finding the optimum weight set and architecture of a recurrent neural emotion classifier based on gravitational search algorithm (GSA) and its binary version (BGSA), respectively. This hybrid model is called GSA-BGSA in this paper. By considering prosody-related features (such as pitch-related, formant-related, energy contour-related, and timing features), voice quality features (such as mean and standard deviation of pitch and amplitude perturbation quotients (APQs)), and spectral-based features (such as MFCC-based features) of speech signal, a rich feature set including 164 features was constructed. With the aim of selecting more efficient features and reducing the number of input features to the recurrent neural network (RNN), the sequential forward feature selection (SFFS) was employed as a fast feature selection method. Experimental tests on Berlin emotional database demonstrated the superior performance of proposed hybrid GSA-BGSA method over similar hybrid methods based on particle swarm optimisation (PSO) algorithm and its binary version (BPSO), PSO and discrete firefly algorithm (DFA), and hybrid of error back-propagation (EBP) and genetic algorithm (GA) that were used for such optimisations.
Section 2 of this paper reviews the background and related work on optimising ANNs. Section 3 explains the structure of the RNN model used in this study. The details of hybrid GSA-BGSA algorithm are presented in Section 4. The feature set is introduced in Section 5. The brief review of Berlin emotional speech dataset and the experimental results are provided in Section 6. In this way, the performance of proposed method is compared with similar hybrid methods such as EBP-GA, PSO-BPSO, PSO-DFA, and some other emotion recognition systems implemented in recent years and tested on Berlin emotional database. Section 7 concludes the paper and mentions the future research directions.
2. Related work on optimising ANNs
Note that ANN is a nature-based computing technique that was developed as a parallel-distributed network model based on the biological learning process of human brain. The mostly used training algorithm for ANNs, especially multi-layer perceptron (MLP), is the EBP algorithm which is a gradient-based method. However, some inherent problems exist in the EBP algorithm. One of these problems is trapping in local minima, especially for nonlinearly separable pattern classification problems or complex function approximation problems (Gori & Tesi, Citation1992).
To overcome the problem of multiple local minima in ANNs, several stochastic methods were proposed such as simulated annealing (SA) (Sexton, Dorsey, & Johnson, Citation1999) and GA (Sexton, Dorsey, & Johnson, Citation1998) that can find the globally optimal solution with a certain probability.
On the other hand, deterministic techniques (such as tabu search, branch-and-bound, and generalised cutting plane (PintÈr, Citation1996) can find guaranteed optimal solutions by spending high computational cost. However, modified versions of deterministic techniques were proposed as relatively fast computational algorithms for ANN optimisation (such as the cutting angle method proposed by Beliakov and Abraham (Citation2002) in which the ANN was initially trained using the cutting angle method and then fine-tuning was performed using gradient descent or other optimisation techniques).
For this purpose, a meta-learning framework, as an evolutionary-based algorithm for ANN optimisation, was proposed in (Beliakov & Abraham, Citation2002) for training and automatic design of the ANNs (). The purpose of the proposed method in this study is similar to the meta-learning framework introduced by Beliakov and Abraham (Citation2002); however, a hybrid swarm intelligence-based method was used instead of an evolutionary-based algorithm. In this way, GA (e.g.) searches in a multi-dimensional space based on its global searching capability and varies the number of hidden layers and hidden neurons through application of the genetic operators and evaluation of different architectures according to a fitness function.
Figure 1. Evolutionary-based meta-learning algorithm for ANN optimisation (Beliakov & Abraham, Citation2002).
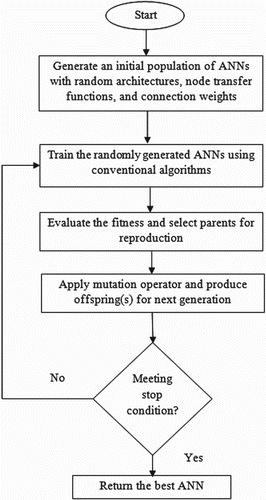
Note that the training performance is sensitive to the choice of algorithm's parameters and initial values of the ANN's weights. In other words, selecting the appropriate network architecture and weight parameters strongly affect the convergent behaviour of the EBP algorithm (Ye, Qiao, Li, & Ruan, Citation2007).
Other computational intelligence (CI)-based methods were also proposed for ANN optimisation in recent decade (). The role of these methods can be classified into three groups: (a) selecting the optimised architecture, (b) determining the optimised training parameters and/or weights, and (c) obtaining the optimal structure and training weights. The proposed method in this study obtained the optimal structure and training weights of an RNN.
Table 1. Sample CI-based proposed methods for ANN optimisation in recent years.
The GSA is a heuristic algorithm introduced by Rashedi, Nezamabadi-pour, and Saryazdi (Citation2009) and is based on the gravitational law and laws of motion. GSA has a flexible and well-balanced mechanism to enhance exploration and exploitation abilities. A hybrid GSA-BGSA algorithm was used in this study to optimise the network structure (i.e. the number of hidden layer nodes in a recurrent neural network) using BGSA and the connection weights of this network using GSA. The initial number of hidden nodes of the neural network was considered as 75% of the input features (Salchenberger, Cinar, & Lash, Citation1992) and varied by iterations to achieve the minimum mean squared error.
The proposed method has similarities to the hybrid methods introduced in (Beliakov & Abraham, Citation2002) or listed in , because most of these methods employed heuristic and population-based search algorithms such as GA, SA, PSO, and GSA. Most of these heuristic algorithms had a stochastic behaviour and did search in a parallel fashion with multiple initial points. However, the proposed method is different from the mentioned methods because of using BGSA and GSA in optimising weights and number of hidden nodes, respectively. The same idea was proposed in (Abraham, Citation2002) for optimising architecture, node transfer function and connection weights using evolutionary search mechanism while training network using EBP or Levenberg-Marquardt (LM) in a parallel mode.
3. RNN model equipped with switches in hidden layer
Feedback connections in the RNNs make them ideal for temporal information processing problems. However, the training of RNNs is much more difficult as compared to the static ANNs. It is essential to use an algorithm for automatic determining of suitable structure and weights of the RNNs. As mentioned earlier, this algorithm should perform two tasks: (a) determining the number of hidden layers and constituent nodes, and (b) determining the connection weight values.
An RNN-based classifier was optimised in this study using a GSA-BGSA hybrid algorithm. In this way, BGSA (Rashedi, Nezamabadi-pour, & Saryazdi, Citation2010) was employed to determine the structure of the RNN (i.e. the number of hidden nodes) and GSA (Rashedi et al., Citation2009) was used to adjust the training parameters (including weights, initial inputs of the context nodes, and the self-feedback coefficient).
A modified Elman-type RNN (Lin and Hong, Citation2011) was used in this study. It is noted that Elman ANN is a partial RNN model (Elman, Citation1990) consists of four layers: input, hidden, context, and output (). The context neurons store the previous output of hidden neurons. The modified Elman network has self-feedback connections with fixed coefficients in the context layer. This self-feedback improves the memorisation ability of network which can enhance the convergence and speed of learning process.
Figure 2. Schematic of a modified Elman-type RNN.
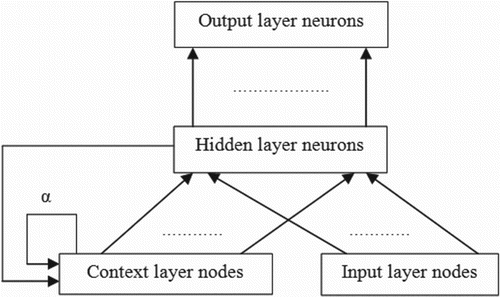
The output of the jth hidden layer neuron is calculated as:
(1)
(1) where k represents the kth iteration,
is the weight between the input and hidden node j, xi is the output of node i,
is the weight between the context node r and hidden node j,
is the output of node r in the context layer, and f [.] is the sigmoid function.
The is calculated as:
(2)
(2) where α is the self-feedback connecting coefficient. The output of the qth output node is calculated as:
(3)
(3)
where
is the weight between the hidden node j and output node q, and g[.] is taken as a linear function.
4. GSA-BGSA hybrid for optimising RNN
4.1. Review of GSA and BGSA
Rashedi et al. (Citation2009) introduced an optimisation algorithm based on the law of gravity and mass interactions. In GSA, a set of agents called masses were introduced to find the optimum solution by simulation of Newtonian laws of gravity and motion. The performance of objects were measured by their masses, and all these objects attracted each other by the gravity force, while this force caused a global movement of all objects towards the objects with heavier masses.
The mass of each agent is calculated after computing the current population fitness as (Rashedi et al., Citation2009):
(4)
(4) where N, Mi(t) and fiti(t) represent the population size, the mass, and the fitness value of agent i at t, respectively. The best(t) and worst(t) are defined for a minimisation problem as Equations (5) and (6), respectively:
(5)
(5)
(6)
(6)
To compute the acceleration of an agent, the total forces from a set of heavier masses applied on it should be considered based on a combination of the law of gravity and the second law of Newton on motion as (Rashedi et al., Citation2009):
(7)
(7)
where
presents the acceleration of agent i in dimension d. rand is a uniform random in the interval [0, 1], e is a small value, n is the dimension of the search space, and Ri,j(t) is the Euclidean distance between two agents, i and j. kbest is the set of first K agents with the best fitness value and biggest mass, which is a function of time, initialised to K0 at the beginning and decreased with time. Here K0 is set to N (total number of agents) and decreases linearly to 1. G(t) is a decreasing function of time, which is set to G0 at the beginning and decreases linearly or exponentially towards zero with lapse of time. The exponential reduction is given as:
(8)
(8) where tmax is the total number of iterations. It is noted that
indicates the position of agent i in the search space, which is a candidate solution.
Afterwards, the next velocity of an agent is calculated as a fraction of its current velocity added to its acceleration as:
(9)
(9) where
presents the velocity of agent i in dimension d. Then, the position of agent i in dimension d is calculated as:
(10)
(10)
The steps of the GSA algorithm are as follows:
Step 1: Initialisation of Xi(t); i=1,2, … ,N;
Step 2: Fitness evaluation of agents;
Step 3: Update of G(t), best(t), worst(t), and Mi(t); i=1,2, … ,N;
Step 4: Calculation of acceleration and velocity;
Step 5: Update of agents’ position to obtain Xi(t+1); i=1,2, … ,N;
Step 6: Go to Step 2 and repeat until the stopping condition is met.
BGSA was introduced by Rashedi et al. (Citation2010) to extend GSA for tackling binary problems effectively. In BGSA, the position of agents has two values; 0 or 1, and the velocity of an agent represents the probability that a bit (position) takes on 0 or 1. The velocity updating formula remains unchanged, and position updating formula is redefined as:
(11)
(11)
4.2. GSA-BGSA for RNN design
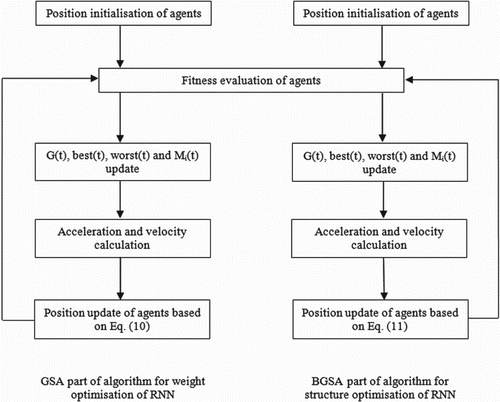
The BGSA searches for the number of hidden nodes (i.e. the context nodes) and GSA works on the optimisation of training parameters for each of the structures (agents) present in the BGSA. In the GSA-BGSA, agents of GSA and BGSA work together and are evaluated simultaneously. Each agent was divided to two sub-agents which were subjected to two independent and consecutive processes. The first one was a regular GSA, that is, the traditional velocity and position update of neural network weights. The second one was BGSA, which allowed the agent to determine the number of nodes in single hidden layer of a recurrent neural network.
Two kinds of agents were defined in the proposed hybrid optimisation algorithm: structure and parameter. The structure agent was a binary string whose entries were 1 or 0 (which showed the existence or no-existence of a hidden node). The length of this string was equal to the maximum expected/allowable number of hidden nodes (Max_H). The parameter agent consisted of Max_H parts where each part included self-feedback coefficient, initial inputs of each context node and all the weight connections based on the order of hidden nodes of the structure agent. Assuming , m, and n nodes in the input, hidden (and context), and output layers, the encoding of each part in the parameter agent is shown in . The number of elements in the parameter agent is
Figure 3. Encoding scheme of each part in the parameter agent.
The MSE function is generally used in fitness evaluation of agents according to the desired optimisation:
(12)
(12) where N is the number of training samples, n is the number of RNN outputs, and
and
are the target and actual outputs of the tth sample at the time k, respectively. The used fitness function in this study considered both the RNN's size and its convergence accuracy as:
(13)
(13) where β is a control coefficient for penalising network size and m is the number of hidden nodes. The hybrid algorithm worked on both error performance and complexity minimisation. The search process of the GSA-BGSA hybrid algorithm for updating the network structure and connection weights is shown in .
Figure 4. GSA-BGSA optimisation method for tuning the structure and weights of recurrent neural network.
5. Feature set for emotion recognition from speech
To extract features, the speech signal was firstly sampled at the rate of 16 kHz. Then, it was windowed by a 25-msec Hamming window considering 10-msec frame shift. The simulations were performed using Matlab R2014a software on a PC with an Intel Core i5–4460 @ 3.2 GHz CPU and 8GB RAM.
Speech features for emotion recognition can be classified into four categories: prosody-related features, voice quality features, spectral-based features, and Teager-energy operator (TEO)-based features (El Ayadi et al., Citation2011). Note that these features were combined to represent the speech signal in the most studies of this field.
The prosody-related features used in this study are listed in . As seen in , the prosody-related features were grouped as follows: pitch contour-related features (33 features), formant-related features (21 features), energy contour-related features (59 features), and timing features (11 features). The estimation of pitch frequency was based on iterative adaptive inverse filtering method (Alku, Citation1992). The formant frequencies and formant bandwidths were estimated using LPC analysis.
Table 2. Prosody-related features used in this study.
In , “maximum”, “minimum”, “average”, “median”, “range”, “standard deviation”, “interquartile range”, and “bandwidth” values are abbreviated as “Max”, “Min”, “Avg”, “Med”, “R”, “SD”, “IQR”, and “BW”, respectively. The first derivative of a feature is shown using prefix “d”; for example, dF0 represents the first derivative of F0.
Voice quality is related to the acoustic correlates such as voice level, voice pitch, voice formants, and feature boundaries (El Ayadi et al., Citation2011, Lugger & Yang, Citation2007). In this study, jitter-related and shimmer-related features were also used for the description of voice quality. Note that jitter and shimmer are the measures of period-to-period fluctuations in F0 and amplitude, respectively. These measures are calculated as Equations (14) and (15), respectively:
(14)
(14)
(15)
(15) where Ti and Ai are the pitch period and the peak amplitude value of the ith window, respectively, and N is the total number of voiced frames in the utterance (Li et al., Citation2007). The mean and SD of pitch perturbation quotient and APQ were used as voice quality-related features in this study (i.e. four features) (Kiliç et al., Citation2004).
The spectral-based features such as MFCCs can model the varying nature of speech spectra under different emotions. The first and second derivatives of spectral features were also included in the feature set to model the temporal dynamic changes in the speech signal. A 36-dimensional MFCC-based vector consisting of 12 MFCCs and their first and second derivatives were used in this study as the spectral-based features.
TEO-based features are used to reflect the energy of the nonlinear energy flow within the vocal tract for a single resonant frequency. Because of using rich energy-related features in this study (as listed in ), the TEO-based features such as TEO-decomposed frequency modulation variation (TEO-FM-Var), normalised TEO autocorrelation envelope area (TEO-Auto-Env), and TEO-based pitch (TEO-Pitch) (Zhou, Hansen, & Kaiser, Citation1998) were not considered in the feature set to reduce redundant features.
The SFFS was used as a simple, fast, effective and popular technique in this study (Kudo & Sklansky, Citation2000). However, the CI-based feature selection algorithms can also be used for this purpose (e.g. those reported by the author in (Sheikhan, Citation2014; Sheikhan & Mohammadi, Citation2013; Sheikhan & Sharifi Rad, Citation2013b). The SFFS algorithm selected 60 more significant features. The features were normalised around their mean and standard deviation as:
(16)
(16)
6. Simulation and experimental results
The popular studio recorded Berlin Emotional Speech Database (EMO-DB) (Burkhardt, Paeschke, Rolfes, Sendlmeier, & Weiss, Citation2005) was used in this study to test the effectiveness of emotion classification using the proposed method. This database covers anger, boredom, disgust, fear, happiness, sadness, and neutral speaker emotions in which ten professional actors speak ten German sentences. The number of utterances in this dataset (whole set) is about 800 (i.e. 700 + some second version); however, only 494 phrases were marked assignable in listening experiments. This limited set was employed in the benchmark comparisons of similar works, as well (Schuller, Vlasenko, Eyben, Rigoll, & Wendemuth, Citation2009). The number of used speech data in this study for seven emotions is reported in . The number of training and test speech data was selected in an experiment as 348 and 146, respectively.
Table 3. Number of EMO-DB speech data used in this study for each emotion.
In this study, the neural emotion classifier was implemented using four methods: hybrid of EBP algorithm (for training) and GA (for structure optimisation) called EBP-GA, PSO-BPSO hybrid algorithm, PSO-DFA, and the proposed GSA-BGSA. Because of stochastic search in heuristic algorithms, 10 runs of each algorithm were performed and the best results were reported. Initial value of weights was generated at random in the range of [−1, 1]. Other parameter settings of four mentioned methods were performed as follows:
EBP-GA hybrid algorithm- Learning rate and momentum coefficient were set to 0.1. The GA parameters were set as: population size: 30, crossover probability: 0.8, mutation probability: 0.1, elitism: 5%, rank-based selection: 0.3, maximum number of hidden nodes: 50, and maximum number of generations: 30.
PSO-BPSO hybrid algorithm- population size: 30, acceleration constants: 2, and inertia factor: decreasing linearly from 0.9 to 0.2 (Eberhart & Kennedy, Citation1995, Kennedy & Eberhart, Citation1997), maximum particle velocity: 4, and maximum number of iterations: 50.
DFA part of hybrid PSO-DFA algorithm- number of fireflies: 30, light intensity at the source: 1, absorption coefficient: 0.22, size of the random step: 0.27, and maximum number of iterations: 50 (Durkota, Citation2011).
GSA-BGSA hybrid algorithm- population size: 30, e: 0.01, G0: 100, g: 20, and maximum number of iterations: 50.
The recognition rates of the proposed neural classifier when employing four hybrid optimisation algorithms are reported in . As seen in , the hybrid GSA-BGSA offered the best average recognition rate among the investigated algorithms. It is important that this performance is achieved using smaller number of hidden nodes.
Table 4. Emotion recognition rate of the proposed RNN-based method optimised by hybrid approaches (the best results over 10 runs).
To perform the speaker-independent experiments, 10-fold cross-validation was used. This validation used utterances from nine speakers for training the classifier and the utterances of a single speaker for testing it. This type of validation tests the speaker-independent performance of the proposed classifier. The average emotion recognition rate of this speaker-independent experiment is reported in . As seen in , the hybrid GSA-BGSA offered the best average recognition rate over total emotions among the investigated algorithms.
Table 5. Average emotion recognition rate of the proposed RNN-based method optimised by hybrid approaches (10-fold cross validation).
The speech data extracted from EMO-DB was unbalanced in this study (as seen in ). From the perspective of classifier training, unbalance in the training data distribution often results in poor performance on the minority class (Tang, Zhang, Chawla, & Krasser, Citation2009). So, better performance estimation (in terms of average recognition rate on total emotions) was reported in Tables and than the real accuracy rate (because of dataset unbalance). Similarly, unbalance in the test data distribution often results in misleading conclusions with certain metrics (Jeni, Cohn, & De La Torre, Citation2013).
The performance of the proposed system is compared with some other emotion recognition systems (). All of these systems used Berlin emotional database; however, different feature sets were employed in these researches. As seen in , the performance of proposed model is superior to most of the reported systems.
Table 6. Performance comparison of proposed GSA-BGSA-optimised RNN emotion recogniser and some other systems tested on Berlin emotional database.
7. Conclusion and future work
In this study, the GSA-BGSA hybrid method was proposed to tune simultaneously the structure and weights of an RNN-based classifier. This optimised neural classifier was employed as an emotion classifier using Berlin emotional database as a public available database in this field. The number of prosody-related, voice quality, and spectral-based features in this system was set to 124, 4, and 36, respectively. To reduce the number of input features to the RNN, the SFFS method was employed.
The performance of the proposed hybrid GSA-BGSA-neural model was compared with peer hybrid models such as EBP-GA, PSO-BPSO, and PSO-DFA used for such optimisations. Experimental results demonstrated that the proposed method obtained better average recognition rate using a lighter network structure as compared with other peer investigated methods. The performance of proposed method was compared with similar systems tested on Berlin emotional database and implemented in recent years, as well. The comparisons showed the superior performance of proposed method which achieved average recognition rates up to 80.2% as compared to most of the systems.
The proposed method can be modified in future works by inserting another feature selection unit such as ones used in similar works on emotion recognition from speech: principal component analysis or linear discriminate analysis (Haq, Jackson, & Edge, Citation2008), fast correlation-based filter (Gharavian et al., Citation2012, Citation2013), other versions of sequential forward selection (Batliner et al., Citation2011; Ververidis & Kotropoulos, Citation2008), least square bound (Altun & Polat, Citation2009), mutual information (Altun & Polat, Citation2009), analysis of variations (Gharavian et al., Citation2013; Sheikhan et al., Citation2013), and combination of decision tree method and the random forest ensemble (Mower et al., Citation2011). In addition, the single neural classifier in this study can be replaced by a multiple-classifier scheme to improve the performance of system such as ones reported in (Albornoz, Milone, & Rufiner, Citation2011; Milton & Tamil Selvi, Citation2014).
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Abraham, A. (2002). Optimization of evolutionary neural networks using hybrid learning algorithms. Proceedings of joint conference on neural networks, Honolulu, Hawaii, 2797–2802.
- Ahmed Hendy, N., & Farag, H. (2013). Emotion recognition using neural network: A comparative study. World Academy of Science, Engineering and Technology, 75, 791–797.
- Ai, H., Litman, D. J., Forbes-Riley, K., Rotaru, M., Tetreault, J., & Purandare, A. (2006). Using system and user performance features to improve emotion detection in spoken tutoring systems. Proceedings of interspeech conference, Pittsburgh, Pennsylvania, 797–800.
- Albornoz, E. M., Milone, D. H., & Rufiner, H. L. (2011). Spoken emotion recognition using hierarchical classifiers. Computer Speech & Language, 25, 556–570.
- Alku, P. (1992). Glottal wave analysis with pitch synchronous iterative adaptive inverse filtering. Speech Communication, 11, 109–118.
- Altun, H., & Polat, G. (2009). Boosting selection of speech related features to improve performance of multi-class SVMs in emotion detection. Expert Systems with Applications, 36, 8197–8203.
- Arias, J. P., Busso, C., & Yoma, N. B. (2014). Shape-based modeling of the fundamental frequency contour for emotion detection in speech. Computer Speech & Language, 28, 278–294.
- Batliner, A., Steidl, S., Schuller, B., Seppi, D., Vogt, T., Wagner, J., … Amir, N. (2011). Whodunnit-searching for the most important feature types signalling emotion-related user states in speech. Computer Speech & Language, 25, 4–28.
- Beliakov, G., & Abraham, A. (2002). Global optimisation of neural networks using a deterministic hybrid approach. Proceedings of international workshop on hybrid intelligent systems, Santiago, Chile, 79–92.
- Bitouk, D., Verma, R., & Nenkova, A. (2010). Class-level spectral features for emotion recognition. Speech Communication, 52, 613–625.
- Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W., & Weiss, B. (2005). A database of German emotional speech. Proceedings of Interspeech Conference, Lisbon, Portugal, 1517–1520.
- Caridakis, G., Karpouzis, K., & Kollias, S. (2008). User and context adaptive neural networks for emotion recognition. Neurocomputing, 71, 2553–2562.
- Chandaka, S., Chatterjee, A., & Munshi, S. (2009). Support vector machines employing cross-correlation for emotional speech recognition. Measurement, 42, 611–618.
- Chen, L., Mao, X., Xue, Y., & Cheng, L. L. (2012). Speech emotion recognition: Features and classification models. Digital Signal Processing, 22, 1154–1160.
- Devillers, L., & Vidrascu, L. (2006). Real-life emotions detection with lexical and paralinguistic cues on human-human call center dialogs. Proceedings of Interspeech Conference, Pittsburgh, Pennsylvania, 801–804.
- Durkota, K. (2011). Implementation of a discrete firefly algorithm for the QAP problem within the sage framework (BSc thesis). Czech Technical University.
- Eberhart, R. C., & Kennedy, J. (1995). Particle swarm optimization. Proceedings of IEEE international conference on neural networks, Perth, WA, 4, 1942–1948.
- El Ayadi, M., Kamel, M. S., & Karray, F. (2011). Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognition, 44, 572–587.
- Elman, J. (1990). Finding structure in time. Cognitive Science, 14, 179–211.
- Fernandez, R., & Picard, R. (2011). Recognizing affect from speech prosody using hierarchical graphical models. Speech Communication, 53, 1088–1103.
- Fersini, E., Messina, E., & Archetti, F. (2012). Emotional states in judicial courtrooms: An experimental investigation. Speech Communication, 54, 11–22.
- Gajšek, R., Struc, V., & Mihelič, F. (2010). Multi-modal emotion recognition using canonical correlations and acoustic features. Proceedings of international conference on pattern recognition, Istanbul, 4133–4136.
- Gharavian, D., & Sheikhan, M. (2010). Emotion recognition and emotion spotting improvement using formant-related features. Majlesi Journal of Electrical Engineering, 4(4), 1–8.
- Gharavian, D., Sheikhan, M., & Ashoftedel, F. (2013). Emotion recognition improvement using normalized formant supplementary features by hybrid of DTW-MLP-GMM model. Neural Computing and Applications, 22, 1181–1191.
- Gharavian, D., Sheikhan, M., Nazerieh, A., & Garoucy, S. (2012). Speech emotion recognition using FCBF feature selection method and GA-optimized fuzzy ARTMAP neural network. Neural Computing and Applications, 21, 2115–2126.
- Gharavian, D., Sheikhan, M., & Pezhmanpour, M. (2011). GMM-based emotion recognition in Farsi language using feature selection algorithms. World Applied Sciences Journal, 14, 626–638.
- Gori, M., & Tesi, A. (1992). On the problem of local minima in back-propagation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 14, 76–86.
- Haq, S., Jackson, P. J. B., & Edge, J. (2008). Audio-visual feature selection and reduction for emotion classification. Proceedings of international conference on auditory-visual speech processing, Queensland, Australia, 185–190.
- Iliev, A. I., Scordilis, M. S., Papa, J. P., & Falcão, A. X. (2010). Spoken emotion recognition through optimum-path forest classification using glottal features. Computer Speech & Language, 24, 445–460.
- Javidi, M. M., & Fazlizadeh Roshan, E. (2013). Speech emotion recognition by using combinations of C5.0, neural network (NN), and support vector machines (SVM) classification methods. Journal of Mathematics and Computer Science, 6, 191–200.
- Jaywant, A., & Pell, M. D. (2012). Categorical processing of negative emotions from speech prosody. Speech Communication, 54, 1–10.
- Jeni, L. A., Cohn, J. F., & De La Torre, F. (2013). Facing imbalanced data-Recommendations for the use of performance metrics. Proceedings of the humaine association conference on affective computing and intelligent interaction, Geneva, Switzerland, 245–251.
- Kamaruddin, N., Wahab, A., & Quek, C. (2012). Cultural dependency analysis for understanding speech emotion. Expert Systems with Applications, 39, 5115–5133.
- Kao, Y., & Lee, L. (2006). Feature analysis for emotion recognition from Mandarin speech considering the special characteristics of Chinese language. Proceedings of international conference on spoken language processing, Pittsburgh, Pennsylvania, 1814–1817.
- Kennedy, J., & Eberhart, R. C. (1997). A discrete binary version of the particle swarm algorithm. Proceedings of IEEE international conference on systems, man, and cybernetics, Orlando, FL, 5, 4104–4108.
- Khanchandani, K. B., & Hussain, M. A. (2009). Emotion recognition using multilayer perceptron and generalized feed forward neural network. Journal of Scientific & Industrial Research, 68, 367–371.
- Kiliç, M. A., Öğöt, F., Dursun, G., Okur, E., Yildirim, I., & Midilli, R. (2004). The effects of vowels on voice perturbation measures. Journal of Voice, 18, 318–324.
- Kockmann, M., Burget, L., & Černocky, J. H. (2011). Application of speaker- and language identification state-of-the-art techniques for emotion recognition. Speech Communication, 53, 1172–1185.
- Kudo, M., & Sklansky, J. (2000). Comparison of algorithms that select features for pattern classifiers. Pattern Recognition, 33, 25–41.
- Kulluk, S., Ozbakir, L., & Baykasoglu, A. (2012). Training neural networks with harmony search algorithms for classification problems. Engineering Applications of Artificial Intelligence, 25, 11–19.
- Li, X., Tao, J., Johnson, M. T., Soltis, J., Savage, A., Leong, K. M., & Newman, J. D. (2007). Stress and emotion classification using jitter and shimmer features. Proceedings of international conference on acoustics, speech and signal processing, Honolulu, Hawaii, 4, 1081–1084.
- Lin, W., & Hong, A. (2011). A new Elman neural network-based control algorithm for adjustable-pitch variable speed wind energy conversion systems. IEEE Transactions on Power Electronics, 26, 473–481.
- López-Cózar, R., Silovsky, J., & Kroul, M. (2011). Enhancement of emotion detection in spoken dialogue systems by combining several information sources. Speech Communication, 53, 1210–1228.
- Lugger, M., & Yang, B. (2007). The relevance of voice quality features in speaker independent emotion recognition. Proceedings of international conference on acoustics, speech and signal processing, 4, Honolulu, Hawaii, 17–20.
- Mariooryad, S., & Busso, C. (2014). Compensating for speaker or lexical variabilities in speech for emotion recognition. Speech Communication, 57, 1–12.
- Meng, C., Xin, S. Z., & Min, L. S. (2014). Neural network ensembles based on copula methods and distributed multiobjective central force optimization algorithm. Engineering Applications of Artificial Intelligence, 32, 203–212.
- Milton, A., & Tamil Selvi, S. (2014). Class-specific multiple classifiers scheme to recognize emotions from speech signals. Computer Speech & Language, 28, 727–742.
- Mirjalili, S. A., Mohd Hashim, S. Z., & Moradian Sardroudi, H. (2012). Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm. Applied Mathematics and Computation, 218, 11125–11137.
- Mower, E., Busso, C., Lee, S., Narayanan, S., & Lee, C. (2011). Emotion recognition using a hierarchical binary decision tree approach. Speech Communication, 53, 1162–1171.
- Origlia, A., Cutugno, F., & Galatà, V. (2014). Continuous emotion recognition with phonetic syllables. Speech Communication, 57, 155–169.
- Pao, T., Chen, Y., Yeh, J., & Chang, Y. (2008). Emotion recognition and evaluation of Mandarin speech using weighted D-KNN classification. International Journal of Innovative Computing, Information and Control, 4, 1695–1709.
- PintÈr, J. (1996). Global optimization in action: Continuous and Lipschitz optimization-algorithms, implementations, and applications. Dordrecht: Kluwer Academic.
- Piotrowski, A. P. (2014). Differential evolution algorithms applied to neural network training suffer from stagnation. Applied Soft Computing, 21, 382–406.
- Polzehl, T., Sundaram, S., Ketabdar, H., Wagner, M., & Metze, F. (2009). Emotion classification in children's speech using fusion of acoustic and linguistic features. Proceedings of interspeech conference, Brighton, UK, 340–343.
- Qasem, S. N., & Shamsuddin, S. M. (2011). Radial basis function network based on time variant multi-objective particle swarm optimization for medical diseases diagnosis. Applied Soft Computing, 11, 1427–1438.
- Rao, K. S., & Koolagudi, S. G. (2013). Robust emotion recognition using pitch synchronous and sub-syllabic spectral features. In A. Neustein (Ed.), Robust emotion recognition using spectral and prosodic features, New York: SpringerBriefs in Speech Technology (pp. 17–46).
- Rashedi, E., Nezamabadi-pour, H., & Saryazdi, S. (2009). GSA: A gravitational search algorithm. Information Sciences, 179, 2232–2248.
- Rashedi, E., Nezamabadi-pour, H., & Saryazdi, S. (2010). BGSA: Binary gravitational search algorithm. Natural Computing, 9, 727–745.
- Rong, J., Li, G., & Chen, Y. P. (2009). Acoustic feature selection for automatic emotion recognition from speech. Information Processing and Management, 45, 315–328.
- Salchenberger, L. M., Cinar, E. M., & Lash, N. A. (1992). Neural networks: A new tool for predicting thrift failures. Decision Sciences, 23, 899–916.
- Schuller, B., Batliner, A., Steidl, S., & Seppi, D. (2011). Recognizing realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Communication, 53, 1062–1087.
- Schuller, B., Vlasenko, B., Eyben, F., Rigoll, G., & Wendemuth, A. (2009). Acoustic emotion recognition: A benchmark comparison of performances. Proceedings of IEEE workshop on automatic speech recognition & understanding, Merano, 552–557.
- Sexton, R., Dorsey, R., & Johnson, J. (1998). Toward global optimization of neural networks: A comparison of the genetic algorithm and backpropagation. Decision Support Systems, 22, 171–185.
- Sexton, R., Dorsey, R., & Johnson, J. (1999). Optimization of neural networks: A comparative analysis of the genetic algorithm and simulated annealing. European Journal of Operational Research, 114, 589–601.
- Sheikhan, M. (2014). Generation of suprasegmental information for speech using a recurrent neural network and binary gravitational search algorithm for feature selection. Applied Intelligence, 40, 772–790.
- Sheikhan, M., & Ahmadluei, S. (2013). An intelligent hybrid optimistic/pessimistic concurrency control algorithm for centralized database systems using modified GSA-optimized ART neural model. Neural Computing and Applications, 23, 1815–1829.
- Sheikhan, M., Bejani, M., & Gharavian, D. (2013). Modular neural-SVM scheme for speech emotion recognition using ANOVA feature selection method. Neural Computing and Applications, 23, 215–227.
- Sheikhan, M., & Hemmati, E. (2012). PSO-optimized hopfield neural network-based multipath routing for mobile ad-hoc networks. International Journal of Computational Intelligence Systems, 5, 568–581.
- Sheikhan, M., & Jadidi, Z. (2014). Flow-based anomaly detection in high-speed links using modified GSA-optimized neural network. Neural Computing and Applications, 24, 599–611.
- Sheikhan, M., & Mohammadi, N. (2013). Time series prediction using PSO-optimized neural network and hybrid feature selection algorithm for IEEE load data. Neural Computing and Applications, 23, 1185–1194.
- Sheikhan, M., Safdarkhani, M. K., & Gharavian, D. (2011). Emotion recognition of speech using small-size selected feature set and ANN-based classifiers: A comparative study. World Applied Sciences Journal, 14, 616–625.
- Sheikhan, M., & Sharifi Rad, M. (2013a). Gravitational search algorithm-optimized neural misuse detector with selected features by fuzzy grids based association rules mining. Neural Computing and Applications, 23, 2451–2463.
- Sheikhan, M., & Sharifi Rad, M. (2013b). Using particle swarm optimization in fuzzy association rules-based feature selection and fuzzy ARTMAP-based attack recognition. Security and Communication Networks, 6, 797–811.
- Shen, W., Guo, X., Wu, C., & Wu, D. (2011). Forecasting stock indices using radial basis function neural networks optimized by artificial swarm algorithm. Knowledge-Based Systems, 24, 378–385.
- Subrahmanya, N., & Shin, Y. C. (2010). Constructive training of recurrent neural networks using hybrid optimization. Neurocomputing, 73, 2624–2631.
- Tang, Y., Zhang, Y.-Q., Chawla, N. V., & Krasser, S. (2009). SVMs modeling for highly imbalanced classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 39, 281–288.
- Tian, F., Gao, P., Li, L., Zhang, W., Liang, H., Qian, Y., & Zhao, R. (2014). Recognizing and regulating e-learners’ emotions based on interactive Chinese texts in e-learning systems. Knowledge-Based Systems, 55, 148–164.
- Väyrynen, E., Toivanen, J., & Seppänen, T. (2011). Classification of emotion in spoken Finnish using vowel-length segments: Increasing reliability with a fusion technique. Speech Communication, 53, 269–282.
- Ververidis, D., & Kotropoulos, C. (2006). Emotional speech recognition: Resources, features, and methods. Speech Communication, 48, 1162–1181.
- Ververidis, D., & Kotropoulos, C. (2008). Fast and accurate sequential floating forward feature selection with the Bayes classifier applied to speech emotion recognition. Signal Processing, 88, 2956–2970.
- Vlasenko, B., Prylipko, D., Böck, R., & Wendemuth, A. (2014). Modeling phonetic pattern variability in favor of the creation of robust emotion classifiers for real-life applications. Computer Speech & Language, 28, 483–500.
- Wu, S., Falk, T. H., & Chan, W. Y. (2009). Automatic recognition of speech emotion using long-term spectro-temporal features. Proceedings of international conference on digital signal processing, Santorini-Hellas, 1–6.
- Wu, S., Falk, T. H., & Chan, W-Y. (2011). Automatic speech emotion recognition using modulation spectral features. Speech Communication, 53, 768–785.
- Xiao, Z., Dellandrea, E., Dou, W., & Chen, L. (2007). Automatic hierarchical classification of emotional speech. Proceedings of International Symposium on Multimedia Workshops, Beijing, 291–296.
- Yaghini, M., Khoshraftar, M. M., & Fallahi, M. (2013). A hybrid algorithm for artificial neural network training. Engineering Applications of Artificial Intelligence, 26, 293–301.
- Yang, B., & Lugger, M. (2010). Emotion recognition from speech signals using new harmony features. Signal Processing, 90, 1415–1423.
- Ye, J., Qiao, J., Li, M., & Ruan, X. (2007). A tabu based neural network learning algorithm. Neurocomputing, 70, 875–882.
- Yeh, J., Pao, T., Lin, C., Tsai, Y., & Chen, Y. (2010). Segment-based emotion recognition from continuous Mandarin Chinese speech. Computers in Human Behavior, 27, 1545–1552.
- Yu, J., Wang, S., & Xi, L. (2008). Evolving artificial neural networks using an improved PSO and DPSO. Neurocomputing, 71, 1054–1060.
- Zhang, J. R., Zhang, J., Lok, T. M., & Lyu, M. R. (2007). A hybrid particle swarm optimization-back-propagation algorithm for feedforward neural network training. Applied Mathematics and Computation, 185, 1026–1037.
- Zhao, L., & Qian, F. (2011). Tuning the structure and parameters of a neural network using cooperative binary-real particle swarm optimization. Expert Systems with Applications, 38, 4972–4977.
- Zhou, G., Hansen, J. H. L., & Kaiser, J. F. (1998). Classification of speech under stress based on features derived from the nonlinear Teager energy operator. Proceedings of international conference on acoustics, speech and signal processing, Seattle, WA, 1, 549–552.